nanograv / holodeck Goto Github PK
View Code? Open in Web Editor NEWMassive Black-Hole Binary Population Synthesis for Gravitational Wave Calculations ≋●≋●≋
Home Page: https://holodeck-gw.readthedocs.io
License: MIT License
Massive Black-Hole Binary Population Synthesis for Gravitational Wave Calculations ≋●≋●≋
Home Page: https://holodeck-gw.readthedocs.io
License: MIT License










































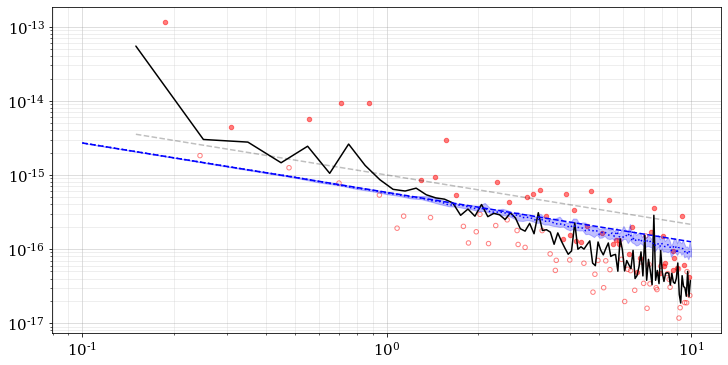
Might be a missing (1+z), in the bandwidth?
Every time holodeck detects a major error or crashes, it should link to this Screen Rant page.
In the function _gws_harmonics_at_evo_fobs in gravwaves.py, it seems that the output foreground signal doesn't include the term "1/d lnf". (I assume the output strain is characteristic strain since the output background single includes the term of 1/d lnf)
Here is part of the code, the output loud is directly from the variabletemp, which is the GW strain I guess.
# --- Calculate GW Signals
temp = hs2 * gne * (2.0 / harms_1d)**2
both = np.sum(temp[:, np.newaxis] * num_pois / dlnf, axis=0)
# Calculate and return the expectation value hc^2 for each harmonic
# (N, H)
gwb_harms = np.zeros_like(harms_2d, dtype=float)
gwb_harms[valid] = temp * num_binaries / dlnf
# (N, H) ==> (H,)
gwb_harms = np.sum(gwb_harms, axis=0)
if np.any(num_pois > 0):
# Find the L loudest binaries in each realizations
loud = np.sort(temp[:, np.newaxis] * (num_pois > 0), axis=0)[::-1, :]
fore = loud[0, :]
loud = loud[:loudest, :]
else:
fore = np.zeros_like(both)
loud = np.zeros((loudest, nreals))
back = both - fore
return both, fore, back, loud, gwb_harms
Current issues:
resource)setup.pyNormal calculation can be almost a factor of 2x faster. For large values of lambda, switch from poisson to normal.
To reproduce see gist here.
Must also
Same issue as noted in #21. There seems to be a systematic offset in the GWB amplitude, where the GWB from a sampled (kalepy.sample_outliers) population is ~10% higher than from the purely continuous, SAM calculation (sam.gwb()). Reason is unclear.

Currently all parameters going into Param_Space classes become new dimensions of the parameter space.
Presumably these could both be handled in a very similar way.
This will naturally vary from one MBH/galaxy to the next.
Cython released v3.0.0 with breaking changes. For now, we should probably just pin cython < 3.0.0. In the future, we should migrate to 3.0.0 https://cython.readthedocs.io/en/latest/src/userguide/migrating_to_cy30.html
I am new to holodeck, so I am sorry if I ask a naive question.
It sames that holodeck.utils.gw_strain_source do not consider the contribution of Merger and Ringdown stage of GW, only the inspiral stage, right?
If so, is there any plan to add the contribution of Merger and Ringdown ?
Thank you very much.
[ ] Ensure that masses are always properly ordered (m1=primary, m2=secondary).
[ ] For host relations, allow either bulge-mass (mbulge) or total stellar-mass (mstar) to be stored.
Running gen_lib.py with large values of NSAMPS (or NREALS) on a cluster leads to segmentation fault. The definition of large here will vary depending on the cluster, but for me it maxes out at just under NSAMPS = 2500 (with NREALS=100).
The error message returned by the Great Lakes cluster reads: mpiexec noticed that process rank 26 with PID 0 on node gl3160 exited on signal 11 (Segmentation fault).
(1) combine SS and 'normal' functions/interfaces to use options instead of separate functions
(2) move all reusable materials from gen_lib_sam.py to librarian.py
(3) add option whether or not to perform fits (consider just moving fits to a post-processing step, instead of concurrent with lib gen)
Basic creation / usage tests for components
Quantitative regression tests for components (i.e. compare against actual values with fixed input parameters)
dynamic_binary_number methodssams/cyutils methodsWhen requesting hardening timescales of 1e-5 and 1e5 Gyr (for example), the resulting interpolated values completely fail to reproduce these timescales and the resulting GWB spectrum is identical.
(1) The code should raise an error for values outside of bounds
(2) The code should raise an error if the resulting interpolated values deviate from the desired hardening timescales by greater than some factor. (Note: currently a warning is raised that the 'normal' interpolant failed, and the 'backup' is being used). Accuracy should be checked for both interpolants.
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import tqdm
import holodeck as holo
from holodeck import utils, plot
from holodeck.constants import YR
mpl.style.use('default') # avoid dark backgrounds from dark theme vscode
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
def run_single_params_model(space, params, fobs_edges, nreals=100, nloudest=5):
param_names = space.param_names
log = space._log
pars = {name: params[pp] for pp, name in enumerate(param_names)}
log.info(f"Loading sam and hard from {params=}")
sam, hard = space.model_for_params(pars, sam_shape=space.sam_shape)
fobs_cents = utils.midpoints(fobs_edges, log=False)
fobs_orb_edges = fobs_edges / 2.0
fobs_orb_cents = fobs_cents / 2.0
log.info(f"Calculating `dynamic_binary_number` for {fobs_cents.size} freqs")
edges, dnum = sam.dynamic_binary_number(hard, fobs_orb=fobs_orb_cents)
edges[-1] = fobs_orb_edges
# integrate for number
log.debug(f"integrating to get number of binaries")
number = utils._integrate_grid_differential_number(edges, dnum, freq=False)
number = number * np.diff(np.log(fobs_edges))
log.debug(f"calculating strains and sources for shape ({fobs_cents.size}, {nreals}), {nloudest=}")
hc_ss, hc_bg, sspar, bgpar = holo.single_sources.ss_gws(
edges, number, realize=nreals, loudest=nloudest, params=True
)
# use_redz = sam._redz_final
# gwb = holo.gravwaves._gws_from_number_grid_integrated(edges, use_redz, number, nreals)
gwb = holo.gravwaves._gws_from_number_grid_integrated(edges, number, nreals)
data = dict(
fobs=fobs_cents, fobs_edges=fobs_edges,
gwb=gwb, hc_ss=hc_ss, hc_bg=hc_bg, sspar=sspar, bgpar=bgpar
)
return data
def run_params_subspace(space, params, fobs_edges, **kwargs):
log = space._log
param_names = space.param_names
npars = len(param_names)
params = np.asarray(params)
# Make sure shapes look good
if params.ndim != 2 or params.shape[1] != npars:
err = f"`params` shape {np.shape(params)} does not match {npars} parameters: {param_names}!"
log.exception(err)
raise RuntimeError(err)
# Make sure all parameters are within excepted bounds
for pp, name in enumerate(param_names):
dist = space._dists[pp]
bads = (params[:, pp] <= dist.extrema[0]) | (dist.extrema[1] <= params[:, pp])
if np.any(bads):
err = f"`params` {pp} {name} are outside of extrema [{dist.extrema[0]:.8e}, {dist.extrema[1]:.8e}]!"
err += f" {utils.stats(params[:, pp])}"
log.exception(err)
raise ValueError(err)
num_samps = params.shape[0]
all_data = []
for ii in tqdm.trange(num_samps):
data = run_single_params_model(space, params[ii], fobs_edges, **kwargs)
all_data.append(data)
return all_data
NUM_FBINS = 14
PTA_DUR = 16.03 # [yrs]
SHAPE = 40
NREALS = 50
space_class = holo.param_spaces.PS_Broad_Uniform_02B
space = space_class(holo.log, 0, SHAPE, None)
dur = PTA_DUR * YR
pta_cad = dur / (2 * NUM_FBINS)
fobs_edges = holo.utils.nyquist_freqs_edges(dur, pta_cad)
draw_params = [
[ 4.57784231, -1.51291368, 10.90450461, 8.85735088, 0.52998213],
[ 6.96691128, -2.38054765, 11.08484247, 9.29421616, 0.45471499],
[ 0.37454247, -2.10501603, 11.62087475, 8.84882612, 0.09778727]
]
# Run full set of `draw_params`
# all_data = run_params_subspace(space, draw_params[:4], fobs_edges, nreals=NREALS)
single_data = run_single_params_model(space, draw_params[0], fobs_edges, nreals=NREALS)
fig, axes = plot.figax(
figsize=[8, 8], nrows=2, hspace=0.4,
xlabel=plot.LABEL_GW_FREQUENCY_YR, ylabel=plot.LABEL_CHARACTERISTIC_STRAIN
)
xx = single_data['fobs'] * YR
# y1 = data['hc_bg']
y1 = np.sqrt(np.sum(single_data['hc_bg'][:, :, np.newaxis]**2 + single_data['hc_ss']**2, axis=-1))
y2 = single_data['gwb']
labels = ['SS', '2x GWB']
for jj, yy in enumerate([y1, 2*y2]):
med, *conf = np.percentile(yy, [50, 25, 75], axis=-1)
cc, = axes[0].plot(xx, med, alpha=0.5, label=labels[jj])
cc = cc.get_color()
axes[0].fill_between(xx, *conf, color=cc, alpha=0.1)
axes[1].plot(xx, np.median(y1, axis=-1)/np.median(y2, axis=-1), 'k--', label='SS/GWB')
axes[1].set_ylabel('ratio')
for ax in axes:
ax.legend()
plot._twin_hz(ax)
plt.show()

See histograms of fo from Bence Becsy:



Currently the outer hardening timescale slope is
Sphinx sucks. Use mkdocs instead.
For example, in the Double Schechter GSMF, there are well characterized uncertainties in the fit parameters. The existing option is to use distributions for these parameters, over their quoted uncertainties - adding a dimension to the parameter space. Should also implement a method where these are randomly sampled over, but not explicitly a dimension of the parameter space.
e.g. using vicente's fitting functions
https://ui.adsabs.harvard.edu/abs/2015MNRAS.449...49R/abstract
Can also consider trying to pre-compute a larger grid of normalization before-hand and interpolating for each construction.
Currently most of the internal calculations are using the holodeck root logger which is not captured in library generation (parallel) runs. Need to combine these, probably by manually passing a logger around instead of grabbing a global-level one.
Invalid bins have z=-1. Interpolating between these values and valid bins thus leads to spurious results (or at least results dependent on the arbitrary choice of negative redshift value). We should use something that is continuous past the age of the universe, i.e. time or scale-factor instead, so that we can more meaningfully continue to interpolate across.
The current implementation should be fairly conservative, so this is not expected to be a notable issue currently.
i.e. zeroing stalled/coalesced systems and using inspiral-delayed redshift.
We can generally get a (semi-analytic) expression for df/dt in the frequency band of interest, so we can use that expression to distribute binaries over frequency instead of using the KDE based on bin-center values which gives lumpy results. This addresses the issues that Bence and Sarah Burke-Spolaor have had.
See also: #43
[ ] Use cython methods in Fixed_Time_2PL
[ ] General cleanup of Fixed_Time_2PL
[ ] Implement tests to check for consistency between Fixed_Time_2PL and Fixed_Time_2PL_SAM
The current dev branch installs, but is not able to run any tests or import due to the error "AttributeError: 'Cosmology' object has no attribute '_H0'" (full trace below). This occurs using a fresh pull from dev.
Test package versions.
platform darwin -- Python 3.9.7, pytest-6.2.5, py-1.11.0, pluggy-1.0.0
testpaths: holodeck/tests
plugins: anyio-3.3.4
Error trace.
holodeck/tests/test_holodeck.py:6: in <module>
import holodeck # noqa
holodeck/__init__.py:36: in <module>
cosmo = cosmology.Cosmology()
holodeck/cosmology.py:43: in __init__
super().__init__(H0=self.H0, Om0=self.Omega0, Ob0=self.OmegaBaryon)
../../../../miniconda3/envs/holodeck/lib/python3.9/site-packages/astropy/cosmology/flrw.py:2064: in __init__
super().__init__(H0=H0, Om0=Om0, Ode0=0.0, Tcmb0=Tcmb0, Neff=Neff,
../../../../miniconda3/envs/holodeck/lib/python3.9/site-packages/astropy/cosmology/flrw.py:1435: in __init__
super().__init__(*args, **kw) # guaranteed not to have `Ode0`
../../../../miniconda3/envs/holodeck/lib/python3.9/site-packages/astropy/cosmology/flrw.py:1541: in __init__
super().__init__(H0=H0, Om0=Om0, Ode0=Ode0, Tcmb0=Tcmb0, Neff=Neff,
../../../../miniconda3/envs/holodeck/lib/python3.9/site-packages/astropy/cosmology/flrw.py:147: in __init__
self._h = self._H0.value / 100.
E AttributeError: 'Cosmology' object has no attribute '_H0'
[ ] Make sure all parameters are used: pop elements, then make sure none remain
See, for example, the end of continuous_observational.ipynb
This should make lower redshift values more accurate --- which is where accuracy is more important!
Binaries which do not reach the target frequencies before redshift 0 are still be included in the GWB calculation! There should be a flag to turn this on-off, and the default should be that they are NOT included (the physical case).
Currently there is a for-loop over frequencies, at each integration step. This shouldn't be necessary as we should be able to continually walk through the target frequencies while we iterate over integration steps. The loop currently breaks out when the target frequencies are outside of the steps, so the redundancy isn't horrific, but it could still be improved significantly.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.