Scripts to help with text extraction from (some) PDF files.
(Specifically: fix incorrect/incomplete ToUnicode CMap, i.e. the mapping between individual glyphs and Unicode text.)
Text that requires complex text layout (because of being in Indic scripts, say) cannot be copied correctly from PDFs, unless annotated with ActualText. Here is a bunch of tools that may help in some cases.
Roughly, the idea is to
- from the PDF file, extract
- the current glyph<->Unicode mapping (if present), and
- the runs of text present (as character codes), per font
- use this information (and the shapes of the glyphs) to assist with manually associating each glyph with its equivalent Unicode sequence,
- use this correct mapping to obtain Unicode text: either
- convert the text runs extracted earlier, or
- post-process the PDF file to wrap each text run inside
/ActualText.
Some PDF files are just a collection of images (scans of pages) — we ignore those (for those, use OCR). In any other PDF file that contains text streams (e.g. one where you can select a run of text), the text is displayed by laying out glyphs from a font. For example, in a certain PDF that uses the font Noto Sans Devanagari, the word प्राप्त may be formed by laying out four glyphs:
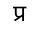
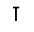
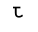
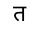
In this font, these glyphs happen to have numerical IDs (like 0112, 0042, 00CB, 0028) that are font-specific. If we'd like to get text out of this, and the PDF does not provide it with /ActualText, we need to map the four glyphs to the corresponding Unicode scalar values:
- 0112 (
) maps to
- 092A DEVANAGARI LETTER PA
- 094D DEVANAGARI SIGN VIRAMA
- 0930 DEVANAGARI LETTER RA
- 0042 (
) maps to
- 093E DEVANAGARI VOWEL SIGN AA
- 00CB (
) maps to
- 092A DEVANAGARI LETTER PA
- 094D DEVANAGARI SIGN VIRAMA
- 0028 (
) maps to
- 0924 DEVANAGARI LETTER TA
The PDF file itself may already contain such a mapping (CMap), but it is often incomplete, missing nontrivial cases like the first glyph above.
Even after the mapping is fixed, a second problem is that, roughly speaking, the glyph ids are laid out in visual order while Unicode text is in phonetic order. So the correspondence may be nontrivial. See the example on page 36 here; a couple more examples below:
-
The word विकर्ण may be laid out as:
and we want this to correspond to the following sequence of Unicode codepoints:
- 0935 DEVANAGARI LETTER VA
- 093F DEVANAGARI VOWEL SIGN I
- 0915 DEVANAGARI LETTER KA
- 0930 DEVANAGARI LETTER RA
- 094D DEVANAGARI SIGN VIRAMA
- 0923 DEVANAGARI LETTER NNA
(The first glyph corresponds to the second codepoint, and the last glyph corresponds to the fourth and fifth codepoints.)
-
The word धर्मो may be laid out as:
and the word सर्वांग as:
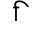

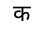

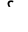
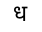
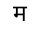
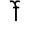
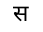
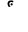

(TODO)
(But see: this comment and these files 1 2 3 4.)
(Short version: Run make and follow instructions.)
- (Not part of this repository.) Prerequisites:
- Make sure
mutoolis installed (and also Python and Rust). - If you know fonts that may be related to the fonts in the directory, run
ttx(from fonttools) on them, and put the resulting files inside thework/helper_fonts/directory.
- Make sure
- Run
make, from within thework/directory. This will do the following:- Extracts the font data from the PDF file, using
mutool extract. - Dumps each glyph from each font as a bitmap image, using the
dump-glyphsbinary from this repository. - Extracts each "text operation" (
Tj,TJ,',"; see 9.4.3 Text-Showing Operators in the PDF 1.7 spec) in the PDF (which glyphs from which font were used), using thedump-tjsbinary from this repository. - Runs the
sample-runs.pyscript from this repository, which- generates the glyph_id to Unicode mapping known so far (see this comment),
- generates HTML pages with some visual information about each glyph used in the PDF (showing it in context with neighbouring glyphs etc) (example).
- Extracts the font data from the PDF file, using
- Create a new directory called
maps/manual/and- copy the
tomlfiles undermaps/look/into it, - (The main manual grunt work needed) Edit each of those TOML files, and (using the HTML files that have been generated), for each glyph that is not already mapped in the PDF itself, add the Unicode mapping for that glyph. (Any one format will do; the existing TOML entries are highly redundant but you can be concise: see the comment.)
- copy the
- Run
makeagain. This will do the following:- Validates that the TOML files you generated are ok (it won't catch mistakes in the Unicode mapping though!), and
- (This is slow, may take ~150 ms per page.) Generates a copy of your original PDF, with data in it about the actual text corresponding to each text operation.
All this has been tested only with one large PDF. These scripts are rather hacky and some decisions about PDF structure etc are hard-coded; for other PDFs they will likely need to be changed.
TODO: Read this answer and try qpdf/mutool-clean, to simplify parsing work: https://stackoverflow.com/questions/3446651/how-to-convert-pdf-binary-parts-into-ascii-ansi-so-i-can-look-at-it-in-a-text-ed/3483710#3483710



