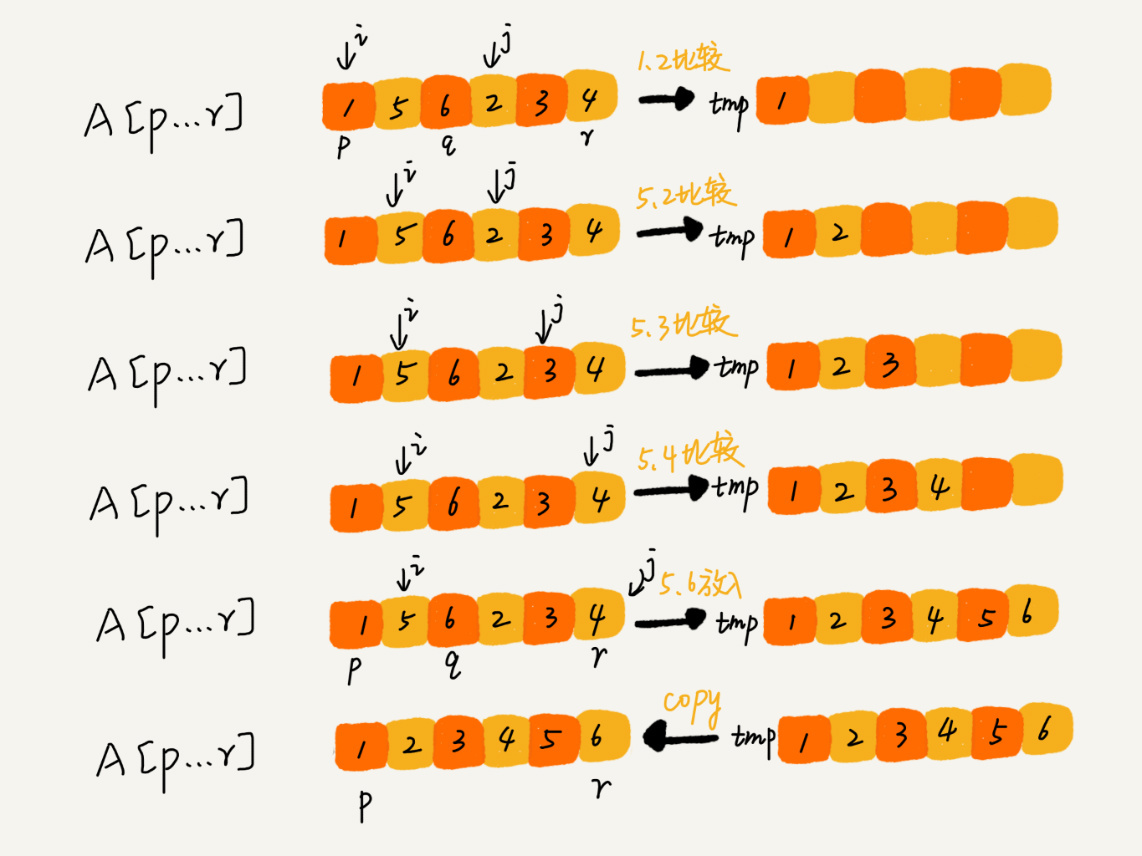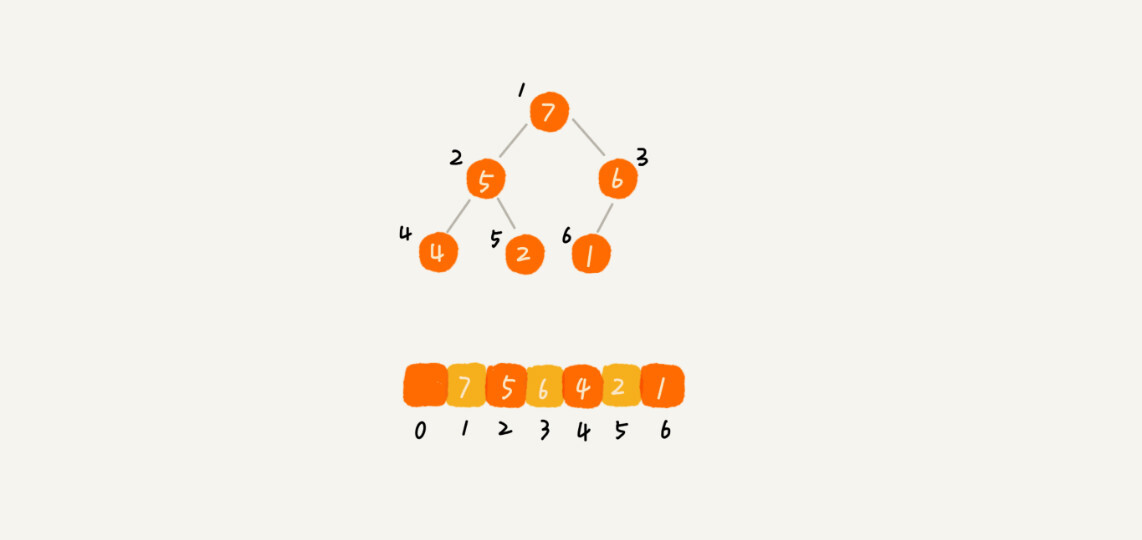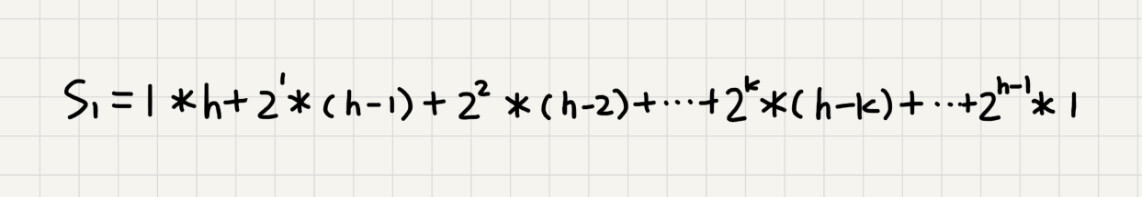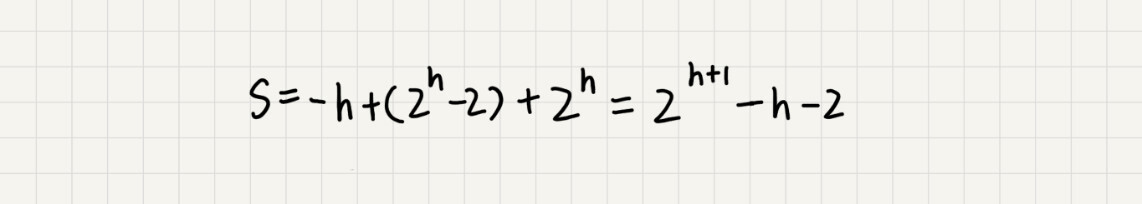silent-tan / arts Goto Github PK
View Code? Open in Web Editor NEW知道为什么要做这个事,会比直接要做这个事更重要。
知道为什么要做这个事,会比直接要做这个事更重要。

- 寻找两个有序数组的中位数
给定两个大小为 m 和 n 的有序数组 nums1 和 nums2。
请你找出这两个有序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。
你可以假设 nums1 和 nums2 不会同时为空。
解法一:
class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int nums1Len = nums1.length;
int nums2Len = nums2.length;
if (nums1Len == 0) {
if (nums2Len % 2 == 0) {
return (nums2[nums2Len / 2 - 1] + nums2[nums2Len / 2]) / 2.0;
} else {
return nums2[nums2Len / 2];
}
}
if (nums2Len == 0) {
if (nums1Len % 2 == 0) {
return (nums1[nums1Len / 2 - 1] + nums1[nums1Len / 2]) / 2.0;
} else {
return nums1[nums1Len / 2];
}
}
int newLen = (nums1Len + nums2Len);
// 中位数下的索引
int targetIndex = newLen / 2;
int[] arr = new int[newLen];
int i = 0, j = 0, count = 0;
while (i < nums1Len && j < nums2Len) {
if (count > targetIndex) {
break;
}
int num1Temp = nums1[i];
int nums2Temp = nums2[j];
if (num1Temp > nums2Temp) {
arr[count++] = nums2Temp;
j++;
} else {
arr[count++] = num1Temp;
i++;
}
}
// 有三种情况
// 一种是num1取空
// 一种是num2取空
// 一种是count取到目标值
int[] stayArr = nums1;
int stayStart = i;
if (i == nums1Len) {
stayArr = nums2;
stayStart = j;
}
while (count <= targetIndex) {
arr[count++] = stayArr[stayStart++];
}
if (newLen % 2 == 0) {
return (arr[targetIndex] + arr[targetIndex - 1]) / 2.0;
} else {
return arr[targetIndex];
}
}
}
复杂度分析:求中位数,k = (m + n) / 2分奇偶情况,奇长度则 arr[k],偶长度则 (a[k] + a[k-1]) / 2;又因为两个数组是有序的,所以每次可以取两个数组头部最小的元素,直到临时数组中元素计算达到k。该算法时间复杂度为 O(m+n),需要额外的空间 O(m+n)
// TODO
解法二:
原文链接 https://itnext.io/request-id-tracing-in-node-js-applications-c517c7dab62d
如果你曾经用nodejs写过后端服务,你就会知道通过日志列表去跟踪相同的 HTTP 请求会是一个麻烦,通常你可以打印下面这样的日志:
[07/Nov/2018:15:48:11 +0000] User sign-up: starting request validation
[07/Nov/2018:15:48:11 +0000] User sign-up: starting request validation
[07/Nov/2018:15:48:12 +0000] User sign-up: request validation success
[07/Nov/2018:15:48:13 +0000] User sign-up: request validation failed. Reason:
...如上,日志混合在一起,没有一个好的方式去确认哪些是相同的请求。但是当你查看下面这样的日志时:
[07/Nov/2018:15:48:11 +0000] [request-id:550e8400-e29b-41d4-a716-446655440000] User sign-up: starting request validation
[07/Nov/2018:15:48:11 +0000] [request-id:340b4357-c11d-31d4-b439-329584783999] User sign-up: starting request validation
[07/Nov/2018:15:48:12 +0000] [request-id:550e8400-e29b-41d4-a716-446655440000] User sign-up: request validation success
[07/Nov/2018:15:48:13 +0000] [request-id:340b4357-c11d-31d4-b439-329584783999] User sign-up: request validation failed. Reason:
...注意到 [request-id:*] 部分都包含了请求标识,这些标识允许你过滤出属于相同请求的日志记录。此外,如果你的应用服务器是通过 HTTP 彼此通讯的微服务,请求标识符可以在HTTP 标头中发送,并用于跨链上所有的微服务生成的日志跟踪请求链。很难去估量这个特征在问题排查还有检测应用方面是多么的有价值
作为一个开发者,你可能希望在同一个地方去配置应用框架或者日志库,从而可以自动生成请求ID和打印出来。但是很不幸,在nodejs中这不是个容易的问题
这就是本文想讨论的一个问题和一种可能的解决方案
在很多语言和平台中,像JVM或者Java Servlet容器这些围绕多线程架构购将的 HTTP 服务器,因为阻塞了 I/O,所以这不会是个问题。如果我们将处理HTTP请求的线程标识符放进日志中,那么这个标识符可能已经用作跟踪特定请求的自然过滤器参数。这种方式不是很理想,但是可以通过使用线程本地存储(TLS)进一步增强。TLS 是一种典型的方式去在当前线程中关联的上下文中存储或者检索键值对。在我们的案例中,它被用于存储每个心情求生成的 id。很多日志库都通过TLS实现了这个功能。作为举例,可以去看 SLFSJ 的文档。
由于急于时间循环的nodejs具有异步特性,因此没有什么像线程本地存储那样的东西,因为你的JS代码就是跑在一个单线程上的。如果没有这种API或者类似的API,则必须在整个请求出调用中传递一个包含请求ID的上下文对象。
让我们看一下类似的简单express应用
'use strict'
// a primitive logger object
const logger = {
info: console.log
}
const express = require('express')
const uuidv4 = require('uuid/v4')
const app = express()
app.get('/', function (req, res) {
req._id = uuidv4(); // generate and store a request id
logger.info(`Started request handling, request id: ${req._id}`)
// pass `req` object into the nested call
fakeDbAccess(req)
.then((result) => res.json(result))
})
async function fakeDbAccess (req) {
return new Promise((resolve) => {
setTimeout(() => {
logger.info(`Logs from fakeDbAccess, request id: ${req._id}`)
resolve({ message: 'Hello world' })
}, 0)
})
}
app.listen(3000, (err) => {
if (err) {
logger.err('The app could not start')
}
logger.info('The app is listening on 3000')
})在这个虚构的应用程序中,我们必须将 req 对象传递给 fakeDbAccess 函数,以便能够将请求 ID 输出到日志。在一个具有很多路由或者模块的真实应用中,这就会非常冗余并且很容易出错。
幸运的是,nodejs社区很久之前就已经考虑TLS的替代方案了,其中一种最流行的方式是 CLS 本地持续存储
第一个CLS的实现是 continuation-local-store 这个库,它这样定义 CLS:
持续本地存储和线程编程中的线程本地存储类似,但是是基于node风格的回调链,而不是线程
如果你去看这个库的API,你会发现比Java的TLS更为复杂。但是在核心部分,它们又很相似。它允许你去将上下文对象和调用链关联,并在之后使用它
最初这个库是基于 process.addAsyncListener 这个API,这个API直到 nodejs v0.12版本的才会提供,但是可以通过 polyfill 的方式去获取这个API。这个polyfill 有大量的修补,旨在包装内置的Node API。这就是为什么不应该考虑原始库和现代版本的nodejs结合使用的原因。
幸运的是,有一个后续的版本(或者更准确来说是这个库的一个fork项目),叫做 cls-hooked 。在nodejs>=8.2.1 中使用了 async hooks 这个node内置API。尽管这个API还是个实验性API,但是这个选择比使用一个polyfill更加好,如果你相对 Async hooks 这个API更加了解,可以参考这里
如你所知,如果你希望在你的nodejs应用中获取request id,那么你需要使用 cls-hooked 并且在你的项目中合适地引入它。但是你可能希望使用一个能够帮你把这些细节封装起来的库
最近我搜索了很多这些库,但是并没有找好一个和这个目的相匹配的库。当然,有几个集成了web框架的库,比如express。另一个方面,也有通过中间件提供request id。但是我没有找到一个库能够将CLS和请求ID结合解决request id追踪问题。
所以,可以看一下 cls-rtracter 这个库,他解决了上述的问题。它提供了express和koa的中间件,实现了基于CLS去生成request id,允许在任何你调用链上获取request id
cls-rtracter 集成需要两步:第一步是将中间件放在合适的位置,第二步是配置你的日志
如下:
'use strict'
const rTracer = require('cls-rtracer')
// that how you can configure winston logger
const { createLogger, format, transports } = require('winston')
const { combine, timestamp, printf } = format
// a custom format that outputs request id
const rTracerFormat = printf((info) => {
const rid = rTracer.id()
return rid
? `${info.timestamp} [request-id:${rid}]: ${info.message}`
: `${info.timestamp}: ${info.message}`
})
const logger = createLogger({
format: combine(
timestamp(),
rTracerFormat
),
transports: [new transports.Console()]
})
// now let's configure and start the Express app
const express = require('express')
const app = express()
app.use(rTracer.expressMiddleware())
app.get('/', function (req, res) {
logger.info('Starting request handling')
fakeDbAccess()
.then((result) => res.json(result))
})
async function fakeDbAccess () {
return new Promise((resolve) => {
setTimeout(() => {
logger.info('Logs from fakeDbAccess')
resolve({ message: 'Hello from cls-rtracer Express example' })
}, 0)
})
}
app.listen(3000, (err) => {
if (err) {
logger.err('The app could not start')
}
logger.info('The app is listening on 3000')
})app运行会生成如下日志:
2018-12-06T10:49:41.564Z: The app is listening on 3000
2018-12-06T10:49:49.018Z [request-id:f2fe1a9e-f107-4271-9e7a-e163f87cb2a5]: Starting request handling
2018-12-06T10:49:49.020Z [request-id:f2fe1a9e-f107-4271-9e7a-e163f87cb2a5]: Logs from fakeDbAccess
2018-12-06T10:49:53.773Z [request-id:cd3a33a9-32cb-453b-a0f0-e36c65ff411e]: Starting request handling
2018-12-06T10:49:53.774Z [request-id:cd3a33a9-32cb-453b-a0f0-e36c65ff411e]: Logs from fakeDbAccess
2018-12-06T10:49:54.908Z [request-id:8b352536-d714-4838-a372-a8e2cfcb4f53]: Starting request handling
2018-12-06T10:49:54.910Z [request-id:8b352536-d714-4838-a372-a8e2cfcb4f53]: Logs from fakeDbAccess请注意,集成本身包含了由 rTracker.expressMiddleware() 函数调用生成的express中间件,以及通过 rTracer.id() 调用获取请求ID
原生实现immutable对象
| 算法 | 时间复杂度 | 是否稳定 | 是否原地排序 |
|---|---|---|---|
| 冒泡算法 | O(n^2) | √ | √ |
| 插入排序 | O(n^2) | √ | √ |
| 选择排序 | O(n^2) | × | √ |
| 归并排序 | O(nlogn) | √ | × |
| 快速排序 | O(nlogn) | × | √ |
| 桶排序 | O(n) | √ | × |
| 计数排序 | O(n) | √ | × |
| 基数排序 | O(n) | √ | × |
从时间复杂度来看,最优的应该是选择线性排序,但是因为适合线性排序的场景都比较特殊,所以如果是通用算法的话,线性排序显然不适合。
在小规模数据上,O(n^2) 并不代表其真实的执行时间,只是表示其执行时间的增长速度,所以可以选择插入排序(冒泡在交换次数上比插入排序需要执行的步骤多)。
而大规模数据的话,O(nlogn) 显然更加高效,为了兼顾任意数据规模的排序,O(nlogn) 时间复杂度的排序算法显然更适合作为通用、高性能的排序函数的实现。O(nlogn) 算法有两种,归并和快排,我们知道归并需要的空间更多,这个是避免不了的;而快排则在分区点选择不合理的情况下,算法时间复杂度会退化到 O(n^2) ,那么如果我们能够设置合理的分区点,快排就是我们最理想的选择了
主要从优化分区点入手,使得至少分区点pivot的选择尽可能避免出现分开的数据极度不均衡,下面是两个比较常用的分区算法:
三数取中法
取首尾中三个数进行比较,选择中间的数作为分区点。
随机法
每次随机选择一个分区点,这样虽然不能保证每次都可以选择到最优的分区点,但是相对地来说,也不会轻易选择到最糟糕的点
另外,我们知道快排是通过递归实现的,可能存在递归深度过大导致栈溢出。这种情况有两种处理方法:一种限制递归深度,另外一种是模拟实现一个函数调用栈
- 判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
/**
* @param {number} x
* @return {boolean}
*/
var isPalindrome = function (x) {
if (x < 0) {
return false;
}
var arr = x.toString().split('');
var count = arr.length / 2;
var result = true;
for (var i = 0; i < count; i++) {
var last = arr.length - 1 - i;
if (arr[i] !== arr[last]) {
result = false;
break;
}
}
return result;
};时间复杂度为 O(n)
bool isPalindrome(int x){
if (x < 0 || (x % 10 == 0 && x != 0)) { return false; }
int revert = 0;
while(x > revert) {
revert = revert * 10 + x % 10;
x /= 10;
}
return x == revert || x == revert / 10;
}时间复杂度为 O(log(n))
因为我 review 的目的一方面是为了提高英文水平,另一方面是学习,,所以就直接翻译了
原文链接 https://levelup.gitconnected.com/4-custom-hooks-to-boost-your-react-app-d54aefe34061
自第一个稳定版本发布后,React Hooks 改变了前端开发者写 React Component 的方式。这是这一类库发展的一个正常步骤,新特征的引入决定了哪些类库能够在前端发展的持续竞争中走得更远。React 已经是一个备受推崇的前端库类了,但是有了React hooks,React 迈进了新的一步
React hooks 可以让开发者使用函数组件(Functional Component)去控制副作用(Side Effect),而不是通过 类组件(Class Component) 的方式以及其生命周期如 componentDidMount 、componentDidUpdate 等,除此外,它允许开发进行逻辑复用,减少重复代码和错误
React 通过内置的hooks为组件控制流程提供了使用功能,但是更加酷炫的是通过组合这些内置的hooks创建自定义的hooks
有很多库提供了自定义的hooks,而且有的甚至比我们在这里创建的功能处理得更好。但是,能够看到我们每天已经在使用的场景背后发生了什么
usePrefetch hook 通过懒加载在首屏不需要的次要组件去提高主页面的加载时间,目的是为了减少主包的大小和让应用能够更快响应
在我们的例子中,我们假设我们的页面中有:
在我们点击按钮之前,modal不应该被渲染,因为我们还不需要它。但是如果我们在主组件开头进行 import 引入去下载它的代码,因为它被包含在主包(bundle)中。而我们希望通过懒加载的方式把它从主组件中分类,然后当主组件第一次被渲染的时候进行预加载 modal 组件
function usePrefetch(factory) {
const [component, setComponent] = useState(null);
useEffect(() => {
factory();
const com = lazy(factory);
setComponent(com);
}, [factory]);
return component;
}
const importModal = () => import('./modal')
const App = (props) => {
const [isShown, setIsShown] = useState(false);
const Modal = usePrefetch(importModal);
return (
<>
<div>main content</div>
<button click={() => setIsShown(true)}>show modal</button>
<Suspense fallback={<h1>waiting for</h1>}>
{isShown && <Modal />}
</Suspense>
</>
)
}QA: 为什么需要定义一个 importModal 函数,因为如果用内联的方式,那么每次都会调用的是新函数,这导致useEffect函数会在每次render的时候都调用
这个hooks 会实时获取当前的地理位置
const useGeo = (opt) => {
const [isLoading, setIsLoading] = useState(true);
const [error, setError] = useState(null);
const [geo, setGeo] = useState({});
let isLoad = true;
let id;
function onSuccess(event) {
if(isLoad) {
setIsLoading(false);
setGeo(event.coords);
}
}
function onFailure(error) {
if(isLoad) {
setIsLoading(false);
setError(error)
}
}
useEffect(() => {
navigation.geolacation.getCurrentPosition(onSuccess, onFailure, opt);
id = navigation.geolocation.watchPosition(onSuccess, onFailure, opt);
return () => {
isLoad = false;
navigation.geolocation.clearWatch(id)
}
}, [opt])
return { geo, isLoading, error }
}
const App = () => {
const { geo, isLoading, error } = useGeo();
return !isLoading && !error ? (
<div>
<h1>lat: {geo.latitude}</h1>
<h1>lon: {geo.longitude}</h1>
</div>
)
}useInternal hooks 可能是最知名的自定义hook了,是由 Dan Abramov 写的
function useInternal(callback, delay) {
const [saveCallback] = useRef();
useEffect(() => {
savedCallback.current = callback;
}, [callback]);
useEffect(() => {
function tick() {
saveCallback.current();
}
if(delay !== null) {
let id = setInterval(tick, delay);
return () => clearInternal(id)
}
}, [delay])
}
const App = () => {
let [count, setCount] = useState(0);
useInterval(() => {
setCount(count + 1)
}, 1000)
return <h1>{count}</h1>
}偶尔,开发者总是面对需求去实现一个高效的倒计时定时器
function useTimer(ms) {
function decreaseSecond(state) {
let {dd, hh, mm, ss} = state;
if(ss > 0) ss --;
else if (mm > 0) {
ss = 59;
mm--;
} else if(hh > 0) {
ss = 59;
mm = 59;
hh--;
} else if(dd > 0) {
ss = 59;
mm = 59;
hh = 59;
dd--;
} else {
return state;
}
return { dd, hh, mm, ss};
}
function reducer(state, action) {
switch (action.type) {
case 'SET_TIME':
return action.timeState;
case 'DESCREASE_SECOND':
return decreaseSecond(state);
}
}
const initState = {
dd: 0,
mm: 0,
hh: 0,
ss: 0
}
const [timer, dispatch] = useReducer(reducer, initState);
useEffect(() => {
const timeDate = new Date(ms);
const timeState = {
dd: Math.floor(timeDate / (1000 * 60 * 60 * 24)),
hh: Math.floor((timeDate % (1000 * 60 * 60 * 24)) / (1000 * 60 * 60)),
mm: Math.floor((timeDate % (1000 * 60 * 60)) / (1000 * 60)),
ss: Math.floor((timeDate % (1000 * 60)) / 1000)
}
dispatch({ type: 'SET_TIME', timeState});
}, [ms]);
useInterval(() => {
dispatch({ type: 'DESCREASE_SECOND'})
}, 1000);
return timer;
}
function App() {
const ms = 86400000;
const {dd, mm, hh, ss} = useTimer(ms);
return <h1>{`${dd}:${hh}:${mm}:${ss}`}</h1>
}读后评论:
文章简单地介绍了react hook的出现的原因是更加关注逻辑的重用。而通过文章的四个自定义hook,也为我编写react-hook提供了思路,进一步理解了react hook。在通过其他资料的阅读,发现react在关注横切面的发展历程为 mixin => hoc => react hook。就目前来看,create hook不是银弹,没有到非要不可,但是看官方的姿态,这会是react的重点发展方向,目前业内的知名库类都慢慢有了react-hook,这也促进了react hook的进一步成熟和稳定。在实际业务开发中,我逐渐使用react-hook进行开发有几个直接体会:代码的确变少了,测试更加容易了,写业务的逻辑更清晰了,也开始慢慢抽离一些可以复用的业务逻辑
本周主要是一个关于项目切换 typescript 的时候最好应该切入的地方。就本周的实践开始部分切换typescript,因为后端接口需要把某个接口的 account_id 从 number 改成 string 类型,所以需要替换 interface 中属性的类型,就接口的类型更改后,因为为了快速切换的原因,目前大部分的类型还在使用any,所以导致改起来异常痛苦。就前端后分工来说,我们可以先保证和接口交互层相关的类型编写,再逐步改造全站。
本次主要是分享本周系统学习算法的一个笔记,之前总是容易忽略的时间复杂度分析,总算知道为什么学不好算法了,原来第一步就不够重视,哈哈哈哈哈 : )
算法本质是为了更好地解决问题,体现在时间更快,空间更少上。
为什么要掌握统计算法的执行效率和资源消耗的方法?
通过掌握分析方法,我们可以通过代码快速估算算法的执行效率和资源消耗,然后对比其他的算法,获得更优的解决方案
大O表示法用来表示算法的时间复杂度,他不是代码执行的真正时间,而是表示代码执行时间随数据增长的趋势
1. 只关注循环执行次数最多的一段代码
通常来说,因为我们关注的是变化趋势,所以我们可以忽略常量、低阶和系数,而去关注最大阶的量级。所以,我们在分析一个算法或者代码的时间复杂度时、关注循环次数最多的那段代码就行了
2. 加法法则:总复杂度等于量级最大的那段代码的复杂度
分析每个部分的时间复杂度,然后取量级最大的那个部分作为整体的时间复杂度
3. 乘法法则:嵌套代码的复杂度等于嵌套内外复杂度的成绩
有四种衡量的标准:
前两者顾名思义,理解就是字面上的意思:
最好情况时间复杂度的意思是在最理想的情况下,代码的执行时间复杂度
最坏情况时间复杂度的意思是在最坏的情况下,代码的执行的时间复杂度
简单举个栗子:
int find_num(int[] arr, int n, int x) {
int i = 0;
int pos = 0;
for(; i < n; i++) {
if(arr[i] == x) {
pos = i;
break;
}
}
return pos;
}上述栗子最好的情况就是 i=0的时候就查找到元素 , 这时候的时间复杂度为O(1) ;而最坏的情况则是没有找到元素,时间复杂度为 O(n)
然而在实际中,最好情况时间复杂度和最坏情况时间复杂度都是在最极端下才会发生的,为了更好的表示平均情况下的复杂度,需要引入平均情况时间复杂度。
什么是 平均情况时间复杂度,可以简单理解为把最好情况和最坏情况之间的每一种情况需要遍历数组的次数相加,然后除以总的情况个数。
通过上面例子进行平均情况时间复杂度分析。
总体的概率相加为 (1+3n)/4 , 这个值就是平均情况时间复杂度,是概率论中的加权平均数,也叫期望值,所以平均情况时间复杂度也叫加权平均时间复杂度或者期望时间复杂度。用大O表示法表示其复杂度,其复杂度仍是 O(n)
在同一个代码块下,因为代码运行的不同情况,其时间复杂度有量级的差距,所以用这三个复杂度来进行衡量和区分。
而最后一种摊分时间复杂度的场景是作用于代码执行的各种情况具有循环规律性的时候采用的一种代码执行复杂度的衡量
- 最长回文子串:给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
/**
* @param {string} s
* @return {string}
*/
var longestPalindrome = function(s) {
function findStrLen(str, centerLeft, centerRight) {
var L = centerLeft, R = centerRight;
while(L >= 0 && R < str.length && str[L] === str[R]) {
L--;
R++;
}
// R - L + 1 是 R 和 L 之间的长度,但因为 L 和 R 最终都会多自增一次,所以需要 -2
return R - L + 1 - 2;
}
var startIndex = 0, endIndex = 0;
for(var i=0; i<s.length; i++) {
var len1 = findStrLen(s, i, i);
var len2 = findStrLen(s, i, i+1);
var len = Math.max(len1, len2);
if(len > (endIndex - startIndex + 1)) {
if(len % 2 === 0) { // 有两个中心
var temp = (len - 2) / 2;
startIndex = i - temp;
endIndex = i + 1 + temp;
} else {
var temp = (len - 1) / 2;
startIndex = i - temp;
endIndex = i + temp;
}
}
}
return s.slice(startIndex, endIndex + 1);
};时间复杂度分析:结合第一周的复杂度分析技巧,复杂度是嵌套乘绩:O(n^2)
React 的 记忆(Memoizing) 是一个性能相关的特征,目的是加快组件的渲染过程。这项技术被应用于广泛的学科,从游戏引擎到 互联网应用。这篇文章主要探究 React 中的记忆技术,涵盖了 API 和示例用例
记忆在计算机编程中是一个令人熟悉的概念,它的目的是为了加速程序的运行。主要是通过缓存高耗时函数的运行结过和重新使用这些缓存去避免高耗时操作:
尽管记忆可以节省很多处理周期,但是它的使用程度是有限制的,这是由于系统内存限制所决定的。当和 React 结合在一起的时候,我们可以缓存 render 函数的返回结果,或者仅仅是函数返回的 JSX。
记忆可以应用于类组件和函数组件,这个特征的实现由两种方式:高阶组件(HOC)和 React Hooks
考虑通过记忆可以缓存你的应用到什么程度是明智的,即使我个人没有遇到内存限制的问题,但相比笔记本和台式机,移动端不可避免只有更少的内存去利用。
React 中的记忆技术不保证你的组件都会被缓存,但是会基于入可用资源这些因素尽最大的努力
无可否认,快速响应式的 UI 对于终端用户来说更加友好,并且通过交互体验(experience delivered)对于品牌认可也非常有用。一个 UI 响应如果超过 100 毫秒就会被终端用户察觉到异常。为了应用流畅,100毫秒内是组件重新渲染或者 UI 反馈的一个理想时间。
Memoizing 是一个保证情况继续存在的技术. 在开始示例前先探究 React 是如何实现记忆功能的
记忆技术在React中主要用于提高渲染速度,同时减少渲染操作,在初始渲染周期中缓存组件的 render() 的结果,并在相同输入(包括 props、state、class属性、函数变量)的情况下重新使用它。
为了避免 render() 操作重复执行生成相同的结果,我们可以缓存初始化 render() 的结果,并且在下次组件渲染的时候在内存中引用该结果。
你可能会想到 React.PureComponent 就是做这个的! React.PureComponent 实际上就是一种性能优化, 它实现在 componentShouldUdpdate() 声明周期中和前一次渲染的 props 和 state 进行浅比较。如果相等,那么组件就不会重新渲染。
class MyComponent extends React.PureComponent {
// ...
}浅比较意味着只有组件的 props 和 states 才会比较,而子组件的 props 和 states 不会。
React.PureComponent 仅仅适用于类组件,因为它依赖类组件的生命周期和 State 进行实现。为了弥补这个不足,React 提供了 React.memo 这个 API。React.memo 是一个高阶组件,它实现对组件两次渲染的 props 进行浅比较以确认是否需要进行重新渲染。这个高阶组件同样适用函数组件
function WrapComponent(props) {
// TODO
}
const MyComponent = React.memo(WrapComponent);React.memo 也提供了第二个参数让我们提供自己的比较函数,在确定组件是否需要的问题上提供了更多的粒度
function myComparison(preProps, nextProps) {
// TODO
}
export default React.Memo(MyComponent, myComparison);一般上,我们将包装在 HOC 中的组件称为 WrappedComponent , 通常记忆组件会被单独定义,并且作为默认导出。
下面是是否需要去实现一个比较函数的几种情况
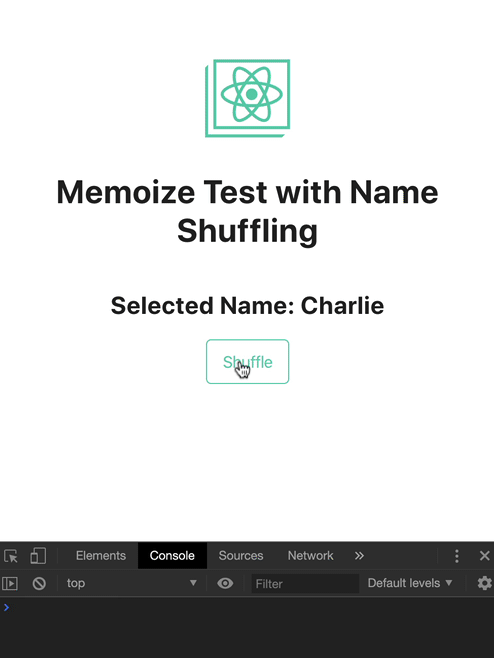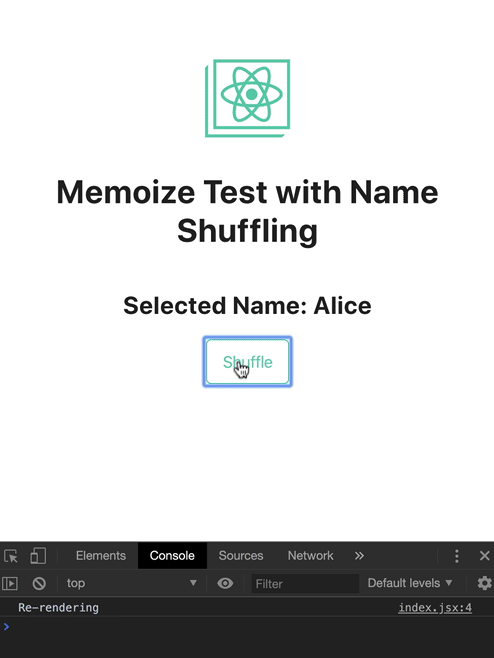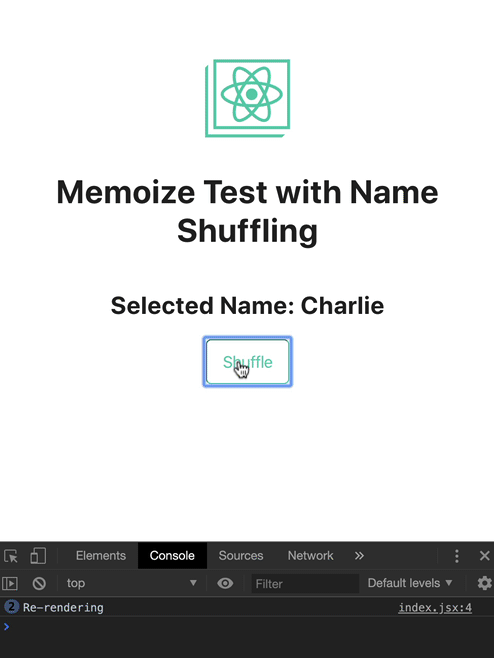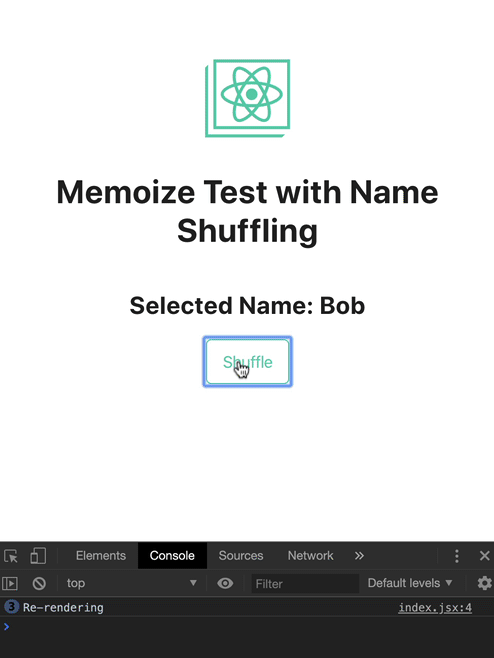
web socket事件 或者 rxjs ,并且只希望从服务拉取确定的数据后才进行重新渲染。本质上,我们可以在比较函数中引用全局变量,以便外部因素可以确定组件是否需要重新刷新false 去临时覆盖缓存,强制在每次 re-render 的时候进行刷新组件并且返回默认组件查看下面的例子去观察 React.memo 的运行情况,我们会随机选择一组名字传递给 NameShuffling 组件.
这个例子你可以在 codesandbox 尝试并且观察 console,下面的截图说明在这个组件内发生的情况,NameShuffling 仅在 name 发生改变的时候进行重新渲染
在 APP 组件中,我们通过 getName 函数指派了一个随机的名字给 state
// 类属性
names = [
'Alice',
'Bob'
];
// 随机选择一个名字
getName = () => {
const index = Math.floor(Math.random() * (this.names.length - 1));
return (this.names[index]);
}
state 中 name 的值会传递给 NameShuffling 组件,为了更新这个值,Shuffle 按钮调用 getName() 去设置 App state 中的 name
NameShuffling 是我们需要记忆的组件.它是一个包装在 React.memo 中的函数组件:
import React, { memo } from 'react';
function WrappedComponent (props) {
console.log('Re-rendering');
return (
<h2>Selected Name: {props.name}</h2>
);
}
export const NameShuffling = memo(WrappedComponent);
export default NameShuffling;
我们在这里也可以提供比较函数,检测 name 是否和上次 render 的不一样。我们也可以引用全局变量或者外部的过程
// 函数上下文外的 API
const someGlobalVar = {
ready: 1
};
function areNamesEqual (prevProps, nextProps) {
return prevProps.name !== nextProps.name && someGlobalVar.ready === 1;
}
这里当 someGlobalVar 中的 ready 为 1或者 name 发生改变的时候才会去进行重新渲染。当 someGlobalVar 是一个服务器响应的时候,那么服务端就可以控制组件什么时候可以进行重新渲染,这在当组件要显示所有结果之前等待获取完整数据列表的时候很有用
如果一个函数中没有 props 或者 state 依赖,那么这个函数作为 props 传递给记忆组件,记忆组件也可以正常工作。我们后面也将会通过 useCallback 进一步(further down)介绍将回调函数作为 props 或者 state应该怎么处理。
在示例中,函数被传递给 NameShuffling 去清除当前被选择的名字,这回触发重新渲染,因为 name 被改变了
// 添加清除state中的name的功能
clearName = () => {
this.setState({ name: null });
}
render() {
return (
...
<NameShuffling
name={this.state.name}
clearName={this.clearName}
/>
...
);
}
NameShuffling 包括了一个清除按钮,显示当前选择的名字或者如果没有选择到名字就显示为 None:
function WrappedComponent (props) {
return (
<>
<h2>Selected Name: {props.name ? props.name : 'None'}</h2>
<button
onClick={() => { props.clearName() }}>Clear
</button>
</>
);
}
因为我们的组件已经被记忆了,重复点击 Clear 在 name 被设置为 null 后不会再触发重新渲染
上述就完成了最基础的 demo,现在我们进入一个使用了多个记忆方法、更加复杂的场景
还可以使用Hooks和功能组件进行记忆化,并且使用比围绕组件和props构建的 React.memo 副本更加灵活的API。
更具体地说,我们可以通过 useMemo 包装组件的内联 JSX 返回,也可以将Memoized结果存储为变量。我们也可以通过使用 useCallback hook去记忆回调函数,这个 hook 等同于 useMemo,只是语法有轻微的不用。
useCallback 解决了之前提到函数作为props的问题,如果没有记忆该函数,则该函数会在重新渲染的时候被重新定义. 下面我们在示例中给出这个解决方案
useMemo 函数将一个函数作为第一个参数,然后可以提供额外的一组元素作为依赖,这些数值如果发生改变会触发重新渲染
const result = useMemo(() => computeComponentOrValue(a, b), [a, b]);
useCallback 一般和 useMemo 组合一起去记忆内嵌套的函数,有一个类似的定义
const memoizedCallback = useCallback(
() => {
doSomething(a, b);
},
[a, b]
);
React 文档说明两者的区别是,useMemo 被使用去 创建函数 , 而 useCallback 则用于内嵌套的函数。初看上去不是十分清晰,所以我们进入到 Name shuffling 示例中去重构我们的代码,结合 React.memo 实现这些 hooks
请看 codesandbox 中的 AppFunctional.js , 请将 index.js 中的组件引用该组件作为根组件进行查看
聚焦到 AppFunctional.js
useMemo 的使用方式类似 React.memo. 相比之前用 React.memo 去包装 NameShuffling 组件, 我们会使用 useMemo 直接包装显示 name 的内联 JSXuseCallback 会被用于记忆 getName() 和 clearName() 方法. getName() 会使用 names 数组作为它的唯一依赖 , 只有从列表中添加或者删除name的时候才会更新。 clearName() 则没有任何依赖, 会在初始化后知道组件卸载React.Memo 去包装 <Button /> 组件确保他们不会被重新渲染. useCallback 函数将会传递给这些按钮names 数组提升到更高一层的组件中, 而 useCallback 和 useMemo hooks 会在子组件中定义, 将顶层数据和组件逻辑分开下图说明了 APP 组件的结构:
下面我们会看一下能够让记忆正常工作的关键地方
useCallback 对象传递// 记忆回调方法
const getName = React.useCallback(
() => {
const index = Math.floor(Math.random() * (names.length));
setName(names[index]);
},
[names]
);
const clearName = React.useCallback(() => {
setName(null)
}, []);
如果我们只是简单地将getName()和clearName()函数作为props传递,则在重新渲染父组件时它们将被识别为不同的函数。实际上,在组件重新渲染时,我们会重新定义这些函数。这些不是我们想要的
useCallback 解决了这个问题。getName() 函数仅在 names 发生更改时才更新,这是它的唯一依赖项。 这是有意义的,因为 names.length 可能不同,并且 names 数组可能包含不同的值。 除此方案外,getName()将 始终保持不变。这是 useCallback 的绝佳用例。
clearName() 也会被记忆, 但是没有依赖会去触发它进行更新
useMemo在这种情况下,将 useMemo() 嵌入 <Shuffle /> 组件的 return 语句中的效果很好。我们可以清楚地看到我们想要记忆的组件:
// 内联 JSX 使用 useMemo
return (
...
{React.useMemo(
() => {
console.log('Name re-render');
return (
<h2>Selected Name: {name ? name : 'None'}</h2>
);
},
[name]
)}
...
);
我们选择记忆上面的
name 发生更改时才重新渲染它。React.memo 去防止他们被重新渲染React.memo 被再次用于 <Button /> 组件,以进行较浅的props比较,以确定是否应重新渲染它们。 因为我们传递的是已记忆的回调函数(以及原始的 label 字符串),所以没有任何理由去重新渲染按钮,因为回调函数和标签将始终保持不变。
The <Button /> component is simply a wrapped <WrappedButton /> component courtesy of the React.memo HOC. This is how it has been implemented:
<Button /> 组件被由React.memo 实现的 <WrappedButton /> 组件进行简单包装
function WrappedButton (props) {
console.log('button Re-render');
return (
<button
onClick={() => {
props.click();
}}
>
{props.label}
</button>
);
}
const Button = React.memo(WrappedButton);
console.log 语句用于调试目的,以便在控制台中清楚是否进行了重新渲染。
为了有效地使用这些API,请考虑以下几点,以确保您的应用程序不会产生缺陷,同时利用 记忆 进行性能提升:
componentDidMount,componentDidUpdate 和 componentDidCatch 中使用,而对于函数组件,应该使用 useEffect评论:真的很不错的一篇干货文章,一方面梳理了 Memorize 的这个之前很少使用的功能,另一方面详细解释了 Memorize 的一些实践,对于性能优化方面觉得真的有所作为了
本周主要分享一个循环队列的空队列和满队列的判断技巧,假定指向队头的指针为head,指向队尾的指针是tail,队列长度为 n:
空队列的时候:head == tail
满队列的时候: (tail + 1) % n == head
写链表代码技巧:
class Solution {
public int bitCount(int num) {
int count = 1;
int tmp = num;
while(tmp >= 10) {
tmp /= 10;
++count;
}
return count;
}
public void swap(int[] nums, int a, int b) {
int tmp = nums[a];
nums[a] = nums[b];
nums[b] = tmp;
}
/**
* 是否应该交换
* @param a
* @param b
* @return true表示需要交换
*/
public boolean compare(int a, int b) {
int aBit = bitCount(a);
int bBit = bitCount(b);
// 相同位数,直接比较大小
if (aBit == bBit && a > b) {
return true;
}
if (aBit != bBit) {
// 考虑到溢出的问题
long ca = (long) a * (int)Math.pow(10, bBit) + (long) b;
long cb = (long) b * (int)Math.pow(10, aBit) + (long) a;
return ca > cb;
}
return false;
}
// 分区点
public int partition(int[] nums, int start, int end) {
int pivot = nums[end];
int i = start, j = start;
for (; j <= end; ++j) {
// 倒序
if (this.compare(nums[j], pivot)) {
this.swap(nums, i, j);
++i;
}
}
swap(nums, i, end);
return i;
}
// 快排
public void sort(int[] nums, int start, int end) {
if (start >= end) {
return;
}
int pivotIndex = this.partition(nums, start, end);
this.sort(nums, start, pivotIndex - 1);
this.sort(nums, pivotIndex + 1, end);
}
public String largestNumber(int[] nums) {
this.sort(nums, 0, nums.length - 1);
String result = "";
for (int num: nums) {
// 考虑多0情况
if ((num + "").equals(result) && result.equals("0")) {
continue;
}
result = result.concat(num + "");
}
return result;
}
}主要使用了快排,时间复杂度为 O(nlogn)
原文链接 https://medium.com/swlh/4-things-you-might-not-know-you-can-do-in-react-be234bdcab1b?
React 自在2013年发布第一个版本依赖,已经受到越来越多的关注和被人采用。成为开发者最喜爱和最想要的web库毫无意外,因为它就是目前最流行的JavaScript库
其中有一个原因让React对我来说十分吸引,尽管使用了那么多年,你仍然可以从它身上发现新的技术和技巧。尽管这些我即将介绍的技术可能不会经常使用,但是在正确的场景下使用,它们会非常强大。那么事不宜迟(So without futher ado),下面我就是你可能不知道可以在React中完成的四件事
我们都知道在 React 中创建数组元素的时候需要包含 key 属性。但是我们为什么需要首先使用它?这是因为 key 能够 识别哪些项被改变、添加或者删除
想象你有一个字符串数组 ['Dog', 'Cat', 'Owl'] ,你打算将他们渲染在一个组件内。在初始化渲染后,你想要添加一个额外项到数组的开头,基本上就是将原本的三个元素推到末尾。而如果没有 key 属性,React 会改变前三项而不是保留他们,尽管它们没有被改变,只是需要切换下位置就可以了。那么如果有 key 的情况下,如果这些元素有 key 属性,React 就可以根据 key 的值去确认实际需要改变的,而不是重新渲染每一项。
基于以上,我们也可以在其他情况下使用 key 属性去达到我们的目的。因为 key 属性能够告知组件标识被改变,所以我们就有可能在需要时重新实例化这个组件。下面是一个简单的计时器🌰,你可以在 codesandbox
const App = () => {
const [key, setKey] = React.useState(0);
return (
<div>
<Counter key={key} />
<button onClick={() => setKey(key + 1)}>
Reset the state from parent
</button>
</div>
);
};
const Counter = () => {
const [count, setCount] = React.useState(0);
return (
<div>
<p>Current count: {count}</p>
<button onClick={() => setCount(count + 1)}>+</button>
<button onClick={() => setCount(count - 1)}>-</button>
</div>
);
};通过概念 App 组件中的 key,我们可以简单地组重置 Counter 组件内的状态。这个技巧有时候确实十分方便,但是你意识到可能会造成的性能影响。
这个技巧不像第一个那么难,相反十分简单和明了,尽管我很少看到它被使用。
React 推荐使用组合而不是继承在组件间重用代码,所以才有 props.children 。但是有时候你希望传递多个 props.children ,所以你可以创建自己的传递组件的约定。你可能找到一些参考,在你的组件中使用 插槽 或者 孔 的一些思路,看一下 简单的例子
const SidebarSimple = () => <div>I'm a sidebarrrr</div>;
const Sidebar = () => <div>I'm a sidebar :)</div>;
const Layout = ({ children, leftPanel, rightPanel }) => (
<div>
<div>{leftPanel}</div>
<main>{children}</main>
<div>{rightPanel}</div>
</div>
);
const App = () => {
const [sidebarC, setSidebarC] = useState(<SidebarSimple />);
const Settings = () => (
<button onClick={() => setSidebarC(<Sidebar />)}>
Click here to change the sidebar
</button>
);
return (
<Layout leftPanel={sidebarC} rightPanel={<Settings />}>
<p>Hello from main!</p>
</Layout>
);
};这就让 Layout 组件变得更加容易扩展,因为我们可以自由改变 leftPanel/rightPanel。我们可以将组件传递给插槽甚至是直接传递JSX,它都能正常工作
下面使用 useState 重构我们的第一个 Counter 例子,这里我们通过更新自身的状态值去改变 Counter 的计数,实现每秒自动加1,我们很自然会这样写,你可以在 这里 查看重构后的例子
React.useEffect(() => {
let counterInterval = setInterval(() => {
setCount(count + 1)
}, 1000)
return () => clearInterval(counterInterval)
}, [])尽管我们设置了更新,但是它只会更新到1然后就停止了。事实上,如果你观察到console,你就会发现count在 setInterval 函数中的值一直为 0
为什么会这样?因为 count 变量在 setInterval 中初始化后会被捕获住,所以 count 在 setInterval 中会一直为0。我们可以通过在 useEffect 依赖项数组中指定 count 来解决这个问题,但是这意味着每次更改值的时候我们都需要重新清楚定时器并重新创建,这简而言之就很不理想了。但是,我们也可以通过使用之前的状态进行函数更新,更改很简单,但是确实解决了我们的问题。可以通过 这里 进行测试
let counterInterval = setInterval(() => {
setCount(count => count + 1)
}, 1000)现在,我们不需要依赖指定数组的值,而且问题也得到了解决。你需要做的是每次都是用之前的状态去进行更新,关键是你可以传递一个函数给更新函数
由于我们测试了 useState 的消耗,我觉得提出通过延迟创建这些高消耗的对象是有必要的
有两种hooks的方式去延迟创建昂贵的对象。你可以使用 useMemo ,这种方式是我见过最多的,可以通过使用依赖项数组来缓存计算结果
const value = useMemo(() => calculation(a, b), [a, b]);如果你的计算有依赖,这就目前来说也是最好的方式去创建一个对象。但是,它仅仅作为一个提示性的存在,并不能保证该计算将不会被重新运行。
另外,如果你没有计算依赖,仅仅想创建一个对象,那么你可以传一个函数给 useState,像下面这样:
const App = props => {
const [state, setState] = React.useState(() => {
const init = expensiveCalculation(props);
return init;
});
return <Chart data={state} />;
};这看起来很少见,但是我觉得这值得一提。
译者评论:
第一第二点在平时组件化开花中场景还是挺多的,也有使用到,而第三点因为刚刚使用 React hooks 的原因,确实很大帮助,但是文中并没有说为什么这样做可以解决这个问题。第四点同第三点。
关于为什么的问题要留到之后对 hook 的实现原理进行源码解读才能给到一个比较完整的见解
通过 URLSearchParams 内置 API 去查询 url 相关:
const urlPrams = new URLSearchParams(window.location.search);
// 查询是否包含某个参数
console.log(urlPrams.has('xxx');
// 查询某个参数的值
console.log(urlPrams.get('xxx');
// 添加一个参数
console.log(urlPrams.append('xxx', 'yyy'));本周重温了时间复杂度为 O(nlogn) 的两种算法:归并排序 和 快速排序 ,主要使用了分治的**
| 算法 | 是否原地算法 | 是否稳定 | 最好 | 最坏 | 平均 |
|---|---|---|---|---|---|
| 归并排序 | 否 | 是 | O(nlogn) | O(nlogn) | O(nlogn) |
| 快速排序 | 是 | 否 | O(nlogn) | O(n^2) | O(nlogn) |
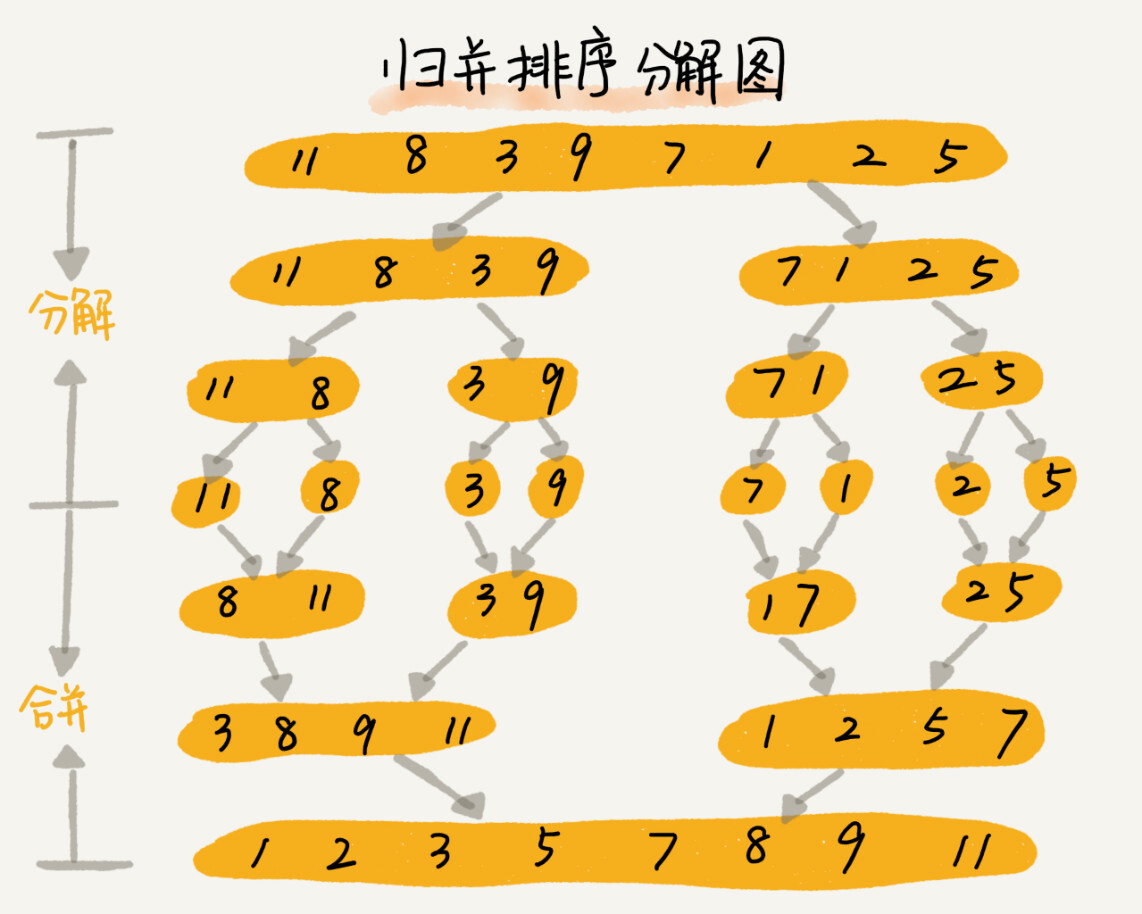
归并排序的核心**是,如果要排序一个数组,那么先把数组从中间分成两个部分,然后对这两个部分分别排序,再讲排好序的两部分合并在一起,这样整个数组就有序了
这和递归的**很想,事实上,分治算法一般都是用递归来实现的。分治是一种解决问题的处理**,递归是一种编程技巧
1. 一个问题分解成多个问题的解
2. 分析得出递推公式
从1观察可以得到分开的前后两个数组,每个数组还可以继续分成前后两个数组,然后对这两个数组进行排序合并
3. 终止条件
当数组只有一个元素的时候,数组不可再进行分隔
递归公式如下:
// 递推公式
merge_sort(p, r) = merge(merge_sort(p, q), merge_sort(q+1, r))
// 终止条件为 p >= r 将不用再继续分解
merge_sort(p, r) ,表示给下标从 p 到 r 之间(包括)的元素进行排序。将这个排序问题转为两个子问题,merge_sort(p, q) 和 merge_sort(q+1, r) ,其中下标 q 等于 p 和 r 的中间位置,也即 (p+r)/2。
merge(arr1, arr2),表示将两个数组进行排序合并。
public void mergeSort(int[] a, start, end) {
if(start >= end) return;
int mid = (start + end) / 2;
mergeSort(a, start, mid);
mergeSort(a, mid+1, end);
merge(a, start, end);
}那么如何实现 merge(int[] a, int start, int end) 函数呢?
public void merge(int[] a, start, end) {
int mid = (start + end) / 2;
int i = start;
int j = mid + 1;
// 申请一个和a相同的tmp空间
int tmpLen = end - start + 1;
int[] tmp = new int[tmpLen];
int tmpIndex = 0;
while(i <= mid && j <= end) {
if(a[i] <= a[j]) {
tmp[tmpIndex++] = a[i++];
} else {
tmp[tmpIndex++] = a[j++];
}
}
// 判断哪个子数组还有数组
int stayStart = i;
int stayEnd = mid;
if(j <= end) {
stayStart = j;
stayEnd = end;
}
while(stayStart <= stayEnd) {
tmp[tmpIndex++] = a[stayStart++];
}
// 将tmp数组复制到原数组
for(int index = 0; index <= tmpLen - 1; ++index) {
a[start++] = tmp[index];
}
}算法分析:
归并排序是稳定的排序算法吗?
是,算法的稳定性,主要通过merge函数进行判断,在合并过程中,保证了相同元素的顺序,所以归并排序是一个稳定的排序算法
时间复杂度分析
在递归的场景中,我们将问题a分解成b和c两个子问题,解决b、c后,把两个结果合成a的结果。加入求加a问题的时间是 T(a),求解b、c的时间为 T(b) 和 T(c)。那么
T(a) = T(b) + T(c) + k
其中k是将两个子问题合并成问题a所消耗的时间
不仅递归求解的问题可以写成递推公式,递归代码的时间复杂度也可以写成递推公式
假设对n个元素进行归并排序需要的时间是 T(n),那么分解成两个子数组,每个子数组排序的时间都是 T(n/2)。merge 函数合并两个有序数组的时间复杂度是 O(n),所以归并排序的时间复杂度公式为:
T(1) = C; 当n=1时,只需要常量级的执行时间,表示为C
T(n) = 2*T(n/2) + n; n>1
对上述公式进行推导:
T(n) = 2T(n/2) + n
= 2(2T(n/4) + n/2) + n = 4T(n/4) + 2n;
= 2(2(2T(n/8) + n/4)+ n/2) + n = 8T(n/8) + 3n;
= 2(2(2(2T(n/16) + n/8) + n/4) + n/2) + n = 16T(n/16) + 4n;
= 2^kT(n/(2^k)) + kn
最后可以得到 T(n) = 2^kT(n/(2^k)) + kn 。当T(n/(2^k)) = T(1),即
n / (2^k) = 1
n = 2 ^ k
k = log(2)n
将 k 代入上面推导出来的公式,可以得到
T(n) = 2^log(2)n * T(n/2^(log(2)n)) + n*log(2)n
= n * T(1) + nlog(2)n
= Cn + nlogn
从算法实现来看,归并排序的执行效率与要排序的原始数组的有序程度无关,所以时间复杂度是很稳定的,不管最好情况、最坏情况还是平均情况,从上述可以得到归并排序的时间复杂度为 O(nlogn)
空间复杂度是多少
尽管每次合并操作都需要申请额外的空间,但是合并完成,临时空间就被释放了。在任意时刻,CPU只会有一个函数在执行,所以就只会有一个临时空间的内存在使用,而合并所需要申请的空间最大不会超过数组的长度n,所以归并排序的空间复杂度为 O(n)
快速排序也是使用分治的**,但是实现思路却和归并排序完全不一样。
快排的思路是:
根据分治递归的**,我们可以递归下标从p到q-1之间的数据和下标从q+1到r之间的数据,知道区间缩小为1,就说明所有的数据是有序的了。
根据递推公式推导的三个条件,可以得到递推公式如下:
递推公式:
quick_sort(p...r) = quick_sort(p...q-1) + quick_sort(q+1...r)
终止条件:
p>=r
public void quickSort(int[] a, int start, int end) {
if(start >= end) return;
int pivotIndex = partition(a, start, end); // 获取分区点
quickSort(a, start, pivotIndex - 1);
quickSort(a, pivotIndex + 1, end);
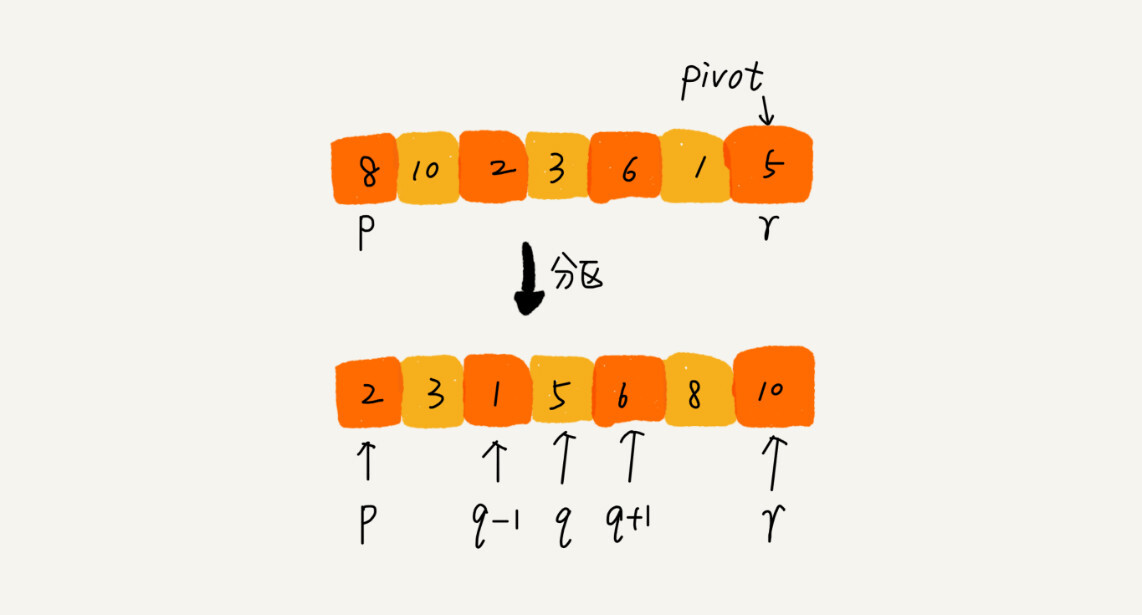
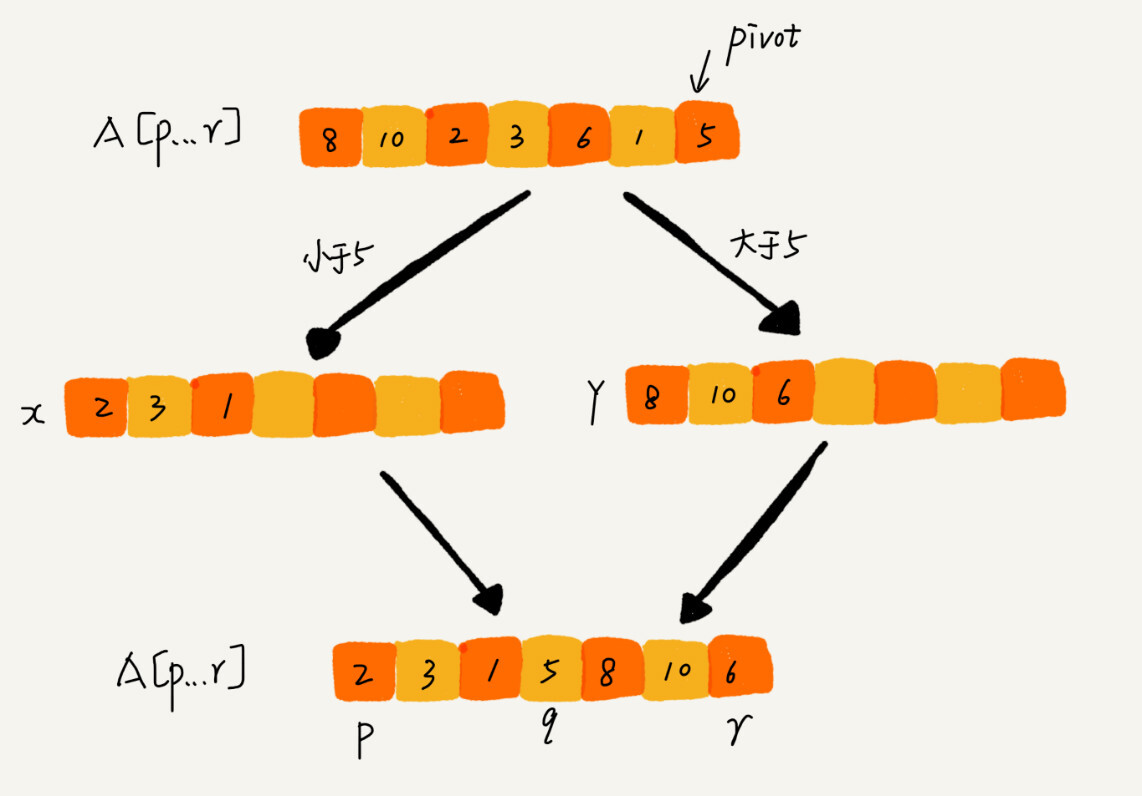
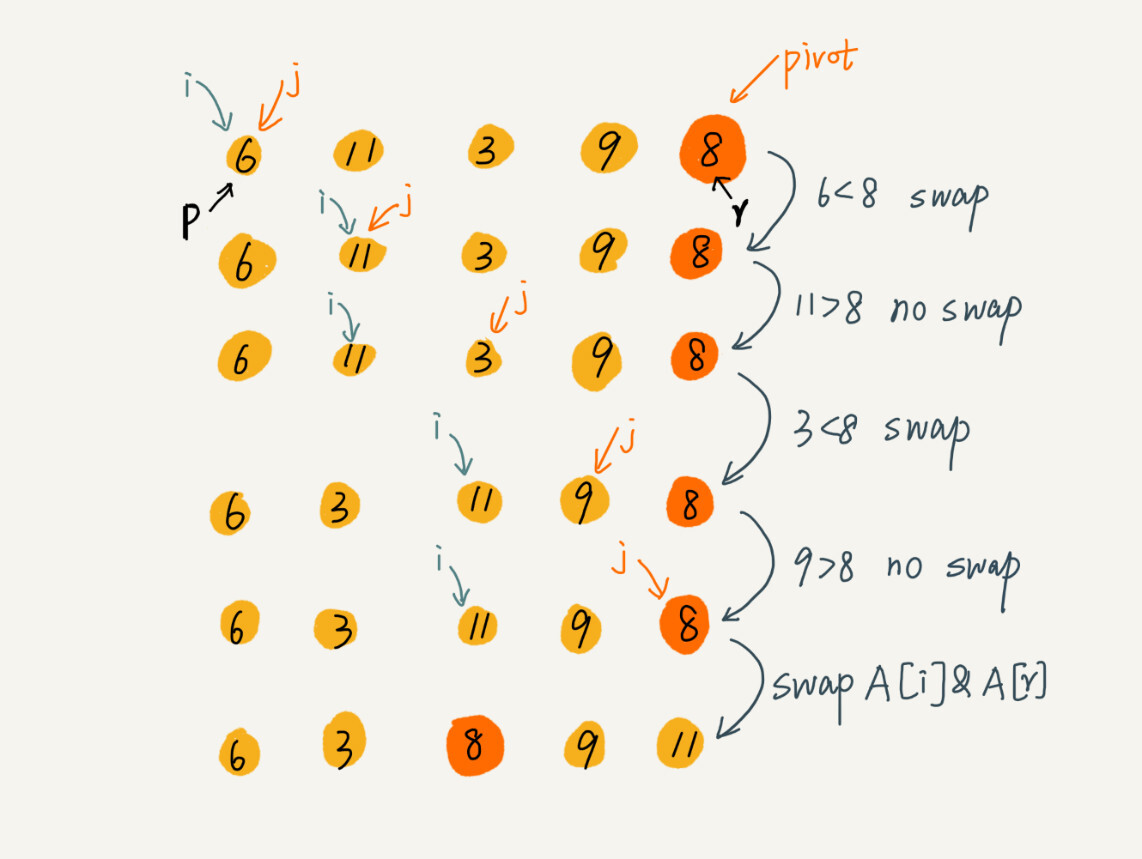
}其中 partition 分区函数需要做三件事:
对于如何分区,简单地,可以申请两个数组X和Y,遍历A[p...r]数组,将小于pivot的元素拷贝到临时数组X,将大于pivot的元素拷贝到临时数组Y,最后将两个临时数组中的数据按顺序拷贝到A[p...r]
如何按照这个思路实现,partition 函数需要更多的额外空间,所以快排就不是原地排序算法了。如果希望快排是原地排序算法,那么空间复杂度就要是 O(1),所以我们需要在原数组上进行分区操作。
public void swap(int[] arr, int a, int b) {
int temp = arr[b];
arr[b] = arr[a];
arr[a] = temp;
}
public int partition(int[] a, int start, int end) {
// 最后一个元素为pivot
int pivot = a[end];
// 通过i,把A[start...end]分割成两个部分
// A[start...i-1]的元素都是小于pivot
// A[i+1...end]都是大于pivot
// 初始小于空间队尾为空,大于空间队头为start
// i表示小于空间队尾的下一个元素
int i = start;
// j 将区间分为已处理和未处理两个部分
for(int j=start; j<end; ++j) {
// 如果a[j]小于pivot,把a[j]放到小于区间队尾
if(a[j] < pivot) {
// 交换i,j元素
swap(a, i, j);
// i指向新的小于区间的下一个元素
i += 1;
}
}
// 交换小于空间的下一个元素指向i和pivot的索引
swap(a, i, end);
return i;
}算法分析:
快排是原地排序算法吗?
是,通过算法实现知道,算法执行过程过并没有申请额外的空间,所以空间复杂度为 O(1)
快排是一个稳定算法吗?
不是,pivot和i的元素如果相同情况下,因为在分区阶段最后会交换pivot和元素i,所以顺序会发生变化,所以是不稳定的算法
时间复杂度分析
快排也是使用递归的实现,由上面我们知道递推公式为
T(1) = C;
T(n) = 2*T(n/2) + n; n>1
在快排中,如果要上面公式成立,pivot需要刚好把数组分成大小接近相等的两个小区间,这时候为最好情况,所以最好情况时间复杂度为 O(nlogn) 。而我们每次选择最后一个元素为pivot,那每次分区得到的区间都是不均等的。我们需要进行大约n次分区操作,才能完成快排的整个过程,每次分区我们平均要扫描大约n/2个元素,所以最坏情况时间复杂度为 O(n^2)
在大部分情况下,其时间复杂度为 O(nlogn),在极少数情况下为 O(n^2),根据均摊的计算方法,平均情况时间复杂度为最好情况时间复杂度,为 O(nlogn)
O(n)时间复杂度内求无序数组中的第 K 个元素,会想到我们的快排算法,将区间A[0...n-1]的最后一个元素A[n-1]作为pivot,对数组A[0...n-1]原地分区,这样数组就分成了三个部分 A[0...p-1],A[p],A[p+1...n-1]
分析这个求解过程的执行时间:
第一次查找,需要对大小为n的数组执行分区操作,需要遍历n个元素;第二次则对n/2个元素执行分区操作,需要遍历n/2个元素;第n次需要进行n/n=1个元素进行分区操作,扫描1个元素。那么总的时间为 n+n/2+n/4+n/8+...+1,有等比数列求和为 2n-1,时间复杂度为 O(n)
- Z 字形变换:将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。
class Solution {
public String convert(String s, int numRows) {
if (numRows < 2) {
return s;
}
List<StringBuilder> rows = new ArrayList<>();
for(int i = 0; i < numRows; i++) {
rows.add(new StringBuilder());
}
int count = 0, flag = -1;
for (char c: s.toCharArray()) {
rows.get(count).append(c);
if (count == 0 || count == numRows - 1) {
flag *= -1;
}
count += flag;
}
StringBuilder res = new StringBuilder();
for (StringBuilder row : rows) {
res.append(row);
}
return res.toString();
}
}
在 es6 出现之前,我们为了引用不同的js文件,在单个html中有多个script标签,比如:
<script type="text/javascript" src="home.js"></script>
<script type="text/javascript" src="profile.js"></script>
<script type="text/javascript" src="user.js"></script>所以,如果在这些不同的js文件中有一个变量名相同的话,就会产生命名冲突,从而你不知道你获得的值实际上是什么。es6 通过 模块 的概念去解决这个问题
我们写的每一个js文件都作为一个模块,在这个模块中的变量和函数在其他文件中无法获取,除非我们将他们从文件中暴露出去并且在其他引用文件中导入。所以说,函数和变量对于文件来说是私有的,如果不向外暴露就不能被外部的文件进行访问。
有两种方式进行对外暴露:
暴露当个值作为 named export,可以这样做:
export const temp = "This is some dummy text";也可以在单独的行上面而不是变量声明前写 export 语句,并在大括号中指定要导出的内容
const temp1 = "This is some dummy text1";
const temp2 = "This is some dummy text2";
export { temp1, temp2 };注意这里,export 语法不是一个对象语法,所以在 es6 中,我们不能通过键值对去导出一些东西:
// 在 es6 中是不支持的
export { key1: value1, key2: value2 }而导入我们导出的 named export,可以使用 import 语法:
import { temp1, temp2 } from './filename';
注意,当从某个文件导入一些东西的时候,是不需要添加 .js 扩展名的,因为这个被默认作为扩展名了
// 从当前的目录下导入 functions.js 文件
import { temp1, temp2 } from './functions';
// 从当前的父目录下导入 functions.js 文件
import { temp1 } from '../functions';
可以通过 这个例子 去测试 import 和 export 语法,这个例子中我们只用 import 和 export 语法去计算圆形的面积
值得注意的是,导入的命名必须和导出的命名匹配
所以如果你这样导出的话
// constants.js
export const PI = 3.14159;
就必须这样导入
import { PI } from './constants';
而不能使用其他的命名
import { PiValue } from './constants'; // 这样会抛出错误
但是如果我们有相同的导出变量名,那么我们可以通过重命名的方式进行导入
import { PI as PIValue } from './constants';
这里我们重新命名 PI 为 PIValue,所以这里我们就不能再使用 PI 变量了,我们必须使用 PIValue 变量去获取导出的 PI 的值
我们也可以通过如下方式进行重命名导出
// constants.js
const PI = 3.14159;
export { PI as PIValue };
这样我们就必须引入 PIValue
import { PIValue } from './constants';
导出一个 export 命名,我们必须先进行声明
export 'hello'; // ×
export const greeting = 'hello'; // √
export { name: 'David' }; // ×
export const object = { name: 'David' }; // √
import 多个 export 命名的顺序是不重要的
可以查看 这个例子
在 components/validations.js 中, 我们这样导出验证函数:
export { isValidEmail, isValidPhone, isEmpty };
在 index.js 中我们这样导入验证函数:
import { isEmpty, isValidEmail } from "./components/validations";
如你所见,我们以任意顺序只导入我们所需要的 export 命名,因为我们不需要检测引用文件中导出的顺序。
之前说的,单个文件最多只能有一个默认导出。你可以有多个命名导出,但是只能有一个默认导出
声明一个缺省导出可以通过在 export 关键字前添加 default 关键字
//constants.js
const name = 'David';export default name;
在引入缺省导出的时候我们不用和引入命名导出一样使用大括号
import name from './constants';
如果你又多个命名导出和一个缺省导出
// constants.js
export const PI = 3.14159;export const AGE = 30;const NAME = "David";export default NAME;
通过一行语句去引入所有的导出,我们可以在大括号前使用缺省导出
// NAME 是缺省导出,PI 和 AGE 是命名导出
import NAME, { PI, AGE } from './constants';
缺省导出的一个特点是当进行导入的时候,我们可以改变导出变量的名字
// constants.js
const AGE = 30;
export default AGE;
那么在其他文件中引入的时候,我们可以使用另外一个名字
import myAge from ‘./constants’;
console.log(myAge); // 30
这里我们将默认导出的变量名 AGE 改为了 myAge
缺省导出的另一个注意的地方是,默认导出关键词不可以在变量声明前
// constants.js
export default const AGE = 30; // ×
所以我们必须在单独一行上面使用 export default
// constants.js
const AGE = 30;
export default AGE;
但是,我们却可以这样默认导出一个对象
//constants.js
export default {
name: "Billy",
age: 40
};
在其他文件中使用:
import user from './constants';
console.log(user.name); // Billy
console.log(user.age); // 40
下面是导入所有导出变量的方式:
import * as constants from './constants';
这样我们就导出了我们在 constants.js 中所有的命名或者缺省导出,并且存储在 constants 变量中
// constants.js
export const USERNAME = "David";
export default {
name: "Billy",
age: 40
};
在其他文件中可以这样使用:
// test.js
import * as constants from './constants';
console.log(constants.USERNAME); // David
console.log(constants.default); // { name: "Billy", age: 40}
console.log(constants.default.age); // 40
如果你希望在单独的一行导出缺省和命名导出,可以这样结合使用:
// constants.js
const PI = 3.14159;
const AGE = 30;
const USERNAME = "David";
const USER = {
name: "Billy",
age: 40
};
export { PI, AGE, USERNAME, USER as default };
这里我们导出 USER 作为默认导出,还有其他作为命名导出
在其他文件中你可以这样使用,可以在这里进行测试
import USER, { PI, AGE, USERNAME } from "./constants";
1. 在 es6 中,在一个文件中声明的数据在其他文件中不可以访问,除非在这个文件中进行导出操作,并且在其他文件中进行导入
2. 如果我们在一个文件中导出 class 声明,可以使用默认导出,否则可以使用命名导出。我们也可以在一个文件中同时进行默认导出和命名导出
评论:比较浅的一篇文章,其他说说 es6 的 import/export 和 common.js 的 require/module.exports 会更让人觉得不错
本次带来几个命令行技巧:
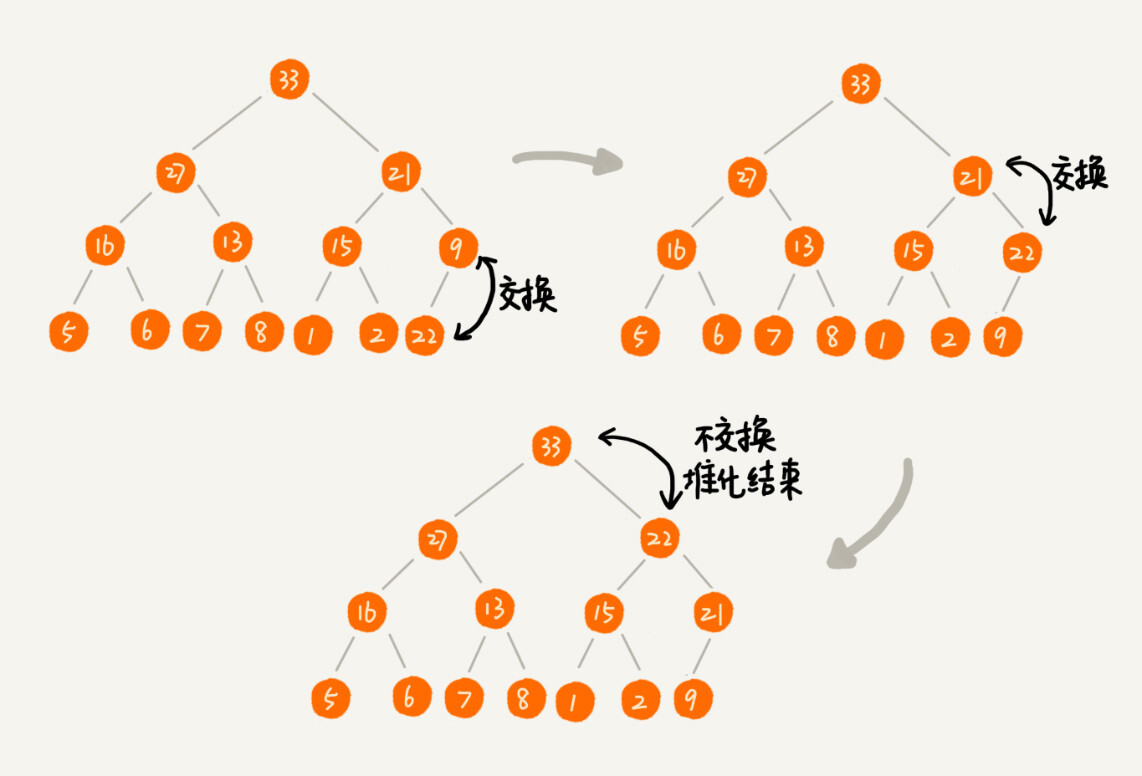
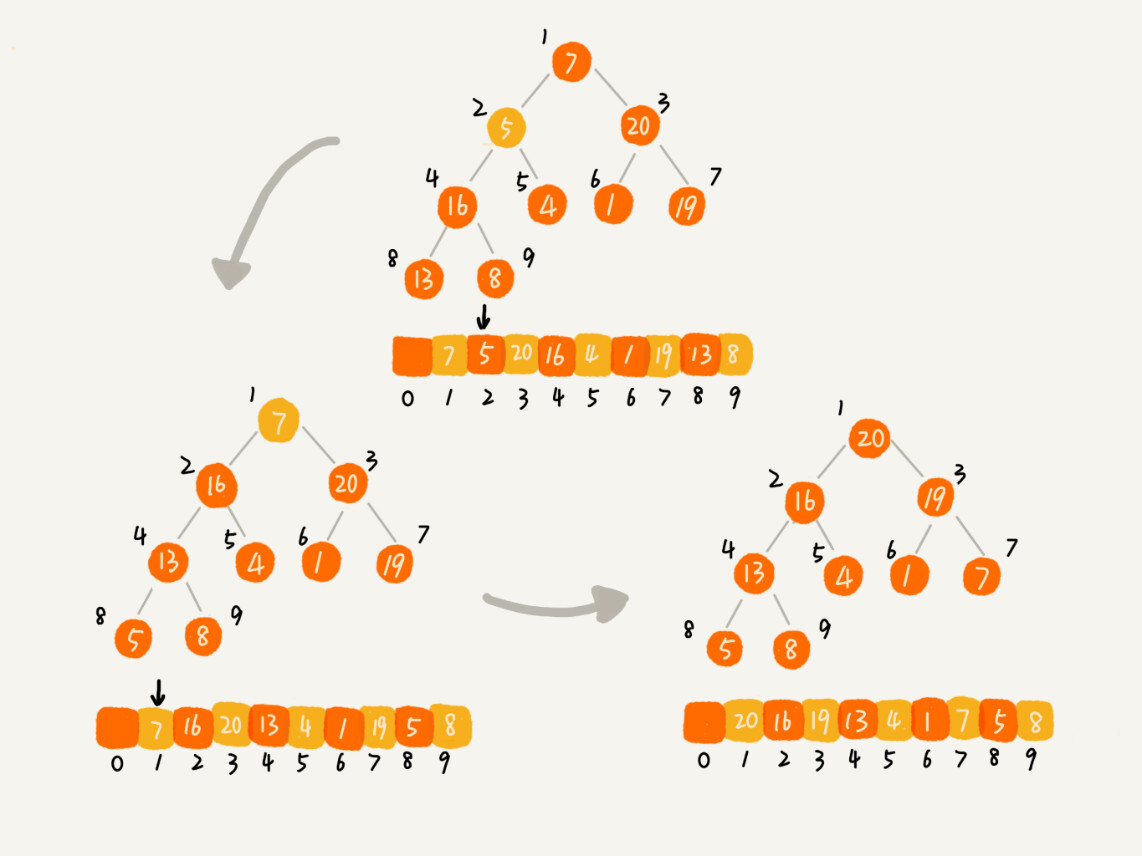
alias dev="cd ~/Document" 可以快速跳转到 Document 文件夹alias gc="git commit -m $1" 可以简洁 git commit 命令pbcopy < ~/.ssh/id_rsa.pub 复制公钥grep "<keyword>" | pbcopy 结合管道进行复制ctrl + r: 可以对输入的命令历史进行搜索:X堆是一种特殊的树,堆这种数据结构应用场景很多,最经典的就是堆排序。堆排序是一种原地的、时间复杂度为 O(nlogn) 的排序算法
我们知道快排的时间复杂度也是 O(nlogn) ,但是快排不是一种稳定的排序算法,那为什么实际开发中,快速排序的性能还要比堆排序好呢?
堆有两个特征:
(其中1,2是大顶堆,3是小顶堆,4不是堆)
堆是一个完全二叉树,所以适合用数据来存储堆,因此,不需要存储左右指针,而是通过数组下标就可以找到左右子节点和父节点
下标为i的节点的左节点下标为 i * 2,右节点下标为 2 * i + 1,父节点下标为 i/2
插入一个元素后,我们需要继续满足堆的特性,所以我们可能需要对堆进行调整,这个调整过程叫做 堆化
堆化有两种方法:
堆化的过程很简单,就是顺着节点所在的路径,向上或者向下,对比,交换。
向上堆化的过程具体来说就是将新的元素和父节点对比大小,如果不满足子节点小于等于父节点的大小关系,就交换这两个元素,一直重复这个过程直到满足父子关系
代码实现:
package com.muaen.heap;
public class Heap {
// 数组,从下标1开始存储数据
private int[] a;
// 最大存储的元素数量
private int max;
// 已经存储的数据
private int count;
public Heap(int max) {
a = new int[max+ 1];
this.max = max;
count = 0;
}
public void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
public void insert(int data) {
if (count >= max) {
return;
}
++count;
a[count] = data;
int current = count;
// 如果比父节点大就交换两个节点
while (current / 2 > 0 && a[current] > a[current / 2]) {
swap(a, current, current / 2);
current = current / 2;
}
}
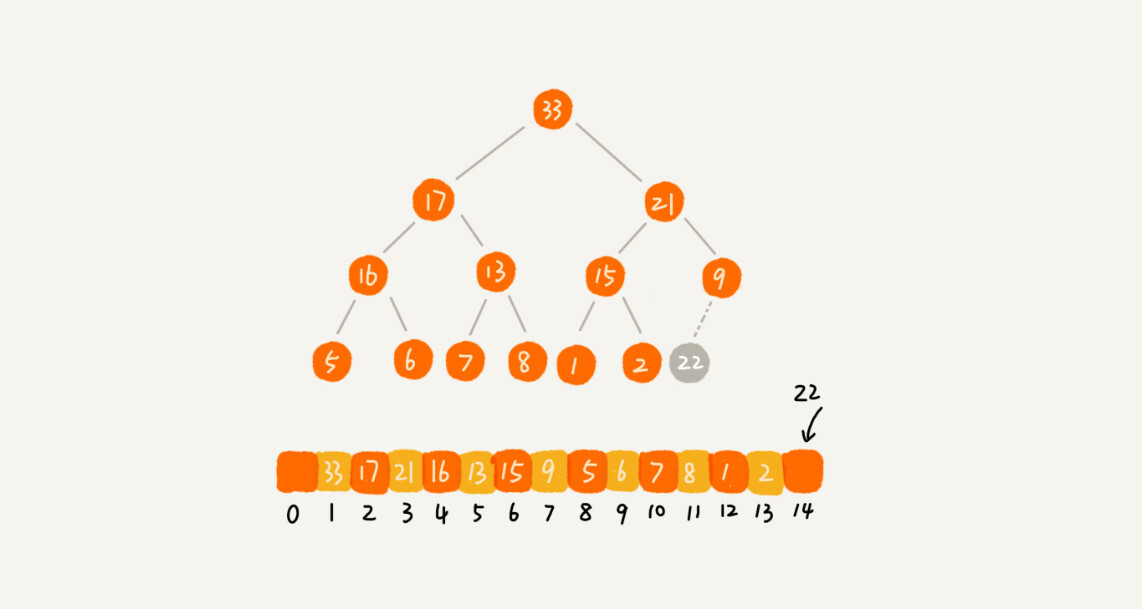
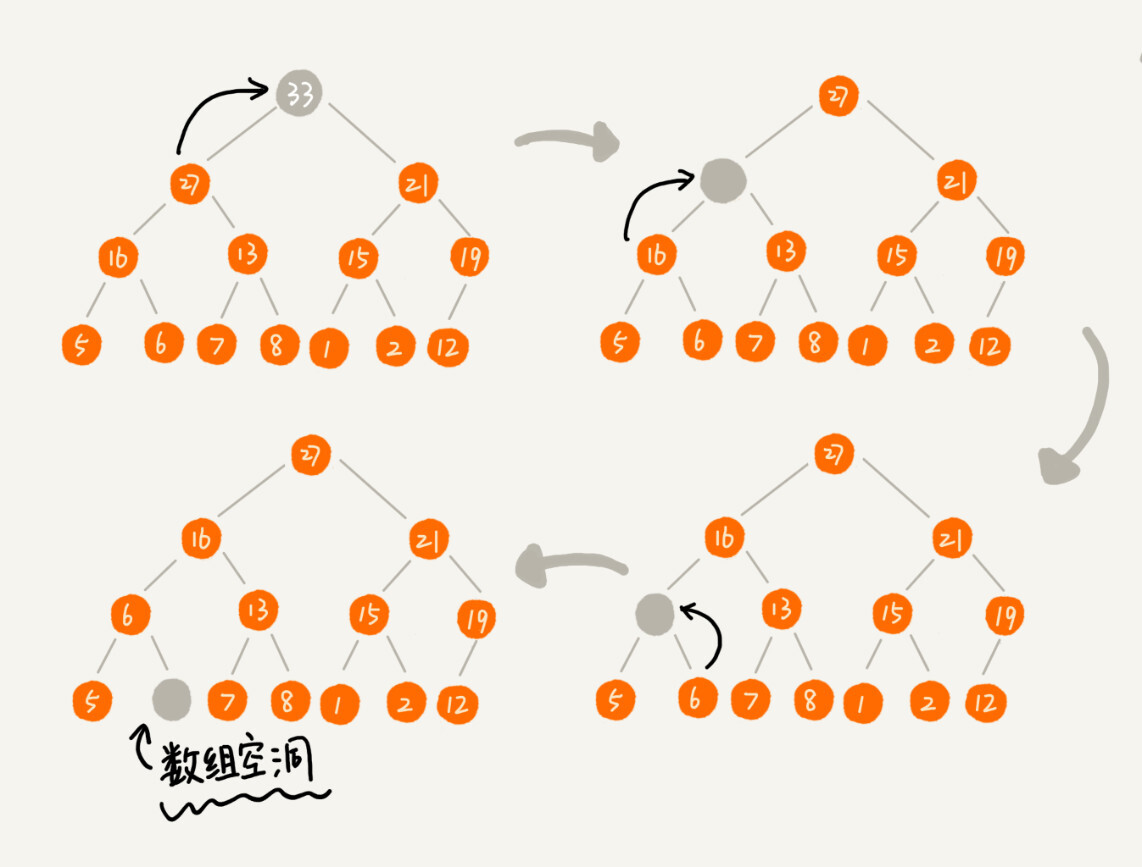
}假设我们要删除操作的堆是大顶堆,如果我们要删除最大元素,即堆顶,那么我们就要把第二大的元素放在堆顶,然后迭代删除第二大节点,知道叶子节点被删除。但是这样就有可能出现数组空洞,不符合完全二叉树的特征。
那换一种思路,把最后一个叶子节点放在堆顶,然后实行自上向下的堆化方法。对比节点和子节点大小,交换,重复这个过程直到满足父子关系
/**
* 删除堆顶元素
*/
public void removeMax() {
if (count == 0) {
return;
}
// 最后一个点放在堆顶
a[1] = a[count];
--count;
heapify(a, max, 1);
}
/**
* 从某个索引开始进行堆化
*
* @param arr 堆
* @param max 堆尾索引
* @param current 堆化索引
*/
public void heapify(int[] arr, int max, int current) {
while (true) {
int maxPos = current;
if (current * 2 <= max && arr[current] < arr[current * 2]) {
maxPos = current * 2;
}
if ((current * 2 + 1) <= max && arr[maxPos] < arr[current * 2 + 1]) {
maxPos = current * 2 + 1;
}
if (maxPos == current) {
break;
}
swap(arr, current, maxPos);
current = maxPos;
}
}一个包含n个节点的堆的高度最多不会超过 log2n ,就我们看到的堆化过程就是一个比较和交换的过程,交换次数最多不过是顺着节点所在的路径数量,所以说堆化的过程时间复杂度和堆的高度成正比,也就是 O(logn),所以堆插入和堆删除操作的时间复杂度都为 O(logn)
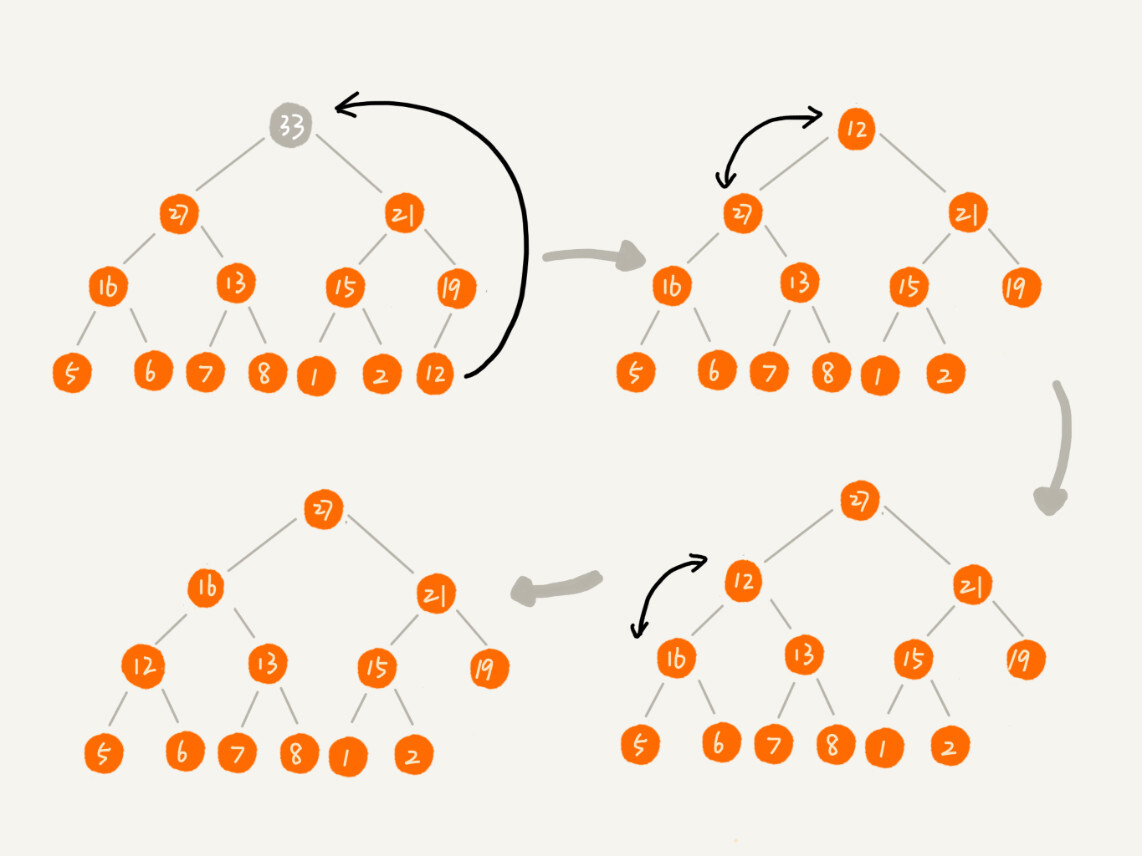
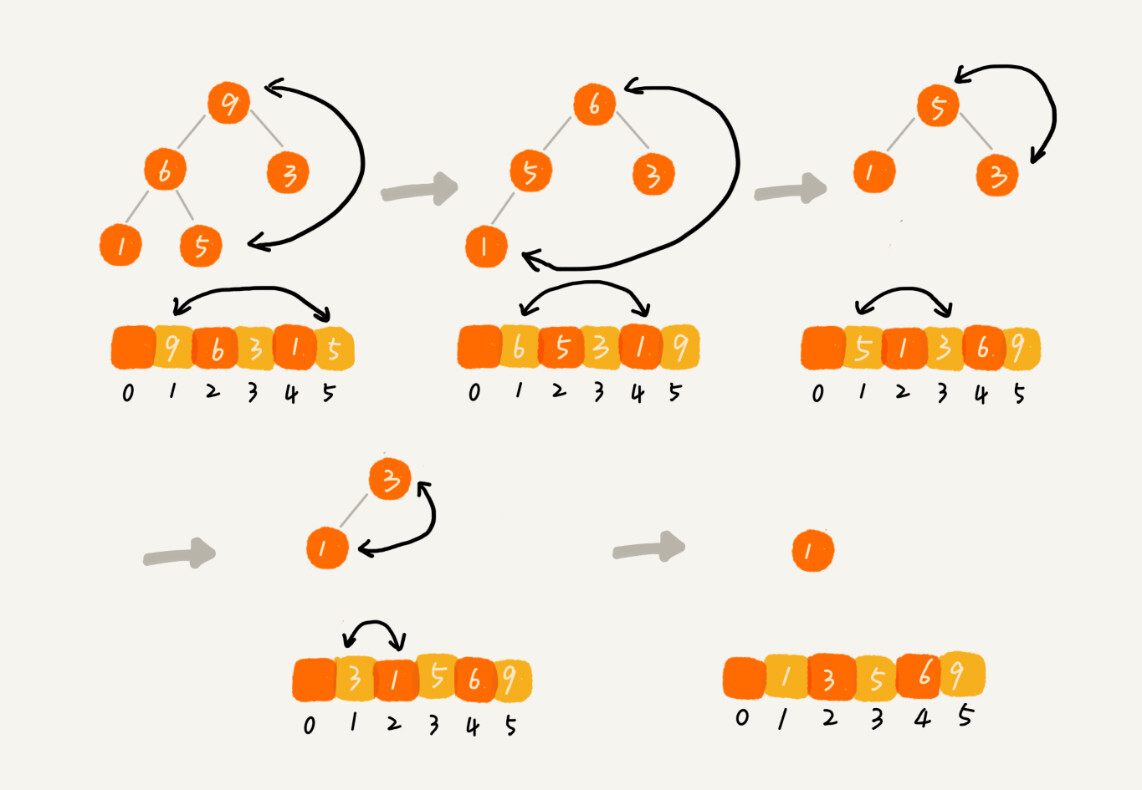
堆排序主要就是将要排序的数据建立成堆,然后不断取出堆顶交换到数组头部的过程。堆排序的实现有两个过程:
建堆也有两种思路:
第一种思路,初始是下标为1的数据,然后调用前面说到的堆插入操作,把第2到第n个元素插入到堆中我们就得到了一个堆。实际上就是将元素从前到后进行遍历建立堆的,并且堆化过程是从下往上的
另一种思路是元素从后往前遍历,堆化过程从上到下。因为从上往下进行堆化,所以叶子节点是没有必要进行堆化的,因此可以从最后一个非叶子节点开始从后往前遍历
那么进行建堆的一个关键细节是如何确定最后一个非叶子节点的索引下标呢?
我们知道对于最后一个非叶子节点的索引 i 来说,它的左节点是 2i,右节点是 2i + 1(假设有右节点的话),也就是说,2i = n 或者 2i+1=n,也即 i = n/2 或者 i = n/2 + 1/2。又因为i为整数,所以 i = n/2
private static void buildHeap(int[] arr, int n) {
for(int i=n/2; i >= 1; --i) {
heapify(arr, n, i);
}
}
private static void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
private static void heapify(int[] arr, int n, int current) {
while(true) {
int maxPos = current;
if(2*current <= n && arr[current] < arr[2*current]) {
maxPos = 2 * current;
}
if(2*current + 1<= n && arr[maxPos] < arr[2*current+1]) {
maxPos = 2 * current + 1;
}
if(maxPos == current) {
break;
}
swap(arr, maxPos, current);
current = maxPos;
}
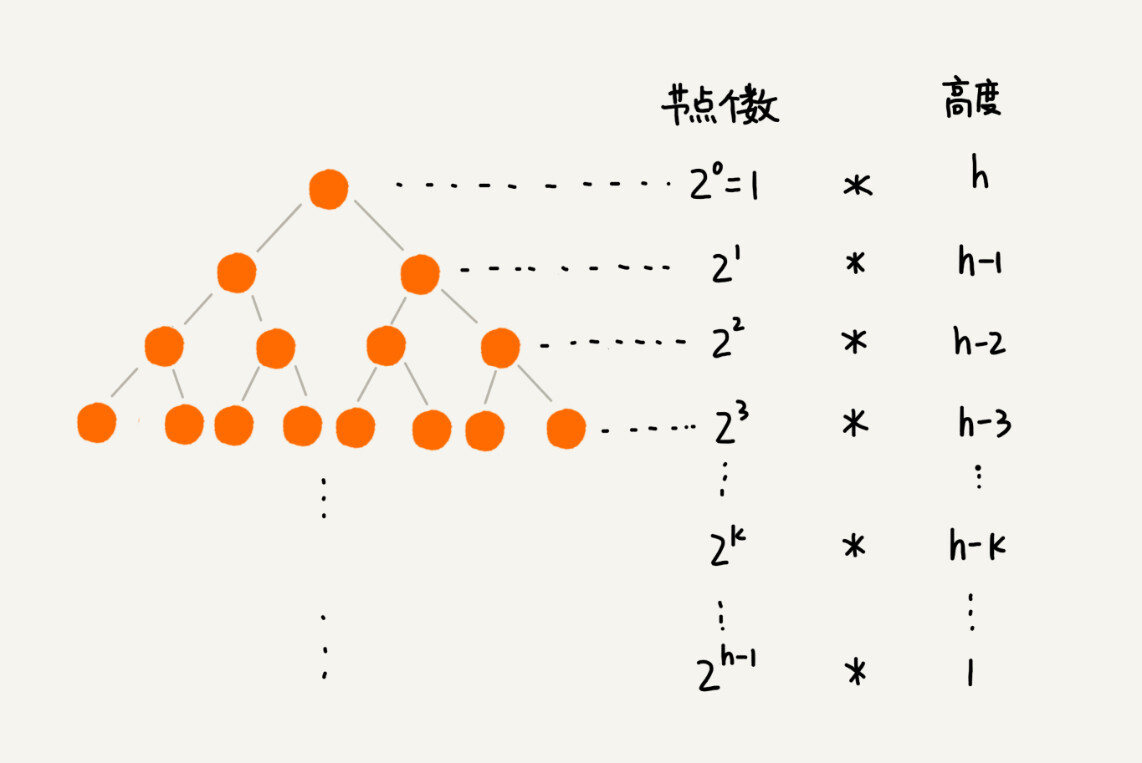
}堆化的时间复杂度和高度有关,又因为叶子节点不需要堆化,所以建堆的时间复杂度就是所有非叶子节点的堆化时间。先了解每一层节点的高度为
那么每个非叶子节点的高度求和就是:
通过错位相加减:
得到
因为 h = logn,则S=O(n)
由上一步建堆操作,我们得到了一个大顶堆,堆顶就是最大元素,那么我们每次删除堆顶操作,并把堆顶元素和数组尾部的元素交换,那么这时候我们就得到了最大的元素在下标为n的位置。删除堆顶元素后,经过堆化后继续删除堆顶重复上述操作直到堆中元素为0,排序就完成了。
public void sort(int[] arr, int n) {
buildHeap(arr, n);
int k = n;
while(k > 1) {
swap(arr, 1, k);
--k;
heapify(arr, k, 1);
}
}时间复杂度
因为某一个节点堆化的时间复杂度为 O(logn),所以总体堆化时间复杂度为 O(nlogn)。而建堆的时间复杂度为 O(n),所以总体上时间复杂度为 O(logn)
堆排序不是稳定算法,因为在排序过程中会不断堆顶和最后节点元素互换,可能会改变相同元素的顺序
是原地排序,在排序过程中不需要额外申请空间
为什么快排比堆排序性能好
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.