This pytorch project built a model that can normalize noise vietnamese user generated text. Source base pointer-summary and datblue-pointer-summary-with-pretrained-fasttext
My model like:
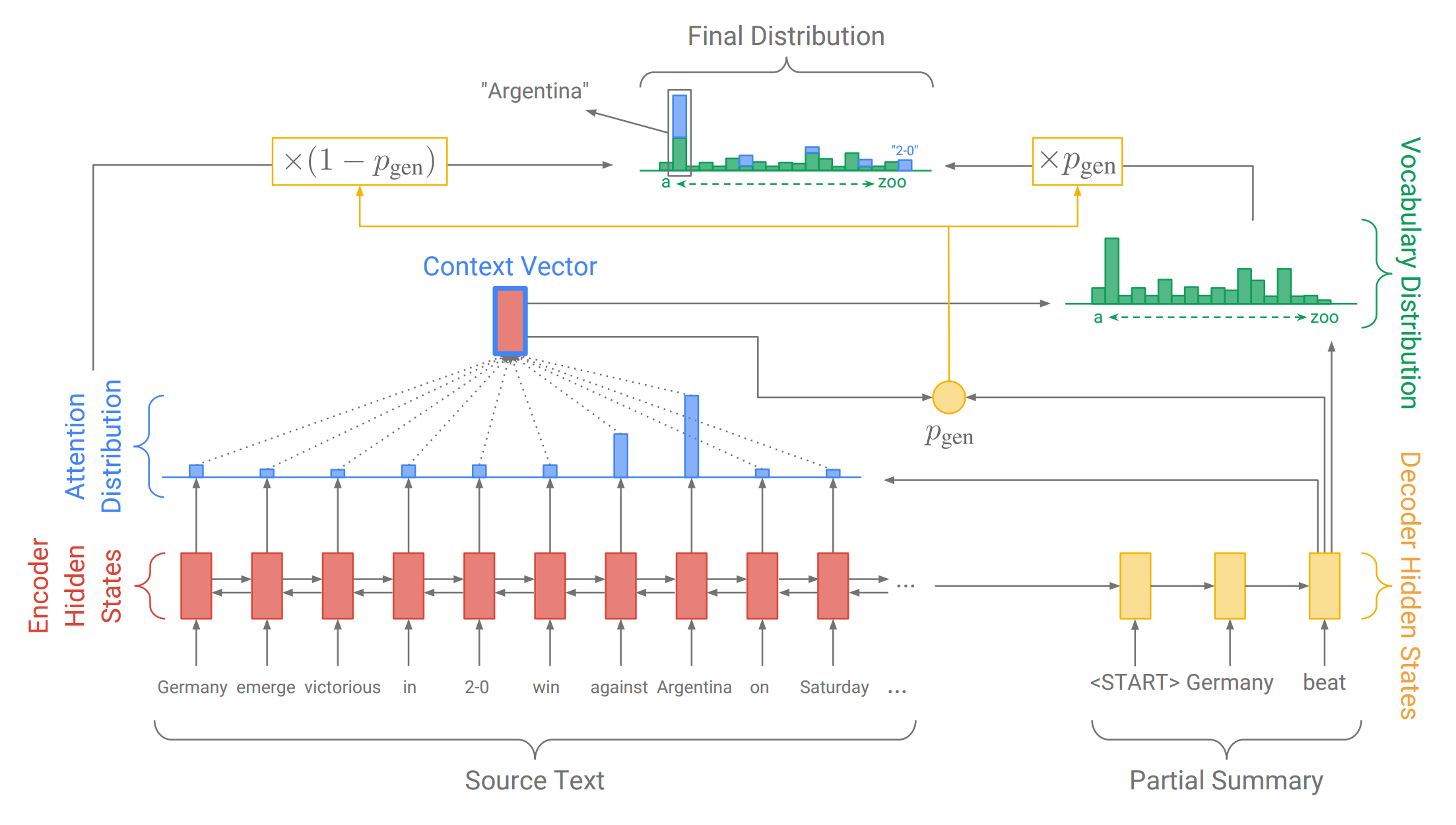
With pretrainned fastText model as input vector
git clone https://github.com/minhquang4334/vietnamese-accentizer.git
cd data_precessing/
python make_datafiles.py
processed data saved in finished_files/ as
test.bin
val.bin
train.bin
If you want to process your data, you can change three lines in make_datafiles.py
all_train_urls = "corrector_dataset_full/train_set.txt"
all_val_urls = "corrector_dataset_full/val_set.txt"
all_test_urls = "corrector_dataset_full/test_set.txt"
Of course your data files have to formed like my data files
Pointer generator networks has pretrained fasttext model.
So you can build your pretrained fasttext model with this tutorial
My pretrained fasttext model was trainned by 1 milion vietnamese articles.
Change your config in data_util/config.py
Change link to your data files:
train_data_path = "../finished_files/chunked/train_*"
eval_data_path = "../finished_files/val.bin"
decode_data_path = "../finished_files/test.bin"
vocab_path = "../finished_files/vocab"
log_root = "log"
fasttext_path = "/home/datbtd/torch_sum/ft_summarizer/data_util/fasttext.bin"
If used pretrainned fastText model, emb_dim must be equal embedding dimension of pretrained model
emb_dim=EMBEDDING_DIMENSION_OF_PRETRAINED_FASTTEXT_MODEL
Change batch_size and max_iterations:
batch_size=64
max_iterations=200000
**I recommend batch_size=64 and you can compute max_iterations how model can train all dataset through 5->7 epochs
If you dont have trained model
./start_train.sh
If you have trained model
./start_train.sh YOUR_LINK_TO_TRAINED_MODEL
You can decode with your trained model. My Decode model use Beam Search stragegy for find the best result.
./start_decode.sh YOUR_LINK_TO_TRAINED_MODEL_YOU_WANT_TO_DECODE
Eval
./start_eval.sh YOUR_LINK_TO_TRAINED_MODEL_YOU_WANT_TO_EVAL
@author minhquang4334
@contact: [email protected]


