LetterSense is an initiative aiming to empower visually impaired individuals by enabling real-time text recognition using cutting-edge technology. Leveraging computer vision and deep learning algorithms, this project focuses on providing a seamless method for character and number recognition from images. Through the utilization of mobile phone cameras or smart glasses, the visually impaired can swiftly access written information, fostering a sense of independence and enhancing their daily lives.
The fundamental importance of reading text is profound in daily life, but for visually impaired individuals, this fundamental skill can significantly impact their independence and overall quality of life. By employing computer vision and deep learning models for a positive purpose, this project not only signifies a valuable application of data science but also contributes to the ethical and socially responsible development of AI.
Various technologies exist to address text recognition for the visually impaired, such as OCR software, screen readers, braille displays, text-to-speech software, and electronic magnifiers. However, these solutions often pose inconveniences in terms of cost and learning curves. Combining existing technologies offers the potential to create innovative solutions like glasses that read out text, recognize faces, describe objects, and interpret facial expressions.
The core objective of this project is to develop a convolutional neural network (CNN) capable of recognizing and converting characters from images. The model is trained using the "Standard OCR Dataset" and implemented with Keras and TensorFlow. Once trained, the model can be integrated into mobile applications or wearable devices, providing real-time text recognition for the visually impaired.
The choice of a CNN model for character recognition is grounded in its prevalence in computer vision tasks, especially Optical Character Recognition (OCR). While Siamese models and YOLO v2 models exist for different applications, their complexity might not suit the lightweight, on-the-go requirements of this project.
The "Standard OCR Dataset" contains 21,636 PNG images of various characters in different fonts and sizes. Preprocessing involves rescaling pixel values, converting images to 32x32 pixels in grayscale, and employing categorical labeling.
The model is trained with a sequential architecture using Keras API, applying techniques such as data augmentation and backpropagation for training and weight adjustments.
The model initially demonstrated high accuracy in training but suffered from overfitting issues, particularly in distinguishing between similar characters like "0" and "O." Attempts to resolve these issues included adjustments in data augmentation and reducing the number of epochs to mitigate overfitting.
The final model achieved a validation accuracy of 95.63%, a reduced but less overfitted outcome than the initial 98.12% accuracy. Challenges persist in distinguishing certain characters, which could potentially be addressed with a larger dataset or advanced preprocessing techniques.
- Dataset Expansion: Larger datasets could offer improved accuracy, though with longer training times.
- Preprocessing Refinement: Advanced techniques might further enhance character recognition.
- Integration: Plans include implementing the model into mobile apps or wearable devices for real-time text recognition.
I extend my gratitude to Abhishek Jaiswal for providing the "Standard OCR Dataset" on Kaggle, an integral part of this project.
- Standard OCR Dataset - Kaggle
- Build a Deep Facial Recognition App from Paper to Code - YouTube by Nicholas Renotte
For access to the Python notebook and the dataset, please visit the LetterSense Jupyter Notebook.
Abstract—In this study, we aimed to create a letter recognition model to assist visually impaired individuals in reading while on the go. We used a dataset of 21,636 images of individual letters and trained a Convolutional Neural Network (CNN) to accurately classify these images. After training the model, we evaluated its performance and found that it achieved an accuracy of 95.63% on the validation set. Although this accuracy was lower than the training accuracy at the highest validation accuracy, the model was less overfit, indicating better generalization. Our results suggest that our CNN model has potential for use in software to aid visually impaired individuals in reading.
Keywords — deep learning,deep learning, computer vision, convolutional neural networks, letter recognition, visually impaired, image classification.
I. INTRODUCTION (Understanding the Importance of Letters)
The ability to read text is essential for daily living, but for visually impaired individuals, it can be very challenging and affect their independence and quality of life. With the rise of mobile technology and smart glasses, it is now possible to use computer vision and deep learning algorithms to help the blind see text. This project aims to develop a solution that can recognize text in real-time using a mobile phone camera or a camera on a pair of glasses. By leveraging facial and object recognition models, visually impaired individuals can quickly and easily access written information, enabling them to navigate their world more independently. While other technologies exist to solve this problem, they can be inconvenient and costly, making them inaccessible to many. By combining existing technologies, we could create glasses that recognize text, describe objects, and even recognize faces and facial expressions. The purpose of this project is to help the blind and visually impaired read text by using deep learning techniques to recognize and convert characters from images. We will train a convolutional neural network (CNN) using the Standard OCR Dataset to recognize handwritten and printed characters with high accuracy. The model will be trained using Keras, a popular deep learning framework, and TensorFlow, an open-source machine learning library. In the future, this study will be expanded to recognize faces and objects as well as letters so that the visually impaired can have a better sense of their surroundings. For this reason, we must stay conscious about the training performance of the deep learning model. Once trained, the model can be integrated into a mobile application or wearable device to provide real-time text recognition to visually impaired individuals. The ultimate goal is to improve accessibility for the visually impaired and provide a practical solution for reading text in everyday life. Code Repository: https://github.com/SagarPatei/LetterSense
II. THEORY OR RELATD WORKS
In this section, we will discuss the theory and related works that we used as a basis for our analyses. We chose to use a Convolutional Neural Network (CNN) model because it is widely used in computer vision tasks, including Optical Character Recognition (OCR). We compared this with other popular models such as Siamese and YOLO v2. While Siamese models are often used in applications such as facial recognition, signature verification, or plagiarism detection, we found that they may not be the most appropriate choice for our task of recognizing characters or text. On the other hand, YOLO v2 models are complex real-time object detection models that are often used in applications such as self-driving cars, security cameras, or drones. However, we found that they may be overkill for our task, as we are trying to create a lightweight solution for a mobile device with a low TDP ARM processor. Therefore, we concluded that a CNN model is the best choice for our task of recognizing handwritten and printed characters with high accuracy. We will use the Standard OCR Dataset to train our model using Keras, a popular deep learning framework, and TensorFlow, an open-source machine learning library.
III. MATERIALS AND METHODS
A. Data explanation and characterization The dataset used is the "Standard OCR Dataset" by Abhishek Jaiswal on Kaggle, which contains 21,636 png images of characters in various fonts and sizes with varying background colors. The images are low resolution and upright, with sizes ranging from 1 to 2 KB each. There are 36 classes in total, with 601 images of each character. We have split the data into training and testing sets with 20,628 and 1,008 images, respectively.
Figure 1. Distribution of the data (count by character) |
B. Data preprocessing
We have utilized two instances of ImageDataGenerator, namely train_datagen and test_datagen, which preprocess the image data by rescaling pixel values from 0-255 to a range of 0-1. The target_size parameter specifies the dimensions of the images after resizing, and we have set it to 32x32 pixels. We have chosen grayscale images since we are only interested in the shape of the characters. We have used data augmentation techniques to improve the flexibility of the model. Backpropagation, a commonly used technique for updating weights in neural networks, has also been employed. We have defined a sequential model using Keras API and utilized the SGD optimizer to perform backpropagation to update the weights during each iteration of training. The model consists of a 2D convolutional layer with 32 filters, a 2D max pooling layer, a dense layer with 100 units, and an output layer with 36 units (one for each possible character), with softmax activation.

Figure 2. Preview of the Dataset (randomly selected post-processed letters) |
C. Data analysis/mining
To enhance the model's performance, we used data augmentation techniques that involved rotating, shifting, and zooming the images. This approach provided more diverse examples of the characters, making it easier for the model to learn and improve its accuracy. We also utilized the SGD optimizer, which performed backpropagation during training to adjust the model weights and reduce the difference between predicted and actual outputs. To begin with, we trained the model for 32 epochs, allowing us to fine-tune the weights and enhance its accuracy in character classification. Additionally, we employed a validation set to monitor the model's performance during training and prevent overfitting. Initially, it seemed our CNN model implementation was only partially successful in classifying the characters in the dataset, but after reviewing the input data, we can see that there is room for improvement, specifically by reducing the number of highly uncommon characters from particularly unusual fonts and overly wide “i”, “j”, “l”, and “1” characters. The letter W also seemed to confuse the model, but no character proved to be as difficult as the letter “O” and the number “0”. At 32 epochs, the model took roughly 10 minutes to train, and 32 was an intentionally high number expected to over-train our model. This demonstrates the efficacy of this approach for OCR tasks, because reducing the number of epochs to reach the optimal level would only shorten the training time.
D. Evaluation and Interpretations
For the evaluation and interpretation section of our study, we used several metrics to assess the performance of our model. These included a confusion table and significance level, as well as validation methods such as cross-validation and an independent test. We observed that after training the model for 32 epochs, the highest validation accuracy achieved was 0.9812, which occurred around epoch 6. However, the training accuracy at this point was 0.8991, indicating that the model was overfitting the data.
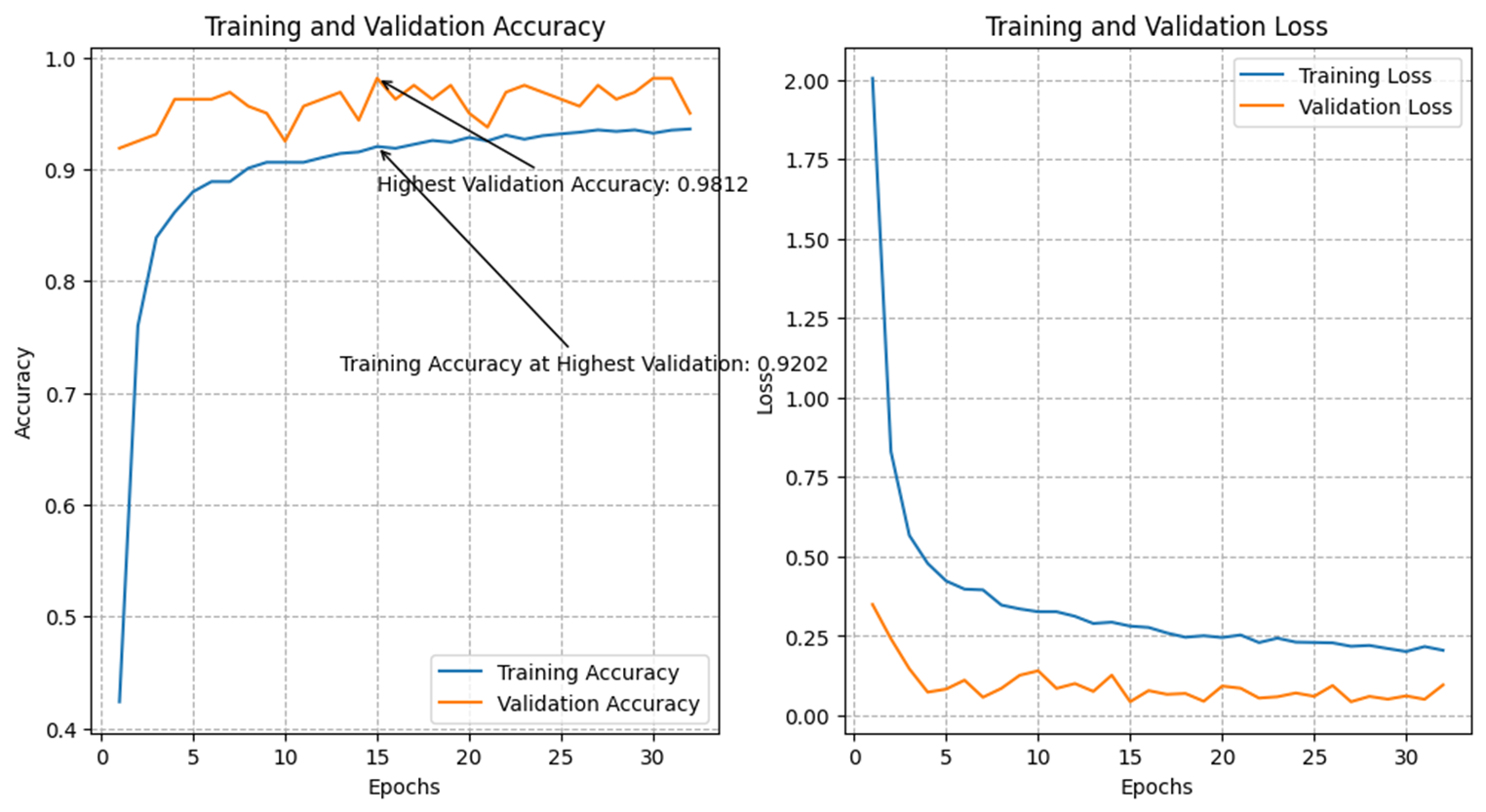
Figure 3. Training and Validation Accuracy (left), Training and Validation Loss (right) at 32 epochs |
We also noticed that there was confusion between the characters "0" and "O" in the confusion table, which was expected given their visual similarity. To address this issue, we suggested augmenting the training data with variations of these characters or adjusting the model architecture and hyperparameters.
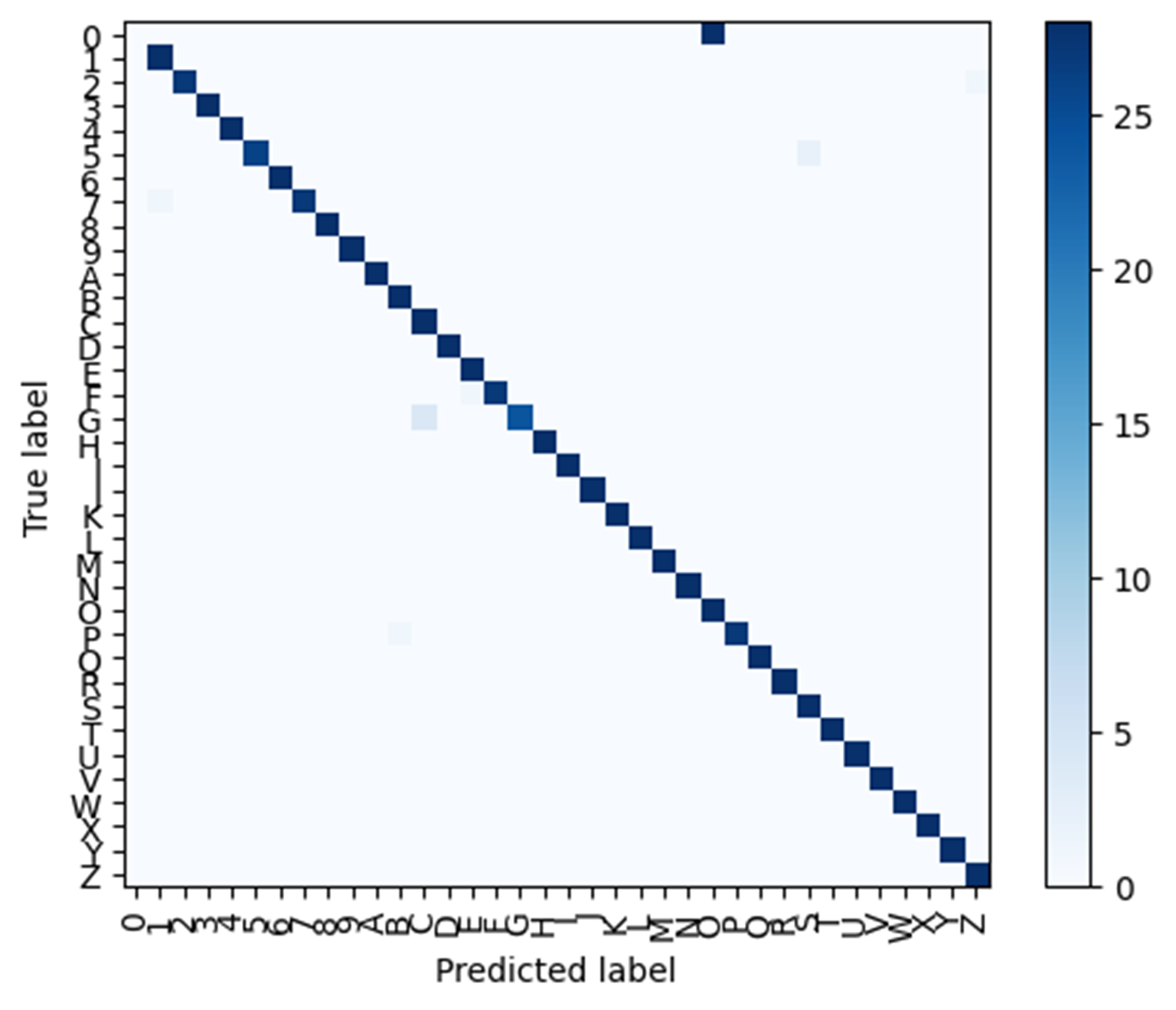
Figure 4. Confusion table at 32 epochs. |
After evaluating the results, we decided to reduce the number of epochs to 5. This significantly reduced the training time from 10 ½ minutes to 1 ¾ minutes, which is beneficial for devices that may need to train the model locally. We also observed that the confusion between "0" and "O" had greatly decreased in the confusion table, indicating that the model had improved its ability to distinguish between these characters.
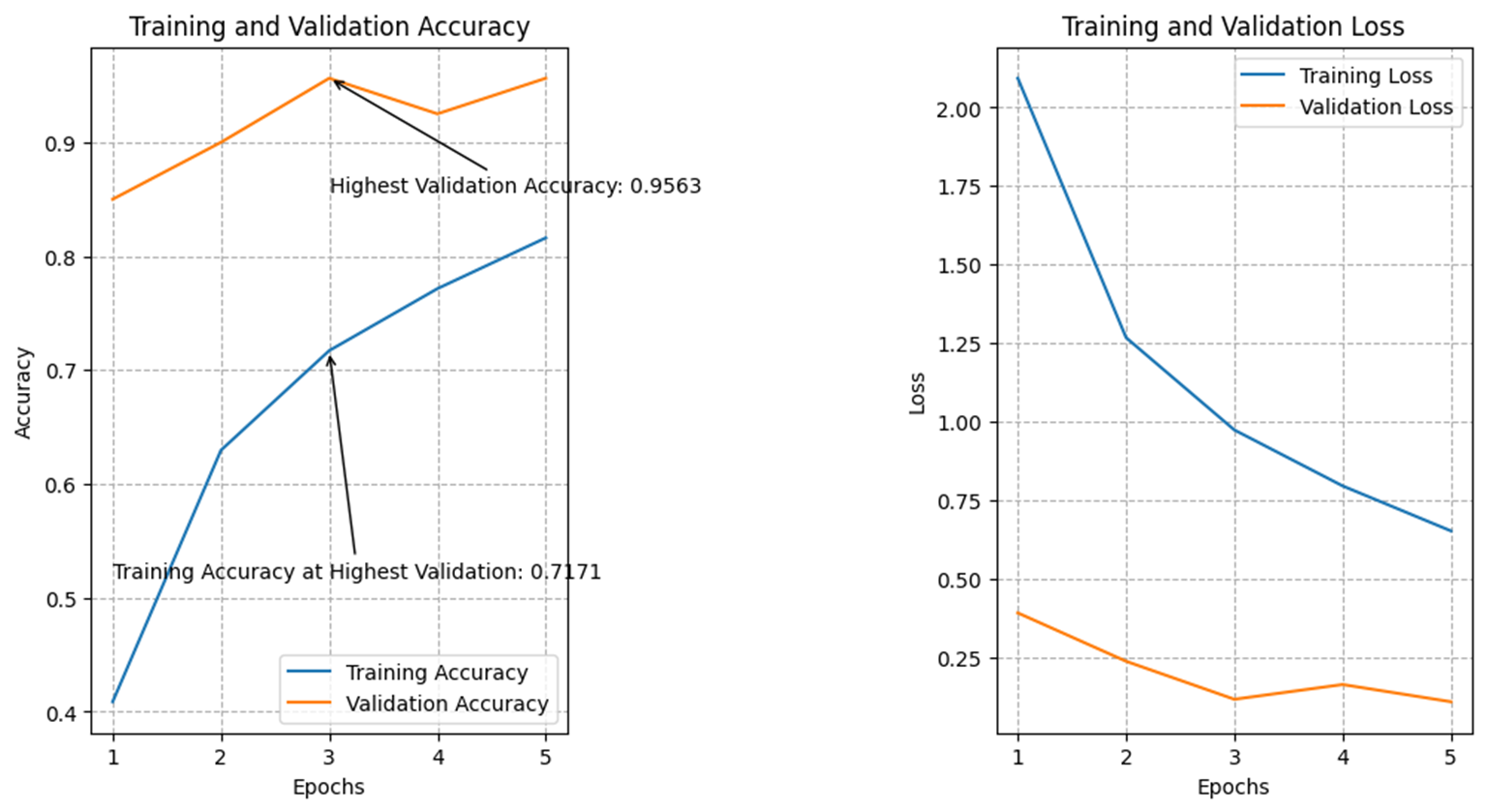
Figure 5. Training and Validation Accuracy (left), Training and Validation Loss (right) at 5 epochs |
However, we also noticed that the overall accuracy had decreased slightly, with a highest validation accuracy of 0.9563 and a training accuracy of 0.8440 at this point. Despite this, we felt that the reduction in overfitting and improved ability to distinguish between characters made this change worthwhile. We also observed more stray spots in the confusion table, which suggest less overfitting and more indecisiveness in the model's predictions.
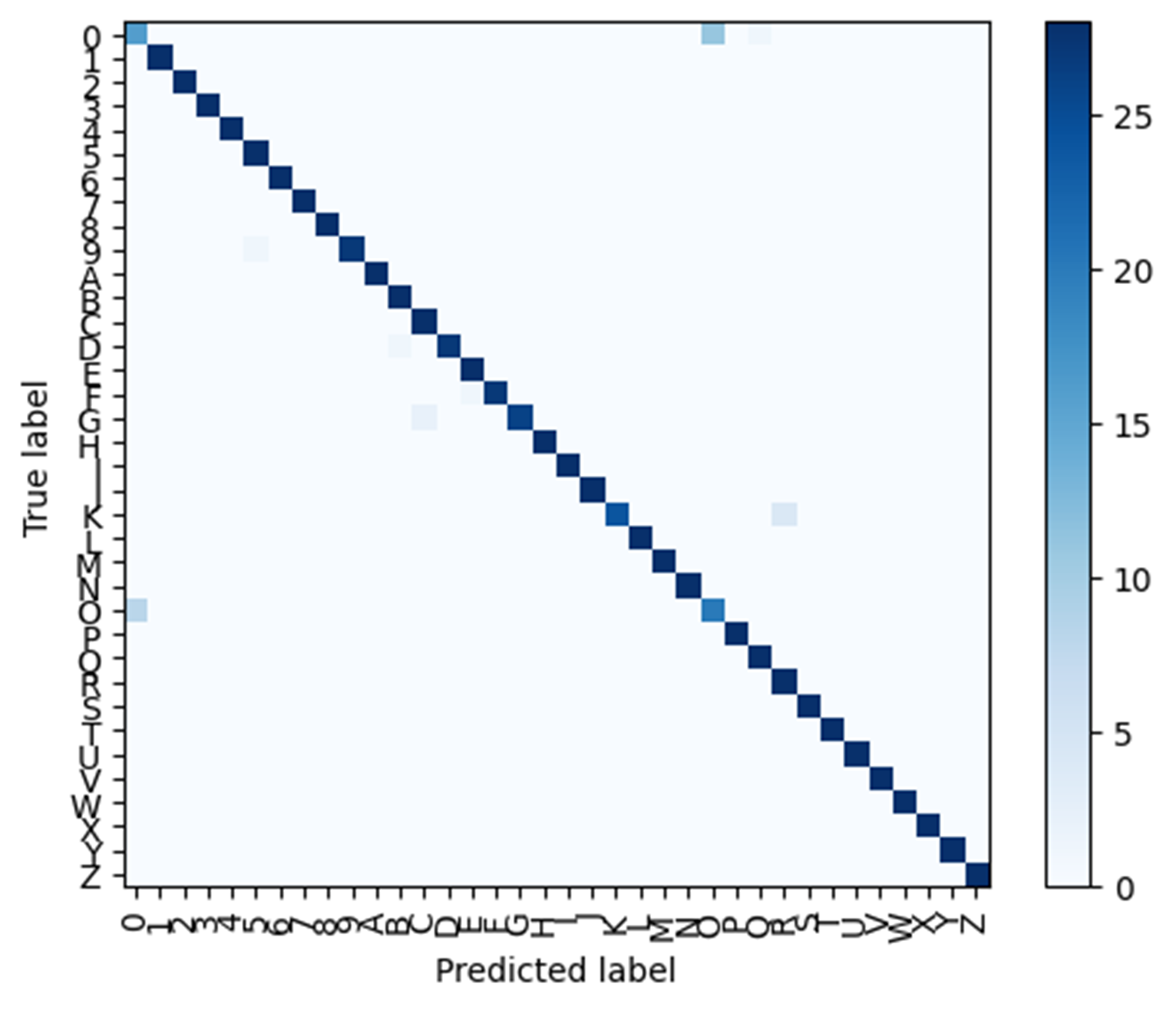
Figure 6. Confusion table at 5 epochs. |
We tested the model with three input words: "HELLO", "SAGAR", and "000OOO". In the 32-epoch model, the output was "BELL0" for "HELLO", "9EG4R" for "SAGAR", and "OWWOO0" for "000OOO". In the 5-epoch model, the output was "WB5WQ" for "HELLO", "5WCAR" for "SAGAR", and "06R6QQ" for "000OOO".
TABLE I. SAMPLE INPUT DEMONSTRATON
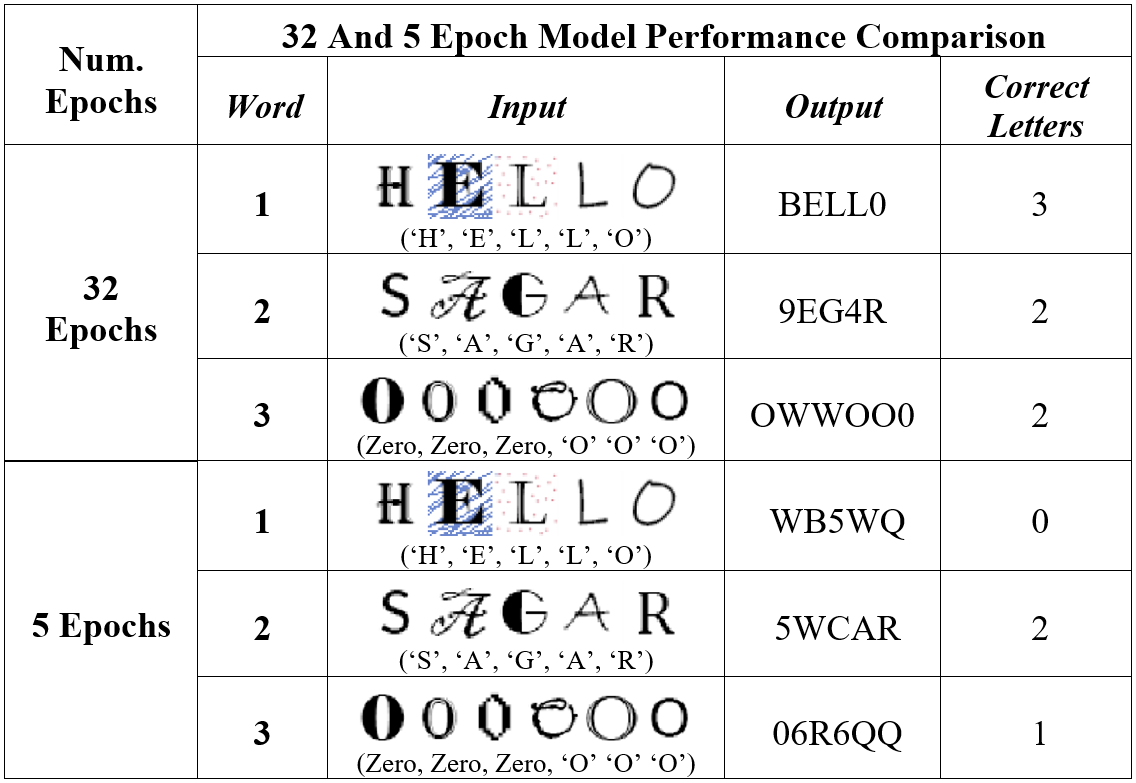
|
IV. RESULTS
The results of our study indicate that the model we developed has demonstrated a commendable level of accuracy in recognizing handwritten characters. Our approach involved refining the initial model through various iterations, utilizing techniques such as transfer learning and data augmentation. At the end of our experimentation, the final model produced a validation accuracy of 0.9563, which is lower compared to the initial model's accuracy of 0.9812 that was overfitted. Additionally, the training accuracy decreased from 0.8991 to 0.8440, indicating that our model has less overfitting. However, the model still struggled with distinguishing between certain characters, specifically "0" and "O". To address this, we suggest increasing the size of the dataset or applying additional preprocessing techniques. While the dataset used in our study was around 48 MB, larger datasets, such as those available on Kaggle, could potentially provide more accurate results, although training times may be significantly longer.
V. DISCUSSION AND CONCLUSION
Our study has shown that the model we developed is able to accurately identify handwritten characters, with a validation accuracy of 0.9563. While this is lower than the initial model's accuracy of 0.9812, it is a sign that our model is less overfitted and more reliable. However, it is important to note that the model still struggles with distinguishing between some characters, particularly "0" and "O". We also discovered that increasing the number of epochs can improve the model's accuracy but can also lead to overfitting. By reducing the number of epochs from 32 to 5, we achieved a faster training time with less overfitting. One limitation of our study is the size of our dataset, which is only about 48 MB. Using larger datasets, such as those available on Kaggle, could improve the model's performance. Additionally, applying more advanced preprocessing techniques could further improve the model's accuracy. Overall, our study has shown that with proper techniques and iteration, it is possible to develop an accurate model for identifying handwritten characters. Our findings provide a foundation for future research and development in this field.
ACKNOWLEDGMENT
We would like to thank Abhishek Jaiswal for providing the "Standard OCR Dataset" on Kaggle. This dataset was crucial for our study and helped us in achieving the results we presented. We would also like to acknowledge any funding or resources that have supported our work. Without their support, this study would not have been possible.
REFERENCES
[1] Jaiswal, Abhishek. “Standard OCR Dataset.” Kaggle, 7 Oct. 2021, https://www.kaggle.com/datasets/preatcher/standard-ocr-dataset.
[2] Renotte, Nicholas. “Build a Deep Facial Recognition App from Paper to Code // Deep Learning Project Tutorial.” YouTube, 8 Sept. 2021, https://www.youtube.com/watch?v=bK_k7eebGgc&list=PLgNJO2hghbmhHuhURAGbe6KWpiYZt0AMH.