AOT-GAN: Aggregated Contextual Transformations for High-Resolution Image Inpainting
Yanhong Zeng, Jianlong Fu, Hongyang Chao, and Baining Guo.
If any part of our paper and code is helpful to your work, please generously cite and star us 😘 😘 😘 !
@inproceedings{yan2021agg,
author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang and Guo, Baining},
title = {Aggregated Contextual Transformations for High-Resolution Image Inpainting},
booktitle = {Arxiv},
pages={-},
year = {2020}
}
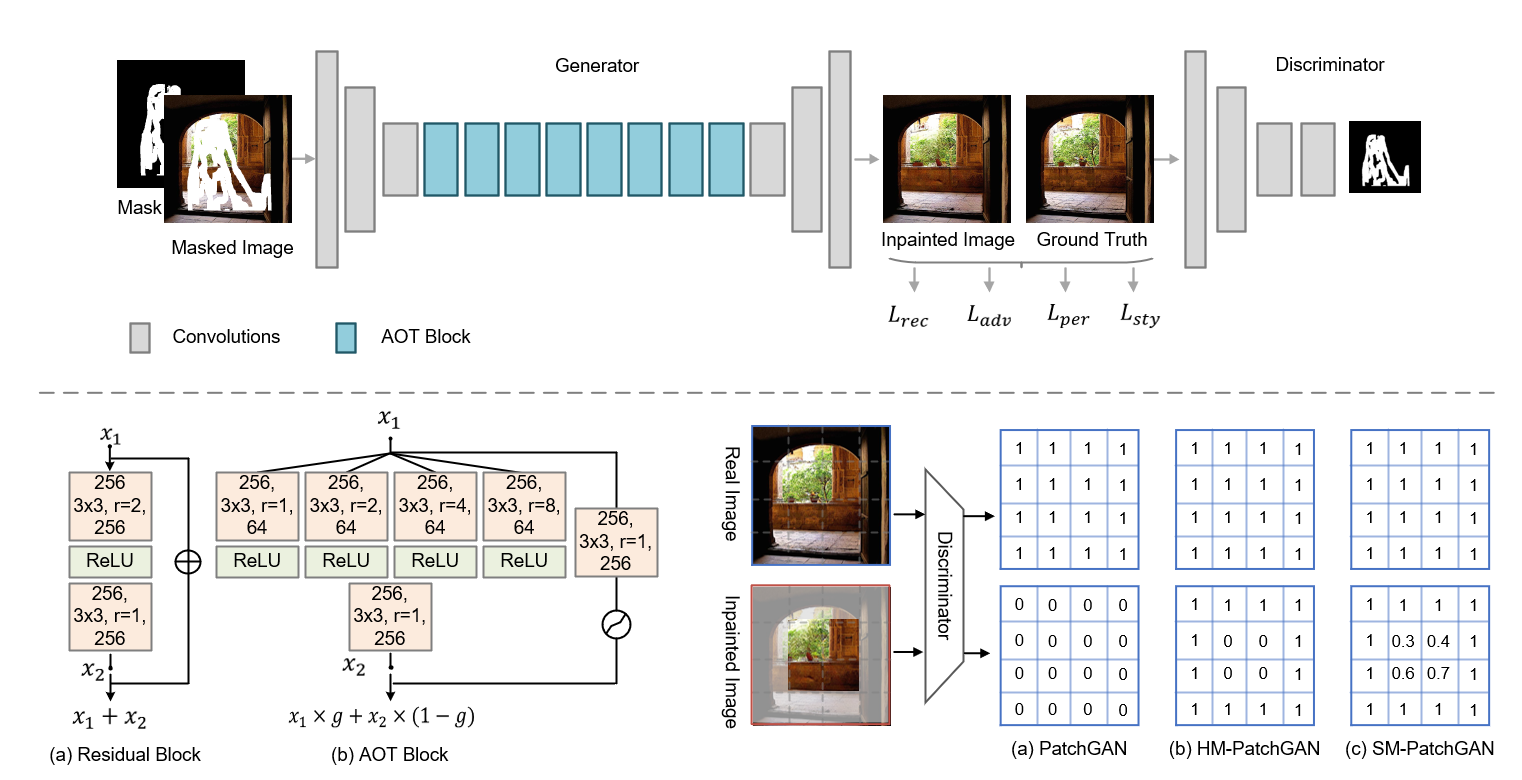
Despite some promising results, it remains challenging for existing image inpainting approaches to fill in large missing regions in high resolution images (e.g., 512x512). We analyze that the difficulties mainly drive from simultaneously inferring missing contents and synthesizing fine-grained textures for a extremely large missing region. We propose a GAN-based model that improves performance by,
- Enhancing context reasoning by AOT Block in the generator. The AOT blocks aggregate contextual transformations with different receptive fields, allowing to capture both informative distant contexts and rich patterns of interest for context reasoning.
- Enhancing texture synthesis by SoftGAN in the discriminator. We improve the training of the discriminator by a tailored mask-prediction task. The enhanced discriminator is optimized to distinguish the detailed appearance of real and synthesized patches, which can in turn facilitate the generator to synthesize more realistic textures.

![]()
- python 3.8.8
- pytorch (tested on Release 1.8.1)
Clone this repo.
git clone [email protected]:researchmm/AOT-GAN-for-Inpainting.git
cd AOT-GAN-for-Inpainting/
For the full set of required Python packages, we suggest create a Conda environment from the provided YAML, e.g.
conda env create -f environment.yml
conda activate inpainting
- download images and masks
- specify the path to training data by
--dir_imageand--dir_mask.
- Training:
- Our codes are built upon distributed training with Pytorch.
- Run
cd src python train.py - Resume training:
cd src python train.py --resume - Testing:
cd src python test.py --pre_train [path to pretrained model] - Evaluating:
cd src python eval.py --real_dir [ground truths] --fake_dir [inpainting results] --metric mae psnr ssim fid
Download the model dirs and put it under experiments/
- Download the pre-trained model parameters and put it under
experiments/ - Run by
cd src
python demo.py --dir_image [folder to images] --pre_train [path to pre_trained model] --painter [bbox|freeform]
- Press '+' or '-' to control the thickness of painter.
- Press 'r' to reset mask; 'k' to keep existing modifications; 's' to save results.
- Press space to perform inpainting; 'n' to move to next image; 'Esc' to quit demo.
![]()
Visualization on TensorBoard for training is supported.
Run tensorboard --logdir [log_folder] --bind_all and open browser to view training progress.
This project is released under the Apache 2.0 license. Please see the LICENSE file for more information.
We would like to thank edge-connect, EDSR_PyTorch.















































































































