![]()


The extension for ANTLR4 support in Visual Studio Code.
Externalized the formatter into an own Node.js package for broader use.
If you want to create your own version of this extension or plan to contribute to its development then follow the steps outlined in the contribute.md document.
- Syntax coloring for ANTLR grammars (.g and .g4 files)
- Comes with an own beautiful color theme, which not only includes all the recommended groups, but also some special rules for grammar elements that you won't find in other themes (e.g. alt labels and options). They are, immodestly, named
Complete DarkandComplete Light.
- Code suggestions for all rule + token names, channels, modes etc. (including built-in ones).
- Symbol type + location are shown on mouse hover. Navigate to any symbol with Ctrl/Cmd + Click. This works even for nested grammars (token vocabulary + imports).
- Symbol list for quick navigation (via Shift + Ctrl/Cmd + O).
- In the background syntax checking takes place, while typing. Also some semantic checks are done, e.g. for duplicate or unknown symbols.
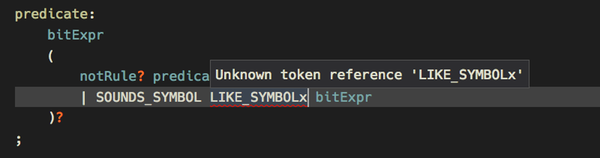
- When parser generation is enabled (at least for internal use) ANTLR4 itself is used to check for errors and warnings. These are then reported instead of the internally found problems and give you so the full validation power of ANTLR4.
There are a number of documentation files for specific topics:
- Extension Settings
- Parser generation
- Grammar Debugging
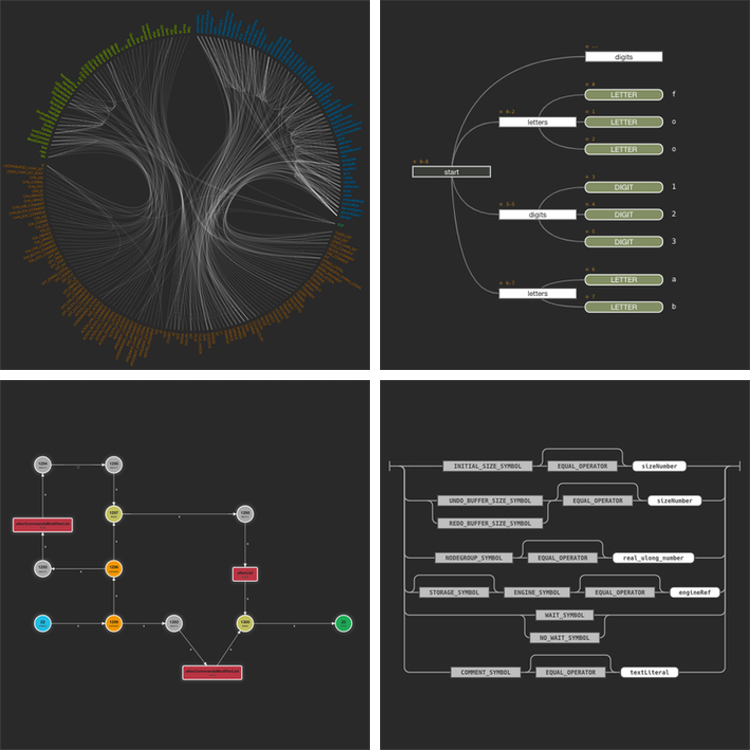
- Graphical Visualizations
- Grammar Formatting
- Sentence Generation
- There is an option to switch on rule reference counts via Code Lens. This feature is switchable independent of the vscode Code Lens setting.
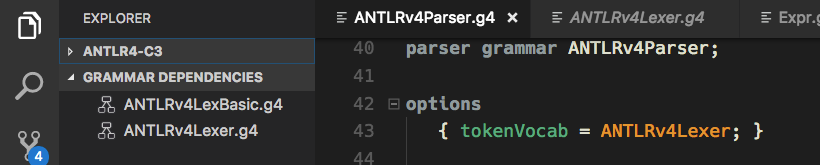
- For each grammar its dependencies are shown in a sidebar view (i.e. token vocabulary and imports).
See the Git issue tracker.
Bug fixing and what feels appealing to hack on.
- Upgraded dependencies.
- Fixed bug #242 Visual parse tree not showing for version 2.4.5
- Upgraded to the latest formatter package to fix a number of issues.
- Updated 3rd party dependencies.
- Extracted the formatter into an own Node.js package for broader use.
- Added new animation to call graphs, which highlights (in steps) which rule calls another rule. This is an implementation from Garry Miller.
- Fixed bug #134 alignColons formatting setting affects semicolon on first line
- Fixed bug #151: Formatting comments adds empty lines in some situations
- Fixed bug #150: Language server fails to accept 'fail' option after semantic predicate.
- Added support for predicate options.
- Fixed bug #180: How to pass multi CLI arguments to antlr?
- Fixed bug #182: Setting no generation language should not automatically apply Java as default
- Fixed bug #210: RangeError: Maximum call stack size exceeded
- Added a check to avoid endless recursion if a grammar uses itself as token vocabulary.
- Added a new semantic check for this (erroneous situation).
- Interpreter data is now also regenerated on start of the extension, if the grammar is newer than existing data and diagnostic checks are executed on startup.
- Fixed bug #235: Extension does not work on Windows
- Switched to a new TypeScript runtime (antlr4ng), which supports the latest features from ANTLR4 (e.g. case sensitive identifiers).
- Fixed bug #195: Extension breaks if filename ends with Parser
- Fixed bug #197: Use lexer token labels when generating tokens in debug console
- Fixed bug #218: Activation fails with TypeError: Invalid host defined options
- Fixed bugs in the formatter (last token removal and wrong action with copy/paste).
- Fixed a bug in the ATN graph renderer, where rule name + index were not properly updated, when navigating between rules.
- Railroad diagrams received a big overhaul:
- Updated to latest version of the generation script.
- Added a button for exporting all diagrams in the all-rules list to individual SVG files.
- Added a new option to specify a character length in a line, after which an path is wrapped. This is useful for long alternatives.
- All CSS rules (including custom ones) are now inlined into exported SVG files, to avoid CSP problems.
- The all-rules list can now be filtered by typing a regular expression and only the visible diagrams are exported.
- A new option allows to strip out a part of rule names (e.g. a common
_SYMBOLsuffix), while rendering the SVG.
A bug fix release for even stricter content security policies in VS Code starting at version 1.73.
- Fixed bug #192: Broken Parse Tree Window on VSCode v1.73
- Now using ANTLR 4.9. Cannot use the just released 4.10 because of TS runtime incompatibilities.
- Fixed bug #104: Cannot read property 'document' of undefined error being thrown
- Fixed bug #120: "antlr4.customcss": probably wrong type configuration.
- Improved ATN diagrams:
- Unused ATN states are no longer visible in the graph.
- Initial rendering of the graph is now much faster, by doing the initial element position computation as a separate step, instead of animating that.
- Transitions for actions, predicates and precedence predicates now show a label that indicates their type.
- The action transitions now show their action (or predicate) in the ATN graph as additional label.
- The custom CSS setting name has been changed to cause no spelling trouble (from
customcsstocustomCSS). Documentation was updated as well.
- Improved predicate execution:
- Simplified the required JS code for predicate simulation in the debugger, sentence generation and test execution. See Grammar Debugging for details.
- Labels for links now rotate sooner to horizontal position (45° instead of 75° of link angle), which makes for a nicer display.
- Improved sentence generation:
- Sentence generation is now available in grammar files. See Sentence Generation for details.
- Show a special char if no printable char could be generated (due to filtering).
- For virtual tokens the name is now printed instead of nothing (as they have no attached label), if no mapping is specified for them.
- Inclusion of Unicode line terminators can now be enabled, to allow generating them where possible.
- Sentence generation can now be configured per grammar. See the documentation for that.
- Improved action and predicate handling/display:
- Named actions, standard actions and predicates now have hover information.
- Action types are now grouped for more details in the "Actions & Predicates" section. This also is part of better predicate handling (correct action index).
- There are now separate entries for local and global named actions.
- Exception blocks, lexer actions (more, pushMode etc.) and similar action blocks are tagged properly in the symbol table now and show as such in the actions section.
- Action transitions in the ATN graph now show their type + index.
- Elements in railroad diagrams now have a CSS class, to make them better customizable.
- D3.js is a dependency of the extension and hence shipped with it. But the webviews downloaded an own copy of that lib for their work. Now they use the shipped D3.js code.
- There is now a language injection definition for Markdown files, to syntax highlight ANTLR4 code in these files. Just specify
antlras language for triple-backtick code blocks to see it. - Improved the file generation process:
- Generation continues if multiple files take part (e.g. those imported) and one of them has an error.
- Errors coming up while running Java are now reported to the frontend. Also shows a hint if no Java is installed.
- You can now specify an alternative ANTLR4 jar file for parser generation and also use custom parameters. Both values can be set in the generation settings of the extension.
- Handling of debug configuration has been changed to what is the preferred way by the vscode team, supporting so variables there now.
- Further work has been done on the sentence generation feature, but it is still not enabled in the extension, due to a number of issues. Help is welcome to finished that, if someone has a rather urgent need for this.
- The extension view for ANTLR4 grammars now shows only relevant views for a specific grammar (e.g. no lexer modes, if a parser grammar is active).
- Code evaluation for grammar predicates has been changed to use an own VM for isolation. Plays now better with vscode (no need anymore to manually modify the imports cache).
- Updated ANTLR4 jar to latest version (4.8.0). It's no longer a custom build, but the official release.
- ESList has been enabled and the entire code base has been overhauled to fix any linter error/warning.
- Update to latest
antlr4tsversion. - Added a new view container with sidebar icon for ANTLR4 files.
- Added lists of actions and predicates in a grammar to the sidebar.
- Added support for predicates in grammars. Code must be written in Javascript.
- Improved stack trace display in debug view.
- Reorganized documentation, with individual documents for specific aspects like debugging.
- Enhanced parsing support for tests, with an overhaul of the lexer and parser interpreters.
- Textual parse trees now include a list of recognized tokens.
- Improved sentence generation, using weight based ATN graph traveling. Added full Unicode support for identifier generation and a dedicated test for this. Still, the sentence generator is not yet available in the editor.
- Overhaul of most of the used extension icons (with support for light + dark themes).
- Added a reference provider.
- Fixed Bug #87: Omitting start rule doesn't fallback to first parser rule (when debugging)
- Graphs no longer need an internet connection (to load D3.js). Instead it's taken from the D3 node module.
- Added content security policies to all graphs, as required by vscode.
- Fixed Bug #41: Plugin Internal Error on EOF
- Fixed Bug #48: Not possible to use ${} macros in launch.json
- Merged PR #59: Fix CodeLens positions being off by one while editing and reference count being wrong
- Fixed re-use of graphical tabs (web views), to avoid multiple tabs of the same type for a single grammar. Also, parse tree tabs now include the grammar's name in the title, just like it is done for all other tabs.
- Added live visual parse trees and improved their handling + usability. No more jumping and zooming to default values on each debugger run.
- Fixed a number of TS warnings.
- Added two parse tree related settings (allowing to specify the initial layout + orientation).
- Improved handling of certain ANTLR4 errors.
- Re-enabled the accidentally disabled code completion feature.
- Fixed Bug #36: "$antlr-format off" removes remaining lines in file
- Fixed Bug #37: Debugging gets stuck with visualParseTree set to true
- Updated tests to compile with the latest backend changes.
- Fixed a bug when setting up a debugger, after switching grammars. Only the first used grammar did work.
- Fixed Bug #28: ATN graph cannot be drawn even after code generation.
- Fixed another bug in interpreter data file names construction.
- Bug fix for wrong interpreter data paths.
- Implicit lexer tokens are now properly handled.
- Fixed a bug in the formatter.
- The extension and its backend module (formerly known as antlr4-graps) have now been combined. This went along with a reorganization of the code.
- A rename provider has been added to allow renaming symbols across files.
- Added grammar debugger.
- Added graphical and textual parse tree display.
- Added dependency graph.
- Added call graph.
- Added ATN graphs.
- Added SVG export for ATN graphs + railroad diagrams.
- Now showing a progress indicator for background tasks (parser generation).
- Added code lens support.
- Added code completion support.
- Finished the light theme.
- Rework of the code - now using Typescript.
- Adjustments for reworked antlr4-graps nodejs module.
- Native code compilation is a matter of the past, so problems on e.g. Windows are gone now.
- No longer considered a preview.
- Updated the symbol handling for the latest change in the antlr4-graps module. We now also show different icons depending on the type of the symbol.
- Updated prebuilt antlr4-graps binaries for all platforms.
- Quick navigation has been extended to imports/token vocabularies and lexer modes.
- The symbols list now contains some markup to show where a section with a specific lexer mode starts.
- Fixed also a little mis-highlighting in the language syntax file.
- Added a license file.
Marked the extension as preview and added prebuilt binaries.
- full setup of the project
- added most of the required settings etc.
- included dark theme is complete
For further details see the Git commit history.
The dependencies view icons have been taken from the vscode tree view example.



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


















































































































































