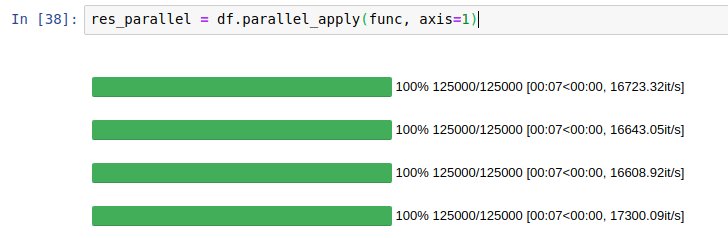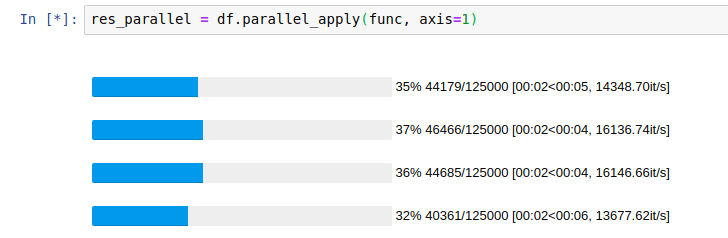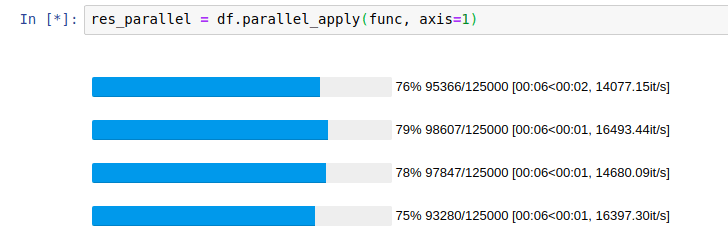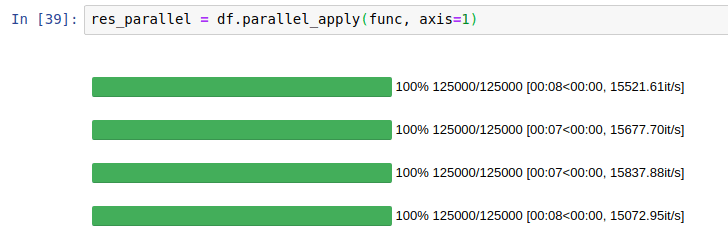
E0731 19:23:55.184354 7351 io.cc:215] Error reading from socket.
It is quite cryptic and I could not find anything else on this particular error. That's why I am opening this issue. I am running this on the Google Cloud Compute instance: n1-highcpu-32 (32 vCPUs, 28.8 GB memory). I still believe that it is related to the pandarallel package since I end up with this exception when I CTRL+C out of the Error loop:
Traceback (most recent call last):
File "shapesplit.py", line 290, in <module>
main()
File "shapesplit.py", line 58, in main
distribute_raster_series(region, year, collection, parcels, overwrite, stop_early=stop_early)
File "shapesplit.py", line 270, in distribute_raster_series
distribute_raster(raster, parcels, collection, overwrite=overwrite)
File "shapesplit.py", line 235, in distribute_raster
result = parcels.parallel_apply(mapping_function, axis=1, args=(offset, rastername, local_filename, collection))
File "/home/marc/miniconda3/lib/python3.7/site-packages/pandarallel/utils.py", line 74, in wrapper
client.delete(client.list().keys())
File "pyarrow/_plasma.pyx", line 741, in pyarrow._plasma.PlasmaClient.list
File "pyarrow/error.pxi", line 87, in pyarrow.lib.check_status
pyarrow.lib.ArrowIOError: Connection reset by peer
Waiting up to 5 seconds.
Sent all pending logs.
Process ForkPoolWorker-15:
Traceback (most recent call last):
File "/home/marc/miniconda3/lib/python3.7/site-packages/multiprocess/process.py", line 297, in _bootstrap
self.run()
File "/home/marc/miniconda3/lib/python3.7/site-packages/multiprocess/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "/home/marc/miniconda3/lib/python3.7/site-packages/multiprocess/pool.py", line 121, in worker
result = (True, func(*args, **kwds))
File "/home/marc/miniconda3/lib/python3.7/site-packages/multiprocess/pool.py", line 44, in mapstar
return list(map(*args))
File "/home/marc/miniconda3/lib/python3.7/site-packages/pathos/helpers/mp_helper.py", line 15, in <lambda>
func = lambda args: f(*args)
File "/home/marc/miniconda3/lib/python3.7/site-packages/pandarallel/dataframe.py", line 14, in worker_apply
client = plasma.connect(plasma_store_name)
File "pyarrow/_plasma.pyx", line 805, in pyarrow._plasma.connect
File "pyarrow/error.pxi", line 83, in pyarrow.lib.check_status
File "/home/marc/miniconda3/lib/python3.7/site-packages/pyarrow/compat.py", line 115, in frombytes
def frombytes(o):
KeyboardInterrupt