






A dictionary magician in the form of a module!
| Author: | Tasdik Rahman |
|---|
Contents
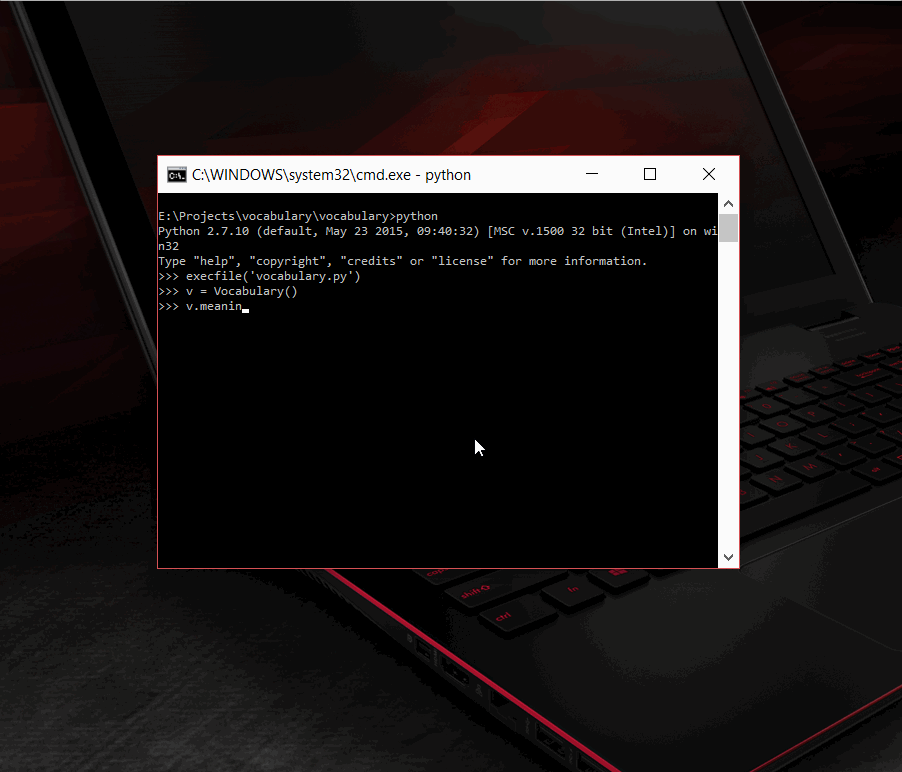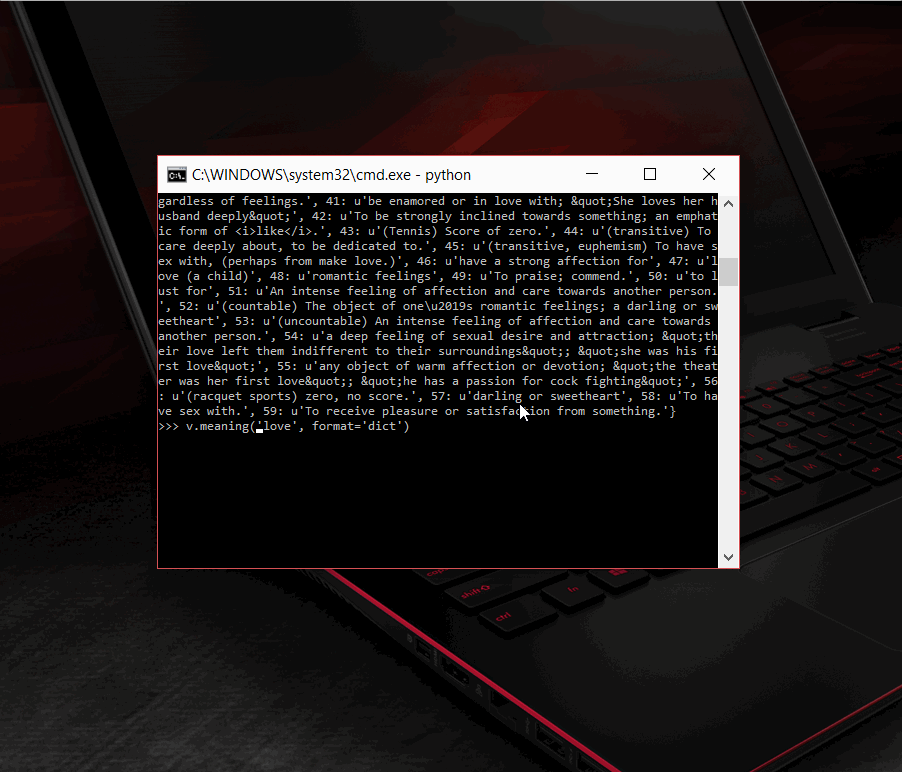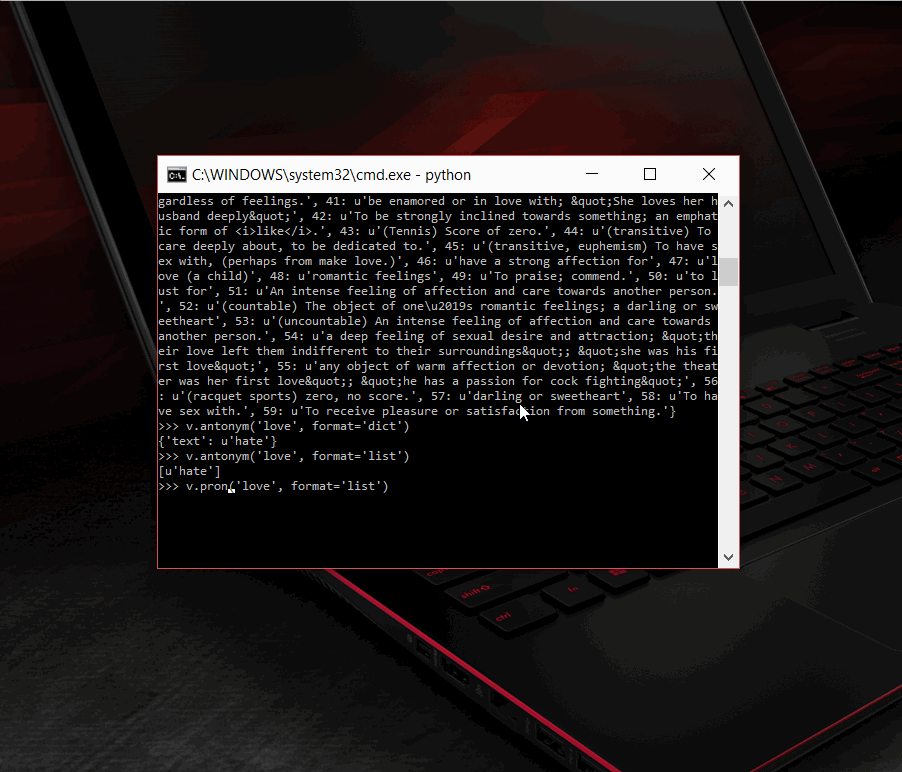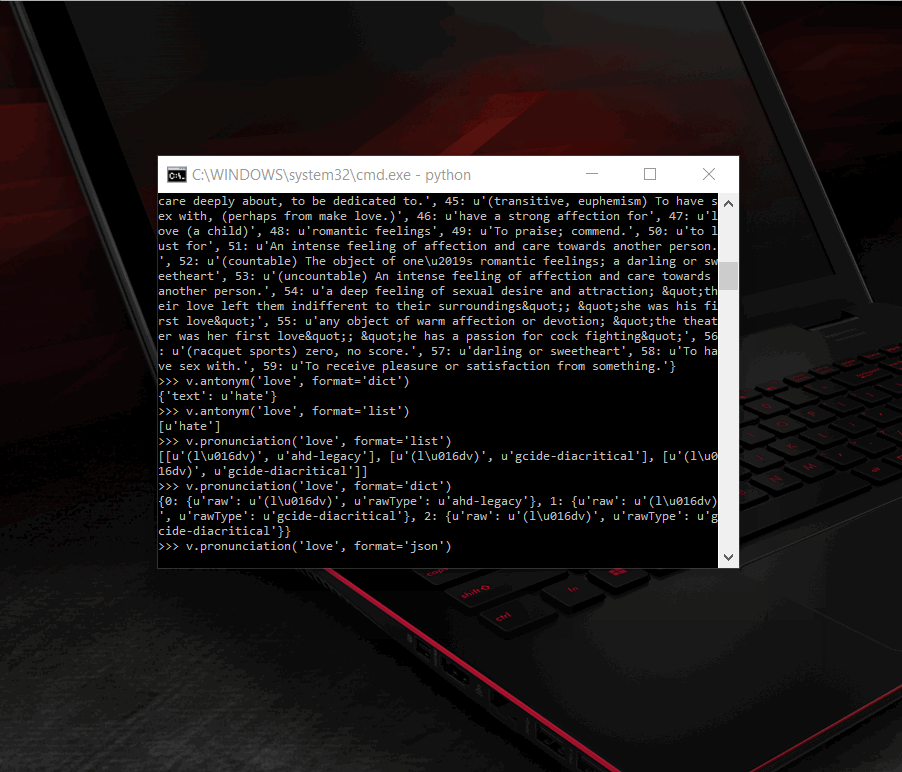
For a given word, using Vocabulary, you can get its
- Meaning
- Synonyms
- Antonyms
- Part of speech : whether the word is a
noun,interjectionor anadverbet el - Translate : Translate a phrase from a source language to the desired language.
- Usage example : a quick example on how to use the word in a sentence
- Pronunciation
- Hyphenation : shows the particular stress points(if any)
- Written in uncomplicated
Python - Returns
JSONobjects,PYTHONdictionaries and lists - Minimum dependencies ( just uses requests module )
- Easy to install
- A decent substitute to
Wordnet(well almost!) Wanna see? Here is a small comparison - Stupidly easy to use
- Fast!
- Supports
- both,
python2.*andpython3.* - Works on Mac, Linux and Windows
- both,
Wordnet is a great resource. No doubt about it! So why should you
use Vocabulary when we already have Wordnet out there?
Let's say you want to find out the synonyms for the word car.
- Using
Wordnet
>>> from nltk.corpus import wordnet
>>> syns = wordnet.synsets('car')
>>> syns[0].lemmas[0].name
'car'
>>> [s.lemmas[0].name for s in syns]
['car', 'car', 'car', 'car', 'cable_car']
>>> [l.name for s in syns for l in s.lemmas]
['car', 'auto', 'automobile', 'machine', 'motorcar', 'car', 'railcar', 'railway_car', 'railroad_car', 'car', 'gondola', 'car', 'elevator_car', 'cable_car', 'car']- Doing the same using
Vocabulary
>>> from vocabulary.vocabulary import Vocabulary as vb
>>> vb.synonym("car")
'[{
"seq": 0,
"text": "automobile"
}, {
"seq": 1,
"text": "cart"
}, {
"seq": 2,
"text": "automotive"
}, {
"seq": 3,
"text": "wagon"
}, {
"seq": 4,
"text": "motor"
}]'
>>> ## load the json data
>>> car_synonyms = json.loads(vb.synonym("car"))
>>> type(car_synonyms)
<class 'list'>
>>>So there you go. You get the data in an easy JSON format.
You can go on comparing for the other methods too.
1.4.1 Option 1: installing through pip (Suggested way)
$ pip install vocabulary
If you are behind a proxy
$ pip --proxy [username:password@]domain_name:port install vocabulary
Note: If you get command not found then
$ sudo apt-get install python-pip should fix that
$ git clone https://github.com/tasdikrahman/vocabulary.git
$ cd vocabulary/
$ pip install -r requirements.txt
$ python setup.py install
For a detailed usage example, refer the documentation at Read the Docs
Please refer Contributing page for details
Join us on our Gitter channel if you want to chat or if you have any questions in your mind.
- Huge shoutout to @tenorz007 for adding the ability to return the API response as different data structures.
- Thanks to Anton Relin for adding the translate module.
- And a big shout out to all the contributers for their contributions
Please refer Changelog page for details
Please report the bugs at the issue tracker
Other similar software inspired by Vocabulary
- Vocabulary : The
Go langport of thispythoncounterpart - woordy : Gives back word translations
- guile-words : The
Guile Schemeport of thispythoncounterpart
- In python2, when using the method Vocabulary.synonym() or Vocabulary.pronunciation()
>>> vb.synonym("car")
[{
"seq": 0,
"text": "automotive"
}, {
"seq": 1,
"text": "motor"
}, {
"seq": 2,
"text": "wagon"
}, {
"seq": 3,
"text": "cart"
}, {
"seq": 4,
"text": "automobile"
}]
>>> type(vb.pronunciation("hippopotamus"))
<class 'list'>
>>> json.dumps(vb.pronunciation("hippopotamus"))
'[{"raw": "(h\\u012dp\\u02cc\\u0259-p\\u014ft\\u02c8\\u0259-m\\u0259s)", "rawType": "ahd-legacy", "seq": 0}, {"raw": "HH IH2 P AH0 P AA1 T AH0 M AH0 S", "rawType": "arpabet", "seq": 1}]'
>>>You are being returned a list object instead of a JSON object.
When returning the latter, there are some unicode issues. A fix for
this will be released soon.
I may suggest python-ftfy which can help you in this matter.
Built with ♥ by Tasdik Rahman under the MIT License ©
You can find a copy of the License at http://prodicus.mit-license.org/








































































































































