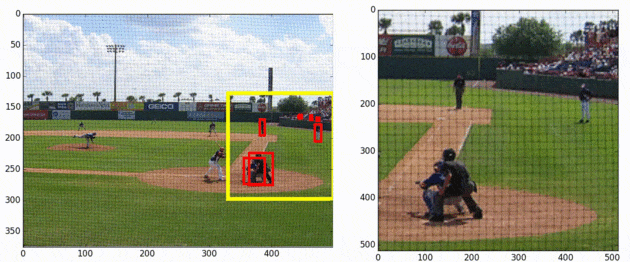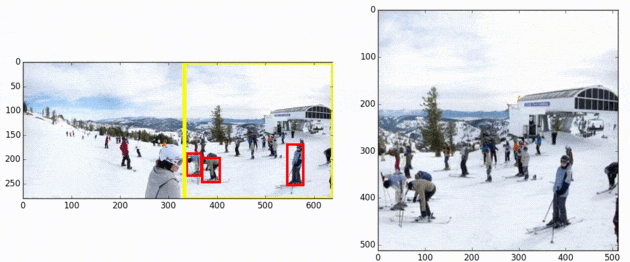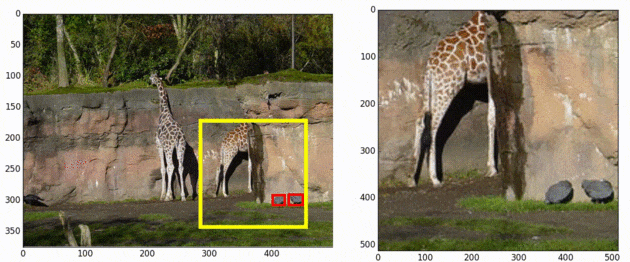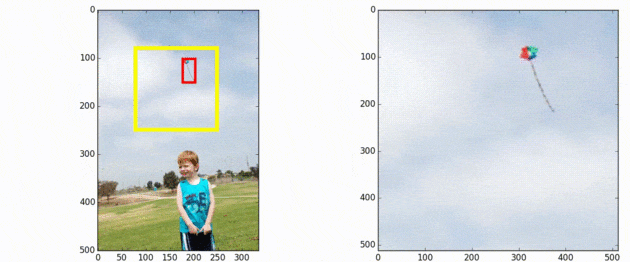
SNIPER is an efficient multi-scale training approach for instance-level recognition tasks like object detection and instance-level segmentation. Instead of processing all pixels in an image pyramid, SNIPER selectively processes context regions around the ground-truth objects (a.k.a chips). This significantly speeds up multi-scale training as it operates on low-resolution chips. Due to its memory-efficient design, SNIPER can benefit from Batch Normalization during training and it makes larger batch-sizes possible for instance-level recognition tasks on a single GPU. Hence, we do not need to synchronize batch-normalization statistics across GPUs and we can train object detectors similar to the way we do image classification!
AutoFocus, on the other hand, is an efficient multi-scale inference algorithm for deep-learning based object detectors. Instead of processing an entire image pyramid, AutoFocus adopts a coarse to fine approach and only processes regions that are likely to contain small objects at finer scales. This is achieved by predicting category agnostic segmentation maps for small objects at coarser scales, called FocusPixels. FocusPixels can be predicted with high recall, and in many cases, they only cover a small fraction of the entire image. To make efficient use of FocusPixels, an algorithm is proposed which generates compact rectangular FocusChips which enclose FocusPixels. The detector is while processing finer scales.
SNIPER is initially described in the following paper published at NeurIPS 2018:
SNIPER: Efficient Multi-Scale Training Bharat Singh*, Mahyar Najibi*, and Larry S. Davis (* denotes equal contribution) NeurIPS, 2018.
AutoFocus is initially described in the following paper published at ICCV 2019:
AutoFocus: Efficient Multi-Scale Inference Mahyar Najibi*, Bharat Singh*, and Larry S. Davis (* denotes equal contribution) ICCV, 2019.
- Train with a batch size of 160 images with a ResNet-101 backbone on 8 V100 GPUs
- NO PYTHON LAYERS (Every layer is optimized for large batch sizes in CUDA/C++)
- HALF PRECISION TRAINING with no loss in accuracy
- 5 Images/second during inference on a single V100 GPU, 47.8/68.2 on COCO using ResNet-101 and without training on segmentation masks
- Use the lightweight MobileNetV2 model trained with SNIPER to get 34.3/54.5 on COCO without training on segmentation masks
- The R-FCN-3K branch is also powered by SNIPER. Now 21% better than YOLO-9000 on ImageNetDet. This branch also supports on-the-fly training (in seconds) with very few samples (no bounding boxes needed!)
- Train on OpenImagesV4 (14x bigger than COCO) with ResNet-101 in 3 days on a p3.x16.large AWS instance!
Here are the COCO results for SNIPER trained using this repository. The models are trained on the trainval set (using only the bounding box annotations) and evaluated on the test-dev set.
| network architecture | pre-trained dataset | test dataset | mAP | [email protected] | [email protected] | mAP@S | mAP@M | mAP@L | |
|---|---|---|---|---|---|---|---|---|---|
| SNIPER | ResNet-101 | ImageNet | test-dev15 | 46.5 | 67.5 | 52.2 | 30.0 | 49.4 | 58.4 |
| SNIPER | ResNet-101 | OpenImagesV4 | test-dev15 | 47.8 | 68.2 | 53.6 | 31.5 | 50.4 | 59.8 |
| SNIPER | MobileNetV2 | ImageNet | test-dev15 | 34.3 | 54.4 | 37.9 | 18.5 | 36.9 | 46.4 |
| AutoFocus | ResNet-101 | OpenImagesV4 | val-2017 | 47.5 | 67.7 | 53.2 | 33.3 | 51.2 | 60.8 |
You can download the OpenImages pre-trained model by running bash scripts/download_pretrained_models.sh. The SNIPER detectors trained on both COCO (ResNet-101 and MobileNetV2) and PASCAL VOC datasets and the AutoFocus model trained on the COCO dataset (ResNet-101) can be downloaded by running bash scripts/download_sniper_autofocus_detectors.sh.
SNIPER is released under Apache license. See LICENSE for details.
@article{najibi2019autofocus,
title={{AutoFocus}: Efficient Multi-Scale Inference},
author={Najibi, Mahyar and Singh, Bharat and Davis, Larry S},
journal={ICCV},
year={2019}
}
@article{sniper2018,
title={{SNIPER}: Efficient Multi-Scale Training},
author={Singh, Bharat and Najibi, Mahyar and Davis, Larry S},
journal={NeurIPS},
year={2018}
}
@article{analysissnip2017,
title={An analysis of scale invariance in object detection-snip},
author={Singh, Bharat and Davis, Larry S},
journal={CVPR},
year={2018}
}
- Installation
- Running the demo
- Training a model with SNIPER / AutoFocus
- Evaluting SNIPER / AutoFocus models
- Other methods and branches in this repo (SSH Face Detector, R-FCN-3K, open-images)
- Clone the repository:
git clone --recursive https://github.com/mahyarnajibi/SNIPER.git
- Compile the provided MXNet fork in the repository.
You need to install CUDA, CuDNN, OpenCV, and OpenBLAS. These libraries are set to be used by default in the provided config.mk file in the SNIPER-mxnet repository. You can use the make command to build the MXNet library:
cd SNIPER-mxnet
make -j [NUM_OF_PROCESS] USE_CUDA_PATH=[PATH_TO_THE_CUDA_FOLDER]
If you plan to train models on multiple GPUs, it is optional but recommended to install NCCL and build MXNet with the NCCL support as instructed below:
make -j [NUM_OF_PROCESS] USE_CUDA_PATH=[PATH_TO_THE_CUDA_FOLDER] USE_NCCL=1
In this case, you may also need to set the USE_NCCL_PATH variable in the above command to point to your NCCL installation path.
If you need more information on how to compile MXNet please see here.
- Compile the C++ files in the lib directory. The following script compiles them all:
bash scripts/compile.sh
- Install the required python packages:
pip install -r requirements.txt
For running the demo, you need to download the provided SNIPER models. The following script downloads SNIPER models and extracts them into the default location:
bash download_sniper_autofocus_detectors.sh
After downloading the model, the following command would run the SNIPER detector trained on the COCO dataset with the default configs on the provided sample image:
python demo.py
If everything goes well, the sample detections would be saved as data/demo/demo_detections.jpg.
You can also run the detector on an arbitrary image by providing its path to the script:
python demo.py --im_path [PATH to the image]
However, if you plan to run the detector on multiple images, please consider using the provided multi-process and multi-batch main_test module.
You can also test the provided SNIPER model based on the MobileNetV2 architecture trained on the COCO dataset by passing the provided config file as follows:
python demo.py --cfg configs/faster/sniper_mobilenetv2_e2e.yml
For training SNIPER/AutoFocus, you first need to download the pre-trained models and configure the datasets as described below.
Running the following script downloads and extracts the pre-trained models into the default path (data/pretrained_model):
bash download_pretrained_models.sh
Please follow the official COCO dataset website to download the dataset. After downloading the dataset you should have the following directory structure:
data
|--coco
|--annotations
|--images
Please download the training, validation, and test subsets from the [official Pascal VOC dataset website (http://host.robots.ox.ac.uk/pascal/VOC/). After downloading the dataset you should have the following directory structure:
data
|--VOCdevkit
|--VOC2007
|--VOC2012
You can train the SNIPER detector with or without negative chip mining as described below.
Negative chip mining results in a relative improvement in AP (please refer to the paper for the details). To determine the candidate hard negative regions, SNIPER uses proposals extracted from a proposal network trained for a short training schedule.
For COCO and Pascal VOC datasets, we provide the pre-computed proposals. The following commands download the pre-computed proposals, extracts them into the default path (data/proposals), and trains the SNIPER detector with the default parameters on the COCO dataset:
bash download_sniper_neg_props.sh
python main_train.py
For training on Pascal VOC with the provided pre-computed proposals, you can run python main_train.py --cfg configs/faster/sniper_res101_e2e_pascal_voc.yml.
However, it is also possible to extract the required proposals using this repository (e.g. if you plan to train SNIPER on a new dataset). We provided an all-in-one script that performs all the required steps for training SNIPER with Negative Chip Mining. Running the following script trains a proposal network for a short cycle (i.e. 2 epochs), extract the proposals, and train the SNIPER detector with Negative Chip Mining:
bash train_neg_props_and_sniper.sh --cfg [PATH_TO_CFG_FILE]
You can disable the negative chip mining by setting the TRAIN.USE_NEG_CHIPS to False. This is useful if you plan to try SNIPER on a new dataset or want to shorten the training cycle. In this case, the training can be started by calling the following command:
python main_train.py --set TRAIN.USE_NEG_CHIPS False
In any case, the default training settings can be overwritten by passing a configuration file (see the configs folder for example configuration files).
The path to the configuration file can be passed as an argument to the above script using the --cfg flag.
It is also possible to set individual configuration key-values by passing --set as the last argument to the module
followed by the desired key-values (i.e. --set key1 value1 key2 value2 ...).
Please note that the default config files have the same settings used to train the released models.
If you are using a GPU with less amount of memory, please consider reducing the training batch size
(by setting TRAIN.BATCH_IMAGES in the config file or passing --set TRAIN.BATCH_IMAGES [DISIRED_VALUE] as the last argument to the module).
Also, multi-processing is used to process the data. For smaller amounts of memory, you may need to reduce the number of
processes and number of threads according to your system (by setting TRAIN.NUM_PROCESS and TRAIN.NUM_THREAD respectively).
For training SNIPER with the AutoFocus FocusPixel prediction branch, you can pass the AutoFocus config files (e.g. configs/faster/sniper_res101_e2e_autofocus.yml and configs/faster/sniper_res101_e2e_mask_autofocus.yml) to the main_train.py script. The default AutoFocus training hyper-parameters (for defining positive, negative, or don't care FocusPixels) can be modified through the config files. Please refer to the paper for more details.
Evaluating the provided SNIPER models
The repository provides a set of pre-trained SNIPER models which can be downloaded by running the following script:
bash download_sniper_detector.sh
This script downloads the model weights and extracts them into the expected directory. To evaluate these models on COCO test-dev with the default configuration, you can run the following script:
python main_test.py
For performing inference with AutoFocus, you can run the main_test.py script by passing the AutoFocus config file:
python main_test.py --cfg sniper_res101_e2e_mask_autofocus.py
It is possible to modify the AutoFocus default hyper-parameters through the config file to control the speed-accuracy tradeoff. Please see the paper for more details.
If inference is performed on the COCO test-dev set, a json file containing the detections on the test-dev is produced which can be zipped and uploaded to the COCO evaluation server.
The default SNIPER settings can be also overwritten by passing the path to a configuration file with the --cfg flag
(See the configs folder for examples). It is also possible to set individual configuration key-values by passing --set as the last argument to the module followed by the desired key-values (i.e. --set key1 value1 key2 value2 ...).
As an example, for evaluating the provided PASCAL VOC pre-trained model on the VOC 2007 test-set you can pass the provided PASCAL config file to the script:
python main_test.py --cfg configs/faster/sniper_res101_e2e_pascal_voc.yml
Please note that the evaluation is performed in a multi-image per batch and parallel model forward setting. In case of lower GPU memory, please consider reducing the batch size for different scales (by setting TEST.BATCH_IMAGES) or reducing the number of parallel jobs (by setting TEST.CONCURRENT_JOBS in the config file).
Evaluating a model trained with this repository
For evaluating a model trained with this repository, you can run the following script by passing the same configuration file used during the training.
The test settings can be set by updating the TEST section of the configuration file (See the configs folder for examples).
python main_test.py --cfg [PATH TO THE CONFIG FILE USED FOR TRAINING]
This repo also contains the R-FCN-3k detector.

Please switch to the R-FCN-3k branch for specific instructions.
This repo also contains modules to train on the open-images dataset. Please switch to the openimages2 branch for specific instructions. The detector on OpenImagesV4 was trained with Soft Sampling.

The SSH face detector would be added to this repository soon. In the meanwhile, you can use the code available at the original SSH repository.



























































































































































































