
module load openmpi/4.1.0/gcc-8.4.0conda activate /projects/mluq/condaEnvs/uips
conda create --name uips python=3.10conda activate uipsgit clone https://github.com/NREL/Phase-space-sampling.gitcd Phase-space-samplingpip install -e .
Test
bash tutorials/run2D.sh
pip install uips
Test
import os
import numpy as np
from prettyPlot.parser import parse_input_file
from prettyPlot.plotting import plt, pretty_labels, pretty_legend
from uips import UIPS_INPUT_DIR
from uips.wrapper import downsample_dataset_from_input
import uips.utils.parallel as par
ndat = int(1e5)
nSampl = 100
ds = np.random.multivariate_normal([0, 0], np.eye(2), size=ndat)
np.save("norm.npy", ds)
inpt = parse_input_file(os.path.join(UIPS_INPUT_DIR, "input2D"))
inpt["dataFile"] = "norm.npy"
inpt["nWorkingData"] = f"{ndat} {ndat}"
inpt["nEpochs"] = f"5 20"
inpt["nSamples"] = f"{nSampl}"
best_files = downsample_dataset_from_input(inpt)
if par.irank == par.iroot:
downsampled_ds = {}
for nsamp in best_files:
downsampled_ds[nsamp] = np.load(best_files[nsamp])["data"]
fig = plt.figure()
plt.plot(ds[:, 0], ds[:, 1], "o", color="k", label="full DS")
plt.plot(
downsampled_ds[nSampl][:, 0],
downsampled_ds[nSampl][:, 1],
"o",
color="r",
label="downsampled",
)
pretty_labels("", "", 14)
pretty_legend()
plt.savefig("normal_downsample.png")The purpose of the tool is to perform a smart downselection of a large number of datapoints. Typically, large numerical simulations generate billions, or even trillions of datapoints. However, there may be redundancy in the dataset which unnecessarily constrains memory and computing requirements. Here, redundancy is defined as closeness in feature space. The method is called phase-space sampling.
bash tutorials/run2D.sh: Example of downsampling a 2D combustion dataset. First the downsampling is performed (mpiexec -np 4 python tests/main_from_input.py -i inputs/input2D). Then the loss function for each flow iteration is plotted (python postProcess/plotLoss.py -i inputs/input2D). Finally, the samples are visualized (python postProcess/visualizeDownSampled_subplots.py -i inputs/input2D). All figures are saved under the folder Figures.
The code is GPU+MPI-parallelized: a) the dataset is loaded and shuffled in parallel b) the probability evaluation (the most expensive step) is done in parallel c) downsampling is done in parallel d) only the training is offloaded to a GPU if available. Memory usage of root processor is higher than other since it is the only one in charge of the normalizing flow training and sampling probability adjustment. To run the code in parallel, mpiexec -np num_procs python tests/main_from_input.py -i inputs/input2D.
In the code, arrays with suffix _ denote data distributed over the processors.
The computation of nearest neighbor distance is parallelized using the sklearn implementation. It will be accelerated on systems where hyperthreading is enabled (your laptop, but NOT the Eagle HPC)
When using GPU+MPI-parallelism on Eagle, you need to specify the number of MPI tasks (srun -n 36 python tests/main_from_input.py)
When using MPI-parallelism alone on Eagle, you do not need to specify the number of MPI tasks (srun python tests/main_from_input.py)
Running on GPU only accelerate execution by ~30% for the examples provided here. Running with many MPI-tasks linearly decreases the execution time for probability evaluation, as well as memory per core requirements.
Parallelization tested with up to 36 cores on Eagle.
Parallelization tested with up to 4 cores on MacOS Monterey v12.7.1.
We provide the data for running a 2D downsampling example. The data is located at data/combustion2DToDownsampleSmall.npy.
The dataset to downsample has size
All hyperparameters can be controlled via an input file (see tutorials/run2D.sh).
We recommend fixing the number of flow calculation iteration to 2.
When increasing the number of dimensions, we recommend adjusting the hyperparameters. A 2-dimensional example (inputs/input2D) and an 11-dimensional (inputs/highdim/input11D) example are provided to guide the user.
It may not be obvious to evaluate how uniformly distributed are the obtained phase-space samples. During the code execution, a mean dist is displayed. This corresponds to the average distance to the nearest neighbor of each data point. The higher the distance, the more uniformly distributed is the dataset. At first, the distance is shown for a random sampling case. Then it is displayed at every iteration. The mean distance should be higher than for the random sampling case. In addition, the second iteration should lead better mean distance than the first one. A warning message is displayed in case the second flow iteration did not improve the sampling. An error message is displayed in case the last flow iteration did not improve the sampling compared to the random case.
The computational cost associated with the nearest neighbor computations scales as
During training of the normalizing flow, the negative log likelihood is displayed. The user should ensure that the normalizing flow has learned something useful about the distribution by ensuring that the loss is close to being converged. The log of the loss is displayed as a csv file in the folder TrainingLog. The loss of the second training iteration should be higher than the first iteration. If this is not the case or if more iterations are needed, the normalizing flow trained may need to be better converged. A warning message will be issued in that case.
A script is provided to visualize the losses. Execute python plotLoss.py -i inputs/input2D where input2D is the name of the input file used to perform the downsampling.
Suppose one wants to downsample an dataset where
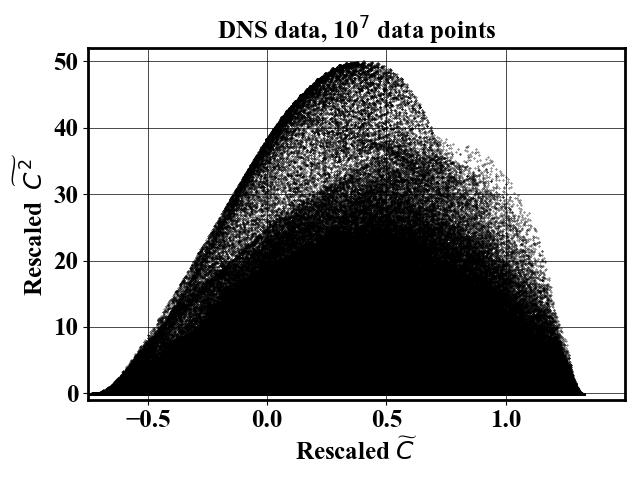
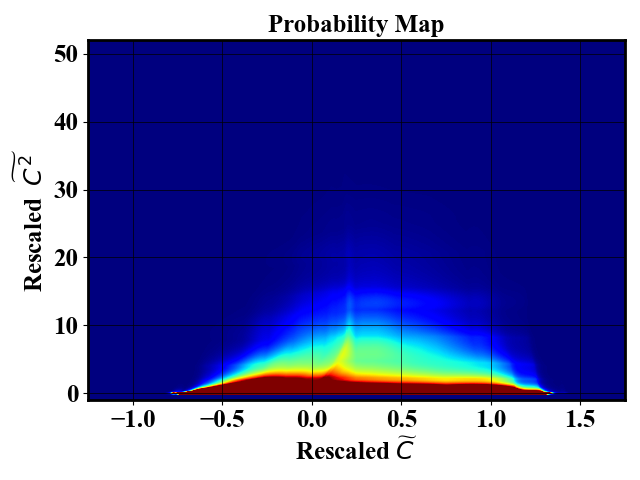
Next, the code uses the probability map to define a sampling probability which downselect samples that uniformly span the feature space. The probability map is obtained by training a Neural Spline Flow which implementation was obtained from Neural Spline Flow repository. The number of samples in the final dataset can be controlled via the input file.
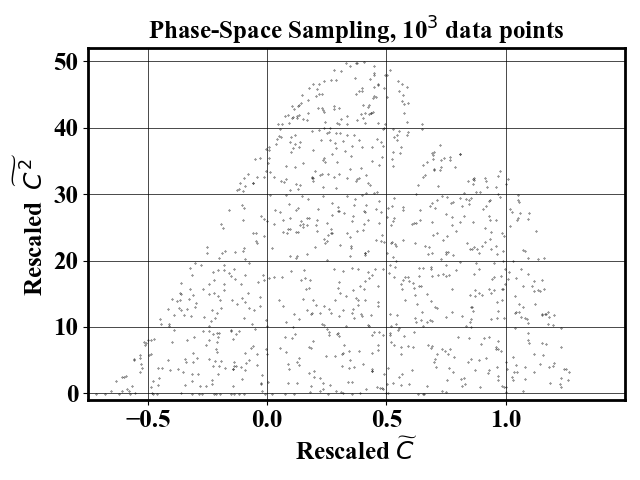
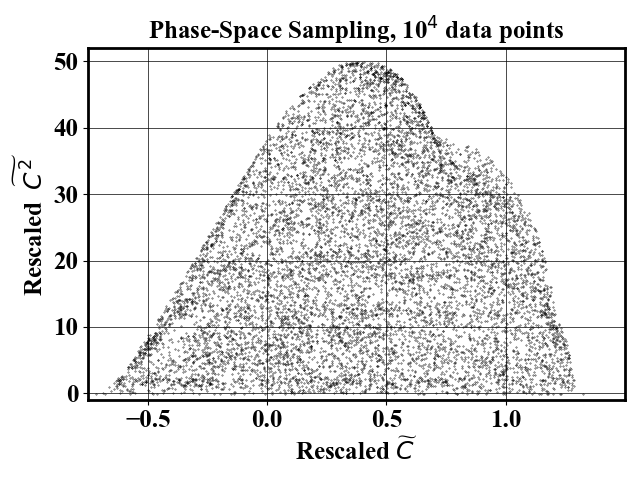
For comparison, a random sampling gives the following result
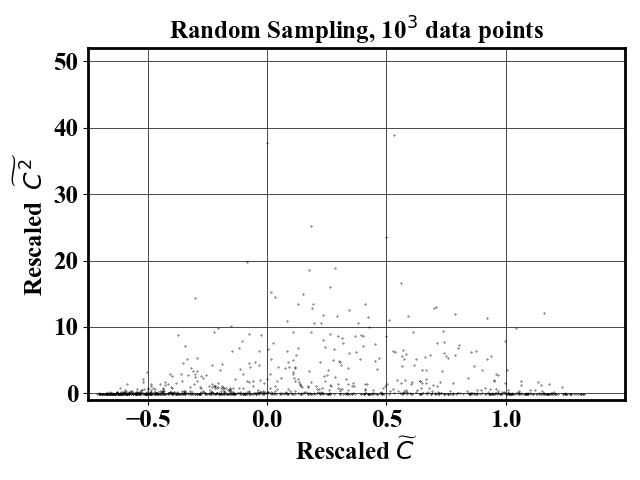
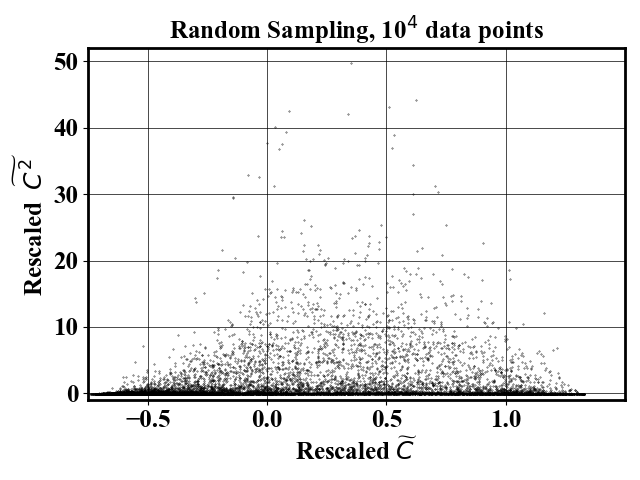
Input file is provided in inputs/highdim/input11D
The folder data-efficientML is NOT necessary for using the phase-space sampling package. It only contains the code necessary to reproduce the results shown in the paper:
Code formatting and import sorting are done automatically with black and isort.
Fix imports and format : pip install black isort; bash fixFormat.sh
Spelling is checked but not automatically fixed using codespell
Published version (open access)
Preprint version (open access)
@article{hassanaly2023UIPS,
title={Uniform-in-Phase-Space Data Selection with Iterative Normalizing Flows},
author={Hassanaly, Malik and Perry, Bruce A. and Mueller, Michael E. and Yellapantula, Shashank},
journal={Data-centric Engineering},
pages={e11},
volume={4},
year={2023},
publisher={Cambridge University Press}
}
Overview presentation in documentation/methodOverview.pptx
Malik Hassanaly: (malik.hassanaly!at!nrel!gov)











