파이썬을 이용해 추천 알고리즘을 구현하고
스프링과 뷰를 활용해
사용자의 기술 스택에 맞는 채용 공고 및 새로운 기술 스택을 추천하는 웹 서비스를 제공합니다.
🐾 5리너9리의 팀원을 소개하겠습니다.
| 김가은 | 박정주 | 장은정 | 조수지 |
|---|---|---|---|
| 백 | 풀스택 | 백 | 프론트 |
| JPA 서버 구축 협업 필터링 |
구글 트렌드 데이터 추천 알고리즘 배포 |
JPA 서버 구축 데이터 수집 및 정제 카카오 공유하기 |
데이터 연동 디자인 |
4차 산업혁명이란 말이 심심치 않게 들려오는 요즘, IT 기업에 취업하기를 꿈꾸는 사람들의 수는 늘어만 가고 있습니다. 하지만 나에게 맞는 채용공고를 알려주는 사이트는 찾기가 힘듭니다. 처음 IT 분야에 관심을 가진 사람들은 무엇을 준비해야 할 지 고민하기도 합니다. 그런 사람들을 위한 채용 공고 및 기술 스택 추천 서비스가 바로 나를 찾아줘입니다.
- 사용자의 기술 스택 및 희망 직무를 바탕으로 맞춤 공고를 추천해드립니다.
- 내가 찜한 공고를 찜한 다른 사용자의 공고를 추천해드립니다.
- 사용자 맞춤 공고에서 빈번하게 요구하는 기술 스택이지만 사용자가 갖추지 못한 기술 스택을 추천해드립니다.
- 기업에서 선호하는 기술 스택 통계를 제공해드립니다.
모든 채용 공고 데이터는 사람인 API에서 제공받았습니다.
사용자의 기술 스택과 희망 직무 데이터를 받아서 채용 공고와 피어슨 유사도를 통해 측정합니다.
총 맞춤 공고는 60개 중에서 유사도가 가장 높은 6개만 노출시켜줍니다.
# 피어슨 유사도
def sim_pearson(data, id1, id2):
avg_id1 = 0
avg_id2 = 0
count = 0
for tech in data[id1]:
if tech in data[id2]:
avg_id1 = data[id1][tech]
avg_id2 = data[id2][tech]
count += 1
avg_id1 = avg_id1 / count
avg_id2 = avg_id2 / count
sum_id1 = 0
sum_id2 = 0
sum_id1_id2 = 0
count = 0
for tech in data[id1]:
if tech in data[id2]:
sum_id1 += pow(data[id1][tech] - avg_id1, 2)
sum_id2 += pow(data[id2][tech] - avg_id2, 2)
sum_id1_id2 += (data[id1][tech] - avg_id1) * (data[id2][tech] - avg_id2)
return sum_id1_id2 / (math.sqrt(sum_id1) * math.sqrt(sum_id2))
# 가장 유사도 높은 거 뽑기
def top_match(data, id, index=3, sim_function=sim_pearson):
li = []
for i in data: # 딕셔너리를 돌고
if id != i: # 자기 자신이 아닐때만
li.append((sim_function(data, id, i), i)) # sim_function()을 통해 상관계수를 구하고 li[]에 추가
li.sort() # 오름차순
li.reverse() # 내림차순
return li[:index]협업 필터링 알고리즘 중 사용자 기반 추천 알고리즘을 구현했습니다.
내가 찜한 공고를 찜한 다른 사용자의 찜 공고 목록과 비교해서 내가 찜하지 않은 채용공고를 추천합니다.
def getRecommendation(data, myId, sim_function=sim_pearson):
result = top_match(data, myId)
# print(result)
simSum = 0 # 유사도 합을 위한 변수
score = 0 # 평점 합을 위한 변수
li = [] # 리턴을 위한 리스트
score_dic = {} # 유사도 총합을 위한 dic
sim_dic = {} # 평점 총합을 위한 dic
for sim, otherId in result: # 튜플이므로 한번에
if sim <= 0:
continue # 유사도가 양수인 사람만
for recruit in data[otherId]:
if data[otherId][recruit] == 1 and recruit not in data[myId]: # 내 찜 목록에 없는데 그 사람 찜 목록에 있으면
score += sim * data[otherId][recruit]
score_dic.setdefault(recruit, 0) # 기본값 설정
score_dic[recruit] += score # 합계 구함
sim_dic.setdefault(recruit, 0)
sim_dic[recruit] += sim
continue
if (data[myId][recruit] == 0 or recruit not in data[myId]) and data[otherId][recruit] == 1: # 나는 찜 안 했는데 그 사람은 찜한 목록
# if recruit in data[myId] and data[otherId][recruit] == 1: # 나는 찜 안 했는데 그 사람은 찜한 목록
score += sim * data[otherId][recruit] # 그 사람의 찜 공고
score_dic.setdefault(recruit, 0) # 기본값 설정
score_dic[recruit] += score # 합계 구함
# 조건에 맞는 사람의 유사도의 누적합을 구한다
sim_dic.setdefault(recruit, 0)
sim_dic[recruit] += sim
score = 0 # 공고가 바뀌었으니 초기화한다
for key in score_dic:
score_dic[key] = sim_dic[key] != 0 and score_dic[key] / sim_dic[key] or 1.0 # 평점 총합 / 유사도 총합
li.append((score_dic[key], key)) # list((tuple))의 리턴을 위해서.
li.sort() # 오름차순
li.reverse() # 내림차순
return li사용자 맞춤 공고 60개 중에서 사용자에게 없는 기술 스택을 요구하는 경우 해당 기술 스택을 추천합니다.
각 스택 별로 빈도 수를 저장하여 빈도가 10 이상이면 추천을 해 줍니다.
@Override
public List<String> getRecommendLanguage(String userId, List<RecruitDTO> matchRecruitList) {
String[] LanguageList = { "Java", "Python", "C", "C++", "C#", "Visual Basic .NET", "JavaScript", "PHP", "SQL",
"Go", "R", "Assembly", "Swift", "Ruby", "MATLAB", "PL/SQL", "Perl", "Visual Basic", "Objective-C",
"Delphi/Object" };
System.out.println(userId);
User myInfo = accountRepo.findById(Long.parseLong(userId))
.orElseThrow(() -> new IllegalArgumentException("없는 id입니다."));
String myTechStack = myInfo.getTechStack();
List<String> myTechStackList = Arrays.asList(myTechStack.split(","));
int[] countMatchTechStack = new int[20];
for (int i = 0; i < matchRecruitList.size() / 2; i++) {
List<String> matchRecruitTechStack = Arrays
.asList(matchRecruitList.get(i).getTechStack().replace("·", ",").split(","));
for (int j = 0; j < LanguageList.length; j++) {
for (int k = 0; k < matchRecruitTechStack.size(); k++) {
String language = LanguageList[j] == "JavaScript" ? "자바스크립트" : LanguageList[j];
if (matchRecruitTechStack.get(k).contains(language)) {
countMatchTechStack[j]++;
break;
}
}
}
}
List<String> recommendLanguageList = new ArrayList<>();
for (int i = 0; i < 20; i++) {
if (countMatchTechStack[i] > 10) {
recommendLanguageList.add(LanguageList[i]);
}
}
for (int j = 0; j < myTechStackList.size(); j++) {
if (recommendLanguageList.contains(myTechStackList.get(j).trim())) {
recommendLanguageList.remove(myTechStackList.get(j).trim());
}
}
return recommendLanguageList;
}카카오 소셜 로그인을 한 사용자는 채용 공고를 카카오 메세지로 공유할 수 있습니다. 나를 찾아줘에 카카오 소셜 로그인을 한 기록이 있는 사용자 중에 내 카카오톡 친구인 사용자에게 마음에 드는 채용 공고를 보내줄 수 있습니다.
def main(access_token, recruit_id, receiver_uuids):
print(receiver_uuids)
uuids=receiver_uuids.split('*')
tmp=""
for i in uuids:
tmp+='"'+i+'",'
tmp=tmp[:len(tmp)-1]
conn = pymysql.connect(host='localhost', user='root', password='ssafy', db='test', charset='utf8')
curs = conn.cursor()
# sql = "select * from recruits where recruit_id = (select recruit_id from recommend where user_id = "+user_id+" ) "
sql = "select * from recruit where id = " + recruit_id
curs.execute(sql)
rows = curs.fetchall()
rows_data = pd.DataFrame(rows)
like_cnt=100
title = rows_data[8][0]
image_url=rows_data[3][0]
if(image_url == ''):
image_url="http://mud-kage.kakao.co.kr/dn/NTmhS/btqfEUdFAUf/FjKzkZsnoeE4o19klTOVI1/openlink_640x640s.jpg"
description = rows_data[7][0]
recruit_url=rows_data[9][0]
print(title)
print(description)
# image_url="http://mud-kage.kakao.co.kr/dn/NTmhS/btqfEUdFAUf/FjKzkZsnoeE4o19klTOVI1/openlink_640x640s.jpg"
template_dict_data = str({
"object_type": "feed",
"content": {
"title": title,
"description": description,
"image_url": image_url,
"image_width": 640,
"image_height": 640,
"link": {
"web_url": recruit_url,
"mobile_web_url": recruit_url,
"android_execution_params": recruit_url,
"ios_execution_params": recruit_url
}
},
"social": {
"like_count": like_cnt
},
"buttons": [
{
"title": "웹으로 이동",
"link": {
"web_url": recruit_url,
"mobile_web_url": recruit_url
}
}
]
})
kakao_to_me_uri = 'https://kapi.kakao.com//v1/api/talk/friends/message/default/send'
headers = {
'Content-Type': "application/x-www-form-urlencoded",
'Authorization': "Bearer " + access_token,
}
template_object = str(json.dumps(template_dict_data))
template_object = template_object.replace("\"", "")
template_object = template_object.replace("'", "\"")
params = {}
params['receiver_uuids'] = '['+tmp+']'
params['template_object'] = template_object
response = requests.request(method="POST", url=kakao_to_me_uri, params=params, headers=headers)
print(response.json())
if __name__ == "__main__":
main(sys.argv[1] , sys.argv[2] , sys.argv[3])

JPA를 이용한 REST API를 구축했습니다. JPA란 자바 ORM 기술에 대한 API 표준 명세로 ORM을 사용하기 위한 인터페이스를 모아둔 것으로 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스입니다.
기존의 REST API 방식은 SQL Query로 'SELECT * FROM MEMBER'라고 호출하는 방식이었습니다. ORM을 사용하면 Member 테이블과 매핑된 객체 member를 사용해서 member.findAll()이라는 메서드 호출을 통해 데이터 조회를 할 수 있습니다.
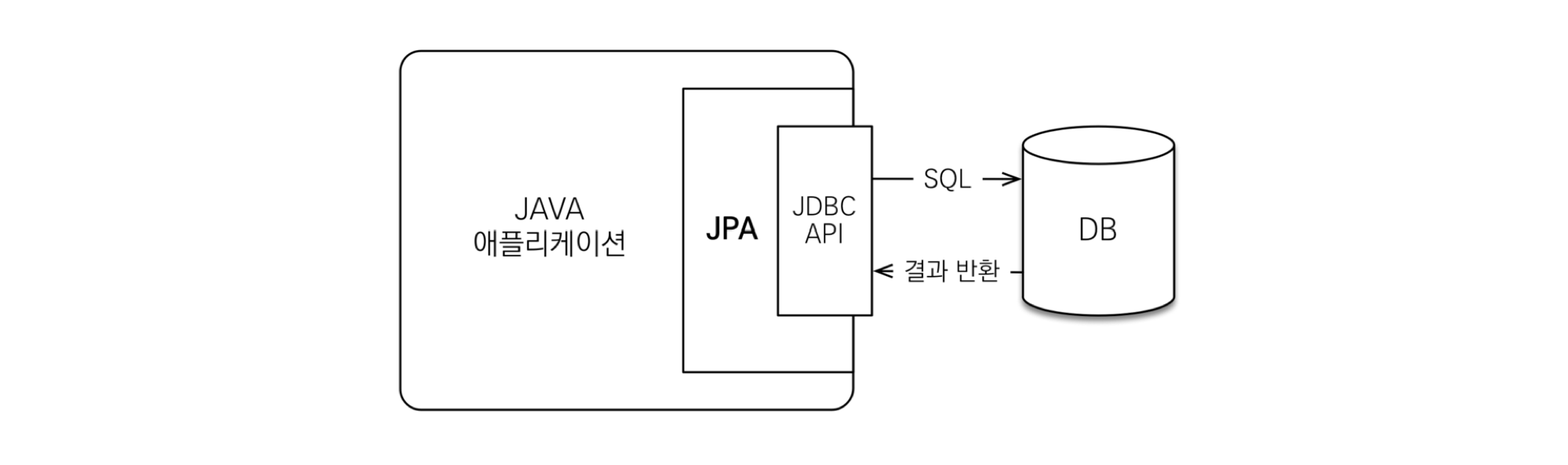
JPA는 어플리케이션과 JDBC 사이에서 동작합니다. 개발자가 JPA를 사용하면 JPA 내부에서 JDBC API를 사용하여 SQL을 호출해 DB와 통신하는 것으로 개발자가 JDBC API를 사용하는 것은 아닙니다.
JPA는 생산성이 뛰어나고 유지보수가 용이하며 DMBC에 대한 종속성을 줄일 수 있다는 장점이 있습니다. 하지만 구축이 어렵고 복잡한 쿼리 사용에 불리합니다.
스케쥴러 작업을 통해서 데이터 수집 및 정제를 자동 업데이트 되도록 했습니다.
스프링을 자동 실행시키는 것은 물론이고 cli를 이용하여 python 파일도 스케쥴링했습니다.
- 사람인 공고, 구글 트렌드 업데이트
- 사람인 마감 공고 삭제
- 추천 알고리즘 업데이트
- 프로그래밍 언어 텍스트마이닝 실행
- 프로그래밍 언어 순위 업데이트를 모두 스케쥴링했습니다.
스프링에서 자체적으로 제공하는 **Scheduled Annotation**을 사용했습니다.
-
scedule 기능 켜기
스프링 부트가 실행될 메인 함수 파일(자바 설정 관련 클래스)에
@EnableScheduling을 추가해줍니다.// SSAFYApplication.java import org.springframework.scheduling.annotation.EnableScheduling; @EnableScheduling
-
실행주기 설정하기
(cron = "* * * * * *") 초(0-59) 분(0-59) 시간(0-23) 일(1-31) 월(1-12) 요일(0-7) . -
Service에 스케쥴러 구현하기
API call이 왔을 때 실행되는 Controller가 아닌
Service측에서 구현해야 합니다.Service는
Dao가 DB에서 받아온 데이터를 가공합니다.Controller는 시스템에 들어오는 요청에 대한 응답을 담당합니다.
SHA256 해시 알고리즘을 사용하여 password를 암호화했습니다.
SHA256 해시 알고리즘은 단방향 암호화 알고리즘으로 다시 평문으로(복호화) 되돌릴 수 없는 암호화 알고리즘입니다. 어떤 길이의 입력값이라도 256비트의 고정된 결과값을 출력하고 하나만 다른 입력값을 넣어도 전혀 다른 값이 출력된다는 특징을 지니고 있어 사용자의 패스워드 암호화에 많이 사용됩니다.
JWT는 세션 상태를 저장하는 게 아니라 필요한 정보를 토큰 body에 저장해 사용자가 가지고 있다가 증명서처럼 사용하는 토큰 기반 인증 방식입니다.
추가 저장소가 필요 없어서 세션/쿠키보다 정보가 탈취될 가능성이 적습니다.





