



Warp 10 is a modular open source platform shaped for the IoT that collects, stores and allows you to analyze sensor data. It offers both a Time Series Database and a powerful analysis environment that can be used together or independently. Learn more
- Increase the storage capacity of your historical data and reduce your storage bill while preserving all analysis capabilities
- Deploy a real time database that scales with your time series needs
- Enhance your existing tools with a ubiquitous analysis environment dedicated to time series data
- Streamlining KPIs and data visualization across your organization
- Enable your business applications to interact easily with your system's data
The Warp 10 Platform integrates into existing datalake infrastructures and provides storage and analytics solutions tailored for time series data which can be leveraged from existing tools.
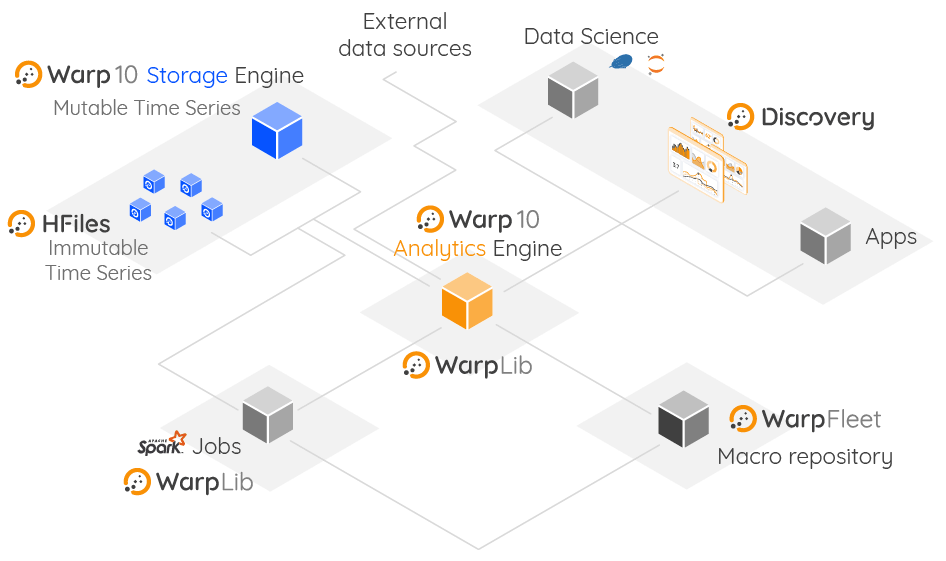
| Component | Description |
|---|---|
| Storage Engine | Securely ingest data coming from devices, supporting high throughput, delayed and out-of-order data with support for a wide variety of protocols such as HTTP, MQTT, or Kafka. Read more |
| History Files | Efficiently compact stable data and store the resulting files onto any filesystem or cloud object store while retaining the same access flexibility as data stored in the Warp 10 Storage Engine. Read more |
| Analytics Engine | Leverage WarpLib, a library of over 1300 functions designed specifically for time series data manipulation. Increase the efficiency of data teams thanks to the WarpScript programming language, which uses WarpLib and interacts with a large ecosystem. |
| Dynamics Dashboards | Create highly dynamic dashboards from your time series data. Discovery is a dashboard as code tool dedicated to Warp 10 technology. Display your data through an entire dashboard. Read more |
| Business Applications | Enable business applications to benefit from the wealth of knowledge present in time series data by connecting those applications to the analytics and storage engines provided by the Warp 10 platform. Read more |
The Storage Engine, The Analytics Engine, History Files and Dynamics Dashboards can be used together or separately.
The Warp 10 platform is available in three versions, Standalone, Standalone+ and Distributed. All versions provide the same level of functionality except for some minor differences, the complete WarpScript language is available in both versions. They differ mainly by the way the Storage Engine is implemented.
| Version | Description |
|---|---|
| Standalone | The Standalone version is designed to be deployed on a single server whose size can range from a Raspberry Pi to a multi CPU box. It uses LevelDB as its storage layer or an in-memory datastore for cache setups. All features (storage, analysis) are provided by a single process, hence the name standalone. Multiple Standalone instances can be made to work together to provide High Availability to your deployment. This is provided via a replication mechanism called Datalog. |
| Standalone+ | Warp 10 with a FoundationDB backend. It is a middle ground between the standalone and distributed versions, basically a standalone version but with storage managed by FoundationDB instead of LevelDB. |
| Distributed | The Distributed version coordinates multiple processes on multiple servers. The Storage layer uses FoundationDB for data persistence. Communication between processes is done through Kafka and ZooKeeper. This version is suitable for heavy workloads and giant datasets. Scalability comes with a price, the added complexity of the architecture. |
We strongly recommend that you start with the Onboarding tutorials to learn how Warp 10 works, and how to perform basic operations with WarpScript. To deploy your own instance, read the getting started.
Learn more by browsing the documentation.
To test Warp 10 without installing it, try the free sandbox where you can get your hands on in no time.
For quick start:
./warp10.sh init standalone
./warp10.sh startThe team has put lots of efforts into the documentation of the Warp 10 Platform, there are still some areas which may need improving, so we count on you to raise the overall quality.
We understand that discovering all the features of the Warp 10 Platform at once can be intimidating, that’s why you have several options to find answers to your questions:
- Explore the blog and especially the Tutorials and Thinking in WarpScript categories
- Explore the tutorials on warp10.io
- Join the Lounge, the Warp 10 community on Slack
- Ask your question on StackOverflow using warp10 and warpscript tags
- Get informed of the last news of the platform thanks to Twitter and the newsletter
Our goal is to build a large community of users to move our platform into territories we haven't explored yet and to make Warp 10 and WarpScript the standards for sensor data and the IoT.
Open source software is built by people like you, who spend their free time creating things the rest of the community can use.
You want to contribute to Warp 10? We encourage you to read the contributing page before.
Should you need commercial support for your projects, SenX offers support plans which will give you access to the core team developing the platform.
Don't hesitate to contact us at [email protected] for all your inquiries.
Warp 10, WarpScript, WarpFleet, Geo Time Series and SenX are trademarks of SenX S.A.S.


























































































































