This repository contains code for the paper "The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction," by Pratyusha Sharma, Jordan T. Ash and Dipendra Misra ICLR 2024.
Website: https://pratyushasharma.github.io/laser/
Updates:
- Jan 18th, 2024: Refactoring is happening in the refactor branch. We are working to release it quickly and thank you for your patience.
- Jan 7th, 2024: Results table has been created on the website.
- Jan 4th, 2024: Discussions page is open. Feel free to use it to suggest new topics/ideas/results that are not covered by issues.
This is an early development release. We will do a major refactor in Jan 2024 to make the code easier to use and more flexible.
We welcome issues and pull requests. If you report a new result using LASER on a given LLM and NLP task, please issue a pull request and we'll add it to the website's leaderboard.
LAyer-SElective Rank-Reduction, abbreviated as LASER, is an intervention where we replace a selected weight matrix in the transformer architecture of an LLM with its low-rank approximation. A single LASER transformation consists of 3 hyperparameters: the layer number to modify (ℓ) such as 16th layer, the parameter type (τ) such as the first MLP layer, and the fraction of the maximum rank to retain (ρ) such as 0.01 fraction of the rank. We can write this transformation as (ℓ, τ, ρ) and we can compose these transformations and apply them in parallel. The low-rank approximation is performed using SVD. Figure below from our paper shows an illustration.
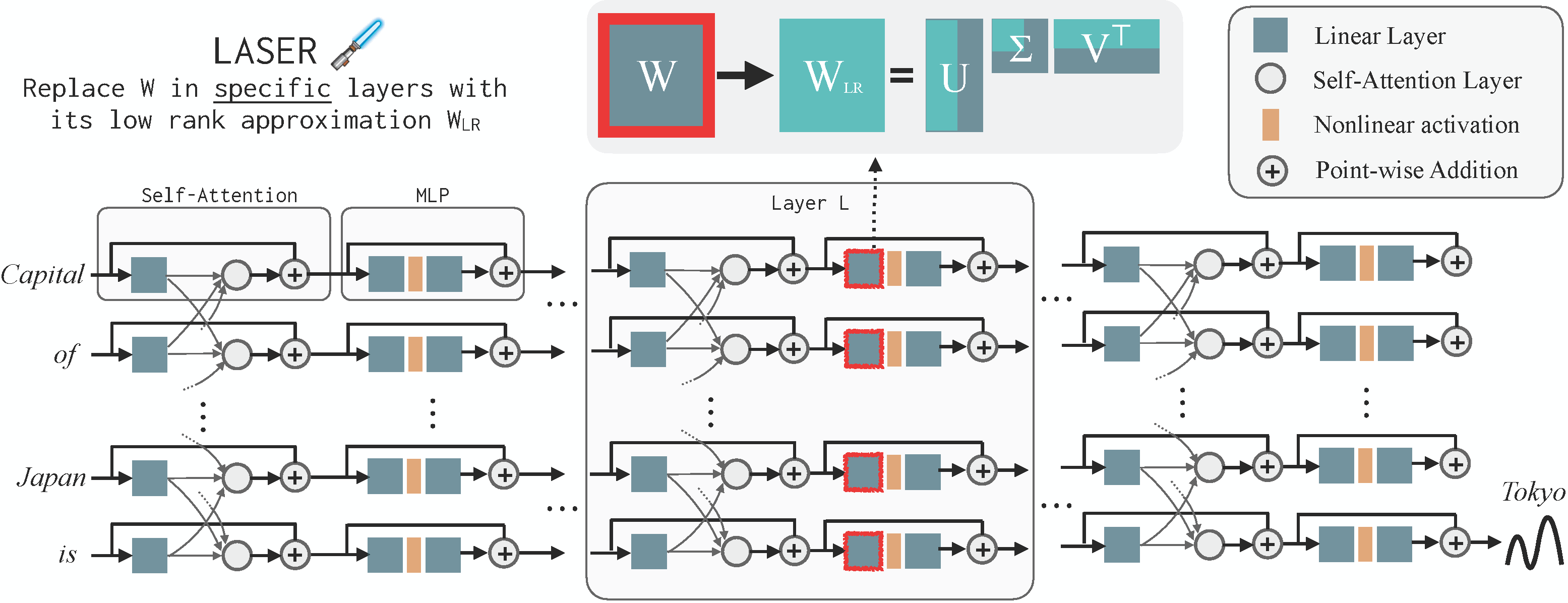
LASER can give significant performance improvements on question-answerting tasks without additional model training. Our paper presents various results related to evaluating LASER on 3 different LLMs and several LLM benchmarks. This repository contains the code to reproduce these results.
We first discuss installing the code and then discuss how to run an experiment.
To install the experiment, please install the pip file. We chiefly just need pytorch and the datasets and transformers package from huggingface. It might be a good idea to create a conda environment.
pip3 install -r requirements.txtOptionally, if you want to experiment with the CounterFact dataset then run the following script to download it. All other datasets are available on HuggingFace.
python scripts/get_counterfact.pyAt the moment, each setup is its own file. To run an experiment that performs a single LASER transformer to GPTJ on the Fever dataset, you can run:
python3 intervention_gptj_fever.py --lname fc_in --rate 9.9 --lnum 26here lnum is ℓ, lname is τ, and rate is related to ρ by ρ = 1 - 0.1 * rate. The rate is a value between [0, 10.0] and measures how many components to throw away with 10 means all components are thrown away and we get a 0 matrix and 0 means all components are retained and we retain the original matrix. The use of rate is for legacy reasons and we will refactor the code to directly use ρ in the future. The mapping for lname that we use is:
| lname | description |
|---|---|
| dont | use the base model and dont perform intervention |
| fc_in | first layer of MLP |
| fc_out | second layer of MLP |
| fc_up | a third MLP weight matrix in some LLM, used for Hadamard multiplication |
| mlp | all MLP weight matrices {fc_in, fc_up, fc_out} |
| k_proj | key matrix in self attention |
| v_proj | value matrix in self attention |
| q_proj | query matrix in self attention |
| out_proj | output matrix in self attention |
| attn | all attention weight matrices |
Please do note that if you add a new LLM, then you have to adapt the laser package to implement mappings. For example, see the mappings for Llama2 here. You also need to update the Laser wrapper to work with the new LLM here.
Note that the above experiments will save accuracies and log-losses for each datapoint. In some files, one has to take the validation set (first 20% examples) and do hyperparameter selection separately, and then compute the accuracy on the test set (remaining 80% examples) with the chose hyperparameters. In the future, we will refactor the code to make this very easy to do.
Code is inside the src folder. The main experiment files are top-level inside the src. The filename convention is intervention_<llm-name>_<dataset-name>.py where <llm-name> is the name of the LLM and <dataset-name> is the name of the dataset. For BigBench, the dataset split is often specified with an additional flag --split. Please see the codebase for details of command line arguments. We will provide a comprehensive tutorial later.
The code for performing laser is inside the laser package. We use PyTorch to do SVD and compute low-rank approximation. The code for low-rank approximation happens here. The code for reading and processing dataset is inside dataset_util. Finally, metrics and logging are done using the study_utils.
If you find this codebase useful, then please cite the following paper. Additionally, feel free to send a PR or an email and we will cite your result/paper on the leaderboard.
@article{sharma2023truth,
title={The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction},
author={Sharma, Pratyusha and Ash, Jordan T and Misra, Dipendra},
journal={arXiv preprint arXiv:2312.13558},
year={2023}
}






















































































































