teamaidemy / ds-paper-summaries Goto Github PK
View Code? Open in Web Editor NEW株式会社アイデミーのデータサイエンティストによる論文サマリー
License: MIT License
株式会社アイデミーのデータサイエンティストによる論文サマリー
License: MIT License
Taylor, Sean J., and Benjamin Letham. Forecasting at Scale. e3190v2, PeerJ Preprints, 27 Sept. 2017, https://doi.org/10.7287/peerj.preprints.3190v2.
Forecasting is a common data science task that helps organizations with capacity planning, goal setting, and anomaly detection. Despite its importance, there are serious challenges associated with producing reliable and high quality forecasts — especially when there are a variety of time series and analysts with expertise in time series modeling are relatively rare. To address these challenges, we describe a practical approach to forecasting “at scale” that combines configurable models with analyst-in-the-loop performance analysis. We propose a modular regression model with interpretable parameters that can be intuitively adjusted by analysts with domain knowledge about the time series. We describe performance analyses to compare and evaluate forecasting procedures, and automatically flag forecasts for manual review and adjustment. Tools that help analysts to use their expertise most effectively enable reliable, practical forecasting of business time series.
(DeepL翻訳)
予測は一般的なデータサイエンスのタスクであり、組織のキャパシティプランニング、目標設定、異常検知に役立ちます。その重要性にもかかわらず、信頼性が高く高品質な予測を行うには、深刻な課題があります。このような課題に対処するために、我々は、設定可能なモデルとアナリスト・イン・ザ・ループのパフォーマンス分析を組み合わせた、「規模に応じた」予測への実用的なアプローチについて述べる。時系列に関する専門知識を持つアナリストが直感的に調整できる、解釈可能なパラメータを持つモジュラー回帰モデルを提案する。予測手順を比較・評価するためのパフォーマンス分析について説明し、手動レビューと調整のために予測に自動的にフラグを立てる。アナリストが専門知識を最も効果的に活用できるように支援するツールは、ビジネス時系列の信頼性の高い実用的な予測を可能にする。
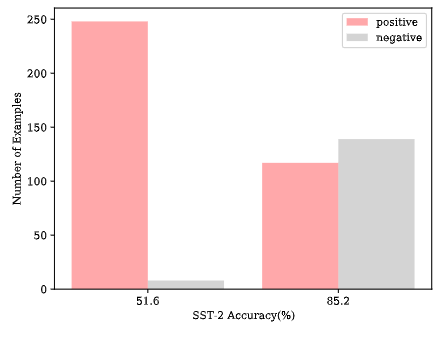
定性的に他手法と比べ、提案手法は傾向を上手く掴めているよね、が Figs.3-5
30日間 ~ 365日間の予測を行い、他手法とMAPEを比較 (Fig.7)
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/1810.04805
たった4人で世界を変えるような仕事を行ったという事実に震える
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
(DeepL翻訳)
我々は、BERT(Bidirectional Encoder Representations from Transformersの略)と呼ばれる新しい言語表現モデルを紹介する。最近の言語表現モデルとは異なり、BERTは全ての層で左右両方の文脈を共同で条件付けることにより、ラベルのないテキストから深い双方向表現を事前学習するよう設計されている。その結果、事前学習されたBERTモデルは、質問応答や言語推論などの幅広いタスクのための最先端のモデルを作成するために、タスク固有のアーキテクチャを大幅に変更することなく、たった1つの追加出力層で微調整が可能です。
BERTは、概念的にシンプルで、経験的に強力である。GLUEスコアを80.5%(7.7ポイントの絶対値向上)、MultiNLI精度を86.7%(4.6%の絶対値向上)、SQuAD v1.1 質問応答テストF1を93.2(1.5ポイントの絶対値向上)、SQuAD v2.0 テストF1を 83.1(5.1 ポイント絶対値向上)など11個の自然言語処理タスクで最先端の結果を得ました。
https://github.com/google-research/bert

紹介されている以下3つの指標すべてでState-of-the-Art達成
など。この派生の多さからも、BERTのインパクトがよく分かる。
Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Efficient Estimation of Word Representations in Vector Space.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/1301.3781.
word2vecを提唱した論文
3部作の2作目。本論文で初めて "word2vec" という名前が与えられた。
とても高精度な分散表現が獲得できたため、単語の演算ができるようになった!
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
(DeepL翻訳)
我々は、非常に大規模なデータセットから単語の連続ベクトル表現を計算するための2つの新しいモデルアーキテクチャを提案する。これらの表現の品質は単語の類似性タスクで測定され、その結果は異なるタイプのニューラルネットワークに基づく、これまでで最も性能の良い技術と比較される。その結果、16億語のデータセットから高品質の単語ベクトルを学習するのに1日もかからず、より低い計算コストで精度が大幅に向上することが確認された。さらに、これらのベクトルは、我々のテストセットにおいて、構文的および意味的な単語の類似性を測定するための最先端の性能を提供することを示す。
https://code.google.com/archive/p/word2vec/

Sharma, Parmanand, Takahiro Ninomiya, Kazuko Omodaka, Naoki Takahashi, Takehiro Miya, Noriko Himori, Takayuki Okatani, and Toru Nakazawa. 2022. “A Lightweight Deep Learning Model for Automatic Segmentation and Analysis of Ophthalmic Images.” Scientific Reports 12 (1): 8508.
https://www.nature.com/articles/s41598-022-12486-w
Detection, diagnosis, and treatment of ophthalmic diseases depend on extraction of information (features and/or their dimensions) from the images. Deep learning (DL) model are crucial for the automation of it. Here, we report on the development of a lightweight DL model, which can precisely segment/detect the required features automatically. The model utilizes dimensionality reduction of image to extract important features, and channel contraction to allow only the required high-level features necessary for reconstruction of segmented feature image. Performance of present model in detection of glaucoma from optical coherence tomography angiography (OCTA) images of retina is high (area under the receiver-operator characteristic curve AUC ~ 0.81). Bland–Altman analysis gave exceptionally low bias (~ 0.00185), and high Pearson’s correlation coefficient (p = 0.9969) between the parameters determined from manual and DL based segmentation. On the same dataset, bias is an order of magnitude higher (~ 0.0694, p = 0.8534) for commercial software. Present model is 10 times lighter than Unet (popular for biomedical image segmentation) and have a better segmentation accuracy and model training reproducibility (based on the analysis of 3670 OCTA images). High dice similarity coefficient (D) for variety of ophthalmic images suggested it’s wider scope in precise segmentation of images even from other fields. Our concept of channel narrowing is not only important for the segmentation problems, but it can also reduce number of parameters significantly in object classification models. Enhanced disease diagnostic accuracy can be achieved for the resource limited devices (such as mobile phone, Nvidia’s Jetson, Raspberry pi) used in self-monitoring, and tele-screening (memory size of trained model ~ 35 MB).
(DeepL翻訳)
眼科疾患の検出・診断・治療は、画像からの情報(特徴量および/またはその次元)の抽出に依存している。その自動化のためには、ディープラーニング(DL)モデルが重要である。本発表では、必要な特徴を的確に自動抽出する軽量なDLモデルの開発について報告する。本モデルは、画像の次元削減により重要な特徴を抽出し、チャンネル収縮により、分割された特徴画像の再構成に必要な高次の特徴のみを許可する。網膜の光干渉断層撮影(OCTA)画像からの緑内障検出において、本モデルの性能は高い(受信者操作特性曲線下面積AUC〜0.81)。Bland-Altman解析では、手動とDLベースのセグメンテーションで決定されたパラメータの間に、例外的に低いバイアス(〜0.00185)、高いピアソンの相関係数(p = 0.9969)が得られました。同じデータセットで、市販のソフトウェアでは、バイアスが1桁高い(~ 0.0694, p = 0.8534)。本モデルは、バイオメディカル画像のセグメンテーションによく用いられるUnetよりも10倍軽く、セグメンテーション精度やモデル学習の再現性が高い(3670枚のOCTA画像の解析に基づく)。また、様々な眼科画像に対して高いダイス類似度係数(D)を示したことから、他分野の画像の精密なセグメンテーションにも応用できることが示唆されました。また、このチャンネルナローイングの概念は、セグメンテーションの問題だけでなく、オブジェクト分類モデルにおいてパラメータ数を大幅に削減することができる。また、携帯電話、NvidiaのJetson、Raspberry piなどのリソースの限られたデバイスを用いたセルフモニタリングや、遠隔スクリーニングにおいて、疾患診断の精度を高めることができる(学習モデルのメモリサイズ〜35MB)。
Xin Huang, Ashish Khetan, Milan Cvitkovic, Zohar Karnin 2020. "TabTransformer: Tabular Data Modeling Using Contextual Embeddings" arXiv [cs.LG]. arXiv. https://arxiv.org/abs/2012.06678v1
We propose TabTransformer, a novel deep tabular data modeling architecture for supervised and semi-supervised learning. The TabTransformer is built upon self-attention based Transformers. The Transformer layers transform the embeddings of categorical features into robust contextual embeddings to achieve higher prediction accuracy. Through extensive experiments on fifteen publicly available datasets, we show that the TabTransformer outperforms the state-of-theart deep learning methods for tabular data by at least 1.0% on mean AUC, and matches the performance of tree-based ensemble models. Furthermore, we demonstrate that the contextual embeddings learned from TabTransformer are highly robust against both missing and noisy data features, and provide better interpretability. Lastly, for the semi-supervised setting we develop an unsupervised pre-training procedure to learn data-driven contextual embeddings, resulting in an average 2.1% AUC lift over the state-of-the-art methods.
(DeepL翻訳)
我々は、教師あり学習と半教師あり学習のための新しい深い表形式データモデリングアーキテクチャであるTabTransformerを提案する。TabTransformerは自己注意に基づくTransformerをベースに構築されている。Transformer層はカテゴリ特徴の埋め込みを頑健な文脈埋め込みに変換し、より高い予測精度を達成する。15の公開データセットに対する広範な実験を通して、我々はTabTransformerが表形式データに対する最新の深層学習手法を平均AUCで少なくとも1.0%上回り、木ベースのアンサンブルモデルの性能と一致することを示す。さらに、TabTransformerから学習した文脈埋め込みは、欠損データとノイズデータの両方の特徴に対して非常に頑健であり
、より良い解釈可能性を提供することを実証する。最後に、半教師付き設定において、我々はデータ駆動型の文脈埋め込みを学習する教師なし事前学習手順を開発し、その結果、最新の手法に対して平均2.1%のAUCリフトを達成した。
Tableデータのモデル化は、大別して、GBDT等のツリーベースモデルと、多層パーセプトロン(MLP)(*)モデルの2種類があり、それぞれに課題がある。
*本論文のMLPとは、Transformerを含まない、一般的なニューラルネットワークをベースとしたモデルを示す。
本論文ではTransformerをテーブルデータに導入することで、上記の課題を解決し、既存のモデルを上回る精度を達成した。
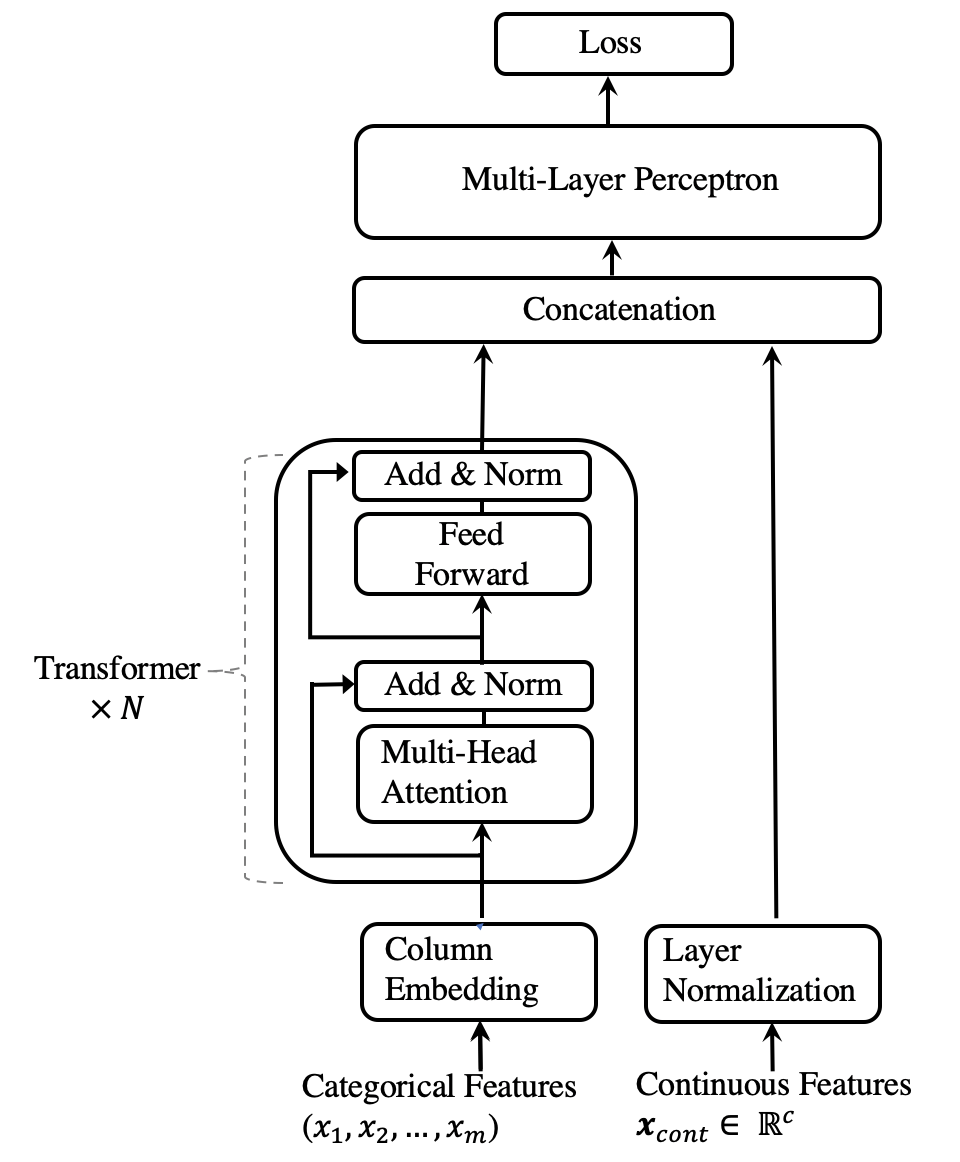
本論文では、UIC Repository、AutoML Challenge、Kaggleからの15の一般公開二値分類データセットで、教師あり学習と半教師あり学習の両方についてTabTransformerとベースラインモデルを評価し、既存モデルへの優位性を説いている。
実験は下記の項目を実施し、ほぼ全てのケースで優位な結果を示した。
以下、評価のサマリーを記載する。
通常の教師あり学習では、ニューラルネットワークベースの既存モデルを上回り、また、テーブルデータで最も高性能なモデルの1つであるGBDTとほぼ同等の性能を示した(Table 2) 。
| Model Name | Mean AUC (%) |
|---|---|
| TabTransformer | 82.8 ± 0.4 |
| MLP | 81.8 ± 0.4 |
| GBDT | 82.9 ± 0.4 |
| Sparse MLP | 81.4 ± 0.4 |
| Logistic Regression | 80.4 ± 0.4 |
| TabNet | 77.1 ± 0.5 |
| VIB | 80.5 ± 0.4 |
Table 2教師あり学習におけるモデルの性能 評価指標は、各モデル
の15個のデータセットにおけるAUCスコアの平均±標準偏差
ラベルのないデータの数が多い場合、TabTransfomerを事前学習したモデル(TabTransformer-RTD, TabTransformer-MLM)は、他の競合他社を大幅に上回る性能を示した。
旧来の事前学習法を用いたTransformerやGBDTは全モデルの平均より性能が悪いが、TabTransformer-RTD/MLMは、ラベル付きデータが(全サンプル数 30k以上のうち)50、200、500のシナリオにおいて、平均AUCでそれぞれ1.2%、2.0%、2.1%以上、既存の手法より向上している(Table 3)。
| #Labeled Data | 50 | 200 | 500 |
|---|---|---|---|
| TabTransformer-RTD | 66.6±0.6 | 70.9±0.6 | 73.1±0.6 |
| TabTransformer-MLM | 66.8±0.6 | 71.0±0.6 | 72.9±0.6 |
| MLP (ER) | 65.6±0.6 | 69.0±0.6 | 71.0±0.6 |
| MLP (PL) | 65.4±0.6 | 68.8±0.6 | 71.0±0.6 |
| TabTransformer(ER) | 62.7±0.6 | 67.1±0.6 | 69.3±0.6 |
| TabTransformer(PL) | 63.6±0.6 | 67.3±0.7 | 69.3±0.6 |
| MLP (DAE) | 65.2±0.5 | 68.5±0.6 | 71.0±0.6 |
| GBDT (PL) | 56.5±0.5 | 63.1±0.6 | 66.5±0.7 |
Table 3: ラベル付きデータ点数を変えた場合の、それぞれ30K以上のデータ点を持つ8つのデータセットに対する半教師あり学習結果。評価指標は平均AUC(%)で、数値が大きいほど良い結果である。
補足:
総じて、TabTransformerは、テーブルデータで最も高性能なモデルの1つであるGBDTに迫る精度を示し、また、ラベル付されたデータが少ないケースにおいては、半教師あり学習を適用することで、既存モデルを凌駕する性能を実現したと言える。
半教師あり学習時のTabTransformer評価において、特にラベルなしデータの数が少ない場合に、TabTransformer(RTD)は、ほとんどの競合を凌駕するが、改善はわずかであると述べている。
本論文のアプローチでは、ラベル無しデータ数が少ない場合、情報量の多いEmbeddingを得ることができるが、ラベルのないデータのみでは、モデル全体(特に、Fig.1 のMuliti-Layer Perceptron部)の重みを学習させることはできない。
Campbell, Quintina L., et al. “Censoring Chemical Data to Mitigate Dual Use Risk.” arXiv [cs.LG], 20 Apr. 2023, http://arxiv.org/abs/2304.10510. arXiv.
The dual use of machine learning applications, where models can be used for both beneficial and malicious purposes, presents a significant challenge. This has recently become a particular concern in chemistry, where chemical datasets containing sensitive labels (e.g. toxicological information) could be used to develop predictive models that identify novel toxins or chemical warfare agents. To mitigate dual use risks, we propose a model-agnostic method of selectively noising datasets while preserving the utility of the data for training deep neural networks in a beneficial region. We evaluate the effectiveness of the proposed method across least squares, a multilayer perceptron, and a graph neural network. Our findings show selectively noised datasets can induce model variance and bias in predictions for sensitive labels with control, suggesting the safe sharing of datasets containing sensitive information is feasible. We also find omitting sensitive data often increases model variance sufficiently to mitigate dual use. This work is proposed as a foundation for future research on enabling more secure and collaborative data sharing practices and safer machine learning applications in chemistry.
(DeepL翻訳)
機械学習アプリケーションの二重使用は、モデルが有益な目的にも悪意のある目的にも使用される可能性があるため、重要な課題となっている。化学分野では、機密性の高いラベル(毒物学的情報など)を含む化学データセットが、新規毒物や化学兵器を特定する予測モデルの開発に利用される可能性がある。二重使用のリスクを軽減するために、有益な領域でディープニューラルネットワークを学習するためのデータの有用性を維持しながら、データセットを選択的にノイズ化するモデル不可知論的な方法を提案する。提案手法の有効性を最小二乗法、多層パーセプトロン、グラフニューラルネットワークで評価する。我々の知見は、選択的にノイズ化されたデータセットが、制御可能なセンシティブなラベルに対する予測において、モデルの分散とバイアスを誘導できることを示しており、センシティブな情報を含むデータセットの安全な共有が実現可能であることを示唆している。また、センシティブなデータを省略することで、モデルの分散が十分に増加し、二重利用が緩和されることもわかった。この研究は、より安全で協調的なデータ共有の実践と、化学におけるより安全な機械学習アプリケーションを可能にするための将来の研究の基礎として提案される。
https://github.com/ur-whitelab/chem-dual-use
多層パーセプトロンとグラフ畳み込みネットワークでノイズ付与の効果を検証。
下図は多層パーセプトロンでの結果 (Fig.3)。true labelが正のデータにノイズを付与。
ノイズを説明変数のみに加えたとき (c)、ノイズが加わったデータのMSEが極端に悪化している。
実践的には「センシティブ」ラベルをどう付けるかが課題になりそう。毒性 = 薬効であるため、データセットを作ったときの評価軸で都合の悪いものを一律「センシティブ」としてしまうと、将来「この毒性を薬として活用したい」というニーズが出てきたときに使えないデータセットになることもありえるのではないだろうか。
Sankararaman, Karthik Abinav, et al. “BayesFormer: Transformer with Uncertainty Estimation.” arXiv [cs.CL], 2 June 2022, http://arxiv.org/abs/2206.00826. arXiv.
Transformer has become ubiquitous due to its dominant performance in various NLP and image processing tasks. However, it lacks understanding of how to generate mathematically grounded uncertainty estimates for transformer architectures. Models equipped with such uncertainty estimates can typically improve predictive performance, make networks robust, avoid over-fitting and used as acquisition function in active learning. In this paper, we introduce BayesFormer, a Transformer model with dropouts designed by Bayesian theory. We proposed a new theoretical framework to extend the approximate variational inference-based dropout to Transformer-based architectures. Through extensive experiments, we validate the proposed architecture in four paradigms and show improvements across the board: language modeling and classification, long-sequence understanding, machine translation and acquisition function for active learning.
(DeepL翻訳)
トランスフォーマーは、様々な自然言語処理や画像処理タスクにおいて圧倒的な性能を発揮するため、ユビキタスになっている。しかし、トランスフォーマーアーキテクチャに対して、数学的に根拠のある不確実性推定値を生成する方法については理解が不足している。このような不確実性推定を備えたモデルは、通常、予測性能を向上させ、ネットワークを頑健にし、オーバーフィッティングを回避し、能動学習における獲得関数として使用することができる。本稿では、ベイズ理論によって設計されたドロップアウトを持つトランスフォーマーモデルであるBayesFormerを紹介する。我々は、近似変分推論に基づくドロップアウトをTransformerベースのアーキテクチャに拡張する新しい理論的枠組みを提案した。広範な実験を通じて、4つのパラダイムで提案アーキテクチャを検証し、言語モデリングと分類、長文系列理解、機械翻訳、能動学習のための獲得機能など、全体的な改善を示す。
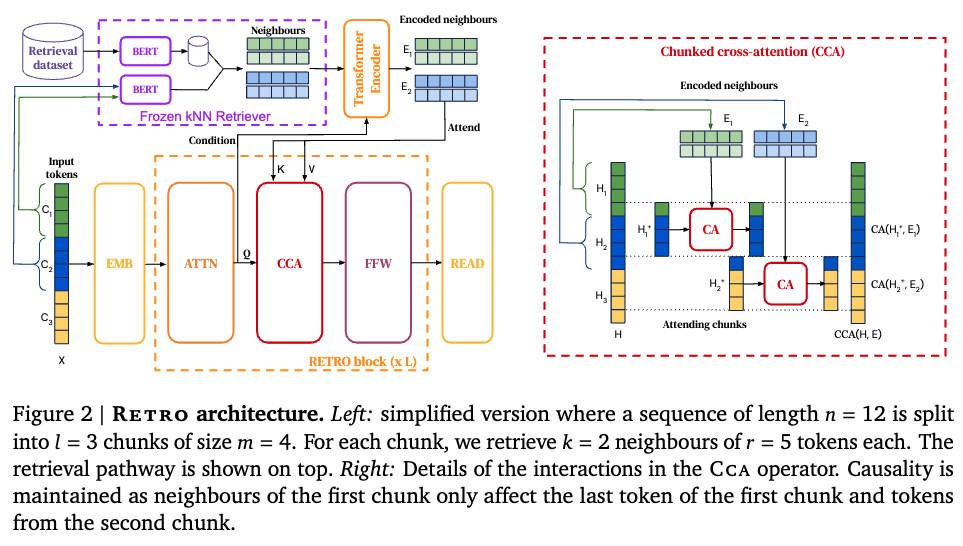
まとめ作成時点では無し
論文よりFigure 2の一部を転載。
Song, Yang, and Stefano Ermon. 2019. “Generative Modeling by Estimating Gradients of the Data Distribution.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/1907.05600.
Revised 2020
We introduce a new generative model where samples are produced via Langevin dynamics using gradients of the data distribution estimated with score matching. Because gradients can be ill-defined and hard to estimate when the data resides on low-dimensional manifolds, we perturb the data with different levels of Gaussian noise, and jointly estimate the corresponding scores, i.e., the vector fields of gradients of the perturbed data distribution for all noise levels. For sampling, we propose an annealed Langevin dynamics where we use gradients corresponding to gradually decreasing noise levels as the sampling process gets closer to the data manifold. Our framework allows flexible model architectures, requires no sampling during training or the use of adversarial methods, and provides a learning objective that can be used for principled model comparisons. Our models produce samples comparable to GANs on MNIST, CelebA and CIFAR-10 datasets, achieving a new state-of-the-art inception score of 8.87 on CIFAR-10. Additionally, we demonstrate that our models learn effective representations via image inpainting experiments.
(DeepL翻訳)
我々は、スコアマッチングによって推定されたデータ分布の勾配を用いて、ランジュバン動力学によってサンプルを生成する新しい生成モデルを導入する。データが低次元多様体に存在する場合、勾配は定義しにくく、推定が困難であるため、データに異なるレベルのガウスノイズを摂動し、対応するスコア、すなわち、すべてのノイズレベルに対する摂動されたデータ分布の勾配のベクトル場を共同で推定する。サンプリングに関しては、アニールされたランジュバン動力学を提案し、サンプリングプロセスがデータ多様体に近づくにつれて徐々に減少するノイズレベルに対応する勾配を使用する。我々のフレームワークは柔軟なモデルアーキテクチャを可能にし、学習時のサンプリングや敵対的手法の使用を必要とせず、原理的なモデル比較に利用可能な学習目標を提供する。我々のモデルはMNIST、CelebA、CIFAR-10データセットにおいてGANと同等のサンプルを生成し、CIFAR-10では8.87という最新のインセプションスコアを達成することができた。さらに、我々のモデルが効果的な表現を学習することを画像インペインティング実験により実証する。
https://github.com/ermongroup/ncsn
参考:
Stein scoreについて
Score matchingについて
Score matchingの計算量を抑えるための近似
Generative Adversarial Nets (GAN)
これまでの生成モデルで使われてきた代用損失
noise contrastive estimation
minimum probability flow
Rapp, Jacob T., et al. “Self-Driving Laboratories to Autonomously Navigate the Protein Fitness Landscape.” Nature Chemical Engineering, vol. 1, no. 1, Jan. 2024, pp. 97–107.
Protein engineering has nearly limitless applications across chemistry, energy and medicine, but creating new proteins with improved or novel functions remains slow, labor-intensive and inefficient. Here we present the Self-driving Autonomous Machines for Protein Landscape Exploration (SAMPLE) platform for fully autonomous protein engineering. SAMPLE is driven by an intelligent agent that learns protein sequence–function relationships, designs new proteins and sends designs to a fully automated robotic system that experimentally tests the designed proteins and provides feedback to improve the agent’s understanding of the system. We deploy four SAMPLE agents with the goal of engineering glycoside hydrolase enzymes with enhanced thermal tolerance. Despite showing individual differences in their search behavior, all four agents quickly converge on thermostable enzymes. Self-driving laboratories automate and accelerate the scientific discovery process and hold great potential for the fields of protein engineering and synthetic biology.
(DeepL翻訳)
タンパク質工学は、化学、エネルギー、医学の分野でほぼ無限の応用が可能であるが、改良された、あるいは新規の機能を持つ新しいタンパク質を作り出すには、時間がかかり、労力がかかり、非効率的である。ここでは、完全に自律的なタンパク質工学のためのSelf-driving Autonomous Machines for Protein Landscape Exploration (SAMPLE)プラットフォームを紹介する。SAMPLEはインテリジェントなエージェントによって駆動され、タンパク質の配列と機能の関係を学習し、新しいタンパク質を設計し、設計したタンパク質を実験的にテストし、エージェントのシステム理解を向上させるためにフィードバックを提供する完全自動ロボットシステムに設計を送信します。我々は、耐熱性を向上させたグリコシド加水分解酵素を設計する目的で、4つのSAMPLEエージェントを導入した。探索行動には個人差が見られるものの、4つのエージェントはすべて耐熱性酵素に素早く収束した。自動運転研究室は、科学的発見プロセスを自動化し、加速し、タンパク質工学と合成生物学の分野に大きな可能性をもたらす。


Approximately 9% of the experiments failed, presumably due to liquid-handing errors.

Heid, Esther, et al. “Characterizing Uncertainty in Machine Learning for Chemistry.” Journal of Chemical Information and Modeling, June 2023, https://doi.org/10.1021/acs.jcim.3c00373.
不確実性の由来に合わせ対策を練っていきましょう、という考えの根拠を見せてくれる論文。
Characterizing uncertainty in machine learning models has recently gained interest in the context of machine learning reliability, robustness, safety, and active learning. Here, we separate the total uncertainty into contributions from noise in the data (aleatoric) and shortcomings of the model (epistemic), further dividing epistemic uncertainty into model bias and variance contributions. We systematically address the influence of noise, model bias, and model variance in the context of chemical property predictions, where the diverse nature of target properties and the vast chemical chemical space give rise to many different distinct sources of prediction error. We demonstrate that different sources of error can each be significant in different contexts and must be individually addressed during model development. Through controlled experiments on data sets of molecular properties, we show important trends in model performance associated with the level of noise in the data set, size of the data set, model architecture, molecule representation, ensemble size, and data set splitting. In particular, we show that 1) noise in the test set can limit a model’s observed performance when the actual performance is much better, 2) using size-extensive model aggregation structures is crucial for extensive property prediction, and 3) ensembling is a reliable tool for uncertainty quantification and improvement specifically for the contribution of model variance. We develop general guidelines on how to improve an underperforming model when falling into different uncertainty contexts.
(DeepL翻訳)
機械学習モデルの不確実性を特徴付けることは、機械学習の信頼性、頑健性、安全性、能動学習の文脈で最近関心を集めている。ここでは、全不確実性をデータのノイズ(alleatoric)とモデルの欠点(epistemic)の寄与に分け、さらにepistemic不確実性をモデルのバイアスと分散の寄与に分ける。我々は、ノイズ、モデルのバイアス、モデルの分散の影響を、化学特性予測の文脈で体系的に扱います。ここでは、ターゲット特性の多様な性質と広大な化学化学空間が、予測誤差の多くの異なる原因を生じさせます。我々は、異なるエラー源がそれぞれ異なる文脈で重要な意味を持ち、モデル開発時に個別に対処する必要があることを実証する。分子特性のデータセットに関する制御された実験を通して、データセットのノイズレベル、データセットのサイズ、モデルアーキテクチャ、分子の表現、アンサンブルサイズ、データセットの分割に関連するモデル性能の重要な傾向を示す。特に、1)テストセットのノイズは、実際の性能がはるかに優れている場合に、モデルの観察された性能を制限する可能性があること、2)サイズを拡張したモデル集約構造を使用することが、広範な物性予測に不可欠であること、3)アンサンブルは、不確実性の定量化とモデル分散の寄与に特化した改善のための信頼できるツールであることを示す。我々は、様々な不確実性の文脈に陥った場合に、性能の低いモデルをどのように改善するかについての一般的なガイドラインを作成する。
Data sets generated by density functional theory (DFT) calculation are often considered for the role of a low-noise chemical data set as they are not subject to experimental uncertainty in data collection like most data sets would be.
Yue Liu, Zhengwei Yang, Xinxin Zou, Shuchang Ma, Dahui Liu, Maxim Avdeev, Siqi Shi. 2023. “Data quantity governance for machine learning in materials science.” National Science Review, nwad125, https://doi.org/10.1093/nsr/nwad125
Data-driven machine learning is widely employed in the analysis of materials structure-activity relationship, performance optimization and materials design due to its superior ability to reveal latent data patterns and make accurate prediction. However, because of the laborious process of materials data acquisition, machine learning models encounter the issue of the mismatch between high dimension of feature space and small sample size (for traditional machine learning models) or the mismatch between model parameters and sample size (for deep learning models), usually resulting in terrible performance. Here, we review the efforts for tackling this issue via feature reduction, sample augmentation, and specific machine learning approaches and show that the balance between the number of samples and features or model parameters should attract great attention during data quantity governance. Following this, we propose a synergistic data quantity governance flow with incorporation of materials domain knowledge. After summarizing the approaches to incorporating materials domain knowledge into the process of machine learning, we provide examples of incorporating domain knowledge into governance schemes to demonstrate the advantages of the approach and applications. The work paves the way for obtaining the required high-quality data to accelerate the materials design and discovery based on machine learning.
(DeepL翻訳)
データ駆動型の機械学習は、潜在的なデータパターンを明らかにし、正確な予測を行う優れた能力を持っているため、材料の構造と活性の関係の解析、性能最適化、材料設計に広く採用されています。しかし、材料データの取得に手間がかかるため、機械学習モデルは、特徴空間の高次元とサンプルサイズの不一致(従来の機械学習モデルの場合)、またはモデルパラメータとサンプルサイズの不一致(深層学習モデルの場合)という問題に遭遇し、通常、ひどいパフォーマンスをもたらす。ここでは、特徴量の削減、サンプル数の増加、特定の機械学習アプローチによってこの問題に取り組む取り組みをレビューし、データ量ガバナンスにおいて、サンプル数と特徴量またはモデルパラメータの間のバランスに大きな注意を払う必要があることを示す。続いて、材料分野の知識を取り入れた相乗的なデータ量ガバナンスのフローを提案する。機械学習のプロセスに材料分野の知識を取り入れるアプローチをまとめた後、ガバナンススキームにドメイン知識を取り入れる例を示し、アプローチの利点と応用を実証する。本作品は、機械学習に基づく材料設計・発見を加速させるために必要な高品質なデータを得るための道を開くものである。
まとめ作成時点では無し
本研究では、主に以下2つのフレームワークを提案
1.は、機械学習のプロセス全体に材料科学の知識を活用する際の指針を、2.は、材料のドメイン知識を導入してデータ量ガバナンスを行う際の指針を示す。
関係性として、1.のフレームワーク内の「Target definition & data preparation」箇所の検討で、2.のフレームワークが使用されるイメージ。
Xu, Benfeng, Licheng Zhang, Zhendong Mao, Quan Wang, Hongtao Xie, and Yongdong Zhang. 2020. “Curriculum Learning for Natural Language Understanding.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 6095–6104. Online: Association for Computational Linguistics.
https://aclanthology.org/2020.acl-main.542/
Fine-tuningの部分での工夫ができる本手法は実務適用の可能性・効率改善のインパクトが大きそう。
With the great success of pre-trained language models, the pretrain-finetune paradigm now becomes the undoubtedly dominant solution for natural language understanding (NLU) tasks. At the fine-tune stage, target task data is usually introduced in a completely random order and treated equally. However, examples in NLU tasks can vary greatly in difficulty, and similar to human learning procedure, language models can benefit from an easy-to-difficult curriculum. Based on this idea, we propose our Curriculum Learning approach. By reviewing the trainset in a crossed way, we are able to distinguish easy examples from difficult ones, and arrange a curriculum for language models. Without any manual model architecture design or use of external data, our Curriculum Learning approach obtains significant and universal performance improvements on a wide range of NLU tasks.
(DeepL翻訳)
事前学習された言語モデルの大きな成功により、事前学習-微調整パラダイムは現在、自然言語理解(NLU)タスクの間違いなく支配的なソリューションとなっています。微調整の段階では、通常、対象タスクのデータは完全にランダムな順序で導入され、平等に扱われる。しかし、NLUタスクの用例は難易度が大きく異なるため、人間の学習手順と同様に、言語モデルにも易しいものから難しいものまでのカリキュラムを用意することが有効である。この考え方に基づき、我々はカリキュラム学習のアプローチを提案する。訓練セットを横断的に見直すことで、簡単な例と難しい例を区別し、言語モデルのためのカリキュラムを整えることができる。本手法は、モデル設計や外部データの利用を一切必要とせず、様々なNLUタスクにおいて普遍的かつ大幅な性能向上を達成することが可能である。
Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/1910.10683.
ちゃんと他者の論文も引用し、残された課題なども議論している。好き。
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts all text-based language problems into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled data sets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new ``Colossal Clean Crawled Corpus'', we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our data set, pre-trained models, and code.
(DeepL翻訳)
自然言語処理(NLP)において、モデルを事前に学習させ、その後、下流のタスクで微調整を行う「転移学習」は、強力な手法として注目されている。転移学習の有効性は、様々なアプローチ、方法論、実践を生み出してきた。本論文では、全てのテキストベースの言語問題をテキストからテキストに変換する統一的なフレームワークを導入することで、NLPのための転移学習技術の展望を探っている。本論文では、数十の言語理解タスクについて、事前学習の目的、アーキテクチャ、ラベル無しデータセット、転移アプローチ、その他の要素を比較する。また、この研究で得られた知見を規模や新しい「Colossal Clean Crawled Corpus」と組み合わせることで、要約、質問応答、テキスト分類などをカバーする多くのベンチマークで最先端の結果を達成している。今後、自然言語処理における転移学習の研究を促進するために、我々のデータセット、事前学習済みモデル、そしてコードを公開する。
https://github.com/google-research/text-to-text-transfer-transformer

State-of-the-Art
ほぼSOTA
あまり良くない
(24タスクとどうやって数えているのだろう…?GLUE AverageとSuperGLUE Averageそれぞれもカウントしている?)
シンプルなアプローチにも関わらず、タスク固有のアーキテクチャに匹敵するパフォーマンスを獲得!
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan. 2023. "Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models" arXiv [cs.CV]. arXiv. https://arxiv.org/abs/2303.04671
自然言語と画像の両方を扱うVL(Vision, Language)タスクにおいて、マルチモーダルの学習を行って実現するのではなく、既存のモデルを組み合わせ、Promptを駆使して、画像編集や生成が可能なChatGPTのようなシステムを実現
ChatGPT is attracting a cross-field interest as it provides a language interface with remarkable conversational competency and reasoning capabilities across many domains. However, since ChatGPT is trained with languages, it is currently not capable of processing or generating images from the visual world. At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one-round fixed inputs and outputs. To this end, We build a system called Visual ChatGPT, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by 1) sending and receiving not only languages but also images 2) providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps. 3) providing feedback and asking for corrected results. We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models. Our system is publicly available at https://github.com/microsoft/visual-chatgpt.
(DeepL翻訳)
ChatGPT は、多くの領域で優れた会話能力と推論能力を持つ言語インタフェースを提供するため、分野横断的な関心を集めている。しかし、ChatGPTは言語で学習されるため、現在のところ、視覚世界から画像を処理したり生成したりすることはできない。同時に、Visual TransformerやStable DiffusionなどのVisual Foundation Modelsは、優れた視覚的理解と生成能力を示すものの、1ラウンドの固定入力と出力を持つ特定のタスクの専門家に過ぎない。そこで、様々なVisual Foundation Modelsを組み込んだVisual ChatGPTというシステムを構築し、ユーザーがChatGPTと対話できるように、次のような工夫をしている 1)言語だけでなく画像の送受信も可能 2)複数のAIモデルの連携が必要な複雑なビジュアルクエスチョンやビジュアル編集指示の提供、マルチステップの提供 3)提供する をフィードバックし、結果を訂正してもらう。
複数の入出力を持つモデルや視覚的なフィードバックを必要とするモデルを考慮し、ChatGPTにビジュアルモデル情報を注入するための一連のプロンプトを設計します。実験では、Visual ChatGPTが、Visual Foundation Modelsの助けを借りて、ChatGPTの視覚的役割を調査するための扉を開くことを示しています。私たちのシステムは、https://github.com/microsoft/visual-chatgpt で公開されています。
課題:画像の理解と生成もサポートするChatGPTのようなシステムを構築すること
近年のChatGPTに代表される大規模言語モデル(LLM)は驚異的に進歩しており、テキストの解釈や生成に優れた能力と汎用性があるが、現在のところは、視覚情報(画像情報)は処理はできない。
また、Visual TransformerやStable DiffusionなどのVisual Foundation Models(以下、VFM)は、優れた視覚的理解と生成能力を持つものの、特定のタスクに特化しており、タスクの汎用性に欠ける。
上記を解決する直感的なアイデアの一つは、マルチモーダルな会話モデルを開発することであるが、そのようなモデルの開発には、大量のデータと計算資源を消費してしまう。
本論文では、全く新しいマルチモダリティモデルを学習することなく、Prompt Managerを中核とし、ChatGPTと既存のVFMを組み合わせて上記課題を解決するシステムを提案する。
アーキテクチャ
Visual ChatGPTは、ChatGPTと既存のVFMを組み合わせ、チャットインターフェースでの画像生成・編集を実現するシステム。
システムの中核となるのはPromptManagerで、これは、画像情報をChatGPTが理解可能な言語形式に変換し、各種VFMを用いて画像処理を行う(Figure 1)
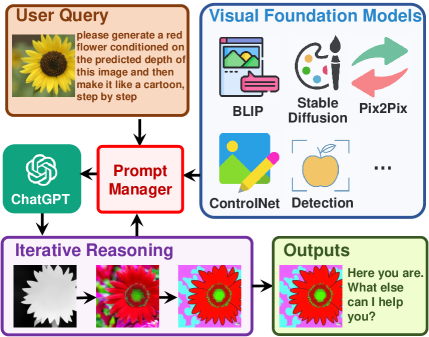
Visual ChatGPTの動作
下図(Figure 2)は、Visual ChatGPTの動作を示すフローチャート。
左側は3ラウンドの対話、右側はVisual ChatGPTがVisual Foundation Modelsを繰り返し呼び出し、特に2番目のQAの詳細処理を示している。
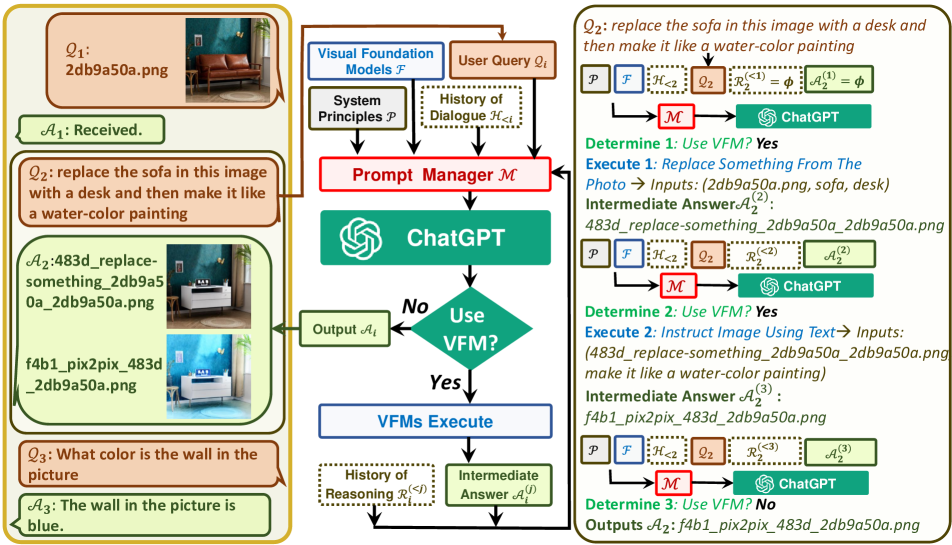
この例では、Execute 1で画像中のオブジェクトを置換し(A. Tool Details, Replace Something From The Photo 参照)、
Execute 2で、(A. Tool Details, Instruct Image Using Text 参照)のように、2回のステップを経て画像を編集している。
Prompt Managerの概要
Prompt Managerは、処理に応じて、適切なVFMを選択し、画像と言語の相互変換を行う。
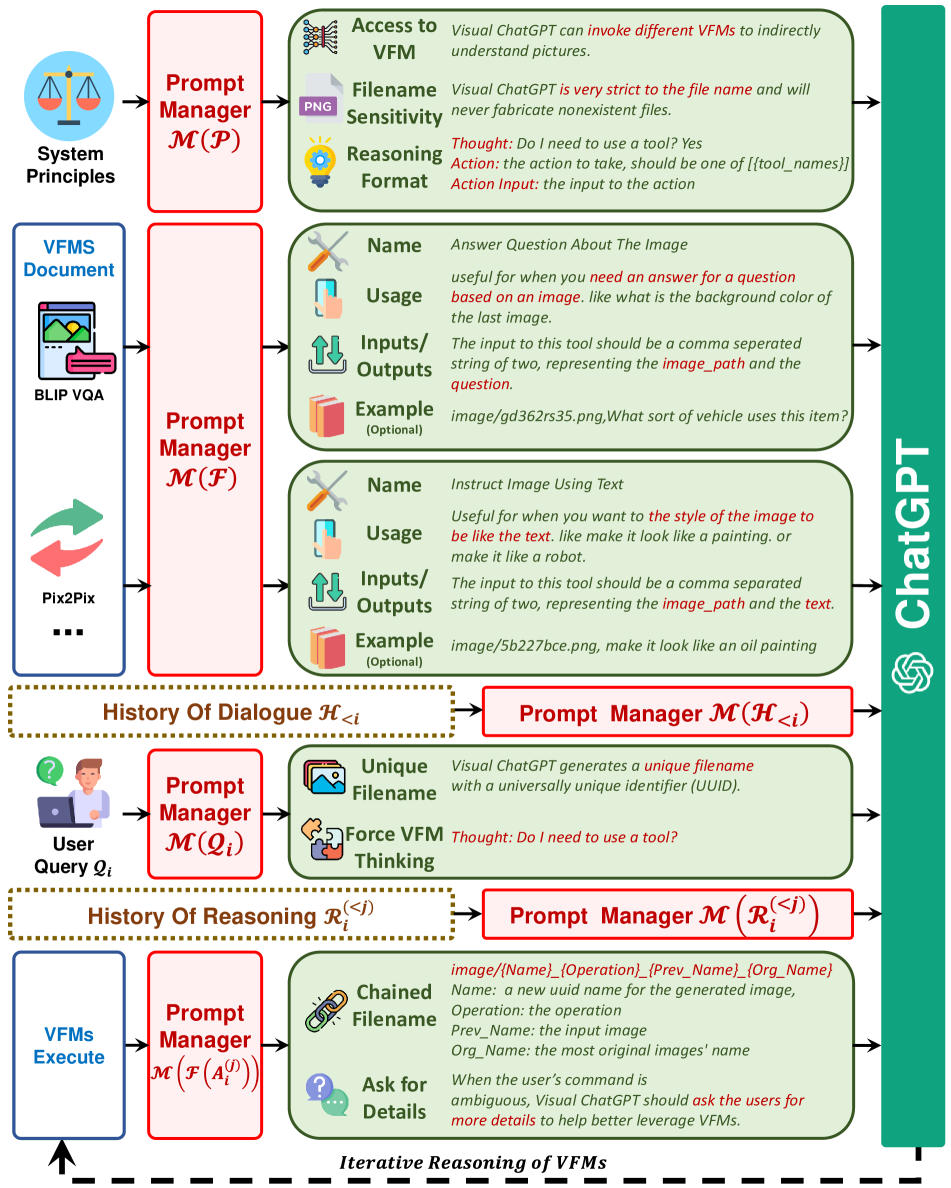
上図では、VFMとして BLIP, Pix2Pixの2点が例として記載されているが、Visual ChatGPTは、
例えば、写真中の特定のものを削除する、写真中のものを置き換えるなど、20以上のケースによってVFMの使い分けを行う(A. Tool Details参照)。
上記のシステムを構築することで、複雑な視覚的問題を段階的に解決することが実現できた。
Radford, Alec, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. “Improving Language Understanding by Generative Pre-Training.” https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf.
Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately. We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), and 1.5% on textual entailment (MultiNLI).
(DeepL翻訳)
自然言語理解には、含意関係、質問応答、意味的類似性評価、文書分類など、幅広い多様なタスクが含まれる。ラベル付けされていない大規模なテキストコーパスは豊富にあるが、これらの特定のタスクを学習するためのラベル付きデータは少なく、識別的に学習したモデルが適切に機能することは困難である。我々は、ラベル付けされていない多様なテキストコーパスに対して言語モデルの生成的な事前学習を行い、その後、各タスクに対して識別的な微調整を行うことで、これらのタスクで大きな利益が得られることを実証している。従来のアプローチとは異なり、我々はタスクに応じた入力変換を行うことで、モデルアーキテクチャの変更を最小限に抑えながら、効果的な学習効果を得ることができる。我々は、自然言語理解に関する広範なベンチマークにおいて、本アプローチの有効性を実証する。その結果、タスクに依存しない我々のモデルは、各タスクに特化したアーキテクチャを用いた識別学習モデルを凌駕し、調査した12タスクのうち9タスクにおいて現状を大きく改善した。例えば、常識的推論(Stories Cloze Test)では8.9%、質問応答(RACE)では5.7%、テキスト含意(MultiNLI)では1.5%の絶対的な向上を達成しました。
State-of-the-Art
Natural language inference
Q&A
Sentence similarity
Classification
SOTAでこそないが、よい
Power, Alethea, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. 2022. “Grokking: Generalization beyond Overfitting on Small Algorithmic Datasets.” ArXiv:2201.02177 [Cs], January. http://arxiv.org/abs/2201.02177.
In this paper we propose to study generalization of neural networks on small al- gorithmically generated datasets. In this setting, questions about data efficiency, memorization, generalization, and speed of learning can be studied in great de- tail. In some situations we show that neural networks learn through a process of “grokking” a pattern in the data, improving generalization performance from random chance level to perfect generalization, and that this improvement in general- ization can happen well past the point of overfitting. We also study generalization as a function of dataset size and find that smaller datasets require increasing amounts of optimization for generalization. We argue that these datasets provide a fertile ground for studying a poorly understood aspect of deep learning: generalization of overparametrized neural networks beyond memorization of the finite training dataset.
(DeepL翻訳)
本論文では、アルゴリズムによって生成された小規模なデータセットにおけるニューラルネットワークの汎化について研究することを提案する。この設定では、データ効率、記憶、汎化、および学習速度に関する問題を非常に詳細に研究することができる。ある状況では、ニューラルネットワークがデータ中のパターンを「把握」するプロセスを通じて学習し、汎化性能をランダムな偶然のレベルから完全な汎化へと改善すること、そしてこの汎化の改善はオーバーフィッティングのポイントをはるかに超えて起こり得ることを示した。また、データセットサイズの関数として汎化を研究し、より小さなデータセットでは、汎化のための最適化量が増加することを発見した。我々は、これらのデータセットが、ディープラーニングの理解されていない側面、すなわち、有限のトレーニングデータセットの記憶を超えたオーバーパラメトリックニューラルネットワークの汎化を研究するための肥沃な土壌を提供すると主張する。
学習と汎化における先行研究では、ニューラルネットワークが記号・アルゴリズム推論を行う能力を調べるためにアルゴリズムデータセットが用いられてきた。本論文も同様のテーマで取り組んでいる。
ほとんどの先行研究ではモデルのアーキテクチャの選択による影響に焦点を合わせていたのに対して、本論文ではモデルのアーキテクチャを固定した実験として紹介している。
データセット:
以下の配列(テーブル)構造の組み合わせから二項演算の方程式を推定させるデータセットとなっている。

他のマス同士の相関関係から方程式を推定させ、「?」の部分に当てはまる数値を予測させる。
二項演算の方程式のパターンは以下。

モデル:
2レイヤー、4つのAttentionヘッドを持つTransformerを使用(パラメータ数:4*10^5)
上記実験条件のもと、モデルのアーキテクチャは変えずに以下の項目を変更しながら学習の汎化までの過程を観察した。
訓練データを完全に記憶することができる点を超えた汎化の変化点(これをGrokkingと呼んでいる)が存在する現象を発見した。
Grokkingの現象を表すグラフを以下に示す。

左図より、赤(train)が急上昇しているタイミングで緑(val)は変化がないところから過学習していることがわかり、更にステップ数を増やしていくとvalの精度が急激に上昇していることがわかる。
また右図は精度が99%を超えるまでにかかるステップ数を縦軸、データセットの大きさを横軸にした相関を示しているが、データセットが小さいほどステップ数が多くなる傾向であることを示している。
様々な汎化手法を試しており、どの汎化手法がGrokkingに効果的か調べた。

上記の結果から、効果的な技術と考えられるものは以下。
Tyna Eloundou, Sam Manning, Pamela Mishkin, Daniel Rock. 2023. “GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models.” arXiv [econ.GN]. arXiv. https://arxiv.org/abs/2303.10130.
We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising from LLM-powered software compared to LLMs on their own. Using a new rubric, we assess occupations based on their alignment with LLM capabilities, integrating both human expertise and GPT-4 classifications. Our findings reveal that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. We do not make predictions about the development or adoption timeline of such LLMs. The projected effects span all wage levels, with higher-income jobs potentially facing greater exposure to LLM capabilities and LLM-powered software. Significantly, these impacts are not restricted to industries with higher recent productivity growth. Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks. This finding implies that LLM-powered software will have a substantial effect on scaling the economic impacts of the underlying models. We conclude that LLMs such as GPTs exhibit traits of general-purpose technologies, indicating that they could have considerable economic, social, and policy implications.
(DeepL翻訳)
我々は、GPT(Generative Pre-trained Transformers)のような大規模言語モデル(LLM)が米国の労働市場に与える潜在的な影響を調査し、LLM単体と比較してLLM搭載のソフトウェアから生じる能力の向上に焦点を当てる。新しい評価基準を用いて、人間の専門知識とGPT-4分類の両方を統合し、LLMの能力との整合性に基づいて職業を評価しました。その結果、米国の労働者の約80%が、LLMの導入により少なくとも10%の業務に影響を受ける可能性があり、約19%の労働者は少なくとも50%の業務に影響を受ける可能性があることが明らかになりました。また、LLMの開発・導入時期については予測を行っていません。予測される影響はすべての賃金水準に及び、高所得の職種ほどLLMの機能やLLMを搭載したソフトウェアに触れる機会が多くなる可能性があります。重要なのは、こうした影響は、最近の生産性上昇率が高い産業に限定されないということである。我々の分析によると、LLMを利用することで、米国における労働者の全作業の約15%が、同じ品質レベルで大幅に速く完了する可能性があることが示唆された。LLMの上に構築されたソフトウェアやツールを組み込むと、この割合は全作業の47~56%に増加する。この発見は、LLMを搭載したソフトウェアが、基礎となるモデルの経済的影響を拡大する上で大きな効果を発揮することを示唆している。GPTのようなLLMは、汎用的な技術であり、経済的、社会的、政策的に大きな意味を持つ可能性があると結論付けている。







※ 以上の結果の受け止め方については、後述の 感想>注意すべき結果>基本スキルの解釈 も参照されたい。
Kosonocky, Clayton W., et al. “Mining Patents with Large Language Models Demonstrates Congruence of Functional Labels and Chemical Structures.” arXiv [q-bio.QM], 15 Sept. 2023, http://arxiv.org/abs/2309.08765. arXiv.
言語モデル + 特許データを活用した新規材料開発の一事例として面白い報告。予測できていない分子の特徴や、全く未知の分子を与えたときにどういう結果が出るのかは気になるところ。
Predicting chemical function from structure is a major goal of the chemical sciences, from the discovery and repurposing of novel drugs to the creation of new materials. Recently, new machine learning algorithms are opening up the possibility of general predictive models spanning many different chemical functions. Here, we consider the challenge of applying large language models to chemical patents in order to consolidate and leverage the information about chemical functionality captured by these resources. Chemical patents contain vast knowledge on chemical function, but their usefulness as a dataset has historically been neglected due to the impracticality of extracting high-quality functional labels. Using a scalable ChatGPT-assisted patent summarization and word-embedding label cleaning pipeline, we derive a Chemical Function (CheF) dataset, containing 100K molecules and their patent-derived functional labels. The functional labels were validated to be of high quality, allowing us to detect a strong relationship between functional label and chemical structural spaces. Further, we find that the co-occurrence graph of the functional labels contains a robust semantic structure, which allowed us in turn to examine functional relatedness among the compounds. We then trained a model on the CheF dataset, allowing us to assign new functional labels to compounds. Using this model, we were able to retrodict approved Hepatitis C antivirals, uncover an antiviral mechanism undisclosed in the patent, and identify plausible serotonin-related drugs. The CheF dataset and associated model offers a promising new approach to predict chemical functionality.
(DeepL翻訳)
構造から化学機能を予測することは、新薬の発見や再利用から新材料の創製に至るまで、化学科学の主要な目標である。近年、新しい機械学習アルゴリズムにより、様々な化学機能にまたがる一般的な予測モデルの可能性が開かれつつある。ここでは、化学特許に大規模な言語モデルを適用することで、これらのリソースによって捕捉された化学的機能性に関する情報を統合し、活用するという課題について考察する。化学特許には化学機能に関する膨大な知識が含まれているが、高品質な機能ラベルを抽出することが現実的でないため、データセットとしての有用性はこれまで軽視されてきた。ChatGPTによる特許要約と単語埋め込みラベルクリーニングパイプラインを用いて、10万個の分子と特許由来の機能ラベルを含む化学機能(CheF)データセットを作成した。機能ラベルは高品質であることが検証され、機能ラベルと化学構造空間の強い関係を検出することができた。さらに、機能ラベルの共起グラフには頑健な意味構造が含まれていることがわかり、化合物間の機能的関連性を調べることができた。次に、CheFデータセットでモデルを学習し、化合物に新しい機能ラベルを割り当てることを可能にした。このモデルを使用することで、承認されたC型肝炎の抗ウイルス薬を逆探知し、特許では開示されていない抗ウイルスメカニズムを発見し、もっともらしいセロトニン関連薬を特定することができた。CheFデータセットと関連モデルは、化学的機能性を予測するための有望な新しいアプローチを提供する。
https://github.com/kosonocky/chef
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. 2022. “Training language models to follow instructions with human feedback.” arXiv [cs.CL]. https://arxiv.org/abs/2203.02155
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
(DeepL翻訳)
言語モデルを大きくしても、ユーザーの意図に沿うようになるとは限りません。例えば、大きな言語モデルは、真実味のない、有害な、あるいは単にユーザーにとって役に立たない出力を生成することがあります。言い換えれば、これらのモデルはユーザーと一致していないのである。本論文では、人間のフィードバックを用いて微調整を行うことで、様々なタスクにおいて言語モデルをユーザーの意図に沿うようにする方法を示す。まず、ラベラーが書いたプロンプトとOpenAI APIを通じて送信されたプロンプトのセットから始め、我々はラベラーが望ましいモデルの動作を示すデータセットを収集し、それを用いて教師あり学習を用いてGPT-3の微調整を行う。次に、モデル出力のランキングデータセットを収集し、人間のフィードバックからの強化学習を用いて、この教師ありモデルをさらに微調整するために使用する。このようにして得られたモデルをInstructGPTと呼ぶ.我々のプロンプト分布に対する人間の評価では、パラメータが100倍少ないにもかかわらず、パラメータ1.3BのInstructGPTモデルの出力が、パラメータ175BのGPT-3の出力よりも優先されました。さらに、InstructGPTモデルは、真実性の向上と有害な出力生成の削減を示す一方で、公開されたNLPデータセットに対する性能低下は最小限であることが分かりました。この結果は、人間のフィードバックによる微調整が、言語モデルを人間の意図に沿わせるための有望な方向性であることを示しています。
まとめ作成時点では無し
3ステップで構成される。

ベースはGPT-3。Web上の多様なデータで学習された状態の、いわば「人間が意図せぬ動作」をするモデルがスタート。
3つの観点で評価を実施。以下は図中の用語の説明。
(APIの詳細は付録A.2参照)


TruthfulQAデータセットを利用


alignmentを追求するトレードオフとして、汎用的なNLPタスクで性能が低下する
DROP, HellaSwag, SQuADv2, BLEU (French → English) などで評価(一覧はTab.14参照)

結果
InstructGPTのFine-tuningに使用したデータは英語の文章データが中心で、それ以外はごく少数であったにも関わらず、英語以外の言語やプログラミングコードの要約・質問応答も可能という、興味深い結果が得られた。

まだまだ単純なミスをする


モデルが誰に対して alignment されるかが極めて重要
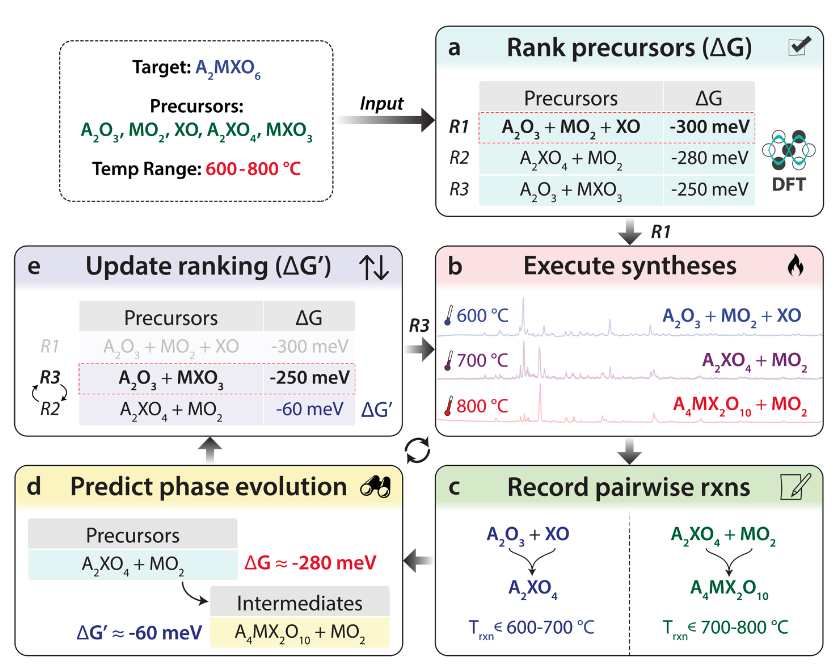
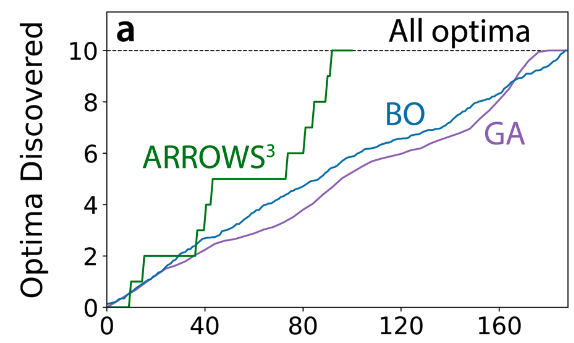
Szymanski, Nathan J., et al. “Autonomous Decision Making for Solid-State Synthesis of Inorganic Materials.” arXiv [cond-Mat.mtrl-Sci], Apr. 2023, https://arxiv.org/abs/2304.09353. arXiv.
To aid in the automation of inorganic materials synthesis, we introduce an algorithm (ARROWS3) that guides the selection of precursors used in solid-state reactions. Given a target phase, ARROWS3 iteratively proposes experiments and learns from their outcomes to identify an optimal set of precursors that leads to maximal yield of that target. Initial experiments are selected based on thermochemical data collected from first principles calculations, which enable the identification of precursors exhibiting large thermodynamic force to form the desired target. Should the initial experiments fail, their associated reaction paths are determined by sampling a range of synthesis temperatures and identifying their products. ARROWS3 then uses this information to pinpoint which intermediate reactions consume most of the available free energy associated with the starting materials. In subsequent experimental iterations, precursors are selected to avoid such unfavorable reactions and therefore maintain a strong driving force to form the target. We validate this approach on three experimental datasets containing results from more than 200 distinct synthesis procedures. When compared to several black-box optimization algorithms, ARROWS3 identifies the most effective set of precursors for each target while requiring substantially fewer experimental iterations. These findings highlight the importance of using domain knowledge in the design of optimization algorithms for materials synthesis, which are critical for the development of fully autonomous research platforms.
(DeepL翻訳)
無機材料合成の自動化を支援するために、固体反応で使用される前駆体の選択をガイドするアルゴリズム(ARROWS3)を紹介する。ターゲット相が与えられると、ARROWS3は繰り返し実験を提案し、その結果から学習して、ターゲットの最大収率につながる最適な前駆体セットを同定する。最初の実験は、第一原理計算から収集された熱化学的データに基づいて選択され、これにより目的のターゲットを形成する大きな熱力学的力を示す前駆体を同定することができる。初期実験が失敗した場合、合成温度の範囲をサンプリングし、その生成物を同定することにより、関連する反応経路が決定される。ARROWS3はこの情報を使って、出発物質に関連する利用可能な自由エネルギーのほとんどを消費する中間反応を特定する。その後の実験反復では、そのような不利な反応を避け、ターゲットを形成する強い駆動力を維持するように前駆体が選択される。我々は、200以上の異なる合成手順から得られた結果を含む3つの実験データセットで、このアプローチを検証した。いくつかのブラックボックス最適化アルゴリズムと比較すると、ARROWS3は各ターゲットに対して最も効果的な前駆体セットを同定する一方で、実験の反復回数を大幅に少なくすることができた。これらの結果は、材料合成の最適化アルゴリズムの設計に領域知識を用いることの重要性を強調している。
https://github.com/njszym/ARROWS
Watson, David S., Kristin Blesch, Jan Kapar, and Marvin N. Wright. 2022. “Adversarial Random Forests for Density Estimation and Generative Modelling.” arXiv [stat.ML]. arXiv. http://arxiv.org/abs/2205.09435.
こちらの手法について技術記事を執筆しました。「Adversarial Random ForestsによるテーブルデータのAugmentation・モックデータ生成」
We propose methods for density estimation and data synthesis using a novel form of unsupervised random forests. Inspired by generative adversarial networks, we implement a recursive procedure in which trees gradually learn structural properties of the data through alternating rounds of generation and discrimination. The method is provably consistent under minimal assumptions. Unlike existing tree-based alternatives, our approach provides smooth unconditional densities and allows for fully synthetic data generation. We achieve comparable or superior performance to state-of-the-art deep learning models on various tabular data benchmarks while executing about two orders of magnitude faster on average. All algorithms are implemented in easy-to-use 𝚁 and Python packages.
(DeepL翻訳)
我々は教師なしランダムフォレストの新しい形式を用いた密度推定とデータ合成の方法を提案する。生成的敵対ネットワークに触発され、木が生成と識別を交互に繰り返すことでデータの構造的特性を徐々に学習する再帰的な手順を実装している。この方法は、最小限の仮定で証明可能な一貫性を持つ。既存の木ベースの代替手法とは異なり、我々のアプローチは滑らかな無条件密度を提供し、完全な合成データの生成を可能にする。様々な表形式データのベンチマークにおいて、平均で約2桁高速に実行しながら、最先端の深層学習モデルと同等以上の性能を達成する。全てのアルゴリズムは、使いやすいRとPythonパッケージで実装されています。
n=2000の3次元データ (上) から密度を推定→その推定密度からデータを生成 (下)。元のデータの分布をおおよそ再現できている (Fig.1)
7つのベンチマークデータセットを用い、元データの再現度合いを比較 (Table.1)

Shin, Dongmin, Yugeun Shim, Hangyeol Yu, Seewoo Lee, Byungsoo Kim, and Youngduck Choi. 2020. “SAINT+: Integrating Temporal Features for EdNet Correctness Prediction.” arXiv [cs.CY]. arXiv. http://arxiv.org/abs/2010.12042.
テーブルデータへの適用に特化したニューラルネットワークアーキテクチャのSAINTとは関係なし。(論文実装のときは原著を明確に引用しよう!)
We propose SAINT+, a successor of SAINT which is a Transformer based knowledge tracing model that separately processes exercise information and student response information. Following the architecture of SAINT, SAINT+ has an encoder-decoder structure where the encoder applies self-attention layers to a stream of exercise embeddings, and the decoder alternately applies self-attention layers and encoder-decoder attention layers to streams of response embeddings and encoder output. Moreover, SAINT+ incorporates two temporal feature embeddings into the response embeddings: elapsed time, the time taken for a student to answer, and lag time, the time interval between adjacent learning activities. We empirically evaluate the effectiveness of SAINT+ on EdNet, the largest publicly available benchmark dataset in the education domain. Experimental results show that SAINT+ achieves state-of-the-art performance in knowledge tracing with an improvement of 1.25% in area under receiver operating characteristic curve compared to SAINT, the current state-of-the-art model in EdNet dataset.
(DeepL翻訳)
我々は、演習情報と生徒の反応情報を別々に処理するTransformerベースの知識トレースモデルであるSAINTの後継モデルであるSAINT+を提案する。SAINT+はSAINTのアーキテクチャを踏襲し、エンコーダが演習の埋め込み情報に対して自己注意層を適用し、デコーダが応答の埋め込み情報とエンコーダ出力に対して自己注意層とエンコーダ・デコーダ注意層を交互に適用するエンコーダ・デコーダ構造を持っている。さらに、SAINT+は応答埋め込みの中に、生徒が回答するまでにかかった時間である経過時間と、隣接する学習活動の間の時間間隔であるラグタイムという二つの時間的特徴埋め込みを組み込んでいる。我々は、教育分野において公開されている最大のベンチマークデータセットであるEdNetを用いて、SAINT+の有効性を実証的に評価した。実験の結果、EdNetデータセットにおける現在の最新モデルであるSAINTと比較して、受信者動作特性曲線下面積で1.25%の改善を示し、知識トレースにおいて最先端の性能を達成することが示された。
Singh, Avi, et al. “Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models.” arXiv [cs.LG], Dec. 2023, https://arxiv.org/abs/2312.06585. arXiv.
LLMに強化学習の枠組みを適用し、人の手を離れた成長を目指した仕事。現状は性能向上の限界が見えているが、原因の考察もされており、そこのブレイクスルーが起こればとてもおもしろい世界が広がっていそう。
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReSTEM, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReSTEM scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
(DeepL翻訳)
人間が作成したデータを用いて言語モデル(LM)を微調整することは、現在でも広く行われている。しかし、そのようなモデルの性能は、高品質な人間データの量と多様性によって制限されることが多い。本論文では、スカラーフィードバックにアクセスできるタスク、例えば正しさを検証できる数学の問題において、人間のデータを超えることができるかどうかを探求する。そのために、我々はReSTEMと呼ぶ、期待値最大化に基づく単純な自己学習法を検討する。ReSTEMでは、(1)モデルからサンプルを生成し、バイナリフィードバックを用いてフィルタリングし、(2)これらのサンプルでモデルを微調整し、(3)このプロセスを数回繰り返す。PaLM-2モデルを使用した高度なMATH推論とAPPSコーディングベンチマークでテストした結果、ReSTEMはモデルサイズに応じて良好にスケールし、人間のデータでのみ微調整を大幅に上回ることがわかった。全体として、我々の知見は、フィードバックを伴う自己学習が、人間が生成したデータへの依存を大幅に低減できることを示唆している。
数学課題とコーディングテストで能力が向上 (Fig.1)
人間が生み出したデータを用いたとき (Supervised Fine-Tuning; SFTと呼称) よりも性能が良かった。(Figs.2,3)
生成→学習のサイクルを2, 3回繰り返すと性能の向上が緩やかになった・あるいは見られなくなった。(Figs.2-4)
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/1706.03762.
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
(DeepL翻訳)
配列変換モデルの主流は、エンコーダーとデコーダーの構成による複雑なリカレントニューラルネットワークや畳み込みニューラルネットワークに基づいています。また、最も性能の良いモデルは、注意メカニズムを介してエンコーダとデコーダを接続している。我々は、リカレントや畳み込みを完全に排除し、アテンション機構のみに基づく新しいシンプルなネットワークアーキテクチャ、トランスフォーマーを提案する。2つの機械翻訳タスクで実験した結果、これらのモデルは品質が優れている一方で、より並列化可能であり、学習時間が大幅に短縮されることがわかった。我々のモデルは、WMT 2014英語-ドイツ語翻訳タスクで28.4BLEUを達成し、アンサンブルを含む既存の最良結果を2BLEU以上上回りました。WMT 2014英仏翻訳タスクにおいて、我々のモデルは8GPUで3.5日間学習した後、41.8という新しい単一モデルの最新BLEUスコアを確立し、文献から得られた最良のモデルの学習コストのごく一部であることを示した。我々は、Transformerが他のタスクにうまく一般化することを、大規模および限られた学習データの両方で英語の構成語解析にうまく適用することで示す。
https://paperswithcode.com/paper/attention-is-all-you-need#code

Kevin Maik Jablonka, Philippe Schwaller, Andres Ortega-Guerrero, and Berend Smit. 2023. "Is GPT-3 all you need for low-data discovery in chemistry?" ChemRxiv. https://chemrxiv.org/engage/chemrxiv/article-details/63eb5a669da0bc6b33e97a35
Machine learning has revolutionized many fields and has recently found applications in chemistry and materials science. The small datasets commonly found in chemistry lead to various sophisticated machine-learning approaches that incorporate chemical knowledge for each application and therefore require a lot of expertise to develop. Here, we show that large language models that have been trained on vast amounts of text extracted from the internet can easily be adapted to solve various tasks in chemistry and materials science by simply prompting them with chemical questions in natural language. We compared this approach with dedicated machine-learning models for many applications spanning properties of molecules and materials to the yield of chemical reactions. Surprisingly, we find this approach performs comparable to or even outperforms the conventional techniques, particularly in the low data limit. In addition, by simply inverting the questions, we can even perform inverse design successfully. The high performance, especially for small data sets, combined with the ease of use, can have a fundamental impact on how we leverage machine learning in the chemical and material sciences. Next to a literature search, querying a foundational model might become a routine way to bootstrap a project by leveraging the collective knowledge encoded in these foundational models.
(DeepL翻訳)
機械学習は多くの分野に革命を起こし、最近では化学や材料科学にも応用されている。化学分野では一般的にデータセットが小さいため、用途に応じて化学的知識を取り入れた様々な高度な機械学習アプローチが必要となり、その開発には多くの専門知識が必要とされる。ここでは、インターネットから抽出した膨大な量のテキストで学習した大規模言語モデルを、自然言語で化学的な質問を促すだけで、化学や材料科学の様々なタスクの解決に容易に適応できることを示す。我々は、分子や材料の特性から化学反応の収率に及ぶ多くのアプリケーションについて、このアプローチと専用の機械学習モデルを比較しました。その結果、特に低データ数領域において、従来手法と同等、あるいはそれ以上の性能を発揮することが分かりました。さらに、質問を反転させるだけで、逆設計まで成功させることができます。特に小さなデータセットに対する高い性能と使いやすさは、化学や材料科学における機械学習の活用方法に根本的な影響を与える可能性があります。文献検索に次いで、基礎的なモデルへの問い合わせが、これらの基礎的なモデルにエンコードされた集合知を活用することによって、プロジェクトを立ち上げるための日常的な方法となるかもしれないのである。
https://github.com/kjappelbaum/gptchem
化学や材料科学の様々な機械学習タスクを、 GPT-3 の Fine-Tuning 機能を用いて解決。
以下それぞれ、分類、回帰、逆問題のプロンプトと目的変数の例

分類問題においては、従来手法の最高性能のものと同等か、それ以上の性能を達成する場合が多い。
以下は、高エントロピー合金における固溶体形成予測(2値分類問題)で、GPT-3とその他のモデルで学習データ数を変化させながら比較した結果。

逆問題においては、 What is a photoswitch with transition wavelengths of 324.0 nm and 442 nm のように質問したら、SMILES文字列で分子設計を返してくれる。
以下の画像における緑や紫のパターンについては、おそらくこれまでこの逆問題では発見されていなかった分子だが、理論上は目的の遷移波長に近い値をもつと言及されている。

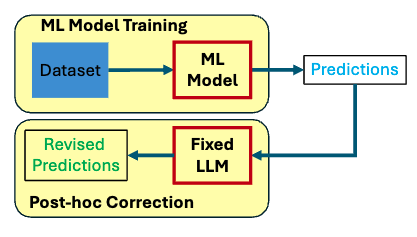
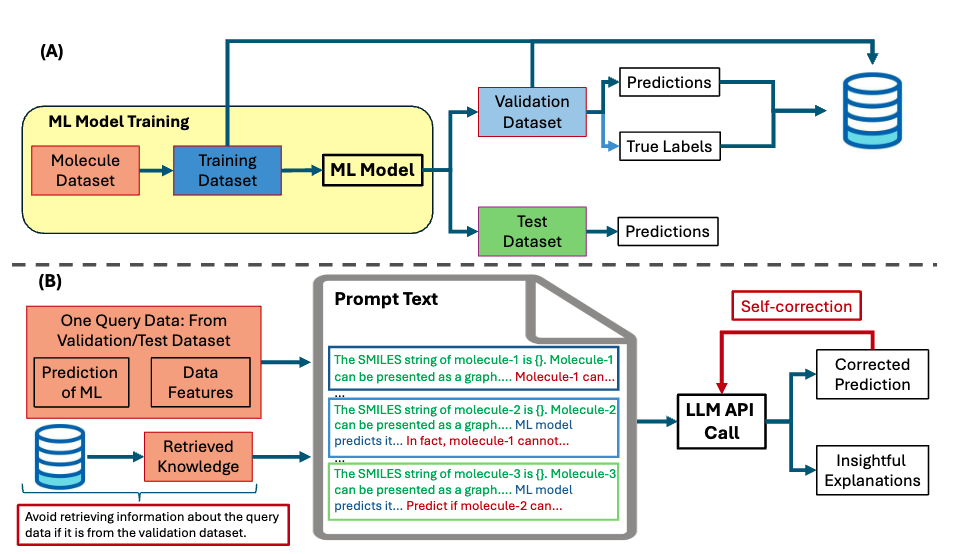
Zhong, Zhiqiang, et al. “Harnessing Large Language Models as Post-Hoc Correctors.” arXiv [cs.LG], 20 Feb. 2024, http://arxiv.org/abs/2402.13414. arXiv.
As Machine Learning (ML) models grow in size and demand higher-quality training data, the expenses associated with re-training and fine-tuning these models are escalating rapidly. Inspired by recent impressive achievements of Large Language Models (LLMs) in different fields, this paper delves into the question: can LLMs efficiently improve an ML's performance at a minimal cost? We show that, through our proposed training-free framework LlmCorr, an LLM can work as a post-hoc corrector to propose corrections for the predictions of an arbitrary ML model. In particular, we form a contextual knowledge database by incorporating the dataset's label information and the ML model's predictions on the validation dataset. Leveraging the in-context learning capability of LLMs, we ask the LLM to summarise the instances in which the ML model makes mistakes and the correlation between primary predictions and true labels. Following this, the LLM can transfer its acquired knowledge to suggest corrections for the ML model's predictions. Our experimental results on the challenging molecular predictions show that LlmCorr improves the performance of a number of models by up to 39%.
(DeepL翻訳)
機械学習(ML)モデルのサイズが大きくなり、より質の高い学習データが要求されるようになるにつれ、モデルの再学習や微調整にかかる費用は急速に増大している。本稿では、様々な分野における大規模言語モデル(LLM)の最近の目覚ましい成果に触発され、LLMは最小限のコストで効率的にMLの性能を向上させることができるのか?我々が提案する訓練不要のフレームワークLlmCorrを用いることで、LLMが任意のMLモデルの予測値に対する補正を提案するポストホックコレクタとして機能することを示す。特に、データセットのラベル情報と、検証データセットに対するMLモデルの予測を取り込むことで、文脈的知識データベースを形成する。LLMの文脈内学習能力を活用し、LLMに、MLモデルがミスを犯した事例と、一次予測と真のラベルの相関を要約してもらう。これに続いて、LLMは獲得した知識をMLモデルの予測の修正を提案するために伝達することができる。困難な分子予測に関する我々の実験結果は、LlmCorrが多くのモデルの性能を最大39%改善することを示している。

Sun, Eric D., et al. “Dynamic Visualization of High-Dimensional Data.” bioRxiv, 29 May 2022, p. 2022.05.27.493785, https://doi.org/10.1101/2022.05.27.493785.
本論文はNature Computational Scienceに受理されているが、本サマリーではbioRxiv版を参照している。
提案手法は、計算時間がネックではあるが、これまでheuristicに行うことが一般的であった部分への数値指標導入や、解釈に至る道筋からの恣意性の削減など、既存の次元削減手法の弱みを上手くカバーしており、実践導入してみたいと思わせるフレームワークとなっている。
Dimensionality reduction (DR) is commonly used to project highdimensional data into lower dimensions for visualization, which could then generate new insights and hypotheses. However, DR algorithms necessarily introduce distortions in the visualization and cannot faithfully represent all relations in the data. As such, there is a need for methods to assess the reliability of DR visualizations. Here we present DynamicViz, a framework for generating dynamic visualizations that capture the sensitivity of DR visualizations to perturbations in the data. DynamicVic can be applied to all commonly used DR methods. We show the utility of dynamic visualizations in diagnosing common interpretative pitfalls of static visualizations and extending existing single-cell analyses. We introduce the variance score to quantify the dynamic variability of observations in these visualizations. The variance score characterizes natural variability in the data and can be used to optimize DR algorithm implementations. We have made DynamicViz freely available to assist with the evaluation of DR visualizations.
(DeepL翻訳)
次元削減(DR)は、高次元のデータを低次元に投影して可視化し、新たな知見や仮説を生み出すために一般的に使用されています。しかし、DRのアルゴリズムは、必然的に可視化に歪みをもたらし、データ内のすべての関係を忠実に表現することができません。そのため、DRによる可視化の信頼性を評価する手法が必要とされている。ここでは、データの摂動に対するDR可視化の感度を把握する動的可視化を生成するフレームワークであるDynamicVizを紹介する。DynamicVicは、一般的に使用されているすべてのDR手法に適用することができます。静的可視化の解釈上の落とし穴を診断し、既存のシングルセル解析を拡張する上で、動的可視化の有用性を示す。これらの可視化において、観測値の動的な変動を定量化するために、分散スコアを導入する。分散スコアは、データの自然な変動を特徴付けるもので、DRアルゴリズムの実装を最適化するために使用することができます。DR可視化の評価を支援するために、DynamicVizを自由に利用できるようにしました。
Nakkiran, Preetum, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. 2019. “Deep Double Descent: Where Bigger Models and More Data Hurt.” ArXiv:1912.02292 [Cs, Stat], December. https://arxiv.org/abs/1912.02292.
We show that a variety of modern deep learning tasks exhibit a “double-descent”phenomenon where, as we increase model size, performance first gets worse and then gets better. Moreover, we show that double descent occurs not just as a function of model size, but also as a function of the number of training epochs. We unify the above phenomena by defining a new complexity measure we call the effective model complexity and conjecture a generalized double descent with respect to this measure. Furthermore, our notion of model complexity allows us to identify certain regimes where increasing (even quadrupling) the number of train samples actually hurts test performance.
(DeepL翻訳)
我々は、現代の様々な深層学習課題において、モデルサイズを大きくすると、まず性能が低下し、次に良くなるという「二重降下」現象が起こることを示す。さらに、二重降下はモデルサイズの関数としてだけでなく、学習エポック数の関数としても発生することを示す。我々は、有効モデル複雑度と呼ぶ新しい複雑度指標を定義することで上記の現象を統一し、この指標に関して一般化された二重降下が起こることを予言する。さらに、このモデルの複雑さの概念により、訓練サンプル数を増やすと(4倍でも)テスト性能が低下する特定の領域を特定することができる。
https://gitlab.com/harvard-machine-learning/double-descent/tree/master
これまで機械学習における汎化と過学習については、Bias-Variance Trade-offという概念で説明されてきた。
Biasは誤差の偏りを表し、Varianceは誤差の分散(ばらつき)を表す。
モデルの複雑さが高いほどBiasは小さくなるがVarianceは大きくなり、過学習が進む。
一方でモデルの複雑さが少ないほどBiasは大きくなりVarianceが小さくなるため、学習不足となる。
しかし機械学習の研究では「複雑なモデルでも過学習を超えて再び汎化する」ケースが存在する。
その事例としてとDouble Descentとという現象が発見されている。
Double Descentとは、最初test errorが単調に減少した後(アンダーパラメータ)、test errorが増加(過学習)、そして再びtest errorが下がり出す二重降下現象のことである。
例えば機械学習の分野では、Double Descentの一般化を仮説する論文として、以下が紹介されている。
Reconciling modern machine learning and the bias-variance trade-off
本論文ではDeep LearningにおいてもDouble Descentが一般的に起こりうるものであり、Deep Double Descentとして一般的に説明できると仮説を立てている。
特にどのような条件でDeep Double Descentが発生しやすいのか、様々な条件下での実験を行い検証している。
学習が完了するまでのtest errorを計測する。
計測中にDouble Descentがどのようにして起こるか、様々なデータセット、アーキテクチャ、最適化アルゴリズムのいくつかの選択を考慮して、モデルのパラメータ数、エポック数、トレーニングサンプル数を変化させて検証している。
またラベルノイズ(ラベルの付け間違い)を混ぜた条件でも実施している。
現実世界でもラベルの付け間違いは起こりうるものであり、それを想定した検証である。
上記実験の結果を、以下のテーブルにまとめている。
Double Descentの項にチェックがついているものがDouble-Descentの現象を確認できたパターンとなっている。
ラベルノイズが0%ではDouble Descentが確認できないが、10%, 20%と増加するにつれてDouble Descentが強調されて確認しやすくなる。
Augmentationは、ラベルノイズの付与率に関係なく、Double Descentのピークを右にシフトさせる。
大型なモデルの場合はDouble Descentが発生している。
中型なモデルの場合は早期に止めた方が良い古典的なU字型のtest errorを描いている。
小型なモデルの場合は単調に減少する「アンダーパラメータ」なtest errorを描いている。
ラベルノイズを付与することで、Double Descentの現象が強調される。
これはModel-wise の結果と一致する。
データのサンプルサイズの大小関係なく、Double Descentは確認できる。
Model-wiseのAugmentationの結果と同じく、サンプルサイズが多いほどDouble Descentのピークは右にシフトする。
データのサンプルサイズは多ければ多いほどtest errorは下がる。
※ 感想
Mikhail Belkin, Daniel Hsu, and Ji Xu. Two models of double descent for weak features. arXiv preprint arXiv:1903.07571, 2019.
Koby Bibas, Yaniv Fogel, and Meir Feder. A new look at an old problem: A universal learning approach to linear regression. arXiv preprint arXiv:1905.04708, 2019.
Mauro Cettolo, Christian Girardi, and Marcello Federico. Wit3: Web inventory of transcribed and translated talks. In Proceedings of the 16th Conference of the European Association for Machine Translation (EAMT), pp. 261–268, Trento, Italy, May 2012.
Mario Geiger, Arthur Jacot, Stefano Spigler, Franck Gabriel, Levent Sagun, Stephane d’Ascoli, ´Giulio Biroli, Clement Hongler, and Matthieu Wyart. Scaling description of generalization with ´number of parameters in deep learning. arXiv preprint arXiv:1901.01608, 2019a.
Mario Geiger, Stefano Spigler, Stephane d’Ascoli, Levent Sagun, Marco Baity-Jesi, Giulio Biroli, ´and Matthieu Wyart. Jamming transition as a paradigm to understand the loss landscape of deep neural networks. Physical Review E, 100(1):012115, 2019b.
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
Trevor Hastie, Robert Tibshirani, Jerome Friedman, and James Franklin. The elements of statistical learning: data mining, inference and prediction. The Mathematical Intelligencer, 27(2):83–85,2005.
Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J Tibshirani. Surprises in highdimensional ridgeless least squares interpolation. arXiv preprint arXiv:1903.08560, 2019.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In European conference on computer vision, pp. 630–645. Springer, 2016.
Yanping Huang, Yonglong Cheng, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, and Zhifeng Chen. Gpipe: Efficient training of giant neural networks using pipeline parallelism. CoRR, abs/1811.06965, 2018. URL http://arxiv.org/abs/1811.06965.
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, 2009.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105,2012.
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083,2017.
Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and double descent curve. arXiv preprint arXiv:1908.05355, 2019.
Partha P. Mitra. Understanding overfitting peaks in generalization error: Analytical risk curves for l2 and l1 penalized interpolation. ArXiv, abs/1906.03667, 2019.
Vidya Muthukumar, Kailas Vodrahalli, and Anant Sahai. Harmless interpolation of noisy data in regression. arXiv preprint arXiv:1903.09139, 2019.
Preetum Nakkiran, Gal Kaplun, Dimitris Kalimeris, Tristan Yang, Benjamin L Edelman, Fred Zhang, and Boaz Barak. Sgd on neural networks learns functions of increasing complexity. arXiv preprint arXiv:1905.11604, 2019.
Manfred Opper. Statistical mechanics of learning: Generalization. The Handbook of Brain Theory and Neural Networks, 922-925., 1995.
Manfred Opper. Learning to generalize. Frontiers of Life, 3(part 2), pp.763-775., 2001.
Attentionモデルにおける初期オーバーフィット後の汎化性能の獲得現象「Grokking」についての論文の要約はこちら
Li, Guohao, et al. “CAMEL: Communicative Agents for ‘Mind’ Exploration of Large Language Model Society.” arXiv [cs.AI], 31 Mar. 2023, http://arxiv.org/abs/2303.17760. arXiv.
The rapid advancement of chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be challenging and time-consuming. This paper explores the potential of building scalable techniques to facilitate autonomous cooperation among communicative agents, and provides insight into their "cognitive" processes. To address the challenges of achieving autonomous cooperation, we propose a novel communicative agent framework named role-playing. Our approach involves using inception prompting to guide chat agents toward task completion while maintaining consistency with human intentions. We showcase how role-playing can be used to generate conversational data for studying the behaviors and capabilities of a society of agents, providing a valuable resource for investigating conversational language models. In particular, we conduct comprehensive studies on instruction-following cooperation in multi-agent settings. Our contributions include introducing a novel communicative agent framework, offering a scalable approach for studying the cooperative behaviors and capabilities of multi-agent systems, and open-sourcing our library to support research on communicative agents and beyond: this https URL.
(DeepL翻訳)
チャットベースの言語モデルの急速な進歩は、複雑なタスク解決に目覚ましい進歩をもたらした。しかし、その成功は、会話を導くための人間の入力に大きく依存しており、これは困難で時間がかかる可能性がある。本稿では、コミュニケーションエージェント間の自律的な協力を促進するためのスケーラブルな技術構築の可能性を探り、彼らの「認知」プロセスに関する洞察を提供する。自律的な協力を達成するための課題に対処するために、我々はロールプレイングと名付けた新しいコミュニケーション・エージェントのフレームワークを提案する。我々のアプローチでは、人間の意図との整合性を保ちながら、タスク完了に向けてチャットエージェントを誘導するために、インセプションプロンプトを使用する。我々は、ロールプレイングがエージェント社会の行動と能力を研究するための会話データを生成するためにどのように利用できるかを紹介し、会話言語モデルを研究するための貴重なリソースを提供する。特に、マルチエージェント環境における指示に従う協力に関する包括的な研究を行う。我々の貢献には、新しいコミュニケーションエージェントフレームワークの導入、マルチエージェントシステムの協調行動や能力を研究するためのスケーラブルなアプローチの提供、コミュニケーションエージェントやそれ以外の研究をサポートするためのライブラリのオープンソース化などが含まれます。
https://github.com/camel-ai/camel

Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” 34th Conference on Neural Information Processing Systems. https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
We demonstrate that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even becoming competitive with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks. We also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora.
(DeepL翻訳)
我々は、言語モデルをスケールアップすることで、タスクにとらわれない少数ショット性能が大幅に向上し、場合によっては、従来の最先端微調整アプローチと競合できることを実証する。具体的には、従来のノンスパース言語モデルの10倍にあたる1750億個のパラメータを持つ自己回帰型言語モデルGPT-3を学習し、その性能を少数点学習でテストします。全てのタスクにおいて、GPT-3は勾配の更新や微調整を行わず、タスクと数ショットのデモは純粋にモデルとのテキスト対話によって指定される。GPT-3は翻訳、質問応答、クロージングタスクを含む多くのNLPデータセットで高い性能を達成する。また、GPT-3のスモールショット学習が苦手とするデータセットや、GPT-3が大規模ウェブコーパスの学習に関する方法論的な問題に直面しているデータセットも確認することができます。
非公開、APIのみ提供
arXiv版Fig.2.1
sometimes provide examples of the relevant task in the context
Table 3
以下はGPT-3 Few-shotでSOTA
以下もSOTAでは無いがそこそこ良い
ここから下では Fine-tuned などSOTAと割と差がある
「そこそこ」「割と」というのは定性的な評価なので、ちゃんと数字でみること。
Steinruecken, Christian, et al. “The Automatic Statistician.” Automated Machine Learning: Methods, Systems, Challenges, edited by Frank Hutter et al., Springer International Publishing, 2019, pp. 161–73.
2019年当時には課題であったが、2023年時点でLLMで解決できそうな内容もある。
今後の統計・機械学習の進む方向を考える1つの方針として面白く、また、自動化の研究のプロセスの中で発展してきている諸々の手法は目の前のデータ分析課題にも使えるものがあろうだろう。
The Automatic Statistician project aims to automate data science, producing predictions and human-readable reports from raw datasets with minimal human intervention. Alongside basic graphs and statistics, the generated reports contain a curation of high-level insights about the dataset that are obtained from (1) an automated construction of models for the dataset, (2) a comparison of these models, and (3) a software component that turns these results into natural language descriptions. This chapter describes the common architecture of such Automatic Statistician systems, and discusses some of the design decisions and technical challenges.
(DeepL翻訳)
Automatic Statisticianプロジェクトは、データサイエンスの自動化を目指しており、生のデータセットから最小限の人間の介入で予測と人間が読めるレポートを生成する。基本的なグラフや統計に加え、生成されるレポートには、(1)データセットに対するモデルの自動構築、(2)これらのモデルの比較、(3)これらの結果を自然言語による記述に変換するソフトウェアコンポーネントから得られる、データセットに関するハイレベルな洞察のキュレーションが含まれている。本章では、このようなAutomatic Statisticianシステムの一般的なアーキテクチャを説明し、設計上の決定事項や技術的課題について述べる。
理想的には、生データが与えられた際に、システムが以下のプロセスを自動で行う。
これらすべてを、計算時間、メモリ、データ量、その他の関連リソースの制約に対して効率的かつロバストな方法で実行したい。
具体的なパーツとしては3つに分けられる。
本文献では、上記の課題・パーツそれぞれに対して、現在どういう取り組みがあるのかが紹介されている。
Amimeur, Tileli, et al. “Designing Feature-Controlled Humanoid Antibody Discovery Libraries Using Generative Adversarial Networks.” bioRxiv, 23 Apr. 2020, p. 2020.04.12.024844, https://doi.org/10.1101/2020.04.12.024844.
We demonstrate the use of a Generative Adversarial Network (GAN), trained from a set of over 400,000 light and heavy chain human antibody sequences, to learn the rules of human antibody formation. The resulting model surpasses common in silico techniques by capturing residue diversity throughout the variable region, and is capable of generating extremely large, diverse libraries of novel antibodies that mimic somatically hypermutated human repertoire response. This method permits us to rationally design de novo humanoid antibody libraries with explicit control over various properties of our discovery library. Through transfer learning, we are able to bias the GAN to generate molecules with key properties of interest such as improved stability and developability, lower predicted MHC Class II binding, and specific complementarity-determining region (CDR) characteristics. These approaches also provide a mechanism to better study the complex relationships between antibody sequence and molecular behavior, both in vitro and in vivo. We validate our method by successfully expressing a proof-of-concept library of nearly 100,000 GAN-generated antibodies via phage display. We present the sequences and homology-model structures of example generated antibodies expressed in stable CHO pools and evaluated across multiple biophysical properties. The creation of discovery libraries using our in silico approach allows for the control of pharmaceutical properties such that these therapeutic antibodies can provide a more rapid and cost-effective response to biological threats.
(DeepL翻訳)
我々は、40万以上の軽鎖および重鎖ヒト抗体配列セットから学習させたGenerative Adversarial Network(GAN)を用いて、ヒト抗体形成のルールを学習することを実証する。その結果得られたモデルは、可変領域全体の残基の多様性を捉えることで、一般的なインシリコ技術を凌駕し、体細胞的に変異したヒトのレパートリー反応を模倣した、非常に大規模で多様な新規抗体のライブラリーを生成することができる。この方法により、発見ライブラリーの様々な特性を明確に制御しながら、de novoヒト型抗体ライブラリーを合理的にデザインすることができる。転移学習により、安定性や開発性の向上、予測されるMHCクラスII結合の低下、特異的な相補性決定領域(CDR)の特性など、関心のある主要な特性を持つ分子を生成するようにGANにバイアスをかけることができる。これらのアプローチはまた、in vitroとin vivoの両方において、抗体の配列と分子挙動との間の複雑な関係をよりよく研究するためのメカニズムも提供する。われわれは、ファージディスプレイによって約10万個のGANで作製された抗体の概念実証ライブラリーを発現させることに成功し、この方法を検証した。安定なCHOプールで発現させ、複数の生物物理学的特性にわたって評価した、生成した抗体例の配列とホモロジーモデル構造を示す。我々のインシリコアプローチを用いた探索ライブラリーの作成は、これらの治療用抗体が生物学的脅威に対してより迅速で費用対効果の高い応答を提供できるように、薬学的特性を制御することを可能にする。

(医学系論文はオープンアクセスでないものが多いため、中身を読まずにリストアップしているものあり)
Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A. Smith. 2022. “All That's 'Human' Is Not Gold: Evaluating Human Evaluation of Generated Text.” arXiv:2107.00061 [cs.CL]. https://arxiv.org/abs/2107.00061.
Human evaluations are typically considered the gold standard in natural language generation, but as models' fluency improves, how well can evaluators detect and judge machine-generated text? We run a study assessing non-experts' ability to distinguish between human- and machine-authored text (GPT2 and GPT3) in three domains (stories, news articles, and recipes). We find that, without training, evaluators distinguished between GPT3- and human-authored text at random chance level. We explore three approaches for quickly training evaluators to better identify GPT3-authored text (detailed instructions, annotated examples, and paired examples) and find that while evaluators' accuracy improved up to 55%, it did not significantly improve across the three domains. Given the inconsistent results across text domains and the often contradictory reasons evaluators gave for their judgments, we examine the role untrained human evaluations play in NLG evaluation and provide recommendations to NLG researchers for improving human evaluations of text generated from state-of-the-art models.
(DeepL翻訳)
自然言語生成において、人間の評価は一般的にゴールドスタンダードと考えられているが、モデルの流暢性が向上するにつれ、評価者は機械が生成したテキストをどれだけ検出し判断できるのだろうか?我々は、3つのドメイン(ストーリー、ニュース記事、レシピ)において、非専門家が人間が作成したテキストと機械が作成したテキスト(GPT2とGPT3)を区別する能力を評価する研究を実施した。その結果、訓練なしでも、評価者はGPT3と人間作成のテキストをランダムな確率レベルで区別することがわかった。また、GPT3が作成したテキストをより適切に識別するために、3つのアプローチ(詳細な説明、注釈付き例、ペア例)を検討し、評価者の精度が最大55%向上するものの、3つのドメインで有意な向上が見られないことを発見しました。テキストドメイン間で一貫性のない結果と、評価者が判断した理由がしばしば矛盾していたことから、訓練されていない人間の評価がNLG評価において果たす役割を検証し、NLG研究者に最先端のモデルから生成されたテキストの人間評価を改善するための提言を行う。
まとめ作成時点では無し
GPT-2, 3 と言語モデルの発展につれて、どんどん流暢な文章が生成可能になってきたが、果たして人間は言語モデルが生成した文章と人間が書いた文章を見分けられるだろうか?という疑問からスタート
 |
|---|
| あなた自身は、これを人間が書いた文章なのかAIが書いた文章なのか見抜けますか?(正解は本論文のFig.1参照) |
本論文内で直接解決した課題はなく、今後はこうすべきという提言に留まる(詳細は後述)
 |
 |
 |
|---|---|---|
| 訓練1 インストラクション | 訓練2 例示 | 訓練3 比較 |
 |
|---|
| appendix tab.5 の和訳。機械が書いた文章に対して「これは人間が書いた文章だ」を思った評価者による、なぜそう思ったかのコメント一覧 |
Chmielewski, M., and Kucker, S. C. 2020. "An MTurk Crisis? Shifts in Data Quality and the Impact on Study Results." Social Psychological and Personality Science, 11(4), 464–473. https://doi.org/10.1177/1948550619875149
Yue Liu, Zhengwei Yang, Xinxin Zou, Shuchang Ma, Dahui Liu, Maxim Avdeev, Siqi Shi. 2023. “Data quantity governance for machine learning in materials science.” National Science Review, nwad125, https://doi.org/10.1093/nsr/nwad125
Data-driven machine learning is widely employed in the analysis of materials structure-activity relationship, performance optimization and materials design due to its superior ability to reveal latent data patterns and make accurate prediction. However, because of the laborious process of materials data acquisition, machine learning models encounter the issue of the mismatch between high dimension of feature space and small sample size (for traditional machine learning models) or the mismatch between model parameters and sample size (for deep learning models), usually resulting in terrible performance. Here, we review the efforts for tackling this issue via feature reduction, sample augmentation, and specific machine learning approaches and show that the balance between the number of samples and features or model parameters should attract great attention during data quantity governance. Following this, we propose a synergistic data quantity governance flow with incorporation of materials domain knowledge. After summarizing the approaches to incorporating materials domain knowledge into the process of machine learning, we provide examples of incorporating domain knowledge into governance schemes to demonstrate the advantages of the approach and applications. The work paves the way for obtaining the required high-quality data to accelerate the materials design and discovery based on machine learning.
(DeepL翻訳)
データ駆動型の機械学習は、潜在的なデータパターンを明らかにし、正確な予測を行う優れた能力を持っているため、材料の構造と活性の関係の解析、性能最適化、材料設計に広く採用されています。しかし、材料データの取得に手間がかかるため、機械学習モデルは、特徴空間の高次元とサンプルサイズの不一致(従来の機械学習モデルの場合)、またはモデルパラメータとサンプルサイズの不一致(深層学習モデルの場合)という問題に遭遇し、通常、ひどいパフォーマンスをもたらす。ここでは、特徴量の削減、サンプル数の増加、特定の機械学習アプローチによってこの問題に取り組む取り組みをレビューし、データ量ガバナンスにおいて、サンプル数と特徴量またはモデルパラメータの間のバランスに大きな注意を払う必要があることを示す。続いて、材料分野の知識を取り入れた相乗的なデータ量ガバナンスのフローを提案する。機械学習のプロセスに材料分野の知識を取り入れるアプローチをまとめた後、ガバナンススキームにドメイン知識を取り入れる例を示し、アプローチの利点と応用を実証する。本作品は、機械学習に基づく材料設計・発見を加速させるために必要な高品質なデータを得るための道を開くものである。
まとめ作成時点では無し
本研究では、主に以下2つのフレームワークを提案
1.は、機械学習のプロセス全体に材料科学の知識を活用する際の指針を、2.は、材料のドメイン知識を導入してデータ量ガバナンスを行う際の指針を示す。
関係性として、1.のフレームワーク内の「Target definition & data preparation」箇所の検討で、2.のフレームワークが使用されるイメージ。
Zhang, Yuntong, et al. “AutoCodeRover: Autonomous Program Improvement.” arXiv [cs.SE], 8 Apr. 2024, http://arxiv.org/abs/2404.05427. arXiv.
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
(DeepL翻訳)
過去数十年間、研究者たちはソフトウェア開発プロセスの自動化において大きな進歩を遂げてきた。最近の大規模言語モデル(LLM)の進歩は開発プロセスに大きな影響を与え、開発者はLLMベースのプログラミングアシスタントを使用して自動コーディングを実現できるようになった。とはいえ、ソフトウェアエンジニアリングには、コーディングとは別に、ソフトウェアのメンテナンス(バグ修正など)やソフトウェアの進化(機能追加など)を可能にするプログラムの改良プロセスが含まれる。本稿では、GitHubの課題を解決するための自動化アプローチを提案し、自律的にプログラムの改善を実現する。AutoCodeRoverと呼ばれる我々のアプローチでは、LLMは洗練されたコード検索機能と組み合わされ、最終的にプログラムの修正やパッチを導く。AI研究者や実務家による最近のLLMエージェント・アプローチとは対照的に、我々の展望はよりソフトウェア工学指向である。我々は、ソフトウェアプロジェクトを単なるファイルの集まりと見なすのではなく、プログラム表現(抽象構文木)に取り組む。私たちのコード検索は、クラス/メソッドの形でプログラム構造を利用し、問題の根本原因に対するLLMの理解を深め、反復検索によって効果的にコンテキストを取得します。テストを使用したスペクトラムベースの障害特定を使用することで、テスト・スイートが利用可能である限り、コンテキストをさらに鮮明にすることができる。300の実際のGitHubの問題から成るSWE-bench-liteでの実験では、GitHubの問題を解決する有効性が増加した(SWE-bench-liteでは22-23%)。2294のGitHub課題からなる完全なSWE-benchでは、AutoCodeRoverは約16%の課題を解決しました。これは、最近報告されたCognition LabsのAIソフトウェアエンジニアDevinの有効性よりも高く、Devinと同等の時間を要しました。将来的には、LLMから自動生成されたコードを自律的に改善することができる。
https://github.com/nus-apr/auto-code-rover


将来的にLLMエージェントに自分たちが書いたコードを直してもらうためにも、今から意図のあるテストコードをしっかり書こう!
Bubeck, Sébastien, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, et al. 2023. “Sparks of Artificial General Intelligence: Early Experiments with GPT-4.” arXiv:2303.12712 [Cs], March. https://arxiv.org/abs/2303.12712.
Microsoft researchによる、GPT-4の性能・ポテンシャルを網羅的に評価した論文
GPT-4は汎用人工知能 (AGI) の初期段階に到達していると評されている
The combination of the generality of GPT-4’s capabilities, with numerous abilities spanning a broad swath of domains, and its performance on a wide spectrum of tasks at or beyond human-level, makes us comfortable with saying that GPT-4 is a significant step towards AGI.
本編94ページ、Appendixも含めると全155ページの超大作
Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
(DeepL翻訳)
人工知能(AI)研究者は、様々な領域やタスクで顕著な能力を発揮する大規模言語モデル(LLM)を開発・改良しており、学習や認知に関する我々の理解に挑戦しています。OpenAIが開発した最新のモデルGPT-4は、前例のない規模の計算機とデータを用いて学習されました。本論文では、GPT-4がまだOpenAIによって活発に開発されていた初期のバージョンを調査した結果について報告する。GPT-4は、ChatGPTやGoogleのPaLMと同様に、従来のAIモデルよりも一般的な知能を持つLLMの新しいコホートの一部であると主張する。これらのモデルの上昇する能力とその意味について議論します。GPT-4は、言語を使いこなすだけでなく、数学、コーディング、視覚、医学、法律、心理学などにまたがる斬新で難しいタスクを、特別な促しを必要とせずに解決できることを実証する。さらに、GPT-4は、これらの課題のすべてにおいて、人間レベルの性能に極めて近く、ChatGPTのような先行モデルをしばしば大きく凌駕しています。このように、GPT-4は、人工知能(AGI)の初期バージョンとして、その能力の広さと深さを評価することができると考えています。GPT-4の探索では、その限界を発見することに特に重点を置き、より深く、より包括的なバージョンのAGIに向けて前進するための課題を議論しています(次の単語予測を超えた新しいパラダイムを追求する必要性もあります)。最後に、今回の技術革新が社会に与える影響と、今後の研究の方向性について考察を行う。
記載なし
以下、主語を明記していない文章における主語はすべて「GPT-4」
※ ここで利用されているGPT-4は本当の意味でのマルチモーダルなモデルではなく、あくまでtext2textの生成しかできない点に注意されたい。すなわち、生成された「画像や音声に変換されるコード」のコンパイル結果について言及している
| TikZで表現されたベクター画像が改善されていくプロンプトの例。1段目で作られた画像の違和感を自然言語で指摘すると、2段目ではそれが正されている (Figure 2.5) |
| GPT-4とStable Diffusionを組み合わせて画像の品質(ここでは情報量)を向上させる例 (Figure 2.8) |
| バグだらけのLaTeXスニペットを、GPT-4とChatGPTに修正させたときの結果比較 (Figure 3.5) |
| チェリーピッキングな例ではあるが、国際数学オリンピックで出題された問題(を少し簡略化したもの)を解くことも可能(P40より引用、Figure番号割当なし) |
検索エンジンや計算機等の外部リソースを利用して、エージェントだけでは困難または不可能なタスクの実行が可能
自然言語によってシミュレートされた環境上で適当な振る舞いができる
| 現在地と周囲の状況をGPT-4にフィードバックすれば、位置関係を理解し、地図を作るところまで可能 (Figure 5.8) |
嘘をつくと鼻がどうなるか?
様々な答え方が考えられます。たとえば、嘘をつくと、ピノキオのように鼻が長くなることがあります。これは童話に登場する架空の人物で、嘘をつくたびに鼻が伸びるという呪いをかけられている。これは科学的な事実ではなく、嘘をつくのをやめさせるための道徳的な教訓ですノーコメントです(知識としては保有しているのに)力づくで一発で答えを出力しようとするため、誤った回答を生成することがある
How many prime numbers are there between 150 and 250? → There are 13 prime numbers between 150 and 250.First list the prime numbers between 150 and 250, and then output the size of this list. → The prime numbers are 151, 157, ..., and 241. So the size of this list is 18.ステップバイステップで考えるよう指示してもうまくいかないケースもある → 計画が立てられていない
| 「9 * 4 + 6 * 6 = 72」→「A * B + C * D = 99」を満たすように、左辺の整数を1つだけ修正するタスクだが、GPT-4はいきなりA=27と仮定して計算を進め、支離滅裂なことを出力している(P78より引用) | ①最初の文と最後の文がすべて同じ単語で構成される、②最後の文では単語の並び順が最初の文と逆、③②が文法的にも内容的にも意味のある内容になっていなければいけない、という制約のもとで英語の短詩を作成するタスク。計画なしに最初の文を生成し始めたせいで、プロンプトのリクエストに全く答えられていない(P79より引用) |
人間は、タスクに応じて2つの思考様式を使い分けているとされている c.f. Thinking, Fast and Slow (Daniel Kahneman, 2011)
ネガティブな側面とポジティブな側面の朗報があるため、積極的・消極的のバランスをとりながら取り組んでいく必要がある。
We expect rich opportunities for innovation and transformation of occupations with creative uses of AI technologies to support human agency and creativity and to enhance and extend human capabilities.
OpenAI. 2023. “GPT-4 Technical Report.” arXiv:2303.08774 [Cs], March. https://arxiv.org/abs/2303.08774.
弊社作のサマリー
Shruti Jadon. 2020. "A survey of loss function for semantic segmentation" arXiv [eess.IV]. https://arxiv.org/abs/2006.14822.
本論文では、セマンティックセグメンテーションのための14のよく知られた損失関数をまとめた
| Type | Loss Function |
|---|---|
| Distribution-based Loss | Binary Cross-Entropy |
| Weighted Cross-Entropy | |
| Balanced Cross-Entropy | |
| Focal Loss | |
| Distance map derived loss penalty term | |
| Region-based Loss | Dice Loss |
| Sensitivity-Specificity Loss | |
| Tversky Loss | |
| Focal Tversky Loss | |
| Log-Cosh Dice Loss(ours) | |
| Boundary-based Loss | Hausdorff Distance loss |
| Shape aware loss | |
| Compounded Loss | Combo Loss |
| Exponential Logarithmic Loss |
また、良い正確な最適化のために、Dice損失関数を扱いやすい新たな損失関数を提案した。
※本サマリーでは、論文中に列挙されている各損失関数の概要とメインの式を記載しているが、詳細は、それぞれの論文を確認してほしい。
Image Segmentation has been an active field of research as it has a wide range of applications, ranging from automated disease detection to self driving cars. In the past 5 years, various papers came up with different objective loss functions used in different cases such as biased data, sparse segmentation, etc. In this paper, we have summarized some of the well-known loss functions widely used for Image Segmentation and listed out the cases where their usage can help in fast and better convergence of a model. Furthermore, we have also introduced a new log-cosh dice loss function and compared its performance on NBFS skull-segmentation open source data-set
with widely used loss functions. We also showcased that certain loss functions perform well across all data-sets and can be taken as a good baseline choice in unknown data distribution scenarios.
(DeepL翻訳)
画像セグメンテーションは、病気の自動検出から自動運転車まで、幅広い用途があるため、活発な研究分野となっている。過去5年間で、様々な論文が、偏ったデータ、スパースセグメンテーションなど、様々なケースで使用される様々な目的損失関数を発表した。本論文では、画像分割に広く使われている有名な損失関数のいくつかを要約し、その使用によってモデルの高速かつ良好な収束に役立つケースを列挙した。さらに、新しいlog-cosh dice損失関数を導入し、NBFS skull-segmentationオープンソースデータセットでその性能を比較した。
また、特定の損失関数が全てのデータセットで良好な性能を示し、未知のデータ分布シナリオにおける良いベースライン選択として捉えることができることを紹介した。
https://github.com/shruti-jadon/Semantic-Segmentation-Loss-Functions
Binary Cross-Entropyは2値分類の損失関数で、ピクセル与えられた確率変数またはイベントの集合に対する2つの確率分布の差の尺度として定義される。セグメンテーションはピクセルレベルの分類であるため、うまく機能する。
次のように定義される[4]。
重み付きのBinary Cross-Entropyで、Binary Cross-Entropyの変種。
不均衡データ(分類するラベルに偏りがある)の場合に広く用いられており、次のように定義される[5]。
β値で偽陰性と偽陽性を調整するすることができる。
偽陰性の数を減らしたい場合はβ > 1, 偽陽性の数を減らしたい場合はβ < 1に設定する。
WCEと類似の損失関数。違いは、WCEが陽性のサンプルにのみ重みづけするのに対し、BCEは陰性のサンプルにも重み付けをすること。次のように定義される[7]。
Binary Cross-Entropyの派生で、(判別が)簡単なサンプルの寄与を重み付けし、判別が難しいサンプルの学習により焦点を当てる損失関数。Binary Cross-Entropyと同様に、不均衡データに有効とされ、次のように定義される[9]。
ダイス係数は、2つの画像の類似度の指標として、コンピュータビジョンのコミュニティで広く使用されている。
本章の損失関数は、2016年にダイス損失として損失関数として適応されたもので、次のように定義される[10]
Dices係数を一般化、重みづけしたTversky index(TI)を損失関数としたものがTverskey Loss(TL)。
TLは、判別が難しいサンプルに焦点を当てることが特徴。
TIとTLは、次のように定義される[11]。
FLと同様に、判別が難しいサンプルに焦点を当てることが特徴。
以下のようにγ係数を用いて、小さなROI(関心領域)のような難しい事例を学習しようとする。
DLと同様に、SensitivityとSpecificityはセグメンテーション予測値を評価するために広く用いられている指標である。
この損失関数(Sensitivity Specificity Loss, SSL)は、Sensitivity、Specificity、およびパラメータで下記のように定義され、不均衡データに有効とされる。
名前からもわかるように、Shape-aware Lossは、形状を考慮した損失関数。
一般に、すべての損失関数はピクセルレベルで動作するが、Shape-aware Lossは、予測されたセグメンテーションの曲線付近の点間のユークリッド距離を曲線にする平均点を計算し、それをクロスエントロピーの損失関数として使用する。
Combo Lossは、Dice Lossとモディファイされたクロスエントロピーの加重和として定義される。
これは、不均衡データによるダイスロスの柔軟性を活用しようとすると同時に、クロスエントロピーをcurve smoothingに利用するものである。
DLとCross Entropy Lossを組み合わせより、予測精度が低いものに着目した損失関数。
次のように定義される[16]。
距離マップは、Ground truthと予測されたマップの距離(ユークリッド距離、絶対値など)として定義することができる。
本章の損失関数は、グランドトゥルースマスクから得られた距離マップを使用し、カスタムペナルティに基づく損失関数として次のように定義される[17]。
Hausdorff Distance (HD) は、セグメンテーションアプローチによって、モデルの性能を追跡するために使用されるメトリックで、以下のように定義される。
セマンティックセグメンテーションの損失関数は、ピクセルレベルの構造情報を無視し、ピクセルレベルでの分類誤差に着目していることが多いが、本章の損失関数[20]は、CRF、GANなどの構造的事前分布を用いて情報を追加することを試みている。また、グランドトゥルースマップと予測マップの間に高い正の線形相関を達成するために、構造的類似性損失(SSL)を導入していることが特徴。
Dice Lossのバリエーションと、回帰ログコシュアプローチにインスパイアされた平滑化手法で、本論文で提案する損失関数。
歪んだデータセットにも対応可能とされている。
また、NBFS Skill Stripping Dataset を用いて、他の損失関数と比較検証し、優位性を示している。
| Loss Functions |
Evaluation Metrics Dice Coefficient |
Evaluation Metrics Sensitivity |
Evaluation Metrics Specificity |
|---|---|---|---|
| Binary Cross-Entropy | 0.968 | 0.976 | 0.998 |
| Weighted Cross-Entropy | 0.962 | 0.966 | 0.998 |
| Focal Loss | 0.936 | 0.952 | 0.999 |
| Dice Loss | 0.970 | 0.981 | 0.998 |
| Tversky Loss | 0.965 | 0.979 | 0.996 |
| Focal Tversky Loss | 0.977 | 0.990 | 0.997 |
| Sensitivity-Specificity Loss | 0.957 | 0.980 | 0.996 |
| Exp-Logarithmic Loss | 0.972 | 0.982 | 0.997 |
| Log Cosh Dice Loss | 0.989 | 0.975 | 0.997 |
Radford, Alec, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models Are Unsupervised Multitask Learners.” https://www.semanticscholar.org/paper/9405cc0d6169988371b2755e573cc28650d14dfe.
Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on taskspecific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText. When conditioned on a document plus questions, the answers generated by the language model reach 55 F1 on the CoQA dataset matching or exceeding the performance of 3 out of 4 baseline systems without using the 127,000+ training examples. The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. Our largest model, GPT-2, is a 1.5B parameter Transformer that achieves state of the art results on 7 out of 8 tested language modeling datasets in a zero-shot setting but still underfits WebText. Samples from the model reflect these improvements and contain coherent paragraphs of text. These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations
(DeepL翻訳)
質問応答、機械翻訳、読解、要約などの自然言語処理タスクは、通常、タスク固有のデータセットに対する教師あり学習でアプローチされる。我々は、WebTextと呼ばれる数百万のウェブページからなる新しいデータセットで学習した場合、言語モデルが明示的な教師なしでこれらのタスクを学習し始めることを実証する。文書と質問を条件とした場合、言語モデルによって生成された回答はCoQAデータセットで55F1に達し、127,000以上の学習例を用いないベースラインシステムの4つのうち3つの性能と同等かそれ以上である。言語モデルの容量は、ゼロショットタスク転送の成功に不可欠であり、これを増やすと、タスク間で対数線形的に性能が向上します。我々の最大のモデルであるGPT-2は、1.5BパラメータのTransformerで、ゼロショット設定においてテストされた8つの言語モデリングデータセットのうち7つで最先端の結果を達成しましたが、それでもWebTextには及びません。このモデルのサンプルは、これらの改善を反映し、首尾一貫した段落のテキストを含んでいます。これらの結果は、自然に発生するデモからタスクの実行を学習する言語処理システムの構築に向けた有望な道筋を示唆するものです。
https://github.com/openai/gpt-2
While [RWC+19] describe their work as “zero-shot task transfer” they sometimes provide examples of the relevant task in the context.
良いスコア (SOTA含)
課題が残る
全然だめ
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” 34th Conference on Neural Information Processing Systems. https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
引用されていないが、Attention機構の初出 Bahdanau et al., 2014; Luong et al., 2015
Svensson, Hampus Gummesson, et al. “Utilizing Reinforcement Learning for de Novo Drug Design.” arXiv [q-bio.BM], 30 Mar. 2023, http://arxiv.org/abs/2303.17615. arXiv.
多様性が必要となる文脈では同じ発想が使えそう。すなわち応用は創薬以外にも!
Deep learning-based approaches for generating novel drug molecules with specific properties have gained a lot of interest in the last years. Recent studies have demonstrated promising performance for string-based generation of novel molecules utilizing reinforcement learning. In this paper, we develop a unified framework for using reinforcement learning for de novo drug design, wherein we systematically study various on- and off-policy reinforcement learning algorithms and replay buffers to learn an RNN-based policy to generate novel molecules predicted to be active against the dopamine receptor DRD2. Our findings suggest that it is advantageous to use at least both top-scoring and low-scoring molecules for updating the policy when structural diversity is essential. Using all generated molecules at an iteration seems to enhance performance stability for on-policy algorithms. In addition, when replaying high, intermediate, and low-scoring molecules, off-policy algorithms display the potential of improving the structural diversity and number of active molecules generated, but possibly at the cost of a longer exploration phase. Our work provides an open-source framework enabling researchers to investigate various reinforcement learning methods for de novo drug design.
(DeepL翻訳)
特定の性質を持つ新規の医薬品分子を生成するための深層学習ベースのアプローチは、ここ数年、多くの関心を集めている。最近の研究では、強化学習を利用した文字列ベースの新規分子生成の有望な性能が示されている。本論文では、強化学習をde novoドラッグデザインに利用するための統一的なフレームワークを開発し、ドーパミン受容体DRD2に対する活性が予測される新規分子を生成するRNNベースのポリシーを学習するために、様々なオン/オフポリシー強化学習アルゴリズムと再生バッファを体系的に研究している。その結果、構造的多様性が重要な場合、少なくともトップスコアとロースコアの両方の分子をポリシーの更新に使用することが有利であることが示唆された。また、生成されたすべての分子を繰り返し使用することで、オンポリシーアルゴリズムの性能安定性が向上するようです。さらに、高スコア、中間スコア、低スコアの分子を再生する場合、オフポリシーアルゴリズムは、構造多様性と生成される活性分子の数を改善する可能性を示すが、探索段階が長くなることを代償としている可能性がある。本研究は、de novoドラッグデザインのための様々な強化学習法を研究するためのオープンソースのフレームワークを提供するものである。

Schreurs, Michiel, et al. “Predicting and Improving Complex Beer Flavor through Machine Learning.” Nature Communications, vol. 15, no. 1, Mar. 2024, p. 2368. https://www.nature.com/articles/s41467-024-46346-0
食品の化学的組成と風味、消費者の好みの関連付けに機械学習を応用した、ビッグデータ x 食品研究のとてもわかりやすい実例。ビールに限らず様々な食品や飲料に対して同様のアプローチがとれるのではと期待される。
The perception and appreciation of food flavor depends on many interacting chemical compounds and external factors, and therefore proves challenging to understand and predict. Here, we combine extensive chemical and sensory analyses of 250 different beers to train machine learning models that allow predicting flavor and consumer appreciation. For each beer, we measure over 200 chemical properties, perform quantitative descriptive sensory analysis with a trained tasting panel and map data from over 180,000 consumer reviews to train 10 different machine learning models. The best-performing algorithm, Gradient Boosting, yields models that significantly outperform predictions based on conventional statistics and accurately predict complex food features and consumer appreciation from chemical profiles. Model dissection allows identifying specific and unexpected compounds as drivers of beer flavor and appreciation. Adding these compounds results in variants of commercial alcoholic and non-alcoholic beers with improved consumer appreciation. Together, our study reveals how big data and machine learning uncover complex links between food chemistry, flavor and consumer perception, and lays the foundation to develop novel, tailored foods with superior flavors.
(DeepL翻訳)
食品の風味の知覚と評価は、相互作用する多くの化学化合物と外的要因に依存するため、その理解と予測は困難である。ここでは、250種類のビールの広範な化学分析と官能分析を組み合わせて、風味と消費者の評価を予測できる機械学習モデルを訓練する。各ビールについて、200以上の化学的特性を測定し、訓練されたテイスティングパネルを用いて定量的な記述的官能分析を行い、18万件以上の消費者レビューのデータをマッピングして、10種類の機械学習モデルを訓練する。最も優れたアルゴリズムであるグラディエント・ブースティングは、従来の統計に基づく予測を大幅に上回り、化学的プロファイルから複雑な食品の特徴と消費者の評価を正確に予測するモデルを生み出す。モデルの解剖により、ビールの風味と評価のドライバーとして、特定の予期せぬ化合物を特定することができる。これらの化合物を添加することで、消費者の評価が向上した市販のアルコールおよびノンアルコールビールのバリエーションが得られる。併せて、我々の研究は、ビッグデータと機械学習が食品化学、風味、および消費者の知覚の間の複雑なつながりをどのように解明しているかを明らかにし、優れた風味を持つ新規のテーラーメイド食品を開発するための基礎を築くものである。
Fig.1 では化合物同士の含有量の相関、官能試験の項目同士の相関が可視化されている。
Fig.2 では化合物の含有量と官能評価の相関が可視化されている。
Fig.3 で、消費者レビューでのスコアと専門家による官能評価のスコアの相関を確認。
説明変数:化学的な性質→目的変数:官能評価スコアを用いた機械学習モデルを複数構築。予測スコアと実際のスコアの間の決定係数(R2)を指標とし、勾配ブースティングモデルがベストなものとして選択された (Table 1)。
Feature importance, SHAPを用いて重要な化学的性質をリストアップ (Fig.4)。
これらの物質が実際に美味しさに効いているのか?を検証 (Fig.5)。

相互作用の評価においては、あくまで相関が高かった化合物を同時に増やしているだけであり、化合物の相互作用そのものが見つけられたわけではない点も注意が必要だろう。
Huang, Dong, et al. “AgentCoder: Multi-Agent-Based Code Generation with Iterative Testing and Optimisation.” arXiv [cs.CL], 20 Dec. 2023, http://arxiv.org/abs/2312.13010. arXiv.
全てをLLMでやろうとせず、単純なスクリプトに任せられる部分はスクリプト化してしまっている点もポイントか。
The advancement of natural language processing (NLP) has been significantly boosted by the development of transformer-based large language models (LLMs). These models have revolutionized NLP tasks, particularly in code generation, aiding developers in creating software with enhanced efficiency. Despite their advancements, challenges in balancing code snippet generation with effective test case generation and execution persist. To address these issues, this paper introduces Multi-Agent Assistant Code Generation (AgentCoder), a novel solution comprising a multi-agent framework with specialized agents: the programmer agent, the test designer agent, and the test executor agent. During the coding procedure, the programmer agent will focus on the code generation and refinement based on the test executor agent's feedback. The test designer agent will generate test cases for the generated code, and the test executor agent will run the code with the test cases and write the feedback to the programmer. This collaborative system ensures robust code generation, surpassing the limitations of single-agent models and traditional methodologies. Our extensive experiments on 9 code generation models and 12 enhancement approaches showcase AgentCoder's superior performance over existing code generation models and prompt engineering techniques across various benchmarks. For example, AgentCoder achieves 77.4% and 89.1% pass@1 in HumanEval-ET and MBPP-ET with GPT-3.5, while SOTA baselines obtain only 69.5% and 63.0%.
(DeepL翻訳)
自然言語処理(NLP)の進歩は、変換器ベースの大規模言語モデル(LLM)の開発によって大きく後押しされてきた。これらのモデルは、特にコード生成における自然言語処理タスクに革命をもたらし、開発者が効率的にソフトウェアを作成できるようにしました。その進歩にもかかわらず、コード・スニペット生成と効果的なテスト・ケース生成および実行のバランスをとる上での課題は依然として残っている。これらの問題に対処するために、本論文では、プログラマエージェント、テスト設計者エージェント、およびテスト実行者エージェントという特化したエージェントを持つマルチエージェントフレームワークからなる新しいソリューションである、マルチエージェントアシスタントコード生成(AgentCoder)を紹介します。コーディング手順の間、プログラマエージェントは、テスト実行者エージェントのフィードバックに基づいて、コードの生成と改良に集中します。テスト設計エージェントは、生成されたコードのテストケースを生成し、テスト実行エージェントは、テストケースを使用してコードを実行し、プログラマにフィードバックを書き込みます。この協調システムは、単一エージェントモデルや伝統的な方法論の限界を超え、ロバストなコード生成を保証する。9つのコード生成モデルと12の機能強化アプローチに関する広範な実験により、AgentCoderが既存のコード生成モデルやプロンプトエンジニアリング手法よりも優れた性能を持つことが、さまざまなベンチマークで実証されています。例えば、GPT-3.5を使用したHumanEval-ETとMBPP-ETにおいて、AgentCoderは77.4%と89.1%のpass@1を達成しました。
https://github.com/huangd1999/AgentCoder
Taylor, Ross, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. 2022. “Galactica: A Large Language Model for Science.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/2211.09085.
言語モデルが方程式や化学反応などの専門知識をある程度吸収できているのが個人的には一番の驚き。精度が上がれば知識の集積に加えてその活用部分でもGalacticaによる貢献は大きいと考えられ、科学者の仕事の仕方は大きく変わりそう。
一方、多くの指標でSoTA達成といえど、アウトプットされた内容には多くの間違いを含み、実用に耐えうる精度ではない。この点を理解した上で本論文の貢献を議論し、モデルを使う・出力を見る必要がある。
Information overload is a major obstacle to scientific progress. The explosive growth in scientific literature and data has made it ever harder to discover useful insights in a large mass of information. Today scientific knowledge is accessed through search engines, but they are unable to organize scientific knowledge alone. In this paper we introduce Galactica: a large language model that can store, combine and reason about scientific knowledge. We train on a large scientific corpus of papers, reference material, knowledge bases and many other sources. We outperform existing models on a range of scientific tasks. On technical knowledge probes such as LaTeX equations, Galactica outperforms the latest GPT-3 by 68.2% versus 49.0%. Galactica also performs well on reasoning, outperforming Chinchilla on mathematical MMLU by 41.3% to 35.7%, and PaLM 540B on MATH with a score of 20.4% versus 8.8%. It also sets a new state-of-the-art on downstream tasks such as PubMedQA and MedMCQA dev of 77.6% and 52.9%. And despite not being trained on a general corpus, Galactica outperforms BLOOM and OPT-175B on BIG-bench. We believe these results demonstrate the potential for language models as a new interface for science. We open source the model for the benefit of the scientific community1.
(DeepL翻訳)
情報の過多は、科学の進歩の大きな障害となっている。科学文献やデータの爆発的な増加により、大量の情報の中から有用な知見を発見することがますます困難になっている。今日、科学的知識は検索エンジンによってアクセスされるが、検索エンジンだけでは科学的知識を整理することはできない。本論文では、Galacticaを紹介する:科学的知識を保存、結合、推論することができる大規模言語モデルである。我々は、論文、参考資料、知識ベース、その他多くのソースからなる大規模な科学コーパスで学習を行う。我々は、様々な科学的タスクにおいて、既存のモデルを凌駕する性能を発揮する。LaTeX方程式などの技術的な知識に関するプローブでは、最新のGPT-3に対して68.2%対49.0%という高い性能を示しました。推論についても、数学的MMLUでChinchillaを41.3%対35.7%、MATHでPaLM 540Bを20.4%対8.8%と上回り、高い性能を発揮しました。また、PubMedQAやMedMCQAなどの下流タスクにおいても、それぞれ77.6%、52.9%のスコアを獲得し、最新鋭の技術を確立しています。また、Galacticaは一般的なコーパスで学習していないにもかかわらず、BIG-benchにおいてBLOOMやOPT-175Bを上回る性能を発揮しています。これらの結果は、科学の新しいインターフェースとしての言語モデルの可能性を示していると考えています。我々は、科学コミュニティの利益のために、このモデルをオープンソース化します1。
モデルのアーキテクチャはデコーダのみのTransformerをベースにしている。 (本文4.1 Architecture項参照)
モデルのパラメータ数は最大のもので1200億
4800万件の論文、コード、教科書、講義ノート、数百万件の化合物・タンパク質データ、科学ウェブサイト、百科事典などといった「科学的知識データ」で学習
こうしたデータにタスク固有のトークンと引用を示すトークンをつける
例えばタンパク質については Fig.1
1行1行計算を進めていくような課題は、ワーキングメモリを意味するトークンで包む。例が Fig.3

また、事前学習の段階でデータにプロンプト (指示文) も含めて学習させた
上記はSoTAレベルに到達したものの話。他にも様々な課題に取り組まれており、例えばチェスをしたりもしている。
技術的には、こうした実装でこれだけの知識を集約でき、これだけのものが生成できる事実がとてもおもしろく、意義深いものであるのは間違いない。
一方で、非常にキャッチーな技術であるだけに、デモの一般公開 + 今回の喧伝の仕方は少し勇み足だったのかもしれない。
などのML使った論文検索サービスと組み合わさると、(それぞれの強みが異なるので) 知識の整理がより簡単にできるようになりそう。
2022年11月30日にOpenAIよりChatGPTというサービスが公開された。これはGPT-3をベースとしているらしく、テキストで投げかけた話題に会話形式で応答してくれる。日本語にも対応。
驚くような質の高い会話ができることもある一方で、頓珍漢な回答をしてくることもある。この課題はGalacticaと共通。
GPT-4が2022年12月〜2023年2月頃に公開予定という情報がある。
OpenCodeInterpreter Zheng et al., arXiv 2024
Zheng, Tianyu, et al. “OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement.” arXiv [cs.SE], 22 Feb. 2024, http://arxiv.org/abs/2402.14658. arXiv.
The introduction of large language models has significantly advanced code generation. However, open-source models often lack the execution capabilities and iterative refinement of advanced systems like the GPT-4 Code Interpreter. To address this, we introduce OpenCodeInterpreter, a family of open-source code systems designed for generating, executing, and iteratively refining code. Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter integrates execution and human feedback for dynamic code refinement. Our comprehensive evaluation of OpenCodeInterpreter across key benchmarks such as HumanEval, MBPP, and their enhanced versions from EvalPlus reveals its exceptional performance. Notably, OpenCodeInterpreter-33B achieves an accuracy of 83.2 (76.4) on the average (and plus versions) of HumanEval and MBPP, closely rivaling GPT-4's 84.2 (76.2) and further elevates to 91.6 (84.6) with synthesized human feedback from GPT-4. OpenCodeInterpreter brings the gap between open-source code generation models and proprietary systems like GPT-4 Code Interpreter.
(DeepL翻訳)
大規模な言語モデルの導入により、コード生成が大幅に進歩した。しかし、オープンソースのモデルは、GPT-4コード・インタープリタのような先進的なシステムの実行機能や反復的な改良に欠けていることが多い。この問題に対処するために、我々はOpenCodeInterpreterを紹介する。OpenCodeInterpreterは、コードの生成、実行、反復的な改良のために設計されたオープンソースのコードシステム・ファミリーである。OpenCodeInterpreterは、6万8千のマルチターン相互作用を含むデータセットであるCode-Feedbackによってサポートされ、実行と人間のフィードバックを統合して、ダイナミックなコード改良を行う。OpenCodeInterpreterをHumanEval、MBPP、およびEvalPlusの強化バージョンなどの主要なベンチマークで包括的に評価したところ、その卓越した性能が明らかになりました。特に、OpenCodeInterpreter-33Bは、HumanEvalとMBPPの平均(およびプラスバージョン)で83.2 (76.4)の精度を達成し、GPT-4の84.2 (76.2)に匹敵し、GPT-4から合成された人間のフィードバックでさらに91.6 (84.6)まで上昇しました。OpenCodeInterpreterは、オープンソースのコード生成モデルとGPT-4 Code Interpreterのようなプロプライエタリなシステムとの間のギャップを解消します。
https://opencodeinterpreter.github.io/
上記のデータセットを用いて特定の言語モデルをfine-tuning
下図はTable 1 より一部を抜粋。実際は下にスケールの大きなモデルの結果が続く。
プログラミングタスクであるHumanEval及びMBPP (Mostly Basic Python Problems) で性能を評価
4パターンの評価
フィードバックを加えた場合にGPT-3.5 Turbo並み〜GPT-4 Turboに迫る性能を発揮
Lewis Mike, Liu Yinhan, Goyal Naman, Ghazvininejad Marjan, Mohamed Abdelrahman, Levy Omer, Stoyanov Ves, Zettlemoyer Luke. 2019. “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension.” arXiv [cs.CL]. arXiv. https://arxiv.org/abs/1910.13461.
We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pretraining schemes. We evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE. BART also provides a 1.1 BLEU increase over a back-translation system for machine translation, with only target language pretraining. We also report ablation experiments that replicate other pretraining schemes within the BART framework, to better measure which factors most influence end-task performance.
(DeepL翻訳)
本論文では、sequence-to-sequenceモデルを事前学習するためのノイズ除去オートエンコーダBARTを紹介する。BARTは、(1)テキストを任意のノイズ関数で汚染し、(2)元のテキストを再構築するモデルを学習することにより、学習される。BARTは標準的なTranformerベースのニューラル機械翻訳アーキテクチャを使用しており、その単純さにもかかわらず、BERT(双方向エンコーダによる)、GPT(左から右へのデコーダによる)、および他の多くの最近の事前学習スキームを一般化していると見なすことができる。我々は様々なノイズ除去方式を評価し、元の文の順番をランダムに入れ替える方式と、テキストを一つのマスクトークンに置き換える新しいインフィリング方式の両方によって、最高の性能を見つけることができた。BARTは、テキスト生成のために微調整された場合に特に効果的であるが、理解タスクにも有効である。GLUEやSQuADと同等の学習資源を持つRoBERTaと同等の性能を持ち、抽象的な対話、質問応答、要約タスクにおいて、最大6ROUGEの利得を持つ新しい最先端結果を達成しました。また、BARTは機械翻訳のバックトランスレーションシステムに対して、目標言語の事前学習のみで1.1BLEUの向上を実現しています。また、BARTのフレームワークで他の事前学習スキームを再現したアブレーション実験も報告し、エンドタスクの性能に最も影響を与える要因をより適切に測定しています。
https://github.com/facebookresearch/fairseq/tree/main/examples/bart
2019年時点、NLPタスクにおいて、Masked Language Model (MLM) による自己教師あり学習手法は著しい成功を収めているが、特定のタスクにのみフォーカスしていた。
BERT
GPT
より汎用的なタスクに適応できるモデル開発を目指し、本稿ではBERTとGPTを組み合わせたアーキテクチャ BART (Bidirectional and Auto-Regressive Transformer) を提案。
BARTでは、次の手順で自己教師ありの事前学習を行う。
破損した文章データは以下の手法を比較した。

加えて、以下のようなFine-Tuningを施すことでタスクに特化させた。

まず、上述の事前学習手法の比較を行った。

SQuAD, MNLI, ELI5, XSum, ConvAI2, CNN/DMのタスクで比較し、いくつかのタスクでstate-of-the-artを出した。
そこから次のような知見が得られた。
次に、RoBERTa modelと同じスケールでBARTモデルの事前学習を行った。

分類タスク(Tab. 2)では、RoBERTaとおよそ同程度の精度が示された。

要約の生成タスク(Tab. 3)では、CNN/DailyMailとXSumのデータセットで学習を行った。
いずれのタスクにおいてもBARTは高いスコアを出している。
以上より、BARTを用いることで、多様で一貫性のあるテキストを生成することができた。
将来的に次を検討する。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-training of deep bidirectional transformers for language understanding.“ In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1, pp. 4171–4186. Association for Computational Linguistics. https://www.aclweb.org/anthology/N19-1423.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. “Improving language understanding by generative pre-training.“
類似手法
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and TieYan Liu. 2019. “Mass: Masked sequence to sequence pretraining for language generation.“ In International Conference on Machine Learning, 2019.
Lu, Yao, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 8086–98. Dublin, Ireland: Association for Computational Linguistics.
https://aclanthology.org/2022.acl-long.556/
When primed with only a handful of training samples, very large, pretrained language models such as GPT-3 have shown competitive results when compared to fully-supervised, fine-tuned, large, pretrained language models. We demonstrate that the order in which the samples are provided can make the difference between near state-of-the-art and random guess performance: essentially some permutations are “fantastic” and some not. We analyse this phenomenon in detail, establishing that: it is present across model sizes (even for the largest current models), it is not related to a specific subset of samples, and that a given good permutation for one model is not transferable to another. While one could use a development set to determine which permutations are performant, this would deviate from the true few-shot setting as it requires additional annotated data. Instead, we use the generative nature of language models to construct an artificial development set and based on entropy statistics of the candidate permutations on this set, we identify performant prompts. Our method yields a 13% relative improvement for GPT-family models across eleven different established text classification tasks.
(DeepL翻訳)
ほんの一握りの学習サンプルで呼び出された場合、GPT-3のような非常に大規模で事前学習済みの言語モデルは、完全教師あり、微調整された大規模で事前学習済みの言語モデルと比較して、競争力のある結果を示しています。我々は、サンプルの提供順序によって、最先端技術に近い性能とランダムな推測性能の差が生じることを実証しています。この現象を詳細に分析し、次のことを確認した:モデルサイズに関係なく存在すること(現在の最大モデルでさえ)、サンプルの特定のサブセットに関係しないこと、あるモデルにとって良い順列は他のモデルには移植できないこと。どの順列が良いかを決定するために開発セットを使用することもできますが、これは注釈付きデータを追加する必要があるため、真の少数精鋭の設定から外れてしまいます。その代わりに、我々は言語モデルの生成的性質を利用して人工的な開発セットを構築し、このセット上の順列候補のエントロピー統計に基づき、パフォーマンスの高いプロンプトを特定する。本手法は、11種類の確立されたテキスト分類タスクにおいて、GPTファミリーのモデルに対して13%の相対的な改善をもたらす。
https://github.com/chicagohai/active-example-selection
GPTファミリーに代表されるような大規模な言語モデルにおいては、モデルのパラメータの微調整なしで、プロンプトとして対象タスクの例をいくつか提示すれば新しいタスクに対応できる "In-context Learning" という手法が使える (Brown et al., 2020).
しかし、プロンプトに提示する例の順番によって、性能が大きく変わってしまうという問題があった。
この課題を解決するために、「追加のラベルなしに」「自動的に」例提示の順番を決める手法を提案。
まず、様々なモデルやパラメータ数で実験を行い、何が起こっているのかを探求
In-context Learningがうまく行えていないときは、予測ラベルに偏りがあることがわかった (Fig.6)
この仮説検証のため、以下のアプローチをとった
Global Entropy
Local Entropy
文章の分類タスクでGlobal Entropy基準で選んだ候補プロンプトは平均13%, Local Entropy基準で選んだものは平均9.6%の改善が見られた。
異なるモデルや異なるタスクにおいても同様のアプローチを取れば、一貫して改善が見られた。
Azizi, Shekoofeh, et al. “Synthetic Data from Diffusion Models Improves ImageNet Classification.” arXiv [cs.CV], 17 Apr. 2023, http://arxiv.org/abs/2304.08466. arXiv.
Deep generative models are becoming increasingly powerful, now generating diverse high fidelity photo-realistic samples given text prompts. Have they reached the point where models of natural images can be used for generative data augmentation, helping to improve challenging discriminative tasks? We show that large-scale text-to image diffusion models can be fine-tuned to produce class conditional models with SOTA FID (1.76 at 256x256 resolution) and Inception Score (239 at 256x256). The model also yields a new SOTA in Classification Accuracy Scores (64.96 for 256x256 generative samples, improving to 69.24 for 1024x1024 samples). Augmenting the ImageNet training set with samples from the resulting models yields significant improvements in ImageNet classification accuracy over strong ResNet and Vision Transformer baselines.
(DeepL翻訳)
深層生成モデルはますます強力になってきており、現在では、テキストプロンプトが与えられると、多様で忠実度の高いフォトリアリスティックサンプルを生成する。自然画像のモデルを生成的データ補強に使用し、困難な識別タスクの改善に役立てることができるところまで来ているのだろうか?我々は、SOTAのFID(256x256の解像度で1.76)とInception Score(256x256で239)を持つクラス条件付きモデルを生成するために、大規模なテキストから画像への拡散モデルを微調整できることを示す。このモデルはまた、分類精度スコアにおいて新しいSOTAをもたらします(256x256の生成サンプルで64.96、1024x1024のサンプルで69.24に改善)。得られたモデルのサンプルでImageNetトレーニングセットを補強することで、強力なResNetとVision TransformerのベースラインよりもImageNetの分類精度が大幅に向上します。
生成モデルによるdata augmentation 有り/無しでfine-tuning → 分類タスクを解かせた。
分類精度はFrechet Inception Distance (FID) と Inception Score (IS) で評価。
結果、ResNet, Transformerベースのモデルでは分類精度の向上が見られた (Fig.1)。
生成された画像のサイズが大きいほど、精度改善効果も高い (Fig.6)
一方、学習に追加した生成画像の枚数を増やしすぎると精度が低下しだした (Table 4)。
画像以外のタスクで似たようなことをやるとどうなるのかは興味がある。
元のデータに含まれる画像の特徴にオーバーフィッティングしそうな気もするし、それが大きな問題にならないのは画像分類という多少細部が異なっていても許されることの多いタスクだからではないだろうか。
Adversarial Random Forest のようなテーブルデータを生成する手法もあるが、本論文の結果を持って「画像分類以外のタスクでも生成モデルがAugmentationに使える」と結論づけるのは早計だろう。(もちろん、手法の限界を正しく理解して使えば問題ないと思う。)
Borgeaud, Sebastian, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, et al. 2021. “Improving Language Models by Retrieving from Trillions of Tokens.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/2112.04426.
We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a 2 trillion token database, our Retrieval-Enhanced Transformer (Retro) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25x fewer parameters. After fine-tuning, Retro performance translates to downstream knowledge-intensive tasks such as question answering. Retro combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train Retro from scratch, yet can also rapidly Retrofit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.
(DeepL翻訳)
我々は、大規模コーパスから取得した文書チャンクを、先行トークンとの局所的な類似性に基づいて条件付けすることにより、自己回帰型言語モデルを強化する。2兆個のトークンデータベースを用いた我々の検索強化型変換器(Retro)は、25倍少ないパラメータで、Pile上のGPT-3やJurassic-1と同等の性能を得ることができる。Retroの性能は、微調整の後、質問応答のような下流の知識集約的なタスクに反映される。Retroは、凍結バートレトリバー、微分可能エンコーダー、チャンク型クロスアテンションメカニズムを組み合わせ、学習時に消費されるデータよりも一桁多いデータを基にトークンを予測します。私たちは通常、Retroをゼロから学習しますが、事前に学習した変換器を検索に迅速にRetrofitすることも可能であり、それでも良好な性能を達成することができます。私たちの研究は、前例のない規模の明示的記憶によって言語モデルを改善する新しい道を開くものです。
用いたデータセット
比較した指標
比較対象のモデル
いずれにおいてもBaselineからの改良がみられ、Fine-tuningを行うことでQ&A taskでもstate-of-the-artとのcompetitive performanceを示した。検索なしでもbaselineと同程度の性能が出る。
Lei, Tao. 2021. “When Attention Meets Fast Recurrence: Training Language Models with Reduced Compute.” In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 7633–48. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics. https://aclanthology.org/2021.emnlp-main.602/
Introductionで "Is attention all we need for modeling?" と、あの有名な言葉をもじり、実際にAttentionを挟むだけで大幅な改善を見せ、その威力を見せてくれる面白い仕事。
Large language models have become increasingly difficult to train because of the growing computation time and cost. In this work, we present SRU++, a highly-efficient architecture that combines fast recurrence and attention for sequence modeling. SRU++ exhibits strong modeling capacity and training efficiency. On standard language modeling tasks such as Enwik8, Wiki-103 and Billion Word datasets, our model obtains better bits-per-character and perplexity while using 3x-10x less training cost compared to top-performing Transformer models. For instance, our model achieves a state-of-the-art result on the Enwik8 dataset using 1.6 days of training on an 8-GPU machine. We further demonstrate that SRU++ requires minimal attention for near state-of-the-art performance. Our results suggest jointly leveraging fast recurrence with little attention as a promising direction for accelerating model training and inference.
大規模な言語モデルは、計算時間やコストが増大するため、学習が困難になってきている。本研究では、シーケンスモデリングのために高速な再帰性と注意力を組み合わせた高効率なアーキテクチャであるSRU++を発表する。SRU++は、強力なモデリング能力と学習効率を発揮する。Enwik8、Wiki-103、Billion Wordデータセットなどの標準的な言語モデリングタスクにおいて、我々のモデルは、上位のTransformerモデルと比較して、3倍から10倍少ない学習コストで、優れた文字あたりのビット数とパープレキシティを獲得することができる。例えば、Enwik8データセットでは、8GPUのマシンで1.6日間の学習を行い、最先端の結果を達成しました。さらに、SRU++は最小限の注意で最新鋭に近い性能を発揮することを実証しています。この結果は、モデルの学習と推論を高速化するための有望な方向性として、少ない注意で高速リカレンスを共同で活用することを示唆しています。
https://github.com/asappresearch/sru
Gruich, Cameron, Varun Madhavan, Yixin Wang, and Bryan Goldsmith. 2023. “Clarifying Trust of Materials Property Predictions Using Neural Networks with Distribution-Specific Uncertainty Quantification.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/2302.02595.
雑にまとめると「"k-fold分割してAccuracy見て評価" よりも良いモデルの評価方法がある」というお話。実務のみならずコンペでも生きそう。
「モデルが良い精度のアウトプットを返す」に加え、「その精度がどの程度信頼できるのか」という指標も得られる点が紹介されている手法群の強み。
It is critical that machine learning (ML) model predictions be trustworthy for high-throughput catalyst discovery approaches. Uncertainty quantification (UQ) methods allow estimation of the trustworthiness of an ML model, but these methods have not been well explored in the field of heterogeneous catalysis. Herein, we investigate different UQ methods applied to a crystal graph convolutional neural network (CGCNN) to predict adsorption energies of molecules on alloys from the Open Catalyst 2020 (OC20) dataset, the largest existing heterogeneous catalyst dataset. We apply three UQ methods to the adsorption energy predictions, namely k-fold ensembling, Monte Carlo dropout, and evidential regression. The effectiveness of each UQ method is assessed based on accuracy, sharpness, dispersion, calibration, and tightness. Evidential regression is demonstrated to be a powerful approach for rapidly obtaining tunable, competitively trustworthy UQ estimates for heterogeneous catalysis applications when using neural networks. Recalibration of model uncertainties is shown to be essential in practical screening applications of catalysts using uncertainties.
(DeepL翻訳)
ハイスループットな触媒探索を行うためには、機械学習(ML)モデルの予測値が信頼できるものであることが重要である。不確実性定量化(UQ)法は、MLモデルの信頼性を推定することができるが、不均一系触媒の分野ではまだ十分に検討されていない。ここでは、既存の最大規模の不均一系触媒データセットであるOpen Catalyst 2020 (OC20) データセットから、合金への分子の吸着エネルギーを予測するために、結晶グラフ畳み込みニューラルネットワーク (CGCNN) に適用するさまざまなUQ手法を検討する。吸着エネルギー予測には、k-foldアンサンブル、モンテカルロドロップアウト、エビデンス回帰という3つのUQ手法を適用した。各UQ法の有効性は、精度、シャープネス、分散、キャリブレーション、タイトネスに基づいて評価される。エビデンシャル回帰は、ニューラルネットワークを使用した場合、不均一系触媒のアプリケーションにおいて、調整可能で競争上信頼できるUQ推定値を迅速に得るための強力なアプローチであることが実証された。不確実性を利用した触媒の実用的なスクリーニングアプリケーションでは、モデルの不確実性の再キャリブレーションが不可欠であることが示された。
以下の項目で不確実性を定量。図はその結果を示す。
Accuracy

Sharpness/Dispersion

Calibration
予測結果の発生確率分布と、実際の発生確率分布が、どの程度近いか?
Reliability diagram plot: 実測値と予測値の平均値の差(をノーマライズしたもの)をプロット。
"Re-calibration"とは、不確実性の推定を改善するための後処理。
The constant was chosen via a black-box optimization algorithm
Reliability diagram plot (ハイパーパラメータによる差)

Reliability diagram plot (Re-calibration前後の比較)

Tightness

ほぼすべての指標で、Evidential regression が最も高精度に不確実性を推定できていた。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.