![]()
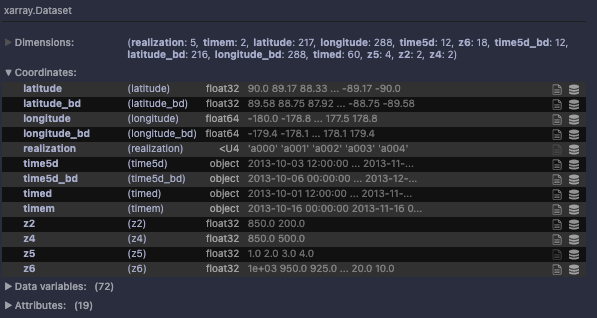
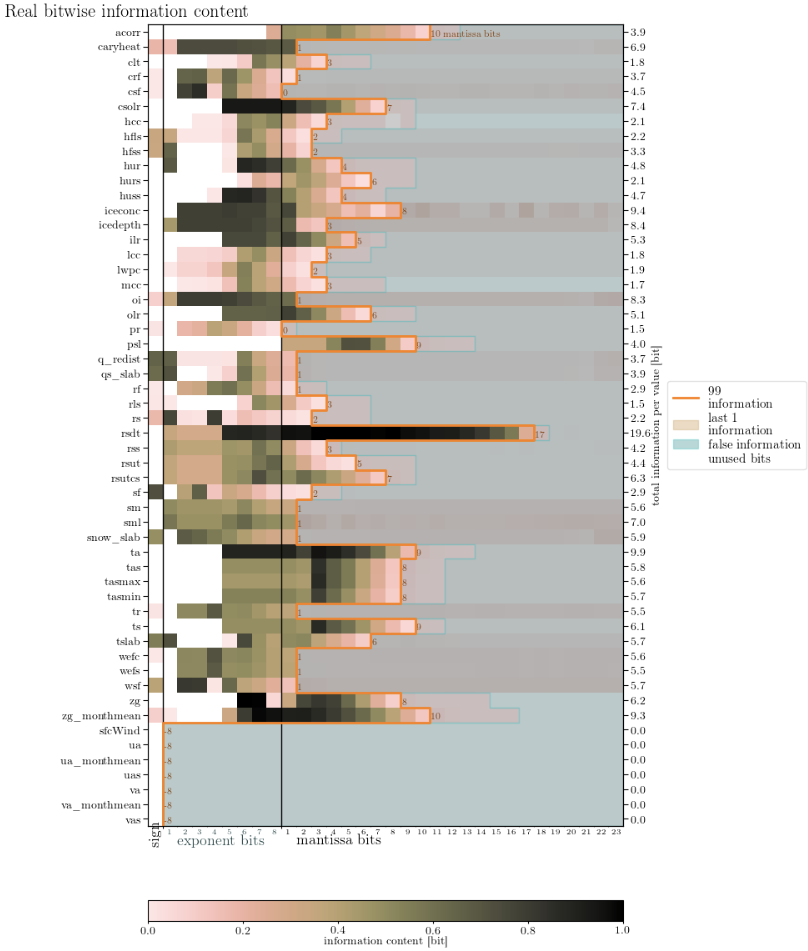
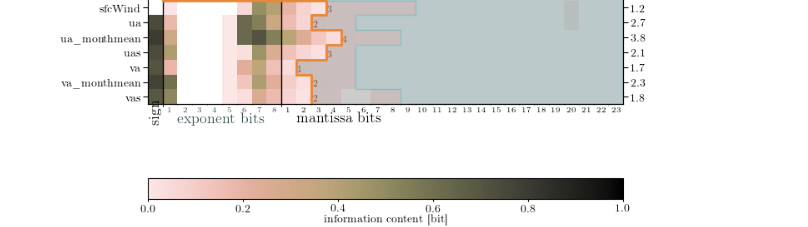
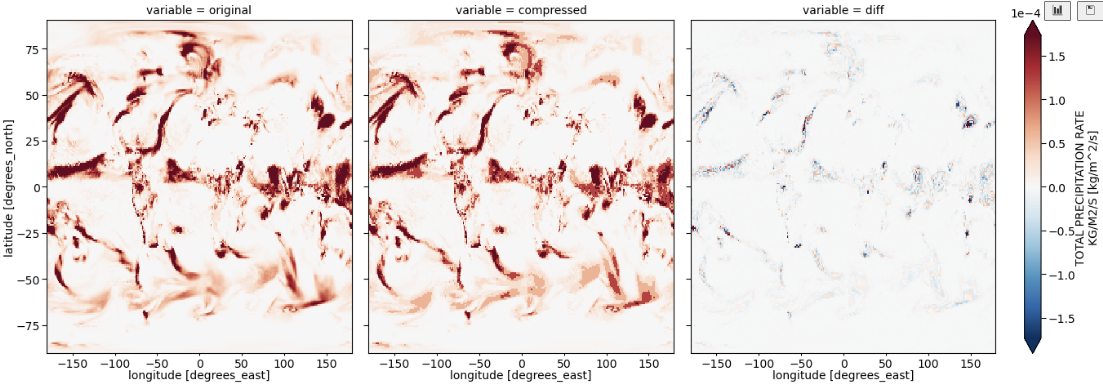
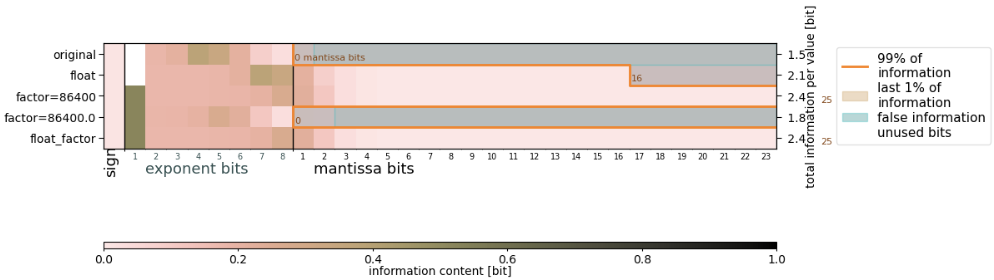
BitInformation.jl is a package for bitwise information analysis and manipulation in Julia arrays. Based on counting the occurrences of bits in floats (or generally any bits type) across various dimensions, this package calculates quantities like the bitwise real information content, the mutual information, the redundancy or preserved information between arrays. From v0.5 onwards masked arrays are also supported.
For bitwise manipulation, BitInformation.jl also implements various rounding modes (IEEE round,shave,set_one, etc.)
efficiently with bitwise operations for any number of bits. E.g. round(x,i) implements IEEE's round to nearest
tie-to-even for any float retaining i mantissa bits. Furthermore, transormations like XOR-delta, bittranspose
(aka bit shuffle), or signed/biased exponents are implemented.
If you'd like to propose changes, or contribute in any form create a pull request or raise an issue. Contributions are highly appreciated!
For an overview of the functionality and explanation see the documentation.
BitInformation.jl is registered in the Julia Registry, so just do
julia>] add BitInformation
where ] opens the package manager. The latest version is automatically installed.
This project is funded by the Copernicus Programme through the ECMWF summer of weather code 2020 and 2021
If you use this package, please cite the following publication
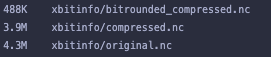
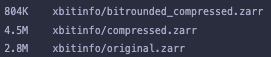
M Klöwer, M Razinger, JJ Dominguez, PD Düben and TN Palmer, 2021. Compressing atmospheric data into its real information content. Nature Computational Science 1, 713–724. 10.1038/s43588-021-00156-2

![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")