simonhaenisch / md-to-pdf Goto Github PK
View Code? Open in Web Editor NEWHackable CLI tool for converting Markdown files to PDF using Node.js and headless Chrome.
Home Page: https://www.npmjs.com/md-to-pdf
License: MIT License
Hackable CLI tool for converting Markdown files to PDF using Node.js and headless Chrome.
Home Page: https://www.npmjs.com/md-to-pdf
License: MIT License


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

























































































































I'm having trouble trying to convert any document.
Everytime I get this exception:

This happens even if my cloned repo is clean.
One thing that I have noticed though is that there seems to be some inconsistency with the evaluation of the content url in the CSS file. If the below structure is used then these are the outcomes:
style/style.css includes:
.class::before {
content: url("img/logo.svg");
}This will evaluate fine for file.md but fail for otherFile.md. It seems that the content url is being evaluated relative to the .md file and not the .css file as it should be.
The css should be:
.class::before {
content: url("../img/logo.svg");
}This is because the content include should be relative to the location of the style.css file, meaning that the css could be applied to any file in any sub directory consistently.
Hi Simon!
Why blank lines (ie those only with carriage return & Lien Feed) are deleted during conversion ?
# Title One
## Subtitle
One sentence after blank line.
An another one sentence after 2 blank lines.


Hi Simon !
How are you ?
Once again I ask for your help !
As you know, I'm using markdown-toc.
Links doesn't work for titles with accentuated characters (in html and pdf).
It's a well-known issue (jonschlinkert/markdown-toc#145).
Would it be possible for md-to-pdf to generate IDs without accentuated and special characters (in order to be homogenous with the slugify function used) ?
For instance, today we have this title in one markdown file :
Un titre de niveau H2 avec 2 caractères accentués
------------
Today, with md-to-pdf, the result in Html is :
<h2 id="un-titre-de-niveau-h2-avec-2-caractères-accentués">Un titre de niveau H2 avec 2 caractères accentués</h2>
I would like please :
<h2 id="un-titre-de-niveau-h2-avec-2-caracteres-accentues">Un titre de niveau H2 avec 2 caractères accentués</h2>
(or
<h2 id="un-titre-de-niveau-h2-avec-2-caract-res-accentu-s">Un titre de niveau H2 avec 2 caractères accentués</h2>
)

Thanks in advance!
Jean
Make use of https://github.com/sindresorhus/ora.
Wonderful project, thank you.
I'd like to request automatically expanding
Could be done purely with CSS (see http://2ality.com/2012/01/numbering-headingshtml.html), but would require extra styles for the TOC (if that get's implemented). Alternatively, it could be done with a custom renderer (see markedjs/marked#334 (comment)), which would be more flexible regarding styling (e. g. font-feature-settings: "tnum"; font-variant-numeric: tabular-nums; and better alignment for the numbering in the TOC).
Allowing a url for the stylesheet option would make it easy to use existing stylesheets without the need to download them, e. g. the Github styles (https://cdnjs.cloudflare.com/ajax/libs/github-markdown-css/2.10.0/github-markdown.min.css).
Hi,
I'm having problems using "windows1252" as default markdown files encoding.
Whenever I use accented chars they became unknown chars when I try to convert the markdown file to pdf.
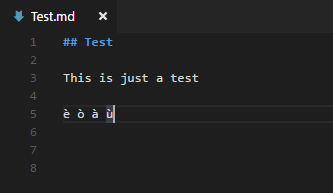
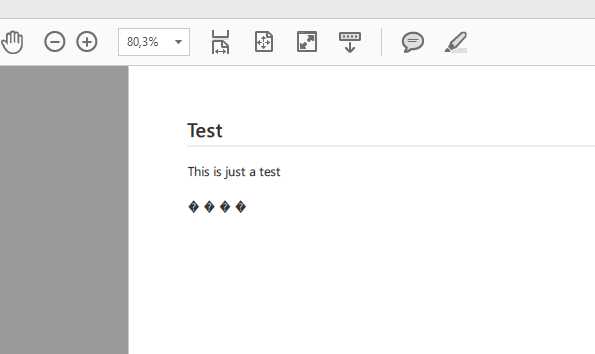
Is there a way (maybe some css style file to edit) to change the output encoding so they match?
So I've run into a bit of an issue I'm scratching my head over. Seems like it could be another race condition type thing.
Sometimes when I compile only some of the CSS rules are applied.
This is the expected output:

This is what sometimes happens:

There doesn't seem to be a consistent way of making this happen, though it does happen quite often.
I have been seeing weird clipping issues on PDFs with numbered lists ranging above 9. Oddly, this appears to only happen during Linux builds on our CI, see Cell_Culture.pdf
But not when running md-to-pdf on Windows, see: Cell_Culture.pdf
Here is the config file used to generate these PDFs
Would this be an issue with md-to-pdf? Or something upstream?
Add a Use a --toc cli argument to.toc class or <!-- TOC --> comment to enable a TOC generator and inject an auto-generated TOC into the html.
Hi Simon !
I'm not able to specify a color background in header or footer.
I saw this issue for puppeteer : "cannot add background color to Header/Footer".
puppeteer/puppeteer#2182
Did you already have encountered this problem ?
Regards,
Jean
Is it possible to implement header and footer ?
The need is to have a footer/header for first page and another footer/header for the rest of the document, with the possibility to include page number.
(I saw this kind of feature in project node-html-pdf (https://github.com/marcbachmann/node-html-pdf).
To make the package easier to use as a dependency of other packages, a programmatic API would probably be helpful for some people. Should be a pretty straight-forward refactoring task.
When installing md-to-pdf as a dev dependency in another project the path to the highlight.js css files will no longer be relative to /md-to-pdf/.
(node:52783) UnhandledPromiseRejectionWarning: Error: ENOENT: no such file or directory, open '/path/to/other-project/node_modules/md-to-pdf/node_modules/highlight.js/styles/monokai.css'
-- ASYNC --
...
In other words the path:
/path/to/other-project/node_modules/md-to-pdf/node_modules/highlight.js/styles/monokai.css
should in this case be:
/path/to/other-project/node_modules/highlight.js/styles/monokai.css
The API of zeit/serve has been refactored into its own module, zeit/serve-handler. serve@6 has a known security vulnerability, so this needs to be updated.
I have a series of documents that we're using for our markdown documentation. Each of them has a title page with a header and footer, which I'm injecting in using the css content property to avoid duplication.
The header contains an image of our company logo, but I've been finding that when I compile the file, sometimes it doesn't load in, leaving just a blank space at the top.
&::before {
content: url("img/logo.svg");
display: block;
height: 80px;
}I can only assume that, as it works perfectly fine around half of the time, that there is some sort of race condition between loading the page in chromium headless and printing out to the pdf.
Hi
The relative path changed... it used to consider the relative path from the execution path, now, it considers relative path from the MD file.
It used to work with:
"stylesheet": [
".\\mystyle.css"
],
when executed from c:\RepoFolderRoot\
Error is:
md2pdf --config-file .\generate_pdf\config.json ./doc1/doc1.md
× generating PDF from ./doc1/doc1.md
→ ENOENT: no such file or directory, open 'c:\RepoFolderRoot\doc1\mystyle.css'
and now works with...
"stylesheet": [
"C:\\RepoFolderRoot\\generate_pdf\\mystyle.css"
],
It is not very convenient for me, as my stylesheet lifecyle is different from doc lifecycle, and I'm not the only one to use this repo (and of course, all of us do not have the same folder organisation....)
Originally posted by @nekloth in #19 (comment)
I think you should choose a license for this repo/package!
Context:
md-to-pdf -v): 2.8.2Describe the bug:
Anchor links doesn't work.
I wrote following basic markdown and convert it to pdf.
- [Anchor1](#anchor1)
- [Anchor 2](#anchor-2)
- [アンカー3](#%E3%82%A2%E3%83%B3%E3%82%AB%E3%83%BC3)
- [アンカー 4](#%E3%82%A2%E3%83%B3%E3%82%AB%E3%83%BC-4)
# Anchor1
ASCII chars and no blank.
# Anchor 2
ASCII chars and blank.
# アンカー3
Japanese chars and no blank.
# アンカー 4
Japanese chars and blank.
Anchor1 and Anchor 2 works well as I expected, but アンカー3 and アンカー 4 doesn't convert as link.
When I hover the cursor on アンカー3 and アンカー 4 in the output PDF, the cursor doesn't change as finger pointer.
But when I output html with --as-html option, the links works fine. <a>tag is perfectly works in Chrome browser.
Please give me any advise for this problem.
Thanks.
Can you please add an example of a js config file in the readme. I tried to export a default object and had no luck.
In my case, I am writing my CV in Markdown and it'd be helpful to have both pdf and html versions to send pdf via email and have an html version on my website.
Add a front-matter parser to allow configuration from within the markdown file.
Benefits:
Hi guys, Im getting this error when trying to convert my .md to .pdf with md-to-pdf README.md command. How can I fix this
assert.js:42
throw new errors.AssertionError({
AssertionError [ERR_ASSERTION]: html-pdf: Failed to load PhantomJS module. You have to set the path to the PhantomJS binary using 'options.phantomPath'
at new PDF (/Users/ymushet/md-to-pdf/node_modules/html-pdf/lib/pdf.js:38:3)
at Object.createPdf [as create] (/Users/ymushet/md-to-pdf/node_modules/html-pdf/lib/index.js:10:14)
at Object. (/Users/ymushet/md-to-pdf/index.js:80:10)
at Module._compile (module.js:635:30)
at Object.Module._extensions..js (module.js:646:10)
at Module.load (module.js:554:32)
at tryModuleLoad (module.js:497:12)
at Function.Module._load (module.js:489:3)
at Function.Module.runMain (module.js:676:10)
at startup (bootstrap_node.js:187:16)
Hello
I'm must be idiot or cursed, but either standard installation and usage does not work... :-/
I'm truing to use md-to-pdf on a Windows 7 and the Ubuntu subsystem of Windows
Following the procedure, on both Windows and subsys Ubuntu, I used the command line npm i -g in the github-cloned folder.
Everything went well.
Then, typed md-to-pdf readme.md and got a:
md-to-pdf: command not found for both systems.
So, I used node c:\temp\md-to-pdf\index.js readme.md (Windows 7) or node /mnt/c/temp/md-to-pdf/index.js readme.md (Ubuntu subsytem) and then, I got (for both):
{ AssertionError [ERR_ASSERTION]: html-pdf: Failed to load PhantomJS module. You have to set the path to the PhantomJS binary using 'options.phantomPath'
THEN, I tried to install PhantomJS on both system using npm install -g [email protected] ... and got the same error for both:
Phantom installation failed { Error: EACCES: permission denied, link '/tmp/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2-extract-1526975751906/phantomjs-2.1.1-linux-x86_64' -> '/usr/lib/node_modules/phantomjs-prebuilt/lib/phantom'
errno: -13,
code: 'EACCES',
syscall: 'link',
path: '/tmp/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2-extract-1526975751906/phantomjs-2.1.1-linux-x86_64',
dest: '/usr/lib/node_modules/phantomjs-prebuilt/lib/phantom' } Error: EACCES: permission denied, link '/tmp/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2-extract-1526975751906/phantomjs-2.1.1-linux-x86_64' -> '/usr/lib/node_modules/phantomjs-prebuilt/lib/phantom'
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] install: `node install.js`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] install script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
May you have an suggestion?
Context:
md-to-pdf -v): 2.8.2Describe the bug:
I'd like to run watch mode with devtools to be able to see the render in Chrome in live but it does not work --> Changes are not displayed
There should be some tests for the stuff in the util folder.
Original text from the markdown file:
This token must be used as the password portion of the HTTP basic authentication header.
Pasted text after copying it from the generated PDF:
.redaeh noitacitnehtua cisab PTTH eht fo noitrop drowssap eht sa desu eb tsum nekot sihT
md2pdf: 2.6.2
Platform: macOS 10.14.4
node: 10.15.0
Problem:
Hey, I apologize if this is a dumb question, but I just can't seem to figure out how to create a repeating background on the pdfs generated using md-to-pdf. I'm wanting to create a parchment effect, instead of a white background on my pdf output. I've been playing around with something like this in my css for testing:
* {
background: url(http://api.thumbr.it/whitenoise-361x370.png?background=ffffffff&noise=5c5c5c&density=13&opacity=62);
background-repeat: repeat;
background-position: center center;
}I also have printBackground: true in my pdf options. The background will show up behind everything except the margin-ed areas:

Any tips/ideas on how to get the background to cover all whitespace on the page?
Context:
md-to-pdf -v): 2.8.2Describe the bug:
I'm just doing a basic test. I have installed the package:
npm i -g md-to-pdf
Next, I try to build the PDF for the basic test that comes with the github repository:
git clone https://github.com/simonhaenisch/md-to-pdf
md-to-pdf md-to-pdf/test/basic/test.md
but I get the following error:
✖ generating PDF from md-to-pdf/test/basic/test.md
→ TROUBLESHOOTING: https://github.com/GoogleChrome/puppeteer/blob/master/docs/troubleshooting.md
However, it's a bit cryptic... I'm not sure which particular error md-to-pdf has found with regards to puppeter or how to debug it. In addition, the cited reference is pretty long, describing diferent kind of problems and not sure which one is the one I could have.
Any help or insight on this would be appreciated. Thanks!
Context:
md-to-pdf -v): 2.8.2Describe the bug:
After executing the command md-to-pdf docs/README.md docs/output.pdf, I get the output:
× generating PDF from docs/README.md
→ spawn EPERM
Thanks for your help,
Hi Simon,
How to set the contents of the header and the footer according to a parameter please?
I'm trying to generate a pdf using the config file, with a css file, but not all CSS is applied. It does not generate an error on the config.
md-to-pdf -v): 2.7.1When I generate a pdf using config, which contains header and footer content and a css file, the generated pdf does not have all css applied. Below I have applied 2 screenshots; one containing how it should look (this does not use a config file, using a css file), and one how it looks with the config file, using a css file.
My config file looks like this:
{
"pdf_options": {
"format": "A4",
"margin": "20mm",
"displayHeaderFooter": false
},
"stylesheet": "style.css"
}
Any idea why the css is not applied as I want it to?


Hi!
When doign md2pdf HowToMarkdown.md
I get and error when generating the PDF, I read the Troubleshooting link but I couldn't find what is cause
x generating PDF from HowToMarkdown.md → TROUBLESHOOTING: https://github.com/GoogleChrome/puppeteer/blob/master/docs/troubleshooting.md
I also get the same error when running md2pdf HowToMarkdown.md --config-file ./config.json
And the config looks like this
{
"stylesheet": [
"https://cdnjs.cloudflare.com/ajax/libs/github-markdown-css/2.10.0/github-markdown.min.css"
],
"css": " .page-break { page-break-after: always; } .markdown-body { font-size: 11px; }",
"body_class": "markdown-body",
"highlight_style": "monokai",
"marked_options": {
"headerIds": false,
"smartypants": true
},
"pdf_options": {
"format": "A5",
"margin": "20mm"
},
"stylesheet_encoding": "utf-8"
}
Hello
I have a doc repo structure like:
RepoFolderRoot
├───doc1
│ doc1.md
│ doc1.pdf
│
├───doc2
│ │ doc2.md
│ │ doc2.pdf
│
├───generate_pdf
│ │ config.json
│ │ mystyle.css
I tried to launch the md2pdf command from the root folder (for scripting) by trying:
md2pdf --config-file .\generate-pdf\config.json .\doc1\doc1.md
or
md2pdf --config-file generate-pdf\config.json .\doc1\doc1.md
or
md2pdf --config-file \generate-pdf\config.json .\doc1\doc1.md
And I always got aWarning: couldn't read config file: \generate-pdf\config.json
If no arguments were given, instead of showing the help, search for all markdown (*.md, *.markdown, *.mdown, *.md.txt) files in the directory the command was invoked from, and compile each of them.
Maybe show a confirmation dialog if there are more than 10 files.
Hi Simon, Hi Jakub,
How are you ?
Thanks to your help last Week, now I am able to generate one pdf from one markdownfile! :-)
How to manage TOC, Header and Footer automatically for several markdown files please?
Each markdown file is a chapter of a help guide. I need to convert each md file in html and pdf.
I would like to keep the already specified style levels in order to automatically generate a table of contents and apply formatting with a CSS.
For instance, how is it possible to take in account the yaml file for pdf_options displayed in your main readme?
I have already looked at some issues in your website. Nevertheless, maybe do you have other examples which can help me?
Thanks in advance for your help.
Regards,
Jean
Could add a watch mode to watch the given markdown file and regenerate the PDF every time it changes. Might be useful when the preview is open next to the editor, like in the screenshot (not sure whether PDF viewers on system other than macOS refresh the preview though).
It can be usefull to have the pages options (page size, margins) in parameters in command line.
Problem:
It'd be very powerful if md-to-pdf can also render inline PlantUML diagrams when converting .md to .pdf
Solution:
Use a PlantUML parser to convert text within uml or plantuml code block to SVG image and render them along with the PDF:
```plantuml
@startuml
:Hello world;
:This is defined on
several **lines**;
@enduml
Hello @simonhaenisch ,
I am facing an issue.
---
stylesheet: https://cdnjs.cloudflare.com/ajax/libs/github-markdown-css/2.10.0/github-markdown.min.css
body_class: markdown-body
css: >-
.markdown-body { font-size: 11px; }
.markdown-body pre>code { white-space: pre-wrap; }
---
BJT | MOSFET
----|-------
Bipolar junction transitor | Metal Oxide Semiconductor <br/> Field effect transistor
3 terminal - C, B, E | 4 terminal - S, G, D, B(body/substrate)
for low current applicaions | high power applications
less commonly used in A & D circuits | most commonly used
depends on current at base | depends on voltage at insulated oxide gate electrode
replaced the old vacuum tubes | voltage controlled device
cheap | costlier
conduction is due to majority & minority carriers | only due to majority carriers


Thanks,
Have a nice day :)
I'm trying to include images in my header, using the option file. My config.json file looks like:
{
"highlight_style": "monokai",
"html_pdf_options": {
"format": "A4",
"border": "15mm",
"header": {
"height": "15mm",
"contents": "<div style='width:100%;text-align: right; border-bottom: 1pt solid #eeeeee;'><font size='-1'>A <b>Team</b><em>A</em> document</font> <img style=\"vertical-align:middle;margin-right:10px;margin-left:10px;\" width=\"60px\" src=\"https://goo.gl/HkfCvS\"/> </div>"
},
"footer": {
"height": "15mm",
"contents": {
"default": "<hr width='110%'><div style='float:right;'>Page {{page}}/{{pages}}</div>"
}
}
}
}As a result, I can see the picture location, but only white space instead of of picture...
Even if I remove any style option, the picture never displays.
Can we have conversion log (PhantomJS ?) ? That could help to understand the situation...
Thanks
Nekloth
Following some discussion on issue #14, I would like to change the API to allow to pass multiple input files via shell globbing. This will be a breaking change because currently the second input argument is treated as the pdf output filename.
$ md-to-pdf **/*.mdThe shell would expand the glob into an array of files that will be passed as input arguments (leaving the glob expansion to the shell rather than dealing with it using some npm package).
Might be helpful for scripting to add a (might actually not need a flag, can just detect whether there is anything coming in on --stdio flag or similar nameprocess.stdin) to read the markdown from stdin and output the PDF to stdout, which would allow to redirect it into a file the UNIX way, i. e.
$ cat file.md | md-to-pdf --stdio >> output.pdfIf anyone would be interested in this, please leave a +1 or comment (:
Context:
md-to-pdf -v): 2.8.1Describe the bug:
If you have both the highlight_style and pdf_options in a config.json file, the highlighting doesn't quite work. With styles like "monokai" and "darcula" the background should be black, but this is completely lost. Sample config.json that won't work:
{
"highlight_style": "darcula",
"pdf_options": {
"format": "Letter",
"margin": "10mm"
}
}
But the following will work:
{
"highlight_style": "darcula"
}
I'd like to request the ability to instruct the parser to follow file links to other markdown files, to combine multiple documents into one.
Context:
md-to-pdf -v): 2.7.1Describe the bug:
(A clear and concise description of what the bug is. Feel free to include screenshots.)
Dear Support Team,
After installed successfully "md-to-pdf" on Debian 8.11, I’ve tried to convert my first markdown file in pdf.
Unfortunately, I encountered this error message :

Thanks for your help.
Regards,
Jean Salmon
Problem:
Currently, to have a complete PDF documentation, the whole of chapter have to be written just in one md file.
Solution:
That will great if it is possible to inclide another md file like that for example :
[include](chapter1.md)
Hey @simonhaenisch! 👋
Just wanted to reach out about funding your work on md-to-pdf.
@transitive-bullshit and I are both open source maintainers, and we're currently exploring new ways to make OSS funding a viable source of income.
We're currently looking at building SaaS APIs on top of existing OSS libraries, reserving the majority of profits for the original authors. We've built a few at this point, but want to keep adding more.
I think md-to-pdf could make a really handy SaaS API, and I'd love to build one out. We'd handle dev, auth, billing and support so you wouldn't have to do anything.
Looking forward to hearing your thoughts! 🙏
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.