mapget is a server-client solution for cached map feature data retrieval.
Main Capabilities:
- Coordinating requests for map data to various map data source processes.
- Integrated map data cache based on RocksDB, or a simple in-memory cache.
- Simple data-source API with bindings for C++, Python and JS.
- Compact GeoJSON feature storage model - 25 to 50% smaller than BSON/msgpack.
- Integrated deep feature filter language based on (a subset of) JSONata
- PIP-installable server and client component.
The mapget package is deployed to PyPI for any Python version between 3.8 and 3.11. Simply running pip install mapget is enough to get you started:
python -m mapget servewill run a server,python -m mapget fetchallows you to talk to a remote server,- you can also use the Python package to write a data source, as documented here.
If you build mapget from source as described below, you obtain an executable that can be used analogously to the Python package with mapget serve or mapget fetch.
The command line parameters for mapget and its subcommands can be viewed with:
mapget --help
mapget fetch --help
mapget serve --help(or python -m mapget --help for the Python package).
The mapget executable can parse a config file with arguments supported by the command line interface. The path to the config file can be provided to mapget via command line by specifying the --config parameter.
Sample configuration files can be found under examples/config:
- sample-first-datasource.toml and sample-second-datasource.toml will configure mapget to run a simple datasource with sample data. Note: the two formats in config files for subcommand parameters can be used interchangeably.
- sample-service.toml to execute the
mapget servecommand. The instance will fetch and serve data from sources started withsample-*-datasource.tomlconfigs above.
mapget supports persistent tile caching using a RocksDB-backed cache, and non-persistent
in-memory caching. The CLI options to configure caching behavior are:
| Option | Description | Default Value |
|---|---|---|
-c,--cache-type |
Choose between "memory" or "rocksdb" (Technology Preview). | memory |
--cache-dir |
Path to store RocksDB cache. | mapget-cache |
--cache-max-tiles |
Number of tiles to store. Tiles are purged from cache in FIFO order. Set to 0 for unlimited storage. | 1024 |
--clear-cache |
Clear existing cache entries at startup. | false |
At the heart of mapget are data sources, which provide map feature data for a specified tile area on the globe and a specified map layer. The data source must provide information as to
- Which map it can serve (e.g. China/Michigan/Bavaria...). In the component overview, this is reflected in the
DataSourceInfoclass. - Which layers it can serve (e.g. Lanes/POIs/...). In the component overview, this is reflected in the
LayerInfoclass. - Which feature types are contained in a layer (e.g. Lane Boundaries/Lane Centerlines),
and how they are uniquely identified. In the component overview, this is reflected in the
FeatureTypeInfoclass.
Feel free to check out the sample_datasource_info.json. As the mapget Service is asked for a tile, e.g. using the GET /tiles REST API,
it first queries its cache for the relevant data. On a cache miss, it proceeds
to forward the request to one of its connected data sources for the specific requested
map.
The atomic units of geographic data which are served by mapget are Features. The content of a mapget feature is aligned with that of a feature in GeoJSON: A feature consists of a unique ID, some attributes, and some geometry. mapget also allows features to have a list of child feature IDs. Note: Feature geometry in mapget may always be 3D.
- TODO: Document JSON representation.
- TODO: Document Feature ID schemes.
- TODO: Document Geometry Types.
For performance reasons, mapget features are always served in a set covering
a whole tile. Each tile is identified by a zoom level z and two grid
coordinates x and y. mapget uses a binary tiling scheme for
the earths surface: The zoom level z controls the number of subdivisions for
the WGS84 longitudinal [-180,180] axis (columns) and latitudinal [-90,90] axis (rows).
The tile x coordinate indicates the column, and the y coordinate indicates the row.
On level zero, there are two columns and one row. In general, the number of rows is 2^z,
and the number of columns is 2^(z+1).
The content of a tile is (leniently) coupled to the geographic extent of its tile id, but also to the map layer it belongs to. When a data source creates a tile, it associates the created tile with the name of the map - e.g. "Europe-HD", and a map data layer, e.g. "Roads" or Lanes.
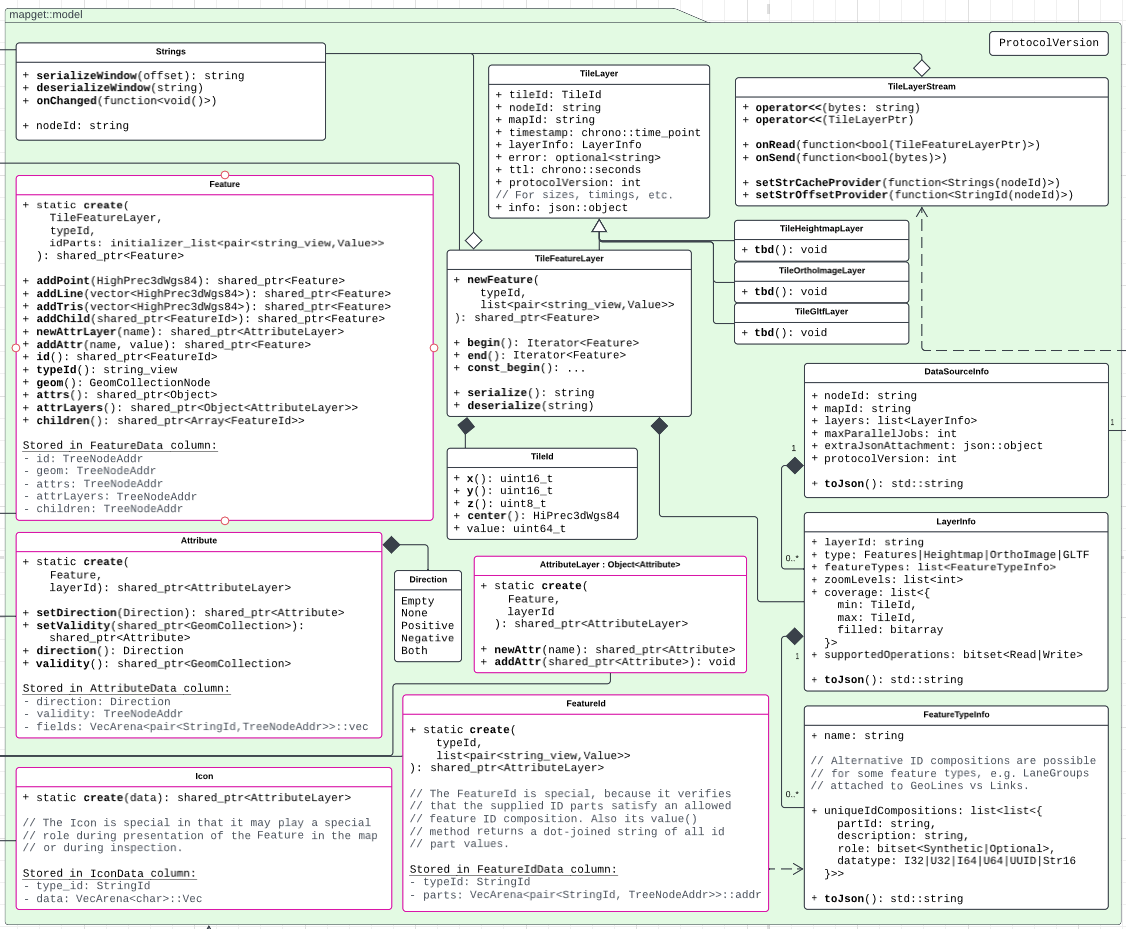
The following diagram provides an overview over the libraries, their contents, and their dependencies:

mapget consists of four main libraries:
- The
mapget-modellibrary is the core library which contains the feature-model abstractions. - The
mapget-servicelibrary contains the mainService,ICacheandIDataSourceabstractions. Using this library, it is possible to use mapget in-process without any HTTP dependencies or RPC calls. - The
mapget-http-servicelibrary binds a mapget service to an HTTP server interface, as described here. - The
mapget-http-datasourcelibrary provides aRemoteDataSourcewhich can connect to aDataSourceServer. This allows running a data source in an external process, which may be written using any programming language.
mapget has the following prerequisites:
- C++17 toolchain
- CMake 3.14+
- Python3
- Ninja build system (not required, but recommended)
- gcovr, if you wish to run coverage tests:
pip install gcovr - Python wheel package, if you wish to build the mapget wheel:
pip install wheel
Build mapget with the following command:
mkdir build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release -G Ninja
cmake --build .If you wish to skip building mapget wheel, deactivate the MAPGET_WITH_WHEEL CMake
option in the second command:
cmake .. -DCMAKE_BUILD_TYPE=Release -DMAPGET_WITH_WHEEL=OFF -G Ninjamapget build can be configured using the following variables:
| Variable Name | Details |
|---|---|
MAPGET_WITH_WHEEL |
Enable mapget Python wheel (output to WHEEL_DEPLOY_DIRECTORY). |
MAPGET_WITH_SERVICE |
Enable mapget-service library. Requires threads. |
MAPGET_WITH_HTTPLIB |
Enable mapget-http-datasource and mapget-http-service libraries. |
MAPGET_ENABLE_TESTING |
Enable testing. |
MAPGET_BUILD_EXAMPLES |
Build examples. |
The logging behavior of mapget can be customized with the following environment variables:
| Variable Name | Details | Value |
|---|---|---|
MAPGET_LOG_LEVEL |
Set the spdlog output level. | "trace", "debug", "info", "warn", "err", "critical" |
MAPGET_LOG_FILE |
Optional file path to write the log. | string |
MAPGET_LOG_FILE_MAXSIZE |
Max size for the logfile in bytes. | string with unsigned integer |
This example shows, how you can use the basic non-networked mapget::Service
in conjunction with a custom data source class which implements the mapget::DataSource interface.
This example shows how you can write a minimal networked data source service.
This example shows, how you can write a data source service in Python.
You can simply pip install mapget to get access to the mapget Python API.
The mapget library provides simple C++ and HTTP/REST interfaces, which may be
used to satisfy the following use-cases:
- Obtain streamed map feature tile data for given constraints.
- Locate a feature by its ID within any of the connected sources.
- Describe the available map data sources.
- View a simple HTML server status page (only for REST API).
- Instruct the cache to populate itself within given constraints from the connected sources.
The HTTP interface implemented in mapget::HttpService is a view on the C++ interface,
which is implemented in mapget::Service. Detailed endpoint descriptions:
| Endpoint | Method | Description | Input | Output |
|---|---|---|---|---|
/sources |
GET | Describe the connected Data Sources | None | application/json: List of DataSourceInfo objects. |
/tiles |
POST | Get streamed features, according to hard constraints. Accepts encoding types text/jsonl or application/binary |
List of objects containing mapId, layerId, tileIds, and optional maxKnownFieldIds. |
text/jsonl or application/binary |
/status |
GET | Server status page | None | text/html |
/locate |
POST | Obtain a list of tile-layer combinations providing a feature that satisfies given ID field constraints. | application/json: List of external references, where each is a Request object with mapId, typeId and featureId (list of external ID parts). |
application/json: List of lists of Resolution objects, where each corresponds to the Request object index. Each Resolution object includes tileId, typeId, and featureId. |
For example, the following curl call could be used to stream GeoJSON feature objects
from the MyMap data source defined previously:
curl -X POST \
-H "Content-Type: application/json" \
-H "Accept: application/jsonl" \
-H "Connection: close" \
-d '{
"requests": [
{
"mapId": "Tropico",
"layerId": "WayLayer",
"tileIds": [1, 2, 3]
}
]
}' "http://localhost:8080/tiles"If we use "Accept: application/binary" instead, we get a binary stream of
tile data which we can also parse in C++, Python or JS. Here is an example in C++, using
the mapget::HttpClient class:
#include "mapget/http-service/http-client.h"
#include <iostream>
using namespace mapget;
void main(int argc, char const *argv[])
{
HttpClient client("localhost", service.port());
auto receivedTileCount = 0;
client.request(std::make_shared<LayerTilesRequest>(
"Tropico",
"WayLayer",
std::vector<TileId>{{1234, 5678, 9112, 1234}},
[&](auto&& tile) { receivedTileCount++; }
))->wait();
std::cout << receivedTileCount << std::endl;
service.stop();
}Keep in mind, that you can also run a mapget service without any RPCs in your application. Check out examples/cpp/local-datasource on how to do that.
The /locate endpoint allows clients to obtain a list of tile-layer combinations that provide a feature satisfying given ID field constraints. This is crucial for applications needing to find specific data points within the massive datasets typically associated with map services. The endpoint uses a POST method due to the complexity and length of the queries, which involve resolving external references to data.
Details:
-
Input: The input is a list of requests, each corresponding to an external reference that needs to be resolved. Each request object includes:
typeId: Specifies the type of feature to locate.featureId: An array representing the external ID parts, where each part consists of a field name and value. This array is used to identify the feature uniquely. The used id scheme may be a secondary scheme.
-
Output: The output is a nested list structure where each outer list corresponds to an input request object. Each of these lists contains resolution objects that provide details about where the requested feature can be found within the map data. Each resolution object includes:
tileId: The key of the map tile containing the feature.typeId: The type of feature found, which should match thetypeIdspecified in the request.featureId: An array of ID parts similar to the input but typically using the primary feature ID scheme of the data source.
This design allows clients to batch queries for multiple features in a single request, improving efficiency and reducing the number of required HTTP requests. It also supports the use of different ID schemes, accommodating scenarios where the request and response might use different identifiers for the same data due to varying external reference standards.
Note, that a locate resolution must be provided by a datasource for the specified map, which implements the onLocateRequest callback.
TODO: expand and polish this section stub.
-
Client (
erdblicketc.) sends a composite list of requests tomapget. Requests are batched because browsers limit the number of concurrent requests to one domain, but we want to stream potentially hundreds of tiles. -
mapgetchecks if all requested map+layer combinations can be fulfilled with data sources- yes: create tile requests, stream responses back to client,
- no: return 400 Bad Request (client needs to refresh its info on map availability).
-
A data source drops offline /
mapgetrequest fails during processing?cpp-httplibcleanup callback returns timeout response (probably status code 408).