
Welcome to ALICE Overwatch*, a project to provide real-time online data monitoring and quality assurance using timestamped data from the ALICE High Level Trigger (HLT) and Data Quality Monitoring (DQM). See the Web App to access Overwatch displaying ALICE data.
NOTE: With the end of Run 2, Overwatch is now complete.
Along with a variety of dependencies which can be handled by pip, ROOT is required. ROOT 6 is recommended.
To setup for local development is fairly straightforward.
$ git clone https://github.com/raymondEhlers/OVERWATCH.git overwatch
$ cd overwatch
# Install webApp static data (Google Polymer and jsRoot)
$ cd overwatch/webApp/static && bower install && git clone https://github.com/root-project/jsroot.git jsRoot && cd -
# Probably best to do this in a virtualenv. The overwatch setup.py can't install this automatically.
$ pip install git+https://github.com/SpotlightKid/flask-zodb.git
# Install for local development
$ pip install -e .As an alternative for advanced users or deployments, a docker image is available on Docker Hub under the name
rehlers/overwatch. Be certain to mount a directory containing data into the image so it can be used! Note
that you will likely want to use this image interactively (-it) and may want to remove the container when you
are done (--rm). If the data is in a folder called data, it should look something like:
$ docker run -it --rm -v data:/overwatch/data rehlers/overwatch:latest-py3.6.7 /bin/bashFor just running Overwatch (ie. performing no development at all), it is also available on PyPI to install via pip.
# Required as a prerequisite since it is not available on PyPI.
$ pip install git+https://github.com/SpotlightKid/flask-zodb.git
# Install the final package
$ pip install aliceOverwatchNote that the Overwatch package on PyPI includes all of JSRoot and Polymer components so that it can run out
of the box! While this is useful, it is important to remember that these dependencies must also be kept up to
date.
To use most parts of the Overwatch project, you need some data provided by the HLT. The latest five runs of data received by Overwatch can be accessed here. The login credentials are available on the ALICE TWiki. It includes at least the combined file and the file from which it is built. If the run is sufficiently long, it will include an additional file for testing of the time slice functionality.
Create a basic configuration file named config.yaml containing something like:
# Main options
# Enable debug settings, messages at the debug level
debug: true
loggingLevel: "DEBUG"
# Reprocess the data each time, even if it is not detected as needed. It can be useful
# to test modifications to the processing
forceReprocessing: true
# The directory defaults to "data", which is the recommended name
dataFolder: &dataFolder "path/to/data"Then, start processing the data with:
$ overwatchProcessingFor the webApp, add something similar to the following to your config.yaml:
# Define users for local usage
_users: !bcrypt
# The key, (below is "username") is the the name of your user, while the value, (below is "password") is your password
username: "password"
# Continue to keep debug: true . It often helps with ZODB difficulties.Then, to start the webApp for data visualization, run:
$ overwatchWebAppBy default, the webApp will be available at http://127.0.0.1:8850 using the flask development server (not for production). Login with the credentials that were specified in your configuration file.
- Overwatch Overview and Architecture
- Overwatch Configuration
- Overwatch Executables
- Overwatch Deployment
- Using Overwatch Data
- Citation
- Additional Resources
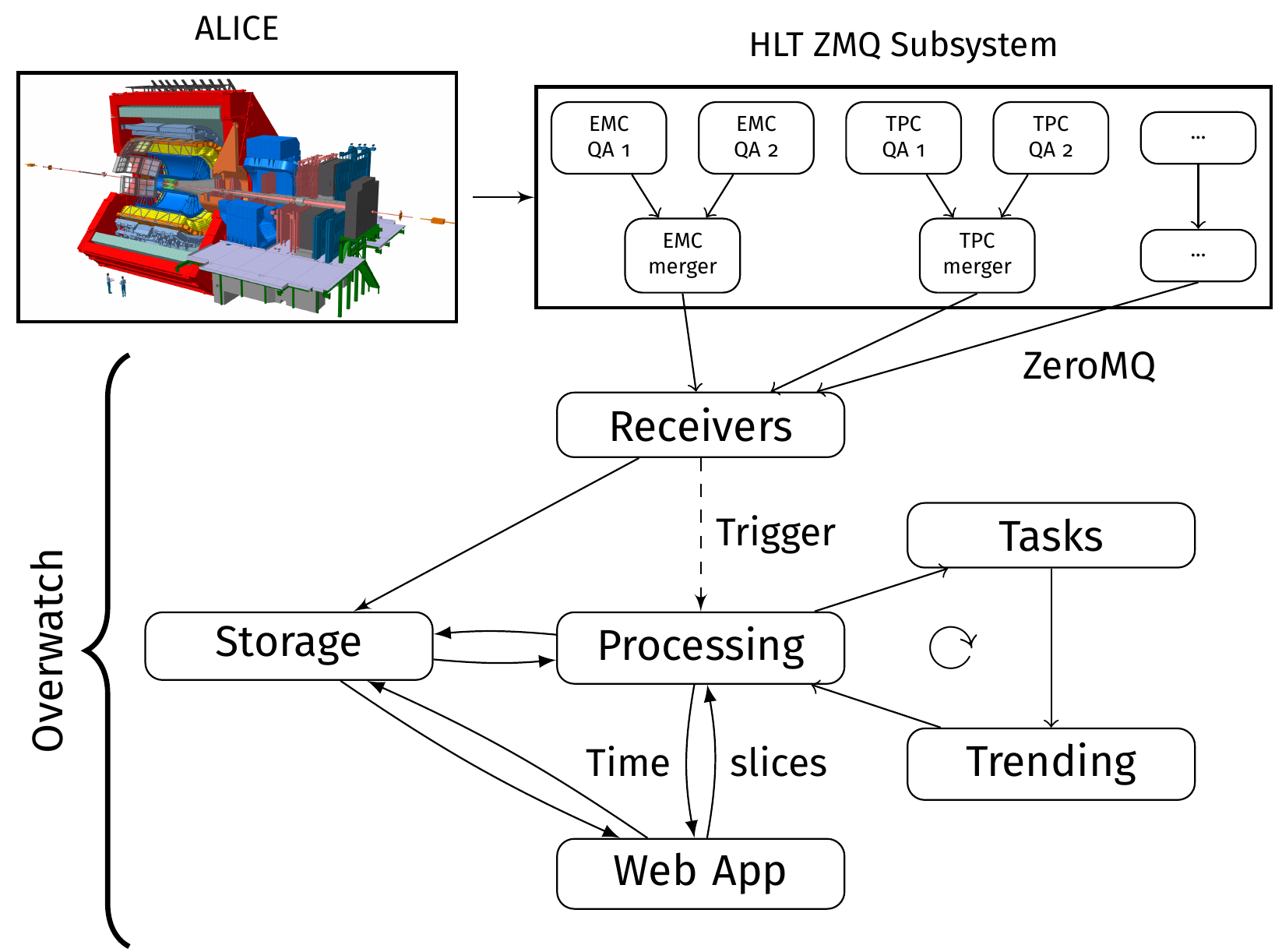
The Overwatch architecture is as shown above. Incoming data is handled by the receivers, which then make that data available to be processed by the processing module. The output of the processing is then visualized via the WebApp. In terms of code, the dependencies are as follows:
python modules
---
base <- processing <- webApp
<- dqmReceiver
c++
---
zmqReceiver
Further information on each component is available in the sections below. More detailed technical information is available in the READMEs for each package, as well as in the code documentation.
The main processing component of Overwatch is responsible for transforming the received data into a viewable
form, while also extracting derived quantities and performing checks for alarms. The main processing module is
written in python and depends heavily on PyROOT, with some functionality implemented through numpy. The module
is located in overwatch/processing, with the file processRuns.py driving the processing.
At a high level, the processing pipeline looks like:
- Extract run metadata (run number, HLT mode, detector subsystem being processed, available histograms in the particular run, etc).
- Determine which runs need processing.
- For example, if a new file has arrived for a particular run, then that run should be processed.
- If the run is new, determine which objects (histograms) are included and to which groups they belong, which processing functions need to be run, etc.
- The processing functions are implemented by each detector and called when requested by the particular detector.
- Apply those processing functions for each object (histogram), and store the outputs.
Each detector (also known as a subsystem) is given the opportunity to plug into the processing pipeline at nearly every stage. Each one is identified by the three letter detector name. The detector specific code is located in overwatch/processing/detectors/ and can be enable through the processing configuration.
The web app visualizes the information provided by the processing. The WebApp is based on flask and serves
the various forms of visualization, as well as providing an interface to request on-demand processing of the
data with customized parameters. Note that this causes a direct dependence on the processing module. The main
mode of visualization is via json files displayed using JSRoot, which provides interactivity with the data.
The receivers are responsible for receiving data from the various input sources and writing them out. Receivers write out ROOT files with the same filename information, thereby allowing for them to be processed the same regardless of their source.
Note that these receivers need to be deployed in the production environment, but would rarely, if ever, need to be used by standard Overwatch users!
Data from the HLT consists of ROOT TObject-derived objects sent via ZeroMQ (ZMQ). The receiver is built in C++, with dependencies on HLT files automatically downloaded, compiled, and linked with the receiver code when the receiver is compiled.
Installation follows the typical CMake pattern for an out of source build. When configuring, remember to specifying
the location of ZMQ and ROOT as necessary. Once built, the receiver executable is named zmqReceive. A variety of
options are available - for the precise options, see the help (-h or --help).
Note that if there is a ROOT version mismatch (for example, ROOT 5 on the HLT but ROOT 6 for Overwatch), it is imperative to request the relevant ROOT streamers with the '--requestStreamers' option. Note that this option can potentially trigger an internal ROOT bug, and therefore should not be used too frequently. Thus, the request is only sent once when the receiver is started, and it should not be frequently restarted.
Data from DQM consists of ROOT files sent via a rest API. The DQM receiver code is written as a flask app.
The web app is installed as part of the Overwatch package and can be run using the flask development server
via overwatchDQMReceiver. It is configured using the same system as the rest of the Overwatch package, as
described here.
For the APIs that are made available, please see the main server code in overwatch/receiver/dqmReceiver.py.
Overwatch is configured via options defined in YAML configuration files. There is one configuration file each for the Overwatch module (DQM receiver, processing, and webApp). Given the dependency of the various module on each other, the configuration files are also interconnected. For example, if the webApp is loaded, it will also load the processing configuration, along with the other configurations on which the processing depends. In particular, below is the ordered precedence for configuration files.
./config.yaml
~/overwatch{Module}.yaml
overwatch/webApp/config.yaml
overwatch/processing/config.yaml
overwatch/receiver/config.yaml
overwatch/base/config.yaml
The ordering of the configuration files means that values can be overridden in configurations that defined
with a higher precedence. For example, to enable debugging, simply set debug: true in your ./config.yaml
(stored in your current working directory) - it will override the definition of debug as false in the base
configuration.
For a list of the available configuration options, see the config.yaml file in the desired module.
In addition to processing and web application, there are a number of other executables available within the Overwatch project. They predominately play supporting roles for those two main packages.
A large number of executables are based on modules defined in overwatch.base. For further information, see
the documentation and the README in overwatch.base. The following executables are defined there:
overwatchDeploy- Handle execution of Overwatch executables in deployments. Although not recommended, it can also be used locally. See also belowoverwatchUpdateUsers- Simple helper to update the database with the user information defined in the configuration.overwatchReceiverDataTransfer- Transfer data received by the ZMQ and DQM receivers to other Overwatch sites and EOS.overwatchReplay- Replay processed Overwatch data as if it was newly received. Allows for full trending and other testing of the data receiving process.overwatchReplayDataTransfer- Replay process Overwatch data to a specified data at a high rate. It is a more general tool thanoverwatchReplayand is used for moving processed data viaoverwatchReceiverDataTransfer.
The DQM receiver is defined in overwatch.receiver. For further information, see the documentation and the
README in overwatch.receiver. The following executables are defined there:
overwatchDQMReceiver- Receiver data from the AMORE DQM system. Usage requires coordination with the DQM project.overwatchReceiverMonitor- Monitor the ZMQ receivers via timestamps written by the C++ executables to ensure that they haven't died.
The ZMQ receiver is defined in receiver.src. It is a small C++ code base which receives files from the HLT
and writes them to disk. It automatically downloads and compiles a few minor AliRoot dependency classes as
needed, such that the only dependencies that must be install are ZMQ and ROOT. For further information, see
the documentation and the README in receiver. The following executables are defined there:
zmqReceive- The main executable which handles receiving QA information from the HLT.
All of the components of Overwatch can be configured and launched by the overwatchDeploy executable.
Overwatch is intended to be deployed with a docker image. Within this image, configurations are managed by
supervisord. All web apps are deployed behind nginx.
The Dockerfiles and additional information is available in the docker directory.
For a configuration file containing all available options, see overwatch/base/deployConfig.yaml. Note that
this particular file is not considered when configuring a deployment - it only considers the file that is passed
to it.
The role of the image is determined by the configuration passed into the environment variable config. Available configuration options are described in the section on configuring Overwatch for deployment.
The image can then be run with something like (using an external configuration file call config.yaml):
$ docker run -d -v data:/overwatch/data -e config="$(config.yaml)" rehlers/overwatchThere is a simple utility to update the users in the ZODB database. It can be called via
overwatchUpdateUsers (it takes no arguments). It will use the username/password values stored in the
config.yaml.
Overwatch has time-stamped, persistently stored EMCal and HLT subsystem data dating back to November 2015. The TPC joined around April 2016 (Note that the HLT contains some data from various subsystems, such as the V0). This data is available through the end of Run 2 in December 2018, with the exception of the period between approximately mid-August to mid-October 2018, where some data was lost due to infrastructure issues.
For further detailed information no usage of this data, please see the additional resources .
This data can be accessed in a few different ways:
- For small data volumes, the underlying data files can be accessed directly via the Web App. Simply select the subsystem ROOT files from the main run list, and select the files to download.
- For larger volumes, there are a few options:
- The unprocessed data is also archived on EOS. It is stored in
/eos/experiment/alice/overwatch. To access this data, send a request to Raymond and ALICE Offline. - REST API file access is also possible under certain circumstances - contact Raymond if this is needed.
- The unprocessed data is also archived on EOS. It is stored in
To successfully use the Overwatch data, a few things must be kept in mind:
- Each timestamp is in the CERN time zone. For properly handling these times, I recommend the
pendulumpython package. For a concrete example, seeoverwatch.utilities.base.extractTimeStampFromFilename. - Each data file is cumulative. To get the data received between time n and n+1, one must subtract the
histogram, graph, or other object at time n+1 from the object at time n. From examples of and further
information on how to do this, see
overwatch.processing.mergeFiles. - The data was requested every minute, but the data is not from precisely only that minute. The HLT runs the QA components in a round-robin configuration through the HLT cluster. The new data that is received corresponds to data the components sent into the mergers within that minute. The rate at which the QA components send their data depends on the particular subsystem, but is often on the order of every 5 minutes. So the precision of the data is only on the order of approximately a few minutes.
In general, Overwatch provides functionality to simplify working with this data, even if you don't want to use
all of the overwatch processing features. A much more detailed information on how all of this is handled can
be found in the documentation and code in overwatch.processing.moveFiles.
Please cite Overwatch as:
@misc{raymond_ehlers_2018_1309376,
author = {Raymond Ehlers and
James Mulligan},
title = {ALICE Overwatch v1.0},
month = jul,
year = 2018,
doi = {10.5281/zenodo.1309376},
url = {https://doi.org/10.5281/zenodo.1309376}
}
OVERWATCH: Online Visualization of Emerging tRends and Web Accessible deTector Conditions using the HLT.

















