I am new in pytorch. I have a problem with my model when I run my code I have this error.
pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [53,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [54,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [55,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [56,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [57,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [58,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [59,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [60,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [61,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [62,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [63,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [0,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [1,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [2,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [3,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [4,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [5,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [6,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [7,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [8,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [9,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [10,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [11,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [12,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [13,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [14,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [15,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [16,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [17,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [18,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [19,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [20,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [21,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [22,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [23,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [24,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [25,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [26,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [27,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [28,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [29,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [30,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed. /pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [4,0,0], thread: [31,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
Traceback (most recent call last):
File "/usr/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"main", mod_spec)
File "/usr/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/experiments.py", line 414, in
run_experiment(args)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/experiments.py", line 405, in run_experiment
demo(args)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/experiments.py", line 362, in demo
output = t2sql.process(text, schema.name)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/demos/demos.py", line 153, in process
sql_query = self.translate(example)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/demos/demos.py", line 125, in translate
model_ensemble=self.model_ensemble, verbose=False)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/semantic_parser/learn_framework.py", line 157, in inference
outputs = self.forward(formatted_batch, model_ensemble)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/semantic_parser/learn_framework.py", line 129, in forward
decoder_ptr_value_ids=decoder_ptr_value_ids)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1051, in call_impl
return forward_call(*input, **kwargs)
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/semantic_parser/bridge.py", line 100, in forward
no_from=(self.dataset_name == 'wikisql'))
File "/content/gdrive/MyDrive/textTosql/spider_model/TabularSemanticParsing/src/semantic_parser/decoding_algorithms.py", line 218, in beam_search
m_field_masks.scatter_add(index=db_scope_update_idx, src=db_scope_update_mask.long(), dim=1)
RuntimeError: CUDA error: device-side assert triggered
`
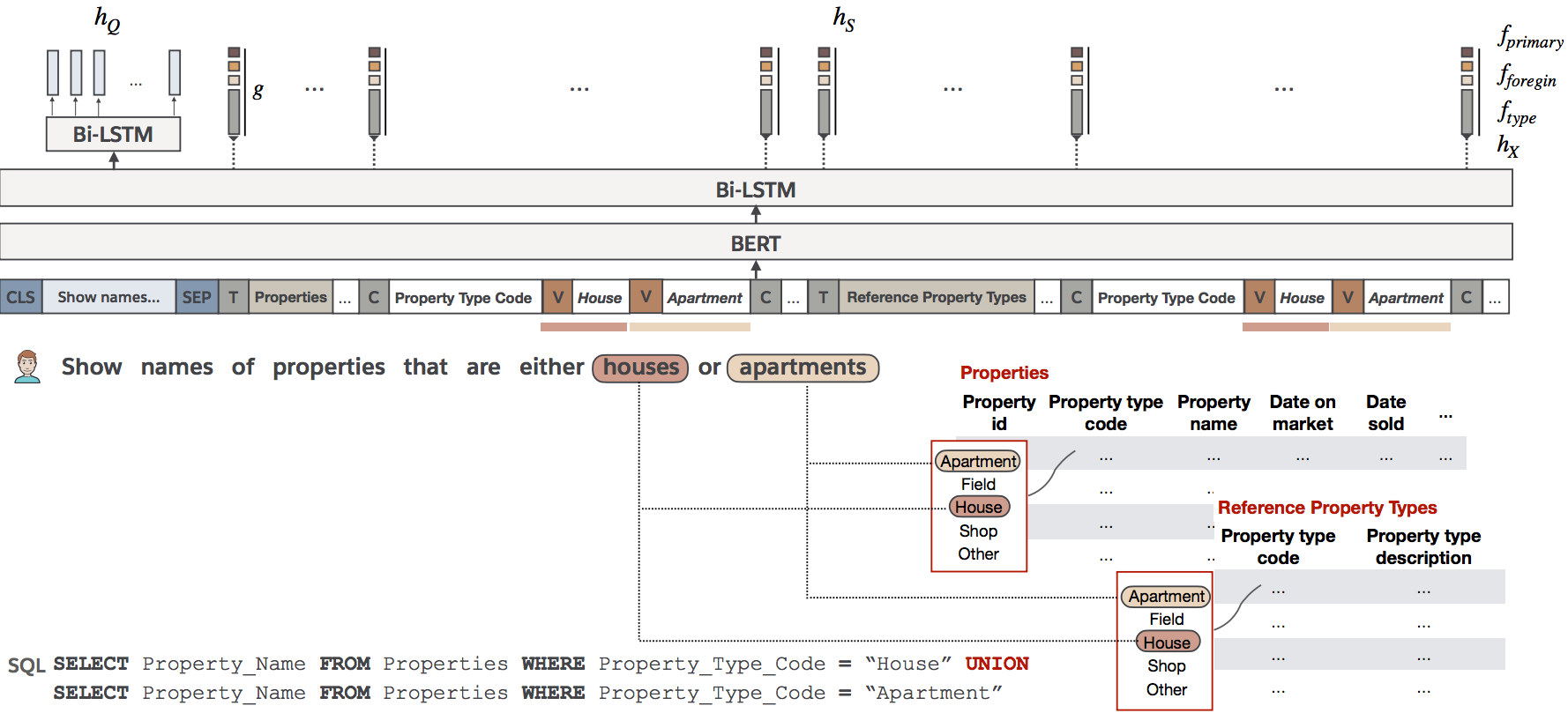
I don't have a very advanced knowledge in ML and in Pytorch some blog talks about Inconsistency between the number of labels/classes and the number of output units. where I can change that. Here is the configuration used
`
#!/usr/bin/env bash
data_dir="/notebooks/TabularSemanticParsing/data/spider"
db_dir="/notebooks/TabularSemanticParsing/data/spider/database"
dataset_name="spider"
model="bridge"
question_split="True"
query_split="False"
question_only="True"
normalize_variables="False"
denormalize_sql="True"
omit_from_clause="False"
no_join_condition="False"
table_shuffling="True"
use_lstm_encoder="True"
use_meta_data_encoding="True"
use_graph_encoding="False"
use_typed_field_markers="False"
use_picklist="True"
anchor_text_match_threshold=0.85
no_anchor_text="False"
top_k_picklist_matches=2
sql_consistency_check="True"
atomic_value_copy="False"
process_sql_in_execution_order="True"
share_vocab="False"
sample_ground_truth="False"
save_nn_weights_for_visualizations="False"
vocab_min_freq=0
text_vocab_min_freq=0
program_vocab_min_freq=0
max_in_seq_len=512
max_out_seq_len=60
num_steps=100000
curriculum_interval=0
num_peek_steps=1000
num_accumulation_steps=2
save_best_model_only="True"
train_batch_size=8
dev_batch_size=8
encoder_input_dim=1024
encoder_hidden_dim=400
decoder_input_dim=400
num_rnn_layers=1
num_const_attn_layers=0
use_oracle_tables="False"
num_random_tables_added=0
use_additive_features="False"
schema_augmentation_factor=1
random_field_order="False"
data_augmentation_factor=1
augment_with_wikisql="False"
num_values_per_field=0
pretrained_transformer="bert-large-uncased"
fix_pretrained_transformer_parameters="False"
bert_finetune_rate=0.00006
learning_rate=0.0005
learning_rate_scheduler="inverse-square"
trans_learning_rate_scheduler="inverse-square"
warmup_init_lr=0.0005
warmup_init_ft_lr=0.00003
num_warmup_steps=4000
emb_dropout_rate=0.3
pretrained_lm_dropout_rate=0
rnn_layer_dropout_rate=0
rnn_weight_dropout_rate=0
cross_attn_dropout_rate=0
cross_attn_num_heads=8
res_input_dropout_rate=0.2
res_layer_dropout_rate=0
ff_input_dropout_rate=0.4
ff_hidden_dropout_rate=0.0
grad_norm=0.3
decoding_algorithm="beam-search"
beam_size=16
bs_alpha=1.05
data_parallel="False"
`

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")



















































































































