open-policy-agent / community Goto Github PK
View Code? Open in Web Editor NEWThe Community repository is the place to go for support with OPA and OPA Sub-Projects, like Conftest and Gatekeeper.
Home Page: https://www.openpolicyagent.org/
The Community repository is the place to go for support with OPA and OPA Sub-Projects, like Conftest and Gatekeeper.
Home Page: https://www.openpolicyagent.org/












































Originally posted by LionOnTheChase February 16, 2022
Hi,
We are trying to preload policy data from an external endpoint during OPA initialization so that it can be used during the evaluation of policies. How can we do this?
Details:
We want to use OPA Envoy as a sidecar to enforce authorization of incoming requests to microservices in our cluster. Every microservice would expose a swagger endpoint which would provide the endpoint-privilege needed mapping.
Using this endpoint-privilege mapping, OPA would evaluate whether an incoming request can be allowed access or not. The incoming request would be matched with one of the entries in path-privilege map, and thus OPA would know which privilege needs to be checked in the user's token.
Now, I see that writing an OPA plugin could help us invoke the localhost/service/swagger.yaml file and parse it to derive the endpoint-privilege mapping.
Are there any other alternatives to ensure that this swagger data is preloaded by the time OPA receives any requests for policy evaluation?
I can think of using another sidecar which hits the swagger, parses it and pushes the endpoint-privilege mapping to OPA . This we could do in a java application.
Are there any simpler alternatives - can we do this stuff in OPA policy itself without compromising performance ?
Originally posted by peteroneilljr September 30, 2021
This is the place to find answers to your OPA questions. The OPA community prides itself on sharing information. So feel free to share your insights as you grow your OPA knowledge.
Check the Docs! The OPA community has put in a lot of time to create Docs for OPA and Rego. Remember to double-check the Docs and provide any relevant links with your question. Providing links makes it easy for future readers to understand what you're referencing.
Link your Rego Playground. You will have a MUCH higher chance of receiving a response if you create an example in a Rego Playground. Providing a code sample with your question removes any ambiguity and saves everyone a lot of time.
Give Back! Being helpful is a core value of the OPA community. If you've found the information here useful take a second and see if you can answer a question for someone else.
Be Nice! No matter how silly or simple you think a question is, everyone deserves respect. If someone seems misguided, simply nudge them back in the right direction.
Share knowledge! Sharing is another core value of the OPA community. New members are starting their OPA journey every day and think how helpful it would have been to start with the knowledge you have now.
To contribute an example, start a thread with the question you originally had. Then in a separate post, provide the working code and instructions. You can even mark your response as the answer to let everyone know. Check this Example
Have a conversation with your peers. Starting a thread in the community category is a great way to have an ongoing discussion with a globally distributed community. Want to know who will be at the next big conference, or just looking for recommendations on which blogs to read? Start a thread, and you might find the best next read. Check this Example
This forum is subject to the OPA Code Of Conduct.
Dear All,
I have a requirement to check the order of the input keys with the order of the data available in data.json
example:
{"input" : [{"name":"Daniel", "age":23, "gender":"male","location":"Switzerland"},{"name":"Moorthy", "age":43, "location":"Switzerland","gender":"male"}] }
data.json {"orderofheader": ["name","age","gender","location"]}
In this example the order of keys in the 2nd object of the input is not as expected and hence the result should be false .
I have tried below approach but i couldn't do arithmetic operation to increment the value of a variable .
package play
import data.orderofheader
import future.keywords.in
default ordercheck=false
ordercheck_result[message]{
headers:=input[]
i:=0
j:=1
some key, in headers
not has_key(key, i)
i=sum({i, j}) #----------Its not working
#i=i+1 ----------Its not working
#i=i+j ----------Its not working
#z:=i+j ------it works but couldn't increment the z value further since reassigning different value is not possible
#message:=sprintf("index is %v and Key is %v",[z, key])
message:=sprintf("The value of the header '%v' in the given input is not in proper order ", [key])
}
has_key(key,i){
key==orderofheader[i]
}
In General, if i assign a value to a variable say i:=0 then im not able to overwrite the value of the variable.
On side Note: Is there a way to get the current index value of the key while using "some key, _ in headers"
Could any of you advice on any workaround ?
Hi,
I'm trying to get the union of two objects where one of the objects may be optional. i.e. undefined (one object is coming from data and the other from input and may or may not be there). I tried using object.union(objectA, objectB), however if one of the args is undefined the result is also undefined.
Does somebody have an idea how to solve that issue?
Original Requestor: ken_wee.pok
Original Thread: https://openpolicyagent.slack.com/archives/C1H0ZF6BE/p1649675395.948639
Message:
Hi everyone, I'm wondering if anybody had looked into/experimented the https://docs.dapr.io/reference/components-reference/supported-middleware/middleware-opa/OPA middleware> integration for DAPR? I have some questions with regards to the workings of OPA deployed in that manner, and not sure if this is a right place to ask? My question is specifically on
No response
No response
No response
Hello Team,
I am also working on it but I think since I am still learning, it is good to also ask the community so we learn from the best practice.
May I ask if any rego snippets that can be provided that to add environment variables to every container and init container in a multiple container pod?
thanks.
No response
No response
We did deploy OPA-ISTIO-PLUGIN with previous version [ istio 1.5.6 ] using MutatingWebhookConfiguration and admission-controller. Which help us to decouple application deployment file and opa configuration files. [ Which was our expectation also ].
In recent past we are planning to upgrade istio to latest version [1.7.4 ] and trying to consider upgrade OPA plugin also.
But surprisingly we have noticed, in recent deployment approach, there is nothing like OPA-ISTIO-PLUGIN, whereas it is now OPA-ENVOY-PLUGIN. [ Which i can understand for generic behavior ], but I haven't found any MutatingWebhookConfiguration and admission-controller in OPA-ENVOY-PLUGIN deployment.
Don't we have any process to use MutatingWebhookConfiguration and admission-controller and make OPA and APPLICATION deployment files loosely coupled in latest OPA-ENVOY-PLUGIN deployment process. If we have, could you please provide me the implementation approach, else we will stuck in middle because we have already implement opa-istio-plugin using admission controller.
I find the rego documentation utterly incomprehensible. For example, I feel this is an important statement:
"When evaluating rule bodies, OPA searches for variable bindings that make all of the expressions true."
But what does that even mean?
What searches? What does it search?
I'm trying to write a simple policy "Dave can do a, b, c; Mary can do x, y, z), and after 2 days, all I can get from OPA are errors.
Not able to find any documentation or example to understand how I can push incremental data ( only the changes) to OPA. It is not possible to load whole data for smaller changes for us. Can someone please guide me.
Originally posted by jiangduzi July 21, 2023
Need help, I want to reference different rego files in main.rego based on input.name. Then call custom functions defined inside that rego file but getting errors during compilation "rego_compile_error: called function policy.test shadowed".
My rego just like this:
main.rego
package play
import data.play.policies
allow {
policy := policies[input.name]
policy.test(input.params)
}policy1.rego
package play.policies.policy1
test(params) {
params["env"] == "dev"
}policy2.rego
package play.policies.policy2
test(params) {
params["env"] == "prod"
}
```</div>In a use-case where OPA is being used as authorization provider from Envoy, what is the format with which OPA receives input from Envoy?
From postman I am calling my endpoint by passing the header x-custom-header: foo. It is first routed to envoy sidecar which in turn calls OPA and forwards the request headers to OPA. What is the format/pattern in which OPA receives the Http request? Please advise.
Request example:
GET /api/v1/employees/departments
Accept: */*
x-custom-header : foo
I have been working with opa test -c with the example from https://www.openpolicyagent.org/docs/latest/policy-testing/. When I condense the rego from example.rego to
package authz
allow { input.path == ["users"]; input.method == "POST"; }
allow { some profile_id; input.path = ["users", profile_id]; input.method == "GET"; profile_id == input.user_id; }
And remove all test in example_test.rego except for test_post_allowed
package authz
test_post_allowed {
allow with input as {"path": ["users"], "method": "POST"}
}
The coverage result shows the example.rego was covered only 20 percent.
{
"files": {
"example.rego": {
"covered": [
{
"start": {
"row": 3
},
"end": {
"row": 3
}
}
],
"not_covered": [
{
"start": {
"row": 4
},
"end": {
"row": 4
}
},
{
"start": {
"row": 4
},
"end": {
"row": 4
}
},
{
"start": {
"row": 4
},
"end": {
"row": 4
}
},
{
"start": {
"row": 4
},
"end": {
"row": 4
}
}
],
"coverage": 20
},
"tests/test.rego": {
"covered": [
{
"start": {
"row": 3
},
"end": {
"row": 4
}
}
],
"coverage": 100
}
},
"coverage": 42.85
}
I think coverage is counted from statements but the first allow definition has 2 statements and the second has 4, so coverage should be 33%. Overall I would think that if statements were counted then it shouldn't matter how the rego is formatted, but if I leave example.rego in the original format and only run test_post_allowed then I get a coverage on example.rego equal to "coverage": 42.85.
Copy the code blocks above for example.rego and example_test.rego and run opa test . -c. You should get the same result I have posed above.
opa version
Version: 0.28.0
Build Commit: 3fbcd71
Build Timestamp: 2021-04-27T13:51:34Z
Go Version: go1.15.8
WebAssembly: unavailable
The API of array type
I'd like to know if operation like append and extend is supported by array. If yes, could you point me to any doc link? If not, what's the best practice to achieve this in the current REGO? Can it be added in REGO natively in the future?
It may be very simple question if people already know answer to it ,what I want to achieve is inside rego I want to specify a simple if string equals condition , however base string I want to provide at runtime , depending on many conditions.
For example I want to check if max days since login has passed then fail policy and don't let it pass , now max days for each of specific area/company is set by users. E.g. for america people says it should be 5 days and for india people says 4 days. So can I pass this max value at runtime to opa to evaluate. There can be thousand of such values and hence putting all values and doing if else is not possible.
L
.
For example, I have a policy to grant access and it will be used at two different code paths. Do I need to create two different policies?
package main
import (
"context"
"fmt"
"github.com/open-policy-agent/opa/rego"
)
func main() {
ctx := context.Background()
module := `
package example
allow {
input.subject.user = "alice"
input.auth_type = "hmac"
}
allow {
input.subject.user = "john"
input.auth_type = "api_key"
}
`
pre := map[string]interface{}{"auth_type": "hmac"}
r := rego.New(
rego.Query("data.example.allow"),
rego.Module("example.rego", module),
rego.Input(pre),
)
pr, err := r.PartialResult(ctx)
if err != nil {
panic(err.Error())
}
input := map[string]interface{}{
"subject": map[string]interface{}{
"user": "alice",
},
}
rr := pr.Rego(rego.Input(input))
rs, err := rr.Eval(ctx)
if err != nil {
panic(err.Error())
} else {
fmt.Printf("allowed: %v\n", rs.Allowed())
}
}allowed: true
allowed: false
Thanks
https://github.com/orgs/open-policy-agent/discussions/399
https://github.com/orgs/open-policy-agent/discussions/408
Originally posted by yashas224 April 18, 2023
Hi,
I have this as bundle config
services:
This is my deployment with OPA sidecar
apiVersion: apps/v1
kind: Deployment
metadata:
name: bundle-consumer-app
spec:
replicas: 1
selector:
matchLabels:
app: bundle-consumer-app
template:
metadata:
labels:
app: bundle-consumer-app
name: opa
spec:
containers:
- name: bundle-consumer-app
image: bundle-consumer-app
imagePullPolicy: Never
ports:
- containerPort: 8080
- name: opa
image: openpolicyagent/opa:0.51.0
ports:
- name: http
containerPort: 8181
args:
- "run"
- "--ignore=.*" # exclude hidden dirs created by Kubernetes
- "--server"
- "--config-file"
- "/policies/bundle-config.yaml"
volumeMounts:
- readOnly: true
mountPath: /policies
name: policy-config
livenessProbe:
httpGet:
scheme: HTTP # assumes OPA listens on localhost:8181
port: 8181
initialDelaySeconds: 5 # tune these periods for your environment
periodSeconds: 5
readinessProbe:
httpGet:
path: /health?bundle=true # Include bundle activation in readiness
scheme: HTTP
port: 8181
initialDelaySeconds: 5
periodSeconds: 5
volumes:
- name: policy-config
configMap:
name: policy-config
Opa container is not able to download the bundle.
logs from opa container:
{"level":"error","msg":"Bundle load failed: request failed: Get "http://docker.for.mac.localhost:8080/bundle-provider/download/local-policy.tar.gz\": dial tcp: lookup docker.for.mac.localhost on 10.96.0.10:53: read udp 10.1.0.158:47705-\u003e10.96.0.10:53: read: connection refused","name":"authz","plugin":"bundle","time":"2023-04-17T20:51:08Z"}
Can someone help me here?
opa-envoy-plugin extends OPA with a gRPC server, and it always returns 403 for all denied requests. But opa can be used for both authentication and authorization, I want to return 401 when authentication is failed, is the opa-envoy-plugin able to do that?
Hello, I am new to OPA and rego code and I am trying to implement a policy in my test environment. In the below constraint template, I am trying to import the resourcequota data configured in all of the namespaces of a cluster. Below constraint template's objective is to deny pod creation if the namespace where it is supposed to create does not have resource quota defined.
Blog referred to create this template: https://www.magalix.com/blog/how-to-force-kubernetes-namespaces-to-have-resourcequotas-defined-using-opa
Image used for the below constraint template : openpolicyagent/gatekeeper:v3.8.1
apiVersion: templates.gatekeeper.sh/v1
kind: ConstraintTemplate
metadata:
name: k8sresourcequota
spec:
crd:
spec:
names:
kind: K8sResourceQuota
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8sresourcequota
import data.kubernetes.resourcequotas
violation[{"msg": msg}] {
input.request.kind.kind == "Pod"
# Extract the the namespace from the request information
requestns := input.request.object.metadata.namespace
# Is it part of the existing resource quotas?
existingrqs := {e | e := resourcequotas[][].metadata.namespace}
not ns_exists(requestns,existingrqs)
msg = sprintf("The Pod %v could not be created because the %v namespace does not have ResourceQuotas defined",[input.request.object.metadata.name,input.request.object.metadata.namespace])
}
ns_exists(ns,arr){
arr[_] = ns
}
But when I try to apply this file, I get the following error. Why is it showing bad import? From where can I check, the types of import that can be included in the rego code.
Error from server: error when creating "template.yaml": admission webhook "validation.gatekeeper.sh" denied the request: invalid ConstraintTemplate: invalid import: bad import
Originally posted by nitheshrayuduv February 13, 2023
If I start the OPA application in windows using the below run command.
opa run --server --log-level debug --tls-cert-file public.crt --tls-private-key-file private.key --authentication=token --authorization=basic
Always ending up with, Is there any other API endpoint and REGO policy i need to add, and how to add it ?
{
"code": "internal_error",
"message": "authorization policy missing or undefined"
}
The Feedback repository is a central location for all the OPA subprojects to use GitHub Discussions.
If you have a question you'd like to discuss with the OPA community, head over to the Discussions Tab.
If you have a bug to report please file an issue in the respective repository.
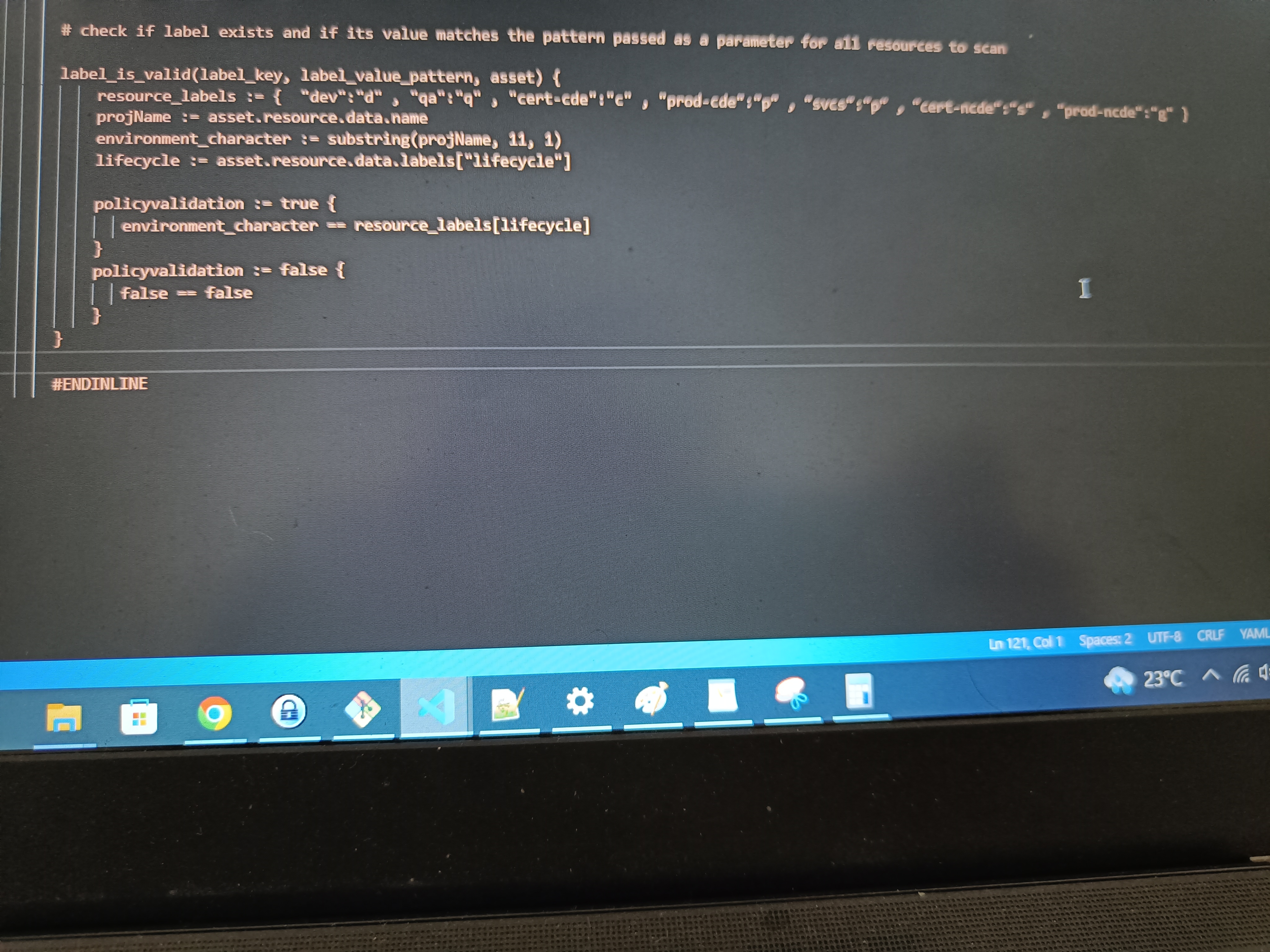
I have a use-case where I need to implement multiple rules in the Rego file to validate GET, POST endpoints with different x-incoming-flow custom header. For example in the example below; my intension is to allow HR applications (indicated by request hr-flow) to retrieve basic demographic information. Similarly allow finance applications (indicated by finance-flow) to update finance information. The headers are passed by consuming applications.
In this use-case, what is the best practice to prepare the rules? Do I need to write multiple allow blocks or is there a better way to write them in a single allow block. Please advise
package demo
import input.attributes.request.http as http_request
default allow = false
allow {
#Allow GET:/api/v1/employees/demographics if it has x-incoming-flow as `hr-flow`
http_request.method="GET"
http_request.path == "/api/v1/employees/demographics"
http_request.headers["x-incoming-flow"] == "hr-flow"
}
allow {
#Allow POST:/api/v1/employees/salaries if it has x-incoming-flow as `finance-flow`
http_request.method="POST"
http_request.path == "/api/v1/employees/salaries"
http_request.headers["x-incoming-flow"] == "finance-flow"
}
Input 1: -- Output should be true
{
"attributes": {
"request": {
"http": {
"method": "GET",
"path": "/api/v1/employees/demographics",
"headers": {
"x-incoming-flow": "hr-flow"
}
}
}
}
}
Input 2: -- Output should be false
{
"attributes": {
"request": {
"http": {
"method": "GET",
"path": "/api/v1/employees/demographics",
"headers": {
"x-incoming-flow": "deparments-flow"
}
}
}
}
}
Input 3: -- Output should be true
{
"attributes": {
"request": {
"http": {
"method": "POST",
"path": "/api/v1/employees/finance",
"headers": {
"x-incoming-flow": "finance-flow"
}
}
}
}
}
From discussion #142
Issue reported by @jj80
Originally posted by jj80 March 4, 2022
We are using opa 0.36 and noticed long response times in patch replace operations.
Here is sample of request
{
"client_addr": "XXXX",
"level": "info",
"msg": "Received request.",
"req_body": "[{\"op\":\"replace\",\"path\":\"Acls/XYZ\",\"value\":{\"X\":\"A\",\"XYZ\":[\"12345\"],\"LIST\":[\"3456\",\"4567\",\"5678\",\"6789\",\"789\",\"890\",\"9012\",\"01111\",\"55558\",\"3434343\",\"5453422\",\"43242345\",\"5354353\",\"5345345\",\"5646546\",\"5345345\",\"87974466\",\"4456411\",\"445477\",\"6879911\",\"7842313\",\"5411000\",\"364894\",\"321888\",\"7779912\",\"799\",\"3488931\",\"48941699\",\"971fddfg61\"],\"OOO\":null,\"WER\":false}}]",
"req_id": 30460,
"req_method": "PATCH",
"req_params": {},
"req_path": "/v1/data/AAA/BB/CCC",
"time": "2022-03-04T08:48:42Z"
}Response is like
{
"client_addr": "XXXX",
"level": "info",
"msg": "Sent response.",
"req_id": 30460,
"req_method": "PATCH",
"req_path": "/v1/data/AAA/BB/CCC",
"resp_body": "",
"resp_bytes": 0,
"resp_duration": 25305.964576,
"resp_status": 204,
"time": "2022-03-04T08:49:08Z"
}As you can see response time is 25 secs and for multiple similar requests it simple adds up.
We have about 10k entries.
It looks like it is dependent on value and and number of entries. With more values in LIST delay grows.
Is there anything I can do about this?
Does it mean that till patch is processed I will get outdated data?
Original Requestor: aimtiaz
Original Thread: https://openpolicyagent.slack.com/archives/CBR63TK2A/p1649170893.320489
Message:
Hi! Very new to OPA and I'm looking to lint rego test files. Essentially, looking through each of the test files, and ensuring that they follow the format of [test][package_name][test_name].
I couldn't find anything similar, and opa fmt did not seem like it would fit my use case. Has anybody done something similar or would I need to roll my own linter?
Thank you 🙂
Original Requestor: anthonyabarbieri
Original Thread: https://openpolicyagent.slack.com/archives/CLE8VEKGT/p1650889161.145719
Message:
Hey Folks, I put together a setup-conftest action this weekend based off the setup-opa action in the OPA organization. It downloads the conftest binary and adds it to the path for use in other steps: https://github.com/princespaghetti/setup-conftest
Original Requestor: zia.ur-rehman
Original Thread: https://openpolicyagent.slack.com/archives/CDTN970AX/p1652361341.359949
Message:
Hi Everyone, OPA is writing some stuff to disk what is it?
Hi,
I have been using OPA Rego policies to configure user role based access and OPA is giving suitable decisions.
However I am interested in configuring an IP based access and tried with the following rego policy for allow decision
package abc
default allow = false
allow {
input.method = "GET"
input.addrs = [":8181"]
}
to allow the localhost running server.
input.json query
{
"method": "GET",
"addrs": [":8181"]
}
The policy evaluated for the input is not resulting for allow = true or false
Please suggest the feature for testing IPs and MAC address in this context to manage decisions for the incoming IP, MAC address.
With regards,
Shashank
The results of API call should be the same command line or Playground
API calls always returns false
Here is my simple policy (playPolicy.rego):
package play
default allow = false
allow {
input.method == "GET"
}
Here is my input file (playInput.json)
{
"method": "GET"
}
when I try this using RegoPlayground, the evaluation is true (https://play.openpolicyagent.org/p/cIWCURitWQ)
I then tried it using command line (I am using OPA 0.34.1)
Then I deployed a docker container (downloaded from the official location) out of port 9090. I tried port 8181 on my linux as well also I tried various opa versions as well, same results.
docker run -d -p 9090:9090 --name opa openpolicyagent/opa:0.34.1 run --server --log-level debug -a :9090
Then I uploaded my policy using following command:
curl -X PUT --data-binary @playPolicy.rego localhost:9090/v1/policies/play
Then I used GET to retrieve the contents
curl localhost:9090/v1/policies/play
all looked good
Then I query with following call to get results and I got false, which is very strange!
curl -X POST localhost:9090/v1/data/play/allow -d @playInput.json -H 'Content-Type: application/json'
Tried with PostMan as well, same results
As part of debug, I added print() to my policies and run it on command line. my value was printed out correctly and the return was true. So am I calling API wrong? I added ?explain=full&pretty to the API call. although I dont quite understand the meaning of it, here is detail:
{
"explanation": [
"query:1 Enter data.play.allow = _",
"query:1 | Eval data.play.allow = _",
"query:1 | Index data.play.allow (matched 0 rules)",
"play:3 | Enter data.play.allow",
"play:3 | | Eval true",
"play:3 | | Exit data.play.allow",
"query:1 | Exit data.play.allow = _",
"query:1 Redo data.play.allow = _",
"query:1 | Redo data.play.allow = _",
"play:3 | Redo data.play.allow",
"play:3 | | Redo true"
],
"result": false
}
Please help. Many thanks!!!
Original Requestor: raje.g.995
Original Thread: https://openpolicyagent.slack.com/archives/CBR63TK2A/p1648828146.908049
Message:
Hi, I am trying to use sync.yaml -> config to load some CRDs to evaluate my OPA Gatekeeper in EKS.
I am facing issues in loading those CRDS. I have installed the sync.yaml correctly.
Steps followed -
Installed OPA
Installed sync.yaml to load the CRDs dynamically.
Issue :
While evaluating the policy in the constrainttemplate , OPA is not able to list those objects.
Sample sync.yaml
# Sync.yaml
apiVersion: http://config.gatekeeper.sh/v1alpha1config.gatekeeper.sh/v1alpha1>
kind: Config
metadata:
name: config
namespace: "gatekeeper-system"
spec:
sync:
syncOnly:
- group: "http://project.team.orchestrator.predix.ioproject.team.orchestrator.predix.io>"
version: "v1alpha1"
kind: Environment
- group: "http://project.team.orchestrator.predix.ioproject.team.orchestrator.predix.io>"
version: "v1alpha1"
kind: "DeveloperProjectControl"
Sample policy constrainttemplate
apiVersion: http://templates.gatekeeper.sh/v1beta1templates.gatekeeper.sh/v1beta1>
kind: ConstraintTemplate
metadata:
name: developerprojectcontrolnotexist
spec:
crd:
spec:
names:
kind: DeveloperProjectControlNotExist
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package developerprojectcontrolnotexist
violation[{"msg": msg1}] {
input.review.object.kind != "DeveloperProjectControl"
ns := input.review.object.metadata.namespace
ns != "NS"
#msg1 := sprintf("VALUE - %v ", [data.inventory.namespace[ns]["http://project.team.orchestrator.predix.io/v1alpha1project.team.orchestrator.predix.io/v1alpha1>"]])
dpcObject := object.get(data.inventory.namespace[ns]["http://project.team.orchestrator.predix.io/v1alpha1project.team.orchestrator.predix.io/v1alpha1>"],"DeveloperProjectControl", "NOTFOUND")
dpcObject == "NOTFOUND"
msg1 := sprintf("No developerprojectcontrol object present in the namespace ", [dpcObject])
}
Here the dpcObject value is {} and instead of NOTFOUND , when the corresponding object - DeveloperProjectControl is not present in the namespace.
My current scenario is to do an authentication function
The data source has a large amount of data and is continuously updated (including the addition, deletion and modification of permissions);
I hope that the data source can be loaded into OPA quickly when OPA is started; And it can keep updating with the data source efficiently
I think of two ways now, but I don't think they are very perfect
Use bundle to load tar at one time GZ file; However, it can only update through polling. This time, there is a delay, which makes the process very inefficient; I expect to update the loaded data through the restapi, but I'm sorry to prompt "path bindings is owned by bundle " authz \ "
When OPA is started, 5g data is loaded into OPA through restapi; Subsequent updates through API; This disadvantage feels that a large amount of data needs to be written through the API. I don't know how the performance is; Of course, I can deploy multiple OPAs by business; The feeling is not very perfect;
I don't know if there is a good solution to load quickly and update the data in it
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}