nagataka / read-a-paper Goto Github PK
View Code? Open in Web Editor NEWSurvey
Survey







Multi-Level Discovery of Deep Options
Roy Fox, Sanjay Krishnan, Ion Stoica, Ken Goldberg
UC Berkeley
Proposed "Discovery of Deep Options (DDO)" algorithm
https://arxiv.org/abs/1705.08080
Yuke Zhu, Daniel Gordon, Eric Kolve, Dieter Fox, Li Fei-Fei, Abhinav Gupta, Roozbeh Mottaghi, Ali Farhadi
Allen Institute for Artificial Intelligence, CMU, Stanford, and UW
David Ha, Jürgen Schmidhuber
Proposed a novel reinforcement learning agent architecture consists of world model which learn a compressed spatial and temporal representation of the environment in an unsupervised manner, and controller.
Network architecture is the following:

Most existing model-based approaches learn a model of the RL environment, but still train on the actual environment. In this work, they explored fully replacing an actual RL environment with a generated one, training our agent’s controller only inside of the environment generated by its own internal world model, and transfer this policy back into the actual environment.
In this experiment, the world model (V and M) has no knowledge about the actual reward signals from the environment. Its task is simply to compress and predict the sequence of image frames observed. Only the Controller (C) Model has access to the reward information from the environment.
Scalability?
How far this model can predict?
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, Pieter Abbeel
UC Berkeley, OpenAI
z in the GAN. In this paper, they decompose the input noise vector into two parts:
GAN's minimax game formalization

InfoGAN's formulation where I is a mutual information

Pierre-Luc Bacon, Jean Harb, Doina Precup
McGill University
The proposed method enable a gradual learning process of the intra-option policies and termination functions, simultaneously with the policy over them.
An Improved Minimum Error Entropy Criterion with Self Adjusting Step-Size
Seungju Han, Sudhir Rao, D. Erdogmus, J. Principe
University of Florida and Oregon Health and Science University
Comparison with MEE
MEE\mbox{-}SAS: J(e) = min_{\mathbf w}[V(0) - V(e)]^2
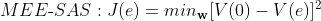
where
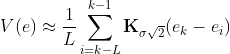
See the section "INFORMATION THEORETIC CRITERIA" for derivation.
Tested the performance for two classic problems of system identification and prediction
As stated in the paper, the following part might suggest the important point to think about adaptive step-size:
"However, we show that MEE performs better than MEE-SAS in situations where tracking ability of the optimal solution is required like in the case of non-stationary signals."


Introduce β-VAE, a new state-of-the-art framework for automated discovery of interpretable factorized latent representations from raw image data in a completely unsupervised manner
Main contributions are the following:
introduce an adjustable hyperparameter β that balances latent channel capacity and independence constraints with reconstruction accuracy
Unlike InfoGAN, β-VAE is stable to train, makes few assumptions about the data and relies on tuning a single hyperparameter β, which can be directly optimised through a hyperparameter search using weakly labelled data or through heuristic visual inspection for purely unsupervised data
"With β > 1 the model is pushed to learn a more efficient latent representation of the data, which is disentangled if the data contains at least some underlying factors of variation that are independent."
Assuming V and W which are ground truth data generative factors (See chapter 2): conditionally independent factors v and conditionally dependent factors w
data generation is governed by these factors as p(x|v,w) and it is called Sim(v,w), where 'Sim' comes from "the true world Simulator"
Relationship with a set of generative latent factors z: p(x|z) approximates p(x|v,w)
Learn z with a posterior q(z|x)
the prior distribution is an isotropic unit Gaussian (p(z) = N(0,I))
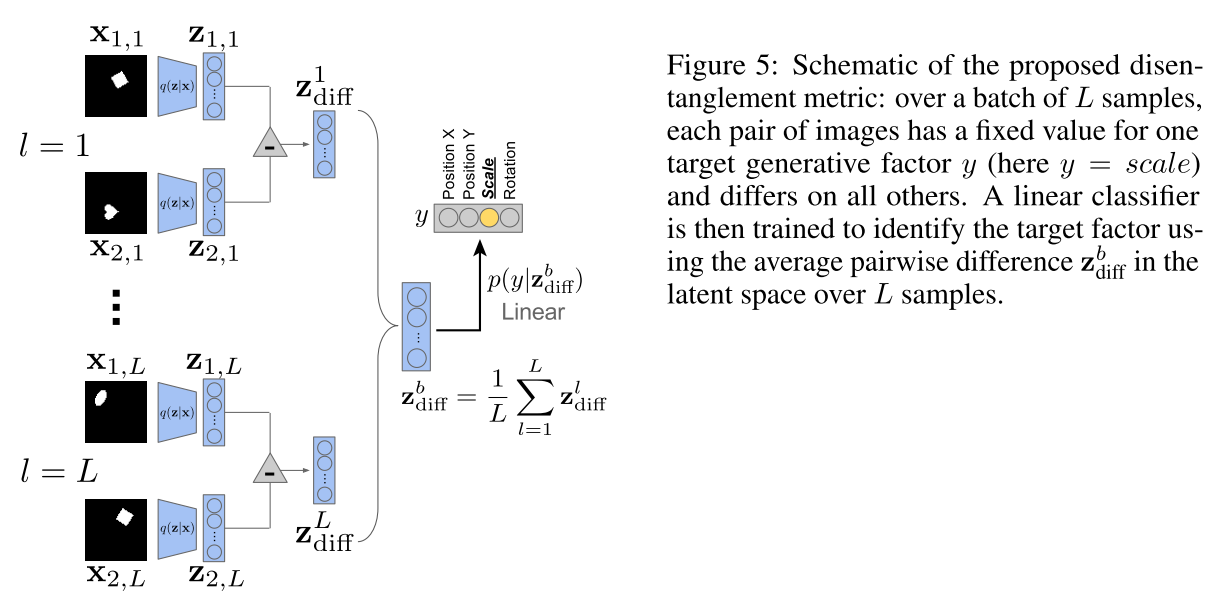
A linear classifier based approach.
Fix one of the generative factors and randomly sampling all others. The goal of the classifier is to predict the index y of the generative factor that was kept fixed.
Contrastive Explanations for Reinforcement Learning via Embedded Self Predictions
Zhengxian Lin, Kin-Ho Lam, Alan Fern
Oregon State
One-sentence
The authors propose an architecture than can explain why an agent prefer one action over another one by utilizing integrated gradients to explain the association between value function and its input-GVF features.
Full
This work proposes an architecture that can explain why an agent prefers one action over another. First, they use GVF to learn accumulated manual designed features which are easier for human to understand. Second, the value function is not based on raw state representation but based on GVF features. Then when we want to understand why the Q(a) is higher than Q(b), we can associate Q(a) - Q(b) with the GVF features. Third, they use integrated gradients to find the importance of GVF features to the difference between Q(a) and Q(b). Briefly speaking, integrated gradients is a local explanation method that approximates the non-linear function with a linear function. The weights in the approximated linear function could be used directly to indicate the influence or importance of input features. Finally, they also used minimal sufficient explanation (MSX) to handle the problem of large number of GVF features.
No benchmark I think
GVF, Integrated gradients, RL explanability
Demonstrate how their approach help people to understand the agent behaviors on several simple but interesting tasks. Good experiments and demonstration. It's understandable that the tasks are relative simple.
It's a very interesting method but can be hard to be successful in more complicated tasks. One thing we can learn from that they provide some proof in table-based case. It's not hard, but you know, math is a trick for top conferences.
I will probably not do extended reading since I don't see the potential of future work or its application on more complex tasks. But I'm happy to see they use integrated gradients. I might also read MSX if I have a chance to use it.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Official Code
Kurtland Chua, Roberto Calandra, Rowan McAllister, Sergey Levine
UC Berkeley

Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
Show that the use of dropout (and its variants) in NNs can be interpreted as a Bayesian approximation of a well known probabilistic model: the Gaussian process (GP)
以下三つが本論文の貢献
https://arxiv.org/abs/1705.08049
Steven W Chen, Nikolay Atanasov, Arbaaz Khan, Konstantinos Karydis, Daniel D. Lee, Vijay Kumar
UPenn
Unlike traditional feedback motion planning approaches that rely on accurate global maps, our approach can infer appropriate actions directly from sensed information by using a neural network policy representation
https://arxiv.org/abs/1705.10092
Mingming Li, Rui Jiang, Shuzhi Sam Ge, Tong Heng Lee
NUS
Deep Reinforcement Learning with Double Q-learning
Hado van Hasselt, Arthur Guez, David Silver
Google DeepMind
Learning deep structured semantic models for web search using clickthrough data
Po-Sen Huang (UIUC), Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, Larry Heck(MSR)
DARLA: Improving Zero-Shot Transfer in Reinforcement Learning
Consists of a three stage pipeline
replaces the reconstruction loss in the VAE objective as follows


"the disentangled model used for DARLA was trained with a β hyperparameter value of 1"
This review is also informative.
https://openreview.net/forum?id=HygS7n0cFQ
Ramtin Keramati, Jay Whang, Patrick Cho, Emma Brunskill
Stanford
achieve positive reward in the notoriously difficult Atari game Pitfall! within 50 episodes. Almost no RL methods have achieved positive reward on Pitfall! without human demonstrations, and even with demonstrations, such approaches often take hundreds of millions of frames to learn (Aytar et al., 2018; Hester et al., 2017).
we assume two forms of prior knowledge–a predefined object representation and a class of potential model features
Think about A simple neural network module for relational reasoning as one of the reviewer suggested.
Overcoming catastrophic forgetting in neural networks
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, Raia Hadsell
DeepMind
Learning Latent Dynamics for Planning from Pixels
Official repo: google-research/planet
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, James Davidson
Google Brain, University of Toronto, DeepMind, Google Research, University of Michigan
"Model" in this architecture refers three thigs:
and policy

Regarding recurrent network for planning, they claim the following:
our experiments show that both stochastic and deterministic paths in the transition model are crucial for successful planning
and the network architecture looks like Figure2 (c) which is called Recurrent state-space model (RSSM)

Experiments in continuous control tasks:
Cartpole Swing Up, Reacher Easy, Cheetah Run, Finger Spin, Cup Catch, and Walker Walk from DeepMind control suite
Confirmed that the proposed model achieved comparable performance to the best model-free algorithms while using 200× fewer episodes and similar or less computation time.
Broader contextual review:
Hierarchical Reinforcement Learning with the MAXQ Value Function Decomposition
Thomas G. Dietterich
Oregon State University
Proposed MAXQ decomposition by which express value function in a hierarchical manner.
In addition, proposed MAXQ Q-learning algorithm based on MAXQ, which is an online model-free algorithm. The author proved that this algorithm is guaranteed to converge "recursive optimal policy" which is a locally optimal policy.
Three approaches to express subtasks
In this context, these are the previous works
First, introduce
Then, decompose it as follows:


The taxi problem
MAXQ itself is not a method to learn the structure of hierarchy itself. Techniques like Bayesian Belief Nets (Pearl, 1998) would be one of the key as the author wrote in the paper.
Some readers may be disappointed that MAXQ provides no way of learning the structure of
the hierarchy. Our philosophy in developing MAXQ (which we share with other reinforcement learning researchers, notably Parr and Russell) has been to draw inspiration from the development of Belief Networks (Pearl, 1988). Belief networks were first introduced as a formalism in which the knowledge engineer would describe the structure of the networks and domain experts would provide the necessary probability estimates. Subsequently, methods were developed for learning the probability values directly from observational data. Most recently, several methods have been developed for learning the structure of the belief networks from data, so that the dependence on the knowledge engineer is reduced.
In terms of terminate condition of a subtask,Dean and Lin (1995) could be a good reference
the termination predicate method requires the programmer to guess the relative desirability of the different states in which the subtask might terminate. This can also be difficult, although Dean and Lin show how these guesses can be revised automatically by the learning algorithm"
Model-based reinforcement learning for biological sequence design
Christof Angermueller, David Dohan, David Belanger, Ramya Deshpande, Kevin Murphy, Lucy Colwell
Ref: Algorithm 1: DyNA PPO
Our method updates the policy’s parameters using sequences x generated by the current policy πθ(x), but evaluated using a learned surrogate f'(x), instead of the true, but unknown, oracle reward function f(x).
https://arxiv.org/abs/1705.08080
Yuke Zhu, Daniel Gordon, Eric Kolve, Dieter Fox, Li Fei-Fei, Abhinav Gupta, Roozbeh Mottaghi, Ali Farhadi
Allen Institute for Artificial Intelligence, CMU, Stanford, University of Washington
address the problem of visual semantic planning: the task of predicting a sequence of actions from visual observations that transform a dynamic environment from an initial state to a goal state.
背景として以下を少し詳細にフォローしておきたい。
Neuroscience と所謂 AI のこれまでの研究と発展について振り返りつつ、Past / Present / Future についてまとめたサーベイ。
AI システムにおいては、人体の(脳の)仕組みを模した Neuromorphic computing のようなアプローチと、厳密には実態に即さなくても良く欲しい結果が得られれば良しとするアプローチがある。(DeepMindでの著者の仕事も主には後者であって、"biological plausibility is a guid" と本文でも描かれている。もちろんDeepMindにはNeuroscienceガチ勢は沢山居て、Hassabis氏含め皆両方の方向性の進歩とその絶妙なバランス/ブレンドを志向しているのだろうけど)
著者は、NeuroscienceのAI分野に対するベネフィットとして以下の二点を挙げている。
http://www.cell.com/neuron/pdf/S0896-6273(17)30509-3.pdf
Demis Hassabis,1,2,* Dharshan Kumaran,1,3 Christopher Summerfield,1,4 and Matthew Botvinick1,2
個人的に気になったのは以下など
Learning Invariant Representations for Reinforcement Learning without Reconstruction
Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, Sergey Levine
UCB, FAIR, McGill, Oxford
One-sentence
It proposes an approach of representation learning for RL to focus on task-relevant features while ignoring task-irrelevant ones based on the idea of bisimulation.
Full
Appropriate representation could help RL agents to learn faster and also achieve other benefits such as improved generalization. In this work, the authors propose Deep Bisimulation for Control (DBC) to learn RL control and also representation at the same time. Bisimulation metric provides a measurement of the similarity of two states based on the reward and state transition dynamics. The idea of this work is that the l1 distance of two latent state representation should approximate the bisimulation metric of the two states. One nice thing of this approach is that since bisimulation metric will consider task-relevant information only, the constraint or regularization on latent state representation learning drives the representation to ignore task-irrelevant features. This is well demonstrated by CARLA tasks.
Another thing to notice is that they used iterative update (policy, environment model and representation) in implementation. Sometimes engineering tricks are important to make your fancy idea really work.
Compared with other representation learning approaches such as reconstruction-based or contrastive learning based approaches.
Bisimulation metric
It's actually related to our work Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation
. Our approach could be categorized into reconstruction-based state representation learning approaches. I agree representation learning could matter a lot for RL.
Bisimulation is also interesting and have a good potential for further research. It could have more utilization in RL.
Their idea is simple but interesting. Their section 5 of proof could be a good plus. Their experiments are also valid.
Learning continuous latent space models for representation learning
Scalable methods for computing state similarity in deterministic Markov decision processes.
Nirat Saini, Khoi Pham, Abhinav Shrivastava
UMD
The question "How Can We Better Capture Subtly Distinct Features Associated with Attributes?"
Prior works employ supervision from the linguistic space, and use pre-trained word embeddings to better separate and compose attribute-object pairs for recognition.


MIT-States [24] and UT-Zappos [56] are commonly used to study this task
Not sure how well the object affinity network learns the attr? (v’_attr)
Same for the attribute affinity network. How well this network learns obj? (v’_obj)
Not only L_attr and L_obj, but also L_seen and L_unseen work together to shape these embeddings.
https://arxiv.org/abs/1606.01868
Marc G. Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, Remi Munos
DeepMind
Proposed 'pseudo-count' approach to have an agent explore unknown environment.
Advantage compared to count-based approach:
Solve a following equation:

where 
This is the probability assigned to x by the density model after observing a new occurrence of x. Density model is Context Tree Switching (Bellemare et al 2014)
 is a pseudo-count function and
is a pseudo-count function and
 is a pseudo-count total.
is a pseudo-count total.
Add a bonus which is

Atari 2600 games using Arcade Learning Environment (ALE). Especially, Montezuma's revenge showed novel result.
Quote from the paper:
We did not address the question of where the generalization comes from. Clearly, the choice of density model induces a particular metric over the state space. A better understanding of this metric should allow us to tailor the density model to the problem of exploration.
There may be a mismatch in the learning rates of the density model and the value function: DQN learns much more slowly than our CTS model. As such, it should be beneficial to design value functions compatible with density models (or vice-versa).
Although we focused here on countable state spaces, we can as easily define a pseudo-count in terms of probability density functions. At present it is unclear whether this provides us
Reinforcement Learning with Unsupervised Auxiliary Tasks
Max Jaderberg, Volodymyr Mnih, Wojciech Marian Czarnecki, Tom Schaul, Joel Z Leibo, David Silver, Koray Kavukcuoglu
DeepMind
Autoencoding beyond pixels using a learned similarity metric
Official implementation
- They use DeepPy which seems the author's original deep learning framework..
Anders Boesen Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, Ole Winther
Technical University of Denmark, University of Copenhagen, Twitter
Combine VAEs and GANs.
Propose to use learned feature representations in the GAN discriminator as basis for the VAE reconstruction objective.
Thereby, replace element-wise errors with feature-wise errors.
Moreover, show that the network is able to disentangle factors of variation in the input data distribution and discover visual attributes in the high-level representation of the latent space.


Conducted experiments with CelebA dataset and showed that the generative models trained with learned similarity measures produced better image samples than models trained with element-wise error measures.
How is performance in terms of computational cost?
How to determine when to finish GANs training? (maybe need to check the code)
How is performance. It may faster or computationaly less expensive compare to MSE?
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
Code
Lantao Yu, Weinan Zhang, Jun Wang, Yong Yu
Shanghai Jiao Tong University, University College London
Proposed a sequence generation framework called SeqGAN
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
How (not) to train your generative model: Sched- uled sampling, likelihood, adversary?
Auto-Encoding Variational Bayes
Diederik P. Kingma, Max Welling
Universiteit van Amsterdam
Adversarial Feature Matching for Text Generation
Yizhe Zhang, Zhe Gan, Kai Fan, Zhi Chen, Ricardo Henao, Dinghan Shen, Lawrence Carin
Duke University
Exploration by Random Network Distillation
Yuri Burda, Harrison Edwards, Amos Storkey, Oleg Klimov
OpenAI & Univ. of Edinburgh
Comparison with Pseudo-count? (Bellemare et al., 2016)
Define exploration bonus as the prediction error for a problem related to the agent's transitions.
The prediction error is expected to be higher for novel states dissimilar to the ones the predictor has been trained on. This characteristic is exactly what we expect to see for exploration bonus.
Combine intrinsic rewards with extrinsic rewards. This paper also suggests to use non-episodic intrinsic reward.
How to incentivize long time decision is one of the key future work as stated in the paper.
global exploration that involves coordinated decisions over long time horizons is beyond the reach of our method
(e.g. in Montezuma's Revenge, the agent needs to save some keys for the future rather consuming it soon)
Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning
https://openreview.net/forum?id=SJJQVZW0b
PILCO: a model-based and data-efficient approach to policy search
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
In this paper, we introduce pilco, a practical, data-efficient model-based policy search method. Pilco reduces model bias, one of the key problems of model-based reinforcement learning, in a principled way. By learning a probabilistic dynamics model and explicitly incorporating model uncertainty into long-term planning, pilco can cope with very little data and facilitates learning from scratch in only a few trials. Policy evaluation is performed in closed form using state-of-the-art approximate inference. Furthermore, policy gradients are computed analytically for policy improvement. We report unprecedented learning efficiency on challenging and high-dimensional control tasks.
The framework consists of the dynamics model, analytic approximate policy evaluation, and gradient- based.

Compute probability distribution at time step t as p_\theta (x_t), then compute the cost function J^\pi(\theta)
cost c(x) can be solved analytically (eq. 25)
Analytic derivatives of J can be computed, and "standard gradient-based non-convex optimization methods, e.g., CG or L- BFGS" are used to update the parameter \theta
Sutton, R.S. Machine Learning (1988) 3: 9. https://doi.org/10.1023/A:1022633531479
Universal Value Function Approximators (ICML'15)
Tom Schaul, Dan Horgan, Karol Gregor, and David Silver
Google DeepMind
Selective Dyna-Style Planning Under Limited Model Capacity, ICML2020
Zaheer Abbas, Samuel Sokota, Erin J. Talvitie, Martha White


To show that Heteroscedastic Regression can estimates predictive uncertainty due to model inadequacy, the authors conducted an experiments to compare with four other methods:
Information gathering の問題を POMDP として設定、ポリシー学習に "clairvoyant oracle" という完全な情報を模倣する手法を提案。
https://arxiv.org/abs/1705.07834
Sanjiban Choudhury, Ashish Kapoor, Gireeja Ranade, Sebastian Scherer, and Debadeepta Dey
CMU and MSR
※ "This work was conducted by Sanjiban Choudhury as part of a summer internship at Microsoft Research, Redmond, USA" だそうだ
clairvoyant oracle: an oracle that at train time has full knowledge about the world map and can compute maximally informative sensing locations.
この情報を imitate する。
個人的に、この手法の凄さがイマイチまだピンときていない。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.