PPL Correlation Command
Overview
In the past year OpenSearch Observability & security teams have been busy with many aspects of improving data monitoring and visibility.
The key idea behind our work was to enable the users to dig in their data and emerge the hidden insight within the massive corpus of logs, events and observations.
One fundamental concept that will help and support this process is the ability to correlate different data sources according to common dimensions and timeframe.
This subject is well documented and described and this RFC will not dive into the necessity of the correlation (appendix will refer to multiple resources related) but for the structuring of the linguistic support for such capability .
Problem definition
In the appendix I’ll add some formal references to the domain of the problem both in Observability / Security, but the main takeaway is that such capability is fundamental in the daily work of such domain experts and SRE’s.
The daily encounters with huge amount of data arriving from different verticals (data-sources) which share the same time-frames but are not synchronized in a formal manner.
The correlation capability to intersect these different verticals according to the timeframe and the similar dimensions will enrich the data and allow the desired insight to surface.
Example
Lets take the Observability domain for which we have 3 distinct data sources
- Logs
- Metrics
- Traces
Each datasource may share many common dimensions but to be able to transition from one data-source to another its necessary to be able to correctly correlate them.
According to the semantic naming conventions we know that both logs, traces and metrics
Lets take the following examples:
Log
{
"@timestamp": "2018-07-02T22:23:00.186Z",
"aws": {
"elb": {
"backend": {
"http": {
"response": {
"status_code": 500
}
},
"ip": "10.0.0.1",
"port": "80"
},
...
"target_port": [
"10.0.0.1:80"
],
"target_status_code": [
"500"
],
"traceId": "Root=1-58337262-36d228ad5d99923122bbe354",
"type": "http"
}
},
"cloud": {
"provider": "aws"
},
"http": {
"request": {
...
},
"communication": {
"source": {
"address": "192.168.131.39",
"ip": "192.168.131.39",
"port": 2817
}
},
"traceId": "Root=1-58337262-36d228ad5d99923122bbe354"
}
This is an AWS ELB log arriving from a service residing on aws.
It shows that a backend.http.response.status_code was 500 - which is an error.
This may come up as part of a monitoring process or an alert triggered by some rule. Once this is identified, the next step would be to collect as much data surrounding this event so that an investigation could be done in the most Intelligent and thorough way.
The most obviously step would be to create a query that brings all data related to that timeframe - but in many case this is too much of a brute force action.
Data may be too large to analyze and would result in spending most of the time only filtering the none-relevant data instead of actually trying to locate the root cause of the problem.
Suggest Correlation command
The next approach would allow to search in a much fine-grained manner and further simplify the analysis stage.
Lets review the known facts - we have multiple dimensions that can be used to correlate data data from other sources:
So assuming we have the additional traces / metrics indices available and using the fact that we know our schema structure (see appendix with relevant schema references) we can generate a query for getting all relevant data bearing these dimensions during the same timeframe.
Here is a snipped of the trace index document that has http information that we would like to correlate with:
{
"traceId": "c1d985bd02e1dbb85b444011f19a1ecc",
"spanId": "55a698828fe06a42",
"traceState": [],
"parentSpanId": "",
"name": "mysql",
"kind": "CLIENT",
"@timestamp": "2021-11-13T20:20:39+00:00",
"events": [
{
"@timestamp": "2021-03-25T17:21:03+00:00",
...
}
],
"links": [
{
"traceId": "c1d985bd02e1dbb85b444011f19a1ecc",
"spanId": "55a698828fe06a42w2",
},
"droppedAttributesCount": 0
}
],
"resource": {
"service@name": "database",
"telemetry@sdk@name": "opentelemetry",
"host@hostname": "ip-172-31-10-8.us-west-2.compute.internal"
},
"status": {
...
},
"attributes": {
"http": {
"user_agent": {
"original": "Mozilla/5.0"
},
"network": {
...
}
},
"request": {
...
}
},
"response": {
"status_code": "200",
"body": {
"size": 500
}
},
"client": {
"server": {
"socket": {
"address": "192.168.0.1",
"domain": "example.com",
"port": 80
},
"address": "192.168.0.1",
"port": 80
},
"resend_count": 0,
"url": {
"full": "http://example.com"
}
},
"server": {
"route": "/index",
"address": "192.168.0.2",
"port": 8080,
"socket": {
...
},
"client": {
...
}
},
"url": {
...
}
}
}
}
}
In the above document we can see both the traceId and the http’s client/server ip that can be correlated with the elb logs to better understand the system’s behaviour and condition .
New Correlation Query Command
Here is the new command that would allow this type of investigation :
source alb_logs, traces | where alb_logs.ip="10.0.0.1" AND alb_logs.cloud.provider="aws"|
correlate exact fields(traceId, ip) scope(@timestamp, 1D) mapping(alb_logs.ip = traces.attributes.http.server.address, alb_logs.traceId = traces.traceId )
Lets break this down a bit:
1. source alb_logs, traces allows to select all the data-sources that will be correlated to one another
2. where ip="10.0.0.1" AND cloud.provider="aws" predicate clause constraints the scope of the search corpus
3. correlate exact fields(traceId, ip) express the correlation operation on the following list of field :
- ip has an explicit filter condition so this will be propagated into the correlation condition for all the data-sources
- traceId has no explicit filter so the correlation will only match same traceId’s from all the data-sources
The fields names indicate the logical meaning the function within the correlation command, the actual join condition will take the mapping statement described bellow.
The term exact means that the correlation statements will require all the fields to match in order to fulfill the query statement.
Other alternative for this can be approximate that will attempt to match on a best case scenario and will not reject rows with partially match.
Addressing different field mapping
In cases where the same logical field (such as ip ) may have different mapping within several data-sources, the explicit mapping field path is expected.
The next syntax will extend the correlation conditions to allow matching different field names with similar logical meaning
alb_logs.ip = traces.attributes.http.server.address, alb_logs.traceId = traces.traceId
It is expected that for each field that participates in the correlation join, there should be a relevant mapping statement that includes all the tables that should be joined by this correlation command.
Example**:**
In our case there are 2 sources : alb_logs, traces
There are 2 fields: traceId, ip
These are 2 mapping statements : alb_logs.ip = traces.attributes.http.server.address, alb_logs.traceId = traces.traceId
Scoping the correlation timeframes
In order to simplify the work that has to be done by the execution engine (driver) the scope statement was added to explicitly direct the join query on the time it should scope for this search.
scope(@timestamp, 1D) in this example, the scope of the search should be focused on a daily basis so that correlations appearing in the same day should be grouped together. This scoping mechanism simplifies and allows better control over results and allows incremental search resolution base on the user’s needs.
Diagram
These are the correlation conditions that explicitly state how the sources are going to be joined.
[Image: Screenshot 2023-10-06 at 12.23.59 PM.png]* * *
Supporting Drivers
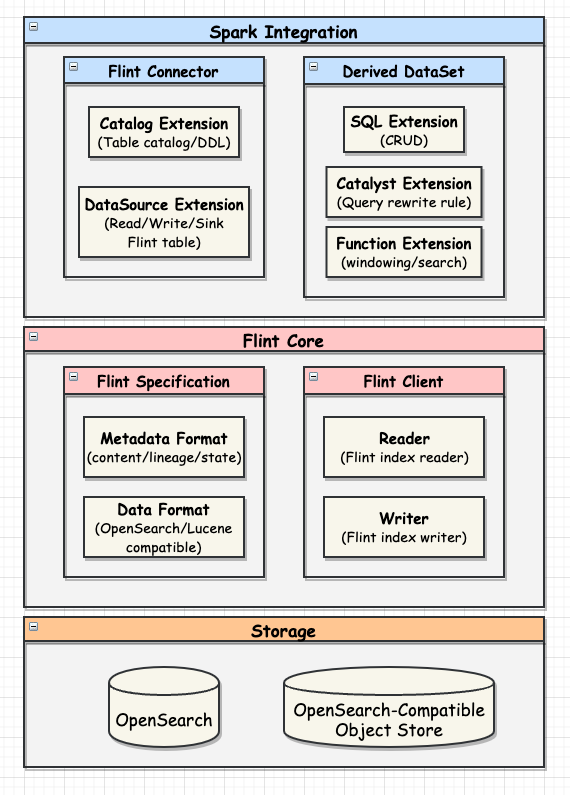
The new correlation command is actually a ‘hidden’ join command therefore the only following PPL drivers support this command:
- ppl-spark
In this driver the correlation command will be directly translated into the appropriate Catalyst Join logical plan
Example:
source alb_logs, traces, metrics | where ip="10.0.0.1" AND cloud.provider="aws"| correlate exact on (ip, port) scope(@timestamp, 2018-07-02T22:23:00, 1 D)
Logical Plan:
'Project [*]
+- 'Join Inner, ('ip && 'port)
:- 'Filter (('ip === "10.0.0.1" && 'cloud.provider === "aws") && inTimeScope('@timestamp, "2018-07-02T22:23:00", "1 D"))
+- 'UnresolvedRelation [alb_logs]
+- 'Join Inner, ('ip && 'port)
:- 'Filter (('ip === "10.0.0.1" && 'cloud.provider === "aws") && inTimeScope('@timestamp, "2018-07-02T22:23:00", "1 D"))
+- 'UnresolvedRelation [traces]
+- 'Filter (('ip === "10.0.0.1" && 'cloud.provider === "aws") && inTimeScope('@timestamp, "2018-07-02T22:23:00", "1 D"))
+- 'UnresolvedRelation [metrics]
Catalyst engine will optimize this query according to the most efficient join ordering.
Appendix