A tool for easier PostgreSQL development.
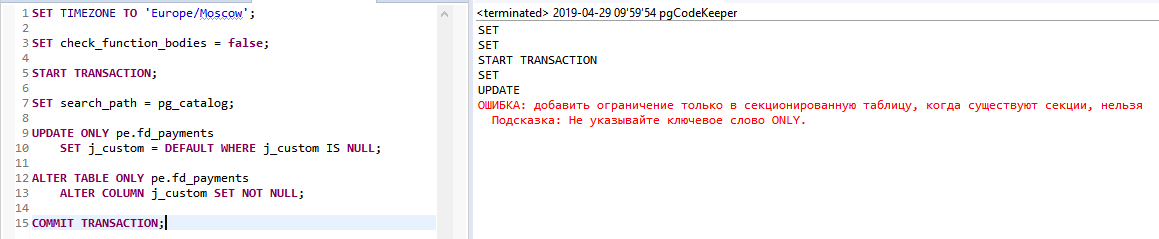
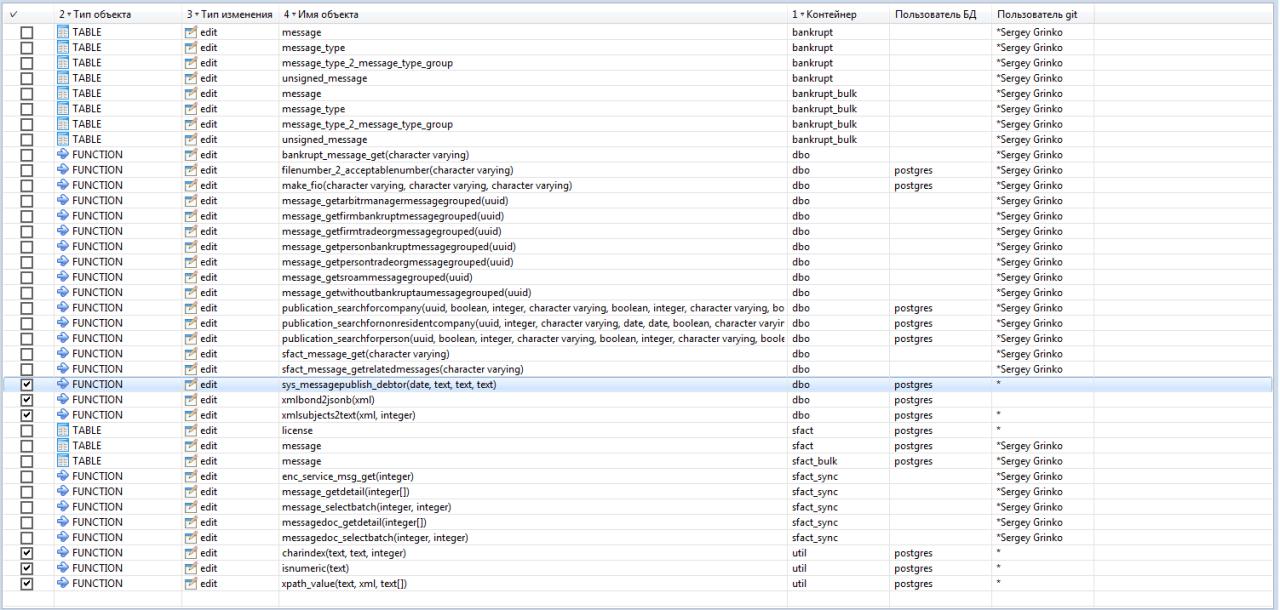
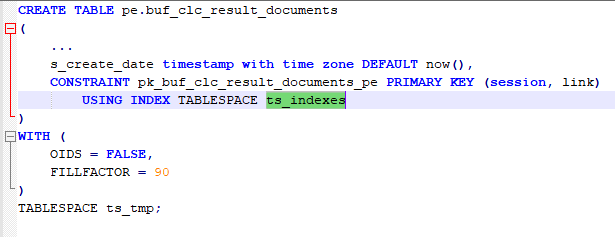
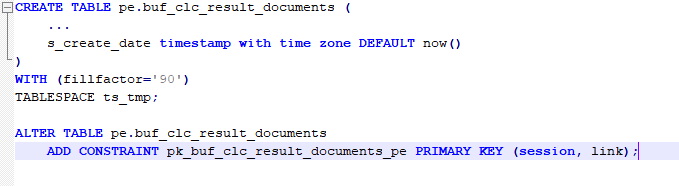
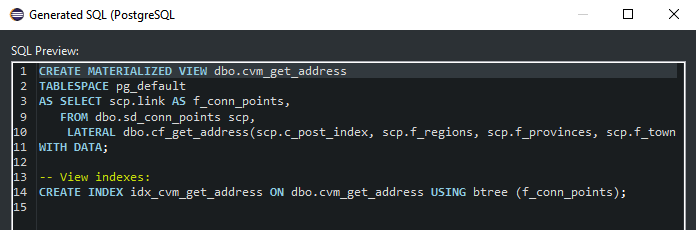
- Comparing database code is very easy now. Compare live DB instances, pg_dump output, as well as pgCodeKeeper projects.
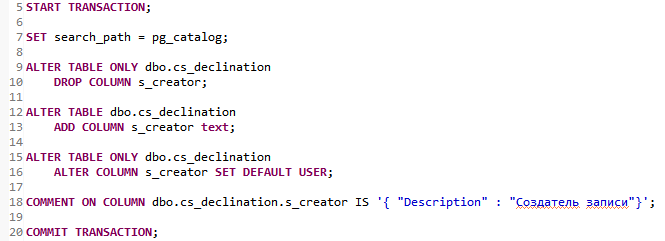
- Generate migration scripts via a user-friendly interface. You can use both live DB instances and DB dumps as initial data. You can also compare pgCodeKeeper projects — useful when working with versions control systems.
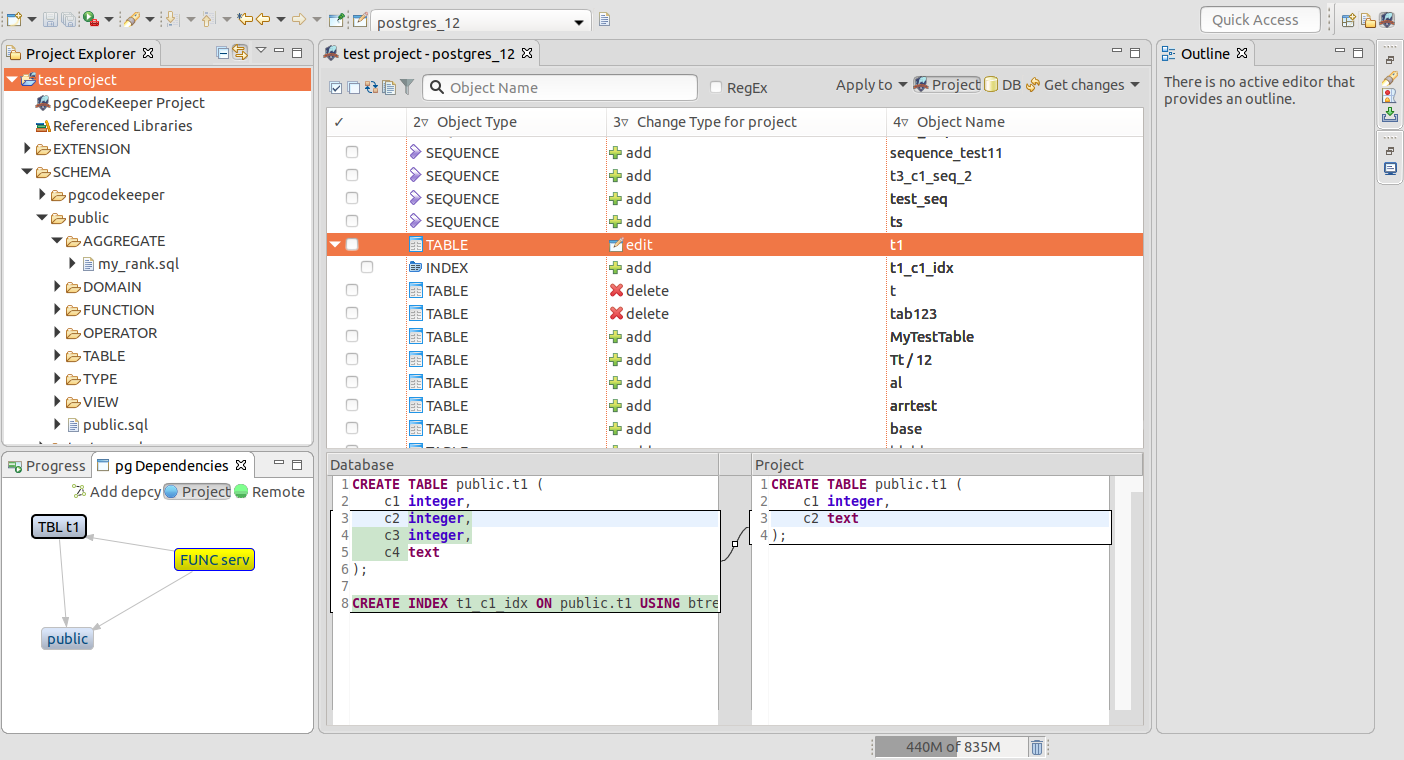
- pgCodeKeeper is an Eclipse IDE plug-in. The DB code is saved as an Eclipse project, and the project can be tracked under any of the versions control systems supported by Eclipse — Git, SVN, Mercurial, CVS and many others.

pgCodeKeeper requires Java (JRE) 11+ to run.
You can download prebuilt packages and CLI version from GitHub releases.
If you already have Eclipse IDE installed you can install pgCodeKeeper plugin using Marketplace or https://pgcodekeeper.org/update/ update site.
Build requires Java (JDK) 11+ and Apache Maven 3.6+.
git clone https://github.com/pgcodekeeper/pgcodekeeper.git
cd pgcodekeeper
mvn verifyBinaries will be created in ru.taximaxim.codekeeper.mainapp/product/rcp/target/products
CLI package will be created in ru.taximaxim.codekeeper.mainapp/product/standalone/target/products
- If you have any questions, suggestions, ideas, etc - contact us in our Telegram chat or create an issue.
- Pull requests are welcome.
- Visit https://pgcodekeeper.org for more information.
- Thanks for using pgCodeKeeper!
The project consists of several modules that implement Eclipse RCP plugins (and, by extension, OSGi bundles).
pom.xml- first, root pom.xml defines Maven build order and environment. Not required for application development.ru.taximaxim.codekeeper.core- the core module containing database schema classes and loaders, comparison logic, SQL code generators and parsers.ru.taximaxim.codekeeper.cli- CLI implementation module.ru.taximaxim.codekeeper.ui- GUI module, Eclipse integration.
ru.taximaxim.codekeeper.core.tests- majority of unit and functional tests.ru.taximaxim.codekeeper.cli.tests- tests for CLI.ru.taximaxim.codekeeper.ui.tests- tests for pieces of logic that were implemented in UI module instead of the core module.
ru.taximaxim.codekeeper.mainapp- "branding plugin", provides Eclipse with feature information, images, etc. Also contains development Target platform files.ru.taximaxim.codekeeper.mainapp/report- tests coverage report module.ru.taximaxim.codekeeper.mainapp/feature- Eclipse feature module.ru.taximaxim.codekeeper.mainapp/updatesite- Eclipse p2 repository/update site module.ru.taximaxim.codekeeper.mainapp/product/rcp- Eclipse product description, used to build pgCodeKeeper packages.ru.taximaxim.codekeeper.mainapp/product/standalone- Eclipse product description, used to build CLI version packages.ru.taximaxim.codekeeper.mainapp/deploy- GitHub deploy module.
This module was derived from apgdiff project. At this point it is almost fully rewritten according to our needs.
Primary packages of this module are:
ru.taximaxim.codekeeper.core.schema- contains classes that describe SQL objects. Each class contains object properties, creation SQL code generator, object comparison logic and ALTER code generator. Notable classes:PgStatement- all object classes must be derived from this one. Defines main API for working with objects.PgDatabase- root class for every loaded database schema.GenericColumn- generic reference to any object (used to be a column reference).
ru.taximaxim.codekeeper.core.schema.meta- simplified SQL object classes for database structure serialization.ru.taximaxim.codekeeper.core.schema.meta(resources) - serialized descriptions of PostgreSQL's system objects (built using JdbcSystemLoader).ru.taximaxim.codekeeper.core.loader- database schema loaders: project, SQL file, JDBC, library.ProjectLoader- loads a database from project structure. (!) Keep in sync withUIProjectLoader.PgDumpLoader- loads objects into a database structure from a file. (!) Keep in sync withPgUIDumpLoader.
ru.taximaxim.codekeeper.core.loader(resources) - SQL queries for JdbcLoaders, used by Java code viaJdbcQueries.ru.taximaxim.codekeeper.core.loader.jdbc- classes that create schema objects based on JDBC ResultSets.ru.taximaxim.codekeeper.core.parsers.antlr- generated ANTLR4 parser code, plus utility parser classes. Notable classes:AntlrParser- factory methods for parser creation and parallel parser operations.QNameParser- utility class for parsing and splitting qualified names.ScriptParser- simple parser that splits statements for later execution.Custom(T)SQLParserListener- main entry point for parsing SQLs into schema objects.
ru.taximaxim.codekeeper.core.parsers.antlr.statements- processor classes that create schema objects based on parser-read data. Notable classes:ParserAbstract- common base class for all processors.
ru.taximaxim.codekeeper.core.parsers.antlr.expr- expression analysis classes: find dependencies in expressions and infer expression types for overloaded function call resolution.ru.taximaxim.codekeeper.core.parsers.antlr.expr.launcher- support for parallel expression analysis.ru.taximaxim.codekeeper.core.formatter- SQL and pl/pgsql code formatters.ru.taximaxim.codekeeper.core- util and general-purpose classes. Notable classes:PgDiff- entry point for database schema diff operations.
ru.taximaxim.codekeeper.core.model.difftree- classes representing and creating an object diff tree. Notable classes:DbObjType- enum of all SQL object types supported by the program.TreeElement- a node in an object diff tree.DiffTree- object diff tree factory.TreeFlattener- filters and flattens the tree into a list of nodes according to requested parameters.
ru.taximaxim.codekeeper.core.model.graph- object dependency graph classes, built using JGraphT library. Notable classes:DepcyGraph- the dependency graph and its builder.DepcyResolver- main script building algorithm. Creates a list ofStatementActions according to requested object changes and object dependencies.DepcyTreeExtender- extends an object diff tree according to object dependencies.DepcyWriter- prints a dependency tree for an object.
ru.taximaxim.codekeeper.core.model.exporter- classes that save and update the project files on disk. Notable classes:ModelExporter,MsModelExporter,AbstractModelExporter- exporters for PG and MS projects and their common abstract part.OverridesModelExporter- exports project structure containing only permission overrides.
ru.taximaxim.codekeeper.core.sql- a categorized list of all PostgreSQL keywords. Generated from PostgreSQL source.ru.taximaxim.codekeeper.core.ignoreparser- builder forIgnoreLists.ru.taximaxim.codekeeper.core- main package containing general stuff: e.g. string constants, utils.antlr-src- sources for ANTLR4 parsers. We maintain parsers for PostgreSQL, pl/pgsql, T-SQL, and also our custom Ignore Lists and PostgreSQL ACLs syntax.
These need to be built using your preferred ANTLR4 builder intoru.taximaxim.codekeeper.core.parsers.antlrpackage.
Majority of code in this module implements Eclipse integration, and also wraps core logic into a more UI-suitable forms.
plugin.xml- main Eclipse integration file. All integration code is referenced from here.ru.taximaxim.codekeeper.ui.editors- main project editor and its supporting classes. Notable classes:ProjectEditorDiffer- main project editor. Loads and compares databases, allows user to select changes and saves the into project or generates and diff script for the database.
ru.taximaxim.codekeeper.ui.differ- classes for diff creation. Notable classes:DbSource- an abstraction, factory, and implementations for various database loaders.TreeDiffer,Differ- first creates a diff tree, second creates a diff script based on the tree and user selection.DiffTableViewer- GUI element responsible for showing tree diff elements. Part ofProjectEditorDifferseparated for reuse in other UIs.
ru.taximaxim.codekeeper.ui.pgdbproject- project classes and various project wizards (New, Import, etc). Notable classes:PgDbProject- utility wrapper for Eclipse'sIProject.
ru.taximaxim.codekeeper.ui.pgdbproject.parser- UI-specific parts of database loaders. Notable classes:PgDbParser- stores, serializes and updates project indices (object metadata and references).UIProjectLoader- loads a database from project structure in Eclipse Workspace. (!) Keep in sync withProjectLoader.PgUIDumpLoader- loads objects into a database structure from an Eclipse'sIFile. (!) Keep in sync withPgDumpLoader.
ru.taximaxim.codekeeper.ui.builders- Project Builders launch project index updates (metadata, errors etc) when an IDE build is triggered.ru.taximaxim.codekeeper.ui.sqledit- SQL code editor. Notable classes:SQLEditorSourceViewerConfiguration- main editor configuration class, ties in most other editor classes.
ru.taximaxim.codekeeper.ui.dbstore- database connection storage and GUI selection classes. Notable classes:DbInfo- database connection parameters.
ru.taximaxim.codekeeper.ui.handlers- handlers for commands (IDE actions) registered with Eclipse inplugin.xml.ru.taximaxim.codekeeper.ui.job- singleton wrapper for EclipseJobs.ru.taximaxim.codekeeper.ui.dialogs- various dialogs. Notable classes:ExceptionNotifier- reports and logs errors using Eclipse'sStatusManager.
ru.taximaxim.codekeeper.ui.externalcalls- logic for calling external utilities (pg_dump etc).ru.taximaxim.codekeeper.ui.generators- value generator for dummy data generation wizard (MockDataWizard).ru.taximaxim.codekeeper.ui.prefs- Eclipse Preferences integration - global program settings.ru.taximaxim.codekeeper.ui.properties- per-project settings.ru.taximaxim.codekeeper.ui.reports- Google Analytics reports.ru.taximaxim.codekeeper.ui.views- views showing misc info. Notable classes:DepcyGraphView- shows dependency graph for objects currently selected in Project Editor.ProjectOverrideView- shows library objects overridden by the project in current Project Editor.ResultSetView- shows rows returned by SELECT or other commands executed in a script in SQL Editor.
ru.taximaxim.codekeeper.ui.views.navigator- Eclipse Project Explorer integration, see alsoplugin.xmlru.taximaxim.codekeeper.ui- main package containing general stuff: e.g. string constants, utils. Notable classes:UiSync- exception safety wrapper around SWT'sDisplay.asyncExec(). (!) Use this instead of callinggetDisplay().asyncExec().UIConsts- majority of string IDs and other constants commonly used in UI.
Majority of tests are here.
ru.taximaxim.codekeeper.core-PgDiffTest,MsDiffTest- these test cases load old and new database schemas, generate a migration script and compare it to the expected diff file.ru.taximaxim.codekeeper.core.depcies- tests here work similarly to simple diff tests above, except the concept of "user selection" is added. Migration script is built only with objects inusrfiles as starting points, other objects must be added to the script via dependency mechanism.ru.taximaxim.codekeeper.core.loader-PgAntlrLoaderTest,MsAntlrLoaderTest- these tests load simple schemas from files and compare loaded PgDatabase objects with predefined ones.ru.taximaxim.codekeeper.core.parsers- these tests simply parse test pieces of code (taken from PostgreSQL source) to verify parser validity.ru.taximaxim.codekeeper.core.parsers.antlr.expr- these tests verify expression analysis and type inference mechanism.ru.taximaxim.codekeeper.core.model.exporter- these test update exported project directories and verify which files have actually been changed.
Simple tests for core logic wrappers: DbSource, Differ, ProjectUpdater.
General program lifecycle goes as follows:
PgDiffArgumentsobject is filled with operation parameters.PgDatabases are loaded from requested sources, including their libraries and privilege overrides. Ignored schemas are skipped at this step.- During the load dependencies of each object are found and recorded. Expressions are also analyzed to extract their dependencies including overloaded function calls.
- All parser and expression analysis operations are run in parallel using
AntlrParser.ANTLR_POOLthread pool to speed up the process. Parallel operations are serialized by callingfinishLoadersat the end of each loading process.
- The diff tree (represented by root
TreeElement) is created by comparing twoPgDatabases. In GUI this is then shown to the user to assess the situation and choose objects to work with. - The diff tree, now containing "user selection", is used to selectively update project files on disk, or to generate a migration script.
- In latter case, each "selected" TreeElement is passed to
DepcyResolverto generate script actions fulfilling the requested change, including actions on dependent objects. To do this, JGraphT object dependency graphs are built using dependency information found at the loading stage. - Generated actions are now converted into SQL code with some last-moment post-processing and filtering.
- Generated SQL script is written to a file/stdout or shown in the GUI for user to review and run on their database.