update time:2020/3/7
Auto created by algorithm-work
KeyWords:反转、回文、哈夫曼、压缩与解压缩
| # | Title | Topic |
|---|---|---|
| 1 | 反转次数 | a[i]>a[j]和i<j,则a[i]和a[j]形成反转 |
| 2 | 回文分区 | 给定一个字符串,如果分区的每个子字符串都是回文,则字符串的分区是回文分区 |
| 3 | HuffmanCode | 实现压缩和解压缩功能的软件 |
实验目的:1.掌握分治算法的基本**(分-治-合)、技巧和效率分析方法。
2.熟练掌握用递归设计分治算法的基本步骤(基准与递归方程)。
3.学会利用分治算法解决实际问题。
实验要求:采用分治法,实现输入一个数组,计算出数组的反转次数(即逆序个数)
硬件: 笔记本电脑
软件:IntelliJ IDEA
语言实现:Java
- 实验原理
分治法**:分治法,即分而治之也。将一个难以解决的大问题划分为一些规模较小的子问题,分别求解各个子问题,然后合并子问题的解得到原问题的解。
在一个排列中,如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数,那么它们就称为一个逆序。一个排列中逆序的总数就称为这个排列的逆序数。如2431中,21,43,41,31是逆序。分治法求逆序数相当于在归并排序的过程中加上相应的逆序数的数目。而归并排序的基本算法原理是:将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序,即将原序列先两两分割到最小单位,再将分割后的序列不断两两组合,排列成有序的集合,也称为二路归并。
以下为一个例子:
设有数列{6,202,100,301,38,8,1}
初始状态:6,202,100,301,38,8,1
第一次归并后:{6,202},{100,301},{8,38},{1},比较次数:3;
第二次归并后:{6,100,202,301},{1,8,38},比较次数:4;
第三次归并后:{1,6,8,38,100,202,301},比较次数:4;
总的比较次数为:3+4+4=11;
逆序数为14;
-
实验内容
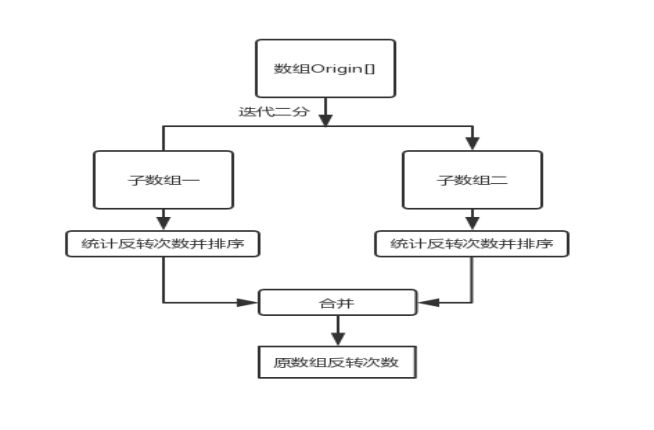
①总体思路统计一个数组的反转次数时,先将一个数组采用迭代二分,统计两个数组的反转次数,并将两个数组变成有序数组,再统计整体数组的反转次数。
②基本流程
1)将原数组划分为两个子数组
2)对两个数组进行排序
3)将两个数组有序的结合,合成一个有序数组,计算反转次数 ③具体函数实现
算法的主要内容分为“分”和“治”两部分。
1)分即把未排序的数组采用迭代的方式二分。
void MergeSort(int start,int end) {
if(start<end) {
int middle=(start+end)/2;
MergeSort(start,middle);
MergeSort(middle+1,end);
Merge(start,middle,end);
}
} 2)其中Merge函数是“治”部分的函数。
治就是把二分后的数组不断按照有序的方式组合,合并成一个有序的数组。
下面介绍Merge函数:
start到middle为第一部分,middle+1到end为第二部分,Merge函数就是把这两部分变为有序的数组。
void Merge(int start,int middle,int end) {
int ptr0=0;
//指向第一段开始
int ptr1=start;
//指向第二段开始
int ptr2=middle+1;
while(ptr1<=middle && ptr2<=end) {
if(this.Origin[ptr1]<this.Origin[ptr2]) {
temp[ptr0++]=Origin[ptr1++];
}
else {
temp[ptr0++]=Origin[ptr2++];
Res=Res+middle-ptr1+1;//记录逆序数
}
}
while(ptr1<=middle) {
temp[ptr0++]=Origin[ptr1++];
}
while(ptr2<=end) {
temp[ptr0++]=Origin[ptr2++];
}
//将排序后的结果返回
for(int i=0;i<end-start+1;i++) {
Origin[start+i]=temp[i];
}
}Ptr0为指向temp的指针,用来存放排序后的数据,ptr1为第一段数据的指针,ptr2为第二段数据的指针。第一个while循环用来比较第一段和第二段的数据的大小,有序的数据放入temp数组中,剩下的两个while循环用来将两段数据中末尾未放入temp数组中。至此temp数组中放的就是本次Merge函数将两段数据整合成一段有序数据的结果。
该程序时间复杂度为:O(n)= log(n)
空间复杂度分析:int arr[]=new int[length]分配空间,其他不分配空间
则空间复杂度:O(n)=n
- 实验目的:1.掌握动态规划算法的基本**,包括最优子结构性质和基于表格的最优值计算方法。
2. 熟练掌握分阶段的和递推的最优子结构分析方法。
3. 学会利用动态规划算法解决实际问题。 - 实验要求:使用动态规划法,实现输入一个字符串,求出将这个字符串分割成回文字串的最小次数
硬件: 笔记本电脑
软件:IntelliJ IDEA
语言实现:Java
该算法利用了动态规划,动态规划算法是通过拆分问题,定义问题状态和状态之间的关系,使得问题能够以递推(或者说分治)的方式去解决。
维护数组dp[],dp[i]代表(0,i)最小的回文切割。遍历字符串,当子串s.substr(0,i+1)(包括i位置的字符)是回文时,dp[i]=0,即表示不用切割,若不是回文,则令dp[i]=i,表示至少要切i刀(有i+1个字符)。对于任意大于1的 i,如果s.substr(j,i+1)(j<=i,即遍历i之前的每个子串)
是回文时,转移方程:dp[i]=min(dp[i],dp[j-1]+1),因为若是,则只要增加一刀,就可以分为两个子串了;若不是,则取dp[i]=min(dp[i],dp[i-1]+1),因为,为回文串时,状态转移方程中j-1>=0,说明,首字符没有考虑,若出现如“efe”的情况时,dp[i]的值就小于dp[ i-1 ]+1。
- 实验内容:
- 总体思路
定义dp[]数组用来记录当前子字符串的最小分割数,定义Palindrome()函数用来判定子字符串是否为回文子串。依次判断s.substring(0,i+1))是否回文,是则不需要分割(为零),否则记录dp[i].再判断(0,i)中是否需要分割,如果子字符串为回文则继续记录值。最后dp[s.length-1]就是求取的结果
- 基本流程
定义动态规划数组dp,dp[i]的含义是子串str[0…i]至少需要切割几次,才能把str[0…i]全部切成回文子串。那么dp[len-1]就是最后的结果。
从左往右依次计算dp[i]的值,i初始为0,具体计算过程如下:
①假设j处在0到i之间,如果str[j…i]是回文串,那么dp[i]的值可能是dp[j-1] + 1,其含义是在str[0…i]上,既然str[j…i]是回文串,那么它可以自己作为一个分割的部分,剩下的部分str[0…j-1]继续做最经济的分割,也就是dp[j-1]的值。
②根据步骤②的方式,让j在i到0的位置上枚举,那么所有可能中最小值就是dp[i]的值,即dp[i]=Math.min(dp[i],dp[j-1]+1)(0<= j <= i,且str[j…i]必须是回文串)}。
③如何快速方便的判断str[j…i]是否为回文串?
1)定义两个起点和终点指针,依次递增判断两个点是否相等,直到判断完毕
2)在计算dp数组的过程中,位置i是从左向右依次计算的。而对于每一个i来说,又依次从i位置向左遍历所有的位置,以此来决策dp[i]。 - 部分函数实现
①定义起点和终点指针,依次判断两个点是否相等,直到判断完毕

static boolean Palindrome(String str1){//判断分割的字符是否为回
int begin=0;int end=str1.length()-1;
while (begin<end)
if(str1.charAt(begin++) != str1.charAt(end--)) return false;
return true;
}②设立数组dp[]获取字符串的最小分割数,dp[s.length-1]就是最小分割数
int[] dp=new int[s.length()];③将str字符串分成若干个子问题进行求解,依次从左往右遍历子字符串,dp[i]初始值为0,不管当前字符串是否为回文,都对剩下的部分进行判断,以求得最小分割数
for (int i = 1; i <s.length(); i++) {
dp[i]=Palindrome(s.substring(0,i+1))?0:i;
for (int j = i; j >=1 ; j--) {
if (Palindrome(s.substring(j,i+1))){
dp[i]=Math.min(dp[i],dp[j-1]+1);
}
}
}- 时间复杂度分析:
当i=m时,j可以取m,m-1...2,1,所以最内循环共进行(m+1)m/2次,所以i从1到n,则循环总共进行:1+3+6+...+n(n-1)/2+(n+1)n/2=n(n+1)(n+2)/2 - 空间复杂度分析:
程序所需的空间主要是通过int[] dp=new int[s.length()]数组分配存储空间,所以该空间复杂度为:
- 实验目的:使用Huffman编码,实现一个压缩和解压缩功能的软件
- 实验要求:1.测试压缩率
2.测试解压缩速度
硬件: 笔记本电脑
软件:IntelliJ IDEA
语言实现:Java
(i)压缩原理
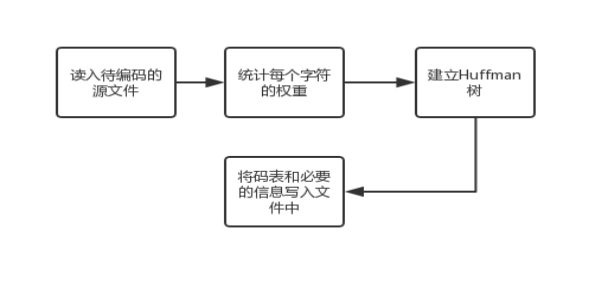
1、统计字符种类及权重:ASCII码值当下标,字符频度当对应下标的值。
2、构建哈夫曼树:初始化优先级队列q1、合并左右子树
3、构建哈夫曼编码:遍历哈夫曼树得到每个字符的编码存入数组中,将编码和文件内容对应输出
4、生成压缩文件(.zip后缀名):分为哈夫曼编码和尾部数据。哈夫曼编码主要把哈夫曼编码长度以字符写入,其次将长度以字节写入。尾部数据分为三部分,一是每个字符以字符写入,二是将权重的长度以字节写入,三是权重。
❗️注意事项:给目标文件写二进制数据时,最后一个字节如果不满八位,会产生垃圾数据,如果不进行处理,在解压后,就不能完整的还原。所以,需计算最后一个字节中的有效位数。
(ii)解压原理
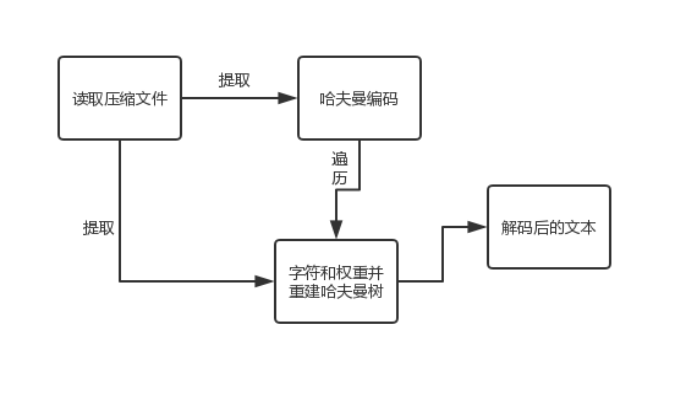
1、获取压缩文件内容:得到一个字节的编码长度字节数,根据长度截取后面的几个字节则为长度
2、获得哈夫曼编码:将剩下的字符全部转换成二进制位,再根据第一步得到的长度截取,得到哈夫曼编码
3、获得字符种类和权重:利用for依次循环遍历字符,第一个为文件字符,第二个为权重字符长度,根据长度截取后面的字符数。得到字符种类和权重的二位数组
4、根据二维数组构建哈夫曼树,根据哈夫曼编码编码树,'1'向左子树走,'0'向右子树走,得到文件内容
哈夫曼编码(Huffman Coding),又称霍夫曼编码或最佳码,是可变字长编码(VLC)的一种,属于无损压缩。该方法完全依据字符出现概率来构造码字,出现概率大的符号码长短,概率小的码长大,能有效的减小码长,对于概率分布相差大的信源压缩效率高,而对于接近于等概分布的信源压缩效率低。
(i)压缩内容
①哈夫曼树结点的构造
class Tree{//哈夫曼树
Node root;
public Tree(){}
public Tree(int weight,String element){}
public Tree(Tree tree0,Tree tree1){//两个子树链接成一个树
}
class Node{
String element;//该结点字符
Node lchild;//左子树
Node rchild;//右子树
int weight;//该字符的权重
String code="";//该字符的编码
public Node(){
}
public Node(int weight,String element){
}
}
}哈夫曼树编码:private static String huffmancode="";
②压缩流程图
③相关函数实现
- 获得txt文件内容
while ((r = input.read()) != -1){
str=str+(char)r+"";
}- 统计字符和对应的权重
for(int i=0;i<256;i++){
charWeight[i]=0;
codes[i]="";
}- 优先数队列,由于在创建哈夫曼树时需要一直更新队列并排序,将存储的字符和权重的数组依次加入队列。
Queue<Tree> q1=new PriorityQueue<Tree>(cmp);//优先数队列,一直更新排序
for(int i=0;i<huffSting[0].length;i++){
q1.add(new Tree(Integer.parseInt(huffSting[1][i]),huffSting[0][i]));
}- 将队列中的数据加入哈夫曼树结点中,每次加入都会合并两个结点成为一个新的树
while (q1.size()>1){
Tree tree1=q1.peek();
q1.poll();
Tree tree2=q1.peek();
q1.poll();
Tree newTree=new Tree(tree1,tree2);
q1.add(newTree);
}用for循环输出得到哈夫曼编码
for(int i=0;i<str.length();i++){
String temp=huffmancode;
System.out.print(codes[str.charAt(i)]);
huffmancode=temp+codes[str.charAt(i)];
} (ii)解压缩
①相关函数实现
- 解压缩读取压缩文件内容,获得编码文件
File file=new File("./"+pathname);
FileInputStream InputStream=new FileInputStream(file);
int r;
while ((r = InputStream.read())!= -1){
str1=str1+(char)r+"";
}- 通过截取字符得到哈夫曼编码
for(int i=1+firstchar;i<str1.length();i++){//转换成二进制的code
if(Integer.toBinaryString(str1.charAt(i)).length()==8){
str=str+Integer.toBinaryString(str1.charAt(i));
}else{
String
tempStrw=""+Integer.toBinaryString(str1.charAt(i));
for(int j=0;j<(8-Integer.toBinaryString(str1.charAt(i)).length());j++){
tempStrw='0'+tempStrw;
}
str=str+tempStrw;
}
}- 读取压缩文件字符,截取编码后,后面的字符每三块为一部分,依次遍历放入数组中,得到哈夫曼树
for(int i=0;i<str1.length();){
HuffmanStr[0][mx++]=str1.charAt(i)+"";
tempCar=str1.charAt(i+1);
HuffmanStr[1][mx1++]=str1.substring(i+2,i+2+(int)tempCar);
i=i+2+(int)tempCar;
}
4.用对应的编码遍历哈夫曼树得到源文件
Tree.Node temp=huffmanTree.root;
for(int i=0;i<str.length();i++){
if(str.charAt(i)=='0'){
if(temp.lchild!=null){
temp=temp.lchild;
}
}else if(str.charAt(i)=='1'){
if(temp.rchild!=null){
temp=temp.rchild;
}
}
if(temp.rchild==null&&temp.lchild==null){
System.out.print(temp.element);
temp=huffmanTree.root;
}
}
②解码流程图
(iii)主函数流程图

- 时间复杂度分析:
程序所用时间为,其中n为输入字符的种类,N为输入字符的总数量,当输入字符总数量N一直增大时,字符种类n不会再增加,相对于N为常量。以输入字符的总数量n作为输入规模,本程序的时间复杂度 - 空间复杂度分析:
本程序主要定义了二维数组String[][] huffSting用来存储字符和权重,故该程序空间复杂度为:
压缩效率=1607/2573=62.4%
压缩解码用时:54ms
在本实验中,哈夫曼的压缩与解压缩让我收获很多,但是压缩的文本压缩率只有60%左右。在之前没有存储哈夫曼树,压缩率达到40%。而文件的解压就在于压缩时需要往文件里写入什么样的头部数据,头部数据决定了压缩率。刚开始往文件里写入文件字符、字符权重,但在解压提取存储字符时,字符的权重达到一定数量,存储的字符数将会变长,不知往后提取几个字符。只能多往文件写入索引字符,让程序知道需要往后读取几个字符。虽然这样做压缩率变大了,但对于大型文件可以忽略不计的。
①哈夫曼字符与权重的快速排序
使用优先数队列PriorityQueue
②哈夫曼树的存储
使用tree对象,存储子节点
③哈夫曼编码存储
字符串数组存储,解压函数使用字符串截取函数截取得到
④怎么解压文件
读取头部数据,获取哈夫曼编码,得到源文件字符
⑤写入哈夫曼编码注意事项
写编码可以采用位运算,但我是把每八个字符合成一个char型变量,最后需要判断最后够不够八位,不够则补位。