
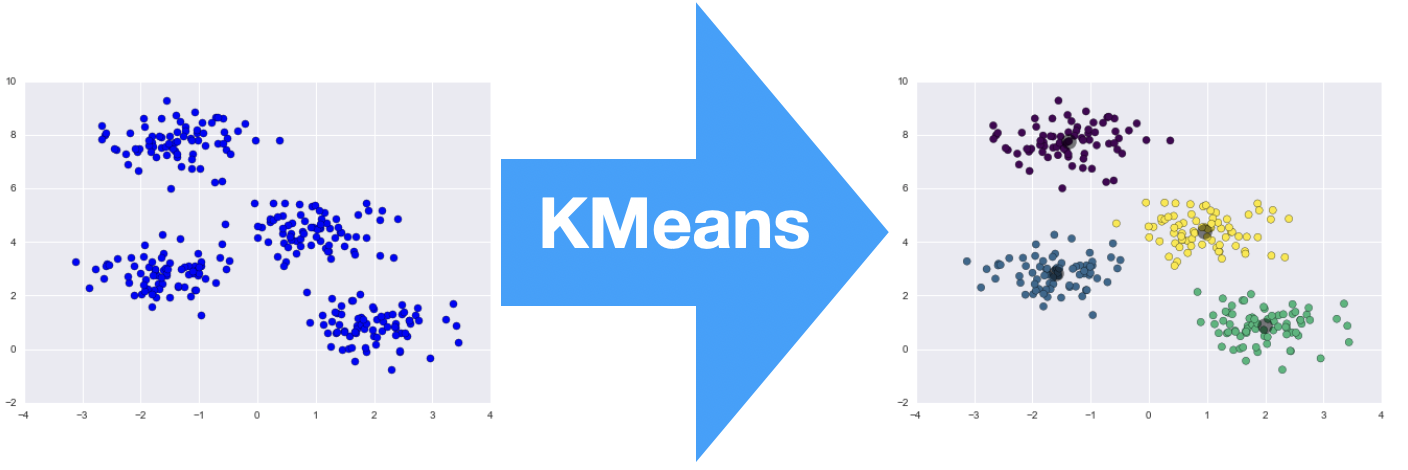


K means clustering written by Python using Pandas and Scikit for manipuliate the xlsx data set.
- Python 2.7
- Git 2.26
- PyCharm IDEA (recommend)
You can modify or contribute to this project by following the steps below:
1. Clone the repository
-
Open terminal ( Ctrl + Alt + T )
-
Clone to a location on your machine.
# Clone the repository
$> git clone https://github.com/attiasas/k-means-clustering.git
# Navigate to the directory
$> cd k-means-clustering2. launch of the project
# run
$> python k-means-clustering.py-
Choose a path include the files that in /dir
dataset.xlsx (the data set for the K Means Algorithm you would like to cluster) -
Click "Preprocces" and wait serval of seconds till success message will appear.
-
Click "Cluster"

This program is free software: you can redistribute it and/or modify it under the terms of the MIT LICENSE as published by the Free Software Foundation.




