数据集国内下载,百度云【数据集2.9GB+论文+代码】

霍普金斯大学出品的大规模人群计数数据集,共4372张图像,共计151万个注释,包含下雪、下雨、雾霾等恶劣天气及光照条件下的图片514张(13.6万个标注),非常具有挑战性。
作者:Vishwanath A. Sindagi, Rajeev Yasarla, Vishal M. Patel
链接:https://arxiv.org/pdf/2004.03597.pdf
数据集下载:http://www.crowd-counting.com/ (官方下载源为Google Drive,如下载不便,欢迎关注微信公众号“arXiv每日学术速递”回复“arxiv”获取百度网盘下载地址,包含【数据集2.9GB+代码+论文PDF】)
鉴于单张图像在现实世界中的广泛应用,基于单幅图像的人群计数近年来受到了人们的广泛关注。近年来,学者们已经提出了多种方法来解决在人群计数中遇到的各种问题,这些方法大部分是需要大量标定数据来训练网络参数的卷积神经网络方法。考虑到这一点,我们引入了一个新的大规模无约束人群计数数据集(JHU-GROUP++),该数据集包含4372张图像,共计151万个注释。
与现有的数据集相比,JHU-GROUP++数据集是在各种不同的场景和环境条件下收集的。数据集包括一些基于恶劣天气变化和光照变化的图像,这使得它成为一个非常具有挑战性的数据集。此外,数据集由image-level 和 head-level的丰富注释组成。
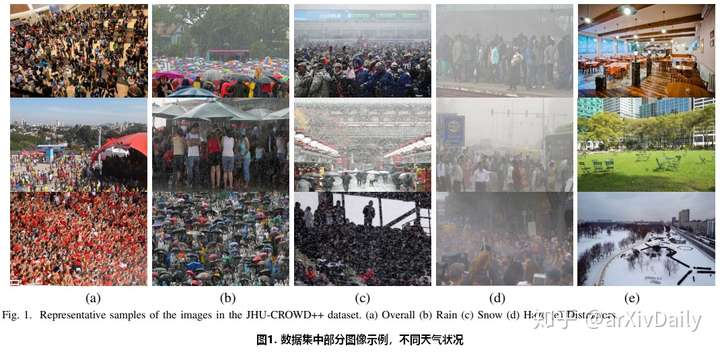
与JHU-CROWD数据集相比的改进:
- 图片数量更多:数据集中的图像从4,250增加到4,372;
- 标注(annotations)更多:新的数据集注释增加了31%,从115万增加到了151万;
- 更好的标注scale:在新的数据集中,提供了更好的标注scale,其中包括每个头部的大约宽度和高度。
不同的人群计数数据集之间的比较:
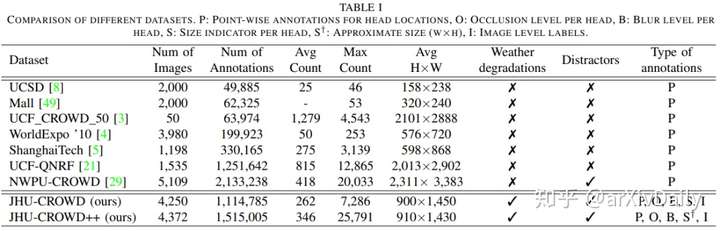
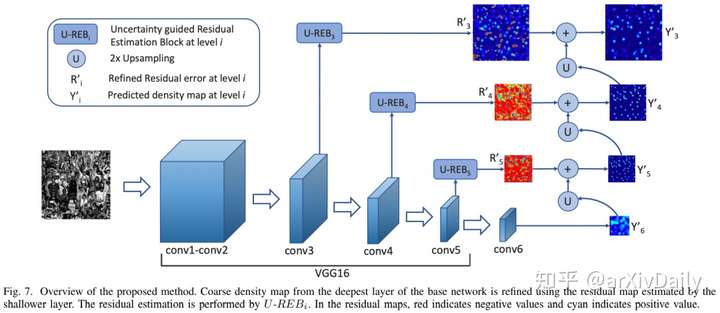
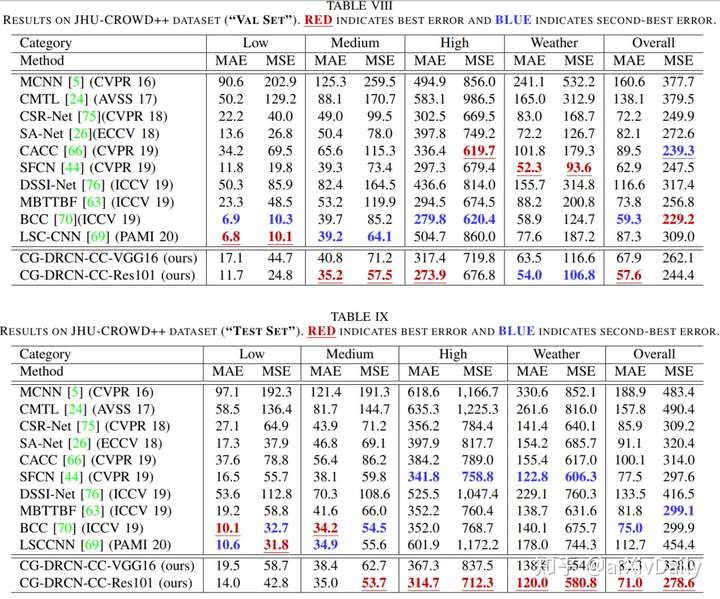
作者在此数据集上对最新的几种方法进行了评估和比较。在此基础上,提出了一种新的人群计数网络,该网络通过残差估计逐步生成人群密度图。该方法以VGG16为骨干网络,利用最后一层生成的密度图作为粗略预测,利用残差学习逐步细化生成更精细的密度图。此外,残差学习由基于不确定性的置信度加权机制引导,该机制仅允许高置信度残差在细化路径中流动。本文提出的置信度指导的深度残差计数网络(CG-DRCN)在最近的复杂数据集上进行了评估,并在误差方面取得了显著的改善。
在互联网上搜索图像用到的关键字:

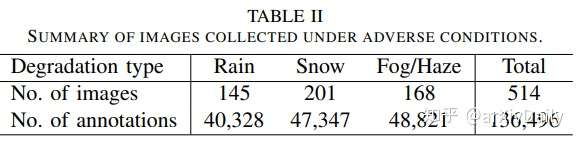
恶劣条件下的图片数量:下雨天145张,40328个注释;下雪天201张,47347个注释;雾天/雾霾天168张,48821个标注。
head-level标注示例:

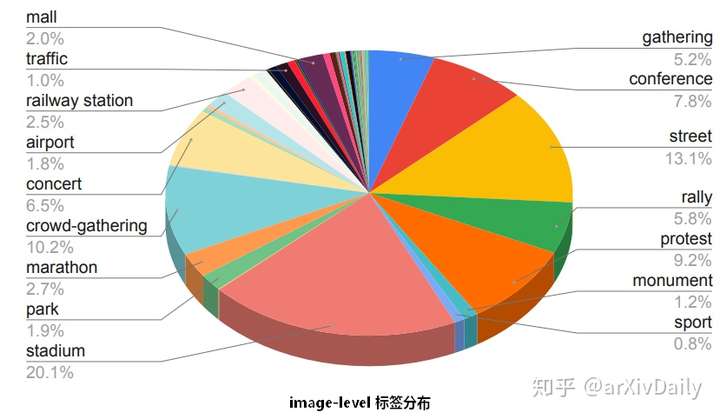
image-level 标签分布:
不同人群密度的图片数量分布:

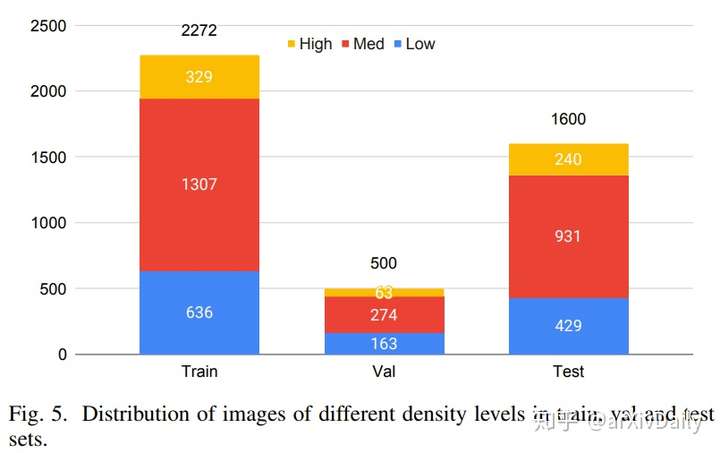
训练、验证和测试集中不同密度的图片分布:
本文提出的人群检测方法示意图:
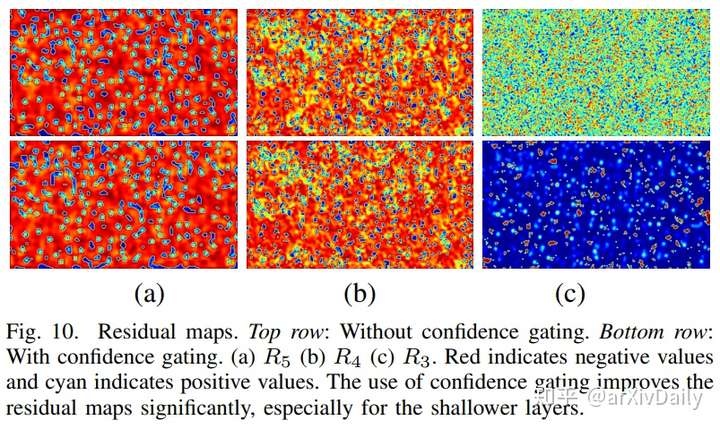
基准网络性能:
基准网络效果示例:





