Coldsweat is a self-hosted Python 3 web RSS aggregator and reader compatible with the Fever API. This means that you can connect Coldsweat to a variety of clients like Reeder for iOS or Mac OS X ReadKit app and use it to sync them together.
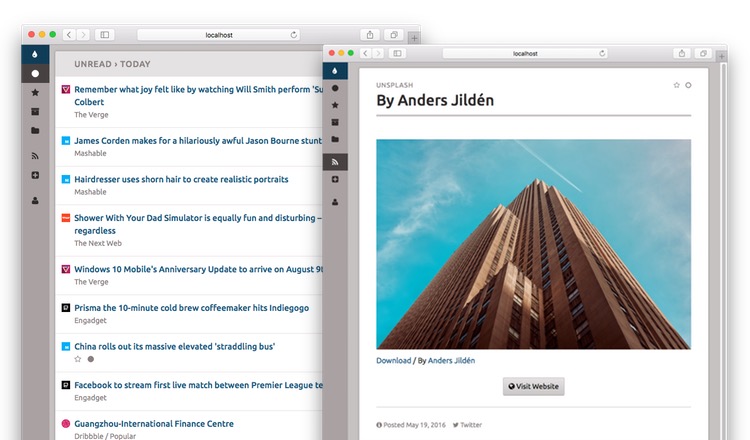
- Web interface to read and add feeds
- Compatible with existing Fever desktop and mobile clients
- Multi-user support
- Basic support for grouping of similar items
Let's see how you can take a peek at what Coldsweat offers running it on your machine.
Note: you can install Coldsweat in the main Python environment of your machine or in a virtual environment, which is the recommended approach, since its dependencies may clash with packages you have already installed. Learn more about virtual environments here.
Coldsweat is Flask application distributed as a Python wheel, hence you can install it from PyPI using the, hopefully familiar, pip utility:
$ pip install coldsweat
The install procedure will also create a coldsweat command, available in your terminal.
Once installed, create a new user specifing email and password with the setup command:
$ coldsweat setup [email protected] -p somepassword
If you prefer you can enter the password interactively:
$ coldsweat setup [email protected]
Enter password for user [email protected]: ************
Enter password (again): ************
Setup completed for [email protected]
Email and password will be needed to access the web UI and use the Fever API sync with your favourite RSS client.
Like other RSS software Coldsweat uses the OPML format to import multiple feeds with a single operation:
$ coldsweat import /path/to/subscriptions.opml [email protected] -f
The -f option tells Coldsweat to fetch the feeds right after the import step.
To update all the feeds run the fetch command:
$ coldsweat fetch
You should use cron or similar utilities to schedule feed fetches periodically.
Then you can run the Flask development web server and access the web UI:
$ coldsweat run
* Serving Flask app 'coldsweat'
* Debug mode: off
* Running on http://127.0.0.1:5000
...
See Setup and Deploy pages for additional information.
Upgrade to the latest Coldsweat version with:
$ pip install -U coldsweat
Note: there's no upgrade path from previous 0.9.x releases. Your best bet if to export OPML subscriptions and import them in the new 0.10 release.
See Contributing page.
- Runs on Python 3.9 and up
- Completely rebuilt using Flask web framework
- Supports SQLite, PostgreSQL, and MySQL databases
- HTTP-friendly fetcher
- Tested with latest versions of Chrome, Safari, and Firefox
I'm fed up of online services that are here today and gone tomorrow. Years ago, after the Google Reader shutdown it was clear to me that the less we rely on external services the more the data we care about are preserved. With this in mind I'm writing Coldsweat. It is my personal take at consuming feeds today.
Coldsweat started in July 2013 as a fork of Bottle Fever by Rui Carmo. After several years of pause I've restarted to develop Coldsweat using Python 3 and the latest crop of web technologies.















































































































