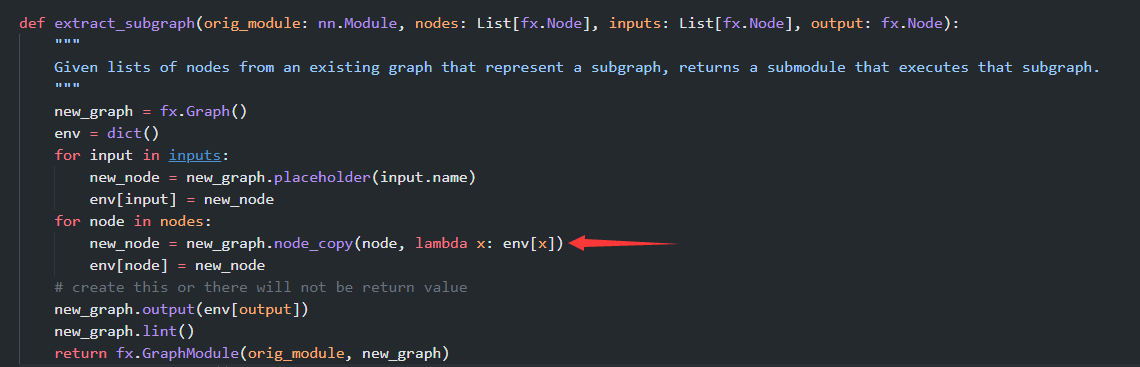
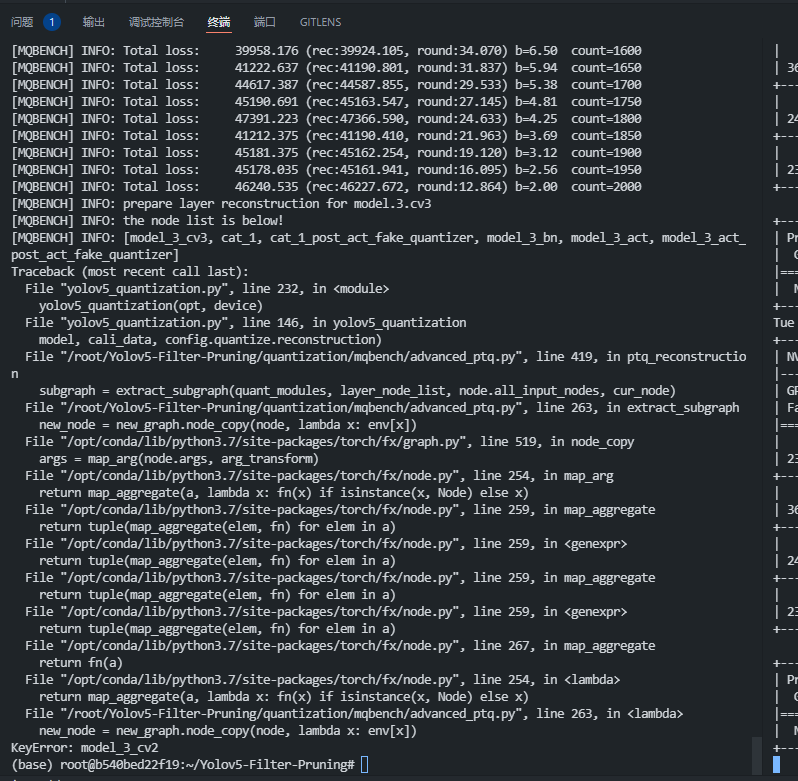
I tried again and the error occurs in the same place but not the same argument. The full output of it :
Apex recommended for faster mixed precision training: https://github.com/NVIDIA/apex
Using CUDA device0 _CudaDeviceProperties(name='TITAN Xp', total_memory=12196MB)
[MQBENCH] INFO: Quantize model Scheme: Tensorrt Mode: Training
[MQBENCH] INFO: Weight Qconfig:
FakeQuantize: AdaRoundFakeQuantize Params: {}
Oberver: MSEObserver Params: Symmetric: False / Bitwidth: 8 / Per channel: True / Pot scale: False / Extra kwargs: {'p': 2.4}
[MQBENCH] INFO: Activation Qconfig:
FakeQuantize: FixedFakeQuantize Params: {}
Oberver: EMAMSEObserver Params: Symmetric: False / Bitwidth: 8 / Per channel: False / Pot scale: False / Extra kwargs: {'p': 2.4}
[MQBENCH] INFO: Replace module to qat module.
[MQBENCH] INFO: Insert act quant x_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_0_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_3_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_3_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_3_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant add_1_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_1_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_3_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_3_cv4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant add_2_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_m_1_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_m_1_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant add_3_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_m_2_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_m_2_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant add_4_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_2_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_5_cv4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_6_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant add_5_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_m_1_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_m_1_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant add_6_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_m_2_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_m_2_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant add_7_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_3_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_7_cv4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_8_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_9_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_4_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_9_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_10_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_10_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_10_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_5_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_10_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_10_cv4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_11_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_6_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_14_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_14_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_14_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_7_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_14_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_14_cv4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_15_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_8_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_18_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_18_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_18_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_9_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_18_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_18_cv4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_10_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_21_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_21_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_21_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_11_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_21_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_21_cv4_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_12_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_24_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_24_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_24_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant cat_13_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_24_act_post_act_fake_quantizer
[MQBENCH] INFO: Insert act quant model_24_cv4_conv_post_act_fake_quantizer
begin calibration now!
[MQBENCH] INFO: Enable observer and Disable quantize for act_fake_quant
[MQBENCH] INFO: Enable observer and Disable quantize for weight_fake_quant
begin advanced PTQ now!
[MQBENCH] INFO: Disable observer and Disable quantize.
[MQBENCH] INFO: Disable observer and Enable quantize.
[MQBENCH] INFO: prepare layer reconstruction for model.0.conv
[MQBENCH] INFO: the node list is below!
[MQBENCH] INFO: [model_0_conv, model_0_conv_post_act_fake_quantizer]
[MQBENCH] INFO: GraphModule(
(model_0_conv_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.08819], device='cuda:0'), zero_point=tensor([0], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=0.0, max_val=22.489063262939453 ch_axis=-1 pot=False)
)
(model): Module(
(0): Module(
(conv): ConvReLU2d(
3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(weight_fake_quant): AdaRoundFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_channel_affine, ch_axis=0, scale=List, zero_point=List
(activation_post_process): MSEObserver(min_val=List, max_val=List ch_axis=0 pot=False)
)
)
)
)
)
def forward(self, x_post_act_fake_quantizer):
model_0_conv = getattr(self.model, "0").conv(x_post_act_fake_quantizer); x_post_act_fake_quantizer = None
model_0_conv_post_act_fake_quantizer = self.model_0_conv_post_act_fake_quantizer(model_0_conv); model_0_conv = None
return model_0_conv_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for model_0_conv_post_act_fake_quantizer
Init alpha to be FP32
[MQBENCH] INFO: The world size is 1.
[MQBENCH] INFO: start tuning by adaround
[MQBENCH] INFO: Total loss: 3539151.000 (rec:3539151.000, round:0.000) b=20.00 count=50
[MQBENCH] INFO: Total loss: 3210827.750 (rec:3210827.750, round:0.000) b=20.00 count=100
[MQBENCH] INFO: Total loss: 3043429.500 (rec:3043429.500, round:0.000) b=20.00 count=150
[MQBENCH] INFO: Total loss: 3222497.000 (rec:3222497.000, round:0.000) b=20.00 count=200
[MQBENCH] INFO: Total loss: 3222481.750 (rec:3222481.750, round:0.000) b=20.00 count=250
[MQBENCH] INFO: Total loss: 3222472.000 (rec:3222472.000, round:0.000) b=20.00 count=300
[MQBENCH] INFO: Total loss: 2805912.000 (rec:2805912.000, round:0.000) b=20.00 count=350
[MQBENCH] INFO: Total loss: 3222206.250 (rec:3222202.250, round:3.956) b=20.00 count=400
[MQBENCH] INFO: Total loss: 3873423.750 (rec:3873419.750, round:3.885) b=19.44 count=450
[MQBENCH] INFO: Total loss: 3222203.000 (rec:3222199.250, round:3.812) b=18.88 count=500
[MQBENCH] INFO: Total loss: 2942019.250 (rec:2942015.500, round:3.754) b=18.31 count=550
[MQBENCH] INFO: Total loss: 2805662.750 (rec:2805659.000, round:3.698) b=17.75 count=600
[MQBENCH] INFO: Total loss: 3461206.500 (rec:3461202.750, round:3.633) b=17.19 count=650
[MQBENCH] INFO: Total loss: 3595007.750 (rec:3595004.250, round:3.568) b=16.62 count=700
[MQBENCH] INFO: Total loss: 3461003.500 (rec:3461000.000, round:3.505) b=16.06 count=750
[MQBENCH] INFO: Total loss: 3753907.250 (rec:3753903.750, round:3.447) b=15.50 count=800
[MQBENCH] INFO: Total loss: 3093474.250 (rec:3093470.750, round:3.391) b=14.94 count=850
[MQBENCH] INFO: Total loss: 3873098.000 (rec:3873094.750, round:3.344) b=14.38 count=900
[MQBENCH] INFO: Total loss: 3332251.250 (rec:3332248.000, round:3.295) b=13.81 count=950
[MQBENCH] INFO: Total loss: 3594865.000 (rec:3594861.750, round:3.241) b=13.25 count=1000
[MQBENCH] INFO: Total loss: 3093389.750 (rec:3093386.500, round:3.188) b=12.69 count=1050
[MQBENCH] INFO: Total loss: 3872996.500 (rec:3872993.250, round:3.139) b=12.12 count=1100
[MQBENCH] INFO: Total loss: 3753790.000 (rec:3753787.000, round:3.086) b=11.56 count=1150
[MQBENCH] INFO: Total loss: 2923425.000 (rec:2923422.000, round:3.033) b=11.00 count=1200
[MQBENCH] INFO: Total loss: 3594803.250 (rec:3594800.250, round:2.975) b=10.44 count=1250
[MQBENCH] INFO: Total loss: 3332164.500 (rec:3332161.500, round:2.916) b=9.88 count=1300
[MQBENCH] INFO: Total loss: 2870452.500 (rec:2870449.750, round:2.854) b=9.31 count=1350
[MQBENCH] INFO: Total loss: 3753696.750 (rec:3753694.000, round:2.788) b=8.75 count=1400
[MQBENCH] INFO: Total loss: 2945751.250 (rec:2945748.500, round:2.721) b=8.19 count=1450
[MQBENCH] INFO: Total loss: 3753680.000 (rec:3753677.250, round:2.652) b=7.62 count=1500
[MQBENCH] INFO: Total loss: 3460759.750 (rec:3460757.250, round:2.577) b=7.06 count=1550
[MQBENCH] INFO: Total loss: 3221720.500 (rec:3221718.000, round:2.496) b=6.50 count=1600
[MQBENCH] INFO: Total loss: 3538183.500 (rec:3538181.000, round:2.407) b=5.94 count=1650
[MQBENCH] INFO: Total loss: 3209970.000 (rec:3209967.750, round:2.308) b=5.38 count=1700
[MQBENCH] INFO: Total loss: 3460724.250 (rec:3460722.000, round:2.198) b=4.81 count=1750
[MQBENCH] INFO: Total loss: 3042632.750 (rec:3042630.750, round:2.079) b=4.25 count=1800
[MQBENCH] INFO: Total loss: 2923285.500 (rec:2923283.500, round:1.945) b=3.69 count=1850
[MQBENCH] INFO: Total loss: 3594662.250 (rec:3594660.500, round:1.791) b=3.12 count=1900
[MQBENCH] INFO: Total loss: 3872818.500 (rec:3872817.000, round:1.612) b=2.56 count=1950
[MQBENCH] INFO: Total loss: 3753604.000 (rec:3753602.500, round:1.396) b=2.00 count=2000
[MQBENCH] INFO: prepare layer reconstruction for model.1.conv
[MQBENCH] INFO: the node list is below!
[MQBENCH] INFO: [model_1_conv, model_1_conv_post_act_fake_quantizer]
[MQBENCH] INFO: GraphModule(
(model_1_conv_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.10162], device='cuda:0'), zero_point=tensor([0], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=0.0, max_val=25.912405014038086 ch_axis=-1 pot=False)
)
(model): Module(
(1): Module(
(conv): ConvReLU2d(
16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)
(weight_fake_quant): AdaRoundFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_channel_affine, ch_axis=0, scale=List, zero_point=List
(activation_post_process): MSEObserver(min_val=List, max_val=List ch_axis=0 pot=False)
)
)
)
)
)
def forward(self, model_0_conv_post_act_fake_quantizer):
model_1_conv = getattr(self.model, "1").conv(model_0_conv_post_act_fake_quantizer); model_0_conv_post_act_fake_quantizer = None
model_1_conv_post_act_fake_quantizer = self.model_1_conv_post_act_fake_quantizer(model_1_conv); model_1_conv = None
return model_1_conv_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for model_1_conv_post_act_fake_quantizer
Init alpha to be FP32
[MQBENCH] INFO: The world size is 1.
[MQBENCH] INFO: start tuning by adaround
[MQBENCH] INFO: Total loss: 1575079.750 (rec:1575079.750, round:0.000) b=20.00 count=50
[MQBENCH] INFO: Total loss: 1575079.250 (rec:1575079.250, round:0.000) b=20.00 count=100
[MQBENCH] INFO: Total loss: 1470952.500 (rec:1470952.500, round:0.000) b=20.00 count=150
[MQBENCH] INFO: Total loss: 1300293.250 (rec:1300293.250, round:0.000) b=20.00 count=200
[MQBENCH] INFO: Total loss: 1304137.125 (rec:1304137.125, round:0.000) b=20.00 count=250
[MQBENCH] INFO: Total loss: 1616733.500 (rec:1616733.500, round:0.000) b=20.00 count=300
[MQBENCH] INFO: Total loss: 1646501.125 (rec:1646501.125, round:0.000) b=20.00 count=350
[MQBENCH] INFO: Total loss: 1325806.375 (rec:1325763.375, round:43.054) b=20.00 count=400
[MQBENCH] INFO: Total loss: 1325726.125 (rec:1325684.125, round:41.956) b=19.44 count=450
[MQBENCH] INFO: Total loss: 1344530.250 (rec:1344489.500, round:40.739) b=18.88 count=500
[MQBENCH] INFO: Total loss: 1646303.125 (rec:1646263.750, round:39.414) b=18.31 count=550
[MQBENCH] INFO: Total loss: 1302296.750 (rec:1302258.750, round:38.059) b=17.75 count=600
[MQBENCH] INFO: Total loss: 1366993.125 (rec:1366956.375, round:36.708) b=17.19 count=650
[MQBENCH] INFO: Total loss: 1302282.500 (rec:1302247.000, round:35.524) b=16.62 count=700
[MQBENCH] INFO: Total loss: 1574807.500 (rec:1574772.875, round:34.652) b=16.06 count=750
[MQBENCH] INFO: Total loss: 1637826.375 (rec:1637792.375, round:33.994) b=15.50 count=800
[MQBENCH] INFO: Total loss: 1444923.375 (rec:1444890.000, round:33.409) b=14.94 count=850
[MQBENCH] INFO: Total loss: 1300030.750 (rec:1299997.875, round:32.837) b=14.38 count=900
[MQBENCH] INFO: Total loss: 1303803.750 (rec:1303771.500, round:32.255) b=13.81 count=950
[MQBENCH] INFO: Total loss: 1302106.750 (rec:1302075.125, round:31.657) b=13.25 count=1000
[MQBENCH] INFO: Total loss: 1616274.375 (rec:1616243.375, round:31.059) b=12.69 count=1050
[MQBENCH] INFO: Total loss: 1629899.750 (rec:1629869.250, round:30.472) b=12.12 count=1100
[MQBENCH] INFO: Total loss: 1487585.250 (rec:1487555.375, round:29.897) b=11.56 count=1150
[MQBENCH] INFO: Total loss: 1299870.875 (rec:1299841.625, round:29.275) b=11.00 count=1200
[MQBENCH] INFO: Total loss: 1290767.875 (rec:1290739.250, round:28.602) b=10.44 count=1250
[MQBENCH] INFO: Total loss: 1470381.375 (rec:1470353.500, round:27.921) b=9.88 count=1300
[MQBENCH] INFO: Total loss: 1487473.500 (rec:1487446.250, round:27.240) b=9.31 count=1350
[MQBENCH] INFO: Total loss: 1299758.250 (rec:1299731.750, round:26.540) b=8.75 count=1400
[MQBENCH] INFO: Total loss: 1637492.875 (rec:1637467.125, round:25.801) b=8.19 count=1450
[MQBENCH] INFO: Total loss: 1299750.875 (rec:1299725.875, round:25.026) b=7.62 count=1500
[MQBENCH] INFO: Total loss: 1366667.625 (rec:1366643.375, round:24.194) b=7.06 count=1550
[MQBENCH] INFO: Total loss: 1616043.625 (rec:1616020.375, round:23.299) b=6.50 count=1600
[MQBENCH] INFO: Total loss: 1629663.625 (rec:1629641.250, round:22.344) b=5.94 count=1650
[MQBENCH] INFO: Total loss: 1637379.750 (rec:1637358.375, round:21.319) b=5.38 count=1700
[MQBENCH] INFO: Total loss: 1487367.000 (rec:1487346.750, round:20.197) b=4.81 count=1750
[MQBENCH] INFO: Total loss: 1637375.500 (rec:1637356.500, round:18.948) b=4.25 count=1800
[MQBENCH] INFO: Total loss: 1469221.625 (rec:1469204.125, round:17.536) b=3.69 count=1850
[MQBENCH] INFO: Total loss: 1344037.125 (rec:1344021.250, round:15.918) b=3.12 count=1900
[MQBENCH] INFO: Total loss: 1487311.250 (rec:1487297.250, round:14.057) b=2.56 count=1950
[MQBENCH] INFO: Total loss: 1303450.875 (rec:1303439.000, round:11.883) b=2.00 count=2000
[MQBENCH] INFO: prepare layer reconstruction for model.2.conv
[MQBENCH] INFO: the node list is below!
[MQBENCH] INFO: [model_2_conv, model_2_conv_post_act_fake_quantizer]
[MQBENCH] INFO: GraphModule(
(model_2_conv_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.07901], device='cuda:0'), zero_point=tensor([0], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=0.0, max_val=20.147693634033203 ch_axis=-1 pot=False)
)
(model): Module(
(2): Module(
(conv): ConvReLU2d(
32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)
(weight_fake_quant): AdaRoundFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_channel_affine, ch_axis=0, scale=List, zero_point=List
(activation_post_process): MSEObserver(min_val=List, max_val=List ch_axis=0 pot=False)
)
)
)
)
)
def forward(self, model_1_conv_post_act_fake_quantizer):
model_2_conv = getattr(self.model, "2").conv(model_1_conv_post_act_fake_quantizer); model_1_conv_post_act_fake_quantizer = None
model_2_conv_post_act_fake_quantizer = self.model_2_conv_post_act_fake_quantizer(model_2_conv); model_2_conv = None
return model_2_conv_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for model_2_conv_post_act_fake_quantizer
Init alpha to be FP32
[MQBENCH] INFO: The world size is 1.
[MQBENCH] INFO: start tuning by adaround
[MQBENCH] INFO: Total loss: 1022320.125 (rec:1022320.125, round:0.000) b=20.00 count=50
[MQBENCH] INFO: Total loss: 1012533.938 (rec:1012533.938, round:0.000) b=20.00 count=100
[MQBENCH] INFO: Total loss: 1050814.500 (rec:1050814.500, round:0.000) b=20.00 count=150
[MQBENCH] INFO: Total loss: 1190185.875 (rec:1190185.875, round:0.000) b=20.00 count=200
[MQBENCH] INFO: Total loss: 996599.250 (rec:996599.250, round:0.000) b=20.00 count=250
[MQBENCH] INFO: Total loss: 1050711.375 (rec:1050711.375, round:0.000) b=20.00 count=300
[MQBENCH] INFO: Total loss: 1149552.250 (rec:1149552.250, round:0.000) b=20.00 count=350
[MQBENCH] INFO: Total loss: 1022317.188 (rec:1022144.812, round:172.386) b=20.00 count=400
[MQBENCH] INFO: Total loss: 1012527.938 (rec:1012360.938, round:166.975) b=19.44 count=450
[MQBENCH] INFO: Total loss: 1305114.000 (rec:1304953.000, round:161.035) b=18.88 count=500
[MQBENCH] INFO: Total loss: 1177806.500 (rec:1177651.875, round:154.631) b=18.31 count=550
[MQBENCH] INFO: Total loss: 1022247.688 (rec:1022099.750, round:147.910) b=17.75 count=600
[MQBENCH] INFO: Total loss: 1079310.000 (rec:1079168.375, round:141.625) b=17.19 count=650
[MQBENCH] INFO: Total loss: 1268717.500 (rec:1268581.000, round:136.557) b=16.62 count=700
[MQBENCH] INFO: Total loss: 1177739.000 (rec:1177606.250, round:132.722) b=16.06 count=750
[MQBENCH] INFO: Total loss: 996573.312 (rec:996443.750, round:129.561) b=15.50 count=800
[MQBENCH] INFO: Total loss: 1268653.875 (rec:1268527.250, round:126.623) b=14.94 count=850
[MQBENCH] INFO: Total loss: 1160553.625 (rec:1160429.750, round:123.814) b=14.38 count=900
[MQBENCH] INFO: Total loss: 1125875.125 (rec:1125754.000, round:121.146) b=13.81 count=950
[MQBENCH] INFO: Total loss: 996476.125 (rec:996357.625, round:118.517) b=13.25 count=1000
[MQBENCH] INFO: Total loss: 1080828.375 (rec:1080712.500, round:115.918) b=12.69 count=1050
[MQBENCH] INFO: Total loss: 1050525.375 (rec:1050412.125, round:113.307) b=12.12 count=1100
[MQBENCH] INFO: Total loss: 996359.562 (rec:996248.938, round:110.646) b=11.56 count=1150
[MQBENCH] INFO: Total loss: 1238611.125 (rec:1238503.250, round:107.931) b=11.00 count=1200
[MQBENCH] INFO: Total loss: 1268448.625 (rec:1268343.500, round:105.166) b=10.44 count=1250
[MQBENCH] INFO: Total loss: 1194375.125 (rec:1194272.750, round:102.322) b=9.88 count=1300
[MQBENCH] INFO: Total loss: 1189787.625 (rec:1189688.250, round:99.391) b=9.31 count=1350
[MQBENCH] INFO: Total loss: 1149302.125 (rec:1149205.750, round:96.362) b=8.75 count=1400
[MQBENCH] INFO: Total loss: 1268396.875 (rec:1268303.625, round:93.201) b=8.19 count=1450
[MQBENCH] INFO: Total loss: 1080680.375 (rec:1080590.500, round:89.817) b=7.62 count=1500
[MQBENCH] INFO: Total loss: 1149271.250 (rec:1149185.000, round:86.198) b=7.06 count=1550
[MQBENCH] INFO: Total loss: 1268374.250 (rec:1268291.875, round:82.328) b=6.50 count=1600
[MQBENCH] INFO: Total loss: 1125635.875 (rec:1125557.625, round:78.223) b=5.94 count=1650
[MQBENCH] INFO: Total loss: 1025074.938 (rec:1025001.062, round:73.882) b=5.38 count=1700
[MQBENCH] INFO: Total loss: 1177378.875 (rec:1177309.625, round:69.255) b=4.81 count=1750
[MQBENCH] INFO: Total loss: 1160254.875 (rec:1160190.625, round:64.281) b=4.25 count=1800
[MQBENCH] INFO: Total loss: 1050356.625 (rec:1050297.750, round:58.832) b=3.69 count=1850
[MQBENCH] INFO: Total loss: 1149190.125 (rec:1149137.375, round:52.783) b=3.12 count=1900
[MQBENCH] INFO: Total loss: 1177344.125 (rec:1177298.125, round:45.972) b=2.56 count=1950
[MQBENCH] INFO: Total loss: 996172.812 (rec:996134.625, round:38.158) b=2.00 count=2000
[MQBENCH] INFO: prepare layer reconstruction for model.3.cv1.conv
[MQBENCH] INFO: the node list is below!
[MQBENCH] INFO: [model_3_cv1_conv, model_3_cv1_conv_post_act_fake_quantizer]
[MQBENCH] INFO: GraphModule(
(model_3_cv1_conv_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.03633], device='cuda:0'), zero_point=tensor([0], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=0.0, max_val=9.263504028320312 ch_axis=-1 pot=False)
)
(model): Module(
(3): Module(
(cv1): Module(
(conv): ConvReLU2d(
64, 32, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): AdaRoundFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_channel_affine, ch_axis=0, scale=List, zero_point=List
(activation_post_process): MSEObserver(min_val=List, max_val=List ch_axis=0 pot=False)
)
)
)
)
)
)
def forward(self, model_2_conv_post_act_fake_quantizer):
model_3_cv1_conv = getattr(self.model, "3").cv1.conv(model_2_conv_post_act_fake_quantizer); model_2_conv_post_act_fake_quantizer = None
model_3_cv1_conv_post_act_fake_quantizer = self.model_3_cv1_conv_post_act_fake_quantizer(model_3_cv1_conv); model_3_cv1_conv = None
return model_3_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for model_3_cv1_conv_post_act_fake_quantizer
Init alpha to be FP32
[MQBENCH] INFO: The world size is 1.
[MQBENCH] INFO: start tuning by adaround
[MQBENCH] INFO: Total loss: 104984.023 (rec:104984.023, round:0.000) b=20.00 count=50
[MQBENCH] INFO: Total loss: 88707.805 (rec:88707.805, round:0.000) b=20.00 count=100
[MQBENCH] INFO: Total loss: 101765.180 (rec:101765.180, round:0.000) b=20.00 count=150
[MQBENCH] INFO: Total loss: 85504.398 (rec:85504.398, round:0.000) b=20.00 count=200
[MQBENCH] INFO: Total loss: 90762.773 (rec:90762.773, round:0.000) b=20.00 count=250
[MQBENCH] INFO: Total loss: 85503.766 (rec:85503.766, round:0.000) b=20.00 count=300
[MQBENCH] INFO: Total loss: 107946.148 (rec:107946.148, round:0.000) b=20.00 count=350
[MQBENCH] INFO: Total loss: 90780.094 (rec:90760.984, round:19.107) b=20.00 count=400
[MQBENCH] INFO: Total loss: 107402.766 (rec:107384.234, round:18.528) b=19.44 count=450
[MQBENCH] INFO: Total loss: 107402.000 (rec:107384.094, round:17.908) b=18.88 count=500
[MQBENCH] INFO: Total loss: 90778.031 (rec:90760.828, round:17.205) b=18.31 count=550
[MQBENCH] INFO: Total loss: 86059.000 (rec:86042.539, round:16.464) b=17.75 count=600
[MQBENCH] INFO: Total loss: 90776.555 (rec:90760.805, round:15.751) b=17.19 count=650
[MQBENCH] INFO: Total loss: 86053.188 (rec:86038.055, round:15.130) b=16.62 count=700
[MQBENCH] INFO: Total loss: 90340.594 (rec:90325.953, round:14.639) b=16.06 count=750
[MQBENCH] INFO: Total loss: 94209.672 (rec:94195.453, round:14.219) b=15.50 count=800
[MQBENCH] INFO: Total loss: 104980.758 (rec:104966.906, round:13.854) b=14.94 count=850
[MQBENCH] INFO: Total loss: 104980.453 (rec:104966.898, round:13.551) b=14.38 count=900
[MQBENCH] INFO: Total loss: 107382.312 (rec:107369.055, round:13.256) b=13.81 count=950
[MQBENCH] INFO: Total loss: 86042.688 (rec:86029.703, round:12.988) b=13.25 count=1000
[MQBENCH] INFO: Total loss: 101750.539 (rec:101737.820, round:12.716) b=12.69 count=1050
[MQBENCH] INFO: Total loss: 88696.070 (rec:88683.656, round:12.417) b=12.12 count=1100
[MQBENCH] INFO: Total loss: 87091.375 (rec:87079.273, round:12.100) b=11.56 count=1150
[MQBENCH] INFO: Total loss: 107925.648 (rec:107913.859, round:11.790) b=11.00 count=1200
[MQBENCH] INFO: Total loss: 88690.602 (rec:88679.125, round:11.475) b=10.44 count=1250
[MQBENCH] INFO: Total loss: 87085.820 (rec:87074.672, round:11.147) b=9.88 count=1300
[MQBENCH] INFO: Total loss: 101740.039 (rec:101729.234, round:10.805) b=9.31 count=1350
[MQBENCH] INFO: Total loss: 86021.062 (rec:86010.609, round:10.452) b=8.75 count=1400
[MQBENCH] INFO: Total loss: 86020.656 (rec:86010.570, round:10.084) b=8.19 count=1450
[MQBENCH] INFO: Total loss: 91561.102 (rec:91551.406, round:9.694) b=7.62 count=1500
[MQBENCH] INFO: Total loss: 111278.703 (rec:111269.430, round:9.277) b=7.06 count=1550
[MQBENCH] INFO: Total loss: 85475.719 (rec:85466.891, round:8.827) b=6.50 count=1600
[MQBENCH] INFO: Total loss: 86016.086 (rec:86007.742, round:8.341) b=5.94 count=1650
[MQBENCH] INFO: Total loss: 88679.156 (rec:88671.328, round:7.831) b=5.38 count=1700
[MQBENCH] INFO: Total loss: 85473.922 (rec:85466.633, round:7.287) b=4.81 count=1750
[MQBENCH] INFO: Total loss: 91554.492 (rec:91547.789, round:6.707) b=4.25 count=1800
[MQBENCH] INFO: Total loss: 107909.867 (rec:107903.789, round:6.079) b=3.69 count=1850
[MQBENCH] INFO: Total loss: 108901.992 (rec:108896.586, round:5.403) b=3.12 count=1900
[MQBENCH] INFO: Total loss: 90728.711 (rec:90724.047, round:4.667) b=2.56 count=1950
[MQBENCH] INFO: Total loss: 101727.688 (rec:101723.836, round:3.852) b=2.00 count=2000
[MQBENCH] INFO: prepare layer reconstruction for model.3.m.0.cv1.conv
[MQBENCH] INFO: the node list is below!
[MQBENCH] INFO: [model_3_m_0_cv1_conv, model_3_m_0_cv1_conv_post_act_fake_quantizer]
[MQBENCH] INFO: GraphModule(
(model_3_m_0_cv1_conv_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.03124], device='cuda:0'), zero_point=tensor([0], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=0.0, max_val=7.966949939727783 ch_axis=-1 pot=False)
)
(model): Module(
(3): Module(
(m): Module(
(0): Module(
(cv1): Module(
(conv): ConvReLU2d(
32, 32, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): AdaRoundFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_channel_affine, ch_axis=0, scale=List, zero_point=List
(activation_post_process): MSEObserver(min_val=List, max_val=List ch_axis=0 pot=False)
)
)
)
)
)
)
)
)
def forward(self, model_3_cv1_conv_post_act_fake_quantizer):
model_3_m_0_cv1_conv = getattr(getattr(self.model, "3").m, "0").cv1.conv(model_3_cv1_conv_post_act_fake_quantizer); model_3_cv1_conv_post_act_fake_quantizer = None
model_3_m_0_cv1_conv_post_act_fake_quantizer = self.model_3_m_0_cv1_conv_post_act_fake_quantizer(model_3_m_0_cv1_conv); model_3_m_0_cv1_conv = None
return model_3_m_0_cv1_conv_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for model_3_m_0_cv1_conv_post_act_fake_quantizer
Init alpha to be FP32
[MQBENCH] INFO: The world size is 1.
[MQBENCH] INFO: start tuning by adaround
[MQBENCH] INFO: Total loss: 74922.727 (rec:74922.727, round:0.000) b=20.00 count=50
[MQBENCH] INFO: Total loss: 90180.148 (rec:90180.148, round:0.000) b=20.00 count=100
[MQBENCH] INFO: Total loss: 74915.336 (rec:74915.336, round:0.000) b=20.00 count=150
[MQBENCH] INFO: Total loss: 73166.547 (rec:73166.547, round:0.000) b=20.00 count=200
[MQBENCH] INFO: Total loss: 72276.906 (rec:72276.906, round:0.000) b=20.00 count=250
[MQBENCH] INFO: Total loss: 90175.766 (rec:90175.766, round:0.000) b=20.00 count=300
[MQBENCH] INFO: Total loss: 72275.961 (rec:72275.961, round:0.000) b=20.00 count=350
[MQBENCH] INFO: Total loss: 90108.414 (rec:90098.922, round:9.493) b=20.00 count=400
[MQBENCH] INFO: Total loss: 92421.492 (rec:92412.227, round:9.269) b=19.44 count=450
[MQBENCH] INFO: Total loss: 73170.367 (rec:73161.320, round:9.049) b=18.88 count=500
[MQBENCH] INFO: Total loss: 90901.281 (rec:90892.445, round:8.837) b=18.31 count=550
[MQBENCH] INFO: Total loss: 77723.289 (rec:77714.672, round:8.619) b=17.75 count=600
[MQBENCH] INFO: Total loss: 77713.320 (rec:77704.906, round:8.412) b=17.19 count=650
[MQBENCH] INFO: Total loss: 77236.125 (rec:77227.891, round:8.231) b=16.62 count=700
[MQBENCH] INFO: Total loss: 82413.883 (rec:82405.820, round:8.064) b=16.06 count=750
[MQBENCH] INFO: Total loss: 77230.914 (rec:77222.992, round:7.918) b=15.50 count=800
[MQBENCH] INFO: Total loss: 89802.352 (rec:89794.555, round:7.800) b=14.94 count=850
[MQBENCH] INFO: Total loss: 73140.039 (rec:73132.367, round:7.674) b=14.38 count=900
[MQBENCH] INFO: Total loss: 73135.469 (rec:73127.945, round:7.525) b=13.81 count=950
[MQBENCH] INFO: Total loss: 72246.219 (rec:72238.844, round:7.377) b=13.25 count=1000
[MQBENCH] INFO: Total loss: 86495.039 (rec:86487.812, round:7.226) b=12.69 count=1050
[MQBENCH] INFO: Total loss: 92371.758 (rec:92364.688, round:7.072) b=12.12 count=1100
[MQBENCH] INFO: Total loss: 77215.203 (rec:77208.281, round:6.918) b=11.56 count=1150
[MQBENCH] INFO: Total loss: 90134.648 (rec:90127.891, round:6.759) b=11.00 count=1200
[MQBENCH] INFO: Total loss: 74565.508 (rec:74558.906, round:6.603) b=10.44 count=1250
[MQBENCH] INFO: Total loss: 90058.266 (rec:90051.820, round:6.447) b=9.88 count=1300
[MQBENCH] INFO: Total loss: 78599.281 (rec:78593.000, round:6.279) b=9.31 count=1350
[MQBENCH] INFO: Total loss: 74871.906 (rec:74865.812, round:6.093) b=8.75 count=1400
[MQBENCH] INFO: Total loss: 74869.305 (rec:74863.414, round:5.894) b=8.19 count=1450
[MQBENCH] INFO: Total loss: 73118.312 (rec:73112.625, round:5.685) b=7.62 count=1500
[MQBENCH] INFO: Total loss: 73114.555 (rec:73109.086, round:5.471) b=7.06 count=1550
[MQBENCH] INFO: Total loss: 90841.016 (rec:90835.766, round:5.249) b=6.50 count=1600
[MQBENCH] INFO: Total loss: 90840.742 (rec:90835.727, round:5.016) b=5.94 count=1650
[MQBENCH] INFO: Total loss: 72227.391 (rec:72222.625, round:4.765) b=5.38 count=1700
[MQBENCH] INFO: Total loss: 74859.797 (rec:74855.312, round:4.485) b=4.81 count=1750
[MQBENCH] INFO: Total loss: 82375.586 (rec:82371.414, round:4.174) b=4.25 count=1800
[MQBENCH] INFO: Total loss: 77658.773 (rec:77654.953, round:3.824) b=3.69 count=1850
[MQBENCH] INFO: Total loss: 90828.023 (rec:90824.586, round:3.436) b=3.12 count=1900
[MQBENCH] INFO: Total loss: 77655.438 (rec:77652.430, round:3.004) b=2.56 count=1950
[MQBENCH] INFO: Total loss: 73101.320 (rec:73098.805, round:2.517) b=2.00 count=2000
[MQBENCH] INFO: prepare layer reconstruction for model.3.m.0.cv2.conv
[MQBENCH] INFO: the node list is below!
[MQBENCH] INFO: [model_3_m_0_cv2_conv, model_3_m_0_cv2_conv_post_act_fake_quantizer]
[MQBENCH] INFO: GraphModule(
(model_3_m_0_cv2_conv_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.04500], device='cuda:0'), zero_point=tensor([0], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=0.0, max_val=11.474054336547852 ch_axis=-1 pot=False)
)
(model): Module(
(3): Module(
(m): Module(
(0): Module(
(cv2): Module(
(conv): ConvReLU2d(
32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(weight_fake_quant): AdaRoundFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_channel_affine, ch_axis=0, scale=List, zero_point=List
(activation_post_process): MSEObserver(min_val=List, max_val=List ch_axis=0 pot=False)
)
)
)
)
)
)
)
)
def forward(self, model_3_m_0_cv1_conv_post_act_fake_quantizer):
model_3_m_0_cv2_conv = getattr(getattr(self.model, "3").m, "0").cv2.conv(model_3_m_0_cv1_conv_post_act_fake_quantizer); model_3_m_0_cv1_conv_post_act_fake_quantizer = None
model_3_m_0_cv2_conv_post_act_fake_quantizer = self.model_3_m_0_cv2_conv_post_act_fake_quantizer(model_3_m_0_cv2_conv); model_3_m_0_cv2_conv = None
return model_3_m_0_cv2_conv_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for model_3_m_0_cv2_conv_post_act_fake_quantizer
Init alpha to be FP32
[MQBENCH] INFO: The world size is 1.
[MQBENCH] INFO: start tuning by adaround
[MQBENCH] INFO: Total loss: 37715.312 (rec:37715.312, round:0.000) b=20.00 count=50
[MQBENCH] INFO: Total loss: 41225.355 (rec:41225.355, round:0.000) b=20.00 count=100
[MQBENCH] INFO: Total loss: 44845.805 (rec:44845.805, round:0.000) b=20.00 count=150
[MQBENCH] INFO: Total loss: 45799.879 (rec:45799.879, round:0.000) b=20.00 count=200
[MQBENCH] INFO: Total loss: 50526.023 (rec:50526.023, round:0.000) b=20.00 count=250
[MQBENCH] INFO: Total loss: 46262.328 (rec:46262.328, round:0.000) b=20.00 count=300
[MQBENCH] INFO: Total loss: 46661.832 (rec:46661.832, round:0.000) b=20.00 count=350
[MQBENCH] INFO: Total loss: 44792.629 (rec:44706.270, round:86.358) b=20.00 count=400
[MQBENCH] INFO: Total loss: 50602.289 (rec:50518.762, round:83.526) b=19.44 count=450
[MQBENCH] INFO: Total loss: 44917.375 (rec:44837.086, round:80.288) b=18.88 count=500
[MQBENCH] INFO: Total loss: 41291.262 (rec:41214.719, round:76.543) b=18.31 count=550
[MQBENCH] INFO: Total loss: 44213.484 (rec:44141.004, round:72.481) b=17.75 count=600
[MQBENCH] INFO: Total loss: 46723.406 (rec:46654.953, round:68.454) b=17.19 count=650
[MQBENCH] INFO: Total loss: 38436.500 (rec:38371.410, round:65.089) b=16.62 count=700
[MQBENCH] INFO: Total loss: 39184.832 (rec:39122.195, round:62.638) b=16.06 count=750
[MQBENCH] INFO: Total loss: 46708.672 (rec:46647.875, round:60.795) b=15.50 count=800
[MQBENCH] INFO: Total loss: 44473.789 (rec:44414.590, round:59.198) b=14.94 count=850
[MQBENCH] INFO: Total loss: 39177.609 (rec:39119.922, round:57.687) b=14.38 count=900
[MQBENCH] INFO: Total loss: 39995.133 (rec:39938.891, round:56.242) b=13.81 count=950
[MQBENCH] INFO: Total loss: 39993.488 (rec:39938.703, round:54.785) b=13.25 count=1000
[MQBENCH] INFO: Total loss: 45231.879 (rec:45178.508, round:53.372) b=12.69 count=1050
[MQBENCH] INFO: Total loss: 37747.441 (rec:37695.473, round:51.970) b=12.12 count=1100
[MQBENCH] INFO: Total loss: 44648.543 (rec:44597.988, round:50.554) b=11.56 count=1150
[MQBENCH] INFO: Total loss: 44176.258 (rec:44127.168, round:49.091) b=11.00 count=1200
[MQBENCH] INFO: Total loss: 39979.871 (rec:39932.332, round:47.540) b=10.44 count=1250
[MQBENCH] INFO: Total loss: 46283.957 (rec:46238.078, round:45.878) b=9.88 count=1300
[MQBENCH] INFO: Total loss: 45815.332 (rec:45771.234, round:44.098) b=9.31 count=1350
[MQBENCH] INFO: Total loss: 37730.723 (rec:37688.531, round:42.191) b=8.75 count=1400
[MQBENCH] INFO: Total loss: 50532.953 (rec:50492.746, round:40.207) b=8.19 count=1450
[MQBENCH] INFO: Total loss: 50530.844 (rec:50492.684, round:38.161) b=7.62 count=1500
[MQBENCH] INFO: Total loss: 44718.082 (rec:44682.020, round:36.063) b=7.06 count=1550
[MQBENCH] INFO: Total loss: 41224.871 (rec:41190.969, round:33.901) b=6.50 count=1600
[MQBENCH] INFO: Total loss: 39137.375 (rec:39105.684, round:31.691) b=5.94 count=1650
[MQBENCH] INFO: Total loss: 44428.445 (rec:44399.043, round:29.402) b=5.38 count=1700
[MQBENCH] INFO: Total loss: 45190.570 (rec:45163.543, round:27.029) b=4.81 count=1750
[MQBENCH] INFO: Total loss: 45187.898 (rec:45163.363, round:24.536) b=4.25 count=1800
[MQBENCH] INFO: Total loss: 39127.074 (rec:39105.195, round:21.881) b=3.69 count=1850
[MQBENCH] INFO: Total loss: 47384.465 (rec:47365.414, round:19.051) b=3.12 count=1900
[MQBENCH] INFO: Total loss: 44413.383 (rec:44397.352, round:16.032) b=2.56 count=1950
[MQBENCH] INFO: Total loss: 50498.168 (rec:50485.352, round:12.818) b=2.00 count=2000
[MQBENCH] INFO: prepare layer reconstruction for model.3.cv3
[MQBENCH] INFO: the node list is below!
[MQBENCH] INFO: [model_3_cv3, cat_1, cat_1_post_act_fake_quantizer, model_3_bn, model_3_act, model_3_act_post_act_fake_quantizer]
[MQBENCH] INFO: GraphModule(
(cat_1_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.10376], device='cuda:0'), zero_point=tensor([146], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=-15.115386009216309, max_val=11.34388256072998 ch_axis=-1 pot=False)
)
(model_3_act_post_act_fake_quantizer): FixedFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_tensor_affine, ch_axis=-1, scale=tensor([0.05508], device='cuda:0'), zero_point=tensor([39], device='cuda:0', dtype=torch.int32)
(activation_post_process): EMAMSEObserver(min_val=-2.1693410873413086, max_val=11.876273155212402 ch_axis=-1 pot=False)
)
(model): Module(
(3): Module(
(cv3): Conv2d(
32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False
(weight_fake_quant): AdaRoundFakeQuantize(
fake_quant_enabled=tensor([1], device='cuda:0', dtype=torch.uint8), observer_enabled=tensor([0], device='cuda:0', dtype=torch.uint8), quant_min=0, quant_max=255, dtype=torch.quint8, qscheme=torch.per_channel_affine, ch_axis=0, scale=List, zero_point=List
(activation_post_process): MSEObserver(min_val=List, max_val=List ch_axis=0 pot=False)
)
)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): LeakyReLU(negative_slope=0.1, inplace=True)
)
)
)
import torch
def forward(self, model_3_cv2, add_1_post_act_fake_quantizer):
model_3_cv3 = getattr(self.model, "3").cv3(add_1_post_act_fake_quantizer); add_1_post_act_fake_quantizer = None
cat_1 = torch.cat((model_3_cv3, model_3_cv2), dim = 1); model_3_cv3 = model_3_cv2 = None
cat_1_post_act_fake_quantizer = self.cat_1_post_act_fake_quantizer(cat_1); cat_1 = None
model_3_bn = getattr(self.model, "3").bn(cat_1_post_act_fake_quantizer); cat_1_post_act_fake_quantizer = None
model_3_act = getattr(self.model, "3").act(model_3_bn); model_3_bn = None
model_3_act_post_act_fake_quantizer = self.model_3_act_post_act_fake_quantizer(model_3_act); model_3_act = None
return model_3_act_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for cat_1_post_act_fake_quantizer
[MQBENCH] INFO: learn the scale for model_3_act_post_act_fake_quantizer
Init alpha to be FP32
[MQBENCH] INFO: The world size is 1.
[MQBENCH] INFO: start tuning by adaround
Traceback (most recent call last):
File "yolov5_quantization.py", line 232, in <module>
yolov5_quantization(opt, device)
File "yolov5_quantization.py", line 146, in yolov5_quantization
model, cali_data, config.quantize.reconstruction)
File "/root/Yolov5-Filter-Pruning/quantization/mqbench/advanced_ptq.py", line 459, in ptq_reconstruction
subgraph_reconstruction(subgraph, cached_inps, cached_oups, config)
File "/root/Yolov5-Filter-Pruning/quantization/mqbench/advanced_ptq.py", line 261, in subgraph_reconstruction
out_quant = subgraph(*cur_inp)
File "/opt/conda/lib/python3.7/site-packages/torch/fx/graph_module.py", line 308, in wrapped_call
return cls_call(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
TypeError: forward() missing 1 required positional argument: 'add_1_post_act_fake_quantizer'