log4j-sniffer crawls for all instances of log4j on disk within a specified directory. It can be used to determine whether there are any vulnerable instances of log4j within a directory tree and report or delete them depending on the mode used.
Scanning for versions affected by CVE-2021-44228, CVE-2021-45046, CVE-2021-45105 and CVE-2021-44832 is currently supported.
log4j-sniffer will scan a filesystem looking for all files of the following types based upon suffix:
- Zips: .zip
- Java archives: .jar, .war, .ear
- Tar: .tar, .tar.gz, .tgz, .tar.bz2, .tbz2
Archives containing other archives will be recursively inspected up to a configurable maximum depth.
See the log4j-sniffer crawl --help output for options on nested archive inspection.
It will look for the following:
- Jar files matching
log4j-core-<version>.jar, including those nested within another archive - Class files named
org.apache.logging.log4j.core.net.JndiManagerwithin Jar files or other archives and check against md5 hashes of known versions - Class files named
JndiManagerin other package hierarchies and check against md5 hashes of known versions - Matching of the bytecode of classes named JndiManager against known classes (see below for more details)
- Matching of bytecode within obfuscated or shaded jars for partial matches against known classes (see below)
If Go is available on the host system, the following command can be used to install this program:
go install github.com/palantir/log4j-sniffer@latest
This repository also publishes binaries that can be downloaded and executed.
log4j-sniffer executables compiled for linux-amd64, darwin-amd64, darwin-arm64 and windows-amd64 architectures are available on the releases page.
This tool is intensive and is recommended to be run with low priority settings.
On Linux:
ionice -c 3 nice -n 19 log4j-sniffer crawl /path/to/a/directory
Output for vulnerable files looks as follows:
[INFO] Found archive with name matching vulnerable log4j-core format at examples/single_bad_version/log4j-core-2.14.1.jar
[INFO] Found JndiManager class that was an exact md5 match for a known version at org/apache/logging/log4j/core/net/JndiManager.class
[INFO] Found JndiLookup class in the log4j package at org/apache/logging/log4j/core/lookup/JndiLookup.class
[MATCH] CVE-2021-44228, CVE-2021-45046, CVE-2021-45105, CVE-2021-44832 detected in file examples/single_bad_version/log4j-core-2.14.1.jar. log4j versions: 2.14.0-2.14.1, 2.14.1. Reasons: JndiLookup class and package name matched, jar name matched, JndiManager class and package name matched, class file MD5 matched
Files affected by CVE-2021-44228 or CVE-2021-45046 or CVE-2021-45105 or CVE-2021-44832 detected: 1 file(s)
1 total files scanned, skipped identifying 0 files due to config, skipped 0 paths due to permission denied errors, encountered 0 errors processing paths
- Locate releases.
- You will need a different asset depending on the generation of your Mac.
- Select the asset with “macos-amd” in the file name for older Intel Macs.
- Select “macos-arm” for newer m1 Macs
- Confirm that the file is downloading to your “Downloads” folder.
- Once the download is complete, click on the file to open.
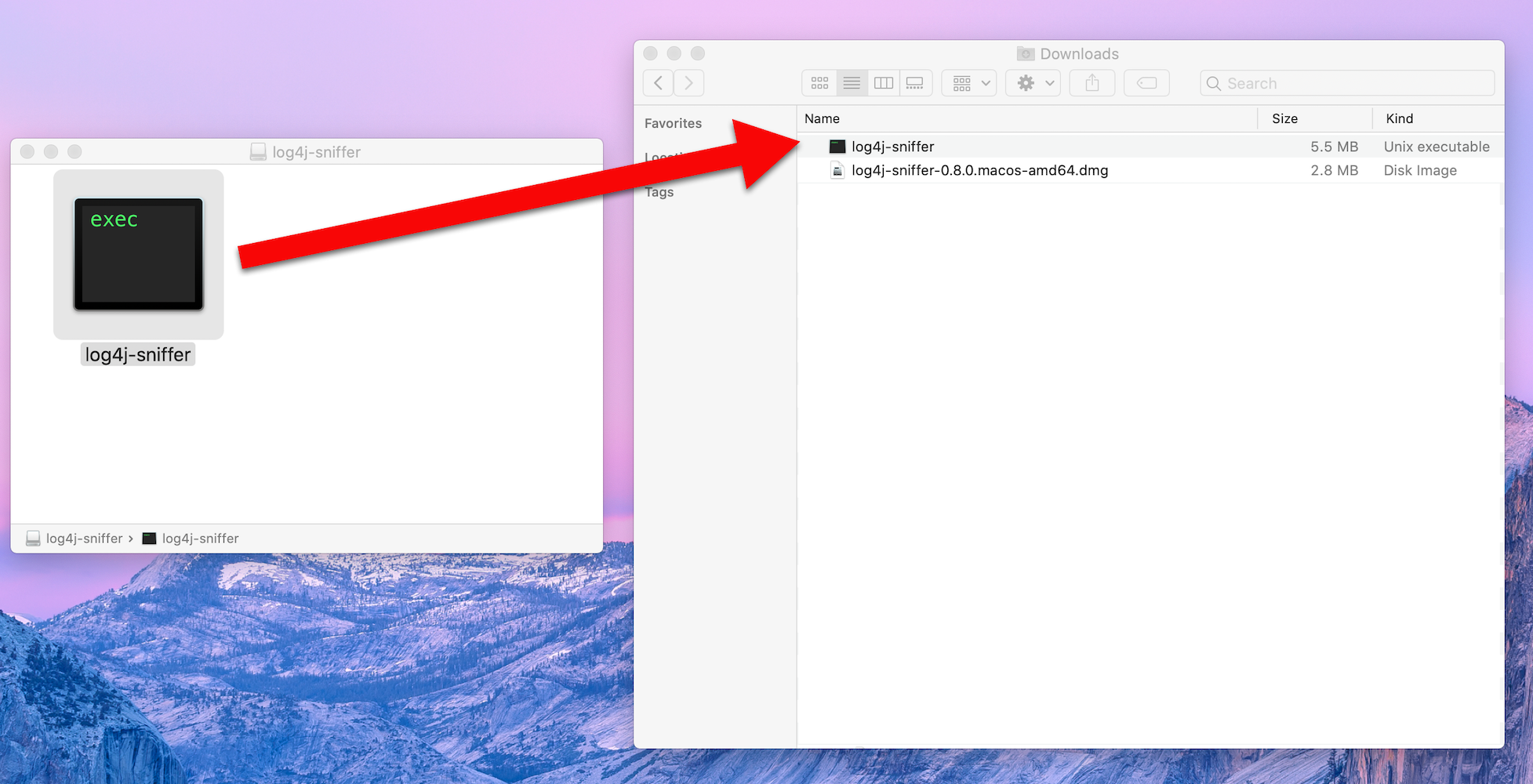
- Drag and drop the “log4j-sniffer” icon into your Downloads through the Finder.
- Open a Finder window by searching for “Finder” using the magnifying glass on the top right of your screen, or selecting the icon in your Dock.
- Drag and drop the “log4j-sniffer” icon into Downloads.

- Open the Terminal by searching for “Terminal” using the magnifying glass in the top right corner of the screen.
- Run
~/Downloads/log4j-sniffer crawl / --ignore-dir="^/dev"to crawl the entire system- Run
~/Downloads/log4j-sniffer crawl /PATH/TO/YOUR/FOLDERto crawl specific folders - If your computer is unable to locate log4j-sniffer, you may have to make it executable before using it. In your terminal, run the following:
chmod +x ~/Downloads/log4j-sniffer./log4j-sniffer crawl /PATH/TO/YOUR/FOLDER
- Run
- Locate [releases] (https://github.com/palantir/log4j-sniffer/releases).
- Select the Windows asset.
- Confirm that the file is downloading to your “Downloads” folder.
- Type "Command Prompt" into the search bar at the bottom and in the right pane click "Run as administrator".
- Navigate to your Downloads folder, e.g.
cd C:\Users\yourname\Downloads - Run
log4j-sniffer-1.1.0-windows-amd64.exe crawl C:\to crawl the entire system, substituting the drive of your choice, e.g.C:\,D:\- Run
log4j-sniffer-1.1.0-windows-amd64.exe crawl C:\PATH\TO\YOUR\FOLDERto crawl specific folders
- Run
The primary command for the tool is crawl which takes an argument that is the path to the directory to be crawled.
Thus, the standard usage is:
log4j-sniffer crawl [pathToDirectory]
The standard mode prints output in a human-readable format and prints a summary that states the number of vulnerabilities found after running.
Specifying the --json flag makes it such that the output of the program is all in JSON: each line of output is JSON
that describes the vulnerability that is found, and if summary mode is enabled then the final summary is also output as
a line of JSON.
Here is an example of the output with --json:
{"message":"CVE-2021-44228, CVE-2021-44832, CVE-2021-45046, CVE-2021-45105 detected","filePath":"examples/inside_a_dist/wrapped_log4j.tar.gz","detailedPath":"examples/inside_a_dist/wrapped_log4j.tar.gz!log4j-core-2.14.1.jar","cvesDetected":["CVE-2021-44228","CVE-2021-44832","CVE-2021-45046","CVE-2021-45105"],"findings":["jndiLookupClassPackageAndName","jarNameInsideArchive","jndiManagerClassPackageAndName","classFileMd5"],"log4jVersions":["2.14.0-2.14.1","2.14.1"]}
{"filesScanned":1,"permissionDeniedErrors":0,"pathErrors":0,"pathsSkipped":0,"numImpactedFiles":1}
The JSON fields have the following meaning:
- message: information about the output
- filePath: the path to the file on disk where the vulnerability was detected
- detailedPath: the path to the vulnerable contents, which may be an archived file multiple levels nested. Nesting levels are separated by a '!'
- cvesDetected: CVEs matched against the version found
- log4jVersions: the versions detected at this location based on all applied detections, note that some detections are more accurate than others and so a range of versions might be reported
The findings array reports the following possible values:
- jndiLookupClassName: there was a .class file called
JndiLookup - jndiLookupClassPackageAndName: there was a .class file called
JndiLookupwith a package oforg.apache.logging.log4j.core.lookup - jndiManagerClassName: there was a .class file called
JndiManager - jndiManagerClassPackageAndName: there was a .class file called
JndiManagerwith a package oforg.apache.logging.log4j.core.net - jarNameMatched: the file scanned was a .jar file called
log4j-core-<version>.jar - jarNameInsideArchiveMatched: there was a .jar file called
log4j-core-<version>.jarinside the archive - classFileMd5Matched: there was a class file called
JndiManagerthat matched the md5 hash of a known version - classBytecodeInstructionMd5: the bytecode of a class file called
JndiManagerexactly matched a known version, see the Bytecode matching section for more details - jarFileObfuscated: the jar the match was found in appeared to be obfuscated
- classBytecodePartialMatch: the bytecode of a class file called
JndiManager, or a class within an obfuscated jar, partially matched the bytecode of a known version, see the Bytecode partial matching section for more details
The summary outlines:
- filesScanned: the total number of files crawled
- permissionDeniedErrors: the number of directories or files that could not be read due to permissions
- pathErrors: the number of paths where an unexpected error occurred while trying to identify bad log4j versions
- pathsSkipped: the numbers of paths skipped from full identification of bad log4j versions due to the config options set
- numImpactedFiles: the total number of files impacted
- findings: the total number of findings previously output. For file path only mode, this will equal the number of impacted files.
Specifying --summary=false makes it such that the program does not output a summary line at the end. In this case,
the program will only print output if vulnerabilities are found.
The following tables shows when each finding is reported based on our testing:
| Unmodified log4j-core-2.14.1.jar | JndiLookup removed log4j-core-2.14.1.jar | Inside a fat jar (no renaming) | |
|---|---|---|---|
| jndiLookupClassName | |||
| jndiLookupClassPackageAndName | ✅ | ✅ | |
| jndiManagerClassName | |||
| jndiManagerClassPackageAndName | ✅ | ✅ | ✅ |
| jarNameMatched | ✅ | ✅ | |
| jarNameInsideArchiveMatched | |||
| classFileMd5Matched | ✅ | ✅ | ✅ |
| bytecodeInstructionMd5Matched | |||
| jarFileObfuscated | |||
| classBytecodePartialMatch | |||
| Detected | ✅ | ✅ | ✅ |
| Shaded (packages renamed only) | Shaded (all renamed) | Shaded/obfuscated (bytecode optimised) | |
|---|---|---|---|
| jndiLookupClassName | ✅ | ||
| jndiLookupClassPackageAndName | |||
| jndiManagerClassName | ✅ | ||
| jndiManagerClassPackageAndName | |||
| jarNameMatched | |||
| jarNameInsideArchiveMatched | |||
| classFileMd5Matched | |||
| bytecodeInstructionMd5Matched | ✅ | ||
| jarFileObfuscated | ✅ | ||
| classBytecodePartialMatch | ✅ | ✅ | |
| Detected | ✅ | ✅ | ✅ |
| log4j-core-2.14.1.jar inside a .tgz file | Heavily obfuscated (additional bytecode instructions inserted) | |
|---|---|---|
| jndiLookupClassName | ||
| jndiLookupClassPackageAndName | ✅ | |
| jndiManagerClassName | ||
| jndiManagerClassPackageAndName | ✅ | |
| jarNameMatched | ||
| jarNameInsideArchiveMatched | ✅ | |
| classFileMd5Matched | ✅ | |
| bytecodeInstructionMd5Matched | ||
| jarFileObfuscated | ||
| classBytecodePartialMatch | ||
| Detected | ✅ | ❌ |
Some of these detections may require non-default settings depending on the file scanned. Some detections may not identify all cases, common shading and obfuscation has been tested but it is not possible to cover every possible change that could be made by such a tool.
If a class is shaded (for example, to build a fat jar), then the bytecode is rewritten to update the package. This means the hash of the class will no longer match against known versions, nor will the class appear where expected within a jar.
To account for this, we perform a less accurate hash of a class file: we only hash the fixed parts of the bytecode defining each method, ignoring all parts that might vary upon shading. We take an md5 hash of the resulting bytecode and compare against known versions.
Testing against shaded jars shows this matches when the package version has been changed but the class otherwise left intact. Shading which further modifies classes, such as by removing methods, will not be found with this approach.
If the event of more aggressive shading, which deletes unused methods, or obfuscated being applied in order to compress the Jar size bytecode matching will not produce matches. The class of interest may also no longer be called JndiManager or appear under a package hierarchy that indicates the presence of log4j.
For these cases we have implemented partial bytecode matching based on signatures generated from obfuscated versions of the log4j jar compared against the version as shipped.
By default we apply this detection to classes called JndiManager which have not been matched by md5 or full bytecode matching, or to all classes in Jar files with an average package and class name length both under 3.
A match here is likely but not guaranteed to be log4j within the reported version range. Obfuscation aimed to preventing reverse engineering rather than simply compressing the Jar size may also cause false negatives.
Testing against know shaded jars in open source products, such as the Hive jdbc driver, has shown this approach to produce matches.
Crawl filesystem to scan for jars vulnerable to CVE-2021-45046.
Root must be provided and can be a single file or directory.
If a directory is provided, it is traversed and all files are scanned.
Use the ignore-dir flag to provide directories of which to ignore all nested files.
Usage:
log4j-sniffer crawl <root> [flags]
Flags:
--archive-open-mode string Supported values:
standard - standard file opening will be used. This may cause the filesystem cache to be populated with reads from the archive opens.
directio - direct I/O will be used when opening archives that require sequential reading of their content without being able to skip to file tables at known locations within the file.
For example, "directio" can have an effect on the way that tar-based archives are read but will have no effect on zip-based archives.
Using "directio" will cause the filesystem cache to be skipped where possible. "directio" is not supported on tmpfs filesystems and will cause tmpfs archive files to report an error. (default "standard")
--archives-per-second-rate-limit int The maximum number of archives to scan per second. 0 for unlimited.
--directories-per-second-rate-limit int The maximum number of directories to crawl per second. 0 for unlimited.
--disable-cve-2021-44832-detection Disable detection of CVE-2021-44832 in versions up to 2.17.0
--disable-cve-2021-45105-detection Disable detection of CVE-2021-45105 in versions up to 2.16.0
--disable-detailed-findings Do not print out detailed finding information when not outputting in JSON.
--disable-flagging-jndi-lookup Do not report results that only match on the presence of a JndiLookup class.
Even when disabled results which match other criteria will still report the presence of JndiLookup if relevant.
--disable-unknown-versions Only output issues if the version of log4j can be determined (note that this will cause certain detection mechanisms to be skipped)
--enable-obfuscation-detection Enable applying partial bytecode matching to Jars that appear to be obfuscated. (default true)
--enable-partial-matching-on-all-classes Enable partial bytecode matching to all class files found.
--enable-trace-logging Enables trace logging whilst crawling. disable-detailed-findings must be set to false (the default value) for this flag to have an effect.
--file-path-only If true, output will consist of only paths to the files in which CVEs are detected
-h, --help help for crawl
--ignore-dir strings Specify directory pattern to ignore. Use multiple times to supply multiple patterns.
Patterns should be relative to the provided root.
e.g. ignore "^/proc" to ignore "/proc" when using a crawl root of "/"
--json If true, output will be in JSON format
--maximum-average-obfuscated-class-name-length int The maximum class name length for a class to be considered obfuscated. (default 3)
--maximum-average-obfuscated-package-name-length int The maximum average package name length a class to be considered obfuscated. (default 3)
--nested-archive-disk-swap-dir string When nested-archive-disk-swap-max-size is non-zero, this is the directory in which temporary files will be created for writing temporary large nested archives to disk. (default "/tmp")
--nested-archive-disk-swap-max-size uint The maximum size in bytes of disk space allowed to use for inspecting nest archives that are over the nested-archive-max-size.
By default no disk swap is to be allowed, nested archives will only be inspected if they fit into the configured nested-archive-max-size.
When an archive is encountered that is over the nested-archive-max-size, an the archive may be written out to a temporary file so that it can be inspected without a large memory penalty.
If large archives are nested within each other, an archive will be opened only if the accumulated space used for archives on disk would not exceed the configured nested-archive-disk-swap-max-size.
--nested-archive-max-depth uint The maximum depth to recurse into nested archives.
A max depth of 0 will open up an archive on the filesystem but not any nested archives.
--nested-archive-max-size uint The maximum compressed size in bytes of any nested archive that will be unarchived for inspection.
This limit is made a per-depth level.
The overall limit to nested archive size unarchived should be controlled
by both the nested-archive-max-size and nested-archive-max-depth. (default 5242880)
--per-archive-timeout duration If this duration is exceeded when inspecting an archive,
an error will be logged and the crawler will move onto the next file. (default 15m0s)
--summary If true, outputs a summary of all operations once program completes (default true)
Archives can both contain many files listed and have other archives nested within them. If either is followed without limit then it would be possible to cause scans to take either an unacceptable amount of time or consume an acceptable amount of memory.
--per-archive-timeout allows for control of the maximum time a single archive will be examined.
--nested-archive-max-size and --nested-archive-max-depth control how many nested archives are opened, and how large each one may be. The total memory required will be on the order to the product of these two values.
While nice and ionice on Linux and other platform specific tooling can be used to limit the priority of processes it may be desired to further limit resource use. One example is when running on AWS instances with a burst balance for IO, which might be consumed by running this tool leading to a negative impact on other processes running on that instance.
--directories-per-second-rate-limit and --archives-per-second-rate-limit limit how quickly directories will be traversed and how quickly archives will be processed.
For partial bytecode matching we apply a heuristic for whether a Jar is obfuscated. This is because the partial matching is expensive to apply and as such running it on every matching Jar on a system may not be feasible.
The heuristic used is that both the average package name length and class name length need to be below a certain value for a Jar to be considered obfuscated. By default this is 3. You can tune these values using --maximum-average-obfuscated-class-name-length and --maximum-average-obfuscated-package-name-length.
If you wish to turn off obfuscation detection entirely then --enable-obfuscation-detection can be used. If instead you wish to apply partial matching to all Jars, regardless of whether they appear obfuscated, then you can use --enable-partial-matching-on-all-classes.
If you do not wish to report results for CVE-2021-45105 or CVE-2021-44832 then pass the --disable-cve-2021-45105-detection or --disable-cve-2021-44832-detection flags to the crawl command.
By default, both CVE-2021-45046 and CVE-2021-45105 will be reported.
Running on Linux against the entire filesystem at a low priority:
ionice -c 3 nice -n 19 log4j-sniffer crawl / --ignore-dir "^/dev" --ignore-dir "^/proc"
Running against a specific Jar with all limits removed:
log4j-sniffer crawl jar-under-suspicion.jar --enable-partial-matching-on-all-classes --nested-archive-max-depth 255 --nested-archive-max-size 5242880000
Most of the flags are shared with the crawl command and so it is recommended that delete be run using configuration that is known to not negatively impact performance of a host.
Delete files containing log4j vulnerabilities.
Crawl the file system from root, detecting files containing log4j-vulnerabilities and deleting them if they meet certain requirements determined by the command flags.
Root must be provided and can be a single file or directory.
Dry-run mode is enabled by default, where a line will be output to state where a file would be deleted when running not in dry run mode.
It is recommended to run using dry-run mode enabled, checking the logged output and then running with dry-run disabled using the same configuration flags.
Use --dry-run=false to turn off dry-run mode, enabling deletes.
When used on windows, deleting based on file ownership is unsupported and skip-owner-check should be used instead of filepath-owner.
Usage:
log4j-sniffer delete <root> [flags]
Examples:
Delete all findings nested beneath /path/to/dir that are owned by foo and contain findings that match both classFileMd5 and jarFileObfuscated.
log4j-sniffer delete /path/to/dir --dry-run=false --filepath-owner ^/path/to/dir/.*:foo --finding-match classFileMd5 --finding-match jarFileObfuscated
Flags:
--archive-open-mode string Supported values:
standard - standard file opening will be used. This may cause the filesystem cache to be populated with reads from the archive opens.
directio - direct I/O will be used when opening archives that require sequential reading of their content without being able to skip to file tables at known locations within the file.
For example, "directio" can have an effect on the way that tar-based archives are read but will have no effect on zip-based archives.
Using "directio" will cause the filesystem cache to be skipped where possible. "directio" is not supported on tmpfs filesystems and will cause tmpfs archive files to report an error. (default "standard")
--archives-per-second-rate-limit int The maximum number of archives to scan per second. 0 for unlimited.
--directories-per-second-rate-limit int The maximum number of directories to crawl per second. 0 for unlimited.
--disable-cve-2021-44832-detection Disable detection of CVE-2021-44832 in versions up to 2.17.0
--disable-cve-2021-45105-detection Disable detection of CVE-2021-45105 in versions up to 2.16.0
--dry-run When true, a line with be output instead of deleting a file. Use --dry-run=false to enable deletion. (default true)
--enable-obfuscation-detection Enable applying partial bytecode matching to Jars that appear to be obfuscated. (default true)
--enable-partial-matching-on-all-classes Enable partial bytecode matching to all class files found.
--enable-trace-logging Enables trace logging whilst crawling. disable-detailed-findings must be set to false (the default value) for this flag to have an effect.
--filepath-owner strings Provide a filepath pattern and owner template that will be used to check whether a file should be deleted or not when it is deemed to be vulnerable.
Multiple values can be provided and values must be provided in the form filepath_pattern:owner_template, where a filepath pattern and owner template are colon separated.
When a file is deemed to be vulnerable, the path of the file containing the vulnerability will be matched against all filepath patterns.
For all filepath matches, the owner template will be expanded against the filepath pattern match to resolve to a file owner value that the actual file owner will then be compared against.
Owner templates may use template variables, e.g. $1, $2, $name, that correspond to capture groups in the filepath pattern. Please refer to the standard go regexp package documentation at https://pkg.go.dev/regexp#Regexp.Expand for more detailed expanding behaviour.
If no filepaths match, the file will not be deleted. If any filepaths match, all matching filepath patterns' corresponding expanded templated owner values must match against the actual file owner for the file to be deleted.
Architecture-specific behaviour:
- linux-amd64: libc-backed code is used, which is able to infer the owner of a file over a broad range of account setups.
- linux-arm64: only the user running or users from /etc/passwd will be available to infer file ownership.
- darwin-*: only the user running or users from /etc/passwd will be available to infer file ownership.
- windows-*: file ownership is unsupported and --skip-owner-check should be used instead.
Examples:
--filepath-owner ^/foo/bar/.+:qux would consider /foo/bar/baz for deletion only if it is owned by qux.
--filepath-owner ^/foo/bar/.+:qux and --filepath-owner ^/foo/bar/baz/.+:quuz would not consider /foo/bar/baz/corge for deletion if owned by either qux or quuz because both would need to match.
--filepath-owner ^/foo/(\w+)/.*:$1 would consider /foo/bar/baz for deletion only if it is owned by bar.
--finding-match strings When supplied, any vulnerable finding must contain all values that are provided to finding-match for it to be considered for deletion.
These values are considered on a finding-by-finding basis, i.e. an archive containing two separate vulnerable jars will only be deleted if either of the contained jars matches all finding-match values.
Supported values are as follows, but can be provided case-insensitively:
- ClassBytecodeInstructionMd5
- ClassBytecodePartialMatch
- ClassFileMd5
- JarFileObfuscated
- JarName
- JarNameInsideArchive
- JndiLookupClassName
- JndiLookupClassPackageAndName
- JndiManagerClassName
- JndiManagerClassPackageAndName
Example:
--finding-match classFileMd5 and --finding-match jarFileObfuscated would only delete a file containing a vulnerability if the vulnerability contains a class file hash match and an obfuscated jar name.
If a vulnerable finding contained only one of these finding-match values then the file would not be considered for deletion.
-h, --help help for delete
--ignore-dir strings Specify directory pattern to ignore. Use multiple times to supply multiple patterns.
Patterns should be relative to the provided root.
e.g. ignore "^/proc" to ignore "/proc" when using a crawl root of "/"
--maximum-average-obfuscated-class-name-length int The maximum class name length for a class to be considered obfuscated. (default 3)
--maximum-average-obfuscated-package-name-length int The maximum average package name length a class to be considered obfuscated. (default 3)
--nested-archive-disk-swap-dir string When nested-archive-disk-swap-max-size is non-zero, this is the directory in which temporary files will be created for writing temporary large nested archives to disk. (default "/tmp")
--nested-archive-disk-swap-max-size uint The maximum size in bytes of disk space allowed to use for inspecting nest archives that are over the nested-archive-max-size.
By default no disk swap is to be allowed, nested archives will only be inspected if they fit into the configured nested-archive-max-size.
When an archive is encountered that is over the nested-archive-max-size, an the archive may be written out to a temporary file so that it can be inspected without a large memory penalty.
If large archives are nested within each other, an archive will be opened only if the accumulated space used for archives on disk would not exceed the configured nested-archive-disk-swap-max-size.
--nested-archive-max-depth uint The maximum depth to recurse into nested archives.
A max depth of 0 will open up an archive on the filesystem but not any nested archives.
--nested-archive-max-size uint The maximum compressed size in bytes of any nested archive that will be unarchived for inspection.
This limit is made a per-depth level.
The overall limit to nested archive size unarchived should be controlled
by both the nested-archive-max-size and nested-archive-max-depth. (default 5242880)
--per-archive-timeout duration If this duration is exceeded when inspecting an archive,
an error will be logged and the crawler will move onto the next file. (default 15m0s)
--skip-owner-check When provided, the owner of a file will not be checked before attempting a delete.
Produces hashes to identify a class file within a JAR.
The entire class is hashed to allow for matching against the exact version.
The bytecode opcodes making up the methods are hashed, for matching versions
with modifications.
Use the class-name option to change which class is analysed within the JAR.
Usage:
log4j-sniffer identify <jar> [flags]
Flags:
--class-name string Specify the full class name and package to scan.
Defaults to the log4j JdniManager class. (default "org.apache.logging.log4j.core.net.JndiManager")
-h, --help help for identify
Identify runs against a Jar and produces both an md5 hash and a bytecode instruction hash. The primary purpose for this command is generating signatures for the crawl command.
Example output:
$ log4j-sniffer identify examples/single_bad_version/log4j-core-2.14.1.jar
Size of class: 5029
Hash of complete class: f1d630c48928096a484e4b95ccb162a0
Hash of all bytecode instructions: 8139e14cd3955ef709139c3f23d38057-v0
Compares the classes specified within source_jar and target_jar.
Outputs the parts the jars have in common in order to build signatures for matching.
The class names must be fully qualified and not end with .class.
Usage:
log4j-sniffer compare <source_jar> <class> <target_jar> <class> [flags]
Flags:
-h, --help help for compare
Compare two classes and output similar bytecode in hex encoding. The primary purpose of this command is to produce signatures for partial bytecode matching. It is not intended to provide useful output if run against Jar files of unknown construction.














































































































































































































