 |
|---|
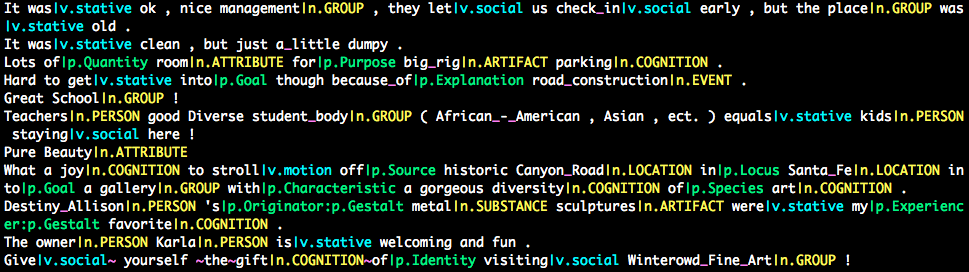
| STREUSLE annotations visualized with streusvis.py |
STREUSLE stands for Supersense-Tagged Repository of English with a Unified Semantics for Lexical Expressions. The text is from the web reviews portion of the English Web Treebank [9]. STREUSLE incorporates comprehensive annotations of multiword expressions (MWEs) [1] and semantic supersenses for lexical expressions. The supersense labels apply to single- and multiword noun and verb expressions, as described in [2], and prepositional/possessive expressions, as described in [3, 4, 5, 6, 7, 8]. Lexical expressions also feature a lexical category label indicating its holistic grammatical status; for verbal multiword expressions, these labels incorporate categories from the PARSEME 1.1 guidelines [15]. For each token, these pieces of information are concatenated together into a lextag: a sentence's words and their lextags are sufficient to recover lexical categories, supersenses, and multiword expressions [8].
🧮 Corpus Stats: >55k words, >3k multiword expression instances, >22k supersense-tagged expressions
👩💻 Using the data: The canonical file with source annotations is streusle.conllulex. For scripting, the JSON format will likely be preferred. See Formats below.
🤖 Tagger: Code for a lexical semantic recognition tagger [8] trained on STREUSLE can be downloaded at: https://github.com/nelson-liu/lexical-semantic-recognition/
Release URL: https://github.com/nert-nlp/streusle
Additional information: http://www.cs.cmu.edu/~ark/LexSem/
Online corpus search in ANNIS: https://corpling.uis.georgetown.edu/annis/#_c=c3RyZXVzbGVfNC4z (instructions)
Browse semantic annotations of prepositions/possessives on the Xposition website [17]: http://www.xposition.org/en/
The English Web Treebank sentences were also used by the Universal Dependencies (UD) project as the primary reference corpus for English [10]. STREUSLE incorporates the syntactic and morphological parses from UD_English-EWT v2.10 (released May 15, 2022); these follow the UD v2 standard.
This dataset's multiword expression and supersense annotations are licensed under a Creative Commons Attribution-ShareAlike 4.0 International license (see LICENSE). The UD annotations are redistributed under the same license. The source sentences and PTB part-of-speech annotations, which are from the Reviews section of the English Web Treebank (EWTB; [9]), are redistributed with permission of Google and the Linguistic Data Consortium, respectively.
An independent effort to improve the MWE annotations from those in STREUSLE 3.0 resulted in the HAMSTER resource [14]. The HAMSTER revisions have not been merged with the 4.0 revisions, though we intend to do so for a future release.
-
streusle.conllulex: Full dataset.
-
STATS.md, LEXCAT.txt, MWES.txt, SUPERSENSES.txt: Statistics summarizing the full dataset.
-
train/, dev/, test/: Data splits established by the UD project and accompanying statistics.
-
releaseutil/: Scripts for preparing the data for release.
-
ACKNOWLEDGMENTS.md: Contributors and support that made this dataset possible.
-
CONLLULEX.md: Description of data format.
-
EXCEL.md: Instructions for working with the data as a spreadsheet.
-
LICENSE.txt: License.
-
ACL2018.md: Links to resources reported in [7].
-
conllulex2json.py: Script to validate the data and convert it to JSON.
-
json2conllulex.py: Script to convert STREUSLE JSON to .conllulex.
-
conllulex2csv.py: Script to create an Excel-readable CSV file with the data.
-
csv2conllulex.py: Script to convert an Excel-generated CSV file to .conllulex.
-
conllulex2UDlextag.py: Script to remove all STREUSLE fields except lextags.
-
UDlextag2json.py: Script to unpack lextags, populating remaining STREUSLE fields.
-
normalize_mwe_numbering.py: Script to ensure MWEs within each sentence are numbered in a consistent order.
-
govobj.py: Utility for adding heuristic preposition/possessor governor and object links to the JSON.
-
lexcatter.py: Utilities for working with lexical categories.
-
mwerender.py: Utilities for working with MWEs.
-
supersenses.py: Utilities for working with supersense labels.
-
streusvis.py: Utility for browsing MWE and supersense annotations.
-
supdate.py: Utility for applying lexical semantic annotations made by editing the output of streusvis.py.
-
tagging.py: Utilities for working with BIO-style tags.
-
tquery.py: Utility for searching the data for tokens that meet certain criteria.
-
tupdate.py: Utility for applying lexical tag changes made by editing the output of tquery.py.
-
streuseval.py: Unified evaluation script for MWEs and supersenses.
-
psseval.py: Evaluation script for preposition/possessive supersense labeling only.
-
pssid/: Heuristics for identifying SNACS targets.
-
setup.py: Setup script for installing this as a Python package via setuptools.
-
The canonical data format for STREUSLE 4.0+ is the CONLLULEX tabular format. It extends the CoNLL-U format from the Universal Dependencies project with additional columns for lexical semantic annotations. (The .sst and .tags formats from STREUSLE 3.0 are not expressive enough and are no longer supported.)
-
Scripts support conversion between .conllulex and a JSON format: conllulex2json.py, json2conllulex.py. A JSON file can be enriched with syntactic details of the preposition/possessive relations via the govobj.py script. JSON files are included in the train, dev, and test subdirectories.
-
Other scripts support conversion between .conllulex and Excel-compatible CSV.
-
Luke Gessler has written a module for the Pepper tool so that STREUSLE data can be converted to other Pepper-supported formats, including PAULA XML and ANNIS. See instructions for converting.
Citations describing the annotations in this corpus (main STREUSLE papers in bold):
-
[1] Nathan Schneider, Spencer Onuffer, Nora Kazour, Emily Danchik, Michael T. Mordowanec, Henrietta Conrad, and Noah A. Smith. Comprehensive annotation of multiword expressions in a social web corpus. Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavík, Iceland, May 26–31, 2014. http://people.cs.georgetown.edu/nschneid/p/mwecorpus.pdf
-
[2] Nathan Schneider and Noah A. Smith. A corpus and model integrating multiword expressions and supersenses. Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, Colorado, May 31–June 5, 2015. http://people.cs.georgetown.edu/nschneid/p/sst.pdf
-
[3] Nathan Schneider, Jena D. Hwang, Vivek Srikumar, Meredith Green, Abhijit Suresh, Kathryn Conger, Tim O'Gorman, and Martha Palmer. A corpus of preposition supersenses. Proceedings of the 10th Linguistic Annotation Workshop, Berlin, Germany, August 11, 2016. http://people.cs.georgetown.edu/nschneid/p/psstcorpus.pdf
-
[4] Jena D. Hwang, Archna Bhatia, Na-Rae Han, Tim O’Gorman, Vivek Srikumar, and Nathan Schneider. Double trouble: the problem of construal in semantic annotation of adpositions. Proceedings of the Sixth Joint Conference on Lexical and Computational Semantics, Vancouver, British Columbia, Canada, August 3–4, 2017. http://people.cs.georgetown.edu/nschneid/p/prepconstrual2.pdf
-
[5] Nathan Schneider, Jena D. Hwang, Vivek Srikumar, Archna Bhatia, Na-Rae Han, Tim O'Gorman, Sarah R. Moeller, Omri Abend, Adi Shalev, Austin Blodgett, and Jakob Prange (June 15, 2022). Adposition and Case Supersenses v2.6: Guidelines for English. arXiv preprint. https://arxiv.org/abs/1704.02134
-
[6] Austin Blodgett and Nathan Schneider (2018). Semantic supersenses for English possessives. Proceedings of the 11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, May 9–11, 2018. http://people.cs.georgetown.edu/nschneid/p/gensuper.pdf
-
[7] Nathan Schneider, Jena D. Hwang, Vivek Srikumar, Jakob Prange, Austin Blodgett, Sarah R. Moeller, Aviram Stern, Adi Bitan, and Omri Abend. Comprehensive supersense disambiguation of English prepositions and possessives. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, July 15–20, 2018. http://people.cs.georgetown.edu/nschneid/p/pssdisambig.pdf
Related work:
-
[8] Nelson F. Liu, Daniel Hershcovich, Michael Kranzlein, and Nathan Schneider (2021). Lexical semantic recognition. Proceedings of the 17th Workshop on Multiword Expressions (MWE 2021), Online, August 6, 2021. https://people.cs.georgetown.edu/nschneid/p/lsr.pdf (tagger code)
-
[9] Ann Bies, Justin Mott, Colin Warner, and Seth Kulick. English Web Treebank. Linguistic Data Consortium, Philadelphia, Pennsylvania, August 16, 2012. https://catalog.ldc.upenn.edu/LDC2012T13
-
[10] Natalia Silveira, Timothy Dozat, Marie-Catherine de Marneffe, Samuel R. Bowman, Miriam Connor, John Bauer, and Christopher D. Manning (2014). A gold standard dependency corpus for English. Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavík, Iceland, May 26–31, 2014. http://www.lrec-conf.org/proceedings/lrec2014/pdf/1089_Paper.pdf
-
[11] Nathan Schneider, Emily Danchik, Chris Dyer, and Noah A. Smith. Discriminative lexical semantic segmentation with gaps: running the MWE gamut. Transactions of the Association for Computational Linguistics, 2(April):193−206, 2014. https://people.cs.georgetown.edu/nschneid/p/mwe.pdf
-
[12] Nathan Schneider, Jena D. Hwang, Vivek Srikumar, and Martha Palmer. A hierarchy with, of, and for preposition supersenses. Proceedings of the 9th Linguistic Annotation Workshop, Denver, Colorado, June 5, 2015. https://people.cs.georgetown.edu/nschneid/p/pssts.pdf
-
[13] Nathan Schneider, Dirk Hovy, Anders Johannsen, and Marine Carpuat. SemEval-2016 Task 10: Detecting Minimal Semantic Units and their Meanings (DiMSUM). Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, California, June 16–17, 2016. http://people.cs.georgetown.edu/nschneid/p/dimsum.pdf
-
[14] King Chan, Julian Brooke, and Timothy Baldwin. Semi-automated resolution of inconsistency for a harmonized multiword expression and dependency parse annotation. Proceedings of the 13th Workshop on Multiword Expressions, Valencia, Spain, April 4, 2017. http://www.aclweb.org/anthology/W17-1726
-
[15] PARSEME Shared Task 1.1 - Annotation guidelines. 2018. http://parsemefr.lif.univ-mrs.fr/parseme-st-guidelines/1.1/?page=home
-
[16] Daniel Hershcovich, Nathan Schneider, Dotan Dvir, Jakob Prange, Miryam de Lhoneux, and Omri Abend. Comparison by conversion: reverse-engineering UCCA from syntax and lexical semantics. Proceedings of the Second International Workshop on Designing Meaning Representations, Online, December 13, 2020. https://arxiv.org/abs/2011.00834 (rule-based system, statistical system)
-
[17] Luke Gessler, Austin Blodgett, Joseph Ledford, and Nathan Schneider (2022). Xposition: An online multilingual database of adpositional semantics. Proceedings of the 13th Linguistic Resources and Evaluation Conference, Marseille, France, June 20-25, 2022. https://people.cs.georgetown.edu/nschneid/p/xposition.pdf (website)
Questions should be directed to:
Nathan Schneider
[email protected]
http://nathan.cl
The 4.0 release [7] updates the inventory and application of preposition supersenses, applies those supersenses to possessives (detailed in [6]), incorporates the syntactic annotations from the Universal Dependencies project, and adds lexical category labels to indicate the holistic grammatical status of strong multiword expressions. The 4.1 release adds subtypes for verbal MWEs (VID, VPC.{full,semi}, LVC.{full,cause}, IAV) according to PARSEME 1.1 guidelines [15]. The 4.2 and 4.3 releases revise some of the semantic annotations. The 4.4 release updates only UD annotations. The 4.5 release updates UD annotations and renames a couple of semantic labels.
- STREUSLE 4.5: 2022-06-15.
- Update SNACS annotations to the v2.6 standard (automatically rename p.Causer -> p.Force and p.RateUnit -> p.SetIteration).
- Update UD to v2.10. This affects many UPOS tags and lemmas, especially for proper names. The UD update also introduces lines encoding multiword tokens (not to be confused with multiword expressions) for clitics.
- STREUSLE 4.4: 2020-11-04.
- Update govobj.py to recognize a different style of annotation for preposition stranding.
- Update UD to v2.6.
- Link from README to [16], a new paper on converting STREUSLE annotations to UCCA (Universal Conceptual Cognitive Annotation), which uses this version of the data in experiments.
- STREUSLE 4.3: 2020-05-01.
- Updated preposition/possessive annotations to SNACS v2.5 guidelines ([5], specifically https://arxiv.org/abs/1704.02134v6), which includes changes in the set of labels.
- Added a sentence that had been omitted from a document in the training set.
- Updated UD parses to the latest dev version (post-v2.5). This improves lemmas for misspelled words and adds paragraph boundaries.
- Link from README to new Pepper converter module.
- Link from README to online search tool using ANNIS.
- STREUSLE 4.2: 2020-01-01.
- Added streuseval.py, a unified evaluation script for MWEs + supersenses (issue #31).
- Added streusvis.py, for viewing sentences with their MWE and supersense annotations.
- Added supdate.py (sentence-wise) and tupdate.py (token-wise) for editing lexical semantic annotations (issue #54).
- Added format conversion scripts conllulex2json.py, conllulex2UDlextag.py, and UDlextag2json.py.
- Normalized the way MWEs within a sentence are numbered in markup (normalize_mwe_numbering.py, issue #42).
- Several improvements to govobj.py (most notably issue #35, affecting 184 tokens, and a small fix in 58db569 which affected 53 tokens).
- Subdirectories for splits (train/, dev/, test/) now include .json and .govobj.json files alongside the source .conllulex.
- Added release preparation scripts under releaseutil/.
- Added setup.py.
- Fixed a very small bug in tquery.py affecting the display of sentence-final matches, and made minor changes in functionality involving null values and negative constraints; token-level attributes of multiword expressions; and a new option to filter by sentence length.
- Manually corrected all tokens with the placeholder lexcat symbol
!!@(introduced in v4.0) to have a real lexcat and, if appropriate, a supersense (issue #15). - A number of revisions to SNACS (preposition/possessive supersense) annotations coordinated with updated guidelines ([5], specifically SNACS v2.4, https://arxiv.org/abs/1704.02134v5; this incorporates updates for SNACS v2.3 as well).
- Minor corrections in the data and validation improvements.
- Updated UD parses to the latest dev version (post-v2.5). Among other things, this improves lemmas for words with nonstandard spellings.
- STREUSLE 4.1: 2018-07-02. Added subtypes to verbal MWEs (871 tokens) per PARSEME Shared Task 1.1 guidelines [15]; some MWE groupings revised in the process. Minor improvements to SNACS (preposition/possessive supersense) annotations coordinated with updated guidelines ([5], specifically https://arxiv.org/abs/1704.02134v3). Implementation of SNACS (preposition/possessive supersense) target identification heuristics from [7]. New utility scripts for listing/filtering tokens (tquery.py) and converting to and from an Excel-compatible CSV format.
- STREUSLE 4.0: 2018-02-10. Updated preposition supersenses to new annotation scheme (4398 tokens). Annotated possessives (1117 tokens) using preposition supersenses. Revised a considerable number of MWEs involving prepositions. Added lexical category for every single-word or strong multiword expression. New data format (.conllulex) integrates gold syntactic annotations from the Universal Dependencies project.
- STREUSLE 3.0: 2016-08-23. Added preposition supersenses
- STREUSLE 2.1: 2015-09-25. Various improvements chiefly to auxiliaries, prepositional verbs; added
`pclass label as a stand-in for preposition supersenses to be added in a future release, and`ifor infinitival 'to' where it should not receive a supersense. From 2.0 (not counting`pand`i):- Annotations have changed for 877 sentences (609 involving changes to labels, 474 involving changes to MWEs).
- 877 class labels have been changed/added/removed, usually involving a non-supersense label or triggered by an MWE change. Most frequently (118 cases) this was to replace
stativewith the auxiliary label`a. In only 21 cases was a supersense label replaced with a different supersense label.
- STREUSLE 2.0: 2015-03-29. Added noun and verb supersenses
- CMWE 1.0: 2014-03-26. Multiword expressions for 55k words of English web reviews




































































