
The site is for those who know nothing of R or even of programming, and seek a quick, painless entree to the world of R.
-
FAST: You'll already be doing good stuff -- useful data analysis --- in R in your very first lesson.
-
No prerequisites: If you're comfortable with navigating the Web, you're fine. This tutorial is aimed at you, not experienced C or Python coders.
-
No polemics: You won't be made to feel guilty for not using an instructor's favorite R tool or style, including mine. :-)
-
No frills: E.g. no IDEs (Integrated Development Environments). RStudio, ESS etc. are great, but you shouldn't be burdened with learning R and learning an IDE at the same time. This can come later, optionally.
-
"When in doubt, Try it out!" This is a motto I devised for teaching. If you are unclear or curious about something, try it out! Just devise a little experiment, and type in the code. Don't worry -- you won't "break" things.
-
Nonpassive approach: Passive learning, just watching the screen is NO learning. There will be occasional Your Turn sections, in which you the learner must devise and try your own variants on what has been presented. Sometimes the tutorial will be give you some suggestions, but even then, you should cook up your own variants to try.
-
Contribute your own lessons!: Yes, "your name in lights"; see below.
For the time being, the main part of this online course will be this README.md file. It is set up as a potential R package, though, and I may implement that later.
GPL-3: Permission granted to copy/modify, provided the source (N. Matloff) is stated. No warranties.
The color figure at the top of this file was generated by our prVis package, run on a famous dataset called Swiss Roll.
-
You will just be using R from the command line here. Most tutorials, say the excellent one by R-Ladies Sydney, start with RStudio. It is a very attractive, powerful IDE. But even the R-Ladies tutorial laments that RStudio can be "overwhelming." Here we stick to the R command line, and focus on data analysis, not advanced tools.
-
Nonpassive learning is absolutely key! So even if the output of an R command is shown here, run the command yourself in your R console, by copy-and-pasting from this document.
-
Similarly, the Your Turn sections are absolutely crucial. Devise your own little examples, and try them out!
-
Also similarly: I cannot teach you how to program. I can merely give you the tools, e.g. R vectors, and some examples. For a given desired programming task, then, you must creatively put these tools together to attain the goal. Treat it like a puzzle! I think you'll find that if you stick with it, you'll find you're pretty good at it. After all, we can all work puzzles.
If there is any interest, it would be fun for some useRs out there to contribute lessons here. Both experts and novices are encouraged, especially the latter! It's like what happens in a classroom, where only a few students ask questions and the rest are too shy to do so. Don't be shy! Maybe do one with a friend. I'll help you through the kinks, and your name will be displayed with your contribution.
You'll need to install R, from the R Project site. Start up R, either by clicking an icon or typing 'R' in a terminal window.
As noted, this tutorial will be "bare bones." In particular, there is no script to type your command for you. Instead, you will either copy-and-paste from the test here, or type by hand. (Note that the code lines here will all begin with the R interactive prompt, '>'; that should not be typed.)
The R command prompt is '>'. It will be shown here, but you don't type it.
So, just type '1+1' then hit Enter. Sure enough, it prints out 2:
> 1 + 1
[1] 2But what is that '[1]' here? It's just a row label. We'll go into that later, not needed yet.
R includes a number of built-in datasets, mainly for illustration purposes. One of them is Nile, 100 years of annual flow data on the Nile River.
Let's find the mean flow:
> mean(Nile)
[1] 919.35Here mean is an example of an R function, and in this case Nile is an argument -- fancy way of saying "input" -- to that function. That output, 919.35, is called the return value or simply value.
Since there are only 100 data points here, it's not unwieldy to print them out:
> Nile
Time Series:
Start = 1871
End = 1970
Frequency = 1
[1] 1120 1160 963 1210 1160 1160 813 1230 1370 1140 995 935 1110 994 1020
[16] 960 1180 799 958 1140 1100 1210 1150 1250 1260 1220 1030 1100 774 840
[31] 874 694 940 833 701 916 692 1020 1050 969 831 726 456 824 702
[46] 1120 1100 832 764 821 768 845 864 862 698 845 744 796 1040 759
[61] 781 865 845 944 984 897 822 1010 771 676 649 846 812 742 801
[76] 1040 860 874 848 890 744 749 838 1050 918 986 797 923 975 815
[91] 1020 906 901 1170 912 746 919 718 714 740Now you can see how the row labels work. There are 15 numbers per row, here, so the second row starts with the 16th, indicated by '[16]'.
R has great graphics, not only in base R but also in user-contributed packages, such as ggplot2 and lattice. But we'll start with a very simple, non-dazzling one, a no-frills histogram:
> hist(Nile)No return value for the hist function, but it does create the graph (shown here; it should be on your screen too).
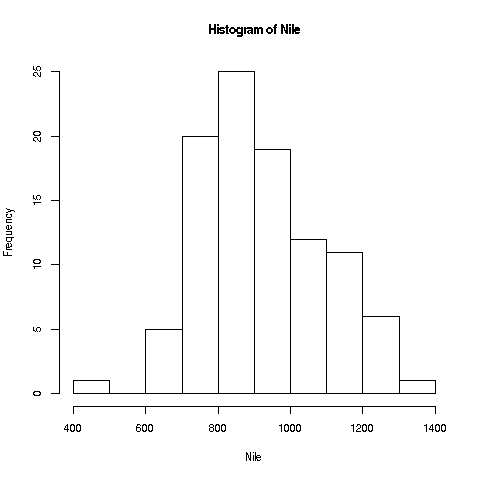
Your Turn: The hist function draws 10 bins in the histogram by default, but you can choose other values, by specifying a second argument to the function, named breaks:
> hist(Nile,breaks=20)would draw the histogram with 20 bins. Try plotting using several different large and small values of the number of bins.
R has lots of online help, which you can access via '?'. E.g. typing
> ?histwill tell you to full story on all the options available for the hist function. Note, there are far too many for you to digest for now, but it's a vital resource to know.
Your Turn: Look at the online help for mean and Nile.
Now, one more new thing for this first lesson. Say we want to find the mean flow after year 1950. Since 1971 is the 100th year, 1951 is the 80th. How do we designate the 80th through 100th elements in the Nile data?
First, note that a set of numbers such as Nile is called a vector. Individual elements can be accessed using subscripts or indices (singular is index), which are specified using brackets, e.g.
> Nile[2]
[1] 1160for the second element (which we see above is indeed 1160).
The value 2 here is the index.
The c ("concatenate") function builds a vector, stringing several numbers together. E.g. we can get the 2nd, 5th and 6th:
> Nile[c(2,5,6)]
[1] 1160 1160 1160And 80:100 means all the numbers from 80 to 100. So, to answer the above question on the mean flow during 1951-1971, we can do
> mean(Nile[80:100])
[1] 877.6667If we plan to do more with that time period, we should make a copy of it:
> n80100 <- Nile[80:100]
> mean(n80100)
[1] 877.6667
> sd(n80100)
[1] 122.4117The function sd finds the standard deviation.
Note that we used R's assignment operator here to copy those particular Nile elements to n80100. (In most situations, you can use "=" instead of "<-", but why worry about what the exceptions might be? They are arcane, so it's easier just to always use "<-".)
We can pretty much choose any name we want; "n80100" just was chosen to easily remember this new vector's provenance. (But names can't include spaces, and must start with a letter.)
Note that n80100 now is a 21-element vector. Its first element is now element 80 of Nile:
> n80100[1]
[1] 890
> Nile[80]
[1] 890Keep in mind that although Nile and n80100 now have identical contents, they are separate vectors; if one changes, the other will not.
Your Turn: Devise and try variants of the above, say finding the mean over the years 1945-1960.
Another oft-used function is length, which gives the length of the vector, e.g.
> length(Nile)
[1] 100Leave R by typing 'q()' or ctrl-d. (Answer no to saving the workspace.)
Continuing along the Nile, say we would like to know in how many years the level exceeded 1200. Let's first introduce R's sum function:
> sum(c(5,12,13))
[1] 30Here the c function ("concatenate") built a vector consisting of 5, 12 and 13. That vector was then fed into the sum function, returning 5+12+13 = 30.
By the way, the above is our first example of function composition, where the output of one function, c here, is fed as input into another, sum in this case.
We can now use this to answer our question on the Nile data:
> sum(Nile > 1200)
[1] 7But how in the world did that work? Bear with me a bit here. Let's look at a small example first:
> x <- c(5,12,13)
> x > 8
[1] FALSE TRUE TRUE
> sum(x > 8)
[1] 2First, that 8 was recycled into 3 8s, i.e. the vector (8,8,8), in order to have the same length as x. This sets up an element-by-element comparison. Then, the 5 was compared to the first 8, yielding FALSE i.e. 5 is NOT greater than 8. Then 12 was compared to the second 8, then 13 with the third. So, we got the vector (FALSE,TRUE,TRUE).
Fine, but how will sum add up some TRUEs and FALSEs? The answer is that R, like most computer languages, treats TRUE and FALSE as 1 and 0, respectively. So we summed the vector (0,1,1), yielding 2.
Your Turn: Try a few other experiments of your choice using sum. I'd suggest starting with finding the sum of the first 25 elements in Nile. You may wish to start with experiments on a small vector, say (2,1,1,6,8,5), so you will know that your answers are correct. Remember, you'll learn best nonpassively. Code away!
Right after vectors, the next major workhorse of R is the data frame. It's a rectangular table consisting of one row for each data point.
Say we have height, weight and age on each of 100 people. Our data frame would have 100 rows and 3 columns. The entry in, e.g., the second row and third column would be the age of the second person in our data.
As our first example, consider the ToothGrowth dataset built-in to R. Again, you can read about it in the online help (the data turn out to be on guinea pigs, with orange juice or Vitamin C as growth supplements). Let's take a quick look from the command line.
> head(ToothGrowth)
len supp dose
1 4.2 VC 0.5
2 11.5 VC 0.5
3 7.3 VC 0.5
4 5.8 VC 0.5
5 6.4 VC 0.5
6 10.0 VC 0.5R's head function displays (by default) the first 6 rows of the given dataframe. We see there are length, supplement and dosage columns.
The head function works on vectors too:
> head(ToothGrowth$len)
[1] 4.2 11.5 7.3 5.8 6.4 10.0To avoid writing out the long word "ToothGrowth" repeatedly, let's make a copy.
> tg <- ToothGrowthHow large is the dataset?
> dim(tg)
[1] 60 3Ah, 60 rows and 3 columns (60 guinea pigs, 3 measurements each).
Dollar signs are used to denote the individual columns. E.g. we can print out the mean length; tg$len is the tooth length column, so
> mean(tg$len)
[1] 18.81333Subscripts in data frames are pairs, specifying row and column numbers. To get the element in row 3, column 1:
> tg[3,1]
[1] 7.3which matches what we saw above. Or, use the fact that tg$len is a vector:
> tg$len[3]
[1] 7.3The element in row 3, column 1 in the data frame tg is element 3 in the vector tg$len.
Some data frames don't have column names, but that is no obstacle. We can use column numbers, e.g.
> mean(tg[,1])
[1] 18.81333One can extract subsets of data frames, using either some of the rows or some of the columns, e.g.:
> z <- tg[2:5,c(1,3)]
> z
len dose
2 11.5 0.5
3 7.3 0.5
4 5.8 0.5
5 6.4 0.5Here we extracted rows 2 through 5, and columns 1 and 3, assigning the result to z. To extract those columns but keep all rows, do
> y <- tg[ ,c(,1,3)]i.e. leave the row specification field empty.
Your Turn: Devise your own little examples with the ToothGrowth data. For instance, write code that finds the number of cases in which the length was less than 16. Also, try some examples with another built-in R dataset, faithful. This one involves the Old Faithful geyser in Yellowstone National Park in the US. The first column gives duration of the eruption, and the second has the waiting time since the last eruption.
Each object in R has a class. The number 3 is of the 'numeric' class, the character string 'abc' is of the 'character' class, and so on. (In R, class names are quoted; one can use single or double quotation marks.) Note that vectors of numbers are of 'numeric' class too; actually, a single number is considered to be a vector of length 1. So, c('abc','xw'), for instance, is 'numeric' as well.
What about tg and tg$supp?
> class(tg)
[1] "data.frame"
> class(tg$supp)
[1] "factor"R factors are used when we have categorical variables. If in a genetics study, say, we have a variable for hair color, that might comprise four categories: black, brown, red, blond. We can find the list of categories for tg$supp as follows:
> levels(tg$supp)
[1] "OJ" "VC"The supplements were either orange juice or Vitamin C.
Factors can sometimes be a bit tricky to work with, but the above is enough for now. Let's see how to apply the notion in the current dataset.
Let's compare mean tooth length for the two types of supplements:
> tgoj <- tg[tg$supp == 'OJ',]
> tgvc <- tg[tg$supp == 'VC',]
> mean(tgoj$len)
[1] 20.66333
> mean(tgvc$len)
[1] 16.96333What did that first line do? We extracted the rows of tg for which the suppolement was orange juice, with no restriction on columns, and assigned the result to tgoj. (Once again, we can choose any name; we chose this one to help remember what we put into that variable.)
Often in R there is a shorter, more compact way of doing things. That's the case here; we can use the magical tapply function:
> tapply(tg$len,tg$supp,mean)
OJ VC
20.66333 16.96333 In English: "Split tg$len into two groups, according to the value of tg$supp, then apply mean to each group." Note that the result was returned as a vector:
> z <- tapply(tg$len,tg$supp,mean)
> z[1]
OJ
20.66333
> z[2]
VC
16.96333 That can be quite handy, because we can use that result in subsequent code.
Instead of mean, we can use any function as that third argument in tapply. Here is another example, using the built-in dataset PlantGrowth:
> tapply(PlantGrowth$weight,PlantGrowth$group,length)
ctrl trt1 trt2
10 10 10 Here tapply split the weight vector into subsets according to the group variable, then called the length function on each subset. We see that each subset had length 10, i.e. the experiment had assigned 10 plants to the control, 10 to treatment 1 and 10 to treatment 2.
Your Turn: One of the most famous built-in R datasets is mtcars, which has various measurements on cars from the 60s and 70s. Lots of opportunties for you to cook up little experiments here! You may wish to start by comparing the mean miles-per-gallon values for 4-, 6- and 8-cylinder cars. Another suggestion would be to find how many cars there are in each cylinder category, using tapply.
By the way, the mtcars data frame has a "phantom" column.
> head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1That first column seems to give the make (brand) and model of the car. Yes, it does -- but it's not a column. Behold:
> head(mtcars[,1])
[1] 21.0 21.0 22.8 21.4 18.7 18.1Sure enough, column 1 is the mpg data, not the car names. But we see the names there on the far left! The resolution of this seeming contradiction is that those car names are the row names of this data frame:
> row.names(mtcars)
[1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710"
[4] "Hornet 4 Drive" "Hornet Sportabout" "Valiant"
[7] "Duster 360" "Merc 240D" "Merc 230"
[10] "Merc 280" "Merc 280C" "Merc 450SE"
[13] "Merc 450SL" "Merc 450SLC" "Cadillac Fleetwood"
[16] "Lincoln Continental" "Chrysler Imperial" "Fiat 128"
[19] "Honda Civic" "Toyota Corolla" "Toyota Corona"
[22] "Dodge Challenger" "AMC Javelin" "Camaro Z28"
[25] "Pontiac Firebird" "Fiat X1-9" "Porsche 914-2"
[28] "Lotus Europa" "Ford Pantera L" "Ferrari Dino"
[31] "Maserati Bora" "Volvo 142E" Most real-world data is "dirty," i.e. filled with errors. The famous New York taxi trip dataset, for instance, has one trip destination whose lattitude and longitude place it in Antartica! The impact of such erroneous data on one's statistical analysis can be anywhere from mild to disabling. Let's see below how one might ferret out bad data. And along the way, we'll cover several new R concepts.
We'll use the famous Pima Diabetes dataset. Various versions exist, but we'll use the one that is included in faraday, an R package compiled by Julian Faraway, author of several popular books on statistical regression analysis in R.
I've placed the data file, Pima.csv, on my Web site. Here is how you can read it into R:
> pima <- read.csv('http://heather.cs.ucdavis.edu/FasteR/data/Pima.csv',header=TRUE)The dataset is in a CSV ("comma-separated values") file. Here we read it, and assigned the resulting data frame to a variable we chose to name pima.
Note that second argument, 'header=TRUE'. A header in a file, if one exists, states what names the columns in the data frame are to have. If the file doesn't have one, set header to FALSE. You can always add names to your data frame later (future lesson).
It's always good to take a quick look at a new data frame:
> head(pima)
pregnant glucose diastolic triceps insulin bmi diabetes age test
1 6 148 72 35 0 33.6 0.627 50 1
2 1 85 66 29 0 26.6 0.351 31 0
3 8 183 64 0 0 23.3 0.672 32 1
4 1 89 66 23 94 28.1 0.167 21 0
5 0 137 40 35 168 43.1 2.288 33 1
6 5 116 74 0 0 25.6 0.201 30 0
> dim(pima)
[1] 768 9768 people in the study, 9 variables measured on each.
Since this is a study of diabetes, let's take a look at the glucose variable.
> table(pima$glucose)
0 44 56 57 61 62 65 67 68 71 72 73 74 75 76 77 78 79 80 81
5 1 1 2 1 1 1 1 3 4 1 3 4 2 2 2 4 3 6 6
82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101
3 6 10 7 3 7 9 6 11 9 9 7 7 13 8 9 3 17 17 9
102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121
13 9 6 13 14 11 13 12 6 14 13 5 11 10 7 11 6 11 11 6
122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141
12 9 11 14 9 5 11 14 7 5 5 5 6 4 8 8 5 8 5 5
142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161
5 6 7 5 9 7 4 1 3 6 4 2 6 5 3 2 8 2 1 3
162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181
6 3 3 4 3 3 4 1 2 3 1 6 2 2 2 1 1 5 5 5
182 183 184 186 187 188 189 190 191 193 194 195 196 197 198 199
1 3 3 1 4 2 4 1 1 2 3 2 3 4 1 1 Uh, oh! 5 women in the study had glucose level 0. Presumably this is not physiologically possible.
Let's consider a version of the glucose data that excludes these 0s.
> pg <- pima$glucose
> pg1 <- pg[pg > 0]
> length(pg1)
[1] 763As before, the expression "pg > 0" creates a vector of TRUEs and FALSEs. The filtering "pg[pg > 0]" will only pick up the TRUE cases, and sure enough, we see that pg1 has only 763 cases, as opposed to the original 768.
Did removing the 0s make much difference? Turns out it doesn't:
> mean(pg)
[1] 120.8945
> mean(pg1)
[1] 121.6868But still, these things can in fact have major impact in many statistical analyses.
R has a special code for missing values, NA, for situations like this. Rather than removing the 0s, it's better to recode them as NAs. Let's do this, back in the original dataset so we keep all the variables in one object:
> pima$glucose[pima$glucose == 0] <- NANote the double-equal sign! If we wish to test whether, say, a and b are equal, the expression must be "a == b", not "a = b"; the latter would do "a <- b".
As a check, let's verify that we now have 5 NAs in the glucose variable:
> sum(is.na(pima$glucose))
[1] 5Here the built-in R function is.na will return a vector of TRUEs and FALSEs. Recall that those values can always be treated as 1s and 0s. Thus we got our count, 5.
Let's also check that the mean comes out right:
> mean(pima$glucose)
[1] NAWhat went wrong? By default, the mean function will not skip over NA values; thus the mean was reported as NA too. But we can instruct the function to skip the NAs:
> mean(pima$glucose,na.rm=TRUE)
[1] 121.6868Your Turn: Determine which other columns in pima have suspcious 0s, and replace them with NA values.
Now, look again at the plot we made earlier of the Nile flow histogram. There seems to be a gap between the numbers at the low end and the rest. What years did these correspond to?
We saw earlier how handy the tapply function can be. Let's look at a related one, split.
Earlier we mentioned the built-in dataset mtcars, a data frame. Consider mtcars$mpg, the column containing the miles-per-gallon data. Again, to save typing, let's make a copy first:
> mtmpg <- mtcars$mpgSuppose we wish to split the original vector into three vector, one for 4-cylinder cars, one for 6 and one for 8. We could do
> mt4 <- mtmpg[mtcars$cyl == 4]and so on.
Your Turn: In order to keep up, make sure you understand how that line of code works, with the TRUEs and FALSEs etc. First print out the value of mtcars$cyl == 4, and go from there.
But there is a cleaner way:
> mtl <- split(mtmpg,mtcars$cyl)
> mtl
$`4`
[1] 22.8 24.4 22.8 32.4 30.4 33.9 21.5 27.3 26.0 30.4 21.4
$`6`
[1] 21.0 21.0 21.4 18.1 19.2 17.8 19.7
$`8`
[1] 18.7 14.3 16.4 17.3 15.2 10.4 10.4 14.7 15.5 15.2 13.3 19.2 15.8 15.0a
> class(mtl)
[1] "list"In English, the call to split said, "Split mtmpg into multiple vectors, with the split criterion being the values in mtcars$cyl."
Now mtl, an object of R class "list", contains the 3 vectors. We can access them individually with the dollar sign notation:
> mtl$`4`
[1] 22.8 24.4 22.8 32.4 30.4 33.9 21.5 27.3 26.0 30.4 21.4Or, we can use indices, though now with double brackets:
> mtl[[1]]
[1] 22.8 24.4 22.8 32.4 30.4 33.9 21.5 27.3 26.0 30.4 21.4Looking a little closer:
> head(mtcars$cyl)
[1] 6 6 4 6 8 6We see that the first car had 6 cylinders, so the first element of
mtmpg, 21.0, was thrown into the 6 pile, i.e. mtl[[2]], and so on.
And of course we can make copies for convenience:
> m4 <- mtl[[1]]
> m6 <- mtl[[2]]
> m8 <- mtl[[3]]Lists are especially good for mixing types together in one package:
> l <- list(a = c(2,5), b = 'sky')
> l
$a
[1] 2 5
$b
[1] "sky"By the way, it's no coincidence that a dollar sign is used for delineation in both data frames and lists; data frames are lists. Each column is one element of the list. So for instance,
> mtcars[[1]]
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
[16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
[31] 15.0 21.4Here we used the double-brackets list notation to get the first element of the list, which is the first column of the data frame.
Here we'll learn several new concepts, using the Nile data as our starting point.
If you look again at the histogram of the Nile we generated, you'll see a gap between the lowest numbers and the rest. In what year(s) did those really low values occur? Let's plot the data:
> plot(Nile)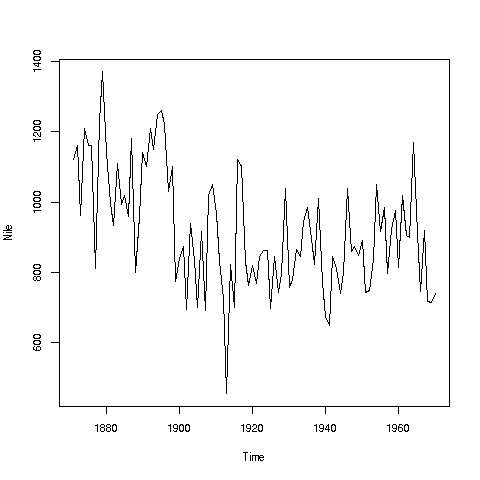
Looks like maybe 1912 or so. Is this an error? Or was there some big historical event then? This would require more than R to track down, but at least R can tell us which year or years correspond to the unusually low flow. Here is how:
We see from the graph that the unusually low value was below 600. We can use R's which function to see when that occurred:
> which(Nile < 600)
[1] 43As before, make sure to understand what happened in this code. The expression "Nile < 600" yields 100 TRUEs and FALSEs. The which then tells us which of those were TRUEs.
So, element 43 is the culprit here, corresponding to year 1871+42=1913. Again, we would have to find supplementary information in order to decide whether this is a genuine value or an error.
Of course, since this is a small dataset, we could have just printed out the entire data and visually scanned it for a low number. But what if the length of the data vector had been 100,000 instead of 100? Then the visual approach wouldn't work. Moreover, a goal of programming is to automate tasks, rather than doing them by hand.
Your Turn: There appear to be some unusually high values as well, e.g. one around 1875. Determine which year this was, using the techniques presented here. Also, try some similar analysis on the built-in AirPassengers data. Can you guess why those peaks are occurring?
Here is another point: That function plot is not quite so innocuous as it may seem.
> plot(mtcars$wt,mtcars$mpg)In contrast to the previous plot, in which our data were on the vertical axis and time was on the horizontal, now we are plotting two datasets, against each other.
There are a couple of important points here. First, as we might guess, we see that the heavier cars tended to get poorer gas mileage. But here's more: That plot function is pretty smart!
Why? Well, plot knew to take different actions for different input types. When we fed it a single vector, it plotted those numbers against time. When we fed it two vectors, it knew to do a scatter plot.
In fact, plot was even smarter than that. It noticed that Nile is not just of 'numeric' type, but also of another class, 'ts' ("time series"):
> is.numeric(Nile)
[1] TRUE
> class(Nile)
[1] "ts"So, it put years on the horizontal axis, instead of indices 1,2,3,...
And one more thing: Say we wanted to know the flow in the year 1925. The data start at 1871, so 1925 is 1925 - 1871 = 54 years later. The means the flow for that year is in element 1+44 = 55.
> Nile[55]
[1] 698OK, but why did we do this arithmetic ourselves? We should have R do it:
> Nile[1925 - 1871 + 1]
[1] 698R did the computation 1925 - 1871 + 1 itself, yielding 55, then looked up the value of Nile[55]. This is the start of your path to programming.
How does one build a house? There of course is no set formula. One has various tools and materials, and the goal is to put these together in a creative way to produce the end result, the house.
It's the same with R. The tools here are the various functions, e.g. mean and which, and the materials are one's data. One then must creatively put them together to achieve one's goal, say ferreting out patterns in ridership in a public transportation system. Again, it is a creative process; there is no formula for anything. But that is what makes it fun, like solving a puzzle.
And...we can combine various functions in order to build our own functions. This will come in future lessons.