maziqing / fedformer Goto Github PK
View Code? Open in Web Editor NEWLicense: MIT License
License: MIT License










































































































您好,看到Dataset_Pred有inverse参数,但是没提出来,手动改成了true,还是没生效,请问这个是什么原因导致呢?
您好,我想问一下我用pred.npy、true.npy、real_prediction.npy画出来的图像有负值,图中表现出来的数据集里的真实值也为负,但我的数据集是降雨量数据,这个不可能为负值,所以我想问一下是哪里出现了问题?
try to run which in FEDformer.py get an error which was in class series_decomp_multi(nn.Module) in Autoformer_enc_dec.py:
I don't know how to fix it, and the tensor's dimension is not match: one is (3, 95, 7), another is (3,96,7).
Guess it should be (3,96,7)
Wishing to get your help! Thanks.
if __name__ == '__main__':
class Configs(object):
ab = 0
modes = 32
mode_select = 'random'
# version = 'Fourier'
version = 'Wavelets'
moving_avg = [12, 24]
L = 1
base = 'legendre'
cross_activation = 'tanh'
seq_len = 96
label_len = 48
pred_len = 96
output_attention = True
enc_in = 7
dec_in = 7
d_model = 16
embed = 'timeF'
dropout = 0.05
freq = 'h'
factor = 1
n_heads = 8
d_ff = 16
e_layers = 2
d_layers = 1
c_out = 7
activation = 'gelu'
wavelet = 0
configs = Configs()
model = Model(configs)
print('parameter number is {}'.format(sum(p.numel() for p in model.parameters())))
enc = torch.randn([3, configs.seq_len, 7])
enc_mark = torch.randn([3, configs.seq_len, 4])
dec = torch.randn([3, configs.seq_len//2+configs.pred_len, 7])
dec_mark = torch.randn([3, configs.seq_len//2+configs.pred_len, 4])
out = model.forward(enc, enc_mark, dec, dec_mark)
print(out)class series_decomp_multi(nn.Module):
"""
Series decomposition block
"""
def __init__(self, kernel_size):
super(series_decomp_multi, self).__init__()
self.moving_avg = [moving_avg(kernel, stride=1) for kernel in kernel_size]
self.layer = torch.nn.Linear(1, len(kernel_size))
def forward(self, x):
moving_mean = []
for func in self.moving_avg:
moving_avg = func(x)
moving_mean.append(moving_avg.unsqueeze(-1))
moving_mean = torch.cat(moving_mean, dim=-1)
moving_mean = torch.sum(moving_mean * nn.Softmax(-1)(self.layer(x.unsqueeze(-1))), dim=-1)
res = x - moving_mean
return res, moving_mean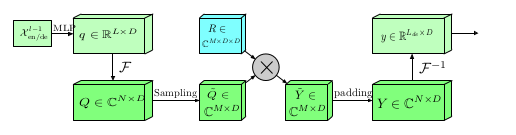
def forward(self, q, k, v, mask):#
# size = [B, L, H, E]-Batch,Length,Height,Element
B, L, H, E = q.shape
x = q.permute(0, 2, 3, 1)#
# Compute Fourier coefficients
x_ft = torch.fft.rfft(x, dim=-1) #拿到DFT对时间序列变换的复数值x(0),...,x(n) -> X(0),...,X(n)
# Perform Fourier neural operations
out_ft = torch.zeros(B, H, E, L // 2 + 1, device=x.device, dtype=torch.cfloat)
for wi, i in enumerate(self.index):
out_ft[:, :, :, wi] = self.compl_mul1d(x_ft[:, :, :, i], self.weights1[:, :, :, wi])
# Return to time domain
x = torch.fft.irfft(out_ft, n=x.size(-1))
return (x, None)
Dear author:
Sorry to bother you so many times, one more question about the padding operation,I haven't see the padding process in FEB-module block,could you please mildly explain this.
Hi,
Nice work, thanks for shearing.
I have a problem while using the git, when running train using bash ./scripts/run_M.sh, the running stuck after printing:
train 34369
val 11425
test 11425
and remains stuck until I stop it myself.
I tried to debug it and found out the stuck happens on exp_main.py , after the command iter_count += 1.
do you have an idea why does it happen?
thanks in advance,
Roi
Hello,
I tried to reproduce the results of the paper with the mwt block on the traffic data set but was unable to do so. I ran the code with the following args set:

with the addition of "--version Wavelets" and changing the "--features" from S to M. However, the model MSE score reached only about 0.585 after even more than three epochs versus the 0.562 MSE score that was reported in the paper for prediction length of 96.
Are there any other parameters that need to be changed in order to reproduce the performance reported in the paper when using the wavelets?
Thanks in advance!
Thank you very much for your contribution, which has been a great help to me.
When I implemented your work, I found that the number of parameters for FEDformer is 16303127, but the number of parameters for the comparison models Autoformer, Informer, and Transformer is only 1000 0000+. Does this lose the point of comparison.
Hey, thank you for this great study!
I have a question about the structure of FEA-f which you mentioned in the paper.
You mentioned that after achieving the scores from the activation function and Q_tild, K_tild we need to multiply it by the V_tild. But actually, in the code, there is no use in V at all and the multiplication is with V_tild which we already used.
So why is the change or/and what is the idea behind using the keys as values?
Thank you!
FEDformer/layers/FourierCorrelation.py
Line 118 in 306add5
Ex. in the Electricity dataset the target is OT Column, how we can pass all the columns as time series and get forecast for the respective time series?
bash ./scripts/run_M.sh#Multi-variate
bash ./scripts/run_S.sh#Single-variate
Thank you very much for making the code public. On line 119 of FourierCorrelation.py, I have a question.
xqkv_ft = torch.einsum("bhxy,bhey->bhex", xqk_ft, xk_ft_)
Why is the last parameter xk_ft_ the Fourier coefficient of key and not the Fourier coefficient of value?
Thanks for responding my last question,I got a new ques,if it's convenient for you to respond:
modes = min(modes, seq_len//2)#选取最小值不是默认的modes=64就是seq_len//2,modes if mode_select_method == 'random': index = list(range(0, seq_len // 2))#丢小数的除法,比如 5/2=2.5 5//2=2 np.random.shuffle(index)#随机打乱index数组,也就是打乱傅里叶分量的基,为了方便后续选取随机的基,这里基也减小到了64或seq_len的一半 index = index[:modes] else: index = list(range(0, modes))
这里的modes意思是选取傅里叶变换的基的个数吗
作者您好,感谢您的开源。
我在复现论文Table 2时和表中的结果有一些差别,具体是在ECL数据集上跑了以下两个实验:
(1)使用run_S.sh跑了FEDformer,预测长度设置为96,其余参数设置和实验结果如下,略优于论文中的MSE:0.253; MAE:0.370;
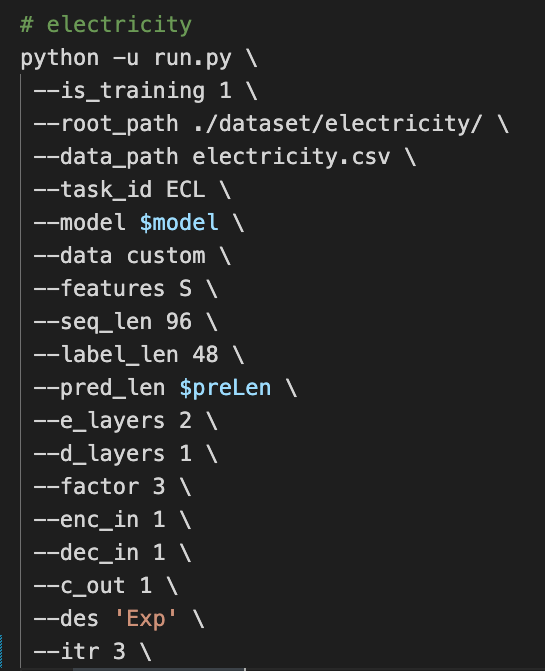

(2)使用run_M.sh跑了Informer,预测长度设置为96,其余参数设置和实验结果如下,比论文中的MSE:0.274; MAE:0.368要差;
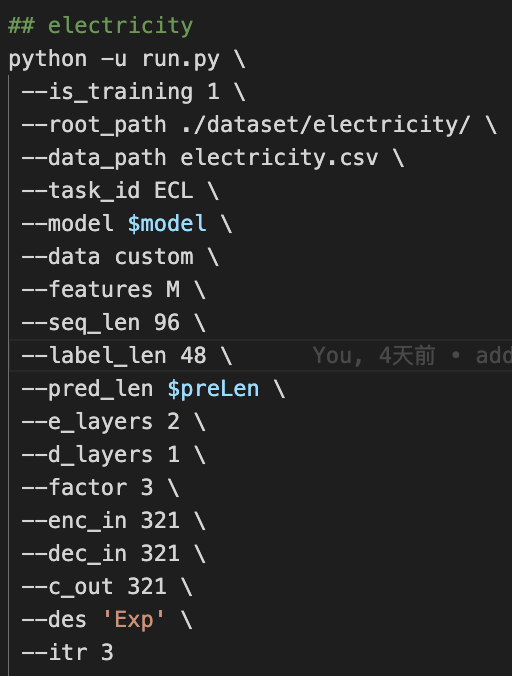

请问以上的实验结果是在正常的波动范围内么,还是我有哪些地方疏忽了,感谢您的回复。
Two layers have the number of heads hard coded to 8 causing issues when using a different number of heads
Hello Colleagues,
I just try to use FEDformer to run some LSTP tasks, and I directly use your default configurations in the run.py.
--------------------First Question (Multi-GPU usage)------------------------
But the RuntimeError shows Unconvertible NCCL type when the model uses the nn.DataParallel to parallelize. Have you ever encountered such issues when conducting experiments before? Thanks for your possible suggestions and help.
By the way, I use the Pytorch Version 1.5 and previously have used the Autoformer to conduct the same tasks but didn't receive similar errors from Pytorch. The difference between those is using the Frontier Transform (parser's default is to use Frontier) to decompose the time series.
In your codes implementing the Frontier module in the layers/FrontierCorrelation.py, the param modes seems to control the Frontier based configs, I don't know whether some ops between the modes and the length of the sequence denoted as seq_len will affect the training. However, I have modified the value of modes to less than seq_len to satisfy the index = index[:modes] line in your codes, but the errors still exist.
--------------------Second Question (Complex Multiplication)--------------------
I try to directly update the Pytorch to v1.9 and now I can use multiple GPUs to train. So the first question may be solved by updating due to incompatibility. However, I find another problem occurs in the complex multiplication op (see the attached figure) and the errors show einsum() the number of subscripts in the equation (3) does not match the number of dimensions (4) for operand 1 and no ellipsis was given (see the attached figure). It's noted that this time I entirely use your raw codes and the problems also exist, so maybe some issues indeed need to be solved.
You can directly email [email protected] and look forward to your reply!
In your paper, you said this model could outperform Autoformer and Transformer-based variants by almost 20%, so I would like to kindly ask about some issues and hope I can use this in my research later on.
Best
Attached figures:

shows the Pytorch backend uses the nn.DataParallel to run on multiple GPUs.

if the comm.py means communications among processes, there may be some errors in this part. But the Autoformer doesn't have this issue, so maybe it's because of the Frontier part? But this may be also a compatibility issue, so if you think it's worth discussing we can solve this issue by discussing in the email since you also just open-sourced the codes days before. It can benefit the entire community maybe.


complex multiplication issue
I would like to ask about information leakage.
Suppose I split the data into training and testing sets. Now I want to perform a decomposition operation, empirical mode decomposition or wavelet transform, or the seasonal trend decomposition method mentioned by the author, then I should only decompose the training set. If I decompose the training set and the data set together, it means that I know the future data, use the future data but still predict the future data.
What I would like to ask the author or discuss with you here is whether the many time series prediction models based on Transformer involve the defect of data leakage?
how can i get dataset in the code?
Thanks for this great work, but I still have a question about zero-padding operation for the result of inverse Fourier transform:
In your code, you seem to adopt different padding patterns in fourier self-attention and fourier cross-attention.
self-attention:

cross-attention:

This is inconsistent.
Dear Ma,
Thanks for your job and open source code.
Here is a question I would like to ask you in all honesty. My own datasets do not contain a 'Date' column because it is a long time data sampled at a certain sample rate (sr). Instead, it may only last a few tens of minutes, but there are actually minutes * 60 * sr of data in each dataset. How should I apply my personal data set to FedFormer?
I would be grateful if you could answer my questions.
Thanks for your great work and attention.
The Error is:
when I run the run.py,use params "--freq"= '15min',Then:
File ".\FEDformer-master-min\layers\Embed.py", line 99, in init
d_inp = freq_map[freq]
KeyError: '15min'
and The Q is How to use '--freq' param with the value: '5min' or '15min'?
Hello colleagues,
Following this closed issue: https://github.com/MAZiqing/FEDformer/issues/10
Do you have any suggestions on solving the torch.einsum tracebacks?
Appreciate if I can receive a reply. I suppose torch.fft modules be not changed since 1.8, so that will not be the reason.
Best
I have noticed that when I try to reproduce the code, it popped out two error messages while I was under the environment the same as Informer's:
ModuleNotFoundError: No module named 'einops'
and
ModuleNotFoundError: No module named 'sympy'
Then I found it could be solved by using these codes as follows
pip install einops
and
pip install sympy
I have downloaded the ETTh1 data set and one of the weather data sets, and run the same data set with FEDformer, Autoformer, Informer and Transformer provided by you respectively, but the effect is different from that shown in your paper. The result of my running is as follows: I made the input length and the prediction length both 96. Is where I did not adjust the hyperparameter?

I run Autoformer but get the following errors.
According to this issue #5, I modified this line to self.use_wavelet = False.
Could you investigate the following issue?
Traceback (most recent call last):
File "run.py", line 171, in <module>
main()
File "run.py", line 135, in main
exp.train(setting)
File "~/projects/time_forcast/FEDformer/exp/exp_main.py", line 141, in train
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
File "~/fedformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "~/projects/time_forcast/FEDformer/models/Autoformer.py", line 85, in forward
seasonal_init, trend_init = self.decomp(x_enc)
File "~/fedformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "~/projects/time_forcast/FEDformer/layers/Autoformer_EncDec.py", line 50, in forward
moving_mean = self.moving_avg(x)
File "~/fedformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "~/projects/time_forcast/FEDformer/layers/Autoformer_EncDec.py", line 33, in forward
front = x[:, 0:1, :].repeat(1, self.kernel_size - 1-math.floor((self.kernel_size - 1) // 2), 1)
TypeError: unsupported operand type(s) for -: 'list' and 'int'
Thanks.
Trying to run script:
bash scripts/run_M.sh
Errors are as follows:
Args in experiment: Namespace(L=3, activation='gelu', base='legendre', batch_size=32, c_out=7, checkpoints='./checkpoints/', cross_activation='tanh', d_ff=2048, d_layers=1, d_model=512, data='ETTm1', data_path='ETTm1.csv', dec_in=7, des='Exp', devices='0,1', distil=True, do_predict=False, dropout=0.05, e_layers=2, embed='timeF', enc_in=7, factor=3, features='M', freq='h', gpu=0, is_training=1, itr=3, label_len=48, learning_rate=0.0001, loss='mse', lradj='type1', mode_select='random', model='Autoformer', modes=64, moving_avg=[24], n_heads=8, num_workers=10, output_attention=False, patience=3, pred_len=96, root_path='./dataset/ETT-small/', seq_len=96, target='OT', task_id='ETTm1', train_epochs=10, use_amp=False, use_gpu=False, use_multi_gpu=False, version='Fourier') Use CPU Autocorrelation used ! Traceback (most recent call last): File "run.py", line 130, in <module> exp = Exp(args) # set experiments File "/home/x/FEDformer/exp/exp_main.py", line 20, in __init__ super(Exp_Main, self).__init__(args) File "/home/x/FEDformer/exp/exp_basic.py", line 10, in __init__ self.model = self._build_model().to(self.device) File "/home/x/FEDformer/exp/exp_main.py", line 29, in _build_model model = model_dict[self.args.model].Model(self.args).float() File "/home/x/FEDformer/models/Autoformer.py", line 40, in __init__ [ File "/home/x/FEDformer/models/Autoformer.py", line 43, in <listcomp> AutoCorrelation(False, configs.factor, attention_dropout=configs.dropout, File "/home/x/FEDformer/layers/AutoCorrelation.py", line 35, in __init__ self.use_wavelet = configs.wavelet AttributeError: 'NoneType' object has no attribute 'wavelet'
class FourierBlock(nn.Module):
def __init__(self, in_channels, out_channels, seq_len, modes=0, mode_select_method='random'):
super(FourierBlock, self).__init__()
print('fourier enhanced block used!')
"""
1D Fourier block. It performs representation learning on frequency domain,
it does FFT, linear transform, and Inverse FFT.
"""
# get modes on frequency domain
'''
In frequency domain, only the randomly selected M modes are kept
'''
self.index = get_frequency_modes(seq_len, modes=modes, mode_select_method=mode_select_method)#得到随机打乱选取的基,后续进行DFT操作
print('modes={}, index={}'.format(modes, self.index))
self.scale = (1 / (in_channels * out_channels))
self.weights1 = nn.Parameter(
self.scale * torch.rand(8, in_channels // 8, out_channels // 8, len(self.index), dtype=torch.cfloat))
# Complex multiplication 复数乘法
def compl_mul1d(self, input, weights):
# (batch, in_channel, x ), (in_channel, out_channel, x) -> (batch, out_channel, x)
return torch.einsum("bhi,hio->bho", input, weights)#高维张量的计算
#搞懂这个torch.einsum操作!!!
def forward(self, q, k, v, mask):#注意细节,key,value,mask都没用上
# size = [B, L, H, E]-Batch,Length,Height,Element
B, L, H, E = q.shape
x = q.permute(0, 2, 3, 1)
# Compute Fourier coefficients
x_ft = torch.fft.rfft(x, dim=-1) #拿到DFT对时间序列变换的复数值x(0),...,x(n) -> X(0),...,X(n)
# Perform Fourier neural operations
out_ft = torch.zeros(B, H, E, L // 2 + 1, device=x.device, dtype=torch.cfloat)
for wi, i in enumerate(self.index):
out_ft[:, :, :, wi] = self.compl_mul1d(x_ft[:, :, :, i], self.weights1[:, :, :, wi])
# Return to time domain
x = torch.fft.irfft(out_ft, n=x.size(-1))
return (x, None)
Hello,dear author,you said in question #4 about the explanation for operation before 'When we choose the mode index before DFT and reverse DFT operations, the computation complexity can be further reduced to O(N ). ', but in code you choose the mode randomly after DFT operation and combine the DFT results with module.parameter self.wights,It's a good work for have insights like this that combine DFT results (frequency representation) into model,So,the expression 'When we choose the mode index before DFT and reverse DFT operations, the computation complexity can be further reduced to O(N ).' maybe not very accurate or I lack of understanding of your brilliant work.
请教下scale采用这种方式的原因是什么。感谢。
FEDformer/layers/FourierCorrelation.py
Line 40 in 51a51b5
I was running the script and run into the above error, although I add the absolute path (the parent directory of the utils folder) to my python path using sys.path.insert(0, ). I also tried creating a init.py file in the project directory, still it does not work.
Usually it should work so I run out of ideas. Any ideas?
请教下这里使用Softmax的原因:为什么不简单的对于不同的x-moving_mean求平均。
同时为什么使用x而不是moving_mean自身作为gate?
感谢
您好,感谢您的开源。
我在使用feature=‘MS’模型跑exchange时发现输出维度是8维的,而且loss值很大。
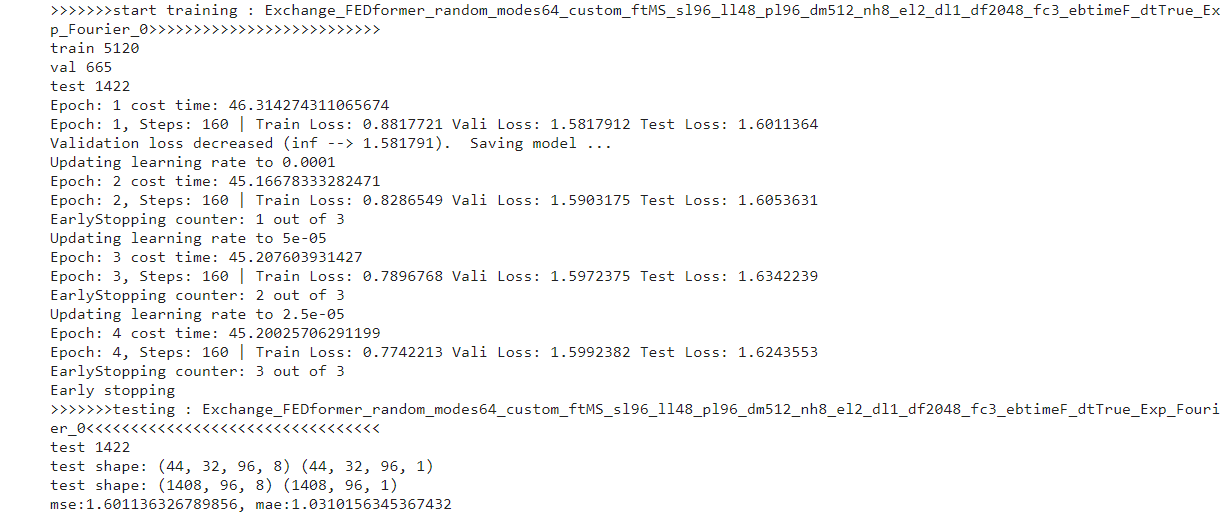
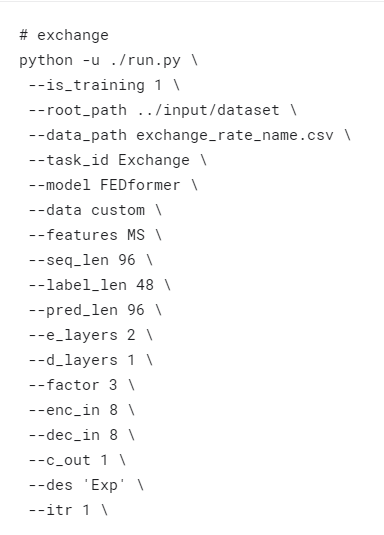
First,thanks for such great work.
I have a little question about the MOE module,could you please simply explain how MOE work theoretically,or give me some literature that I can read,thanks.
Thanks for this great work, but I have a little question about FourierBlock and FourierCrossAttention implemented in code:
you first call torch.permute() on qkv tensor to put the time dimension in the last dimension (Line 52, Line 95~97 in FourierCorrelation.py), and then conduct fft(), einsum() and rfft(). Then, you don't seem to swap the order of the dimensions back and call torch.view() (Line 221 in AutoCorrelation.py) directly to change the shape of the tensor from (B, H, E, L) to (B, L, -1). Is that right?
Thank you for your wonderful work. But i have a little question about the features set as ‘MS’. In the source code of exp_main.py :
f_dim = -1 if self.args.features == 'MS' else 0
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)
loss = criterion(outputs, batch_y)
train_loss.append(loss.item())
My question is that how to promise the dimensions of "outputs" is same as "batch_y". It's really confuse me for a couple days.
Thanks
Hello there, first of all, thanks for the great repository.
I have noticed that with python 3.6 (as named in your prerequisites), installing the requirements with python3 -m pip install -r requirements.txt does not work for multiple reasons:
pytorch-wavelets is a non-existent package, the package is called pytorch-wavelet
pandas==1.4.2 requires python>=3.8
Hello author, thanks for sharing. When the program runs to the positional encoding part, this error is reported:
File "D:\anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\conv.py", line 307, in forward
return self._conv_forward(input, self.weight, self.bias)
File "D:\anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\conv.py", line 300, in _conv_forward
return F.conv1d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode),
RuntimeError: Given groups=1, weight of size [512, 7, 2], expected input[32, 12, 98] to have 7 channels, but got 12 channels instead
How to solve it?
你好,我比对了论文中的公式9和图5中关于Us(L)和Ud(L)的计算流程,请问是否在图中将Us(L)和Ud(L)标反了?
我查阅了这部分的代码,发现代码似乎是按照公式9来进行的。
Dear Ma:
will you release the pretrained weights? thanks.
What is the training length going to the FEDFormer model for the electricity dataset?
It is coming to more than 96, which you have mentioned in the paper.
I can see it in the data factory file.
When I change the param '--features=' ,from 'M' to 'S',follow error return:
RuntimeError: Given groups=1, weight of size [512, 7, 3], expected input[32, 1, 98] to have 7 channels, but got 1 channels instead
I have gpu and torch.cuda.is_available() True

I just use run_M.sh and the training did not use GPU.
hi, thanks for your interesting work!
I train FEDformer in my dataset, and get really lower train and vali loss than Informer and Autoformer.
but when i want to do predict, i keep the same setting as training, a load state_dict error happend. i haven't solved the problem.
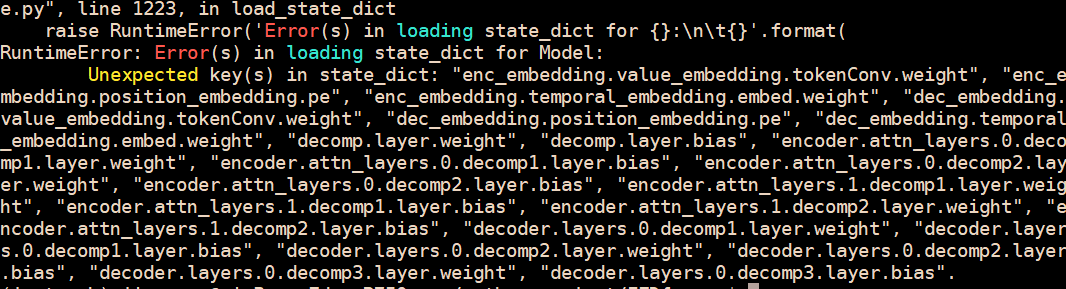
First of all, thank you for such an excellent study.
The results of the Fedformer are awe-inspiring and insightful.
My question is how to understanding this time complexity,could you please talk about it:
When we choose the mode index before DFT and reverse DFT operations, the computation complexity can be further reduced to O(N ).
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.