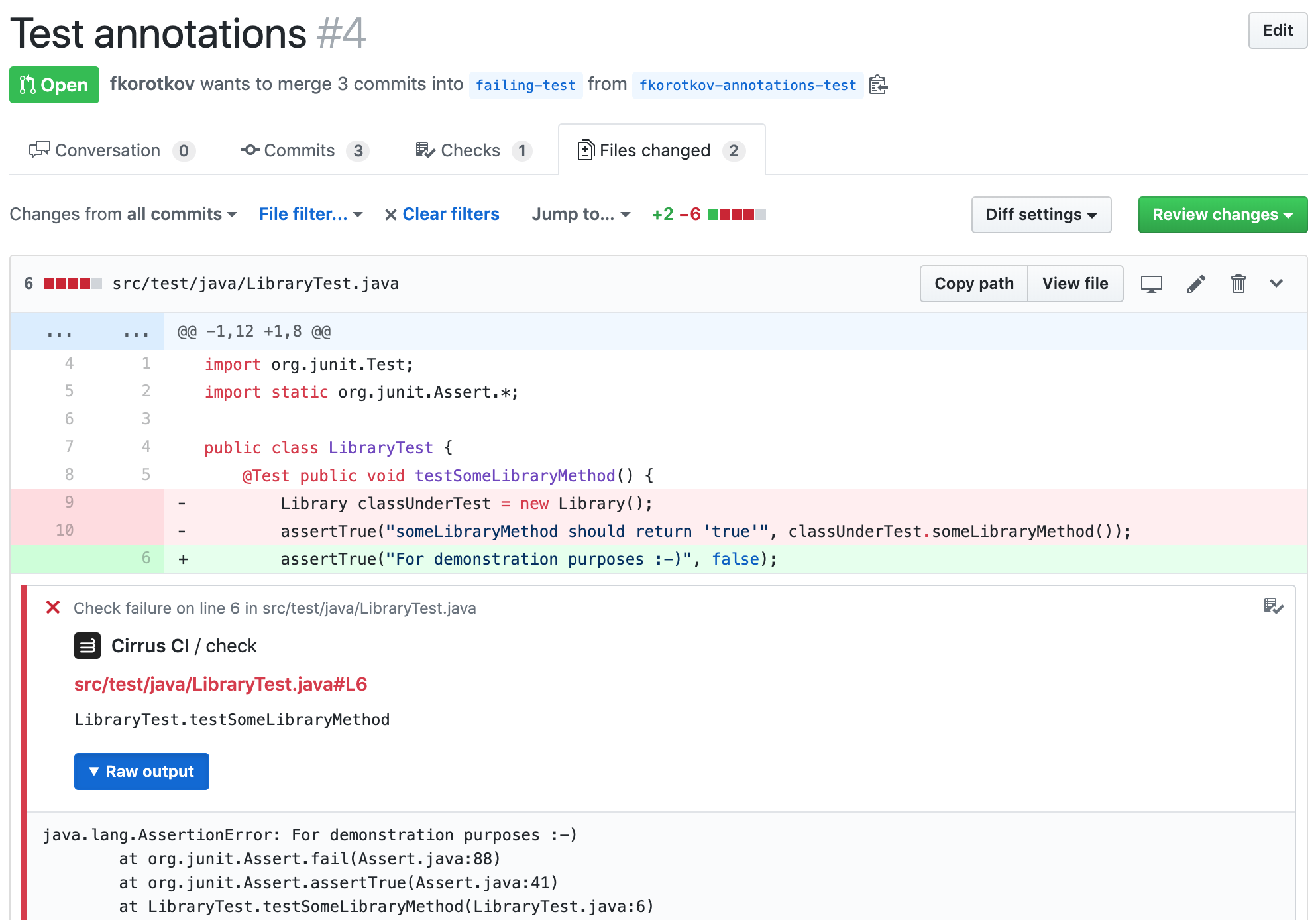
|
99.9M |
101M |
1.01 |
readwrite.H5ADBackedWriteSuite.peakmem_write_compressed('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
100M |
100M |
1 |
readwrite.H5ADBackedWriteSuite.peakmem_write_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
395±2ms |
397±3ms |
1.01 |
readwrite.H5ADBackedWriteSuite.time_write_compressed('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
118±0.5ms |
117±1ms |
1 |
readwrite.H5ADBackedWriteSuite.time_write_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
15.3828125 |
15.6953125 |
1.02 |
readwrite.H5ADBackedWriteSuite.track_peakmem_write_compressed('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
15.35546875 |
15.37109375 |
1 |
readwrite.H5ADBackedWriteSuite.track_peakmem_write_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
91214354 |
91214570 |
1 |
readwrite.H5ADInMemorySizeSuite.track_actual_in_memory_size('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
23564294 |
23564294 |
1 |
readwrite.H5ADInMemorySizeSuite.track_in_memory_size('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
5.26M |
5.26M |
1 |
readwrite.H5ADReadSuite.mem_read_backed_object('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
23.6M |
23.6M |
1 |
readwrite.H5ADReadSuite.mem_readfull_object('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
87.5M |
87.7M |
1 |
readwrite.H5ADReadSuite.peakmem_read_backed('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
107M |
107M |
1 |
readwrite.H5ADReadSuite.peakmem_read_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
78.1±1ms |
77.2±0.3ms |
0.99 |
readwrite.H5ADReadSuite.time_read_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
1.1241426611796983 |
1.129467373760664 |
1 |
readwrite.H5ADReadSuite.track_read_full_memratio('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
111M |
111M |
1 |
readwrite.H5ADWriteSuite.peakmem_write_compressed('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
111M |
110M |
1 |
readwrite.H5ADWriteSuite.peakmem_write_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
336±3ms |
335±2ms |
1 |
readwrite.H5ADWriteSuite.time_write_compressed('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
60.5±0.8ms |
59.1±0.7ms |
0.98 |
readwrite.H5ADWriteSuite.time_write_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
7.5 |
7.5 |
1 |
readwrite.H5ADWriteSuite.track_peakmem_write_compressed('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
6.75 |
7.0 |
1.04 |
readwrite.H5ADWriteSuite.track_peakmem_write_full('http://falexwolf.de/data/pbmc3k_raw.h5ad') |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem((10000, 10000), array([False, True, True, ..., True, True, True])) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem((10000, 10000), slice(0, 1000, None)) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem((10000, 10000), slice(0, 9000, None)) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem((10000, 10000), slice(None, 9000, -1)) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem((10000, 10000), slice(None, None, 2)) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem_adata((10000, 10000), array([False, True, True, ..., True, True, True])) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem_adata((10000, 10000), slice(0, 1000, None)) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem_adata((10000, 10000), slice(0, 9000, None)) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem_adata((10000, 10000), slice(None, 9000, -1)) |
|
119M |
119M |
1 |
sparse_dataset.SparseCSRContiguousSlice.peakmem_getitem_adata((10000, 10000), slice(None, None, 2)) |
|
284±3ms |
286±2ms |
1.01 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem((10000, 10000), array([False, True, True, ..., True, True, True])) |
|
609±4μs |
615±30μs |
1.01 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem((10000, 10000), slice(0, 1000, None)) |
|
4.05±0.08ms |
3.98±0.06ms |
0.98 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem((10000, 10000), slice(0, 9000, None)) |
|
274±2ms |
277±2ms |
1.01 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem((10000, 10000), slice(None, 9000, -1)) |
|
1.35±0.01s |
1.36±0s |
1 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem((10000, 10000), slice(None, None, 2)) |
|
168±2μs |
166±1μs |
0.99 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem_adata((10000, 10000), array([False, True, True, ..., True, True, True])) |
|
45.0±0.7μs |
47.4±1μs |
1.05 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem_adata((10000, 10000), slice(0, 1000, None)) |
|
44.9±0.3μs |
46.6±0.4μs |
1.04 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem_adata((10000, 10000), slice(0, 9000, None)) |
|
45.2±0.8μs |
46.1±0.4μs |
1.02 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem_adata((10000, 10000), slice(None, 9000, -1)) |
|
45.4±1μs |
46.1±0.6μs |
1.02 |
sparse_dataset.SparseCSRContiguousSlice.time_getitem_adata((10000, 10000), slice(None, None, 2)) |


![pre-commit-ci[bot] avatar](https://avatars.githubusercontent.com/in/68672?v=4 "pre-commit-ci[bot]")