modeloriented / localmodel Goto Github PK
View Code? Open in Web Editor NEWLIME-like explanations with interpretable features based on Ceteris Paribus curves. Now on CRAN.
Home Page: https://modeloriented.github.io/localModel
LIME-like explanations with interpretable features based on Ceteris Paribus curves. Now on CRAN.
Home Page: https://modeloriented.github.io/localModel
that would help compare different local explanations
Alternatively:
Thanks for the effort put in this package.
I'm getting an error from individual_surrogate_model line 158
After spending 3 hours debugging this, it doesn't look like I'm having progress.
The main reason is the complexity of individual_surrogate_model.
What does the function in lines 160-179 suppose to do?
Could you please refactor it into a stand-alone function and add a unit test for easier dubbing?
Moreover, individual_surrogate_model does many things. This makes it hard to (a) understand
and (b) test isolate cases.
Thanks

Hi,
I have tried to install the package using devtools
devtools::install_github("ModelOriented/localModel")
but I got an error:
Error in read.dcf(path) :
Found continuation line starting ' person("Mateusz" ...' at begin of record.
Here is my sessionInfo()
R version 3.4.3 (2017-11-30)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 7 x64 (build 7600)
Matrix products: default
locale:
[1] LC_COLLATE=Polish_Poland.1250 LC_CTYPE=Polish_Poland.1250 LC_MONETARY=Polish_Poland.1250
[4] LC_NUMERIC=C LC_TIME=Polish_Poland.1250
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] Rcpp_1.0.1 rstudioapi_0.7 magrittr_1.5 usethis_1.4.0 devtools_2.0.1
[6] pkgload_1.0.2 R6_2.4.0 rlang_0.3.3 tools_3.4.3 pkgbuild_1.0.2
[11] sessioninfo_1.1.1 cli_1.1.0 withr_2.1.2 remotes_2.0.2 yaml_2.2.0
[16] assertthat_0.2.1 digest_0.6.18 rprojroot_1.3-2 crayon_1.3.4 processx_3.2.0
[21] callr_3.0.0 base64enc_0.1-3 fs_1.2.6 ps_1.2.1 curl_3.1
[26] testthat_2.0.0 glue_1.3.1 memoise_1.1.0 compiler_3.4.3 desc_1.2.0
[31] backports_1.1.3 prettyunits_1.0.2
Shapley values
LocalSurrogate
Add links to methodology vignettes to others
Decision trees suck
cause ingredients is already there.
Set.seed correctly when sampling new observations
@mstaniak what about using ingredients instead of ceterisParibus2 ?
It should be 100% compatibile and is more mature so will get CRAN sooner.
Add unit tests for smaller functions after refactoring individual_surrogate_model
I'm using the Titanic dataset to explain a random passenger survival rate.
To do that I fit a GLM model with the following statistics, ordered by p-value:
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| GENDERmale | -2.66 | 0.20 | -13.33 | 0.00 |
| (Intercept) | 4.70 | 0.48 | 9.76 | 0.00 |
| CLASS3rd | -2.50 | 0.32 | -7.91 | 0.00 |
| AGE | -0.04 | 0.01 | -5.57 | 0.00 |
| CLASS2nd | -1.51 | 0.31 | -4.86 | 0.00 |
| SIBSP | -0.38 | 0.11 | -3.47 | 0.00 |
| EMBARKEDSouthampton | -0.66 | 0.23 | -2.91 | 0.00 |
| EMBARKEDQueenstown | -1.08 | 0.38 | -2.88 | 0.00 |
| FARE | 0.00 | 0.00 | -0.43 | 0.67 |
| PARCH | 0.01 | 0.11 | 0.10 | 0.92 |
We can see that GENDER is the most important variable. However, plotting localModel::individual_surrogate_model output doesn't show this variable is important.

Here are some comparisons with other explainers:


We see that the other two methods capture and report GENDER impact.
I think the following print gives a direction for a potential bug. This is the individual_surrogate_model output print. Notice the NA near GENDER

Does that make any sense?
Error in contrasts<-(*tmp*, value = contr.funs[1 + isOF[nn]]) : contrasts can be applied only to factors with 2 or more levels
set.seed(17)
faktor <- sample(c(0, 1), 500, prob = c(0.5, 0.5), replace = T)
table(faktor)
set.seed(17)
numeric <- rnorm(500)
set.seed(17)
y <- (-1)^(faktor)*4*numeric + 0.5 + rnorm(500)
set.seed(17)
X <- data.frame(y = y,
x1 = as.factor(faktor),
x2 = numeric,
x3 = runif(500))
library(randomForest)
library(dplyr)
X_train <- sample_frac(X, 0.8)
X_test <- setdiff(X, X_train)
rf_m <- randomForest(y ~., data = X_train, ntree = 1000)
mean((predict(rf_m, X_test[, -1]) - X_test[, 1])^2)
library(DALEX2)
dalex_explainer <- DALEX2::explain(rf_m, data = X_train[, -1])
library(localModel)
lm_explanation_4 <- individual_surrogate_model(dalex_explainer, X[4, -1],
1000, 17, gaussian_kernel)
Thank you for this great package! Do you intend to publish the latest version soon on CRAN?
My collegues and I would like to use the new functions, but we cannot install packages from Github because of security policies.
Don't use the full ceteris paribus curves, only two parts.
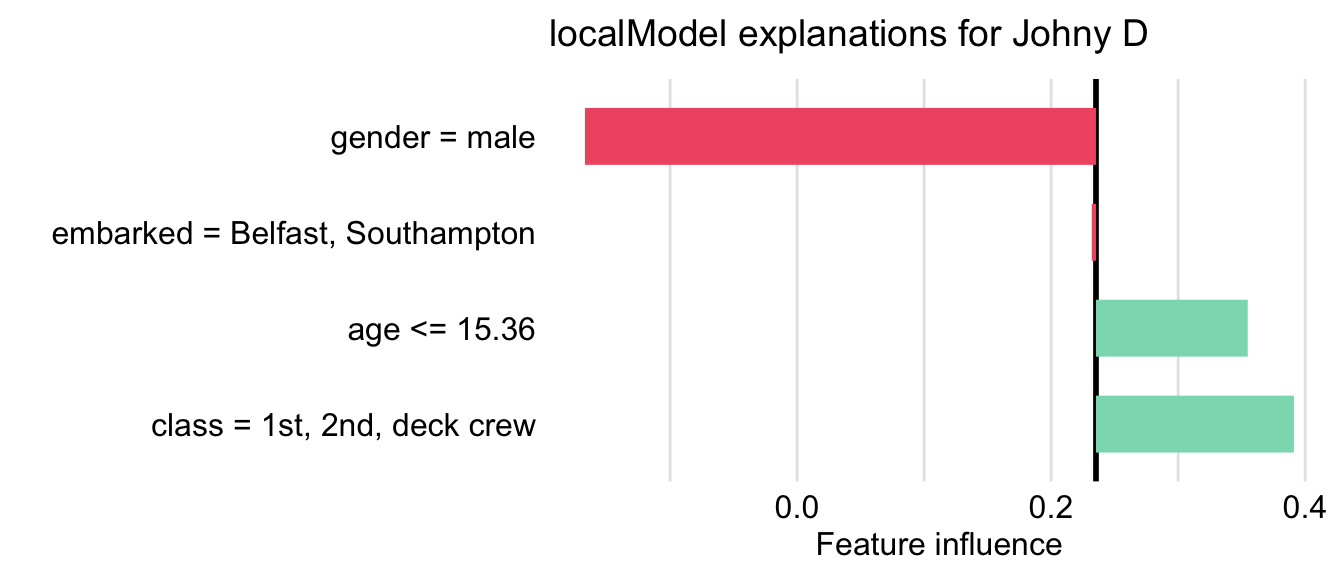
For titanic dataset the random forest model shall increase probability of survival for young passangers.
But this explainer predicts negative influence of young age
library("DALEX")
library("randomForest")
titanic <- archivist::aread("pbiecek/models/27e5c")
titanic_rf_v6 <- archivist::aread("pbiecek/models/31570")
johny_d <- archivist::aread("pbiecek/models/e3596")
library("localModel")
localModel_lok <- individual_surrogate_model(explain_rf_v6, johny_d,
size = 5000, seed = 1313)
plot(localModel_lok)
It is not consistent with ceteris paribus features (which confirm that young age increases survival)
plot_interpretable_feature(localModel_lok, "age")
Please add information about the source of funding to the README.md
## Acknowledgments
Work on this package is financially supported by the NCN Opus grant 2017/27/B/ST6/01307.
The function transform_to_interpretable returns a data frame with the wrong column names.
I'm using the latest localModel version from Github (0.5).
Test case:
library(archivist)
library(DALEX)
library(DALEXtra)
library(randomForest)
titanic <- archivist::aread("pbiecek/models/27e5c")
new_observation <- archivist::aread("pbiecek/models/e3596")
titanic_rf <- archivist::aread("pbiecek/models/4e0fc")
x <- explain(model = titanic_rf,
data = titanic[, -9],
y = titanic$survived == "yes",
label = "Random Forest",
verbose = FALSE)
seed <- 1
I then run this code (taken from individual_surrogate_model function):
x$data <- x$data[, intersect(colnames(x$data), colnames(new_observation)), drop = F]
predicted_names <- assign_target_names(x)
# Create interpretable features
feature_representations_full <- get_feature_representations(x, new_observation,
predicted_names, seed)
encoded_data <- transform_to_interpretable(x, new_observation,
feature_representations_full)
Contents of encoded_data:
class gender age sibsp parch fare
1 gender = male baseline baseline embarked = Belfast, Southampton baseline baseline
2 gender = male age <= 15.36 baseline embarked = Belfast, Southampton baseline baseline
3 gender = male baseline baseline embarked = Belfast, Southampton baseline baseline
parch fare embarked
1 baseline baseline baseline
2 baseline baseline baseline
3 baseline baseline baseline
The column names are not correct: class should be gender, gender should be age, etcetera.
I think this causes the counterintuitive LIME explanation for Johnny D's prediction from the random forest model found in section 9.6.2 of the book Explanatory Model Analysis:
http://ema.drwhy.ai/ema_files/figure-html/limeExplLocalModelTitanic-1.png
This problem is caused by a line of code in the function transform_to_interpretable:
transform_to_interpretable <- function(x, new_observation,
feature_representations) {
encoded_data <- as.data.frame(lapply(feature_representations,
function(x) x[[1]]))
colnames(encoded_data) <- intersect(colnames(new_observation),
colnames(x$data))
encoded_data
}
This solution works for my test case, but might not work for all cases:
transform_to_interpretable <- function(x, new_observation,
feature_representations) {
encoded_data <- as.data.frame(lapply(feature_representations,
function(x) x[[1]]))
colnames(encoded_data) <- colnames(x$data)
encoded_data
}
in which case the new_observation argument is obsolete.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}