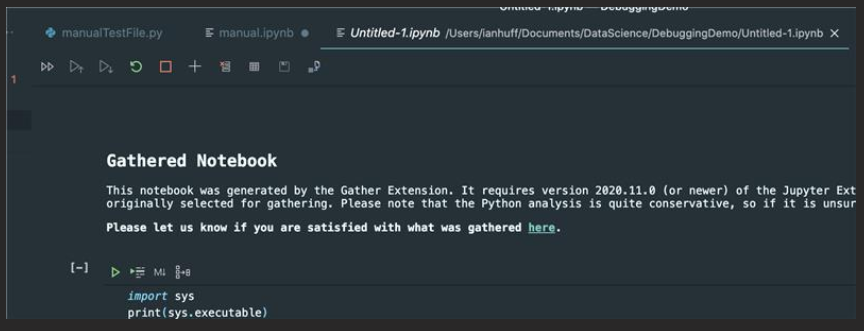
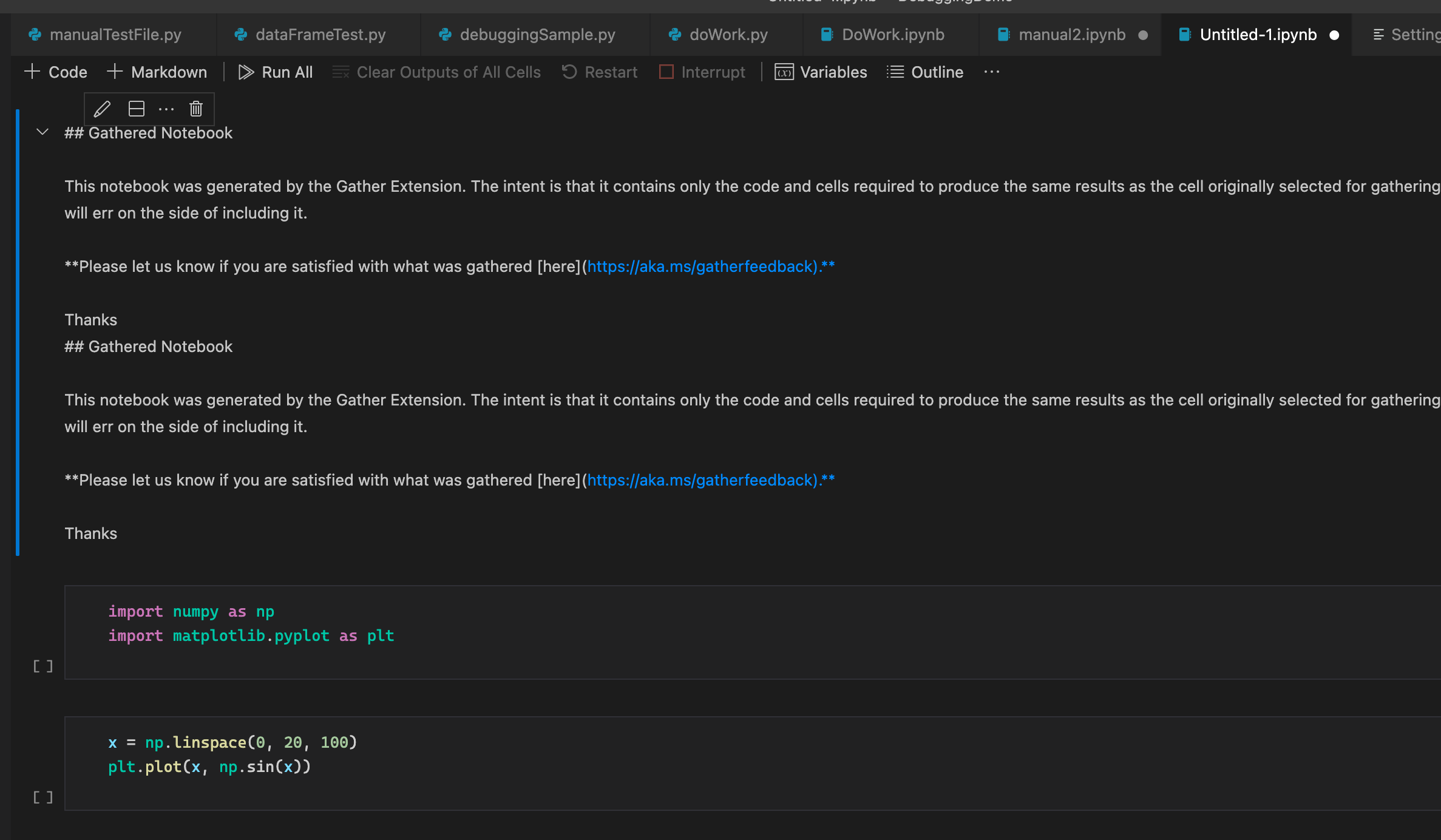
A Visual Studio Code extension that adds the experimental Gather feature to the Jupyter extension on Python code. With one button click on any notebook or Interactive Window cell, Gather uses a static analysis technique to find and then copy all of the dependent code that was used to generate that cell's result into a new notebook or script.
Please note that the Python analysis is quite conservative, so if it is unsure whether a line of code is necessary for execution, it will err on the side of including it in the new notebook/script. We are keen to understand how well this feature works for you so please let us know if you are satisfied with the results you are getting through the survey presented at the top of each gathered file.
-
Step 1. Install both the Jupyter and the Gather extension for Visual Studio Code.
-
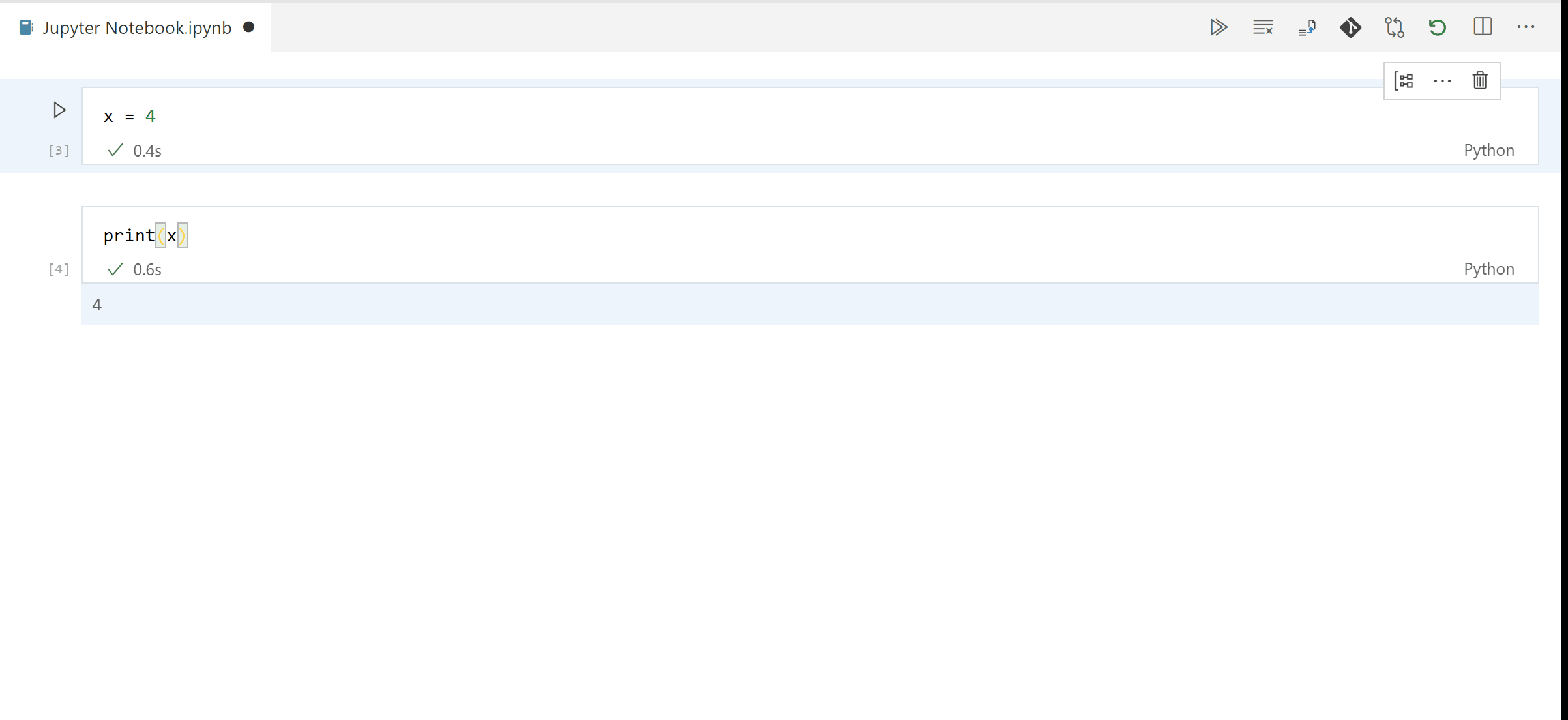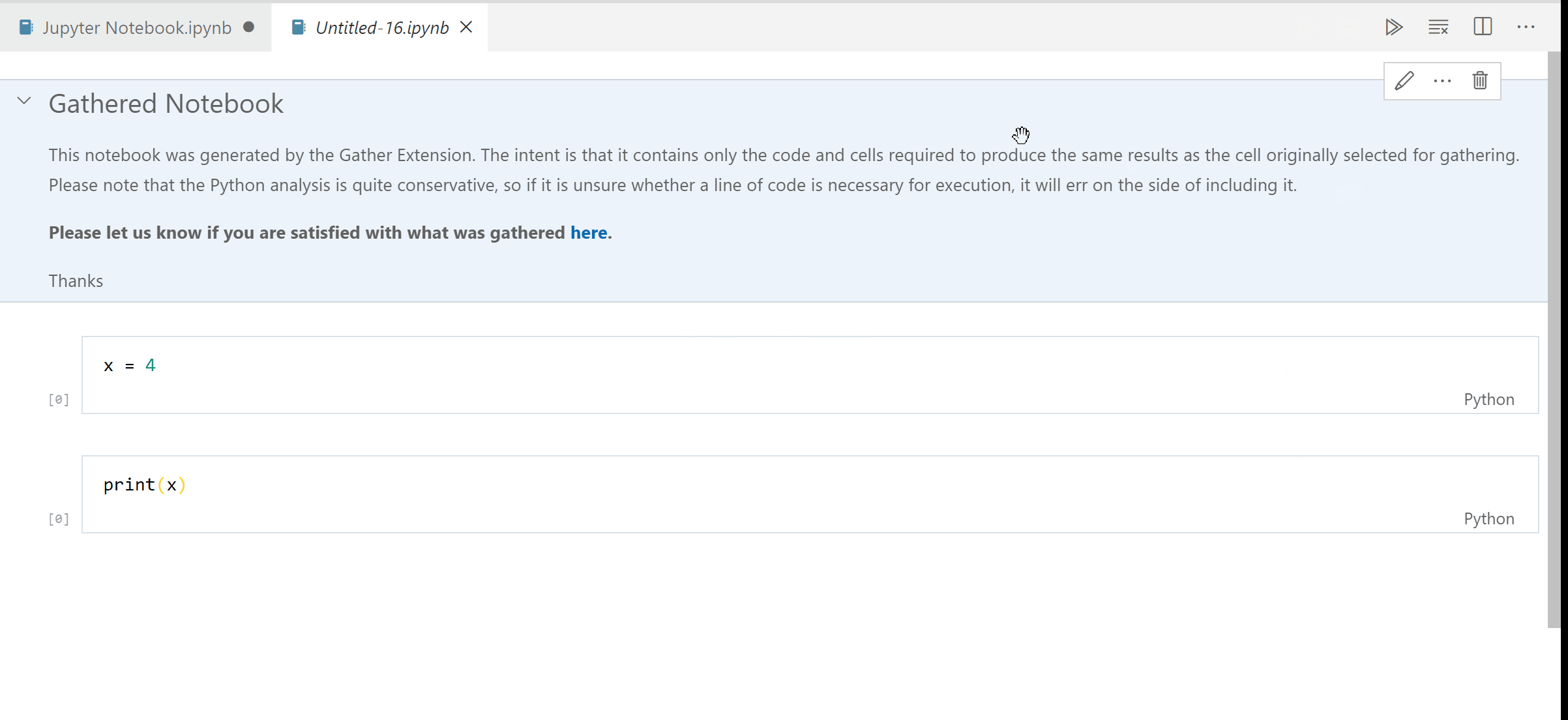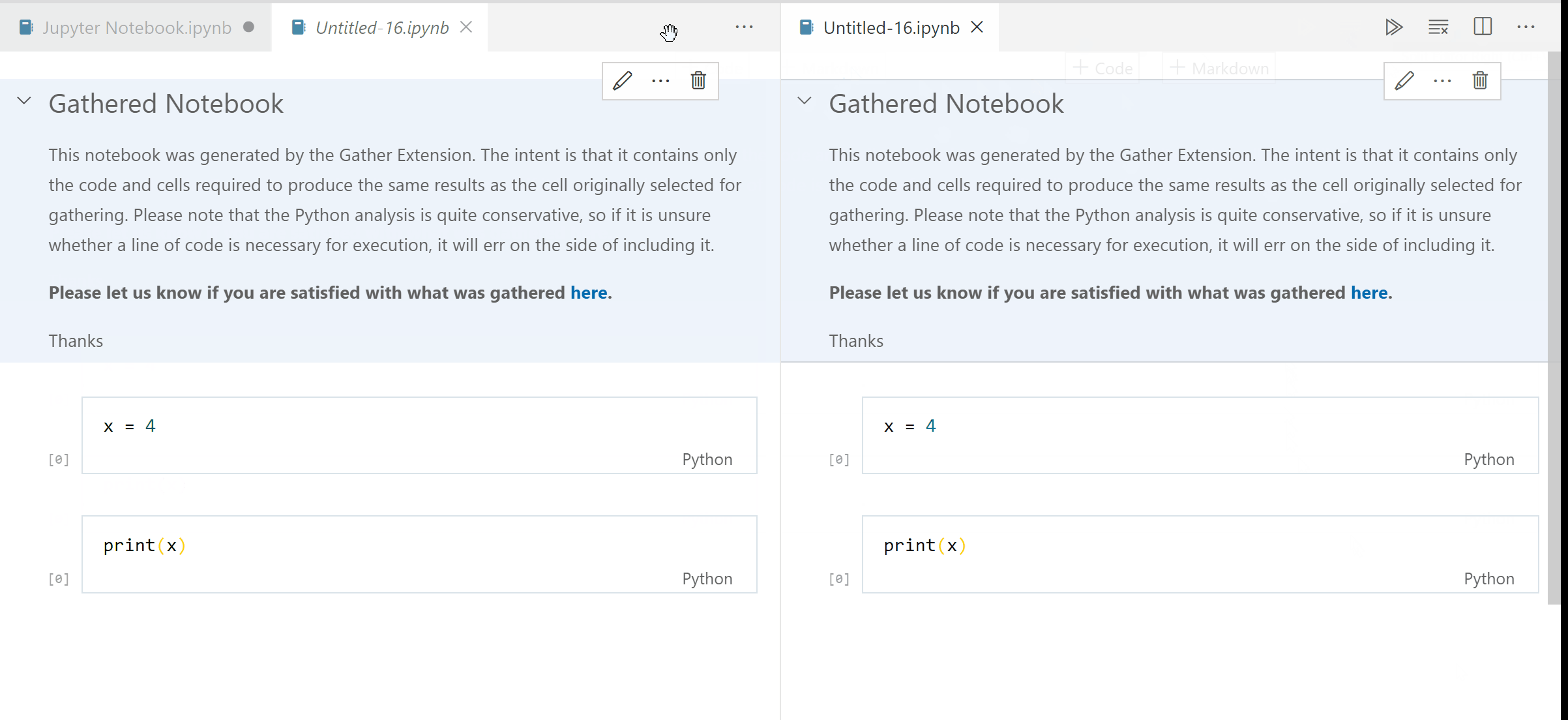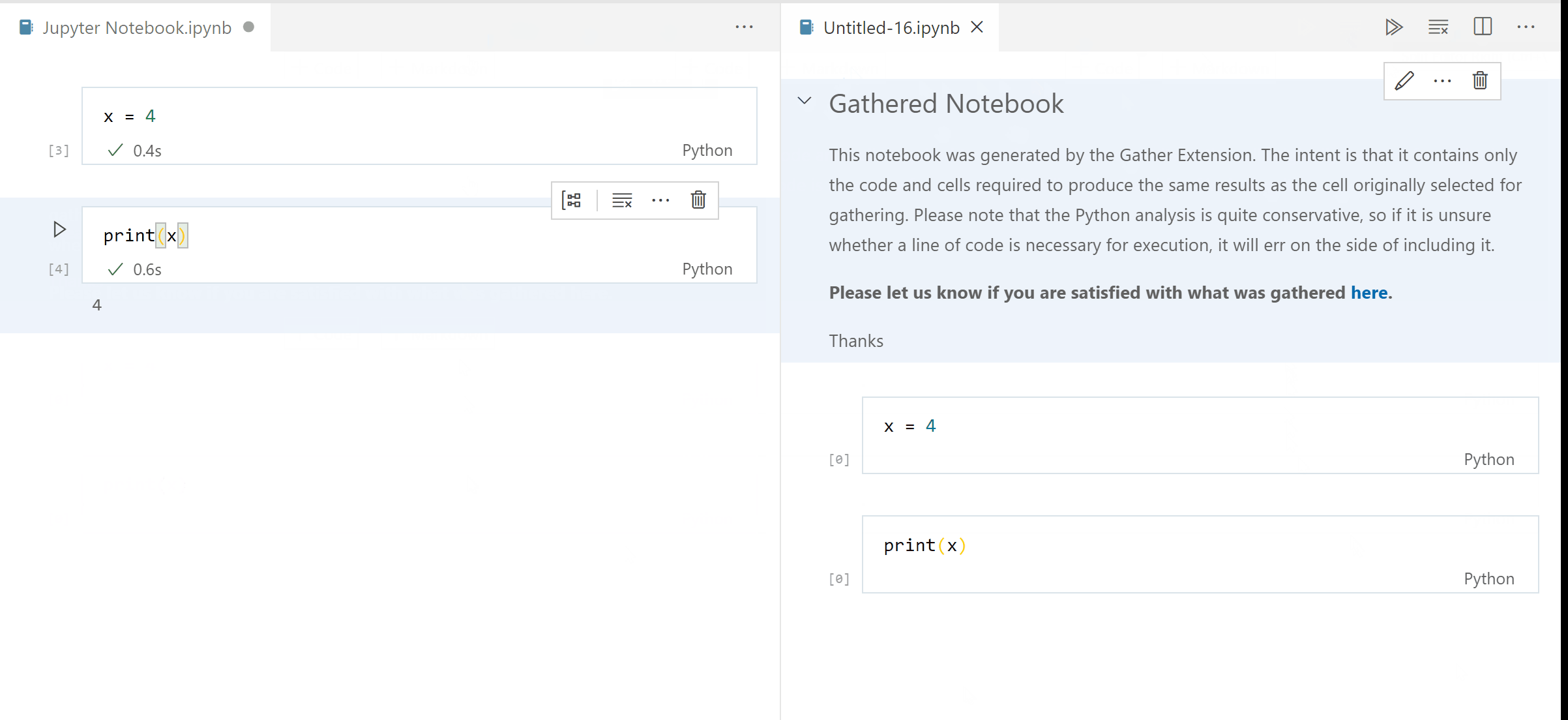
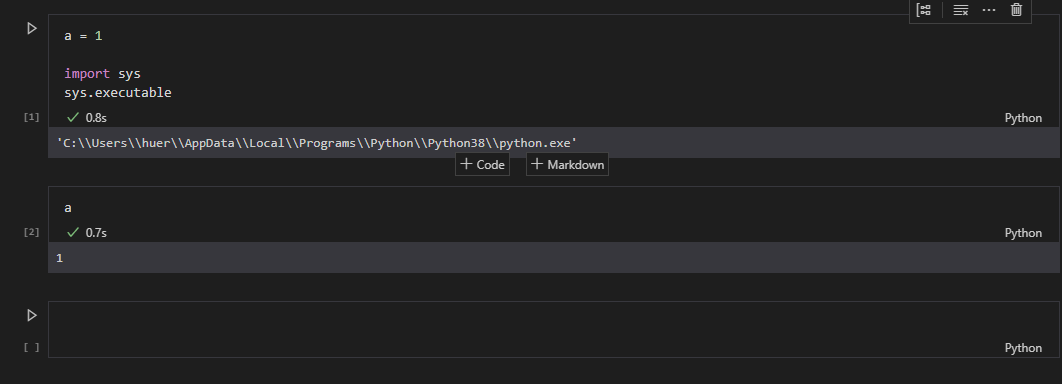
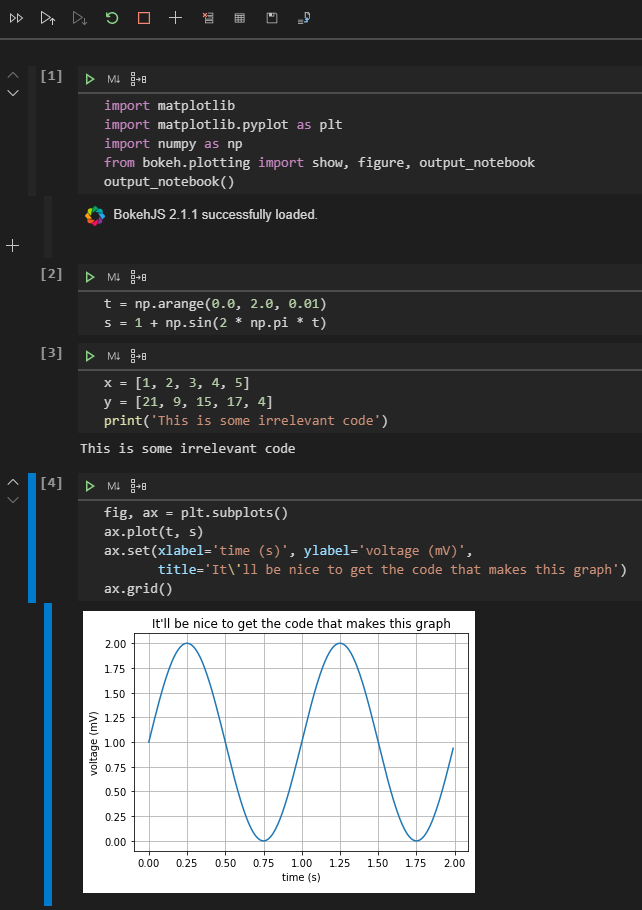
Step 2. Run cells on the Interactive Window or Notebook Editor to do your work.
-
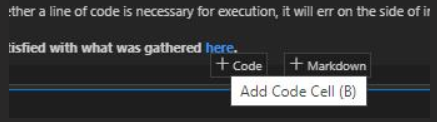
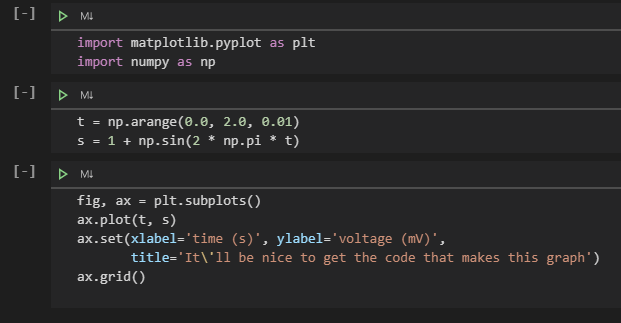
Step 3. When you're satisfied with a cell's output, click the Gather icon to build a new notebook or script that generates that same output.
Gather uses a set of files called "specs" that are used to identify whether each function provided in a Python package modifies kernel state. Currently, the packages that are fully supported are:
- matplotlib
- numpy
- pandas
- random
- sklearn
- a set of built-in Python functions/keywords
It is possible to add packages or APIs to the supported list on your local installation. If you are interested in doing this for your own private work, or would like to contribute to the community to support other popular Python packages, please let us know!
- If you come across a problem, please file an issue.
- If you have a question about how to accomplish something with the extension, please ask on Stack Overflow
- Any and all feedback is appreciated and welcome!
- If someone has already filed an issue that encompasses your feedback, please leave a 👍/👎 reaction on the issue
- Otherwise please file a new issue
This repository uses the private MSR-Python-Analysis npm feed feed for some of its functionality.
After gaining access to that feed, run
- npm run npm-auth
- npm install

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")