

MindsDB is the platform for customizing AI from enterprise data.
With MindsDB, you can deploy, serve, and fine-tune models in real-time, utilizing data from databases, vector stores, or applications, to build AI-powered apps - using universal tools developers already know.

MindsDB integrates with numerous data sources, including databases, vector stores, and applications, and popular AI/ML frameworks, including AutoML and LLMs. MindsDB connects data sources with AI/ML frameworks and automates routine workflows between them. By doing so, we bring data and AI together, enabling the intuitive implementation of customized AI systems.
Learn more about features and use cases of MindsDB here.
To get started, install MindsDB locally via Docker or Docker Desktop, following the instructions in linked doc pages.
MindsDB enhances SQL syntax to enable seamless development and deployment of AI-powered applications. Furthermore, users can interact with MindsDB not only via SQL API but also via REST APIs, Python SDK, JavaScript SDK, and MongoDB-QL.
| 🎯 Solutions | ⚙️ SQL Query Examples |
|---|---|
| 🤖 Fine-Tuning | FINETUNE mindsdb.hf_model FROM postgresql.table; |
| 📚 Knowledge Base | CREATE KNOWLEDGE_BASE my_knowledge FROM (SELECT contents FROM drive.files); |
| 🔍 Semantic Search | SELECT * FROM rag_model WHERE question='What product is best for treating a cold?'; |
| ⏱️ Real-Time Forecasting | SELECT * FROM binance.trade_data WHERE symbol = 'BTCUSDT'; |
| 🕵️ Agents | CREATE AGENT my_agent USING model='chatbot_agent', skills = ['knowledge_base']; |
| 💬 Chatbots | CREATE CHATBOT slack_bot USING database='slack',agent='customer_support'; |
| ⏲️ Time Driven Automation | CREATE JOB twitter_bot ( <sql_query1>, <sql_query2> ) START '2023-04-01 00:00:00'; |
| 🔔 Event Driven Automation | CREATE TRIGGER data_updated ON mysql.customers_data (sql_code) |
MindsDB enables you to deploy AI/ML models, send predictions to your application, and automate AI workflows.
Discover more tutorials and use cases here.
This category of use cases involves tasks that get data from a data source, pass it through an AI/ML model, and write the output to a data destination.

Common use cases are anomaly detection, data indexing/labeling/cleaning, and data transformation.
This example showcases the data enrichment flow, where input data comes from a PostgreSQL database and is passed through an OpenAI model to generate new content which is saved into a data destination.
We take customer reviews from a PostgreSQL database. Then, we deploy an OpenAI model that analyzes all customer reviews and assigns sentiment values. Finally, to automate the workflow for incoming customer reviews, we create a job that generates and saves AI output into a data destination.
-- Step 1. Connect a data source to MindsDB
CREATE DATABASE data_source
WITH ENGINE = "postgres",
PARAMETERS = {
"user": "demo_user",
"password": "demo_password",
"host": "samples.mindsdb.com",
"port": "5432",
"database": "demo",
"schema": "demo_data"
};
SELECT *
FROM data_source.amazon_reviews_job;
-- Step 2. Deploy an AI model
CREATE ML_ENGINE openai_engine
FROM openai
USING
openai_api_key = 'your-openai-api-key';
CREATE MODEL sentiment_classifier
PREDICT sentiment
USING
engine = 'openai_engine',
model_name = 'gpt-4',
prompt_template = 'describe the sentiment of the reviews
strictly as "positive", "neutral", or "negative".
"I love the product":positive
"It is a scam":negative
"{{review}}.":';
DESCRIBE sentiment_classifier;
-- Step 3. Join input data with AI model to get AI output
SELECT input.review, output.sentiment
FROM data_source.amazon_reviews_job AS input
JOIN sentiment_classifier AS output;
-- Step 4. Automate this workflow to accomodate real-time and dynamic data
CREATE DATABASE data_destination
WITH ENGINE = "engine-name", -- choose the data source you want to connect to save AI output
PARAMETERS = { -- list of available data sources: https://docs.mindsdb.com/integrations/data-overview
"key": "value",
...
};
CREATE JOB ai_automation_flow (
INSERT INTO data_destination.ai_output (
SELECT input.created_at,
input.product_name,
input.review,
output.sentiment
FROM data_source.amazon_reviews_job AS input
JOIN sentiment_classifier AS output
WHERE input.created_at > LAST
);
);This category of use cases involves creating AI systems composed of multiple connected parts, including various AI/ML models and data sources, and exposing such AI systems via APIs.

Common use cases are agents and assistants, recommender systems, forecasting systems, and semantic search.
This example showcases AI agents, a feature developed by MindsDB. AI agents can be assigned certain skills, including text-to-SQL skills and knowledge bases. Skills provide an AI agent with input data that can be in the form of a database, a file, or a website.
We create a text-to-SQL skill based on the car sales dataset and deploy a conversational model, which are both components of an agent. Then, we create an agent and assign this skill and this model to it. This agent can be queried to ask questions about data stored in assigned skills.
-- Step 1. Connect a data source to MindsDB
CREATE DATABASE data_source
WITH ENGINE = "postgres",
PARAMETERS = {
"user": "demo_user",
"password": "demo_password",
"host": "samples.mindsdb.com",
"port": "5432",
"database": "demo",
"schema": "demo_data"
};
SELECT *
FROM data_source.car_sales;
-- Step 2. Create a skill
CREATE SKILL my_skill
USING
type = 'text2sql',
database = 'data_source',
tables = ['car_sales'],
description = 'car sales data of different car types';
SHOW SKILLS;
-- Step 3. Deploy a conversational model
CREATE ML_ENGINE langchain_engine
FROM langchain
USING
openai_api_key = 'your openai-api-key';
CREATE MODEL my_conv_model
PREDICT answer
USING
engine = 'langchain_engine',
model_name = 'gpt-4',
mode = 'conversational',
user_column = 'question' ,
assistant_column = 'answer',
max_tokens = 100,
temperature = 0,
verbose = True,
prompt_template = 'Answer the user input in a helpful way';
DESCRIBE my_conv_model;
-- Step 4. Create an agent
CREATE AGENT my_agent
USING
model = 'my_conv_model',
skills = ['my_skill'];
SHOW AGENTS;
-- Step 5. Query an agent
SELECT *
FROM my_agent
WHERE question = 'what is the average price of cars from 2018?';
SELECT *
FROM my_agent
WHERE question = 'what is the max mileage of cars from 2017?';
SELECT *
FROM my_agent
WHERE question = 'what percentage of sold cars (from 2016) are automatic/semi-automatic/manual cars?';
SELECT *
FROM my_agent
WHERE question = 'is petrol or diesel more common for cars from 2019?';
SELECT *
FROM my_agent
WHERE question = 'what is the most commonly sold model?';Agents are accessible via API endpoints.
If you’d like to contribute to MindsDB, install MindsDB for development following this instruction.
You’ll find the contribution guide here.
We are always open to suggestions, so feel free to open new issues with your ideas, and we can guide you!
This project is released with a Contributor Code of Conduct. By participating in this project, you agree to follow its terms.
Also, check out the rewards and community programs here.
If you find a bug, please submit an issue on GitHub here.
Here is how you can get community support:
- Post a question at MindsDB Slack Community.
- Ask for help at our GitHub Discussions.
- Ask a question at Stackoverflow with a MindsDB tag.
If you need commercial support, please contact the MindsDB team.
Made with contributors-img.
Join our Slack community and subscribe to the monthly Developer Newsletter to get product updates, information about MindsDB events and contests, and useful content, like tutorials.
For detailed licensing information, please refer to the LICENSE file.




















































































































































































































































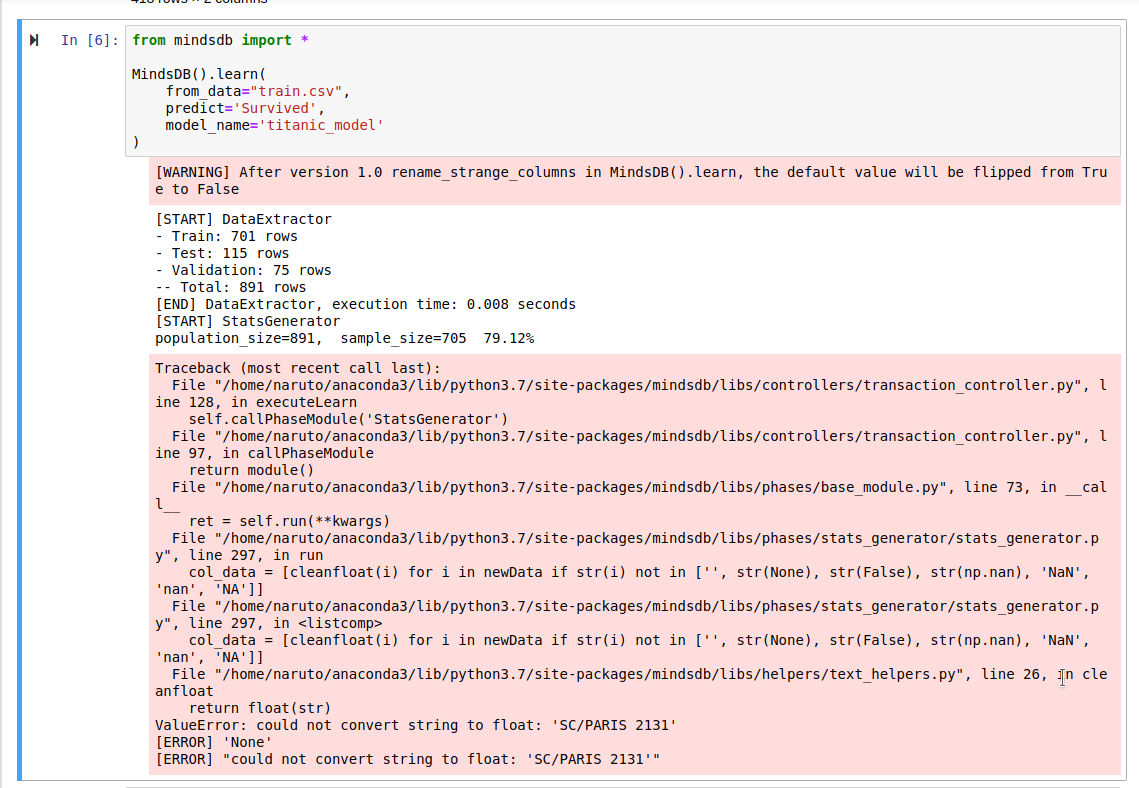


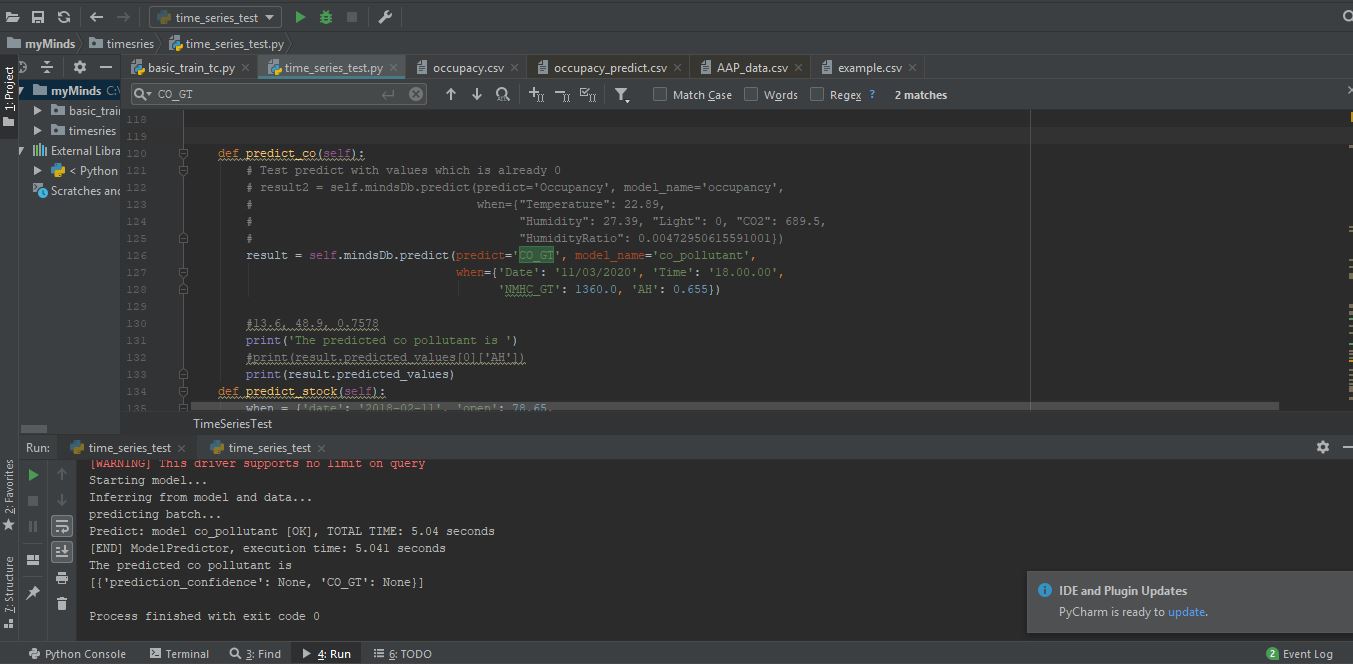

{kind=link}