Keras no es un backend es un API que se conecta con un backend como Tensorflow, Theano, CNTK, PyTorch
En este curso usaremos Keras con Tensorflow
- Las herramientas más conocidas para manejar redes neuronalnes son TensorFlow y PyTorch.
- Keras es una API, se utiliza para facilitar el consumo del backend.
- Utilizaremos la tarjeta GPU, porque permite procesas más datos matemáticos necesarios en el deep learning.
La inteligencia artificial son los intentos de replicar la inteligencia humana en sistemas artificiales.
Machine learning son las técnicas de aprendizaje automático, en donde mismo sistema aprende como encontrar una respuesta sin que alguien lo este programando.
Deep learning es todo lo relacionado a las redes neuronales. Se llama aprendizaje profundo porque a mayor capas conectadas ente sí se obtiene un aprendizaje más fino.
En el Deep learning existen dos grandes problemas:
-
Overfitting: Es cuando el algoritmo “memoriza” los datos y la red neuronal no sabe generalizar.
-
Caja negra: Nosotros conocemos las entradas a las redes neuronales. Sim embargo, no conocemos que es lo que pasa dentro de las capas intermedias de la red.
En un algoritmo de Machine Learning es mucho mas facil explicar como funciona internamente, mientras que las redes neuronales suelen ser cajas negras a no se de trabajar en lograr comprenderlas lo cual requiere un esfuerzo considerable
Es incluso una discusion de etica si es responsable usar las redes neuronales cuando no sabemos como funcionan internamente.
Visualizacion 3D de una red neuronal
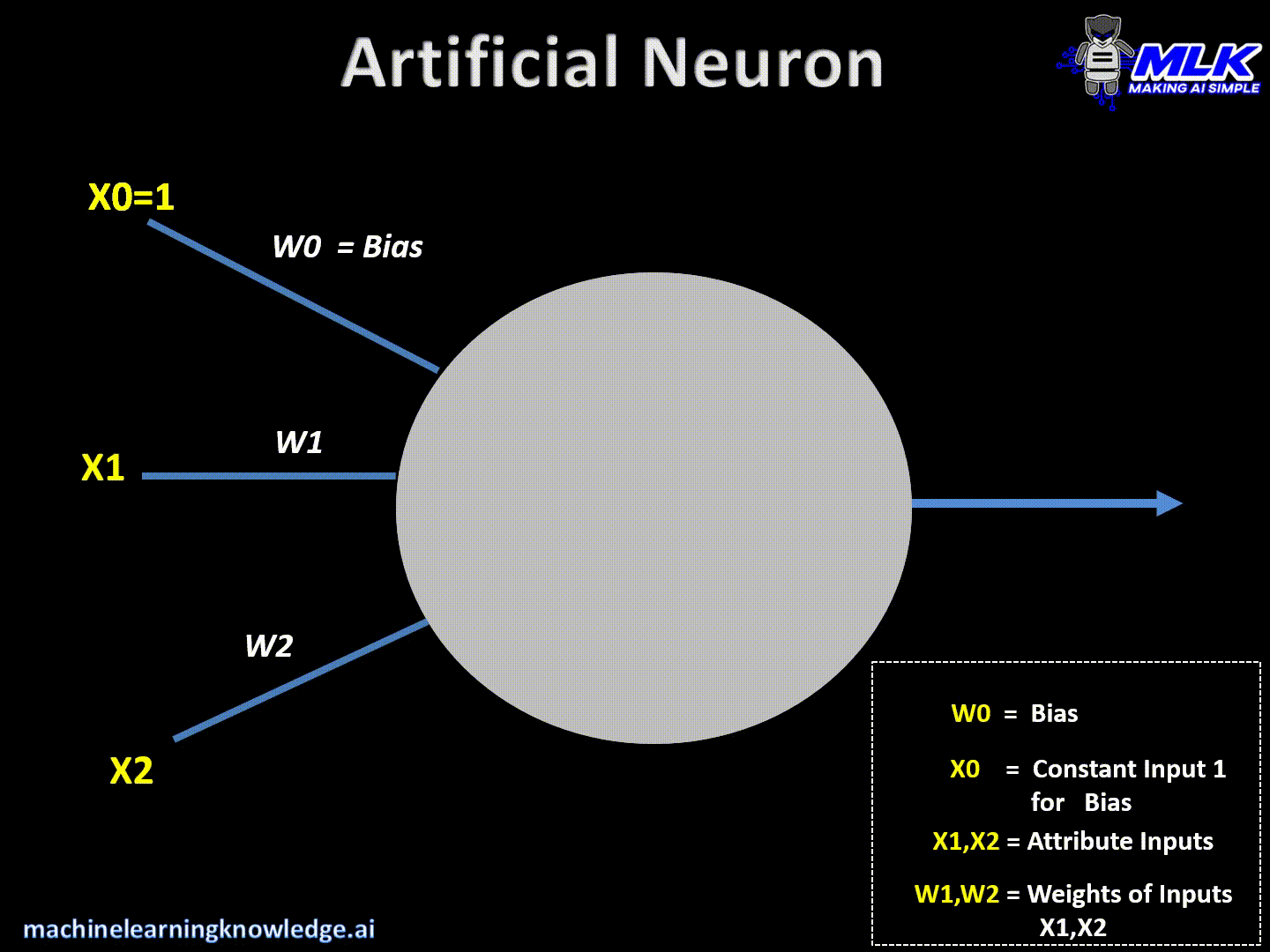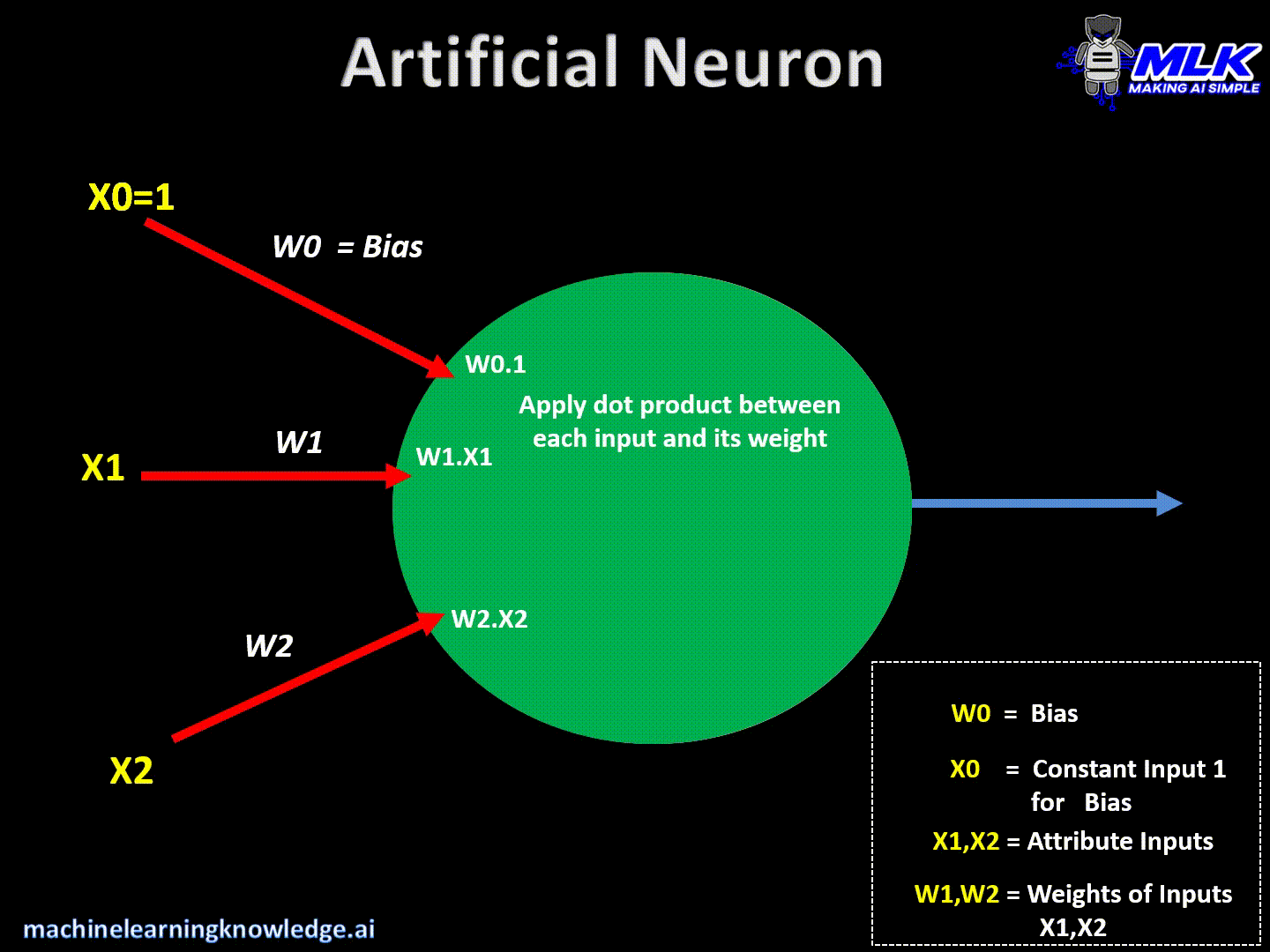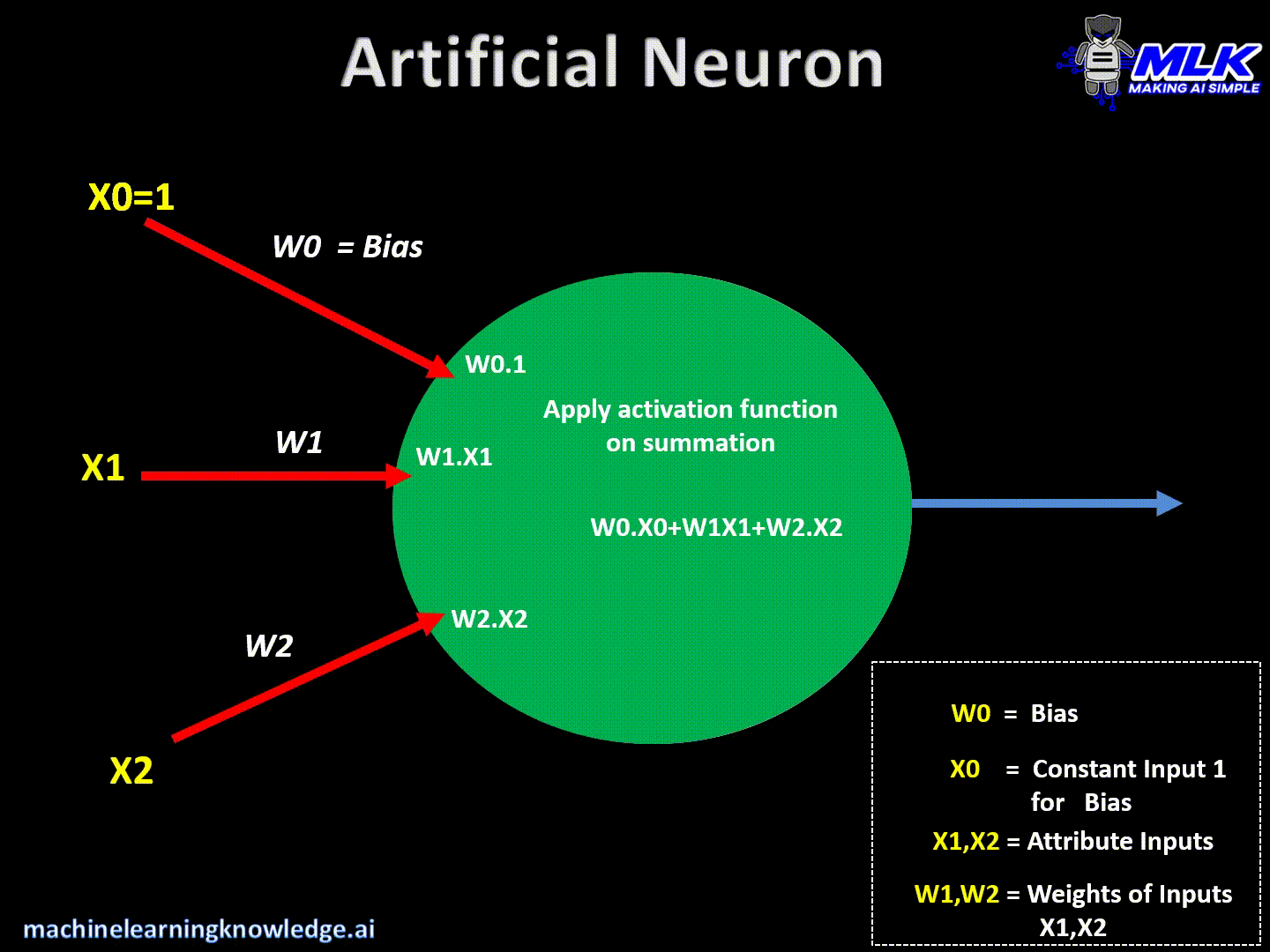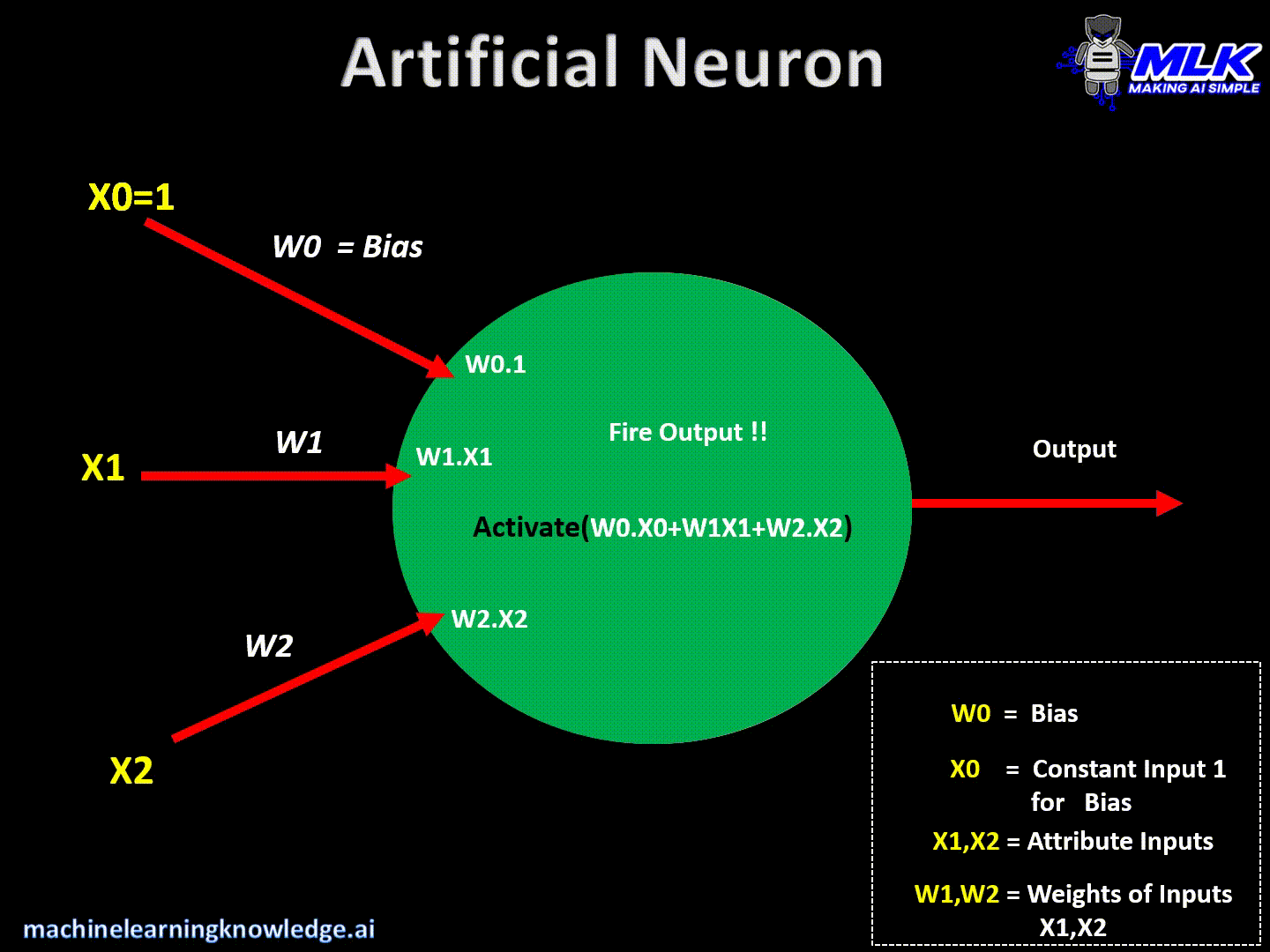
La neurona (perceptron) fue inspirado por las redes neuronales biologicas
El perceptron tiene entradas de datos x1 ... xn tenemos pesos para cada entrada de datos dentro de la neurona tenemos sumas ponderadas
Tenemos la entrada de datos y los pesos de las neuronas, dentro de la neurona se realiza una suma ponderada y a ese resultado se le realiza una funcion de activacion la cual nos da un resultado
En cada iteracion de la red neuronal se cambian los pesos de la entrada para ir optimizando la funcion
Si el nivel de complejidad de un problema es mucho para que la conversion lineal de una neurona lo solucione ejemplo una neuroana XOR el uso de una capa extra de neuronas permite que se pueda resolver el problema.
Una red neuronal esta compuesta de capaz cada capa agrega informacion a la siguiente capa de la red
La capa inicial de entrada es el Input Layer, todas la capaz entrea la inicial y la final son las capas ocultas o Hidden Layers y la capa final es la capa de salida o Output Layer
Cada capa de las red neuronal trabaja con caracteristicas que le fueron pasada de la red anterior
la operacion de una capa de una red a la siguiente se puede comprender como producto la multiplicacion entre una matriz y un vector
y luego se le suma el bias el cual es una constante cuyo valor cambia igual que los pesos
dentro de una red neuronal ocurren miles de operciones de producto punto de matrices, y en cada iteracion se recalculan el valor de los pesos y constantes que se utilizaran en cada operacion.
Existe un problema matematico que si todas las operaciones son lineales no importa la cantidad de capaz el resultado seria una linea la cual perderia todo el aprendizaje hecho, para evitar esto las redes neuronales cuentan con las "funciones de activacion"
Existen porque no se pueden aplicar sumatorias consecutivas de lineas ya que el resultado seria una linea, perdiendo el aprendizaje hecho.
Tipos de funciones de activación:
-
Discretas Conjunto finito de valores
-
Continuas Valores dentro de algun intervalo
-
Función Escalonada si el valor es mayor a 0 da 1 si es menor que 0 da 0 $$ \begin{cases} 1 \text{ si } z >= 0 \ 0 \text{ si } z < 0 \end{cases} $$
-
Función signo/signum $$ \begin{cases} 1 \text{ si } z >= 0 \ -1 \text{ si } z < 0 \end{cases} $$
-
Función Sigmoidal/sigmoid da valores continuos entre 0 y 1 muy buena para el calculo de probabilidades ademas de podersele aplicar derivadas $$ S(x)= \frac {1}{1+e^{-x}} $$
-
Función tangente hiperbólica/tanh Da valores continuos entre -1 y 1.
$$ tanh ( x ) = sinh ( x ) cosh ( x ) = e 2 x − 1 e 2 x + 1 . $$ -
Función rectificada/ReLU (Rectified Linear Units) es de las funciones mas usadas actualmente puede derivarse $$ \begin{cases} z \text{ si } z >= 0 \ 0 \text{ si } z < 0 \end{cases} $$
-
Función Softmax Da la probabilidad de cada una de las posibles salidas se utiliza mucho para realizar calificacion
$$ \sigma(\vec{z}){i}=\frac{e^{z{i}}}{\sum_{j=1}^{K} e^{z_{j}}} $$
Herramienta para la ciencia de datos y funciones de activación


La función de pérdida es muy importante definirla
Se encarga de decirnos si nuestro algoritmo esta prediciendo de una manera correcta, la función toma la prediccion y los valores reales y nos da un score en base a los resultados y asi saber que tan grande es el error de la prediccion
-
MSE - Mean Squared error (Error cuadratico Medio) Eleva los valores al cuadrado para castigar por los valores que estan mas alejados $$ \mathrm{MSE} = \frac{1}{n} \sum_{i=1}^{n}(Y_{i}-\hat{Y}_{i})^2 $$
-
Cross Entropy Es muy bueno para valores categoricos o de clasificacion
Se encarga de medir la distancia entre la prediccion real y el valor de nuestro algoritmo
$$ -\sum_{x}p(x) \log{q(x)} $$
Con la derivada cuando la pendiente da 0 es porque se llego a un pico o a un valle, por lo cual de forma iterativa se busca optimizar la función para encontrar el menor valor de la funcion
http://www.benfrederickson.com/numerical-optimization/
https://www.desmos.com/calculator/l0puzw0zvm
El learning Rate de una funcion dice que tantos pasos realiza la funcion para buscar su punto optimo, si el learning rate es muy bajo la funcion deja de ser eficiente y si el learning rate es muy alto la funcion falla en encontrar el valor minimo al pasar de largo por este punto y no tener la presicion suficiente como para alcanzarlo
Si la funcion alcanza un minimo local pero este no es el minimo global, la funcion esta optmizada mas no optimizada al maximo
para esto casos existen opmizadores como el MSPro el cual le agrega momento y comportamiento fisico a la funciones para evitar que se estanquen en un minimo local
el descenso del gradiente se calcula tomando la funcion de perdida y se calculan sus derivadas parciales en un punto, luego este vector gradiente resultante nos indica hacia donde hay que ir para aumentar el valor al maximo por lo cual lo multiplicamos por -1 y al avanzar en la direccion opuesta realizamos el descenso mas rapido
Backpropagation, teoría Backpropagation, matemáticas
Es el algoritmo que se encarga de distribuir el error calculado por la funcion de partidad a traves de toda la red neuronal, recorriendola red iniciando desde la capa final hasta la capa inicial de entrada.
For the partial derivatives,
For the final layer's error term,
For the hidden layers' error terms,
For combining the partial derivatives for each input-output pair,
For updating the weights,
Espiral con tangente hiperbolica
Tipos de datos por dimension
- Scalar: dimension 0, ejemplo:
2 - Vector: dimension 1, ejemplo
[1,2,3] - Matrix: dimension 2 , ejemplo
[[1,2],[3,4]] - Tensores: 3 Dimensiones o N dimensiones, ejemplo
[[[1,2],[4,5]],[[1,2],[4,5]]]
Matriz, dataframe de filas y columnas
Podemos usar series de Tiempo
Donde tenemos
- cantidad de ejemplos en 1 dimension
- caracteristica de esos ejemplos en otra dimension
- caractersisticas de esos ejemplos con respecto al tiempo en una tercera dimension
- Ancho
- Alto
- Canales de Colores (RGB)
- Cantidad de Ejemplos
https://machinelearningknowledge.ai/
https://machinelearningknowledge.ai/wp-content/uploads/2019/06/Artificial-Neuron-Working.gif
Aunque comumente se dividen los datos en 2
- Entrenamiento
- Test
Para el deep learning y buena practica de machine learning es mejor divirlos en 3
-
Entrenamiento
-
Validacion Con el test de validacion se nos da la oportunidad de cambiar hiperparametros para mejorar como puede ser el learning rate, numero de epochs, etc..
-
Test Con el test ya se usa al final para evaluar como es el comportamiento de mi modelo Testear el resultado final accuracy o unidad de medida que se utilice
¿Por qué hacer esto? por cuestiones de etica para que el modelo se ponga a prueba con datos que jamas allá visto
Racismo por IA: Como dijo el profesor anteriormente, han existido diversos dilemas éticos a lo largo de la historia reciente en los que se describe cómo la Inteligencia Artificial puede tener y ha tenido diversos sesgos que pueden convertir a sus resultados en lo que en un humano pasarían por ser racistas o discriminatorios de alguna forma.
El problema es que estos sesgos, al no poder evaluar detalladamente los ingenieros de software el funcionamiento interno de estos modelos de redes neuronales, no pueden corregirse y pasan desapercibidos.
Un ejemplo:
En un banco, se solicita a un ingeniero de software que haga un modelo que prediga mediante deep learning qué tan probable es recibir beneficios en el banco de otorgar un préstamo a una persona.
Este algoritmo tomaría en cuenta el nivel socioeconómico históricamente inferior de las personas afroamericanas y africanas y decide que tener esta procedencia o raza es una variable de peso que descarta (o hace menos probable) que a esa persona se le otorgue un préstamo.
Esto es un problema, porque el algoritmo no se equivocó, los datos en los que se fundamenta son históricamente reales, sin embargo, es injusto que el banco aplique sistemáticamente esta postura puesto que ello perpetuará esta condición de pobreza o nivel socioeconómico medio-bajo en estas personas (al no recibir tener préstamos fácilmente, no tendrán tantas alternativas para salvar sus negocios y empresas y tenderán más a la bancarrota, etc.).
Es por eso que se ha pensado en prohibir el uso de estos modelos de funcionamiento de caja negra en la toma de cierto tipo de decisiones que podrían resultar en este tipo de conflictos, además que se continúan buscando mecanismos efectivos que puedan tomar en cuenta y corregir este tipo de dilemas éticos.
Overfitting es un problema que ocurre cuando el modelo se aprende de memoria los datos en lugar de aprender acerca del problema que se le presenta
Una red neuronal puede llegar a overfitting porque cada neurona se vuelve más especifica con los datos
Una de las formas más sencillas de reducir el overfitting es usando un modelo más pequeño.
Esto es si tenemos una red demasiado compleja con demasiados parámetros se apegará demasiado a estos datos haciendo overfitting
Y si tenemos una red demasiado sencilla llegaría a underfitting porque no lograría adaptarse al problema siendo tan pequeña
no existe receta de cocina para evitar el underfitting y el overfitting, ni para saber cuántas capas debería tener mi red ni cuantas neuronas debería tener cada capa, aun así, una técnica es empezar con un modelo muy pequeño y una vez cómo se comporta iterar
viene de un problema de hacer los datos más regulares
Occam's Razor "When faced with two equally good hypothesis, always choose the simpler one."
Reducir la complejidad del modelo, para hacer esto debemos reducir los pesos que arroja nuestra red al entrenar, la regularización se lograr con una fórmula matemática
en la cual la regularización castiga la función de perdida utilizando el valor absoluto del peso o el peso al cuadrado multiplicado por un delta
https://compgenomr.github.io/book/logistic-regression-and-regularization.html
https://medium.com/analytics-vidhya/l1-vs-l2-regularization-which-is-better-d01068e6658c
L1 $$ \text{cost} = \sum_{i=0}^N (y_i - \sum_{j=0}^M (x_{ij}W_j)^2 + \lambda \sum_{j=0}^M | W_j|) $$
L2 $$ \text{cost} = \sum_{i=0}^N (y_i - \sum_{j=0}^M (x_{ij}W_j)^2 + \lambda \sum_{j=0}^M W_j^2) $$
aquí siendo el valor decisivo lambda
Otra técnica para reducir el overfitting es el Dropout
la universidad que planteo esto tuvo la idea haciendo fila en un banco y viendo que cada cierta cantidad de personas de la fila avanzaban los cajeros cambiaban de lugar internamente de forma aleatoria Esto lo hacen para evitar que una persona que haga fila para ver un cajero reducir la posibilidad de atender alguien que conozca y que estén conspirando o tenga la intención de hacer algún fraude.
entonces pensaron que tal si mis redes neuronales están conspirando entre si con los valores de entrada, entonces qué tal si muevo mis valores de entrada para que la conspiración no sea tan alta
el dropout consiste durante cada una de las épocas apagar ciertas neuronas de forma aleatoria para reducir el exceso de exactitud que ocasiona el overfitting
que funcion deberia utilizar en mi ultima capa dependiendo del problema

Mas por aprender
- CNN (Convulutional neural network)
- NPL (Natural language process)
- Sequences
- Hyper parameters tuning
- Gans (Generative adversarial networks)
- LSTM (Long short-term memory)
- Callbacks
- Tensorboard
- Y un mundo mas de posibilidades
Deep Learning: Which Loss and Activation Functions should I use?
¿Qué función de activación en la última capa es recomendable para un problema de regresión?
https://platzi.com/clases/2263-redes-neuronales/37456-resolviendo-un-problema-de-regresion/
Es una función de activación muy útil que también cuenta con derivada y funciona perfecto cuando queremos resolver un problema de probabilidad binaria:
https://platzi.com/clases/2263-redes-neuronales/37439-funciones-de-activacion/
¿Cuál es la función del BIAS en la neurona?
https://platzi.com/clases/2263-redes-neuronales/37437-la-neurona-una-pequena-y-poderosa-herramienta/

{kind=link}