![]()


![]()
textX is a meta-language for building Domain-Specific Languages (DSLs) in Python. It is inspired by Xtext.
In a nutshell, textX will help you build your textual language in an easy way. You can invent your own language or build a support for already existing textual language or file format.
From a single language description (grammar), textX will build a parser and a meta-model (a.k.a. abstract syntax) for the language. See the docs for the details.
textX follows the syntax and semantics of Xtext but differs in some places and is implemented 100% in Python using Arpeggio PEG parser - no grammar ambiguities, unlimited lookahead, interpreter style of work.
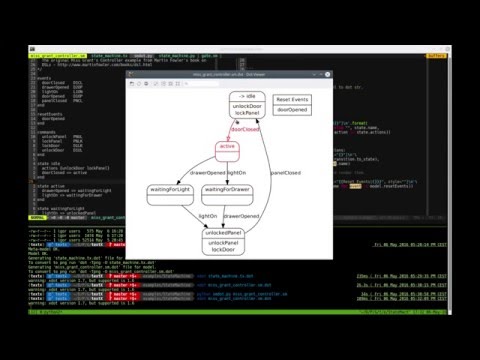
Here is a complete example that shows the definition of a simple DSL for drawing. We also show how to define a custom class, interpret models and search for instances of a particular type.
from textx import metamodel_from_str, get_children_of_type
grammar = """
Model: commands*=DrawCommand;
DrawCommand: MoveCommand | ShapeCommand;
ShapeCommand: LineTo | Circle;
MoveCommand: MoveTo | MoveBy;
MoveTo: 'move' 'to' position=Point;
MoveBy: 'move' 'by' vector=Point;
Circle: 'circle' radius=INT;
LineTo: 'line' 'to' point=Point;
Point: x=INT ',' y=INT;
"""
# We will provide our class for Point.
# Classes for other rules will be dynamically generated.
class Point:
def __init__(self, parent, x, y):
self.parent = parent
self.x = x
self.y = y
def __str__(self):
return "{},{}".format(self.x, self.y)
def __add__(self, other):
return Point(self.parent, self.x + other.x, self.y + other.y)
# Create meta-model from the grammar. Provide `Point` class to be used for
# the rule `Point` from the grammar.
mm = metamodel_from_str(grammar, classes=[Point])
model_str = """
move to 5, 10
line to 10, 10
line to 20, 20
move by 5, -7
circle 10
line to 10, 10
"""
# Meta-model knows how to parse and instantiate models.
model = mm.model_from_str(model_str)
# At this point model is a plain Python object graph with instances of
# dynamically created classes and attributes following the grammar.
def cname(o):
return o.__class__.__name__
# Let's interpret the model
position = Point(None, 0, 0)
for command in model.commands:
if cname(command) == 'MoveTo':
print('Moving to position', command.position)
position = command.position
elif cname(command) == 'MoveBy':
position = position + command.vector
print('Moving by', command.vector, 'to a new position', position)
elif cname(command) == 'Circle':
print('Drawing circle at', position, 'with radius', command.radius)
else:
print('Drawing line from', position, 'to', command.point)
position = command.point
print('End position is', position)
# Output:
# Moving to position 5,10
# Drawing line from 5,10 to 10,10
# Drawing line from 10,10 to 20,20
# Moving by 5,-7 to a new position 25,13
# Drawing circle at 25,13 with radius 10
# Drawing line from 25,13 to 10,10
# Collect all points starting from the root of the model
points = get_children_of_type("Point", model)
for point in points:
print('Point: {}'.format(point))
# Output:
# Point: 5,10
# Point: 10,10
# Point: 20,20
# Point: 5,-7
# Point: 10,10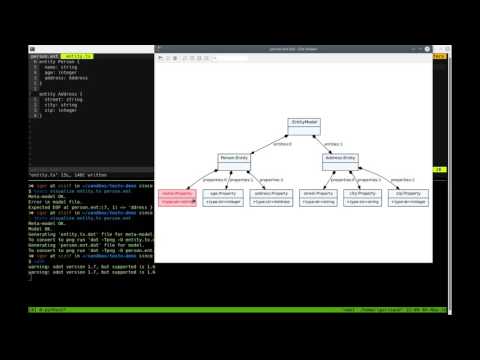
The full documentation with tutorials is available at http://textx.github.io/textX/stable/
You can also try textX in our playground. There is a dropdown with several examples to get you started.
Projects that are currently in progress are:
- textX-LS - support for Language Server
Protocol and VS Code for any textX based language. This project is about to
supersede the following projects:
- textX-languageserver - Language Server Protocol support for textX languages
- textX-extensions - syntax highlighting, code outline
- viewX - creating visualizers for textX languages
If you are a vim editor user check out support for vim.
For emacs there is textx-mode which is also available in MELPA.
You can also check out textX-ninja project. It is currently unmaintained.
For general questions, suggestions, and feature requests please use GitHub Discussions.
For issues please use GitHub issue tracker.
If you are using textX in your research project we would be very grateful if you cite our paper:
Dejanović I., Vaderna R., Milosavljević G., Vuković Ž. (2017). TextX: A Python tool for Domain-Specific Languages implementation. Knowledge-Based Systems, 115, 1-4.
MIT
Tested for 3.8+







































































































































