SingingVoice-MFA-Training and Design of New Mandarin-Syllable-to-phoneme System
Hello, everyone! I'm a graduate student in Shanghai who major in phonetics. I'm highly grateful to my college and my institution (Institute of Linguistics, IOL) for providing me with interdisciplinary knowledge for language studies. My institution offers me a chance to learn about traditional linguistic knowledge and frontiers of speech science. Special thanks to my supervisor Mr. Zhu, who constantly encourages me to pursuit my dream.
Table of Contents
- Singing Voice MFA Acoustic Model Training
- Task 1 : Split TextGrid to Sentence level
- Task 2 : Convert Split TextGrids to Corresponding txt files
- Task 3 : MFA acoustic model training
- Task 4 : Performance of MFA acoustic model (Version 1.0.0)
- Task 5 : My own opinions about the phoneme system and dictionary
- Task 6 : How to use the pretrained model for aligning
- Task 7 : Test of new phoneme system (MFA acoustic model version 2.0.0 and 3.0.0)
- Singing Voice Auto-annotation based on MFA and Praat
2022.09.02
In the Opencpop dataset, the textgirds is given in a level of the whole song. It also offers split wav files in the sentence level, so we need to split the textgrids to the sentence level, which makes them suitable for aligning with split wav files.
split_textgrid_addictive_order.praat is based on praat scripting, where I combined the praat scripts offer by Articulatum and ShaoPengfei. The function of this file (ending with .praat) is to split original textgrids offered by Opencpop to sentence level, with the same name of their corresponding wav slices.
You need to download Praat to make split_textgrid_addictive_order.praat available to be opened. Double click split_textgrid_addictive_order.praat and Praat will automatically open itself.
The only two things you need to do include: 1. Put all original textgrids into the folder original-textgrid (you can change the folder name as you wish) 2. Click the button "Run" in the pop-up window of Praat, and change the path of Directory_name (the folder contains original textgrids) and output_Directory_name (the folder you wish to store the split textgrid).
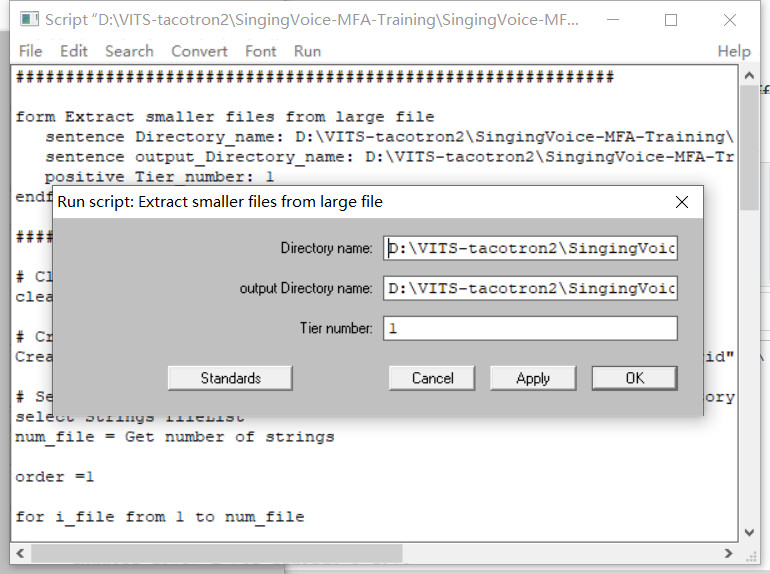
2022.09.03
When you finish task 1, you would get 3756 split textgrids. Every split textgrid would be perfectly aligned with its corresponding wav files (with the same name). You can check it through Praat by randomly opening one split textgrid and one wav file with its same name.
Task 2 helps you get all files required for MFA acoustic model training (split wav files, their transcriptions in the word level saved in txt format, a dictionary containing mapping relations between words and phonemes). The dictionary has been offered here, which was made of a given pinyin to phoneme mapping table offered by Opencpop and 19 Out-of-vocabulary (OOV) word types that I appended on my own.
A jupyter notebook named split_textgrid_to_txt_extractor.ipynb is offered here for task 2. The function of this notebook include: 1. Extract the third tier of textgrid (tier named “音节”) and append the symbols in to list 2. For special symbols [ SP, AP, and _ ] , SP and AP would be remained, _ would be replaced by the final rhyming part of the former Chinese syllable 3. Create 3756 txt files with the same name of 3756 split textgrids.
Taking the textgrid shown in the picture as an example, after we finish task 2, its corresponding txt file would be automatically built in the folder split-textgrid-to-txt, with the content "piao fu zai ai ai AP SP yi i pian ian ian wu nai SP AP ". By the way, thanks to the help of yqzhishen. He made me finally realize that SP refers to silence. AP refers to aspiration, and _ refers to the lengthening of final rhyming part.
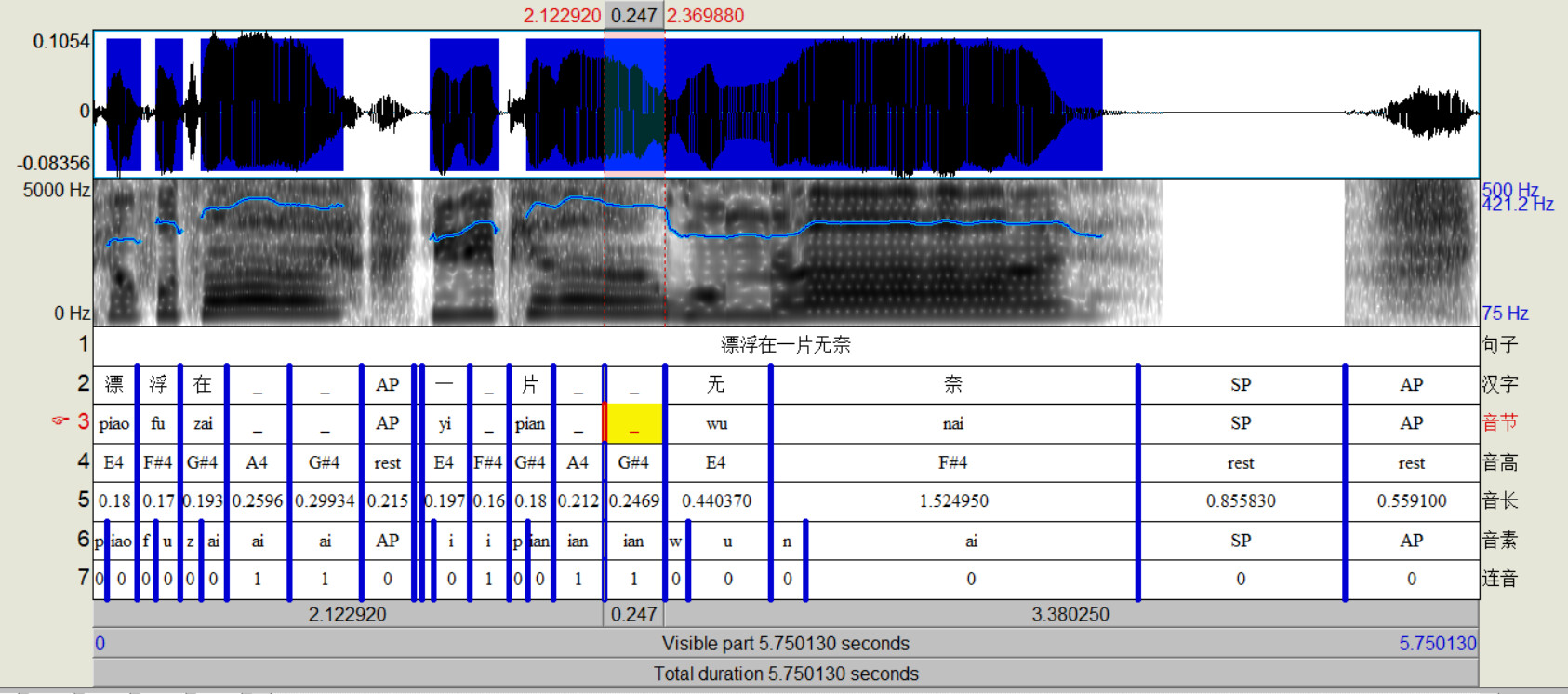
2022.09.04
For the installation of MFA, I highly recommend you to install MFA in the linux system. Windows can activate a sub-system of WSL (Windows Subsystem for Linux). My environment is Ubantu 18.04 and WSL 1.0. Besides, I highly recommend you to install MFA by following the procedures offered by Official Guidelines :
-
MFA can be installed with Anaconda or Miniconda (instruction here).
-
After the installation of Conda, run command
conda create -n aligner -c conda-forge montreal-forced-aligner -
Activate new environment with the command
conda activate aligner -
Check whether MFA has been successfully installed
mfa versionormfa model download acoustic english_us_arpa
To help you be familiar with the process of installation and model training of MFA, I create a jupyter notebook MFA_for_Colab.ipynb. You can open it with google colab and run MFA online by click the button one by one. It contained instructions on MFA model downloading, training and aligning.
To train an acoustic model of MFA, you need to prepare three things (the split wav files, their corresponding transcriptions in the word level saved in txt format, a dictionary that stores the mapping relations between words and phonemes). Here, the split wav files and their corresponding transcriptions are stored in the folder my_corpus, and the dictionary storing mapping relations is my_dictionary.txt.
Then, you can use the command mfa train --clean /content/SingingVoice-MFA-Training/my_corpus /content/SingingVoice-MFA-Training/my_dictionary.txt /content/SingingVoice-MFA-Training/acoustic-model-training/opencpop_acoustic_model.zip /content/SingingVoice-MFA-Training/acoustic-model-training to train your acoustic model for singing voice auto-aligning.
You should pay attention to these four paths here. The first path is where you store the wav files and their transcriptions. The second path is the path of your dictionary. The third path is where you'd like to store the newly trained acoustic model (you can change its name with xxxxx.zip as you wish). The last path is where you'd like to store the newly produced aligned textgrids. mfa train --clean <corpus path> <dictionary path> <acoustic model path> <aligned textgrids path>
After 18000 seconds (approximately 5 hours), we finally get out trained acoustic model for singing voice aligning. I have uploaded this model opencpop_acoustic_model.zip and its corresponding dictionary my_dictionary.txt in the repository and the release. Here is the performance of one example textgrid. The upper one is what we get with newly trained MFA acoustic model. The lower one is its original texgrid labeled by hand.
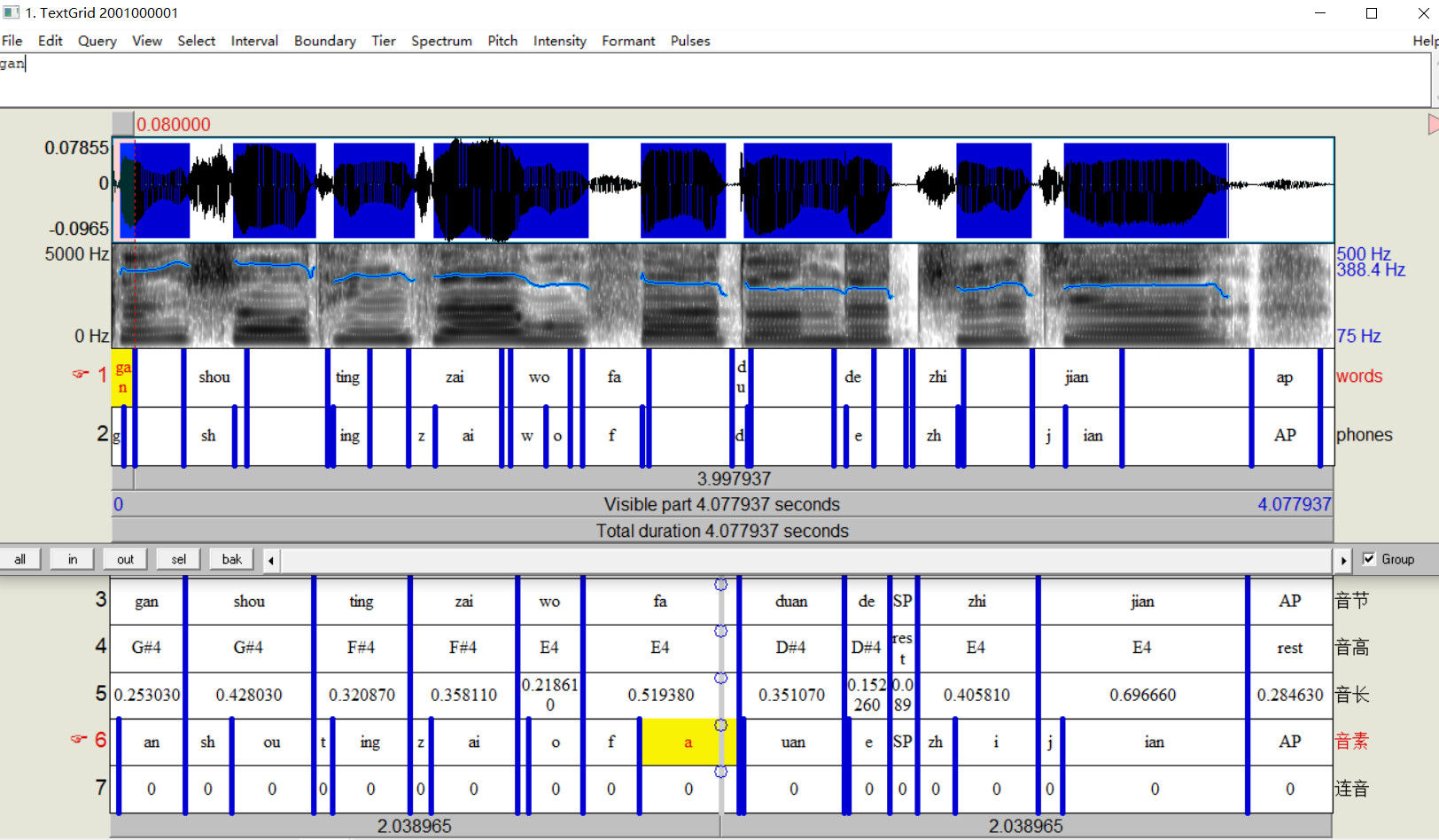
Well, there is good news and bad news here! The good news is that the boundaries of consonants are almost perfect. For every syllable in tier "words", its left boundary is highly approximate to the hand labeling. So the starting point and the interval of consonants are perfect. The bad news is that the interval of rhyming part of Chinese syllables (韵母) is too short, which might need further lengthening by hand. As for the cause of such problem, I tend to attribute this to the phoneme system and dictionary of mapping relation, but I'm not so sure about it until a new phoneme system is applied to our training.
2022.09.05
From the labelling format of Opencpop, the syllables are separated into two parts: consonants (声母) and the rhyming part (韵母). For example, zhuang would be separated to zh and uang. niang would be separated to n and iang. Before I start to express my own opinion, the first and most important thing I'd like to clarify here is that I'm not going to criticize any design of the phoneme system.
Actually, every proposal for the phoneme system has their own strengths and limitations, and all in all, the only two differences between different proposals for the phoneme system and dictionary is the Degree of Segmentation (切分程度) and phoneme-notation-symbols (音位记载符号).
As for the Degree of Segmentation, you can also call it granularity, grain size or particle size (粒度), although such terms are not so perfectly matched here. The mapping relation of words and phonemes in Opencpop dataset belongs to the type of coarse grain (粗粒度). As shown in my_dictionary.txt, long syllables are separated into two parts. The MFA 1.0 dictionary of pinyin, which I uploaded as mandarin_pinyin.txt, belongs to the type of intermediate grain (中等粒度). For example, zhuang would be separated into zh, ua, and ng. niang would be separated into n, ia, and ng. The monophthong, diphthong, and triphthong were not further separated (无论是韵头、韵腹、还是元音韵尾,凡是元音部分都没有被切割开). Only the nasal condas (鼻韵尾) were separated from syllables.
In fact, we could further divide the rhythming part of Chinese syllables in a method of fine grain (细粒度). That is, we could further separate the monophthong, diphthong, triphthong and conda of Chinese syllables into smaller parts. For example:
| 韵母切为韵头、韵腹、元音韵尾、鼻音韵尾 |
|---|
| wen:零声母,韵头u,韵腹e,韵尾n |
| you:零声母,韵头i,韵腹o,韵尾u |
| yuan:零声母,韵头ü,韵腹a,韵尾n |
| tai:声母t,无韵头,韵腹a,韵尾i |
| xiu:声母x,韵头i,韵腹o,韵尾u |
| yong:零声母,韵头i,韵腹o,韵尾ng |
Considering the fact that I'm not a specialist in Mandarin syllable, so I'll recommend several materials here for you, if you are interested in Mandarin syllabic structures. (Note: My translation is not proper here) 1. Mandarin syllabic structures 2. Onset of Mandarin (声母) 3. Nucleus and conda of Mandarin (韵母) 4. Hànyǔ Pīnyīn 5. All possible Hànyǔ Pīnyīn and their transcriptions.
As for phoneme-notation-symbols (音位记载符号), there are at least two types of symbols: pinyin-based-notation-symbols and IPA-based-notation-symbols. Pinyin tends to be in the superficial level, as it is related to Orthography. IPA tends to be in the deep level. A phone would be marked as a new phone when it distinguishes meanings of different words in a language. Here I may take MFA 2.0 pinyin dictionary and MFA 2.0 kind-of-IPA-based dictionary (MFA phone set) as an example.
| Comparison of two notation symbols in different dictionaries |
|---|
| In MFA 2.0 pinyin dictionary, chuan4 shao1 would be mapped as chuan4 ch ua4 n shao1 sh ao1 |
| In MFA 2.0 MFA phone set, 串烧 would be mapped as 1 0.0 0.0 0.0 ʈʂʰ w a˥˩ n ʂ au˥˥ |
Download my_dictionary.txt and opencpop_acoustic_model.zip and use command mfa align <corpus path> <dictionary path> <acoustic model path> <aligned textgrids path>. The first path is where you store the wav files and their transcriptions. The second path is the path of your dictionary. The third path is where you'd like to store the newly trained acoustic model (you can change its name with xxxxx.zip as you wish). The last path is where you'd like to store the newly produced aligned textgrids.
We also put an example for such command in the MFA_for_Colab.ipynb , with the command mfa align /content/SingingVoice-MFA-Training/my_corpus /content/SingingVoice-MFA-Training/my_dictionary.txt /content/SingingVoice-MFA-Training/opencpop_acoustic_model.zip /content/SingingVoice-MFA-Training/acoustic-model-applying
In the future, I might improve the performance of such acoustic model through designing new phoneme systems and adding more singing voice into the training dataset. I'm now starting my new semester. Hope that I could finish these tough works in the future. Best regards!
In the previous part, I have shown my concerns that the Degree of Segmentation (切分程度) might influence the performance of MFA acoustic model. That is because the phoneme system of coarse grain (粗粒度) may reduce the average elements that one phoneme could get for training. For example:
| Chinese Syllables | Rhythming part as a whole | Separated Rhythming Part |
|---|---|---|
| biao | b+iau | b+i+a+u |
| kuai | k+uai | k+u+a+i |
| kuo | k+uo | k+u+o |
| qiu | q+iou | q+i+o+u |
| Total Count | b(1), k(2), q(1), iau(1), uai(1), uo(1), iou(1) | b(1), k(2), q(1), i(3), u(4), a(2), o(2) |
So I made a new folder here named MFA_pinyin_dict, which contains the simplified MFA 2.0 pinyin dictionary without tones. Only the nasal condas (鼻韵尾) and onset (声母) were separated from syllables. For example, zhuang would be separated into zh, ua, and ng. niang would be separated into n, ia, and ng. The monophthong, diphthong, and triphthong were not further separated. From the performance of new MFA acoustic model, we could know the relationship between the accuracy of auto-aligning (自动标注准度) and the particle size of phoneme system (音素系统粒度).
In the past few days, I also made a new phoneme system based on IPA transcription of Chinese syllables. So there are three versions of MFA acoustic models and dictionary: IPA, MFA pinyin and Opencpop. The following picture shows different performances of acoustic models. MFA acoustic model 3.0.0, which is the upper one based on fully separated IPA transcription, is best among all these three models. MFA acoustic model 2.0.0 is in the middle, which is based on MFA 2.0 pinyin dictionary.
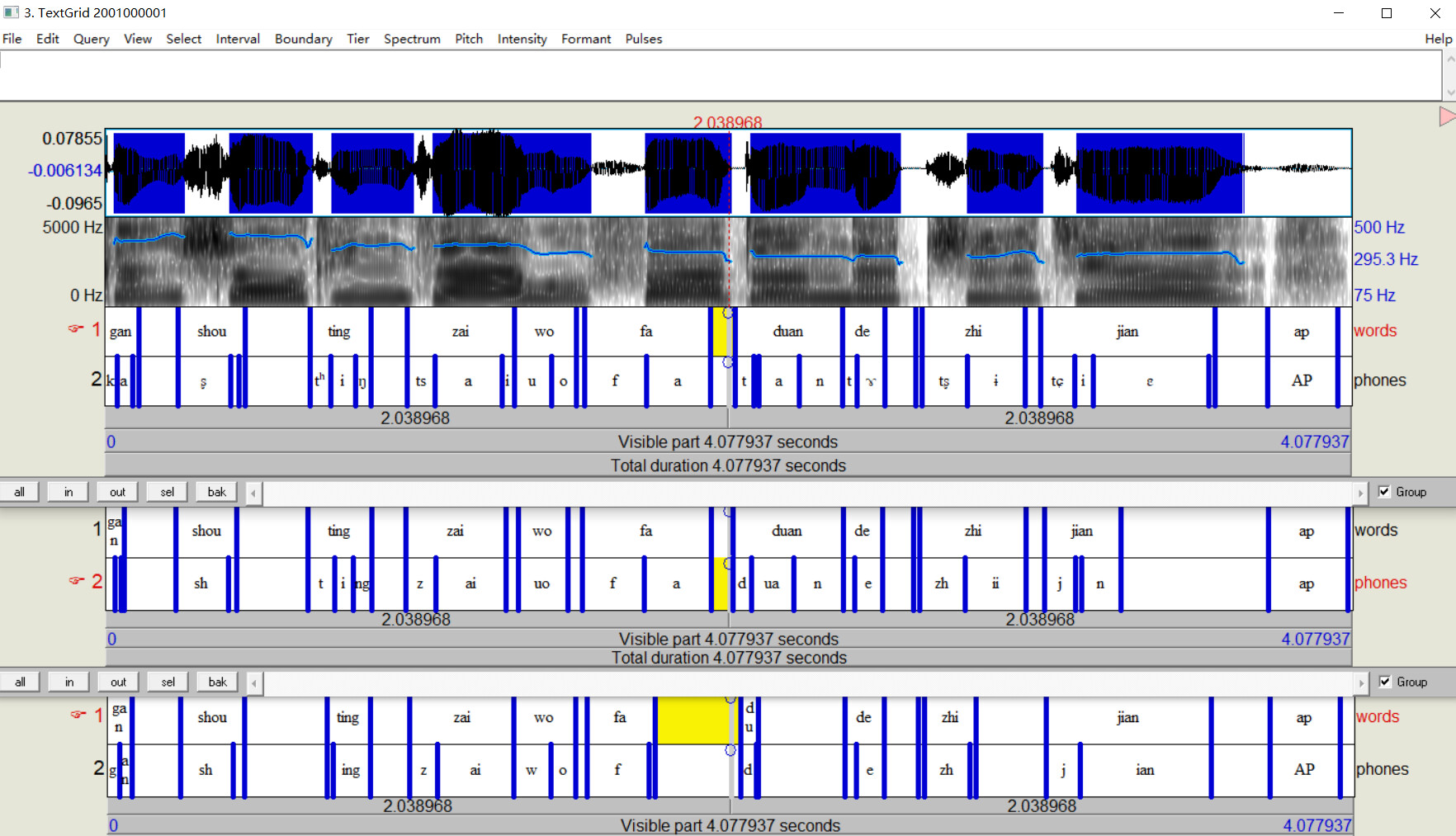
Please check it in AlexandaJerry/SingingVoice-Auto-Alignment-Revised: revised version of the workflow of auto annotation (github.com) . Considering the fact that there are too many folders in current repository, I make a new repository to store my ideas on how to auto-annotate singing voice with the combination of MFA and Praat. I haven't finished its tutorial and instruction, but the project has been proved to be feasible.






