madobet / webooru Goto Github PK
View Code? Open in Web Editor NEWWeb Danbooru
Web Danbooru

































首先跟大家赔个不是,这一章隔了这么久才放出来,实在是笔者状态不好加上懒惰双重影响的缘故,不过晚比没有强,我最终还是把它憋出来了。
比起第五和第六章的理论探讨,这章科普加实践的内容其实应该在前四篇之后,承接的也是前四篇的内容,不过基于我写到哪是哪的坏毛病,只能让它做了第七篇,希望以后整理成小书的时候,可以重新排版。
我们在本书的第一章“空间正义”中写到,我们当下已经进入了晚期资本主义社会,而在第二章“消费主义反抗指南”中,我着重提及了债务对于晚期资本主义经济的拉动作用。
这是它的另一个主要特征。
第一节:这是一头可怜的小绵羊
债务是什么?这个东西用西方传统来讲,也许更有趣。
如果上溯到几千年前,在最早的商业规则中,债务并没有承担太多宏观经济层面的东西,它是属于邻里之间的善举。比如一个中东的游牧民,遇到了一场糟糕的干旱或者几只饥肠辘辘的大猫,于是他很可能就此丧失了赖以谋生的羊群,那么同部落的人就会借自己的羊给这个可怜人照顾,等他恢复元气以后再归还自己借来的羊,这对个人和部落都是有利的,债务在这个时候叫做天使的馈赠也不为过。
因此我们可以看到,第一个世纪之前的犹太人,并没有明确在经典中反对过借贷和放贷行为。
可怜的牧羊人是怎么还清债务呢?他肯定是通过放牧来让小羊变得更多,这时问题就来了,既然羊是借的,那么生了小羊算谁的?借羊人付出了劳动让羊群丰盛,但这羊在出借人那里就不生小羊了吗?当然,出借人又确实没有付出劳动,所以生出来的小羊理应有一部分(而非全部)属于出借人的资产性(羊)收益。
利息诞生了。
当时还没有人发现小羊羔(利息)会是个恶魔,它无论在任何角度,都是说的通的正常所得。这里插一句题外话:文艺复兴时期的经院哲学家创造性的阐述了恶魔没有实体,恶魔就在人间,在你我心中的理论,很难说没有所见所闻小羊羔的因素在。
(Hell is empty, all devils are here)——莎士比亚《暴风雨》
几百年间,这只小羔羊和牧羊人相安无事。直到某一天,在遥远的沙特,一个中年人忧心忡忡的看着自己教会的穷人食不果腹,衣不遮体,他苦思冥想,目光望向了城市**那个巨大的神庙。
他叫穆罕穆德。
时代不同了,这是古典世界一次习以为常的“城市化”。劳动生产率的提高让农牧民可以供养更多的城市人口,古典世界冒出了无数辉煌的城市,彼时在东方的长安,数十万人口的大都市已经建立,人民依靠商业和手工业养活自己。
传统的部落已经被打破,大家都归于一个个或大或小的政权之中,祭司和军事贵族们并不是你温情脉脉的邻居,也不是你住隔壁的堂兄,对于他们来说,本该合理的利息变成了牟利的工具。
穆罕穆德决定在自己的教会之中,彻底杜绝放贷,《古兰经》第30章第39节经文说:“你们为吃利而放的债,欲在他人的财产中增加的,在真主那里,不会增加;你们所施的财物,欲得真主的喜悦的,必得加倍的报酬。”
古兰经严厉的说:“真主准许买卖,而禁止重利”(2:275),但为时已晚,直到今天中东国家还在收取变相的利息,西欧的教会在中世纪时也逐渐对高利贷产生敌视,而遵循千年传统放贷的犹太人,从此一路奔向了被严厉打压的修罗之路。
犹太人的故事不是小羊羔产生的唯一悲剧,它终将席卷全球,以最残酷的方式。
第二节:一封来自资本主义的合同
除了先知,军事贵族和祭司们也有自己的烦恼,虽然他们合法的膨胀了自己的财富,但是很少有人会把自己的城堡卖掉打仗,除非是妄想在东方获得更大收益的十字军。
但是他们拥有国家。
曾有很多贵族试图用国家的信用发债,主要是试图揍另一个贵族,但唯一成功的是威廉国王。因为悲剧的个人权力被限制,他的国家反而更容易获得信任,而资本主义的第一波高潮重商主义使民间的投资热情高涨,二者眉来眼去一下,一拍即合。
国王靠借来的钱揍了一个又一个国王,甚至是陆地上最强大的那个,获取了更多利润,以至于利息不值一提,资本主义展现出了它超绝的魅力,把那只小羊羔摆上了神坛,而在那之前几十年,荷兰人已经静悄悄的完成了公司债务的发行。
我们现在看到的国家债务,公司债务,个人债务的三位一体债务体系就此成型,债务和人类生活点方方面面第一次产生了再也无法分割的联系,一切都靠那张合同上的小羊羔手印实现。
但债并不总是都能还上的,羊羔也会嗜血。 三位一体体系建立以后,资金最大程度的被利用了起来,直到构成了我们今天的世界。我们的幸福和灾难大多都因此而起。
殖民地是有限的,工业革命也不会总是发生,利润并不总能覆盖利息,于是在没有战争和科技飞跃的时代,资本主义会陷入周期性的经济危机。我在第二章说过,资本主义有天然扩大产能的盲目性,哈耶克认为市场能解决这个问题,乃至于洋洋洒洒写了一本巨著《通往奴役之路》,实践证明他是错的,凯恩斯就对此嗤之以鼻。
凯恩斯认为当需求不足的时候,哈耶克说的市场调节是不可能的,马克思说的市场崩溃必然发生,但他也不信马克思的解决方法,他认为通过积极的财政手段比如我们现在看到的一年年的大基建和棚改政策可以有效的拉动经济,刺激需求。再通过积极的货币政策比如降息,印钞来让人贷款消费,让人不消费就贬值……最终拖到下一个工业革命或者战争。
一个小故事是这样的:小迷弟问凯恩斯,老师您这一套都很好,但是长此以往,续不下去的时候怎么办?凯恩斯回答:长此以往我们都会死。
这就是第二章的故事,也是我预测房价必然会被叫停甚至下跌的原因:当资金被楼市锁死,没有新的信贷产生,就没有投资,没有经济,没有一切,房地产是且只是用完就扔的灌尿夜壶罢了。
第三节:恶魔的规则
说到这里,我们就能稍稍一窥这些年发生了什么:2008年世界末日来了,国家开始从外贸转型内需拉动经济,外贸占比一路从70%掉到10%,抗风险能力强了,再也不会有大洪水,但是属于个人的涓涓细流下水道成为定局。
先是四万亿的大基建投资,国家上足了杠杆,为了还这个钱,政府疯狂卖地,杠杆转移到了房地产企业上,最后通过卖房,转移到了你的身上,如果这还不够,就刺激信贷。
五六年前我开始注销全部信用卡,还清一张注销一张。但是与此同时我发现身边欠债的人越来越多了,进入别人疯狂我恐惧的阶段。两年前我开始写《资本主义个人反抗指南》,希望沙滩捡鱼救一个是一个。去年开始消费降级,由奢入俭难,但我硬是降下来了,从最多一个月花一万多到一个月几百块。至此我做到了极限,变成了第三章里说的“漏网之鱼”。
但大环境不会因为我个人的微薄努力产生任何变化,这段时间得知玩小贷的90后甚至比收入更高的80后还要多,而信用卡坏账率也节节升高……随便查查就能看到更多触目惊心的数据。
第二章我们说到“借钱给你买我的东西”是续命主义的基本思路,你自以为的个人行为也是可以被引导的,直到变成“消费习惯”。
所以背景就是政策利好,消费金融大爆发,动机是拉动内需。这是一个简单的理性人行为:适当的债务让人焦虑进而创造更多价值。
对于宏观来说,债务存而不崩是最能带动你的劳动积极性的,你变成了不自觉的奴隶。
但宏观总归是宏观,总有人会变成坏账,变成老赖,变成跑路缅甸签单的老哥,这就是为什么我管2008叫世界末日,只有在这个时候,那头小羔羊才能更多的行走于世间,就像某个封印被解开了,它舒缓着自己的身躯向你施施然走来。
对于小羔羊,没有进坑的人显然可以从我的前文中获得足够的力量,那么已经进坑的人呢?我之前说过,资本主义个人反抗的精髓是“卧室里的反抗”,亦即说走你无法抗衡结构性暴力的前提下,如何利用结构性暴力本身的规则反抗它。
比如:
1、小贷
原则上消费金融是被鼓励的,但是规则是希望你能源源不断的循环借贷,“存而不崩”,所以太过高的利息是杀鸡取卵,这是不被允许的,年化24%以上的利息不受法律保护,而之前的小贷大部分都通过各种名目超过了这个数目,你不光可以不还钱超出的部分,还经常可以协商还本停息,毕竟比起一分拿不回来,他们更希望还有本金可拿。
最恐怖的催收完全可以硬刚,因为你借几千块钱,他们上门催收和起诉的成本都超过你借款的数目,抗过轰炸,是他们求你而不是你求他们。
当然,不要想着不还钱,你不会希望上黑名单也不会希望真的遇到头铁的申请强制执行。
2、信用卡
信用卡是银行的亲儿子,但卡债是相对来说最不用发愁的,你可以利用免息期的空挡,以卡倒卡,以卡养卡,为避免本篇被404,具体措施可以自行百度。
记住,这并不丢人。
3、房产
我们锁死了外汇的流动,为了避免经济断崖式下跌开始了逆周期(如果和美联储同步加息就是顺周期,**的货币机制和美元潮汐也许会单独成文,看不懂这部分的朋友可以自己先行查阅)的货币政策,你随便查看过去几个月的新闻就知道定向放水一波接一波。虽然房地产大概率不会涨价,只会阴跌,但房贷依旧处于历史低点……这恐怕是你唯一可以薅羊毛的机会,设想一下,如果你存钱,100块一年后变成80的购买力,但是你借钱,你能找到最低利息的借钱呢?借了100,一年后变成90,只要房价跌的不会太狠,胜利者就是你,房贷是你能拥有最优质的资产,没错,资产。
结尾:深渊
房贷的故事可能才是本篇的真谛,你凝视深渊里的小羊羔,小羊羔也在深渊中凝视你,很可能你最终需要利用最深的黑色杀死它,但如果不加以控制,黑色必将也杀死你。
比如了解了房贷的故事的人,相当一部分变成了炒房者,这些人玩着最精妙的杠杆游戏,走在最细的钢丝之上,炒完一线炒三线,当他们的资金链紧绷到极限,限售来了,房地产税要来了,等待他们的会是什么?
一套,有且只有一套,你需要省吃俭用压缩一切获得它,也要抽着自己的嘴巴克制自己的贪婪,而这一切可能就会是最难的反抗。
Is there still research to be done in Programming Languages? This essay touches both on the topic of programming languages and on the nature of research work. I am mostly concerned in analyzing this question in the context of Academia, i.e. within the expectations of academic programs and research funding agencies that support research work in the STEM disciplines (Science, Technology, Engineering, and Mathematics). This is not the only possible perspective, but it is the one I am taking here.
PLs are dear to my heart, and a considerable chunk of my career was made in that area. As a designer, there is something fundamentally interesting in designing a language of any kind. It’s even more interesting and gratifying when people actually start exercising those languages to create non-trivial software systems. As a user, I love to use programming languages that I haven’t used before, even when the languages in question make me curse every other line.
But the truth of the matter is that ever since I finished my Ph.D. in the late 90s, and especially since I joined the ranks of Academia, I have been having a hard time convincing myself that research in PLs is a worthy endeavor. I feel really bad about my rational arguments against it, though. Hence this essay. Perhaps by the time I am done with it I will have come to terms with this dilemma.
Back in the 50s, 60s and 70s, programming languages were a BigDeal, with large investments, upfront planning, and big drama on standardization committees (Ada was the epitome of that model). Things have changed dramatically during the 80s. Since the 90s, a considerable percentage of new languages that ended up being very popular were designed by lone programmers, some of them kids with no research inclination, some as a side hobby, and without any grand goal other than either making some routine activities easier or for plain hacking fun. Examples:
Compare this mindset with the context in which the the older well-known programming languages emerged:
Back then, developing a language processor was, indeed, a very big deal. Computers were slow, didn’t have a lot of memory, the language processors had to be written in low-level assembly languages… it wasn’t something someone would do in their rooms as a hobby, to put it mildly. Since the 90s, however, with the emergence of PCs and of decent low-level languages like C, developing a language processor is no longer a BigDeal. Hence, languages like PHP and JavaScript.
There is a lot of fun in designing new languages, but this fun is not an exclusive right of researchers with, or working towards, Ph.Ds. Given all the knowledge about programming languages these days, anyone can do it. And many do. And here’s the first itchy point: there appears to be no correlation between the success of a programming language and its emergence in the form of someone’s doctoral or post-doctoral work. This bothers me a lot, as an academic. It appears that deep thoughts, consistency, rigor and all other things we value as scientists aren’t that important for mass adoption of programming languages. But then again, I’m not the first to say it. It’s just that this phenomenon is hard to digest, and if you really grasp it, it has tremendous consequences. If people (the potential users) don’t care about conceptual consistency, why do we keep on trying to achieve that?
To be fair, some of those languages designed in the 90s as side projects, as they became important, eventually became more rigorous and consistent, and attracted a fair amount of academic attention and industry investment. For example, the Netscape JavaScript hacks quickly fell on Guy Steele’s lap resulting in the ECMAScript specification. Python was never a hack even if it started as a Christmas hobby. Ruby is a fun language and quite elegant from the beginning. PHP… well… it’s fun for possibly the wrong reasons. But the core of the matter is that “the right thing” was not the goal. It seems that a reliable implementation of a language that addresses an important practical need is the key for the popularity of a programming language. But being opportunistic isn’t what research is supposed to be about… (or is it?)
Also to be fair, not all languages designed in the 90s and later started as side projects. For example, Java was a relatively large investment by Sun Microsystems. So was .NET later by Microsoft.
And, finally, all of these new languages, even when created over a week as someone’s pet project, sit on the shoulders of all things that existed before. This leads me to the second itch: one striking commonality in all modern programming languages, especially the popular ones, is how little innovation there is in them! Without exception, including the languages developed in research groups, they all feel like mashups of concepts that already existed in programming languages in 1979, wrapped up in their own idiosyncratic syntax. (I lied: exceptions go to aspects and monads both of which came in the 90s)
So one pertinent question is: given that not much seems to have emerged since 1979 (that’s 30+ years!), is there still anything to innovate in programming languages? Or have we reached the asymptotic plateau of innovation in this area?
I need to make an important detour here on the nature of research.
Perhaps I’m completely off; perhaps producing innovative new software is not a goal of [STEM] research. Under this approach, any software work is dismissed from STEM pursuits, unless it is necessary for some specific goal — like if you want to study some far-off galaxy and you need an IT infrastructure to collect the data and make simulations (S for Science); or if you need some glue code for piecing existing systems together (T for Technology); or if you need to improve the performance of something that already exists (E for Engineering); or if you are a working on some Mathematical model of computation and want to make your ideas come to life in the form of a language (M for Mathematics). This is an extreme submissive view of software systems, one that places software in the back sit of STEM and that denies the existence of value in research in/by software itself. If we want to lead something on our own, let’s just… do empirical studies of technology or become biologists/physicists/chemists/mathematicians or make existing things perform better or do theoretical/statistical models of universes that already exist or that are created by others. Right?
I confess I have a dysfunctional relationship with this idea. Personally, I can’t be happy without creating software things, but I have been able to make my scientist-self function both as a cold-minded analyst and, at times, as an expert passenger in someone else’s research project. The design work, for me, has moved to sabbatical time, evenings and weekends; I don’t publish it [much] other than the code itself and some informal descriptions. And yet, I loathe this situation.
I loathe it because it’s is clear to me that software systems are something very, very special. Software revolutionized everything in unexpected ways, including the methods and practices that our esteemed colleagues in the “hard” sciences hold near and dear for a very long time. The evolution of information technology in the past 60 years has been _way_ off from what our colleagues thought they needed. Over and over again, software systems have been created that weren’t part of any scientific project, as such, and that ended up playing a central role in Science. Instead of trying to mimic our colleagues’ traditional practices, “computer scientists” ought to be showing the way to a new kind of science — maybe that new kind of science or that one or maybe something else. I dare to suggest that the something else is related to the design of things that have software in them. It should not be called Science. It is a bit like Engineering, but it’s not it either because we’re not dealing [just] with physical things. Technology doesn’t cut it either. It needs a new name, something that denotes “the design of things with software in them.” I will call it Design for short, even though that word is so abused that it has lost its meaning.
Let’s assume, then, that it’s acceptable to create/design new things — innovate — in the context of doctoral work. Now comes the real hard question.
If anyone — researchers, engineers, talented kids, summer interns — can design and implement programming languages, what are the actual hard goals that doctoral research work in programming languages seeks that distinguishes it from what anyone can do?
Let me attempt to answer these questions, first, with some well-known goals of language design:
There are other goals, but they are second-order. For example, languages may also need to catch up with innovations in hardware design — multi-core comes to mind. This is a second-order goal, the real goal behind it is to increase performance by taking advantage of potentially higher-performing hardware architectures.
In other words, someone wanting to do doctoral research work in programming languages ought to have one or more of these goals in mind, and — very important — ought to be ready to demonstrate how his/her ideas meet those goals. If you tell me that your language makes something run faster, consume less energy, makes some task easier or results in programs with less bugs, the scientist in me demands that you show me the data that supports such claims.
A lot of research activity in programming languages falls under the performance goal, the Engineering side of things. I think everyone in our field understands what this entails, and is able to differentiate good work from bad work under that goal. But a considerable amount of research activities in programming languages invoke the human productivity argument; entire sub-fields have emerged focusing on the engineering of languages that are believed to increase human productivity. So I’m going to focus on the human productivity goal. The human productivity argument touches on the core of what attracts most of us to creating things: having a direct positive effect on other people. It has been carelessly invoked since the beginning of Computer Science. (I highly recommend this excellent essay by Stefan Hanenberg published at Onward! 2010 with a critique of software science’s neglect of human factors)
Unfortunately, this argument is the hardest to defend. In fact, I am yet to see the first study that convincingly demonstrates that a programming language, or a certain feature of programming languages, makes software development a more productive process. If you know of such study, please point me to it. I have seen many observational studies and controlled experiments that try to do it [5, 6, 7, 8, 9, 10, among many]. I think those studies are really important, there ought to be more of them, but they are always very difficult to do [well]. Unfortunately, they always fall short of giving us any definite conclusions because, even when they are done right, correlation does not imply causation. Hence the never-ending ping-pong between studies that focus on the same thing and seem to reach opposite conclusions, best known in the health sciences. We are starting to see that ping-pong in software science too, for example 7 vs 9. But at least these studies show some correlations, or lack thereof, given specific experimental conditions, and they open the healthy discussion about what conditions should be used in order to get meaningful results.
I have seen even more research and informal articles about programming languages that claim benefits to human productivity without providing any evidence for it whatsoever, other than the authors’ or the community’s intuition, at best based on rational deductions from abstract beliefs that have never been empirically verified. Here is one that surprised me because I have the highest respect for the academic soundness of Haskell. Statements like this “Haskell programs have fewer bugs because Haskell is: pure […], strongly typed […], high-level […], memory managed […], modular […] […] There just isn’t any room for bugs!” are nothing but wishful thinking. Without the data to support this claim, this statement is deceptive; while it can be made informally in a blog post designed to evangelize the crowd, it definitely should not be made in the context of doctoral work unless that work provides solid evidence for such a strong statement.
That article is not an outlier. The Internets are full of articles claiming improved software development productivity for just about every other language. No evidence is ever provided, the argumentation is always either (a) deducted from principles that are supposed to be true but that have never been verified, or (b) extrapolated from ad-hoc, highly biased, severely skewed personal experiences.
This is the main reason why I stopped doing research in Programming Languages in any official capacity. Back when I was one of the main evangelists for AOP I realized at some point that I had crossed the line to saying things for which I had very little evidence. I was simply… evangelizing, i.e. convincing others of an idea that I believed strongly. At some point I felt I needed empirical evidence for what I was saying. But providing evidence for the human productivity argument is damn hard! My scientist self cannot lead doctoral students into that trap, a trap that I know too well.
Moreover, designing and executing the experiments that lead to uncovering such evidence requires a lot of time and a whole other set of skills that have absolutely nothing to do with the time and skills for actually designing programming languages. We need to learn the methods that experimental psychologists use. And, in the end of all that work, we will be lucky if we unveil correlations but we will not be able to draw any definite conclusions, which is… depressing.
But without empirical evidence of any kind, and from a scientific perspective, unsubstantiated claims pertaining to, say, Haskell or AspectJ (which are mostly developed and used by academics and have been the topic of many PhD dissertations) are as good as unsubstantiated claims pertaining to, say, PHP (which is mostly developed and used by non-academics). The PHP community is actually very honest when it comes to stating the benefits of using the language. For example, here is an honest-to-god set of reasons for using PHP. Notice that there are no claims whatsoever about PHP leading to less bugs or higher programmer productivity (as if anyone would dare to state that!); they’re just pragmatic reasons. (Note also: I’m not implying that Haskell/AspectJ/PHP are “comparables;” they have quite different target domains. I’m just comparing the narratives surrounding those languages, the “stories” that the communities tell within themselves and to others)
OK, now that I made 823 enemies by pointing out that the claims about human productivity surrounding languages that have emerged in academic communities — and therefore ought to know better — are unsubstantiated, PLUS 865 enemies by saying that empirical user studies are inconclusive and depressing… let me try to turn my argument around.
Is the high bar of scientific evidence killing innovation in programming languages? Is this what’s causing the asymptotic behavior? It certainly is what’s keeping me away from that topic, but I’m just a grain of sand. What about the work of many who propose intriguing new design ideas that are then shot down in peer-review committees because of the lack of evidence?
This ties back to my detour on the nature of research.
So, we’re back to whether design innovation per se is an admissible first-order goal of doctoral work or not. And now that question is joined by a counterpart: is the provision of scientific evidence really required for doctoral work in programming languages?
If what we have in hand is not Science, we need to be careful not to blindly adopt methods that work well for Science, because that may kill the essence of our discipline. In my view, that essence has been the radical, fast-paced, off the mark design experimentation enabled by software. This rush is fairly incompatible with the need to provide scientific evidence for the design “hopes.”
I’ll try a parallel: drug design, the modern-day equivalent of alchemy. In terms of research it is similar to software: partly based on rigor, partly on intuitions, and now also on automated tools that simply perform an enormous amount of logical combinations of molecules and determine some objective function. When it comes to deployment, whoever is driving that work better put in place a plan for actually testing the theoretical expectations in the context of actual people. Does the drug really do what it is supposed to do without any harmful side effects? We require scientific evidence for the claimed value of experimental drugs. Should we require scientific evidence for the value of experimental software?
The parallel diverges significantly with respect to the consequences of failure. A failure in drug design experimentation may lead to people dying or getting even more sick. A failure in software design experimentation is only a big deal if the experiment had a huge investment from the beginning and/or pertains to safety-critical systems. There are still some projects like that, and for those, seeking solid evidence of their benefits before deploying the production version of the experiment is a good thing. But not all software systems are like that. Therefore the burden of scientific evidence may be too much to bear. It is also often the case that over time, the enormous amount of testing by real use is enough to provide assurances of all kinds.
One good example of design experimentation being at odds with scientific evidence is the proposal that Tim Berners-Lee made to CERN regarding the implementation of the hypertext system that became the Web. Nowhere in that proposal do we find a plan for verification of claims. That’s just a solid good proposal for an intriguing “linked information system.” I can imagine TB-L’s manager thinking: “hmm, ok, this is intriguing, he’s a smart guy, he’s not asking that many resources, let’s have him do it and see what comes of it. If nothing comes of it, no big deal.” Had TB-L have to devise a scientific or engineering assessment plan for that system beyond “in the second phase, we’ll install it on many machines” maybe the world would be very different today, because he might have gotten caught in the black hole of trying to find quantifiable evidence for something that didn’t need that kind of validation.
Granted, this was not a doctoral topic proposal; it was a proposal for the design and implementation of a very concrete system with software in it, one that (1) clearly identified the problem, (2) built on previous ideas, including the author’s own experience, (3) had some intriguing insights in it, (4) stated expected benefits and potential applications — down to the prediction of search engines and graph-based data analysis. Should a proposal like TB-L’s be rejected if it were to be a doctoral topic proposal? When is an unproven design idea doctoral material and other isn’t? If we are to accept design ideas without validation plans as doctoral material, how do we assess them?
In order to do experimental design research AND be scientifically honest at the same time, one needs to let go of claims altogether. In that dreadful part of a topic proposal where the committee asks the student “what are your claims?” the student should probably answer “none of interest.” In experimental design research, one can have hopes or expectations about the effects of the system, and those must be clearly articulated, but very few certainties will likely come out of such type of work. And that’s ok! It’s very important to be honest. For example, it’s not ok to claim “my language produces bug-free programs” and then defend this with a deductive argument based on unproven assumptions; but it’s ok to state “I expect that my language produces programs with fewer bugs [but I don’t have data to prove it].” TB-L’s proposal was really good at being honest.
Finally, here is an attempt at establishing a rigorous criteria for design assessment in the context of doctoral and post-doctoral research:
This criteria has two consequences that I really like: first, it substantiates our intuitions about proposals such as TB-L’s “linked information system” being a fine piece of [design] research work; second, it substantiates our intuitions on the difference of languages like Haskell vs. languages like PHP. I leave that as an exercise to the reader!
I would love to bring design back to my daytime activities. I would love to let my students engage in designing new things such as new programming languages and environments — I have lots of ideas for what I would like to do in that area! I believe there is a path to establishing a set of rigorous criteria regarding the assessment of design that is different from scientific/quantitative validation. All this, however, doesn’t depend on me alone. If my students’ papers are going to be shot down in program committees because of the lack of validation, then my wish is a curse for them. If my grant proposals are going to be rejected because they have no validation plan other than “and then we install it in many machines” or “and then we make the software open source and free of charge” then my wish is a curse for me. We need buy-in from a much larger community — in a way, reverse the trend of placing software research under the auspices of science and engineering [alone].
This, however, should only be done after the community understands what science and scientific methods are all about (the engineering ones — everyone knows about them). At this point there is still a severe lack of understanding of science within the CS community. Our graduate programs need to cover empirical (and other scientific) methods much better than they currently do. If we simply continue to ignore the workings of science and the burden of scientific proof, we end up continuing to make careless religious statements about our programming languages and systems that simply will lead nowhere, under the misguided impression that we are scientists because the name says so.
_Copyright © Crista Videira Lopes. All rights reserved.
Note: this is a work-in-progress essay. I may update it from time to time. Feedback welcome.
_
作者 | 刘忠雨
策划编辑 | 蔡芳芳
AI 前线导读: 图神经网络(GNN,Graph Neural Networks)是 2019 年 AI 领域最热门的话题之一。图神经网络是用于图结构数据的深度学习架构,将端到端学习与归纳推理相结合,业界普遍认为其有望解决深度学习无法处理的因果推理、可解释性等一系列瓶颈问题,是未来 3 到 5 年的重点方向。2019 年图神经网络有哪些研究成果值得关注?2020 年它又将朝什么方向发展?让我们一起来一探究竟。文末有送书福利!
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
本文是 InfoQ“解读 2019”年终技术盘点系列文章之一。
1 GNN:从尝鲜进入快速爆发期
今年以来,图神经网络技术(Graph Neural Network, GNN)得到了学术界极大的关注与响应。各大学术会议纷纷推出 GNN 相关的 workshop,在投中的论文中,以 Graph Network 为关键词的论文数量也呈现井喷之势,下图给出了近三年,上述关键词在各学术会议上的增长趋势:
GNN 在经历过 2017-2018 年两年的孕育期与尝试期之后,在 2018 年末至今的一年多时间里,迎来了快速爆发期。从理论研究到应用实践,可谓是遍地开花,让人应接不暇。在理论研究上,GNN 的原理解释、变体模型以及对各种图数据的拓展适配等工作成为了主流。而在应用实践上,GNN 更是展现出了前所未有的渗透性,从视觉推理到开放性的阅读理解问题,从药物分子的研发到 5G 芯片的设计,从交通流量预测到 3D 点云数据的学习,我们看到了 GNN 极其广阔的应用前景。本文将对近一年各大顶级会议(如 ICML、NIPS、CVPR、ACL、KDD 等)上的 GNN 相关论文进行梳理,重点从理论研究和应用实践两方面解读过去一年 GNN 的进展。由于时间和篇幅有限,本文并没有对每一个方向都进行全面的总结与概括,感兴趣的读者可以根据文中给出的论文链接自行查漏补缺。
2 GNN 的原理、变体及拓展
GNN 作为一个新兴的技术方向,其原理解读以及各类变体与拓展构成了理论研究的热点,这些论文很好地回答了 GNN 的优缺点以及相关的适应性改造问题。
2.1 GNN 原理解读
当前 GNN 研究的第一个热点在于其相关能力的理论化研究。在 “How Powerful are Graph Neural Networks?” 和 “On the equivalence between graph isomorphism testing and function approximation with GNNs” 中,都对 GNN 在图同构问题上的表现进行了探讨。图同构问题是辨别给定的两个图是否一致,同构图如下图所示。这个问题考验了算法对图数据结构的辨别能力,这两篇文章都证明了 GNN 模型具有出色的结构学习能力。图中天然包含了关系,因此许多 GNN 相关的工作就建立在对给定系统进行推理学习的研究上,在这些研究中,“Can graph neural networks help logic reasoning? ” 和 “The Logical Expressiveness of Graph Neural Networks” 论证了 GNN 在逻辑推理上的优秀表现。“All We Have is Low-Pass Filters ” 从低通滤波的层面解释了 GNN 的有效性。这些原理解读,有助于我们对 GNN 的特色专长建立一种更加清晰的认识。
2.2 GNN 的各类变体
GNN 模型的相关变体研究是领域内的另一个热点,这些变体在一些方面提升了 GNN 的能力表现。我们知道 GCN 模型来源于图信号上的傅里叶变换,“Graph Wavelet Neural Network” 引入了图信号上的小波变换来改造 GCN 模型,将卷积计算变换到空域局部邻域内。将数据表征从欧式空间转化到双曲空间,不仅能获得更好地层次化表示,同时能大大节约空间维度,“Hyperbolic Graph Convolutional Neural Networks”和 “Hyperbolic Attention Networks” 同时将 GNN 拓展到了双曲空间上去。
在 “MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing” 和 “Diffusion Improves Graph Learning”中,同时将原始 GCN 中的邻居定义由一阶拓展到高阶,强化了模型低通滤波的特性。
2.3 GNN 在各类图数据及任务上的拓展
图数据是一个种类繁多的数据家族,模型对这些不同类型的数据如何适配,是 GNN 发展的另一重要方向。下表给出了相应的概括:
| 图类型 | 相关说明 | 对应论文 |
|---|---|---|
| 属性图 | 多种节点类型,节点包含属性,最具代表性 | [1] [2] |
| 超图 | 一条边同时连接两个以上节点 | [3] |
| 动态图 | 图结构随时间演化 | [4] |
| 隐式图 | 节点之间没有显式边,需要先学习图的结构 | [5] [6] |
[1]: HetGNN: Heterogeneous Graph Neural Network
https://www.kdd.org/kdd2019/accepted-papers/view/hetgnn-heterogeneous-graph-neural-network
[2]: Representation Learning for Attributed Multiplex Heterogeneous Network
https://arxiv.org/abs/1905.01669
[3]: HyperGCN: A New Method For Training Graph Convolutional Networks on Hypergraphs
https://arxiv.org/abs/1809.02589
[4]: DyRep: Learning Representations over Dynamic Graphs
https://openreview.net/pdf?id=HyePrhR5KX
[5]: Semi-supervised Learning with Graph Learning-Convolutional Networks
[6]: Learning Discrete Structures for Graph Neural Networks
https://arxiv.org/abs/1903.11960
在图数据相关的任务上,图的分类是一个重要而又未完全解决好的问题,其难处在于如何在图数据上实现层次化的池化操作从而获得图的全局表示,“Graph Convolutional Networks with EigenPooling”中给出了一种新的操作思路。
3 GNN 相关应用
近几年,以深度学习为代表的人工智能技术给产业界带来了新的变革。该技术在视觉、语音、文本三大领域取得了极大的应用成果,这种成功,离不开深度学习技术对这三类数据定制化的模型设计工作。脱离于这三类数据之外,图数据是一种更加广泛的数据表示方式,夸张地说,没有任何一个场景中的数据彼此之间是孤立存在的,这些数据之间的关系都可以以图的形式进行表达。下图给出了一些图数据的使用场景:
如何将图数据的学习与深度学习技术进行深度结合成为了一个迫切且紧要的需求。在这样的背景之下,图神经网络技术的兴起恰似一股东风,第一次使得我们看到了深度学习应用到图数据之上的曙光。实际上,在最近一年,GNN 的应用场景不断延伸,覆盖了计算机视觉、3D 视觉、自然语言处理、科研、知识图谱、推荐、反欺诈等场景,下面我们将逐项概括。
3.1 计算机视觉
在前几年跨越了视觉识别的大门之后,推理相关的视觉任务已经成为了了各大 CV 顶会的主要关注点,如:视觉问答、视觉推理、语义图合成、human-object interaction 等,甚至如视觉的基础任务,目标检测也需要用到推理来提升性能。在这些任务中,已经大量出现应用 GNN 的相关工作。下面我们以最常见的视觉问答任务举例说明,在“Relation-Aware Graph Attention Network for Visual Question Answering”一文中,给出了将 GNN 与视觉模型结合的示意图:
在上图中,视觉模型的作用是提取给定图像中的语义区域,这些语义区域与问题一并当做图中的节点,送到一个 GNN 模型中进行推理学习,这样的一种建模方式,可以更加有效地在视觉问答中对问题进行自适应地推理。
另外一个有意思的场景是少样本或零样本学习,由于这类场景下样本十分缺乏,如何充分挖掘样本之间的潜在关联信息(比如标签语义关联、潜层表达关联)就成为了一个至关重要的考量因素,引入 GNN 成为了一个非常自然的动作,相关工作有“Rethinking Knowledge Graph Propagation for Zero-Shot Learning”、“Edge-labeling Graph Neural Network for Few-shot Learning”。
3.2 3D 视觉
3D 视觉是计算机视觉的又一重要发展方向,世界是 3D 的,如何让计算机理解 3D 世界,具有极其重要的现实价值。3D 视觉中,点云数据是一种十分常见的数据表示方法。
点云数据通常由一组坐标点(x,y,z)表示,这种数据由于映射了现实世界中物体的特征,因此存在一种内在的表征物体语义的流行结构,这种结构的学习也是 GNN 所擅长的。需要说明一点的是,在 3D 视觉中流行的是几何学习 Geometry Learning,当下,几何学习与 GNN 在一些场景如点云分割、点云识别等正在深度融合,相关论文有 “Graph Attention Convolution for Point Cloud Segmentation”、“Semantic Graph Convolutional Networks for 3D Human Pose Regression”。
3.3 自然语言处理
GNN 与 NLP 的结合,关键点也在于 GNN 优秀的推理能力。GNN 在一些场景如:阅读理解、实体识别与关系抽取、依存句法分析中都有应用。下面我们以多跳阅读(Multi-hop reading)为例,多跳阅读是说在阅读理解的过程中,往往需要在多篇文档之间进行多级跳跃式的关联与推理,才能找到正确答案,相比较以前的单文档问答数据集,这是一个更具有开放性与挑战性的推理任务。下图给出了多跳阅读的样例:
在“Cognitive Graph for Multi-Hop Reading Comprehension at Scale”一文中,作者基于 BERT 和 GNN 的实现可有效处理 HotPotQA 数据集中有关多跳阅读问题的数百万份文档,在排行榜上的联合 F1 得分为 34.9,而第二名的得分只有 23.6。
3.4 科研场景
如果我们把原子看做图中的节点、化学键看做边,那么分子就可以表征为一张图。这种以图来表示分子的方法,可以将 GNN 结合到很多实际的科研场景中,如蛋白质相互作用点预测、化学反应产物预测等,这些场景有利于将深度学习的快速拟合能力带入进药物研发、材料研发等行业中去,提升研发效率。
在“Circuit-GNN: Graph Neural Networks for Distributed Circuit Design”一文中,作者将 GNN 结合进高频电路设计(如 5G 芯片等)场景,大大提升了电路电磁特性仿真计算的效率。下图给出了系统示意图:
3.5 知识图谱
由于知识图谱本身就是一种图数据,因此知识图谱 +GNN 的组合自然就成了解决各类知识图谱问题的新手段。关系补全或预测问题是知识图谱的一大基础任务,通过关系的推理补全可以大大提升知识图谱的应用质量,下图给出了关系补全的一个实例:
在论文“Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs”中,作者选择用 GNN 对知识图谱进行建模,相比之前基于单独三元组关系的推理,基于 GNN 的方法可以更好地捕捉三元组邻域复杂而隐含的模式信息,这种优势对完成关系补全任务具有十分重要的作用。
实体对齐是知识图谱的另一类任务,给定多个知识图谱,需要首先确定各自图谱中的哪些实体描述的是同一个对象,完成这项工作才能正确地将它们合成一个大的知识图谱。论文“Multi-Channel Graph Neural Network for Entity Alignment”提出了一种基于 GNN 的实体对齐方案,实验表明,在多个数据集上,该方案均取得了最好的效果。
近几年,知识图谱在工业界声势日隆,在这种语境下,我们也称知识图谱为业务图谱,在论文“Estimating Node Importance in Knowledge Graphs Using Graph Neural Networks”中,作者成功运用 GNN 技术对电影业务图谱进行建模,在电影流行度预测上效果表现十分出色。
另外,知识图谱与推荐系统结合也成了近期一个比较热门的方向,这部分可参考下一节推荐系统中的讲解。
3.6 推荐系统
推荐是各大互联网公司十分重要的营收手段,因此一直以来备受工业界与学术界双重关注。过去这几年,推荐系统由早期的协同过滤算法发展到 MF 模型、再到之后的 Wide&Deep,以及基于 Network Embedding 的方法,可以明显地看到基于神经网络的方法正在逐渐占据主要位置,而 GNN 的出现,又一次大大加速了这个技术趋势。
以电商平台的推荐为例,推荐系统的核心数据在于用户 - 商品交互的二部图,而基于神经网络的多数方法将二部图中的实体映射到一个合适的向量空间中去,使得在图上距离越近的两个实体在向量空间中的距离也越近,如下图所示:
GNN 本身是一种深度模型,与推荐系统结合之后,多层 GNN 模型可以更好地捕捉用户与商品之间的高阶协同关系,论文“Neural Graph Collaborative Filtering”中,作者论证了多层 GNN 所带来的“Deep”与“High order”效益对推荐质量的有效提升。
除了推荐系统算法模型本身的研究,另一种思路在于如何使推荐系统有效融合进额外的信息,如用户端社交网络的信息、商品端商品知识图谱的信息。这类信息中通常也蕴含了极强的关系,因此可以非常自然地与用户 - 商品二部图合在一起构成一个更大的异构图。下图给出了与电影知识图谱的结合示意图:
图片来源 https://arxiv.org/pdf/1902.06236.pdf
有了这样的图数据抽象之后,引进 GNN 进行推荐建模也就成了一种自然的选择,相关论文有 KGAT:“ Knowledge Graph Attention Network for Recommendation”、“Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation”、“Session-based Social Recommendation via Dynamic Graph Attention Networks”等。
另外一个十分重要的、也与推荐系统息息相关相关的业务场景是广告点击率(CTR)预测。该场景下的样本通常是由多领域的特征数据构成,比如用户域、设备域、广告域等等,如何建模这些数据域之间的特征交互,成为了该任务的核心。最近基于神经网络的方法都是直接将各个域之间的特征拼接起来然后送到上层的网络模型中,以期得到这些域之间的高阶交互,这种简单的非结构化的拼接方式,会大大限制模型的学习能力。在“Fi-GNN: Modeling Feature Interactions via Graph Neural Networks for CTR Prediction”一文中,作者将各个域之间以图的形式连接起来(下图中的 Feature graph),然后用 GNN 建模各个特征域之间高阶复杂的交互关系,相比之前的模型取得了最好效果。
3.7 反欺诈
反欺诈业务是各大公司保证运营业务与营销业务正常开展的前提,通常我们所面临的欺诈问题包括:垃圾评论、排名欺诈、交易欺诈、薅羊毛、账户盗用等。这些欺诈现象的背后往往是黑产团伙协同作案,大大提高了反欺诈业务的打击成本。
关系数据的挖掘是绝大部分反欺诈业务开展最重要的技术视角,不论是基于欺诈风险传播的关联分析还是基于黑产团伙模式的结构化挖掘,图都是反欺诈业务人员的首选工具。在这样的背景下,GNN 也变得极有发挥空间。例如,论文“Heterogeneous Graph Neural Networks for Malicious Account Detection”中运用 GNN 对支付宝欺诈用户进行识别检测,“Spam Review Detection with Graph Convolutional Networks”中运用 GNN 对咸鱼上的评论进行欺诈识别。
4 GNN 开源项目总结
在 2019 年,图领域出现了不少新的开源项目,一些已有的开源项目也有较大的改善。
1 月,阿里妈妈开源了国内首个支持工业级图深度学习的框架 Euler,内置很多实用的图算法。项目地址:https://github.com/alibaba/euler
3 月,德国多特蒙德工业大学的学者们提出了 Pytorch Geometric ,实现了诸多 GNN 的变体模型,上线之后获得了大佬 Yann LeCun 的推荐。项目地址:https://github.com/rusty1s/pytorch_geometric
5 月,著名图学习框架 DGL 发布 v0.3 版本(目前已经更新至 0.4.1 版本,也补齐了很多 GNN 的变体模型),0.3 版本在性能上有了非常显著的提升,相比 0.2 版本训练速度提高了 19 倍,同时支持亿级规模的图神经网络训练。项目地址:https://github.com/dmlc/dgl
12 月,斯坦福大学的 Jure Leskovec 教授在 NeurlPS 2019 大会演讲中宣布开源 Open Graph Benchmark,通过这一数据集可以更好地评估模型性能等方面的指标。项目地址:http://ogb.stanford.edu
同月,清华大学知识工程研究室(KEG)推出了大规模图表示学习工具包 CogDL,可以让研究者和开发者更加方便地训练和对比用于节点分类、链路预测以及其他图任务的基准或定制模型。项目地址:https://github.com/THUDM/cogdl/
除了上述的项目,GitHub 上图相关的两个论文项目也很不错,总结了近年来各大顶会所有相关论文,收录非常及时全面,推荐大家关注:https://github.com/naganandy/graph-based-deep-learning-literature 和 https://github.com/DeepGraphLearning/LiteratureDL4Graph。
5 展望
展望来年,最可以确定的一点是 GNN 依然会保持如今快速发展的态势。从理论研究上看,不断解构 GNN 相关的原理、特色与不足,进而提出相应地改进与拓展,是非常值得我们关注的部分。另外,关于一直以来研究 GNN 所用的标准数据集,如 Cora、PubMed,这些数据集场景单一、异构性不足,难以对复杂的 GNN 模型进行准确评价,针对这一问题,近期斯坦福大学等开源的 OGB 标准数据集有望大大改善这个现状,在新的评价体系下,哪些工作能够脱颖而出,且让我们拭目以待。
在应用场景上,相信 GNN 能够带给我们更加亮眼的工作,除了在视觉推理、点云学习、关系推理、科研、知识图谱、推荐、反欺诈等领域有广泛应用外,在其他的一些场景,如交通流量预测、医疗影像、组合优化等,也出现了一些 GNN 相关的工作。大体上看,如何准确有效地将图数据与 GNN 二者有机结合到相关场景,是应用上需要着重考虑的事情,相信来年,会出现更多这样的工作来拓展 GNN 的应用边界。
由于微信公众号平台不支持外链,查看文中论文完整链接可移步:https://www.infoq.cn/article/LjmbcEgqZV6dzXlFRsjf
作者介绍:
刘忠雨,毕业于华中科技大学,资深图神经网络技术专家,极验科技人工智能实验室主任和首席技术官。在机器学习、深度学习以及图学习领域有 6 年以上的算法架构和研发经验,主导研发了极验行为验证、深知业务风控、叠图等产品。
文末福利
随着图神经网络的热潮出现,了解和掌握图神经网络相关技术原理已经成为未来从事 AI 相关工作的一种趋势。刘忠雨和他所在技术团队撰写了《深入浅出图神经网络》一书并于近日上市 ,这是第一本系统讲解图神经网络相关基础知识和原理的书籍,适合想要入门并初步实践图神经网络技术的读者,以及对系统学习图神经网络技术感兴趣的读者。本次 AI 前线联合极验技术团队为 AI 前线的粉丝送出**《深入浅出图神经网络》纸质书籍 10 本**!
**方式一:****在本文下方留言给出你想要这本书的理由,截至开奖时间,留言点赞数最高的前 5 位赠送本书(留言择优放出)。****开奖时间:**1 月 10 日(周五)18:00,获奖者每人获得一本。
**方式二:****长按识别下图小程序,参与我们的抽奖活动,由小程序随机抽出 5 位赠送本书。****开奖时间:****1月 10 日(周五)18:00,获奖者每人获得一本。**另附购买地址,请戳「阅读原文」
注意:如果两种方式均获奖的读者,仅送出一本。本活动最终解释权归 AI 前线所有。
点击下方图片即可阅读
美国政府限制AI软件出口;腾讯官方回应暴力裁员:对方多次无故旷工 | AI一周资讯
**你也「在看」吗?**👇
本文要点
- 出于程序紧凑性、执行速度和开发速度上的考虑,在浏览器中运行的语言应该被同构地预编译为 JavaScript。
- 要实现大型 Web 应用开发中的有效合作,模块边界应符合团队的边界。
- 模块内部可以存在动态类型,但在外部应使用静态类型。
- 在客户端和服务器端使用同一技术有助于提升可扩展性。
- Python 在浏览器环境中的发展前景应该与 Python 自身的发展前景相关,而非过多依赖于特定的实现。
后端技术的特点在于可使用各种各样的编程语言实现。对于不同类型的任务,都会有适合的工具。但是在前端却是千篇一律地使用 JavaScript。只有一把锤子的人当然会将所有的问题都看成是钉子。为打破这种限制,JavaScript 的源到源编译器(Source-to-source compiler)日益增多。这类编译器可用于多种语言,例如 Scala、C++、Puby 和 Python。Transcrypt 是一个新推出的开源编译器,可以将 Python 转成 JavaScript,目标是生成大小相近的文件并以 JavaScipt 的速度执行 Python 3.6。
这类日常使用的 JavaScript Web 开发工具如果想要成为一个有吸引力的可选方案,至少需要满足以下三方面的需求:
一个此类转化工具要取得成功,必须要达到上述三个方面的需求。各编译器正尽量在这三个方面需求间达到平衡。对于在日常生产环境中使用的编译器来说,其中任何一个方面都不能被忽略。就 Transcrypt 而言,这三个方面的需求都在特定的 Transcrypt 设计决策中起到了决定性作用。
Web 站点和应用的观感与所用的底层 JavaScript 库有直接的关系。因此想要具有相同的观感,站点或应用必须正确地使用同一软件库。
虽然快速的网络连接可能会隐藏其中的差异,达到同样的页面加载时间,甚至对于在公共网络或托管主机上运行近似大小代码的移动设备也是如此。这使得在加载每个新页面时,不可能去下载一个编译器、虚拟机或较大的运行时。
只有当代码是在服务器端静态预编译成 JavaScript 时,才有可能获得与使用原生 JavaScript 同样的页面启动时间。页面中需要的代码量越大,差别就会变得愈发明显。
要获得相同的持久速度,必须生成高效的 JavaScript 代码。鉴于 JavaScript 虚拟机已针对通用的编程模式做了高度的优化,生成的 JavaScript 应该类似于手工编写的 JavaScript,而不是效仿堆栈机器或是任何其他的底层抽象。
要实现对所有 JavaScript 库的无缝访问,Python 和 JavaScript 必须使用一致的数据格式、一致的调用模型和一致的对象模型。一致的对象模型要求 JavaScript 的基于原型的单继承机制与 Python 的基于多继承的机制融合在一起。应注意的是,JavaScript 近期添加的关键字“class”对于弥合这个根本性的差异需求完全没有影响。
要实现高效调试,必须在源代码层面完成断点设置和代码单步执行这类工作。换句话说,源代码映射是非常有必要的。一旦遇到问题,需要通过检查生成的 JavaScript 代码来找出原因。因此,所生成的 JavaScript 应该与 Python 源代码同构。
利用已有的技术意味着源代码必须是纯 Python 的,而非一些更改了句法的变体。一种稳健的实现做法是使用 Python 的原生解析器。同样,在语义上也必须是存 Python 的,该需求会造成一些实际问题,需要引入编译器指令以维持运行时的效率。
要保护企业在客户端 Python 代码上的投入,工具需要具有持续性。持续可用的客户端 Python 编译器应具有良好的一致性和卓越的性能。如何维持这两者间的平衡是编译器设计中最关键的部分。
Python 至今已连续三年成为排名第一的计算机科学导论课程的教学语言,这一现状足以保证受过培训的 Python 开发人员持续可用。Python 已用于我们所能想到的所有后端计算领域上。如果浏览器端编程可以使用 Python 实现的话,那么所有的 Python 开发人员都可以进行浏览器端编程。这些开发人员曾经设计了长期运行的大型系统,而非孤立的、短期运行的前端脚本代码段。
就生产率而言,Python 在显著增加产出的同时保持了程序运行时的性能,这一点已得到那些从其它编程语言转到 Python 的开发人员的公认。对于那些关键运算来说,比如数值处理和 3D 图形处理,它们所使用的库已经被编译成了本地机器码,这也就是为什么 Python 能够保持运行时的性能。
最后一点,对不断发生变更的需求应具有开放性,这意味要在各个层级上支持模块化和灵活性。基于类的面向对象编程为此做出了很大贡献,它提供了多继承和复杂的包和模块机制。此外,开发人员可以通过使用命名参数和默认参数在不改变现有代码的情况下改变调用签名(call signature)。
一些 Python 的构件与 JavaScript 构件非常近似,尤其是当转译成最新版本的 JavaScrirpt 时。两个语言间明显趋同。具体而言,越来越多的 Python 元素已经融入 JavaScript 中,例如:for...of...、类(以有限的形式)、模块、解析赋值(destructuring assignment)和参数展开(argument spreading)。因为 JavaScript 虚拟机已经对for...of...这类构件做了高度优化,有利于这类 Python 构件转化为最近似匹配的 JavaScript 构件。这样同构转化所生成的 JavaScript 代码能受益于目标语言的优化机制,也易于阅读和调试。
虽然 Transcrypt 中很多的调试是通过源映射(source map)在 Python 中逐步进行的,而不是在 JavaScript 代码中进行的,但是工具不应该隐匿底层的技术,而应揭示底层技术,让开发人员可以完全知道“事情的真相”。这一点更为可取,因为如果使用了编译器指令,在 Python 源代码的任何地方都可以插入原生的 JavaScipt 代码。
下面是一个使用了多继承的代码段,展示了 Python 与 Transcrpyt 转化的 JavaScript 代码之间的同构。原始的 Python 代码是:
class C (A, B):
def \_\_init\_\_ (self, x, y):
A.\_\_init\_\_ (self, x)
B.\_\_init\_\_ (self, y)
def show (self, label):
A.show (self, label)
B.show (self, label)
转化后的 JavaScript 代码是:
var C = __class__ ('C', [A, B], {
get __init__ () {return __get__ (this, function (self, x, y) {
A.__init__ (self, x);
B.__init__ (self, y);
});},
get show () {return __get__ (this, function (self, label) {
A.show (self, label);
B.show (self, label);
});}
});
侧重同构转化的局限性存在于细微之处,有时两个语言之间的差异是难以处理的。例如,Python 中可以使用“+”操作符连接列表,而如果在 JavaScript 中同构地使用“+”操作符,不仅会导致列表被转化为字符串,而且字符串会粘连在一起。当然,a + b可以被转换为__add__ (a, b),,但是因为a和b的类型在运行时才能确定,这会导致即使对于1 + 1这样简单的事情,也会生成函数调用和动态类型检查代码。再给出一个关于如何解释“真值(truthyness)”的例子。空列表在 JavaScript 中的布尔值是True(或者true),而在 Python 中则是False。要在应用中全局地处理这个问题,需要对每个 if 语句执行一次转换,因为在 Python 构件if a:中不能判定a是一个布尔型,还是列表等其它类型。因此 if a:必须转换为if( __istrue__ (a))。如果在内层循环如此使用,会再次导致性能不高。
在 Transcrypt 中,嵌入代码中的编译指令(即编译指示)用于编译本地控制这类构件。这允许了使用标准数学符号编写矩阵计算,例如M4 = (M1 + M2) * M3,同时不会对perimeter = 2 * pi * radius这样的语句生成任何额外的开销。从语法上说,编译指示仅是在编译时执行对__pragma__函数的调用,而非在运行时。导入包含def __pragma__ (directive, parameters): pass的桩模块(stub module),可允许该代码无需修改即可在 CPython 上运行。此外,编译指示可以置于注释中。
Transcrypt 统一了 Python 和 JavaScript 的类型系统,而非让它们毗邻而居并实时转换。数据转换需要花费一些时间,还增大了目标代码的规模以及内存的使用,进而增加了垃圾回收的负担,使得 Python 代码和 JavaScript 库间的交互难以处理。
因此,Transcrypt 的决策是去拥抱 JavaScipt 世界,而非创建一个平行的世界。下面提供了一个使用了 Plotly.js 库的简单例子:
__pragma__ ('jskeys') # 为了方便,允许字典键值使用 JavaScript 风格的不加引号的字符串常值
import random
import math
import itertools
xValues = \[2 * math.pi * step / 200 for step in range (201)\]
yValuesList = \[
\[math.sin (xValue) + 0.5 * math.sin (xValue * 3 + 0.25 * math.sin (xValue * 5)) for xValue in xValues\],
\[1 if xValue <= math.pi else -1 for xValue in xValues\]
\]
kind = 'linear'
Plotly.plot (
kind,
\[
{
x: xValues,
y: yValues
}
for yValues in yValuesList
\],
{
title: kind,
xaxis: {title: 'U (t) \[V\]'},
yaxis: {title: 't \[s\]'}
}
)
其中的编译指示语句是可选的,它允许字典键值忽略引号,只是为了方便。除此之外,代码看上去非常类似于相应的 JavaScript 代码。你可以注意一下代码中是如何使用列表解析式的,这是在 JavaScipt 中依然缺乏的特性。开发人员不用关心 Python 字典的字面量(literal)是如何映射为 JavaScript 字面量对象的,他们可以在编写 Python 代码时使用 Plotly.js 的文档。转化并非是在幕后完成的。在任何情况下,Transcrypt 字典都是一个 JavaScript 对象。
统一类型系统时会产生命名冲突。例如,Python 和 JavaScript 字符串都具有一个split()方法,但是两者在语义上有很大不同。还存在很多类似的冲突情况,Python 和 JavaScript 仍在发展演化,未来还会有其它的冲突。
为了解决这个问题,Transcrpyt 支持别名这一概念。当在 Python 中使用<string>.split时,就会被翻译成一个具有 Python 的split语义的 JavaScript 函数<string>.py_split。在原生 JavaScript 代码中,split指代的是原生 JavaScript 的split方法。可以从 Python 调用 JavaScript 的原生split方法,这时会称其为js_split方法。虽然在 Transcrypt 中对这一类方法预定义了可用的别名,但是开发人员可以自定义新的别名,或是取消已有别名的定义。这种方式可以解决所有统一类型系统所导致的命名冲突问题,无需付出运行时代价,因为别名是在编译时进行的。
别名也允许从 Python 标识符生成 JavaScript 标识符。例如,在 JavaScript 中允许将$符号作为命名的一部分,而在 Python 中是不允许的。Transcrypt 严格遵循 Python 的语法,使用原生 CPython 解析器做解析,语法与 CPython 相同。一部分 JQuery 代码看上去如下:
__pragma__ ('alias', 'S', '$')
def start ():
def changeColors ():
for div in S__divs:
S (div) .css ({
'color': 'rgb({},{},{})'.format (* \[int (256 * Math.random ()) for i in range (3)\]),
})
S__divs = S ('div')
changeColors ()
window.setInterval (changeColors, 500)
因为 Transcrypt 使用编译而非解释,为允许加入极简化(minification)和涉及所有模块的交付,必须在编译前确定导入的库。为此,Transcrypt 还支持 C 风格的条件编译,这可以从下面的代码片段中看到:
__pragma__ ('ifdef', '__py3.6__')
import dashed_numbers_test # import 只用于 Python 3.6,只有在 3.6 中才支持。
__pragma__ ('endif')
在 Transcrypt 运行时中,对 JavaScript 5 和 6 的代码之间的转换使用了同一机制:
\_\_pragma\_\_ ('ifdef', '\_\_esv6\_\_')
for (let aClass of classinfo) {
\_\_pragma\_\_ ('else')
for (var index = 0; index < classinfo.length; index++) {
var aClass = classinfo \[index\];
\_\_pragma\_\_ ('endif')
这种方式考虑了较新版本 JavaScript 中的优化,并保持了向后兼容。在一些情况下,优化的优先级要高于同构:
# 将 i += 1 转化为 i++,i -= 1 转化为 i--。
if type (node.value) == ast.Num and node.value.n == 1:
if type (node.op) == ast.Add:
self.emit ('++')
return
elif type (node.op) == ast.Sub:
self.emit ('--')
return
一些优化是可选的,例如是否能激活调用缓存。这会导致直接重复调用继承而来的方法,而非通过原型链(prototype chain)。
对静态类型优点的认可正在复苏,TypeScript 就是一个很好的例子。与 JavaScript 不同,静态类型语法是 Python 语言不可分割的一部分,Python 原生解析器就支持静态类型语法。但是类型检查本身却留给了第三方工具,最著名的就是 mypy。这是 Jukka Lehtosalo 的一个项目,Python 的创建者 Guido van Rossum 也是该项目的贡献者。为实现在 Transcrypt 中高效地使用 mypy,Transcrypt 团队也为项目贡献了一个轻量级 API,无需经由操作系统直接从另一个 Python 应用激活 mypy。虽然 mypy 依然在开发中,它已经可以在编译时捕获为数不少的输入错误。静态类型检查是可选的,可以在本地通过插入标准类型注解来激活。一个使用注解的例子是 mypy 的 in-porcess API:
def run(params: List[str]) -> Tuple[str, str, int]:
sys.argv = [''] + params
old_stdout = sys.stdout
new_stdout = StringIO()
sys.stdout = new_stdout
old_stderr = sys.stderr
new_stderr = StringIO()
sys.stderr = new_stderr
try:
main(None)
exit_status = 0
except SystemExit as system_exit:
exit\_status = system\_exit.code
sys.stdout = old_stdout
sys.stderr = old_stderr
return new\_stdout.getvalue(), new\_stderr.getvalue(), exit_status
正如上例所示,静态类型可被用于任何适合的位置。在上面的例子中是用在 run 函数的签名中,因为它是 API 模块的一部分,可以被另一个开发人员从外部看到。如果有人错误解释了 API 的参数类型或是返回类型,mypy 将显式地给出一个错误消息,指向产生不匹配的文件和行数。
动态类型这一概念依然处于 Python 和 JavaScript 这些语言的中心位置,因为它允许灵活的数据结构,并有助于降低执行任务所需的代码量。源代码量是十分重要的,因为要理解和维护源代码,首先要通读代码。就此意义而言,实现同一功能,100KB 的 Python 源代码要优于 300KB 的 C++ 源代码,还不存在读取类型定义的困难,这些类型定义中可能会使用模块、显式类型检查和转化代码、重载的构造函数和方法、处理多态数据结构和类型依赖的抽象基类。
对于由单个编程人员编写的、源代码在 100KB 以下的小脚本,动态类型只具有优点,因为只需要非常小的规划和设计,而且编程中所有事情也会有条不紊。但是当应用增大到无法由个人构建而需要团队时,这种平衡就发生了改变。对于这样的应用,即以大约 200KB 以上源代码为特征,编译时类型检查的缺失会导致如下后果:
很多错误只有在运行时才能被捕获,通常是在整个过程的晚期阶段,修复这些问题需要付出高昂的代价,因为这些错误影响了更多已编写好的代码。
由于缺少类型信息,对模块接口可做多种解释。这意味着为了能够正确使用 API,在团队成员间所做的协商需要花费更多的开发时间。
尤其是在大型团队中工作时,动态类型接口会导致不必要的模块耦合。而良好定义的稀疏接口才是我们需要的东西。
即便是只有一个参数的接口,如果参数指向的是一个复杂的、动态类型的对象结构,该接口就无法保证稳定的关注分离。虽然这类“4W”(Who did What,Why and When)编程模式虽然带来了极大的灵活性,但同时也导致了设计的延后,影响到大量已有的代码。
应用“耦合与内聚”范式。模块内部可以在设计决策上具有强耦合,但是模块之间最好是松耦合的,一个更改模块内部结构的设计决策不应该影响到其它的模块。基于上述的原则,在动态类型和静态类型间做出选择时可以参考如下的经验法则:
对于特定的模块内部,设计决策是允许耦合的。将模块设计为内聚实体,会导致更少的源代码量,以及易于对各种实现进行实验。对此,动态类型是一种有效的方法,它可以用最小的设计时间开销换取最大的灵活性。
在模块间的边界上,对于要交换什么信息,开发人员应准确地制定稳定的“合约”。采用这种方法,开发人员可以并行工作,无需经常性地进行协商,他们的目标是固定的,不会发生变化。静态类型适合这些要求,对于哪些信息可以作为 API 的交互载体,它能给出正式的、经机器验证的一致意见。
因此虽然当前的静态类型浪涌看上去像是一个回归,但事实上并不是。动态类型已取得了一席之地,并不会离开。反之也成立,C#这样的传统静态类型语言也已吸收了动态类型概念。但是考虑到使用 JavaScript 和 Python 等语言编写的应用的复杂性与日俱增,有效的模块化、协作和单一验证策略愈发重要。脚本语言正走向成熟。
由于 Web 编程的极大普及,JavaScript 也正受到很多关注和投资。在客户端和服务器使用同一语言有其明显优点。其中的一个优点是,随着应用规模的增长,代码可以从服务器端移动到客户端。
另一个优点是概念上的一致性,这使得开发人员可以同时在前端和后端工作,无需经常在技术间做转换。Node.js 这样平台广受欢迎,正是由于人们希望降低应用客户端和服务器端在概念上的距离。但同时,这也将当前 Web 客户端编程的“放之四海皆准”风险扩展到服务器端。有人认为 JavaScript 是一种足够好的语言。近期的版本将开始支持基于类的面向对象(类似于在原型内胆上覆盖了一层装饰)、模块和命名空间这样的特性。随着 TypeScript 的引入,使用严格类型成为可能,虽然将其集成到语言标准中仍需数年时间。
即使具有这些特性,JavaScript 仍不会成为其它所有语言的终结者。对 JavaScipt 有些言过其实了(译者注:原文借用了习语“骆驼是委员会设计的马”,讽刺委员会喜欢虚张声势)。浏览器语言市场需要的是多样性,事实上所有自由市场需要的都是多样性。这意味着我们能够为手头的工作选择正确的工具,即对钉子选用锤子,对螺丝选用螺丝刀。Python 在设计上从一开始就是以清晰性、精确可读性为准则的。其价值不应被低估。
在未来很长时间内,大多数客户端编程可能仍会选择 JavaScript。但是对于那些考虑替换语言的开发人员,对持续性有影响的因素正是语言的发展动力,而非语言的具体实现。因此最重要的是使用哪种实现,而非选择哪种语言。出于此考虑,Python 无疑是一种有效的、安全的选择。Python 有很大的知名度,越来越多的浏览器在实现中考虑了 Python,同时 Python 在保持性能的同时越来越接近 CPython 的黄金标准。
虽然新的实现会替代现有的实现,但是这个过程会一直遵循一个共识,即 Python 语言应该蕴含什么。直接切换到另一种语言,要比切换到另一个 JavaScript 库或预处理器要容易得多。服务器端的格局已经成形,多种客户端 Python 实现将会继续存在,并展开公平竞争。获胜者将是语言本身。浏览器中的 Python 将会继续下去。
理学硕士Jacques de Hooge是一名 C++ 和 Python 开发人员,生活在荷兰鹿特丹。从代尔夫特科技大学信息理论系毕业之后,他就创立了自己的公司——GEATEC 工程公司。公司致力于实时控制、科学计算、石油天然气勘探和医学影像。他同时也是鹿特丹应用科技大学的兼职教师,讲授 C++、Python、图像处理、人工智能、机器人、实时嵌入系统和线性代数。他当前正在在为鹿特丹 Erasmus 大学开发一种心脏病研究软件。他也是 Transcrypt 开源项目的创始人和首席设计师。
查看英文原文: Transcrypt: Anatomy of a Python to JavaScript Compiler
感谢薛命灯对本文的审校。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 [email protected] 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。
之前在独立开发者社区的群里,有个小伙伴转发了一篇关于产品的文章,是关于一个两度创业成功的人,如何通过他的思考,总结出打造爆款产品的方法论以及实践过程,内容非常详细,可以说是手把手指导也不为过。
我读过之后大呼过瘾。当时小伙伴说他之前想翻译,但苦于没有时间,我就自告奋勇接下了这个任务。这里表示感谢群友嘉文的帮助和校对,使得翻译顺利完成。接下来就不多说了,请欣赏正文。
本文首发于个人公众号「食灯鬼」和「独立开发者」社区,若无授权,请勿转载。
以下文章来自 Rahul Vohra,Superhuman 的创始人和 CEO,一家致力于最快邮件使用体验的初创公司。
所有人都听过产品市场契合(Product / Market fit,以下简称 pmf)驱动初创公司走向成功,而每一家失败的公司背后基本都潜伏着未达到 pmf 的问题。
对于创始人来说,从第一天起就有着尽快达到 pmf 的执念。它既是我们急于清除的巨大障碍,也是让我们夜不能寐、担忧永远无法达成的恐惧。但当我们想要弄明白到底什么是 pmf ,以及如何做到的时候,大部分人很快就认识到并没有一种经过实战检验的方式。
在 2017 年夏天,我正在极力为我的初创公司 Superhuman 找到一条达到 pmf 的道路。通过阅读一些经典的博客和影响深远的文章,我有了一些印象深刻的观察结果。YC 创始人 Paul Graham 认为 pmf 是你做了一些人们需要的东西,而 Sam Altman 认为 pmf 是用户开始自发的宣传你的产品。当然,最常见的定义来自于 Marc Andressed 2007 的 blog:
”判断 pmf 没有达到是很简单的。用户没有从你这里得到太多的价值,他们没有自发的宣传你的产品,使用量没有快速增长,新闻评论不温不火,销售周期过长,以及很多未完成的交易。
而判断 pmf 达到同样也很简单。用户以你所能生产的最大速度购买你的产品,使用量增长的跟你购买服务器一样快。用户把钱堆到你的公司账户。你尽你所能的招聘销售和客户支持人员。媒体人员不断的在打电话给你,因为他们知道你做了一些热门的好东西,想要采访你。你拿到了哈佛商业评论的年度企业家。投资者们蹲守在你的房前”
这是我对 pmf 的最生动的想象,这番画面让我泪流满面。
我们在 2015 成立工厂开始编写 Superhuman 的代码。一年后我们有了 7 个人,我们仍然还在狂热的编码中。到了 2017 年夏天,人数到达了 14 人,依旧是继续编码。这时,我感到了来自团队我和自己的,与日俱增的上线压力。我之前的公司 Rapportive 在更短的时间内启动、扩张并被领英(LinkedIn)收购了。然而此时,我们已经花了两年时间,却什么还没有。
但是不管压力多么巨大,我还是没准备好上线。通常大家都说“不管怎么先上线,看看反响再说”,这对那些只投入了几个月时间,沉没成本还不高的公司可能适用。但是”先上线看看反响“对我来说,太不负责任和鲁莽了,特别是想到我们投入的这几年时间。
而我身为创始人不能把我的感受直接告诉我的团队,这也加剧了我的压力。这些雄心勃勃的工程师为这个产品倾注了全部心血。我没办法跟他们说这个产品还没准备好,更糟糕的是,也没想到任何办法摆脱这种情况。我一直在努力,想要找到正确的语言或者框架来搞清我们当前所处的位置,并规划好之后到达 pmf 的步骤。
因为我找到的关于 pmf 的描述对上线后的公司非常有帮助。如果上线后,收入没有增长,融资困难,媒体毫无兴趣,用户增长非常贫乏,你可以说你没有达到 pmf。但实践中,因为我之前创业成功,在融资上并没有遇到问题。我们有意拒绝了媒体采访邀约。当前我们选择只服务一小部分内测用户,所以也谈不上快速增长。对于处在内测阶段的我们来说,此时没有任何指标可以明确是否达到了 pmf。
这些关于 pmf 的描述都太事后诸葛亮了,太过不切实际。我清楚的知道公司的情况,却没办法把这一点传达给其他人,也不知道公司下一步的计划。
所以我绞尽脑汁想要搞清楚如何让 Superhuman 从当前的位置更进一步,达到 pmf。最后我开始思考:如果我们能衡量 pmf 呢?因为如果你能衡量 pmf,或许你就可以改善它。甚至你可以系统的提高 pmf 直到达到你的预期。
围绕这一目标重新定位,我开始反推达到 pmf 的过程。下面是我的发现,特别是如何清晰的定义 pmf 指标并构建 Superhuman 驱动引擎达到 pmf 的四个步骤。
在我理解 pmf 的过程中,我读了所有我能读到的书,并与每一位我能找到的专家交流。当我遇到肖恩·埃利斯(Sean Ellis)时,一切都改变了。他在 Dropbox、LogMeln 和 Eventbrite 创立之初负责早期增长,后来又创造了“增长黑客”(growth hacker)一词。
我找到的 pmf 定义非常形象和具有说服力,但它们是滞后指标——当投资人蹲守在你的房子外时,你已经达到了 pmf。相反,埃利斯找到了一个先行指标:只需要问问用户,如果你无法使用我们的产品,你会感到多么失望?然后记录回答“非常失望”的人的比例。
埃利斯通过调查将近 100 个初创公司,发现了魔法数 40%。通常少于 40% 的用户回答“非常失望”的公司都努力寻求增长,而那些具有强大吸引力的公司几乎总是超过这个门槛。
Hiten Shah 做了一个有用的尝试,他在 2015 的开放研究项目中,发了埃利斯的问题给 731 个 Slack 的用户,51% 的用户回答如果没有 Slack 的话,他们会非常失望。由此可见 Slack 在 50 万付费用户时已经达到了 pmf。如今,考虑到 Slack 传奇般的成功故事,这点显而易见。不过由此可以看出达到 40% 这个指标有多么艰难。
在这种方法的启发下,我们开始测量 Superhuman 的反响怎么样。根据埃利斯的建议,我们以最近两周使用过产品核心功能至少两次的用户为准。(当时我们应该有 100 到 200 个可调查用户,但是规模更小、更早期的初创公司也不要羞于使用这个方法 —— 大概 40 个左右的回复就可以给出大概正确的方向,远比大部分人想的少)
然后我们开始通过邮件给这些用户发送调查问卷询问以下问题:
A. 非常失望
B. 有点失望
C. 不失望
通过收集的反馈,我们开始分析第一个问题:
只有 22% 的人投票给“非常失望”这个答案,这清楚的表明 Superhuman 没有达到 pmf。虽然这个结果令人沮丧,但我却充满了斗志。我现在有了一个工具可以向团队解释当前的处境,更令人兴奋的是,我们据此有了一个可以提高 pmf 的计划。
下定决心后,我把所有精力都聚焦在如何提高我们的 pmf 。我们需要形成一个达成 pmf 的框架,而用户对每个调查问题的反馈都是该框架的关键素材。
以下是我们 pmf 引擎的四个组件:
通过你的早期宣传,你可能会吸引到各种各样的用户,特别是如果你开了产品发布会同时产品是免费的。
但其中的许多用户可能不是你的目标用户,他们并不真正需要你的产品,你的产品也并不适合他们。你并不想这些人成为你的用户。
作为早期团队,你可以先入为主的将目标市场限制在你认为的细分用户上,但这并不能教给你任何新东西。相反,如果你使用回答“非常失望”的用户作为一个透镜去缩小市场,数据本身就能说明问题,甚至你可能找到新的非常契合你的产品的市场。
对我来说,细分的目的是为了找到产品能拥有更好的 pmf 的领域,这些领域我可能忽略了,或者没有考虑到。
一开始,我们将用户按照第一个问题分组(如果你不再能使用我们的产品,你的感觉如何?)
我们给每个填写问卷的用户分配了一个角色。
接下来,我们研究「非常失望」组的用户(占比最大的 22% 支持者),并利用这些特征来细分市场。在这个简化的例子中,你可以看到我们主要关注创始人、经理、高管和业务发展人员——暂时忽略了所有其他角色。
通过这种更加细分的视角来观察我们的数据,数字变了。通过聚焦「非常失望」组的用户,我们的 pmf 上升了 10 % 之多。虽然离渴求的 40% 还有一点距离,但是我们用最小的努力拉近了距离。
为了更加深入的探索,我想更好的了解真正热爱我们产品的用户。我希望尽可能生动的描绘他们的用户画像,以便激励我的团队给他们更好的服务。
我利用 Julie Supan 的高期望客户框架来做到这点。Supan 指出,高期望客户(HXC)并不是一个具有多重角色的用户,而是在你目标群体中最有洞察力的用户。最重要的是,他们能从你的产品中获得最多好处,并帮你传播口碑。例如, Airbnb 的高期望客户并不只是想要访问新地方,同时也希望拥有归属感。对 Dropbox 而言,他们的高期望客户希望保持井然有序,简化生活并保证他们的工作成果不受损害。
带着这种想法,我试图找出 Superhuman 的高期望客户。我们基于「非常失望」组的用户分析他们对第二个问题的反馈:你认为我们的产品对哪些人最有用?
这是一个非常有力的问题,因为快乐的用户通常都会描绘他们自己,而不是其他人,使用那些对他们最关键的词语。你会了解你的产品对哪些人有用,以及那些会与他们产生共鸣的语言(也为你的市场营销提供了非常有价值的核心视野)。
基于用户的语言 和 Supan 的建议,一个栩栩如生的 Superhuman 高期望客户的用户画像出现在我们眼前:
“妮可是一个努力工作的专业人士,她与许多人打交道。举例来说,她可能是 CEO、创始人、经理或者业务发展人员。妮可长时间工作,往往周末也不休息。她认为自己非常忙,希望能有更多时间。虽然妮可自认很有效率,但她意识到自己还可以做的更好,偶尔会花时间想办法提高自己。她大部分的时间都花在她的收件箱,每天大概阅读 100-200 封邮件以及发送 15-40 封邮件(忙的时候一天可能发送多达 80 封)。 ”
“妮可认为及时响应是她工作的一部分,她也自豪自己能做到这一点。她知道反应迟钝会阻碍她的团队,损害她的声誉或错过机会。她的目标是清空收件箱,但一周往往只能做到两三次。偶尔——大概一年一次——她会删除某个时间点之前处理不过来的邮件。她通常具有成长型思维,对新产品和新技术保持热情,但是在邮件处理这块,她可能还是旧的思维方式。每当使用新的邮件客户端时,她都会怀疑这是否能提高她的效率。”
基于高期望客户,我们整个公司可以比其他任何人都更聚焦于这个细分市场。有些人会争论说这个方法太局限了,创业早期不应该把目光弄的如此狭窄。
”很多人认为将产品局限于一个小的细分市场,会很容易到达天花板——但我不这么认为。”
Paul Graham 解释了为什么:
"当开始创业时,一定有某些用户需要他们的产品——这不是指那些未来可能用到这些产品的人,而是那些现在就迫切需要的人。通常情况下,初期用户群很小。因为如果存在大量用户迫切需要的东西,而且可以通过一个创业公司来满足的话,通常这样的产品已经存在了。这意味着你只能两者选一:要么给大部分人提供有点想要的东西,要么给小部分人提供非常想要的东西。选择后者,不是所有这样的创意都是好的创业点子,但几乎所有好的创业点子都是这类的。"
在另一篇文章中,他对这个观点进行了更加深入的探讨:
“在理论上,这种类型的创业会给初创公司带来麻烦。它们可能会达到一个局部最优值。但实际上,这种情况从未发生。创意的极大值很少是孤立的,大部分很棒的想法都挨着更好的想法。“
从本质上讲,最好做给少部分用户提供「非常想要」的产品,而不是给大量用户提供「有点想要」的产品。在我看来, 对一款为少量用户提供「非常想要」的功能的产品,精确定位细分市场很有帮助,可以减少很多不必要的工作。
然而,仅仅辨识出高期待客户是不够的。我们已经细化了目标用户,现在需要更加深入的挖掘他们的需求。因为我们目前的指标低于 40%,所以需要找出核心用户喜欢 Superhuman 的真正原因——以及如何将更多用户转化成核心用户。
为了深入了解我们将如何改进产品并扩大其吸引力,我发现将精力集中在以下关键问题上很有帮助:
为了理解用户为什么喜欢 Superhuman,我们再一次将目光转向那些离开了我们产品会非常失望的人。这一次,我们关注他们对第三个问题的回答:你觉得我们产品最有用的地方是哪里?
下面是一些引人注目的答案:
通过把这些答案输入到词云,出现了一些共同的主题:热爱我们产品的用户最欣赏它的速度、专注以及键盘快捷键。
通过对产品吸引力的深入理解,我们把注意力转向了如何让更多的用户爱上 Superhuman。
我们接下来要做的可能有点反直觉:我们决定礼貌的忽略来自那些离开这个产品不会感到失望的用户的反馈。
这些用户不应该对你的产品战略有任何的影响。他们会提一些毫无意义的需求,提供病态的用户案例,同时可能非常活跃,再之后他们会毫不犹豫的抛弃产品,留下你一塌糊涂的产品规划。尽管这看起来令人惊讶或痛苦,但不要对他们的反馈作出行动——它将使你在追求 pmf 时误入歧途。
礼貌的无视那些离开你的产品不会感到失望的用户. 他们离爱上你的产品太远了,让他们改变基本上是不可能做到的。
这样就只剩下那些离开我们的产品会感到有点失望的用户了。在某一方面,“有点”意味着机会。吸引的种子已经播下,也许通过一些调整,就可以让他们爱上你的产品。但另一方面,很可能无论你做什么,某些用户都不会爱上你的产品。
为了充分利用这些提供线索的用户,我们进行了进一步的细分。通过分析第三个问题,我们发现喜欢产品的用户认为最有用的地方是速度很快。我们利用这个特征进一步划分用户组。
我们将用户通过速度是否是他们的主要关注点划分为了两组,并通过他们的反馈采取行动:
**对那些有点失望,但速度不是他们主要关注点的用户组:**我们选择礼貌的无视他们,因为我们最主要的产品功能没有跟他们产生共鸣。就算我们开发了所有他们想要的一切,他们也不太可能爱上这个产品。
**对那些有点失望,但速度是他们主要关注点的用户组:**我们重点关注他们的反馈,因为他跟我们的主要功能产生了共鸣。某些功能——可能是一些小功能——就能让他们爱上我们。
聚焦在后一个用户组,我们开始更仔细的研究他们对第四个问题的回答:“怎样才能让我们的产品变得对你来说更有用?”
这是我们看到的:
通过一些分析,我们发现阻碍用户爱上产品的原因非常简单:缺少移动端应用。在 2015 年,我们采取了先从桌面端开始的策略。因为大部分邮件是从桌面端发送的,我们觉得在这里可以创造最大的价值。我们一直计划构建一个移动端应用,但是在我们创业早期——就像每个初创公司一样——我们的筹码只够下注一次。在 2017 年,移动端应用的紧迫性已经非常明显了,它成为了我们 pmf 的关键。
通过更深入的研究,我们发现了一些不太明显但是更有趣的需求:集成第三方、附件处理、日历、统一收件箱、更好的搜索、阅读回执以及其他一些长尾需求。例如,作为一个初创公司,我们内部并没有重度使用自研的日历,所以并没有像重视邮件一样重视日历。通过这次对用户反馈的深入挖掘,我们提高了日历在我们产品中的优先级。
对我们产品的主要优势和缺点有了清晰的认识后,接下来需要做的就是把这些认知应用到构建产品当中。通过满足那些中立用户的需求,尽量让他们转变为狂热用户。
尽管我们理解用户为什么爱上我们以及是什么阻碍他们爱上我们,但一开始我们也很难清晰的认识到如何制定路线图以平衡这两点。
最终我认识到:如果你仅仅专注于增强用户喜欢的功能,你的 pmf 并不会提高。如果你仅仅专注于解决妨碍用户爱上你的问题,你的竞争对手很可能超过你。这个结论指导着我们的产品规划,帮助高效的制定了路线图。
为了让「非常失望」组的用户更喜欢我们,路线图的一半用于以下项目:
**更快的速度:**我们的产品已经很快了,但我们努力让它更快。例如,当前 UI 的响应时间在 100 ms 内,搜索速度比 Gmail 更快。但我们进一步将响应时间缩短到 50 ms 内,并即时呈现搜索结果。
**更多的快捷键:**用户喜欢通过快捷键搞定一切事情。因此我们把快捷键变得更健壮和全面。我们加了一些其他邮件客户端从没有过的快捷键,同时保证当用户输入超过电脑处理速度时,依旧能得到正确的处理结果。
**更多自动化:**用户真的非常在乎效率。但打字速度限制了效率的提高。因此我们开发了代码片段,允许用户自动输入短语、段落、甚至整个邮件。为了节省更多时间,我们进一步完善了代码片段,使其更加健壮,可以添加附件、自动添加抄送人,甚至可以和 CRM 与 ATS 集成。
**更好的设计:**在我们收集的反馈中,看到用户喜欢我们的设计以及一些小细节,因此我们投入了更多精力,做了很多细微的改动,以向用户表达我们对细节的关注。例如,输入“-->" 将自动转成一个右箭头:→。
为了争取那些「喜欢我们产品的速度但是有点失望」的用户,我们的第二部分路线图主要关注如下:
为了给这些工作排序,我们进行了非常简单的成本收益分析:我们给每一个潜在的功能点打上低/中/高的成本标签,以及类似的低/中/高的收益标签。对于路线图中第二部分用于争取「有点失望」的用户的功能,收益很容易计算,只需要统计问卷中对该功能的改进建议数量。对于第一部分,让「非常失望」的用户更喜欢我们的产品,我们只能通过直觉判断收益水平。这是「产品本能」发挥作用的地方,而这种能力基于经验和与客户共情的能力(早期刻画高期待客户的用户画像,对训练产品本能非常有帮助)。
有了上述计划,我们就从「低成本、高收益」的功能点开始尽快发布改进。
我们持续对新用户进行调查问卷,以跟踪 pmf 分数是如何变化的(我们谨慎的确保不会对用户进行重复调查以避免不小心超过 40%)。
回答「非常失望」的用户百分比迅速成为我们最关心的数字。作为最明显的指标,我们分别以每周、每月、每季度的频率跟踪它。为了让这个过程简单点,我们开发了一些定制化工具持续对新用户进行问卷调查,并以不同的时间窗口聚合结果。我们也调整了产品团队的目标,以「非常失望」的用户百分比作为唯一的关键结果设置 OKR,以确保我们持续增加 pmf 分数。
重新调整了产品方向后很快有了成效。在 2017 年夏天刚开始的时候,我们的 pmf 分数为 22%。通过细分仅关注「非常失望」的用户组后,分数为 33%。通过三个季度的努力,分数几乎翻倍达到了 58%。
事情并没有到此结束,我们将一直保持对 pmf 分数的追踪。我认为对于初创公司来说关注该指标是非常有用的,因为随着用户增长,你将会遇到各种各样的用户。早期用户是非常宽容的,尽管产品有着这样那样的问题,他们依旧能享受它带来的好处。但随着你的用户增长,他们的要求会越来越高,渴求其他竞品已有的功能。此时,你的 pmf 分数可能会大大下降。
然而,这没什么好焦虑的,因为总有办法解决。如果你的产品有很强的网络效应(想想 Uber 或者 Airbnb),那么产品价值将随着用户增长同步增长。如果你是一个像 Superhuman 一样的 SaaS 公司,随着用户的增长,你只需要持续改进产品。为了做到这一点,我们每个季度都会用本文提出的这套方法重定我们的路线图,确保足够快的改进 pmf 分数。
随着这个过程的不断演进,我发现了如何定义 pmf 以及衡量它的办法。我们团队通过一个具体指标凝聚在一起,而不是一个令人绝望的抽象目标。通过调查用户,细分市场,了解用户喜欢什么和讨厌什么,然后制定路线图平衡这两点,我们找到了提升 pmf 的方法论。
很难高估 pmf 驱动引擎在我们公司的影响。我们在 Superhuman 所做的一切——从招聘销售、营销人员到融资——都变得轻而易举。团队扩张到了 22 人,NPS(净推荐值)也随着 pmf 不断增长。无论是调查问卷中,还是社交媒体上,用户对产品的喜爱明显提高了。当前的投资者开始问我能不能在下一轮融资前追加更多资金,而外部投资者不断问我他们是否能够投资。
再一次回顾从为 Superhuman 构建 pmf 引擎中所学到的东西,我得到了两个结论:
这是我第一次翻译英文文章,全文译好八千余字,花了不少心思,也算真切体会到了翻译之难,古人常说译文需信达雅,做到信已殊为不易。为了防止误译,经过几番校对才敢发布。但因为经验原因,肯定还有不足的地方,希望大家能指出,以便改进。
当时接下翻译,一方面是为了觉得这篇文章非常不错,希望更多人看到,另一方面也是觉得自己译过一遍,能加深对内容的理解,而不是草草读过。希望大家也能有所收获。
原文地址:https://firstround.com/review/how-superhuman-built-an-engine-to-find-product-market-fit/
感知**经济的真实温度,见证逐梦时代的前行脚步。谁能代表2019年度商业最强驱动力?点击投票,评选你心中的“2019十大经济年度人物”。【我要投票】
本文来源微信公众号“新康界”,作者沐沐。
近年来,我国医药市场规模持续快速增长,并一跃成为仅次于美国的全球第二大医药市场。加之2017年6月我国正式加入ICH以来,CFDA先后通过接受境外临床数据、设立临床急需境外新药名单等政策,大大缩短了国内新药进口的时间。
而得益于我国对创新药的加速准入,跨国药企在**市场的业绩实现了强劲的增长。据各跨国药企公布的2019年三季度报显示,受Keytruda和九价HPV疫苗的驱动,默沙东(MRK.US)**区Q3业绩猛增90%;罗氏(RHHBY.US)、阿斯利康(AZN.US)**区业绩分别增长53%和37%....而良好的增长势头也进一步增强了跨国药企对**市场的信心,越来越多的跨国药企甚至将**市场定位为“未来增长的关键支柱”。我国逐步向全球新药市场中心靠拢。
图表1:2018年跨国药企在**区(或包括**区)的业绩情况
来源:跨国药企财报,中康产业资本研究中心
不过,受一致性评价、医保控费、“4+7”带量采购、医药目录谈判等国内政策措施的影响,跨国药企的一些高价原研药难以进入医院渠道这个重点市场,再加上快速、大比例的仿制替代,原研药的市场份额不断的缩小。
在这种情况下,跨国药企不得不调整其在华的策略。特别是今年,为了稳固甚至进一步加快其在**的布局,诺华(NVS.US)、辉瑞(PFE.US)、赛诺菲(SNY.US)、GSK(GSK.US)、BMS等多家跨国药企频频动作。
图表:2:2019年部分跨国药企在华动向
来源:公开资料,中康产业资本研究中心
从上表可以看出,2019年,跨国药企在华主要作了这些调整:
1、布局创新药研发
一方面,跨国药企在华建立全球新药研发中心,或是对**区已有的研发中心进行运营战略的调整,如罗氏、拜耳就有新的研发中心落成,而诺华则将其上海研发中心的运营重点调整为聚焦于扩大早期临床开发以及后期临床试验的规模和领域上。
另一方面,跨国药企通过与本土药企的合作,扩充产品线,同时依靠本土力量加快新药的审批上市等进程。在今年的进博会上,阿斯利康就与德琪医药、上海和誉生物医药等多个本土创新药企就多个小分子药物建立了合作关系。值得注意的是,阿斯利康与这几家**本土创新药企并不是简单License-out创新药管线的模式,而是形成合作关系共同推进这些小分子创新药在**乃至全球的研发工作。这种合作方式不仅只是联合研发创新药,还能共同分担研发风险与成本,并共同分享上市后商业收益,当然,以后跨国药企与本土企业还可能衍生出更丰富的合作形式。
而通过在**建立研发中心、与本土药企合作等手段,跨国药企在**的新药上市时间会进一步的缩短,甚至与全球新药同步上市。目前,不少跨国药企都透露了其在**的新药上市计划,在未来的5-10年内,预计有超过5家跨国药企会在**提交10-60个新药申请。
图表3:跨国药企未来在**区的新药上市计划
来源:公开资料,中康产业资本研究中心
2、人事调整
回顾2019年,多家跨国药企对其在**市场的掌舵者进行了调整,BMS、赛诺菲、GSK、诺华等跨国药企均包含在内。而这些企业对**区高层的人事调整,可以说是跨国药企在重新审视了**市场的生存法后作出的反应。
如辉瑞与迈兰的“联姻”可以说是今年医药行业最热议的事件之一,这两家的合作其实也算是政策倒逼下的一次抱团取暖。而这个事件也带来了一系列的人事变动,为了适应**市场环境变化,辉瑞普强**区总经理吴锋离任,而后又有5位业务总经理集体辞职。上个月,辉瑞**又一名老将吴琨也告别了长达24年的辉瑞工作生涯。
图表4:2019年部分跨国药企**区高管变动情况
来源:公开资料,中康产业资本研究中心
3、剥离非核心业务
受“4+7”带量采购政策持续推进的影响,跨国药企为了减少原研药受到的冲击,不让部分产品影响业绩,通常都会采取“瘦身”的方式,剥离非核心业务,让自身更加聚焦于核心业务。例如,今年诺华拟以7.9亿元转让剥离技术与药品开发资产后的苏州诺华制药科技有限公司100%的股权给九洲药业,GSK将其苏州工厂以及乙肝药贺普丁出售给复星医药(22.9, 0.30, 1.33%)等。
其实,在**运营的跨国药企从未停止过对本土化研发模式的探索,特别是在目前**医药产业升级、重构的时段,跨国药企进行战略调整已成常态。跨国药企只有顺势而变,才能更好的在**市场存活,当然,需要“变”的不仅是研发模式,还包括营销和市场进入方式等方面。
另外,业内普遍认为,创新产品将是跨国药企未来业绩增长的动力来源,而随着**药品审批的不断提速,跨国药企与本土药企免不了要进行激烈的竞争。而最后谁能从这场争夺战中突围而出,就看其现有的产品布局、销售能力等了。(编辑:刘瑞)
切是理想主义,卡斯特罗是现实主义。切是一个革命家,浪漫的诗人,而卡斯特罗是一个出色的政治家。
当他们八十二人坐着格拉玛号游艇,在古巴登陆,在马埃斯特拉山区里打游击的时候,看不出多大的区别,目标就是推翻巴蒂斯塔政权。但是,革命胜利后,两个人不同的**则表现了出来,最后老老实实守着胜利果实的老卡和兄弟们拦不住要出去浪的切,直到看见他离开家,最后死在外面。
卡斯特罗兄弟想的是坐江山,有古巴就够了。这个符合大多数人利益。而且他针对的只是巴蒂斯塔政权,这种傀儡政权在古巴大搞种植园经济,阶层分化,导致普通民众非常艰苦。卡斯特罗正是看到了这个缺陷,觉得自己出头的机会到了,于是拉起队伍搞革命。
革命成功后,卡斯特罗曾今抱有过幻想,那就是要得到美国的认可,因此军队一进入哈瓦那,卡斯特罗就忙着和美国总统联系,造访纽约,联合国演讲。
性感的胡须,富有激情的演讲,香醇的雪茄,卡斯特罗的到访,在纽约掀起一股古巴热。
然而,当时的美国总统是sb,他们不给任何造反派合作,不但不合作,还安排了猪湾事件。卡斯特罗热脸贴了冷屁股,很尴尬。这个时候,世界另一极,苏联伸出了橄榄枝。

卡斯特罗的人生目标就是弄个古巴老大来做一做,把腐朽破烂的旧政权改造一下。所以,并没有雄霸世界的野心,信仰不信仰社会主义,共产主义,也是政治上的实用选择。要知道,他可是在资本主义殖民地的环境里长大的,从小到大,家庭,教育都不是苏俄那一套。
切·格瓦拉就有很大区别了,他最开始是学医的,照理说和卡斯特罗相比,都算是高帅富。一个文科学霸,一个理科学霸,然而这个理科学霸其实比卡斯特罗这个文科学霸要浪漫,他骑行拉美,体验了人民的疾苦,萌生的愿望是——改造世界。
也就是说,他和卡斯特罗一拍即合的时候,一个人想的是改造下自己的前途,做的就是谋国的生意,一个想的是改造全人类,做的是谋天的生意。他要搞的,是向全世界输出革命。他是不会满足于现实的安稳的。

切访问**的时候,极富政治远见的周总理就曾经向随从私下评价过他,觉得他不现实。有点点危险。
事实上,切是比卡斯特罗有魅力得多的。当时在世界上的影响力也很大。深受年轻人欢迎,甚至迷信。
但是,古巴革命领袖一共是四五个人,不是菲德尔和切两个人,还有小卡,何塞·拉蒙·马查多、阿拉尔孔等等。一个好的老大在打下江山后,想得更多的是利益分配问题。很显然,老卡知道古巴有多大,自己这帮人实力有多大。
那么,老卡究竟有没有为了坐稳位子弄切,把他逼走呢?
这个我们不能臆想,只能根据现有资料来分析。我认为,切的出走,最后客死他乡,主要原因并不是被卡氏**,而是他抛弃了选择现实主义的战友,而战友们也拿他木有办法。
革命成功后,卡斯特罗这个古巴人给切这个外国友人安排的是什么职务呢?
1959年10月,格瓦拉被任命为国家银行行长。这是什么意思?这是个肥差,相当于,兄弟,江山打下来了,金库钥匙我交给你管。不管卡氏处于什么目的,这样对切,就是希望他好好享受一帮人冒着生命危险打下江山的胜利果实的。
1961年,格瓦拉又被任命为工业部长。这是什么意思,我们这个家的建设也归你管。
1962年,赴莫斯科谈判,并最终签署了苏联在古巴部署核武器的计划。
还要怎样?如果老卡不信任切,这些事能够全权委托他吗?
但是。切并不满足于此,他要输出革命,最开始,卡斯特罗也是支持他的。
1964年12月,格瓦拉代表古巴出席联合国第19次大会,之后相继访问了阿尔及利亚、刚果(金)等8个非洲国家和中华人民共和国。当1965年3月14日回到古巴后,他与卡斯特罗在诸如对苏关系、援助第三世界革命等问题上的分歧日趋严重。老卡的意思是差不多得了,切的意思是不行,我要出去解放全人类。
不久,他就辞去了自己的职务,4月1日乘飞机离开了古巴,前往刚果金。切去刚果输出革命的时候,老卡是派兵支持了他的,最后他自己造光了,没脸回古巴。老卡获悉格瓦拉的下落后,极力要求他回到古巴。格瓦拉则明确地声明,除非是为了在拉丁美洲国家进行革命活动,因地利之便,他会在绝对机密的情况下回到古巴进行筹备工作外,他将不再踏上这片土地。最后,他去了玻利维亚,最后牺牲。
切的遗骨被运回古巴后,暂时停放在哈瓦那的何塞·马蒂纪念馆内。何塞·马蒂是古巴国父,相当于孙中山。1997年10月9日(即格瓦拉遇难30周年),古巴国务委员会发出通知,确定当月11日至17日为国丧日,并确定将格瓦拉的遗骨以国葬的规格安葬在他生前战斗过的圣克拉拉。古巴政府为格瓦拉举行了最为隆重的悼念活动和安葬仪式。1997年10月10日古共五大闭幕后,悼念活动相继展开。14日,格瓦拉遗骨移送圣克拉拉。当天,哈瓦那通往圣克拉拉的公路实行管制,任何闲杂车辆不得通行。圣克拉拉数十万群众涌向灵车经过的路旁,灵车经过之处撒满鲜花,场面十分感人。17日上午9时,安葬仪式开始。格瓦拉的遗骨被安放在格瓦拉广场中,同时被安葬的还有6名游击队员的遗骨。卡斯特罗在葬礼上发表讲话,颂扬格瓦拉对古巴革命的杰出贡献,称赞他是革命者和共产党人的楷模。葬礼结束时,卡斯特罗亲自点燃了格瓦拉灵前的长明灯。陵墓上切的巨大铜像是当地民众家家户户捐赠出来的金属熔炼制成的。

圣克拉拉切陵墓。
今天在古巴,你看不到卡斯特罗自己的雕塑,画像,但是一定看得到两个人的,一个是何塞·马蒂,一个就是切。

古巴革命广场上,内政部大楼上的切的灯饰。
可以这么说,卡斯特罗作为一个人格健全的人,法学博士,他对自己这个革命战友,出生入死的兄弟是非常够义气的。
我觉得,切并不值得多少人崇拜。相对来说和英国女王一样长寿的老卡才值得崇拜。
毕竟,活得长,活得好,才是王道。


关于西班牙,拉美政治经济文化,请关注我们的微公:板鸭留学助手
书接上回,断舍离相关的文章大家已经看到很多,中产阶层希望通过找回自己被商品绑架的生活而试图过一种极简主义的生活:但这和健身,有机食品等自我管理追求有任何本质上的区别吗?穷人甚至没有那么多东西可以扔----他们根本没有任何东西。
所以齐泽克说:“自我管理”何尝不是一种当代的禁欲主义呢?这种享乐的禁欲主义与苦行僧没有区别:定期运动,吃健康食物等等。如果当他们没有做到—就象中世纪的苦修者进行了一次手淫一样痛苦,仿佛违背了超我的道德律令,他们想“我怎么能允许自己不优秀,我怎么可以没有做到我对自己的规范性要求?
所以反对消费主义,从反对断舍离开始。但讲明白这一点,还需要绕个弯子。
一、市场经济
相信每一个稍有岁数的人都能记得,我们童年时的官方宣传是:中华民族的传统美德是勤俭节约。但在今天,我们几乎看不到这一切。
这样的转变并非因为官方照顾耳朵生茧的人民群众,唯一的原因是我们的经济结构在近三十年来彻底改变了。在计划经济时代,商品是被统筹制造的。除了生产力本身的有限外,积压的风险大过售罄的风险,所以商品几乎永远是不足的。所以哪怕到了80年代中晚和90年代初计划经济和市场经济双轨制的时候,也经常会出现商品不足的情况,那么这时鼓励大家不消费,少消费就是一个正确选择。
|
|
|
提倡勤俭节约的老宣传画
|
但无论大家是否做好准备,市场经济大潮都汹涌而来,潮水般的商品充斥了我们生活的每一个角落。不过如果仅仅是这样,那似乎是一件好事,但它伴随的是经济的发展逐渐从政府投资和外贸转向消费。这必然导致,曾经被认为是奢侈浪费的行为,反而变成了利国利民的壮举。
道理很简单,有消费工厂才有订单,有订单才会开工雇佣工人,工人被雇佣才有工资----拿去消费。这是一个市场经济下经济增长的基本玩法,具体的恶果就是市场总是盲目扩大产能,导致周期性的产能过剩和经济危机(是不是很熟悉?)。
那么问题就来了,既然资本主义必然周期性的出现经济危机,我们为什么选择资本主义?如果排除了真诚相信资本主义拯救人类的群体的话,笔者个人认为这是因为当代的国家自认为可以通过一些货币和财政手段规避经济危机。
比如量化宽松政策。
二、量化宽松
二十世纪七十年代以前,几乎所有货币都有其锚定物,比如黄金和美元直接挂钩,1盎司黄金定价为35美元。后来财富的增长超出了黄金的储量,再也美有那么多黄金可以拿来和纸币一一对应,于是自然而然的,以国家信用为基础的纯粹信用货币诞生了。
这是一个极为危险的实验,比起欧盟的新自由主义堡垒隐藏着更大的风险,因为央行们陡然发现自己可以人为的逆转经济周期。当经济进入下行轨道,因为锚定物的限制被消除,央行们可以降低利率并且超发货币,刺激病入膏肓的经济。
道理依旧很简单,商品过多,超出了社会的需求,那么理论上应该来一轮崩溃,存活下来最强者应对下一轮增长。但是如果降低利率超发货币,就会促使人们不再储蓄,去购买可能根本用不上的商品,这样工厂继续有订单,工人继续有工作。我们简单的做一个**实验,利率实际为负的情况下,你有没有把钱存银行的心思?利率为10%或者15%的时候呢?
民众的行为是可以被“调节”的,你认为是自由选择的情况下往往是被导向。最大名鼎鼎的量化宽松政策就是美联储的QE计划,被称为直升机撒钱的行为让垂死的经济立刻被打了强心针开始飙升。这一招只要美国先用了,那么所有国家都必须跟着用,为什么呢?虽然人人都知道这样是强行续命,也许经济崩掉再来一轮会更健康。但是问题在于,别人先死的话自己就能活,所以一旦别人开始续命,自己就要被逼着一起续命。
这就是当下和29年最大的不同。
这样做显然是在饮鸩止渴,依旧拿美国举例,08年以来它的GDP增长了23%,但是股市和楼市增长了300%,说明天量的美元都进入了投机领域而非实体经济,市场依旧不信任实体经济。贫富差距飞速拉大(持有资产的人财富膨胀,而无产阶级则没有)之下,经济却没有大的起色。笔者在前文讲过,我国的楼市是同样的道理。那么实际上老百姓没有得到什么实惠,而且储蓄本来也没有多少,拿出来消费了也就没了----大不了月光嘛。再说,我就算去买,我该买的也都买了,不该买的也都买了,总不能让我马桶也买10个吧?
但续命还是要强行续,怎么能倒在黎明前?于是最可怕的一套组合拳出手了。
三、供给侧改革和信贷扩张
首先依旧是一个**实验:如果你买不起房子或者自有住房,如果能让你在房子上花钱呢?好说,我们培养了一批优秀的设计人员,可以让你的房子从简单的精装房变成各种你想要的样子,北欧极简?日式冷淡?迪拜土豪?统统可以!什么?房子小?要不要考虑一下空间折叠装修,这个柜子竖起来是柜子,放下来是床,半折叠还是沙发,最适合你这个28㎡的小户型,家里开趴体都可以!
|
|
|
被改造的当然不止是你的房子,还有你的一整套消费观
|
这就是供给侧改革,这个东西前几年还有另一个名词叫消费升级,就是让本来你已经无法消费的地方继续挖掘出消费空间。
如果你流着眼泪哭着认了说我就是想在家里开咖啡馆,我愿意消费,我买还不行吗?但是我没钱怎么办?
那就更好说了,我贷款给你,你花钱怎么样?如果你懒得翻阅各大行信用卡的发卡量和天量的信贷投放数据,只要看看身边就知道有多少卡奴…他们甚至没有购买房子,单纯是消费导致负债。这就造成了一个很有意思的现象,我借钱给你买我的东西…当然,私营业主和政府并不是一家人,这里的“买东西”,只是“满足需求”的意思。
这样居民不断的上杠杆,虽然我的收入没有增加,但是我的购买力增加了,我可以花呗,可以分期,可以刷卡,我更不想攒钱了,曾经遥不可及的东西显得那么近。需求就这样变成了有效需求。
那么好,现在不光是没有储蓄了,我甚至还背债了。绝秒的是,我觉得这是我的自由选择。更妙的是,我还打心底里拥护这一套逻辑。
四、消费主义社会下独特的文化生态
怎么个拥护法呢?之前看到一个抱怨自己女朋友的帖子,大体上意思是她从不理财,也不储蓄,一分钱没有还要分期买手机,得出的结论是女人没救了。但事实上,前面说的很明白,消费主义的影响是针对全人类的,男性中有理财意识的也不多(甚至欠大钱的大都是男的),所以这与其说是群体特色不如说是时代病。商品充斥你的世界,廉价,精美,痛点把握良好----让你觉得不买就亏了。
更糟糕的是,和钻石一样,商品被和爱情之类的意义强行挂钩,你爱不爱我和你给我不给我买恒久远成为了同一个度量衡,那么我不光要购买商品论证我的阶层以求和身边人同步不是异类,我甚至还得购买商品论证我的真心。另一个更有趣的例子是,农村什么事情都办酒是为了维护自己的利益,你办收了份子,我办也得收回来,那么这就和赌博抽水一样,赢的人要交出一部分水钱,在办酒这里就是宴席钱,那么赢家其实永远只是饭店(庄家)。
类似的例子还能举出很多,七夕情人节,平安夜……都只不过是消费的一个借口,你不消费?你不爱我!甚至连公共假期的设定都不是真的为你的放松而考虑,只是为了更好的塑造消费的条件。
这就是我们的世界,一个囚徒困境的世界,当一个人进行消费升级,那么这个人身边的一群人就会进行消费升级并且达到这个阶层的极限,只为了生存。对1%来说也许不以为意,但是对于中层和下层来说,它往往是灾难性的。
你首先会发现不买吃亏(负利率),其次会发现不买难受(商品真的很好),最后发现不买不行(你需要匹配自己的阶层),这一切就是消费主义的本质。
五、你我他
前面讲到,当年的续命模式是以把一切普通人的保障兑换成消费为经济大环境添砖加瓦的模式,无论是泡沫炸裂的大风波还是疾病灾祸的小风波,最终你都会成为消费主义的牺牲品。当然你可以说我得病就死,不需要保障----那么你会不会想要发展呢?前面说到,r>g资产的持有者在量化宽松中财富不断膨胀,而穷人反而在负债消费,那么实际上,只要通货膨胀在持续,打工就永远比不上哪怕是最愚蠢的投资,所以,你起码会气不过吧?
说到这里事情就逐渐清晰起来,断舍离针对的只是不买难受这一点,本质上是一种禅修,是苦行僧式的自我管理,它非但恶意的忽略了穷人,实际上也并不能真正让自己的生活好起来----一个执行断舍离的人,往往花掉了更多的钱,比如买更精致,溢价更高的东西,再比如去进行房屋装修和购买更上档次的汽车。
|
|
|
本宝宝要执行极简主义了!好!先把房子装修成这样吧!
|
而消费主义并不是自己没有执行力的欲望,而是外部环境的巨大推动让促使你产生欲望,市场是可以培养的嘛。所以如果把基本的重点搞错,具体的措施显然就会错的更离谱。所以断舍离显然是不能被支持的,真正的反抗消费主义首先要反抗商品社会,主动意识到商品社会的逻辑,再加以应对。
曾经有一个有趣的观点是因为中西方文化不同,西方人就是青睐超前消费而**人擅长储蓄,但居民储蓄率断崖式下跌的今天,我们发现西方人的超前消费也是因为社会环境产生变化导致的,同样的变化也会迅速改变**人的消费观。
有趣的是,在现在的西方反而出现了对消费主义的反动,不是断离舍,而是反对商品。西方有一群年轻人,他们选择在垃圾桶里翻找食物和用品,并非贫穷,只是一种生活的态度。我们当然不必做的如此极端,况且在**拾荒可能代表着你在和真正的赤贫者竞争。但也许你应该购买保障性的资产,也许你应该节流,一如我在个人反抗一文中写到的那样,并把消费升级留给富人。
当然,单纯的储蓄依旧会带来贬值的问题,所以也许我们还需要进行一下财产规划,这就将是反抗指南(四)的内容了。
2019-08-07 12:01 来源:全球进出口商品交易会
导读
杭州千点白网络科技有限公司旗下品牌枫火跨境今日发布,将结合理论知识和实战操作,为企业提供跨境电商平台培训、代运营、人才孵化等服务。
看中华东传统外贸和制造企业的转型需求和杭州优越的电商基因,阮雪青选择杭州成为其打开华东市场的“支点”,2018年7月成立杭州千点白网络科技有限公司。专注跨境电商培训的千点白网络,“入杭”一年多,举办20场活动,培训学员超过2000人次,团队也从2人壮大到30人。
杭州千点白网络科技有限公司负责人阮雪青
在大量接触杭州各类卖家时,阮雪青发现得杭州卖家对供应链有着深刻的理解,这使杭州的跨境电商发展更具爆发力。然而,杭州这些卖家们也面临着知识体系建立、电商和传统商业思维切换、人才培养和人员流失等诸多困难,推出枫火跨境品牌正是千点白给出的解决方案。
枫火跨境不受传统培训模式局限,在系统化和立体化的独特教学体系下,以优质的产品和服务为媒介,从各个细节融入陪伴式成长理念,不仅注重为卖家提供专业用心的教学服务,更侧重全角度和高质量的陪伴,见证卖家成长。
值得一提的是,针对工厂型的卖家,枫火跨境推出了亚马逊团队孵化项目,提供从早期基础员工的招聘、深度培训、团队管理等人才服务以及产品设计、供应链管理、品牌管理等全链路的整合,真正帮助希望转型的工厂完成华丽转身,不但可以达到在跨境电商领域的业绩目标,还能拥有自己的运营团队,自主把握未来。
作为不设围墙的跨境电商“社会大学” ,枫火跨境是杭州综试区为解决跨境电商人才问题积蓄的社会力量之一。“杭州综试区认定了包括企业、园区和培训机构在内的十大跨境电商人才社会培训基地,这些基地也将成为杭州跨境电商人才培养的参与者、品牌出海的助力者以及杭州综试区的宣传者。”杭州市综试办外联宣传部部长武长虹表示。返回搜狐,查看更多
责任编辑:
2011年8月的一个中午,美国马萨诸塞州海岸的海面上浮出一条熟悉的背鳍。这条带有白色小斑点的背鳍,属于一头雌性座头鲸。科学家们从上世纪七十年代就开始研究这头座头鲸,并根据她背鳍上的显眼斑点,给它取名为绍特(Salt)。
绍特是一只有着独特标记的座头鲸,自20世纪70年代以来,科学家们一直在研究它。
海鸥号(Shearwater)科考船上,座头鲸研究者乔克·罗宾斯(Jooke Robbins)正用十字弩瞄准绍特,准备射击。十字弩上装着取样箭,箭上装着特制的箭头和黄色浮标。发射!取样箭击中了目标,按照设计,取样箭收回时会带走几立方毫米的肉——相对于鲸的体型,这点伤害就像人被蚊子叮了一下。
罗宾斯和她的团队把收集的样本保存到液氮中,然后送去分析。八年转瞬即逝。在5月份的《分子生物学与进化》杂志上,亚利桑那州立大学癌症演化中心(ACE)的一个研究团队发表论文称,绍特以及其他鲸目动物,包括鲸、海豚和鼠海豚等,进化出了对抗癌症的高明手段,例如一系列的肿瘤抑制基因。
这个新发现,还有此前在大象身上进行的类似研究,都表明一件事:**治疗人类癌症的新方法,可能就隐藏在大型哺乳动物的演化史里,躺在它们遗传密码的某个地方。**可是即使知道了这点,科学家们也正在渐渐地失去研究这些巨型动物的机会。由于受到人类的持续威胁,这些动物的数量以及栖息地的生物多样性,都在急剧下降。
毫无疑问,像绍特这样的鲸本身就具有极高的价值。无论从伦理上还是生态上,保护大型哺乳动物都有很多正当理由。但“它们的基因可能有助于癌症研究”这个想法的确新颖。
“我从没想过,有一天癌症能成为鲸类研究的课题之一,更不要说对任何人类癌症的影响了,”她说,“虽然它非常有价值,让人出乎意料,但我从没计划过研究这个项目。”
从理论上讲,座头鲸绍特这样长寿的大型生物应该有很高的癌症发病率。
癌症始于细胞分裂,先是一个细胞分裂时出错,潜在的致命突变扩散到邻近的细胞,假如这个错误没有被发现被抑制,就会扩散到整个身体,引发癌症。
**鲸和大象同人类一样长寿,而且它们的细胞数量是人类细胞数量的数百倍。可是,它们细胞发生变异、导致癌变、以及癌变致死的频率却都很低。**ACE团队正在研究这种被称为“佩托悖论”(Peto 's Paradox)的奇怪自然现象。“佩托悖论”以英国流行病学家理查德·佩托(Richard Peto)的名字命名。在20世纪70年代末,佩托提出,自然界一定存在某种对抑癌机制的自然选择,因为尽管人类比老鼠的寿命更长,体型也大得多,但两者的患癌几率却很相似。
在2011年,ACE的研究人员和全球其他11个研究所的科学家们首次开始在座头鲸的基因组中研究“佩托悖论”。他们采用的方法就是比较绍特的基因与其他鲸类基因组。根据今年公布的研究结果,鲸基因组中决定细胞分裂方式和时间的部分进化得很快,而且时间点与鲸获得庞大身躯的时间点一致。
北亚利桑那大学的生物学家马克·托里斯(Marc Tollis)于2015年加入并领导ACE,他希望能够将鲸的基因组中的一个抗癌基因转移到其他的小型哺乳动物体内,帮助它们对抗细胞癌变——首先可以在小鼠身上测试,最终应用于人类。
还有些科学家也在研究“佩托悖论”,用的是另一种大型动物——大象。2012年,犹他大学的儿科肿瘤学家乔舒亚·希夫曼(Joshua Schiffman)得知大象的基因组中有额外的抗癌基因拷贝之后,开始致力于研究大象的癌症防御能力。他的病人正是缺乏这种抗癌基因,才导致的李-佛美尼综合征(Li-Fraumeni syndrome)——一种使人易患癌症的罕见遗传病。
希夫曼团队的合作对象包括ACE的卡罗·马利(Carlo Maley)、当地动物园、玲玲马戏团、巴纳姆贝利马戏团以及大象保护中心,在马戏团停止大象表演之前以及兽医定期检查期间收集大象的血液样本。在2015年发表于《美国医学协会杂志》(JAMA)的论文中,他们报告称,大象体内这种额外基因拷贝,能够引发一种程序性细胞死亡,以及一种名为凋亡的癌症防御机制。
当一个细胞分裂并经历某种DNA损伤时——例如,化学物质造成的损伤——细胞要么试图修复自身,要么自我毁灭,防止突变扩散到其他细胞。相比人类细胞,鲸和大象的细胞都更经常地发生凋亡。
希夫曼说:“人是很聪明,但大自然更聪明。经过数亿年的进化,大自然已经找到解决癌症的方法。”
在大象的遗传密码深处,可能藏着治愈人类癌症的线索
希夫曼补充说,很明显大象和鲸鱼经过无数代的进化,已经获得了对癌症的免疫力。他的团队还在寻找大象基因中的其他癌症防御机制,并试图将这些能力转移到人类身上。
“(这些动物)不止是找到了癌症的治疗方法,”他补充说,“更令人兴奋的是它们通过自然进化,找到了从一开始就不得癌症的预防方法。”
现存的90多种鲸类中,有22种已经被基因组测序,测序数据已经添加到美国国家生物技术信息中心数据库(NCBI)中,未来也将有更多基因数据持续不断地添加到其中。但是,当托里斯在2015年开始研究绍特的基因组时,只有5种鲸类的基因组数据。托里斯说,随着新技术出现,测序变得更便宜也更容易,相关的研究领域也得到迅速发展。
科学家还对现存的三种大象的基因组进行了测序。但这只是一个开始,科学家们可能还没有足够的数据来全面了解这些动物是如何抵御癌症的。而由于人类活动导致的生态系统破坏、气候变化等诸多问题正不断蚕食着这些种群,研究人员收集样本的机会越来越少。这些生物越来越难找到,保护它们的法规越来越严格,研究也会被一再拖延。
鉴于这些物种的减少速度,托里斯希望这项研究能让人们认识到癌症研究和环境保护的重要性。
“总而言之,由于我们现在正生活在一场生物大灭绝事件中,”他说,“我们需要每一个保护物种的理由。”
根据国际自然保护联盟(IUCN)的数据,这些大型哺乳动物的保护状况喜忧参半。一些鲸类的种群已经从几个世纪的滥捕中恢复不少,比如座头鲸。而另一些鲸类仍然濒临灭绝,比如北大西洋露脊鲸和塞鲸。
大象的状况也不佳,非洲象被列为易危物种,亚洲象则是濒危物种。
最近,博茨瓦纳解除了为期五年的猎象禁令,日本在7月恢复了商业捕鲸。而保护专家们更关心的是一些不在明处而在暗处的潜在危害因素,比如丧失栖息地。
肯尼亚有个大象研究和保护组织,“拯救大象”(Save the Elephants)。其战略顾问克里斯·索利斯(Chris Thouless)说,大象之所以遭受痛苦,是因为它们以前的栖息地,如今变成了工业区或农田,这也导致了“人-象冲突”。
在斯里兰卡的大象。随着越来越多土地被人类开发,留给大象的栖息地越来越少
世界自然保护联盟的鲸类专家哈尔·怀特海德(Hal Whitehead)说,**在海洋中,鲸鱼正日益受到海洋塑料微粒和船舶噪音的威胁。**因为视觉和嗅觉在水下效率很低,鲸类利用声音来寻找食物、形成社会联系,噪音会令这些动物紧张。
怀特海德补充说:“那些与人类接触最密切的物种,受影响也最严重。”
即使这些物种的数量恢复了,从大量物种中收集基因数据也面临着其他挑战。不列颠哥伦比亚省伯纳比西蒙弗雷泽大学的分子生物学家大卫·贝利(David Baillie)说,仅从一只动物身上提取的样本不能代表整个物种。
从许多样本中获得的某个物种的代表性基因组虽然很有价值,但个体基因组中可能出现的某些奇怪状况也有价值。基因多样性和庞大的种群数量为突变留下了很大的回旋余地,这些突变可能对生物本身和人类都有益处——如果未来人类能正确理解它们的话。
“我们拥有的基因组越多,就越能深入理解冗余的多样性,那是种群结构的基础,”贝利在一封电子邮件中写道。他补充说,“例如,在试图了解对疾病的抗性时,罕见的突变可能非常重要。”
托里斯说,有证据表明,同一物种的不同区域群体之间存在很强的遗传变异,我们需要付出更多的努力来对动物近亲的基因进行分类。
希夫曼也表达了类似的观点,他说,偷猎、栖息地丧失和近亲繁殖已经造成了一个瓶颈,压缩了许多物种的遗传多样性,对那些体型最大的生物尤其如此。
联合国生物多样性公约执行秘书克里斯提娜·帕斯卡·帕默(Cristiana Pașca Palmer)表示,我们还不知道,栖息地和物种损失对医学研究造成了多广泛的影响。
她在一封电子邮件中写道:“大象和鲸鱼等大型物种的消失只是全球生态系统物种多样性急剧减少的一个缩影。当我们采取行动,去保护生物多样性时,我们其实只是在保护人类自己。”
鲸身上潜藏的线索,远比鲸肉有价值得多 | undark
我们不知道人类活动将如何改变这些动物几代之后的基因组,以及如何改变它们拥有的潜力无穷的数据。例如,英国南安普敦大学的研究表明,如果人类继续破坏未开发的栖息地,哺乳动物的体型中位数将缩小四分之一。动物的遗传基因需要适应人类对地球越来越强的控制。一个物种曾用来战胜许多疾病的基因,还有其他有价值的基因突变,可能会不经意间在下一代中迅速消失。
“如果我们失去了在野外研究这些动物的机会,如果我们不保护它们,”希夫曼说,“我们可能会失去许多疾病的治疗方法。”
作者:Doug Johnson
翻译:莫轩
编辑:游识猷
编译来源:Undark
译文版权属于果壳,未经授权不得转载.
如有需要请联系[email protected]
第一章讲到,也许我们可以不使用朱迪斯巴特勒的具体概念而借用她的措施,因为和她提倡的去政治化不同,我们认为去政治化的事情根本不存在。但反抗的最好办法确实是——在卧室里。在卧室里我们可以做很多事情,可以为我们生活的大部分来一次革命。
当然,和一些已经会心一笑的朋友们想的不同,并不是在卧室里玩一些字母圈的娱乐方式就是“革命”了。不过如果我们拿性少数群体举例的话,也许破除性别本质主义的男女分工在LGBT群体中的延续是一个很好的方向——传统的性别分工可能不是因为私有制而产生的,但一定是伴随着私有制社会而被维护的。
又或者目前在北欧很流行的开放关系。
又爱这个又爱那个?那干脆试试让你爱的俩人也相爱好了。互相相爱但是却在性上疲惫?那干脆试试分别约好了。一夫一妻制同样未必产生自私有制,但是确实是伴随着私有制社会而被维护的。
取消男女定位和开放关系的尝试并不是一拍脑袋就能做成型的,它显然需要长期的寻觅,探讨,实验。比如在这样的关系下,财产如何分配?有人借口开放关系而强行脚踏两条船怎么办?旧的一定不好,但是新的也未必好。
开放关系当然不能做成后宫
所以卧室里的反抗被放在第四章,因为每个读者都可以发现,个人反抗必须一环扣一环:没有公社就不可能有开放关系——公社筛选出来大多数经济和观点相近的人,这样才能最大程度上避免财产分配和浑水摸鱼的问题。又比如不克服消费主义影响就不可能真的有什么积蓄让你拿去投资再生产。
也因此,虽然前两章我都在文章的最后指出了理财的重要性,但必须在最后说这个话题。正如段子“大多数理财的本质是你看上他的利息,他看上你的本金”所说,市场推出一切理财产品都是为了盈利,没有之一。比如商业保险本质上是一种对赌协议,虽然对于个体可能刚买就出了需要用上的意外,但是群体上,保险公司几乎稳赚不赔——不然他们雇精算师干什么?
当然,只有更狠没有最狠,有对比才有结论:保险公司相对来说“良心”得多,只是温柔的剪羊毛。但现货白银操盘公司基本是你不亏他不赚。又比如说P2P理财,即便把自设资金池的纯粹骗局筛掉,剩下的依旧可怕。
正常企业和个人需要贷款的时候,首选的是银行,因为银行借贷的利息是所有渠道中最低的。而一切不能在银行获取贷款的企业和个人,实际上都是被银行判断为没有借贷资格的高风险用户,虽然银行借贷的门槛越来越高并且青睐房地产抵押,但是它依旧执行了科学且全面的筛选工作。所以我们很容易就能发现,一切通过P2P渠道贷款的企业和个人,都是被筛剩下的。
现在还有搞美元和外汇的理财陷阱,这个翻绳可能不够用了
所以P2P直接变成了我国的次级贷款,风险高到爆炸。但如果仅仅是这样的话,倒也不是不能做。比如保守的银行一般会按照你资产的50-70%放款,还有空间交给P2P去发挥二次抵押。但是P2P理财往往提供给投资人10%以上的超高回报率,如果算上各种中间环节,借款人的真实借贷成本可能要到20%左右。
那么请问,**在经济下行的当下,做什么买卖能得到20%以上的年化收益率?**贩毒还是倒卖军火?所以实际上小额贷款的主要群体是赌徒,就是字面意思上的那种。于是P2P平台坏账率高的惊人,每年跑路和破产的占总行业的比例达到了其他行业无法想象的地步。
如果从这个角度看,并不存在一个稳妥的理财产品可以让你逃避剥削,但前文着重强调了**“漏网之鱼”原则**,这也就将是我们的突破口。
消费主义的漏网之鱼我们理解,只要灵魂深处闹革命就可以了——它多少还是一件自己的事情。那么理财的又怎样?我们都知道股市中散户70%赔钱,20%持平,10%赚钱。那么这10%在整体收割散户的股市中,就是漏网之鱼。但显然并不是每个人都有高超的股市交易技巧搭配逆天的运气,这没有丝毫的普遍性。
那房子怎么样?涨了很多年了吧。
但不管经济学认为资产泡沫存在不存在,房价对于老百姓来说都太高了。在技术上可以通过保障房建设来解决住房问题。同时对遗产和房产课以重税,只要限制资产外流,就可以有效解决问题。而且国家很可能会主动腰斩房价---或许是维持现价,依靠通货膨胀慢慢稀释资产价格的方式进行。
为的是楼市的资金进入消费市场。
准确讲,为了转型成功,国家甚至一定会让房价掉下来。如果长期中等收入陷阱,体系就会自然崩溃。前文讲到,现在大量资金入场是因为需要注水——稳增长——稳就业——稳天下不乱。通过房地产上下游带动经济增长。
但它也是不可持续的,因为总有一天房价会高到在再也没人买的起的地步。
而且结构转型如果成功,这巨量的资金就必须流入实体经济,因为结构转型四个字归根结底就是把投资拉动经济改为消费拉动经济:如果房产回报还是那么高——甚至仅仅是能维持回报,都不会有人把自己抽出来消费或者投资。
所以强硬的降价政策一定会出现:其中细微的准备工作,实际上可能已经在进行了。房价高企是因为土地出让过少导致的,可以想象几倍于现有住宅用地的土地被释放出来会对房价造成怎样的冲击。
所以兴百姓苦,亡百姓苦。国家需要资金进入房地产,就严控用地,反之则少控甚至不控。相应的,首付比例可能也会提高,包括更严酷的限购措施。
一切都只为经济大局服务。所以房子可能真的碰不得了。这个社会并不真的存在制定规则者之外的躺着赚钱的方式,比如说即便你运气很好找到了一个房价洼地,购房的税费也会占据房款的相当大的大头,如果未来的涨幅不能覆盖税费,那么你实际上还是亏了。
这时如果回到花光每一分钱来对抗通胀的老路上话,那只能说是回到了给消费主义找合理化的老路,所以还是要节流。
在一切之前,先要确立保障。因病因灾因退休至贫算是可以一下子把人打进地狱的情况,如果不考虑这一点,那么一切都无从谈起。那么首先要确定的就是社保。没错,社保是**最有福利国家气质的制度,没有之一。虽然网上铺天盖地的宣传自己理财比社保强,但实际上理财的风险呢?根本不会提及。而宣传最凶的,往往就是理财公司自己。
社保虽然不活到一定岁数不能回本并且压缩财富支配权,但也其长处。比如养老保险是唯一跟着通货膨胀走的产品。一切商业养老年金都是约定利率,讲通胀时讲过,约定利率永远跑不过纸币通胀。
但社保又不是全部,社保没有意外保险,疾病方面保障额度不高,以及大多数重症药物社保不报销。因此需要补充保险。前面也说了商业保险的坑人之处,所以如果想做真正的漏网之鱼,需要找一些市场不推给你的东西。比如互助保险。
互助保险
互助保险其实是保险最原始的模式,无数参保者在一起,每人拿出来一点钱,群体里有人出了风险就用这个钱赔付,它直接把保险公司从中筛掉了,没人从中获利,所以可以以每年几十到二百不等的价格赔付高达30万的保额。
这种模式实际上非常适合互联网,连集体雇佣基本的维护人员的费用都被大大压缩了。但互助保险也有自己的问题,比如初期如何扩张?没有足够的人互保就不成体系,但是没有风投就没法宣传,你不赚钱,风投也不想赚钱?所以也有说互助保险是打着保险做互联网金融的勾当。但无论如何,它是我们能找到的最好的形式——反正每出事一个人才给3元,亏起码是亏不到的。
资金的流动性也很重要,最大的悲剧是不存钱,次之的悲剧是,你有钱但是用钱的时候取不出来。所以保持一定的流动性也是重中之重。
这里就要引出理财的基本原则“3331”。每月盈余的1成拿来购买保障性产品,比如保险。3成拿来当做现金流,3成作为保本理财,3成作为风险投资。
流动性方面,如果放在银行和宝宝类产品里,享受的就是负利率待遇。但活钱一定是要留的。这时可以考虑去地方银行存定期或者购买国债,如果不用钱的话,利率就比宝宝类产品高一些,用钱的话取出定期或者转让国债都非常迅速,而且损失的也仅仅是预期的利息,其他和宝宝类产品一致,把损失降低到最低。
英国脱欧的时候,每个赌脱欧成功的人都预计黄金要大涨,但是有些人选择了购买黄金,有些人则选择了购买黄金股…也许购买黄金的人只得到了25%的涨幅,但是购买黄金股的人既可能大赚80%,也可能莫名其妙的的只赚了15%。
也就是说,无论趋势如何,进入股票市场的时候,个股的选择依旧是考验人的。所以我完全不建议购买任何单支的股票——哪个趋势被你看准,直接去投资趋势好了,如果不相信自己,就去找股指基金,让这帮万恶的投行人去帮你操作。
但是说到黄金,重头戏就来了。第二章中我讲的很明白货币脱离锚定黄金以后,黄金属性的变化。但这依旧是“定价”的。认为黄金仅仅是一般的大宗商品的人非蠢即坏。
黄金看起来涨跌惊人,显得是一个风险投资品的样子。但黄金每次暴涨都能追逐到它最初的购买力并且不再下跌回原位。比如08年危机,黄金最高到 1900+ 美元,在QE开始后暴跌到 1300+ 美元。但没人记得它在 08 年暴涨前远不到 1300+ 美元。
黄金滞后的货币属性,显然投资人信任黄金胜过央行
如果有什么是全世界无政府主义者联合起来的事情,那么肯定不是比特币,而是黄金。正是出于对央行和纸币的不信任,黄金才在市场中自动扮演了准货币的角色,变成了真正的储蓄。
如果你确定一笔钱仅仅是用来长期投资,以保值为目的,那么显然唯一合适的就是全球人民定价的黄金,曾经的黄金还征收保管费,而现在反而因为纸黄金的流行而产生了租赁费(租赁给使用企业,他们付出租金),真是黄金的好年头了。
但我不会给你们推荐产品的,问我也不说
这个小系列的产生是因为之前写了一篇个人反抗,一篇房价的文章,感觉大家很喜欢,自己的兴趣就也也来了。于是按照更合适的顺序把两篇文章扩写成四篇,并且加入更多的理论方面的内容和链接,图片。
现在我们把几篇文章串起来看,我们可以设想一个晚期资本主义下的城市劳动者,不再生活在工厂,而是各种服务业的从业者,身无分文但是受过教育,对生活充满苦闷又不失希望,听起来有点像你也有点像我。
这样的人,聚集起来,从一个公社开始,大家住的很近,一起玩一起讨论,以去逐利的第三方为目的去创造自己的空间,享受私人的,半公共的,公共的空间。并且在更大的范围内利用互助保险和黄金与全世界的反抗者联结起来。这样也许我们不能在可见的未来内击碎那些规则和禁锢,但言语本身就有力量,行为则更是榜样。
资本主义并非不能伤害我们,但是我们可以一起抵御风寒。
问:你写的《资本主义个人反抗指南(三)》好好看!我追着把前面一、二又看了,我自己的职业是记者,最近一段时间的关注点是:资本主义话语的形成,我发现媒体同样在为资本主义撑腰,现在的舆论已经失去了批评性,而且都是同质化、娱乐化、简单化,这样长此以往,个人是不存在独特经验的,他不用去思考,媒体就给出解释,他也乐于去接受,而我认识,这恰恰是资本主义全球化、一体化带来的恶果。好想听你讲讲这些部分。
答:媒体被操控有两方面,美国的例子很好,各党派各自有自己控制的媒体,但几乎所有媒体都是为精英阶层服务的,在英国脱欧的时刻,显然媒体和人民割裂了,精英是全球化的受益者,文一讲了,老百姓是没有在全球化中得利的,所以脱欧的明显以工人阶级和中下层劳动者为主,这些人是占主流的,所谓沉默的大多数就是这些人,为什么沉默,就是因为媒体并不为他们发声。
还有一方面就是媒体也是逐利的,虽然新闻天然的属性是报导事实,但是事实的取舍也有很大余地,你说的娱乐化,简单化也是因为劣币驱逐良币。报导最让人喜欢的东西就会得到发行量和订阅量,那么深度的自然小众化,只能护住基本盘,甚至因为正反馈过程,基本盘也是在缩小的,这个趋势从网络游戏和网络文学中能更清晰的看到。
我所以我虽然不喜欢FEMEN这样靠噱头去抗议的群体,但是不可否认的是,恰好是她们抓住了当下宣传的命门,作为配合,我说的 情境主义 行为艺术者 当然要支持并且做好自己的事情。
前段时间相继写了个人反抗和随便谈谈房子两篇文章,感觉大家对这两个话题非常感兴趣,于是决定把这两篇文章更有条例的重写成四篇,并且增加更多的图片、链接和内容--显然你们已经受够了回龙观和通州的苟且,对真正的生活充满向往。
但那需要钱。
没错,在经济下行的当下,政府需要投资拉动经济稳定增长以确保就业,而投资基建的钱只能来自卖地,而土地被开发商开发成功后最终的接盘者依旧是老百姓,所以国家需要房价永恒上涨来覆盖不断高企的地方政府债务,而我们就因此距离真正的生活越来越遥远。
你要的生活
你的生活
但也不能说完全没有办法。朱迪斯巴特勒的提过一个口号叫“私密生活的反抗”,虽然我并不赞同她去政治化的具体观点,但是这个口号却似乎可以拿来用一下。资本主义在城市中独特的组织形式构成了新的反抗点,就像阿兰巴迪欧所提到的事件的引爆点一样,它积累了,自然就发生了。
但具体的构想却是大卫·哈维提出的:他讲到资本主义的发展是一个涉及全球的地理问题,城市是被资本主义所塑造的,他在《资本的空间》一书中指出当代资本主义生产方式的转变(即从福特制转向后福特制和新福特制),让无产阶级的反抗方式发生着变化,一种网络化和去中心化的反抗结构开始生成,反抗的中心场所也逐渐从工厂转向生活空间。
我们都知道**经济放缓的最大外部因素是国际需求不足--即发达资本主义国家的订单不足了,也许这时我们会去思考内需市场,但是很少有人去思考,为什么是**承担了全球制造国,尤其是低附加值的劳动密集型的位置?
因为全球化。最早美国是全球工厂,美国经济发展,成本上涨后转移到了战后的欧洲,进而是日韩,最后是**。全球化可以解读几乎大半社会问题:西方污染少是因为没有工业,**反之。西方没有血汗工厂而**有,是因为资本的原始积累必须伴随着彻底的剥削。
所以美国最早诞生了属于晚期资本主义特征的嬉皮士运动,而俄罗斯的嬉皮士因为没有相应的社会背景而大都变成了禅修者。这些美国嬉皮士不是产业工人,受过良好教育,厌恶资本主义,他们试图用公社来执行“私密生活的抵抗”。
70年代的公社,他们的生活一如你在《逍遥骑士》中看到的那样
涂成迷幻外壳的大巴车:你需要盯着它飞叶子,疗效很好
他们同吃同住,一起劳动,种植粮食和大麻,读书,冥想,没有私有财产。看起来浪漫至极,但和我们所知道的一样,他们失败了。原因当然有很多,完全取消私有财产违背了人性,禅宗和摇滚乐作为流行文化不会提供稳定的价值观,枯燥的荒野生活等等。
但这一切总结起来,唯一的原因当然是因为他们远离城市:城市是资本主义的血肉驱壳,它最忠实的体现了资本主义的面貌,抵抗必然诞生于城市,成长于城市。我们喜欢读书会,讲座,摇滚现场和莫奈的展览,我们进入大城市就是为了追求这一切,而事实上,它也应当属于我们:我们需要个人空间也需要亲密的互动,我们需要各种各样的无穷尽的信息为我们提供属于自己的信仰,而完全可以保留一颗反抗的心灵。
但这一刻什么时候开始呢?在每一个年轻人都涌入北上广而非沿海的工厂时开始。**在提出“中等收入陷阱”的那一刻就已经进入了晚期资本主义,因为它暗示着下一波产业转移就要开始,越南和印度将要替代我们产业工人的位置(如果不是机器人的话),大部分的就业将诞生于中心城区的服务业而非郊区以及物流发达的工业城市中集中的工厂--但很显然,我们谁也没有意识到这一点。
身处时代之中的人往往什么也意识不到,直到被后人所总结。但我们确实看到了一整个属于城市年轻人的生态的形成,高雅音乐会唱加班,人们的话语中做买卖逐渐被创业所覆盖,民间借贷让位于风投……这是一个好时代,但确实也是最烂的时代,我们作为挣脱原生环境的第一批人,茫然的看着程序员和金融行业突破天际的公司,暗搓搓的想着什么时候自己也能捞一笔?
但设想往往是徒劳的,看看房价和上下班的时间和拥堵,我们发现资本主义的躯体为我们塑造的悖论:房租越贵,越不得不搬得远,住的小,那么交通开支和时间成本也就越高。而如果我们住在市中心,则搞不好直接进入了负债深渊。
那么这时无论是没钱还是没时间,合理的生活和提升都变成了镜花水月。就像《我在底层的生活》所说的那样,每个人都变成了穷忙族。所以我前一段时间反复说,一线城市人口控制的新规并不是赶农民工,而恰好是在赶各地的受过教育的年轻人:他们恰好塑造了一个留下还不如回去的两难氛围,所以才会有所谓逃离北上广。
但显然,逃离北上广以后才会发现回不去的情况时有发生,故乡是异乡…异乡也不是故乡。所以我们需要一种可以留在大城市中心城区过真正的生活的模式,如果它能成功,也就是我们所提到的私密生活的抵抗。
前面讲到大卫哈维认为反抗的地点从工厂转移到生活空间就抓住了这一实质,但具体怎么反抗,我们还要分析一下资本主义的躯体是怎样的。
**的标志性建筑是小区,而不少晚期资本主义国家则是街区。小区是非常有前期资本主义特征的象征:封闭小区往往来自大院文化,是体制内和掘到第一桶金的商人隔绝外界以确保地位和安全的措施。

大院是身份的象征,封闭小区都是大院-精英文化与身份认同的延展
所以我们可以看到一个有趣的现象,越是接近权力中心的地带,封闭小区越是主流,比如北京。封闭小区所暗示的信息是“小区外没有吸引我的东西,我下楼也只愿意和自己同阶层的人一起使用公共设施”,它只能在内外资源(不光是政治经济)彻底不对等的情况下才能出现。
与小区相对立的是街区。

典型的街区之一
典型的街区是打破藩篱的,它在西方同样发扬于大城市的中心地带。街区彻底的和周围的环境氛围糅为一体,乃至形成了独特的街区文化。年轻人们去洗衣房洗衣服,去咖啡馆工作,点楼下披萨店的外卖--这一切事实上是把本来在小区内属于住宅的功能提交给了公共空间去服务。那么这时居住地就不需要太大,比如一个大开间就足够了--拿来开趴体。
也许它是郊区独立住宅的次优选择,但它确实让每个人的租金成本被压到最低,让年轻人也可以在市中心生活下去。
不过虽然比我们更早进入晚期资本主义,西方作为先行者做的却也不大好,街区制也有很严重的问题。比如有街区必然要有商圈,那么马太效应就会要求街区越来越大以承载更全面更丰富的商业体系,那么随之而来的显然就是街区文化的丧失以及拥堵和犯罪率的提高。
那样实际上就不是什么个人抵抗,而只是鸽子笼的再现罢了。

据传为六平米户型,人们依旧需要在一个逼仄的空间内做所有事情
人们不再选择去咖啡馆,那里没有志同道合的人。也不再深夜出门狂欢--万一被当成**呢?所以也许在某个关键时刻到来前(显然,毛主席讲主观能动性也能推动条件发展,这不是消极避世),我们帮不了太多别人。
所以正如大卫哈维所说,碎片化的反抗正在成为现实。
但我们认为碎片需要有节点。节点是什么呢?我们不应当去追寻私有住宅,除了我在前文反复讲的房价必然下跌以外,最重要的是流动。一个社区必然是流动的,无论是人的流动还是社区本身的流动,它需要因为事件引爆而产生变化。
曾经有一些比较成功的案例,但它们都是商业化的,收着昂贵的床位房租却只提供基本的公社服务。但这也是先行的必然,如果硬要在高层中搞出街区,显然房租成本要分摊到每个人身上,那样实际上等于我去租咖啡馆,去租洗衣房,去租图书馆,而不是街区制的真正公共空间的免费使用。

国内某青年空间,以高昂的床位费用换区公社的成立

某空间的图书馆,它不可能是节点,只能是某个情怀创业者的游戏
那么有没有别的办法呢?北京三环内很多大杂院,不少房子被隔出来只有3-4平,也就放一张超大的床。但是这样的生活并不糟糕:出门就是院子,养花养草躺在摇椅上看书,院子周围住的都是同样聚集在文艺圣地附近的文青。出了院子就是各种咖啡馆书店之类的公共空间,我曾经参观了一个朋友的屋子,床上非常华丽,上面有个特别迷幻的吊灯,墙上贴满挂满了东西,床底下和墙上的格子间放私人物品…那感觉其实非常震撼。

北京的典型四合院,是文艺青年们的最爱,一人一间房
这样的生活房租一个月数百块不等。在没有任何组织和理论指导的情况下,在北京的旧城区,因为城市建设保护不允许建设小区,形成了自发的,不涉及财产关系的互助公社。这感觉就像是哥本哈根的国中之国那样:由阿甘本意义上的神圣人(被排斥者)们所建议的半公社街区。
实际上四川也有类似实验:志同道合的人在城市的郊区建立了半公社式的组织,同时满足了价格以及年轻人生活的需求。

私人空间,不涉及财产分配的半公社基本单元

公共空间,共同承载客厅和办公地点的功能
虽然四川和北京的实验都有所不足:前者实际上依旧是封闭而非流动的,无法形成节点去接纳每一个人,犯了嬉皮士的老错误。而后者太过仰赖政策的偶然性,无法像丹麦那样通过社群的抗争获取合法地位以至于推广开来。

哥本哈根的自由城,被称为最后一个乌托邦
但它们依旧为我们指出了一些方向,城市的发展是滞后的,我们即便进入了晚期资本主义,封闭小区却依旧是主流。但街区制的潮流是城市巨型化的必然结果,我们的年轻人也已经随时就位,跃跃欲试,我们相信街区制逐渐普及的那天,无数节点就会随之出现,到时候,也许你我也可以去加入或者建立一个节点,在城市之中展开属于我们的生活。
很多第一次准备考教师资格证的同学,一定是很茫然,丈二和尚摸不着头脑。这里解释下国考与省考的概念,14年以前全国都是省考,就是由各地方教育局组织教师资格证考试,师范生在学校通过考试就直接发证。
先给大家推荐笔试课程
针对非师范0基础的同学,推荐国家教师资格考试网旗下品牌亿师学教师资格笔试课程,全程直播授课,并赠送全套考试教材、试卷、冲刺宝典,还有专属学习群,戳此处查看:
14年以后陆续开始教师资格证国考改革,目前除**、内蒙、西藏是省考外,其余省市都是国考。
国考是国家教育部统一命题考试,全国考生都是考同一张试卷,并且不分师范生与非师范生,二者在考试内容,报考条件等方面都是一样的要求,唯一的区别就是基础不一而而已。
并且国家是鼓励师范生报考教师资格证的,现在网上说国家限制非师范报考,那一定是某些培训机构的招生谣言。
教育部官方回复
下面给大家详细回答教师资格证怎么考?
以下内容是根据最新考试公告整理的报考流程及备考经验分享,由国家教师资格考试网旗下品牌亿师学独家出品,未经授权,严禁转载,建议小伙伴们先收藏并点赞支持下原创,文末还有今年最新考前冲刺资料,可以直接下拉!
**教师资格证报考流程:**笔试报名→笔试考试→面试报名→面试考试→教师资格认定(需要普通话证书)→通过认定→领取证书,以下内容将以此为线索,为大家详细讲解。
1.报名时间
现在全国除云南,山西,青海,黑龙江为一年一考,其他省都是一年两考。
一年一考的省份为每年下半年举行考试,具体时间以各自省市公告为准。
2.报考条件
笔试报名只对报考学历及报考地点有统一规定,符合这两个条件即可报考。国家没有限制非师范报考的说法,这里大家一定不要被某些培训机构的招生谣言忽悠了。
01 .学历要求:
02 .报考地点:
3.报名流程
大家先进行网上笔试报名,报名网站:中小学教师资格考试网,点击查看:笔试报名流程!
中小学教师资格考试网
网上笔试报名后,大家需要等待网上审核或**参加现场审核(**并准备相关材料),待审核通过后进行网上考试缴费,缴费成功即视为笔试报名完成。
**网上审核:**考生在网上进行笔试报名后,相关工作人员会在网上对考生报名条件进行审核,审查是否符合报考条件,考生只需等待审核结果即可。
**现场审核:**考生先网上笔试报名后,需要带上相关材料去当地教育局指定的地方进行现场审核,现场审核的省市有:浙江,上海,湖北(今年下半年新增)其他省市皆为网上审核。
笔试证件:网上审核的省份,笔试直接网上报名即可,不需要任何证件材料,其中笔试,面试都不需要普通话证,面试合格后的认定才需要,需要现场审核的省份按笔试公告要求的材料准备即可。
笔试考试时需要携带身份证、准考证,签字笔、2B铅笔等。
1.笔试科目
**小学笔试不分科,**笔试内容都是一样的。
**初中学科知识与教学能力科目为:**语文、数学、物理、化学、生物、历史、地理、**品德、英语、音乐、美术、体育与健康、信息技术、历史与社会、科学等15个学科;考生选择一个科目报考即可。
**高中学科知识与教学能力科目为:**语文、数学、物理、化学、生物、历史、地理、**政治、英语、音乐、美术、体育与健康、信息技术、通用技术等14个学科,考生选择一个科目报考即可。
最新考试规定
自 2017年下半年开始,中小学教师资格考试初中、高中、中职文化课类别增设“心理健康教育”、“日语”、“俄语”学科;小学类别面试增设“**心理健康教育”、“信息技术”“小学全科”**学科。
上述各类别新增学科的笔试科目一、科目二与已开考学科一致,初中、高中、中职文化课类别新增学科的笔试科目三《学科知识与教学能力》结合面试一并考核。
现在是国考非师范生不需要参加教育学,心理学的考试,跟师范生一样都是考上面的科目。
2.笔试考试大纲
01.幼儿园统考大纲
02.小学统考大纲
03.中学统考大纲
3.笔试成绩计算方式
01.笔试及格分数线
科目一、科目二卷面分数总分均150分,经过教育部考试中心的线性转化后,满分为120分,合格分数线统一转化为70分。
也就是说在查成绩的时候,如果显示70分以上,你的成绩就合格了。
笔试成绩样式
02.分数折算
由于各个笔试科目难度存在差异,其合格分数线也不相同。
为统一各科目的合格分数线,教育部考试中心根据考试标准和当次考试情况,采用线性转换的方法,将考生满分150分的原始成绩换算为满分120分的成绩,并使每个科目的合格分数线统一转换为70分。
原始成绩低于合格分数线的考生,换算后的转换分在70分以下;原始成绩高于合格分数线的考生,换算后的转换分在70分以上。
4.笔试成绩有效期
笔试成绩有效期为2年,在有效期内,考生可以考不同学科的面试,只需加试科目三,但不得跨学段考试。
例:若小明初中语文的笔试成绩合格,在笔试有效期内,我可以考初中数学、初中英语、初中化学等的面试,只需要加试同类考试的科目三。但是,不可以考小学、高中的面试。
以下内容是考生真实备考经历,希望对大家有所帮助!
我是非师范考的初中语文教师资格证,一心是为了后面考教师编制做准备,笔试科目**:综合素质,教育知识与能力,初中语文学科。**
科一《综合素质》
这是最容易的一科,也是我用时最少,得分最高的一科。简单来说这一科分为职业理念、法规、职业道德即三爱两人一种身、基本文化素养、阅读和写作。
职业理念中教育观、学生观、教师观是要快很准的记忆下来的,因为大题靠它拿分。而法律法规在选择题中出现频率较高,所以这部分的复习,我把几部法规记在了小纸条上,吃饭等闲暇时间拿出来巩固一下即可。
而文化素养我没有刻意复习,这部分靠的都是平时的积累,所以也提醒我们平时多看书、多读报。至于阅读和写作,我们从小到大语文的学习都在和他们打交道,所以也不必太过担心,但是最重要的是,作文的写作,一定要站在一个老师的角度去行文构思,要摒除我们还是个学生的束缚,这样才能轻松拿下这一科。
科二《教育知识与能力》
我是最没有把握的,这一科理论性很强,对于记忆的要求也颇高,所以我花费了很多时间和精力。前期我把教材梳理了两遍。
第一遍我把每章每节都仔细的钻研了一下,然而这一遍确是最没有效率的,我能记下的东西寥寥无几,只是大致留下了模糊的印象,知道每一章每一节的内容。
第二遍,我结合了历年真题,错题便是我关注的重中之重,我会把错题对应的内容,在书上找到并吃透这一知识点。
对于选择题而言,每一个选项对应的知识点都要吃透;而辨析题更是你要对理论的灵活掌握,并不是要死记硬背,而是要结合自身的成长,或是实际经历去对应这些理论,这样记忆起来,会起到事半功倍的效果。
考前一个月,我把这一科所涉及到的所有理论、原则、方法罗列到了一张纸上,毕竟读书是一个由厚到薄的过程,每天看着这些理论名称,回忆这些理论的内容,这对于我拿下这一科起到了一个推波助澜的作用。
科三《语文学科知识与教学能力》
我把重心放在了教学设计、教学实施和教学评价上。对于学科知识,由于所学专业是汉语言文学,所以具备了一定的语文素养,而作为非师范生,关于教学的那几项是我的弱点。
复习这一科,你会发现这一科不仅是单纯对知识点的考查,更是对能力的考核。这一科所有的知识点,你只有融会贯通,才能取得高分。这本书很厚,而留给我的时间也不多,我只有结合历年真题,有针对性的看书,才能将效率提高到最大化。
对于教学设计,这个重中之重,不仅是要看真题解析,也可以上网搜索一些优秀的教案,找到自己写教案的风格,最重要的是自己一定要独立的写几篇,所谓孰能生巧,这样在考试时才能有条不紊。
笔试如果备考时间多,可以自己购买教材自学即可。如果是上班族备考时间少,建议报班学习,买视频直播课程就好,价格也不贵,有老师带着学习比自己看书效果好很多,特别是非师范生,这里给大家推荐国家教师资格考试网旗下品牌**亿师学**(专注教师资格证,教师招聘课程培训)。
面试是在笔试考试科目全部合格后才能参加的,笔试单科成绩2年有效,且全国通用,也就是说在A省考的笔试,可以在B省参加面试,前提是符合B省的报考条件。
1.报名时间:
上半年报名时间:4月19号—24号, 面试考试:5月20号。
下半年报名时间:12月10号—13号,面试考试:次年1月4号—5号。
**备注:**具体考试时间要以各自当地面试公告为准。
2.报名条件
面试报名是在笔试成绩全部合格,且在有效期内才行,并对报考学历和报考地点有统一规定,符合这些条件才能报考,这两点要求跟笔试报名一样即可。
3.现场审核
面试在中小学教师资格考试网上报名后,需要携带相关材料到指定地点参加现场审核,审核通过才能进行考试缴费,缴费成功即面试报名完成。
面试报名现场审核材料:
01.在户籍所在地报考的考生(毕业生):
(1)有效期内第二代居民身份证原件;
(2)毕业证书原件;
(3)本人户口本或集体户口证明原件。
02.在工作所在地报考的考生(毕业生):
(1)有效期内第二代居民身份证原件;
(2)毕业证书原件;
(3)人事关系证明(社保缴纳,劳动合同,人事档案等),这里各地具体要求材料不一样,须与当地面试公告为准。
03.在学校所在地报考的考生(在校生):
(1)有效期内第二代居民身份证原件;
(2)有学校名称及注册信息的学生证原件和学校学籍管理部门出具的在籍学习证明。
(3)普通高等院校全日制在读专升本学生还需提供专科毕业证书原件及复印件。
1.面试内容
面试依据教育部印发的《中小学和幼儿园教师资格考试标准(试行)》和《考试大纲(试行)》(面试部分),通过备课(或活动设计)、试讲(或演示)、答辩(或陈述)等环节进行。
主要考核申请人职业道德、心理素质、仪表仪态、言语表达、思维品质等教学基本素养和教学设计、教学实施、教学评价等教学基本技能。
2.面试科目
1.幼儿园教师资格面试不分科目。
2.小学教师资格面试科目分:语文、数学、英语、社会、科学、体育、音乐美术,心理健康教育,信息技术,小学全科。
3.初中教师资格面试科目分:语文、数学、英语、**品德(政治)、历史、地理、物理、化学、生物、音乐、体育与健康、美术、信息科技、历史与社会、科学,心理健康教育,日语,俄语。
4.高中教师资格面试科目分:语文、数学、英语、**品德(政治)、历史、地理、物理、化学、生物、音乐、体育与健康、美术、信息科技、通用技术,心理健康教育,日语,俄语。
5.中等职业学校文化课教师资格面试科目同高级中学。中等职业学校专业课教师资格考生根据所学专业选报相应的面试科目,报考的面试科目须与所学专业一致。
3.面试流程
面试采用结构化、情景模拟等方法,通过备课、试讲、答辩等方式进行。使用教育部考试中心统一研制的面试测评系统。
**(一)候考。**考生持面试准考证、有效期内的居民身份证,按时到达考点,进入候考室候考。
**(二)抽题。**按考点安排,登录面试测评系统,计算机从题库中随机抽取试题(幼儿园类别考生从抽取的2道试题中任选1道,其余类别只抽取1道试题),经考生确认后,系统打印试题清单
**(三)备课。**考生持备课纸、试题清单进入备课室,撰写教案(或活动演示方案),时间20分钟。
**(四)**回答规定问题。考生由工作人员引导进入指定面试室。考官从题库中随机抽取2个规定问题,考生回答,时间5分钟。
**(五)试讲/演示。**考生按照准备的教案(或活动演示方案)进行试讲(或演示),时间10分钟。
**(六)答辩。**考官围绕考生试讲(或演示)内容和测试项目进行提问,考生答辩,时间5分钟。
中等职业学校专业课教师资格、实习指导课教师资格考生面试不参与抽题,按各考区有关要求执行,具体面试方式请考生咨询所报考区主管单位。
面试考试模拟视频
4.分值比例&评分标准
01.分值比例
02.评分标准
01)幼儿园面试评分标准
02)小学面试评分标准
03)中学面试评分标准
5.面试成绩有效期
面试合格证明有效期3年,当考生拿到资格证后,资格证永久有效,只有在编教师需要每5年定期注册一次。(如:公办普通中小学,中等职业学校,幼师在职的在岗教师等)
以下是考生真实备考经验分享,希望对大家有所帮助!
我是面试的是初中语文,因为是非师范第一次参加面试,完全是一脸懵逼的状态。开始我也认为面试比笔试难,其实从考试内容而言,面试更容易,更多的是紧张罢了,多半的人从读书时就没上过台讲话,考试时脑袋就卡克了,所以多练习练习试讲很重要,基本就是试讲决定你能不能考过了。
提前购买自己面试科目的教材,熟悉考试内容,因为面试时是抽题,万一抽到自己陌生的题目就不好办了,面试备考需要自己平时多练习写教案,套用模板,教案占分很低。
结构化问答没有统一答案,多背一些常考的题目,回答时注意:第一要带有相关知识点,第二要体现自己的逻辑性跟问题的全面性,第三要表现自己的沉着冷静,即使不知道怎么答,有自己的观点表述出来即可。
试讲是占分最高的环节,平时只有自己多多练习了,掐好时间。
考官评分主要参考因素:
①基本的知识点千万不能讲错,一旦讲错肯定挂科。
②试讲环节一定要看抽到的题下面的答题要求,不要答偏了。
③放松,不要紧张,自己要把握好节奏。
答辩是最后的环节,是考官根据试讲内容进行提问,一般都是很简单的问题。
个人面试经验
穿着打扮:穿着要得体,别太时尚了。服装要有老师的感觉,别太青春,别穿运动装,牛仔裤运动鞋之类(面试体育除外),面试幼儿千万不要穿着高跟鞋,带跟的鞋都不要,不方便做活动,这是个常识,女生别化浓妆,适当注意自己的行为举止。
至于是否穿西装,我观察发现,大学没毕业的男生基本都是西装革履,正襟危坐,包括我也是休闲西装去的,毕竟让人觉得正式和给考官你很重视的态度。
问候阶段:进去和老师问好。这是必要的礼貌,但是要注意,一定要等他们看到你的时候在鞠躬或者问好。很多时候考官都在低头讨论没有注意到。这时候把材料交给他们就上讲台准备“任人宰割”。
回答阶段:一般考官会先说话,就是诸如欢迎您来面试,宣读时间规则这些。这时候就要调整心态,告诉自己别紧张,从容淡定。结构化面试两个问题,这需要去收集题目,回答要不卑不亢,既不要发挥的无法控制,也别声音太小。
有的人说话的声音只有自己听得见,有的人因为之前看视频说要大声,结果声音响彻楼层。
如果被问到之前准备的题目,不要太激动太兴奋,一方面可能语无伦次地表达,一方面让考官觉得事先准备,有些不满。碰到这种情况应该思考一番,在有条有理地叙述,用理性的分析和有力地表达拿分!
同时提醒大家不要转粉笔,不要手撑着讲台,不要抓耳挠腮,眼神和每个考官有交流。一般有三个考官,据传分别是学科带头人,领导和教育局相关人员。不要只和中间的那位交流过密而忽视旁边的两位。
试讲技巧:因为历史学科的特点加上时间比较紧张,要及时把知识点的背景、时间、过程、任务、事件一一列举出来,不需特别扩充,当然适当扩展可以给考官一种你对史实的掌握非常充分的看法。
注意要提问的方式,可以用个人回答,小组讨论等方式。注意行为动作举止要自然,别过分羞涩或者张狂;
板书技巧:板书位置要合理,板书的时候尽量侧身,且最好安排学生进行学习活动。例如写标题的时候可以布置学生预习课文,板书内容的时候可以和学生互动,既学生说老师写。板书一般标题写中间,补充和无关紧要的写左边,知识点的内容写中间或者右边。同时注意字迹工整大方,别慌乱中错字漏字。
时间问题:规定是10分钟,但是高手一看就知道考生水准的,一般都不会让考生全部讲完。这时候时间把控很关键,如果想知道时间,可以在板书的时候偷看手表。另外,表现越专业,被喊停的概率越大。
答辩问题:问题特别难或者自己不会,不要慌,可以很平和尊敬地和面试官说:**您好,您可以把题目再说一遍么?不会扣分的,这么说没问题。**当然尽可能真实地表达自己的想法,不要不懂装懂,这样会让考官反感。
当然,说完之后没底怎么办?说不定你说完考官说可以了就走了。这时候如果你对自己的回答没把握,可以参照我的做法。
回答结束后接着反问考官:您觉得我讲的如何?考官一般会告诉你讲的好不好,对不对,哪些地方值得商妥。注意被指出问题就算不对也不能打断评委,要虚心接受,表示自己还有很多需要努力的地方,顺着评委。因为毕竟面试者学识尚浅,多听听前辈的意见有利于未来的教育教学生涯。
考官问题:不要被考官的面部表情所影响。你要相信有的考官真的不会笑,有时还会一脸嫌弃,生无可恋或者其他让你感到可能不会通过的表情,你别在意。
**有一个女孩评委一直对她笑,结束还很温情,但最后没过。**考官都历练过的人,不会明显的告诉你过或者不过,除非表现的特别好或者特别一般。
告别问题:注意要檫黑板,别走出去了被叫回来檫黑板,更不要让后来的人来擦黑板。告别的时候关门要注意,别反手就把门关上,声音特别大,应该走出去后面对着把门拉上。
教师资格认定是在面试合格后才能参加,面试成绩3年有效,通过最后这个流程就能领证啦!
1.认定条件
1.未达到国家法定退休年龄,在校生生大四最后一学期在学校所在地申请认定,社会考试可在户籍地或人事关系地申请认定。
2.具备相应的学历条件:
申请幼儿园、小学教师资格:专科及以上学历;
申请初级中学、高级中学、中等职业学校教师资格:本科及以上学历。
3.达到普通话水平测试二级乙等及以上标准,取得相应等级证书(语文,幼儿2甲,其他科目2乙即可)。
4.遵守宪法和法律,具有良好的职业道德,能履行《中华人民共和国教师法》规定的义务,经申请人户籍所在地乡镇人民政府(街道办事处)或所在单位(应届毕业生为就读学校)**品德鉴定合格。
5.持教育部考试中心颁发的考试合格证明的人员,申请小学、初级中学、高级中学和中等职业学校文化课教师资格,“任教学科”栏目应与申请人报考面试科目一致;申请中等职业学校专业课教师资格,“任教学科”栏目应与申请人所学专业一致。
2.认定流程
01.网上报名:
已通过中小学教师资格考试(笔试和面试)的申请人在规定时间内登录**教师资格网进行网上申报。
02.体格检查:
申请人应在规定时间内,持本人身份证、《教师资格人员体格检查表》(粘贴本人近期免冠1寸照片)自行到指定医院进行体检。
03.现场确认:
已完成网上申请的人员到相应的教师资格认定现场确认点提交教师资格申请材料。
教师资格申请材料包括:
1.二代身份证(需在有效期内)原件。
2.学历证书原件,国(境)外学历应同时提交教育部留学服务中心出具的《国(境)外学历认证书》的原件,学历信息经过学信网电子信息比对的可不提交。
3.《申请教师资格人员体格检查表》原件。
4.《个人承诺书》。
5.考试合格证明。
6.近期一寸免冠彩色相片1张。
7.在户籍所在地申请认定的,提交本人户口本或集体户口证明原件;在居住地申请认定的,应当提交有效的居住证原件;以就读学校所在地申请认定的,提交注册信息完整的学生证原件。
认定系统无法验证申请人普通话水平测试等级的,需现场审查验证取得的《普通话水平测试等级证书》原件。
**备注:**各地认定材料具体要求不一样,一定要以当地认定公告为准。
3.认定完成
各地教育(教体)局在受理申请后做出认定结论,根据认定结论,在教育部全国教师资格认定管理信息系统上进行认定数据确认和证书编号,一般一个多月后就能领证啦!
其中高年级教师资格证可以任教低年级教学任务,但是幼儿除外。
针对非师范0基础的同学,强烈推荐国家教师资格考试网旗下品牌亿师学教师资格笔试课程,全程直播授课,专业老师带着学习比自己盲目看书效果更好,并赠送全套考试教材、试卷、冲刺宝典,还有专属学习群,戳此处查看:
如果文章对你有帮助,请不吝点赞!
最后给大家分享今年最新教师资格证考试资料,需要的同学来公众号:教招考试领取!
选择题必背124道(部分)
选择题必背124道(部分)
主观题必背42道(部分)
教学设计通用模板
更多教师资格证考试,教师招聘考试信息,点击关注:
共产党宣言
(1848年)
共产主义者同盟这个在当时条件下自然只能是秘密团体的国际工人组织,1847年11月在伦敦举行的代表大会上委托我们两人起草一个准备公布的详细的理论和实践的党纲。结果就产生了这个《宣言》,《宣言》原稿在二月革命前几星期送到伦敦付印。《宣言》最初用德文出版,它用这种文字在德国、英国和美国至少印过十二种不同的版本。第一个英译本是由海伦·麦克法林女士翻译的,于1850年在伦敦《红色共和党人》杂志上发表,1871年至少又有三种不同的英译本在美国出版。法译本于1848年六月起义前不久第一次在巴黎印行,最近又有法译本在纽约《社会主义者报》上发表;现在有人在准备新译本。波兰文译本在德国本初版问世后不久就在伦敦出现。俄译本是60年代在日内瓦出版的。丹麦文译本也是在原书问世后不久就出版了。
不管最近25年来的情况发生了多大的变化,这个《宣言》中所阐述的一般原理整个说来直到现在还是完全正确的。某些地方本来可以作一些修改。这些原理的实际运用,正如《宣言》中所说的,随时随地都要以当时的历史条件为转移,所以第二章末尾提出的那些革命措施根本没有特别的意义。如果是在今天,这一段在许多方面都会有不同的写法了。由于最近25年来大工业有了巨大发展而工人阶级的政党组织也跟着发展起来,由于首先有了二月革命的实际经验而后来尤其是有了无产阶级第一次掌握政权达两月之久的巴黎公社的实际经验,所以这个纲领现在有些地方已经过时了。特别是公社已经证明:“工人阶级不能简单地掌握现成的国家机器,并运用它来达到自己的目的。”(见《法兰西内战。国际工人协会总委员会宣言》德文版第19页,那里把这个**发挥得更加完备。)其次,很明显,对于社会主义文献所作的批判在今天看来是不完全的,因为这一批判只包括到1847年为止;同样也很明显,关于共产党人对待各种反对党派的态度的论述(第四章)虽然在原则上今天还是正确的,但是就其实际运用来说今天毕竟已经过时,因为政治形势已经完全改变,当时所列举的那些党派大部分已被历史的发展彻底扫除了。
但是《宣言》是一个历史文件,我们已没有权力来加以修改。下次再版时也许能加上一篇论述1847年到现在这段时期的导言。这次再版太仓促了,我们来不及做这件工作。
卡尔·马克思 弗里德里希·恩格斯
1872年6月24日于伦敦
巴枯宁翻译的《共产党宣言》俄文第一版,60年代初由《钟声》印刷所出版。当时西方认为这件事(《宣言》译成俄文出版)是著作界的一件奇闻。这种看法今天是不可能有了。
当时(1847年12月),卷入无产阶级运动的地区是多么狭小,这从《宣言》最后一章《共产党人对各国各种反对党派的态度》中可以看得很清楚。在这一章里,正好没有说到俄国和美国。那时,俄国是欧洲全部反动势力的最后一支庞大后备军;美国正通过移民在吸收欧洲无产阶级的过剩力量。这两个国家,都向欧洲提供原料,同时又都是欧洲工业品的销售市场。所以,这两个国家不管怎样当时都是欧洲现存秩序的支柱。
今天,情况完全不同了!正是欧洲移民,使北美能够进行大规模的农业生产,这种农业生产的竞争震撼着欧洲大小土地所有制的根基。此外,这种移民还使美国能够以巨大的力量和规模开发其丰富的工业资源,以至于很快就会摧毁西欧特别是英国迄今为止的工业垄断地位。这两种情况反过来对美国本身也起着革命作用。作为整个政治制度基础的农场主的中小土地所有制,正逐渐被大农场的竞争所征服;同时,在各工业区,人数众多的无产阶级和神话般的资本积聚第一次发展起来了。
现在来看看俄国吧!在1848-1849年革命期间,不仅欧洲的君主,而且连欧洲的资产者,都把俄国的干涉看作是帮助他们对付刚刚开始觉醒的无产阶级的唯一救星。沙皇被宣布为欧洲反动势力的首领。现在,沙皇在加特契纳成了革命的俘虏,而俄国已是欧洲革命运动的先进部队了。
《共产主义宣言》的任务,是宣告现代资产阶级所有制必然灭亡。但是在俄国,我们看见,除了迅速盛行起来的资本主义狂热和刚开始发展的资产阶级土地所有制外,大半土地仍归农民公共占有。那么试问:俄国公社,这一固然已经大遭破坏的原始土地公共占有形式,是能够直接过渡到高级的共产主义的公共占有形式呢?或者相反,它还必须先经历西方的历史发展所经历的那个瓦解过程呢?
对于这个问题,目前唯一可能的答复是:假如俄国革命将成为西方无产阶级革命的信号而双方互相补充的话,那么现今的俄国土地公有制便能成为共产主义发展的起点。
卡尔·马克思 弗里德里希·恩格斯
1882年1月21日于伦敦
本版序言不幸只能由我一个人署名了。马克思这位比其它任何人都更应受到欧美整个工人阶级感谢的人物,已经长眠于海格特公墓,他的墓上已经初次长出了青草。在他逝世以后,就更谈不上对《宣言》作什么修改或补充了。因此,我认为更有必要在这里再一次明确地申述下面这一点。
贯穿《宣言》的基本**:每一历史时代的经济生产以及必然由此产生的社会结构,是该时代政治的和精神的历史的基础;因此(从原始土地公有制解体以来)全部历史都是阶级斗争的历史,即社会发展各个阶段上被剥削阶级和剥削阶级之间、被**阶级和**阶级之间斗争的历史;而这个斗争现在已经达到这样一个阶段,即被剥削被压迫的阶级(无产阶级),如果不同时使整个社会永远摆脱剥削、压迫和阶级斗争,就不再能使自己从剥削它压迫它的那个阶级(资产阶级)下解放出来,----这个基本**完全是属于马克思一个人的。
这一点我已经屡次说过,但正是现在必须在《宣言》本身的前面也写明这一点。
弗·恩格斯
1883年6月28日于伦敦
《宣言》是作为共产主义者同盟的纲领发表的,这个同盟起初纯粹是德国工人团体,后来成为国际工人团体,而在1848年以前欧洲大陆的政治条件下必然是一个秘密的团体。1847年11月在伦敦举行的同盟代表大会,委托马克思和恩格斯起草一个准备公布的完备的理论和实践的党纲。手稿于1848年1月用德文写成,并在2月24日的法国革命前几星期送到伦敦付印。法译本于1848年六月起义前不久在巴黎出版。第一个英译本是由海伦·麦克法林女士翻译的,于1850年刊载在乔治·朱利安·哈尼的伦敦《红色共和党人》杂志上。同时也出版了丹麦文译本和波兰文译本。
1848年巴黎六月起义这一无产阶级和资产阶级间的第一次大搏斗的失败,又把欧洲工人阶级的社会的和政治的要求暂时推到后面去了。从那时起,争夺**权的斗争,又像二月革命以前那样只是在有产阶级的各个集团之间进行了;工人阶级被迫局限于争取一些政治上的活动自由,并采取中等阶级激进派极左翼的立场。凡是继续显露出生机的独立的无产阶级运动,都遭到无情的镇压。例如,普鲁士警察发觉了当时设在科隆的共产主义者同盟**委员会。一些成员被逮捕,并且在经过18个月监禁之后于1852年10月被交付法庭审判。这次有名的“科隆共产党人案件”从10月4日一直继续到11月12日;被捕者中有7人被判处了3-6年的要塞监禁。宣判之后,同盟即由剩下的成员正式解散。至于《宣言》,似乎注定从此要被人遗忘了。
当欧洲工人阶级重新聚集了足以对**阶级发动另一次进攻的力量的时候,产生了国际工人协会。但是这个协会成立的明确目的是要把欧美正在进行战斗的整个无产阶级团结为一个整体,因此,它不能立刻宣布《宣言》中所提出的那些原则。国际必须有一个充分广泛的纲领,使英国工联,法国、比利时、意大利和西班牙的蒲鲁东派以及德国的拉萨尔派都能接受。马克思起草了这个能使一切党派都满意的纲领,他对共同行动和共同讨论必然会产生的工人阶级的精神发展充满信心。反资本斗争中的种种事件和变迁----失败更甚于胜利----不能不使人们认识到他们的各种心爱的万应灵丹都不灵,并为他们更透彻地了解工人阶级解放的真正的条件开辟道路。马克思是正确的。当1874年国际解散时,工人已经全然不是1864年国际成立时的那个样子了。法国的蒲鲁东主义和德国的拉萨尔主义已经奄奄一息,甚至那些很久以前大多数已同国际决裂的保守的英国工联也渐有进步,以致去年在斯旺西,工联的主席能够用工联的名义声明说:“大陆社会主义对我们来说再不可怕了。”的确,《宣言》的原则在世界各国工人中间都已传播得很广了。
这样,《宣言》本身又重新走上了前台。从1850年起,德文本在瑞士、英国和美国重版过数次。1872年,有人在纽约把它译成英文,并在那里的《伍德赫尔和克拉夫林周刊》上发表。接着又有人根据这个英文本把它译成法文,刊载在纽约的《社会主义者报》上。以后在美国又至少出现过两种多少有些损害原意的英文译本,其中一种还在英国重版过。由巴枯宁翻译的第一个俄文本约于1863年在日内瓦由赫尔岑办的《钟声》印刷所出版;由英勇无畏的维拉·查苏利奇翻译的第二个俄文本,于1882年也在日内瓦出版。新的丹麦文译本于1885年在哥本哈根作为《社会**主义丛书》的一种出版,新的法文译本于1886年刊载在巴黎的《社会主义者报》上。有人根据这个译本译成西班牙文,并于1886年在马德里发表。至于德文的翻印版本,则为数极多,总共至少有12个。亚美尼亚文译本原应于几个月前在君士坦丁堡印出,但是没有问世,有人告诉我,这是因为出版人害怕在书上标明马克思的姓名,而译者又拒绝把《宣言》当做自己的作品。关于用其它文字出版的其它译本,我虽然听说过,但是没有亲眼看到。因此,《宣言》的历史在很大程度上反映着现代工人阶级运动的历史;现在,它无疑是全部社会主义文献中传播最广和最具有国际性的著作,是从西伯利亚到加利福尼亚的千百万工人公认的共同纲领。
可是,当我们写这个《宣言》时,我们不能把它叫作社会主义宣言。在1847年,所谓社会主义者,一方面是指各种空想主义体系的信徒,即英国的欧文派和法国的傅立叶派,这两个流派都已经降到纯粹宗派的地位,并在逐渐走向灭亡;另一方面是指形形色色的社会庸医,他们凭着各种各样的补缀办法,自称要消除一切社会弊病而毫不危及资本和利润。这两种人都是站在工人阶级运动以外,宁愿向“有教养的”阶级寻求支持。只有工人阶级中确信单纯政治变革还不够而公开表明必须根本改造全部社会的那一部分人,只有他们当时把自己叫作共产主义者。这是一种粗糙的、尚欠修琢的、纯粹出于本能的共产主义;但它却接触到了最主要之点,并且在工人阶级当中强大到足以形成空想共产主义,在法国有卡贝的共产主义,在德国有魏特林的共产主义。可见,在1847年,社会主义是中等阶级的运动,而共产主义则是工人阶级的运动。当时,社会主义,至少在大陆上,是“上流社会的”,而共产主义却恰恰相反。既然我们自始就认定“工人阶级的解放应当是工人阶级自己的事情”,那么,在这两个名称中间我们应该选择哪一个,就是毫无疑义的了。而且后来我们也根本没有想到要把这个名称拋弃。
虽然《宣言》是我们两人共同的作品,但我认为自己有责任指出,构成《宣言》核心的基本**是属于马克思的。这个**就是:每一历史时代主要的经济生产方式与交换方式以及必然由此产生的社会结构,是该时代政治的和精神的历史所赖以确立的基础,并且只有从这一基础出发,这一历史才能得到说明;因此人类的全部历史(从土地公有的原始氏族社会解体以来)都是阶级斗争的历史,即剥削阶级和被剥削阶级之间、**阶级和被压迫阶级之间斗争的历史;这个阶级斗争的历史包括有一系列发展阶段,现在已经达到这样一个阶段,即被剥削被压迫的阶级(无产阶级),如果不同时使整个社会一劳永逸地摆脱任何剥削、压迫以及阶级差别和阶级斗争,就不能使自己从进行剥削和**的那个阶级(资产阶级)的控制下解放出来。
在我看来这一**对历史学必定会起到像达尔文学说对生物学所起的那样的作用,我们两人早在1845年前的几年中就已经逐渐接近了这个**。当时我个人独自在这方面达到了什么程度,我的《英国工人阶级状况》一书就是最好的说明。但是到1845年春我在布鲁塞尔再次见到马克思时,他已经把这个**考虑成熟,并且用几乎像我在上面所用的那样明晰的语句向我说明了。
现在我从我们共同为1872年德文版写的序言中引录如下一段话:
“不管最近25年来的情况发生了多大变化,这个《宣言》中所阐述的一般原理整个说来直到现在还是完全正确的。某些地方本来可以作一些修改。这些原理的实际运用,正如《宣言》中所说的,随时随地都要以当时的历史条件为转移,所以第二章末尾提出的那些革命措施根本没有特别的意义。如果是在今天,这一段在许多方面都会有不同的写法了。由于最近25年来大工业有了巨大发展而工人阶级的政党组织也跟着发展起来,由于首先有了二月革命的实际经验而后来尤其是有了无产阶级第一次掌握政权达两月之久的巴黎公社的实际经验,所以这个纲领现在有些地方已经过时了。特别是公社已经证明:‘工人阶级不能简单地掌握现成的国家机器,并运用它来达到自己的目的。’(见《法兰西内战。国际工人协会总委员会宣言》德文版第19页,那里把这个**发挥得更加完备。)其次,很明显,对于社会主义文献所作的批判在今天看来是不完全的,因为这一批判只包括到1847年为止;同样也很明显,关于共产党人对待各种反对党派的态度的论述(第四章)虽然在原则上今天还是正确的,但是就其实际运用来说今天毕竟已经过时,因为政治形势已经完全改变,当时所列举的那些党派大部分已被历史的发展彻底扫除了。
但是《宣言》是一个历史文件,我们已没有权力来加以修改。”
本版译文是由译过马克思《资本论》一书大部分的赛米尔·穆尔先生翻译的。我同他一起把译文校阅过一遍,并且我还加了一些有关历史情况的注释。
弗里德里希·恩格斯
1888年1月30日于伦敦
自从我写了上面那篇序言以来,又需要刊印《宣言》的新的德文版本了,同时《宣言》本身也有种种遭遇,应该在这里提一提。
1882年在日内瓦出版了由维拉·查苏利奇翻译的第二个俄译本,马克思和我曾为这个译本写过一篇序言。可惜我把这篇序言的德文原稿遗失了,所以现在我只好再从俄文译过来,这样做当然不会使原稿增色。下面就是这篇序言:
“巴枯宁翻译的《共产党宣言》俄文第一版,60年代初由《钟声》印刷所出版。当时西方认为这件事(《宣言》译成俄文出版)是著作界的一件奇闻。这种看法今天是不可能有了。在《宣言》最初发表时期(1848年1月)卷入无产阶级运动的地区是多么狭小,这从《宣言》最后一章《共产党人对各国各种反对党派的态度》中可看得很清楚。在这一章里,首先没有说到俄国和美国。那时,俄国是欧洲全部反动势力的最后一支庞大后备军,向美国境内移民吸收着欧洲无产阶级的过剩力量。这两个国家,都向欧洲供给原料,同时又都是欧洲工业品的销售市场。所以,这两个国家不管怎样当时都是欧洲社会秩序的支柱。
今天,情况完全不同了!正是欧洲移民,使北美的农业生产能够大大发展,这种发展通过竞争震撼着欧洲大小土地所有制的根基。此外,这种移民还使美国能够以巨大的力量和规模开发其丰富的工业资源,以至于很快就会摧毁西欧的工业垄断地位。这两种情况反过来对美国本身也起着革命作用。作为美国整个政治制度基础的自耕农场主的中小土地所有制,正逐渐被大农场的竞争所征服;同时,在各工业区,人数众多的无产阶级和神话般的资本积聚第一次发展起来了。
现在来看看俄国吧!在1848-1849年革命期间,不仅欧洲的君主,而且连欧洲的资产者,都把俄国的干涉看作是帮助他们对付刚刚开始意识到自己力量的无产阶级的唯一救星。他们把沙皇宣布为欧洲反动势力的首领。现在,沙皇在加特契纳已成了革命的俘虏,而俄国已是欧洲革命运动的先进部队了。
《共产党宣言》的任务,是宣告现代资产阶级所有制必然灭亡。但是在俄国,我们看见,除了狂热发展的资本主义制度和刚开始形成的资产阶级土地所有制外,大半土地仍归农民公共占有。
那么试问:俄国农民公社,这一固然已经大遭破坏的原始土地公有制形式,是能直接过渡到高级的共产主义的土地所有制形式呢?或者,它还必须经历西方的历史发展所经历的那个瓦解过程呢?
对于这个问题,目前唯一可能的答复是:假如俄国革命将成为西方无产阶级革命的信号而双方互相补充的话,那么现今的俄国公有制便能成为共产主义发展的起点。
卡·马克思 弗·恩格斯
1882年1月21日于伦敦”
大约在同一时候,在日内瓦出版了新的波兰文译本:《共产党宣言》。
随后又于1885年在哥本哈根作为《社会**主义丛书》的一种出版了新的丹麦文译本。可惜这一译本不够完备;有几个重要的地方大概是因为译者感到难译而被删掉了,并且有些地方可以看到草率从事的痕迹,尤其令人遗憾的是,从译文中可以看出,要是译者细心一点,他是能够译得很好的。
1886年在巴黎《社会主义者报》上刊载了新的法译文;这是到目前为止最好的译文。
同年又有人根据这个法文本译成西班牙文,起初刊登在马德里的《社会主义者报》上,接着又印成单行本:《共产党宣言》,卡·马克思和弗·恩格斯着,马德里,社会主义者报社,埃尔南·科尔特斯街8号。
这里我还要提到一件奇怪的事。1887年,君士坦丁堡的一位出版商收到了亚美尼亚文的《宣言》译稿;但是这位好心人却没有勇气把这本署有马克思的名字的作品刊印出来,竟认为最好是由译者本人冒充作者,可是译者拒绝这样做。
在英国多次刊印过好几种美国译本,但都不大确切。到1888年终于出版了一种可靠的译本。这个译本是由我的友人赛米尔·穆尔翻译的,并且在付印以前还由我们两人一起重新校阅过一遍。标题是:《共产党宣言》,卡尔·马克思和弗里德里希·恩格斯着。 经作者认可的英译本, 由弗里德里希·恩格斯校定并加注,1888年伦敦,威廉·里夫斯,东**区弗利特街185号。 这个版本中的某些注释,我已收入本版。
《宣言》有它本身的经历。它出现的时候曾受到当时人数尚少的科学社会主义先锋队的热烈欢迎(第一篇序言里提到的那些译本便可以证明这一点),但是不久以后它就被那随着1848年6月巴黎工人失败而抬起头来的反动势力排挤到后台去了,最后,由于1852年11月科隆共产党人被判刑,它被“依法”宣布为非法。随着与二月革命相联系的工人运动退出公开舞台,《宣言》也退到后台去了。
当欧洲工人阶级又强大到足以重新对**阶级政权发动进攻的时候,产生了国际工人协会。它的目的是要把欧美整个战斗的工人阶级联合成一支大军。因此,它不能从《宣言》中所提出的那些原则出发。它应该有一个不致把英国工联,法国、比利时、意大利和西班牙的蒲鲁东派以及德国的拉萨尔派拒之于门外的纲领。这样一个纲领即国际章程绪论部分,是马克思起草的,其行文之巧妙连巴枯宁和无政府派也不能不承认。至于说到《宣言》中所提出的那些原则的最终胜利,马克思把希望完全寄托于共同行动和共同讨论必然会产生的工人阶级的精神的发展。反资本斗争中的种种事件和变迁,----而且失败更甚于胜利----不能不使进行斗争的人们明白自己一向所崇奉的那些万应灵丹都不灵,并使他们的头脑更容易透彻地了解工人解放的真正的条件。马克思是正确的。1874年,当国际解散的时候,工人阶级已经全然不是1864年国际成立时的那个样子了。罗曼语族各国的蒲鲁东主义和德国特有的拉萨尔主义已经奄奄一息,甚至当时极端保守的英国工联也渐有进步,以致1887年在斯温西,工联的代表大会主席能够用工联的名义声明说:“大陆社会主义对我们来说再不可怕了。”而在1887年,大陆社会主义已经差不多完全是《宣言》中所宣布的那个理论了。因此,《宣言》的历史在某种程度上反映着1848年以来现代工人运动的历史。现在,它无疑是全部社会主义文献中传播最广和最具有国际性的著作,是从西伯利亚到加利福尼亚的世界各国千百万工人共同的纲领。
可是,当《宣言》出版的时候,我们不能把它叫做社会主义宣言。在1847年,所谓社会主义者是指两种人。一方面是指各种空想主义体系的信徒,特别是英国的欧文派和法国的傅立叶派,这两个流派当时都已经缩小成逐渐走向灭亡的纯粹的宗派。另一方面是指形形色色的社会庸医,他们想用各种万应灵丹和各种补缀办法来消除社会弊病而毫不伤及资本和利润。这两种人都是站在工人运动以外,宁愿向“有教养的”阶级寻求支持。至于当时确信单纯政治变革还不够而要求根本改造社会的那一部分工人,则把自己叫作共产主义者。这是一种还没有很好加工的、只是出于本能的、往往有些粗糙的共产主义;但它已经强大到足以形成两种空想的共产主义体系:在法国有卡贝的“伊加利亚”共产主义,在德国有魏特林的共产主义。在1847年,社会主义意味着资产阶级的运动,共产主义则意味着工人的运动。当时,社会主义,至少在大陆上,是上流社会的,而共产主义却恰恰相反。既然我们当时已经十分坚决认定“工人阶级的解放应当是工人阶级自己的事情”,所以我们一刻也不怀疑究竟应该在这两个名称中间选定哪一个名称。而且后来我们也根本没有想到要把这个名称拋弃。
“全世界无产者,联合起来!”当42年前我们在巴黎革命即无产阶级带着自己的要求参加的第一次革命的前夜向世界上发出这个号召时,响应者还是寥寥无几。可是,1864年9月28日,大多数西欧国家中的无产者已经联合成为流芳百世的国际工人协会了。固然,国际本身只存在了9年,但它所创立的全世界无产者永久的联合依然存在,并且比任何时候更加强固,而今天这个日子就是最好的证明。因为今天我写这个序言的时候,欧美无产阶级正在检阅自己第一次动员起来的战斗力量,他们动员起来,组成一支大军,在一个旗帜下,为了一个最近的目的,即早已由国际1866年日内瓦代表大会宣布、后来又由1889年巴黎工人代表大会再度宣布的在法律上确立八小时正常工作日。今天的情景定会使全世界的资本家和地主看到:全世界的无产者现在已经真正联合起来了。
如果马克思今天还能同我站在一起亲眼看见这种情景,那该多好呵!
弗·恩格斯
1890年5月1日于伦敦
从目前已有必要出版《共产党宣言》波兰文新版本这一事实,可以引起许多联想。
首先值得注意的是,近来《宣言》在某种程度上已经成为测量欧洲大陆大工业发展的一种尺度。某一国家的大工业越发展,该国工人想要弄清他们作为工人阶级在有产阶级面前所处地位的愿望也就愈强烈,工人中间的社会主义运动也就越扩大,对《宣言》的需求也就越增长。这样,根据《宣言》用某国文字发行的份数,不仅可以相当准确地判断该国工人运动的状况,而且可以相当准确地判断该国大工业发展的程度。
因此,《宣言》波兰文新版本, 标志着波兰工业的重大发展。 而且从10年前上一版问世以来确实已有这种发展,这是丝毫不容置疑的。俄罗斯的波兰,会议桌上的波兰,已成为俄罗斯帝国的巨大的工业区。俄国大工业分散于各处,一部分在芬兰湾沿岸,一部分在**区(莫斯科和弗拉基米尔),一部分在黑海和亚速海沿岸,还有一些分散在其它地方;波兰工业则集中于一个比较狭小的地区,这种集中所产生的益处和害处,它都感受到了。这种益处是竞争对手俄国工厂主所承认的,他们虽然拚命想把波兰人变成俄罗斯人,同时却要求实行对付波兰的保护关税。至于这种害处,即对波兰工厂主和俄国政府的害处,则表现为社会主义**在波兰工人中间的迅速传播和对《宣言》的需求的日益增长。
但是,波兰工业的迅速发展(它已经超过了俄国工业),又是波兰人民拥有强大生命力的新的证明,是波兰人民即将达到民族复兴的新的保证。而一个独立强盛的波兰的复兴是一件不仅关系到波兰人而且关系到我们大家的事情。欧洲各民族的真诚的国际合作,只有当每个民族都在自己家里完全自主的时候才能实现。1848年革命在无产阶级的旗帜下使无产阶级战士归根到底只是做了资产阶级的工作,这次革命也通过自己的遗嘱执行人路易·波拿巴和俾斯麦实现了意大利、德国和匈牙利的独立。至于波兰,虽然它从1792年以来对革命所作的贡献比这三个国家所作的全部贡献还要大,可是它于1863年在十倍于自己的俄国优势下失败的时候,却被拋弃不管了。波兰贵族既没有能够保持住波兰独立,也没有能够重新争得波兰独立;在资产阶级看来,波兰独立在今天至少是一件无关痛痒的事情。然而这种独立却是实现欧洲各民族和谐的合作所必需的。这种独立只有年轻的波兰无产阶级才能争得,而且在波兰无产阶级手里会很好地保持住。因为欧洲所有其余各国工人都像波兰工人本身一样需要波兰的独立。
弗·恩格斯
1892年2月10日于伦敦
致意大利读者
《共产党宣言》的发表,可以说正好碰上了1848年3月18日这个日子,碰上米兰和柏林发生革命,这是两个民族的武装起义,其中一个处于欧洲大陆中心,另一个处于地中海各国中心;这两个民族在此以前都由于分裂和内部纷争而被削弱并因而遭到外族的**。意大利受奥皇支配,而德国则受到俄国沙皇那种虽然不那么直接、但是同样可以感觉得到的压迫。1848年3月18日的结果使意大利和德国免除了这种耻辱;如果说,这两个伟大民族在1848-1871年期间得到复兴并以这种或那种形式重新获得独立,那么,这是因为,正如马克思所说,那些镇压1848年革命的人违反自己的意志充当了这次革命的遗嘱执行人。
这次革命到处都是由工人阶级干的:构筑街垒和流血牺牲的都是工人阶级,只有巴黎工人在推翻政府的同时也抱有推翻资产阶级**的明确意图。但是,虽然他们已经认识到他们这个阶级和资产阶级之间存在着不可避免的对抗,然而无论法国经济的进展或法国工人群众的精神的发展,都还没有达到可能实现社会改造的程度。因此,革命的果实最终必然被资本家阶级拿去。在其它国家,在意大利、德国、奥地利,工人从一开始就只限于帮助资产阶级取得政权。但是在任何一个国家,资产阶级的**离开民族独立是不行的。因此,1848年革命必然给那些直到当时还没有统一和独立的那些民族----意大利、德国、匈牙利----带来统一和独立。现在轮到波兰了。
由此可见,1848年革命虽然不是社会主义革命,但它毕竟为社会主义革命扫清了道路,为这个革命准备了基础。最近45年以来,资产阶级制度由于在各国引起了大工业的飞速发展,到处造成了人数众多的、紧密团结的、强大的无产阶级;这样它就产生了----正如《宣言》所说----它自身的掘墓人。不恢复每个民族的独立和统一,那就既不可能有无产阶级的国际联合,也不可能有各民族为达到共同目的而必须实行的和睦的与自觉的合作。试想想看,在1848年以前的政治条件下,哪能有意大利工人、匈牙利工人、德意志工人、波兰工人、俄罗斯工人的共同国际行动!
可见,1848年的战斗并不是白白进行的。从这次革命时期起直到今日的这四十五年,也不是白白过去的。这次革命时期的果实已开始成熟,而我的唯一愿望是这个意大利文译本的出版能成为意大利无产阶级胜利的预兆,如同《宣言》原文的出版成了国际革命的预兆一样。
《宣言》十分公正地评价了资本主义在先前所起过的革命作用。意大利曾经是第一个资本主义民族。封建的中世纪的终结和现代资本主义纪元的开端,是以一位大人物为标志的。这位人物就是意大利人但丁,他是中世纪的最后一位诗人,同时又是新时代的最初一位诗人。现在也如1300年那样,新的历史纪元正在到来。意大利是否会给我们一个新的但丁来宣告这个无产阶级新纪元的诞生呢?
弗·恩格斯
1893年2月1日于伦敦
共产党宣言
一个幽灵,共产主义的幽灵,在欧洲游荡。为了对这个幽灵进行神圣的围剿,旧欧洲的一切势力,教皇和沙皇、梅特涅和基佐、法国的激进派和德国的警察,都联合起来了。
有哪一个反对党不被它的当政的敌人骂为共产党呢?又有哪一个反对党不拿共产主义这个罪名去回敬更进步的反对党人和自己的反动敌人呢?
从这一事实中可以得出两个结论:
共产主义已经被欧洲的一切势力公认为一种势力;
现在是共产党人向全世界公开说明自己的观点、自己的目的、自己的意图并且拿党自己的宣言来反驳关于共产主义幽灵的神话的时候了。
为了这个目的,各国共产党人集会于伦敦,拟定了如下的宣言,用英文、法文、德文、意大利文、弗拉芒文和丹麦文公布于世。
至今一切社会的历史都是阶级斗争的历史。
自由民和奴隶、贵族和平民、领主和农奴、行会师傅和帮工,一句话,压迫者和被压迫者,始终处于相互对立的地位,进行不断的、有时隐蔽有时公开的斗争,而每一次斗争的结局是整个社会受到革命改造或者斗争的各阶级同归于尽。
在过去的各个历史时代,我们几乎到处都可以看到社会完全划分为各个不同的等级,看到社会地位分成的多种多样的层次。在古罗马,有贵族、骑士、平民、奴隶,在中世纪,有封建主、臣仆、行会师傅、帮工、农奴,而且几乎在每一个阶级内部又有一些特殊的阶层。
从封建社会的灭亡中产生出来的现代资产阶级社会并没有消灭阶级对立。它只是用新的阶级、新的压迫条件、新的斗争形式代替了旧的。
但是,我们的时代,资产阶级时代,却有一个特点:它使阶级对立简单化了。整个社会日益分裂为两大敌对的阵营,分裂为两大相互直接对立的阶级:资产阶级和无产阶级。
从中世纪的农奴中产生了初期城市的城关市民;从这个市民等级中发展出最初的资产阶级分子。
美洲的发现、绕过非洲的航行,给新兴的资产阶级开辟了新天地。东印度和**的市场、美洲的殖民化、对殖民地的贸易、交换手段和一般的商品的增加,使商业、航海业和工业空前高涨,因而使正在崩溃的封建社会内部的革命因素迅速发展。
以前那种封建的或行会的工业经营方式已经不能满足随着新市场的出现而增加的需求了。工场手工业代替了这种经营方式。行会师傅被工业的中间等级排挤掉了;各种行业组织之间的分工随着各个作坊内部的分工的出现而消失了。
但是,市场总是在扩大,需求总是在增加。甚至工场手工业也不再能满足需要了。于是,蒸汽和机器引起了工业生产的革命。现代大工业化替了工场手工业;工业中的百万富翁,一支一支产业大军的首领,现代资产者,代替了工业的中间等级。
大工业建立了由美洲的发现所准备好的世界市场。世界市场使商业、航海业和陆路交通得到了巨大的发展。这种发展又反过来促进了工业的扩展,同时,随着工业、商业、航海业和铁路的扩展,资产阶级也在同一程度上得到发展,增加自己的资本,把中世纪遗留下来的一切阶级都排挤到后面去。
由此可见,现代资产阶级本身是一个长期发展过程的产物,是生产方式和交换方式的一系列变革的产物。
资产阶级的这种发展的每一个阶段,都伴随着相应的政治上进展。它在封建主**下是被压迫的等级,在公社里是武装的和自治的团体,在一些地方组成独立的城市共和国,在另一些地方组成君主国中的纳税的第三等级;后来,在工场手工业时期,它是等级制君主国或专制君主国中同贵族抗衡的势力,而且是大君主国的主要基础;最后,从大工业和世界市场建立的时候起,它在现代的代议制国家里夺得了独占的政治**。现代的国家政权不过是管理整个资产阶级的共同事务的委员会罢了。
资产阶级在历史上曾经起过非常革命的作用。
资产阶级在它已经取得了**的地方把一切封建的、宗法的和田园诗般的关系都破坏了。它无情地斩断了把人们束缚于天然尊长的形形色色的封建羁绊,它使人和人之间除了赤裸裸的利害关系,除了冷酷无情的“现金交易”,就再也没有任何别的联系了。它把宗教虔诚、骑士热忱、小市民伤感这些情感的神圣发作,淹没在利己主义打算的冰水之中。它把人的尊严变成了交换价值,用一种没有良心的贸易自由代替了无数特许的和自力挣得的自由。总而言之,它用公开的、无耻的、直接的、露骨的剥削代替了由宗教幻想和政治幻想掩盖着的剥削。
资产阶级抹去了一切向来受人尊崇和令人敬畏的职业的神圣光环。它把医生、律师、教士、诗人和学者变成了它出钱招雇的雇佣劳动者。
资产阶级撕下了罩在家庭关系上的温情脉脉的面纱,把这种关系变成了纯粹的金钱关系。
资产阶级揭示了,在中世纪深受反动派称许的那种人力的野蛮使用,是以极端怠惰作为相应补充的。它第一个证明了,人的活动能够取得什么样的成就。它创造了完全不同于埃及金字塔、罗马水道和哥特式教堂的奇迹;它完成了完全不同于民族大迁徙和十字军东征的远征。
资产阶级除非对生产工具,从而对生产关系,从而对全部社会关系不断地进行革命,否则就不能生存下去。反之,原封不动地保持旧的生产方式,却是过去的一切工业阶级生存的首要条件。生产的不断变革,一切社会状况不停的动荡,永远的不安定和变动,这就是资产阶级时代不同于过去一切时代的地方。一切固定的僵化的关系以及与之相适应的素被尊崇的观念和见解都被消除了,一切新形成的关系等不到固定下来就陈旧了。一切等级的和固定的东西都烟消云散了,一切神圣的东西都被亵渎了。人们终于不得不用冷静的眼光来看他们的生活地位、他们的相互关系。
不断扩大产品销路的需要,驱使资产阶级奔走于全球各地。它必须到处落户,到处开发,到处建立联系。
资产阶级,由于开拓了世界市场,使一切国家的生产和消费都成为世界性的了。使反动派大为惋惜的是,资产阶级挖掉了工业脚下的民族基础。古老的民族工业被消灭了,并且每天都还在被消灭。它们被新的工业排挤掉了,新的工业的建立已经成为一切文明民族的生命攸关的问题;这些工业所加工的,已经不是本地的原料,而是来自极其遥远的地区的原料;它们的产品不仅供本国消费,而且同时供世界各地消费。旧的、靠国产品来满足的需要,被新的、要靠极其遥远的国家和地带的产品来满足的需要所代替了。过去那种地方的和民族的自给自足和闭关自守状态,被各民族的各方面的互相往来和各方面的互相依赖所代替了。物质的生产是如此,精神的生产也是如此。各民族的精神产品成了公共的财产。民族的片面性和局限性日益成为不可能,于是由许多种民族的和地方的文学形成了一种世界的文学。
资产阶级,由于一切生产工具的迅速改进,由于交通的极其便利,把一切民族甚至最野蛮的民族都卷到文明中来了。它的商品的低廉价格,是它用来摧毁一切万里长城、征服野蛮人最顽强的仇外心理的重炮。它迫使一切民族——如果它们不想灭亡的话——采用资产阶级的生产方式;它迫使它们在自己那里推行所谓文明,即变成资产者。一句话,它按照自己的面貌为自己创造出一个世界。
资产阶级使农村屈服于城市的**。它创立了巨大的城市,使城市人口比农村人口大大增加起来,因而使很大一部分居民脱离了农村生活的愚昧状态。正象它使农村从属于城市一样,它使未开化和半开化的国家从属于文明的国家,使农民的民族从属于资产阶级的民族,使东方从属于西方。
资产阶级日甚一日地消灭生产资料、财产和人口的分散状态。它使人口密集起来,使生产资料集中起来,使财产聚集在少数人的手里。由此必然产生的结果就是政治的集中。各自独立的、几乎只有同盟关系的、各有不同利益、不同法律、不同政府、不同关税的各个地区,现在已经结合为一个拥有统一的政府、统一的法律、统一的民族阶级利益和统一的关税的统一的民族。
资产阶级在它的不到一百年的阶级**中所创造的生产力,比过去一切世代创造的全部生产力还要多,还要大。自然力的征服,机器的采用,化学在工业和农业中的应用,轮船的行驶,铁路的通行,电报的使用,整个整个大陆的开垦,河川的通航,仿佛用法术从地下呼唤出来的大量人口,——过去哪一个世纪料想到在社会劳动里蕴藏有这样的生产力呢?
由此可见,资产阶级赖以形成的生产资料和交换手段,是在封建社会里造成的。在这些生产资料和交换手段发展的一定阶段上,封建社会的生产和交换在其中进行的关系,封建的农业和工场手工业组织,一句话,封建的所有制关系,就不再适应已经发展的生产力了。这种关系已经在阻碍生产而不是促进生产了。它变成了束缚生产的桎梏。它必须被炸毁,而且已经被炸毁了。
起而代之的是自由竞争以及与自由竞争相适应的社会制度和政治制度、资产阶级的经济**和政治**。
现在,我们眼前又进行着类似的运动。资产阶级的生产关系和交换关系,资产阶级的所有制关系,这个曾经仿佛用法术创造了如此庞大的生产资料和交换手段的现代资产阶级社会,现在像一个魔法师一样不能再支配自己用法术呼唤出来的魔鬼了。几十年来的工业和商业的历史,只不过是现代生产力反抗现代生产关系、反抗作为资产阶级及其**的存在条件的所有制关系的历史。只要指出在周期性的重复中越来越危及整个资产阶级社会生存的商业危机就够了。在商业危机期间,总是不仅有很大一部分制成的产品被毁灭掉,而且有很大一部分已经造成的生产力被毁灭掉。在危机期间,发生一种在过去一切时代看来都好象是荒唐现象的社会瘟疫,即生产过剩的瘟疫。社会突然发现自己回到了一时的野蛮状态;仿佛是一次饥荒、一场普遍的毁灭性战争,使社会失去了全部生活资料;仿佛是工业和商业全被毁灭了,——这是什么缘故呢?因为社会上文明过度,生活资料太多,工业和商业太发达。社会所拥有的生产力已经不能再促进资产阶级文明和资产阶级所有制关系的发展;相反,生产力已经强大到这种关系所不能适应的地步,它已经受到这种关系的阻碍;而它一着手克服这种障碍,就使整个资产阶级社会陷入混乱,就使资产阶级所有制的存在受到威胁。资产阶级的关系已经太狭窄了,再容纳不了它本身所造成的财富了。——资产阶级用什么办法来克服这种危机呢?一方面不得不消灭大量生产力,另一方面夺取新的市场,更加彻底地利用旧的市场。这究竟是怎样的一种办法呢?这不过是资产阶级准备更全面更猛烈的危机的办法,不过是使防止危机的手段越来越少的办法。
资产阶级用来推翻封建制度的武器,现在却对准资产阶级自己了。
但是,资产阶级不仅锻造了置自身于死地的武器;它还产生了将要运用这种武器的人——现代的工人,即无产者。
随着资产阶级即资本的发展,无产阶级即现代工人阶级也在同一程度上得到发展;现代的工人只有当他们找到工作的时候才能生存,而且只有当他们的劳动增殖资本的时候才能找到工作。这些不得不把自己零星出卖的工人,像其它任何货物一样,也是一种商品,所以他们同样地受到竞争的一切变化、市场的一切波动的影响。
由于机器的推广和分工,无产者的劳动已经失去了任何独立的性质,因而对工人也失去了任何吸引力。工人变成了机器的单纯的附属品,要求他做的只是极其简单、极其单调和极容易学会的操作。因此,花在工人身上的费用,几乎只限于维持工人生活和延续工人后代所必需的生活资料。但是,商品的价格,从而劳动的价格,是同它的生产费用相等的。因此,劳动越使人感到厌恶,工资也就越减少。不仅如此,机器越推广,分工越细致,劳动量也就越增加,这或者是由于工作时间的延长,或者是由于在一定时间内所要求的劳动的增加,机器运转的加速,等等。
现代工业已经把家长式的师傅的小作坊变成了工业资本家的大工厂。挤在工厂里的工人群众就象士兵一样被组织起来。他们是产业军的普通士兵,受着各级军士和军官的层层监视。他们不仅是资产阶级的、资产阶级国家的奴隶,并且每日每时都受机器、受监工、首先是受各个经营工厂的资产者本人的奴役。这种专制制度越是公开地把营利宣布为自己的最终目的,它就越是可鄙、可恨和可恶。
手的操作所要求的技巧和气力越少,换句话说,现代工业越发达,男工也就越受到女工和童工的排挤。对工人阶级来说,性别和年龄的差别再没有什么社会意义了。他们都只是劳动工具,不过因为年龄和性别的不同而需要不同的费用罢了。
当厂主对工人的剥削告一段落,工人领到了用现钱支付的工资的时候,马上就有资产阶级中的另一部分人——房东、小店主、当铺老板等等向他们扑来。
以前的中间等级的下层,即小工业家、小商人和小食利者,手工业者和农民——所有这些阶级都降落到无产阶级的队伍里来了,有的是因为他们的小资本不足以经营大工业,经不起较大资本家的竞争;有的是因为他们的手艺已经被新的生产方法弄得不值钱了。无产阶级的队伍就是这样从居民的所有阶级中得到补充的。
无产阶级经历了各个不同的发展阶段。它反对资产阶级的斗争是和它的存在同时开始的。
最初是单个的工人,然后是某一工厂的工人,然后是某一地方的某一劳动部门的工人,同直接剥削他们的单个资产者作斗争。他们不仅仅攻击资产阶级的生产关系,而且攻击生产工具本身;他们毁坏那些来竞争的外国商品,捣毁机器,烧毁工厂,力图恢复已经失去的中世纪工人的地位。
在这个阶段上,工人们还是分散在全国各地并为竞争所分裂的群众。工人的大规模集结,还不是他们自己联合的结果,而是资产阶级联合的结果,当时资产阶级为了达到自己的政治目的必须而且暂时还能够把整个无产阶级发动起来。因此,在这个阶段上,无产者不是同自己的敌人作斗争,而是同自己的敌人的敌人作斗争,即同专制君主制的残余、地主、非工业资产阶级和小资产者作斗争。因此,整个历史运动都集中在资产阶级手里;在这种条件下取得的每一个胜利都是资产阶级的胜利。
但是,随着工业的发展,无产阶级不仅人数增加了,而且它结合成更大的集体,它的力量日益增长,它越来越感觉到自己的力量。机器使劳动的差别越来越小,使工资几乎到处都降到同样低的水平,因而无产阶级内部的利益和生活状况也越来越趋于一致。资产者彼此间日益加剧的竞争以及由此引起的商业危机,使工人的工资越来越不稳定;机器的日益迅速的和继续不断的改良,使工人的整个生活地位越来越没有保障;单个工人和单个资产者之间的冲突越来越具有两个阶级的冲突的性质。工人开始成立反对资产者的同盟;他们联合起来保卫自己的工资。他们甚至建立了经常性的团体,以便为可能发生的反抗准备食品。有些地方,斗争爆发为起义。
工人有时也得到胜利,但这种胜利只是暂时的。他们斗争的真正成果并不是直接取得的成功,而是工人的越来越扩大的联合。这种联合由于大工业所造成的日益发达的交通工具而得到发展,这种交通工具把各地的工人彼此联系起来。只要有了这种联系,就能把许多性质相同的地方性的斗争汇合成全国性的斗争,汇合成阶级斗争。而一切阶级斗争都是政治斗争。中世纪的市民靠乡间小道需要几百年才能达到的联合,现代的无产者利用铁路只要几年就可以达到了。
无产者组织成为阶级,从而组织成为政党这件事,不断地由于工人的自相竞争而受到破坏。但是,这种组织总是重新产生,并且一次比一次更强大,更坚固,更有力。它利用资产阶级内部的分裂,迫使他们用法律形式承认工人的个别利益。英国的十小时工作日法案就是一个例子。
旧社会内部的所有冲突在许多方面都促进了无产阶级的发展。资产阶级处于不断的斗争中:最初反对贵族:后来反对同工业进步有利害冲突的那部分资产阶级;经常反对一切外国的资产阶级。在这一切斗争中,资产阶级都不得不向无产阶级呼吁,要求无产阶级援助,这样就把无产阶级卷进了政治运动。于是,资产阶级自己就把自己的教育因素即反对自身的武器给予了无产阶级。
其次,我们已经看到,工业的进步把**阶级的整批成员拋到无产阶级队伍里去,或者至少也使他们的生活条件受到威胁。他们也给无产阶级带来了大量的教育因素。
最后,在阶级斗争接近决战的时期,**阶级内部的、整个旧社会内部的瓦解过程,就达到非常强烈、非常尖锐的程度,甚至使得**阶级中的一小部分人脱离**阶级而归附于革命的阶级,即掌握着未来的阶级。所以,正像过去贵族中有一部分人转到资产阶级方面一样,现在资产阶级中也有一部分人,特别是已经提高到从理论上认识整个历史运动这一水平的一部分资产阶级**家,转到无产阶级方面来了。
在当前同资产阶级对立的一切阶级中,只有无产阶级是真正革命的阶级。其余的阶级都随着大工业的发展而日趋没落和灭亡,无产阶级却是大工业本身的产物。
中间等级,即小工业家、小商人、手工业者、农民,他们同资产阶级作斗争,都是为了维护他们这种中间等级的生存,以免于灭亡。所以,他们不是革命的,而是保守的。不仅如此,他们甚至是反动的,因为他们力图使历史的车轮倒转。如果说他们是革命的,那是鉴于他们行将转入无产阶级的队伍,这样,他们就不是维护他们目前的利益,而是维护他们将来的利益,他们就离开自己原来的立场,而站到无产阶级的立场上来。
流氓无产阶级是旧社会最下层中消极的腐化的部分,他们在一些地方也被无产阶级革命卷到运动里来,但是,由于他们的整个生活状况,他们更甘心于被人收买,去干反动的勾当。
在无产阶级的生活条件中,旧社会的生活条件已经被消灭了。无产者是没有财产的;他们和妻子儿女的关系同资产阶级的家庭关系再没有任何共同之处了;现代的工业劳动,现代的资本压迫,无论在英国或法国,无论在美国或德国,都是一样的,都使无产者失去了任何民族性。法律、道德、宗教,在他们看来全都是资产阶级偏见,隐藏在这些偏见后面的全都是资产阶级利益。
过去一切阶级在争得**之后,总是使整个社会服从于它们发财致富的条件,企图以此来巩固它们已经获得的生活地位。无产者只有废除自己的现存的占有方式,从而废除全部现存的占有方式,才能取得社会生产力。无产者没有什么自己的东西必须加以保护,他们必须摧毁至今保护和保障私有财产的一切。
过去的一切运动都是少数人的或者为少数人谋利益的运动。无产阶级的运动是绝大多数人的、为绝大多数人谋利益的独立的运动。无产阶级,现今社会的最下层,如果不炸毁构成官方社会的整个上层,就不能抬起头来,挺起胸来。
如果不就内容而就形式来说,无产阶级反对资产阶级的斗争首先是一国范围内的斗争。每一个国家的无产阶级当然首先应该打倒本国的资产阶级。
在叙述无产阶级发展的最一般的阶段的时候,我们循序探讨了现存社会内部或多或少隐蔽着的国内战争,直到这个战争爆发为公开的革命,无产阶级用暴力推翻资产阶级而建立自己的**。
我们已经看到,至今的一切社会都是建立在压迫阶级和被压迫阶级的对立之上的。但是,为了有可能压迫一个阶级,就必须保证这个阶级至少有能够勉强维持它的奴隶般的生存的条件。农奴曾经在农奴制度下挣扎到公社社员的地位,小资产者曾经在封建专制制度的束缚下挣扎到资产者的地位。现代的工人却相反,他们并不是随着工业的进步而上升,而是越来越降到本阶级的生存条件以下。工人变成赤贫者,贫困比人口和财富增长得还要快。由此可以明显地看出,资产阶级再不能做社会的**阶级了,再不能把自己阶级的生存条件当做支配一切的规律强加于社会了。资产阶级不能**下去了,因为它甚至不能保证自己的奴隶维持奴隶的生活,因为它不得不让自己的奴隶落到不能养活它反而要它来养活的地步。社会再不能在它**下生活下去了,就是说,它的存在不再同社会兼容了。
资产阶级生存和**的根本条件,是财富在私人手里的积累,是资本的形成和增殖;资本的条件是雇佣劳动。雇佣劳动完全是建立在工人的自相竞争之上的。资产阶级无意中造成而又无力抵抗的工业进步,使工人通过结社而达到的革命联合代替了他们由于竞争而造成的分散状态。于是,随着大工业的发展,资产阶级赖以生产和占有产品的基础本身也就从它的脚下被挖掉了。它首先生产的是它自身的掘墓人。资产阶级的灭亡和无产阶级的胜利是同样不可避免的。
共产党人同全体无产者的关系是怎样的呢?
共产党人不是同其它工人政党相对立的特殊政党。
他们没有任何同整个无产阶级的利益不同的利益。
他们不提出任何特殊的原则,用以塑造无产阶级的运动。
共产党人同其它无产阶级政党不同的地方只是:一方面,在各国无产者的斗争中,共产党人强调和坚持整个无产阶级共同的不分民族的利益;另一方面,在无产阶级和资产阶级的斗争所经历的各个发展阶段上,共产党人始终代表整个运动的利益。
因此,在实践方面,共产党人是各国工人政党中最坚决的、始终起推动作用的部分;在理论方面,他们胜过其余的无产阶级群众的地方在于他们了解无产阶级运动的条件、进程和一般结果。
共产党人的最近目的是和其它一切无产阶级政党的最近目的一样的:使无产阶级形成为阶级,推翻资产阶级的**,由无产阶级夺取政权。
共产党人的理论原理,决不是以这个或那个世界改革家所发明或发现的**、原则为根据的。
这些原理不过是现在的阶级斗争、我们眼前的历史运动的真实关系的一般表述。废除先前存在的所有制关系,并不是共产主义所独具的特征。
一切所有制关系都经历了经常的历史更替、经常的历史变更。
例如,法国革命废除了封建的所有制,代之以资产阶级的所有制。
共产主义的特征并不是要废除一般的所有制,而是要废除资产阶级的所有制。
但是,现代的资产阶级私有制是建立在阶级对立上面、建立在一些人对另一些人的剥削上面的产品生产和占有的最后而又最完备的表现。
从这个意义上说,共产党人可以把自己的理论概括为一句话:消灭私有制。
有人责备我们共产党人,说我们要消灭个人挣得的、自己劳动得来的财产,要消灭构成个人的一切自由、活动和独立的基础的财产。
好一个劳动得来的、自己挣得的、自己赚来的财产!你们说的是资产阶级所有制以前的那种小资产阶级的、小农的财产吗?那种财产用不着我们去消灭,工业的发展已经把它消灭了,而且每天都在消灭它。
或者,你们说的是现代的资产阶级的私有财产吧?
但是,难道雇佣劳动,无产者的劳动,会给无产者创造出财产来吗?没有的事。这种劳动所创造的是资本,即剥削雇佣劳动的财产,只有在不断产生出新的雇佣劳动来重新加以剥削的条件下才能增加起来的财产。现今的这种财产是在资本和雇佣劳动的对立中运动的。让我们来看看这种对立的两个方面吧。
做一个资本家,这就是说,他在生产中不仅占有一种纯粹个人的地位,而且占有一种社会的地位。资本是集体的产物,它只有通过社会许多成员的共同活动,而且归根到底只有通过社会全体成员的共同活动,才能运动起来。
因此,资本不是一种个人力量,而是一种社会力量。
因此,把资本变为公共的、属于社会全体成员的财产,这并不是把个人财产变为社会财产。这时所改变的只是财产的社会性质。它将失掉它的阶级性质。
现在,我们来看看雇佣劳动。
雇佣劳动的平均价格是最低限度的工资,即工人为维持其工人的生活所必需的生活资料的数额。因此,雇佣工人靠自己的劳动所占有的东西,只够勉强维持他的生命的再生产。我们决不打算消灭这种供直接生命再生产用的劳动产品的个人占有,这种占有并不会留下任何剩余的东西使人们有可能支配别人的劳动。我们要消灭的只是这种占有的可怜的性质,在这种占有下,工人仅仅为增殖资本而活着,只有在**阶级的利益需要他活着的时候才能活着。
在资产阶级社会里,活的劳动只是增殖已经积累起来的劳动的一种手段。在共产主义社会里,已经积累起来的劳动只是扩大、丰富和提高工人的生活的一种手段。
因此,在资产阶级社会里是过去支配现在,在共产主义社会里是现在支配过去。在资产阶级社会里,资本具有独立性和个性,而活动着的个人却没有独立性和个性。
而资产阶级却把消灭这种关系说成是消灭个性和自由!说对了。的确,正是要消灭资产者的个性、独立性和自由。
在现今的资产阶级生产关系的范围内,所谓自由就是自由贸易,自由买卖。
但是,买卖一消失,自由买卖也就会消失。关于自由买卖的言论,也象我们的资产阶级的其它一切关于自由的大话一样,仅仅对于不自由的买卖来说,对于中世纪被奴役的市民来说,才是有意义的,而对于共产主义要消灭买卖、消灭资产阶级生产关系和资产阶级本身这一点来说,却是毫无意义的。
我们要消灭私有制,你们就惊慌起来。但是,在你们的现存社会里,私有财产对十分之九的成员来说已经被消灭了;这种私有制之所以存在,正是因为私有财产对十分之九的成员来说已经不存在。可见,你们责备我们,是说我们要消灭那种以社会上的绝大多数人没有财产为必要条件的所有制。
总而言之,你们责备我们,是说我们要消灭你们的那种所有制。的确,我们是要这样做的。
从劳动不再能变为资本、货币、地租,一句话,不再能变为可以垄断的社会力量的时候起,就是说,从个人财产不再能变为资产阶级财产的时候起,你们说,个性就被消灭了。
由此可见,你们是承认,你们所理解的个性,不外是资产者、资产阶级私有者。这样的个性确实应当被消灭。
共产主义并不剥夺任何人占有社会产品的权力,它只剥夺利用这种占有去奴役他人劳动的权力。
有人反驳说,私有制一消灭,一切活动就会停止,懒惰之风就会兴起。
这样说来,资产阶级社会早就应该因懒惰而灭亡了,因为在这个社会里是劳者不获,获者不劳的。所有这些顾虑,都可以归结为这样一个同义反复:一旦没有资本,也就不再有雇佣劳动了。
所有这些对共产主义的物质产品的占有方式和生产方式的责备, 也被扩及到精神产品的占有和生产方面。正如阶级的所有制的终止在资产者看来是生产本身的终止一样,阶级的教育的终止在他们看来就等于一切教育的终止。
资产者唯恐失去的那种教育,对绝大多数人来说是把人训练成机器。
但是,你们既然用你们资产阶级关于自由、教育、法等等的观念来衡量废除资产阶级所有制的主张,那就请你们不要同我们争论了。你们的观念本身是资产阶级的生产关系和所有制关系的产物,正象你们的法不过是被奉为法律的你们这个阶级的意志一样,而这种意志的内容是由你们这个阶级的物质生活条件来决定的。
你们的利己观念使你们把自己的生产关系和所有制关系从历史的、在生产过程中是暂时的关系变成永恒的自然规律和理性规律,这种利己观念是你们和一切灭亡了的**阶级所共有的。谈到古代所有制的时候你们所能理解的,谈到封建所有制的时候你们所能理解的,一谈到资产阶级所有制你们就再也不能理解了。
消灭家庭!连极端的激进派也对共产党人的这种可耻的意图表示愤慨。
现代的、资产阶级的家庭是建立在什么基础上的呢?是建立在资本上面,建立在私人发财上面的。这种家庭只是在资产阶级那里才以充分发展的形式存在着,而无产者的被迫独居和公开的卖淫则是它的补充。
资产者的家庭自然会随着它的这种补充的消失而消失,两者都要随着资本的消失而消失。
你们是责备我们要消灭父母对子女的剥削吗?我们承认这种罪状。
但是,你们说,我们用社会教育代替家庭教育,就是要消灭人们最亲密的关系。
而你们的教育不也是由社会决定的吗?不也是由你们进行教育的那种社会关系决定的吗?不也是由社会通过学校等等进行的直接的或间接的干涉决定的吗?共产党人并没有发明社会对教育的影响;他们仅仅是要改变这种影响的性质,要使教育摆脱**阶级的影响。
无产者的一切家庭联系越是由于大工业的发展而被破坏,他们的子女越是由于这种发展而被变成单纯的商品和劳动工具,资产阶级关于家庭和教育、关于父母和子女的亲密关系的空话就越是令人作呕。
但是,你们共产党人是要实行公妻制的啊,——整个资产阶级异口同声地向我们这样叫喊。
资产者是把自己的妻子看作单纯的生产工具的。他们听说生产工具将要公共使用,自然就不能不想到妇女也会遭到同样的命运。
他们想也没有想到,问题正在于使妇女不再处于单纯生产工具的地位。
其实,我们的资产者装得道貌岸然,对所谓的共产党人的正式公妻制表示惊讶,那是再可笑不过了。公妻制无需共产党人来实行,它差不多是一向就有的。
我们的资产者不以他们的无产者的妻子和女儿受他们支配为满足,正式的卖淫更不必说了,他们还以互相诱奸妻子为最大的享乐。
资产阶级的婚姻实际上是公妻制。人们至多只能责备共产党人,说他们想用正式的、公开的公妻制来代替伪善地掩蔽着的公妻制。其实,不言而喻,随着现在的生产关系的消灭,从这种关系中产生的公妻制,即正式的和非正式的卖淫,也就消失了。
还有人责备共产党人,说他们要取消祖国,取消民族。
工人没有祖国。决不能剥夺他们所没有的东西。因为无产阶级首先必须取得政治**,上升为民族的阶级,把自身组织成为民族,所以它本身还是民族的,虽然完全不是资产阶级所理解的那种意思。
随着资产阶级的发展,随着贸易自由的实现和世界市场的建立,随着工业生产以及与之相适应的生活条件的趋于一致,各国人民之间的民族隔绝和对立日益消失。
无产阶级的**将使它们更快地消失。联合的行动,至少是各文明国家的联合的行动,是无产阶级获得解放的首要条件之一。
人对人的剥削一消灭,民族对民族的剥削就会随之消灭。
民族内部的阶级对立一消失,民族之间的敌对关系就会随之消失。
从宗教的、哲学的和一般意识形态的观点对共产主义提出的种种责难,都不值得详细讨论了。
人们的观念、观点和概念,一句话,人们的意识,随着人们的生活条件、人们的社会关系、人们的社会存在的改变而改变,这难道需要经过深思才能了解吗?
**的历史除了证明精神生产随着物质生产的改造而改造,还证明了什么呢?任何一个时代的****始终都不过是**阶级的**。
当人们谈到使整个社会革命化的**时,他们只是表明了一个事实:在旧社会内部已经形成了新社会的因素,旧**的瓦解是同旧生活条件的瓦解步调一致的。
当古代世界走向灭亡的时候,古代的各种宗教就被基督教战胜了。当基督教**在18世纪被启蒙**击败的时候,封建社会正在同当时革命的资产阶级进行殊死的斗争。信仰自由和宗教自由的**,不过表明自由竞争在信仰的领域里占**地位罢了。
“但是”,有人会说,“宗教的、道德的、哲学的、政治的、法的观念等等在历史发展的进程中固然是不断改变的,而宗教、道德、哲学、政治和法在这种变化中却始终保存着。
此外,还存在着一切社会状态所共有的永恒的真理,如自由、正义等等。但是共产主义要废除永恒真理,它要废除宗教、道德,而不是加以革新,所以共产主义是同至今的全部历史发展进程相矛盾的。”
这种责难归结为什么呢?至今的一切社会的历史都是在阶级对立中运动的,而这种对立在各个不同的时代具有不同的形式。
但是,不管阶级对立具有什么样的形式,社会上一部分人对另一部分人的剥削却是过去各个世纪所共有的事实。因此,毫不奇怪,各个世纪的社会意识,尽管形形色色、千差万别,总是在某些共同的形式中运动的,这些形式,这些意识形式,只有当阶级对立完全消失的时候才会完全消失。
共产主义革命就是同传统的所有制关系实行最彻底的决裂;毫不奇怪,它在自己的发展进程中要同传统的观念实行最彻底的决裂。
不过,我们还是把资产阶级对共产主义的种种责难撇开吧。
前面我们已经看到,工人革命的第一步就是使无产阶级上升为**阶级,争得**。
无产阶级将利用自己的政治**,一步一步地夺取资产阶级的全部资本,把一切生产工具集中在国家即组织成为**阶级的无产阶级手里,并且尽可能快地增加生产力的总量。
要做到这一点,当然首先必须对所有权和资产阶级生产关系实行强制性的干涉,也就是采取这样一些措施,这些措施在经济上似乎是不够充分的和没有力量的,但是在运动进程中它们会越出本身,而且作为变革全部生产方式的手段是必不可少的。
这些措施在不同的国家里当然会是不同的。
但是,最先进的国家几乎都可以采取下面的措施:
1.剥夺地产,把地租用于国家支出。
2.征收高额累进税。
3.废除继承权。
4.没收一切流亡分子和叛乱分子的财产。
5.通过拥有国家资本和独享垄断权的国家银行,把信贷集中在国家手里。
6.把全部运输业集中在国家手里。
7.按照总的计划增加国营工厂和生产工具,开垦荒地和改良土壤。
8.实行普遍劳动义务制,成立产业军,特别是在农业方面。
9.把农业和工业结合起来,促使城乡对立逐步消灭。
10.对所有儿童实行公共的和免费的教育。取消现在这种形式的儿童的工厂劳动。把教育同物质生产结合起来,等等。
当阶级差别在发展进程中已经消失而全部生产集中在联合起来的个人的手里的时候,公共权力就失去政治性质。原来意义上的政治权力,是一个阶级用以压迫另一个阶级的有组织的暴力。如果说无产阶级在反对资产阶级的斗争中一定要联合为阶级,如果说它通过革命使自己成为**阶级,并以**阶级的资格用暴力消灭旧的生产关系,那么它在消灭这种生产关系的同时,也就消灭了阶级对立和阶级本身的存在条件,从而消灭了它自己这个阶级的**。
代替那存在着阶级和阶级对立的资产阶级旧社会的,将是这样一个联合体,在那里,每个人的自由发展是一切人的自由发展的条件。
(甲)封建的社会主义
法国和英国的贵族,按照他们的历史地位所负的使命,就是写一些抨击现代资产阶级社会的作品。在法国的1830年七月革命和英国的改革运动中,他们再一次被可恨的暴发户打败了。从此就再谈不上严重的政治斗争了。他们还能进行的只是文字斗争。但是,即使在文字方面也不可能重弹复辟时期的老调了。为了激起同情,贵族们不得不装模做样,似乎他们已经不关心自身的利益,只是为了被剥削的工人阶级的利益才去写对资产阶级的控诉书。他们用来泄愤的手段是:唱唱诅咒他们的新**者的歌,并向他叽叽咕咕地说一些或多或少凶险的预言。
这样就产生了封建的社会主义,半是挽歌,半是谤文;半是过去的回音,半是未来的恫吓;它有时也能用辛辣、俏皮而尖刻的评论刺中资产阶级的心,但是它由于完全不能理解现代历史的进程而总是令人感到可笑。
为了拉拢人民,贵族们把无产阶级的乞食袋当做旗帜来挥舞。但是,每当人民跟着他们走的时候,都发现他们的臀部带有旧的封建纹章,于是就哈哈大笑,一哄而散。
一部分法国正统派和“青年英国”,都演过这出戏。
封建主说,他们的剥削方式和资产阶级的剥削不同,那他们只是忘记了,他们是在完全不同的、目前已经过时的情况和条件下进行剥削的。他们说,在他们的**下并没有出现过现代的无产阶级,那他们只是忘记了,现代的资产阶级正是他们的社会制度的必然产物。
不过,他们毫不掩饰自己的批评的反动性质,他们控告资产阶级的主要罪状正是在于:在资产阶级的**下有一个将把整个旧社会制度炸毁的阶级发展起来。
他们责备资产阶级,与其说是因为它产生了无产阶级,不如说是因为它产生了革命的无产阶级。
因此,在政治实践中,他们参与对工人阶级采取的一切暴力措施,在日常生活中,他们违背自己的那一套冠冕堂皇的言词,屈尊拾取金苹果,不顾信义、仁爱和名誉去做羊毛、甜菜和烧酒的买卖。
正如僧侣总是同封建主携手同行一样,僧侣的社会主义也总是同封建的社会主义携手同行的。
要给基督教禁欲主义涂上一层社会主义的色彩,是再容易不过了。基督教不是也激烈反对私有制,反对婚姻,反对国家吗?它不是提倡用行善和求乞、独身和禁欲、修道和礼拜来代替这一切吗?基督教的社会主义,只不过是僧侣用来使贵族的怨愤神圣化的圣水罢了。
(乙)小资产阶级的社会主义
封建贵族并不是被资产阶级所推翻的、其生活条件在现代资产阶级社会里日益恶化和消失的唯一阶级。中世纪的城关市民等级和小农等级是现代资产阶级的前身。在工商业不很发达的国家里,这个阶级还在新兴的资产阶级身旁勉强生存着。
在现代文明已经发展的国家里,形成了一个新的小资产阶级,它摇摆于无产阶级和资产阶级之间,并且作为资产阶级社会的补充部分不断地重新组成。但是,这一阶级的成员经常被竞争拋到无产阶级队伍里去,而且,随着大工业的发展,他们甚至觉察到,他们很快就会完全失去他们作为现代社会中一个独立部分的地位,在商业、工业和农业中很快就会被监工和雇员所代替。
在农民阶级远远超过人口半数的国家,例如在法国,那些站在无产阶级方面反对资产阶级的著作家,自然是用小资产阶级和小农的尺度去批判资产阶级制度的,是从小资产阶级的立场出发替工人说话的。这样就形成了小资产阶级的社会主义。西斯蒙第不仅对法国而且对英国来说都是这类著作家的首领。
这种社会主义非常透彻地分析了现代生产关系中的矛盾。它揭穿了经济学家的虚伪的粉饰。它确凿地证明了机器和分工的破坏作用、资本和地产的积聚、生产过剩、危机、小资产者和小农的必然没落、无产阶级的贫困、生产的无政府状态、财富分配的极不平均、各民族之间的毁灭性的工业战争,以及旧风尚、旧家庭关系和旧民族性的解体。
但是,这种社会主义按其实际内容来说,或者是企图恢复旧的生产资料和交换手段,从而恢复旧的所有制关系和旧的社会,或者是企图重新把现代的生产资料和交换手段硬塞到已被它们突破而且必然被突破的旧的所有制关系的框子里去。它在这两种场合都是反动的,同时又是空想的。
工业中的行会制度,农业中的宗法经济,——这就是它的最后结论。
这一思潮在它以后的发展中变成了一种怯懦的悲叹。
(丙)德国的或“真正的”社会主义
法国的社会主义和共产主义的文献是在居于**地位的资产阶级的压迫下产生的,并且是同这种**作斗争的文字表现,这种文献被搬到德国的时候,那里的资产阶级才刚刚开始进行反对封建专制制度的斗争。
德国的哲学家、半哲学家和美文学家,贪婪地抓住了这种文献,不过他们忘记了:在这种著作从法国搬到德国的时候,法国的生活条件却没有同时搬过去。在德国的条件下,法国的文献完全失去了直接实践的意义,而只具有纯粹文献的形式。它必然表现为关于真正的社会、关于实现人的本质的无谓思辨。这样,第一次法国革命的要求,在18世纪的德国哲学家看来,不过是一般“实践理性”的要求,而革命的法国资产阶级的意志的表现,在他们心目中就是纯粹意志、本来的意志、真正人的意志的规律。
德国著作家的唯一工作,就是把新的法国的**同他们的旧的哲学信仰调和起来,或者毋宁说,就是从他们的哲学观点出发去掌握法国的**。
这种掌握,就象掌握外国语一样,是通过翻译的。
大家知道,僧侣们曾经在古代异教经典的手抄本上面写上荒诞的天主教圣徒传。德国著作家对世俗的法国文献采取相反的作法。他们在法国的原著下面写上自己的哲学胡说。例如,他们在法国人对货币关系的批判下面写上“人的本质的外化”,在法国人对资产阶级国家的批判下面写上所谓“抽象普遍物的**的扬弃”,等等。
这种在法国人的论述下面塞进自己哲学词句的作法,他们称之为“行动的哲学”、“真正的社会主义”、“德国的社会主义科学”、“社会主义的哲学论证”,等等。
法国的社会主义和共产主义的文献就这样被完全阉割了。既然这种文献在德国人手里已不再表现一个阶级反对另一个阶级的斗争,于是德国人就认为:他们克服了“法国人的片面性”,他们不代表真实的要求,而代表真理的要求,不代表无产者的利益,而代表人的本质的利益,即一般人的利益,这种人不属于任何阶级,根本不存在于现实界,而只存在于云雾弥漫的哲学幻想的太空。
这种曾经郑重其事地看待自己那一套拙劣的小学生作业并且大言不惭地加以吹嘘的德国社会主义,现在渐渐失去了它的自炫博学的天真。
德国的特别是普鲁士的资产阶级反对封建主和专制王朝的斗争,一句话,自由主义运动,越来越严重了。
于是,“真正的”社会主义就得到了一个好机会,把社会主义的要求同政治运动对立起来,用诅咒异端邪说的传统办法诅咒自由主义,诅咒代议制国家,诅咒资产阶级的竞争、资产阶级的新闻出版自由、资产阶级的法、资产阶级的自由和平等,并且向人民群众大肆宣扬,说什么在这个资产阶级运动中,人民群众非但一无所得,反而会失去一切。德国的社会主义恰好忘记了,法国的批判(德国的社会主义是这种批判的可怜的回声)是以现代的资产阶级社会以及相应的物质生活条件和相当的政治制度为前提的,而这一切前提当时在德国正是尚待争取的。
这种社会主义成了德意志各邦专制政府及其随从——僧侣、教员、容克和官僚求之不得的、吓唬来势汹汹的资产阶级的稻草人。
这种社会主义是这些政府用来镇压德国工人起义的毒辣的皮鞭和枪弹的甜蜜的补充。
既然“真正的”社会主义就这样成了这些政府对付德国资产阶级的武器,那么它也就直接代表了一种反动的利益,即德国小市民的利益。在德国,16世纪遗留下来的、从那时起经常以不同形式重新出现的小资产阶级,是现存制度的真实的社会基础。
保存这个小资产阶级,就是保存德国的现存制度。这个阶级胆战心惊地从资产阶级的工业**和政治**那里等候着无可幸免的灭亡,这一方面是由于资本的积聚,另一方面是由于革命无产阶级的兴起。在它看来,“真正的”社会主义能起一箭双雕的作用。“真正的”社会主义象瘟疫一样流行起来了。
德国的社会主义者给自己的那几条干瘪的“永恒真理”披上一件用思辨的蛛丝织成的、绣满华丽辞藻的花朵和浸透甜情蜜意的甘露的外衣,这件光彩夺目的外衣只是使他们的货物在这些顾客中间增加销路罢了。
同时,德国的社会主义也越来越认识到自己的使命就是充当这种小市民的夸夸其谈的代言人。
它宣布德意志民族是模范的民族,德国小市民是模范的人。它给这些小市民的每一种丑行都加上奥秘的、高尚的、社会主义的意义,使之变成完全相反的东西。它发展到最后,就直接反对共产主义的“野蛮破坏的”倾向,并且宣布自己是不偏不倚的超乎任何阶级斗争之上的。现今在德国流行的一切所谓社会主义和共产主义的著作,除了极少数的例外,都属于这一类卑鄙龌龊的、令人委靡的文献。
资产阶级中的一部分人想要消除社会的弊病,以便保障资产阶级社会的生存。
这一部分人包括:经济学家、博爱主义者、人道主义者、劳动阶级状况改善派、慈善事业组织者、动物保护协会会员、戒酒协会发起人以及形形式色色的小改良家。这种资产阶级的社会主义甚至被制成一些完整的体系。
我们可以举蒲鲁东的《贫困的哲学》作为例子。
社会主义的资产者愿意要现代社会的生存条件,但是不要由这些条件必然产生的斗争和危险。他们愿意要现存的社会,但是不要那些使这个社会革命化和瓦解的因素。他们愿意要资产阶级,但是不要无产阶级。在资产阶级看来,它所**的世界自然是最美好的世界。资产阶级的社会主义把这种安慰人心的观念制成半套或整套的体系。它要求无产阶级实现它的体系,走进新的耶路撒冷,其实它不过是要求无产阶级停留在现今的社会里,但是要拋弃他们关于这个社会的可恶的观念。
这种社会主义的另一种不够系统、但是比较实际的形式,力图使工人阶级厌弃一切革命运动,硬说能给工人阶级带来好处的并不是这样或那样的政治改革,而仅仅是物质生活条件即经济关系的改变。但是,这种社会主义所理解的物质生活条件的改变,绝对不是只有通过革命的途径才能实现的资产阶级生产关系的消灭,而是一些行政上的改良,这些改良是在这种生产关系的基础上实行的,因而丝毫不会改变资本和雇佣劳动的关系,至多只能减少资产阶级的**费用和简化它的财政管理。
资产阶级的社会主义只有在它变成纯粹的演说辞令的时候,才获得自己的适当的表现。
自由贸易!为了工人阶级的利益;保护关税!为了工人阶级的利益;单身牢房!为了工人阶级的利益。——这才是资产阶级的社会主义唯一认真说出的最后的话。
资产阶级的社会主义就是这样一个论断:资产者之为资产者,是为了工人阶级的利益。
在这里,我们不谈在现代一切大革命中表达过无产阶级要求的文献(巴贝夫等人的著作)。
无产阶级在普遍激动的时代、在推翻封建社会的时期直接实现自己阶级利益的最初尝试,都不可避免地遭到了失败,这是由于当时无产阶级本身还不够发展,由于无产阶级解放的物质条件还没有具备,这些条件只是资产阶级时代的产物。随着这些早期的无产阶级运动而出现的革命文献,就其内容来说必然是反动的。这种文献倡导普遍的禁欲主义和粗陋的平均主义。
本来意义的社会主义和共产主义的体系,圣西门、傅立叶、欧文等人的体系,是在无产阶级和资产阶级之间的斗争还不发展的最初时期出现的。关于这个时期,我们在前面已经叙述过了(见《资产阶级和无产阶级》)。
诚然,这些体系的发明家看到了阶级的对立,以及占**地位的社会本身中的瓦解因素的作用。但是,他们看不到无产阶级方面的任何历史主动性,看不到它所特有的任何政治运动。
由于阶级对立的发展是同工业的发展步调一致的,所以这些发明家也不可能看到无产阶级解放的物质条件,于是他们就去探求某种社会科学、社会规律,以便创造这些条件。
社会的活动要由他们个人的发明活动来代替,解放的历史条件要由幻想的条件来代替,无产阶级的逐步组织成为阶级要由他们特意设计出来的社会组织来代替。在他们看来,今后的世界历史不过是宣传和实施他们的社会计划。
诚然,他们也意识到,他们的计划主要是代表工人阶级这一受苦最深的阶级的利益。在他们的心目中,无产阶级只是一个受苦最深的阶级。
但是,由于阶级斗争不发展,由于他们本身的生活状况,他们就以为自己是高高超乎这种阶级对立之上的。他们要改善社会一切成员的生活状况,甚至生活最优裕的成员也包括在内。因此,他们总是不加区别地向整个社会呼吁,而且主要是向**阶级呼吁。他们以为,人们只要理解他们的体系,就会承认这种体系是最美好的社会的最美好的计划。
因此,他们拒绝一切政治行动,特别是一切革命行动;他们想通过和平的途径达到自己的目的,并且企图通过一些小型的、当然不会成功的试验,通过示范的力量来为新的社会福音开辟道路。
这种对未来社会的幻想的描绘,是在无产阶级还很不发展、因而对本身的地位的认识还基于幻想的时候,同无产阶级对社会普遍改造的最初的本能的渴望相适应的。
但是,这些社会主义和共产主义的著作也含有批判的成分。这些著作抨击现存社会的全部基础。因此,它们提供了启发工人觉悟的极为宝贵的材料。它们关于未来社会的积极的主张,例如消灭城乡对立,消灭家庭,消灭私人营利,消灭雇佣劳动,提倡社会和谐,把国家变成纯粹的生产管理机构,——所有这些主张都只是表明要消灭阶级对立,而这种阶级对立在当时刚刚开始发展,它们所知道的只是这种对立的早期的、不明显的、不确定的形式。因此,这些主张本身还带有纯粹空想的性质。
批判的空想的社会主义和共产主义的意义,是同历史的发展成反比的。阶级斗争越发展和越具有确定的形式,这种超乎阶级斗争的幻想,这种反对阶级斗争的幻想,就越失去任何实践意义和任何理论根据。所以,虽然这些体系的创始人在许多方面是革命的,但是他们的信徒总是组成一些反动的宗派。这些信徒无视无产阶级的历史进展,还是死守着老师们的旧观点。因此,他们一贯企图削弱阶级斗争,调和对立。他们还总是梦想用试验的办法来实现自己的社会空想,创办单个的法伦斯泰尔,建立国内移民区,创立小伊加利亚,即袖珍版的新耶路撒冷,——而为了建造这一切空中楼阁,他们就不得不呼吁资产阶级发善心和慷慨解囊。他们逐渐地堕落到上述反动的或保守的社会主义者的一伙中去了,所不同的只是他们更加系统地卖弄学问,狂热地迷信自己那一套社会科学的奇功异效。
因此,他们激烈地反对工人的一切政治运动,认为这种运动只是由于盲目地不相信新福音才发生的。
在英国,有欧文主义者反对宪章派,在法国,有傅立叶主义者反对改革派。
看过第二章之后,就可以了解共产党人同已经形成的工人政党的关系,因而也就可以了解他们同英国宪章派和北美土地改革派的关系。
共产党人为工人阶级的最近的目的和利益而斗争,但是他们在当前的运动中同时代表运动的未来。在法国,共产党人同社会主义**党联合起来反对保守的和激进的资产阶级,但是并不因此放弃对那些从革命的传统中承袭下来的空谈和幻想采取批判态度的权利。
在瑞士,共产党人支持激进派,但是并不忽略这个政党是由互相矛盾的分子组成的,其中一部分是法国式的**社会主义者,一部分是激进的资产者。
在波兰人中间,共产党人支持那个把土地革命当做民族解放的条件的政党,即发动过1846年克拉科夫起义的政党。
在德国,只要资产阶级采取革命的行动,共产党就同它一起去反对专制君主制、封建土地所有制和小市民的反动性。
但是,共产党一分钟也不忽略教育工人尽可能明确地意识到资产阶级和无产阶级的敌对的对立,以便德国工人能够立刻利用资产阶级**所必然带来的社会的和政治的条件作为反对资产阶级的武器,以便在推翻德国的反动阶级之后立即开始反对资产阶级本身的斗争。
共产党人把自己的主要注意力集中在德国,因为德国正处在资产阶级革命的前夜,因为同17世纪的英国和18世纪的法国相比,德国将在整个欧洲文明更进步的条件下,拥有发展得多的无产阶级去实现这个变革,因而德国的资产阶级革命只能是无产阶级革命的直接序幕。
总之,共产党人到处都支持一切反对现存的社会制度和政治制度的革命运动。
在所有这些运动中,他们都特别强调所有制问题是运动的基本问题,不管这个问题的发展程度怎样。
最后,共产党人到处都努力争取全世界的**政党之间的团结和协调。
共产党人不屑于隐瞒自己的观点和意图。他们公开宣布:他们的目的只有用暴力推翻全部现存的社会制度才能达到。让**阶级在共产主义革命面前发抖吧。无产者在这个革命中失去的只是锁链。他们获得的将是整个世界。全世界无产者,联合起来!
(任卫东 根据 人民出版社 1995年版《马克思恩格斯选集》第一卷 248-307页 输入)
美国的自然资源极为丰富,世所罕见。她拥有经济发展所需的几乎所有的矿藏。其中煤炭储量达35996亿吨,主要集中在宾夕法尼亚和密西西比河流域等地。
其矿区总面积达50万平方英里,占全国土地面积的13%。这就意味着,美国1/8多的土地下都蕴藏着煤。石油储量约240亿吨,主要集中在加利福尼亚、得克萨斯等地。1970年时,其原油产量占世界原油产量的21%,1987年时,其原油产量仍占世界原油产量的15%,居世界第三位。
天然气储量也极为丰富,约56 334亿立方米,在20世纪七八十年代,其产量居世界首位。关于美国铁的含量,美国著名经济学家福克纳在《美国经济史》一书中是这样说的;在20世纪50年代,美国的铁矿资源相当于已知的世界各国铁矿资源的总和。
几乎在美国所有的州都可以找到铁矿。苏必利尔湖地区的储量最为丰富,其产量约占全国总产量的3/4。铜、铅、锌、钼、镁、钨、硫磺、钾盐、磷酸盐等的储量也居世界前列。如1970年,美国钼和镁的产量分别占世界总产量的61%和46%。1929年时,美国铜、钨的产量曾占世界产量的1/3。
此外,金、银、铝、汞、铀、钛等皆有相当可观的储量。据说19世纪中叶加利福尼亚金矿的发现和开采顿时使世界黄金的产量增加了4倍。美国缺少的是镍、锡、铬、锰、钴、金刚石等重要战略原料。
美国的木材资源、水力资源也很丰富。全国森林面积约7.54亿英亩,覆盖率达33%,主要树种为白杉、云杉、胡桃、橡树、槭树、绿柏、黄松、落叶松、柏树等可供商业性开采的树木。全国江河湖泊遍布,被称为“众河之父”的密西西比河其干流和支流的流域面积达322.2万平方公里,不仅为流域农业灌溉提供了充足的水源,而且成为发电的重要动力和运输的重要通道,通航里程达2万多公里,是世界内河航运最发达的水系之一。
五大淡水湖经由河流或运河互相连接,最后通过圣劳伦斯河流人大西洋,使这里也成为繁忙的水上运输通道,远洋海轮可直接进入五大湖。据说通过苏必利尔湖和休伦湖之间运河的货运量甚至相当于通过巴拿马和苏伊士两大运河的货运量。在美国的电力供应中,有11%来自水力。
美国的土地资源也十分丰富,其耕地面积占世界总耕地面积的12%。由于其耕地多为广阔的平原,非常适宜机械化作业。同时,美国大陆本土地处亚热带和温带,大部分地区气候温和,雨量充沛,适合农业生产的发展。如小麦的生长需要25—115厘米的年降水量,美国的年均降水量为67.6厘米,可谓恰到好处。
美国地处西半球,三面环海,近邻无强国。汹涌的大西洋和浩瀚的太平洋又为美国竖起了两道天然屏障,以阻止东半球强国的入侵。同时,美国所处的纬度使她在长达22 680公里的海岸线上拥有充足的不冻港,既可用于商业运输,也可作为海军基地,进攻退守,进退自如。
1801年,美国第三任总统托马斯·杰斐逊在就职演说中自豪地宣称:“我们天赐良邦,其幅员足以容纳子****孙万代”。其时,美国的国土尚只及现今版图的1/3强。
100多年后,当美国版图早已扩展定型后,美国一位叫康马杰的著名学者在《美国精神》一书中更加自豪地宣布:“地球上没有任何地方自然条件如此优越,资源如此丰富,每一个有进取心和运气好的美国人都可以致富”。
确实,美国得天独厚的自然条件、丰富充裕的自然资源为美国的发展提供了极好的前提条件,正是在这一基础之上,美国经过两百多年的发展,由英国的殖民地发展成今天的惟一超级大国。当然,自然条件只是为美国的发展搭建了一个平台,关键还在于美利坚民族的努力奋斗。
更多世界历史文化,敬请关注:欧阳说史返回搜狐,查看更多
责任编辑:
How do I display the list of loaded Linux Kernel modules or device drivers on Linux operating systems?
You need to use lsmod program which show the status of loaded modules in the Linux Kernel. Linux kernel use a term modules for all hardware device drivers.Please note hat lsmod is a trivial program which nicely formats the contents of the /proc/modules, showing what kernel modules are currently loaded.
This is an important task. With lsmod you can verify that device driver is loaded for particular hardware. Any hardware device will only work if device driver is loaded.
Open a terminal or login over the ssh session and type the following command
$ less /proc/modules
Sample outputs:
sha1_generic 1759 4 - Live 0xffffffffa059e000
arc4 1274 2 - Live 0xffffffffa0598000
ecb 1841 2 - Live 0xffffffffa0592000
ppp_mppe 5240 2 - Live 0xffffffffa058b000
ppp_async 6245 1 - Live 0xffffffffa0584000
crc_ccitt 1323 1 ppp_async, Live 0xffffffffa057e000
ppp_generic 19291 6 ppp_mppe,ppp_async, Live 0xffffffffa0572000
slhc 4003 1 ppp_generic, Live 0xffffffffa056c000
ext3 106854 1 - Live 0xffffffffa0546000
jbd 37349 1 ext3, Live 0xffffffffa0533000
sha256_generic 8692 2 - Live 0xffffffffa0525000
aes_x86_64 7340 2 - Live 0xffffffffa0517000
aes_generic 25714 1 aes_x86_64, Live 0xffffffffa050b000
....
...
....
ahci 32950 20 - Live 0xffffffffa007b000
libata 133824 3 ata_generic,pata_jmicron,ahci, Live 0xffffffffa0045000
scsi_mod 126901 3 usb_storage,sd_mod,libata, Live 0xffffffffa0012000
thermal 11674 0 - Live 0xffffffffa0009000
thermal_sys 11942 3 video,processor,thermal, Live 0xffffffffa0000000
To see nicely formatted output, type:
$ lsmod
Sample outputs:
Module Size Used by
sha1_generic 1759 4
arc4 1274 2
ecb 1841 2
ppp_mppe 5240 2
ppp_async 6245 1
crc_ccitt 1323 1 ppp_async
ppp_generic 19291 6 ppp_mppe,ppp_async
slhc 4003 1 ppp_generic
ext3 106854 1
jbd 37349 1 ext3
sha256_generic 8692 2
aes_x86_64 7340 2
aes_generic 25714 1 aes_x86_64
cbc 2539 1
nfsd 254974 13
exportfs 3186 1 nfsd
nfs 241498 0
lockd 57651 2 nfsd,nfs
fscache 29882 1 nfs
nfs_acl 2031 2 nfsd,nfs
auth_rpcgss 33524 2 nfsd,nfs
sunrpc 161756 12 nfsd,nfs,lockd,nfs_acl,auth_rpcgss
fuse 51020 1
dm_crypt 10680 1
it87 15879 0
hwmon_vid 1828 1 it87
coretemp 4325 0
loop 11799 0
snd_pcm 60487 0
usb_storage 40233 0
i915 257462 0
snd_timer 15598 1 snd_pcm
drm_kms_helper 20369 1 i915
snd 46542 2 snd_pcm,snd_timer
ata_generic 3239 0
drm 143120 2 i915,drm_kms_helper
soundcore 4598 1 snd
snd_page_alloc 6265 1 snd_pcm
uhci_hcd 18537 0
i2c_algo_bit 4209 1 i915
psmouse 49969 0
ehci_hcd 32145 0
video 17445 1 i915
i2c_i801 7830 0
evdev 7352 2
pata_jmicron 2280 0
pcspkr 1699 0
serio_raw 3752 0
usbcore 123399 4 usb_storage,uhci_hcd,ehci_hcd
i2c_core 15835 5 i915,drm_kms_helper,drm,i2c_algo_bit,i2c_i801
nls_base 6567 1 usbcore
output 1692 1 video
e1000e 124884 0
button 4650 1 i915
processor 29951 0
ext4 288755 2
mbcache 5050 2 ext3,ext4
jbd2 67175 1 ext4
crc16 1319 1 ext4
dm_mod 53994 6 dm_crypt
raid456 44516 4
md_mod 73936 5 raid456
async_raid6_recov 5186 1 raid456
async_pq 3495 2 raid456,async_raid6_recov
raid6_pq 77179 2 async_raid6_recov,async_pq
async_xor 2494 3 raid456,async_raid6_recov,async_pq
xor 4380 1 async_xor
async_memcpy 1198 2 raid456,async_raid6_recov
async_tx 1750 5 raid456,async_raid6_recov,async_pq,async_xor,async_memcpy
sd_mod 29953 25
crc_t10dif 1276 1 sd_mod
ahci 32950 20
libata 133824 3 ata_generic,pata_jmicron,ahci
scsi_mod 126901 3 usb_storage,sd_mod,libata
thermal 11674 0
thermal_sys 11942 3 video,processor,thermal
First column is Module name and second column is the size of the modules i..e the output format is module name, size, use count, list of referring modules.
Type the following command:
`# modinfo driver-Name-Here
Sample outputs:
filename: /lib/modules/2.6.32-5-amd64/kernel/drivers/net/e1000e/e1000e.ko
version: 1.2.20-k2
license: GPL
description: Intel(R) PRO/1000 Network Driver
author: Intel Corporation, [email protected]
srcversion: AB58ACECA1618E521F58503
alias: pci:v00008086d00001503sv*sd*bc*sc*i*
alias: pci:v00008086d00001502sv*sd*bc*sc*i*
alias: pci:v00008086d000010F0sv*sd*bc*sc*i*
alias: pci:v00008086d000010EFsv*sd*bc*sc*i*
alias: pci:v00008086d000010EBsv*sd*bc*sc*i*
alias: pci:v00008086d000010EAsv*sd*bc*sc*i*
alias: pci:v00008086d00001525sv*sd*bc*sc*i*
alias: pci:v00008086d000010DFsv*sd*bc*sc*i*
alias: pci:v00008086d000010DEsv*sd*bc*sc*i*
alias: pci:v00008086d000010CEsv*sd*bc*sc*i*
alias: pci:v00008086d000010CDsv*sd*bc*sc*i*
alias: pci:v00008086d000010CCsv*sd*bc*sc*i*
alias: pci:v00008086d000010CBsv*sd*bc*sc*i*
alias: pci:v00008086d000010F5sv*sd*bc*sc*i*
alias: pci:v00008086d000010BFsv*sd*bc*sc*i*
alias: pci:v00008086d000010E5sv*sd*bc*sc*i*
alias: pci:v00008086d0000294Csv*sd*bc*sc*i*
alias: pci:v00008086d000010BDsv*sd*bc*sc*i*
alias: pci:v00008086d000010C3sv*sd*bc*sc*i*
alias: pci:v00008086d000010C2sv*sd*bc*sc*i*
alias: pci:v00008086d000010C0sv*sd*bc*sc*i*
alias: pci:v00008086d00001501sv*sd*bc*sc*i*
alias: pci:v00008086d00001049sv*sd*bc*sc*i*
alias: pci:v00008086d0000104Dsv*sd*bc*sc*i*
alias: pci:v00008086d0000104Bsv*sd*bc*sc*i*
alias: pci:v00008086d0000104Asv*sd*bc*sc*i*
alias: pci:v00008086d000010C4sv*sd*bc*sc*i*
alias: pci:v00008086d000010C5sv*sd*bc*sc*i*
alias: pci:v00008086d0000104Csv*sd*bc*sc*i*
alias: pci:v00008086d000010BBsv*sd*bc*sc*i*
alias: pci:v00008086d00001098sv*sd*bc*sc*i*
alias: pci:v00008086d000010BAsv*sd*bc*sc*i*
alias: pci:v00008086d00001096sv*sd*bc*sc*i*
alias: pci:v00008086d0000150Csv*sd*bc*sc*i*
alias: pci:v00008086d000010F6sv*sd*bc*sc*i*
alias: pci:v00008086d000010D3sv*sd*bc*sc*i*
alias: pci:v00008086d0000109Asv*sd*bc*sc*i*
alias: pci:v00008086d0000108Csv*sd*bc*sc*i*
alias: pci:v00008086d0000108Bsv*sd*bc*sc*i*
alias: pci:v00008086d0000107Fsv*sd*bc*sc*i*
alias: pci:v00008086d0000107Esv*sd*bc*sc*i*
alias: pci:v00008086d0000107Dsv*sd*bc*sc*i*
alias: pci:v00008086d000010B9sv*sd*bc*sc*i*
alias: pci:v00008086d000010D5sv*sd*bc*sc*i*
alias: pci:v00008086d000010DAsv*sd*bc*sc*i*
alias: pci:v00008086d000010D9sv*sd*bc*sc*i*
alias: pci:v00008086d00001060sv*sd*bc*sc*i*
alias: pci:v00008086d000010A5sv*sd*bc*sc*i*
alias: pci:v00008086d000010BCsv*sd*bc*sc*i*
alias: pci:v00008086d000010A4sv*sd*bc*sc*i*
alias: pci:v00008086d0000105Fsv*sd*bc*sc*i*
alias: pci:v00008086d0000105Esv*sd*bc*sc*i*
depends:
vermagic: 2.6.32-5-amd64 SMP mod_unload modversions
parm: copybreak:Maximum size of packet that is copied to a new buffer on receive (uint)
parm: TxIntDelay:Transmit Interrupt Delay (array of int)
parm: TxAbsIntDelay:Transmit Absolute Interrupt Delay (array of int)
parm: RxIntDelay:Receive Interrupt Delay (array of int)
parm: RxAbsIntDelay:Receive Absolute Interrupt Delay (array of int)
parm: InterruptThrottleRate:Interrupt Throttling Rate (array of int)
parm: IntMode:Interrupt Mode (array of int)
parm: SmartPowerDownEnable:Enable PHY smart power down (array of int)
parm: KumeranLockLoss:Enable Kumeran lock loss workaround (array of int)
parm: WriteProtectNVM:Write-protect NVM [WARNING: disabling this can lead to corrupted NVM] (array of int)
parm: CrcStripping:Enable CRC Stripping, disable if your BMC needs the CRC (array of int)
Type the following command to see a directory location where your driver files are located:
echo "Kernel drivers dir: \"/lib/modules/$(uname -r)/kernel/drivers/\" \ for Linux kernel version \"$(uname -r)\" "
To view drivers, enter:
ls -l /lib/modules/$(uname -r)/kernel/drivers/
Sample outputs:
acpi block dca fmc hv infiniband lightnvm memstick net parport power regulator ssb uio virtio
ata bluetooth dma fpga hwmon input macintosh message nfc pci powercap remoteproc staging usb vme
atm char edac gpio hwtracing iommu mailbox mfd ntb pcmcia pps rtc target uwb w1
auxdisplay clk extcon gpu i2c ipack mcb misc nvdimm phy ptp scsi thermal vfio watchdog
base cpufreq firewire hid idle isdn md mmc nvme pinctrl pwm spi thunderbolt vhost xen
bcma crypto firmware hsi iio leds media mtd nvmem platform rapidio spmi tty video
The syntax is:
$ find /lib/modules/$(uname -r)/kernel/drivers/ -iname "driver-to-search-here"
To find out if a driver called foo.ko installed or not, run:
$ find /lib/modules/$(uname -r)/kernel/drivers/ -iname "foo.ko"
Find if e1000e driver installed or not:
$ find /lib/modules/$(uname -r)/kernel/drivers/ -iname "*e1000e*.ko" $ find /lib/modules/$(uname -r)/kernel/drivers/ -iname "e1000e.ko"
Run modinfo on driver name:
$ modinfo e1000e
The author is the creator of nixCraft and a seasoned sysadmin, DevOps engineer, and a trainer for the Linux operating system/Unix shell scripting. Get the latest tutorials on SysAdmin, Linux/Unix and open source topics via RSS/XML feed or weekly email newsletter.
编者按:本文来自微信公众号“冲浪普拉斯”(ID:fancheba),作者 徐冲浪 / 田鸭,36氪经授权发布。
-为何娃哈哈要换掉王力宏的代言?
-我可以说吗?说了太伤人了。
-解约是因为王力宏年纪大了,观众会审美疲劳。
新任娃哈哈集团公关部长的宗馥莉对着镜头回答主持人的提问,而她还有另外一个身份,娃哈哈后掌舵人宗庆后的女儿。
2004年,23岁的她进入了父亲一手创办的娃哈哈集团。当时媒体问宗庆后,准备什么时候让女儿接班?
60岁的的宗庆后笑眯眯地说:
「等70岁吧,把女儿扶上马送一程,我也可以轻松一下」。
15年过去了,宗庆后已经74岁,宗馥莉也已经37岁,就连娃哈哈也32岁了。如今,娃哈哈淘汰了王力宏,却还没能淘汰宗庆后。
74岁的宗庆后依然是娃哈哈工作强度最大、时间最长的人。每天早上7点到晚上11点,一周7天,一年365天。
这两年媒体再问及宗庆后退休的事情,他改口说「70岁还是壮年,我还能再干20年」。
01
没有哪个**首富像宗庆后一样,十八般农活,样样精通。
因为家庭成分问题,宗庆后初中就辍学了。他的第一份工作是走街串巷卖爆米花、烤红薯。
在1963年,当时舟山马目农场正在杭州招收知识青年,不论家庭成分,谁都可以报名参加。没多思量,他放下了串巷的背篓,义无反顾的搭上了去农场的车。
最初18岁的宗庆后在马目农场晒过海盐、挖过沟渠、修过大坝、挑过大粪、种过蔬菜,甚至还学会了杀猪。
后来,他又转去绍兴的茶场,从种茶学起,把割稻、烧窑、开山等等所有能做的力气活都干了一个遍。
跨山迈海,一干就是15年。燃尽宗庆后青春的15年,他一共赚到了5000元工资。
1978年,宗庆后返城时已经33岁。回城后他顶替退休的母亲,进入了工农校办的纸箱厂。
不惑之年,宗庆后由背着背篓走街串巷变成了背着工厂的产品挤绿皮火车。
命运筹备机遇的时间,太过漫长,这一蛰伏又是十年。等到人生转机出现的时候,宗庆后已经42岁。
1987年,他借了14万元,与两名退休老师一起承包了连续两年亏损的杭州上城区校办企业经销部,业务也没有脱离他最熟悉的老本行,就是生产冰棍,然后走街串巷卖冰棍儿。
1988年,宗庆后的校办工厂正在为「**保灵」代工花粉口服液。这是一款在当时十分畅销的成人营养口服液。
而在卖冰棍的过程中,宗庆后了解到很多孩子食欲不振、营养不良,这是当时家长们最头痛的问题。
为什么市面上没有一款为儿童定制的营养口服液?平凡的夏日午后,机会就这样悄然抵达宗庆后身旁。
1988年,在浙江医科大学营养学教授朱寿民的帮助下,国内第一款专为儿童设计的营养液面世。
当时,宗庆后在报纸上公开征集品牌名称。
《娃哈哈》这首儿歌红遍大江南北。来信中,有人提议叫「娃哈哈」。
宗庆后一锤定音。
02
这几乎是一场没有悬念的黑马逆袭战。
第一批娃哈哈营养液走下生产线,宗庆后手里只剩10万块钱。当时杭州电视台的广告包年价格是21万元,他没有一丝犹豫借来了钱,倾其所有给娃哈哈打广告。
「喝了娃哈哈,吃饭就是香」这句经典广告词很快传遍千家万户。
有了电视台广告,宗庆后拿出多年走街串巷的看家本事,亲手培养了第一批地推人员。
这些地推员不到两个月,就能拿下一个地区。在「攻下」某个区域后,宗庆后会马上把那些「先锋部队」调动到其他地方继续地推,只留一两个工作人员在当地跟进铺货、结款和巩固市场。
经由频繁攻掠,1988年当年,浙江已经成了娃哈哈的桥头堡。
之后半年时间,「娃哈哈」就成为了孩子和家长们的生活习惯。当时有记录,仅在北京娃哈哈一个月就可以销售30万盒。
为了扩大影响力,宗庆后邀请了专家、学者在各大报纸上亮相,给予营养液正面评价,这无疑成为了最好的代言,娃哈哈间接获得了权威支持。
短短几个月时间,娃哈哈的销售额便达到488万元。3 年时间,宗庆后将娃哈哈的产能扩大了 60 倍,利润暴涨了 100 倍,娃哈哈一年的产值也达到2千万。
随后,为了扩大娃哈哈规模,他兼并了当时负债6700万、库存压货1700万的国营杭州罐头厂。
这样骄傲的成绩,绝不只是广告和地推渠道所完成。
娃哈哈还有自己的「致富经」。
低成本大规模的模仿是90年代**处在野蛮增长期常见的策略。
1991年,娃哈哈瞄上了乐百氏,推出了第二款产品——「果奶」,只用了一年时间就销量破亿。
到了1996年,娃哈哈直接针对乐百氏钙奶推出升级产品——AD钙奶。这款AD钙奶至今都是娃哈哈的王牌产品之一,经久不衰。
在看到可乐热销,娃哈哈也模仿可口可乐推出了非常可乐,凭借价格优势和娃哈哈庞大的营销网络迅速切入农村市场,定位「**人自己的可乐」,大打民族牌受到了市场热捧。
后来,娃哈哈「非常系列」碳酸饮料产最好的时候,销量达到62万吨,约占全国碳酸饮料市场12%的份额,一度逼近百事可乐在**的销量。
靠着模仿和营销,1995年,娃哈哈年产值突破10亿元,利税总额达到了1.8亿元。
这一年**饮料业从此进入了黄金发展期。娃哈哈、乐百氏、北冰洋、天府等等饮料厂,大家都在那几年火速跑马圈地,在各自的省份站稳了脚跟。
而娃哈哈和乐百氏在果奶市场的争夺战,也陷入了焦灼状态。要巩固行业领先地位,就必须引进国外先进的技术,扩大再生产。
几番比对,宗庆后看上了法国品牌,达能。
03
谁也没想到这次联姻引来的是一场跨世纪的旷日持久的商业纠纷。
1996 年,娃哈哈与法国达能集团、香港百富勤公司共同出资建立 5 家合资公司,百富勤后将境外股权卖给了达能,至此,达能拥有了合资公司 51% 的绝对控股地位。
最初的时候,宗庆后与达能、的合作虽算不上愉快,倒也说得过去。后来在采访中宗庆后也曾说过,「和达能方面每个月开一次董事会,你把你的想法跟他说就行了,他基本上能支持的都支持的,虽然在支持进度上可能并不太理想。」
自始至终,娃哈哈和达能之间的信任都是装装样子。
当初娃哈哈与达能又签订了一个商标许可使用协议,规定未经合资公司董事会同意,娃哈哈集团不得将商标许可给其他公司使用,而只能由合资公司单独使用。
但宗庆后压根不理他这一套。娃哈哈自己建立了几十家独资企业,与达能没有任何关系。这些企业一直在使用娃哈哈商标,而其生产的产品则全部通过合资公司来销售,达能方面也一直是采取睁一只眼闭一只眼的态度。
1996年之后到2000年之前,非合资公司的数量共有八家。之后几年,娃哈哈的非合资公司数量猛增,同样利润也猛增,逐渐与合资公司持平。
2006年,达娃合资公司利润10.9亿,而非合资公司利润达到了10.4亿。面对如此可观的利润,达能决定收购娃哈哈的非合资公司。
2006年4月,达能要求以40亿的净资产价格并购娃哈哈非合资公司51%股权,娃哈哈强烈抵制,达娃纠纷爆发。
这场商战,从兄弟到反目成仇用了十年,从**消费者到双方掌门人再到中法两国领导人都参与了进来。
双方打起「口水仗」。达能指责宗庆后未经许可擅自使用娃哈哈商标,宗庆后指责达能设下陷阱,试图恶意收购娃哈哈,国际资本霸占「民族品牌」。
在给董事会的信上,宗庆后直言:我是**人,有**人的人格,不是你要我干什么我就要干什么,我们是平等的,现在不是八国联军火烧圆明园的时候了。
达能也不甘示弱,在娃哈哈总部杭州的多个生产基地进行了长时间的监控,记录了大量与娃哈哈公司有关的影像及文字资料,并向媒体表示宗庆后家族全员移民美国,长期偷税漏税等极具有杀伤力的信息。
两年多里,双方经历了国内、国外的数十起诉讼、仲裁。在两国政府的干预下,娃哈哈与达能取得和解。
2009年9月,达能将其在合资企业中所持的51%股份,作价4.5亿美元出售给娃哈哈,就此退出了合资企业。
从此,宗庆后对资本产生了强烈的抵触心理。
娃哈哈也彻底走上了不负债、不发行债券、不贷款也不上市,完全依靠自有资金运作的特殊道路。
04
此次达娃之战的胜利,娃哈哈意外得收获了「国货之光」的地位。
一切又变得顺利起来。
2008年,娃哈哈集团营业收入达到328.3亿元,2009年436亿元,2010年548.8亿元,2011年678.6亿元,2012年短暂下滑到636.3亿元,2013年达到顶峰782.8亿元。
这样的成绩,让宗庆后连续三年问鼎《福布斯》**内地首富。而距离宗庆后定下的千亿目标也只差一步之遥。
但从2014年开始,互联网电商的崛起,让一切突然变得不可控起来。沃尔玛、大润发、家乐福等百货巨头遭遇寒冬,线下渠道几乎一夜间变了天。
竞品的各种新式包装的新式口味的产品也开始层出不穷,而给娃哈哈创造收益依然是1996年上市至今的纯净水、和2005年上市的营养快线以及2006年生产的爽歪歪。
而在2014年到2016年这三年间,这三款产品的销售额几乎全部腰斩。
娃哈哈和以前一样努力,路子还是几十年来的老路子,复制别人的产品加上自己赖以生存的经销商渠道组合拳出击。娃哈哈快速推出新品,从乳饮料、瓶装水、碳酸饮料到茶饮料、果汁饮料都尝试了。
2013年娃哈哈推出了对标红牛的启力功能饮料。但如今启力已不见踪影,已被后来的乐虎和东鹏特饮超越。
就在去年,娃哈哈又尝试推出了一款娃哈哈开发了护眼饮料「天眼晶睛」。去年4月,宗庆后两次出面,为这一款饮料站台。
且不说这款饮料的保健作用,但这款饮料在投入市场时选择了微商渠道,让大家一时不知所措。最后的结果也可想而知,网上一片微商代理维权的哀嚎。
当然还有针对一二线白领的猫缘咖啡、清透椰子水等等新品。
但显然,时代翻页了,昔日的「致富经」策略也失灵了。
面对瓶颈,宗庆后不是没有想过多一条腿走路。他老人家能想到的跨界,都尝试了一个遍。
2010年进军奶粉行业,推出高端婴幼儿配方奶粉「爱迪生」,至今没有任何起色。
2012年涉足零售业,娃哈哈集团高调宣布进军商业地产,与几家经销商合资成立娃哈哈商业股份有限公司,计划5年内在全国开设100家连锁店。
2014年就爆出亏损严重,拖欠租金等新闻。
2013年,在白酒业告别「黄金十年」之时,娃哈哈斥资150亿高调进入白酒行业,对标的还是「A股股王」茅台的酱香型白酒,酒产地也设在茅台镇,名唤「领酱国酒」。
然而,几年过去了,150亿在酒市场上没砸出一点涟漪。
尝试了这么多路子,但结果却更要命。在超市的货架上,除了营养快线、AD钙奶、瓶装水、八宝粥这三两样产品外,你找不到更多娃哈哈的产品了。
渠道变了,消费者变了、时代变了,但大家还在喝饮料啊。
这位坐高铁只坐二等座,在地摊上买30元秋裤的70岁昔日**首富,需要有人帮他弄明白,世界发生了什么,以及为此娃哈哈该做些什么。
05
看起来,自己的女儿宗馥莉是最好的人选。
这位2004年就加入娃哈哈做基层一路做起的女孩,也有属于自己的娃哈哈成绩。
公开资料显示,2009年到2012年,宗馥莉独立执掌的宏胜集团年营业收入增长率超过30%。如今宏胜集团营收超过百亿,贡献了整个娃哈哈集团约三分之一的销售额。
宗馥莉接过了父亲手中跨界之旅,为了让娃哈哈重回年轻消费者的视野,她尝试做出了更为强势的出击。
2016年夏天,宗馥莉以自己的英文名字KellyOne命名的产品正式上线,这是一款可以线上自己搭配的定制果蔬汁品的产品。
为此还专门开发了微信小程序来方便消费者走个性化定制路线。
这款售价最便宜也要28元的果蔬汁包装新潮,率先在上海试点,按照宗馥莉的说法,她希望这款产品可以跳脱出娃哈哈原有的三四线城市的老路线,直接触达一线城市消费者。
但至今KellyOne的知名度可谓微乎其微,娃哈哈官方几乎没有做过任何宣传。
后来在采访中,记者向宗庆后提到这款产品时,他老人家直言不讳说到:「这个做不大,保质期很短。我不太清楚她在搞什么。」
如果说这只是宗馥莉带领娃哈哈跨出的一小步,那么让十几年坚持不上市的宗庆后松口「娃哈哈也会考虑上市」,是她这两年做出的最大也是最重要的努力。
2017年4月,在香港上市的**糖果发布公告称,恒枫香精香料有限公司计划收购公司不少于50%的股票权,而恒枫香精香料的最终实际拥有人正为宗庆后独女宗馥莉。
第一反应是「娃哈哈要借壳上市」,**糖果的股价闻风而动,直接飙升到0.45港元一线,升幅超过了100%。
但仅仅过了三个月,这场收购就以失败告终。失败的原因有很多种说法,但对比十多年前汇源果汁低调秘密的上市筹备手法,宗馥莉的这次操作确实显得过于高调。
不过,娃哈哈声称此次收购是宗馥莉的个人行为,与集团无关。
但在无路可退的情形下,似乎和资本市场结合是娃哈哈当下不可逃避的选择。
2018年春节,为公司IPO道路肃清障碍,娃哈哈在极短的时间内清理员工持股,将近15000名员工的股份按每股2.6元的价格悉数收回。
在去年,宗馥莉出任了娃哈哈公关部部长。此前,宗馥莉并未在娃哈哈集团担任职务。这次也被外界视为,娃哈哈品牌迎来了宗馥莉时间。
娃哈哈的跨界似乎也有了一丝丝起色。从AD钙奶流心月饼、粽子到跨界彩妆盘,再到今年的让王力宏「退休」,宗馥莉竭尽全力想要让32岁的娃哈哈变得年轻。
就在本月13号,从不做新媒体营销的娃哈哈在抖音入驻了新账号。而「娃哈哈线下奶茶店」招商视频也出现在抖音。
大体上我们也不难看出,娃哈哈线下店加盟与之前火爆的CoCo、1點點似乎也套路类似。
行业红利逐渐消失,但不管是宗馥莉还是更年轻的娃哈哈团队始终没有放弃一轮接一轮的新尝试。
不过宗庆后对女儿的各种品牌营销尝试,给出的评价是「做得很热闹,但没有在销量上直接体现。」
对于此,宗馥莉在访谈时说,「我爸似乎不满意」。
06
宗庆后和宗馥莉父女二人的分歧一直存在。
宗庆后一直是个强硬的「**者」。
娃哈哈多年来都没有设置副总,所有决策都由宗庆后一肩挑。
早年间曾有传闻称,娃哈哈买一把笤帚都需要宗庆后签字。后来,他逐步放权,报批的限度由50元,涨到了2000元。
传闻的真伪无从考证,但娃哈哈的每一款产品从口味、包装到每一条广告,都要经过宗庆后亲自审核是事实无疑。
而宗馥莉初中毕业就去了国外读书,她人生最重要的八年都是在西方思维方式下成长起来的。
宗庆后推崇「家文化」,从来不会主动开除员工。有外地老臣调回总部,宗庆后特设顾问之职作为安排,宗馥莉却直言:不如让他们领一笔钱退休。
宗馥莉管理的进出口公司有员工收到供应商的贿赂,因为合同里面明确禁止贿赂,所以宗馥莉觉得没有商量的余地,应该终止合同。但是,这个供应商找到了宗庆后,后来生意又有了转机。
宗馥莉觉得父亲的做法不对,这是底线,不应该融通。
宗庆后和宗馥莉的分歧,是人情和规则的分歧,更是**式做生意和西方经理人经营方式的分歧。
宗馥莉面对分歧,也曾多次表示,她最大的挫败感正是来自于父亲的不认可。
宗庆后已经74岁,而宗馥莉仍然没有进入娃哈哈的核心管理层。
2011年,在《高朋满座》节目中,主持人问宗馥莉:娃哈哈减去宗庆后等于什么?
宗馥莉说:「等于零。」
八年后,在这档说王力宏年纪太大,需要被淘汰的《至少一小时》节目中,被问到宗庆后在娃哈哈是个什么样的存在?
宗馥莉回答:「神一样的存在。」
过去的这八年是非比寻常,是娃哈哈从山顶坠落,历经失落和焦虑,负重前行的八年。
而尽管大家都做了种种努力和尝试,32岁的娃哈哈依然没能松开宗庆后这根拐杖,学会自己走路。
全文完,感谢你的耐心阅读,不妨右下角顺手点个「在看」。
参考资料:
[1]宗庆后:万有引力原理,红旗出版社,迟宇宙
[2].娃哈哈“超级家长”宗庆后的退休难题,棱镜
[3].独家 |宗庆后回应一切,封面专访
[4]饮料极客宗馥莉专访,商业周刊,彭博
一、女性解放就是人类解放
活跃的参与者们往往把女性解放运动当作一种孤立的,女性反抗男性的运动加以描述和实践。将男权社会和男权文化与现实中的男性等同起来,将男权文化的被动的接受者和主动的维护者等同起来。不得不说这是不周全的判断。
|
|
|
你们好我是男性女权主义者
|
男权社会是伴随着阶级与私有制诞生而诞生的或依靠法律或依靠文化而形成的等级社会,在这个前提下,男人需要承担的仅仅是公侯伯子男,天地君亲师的阶级压迫,而女性,排除少数适应社会的”成功者“,她们不光要接受社会地位的阶级不平等,同时还要接受家庭地位的阶级不平等。而这两种不平等,实际上都是阶级分化与私有制经济在不同领域的不同表现,而非两种不同的矛盾。我们通过人类学与社会学,考古学得出的的研究结论得知,并不存在脱离了私有制与阶级社会的性别沙文主义社会。而未来的共产主义社会也因为生产资料的再分配和生产力的解放,也必将不存在性别压迫。性别压迫总是伴随着私有制而产生,消解。这是由私有制所必然伴随的阶级社会所决定的。也就是说,男女矛盾不是阶级矛盾,而是阶级矛盾的副产品,亦或是说伴生物。按照流行的说法:一个阶级消灭了另一个阶级,人类不会灭亡。而一个性别消灭了另外一个性别是不可想象的。
所以我们必须正视的一个结论是:男人同样是男权社会的受害者,与作为受害者的女人仅有量而无质的区别,男性支持女性解放,就是支持自我解放。支持女性解放,就是支持人类解放。这个解放并不是一个性别以自身的经验和动机为基础而争取权利,而是把性别解放寓于社会本质的斗争之中,从根源上排除掉任何形式的性别沙文主义社会的可能。
如果不了解男权社会作为私有制的阶级社会的性质,那么女权运动反抗的男权社会下的男人也是受害者的这个结论是反直觉的:作为男权社会的”受益者“的男性为什么也是受害者?以**现状为基础举例的话,**式婚姻比较合适。
**式婚姻为什么要求男生有车有房?婚姻作为一个契约关系,是两个不带任何的自然人的结合。而不是一方依附一方或者一方供养一方,所以法律上有婚姻法,而没有嫁娶法。不过虽然法律解释看似公正,但是事实总是受社会“现实”所钳制。结婚要求男方有车有房毫无疑问是对男方,男方家庭的一种巨大的压力和剥削。而事实上女方也未必真的占了便宜——因为作为潜台词的,回报车房等经济待遇的行为,女方要负担起照顾公婆,免费保姆的”责任“,通常在家庭的话语权上也有所降低。也就是说,这样的婚姻事实上构成了一个买卖行为:男方拿金钱向女方家庭和女方自己购买一个永久的佣人和性伴侣。是一种在婚姻法之外起作用的”道德法律“,这样的事情,我们在帝制时代司空见惯,而现代社会,也仅仅是更隐蔽罢了。这样的买卖婚姻毫无疑问是一种双输行为——每个人都觉得自己吃了亏,而人人都是受害者。这就是私有制的阶级社会的男权社会对男女的共同压迫的表征之一。只有在屏蔽了男权社会的影响下,婚姻才能真正平等。
综上所述,男权社会是私有制的阶级社会的表现形式之一,是作为压迫人性,异化作为整体的人类的”背景性的声音“。我们必须了解的是,男人和女人都是受害者,而正是如此,解放女人就是解放男人。女权主义并不是男人的敌人,而恰恰是盟友。
二、后现代能否解释性别?
在今天谈及女性哲学时,稍有认识的朋友首先想到的就是性别的建构论,酷儿理论等。甚至在非学术领域的女权者心中经常也是如此。而这很有可能是一场可怕的误读。
|
|
|
要说我们文化本质主义的领头人……
|
以性别建构论为例,其理论基础是建立在后现代主义的人学核心**“无性别的灵魂”概念之上。亦即是说,剥离了人的种种外设,甚至不依靠人一词的语言学能指。将“人”彻底解构,从此人不再是社会关系的总合,甚至不是一个有血有肉,受外界影响的有机体,而是作为人本源的“白纸一般的灵魂”。我们必须指出,作为出发点来说是好的。因为如果接受了这样的设定,是倾向解开一切性别束缚的。但是这首先并不是为女性争取权利,而是取消性别(事实结果就是女性男性化或男性女性化)。其次这样带来的后果就是,认为性别,性别取向,性别认同全是社会塑造的。而男女大脑结构和激素的巨大差异则被忽略了,这种基于纯粹概念推导的假设其实是反科学的,是另一种文化决定论的神学。因为人的生物属性被忽略了,只存在一张白纸式的灵魂,而这样的灵魂事实上只存在于概念之中。
我们通过了越来越多的科学实践得出结论,性别的相关属性是以生理为基础的文化建构行为决定的,只强调人类的生理属性的本质主义与文化决定论式的性别建构论都是片面的,二元论的。我们对本质主义的指责已经很充沛,但是对文化决定论的声讨却并不多见,不过即便是以哲学的反诘去反驳——“如果现在的差异都是社会造成的,那么在社会之前,差异是如何形成的?”都非常简单的事情,却因为长期的后现代的“唯一选择”而在女性哲学领域消失了。这不能不说是把女权和后现代错误混淆的一个巨大的谬误。在人们看到性别建构等理论时,不把它们归为后现代主义哲学的一个向神学靠拢的有意思的结论,却归为女权主义。而长期来自医学领域的指责也被归在了女权主义的“非科学性”上,而后现代主义却得以幸免,这不能不说是非常不公正的。女权主义者并非必须要接受后现代主义的夹带私货的女权理论才能进行女权运动,也不是读过《圣杯与剑》才能算做一个女权者。
如前文所述,性别建构论是一种现代神学,以解构的方式让人只剩下灵魂——但是这个灵魂其实是虚构的,不存在的。而女性如果想摆脱历史的客体的地位,就要由自己充当主体,没有主体性的主体。摆脱那种标为女权即全盘接受的观点,塑造自己独立的分析,判断能力。独立的提出意见,做出判断。后现代主义在进行了男性或者女性词语都为本质主义的强加附会之后,其理论中形成了巨大的空场。被消解了的女性连带着被消解了的女权主义一同迷失在自我消解的后现代理论之中。因为如果象本质主义的镜中反面那样忽略事实,象本质主义强调本质那样强调文化及其后的文化解构,其必然带来自身逻辑崩溃的结果,就象缺乏变量的数学建模无力为事实做确切的反应一样。后现代主义在批判本质主义中迷失了自己,事实上站在了本质主义在镜中相同的位置上。
我在浏览网上和现实的书店时,看着女性主义哲学的书籍中占大多数的后现代理论。不由得设想着一场没有后现代的女权运动,一个不拿某种只因为占据多数就获得某种一言堂式的话语权的女性哲学氛围。如果抛弃了性别的建构理论,我们就可以免于谈论男人和女人都一样这样的反科学言论(现代的男权支持者正是基于医学的佐证而反对女权主义的,而实际上他们反驳的是对世界背过脸去的后现代主义),也可以免于把男性女性化或者女性男性化的悲剧诞生。更可以在与一些曲解科学的男权者的长期斗争中不再处于不利的地位。如果抛弃了福柯的身体理论,就可以从山外看到福柯分析的是自身,而不是女性或者人类,好像他是一个孤独于世间的人一般。也可以看到他分析的仅仅是身体,而对其他部分的经验加以忽略。如果抛弃了简单的接受福柯,德里达和拉康的结论,就可以发现后现代主义依旧是男性中心主义的——因为它对男性意识形态本身缺乏必要的批判,因为它的主体实践者是男性。就福柯而言,他依旧看不到性别的决定性的影响力。
所以,要后现代,还是女权?我认为,草莓蛋糕应当是蛋糕,而不是草莓。
三、那么剥离了社会本质主义的男女差异及其意义是什么?
男权社会确实在性别固化开始后对其加以强化和颂扬与巩固自己的地位,但是这无法解释性别为什么会产生固化。而科学的解释是——来自几百万年的演化。人类的遗传本能或者说天性几乎完全是来源于文明社会之前,除了高等动物特有的演化历程,至少要追溯到540万年前与黑猩猩分家的时候,这个500多万年的演化确实决定了我们人类很大程度上的“祖先记忆”,也就是说本能,是其所是的原因。
|
|
|
来吧一秒分公母!
|
而细化到男女的分别演化,确实是与分工相关的,到目前为止,一切都处于“应有的常识”。不过后续的知识就比较有意思了。
根据解剖学与神经医学的研究,我们确切知道的男女分别有很多,即便排除了可控的激素影响也是这样,比如男性大脑总体更重,女性大脑联系更紧密。男性在处理空间和运动刺激的时候远远优过女人,女人则在处理语言及语言相关的部分远远高过男人。这不光得到了科学的实证支持,也部分解释了为什么传统意义上的男女分工是如此的不同甚至是隔阂。
虽然男女确实存在远比你想象的大的多的差异,但是现在要讲的后续的知识却多少颠覆了这一观点,首先根据对空间刺激的研究,女性可以通过严格的训练达到接近男性甚至等同的能力。男性的语言系统也并非是不可锻炼的(虽然这无法改变你大脑中神经细胞的分布),对此的解释是表观基因的表达产生了变化,人类可以针对外界刺激做出不同反映,基因就象一个个按钮,是可以开或关而不是固定的,同时这一研究也证明了基因决定论的不靠谱(千钧一发的支持者们可以瞑目了)
所以我们认为最合理的结论是:人类确实在演化过程中产生了男女差异,这些差异有些是无法更改的(比如你的生殖系统,你对疾病的反应,你的性状表达,你的基础脑结构),但是更多的是可塑的,比如能力的锻炼。激素对体态和心理的改变等等。也就是说,虽然我们天生并不相同,但是这不代表我们一定要做不同的事情,男人依旧可以去做看护职业,女人也可以搞科研研究。虽然对大多数男人来说,边打电话边做饭是让人痛苦的,对女人来说,科研研究是枯燥乏味的。但是如果基于兴趣和锻炼,我们依旧可以胜任这些工作。
所以,大部分人也许会喜欢演化赋予他们的角色,但很多人恐怕不会,并且这一部分人可以做好他们被认为是不擅长的工作--只要他们努力。我们应当所做的是尊重社会现实的前提下,抵制过渡解读和完全“不读”者。保障自由选择的权利。
水晶光电的历史业绩非常稳健增长,得益于我们的股权结构:大股东作为财务投资人不参与经营管理,管理团队是小股东,合计股权占比5%。这种股权架构保障了水晶避免大股东对上市公司的占用,也避免了通过虚假信息或热点去追求短期市值,可以说水晶管理团队重点精力放在通过提升经营业绩来回报投资者,是一个比较安全的公司。另一点,得益于水晶在发展中在抓好基础业务的同时,发展战略新业务,并持续进行企业机制改革。我们从创业时的安防产业、进入相机业务、现在以手机业务为基础经营业务,并培育3D成像、新型显示等战略新业务。其他方面,水晶的企业文化、核心价值观等也帮助和促进了水晶光电的稳健成长,时间有限在此不多阐述。
水晶在发展过程中有了一些积累:
从2015年开始,水晶有了一些变化,体现在几个方面:
历史上,水晶受益于智能手机领域,即光学摄像头的发展。未来,我们认为人工智能领域将引领新的潮流,即信息的获取、传递、处理、存储和反馈。其中我们重点关注信息获取和信息反馈。信息获取中注重光学元器件(清晰度等)、3D成像(获取更多的信息),成像方面尤其关注以虚像方式的呈现(VR、AR等新型显示)。
我们认为水晶进入了发展快车道,我们**管理团队希望通过我们的努力,在未来一段时间每年保持20-50%营业收入的增长。**未来3-5年内,我们希望为水晶培养3-4个板块:第一,光学成像元器件:包括红外截止滤光片、小棱镜、打孔晶圆、镀膜晶圆等;第二,生物识别板块,包括窄带滤光片、屏下指纹等,以及其他3D成像元器件和在物联网领域的应用;第三,新型显示尤其是AR,我们和全球领先的知名材料供应商合作共同开发AR领域的高折射晶圆产品,在棱镜式、折返式、光波导等AR方案都有产品布局,我们是全球最好的光波导方案商Lumus重要股东和产业合作伙伴。而且,我们已经在行业应用领域形成了相对稳定的出货。未来AR一旦应用到消费电子市场,将会是多种成像方案并存,我们在核心晶圆、模组、光机制造上都有布局,一旦AR市场起来,我们对自己非常有信心。第四个板块,我们将结合5G时代的到来,在未来与知名的材料商、芯片商等合作,围绕5G时代对元器件的新需求,开发新的产品和元器件,预计到今年或者明年年报将对这一板块单独列示。
经过17年发展,我们形成了很好的一些积累。同时我们在人力资源、研发和企业内部流程上进行了一些变革,通过这一系列变革,我们希望未来水晶能走得更快更好。
【Q&A】
Q1:今年Q4业绩展望?
A1:我将水晶上市以来10多年的季度经营业绩作了梳理,2019Q3是有史最高的单季销售额,9亿多,比去年同期多了2个多亿。从历史数据来看,15-17年Q4的销售额都会比Q3高。但2018Q4销售额下降,主要是因为手机市场需求疲软。对于今年Q4的业绩最终还是要以公司实际生产状况来决定,但目前到10月份,生产负荷仍然比较饱满。我们觉得理论上,Q4收入水平和Q3不会有太大差异,利润我们不作预测,但如果开工率饱满,毛利率相信仍会维持较好水平。我们认为实现全年销售收入20%-50%的增长应该没有问题。
Q2:AR业务的发展?
A2:我们非常重视AR业务:2010年我们就开始介入AR业务。到目前为止,我们是国内上市公司中,少有的几家在AR产业中前沿布局的企业。目前,光波导和非光波导方案都有一些小批量出货,针对特定行业的应用市场,还没有进入消费电子。因为消费电子AR应用还没有很多,很多巨头企业在推出AR开发平台,要形成应用的积累,还需要时间。我们是AR光机模组供应商,也和北美、国内大客户保持密切沟通,今年看来概率不大,希望能在明年推出一些消费者喜爱的产品,我们提供模组产品,并让终端达到合适的价格。可能899/699/599/399美元价位推向市场,比较合适。
目前看来,我们更大的可能是做成一个以AR成像功能为主,并辅以一定的信息获取功能,比如3D摄像头,再配以耳机和Type C,并把运算功能放到手机上,以此来将AR与手机相连接。以这样的一种消费终端,做成一个手机外设,并推向消费电子市场,在我们看来是十分有机会的。
Q3:水晶与光驰未来的合作及投资关系?
A3:在2014年,水晶投资光驰20%股权,成为光驰第一大股东,向光驰派出一名董事,但是不参与日常经营。我们更多是作为偏战略的财务投资人。
2017年12月,光驰在日本上市,当时看好光驰的未来,作为基石投资人按照1460日元的价格认购了93.6万股IPO新股。半年后,光驰股价已经到了3800日元左右,我们将上市前认购的股份减持了90.1万股,为公司带来了1.5亿左右投资收益。在之后仍作为光驰第一大股东,持有约17%的股份。
作为光驰的第一大股东,我们每个月会将光驰的经营业绩按照持股比例进行并表,作为我们的投资收益,但是这部分投资收益需要在分红时才正式体现。同时如果我们减持光驰的股票,又会获得股票减持带来的投资收益。我们通常会对两个可能进行比较:(1)将股份卖出获取资金用于我们自己的日常生产经营能获取多少收益,(2)继续持有光驰股份能分享多少收益。在今年9-10月,考虑到股价相对高位,且持有太多股份对光驰自身不太有利,我们做出选择:将股份减持到15%,收回了约1亿现金。未来,我们将继续作为光驰的第一大股东,在董事会保留席位。
考虑到光驰擅长镀膜装备,而我们在镀膜技术上有优势,我们也组建和合资公司,并同比例追加了投资,希望可以发挥各自优势。
Q4:公司往年毛利率的波动幅度一直较大的原因是什么?
A4:毛利率问题的讨论要分成两个维度:单一产品的毛利率和公司整体的毛利率。
单一产品毛利率通常会在一定时期保持相对稳定,在第一批交付毛利率高一些。到第三批由于新供应商加入,毛利率下降。当然同样的产品随着生命周期过去,毛利率本身存在逐步下降的趋势,并会在一定时间之后退出。
公司整体毛利率受多方影响:
1. 公司的产品多维度:公司综合冷加工技术、薄膜光学技术、半导体光学技术等整合,为客户提供服务。不同产品毛利率会不一样,产品结构的不同会影响公司整体毛利率。
2. 产能利用率问题:通常第一季度开工率不足,受折旧摊销等因素影响,导致公司毛利率不高。从第二三季度开始,随着产能利用率提升,毛利率会也提升。
3. 通常公司新产品有更高的毛利率,而且公司新产品的比重日益增加。
Q5:公司红外截止滤光片在价格竞争方面能否做一个简单的介绍?:
A5:红外截止滤光片的毛利率相对较低,且市场竞争较大。几年前该产品的毛利率为40-50%,现在作为成熟产品,毛利率在25%左右。然而这是重资产产品,毛利率不会下降过大。通常光学产品的毛利率不会低于20%。
看过我博客的朋友,应该都知道我以前经常写爬虫的,但是现在基本上不玩了。以前写过一篇关于pornhub视频接口抓取的文章,当时写那个完全是兴趣使然。不过没想到很多朋友在谷歌上都看到了那篇文章,然后加了我好友一起探讨。
之所以写这篇文章呢,是因为前几天有一位朋友,看了我上面这篇文章,加了我好友并咨询了我一些问题。
应该是最近Pornhub(下面全部简称P站)好像修改了前端的代码,将视频的接口信息全部隐藏起来了。不过我很久都没有看过P站了,也不太了解情况。第二天打开看了一下,发现确实不像以前那样能直接在网页源码中找到视频链接了。
这是以前的P站。
现在的P站。
这两段都是JS代码,但是以前的一看就很清晰明了,而现在的都是些什么鬼玩意儿,怎么还有一大堆的垃圾注释在里面。
不用说,肯定是做了JS混淆。恰好最近在研究JS逆向,本来想着可能比较复杂。应该要下断点,然后查看堆栈调用什么的。因为代码是被压缩过的,所以在chrome开发者工具里直接代码格式化。
在network面板中将代码格式化之后可以看的很清楚,看上面定义的那一堆变量感觉就是我们要的url,而下面就是将变量拼接的最后的视频链接。
我在想P站的程序猿不会真的这么傻吧,难道就这样拼接一堆字符串??所以我就去前面找到定义的那个变量。
然后在控制台输出这个变量的值。
我整个人都傻了,P站的程序猿这么直接的吗?那还混淆个**的代码。以前写个P站的爬虫还得每个URL正则匹配才能提取出来。现在更省事了,都不用爬了,直接把这个变量的值取出来就什么信息都有了。
我严重怀疑P站的前端程序猿是不是写代码的时候看片去了!
所以接下来要想提取出视频的url就很容易了,我本来还是打算用Python来写个脚本直接拿到url的。直接用ExecJS这个库来执行这段被混淆过的JS代码就ok了。但是想了想这样也太简单了吧,没什么意思。要不我写一个Chrome的插件来完成这件事,因为本身视频加载之前JS肯定会执行。那么用插件的方式也更加方便。于是思索了一晚上,第二天一大早就起床撸插件。
插件开发的过程,最关键的问题就是如何将包含所有视频接口信息的变量给提取出来。
一开始我是想到是直接在浏览器的全局变量window中拿到那个变量,这是最简单的办法。我发现通过注入JS代码用console.log(window)输出的全局变量中还是没有包含flashvars_*****这个变量,不清楚为什么。我一开始认为可能是页面onload的时候还没有执行JS所以没有变量信息。后面我想了想要不执行settimeout来实现延迟执行代码,但是还是不行。
于是我决定用另外一个办法,将字符串作为代码执行。也就是写木马最常用到的eval函数。在页面加载时,通过xpath得到混淆JS代码的位置,将它作为一段字符串当成代码执行,这样同样拿到了接口信息。
给大家看一下插件最核心的两段代码content-script.js,也就是注入页面的JS代码。
function Func() {
return new Promise((resolve, reject) => {
var a = document.querySelector("#player >script:nth-child(1)").innerHTML
a = a.split('loadScriptUniqueId')[0]
var c = a.match("flashvars_[0-9]{1,}")[0]
eval(a)
var d = eval(c)
resolve(d)
})
}
window.onload = () => {
Func().then(res => {
var videoType = []
Object.keys(res).forEach((item) => {
if (item.startsWith('quality_')) {
var obj={
key:item,
val:res[item]
}
videoType.push(obj)
}
})
for(var i = 0, len = videoType.length; i < len; i++){
console.log(videoType[i].key,videoType[i].val)
}
chrome.runtime.onMessage.addListener(function(request, sender, sendResponse){
if(request.cmd == 'test')
sendResponse(videoType);
});
})
}
和popup.js也就是插件在浏览器右上角的那个页面的JS。
function sendMessageToContentScript(message, callback)
{
chrome.tabs.query({active: true, currentWindow: true}, function(tabs)
{
chrome.tabs.sendMessage(tabs[0].id, message, function(response)
{
if(callback) callback(response);
});
});
}
sendMessageToContentScript({cmd:'test', value:'test'}, function(videoType)
{
console.log(videoType);
for(var i = 0, len = videoType.length; i < len; i++){
console.log(videoType[i].key,videoType[i].val)
}
var boxEl = document.getElementsByTagName('ul')[0]
//var videoType = [{ key: 'qeqw', val: 'adasda' }, { key: 'qeqw', val: 'adasda' }, { key: 'qeqw', val: 'adasda' }]
var videoStr = ''
videoType.forEach(item => {
videoStr += "<li>" + "<label>清晰度:" + "<span>" + item.key + "</span>" + "</label>" + "<a href=" + item.val + " target='_blank'>下载</a>" + "</li>"
});
boxEl.innerHTML = videoStr
});
popup.js的作用主要就是和content-script.js通信,相互传值。然后在插件中渲染生成页面,JS间传值主要用到了Chrome的API。
插件开发的过程中还涉及到很多细节问题,比如ico的制作,这些就不提了。最后插件的样子大致如下。
当页面加载完成,点击下载就能下载到到原视频了。最后插件写完,顺便上传到了Google商店里,毕竟是自己写的第一个Chrome插件,还是蛮激动的。感兴趣的小伙伴可以下载来试试。
插件源码压缩包:
如果不能从谷歌商店安装的话,可以直接解压导入。
总结:
由于之前一直都是用Python写脚本,对JS不是太熟悉,虽然我只知道怎么去实现,但是我却不能熟练地用JS写出来,这期间向很多问题都是我的同学勾大佬请教的,很感谢大佬的帮忙。不过令我很惊奇的是做开发的同学他们普遍都没用过eval函数,甚至不知道。他们告诉我正常的开发中没有这样用的。但是我感觉搞安全的,基本人人都知道eval,毕竟一开始学习一句话木马的时候就没少接触过。也许做开发和搞安全区别真的挺大的吧。
10月13日更新:
谈一下谷歌插件发布的一些经验。由于写插件之前我根本不知道看P站的人竟然有这么多。大概过去半个多月,就有700多用户了,Amazing!
所以我在前两天就修复了一些插件的bug,并且添加了一些插件的英文翻译。
好像是触发了Chrome插件商店的自动化审查,结果第二天我收到了谷歌给我发来的邮件。
所以赶紧删掉了插件介绍的英文翻译,然后重新发布了插件,然后通过了审查。恰好有朋友发邮件咨询我。
大概就是这样吧,不过我还是想声明一下,真的没有搞黄色[\捂脸]
插件1.2版本更新:
1.取消onload事件,优化插件运行速度,不必等待页面加载完成再获取视频链接信息
2.增加对pornhub会员账号的视频链接提取
3.增加用户提示
区块链是一种安全的共享账本,仅分发给特定网络的成员。区块链通过经过身份验证的网络成员身份基于共享信任。区块链分类账的副本存储在每个成员的计算机上,这使任何成员都可以随时查看整个分类账的内容。区块链还使用公钥和私钥来确保安全性。公钥是唯一标识网络的数字指纹,而私钥则允许网络成员访问区块链分类帐。新事务完成后,分类帐将通过网络进行更新,以供所有成员查看。区块链分类帐是可搜索的,允许成员查找特定的智能合约和交易。本文摘录了一些工业控制相关的区块链观点,为感兴趣的研究者提供一些帮助。
区块链是一种分散的核心架构,广泛用于新兴的数字加密货币中。随着比特币的逐渐接受,它引起了人们的广泛关注并进行了研究。区块链技术具有集中化,区块数据化,无篡改和信任的特点,因此受到企业特别是金融机构的追捧。虽然最初是专门为比特币创建的,但是可以存储任何数字文档,媒体或数据值。这正是使之有可能在工业网络保护环境中使用的原因,它提供了一种将数据存储为交易的安全方式,而智能合约则提供了有关要收集哪些数据,如何使用数据以及哪种数据的详细信息。
区块链可应用于工业控制系统(ICS)以实现网络安全。区块链的关键技术包括:分布式记帐,非对称密码,共识算法和智能合约。区块链技术可以帮助我们更好地实现工业控制系统的网络安全,并使之可靠,安全,高效且低成本。区块链与IoT结合可以实现IoT网络安全并构建基于区块链的ICS网络安全架构模式。区块链技术可以很好地解决包括数据传输不安全,机器故障,数据存储不安全感等问题。区块链网络可以代替工业控制系统的现场网络,可以解决ICS网络安全问题并为物联网安全提供解决方案,基于区块链的工业控制网络安全是非常有意义和可行的。
为什么区块链可能是IoT网络保护的关键? 区块链中每个区块的不变性正是使其成为IIoT基础设施的理想选择的原因。凭借永久,不可更改的记录,区块链构成了基于机器的信任的基础,因为网络中的所有节点均已通过身份验证,并且每笔交易都使用区块链的加密算法进行了验证。汽车行业当前的工业应用突显了区块链作为安全技术IoT解决方案的潜力。例如,丰田汽车使用区块链跟踪来自多个国家,制造商和供应商的零件,直至最终组装。该用例表明,可以将区块链用作提供无与伦比的安全性和可靠性的端到端解决方案。制造工厂内的本地化区块链网状网络可用于安全地监控制造过程,自动化诸如订购耗材之类的任务。
也许最大的挑战将是使行业组织认识到区块链的真正可能性。它需要一种非常不同的方式来查看机器如何通过IT基础架构相互连接。尽管区块链本身相对简单,但其实现却并非如此。该行业处于将区块链应用于工业网络保护以及如何根据每个企业的需求量身定制的调查阶段的早期。
此外,尽管区块链在技术上都是可以实现的,但它们在成熟度,资源需求和可伸缩性方面都面临挑战。这在当前缺乏该技术的公认标准和治理模型,以及缺乏监管和对区块链与现有技术的适当用例的理解中尤为明显。
目前尚不存在区块链标准,治理模型和监管监督的现状。普遍接受的区块链或分布式记帐标准不存在,只有行业组织正在讨论。不仅需要更多与技术相关的标准,例如企业安全性和互操作性,并且诸如法律和监管问题也同样重要。
写在前面:本系列大概会分成三到四个部分,每个部分有三到四个章节,切入点各不相同。如果说资本主义个人反抗指南一到四是从社会和经济学的角度去讲述反抗的意义和做法,那么现在展开的几个章节就会以生物学和心理学为切入点去讲述反抗的意义和做法。我非常希望整个系列完本的时候,不光读者们可以了解作为一个无产阶级如何在这个世界中进行反抗,也希望读者们可以从文章中夹杂的知识中刷新自己的三观,得到新的思路和乐趣。如果都能做到,那就实在太好了。
说到生命与生育的话题,就不得不谈我们为什么要生育和我们为什么不要生育,所以免不得要绕一个超大的弯子。
几乎每个人都有过醉酒的经历,如果酒精上头,比起天旋地转以外,最突出的感受似乎就是“不顾他人”了。难受就要吐,晕眩就要坐下,和外界的联系时有时无,一边感觉身边有人,但一边又感觉自己被收缩向内,距离世界变遥远了。
也许这是最直观的的让我们感受到联系这件事情的体验。
酒精是中枢神经抑制剂,但它恰好抑制的是抑制我们行为的脑区,所以双重否定之下,很巧合的解放了人的思维,所以可以胡乱说话,可以不管不顾。但比起研究醉酒时的糗态,我更好奇的是人在“清醒”时,为什么是现在这个要管要顾的样子。
一、利己与利他
哪怕不知道“母亲”的含义是什么,刚出生的婴儿也会啼哭,会吸吮乳汁,如果我们把这看成是完全内在的利己本能,那么我们显然还有另一种本能:2006年的一项实验表明,在不受任何外界刺激的前提下,1岁半的幼儿会主动向陌生人伸出援手,看到即将滑倒的表演者时,婴儿明显表达出了搀扶的动作,这种与外界基本的互动恰好是我们与生俱来的能力。
|
|
|
性善性恶争论了这么多年,但是孩子可能是非道德性的
|
这种能力显然比前一种能力更复杂,它需要观察,决策和执行,需要占用大脑更多的资源。那么按照演化的逻辑,这种吃力不讨好的行为显然是对生存没有帮助的。另一批研究者也发现了一个有趣的事实,大自然探索杂志2009年第5期为我们提供了如下场景:乔伊斯·普尔是肯尼亚大象研究项目的负责人,自20多年前开始研究这种庞然大物以来,她见过发生在大象之间的许许多多的奇异行为,而让她印象最深刻的莫过于它们之间的“问候礼”——当同一个家庭或组织中的成员久别重逢后产生的那种热烈而欢快的情绪。有一次,她看到50多头大象重逢在一起,它们欢快地高声鸣叫,疯狂地拍打耳朵,相互绕着转圈,所有成员一起发出巨大的隆隆声和吼叫声……她相信这些大象正沉浸在极度兴奋的情绪中,它们发出的隆隆声和吼叫声(似乎)表达了这样一层意思:“喂!伙计,遇见你真是太高兴了!”如果按照纯功利角度讲,他们应当静悄悄的,因为这样更节省体力。
不过演化生物学家并不因此认为演化论就是错误的,他们通常情况下认为,利他的行为最终还是要回归利己。比如保护同族群的幼崽意味着和自己相近的基因可以得到更好的保护。所以利他行为显然是利己行为的延伸。它体现在行为中就是维护群体,而体现在体验中,就是“我帮助他人是为了自己的良心。”
二、我们
但人类的情况显然复杂的多,因为人类似乎是唯一能在一定程度上违背基因命令的族群。我们经常会担忧人工智能会毁灭整个人类,一个做筷子的AI也许会因为做筷子是它的初始目的而把宇宙中所有物质做成筷子,但我们也许多虑了,因为机器人也许并不会一直做筷子。《机器人叛乱》这本书给我们展现了一个有意思的图景:设想一个人身患重病,不得不冬眠到遥远的未来寻求生机,但是任何针对当下可能遇到的危险所做的防备在漫长的岁月中都必然落后,所以这个人设计了一个机器人保护自己,并且赋予了机器人学习适应的能力,让它来保护自己。
那么基因就是这个身患重病的人,我们就是机器人。按照道金斯博士在《最伟大的故事》中的观点,我们和最初覆盖在基因外面起保护作用的蛋白质膜并没有什么本质区别。
|
|
|
在我们担忧机器人叛乱之前,也许先要发现自己就是那个叛乱的机器
|
但是他依旧提出了一个有意思的观点,人类不光是自然的,也是超越自然的,比如虽然先天女性因为生育和月经等角度在演化上“吃亏”了,但是正因为人类的理性可以一定程度上超越简单的防御程序而成为一个有自我学习和思考能力的主体,所以我们才能后天弥补它,显然这也应当是女权主义理论真正的预设前提。
不过同样是这样的适应和思考能力,导致人类发明出了诸如性别本质主义之类(你是男人/女人,所以就该如何,就是如何)的理论来禁锢人群以达成维护私有制的目的。
三、生命
正因为机器人们有了独立思考和适应的能力,他们很大程度上可以违背基因的命令,也许利他行为诞生于维护基因延续的需要,但是利他行为并不局限于延续基因的本能。
前几天走在路上,看到一个流浪汉,乱糟糟的头发,邋遢的衣服。当时就有一种强烈和他搭讪的欲望,一方面很想知道他是怎么生活的,另一方面也想问问他,要不要请他吃顿饭和提供帮助?
当然,最终我觉得这样太唐突和冒失而没有成行,但是事后我仔细剖析了自己的动机:当时我心情并不大好,也许想和他聊聊是想听听更惨的故事来让自己舒服起来,而希望帮助他也是为了满足我自己的同情心。
当时我陡然察觉了一个非常毛骨悚然的结论:从没有任何来自理性的命令训导我在抵触,厌恶的情况下必须帮助一个人,如果我去帮助一个人,显然完全取决于我利己的目的,这和高尚没有丝毫关系。但想过之后又觉得欣慰,至少我觉得这一事实是毛骨悚然的。
如果用另一个例子来表达这件事情的话就是这样:我反对一切把非种间的杀戮合理化为“自然法则”的说法,按照人类近亲黑猩猩的社会组织来说,歧视女性是自然法则,扯掉敌人睾丸,或者杀光敌人男性掠夺女性也是自然法则,按照此逻辑延伸,一切人类的道德和法律都不该存在。
所以正如人们看到“自然法则论”有种自己被洗地成功的踏实感所昭示的那样,他们其实并不如大多数生物那样不假思索的认可杀戮。正是这种“毛骨悚然”和“洗地成功的踏实感”构成了并不依附于纯粹延续自己本能的道德。
儒家有一个说法是“君子远庖厨”,意思是君子不应该接近厨房(屠宰),很多人认为这是一种眼不见为净的伪善,但它实际讲的是恻隐之心。恻隐之心是什么呢?是在(满足自己)吃肉的情况下对动物保持同情,且并不认为这是天然合理的。而长期从事屠宰工作,会让人在漫长的日常行为中丧失这份同情。
北美的印地安猎人在狩猎成功后要感谢猎物,并不是感激它撞上了箭头为人们提供了食物,而是要感激它为人类的自私而做出了牺牲。
|
|
|
它不得病,很可能我就不会得病--利他行为并没有那么伟大
|
四、社会
当然,大家会疑惑的问:仅仅是同情而不去实践,难道不也是一种伪善吗?恰恰相反,人类无法摆脱自己利己的本能,甚至无法拥有一个纯粹的利他行为,毕竟人类不是真社会性动物,但正是基因利己行为为了应对风险的意外产物:独立的思考和适应能力,让我们可以作为机器人而叛乱。我们的人性是诞生自无机物中的有机物,就像生命诞生在洪荒的海洋之中那样。
这种生物学意义上的人性显然是社会进步的源动力之一,也许我们现在为了口腹之欲会让动物陷于悲惨的处境之中,但是当条件成熟,比如人造肉的成本和饲养肉畜的成本接近时,社会就会向食用人造肉去转型。
所以我们的社会会进步,我相信社会的演变遵循其内在的政治经济甚至地理气候的演变,但是我也相信,在条件适时的时候,正是出于对自身地位的不满和对他人巨大的同情,这一丝叛乱的种子才会发芽,掀起诸如女权主义,民权主义,跨性别平权的巨浪。
五、生育
也许大家会认为前面所讲的一切都和具体的生育行为关系不大,但实际上它是一条完整的逻辑链条--绕一个巨大的弯子必不可少。
首先我们知道了生育不是什么本能,甚至本能都是可以被机器人的叛乱所抵抗的,因为对自然的适应让我们拥有了更强大的思考能力去反思一切。其次我们知道了基因未必和我们是一条战线,虽然我们的一切都来自于基因,但是为它服务并不一定符合我们自己的利益,回想一下机器人的例子吧,当灾难来临,机器人陷入保护病人和自己的矛盾时,它应该怎么做?
我们现在就陷入了这样的灾难之中。抚养孩子所造成的精力和经济的损失(可以详细参考我前几章讲消费主义的部分),显然对我们自己极为不利,即便是冷冰冰的利益考量,你又如何能保证孩子可以成材并且可以抚养自己?如果我们再参考前面所讲到的性别本质主义的规训,就会发现必须生育也是一条规训。
|
|
|
嗯。。
|
最后重中之重的事情就是恻隐之心。
我说过,恻隐之心是革命的种子,而革命的萌发则必须在于(因为外部环境变化导致的)自身生存受到威胁+对外界剧烈的同情之下。
也就是说,我们普遍意义上认为是善的事物,大多数情况下必然爆发自你和你同情的人处于同一处境的情况下,毕竟仅靠同情脱离自己的出身实在太难,根本不具备统计学意义,无怪乎马克思会讲经济基础决定上层建筑。
所以生育的本质就向我们展开了:生育会让我们自己受损,也让我们的孩子受损,他们出生于贫富差距日趋严重的现在,大概率的不会幸福,出于慈善原则(如果对方可能因某事受苦,也可能因某事不受苦,那么假设对方会受苦而非不受苦),不应该生育。一如我们同情自己的童年那样同情我们的孩子,这就是你和你同情的人处于同一处境。
而且这一情况还可以扩散到更广泛的领域之中:日本的现状很适合无产阶级学习。生了孩子苦了自己,孩子还被剥削阶级剥削。那么不要孩子的话,就会出现现在这种重体力活高薪而办公室低薪的情况。没受过教育的无产阶级倾向把生育作为彩票无限多生,但是晚期资本主义下的新穷人则选择根本就不生来抵抗。
那么如果把不生育作为对资本主义的个人抵抗的最核心的一步,显然你做到了和你的孩子处于一条战线下,并且和千千万万个受剥削者处于一条战线下,是不是有点像前几章说的通过公社维护小圈子,通过互助保险和全球定价的投资品和维护大圈子的逻辑一样了?
PS:我猜到有人会说养老不光是经济,还有照顾。而我觉得不光应当抚养社会化,养老也应当社会化。另外退一万步讲,二十年前的我们无法设想智能手机和互联网的现在,我们又怎么能在一个科技指数发展的现在去设想二十年后的养老呢?老板!来两个大白!
PS2:都不生育人类没了怎么办?
不可能的啦年轻人,穷人不生还有富人生啊,你还得鼓励他们,支持他们多生育,这能带动消费,拉动就业…利国利民功在千秋啊。
PS3:下一篇可能会讲女权、反思科技或者动物伦理,新穷人和新工人的部分也许会放在系列的第三部分来讲,我尽量把每个部分都构成连贯性,比如看了第一部分再看本部分会更容易接受更多信息并且避免认识上的不对等,但是也要考虑全文的排版问题。
本文总结了Linux添加或者删除用户和用户组时常用的一些命令和参数。
1、建用户:
adduser phpq //新建phpq用户
passwd phpq //给phpq用户设置密码
2、建工作组
groupadd test //新建test工作组
3、新建用户同时增加工作组
useradd -g test phpq //新建phpq用户并增加到test工作组
注::-g 所属组 -d 家目录 -s 所用的SHELL
4、给已有的用户增加工作组
usermod -G groupname username (这个会把用户从其他组中去掉)
usermod -a groupname username
或者:gpasswd -a user group
如果添加了用户,添加了组,然后使这个组里的人都可以sudo 到公共账号下
可以/etc/sudoers.d 下面建立一个文件内容如下 ,就可以是etl组的所有用户都可以无密码的切到etl用户下。
%etl ALL=(ALL) NOPASSWD: /bin/su etl
%etl ALL=(ALL) NOPASSWD: /bin/su - etl
sudo 具体参考 http://www.cnblogs.com/xd502djj/p/6641475.html
5、临时关闭:在/etc/shadow文件中属于该用户的行的第二个字段(密码)前面加上就可以了。想恢复该用户,去掉即可。
或者使用如下命令关闭用户账号:
passwd peter –l
重新释放:
passwd peter –u
6、永久性删除用户账号
userdel peter
groupdel peter
usermod –G peter peter (强制删除该用户的主目录和主目录下的所有文件和子目录)
7、从组中删除用户
编辑/etc/group 找到GROUP1那一行,删除 A
或者用命令
gpasswd -d A GROUP
8、显示用户信息
id user
cat /etc/passwd
更详细的用户和用户组的解说请参考
Linux 用户和用户组详细解说
本文主要讲述在Linux 系统中用户(user)和用户组(group)管理相应的概念;用户(user)和用户组(group)相关命令的列举;其中也对单用户多任务,多用户多任务也做以解说。
本篇文章来源于 PHP资讯 原文链接:http://www.phpq.net/linux/linux-add-delete-user-group.html
Linux 用户(user)和用户组(group)管理概述
、理解Linux的单用户多任务,多用户多任务概念;
Linux 是一个多用户、多任务的操作系统;我们应该了解单用户多任务和多用户多任务的概念;
**
1、Linux 的单用户多任务;
**
单用户多任务;比如我们以beinan 登录系统,进入系统后,我要打开gedit 来写文档,但在写文档的过程中,我感觉少点音乐,所以又打开xmms 来点音乐;当然听点音乐还不行,MSN 还得打开,想知道几个弟兄现在正在做什么,这样一样,我在用beinan 用户登录时,执行了gedit 、xmms以及msn等,当然还有输入法fcitx ;这样说来就有点简单了,一个beinan用户,为了完成工作,执行了几个任务;当然beinan这个用户,其它的人还能以远程登录过来,也能做其它的工作。
**
2、Linux 的多用户、多任务;
**
有时可能是很多用户同时用同一个系统,但并不所有的用户都一定都要做同一件事,所以这就有多用户多任务之说;
举个例子,比如LinuxSir.Org 服务器,上面有FTP 用户、系统管理员、web 用户、常规普通用户等,在同一时刻,可能有的弟兄正在访问论坛;有的可能在上传软件包管理子站,比如luma 或Yuking 兄在管理他们的主页系统和FTP ;在与此同时,可能还会有系统管理员在维护系统;浏览主页的用的是nobody 用户,大家都用同一个,而上传软件包用的是FTP用户;管理员的对系统的维护或查看,可能用的是普通帐号或超级权限root帐号;不同用户所具有的权限也不同,要完成不同的任务得需要不同的用户,也可以说不同的用户,可能完成的工作也不一样;
值得注意的是:多用户多任务并不是大家同时挤到一接在一台机器的的键盘和显示器前来操作机器,多用户可能通过远程登录来进行,比如对服务器的远程控制,只要有用户权限任何人都是可以上去操作或访问的;
**
3、用户的角色区分;
**
用户在系统中是分角色的,在Linux 系统中,由于角色不同,权限和所完成的任务也不同;值得注意的是用户的角色是通过UID和识别的,特别是UID;在系统管理中,系统管理员一定要坚守UID 唯一的特性;
root 用户:系统唯一,是真实的,可以登录系统,可以操作系统任何文件和命令,拥有最高权限;
虚拟用户:这类用户也被称之为伪用户或假用户,与真实用户区分开来,这类用户不具有登录系统的能力,但却是系统运行不可缺少的用户,比如bin、daemon、adm、ftp、mail等;这类用户都系统自身拥有的,而非后来添加的,当然我们也可以添加虚拟用户;
普通真实用户:这类用户能登录系统,但只能操作自己家目录的内容;权限有限;这类用户都是系统管理员自行添加的;
**
4、多用户操作系统的安全;
**
多用户系统从事实来说对系统管理更为方便。从安全角度来说,多用户管理的系统更为安全,比如beinan用户下的某个文件不想让其它用户看到,只是设置一下文件的权限,只有beinan一个用户可读可写可编辑就行了,这样一来只有beinan一个用户可以对其私有文件进行操作,Linux 在多用户下表现最佳,Linux能很好的保护每个用户的安全,但我们也得学会Linux 才是,再安全的系统,如果没有安全意识的管理员或管理技术,这样的系统也不是安全的。
从服务器角度来说,多用户的下的系统安全性也是最为重要的,我们常用的Windows 操作系统,它在系纺权限管理的能力只能说是一般般,根本没有没有办法和Linux或Unix 类系统相比;
**
二、用户(user)和用户组(group)概念;
**
**
1、用户(user)的概念;
**
通过前面对Linux 多用户的理解,我们明白Linux 是真正意义上的多用户操作系统,所以我们能在Linux系统中建若干用户(user)。比如我们的同事想用我的计算机,但我不想让他用我的用户名登录,因为我的用户名下有不想让别人看到的资料和信息(也就是隐私内容)这时我就可以给他建一个新的用户名,让他用我所开的用户名去折腾,这从计算机安全角度来说是符合操作规则的;
当然用户(user)的概念理解还不仅仅于此,在Linux系统中还有一些用户是用来完成特定任务的,比如nobody和ftp 等,我们访问LinuxSir.Org 的网页程序,就是nobody用户;我们匿名访问ftp 时,会用到用户ftp或nobody ;如果您想了解Linux系统的一些帐号,请查看 /etc/passwd ;
**
2、用户组(group)的概念;
**
用户组(group)就是具有相同特征的用户(user)的集合体;比如有时我们要让多个用户具有相同的权限,比如查看、修改某一文件或执行某个命令,这时我们需要用户组,我们把用户都定义到同一用户组,我们通过修改文件或目录的权限,让用户组具有一定的操作权限,这样用户组下的用户对该文件或目录都具有相同的权限,这是我们通过定义组和修改文件的权限来实现的;
举例:我们为了让一些用户有权限查看某一文档,比如是一个时间表,而编写时间表的人要具有读写执行的权限,我们想让一些用户知道这个时间表的内容,而不让他们修改,所以我们可以把这些用户都划到一个组,然后来修改这个文件的权限,让用户组可读,这样用户组下面的每个用户都是可读的;
**
用户和用户组的对应关系是:一对一、多对一、一对多或多对多;
**
一对一:某个用户可以是某个组的唯一成员;
多对一:多个用户可以是某个唯一的组的成员,不归属其它用户组;比如beinan和linuxsir两个用户只归属于beinan用户组;
一对多:某个用户可以是多个用户组的成员;比如beinan可以是root组成员,也可以是linuxsir用户组成员,还可以是adm用户组成员;
多对多:多个用户对应多个用户组,并且几个用户可以是归属相同的组;其实多对多的关系是前面三条的扩展;理解了上面的三条,这条也能理解;
**
三、用户(user)和用户组(group)相关的配置文件、命令或目录;
**
**
1、与用户(user)和用户组(group)相关的配置文件;
**
**
1)与用户(user)相关的配置文件;
**
/etc/passwd 注:用户(user)的配置文件;
/etc/shadow 注:用户(user)影子口令文件;
**
2)与用户组(group)相关的配置文件;
**
/etc/group 注:用户组(group)配置文件;
/etc/gshadow 注:用户组(group)的影子文件;
**
2、管理用户(user)和用户组(group)的相关工具或命令;
**
**
1)管理用户(user)的工具或命令;
**
useradd 注:添加用户 adduser 注:添加用户 passwd 注:为用户设置密码 usermod 注:修改用户命令,可以通过usermod 来修改登录名、用户的家目录等等; pwcov 注:同步用户从/etc/passwd 到/etc/shadow pwck 注:pwck是校验用户配置文件/etc/passwd 和/etc/shadow 文件内容是否合法或完整; pwunconv 注:是pwcov 的立逆向操作,是从/etc/shadow和 /etc/passwd 创建/etc/passwd ,然后会删除 /etc/shadow 文件; finger 注:查看用户信息工具 id 注:查看用户的UID、GID及所归属的用户组 chfn 注:更改用户信息工具 su 注:用户切换工具 sudo 注:sudo 是通过另一个用户来执行命令(execute a command as another user),su 是用来切换用户,然后通过切换到的用户来完成相应的任务,但sudo 能后面直接执行命令,比如sudo 不需要root 密码就可以执行root 赋与的执行只有root才能执行相应的命令;但得通过visudo 来编辑/etc/sudoers来实现; visudo 注:visodo 是编辑 /etc/sudoers 的命令;也可以不用这个命令,直接用vi 来编辑 /etc/sudoers 的效果是一样的; sudoedit 注:和sudo 功能差不多;
**
2)管理用户组(group)的工具或命令;
**
groupadd 注:添加用户组; groupdel 注:删除用户组; groupmod 注:修改用户组信息 groups 注:显示用户所属的用户组 grpck grpconv 注:通过/etc/group和/etc/gshadow 的文件内容来同步或创建/etc/gshadow ,如果/etc/gshadow 不存在则创建; grpunconv 注:通过/etc/group 和/etc/gshadow 文件内容来同步或创建/etc/group ,然后删除gshadow文件;
**
3、/etc/skel 目录;
**
/etc/skel目录一般是存放用户启动文件的目录,这个目录是由root权限控制,当我们添加用户时,这个目录下的文件自动复制到新添加的用户的家目录下;/etc/skel 目录下的文件都是隐藏文件,也就是类似.file格式的;我们可通过修改、添加、删除/etc/skel目录下的文件,来为用户提供一个统一、标准的、默认的用户环境;
[root@localhost beinan]# ls -la /etc/skel/ 总用量 92 drwxr-xr-x 3 root root 4096 8月 11 23:32 . drwxr-xr-x 115 root root 12288 10月 14 13:44 .. -rw-r--r-- 1 root root 24 5月 11 00:15 .bash_logout -rw-r--r-- 1 root root 191 5月 11 00:15 .bash_profile -rw-r--r-- 1 root root 124 5月 11 00:15 .bashrc -rw-r--r-- 1 root root 5619 2005-03-08 .canna -rw-r--r-- 1 root root 438 5月 18 15:23 .emacs -rw-r--r-- 1 root root 120 5月 23 05:18 .gtkrc drwxr-xr-x 3 root root 4096 8月 11 23:16 .kde -rw-r--r-- 1 root root 658 2005-01-17 .zshrc
/etc/skel 目录下的文件,一般是我们用useradd 和adduser 命令添加用户(user)时,系统自动复制到新添加用户(user)的家目录下;如果我们通过修改 /etc/passwd 来添加用户时,我们可以自己创建用户的家目录,然后把/etc/skel 下的文件复制到用户的家目录下,然后要用chown 来改变新用户家目录的属主;
**
4、/etc/login.defs 配置文件;
**
/etc/login.defs 文件是当创建用户时的一些规划,比如创建用户时,是否需要家目录,UID和GID的范围;用户的期限等等,这个文件是可以通过root来定义的;
比如Fedora 的 /etc/logins.defs 文件内容;
`# REQUIRED
# Directory where mailboxes reside, or name of file, relative to the
# home directory. If you do define both, MAIL_DIR takes precedence.
# QMAIL_DIR is for Qmail
#QMAIL_DIR Maildir
MAIL_DIR /var/spool/mail 注:创建用户时,要在目录/var/spool/mail中创建一个用户mail文件;
#MAIL_FILE .mail`
`# Password aging controls:
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_MIN_LEN Minimum acceptable password length.
# PASS_WARN_AGE Number of days warning given before a password expires.
PASS_MAX_DAYS 99999 注:用户的密码不过期最多的天数;
PASS_MIN_DAYS 0 注:密码修改之间最小的天数;
PASS_MIN_LEN 5 注:密码最小长度;
PASS_WARN_AGE 7 注:`
`#
UID_MIN 500 注:最小UID为500 ,也就是说添加用户时,UID 是从500开始的;
UID_MAX 60000 注:最大UID为60000;`
`#
GID_MIN 500 注:GID 是从500开始;
GID_MAX 60000`
`#
#USERDEL_CMD /usr/sbin/userdel_local`
`#
CREATE_HOME yes 注:是否创用户家目录,要求创建;`
**
5、/etc/default/useradd 文件;
**
通过useradd 添加用户时的规则文件;
# useradd defaults file GROUP=100 HOME=/home 注:把用户的家目录建在/home中; INACTIVE=-1 注:是否启用帐号过期停权,-1表示不启用; EXPIRE= 注:帐号终止日期,不设置表示不启用; SHELL=/bin/bash 注:所用SHELL的类型; SKEL=/etc/skel 注: 默认添加用户的目录默认文件存放位置;也就是说,当我们用adduser添加用户时,用户家目录下的文件,都是从这个目录中复制过去的;
**
后记:
**
关于用户(user)和用户组(group)管理内容大约就是这么多;只要把上面所说的内容了解和掌握,用户(user)和用户组(group)管理就差不多了;由于用户(user)和用户组(group)是和文件及目录权限联系在一起的,所以文件及目录权限的操作也会独立成文来给大家介绍;
在Quora上看到过一个解释QE的答案,是面向门外汉的。这个答案在某些理论细节上是简化的,但总的框架没有问题。
翻译了一下,希望有所帮助,也欢迎批评指正~
问:如何给门外汉讲懂“量化宽松”?
原文链接:How do you explain quantitative easing in layman's terms?
译文链接:译读
回答者:Andrei Kolodovski,TRIZ基金执行合伙人
量化宽松的定义:给银行系统注入资金,以此刺激贷款。
重要提示:
本回答是为非专业人士提供“量化宽松”的基本概念。为了方便理解,我简化了很多概念,忽略了一些重要细节。
至于“量化宽松”好不好,这是个专门问题。我只解释,不负责评价。
第一部分:货币与部分准备金银行制度的背景知识
经济要正常运转,离不开货币。经济体系中的货币总量(术语:货币供给)由**银行所管控。**银行是政府创设的机构,专门负责管理货币。像美国的央行叫“美联储”。
货币供给分两部分(这是极为简化的说法):
图里的现金,术语一般叫做“基础货币”,由两部分组成:
通货:有物理形态的货币:譬如纸币,硬币。因为要简化说明,以下的内容中我会忽略这部分。(译者注:经济体系中大多数货币是在银行账目上周转,相比经济体系中的货币总量,通货的数量比较少)
银行准备金:法律规定商业银行必须将部分现金存到央行(美联储),以防有大量储户提存款时,商业银行因大量出贷,无钱可兑,以致破产。
信用则由银行的贷款所创造。商业银行吸收储户存款,再将这些钱借给消费者与商家。银行每吸收一笔存款,就要将其中一部分按某一比率上交央行,成为准备金(译者注:上交准备金后,剩余的存款可以作为贷款,贷款放出后如果又存入银行,成为银行存款,那银行再次上交准备金后又能贷款。最终银行所贷出的钱远大于最初的款项,这就是所谓的信用/货币创造)。这个比率叫准备金率,由美联储所决定,目前美国的准备金率为10%。
准备金率决定了银行所能创造的贷款量的上限。由于准备金率为10%,所以银行最终贷出的贷款数为 x÷10% = 10x 。所以这里的10就是所谓的货币乘数。从这个角度看,货币总的供给量就等于基础货币与货币乘数之积。现代经济体系中,**银行就是通过控制基础货币与货币乘数来管理货币供给的。
第二部分:量化宽松(QE)
经济危机时,银行会出于几方面的考虑大幅降低贷款量。这时候他们自身持有的现金就会多于法定的准备金,形成了“超额储备”。结果就是货币乘数下降,货币供给收缩。
货币供给收缩会导致通货紧缩。通缩对经济来说是死亡漩涡(经济会进入恶性循环)。为远离通缩的威胁,美联储要使货币供给复元。这里有两种方式:
提高货币乘数(图中浅绿色的部分)
增加基础货币(图中深绿色的部分)
这次经济危机时,美联储先是采用了第一种方法,降低利率,让贷款更便宜,刺激对贷款的需求:
靠上面那条线(叫收益率曲线)是经济危机前各年期贷款的利率,下面那条线是现在的利率。可以看到美联储把短期利率的贷款降到了0%,长期贷款则从5%降到了3%。
可惜光靠这些不够。银行的贷款没有复苏,货币供给不断下滑。所以美联储决定用第二个办法,增加基础货币,给银行注入现金:
像这样注入现金就叫”量化宽松(QE)“。如图,量化宽松并没有提高货币总供给——QE只是改变了货币供给的成分。
第三部分:量化宽松的目的?
通过量化宽松注入现金,美联储希望银行能主动去寻找赚钱机会,把这部分现金贷出去,最终使货币乘数恢复。
第一种情况:量化宽松成功刺激了贷款
贷款恢复后,美联储就要撤出之前注入的资金,最后货币供给的规模和成分都回到经济危机发生前。
第二种情况:量化宽松没能刺激到贷款
银行可能会把注入的钱留在超额储备里不贷出去。这样货币乘数仍然会萎靡不振。那我们就要在量化宽松的状态里待很长一段时间,直到经济将之前泡沫破灭的苦果消化。像日本就是这么个情况(所谓失去的十年,失われた10年)。
第三种情况:银行贷款恢复,美联储又没有撤出量化宽松的现金
如果美联储因政治、财政、经济或者其他原因没能退出量化宽松,那恢复正常的货币乘数就会作用在更大的基础货币上。这样货币供给就会有很大的增长,我们就会迎来通货膨胀。
一个男人正在赶赴与初恋女友的约会。
到了约定地点,他被吓了一跳。
左边,有个老人在昏睡。
从房子里走出来的人,满脸紧张,见有人,立即死死压低棒球帽。
他不得不抽几口烟压压惊,再往下走。
他敲门,有人探出头要密码。
再往前深入,氛围更加诡异、神秘。
走廊里,穿着襁褓的男人横行而过。
房间里不断传出男女的尖叫声。
经人带路,他才找到了初恋女友。
房门刚开,他整个人立刻被吓懵。
这造型,参加葬礼的神奇女侠?
到了这里很好奇,还没在怕的,一定要往下看了——
《绑定》(2019)
身着皮衣的女生叫蒂芙,是一名正在攻读心理治疗专业的研究生。
平时,她就在SM俱乐部做兼职,花名“梅夫人”。
她的工作内容,很让人羡慕。
有人会花钱到这里给她全职保姆,带着项圈、黑皮面罩,全天候贴身服侍。
稍微出点错,她就破口大骂。
端来的水烫了,她直接泼在他身上。
这保姆也不敢出声,反而更加小心翼翼,改善自己的工作。
在这里,打骂是家常便饭。
有时,他给梅夫人系鞋带,她一个不满意还会用力踩他手指。
十指连心,正常人都会疼到cry吧。
但这保姆,脸上堆满窃笑。
多余的虐待,就是额外的赏赐。
上面展现的,还只是字母圈的冰山一角。
大家常说的“SM”,其实是BDSM的简称,包括——
绑缚与调教(bondage&discipline,即B/D),
支配与臣服(dominance & submission,即D/S),
施虐与受虐(sadism & masochism,即S/M)。
但,现实中可没那么多现成的**“周瑜黄盖CP”**。
有需求,就会有市场。
有人想被虐,你能给出花式虐人方案,满足客户需求,就能轻轻松松赚钱。
蒂芙抢占了先机,还要做大做强。
她找男主皮特,就是要他做施虐助理。
因为,接下来的客户越来越难搞。
比如弗雷德,求虐的意愿极其强烈。
要把他带到俱乐部,必须得用绑架的形式——
捆绑、扔后备箱、**言语羞辱,**一条龙服务。
这还不够,他还要别人嘲笑他的下体尺寸。
客户强烈渴求,皮特紧张兮兮,也因此练成了连珠炮羞辱技能。
弗雷德非常满意,临分别时,又提出了更诡异的要求。
这个要求有没有完成,派爷后面再说。
皮特孰能生巧,接待的客户和他们的需求,各种突破想象。
比如,有人见到企鹅装才会性奋。
派爷最开始也描述了,很多人光顾这里都是秘密寻访。
因为,在世人观念里,字母圈的事都跟性有关,很脏。
他们对自己的受虐倾向难以启齿。
就算亲密如恋人,也有各种摩擦。
因为亲近,有些隐秘的事,你只敢说给对方听。
如果对方满足不了你,这秘密会成为两人之间的隔阂。
如果对方难以接受,久而久之,亲密关系的裂缝就会越来越大。
有一对夫妻,就遭遇了这个问题。
妻子偷偷跑来俱乐部求助。
为了解决客户的需求,两人外出诊治。
这男士的癖好是,被挠痒。
人前,他儒雅斯文。
但当蒂芙为他挠痒时,他就完全变了模样。
爽到,可以叫娘。
注意看,你会发现——
“花钱找罪受”的基本上都是男人。
奇怪吧,雄性多有支配欲,怎么甘心受此屈辱。
问题症结,其实也在这里。
男权社会给男人太多压力。
为了生活他们不得不连轴转,难有停歇。
只有身体被绑定时,才能宣泄压力。
不过,大众接受度却很低。
上面提到的为丈夫买挠痒服务的妻子,算开明了吧。
但,当她真的听到丈夫的爽叫声,还是羞耻+愤怒。
皮特提供了个挨打服务,才缓解了她的焦虑。
如此亲密的人尚且受不了,更何况社会上的其他人。
蒂芙的专业导师,思维也被冰冷机械的知识困住。
对施虐受虐有很大的误解。
所以你看,蒂芙的工作虽然让人羡慕,但却见不得光。
那她为什么会走上这条路呢?单纯为了钱?
当然不是。
在学生时代,她交往了很多渣男。
那些男人无一例外只是想睡她,占据她的身体。
一直以来,她饱受男人的压迫,内心的压抑变成了虐待的渴望。
正是这份渴望,引导着她走向这份工作。
在工作中,她了解受虐狂的心理和需求,同时弥补了自己的创伤。
男主皮特,梦想着成为一个脱口秀演员。
却因性格过于内向,连舞台都不敢上。
挣不到钱,交不起房租。
胆怯,毁了他的梦想和生活。
一开始,他加入SM俱乐部是为了钱。
后来,在施虐的过程中,他开始掌握主动性。
练就了一个脱口秀演员必需的功底。
发现没,施虐、受虐成了寻找自我的一条路。
就像片名——Bonding。
其余字母都是红色,只有“i”是白色的。
蒂芙和皮特,就是在这项特殊服务里,找回了被创伤和恐惧压制的自己。
也让客户勇敢面对真实的渴望。
故事的最后,蒂芙穿着皮衣制服走向学校的讲台。
用自身的真实经历,击溃照本宣科的填鸭式教学。
另一边,皮特戴着面具,穿着皮衣,勇敢地冲向舞台。
谈笑风生、挥洒自如。
这层面具,曾是他们和世界最安全的距离。
可他们摘开了。
他们努力了那么久,无非是让世界看到自己、理解自己、接纳自己。
那台下的这些观众,这些“审判者”,展现的就是真实的自己么?
并不。
当蒂芙问他们有谁想被捆在椅子上。
不少人纷纷举手。
很显然,他们在生活中有很多焦虑无法释放。
前面派爷聊到,有个客户希望别人用撒尿羞辱他。
但皮特有撒尿困难症,客户一直耐心鼓励。
这不像施虐与受虐,反而是彼此的成长。
几经努力下,皮特通畅了,弗雷德也爽到毫巅。
(嘘嘘.jpg)
觉得变态?觉得脏?
再看看蒂芙的导师。
为人师表,披着光鲜外衣,做着禽兽的恶行。
字母圈的人可能在突破常人的认知,但这些禽兽是在突破做人的底线。
相比之下,谁真的身处在阴暗里,谁更坦荡呢?
看这部剧,派爷很容易想到《性教育》。
它们都以性为切口,讲人该如何直面自己的压抑和欲望。
故事刷完,你看到的,是这些人的曲折成长。
说起来,《绑定》基本没有什么暴露镜头。
但它是更高级的“大尺度”——
暴露出潜藏在伪装下的人性。
有些人,衣冠楚楚,却在暗地里做着苟且之事。
有些人,做着大多数人所不耻的事,却在救赎自己,治愈他人。
这个世界的善与恶、荣与辱,本就难以简单界定。
而想要活得更好。
就必须敢于卸下那层伪装。
以更得体的方式,面对自己真实的欲望。
Homebrew 是最初是 Max Howell 自己写来管理 MacOS 软件的小工具,没想到后来不仅成为了 Github 上拥有贡献者最多的项目,还是 MacOS 系统中事实上的包管理器。
原理上 Homebrew 并不比 apt / yum 高明,甚至 Homebrew (从源码) 安装软件的方式还可能存在安全性问题。Homebrew 可能确实不是好的包管理器,比手动管理要好。
除了官方包管理器的缺失,Homebrew 上位的另一个原因是“平民属性”。Homebrew 本质是 Git 管理起来的安装脚本,这大大降低了发布软件的门槛——人人都能编写脚本,发布软件——这也是为什么 Homebrew 会成为 Github 上拥有贡献者最多的项目(不要低估人们对于管理自己的软件的热情,想想多少人为了 AUR 选择 Arch Linux )。
Homebrew 至少有 4 层 :
Homebrew 有 “家酿” 的意思,基本原理源码下载本地编译
Tap 本质 Git 仓库,也是软件仓库。与别的包管理器不同 Tap 存放的不是编译好的二进制文件,而是 Formula,即下载编译和安装脚本或软件的 Ruby 脚本。
例如,输入命令 brew install foo,Homebrew 就在 Tap 在中寻找与软件 foo 对应的 Ruby 脚本,然后按照脚本定义的方法将 Keg (foo) 下载、编译、安装到 Cellar 中。
Homebrew 有两个官方 Tap,homebrew/homebrew-core 和 homebrew/homebrew-cask。Homebrew Cask 是 macOS 的二进制包,一般用来安装较为大型的软件。 homebrew/homebrew-core 的 Formula 的 上传有一定规则。
Tap 即 Git 仓库 (默认部署在 Github 上)。如果仓库以 homebrew-core 的形式命名则可直接使用短名称跟踪
$ brew tap madobet/core否则需要给出仓库的全称和 URL
$ brew tap github.com/madobet/homebrew-core项目根目录下创建名为 Formula 的文件夹存放所有 Formula (Ruby 脚本)
以 frp 为例,首先去 frp 的 releases 页面复制 Source code.tar.gz -> 链接地址
输入命令:
$ brew create https://github.com/fatedier/frp/archive/v0.25.1.tar.gzHomebrew 会在 /usr/local/Library/Formula/ 下创建名为 frp.rb 的文件,将该文件放入项目的 Formula 文件夹中进行编辑:
# Documentation: https://docs.brew.sh/Formula-Cookbook
# https://www.rubydoc.info/github/Homebrew/brew/master/Formula
# PLEASE REMOVE ALL GENERATED COMMENTS BEFORE SUBMITTING YOUR PULL REQUEST!
class Frp < Formula
desc "A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet."
homepage ""
url "https://github.com/fatedier/frp/archive/v0.25.1.tar.gz"
sha256 "33bda2e559f072e8423d8ef84a66b150c4a5fe986c892cbdd8b5bebe2f7956be"
# depends_on "cmake" => :build
def install
# ENV.deparallelize # if your formula fails when building in parallel
# Remove unrecognized options if warned by configure
system "./configure", "--disable-debug",
"--disable-dependency-tracking",
"--disable-silent-rules",
"--prefix=#{prefix}"
# system "cmake", ".", *std_cmake_args
system "make", "install" # if this fails, try separate make/make install steps
end
test do
# `test do` will create, run in and delete a temporary directory.
#
# This test will fail and we won't accept that! For Homebrew/homebrew-core
# this will need to be a test that verifies the functionality of the
# software. Run the test with `brew test frp`. Options passed
# to `brew install` such as `--HEAD` also need to be provided to `brew test`.
#
# The installed folder is not in the path, so use the entire path to any
# executables being tested: `system "#{bin}/program", "do", "something"`.
system "false"
end
end
类的头部有 4 个变量:
desc "A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet."homepage ""url "https://github.com/fatedier/frp/archive/v0.25.1.tar.gz"sha256 "33bda2e559f072e8423d8ef84a66b150c4a5fe986c892cbdd8b5bebe2f7956be"分别表示 简介 (decs)、主页地址 (homepage)、源码地址 (url)和源码的哈希特征码 (sha256)
其中三项 Homebrew 自动生成,主页地址手动填写。
frp 编译依赖 Golang,添加:
depends_on "go" => :build:build 表示在编译时依赖,其他一些
:test => 在运行 brew test 时依赖:option => 没用过,不知道有啥用:recommended => 也没用过:xcode => 需要依赖 Xcode参考 Homebrew 官方文档: Formula Cookbook
将install 中的参考示例删除,修改为:
def installENV["GOPROXY"] = "https://goproxy.io"system "make"bin.install "bin/frps"bin.install "bin/frpc"endfrp 的根目录存在 go.mod 文件,说明该项目支持 Go Module。网络不佳时可通过环境变量 GOPROXY 设置代理。
frp 提供了 makefile 文件,所以直接使用 make 编译即可。
编译好后得到二进制文件 bin/frps 和 bin/frpc 。通过 bin.instal 将编译好的二进制文件安装到 Homebrew 安装位置。
此时,在终端中执行便可开始安装
$ brew install frp==> Downloading https://github.com/fatedier/frp/archive/v0.25.1.tar.gzAlready downloaded: /Library/Caches/Homebrew/downloads/232cf62ed11cd378e4be4ff49e5469fa3d62b69ab11668bba02af2db080669f6--v0.25.1.tar.gz==> make......有时候安装成功了,但功能不一定完备。我们还可以写两个测试用例来测试一下功能是否完整。
例如,我这里测试了安装的版本是否正确。
test dooutput_s = shell_output("#{bin}/frps -v")assert_match "#{version}", "v"+output_soutput_c = shell_output("#{bin}/frpc -v")assert_match "#{version}", "v"+output_cend终端中输入
$ brew test frpTesting mogeko/taps/frp==> /usr/local/Cellar/frp/v0.25.1/bin/frps -v==> /usr/local/Cellar/frp/v0.25.1/bin/frpc -v完成后的 Formula frp.rb:
class Frp < Formula
desc "A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet."
homepage "https://github.com/fatedier/frp"
version "v0.25.1"
url "https://github.com/fatedier/frp/archive/#{version}.tar.gz"
sha256 "33bda2e559f072e8423d8ef84a66b150c4a5fe986c892cbdd8b5bebe2f7956be"
depends_on "go" => :build
def install
# ENV["GO111MODULE"] = "on"
ENV["GOPROXY"] = "https://goproxy.io"
system "make"
bin.install "bin/frps"
bin.install "bin/frpc"
end
test do
output_s = shell_output("#{bin}/frps -v")
assert_match "#{version}", "v"+output_s
output_c = shell_output("#{bin}/frpc -v")
assert_match "#{version}", "v"+output_c
end
end
除了下载源码 -> 本地编译 -> 安装,也可以使用预编译二进制包 Bottle。一个 Formula 如果有 Bottle ,Homebrew 默认使用 Bottle,这样安装更快更安全。homebrew/homebrew-core 中的 Formula 一般都提供 Bottle。
条件允许,最好为自己的项目添加 Bottle,但二进制文件分发又成了新的问题。
Bottle 在 Ruby 脚本中长这样:
bottle dosha256 "4921af80137af9cc3d38fd17c9120da882448a090b0a8a3a19af3199b415bfca" => :sierrasha256 "c71db15326ee9196cd98602e38d0b7fb2b818cdd48eede4ee8eb827d809e09ba" => :el_capitansha256 "85cc828a96735bdafcf29eb6291ca91bac846579bcef7308536e0c875d6c81d7" => :yosemiteend中间 3 行的 sha256 是二进制文件的哈哈希特征码,后面的 :sierra、:el_capitan 和 :yosemite 是二进制文件对应的系统版本。
Bottle 还可以定义 root_url 等,参考:Homebrew 官方文档: Bottle
通过一下两行命令就可以轻松的制作 Bottle 了 (如果已经安装过 frp 的话使用 reinstall):
$ brew (re)install --build-bottle frp$ brew bottle --json frp不出意外的话会在当前目录下生成两个新文件:frp--v0.25.1.x86_64_linux.bottle.json 和 frp--v0.25.1.x86_64_linux.bottle.tar.gz。frp--v0.25.1.x86_64_linux.bottle.tar.gz 就是打包好的二进制文件。配置好 frp.rb,然后将其上传到 Github Releases 等分发平台就可以了。
可以用 Travis CI 等持续集成平台来制作与发布 Bottle,有兴趣的同学可以自己研究一下。
·End·
撰文丨Soma(中科院神经科学研究所)
编辑丨浦肯野
排版 | 熙祎
昨天,马斯克(Elon Musk)的Neuralink公司发布了最新的脑机接口技术,在发布会上,我们得知,马斯克的新一代脑机接口分为以下四个方面:
线程(Threads)——来自美国国家实验室的Vanessa Tolosa研发的单根多触点柔性电极。
机器人(Robots)——将Threads植入皮层的手术机器人
元件(Electronics)——将记录到的信号进行滤波,数模转换和脉冲检测(spike detection)的电子元件,代表技术为DJ Seo的N1传感器,DJ Seo之前在加州大学伯克利分校做Neural dust项目
算法(Algorithms)——脑机接口算法,由加利福尼亚大学旧金山分校教授Philip Sabes教授开发。
本篇文章就着重于从这四个方面介绍马斯克的Neuralink公司,这两年都干了些啥。
图片来源:Neuralink发布会
我们都知道大脑中有许多神经元,神经元间缔结的关系构成了神经网络,信号在神经元上的主要是通过电脉冲信号(动作电位)进行传递。某种程度上,动作电位反映着我们的“想法”。既然马斯克想要实现人类大脑与机器的通信,则必须要有一种手段记录大脑信号,目前来说信号很多,比如:
图片来源:Neuralink发布会
从时空分别率和信号质量来说,动作电位包含了更多的信息,但记录动作电位也最困难(需要开颅) ,所以马斯克在神经工程领域还是比较认真的,啃了这样一块硬骨头。
介绍线(Threads)之前,我们先来介绍一下现在比较火热的电极,犹他电极(Utah array)和神经像素(Neuropixel)。犹他电极是一个电极组,思路比较简单,就是把许多电极集成在一块上,做手术的时候,就像用气锤往大脑里面砸一个刺猬,这个电极的优点是稳定,已有案例多 ,手术简单,缺点是记录位点较少(最多256),日后取出较难。
图片来源:https://blackrockmicro.com/electrode-types/utah-array/
神经像素是去年的大明星,只有一根电极,但是上面集成了960个记录位点,它的优点是损伤少,可以急性记录,缺点是只有一根,记录位点只有深度,而非平面。
图片来源:https://www.ucl.ac.uk/Neuropixels/
而Neuralink公司的方案是在记录方面集上述两家电极的优势,但是劣势是手术极难,在视频中Vanessa Tolosa展示了一种直径27.5微米的电极——线,这个电极比犹他电极(100微米)和神经像素(70微米)要小很多,更细的电极意味着更小的脑损伤。从视频来看,他们还能提供更多的定制化电极。
图片来源:Neuralink发布会
同时在单根电极上深度不同,记录位点不同,这也是为什么能实现单个传感器(N1 sensor)进行1024通道信号处理,因为Neuralink并不会在一个区域植入1024根电极,而是按64(根)×16(单根记录位点)的方式来植入。
视频里的电极显然是一种柔性电极,能够被掰弯,在电极材料里,硅板电极是刚性电极,金属电极又无法集成多个记录位点,那剩下的选择,只能将电极丝埋入高分子材料中,这种方案一般应用在皮层脑电和外周神经的记录中,但是在皮层动作电位的记录比较少见。
图片来源:Neuralink发布会
所有的柔性电极都会被埋藏在皮质中,它们会随着大脑浮动,所有不用担心“钢针”会划伤大脑组织的问题,并且Neuralink使用的是柔性电极,就像在脑子里埋了一根“头发丝”,十分安全。最终,所有记录的信号都会传递到传感器。
如前文所述,使用Threads这样的电极意味着植入手术难度提升了好几个档次,因为无论是犹他电极还是Neuropixel,最多是将硬脑膜掀开,把电极往里一拍就完事了(当然这些手术也很难),但是使用Threads电极不单要进行这些操作,还得将电极一根根植入。
图片来源:Neuralink发布会
所以,为完成这个艰难的任务,他们在会上提出了一种手术机器人,干起活就像缝纫机一样将一根根电极快速而稳定地植入到皮层中。植入过程中还能避开血管,定制化地确定电极位置,令手术更安全,进一步保证电极的记录效率。
图片来源:Neuralink发布会
归根到底,电极记录到的是神经元的膜电位信号,这种信号非常微小(毫伏级),且大脑内的环境比较复杂,存在各种噪音,那么就必须存在一种硬件,能够对信号进行滤波、放大和模数转换。

图片来源:Neuralink发布会
DJ Seo就带来了他的解决方案,他在芯片上设计了一种Analog pixels单元 ,能够单独对每个通道进行预处理,包括上述所说的滤波等处理,最后记录到的细胞膜表面电位会转换成数字信号。这个芯片中集成了1024个Analog pixels ,要知道神经科学家的多通道记录仪跟一台台式电脑主机差不多大,而Neuralink将这些功能集成在一块芯片上,大大增强了脑机接口的实用性。

图片来源:Neuralink发布会
DJ Seo可以说非常懂神经科学家的心了,在做电生理分析的时候,我们要耗费大量的时间来进行脉冲分选(Spike sorting)来得到动作电位,对动作电位做降维,聚类等等。而DJ Seo大手一挥,以后这些工作通通可以在芯片上自动化完成!

图片来源:Neuralink发布会
借助芯片控制,DJ Seo设计的电子元件可以控制单通道来进行电刺激(0.2微安的振幅,7.8微秒的时间分辨率)。这是一个非常重要的功能,因为动作电位的记录只能帮助我们读取大脑信息,而电刺激能给帮助我们给大脑传递信息,比如视觉,触觉,本体感觉等。

图片来源:Neuralink发布会
这块芯片会钉在颅骨上,这个设计有两个好处,一是用于锚定电极,防止电极因各种意外脱位,二是在较近的位置完成数模转换,减少噪声。

图片来源:Neuralink发布会
这部分是Philip Sabes在负责。Sabes名校出身,在剑桥大学学过两年数学,博士毕业于麻省理工,之后在加州理工做博士后,现在在加州大学旧金山分校做教授,算是地地道道的神经科学专家。笔者有幸听过他的讲座,讲述的是在躯体感觉皮层给予电刺激,让猕猴产生了虚假的“感觉”。

图片来源:https://profiles.ucsf.edu/philip.sabes
可以看出,**Sabes关注运动控制的神经机制,并擅长对躯体感觉皮层进行刺激。**目前来说,脑机接口的控制算法已经极为成熟,来自匹兹堡大学的Andy Schwartz,已经报道多项应用于人的脑机接口工作,其中患者已经能够极为流畅地使用自己的“意念”来实现机械手的控制。Neuralink如果想在脑机接口领域有所建树,使用Threads进行对皮层的精细刺激是一个很好的方向,起码对于高位截瘫患者,这项技术将帮他们重获对躯体的感觉。

因此Sabes的汇报介绍了应用于脑机接口的群体向量算法,并畅想了这项技术的未来,比如将电极植入视觉相关皮层、海马区和前额叶进行记录和刺激,可以实现更多可能的应用。
Tips:
Neuralink计划将电极植入大脑皮层中负责躯体运动控制的初级运动皮层(Primary motor cortex)、背侧前运动皮层(Dorsal premotor cortex)、辅助运动区(Supplementary motor area)和负责躯体感觉的躯体感觉皮层(Somatosensory cortex)这几个位置。


来源:Neuralink发布会
总结:
在这次发布会上,Neuralink确实提出了一种变革性的脑机接口技术。简单来说,“线”让我们得到更多的皮层信息,且更细更软的电极极大的减小了脑损伤,N1传感器也简化了脑机接口的设计,让脑机接口应用于生活变得更有可能。
美国民众本身对侵入式脑机接口有很高的接受度,即便是传统的犹他电极,也有应用于多名高位截瘫患者的案例,但这个数字在**是0 。
而Neuralink提出了一种可用于人的更为安全的方案,相信会令更多患者放下心理负担,从而招募到更多的被试者进行研究,这些基于人群的研究提供的数据将进一步激发脑机接口的发展,也许未来我们会看到脑机接口变成一项成熟的技术造福社会。
附录:
https://www.digitaltrends.com/cool-tech/neuralink-elon-musk-questions/www.digitaltrends.com
很高兴认识你!这是 雨荷原创号 每周末更新 的 第67篇 文章 ~
在 我的转学故事 中,我提到过过我在保送复旦和转学港大的面试之后,都有类似的感受,就是面试之后我就有百分之七八十的把握,我可以拿到这个OFFER了。于是一些读者留言希望我分享自己的面试经验,遂成此文。
对于我很想要的机会,我会花时间精力认真准备练习面试,调整心态。这个过程就像我在 转学故事 里所说,积极探索,建立自己的选择标准,留心机会,积累经验,认真准备,然后一举拿下。
**面试呢,相信大家都有自己的经验和方法,比如说你在面试之前就要了解这家公司,了解这个职位的要求,你要准备好自己的简历,准备一些可能会问到的面试问题,你要提前练习说好你的故事,最好找朋友模拟面试,**等等这些面试方法网上很多啦,这篇文章我想分享关于面试的心理建设和一些肢体语言上的小心机。
1、面试是和陌生人第一次聊天,是互相了解的过程:
**面试是招人之前互相了解的形式,只不过因为场合正式、内容严肃,再加上是和陌生人第一次见面,所以大家容易忽略的一点是,面试是一种聊天,面试是人际沟通的一种形式,**所以所有对于人际沟通有效的方法,都可以运用在面试上。
**既然是聊天的话,那你一定知道一场顺畅的、让双方感觉良好的聊天是什么样的:**没有冲突,很少沉默,一个话题接着一个话题,互相能懂对方在说什么,有内容,对方的情绪波动和你差不多。
面试还有点像约会,哎呀我好紧张,我应该说些什么展现我的才能、我的特别,我要干什么才能让对方对我继续感兴趣,先让我研究一下对方喜欢什么吧!
面试之前我们会花很多时间精力在展现自己的才能这一部分,哎呀我好紧张,怎么办我能胜任这个职位吗,我怎样才能说服对方推销自己。
别忘了,面试也是你了解这个职位每天真正在做什么、了解你未来可能的同事和上司、了解工作形式和工作节奏的过程,这些信息在职位介绍、在你申请的时候,是很难真正了解的。
面试面的不仅是你的能力和你过去的成绩,也会面试你的性格和工作价值观。同时,你也在面试对方的性格和工作价值观,所以说面试是一个互相了解的过程。
一个让双方感觉良好、进程顺利的面试,候选人的说话内容在60%-70%左右,招聘方的说话内容在30%左右,甚至理想情况是互相一半一半。
2、利用第一印象效应:
心理学上的首因效应中第一印象的重要性不言而喻,第一印象不一定是正确的,但却给人的印象最牢固、最鲜明**。你给****别人留下的第一印象会形成别人对你最初的认知,之后对你的了解会整合进入第一印象中。**
面试中从别人见到你、握手、坐下的过程,别人就已经对你形成第一印象了,到你开口说的第一段话,对方已经大概了解你了。回想一下,你与朋友第一次相识是不是也是这样对他形成了第一印象?
既然逃不开第一印象效应,那不如好好思考一下,我们怎样利用第一印象。
你在这次面试中,希望让对方对你产生怎样的印象?
**这里分享我利用第一印象的一个小技巧,在面试之前,我会思考我想给对方留下什么印象?**只需要想3个关键词,比如面试中我想展现自己很confident, passionate and mature。我会在去面试的途中反复默念这3个词,反复默念的过程会让你把目标刻在脑海中,你会不自觉地展现这一面,你的大脑会把这些形容词作用在你的肢体语言和行为表现上的!
3、说好你的故事:
现在很多公司面试采取super day的形式,一天下来车轮战一样面试10多个候选人,当你的面试官结束所有面试,拿起你的简历,他还会记得你是什么样的人?你做过哪些实习?你最引以为豪的事情是什么?你曾经失败的经历是什么?你最能让面试官记住的特别经历、做过的最不一样的事情是什么呢?
如果你能够让面试官在第二天看到你的CV,还能回想起你的经历、特点,你性格中最闪光、最让人印象深刻的地方,那你这场面试就成功了。
所以怎样才能让你从众多优秀的候选人中脱颖而出,让面试官对你印象长存呢?
说好你的故事。说一段你的经历、真实的、有起有落、能够展现你的能力、特点和性格的故事。
4、自信的肢体语言:
面试是你和陌生人第一次正式严肃的聊天,是互相了解的过程,无论是第一印象,还是你在回答面试问题,诉说你的亲身经历的时候,肢体语言都能够帮助你展现你的自信大方,表现你的能力和性格。
来自网络搜索的7-38-55定律:“UCLA的教授Albert Mehrabian于1971年所做的研究揭露,有效的情感和态度沟通包含三大要素:肢体语言、声调和说话内容,信息中有55%的意义来自身体语言(仪态、姿势、表情),38%的意义来自谈话时的声音面(语气、声调、速度),仅有7%的意义来自说出来的内容(遣词用字)。”
在面试中要运用开放式肢体动作,不要垂头丧气,不要太紧张,不要抱着手臂。
第一次见面要好好打扮
,微笑,走路轻快,抬头挺胸,握手要有力度,握手向上一下向下一下就可以松开了,心中默念我想给别人留下的印象的那3个词,放轻松,相信自己!
说话时,语速不要太快也不能太慢,语调平常,讲故事的时候语调语气可以随着故事发展起落,说话要正面积极,不要出现什么负面词汇。
身体稍微向前倾,说话时配合一些手势,可以模仿面试官的小动作,别人模仿自己会让人在潜意识中更喜欢你!
哈佛大学社会心理学家Amy Cuddy表示:“有力的姿势,比如以一个自信的方式站着,即使我们不自信,自信的姿势也能够让我们更加自信有力。”出自Amy Cuddy的TED演讲
5、如果对方气场强大,别慌:
如果面试官气场强大,不停挑战你,要么对方本身工作作风就是这样的,要么他在对你进行压力测试,别慌别紧张,按照自己准备好的、想展示的内容继续说下去。
**如果对方提出了一个很有挑战性的问题,很可能在考察你的应变能力、语言组织能力、以及你的性格特点,**如果你被对方压住了气势,慌了手脚,那就会在对方印象中减分,如果你回答的方式在防御自己、保护自己,甚至是针锋相对,那就更不好了。
在被挑战的情况下,是时候展现你的心理素质、你的应变能力和语言组织能力了!
我们经常说“准备面试”,是在面试之前了解更多关于公司和职位的信息,练习回答面试问题,而你的CV、你的能力、你的心理素质、应变能力和性格是无法在短时间内“准备”出来的。
你无法预测哪天会接到改变人生方向的机会,但是,即使是天上掉馅饼,也需要你有智识能够认出馅饼,有能力抓住馅饼,还要能够消化掉。
愿你在那一天来临之前,就做足准备。
互动问题:你有什么面试小技巧?欢迎留言
坚持原创,喜欢就赞赏吧
也许你还想看:
5、自我介绍的技巧
欢迎转发分享谢谢!~
The CMake tutorial provides a step-by-step guide that covers common build system issues that CMake helps address. Seeing how various topics all work together in an example project can be very helpful. The tutorial documentation and source code for examples can be found in the Help/guide/tutorial directory of the CMake source code tree. Each step has its own subdirectory containing code that may be used as a starting point. The tutorial examples are progressive so that each step provides the complete solution for the previous step.
The most basic project is an executable built from source code files. For simple projects, a three line CMakeLists file is all that is required. This will be the starting point for our tutorial. Create a CMakeLists.txt file in the Step1 directory that looks like:
cmake_minimum_required(VERSION 3.10)
# set the project name
project(Tutorial)
# add the executable
add_executable(Tutorial tutorial.cxx)
Note that this example uses lower case commands in the CMakeLists file. Upper, lower, and mixed case commands are supported by CMake. The source code for tutorial.cxx is provided in the Step1 directory and can be used to compute the square root of a number.
The first feature we will add is to provide our executable and project with a version number. While we could do this exclusively in the source code, using CMakeLists provides more flexibility.
First, modify the CMakeLists file to set the version number.
cmake_minimum_required(VERSION 3.10)
# set the project name and version
project(Tutorial VERSION 1.0)
Then, configure a header file to pass the version number to the source code:
configure_file(TutorialConfig.h.in TutorialConfig.h)
Since the configured file will be written into the binary tree, we must add that directory to the list of paths to search for include files. Add the following lines to the end of the CMakeLists file:
target_include_directories(Tutorial PUBLIC
"${PROJECT_BINARY_DIR}"
)
Using your favorite editor, create TutorialConfig.h.in in the source directory with the following contents:
// the configured options and settings for Tutorial
#define Tutorial_VERSION_MAJOR @Tutorial_VERSION_MAJOR@
#define Tutorial_VERSION_MINOR @Tutorial_VERSION_MINOR@
When CMake configures this header file the values for @Tutorial_VERSION_MAJOR@ and @Tutorial_VERSION_MINOR@ will be replaced.
Next modify tutorial.cxx to include the configured header file, TutorialConfig.h.
Finally, let’s print out the version number by updating tutorial.cxx as follows:
if (argc < 2) {
// report version
std::cout << argv[0] << " Version " << Tutorial_VERSION_MAJOR << "."
<< Tutorial_VERSION_MINOR << std::endl;
std::cout << "Usage: " << argv[0] << " number" << std::endl;
return 1;
}
Next let’s add some C++11 features to our project by replacing atof with std::stod in tutorial.cxx. At the same time, remove #include <cstdlib>.
const double inputValue = std::stod(argv[1]);
We will need to explicitly state in the CMake code that it should use the correct flags. The easiest way to enable support for a specific C++ standard in CMake is by using the CMAKE_CXX_STANDARD variable. For this tutorial, set the CMAKE_CXX_STANDARD variable in the CMakeLists file to 11 and CMAKE_CXX_STANDARD_REQUIRED to True:
cmake_minimum_required(VERSION 3.10)
# set the project name and version
project(Tutorial VERSION 1.0)
# specify the C++ standard
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED True)
Run cmake or cmake-gui to configure the project and then build it with your chosen build tool.
For example, from the command line we could navigate to the Help/guide/tutorial directory of the CMake source code tree and run the following commands:
mkdir Step1_build
cd Step1_build
cmake ../Step1
cmake --build .
Navigate to the directory where Tutorial was built (likely the make directory or a Debug or Release build configuration subdirectory) and run these commands:
Tutorial 4294967296
Tutorial 10
Tutorial
Now we will add a library to our project. This library will contain our own implementation for computing the square root of a number. The executable can then use this library instead of the standard square root function provided by the compiler.
For this tutorial we will put the library into a subdirectory called MathFunctions. This directory already contains a header file, MathFunctions.h, and a source file mysqrt.cxx. The source file has one function called mysqrt that provides similar functionality to the compiler’s sqrt function.
Add the following one line CMakeLists.txt file to the MathFunctions directory:
add_library(MathFunctions mysqrt.cxx)
To make use of the new library we will add an add_subdirectory call in the top-level CMakeLists file so that the library will get built. We add the new library to the executable, and add MathFunctions as an include directory so that the mqsqrt.h header file can be found. The last few lines of the top-level CMakeLists file should now look like:
# add the MathFunctions library
add_subdirectory(MathFunctions)
# add the executable
add_executable(Tutorial tutorial.cxx)
target_link_libraries(Tutorial PUBLIC MathFunctions)
# add the binary tree to the search path for include files
# so that we will find TutorialConfig.h
target_include_directories(Tutorial PUBLIC
"${PROJECT_BINARY_DIR}"
"${PROJECT_SOURCE_DIR}/MathFunctions"
)
Now let us make the MathFunctions library optional. While for the tutorial there really isn’t any need to do so, for larger projects this is a common occurrence. The first step is to add an option to the top-level CMakeLists file.
option(USE_MYMATH "Use tutorial provided math implementation" ON)
# configure a header file to pass some of the CMake settings
# to the source code
configure_file(TutorialConfig.h.in TutorialConfig.h)
This option will be displayed in the CMake GUI and ccmake with a default value of ON that can be changed by the user. This setting will be stored in the cache so that the user does not need to set the value each time they run CMake on a build directory.
The next change is to make building and linking the MathFunctions library conditional. To do this we change the end of the top-level CMakeLists file to look like the following:
if(USE_MYMATH)
add_subdirectory(MathFunctions)
list(APPEND EXTRA_LIBS MathFunctions)
list(APPEND EXTRA_INCLUDES "${PROJECT_SOURCE_DIR}/MathFunctions")
endif()
# add the executable
add_executable(Tutorial tutorial.cxx)
target_link_libraries(Tutorial PUBLIC ${EXTRA_LIBS})
# add the binary tree to the search path for include files
# so that we will find TutorialConfig.h
target_include_directories(Tutorial PUBLIC
"${PROJECT_BINARY_DIR}"
${EXTRA_INCLUDES}
)
Note the use of the variable EXTRA_LIBS to collect up any optional libraries to later be linked into the executable. The variable EXTRA_INCLUDES is used similarly for optional header files. This is a classic approach when dealing with many optional components, we will cover the modern approach in the next step.
The corresponding changes to the source code are fairly straightforward. First, in tutorial.cxx, include the MathFunctions header if we need it:
#ifdef USE_MYMATH
# include "MathFunctions.h"
#endif
Then, in the same file, make which square root function is used dependent on USE_MYMATH:
#ifdef USE_MYMATH
const double outputValue = mysqrt(inputValue);
#else
const double outputValue = sqrt(inputValue);
#endif
Since the source code now requires USE_MYMATH we can add it to TutorialConfig.h.in with the following line:
Exercise: Why is it important that we configure TutorialConfig.h.in after the option for USE_MYMATH? What would happen if we inverted the two?
Run cmake or cmake-gui to configure the project and then build it with your chosen build tool. Then run the built Tutorial executable.
Use ccmake or the CMake GUI to update the value of USE_MYMATH. Rebuild and run the tutorial again. Which function gives better results, sqrt or mysqrt?
Usage requirements allow for far better control over a library or executable’s link and include line while also giving more control over the transitive property of targets inside CMake. The primary commands that leverage usage requirements are:
target_compile_definitionstarget_compile_optionstarget_include_directoriestarget_link_libraries
Let’s refactor our code from Adding a Library (Step 2) to use the modern CMake approach of usage requirements. We first state that anybody linking to MathFunctions needs to include the current source directory, while MathFunctions itself doesn’t. So this can become an INTERFACE usage requirement.
Remember INTERFACE means things that consumers require but the producer doesn’t. Add the following lines to the end of MathFunctions/CMakeLists.txt:
target_include_directories(MathFunctions
INTERFACE ${CMAKE_CURRENT_SOURCE_DIR}
)
Now that we’ve specified usage requirements for MathFunctions we can safely remove our uses of the EXTRA_INCLUDES variable from the top-level CMakeLists, here:
if(USE_MYMATH)
add_subdirectory(MathFunctions)
list(APPEND EXTRA_LIBS MathFunctions)
endif()
And here:
target_include_directories(Tutorial PUBLIC
"${PROJECT_BINARY_DIR}"
)
Once this is done, run cmake or cmake-gui to configure the project and then build it with your chosen build tool or by using cmake --build . from the build directory.
Now we can start adding install rules and testing support to our project.
The install rules are fairly simple: for MathFunctions we want to install the library and header file and for the application we want to install the executable and configured header.
So to the end of MathFunctions/CMakeLists.txt we add:
install(TARGETS MathFunctions DESTINATION lib)
install(FILES MathFunctions.h DESTINATION include)
And to the end of the top-level CMakeLists.txt we add:
install(TARGETS Tutorial DESTINATION bin)
install(FILES "${PROJECT_BINARY_DIR}/TutorialConfig.h"
DESTINATION include
)
That is all that is needed to create a basic local install of the tutorial.
Run cmake or cmake-gui to configure the project and then build it with your chosen build tool. Run the install step by typing cmake --install . (introduced in 3.15, older versions of CMake must use make install) from the command line, or build the INSTALL target from an IDE. This will install the appropriate header files, libraries, and executables.
The CMake variable CMAKE_INSTALL_PREFIX is used to determine the root of where the files will be installed. If using cmake --install a custom installation directory can be given via --prefix argument. For multi-configuration tools, use the --config argument to specify the configuration.
Verify that the installed Tutorial runs.
Next let’s test our application. At the end of the top-level CMakeLists file we can enable testing and then add a number of basic tests to verify that the application is working correctly.
enable_testing()
# does the application run
add_test(NAME Runs COMMAND Tutorial 25)
# does the usage message work?
add_test(NAME Usage COMMAND Tutorial)
set_tests_properties(Usage
PROPERTIES PASS_REGULAR_EXPRESSION "Usage:.*number"
)
# define a function to simplify adding tests
function(do_test target arg result)
add_test(NAME Comp${arg} COMMAND ${target} ${arg})
set_tests_properties(Comp${arg}
PROPERTIES PASS_REGULAR_EXPRESSION ${result}
)
endfunction(do_test)
# do a bunch of result based tests
do_test(Tutorial 4 "4 is 2")
do_test(Tutorial 9 "9 is 3")
do_test(Tutorial 5 "5 is 2.236")
do_test(Tutorial 7 "7 is 2.645")
do_test(Tutorial 25 "25 is 5")
do_test(Tutorial -25 "-25 is [-nan|nan|0]")
do_test(Tutorial 0.0001 "0.0001 is 0.01")
The first test simply verifies that the application runs, does not segfault or otherwise crash, and has a zero return value. This is the basic form of a CTest test.
The next test makes use of the PASS_REGULAR_EXPRESSION test property to verify that the output of the test contains certain strings. In this case, verifying that the the usage message is printed when an incorrect number of arguments are provided.
Lastly, we have a function called do_test that runs the application and verifies that the computed square root is correct for given input. For each invocation of do_test, another test is added to the project with a name, input, and expected results based on the passed arguments.
Rebuild the application and then cd to the binary directory and run ctest -N and ctest -VV. For multi-config generators (e.g. Visual Studio), the configuration type must be specified. To run tests in Debug mode, for example, use ctest -C Debug -VV from the build directory (not the Debug subdirectory!). Alternatively, build the RUN_TESTS target from the IDE.
Let us consider adding some code to our project that depends on features the target platform may not have. For this example, we will add some code that depends on whether or not the target platform has the log and exp functions. Of course almost every platform has these functions but for this tutorial assume that they are not common.
If the platform has log and exp then we will use them to compute the square root in the mysqrt function. We first test for the availability of these functions using the CheckSymbolExists.cmake macro in the top-level CMakeLists. We’re going to use the new defines in TutorialConfig.h.in, so be sure to set them before that file is configured.
include(CheckSymbolExists)
set(CMAKE_REQUIRED_LIBRARIES "m")
check_symbol_exists(log "math.h" HAVE_LOG)
check_symbol_exists(exp "math.h" HAVE_EXP)
Now let’s add these defines to TutorialConfig.h.in so that we can use them from mysqrt.cxx:
// does the platform provide exp and log functions?
#cmakedefine HAVE_LOG
#cmakedefine HAVE_EXP
Modify mysqrt.cxx to include cmath. Next, in that same file in the mysqrt function we can provide an alternate implementation based on log and exp if they are available on the system using the following code (don’t forget the #endif before returning the result!):
#if defined(HAVE_LOG) && defined(HAVE_EXP)
double result = exp(log(x) * 0.5);
std::cout << "Computing sqrt of " << x << " to be " << result
<< " using log and exp" << std::endl;
#else
double result = x;
Run cmake or cmake-gui to configure the project and then build it with your chosen build tool and run the Tutorial executable.
You will notice that we’re not using log and exp, even if we think they should be available. We should realize quickly that we have forgotten to include TutorialConfig.h in mysqrt.cxx.
We will also need to update MathFunctions/CMakeLists so mysqrt.cxx knows where this file is located:
target_include_directories(MathFunctions
INTERFACE ${CMAKE_CURRENT_SOURCE_DIR}
PRIVATE ${CMAKE_BINARY_DIR}
)
After making this update, go ahead and build the project again and run the built Tutorial executable. If log and exp are still not being used, open the generated TutorialConfig.h file from the build directory. Maybe they aren’t available on the current system?
Which function gives better results now, sqrt or mysqrt?
Is there a better place for us to save the HAVE_LOG and HAVE_EXP values other than in TutorialConfig.h? Let’s try to use target_compile_definitions.
First, remove the defines from TutorialConfig.h.in. We no longer need to include TutorialConfig.h from mysqrt.cxx or the extra include in MathFunctions/CMakeLists.
Next, we can move the check for HAVE_LOG and HAVE_EXP to MathFunctions/CMakeLists and then add specify those values as PRIVATE compile definitions.
include(CheckSymbolExists)
set(CMAKE_REQUIRED_LIBRARIES "m")
check_symbol_exists(log "math.h" HAVE_LOG)
check_symbol_exists(exp "math.h" HAVE_EXP)
if(HAVE_LOG AND HAVE_EXP)
target_compile_definitions(MathFunctions
PRIVATE "HAVE_LOG" "HAVE_EXP")
endif()
After making these updates, go ahead and build the project again. Run the built Tutorial executable and verify that the results are same as earlier in this step.
Suppose, for the purpose of this tutorial, we decide that we never want to use the platform log and exp functions and instead would like to generate a table of precomputed values to use in the mysqrt function. In this section, we will create the table as part of the build process, and then compile that table into our application.
First, let’s remove the check for the log and exp functions in MathFunctions/CMakeLists. Then remove the check for HAVE_LOG and HAVE_EXP from mysqrt.cxx. At the same time, we can remove #include <cmath>.
In the MathFunctions subdirectory, a new source file named MakeTable.cxx has been provided to generate the table.
After reviewing the file, we can see that the table is produced as valid C++ code and that the output filename is passed in as an argument.
The next step is to add the appropriate commands to MathFunctions CMakeLists file to build the MakeTable executable and then run it as part of the build process. A few commands are needed to accomplish this.
First, at the top of MathFunctions/CMakeLists, the executable for MakeTable is added as any other executable would be added.
add_executable(MakeTable MakeTable.cxx)
Then we add a custom command that specifies how to produce Table.h by running MakeTable.
add_custom_command(
OUTPUT ${CMAKE_CURRENT_BINARY_DIR}/Table.h
COMMAND MakeTable ${CMAKE_CURRENT_BINARY_DIR}/Table.h
DEPENDS MakeTable
)
Next we have to let CMake know that mysqrt.cxx depends on the generated file Table.h. This is done by adding the generated Table.h to the list of sources for the library MathFunctions.
add_library(MathFunctions
mysqrt.cxx
${CMAKE_CURRENT_BINARY_DIR}/Table.h
)
We also have to add the current binary directory to the list of include directories so that Table.h can be found and included by mysqrt.cxx.
target_include_directories(MathFunctions
INTERFACE ${CMAKE_CURRENT_SOURCE_DIR}
PRIVATE ${CMAKE_CURRENT_BINARY_DIR}
)
Now let’s use the generated table. First, modify mysqrt.cxx to include Table.h. Next, we can rewrite the mysqrt function to use the table:
double mysqrt(double x)
{
if (x <= 0) {
return 0;
}
// use the table to help find an initial value
double result = x;
if (x >= 1 && x < 10) {
std::cout << "Use the table to help find an initial value " << std::endl;
result = sqrtTable[static_cast(x)];
}
// do ten iterations
for (int i = 0; i < 10; ++i) {
if (result <= 0) {
result = 0.1;
}
double delta = x - (result * result);
result = result + 0.5 * delta / result;
std::cout << "Computing sqrt of " << x << " to be " << result << std::endl;
}
return result;
}
Run cmake or cmake-gui to configure the project and then build it with your chosen build tool.
When this project is built it will first build the MakeTable executable. It will then run MakeTable to produce Table.h. Finally, it will compile mysqrt.cxx which includes Table.h to produce the MathFunctions library.
Run the Tutorial executable and verify that it is using the table.
Next suppose that we want to distribute our project to other people so that they can use it. We want to provide both binary and source distributions on a variety of platforms. This is a little different from the install we did previously in Installing and Testing (Step 4) , where we were installing the binaries that we had built from the source code. In this example we will be building installation packages that support binary installations and package management features. To accomplish this we will use CPack to create platform specific installers. Specifically we need to add a few lines to the bottom of our top-level CMakeLists.txt file.
include(InstallRequiredSystemLibraries)
set(CPACK_RESOURCE_FILE_LICENSE "${CMAKE_CURRENT_SOURCE_DIR}/License.txt")
set(CPACK_PACKAGE_VERSION_MAJOR "${Tutorial_VERSION_MAJOR}")
set(CPACK_PACKAGE_VERSION_MINOR "${Tutorial_VERSION_MINOR}")
include(CPack)
That is all there is to it. We start by including InstallRequiredSystemLibraries. This module will include any runtime libraries that are needed by the project for the current platform. Next we set some CPack variables to where we have stored the license and version information for this project. The version information was set earlier in this tutorial and the license.txt has been included in the top-level source directory for this step.
Finally we include the CPack module which will use these variables and some other properties of the current system to setup an installer.
The next step is to build the project in the usual manner and then run CPack on it. To build a binary distribution, from the binary directory run:
To specify the generator, use the -G option. For multi-config builds, use -C to specify the configuration. For example:
To create a source distribution you would type:
cpack --config CPackSourceConfig.cmake
Alternatively, run make package or right click the Package target and Build Project from an IDE.
Run the installer found in the binary directory. Then run the installed executable and verify that it works.
Adding support for submitting our test results to a dashboard is very easy. We already defined a number of tests for our project in Testing Support. Now we just have to run those tests and submit them to a dashboard. To include support for dashboards we include the CTest module in our top-level CMakeLists.txt.
Replace:
# enable testing
enable_testing()
With:
# enable dashboard scripting
include(CTest)
The CTest module will automatically call enable_testing(), so we can remove it from our CMake files.
We will also need to create a CTestConfig.cmake file in the top-level directory where we can specify the name of the project and where to submit the dashboard.
set(CTEST_PROJECT_NAME "CMakeTutorial")
set(CTEST_NIGHTLY_START_TIME "00:00:00 EST")
set(CTEST_DROP_METHOD "http")
set(CTEST_DROP_SITE "my.cdash.org")
set(CTEST_DROP_LOCATION "/submit.php?project=CMakeTutorial")
set(CTEST_DROP_SITE_CDASH TRUE)
CTest will read in this file when it runs. To create a simple dashboard you can run cmake or cmake-gui to configure the project, but do not build it yet. Instead, change directory to the binary tree, and then run:
ctest [-VV] –D Experimental
Remember, for multi-config generators (e.g. Visual Studio), the configuration type must be specified:
ctest [-VV] -C Debug –D Experimental
Or, from an IDE, build the Experimental target.
Ctest will build and test the project and submit the results to the Kitware public dashboard. The results of your dashboard will be uploaded to Kitware’s public dashboard here: https://my.cdash.org/index.php?project=CMakeTutorial.
Generator expressions are evaluated during build system generation to produce information specific to each build configuration.
Generator expressions are allowed in the context of many target properties, such as LINK_LIBRARIES, INCLUDE_DIRECTORIES, COMPILE_DEFINITIONS and others. They may also be used when using commands to populate those properties, such as target_link_libraries(), target_include_directories(), target_compile_definitions() and others.
Generator expressions may be used to enable conditional linking, conditional definitions used when compiling, conditional include directories and more. The conditions may be based on the build configuration, target properties, platform information or any other queryable information.
There are different types of generator expressions including Logical, Informational, and Output expressions.
Logical expressions are used to create conditional output. The basic expressions are the 0 and 1 expressions. A $<0:...> results in the empty string, and <1:...> results in the content of “…”. They can also be nested.
A common usage of generator expressions is to conditionally add compiler flags, such as those as language levels or warnings. A nice pattern is to associate this information to an INTERFACE target allowing this information to propagate. Lets start by constructing an INTERFACE target and specifying the required C++ standard level of 11 instead of using CMAKE_CXX_STANDARD.
So the following code:
# specify the C++ standard
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED True)
Would be replaced with:
add_library(tutorial_compiler_flags INTERFACE)
target_compile_features(tutorial_compiler_flags INTERFACE cxx_std_11)
Next we add the desired compiler warning flags that we want for our project. As warning flags vary based on the compiler we use the COMPILE_LANG_AND_ID generator expression to control which flags to apply given a language and a set of compiler ids as seen below:
set(gcc_like_cxx "$<COMPILE_LANG_AND_ID:CXX,ARMClang,AppleClang,Clang,GNU>")
set(msvc_cxx "$<COMPILE_LANG_AND_ID:CXX,MSVC>")
target_compile_options(tutorial_compiler_flags INTERFACE
"$<${gcc_like_cxx}:$<BUILD_INTERFACE:-Wall;-Wextra;-Wshadow;-Wformat=2;-Wunused>>"
"$<${msvc_cxx}:$<BUILD_INTERFACE:-W3>>"
)
Looking at this we see that the warning flags are encapsulated inside a BUILD_INTERFACE condition. This is done so that consumers of our installed project will not inherit our warning flags.
Exercise: Modify MathFunctions/CMakeLists.txt so that all targets have a target_link_libraries() call to tutorial_compiler_flags.
During Installing and Testing (Step 4) of the tutorial we added the ability for CMake to install the library and headers of the project. During Building an Installer (Step 7) we added the ability to package up this information so it could be distributed to other people.
The next step is to add the necessary information so that other CMake projects can use our project, be it from a build directory, a local install or when packaged.
The first step is to update our install(TARGETS) commands to not only specify a DESTINATION but also an EXPORT. The EXPORT keyword generates and installs a CMake file containing code to import all targets listed in the install command from the installation tree. So let’s go ahead and explicitly EXPORT the MathFunctions library by updating the install command in MathFunctions/CMakeLists.txt to look like:
install(TARGETS MathFunctions tutorial_compiler_flags
DESTINATION lib
EXPORT MathFunctionsTargets)
install(FILES MathFunctions.h DESTINATION include)
Now that we have MathFunctions being exported, we also need to explicitly install the generated MathFunctionsTargets.cmake file. This is done by adding the following to the bottom of the top-level CMakeLists.txt:
install(EXPORT MathFunctionsTargets
FILE MathFunctionsTargets.cmake
DESTINATION lib/cmake/MathFunctions
)
At this point you should try and run CMake. If everything is setup properly you will see that CMake will generate an error that looks like:
Target "MathFunctions" INTERFACE_INCLUDE_DIRECTORIES property contains
path:
"/Users/robert/Documents/CMakeClass/Tutorial/Step11/MathFunctions"
which is prefixed in the source directory.
What CMake is trying to say is that during generating the export information it will export a path that is intrinsically tied to the current machine and will not be valid on other machines. The solution to this is to update the MathFunctions target_include_directories to understand that it needs different INTERFACE locations when being used from within the build directory and from an install / package. This means converting the target_include_directories call for MathFunctions to look like:
target_include_directories(MathFunctions
INTERFACE
$<INSTALL_INTERFACE:include>
)
Once this has been updated, we can re-run CMake and see verify that it doesn’t warn anymore.
At this point, we have CMake properly packaging the target information that is required but we will still need to generate a MathFunctionsConfig.cmake so that the CMake find_package command can find our project. So let’s go ahead and add a new file to the top-level of the project called Config.cmake.in with the following contents:
@PACKAGE_INIT@
include ( "${CMAKE_CURRENT_LIST_DIR}/MathFunctionsTargets.cmake" )
Then, to properly configure and install that file, add the following to the bottom of the top-level CMakeLists:
install(EXPORT MathFunctionsTargets
FILE MathFunctionsTargets.cmake
DESTINATION lib/cmake/MathFunctions
)
include(CMakePackageConfigHelpers)
# generate the config file that is includes the exports
configure_package_config_file(${CMAKE_CURRENT_SOURCE_DIR}/Config.cmake.in
"${CMAKE_CURRENT_BINARY_DIR}/MathFunctionsConfig.cmake"
INSTALL_DESTINATION "lib/cmake/example"
NO_SET_AND_CHECK_MACRO
NO_CHECK_REQUIRED_COMPONENTS_MACRO
)
# generate the version file for the config file
write_basic_package_version_file(
"${CMAKE_CURRENT_BINARY_DIR}/MathFunctionsConfigVersion.cmake"
VERSION "${Tutorial_VERSION_MAJOR}.${Tutorial_VERSION_MINOR}"
COMPATIBILITY AnyNewerVersion
)
# install the configuration file
install(FILES
${CMAKE_CURRENT_BINARY_DIR}/MathFunctionsConfig.cmake
DESTINATION lib/cmake/MathFunctions
)
At this point, we have generated a relocatable CMake Configuration for our project that can be used after the project has been installed or packaged. If we want our project to also be used from a build directory we only have to add the following to the bottom of the top level CMakeLists:
export(EXPORT MathFunctionsTargets
FILE "${CMAKE_CURRENT_BINARY_DIR}/MathFunctionsTargets.cmake"
)
With this export call we now generate a Targets.cmake, allowing the configured MathFunctionsConfig.cmake in the build directory to be used by other projects, without needing it to be installed.
This examples shows how a project can find other CMake packages that generate Config.cmake files.
It also shows how to state a project’s external dependencies when generating a Config.cmake.
By default CMake is model is that a build directory only contains a single configuration, be it Debug, Release, MinSizeRel, or RelWithDebInfo.
But it is possible to setup CPack to bundle multiple build directories at the same time to build a package that contains multiple configurations of the same project.
First we need to ahead and construct a directory called multi_config this will contain all the builds that we want to package together.
Second create a debug and release directory underneath multi_config. At the end you should have a layout that looks like:
─ multi_config
├── debug └── release
Now we need to setup debug and release builds, which would roughly entail the following:
cd debug
cmake -DCMAKE_BUILD_TYPE=Debug ../../MultiPackage/
cmake --build .
cd ../release
cmake -DCMAKE_BUILD_TYPE=Release ../../MultiPackage/
cmake --build .
cd ..
Now that both the debug and release builds are complete we can now use the custom MultiCPackConfig to package both builds into a single release.
cpack --config ../../MultiPackage/MultiCPackConfig.cmake
**特别说明:**要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用
$标记数学公式的开始和结束。如果某条评论中出现了两个$,MathJax 会将两个$之间的内容按照数学公式进行排版,从而导致评论区格式混乱。如果大家的评论中用到了$,但是又不是为了使用数学公式,就请使用\$转义一下,谢谢。
想从头阅读该系列吗?下面是传送门:
宋体12pt:这里是中文,以及标点符号“,。!?:;”This is English. 这一行是6pt。这一行是7pt。这一行是8pt。这一行是9pt。这一行是10pt。这一行是11pt。
黑体12pt:这里是中文,以及标点符号“,。!?:;”This is English. 这一行是6pt。这一行是7pt。这一行是8pt。这一行是9pt。这一行是10pt。这一行是11pt。
微软雅黑12pt:这里是中文,以及标点符号“,。!?:;”This is English. 这一行是6pt。这一行是7pt。这一行是8pt。这一行是9pt。这一行是10pt。这一行是11pt。
serif: This is English, 这是英文中夹杂的中文。This line is 6pt. This line is 7pt. This line is 8pt. This line is 9pt. This line is 10pt. This line is 11pt.
Times New Roman: This is English, 这是英文中夹杂的中文。This line is 6pt. This line is 7pt. This line is 8pt. This line is 9pt. This line is 10pt. This line is 11pt.
Georgia: This is English, 这是英文中夹杂的中文。This line is 6pt. This line is 7pt. This line is 8pt. This line is 9pt. This line is 10pt. This line is 11pt.
sans-serif: This is English, 这是英文中夹杂的中文。This line is 6pt. This line is 7pt. This line is 8pt. This line is 9pt. This line is 10pt. This line is 11pt.
verdana: This is English, 这是英文中夹杂的中文。This line is 6pt. This line is 7pt. This line is 8pt. This line is 9pt. This line is 10pt. This line is 11pt.
Arial: This is English, 这是英文中夹杂的中文。This line is 6pt. This line is 7pt. This line is 8pt. This line is 9pt. This line is 10pt. This line is 11pt.
程序代码:
#include <stdio.h>
int main(){
return 0;//很显然这是为了测试等宽字体
}
先了解字体的分类及其用途。
1、英文字体分为三类,分别是有衬线字体(serif)、无衬线字体(sans-serif)和等宽字体(monospace)。Serif 是有衬线字体,意思是在字的笔画开始、结束的地方有额外的装饰,而且笔画的粗细会有所不同。Sans-serif 就没有这些额外的装饰,而且笔画的粗细差不多。在传统的正文印刷中,普遍认为有衬线字体能带来更佳的可读性(相比无衬线字体),尤其是在大段落的文章中,衬线增加了阅读时对字母的视觉参照。而无衬线字体往往被用在标题、较短的文字段落或者一些通俗读物中。相比严肃正经的有衬线字体,无衬线字体给人一种休闲轻松的感觉。同时,由于无衬线字体笔画比较饱满,所以比较适合电脑屏幕显示,在印刷和打印中,可以用无衬线字体做标题、加粗字体等表示强调。等宽字体就不用多说啦,主要用于终端字体或编程。
2、中文字体可以参照英文字体进行分类,由于中文都是等宽的,所以就只需要区分有衬线(serif)和无衬线(sans-serif)。中文的宋体、仿宋就相当于英文的 serif,所以用于传统印刷和打印效果比较好。而中文的黑体、楷体、圆体等字体相当于英文的 sans-serif,用于电脑屏幕的显示效果比较好,也可以用在印刷和打印中做标题和粗体字。
3、Serif 字体的经典代表有 Georgia 和 Times New Roman,sans-serif 字体的经典代表有 Arial 和Verdana,monospace 字体的经典代表有 Courier New 和 DejaVu Sans Mono。
电脑中的字体既是一门艺术,也是一门技术。要将屏幕上的字体显示得好看难度可不小。字体可以表示为点阵(bitmap),也可以表示为轮廓(outline)。点阵字体不能缩放,轮廓字体可以随意缩放。
1、要获得锐利清晰的效果,小字必须显示为点阵(bitmap),大字可以显示为轮廓;
2、显示轮廓字体时,为了让字体边缘显得比较光滑,需要对字体边缘进行抗锯齿(anti-alias);
3、为了获得更好的效果,字体设计厂家在设计字体的时候,会对字体进行微调(hinting)。字体微调是一项耗时耗力的工作,所以就产生了自动微调技术(autohint);
4、为了让字体在液晶显示器上获得更好的效果(主要也是为了字体边缘光滑),产生了次像素平滑技术(subpixle),微软的 ClearType 技术也属于次像素平滑技术的一种。所谓次像素,是指每个像素中的单独的 R、G、B 分量,所以次像素平滑用好了,字体边缘看起来会更平滑,如果用不好,字体边缘就会显得花花绿绿。也正是因为 CRT 显示器和液晶显示器每个像素的组成方式不一样,所以在 CRT 显示器中不能开次像素平滑。
5、增加屏幕的 dpi,可以增加画字的像素,从而获得更平滑的显示效果。比如在传统的 96dpi 的电脑显示器上,一个 9pt 的字符用 12 个像素绘制,一个 12pt 的字符用 16 个像素绘制,使用轮廓字体确实很难做到平滑。但是在目前的安卓手机、苹果 iPad 等设备上,高分辨率的润眼屏都在 300dpi 以上,画一个 12pt 的字符可以用 50 多个像素,字体平滑自然不是问题,根本不需要使用点阵、微调、抗锯齿、次像素等技术。我认为,随着显示器硬件技术的发展,以上技术都将成为浮云。
这一节很有历史意义。为了向大家充分展示 Linux 桌面系统字体的历史,我安装了 CentOS 5、CentOS 6、CentOS 7、Ubuntu 15.04 和 Ubuntu 18.04,并使用上一节编写的字体测试内容对以上系统的桌面环境的字体显示情况进行了测试。让大家了解 Linux 桌面系统中文字体的五代变迁经历。这五代分别是 CentOS 5 时代的文鼎PL细上海宋和文鼎PL中楷、CentOS 6 时代的 AR PL UMing、CentOS 7 时代的文泉驿黑体、Ubuntu 15.04 时代的 Droid Sans Fallback、Ubuntu 18.04 时代的思源黑体和思源宋体。CentOS 5 发布于 2007 年,比这更早的 Linux 桌面字体的配置是什么样子,以及使用的配置方法是什么,我就不去考究了,前面专门放上几个参考文献的链接,至于更早的字体配置方法,以参考文献中说的为准。
先看上一节的字体测试在 Windows 10 中的显示效果,下图是原始大小:
下图是使用 Ctrl+鼠标滚轮 将字体放大后的效果:
Windows 10 中的显示效果可以当成一个参考标准,虽然网络上仍然还有人对 Windows 的字体渲染技术不太满意,认为跟 MacOS 相比还有差距,但是我已经非常满意了。毕竟 Windows 是一个商业的系统,MicroSoft 是一个有钱的大公司,在字体方面做得还是非常好的。其它在字体方面做得好的公司还有 Apple、Adobe、Google,无一不是有钱的大公司。 这些公司不仅设计了(或者花钱买或者花钱请人设计了)一系列好看的字体,还掌握了很多字体渲染方面的专利。这就使得 Linux 这样的开源系统比较被动了。
从上面两图可以看出,Windows 10 中的字体不管是大号还是小号,都显示得很饱满,而且能够准确区分 serif 和 sans-serif 字体,在 serif 的分类中,又有显示得更好看的 Georgia 和 Times New Roman 字体,在 sans-serif 的分类中,又有显示得更加好看的 Arial 和 Verdana 字体。仔细观看字体并对比,发现在 Windows 10 中, serif 字体不管中英文默认都会以宋体显示,sans-serif 字体不管中英文默认都会以微软雅黑显示。宋体和黑体都是微软买的,中易设计的字体,我们平时用得最多,所以最熟悉。字体比较小时,微软雅黑明显比黑体显示得好看,字体大的时候,微软雅黑和黑体就没有太大的差别了。而且我认为,微软雅黑的引号不好看。宋体字在小字号时,有点阵显示,微软雅黑和 Verdana 在小字号时,也有非常好的 hinting。
Hinting 需要两方面的支持,一是设计字体时,针对字体进行微调,这是一项耗时耗力的工作,所以大公司才搞得起;二是字体渲染时,渲染技术要支持字体中的 hinting 信息。而对 TrueType 字体中的 hinting 进行渲染的技术是有专利壁垒的,所以在早期的 Linux 系统中,使用的 freetype 字体渲染库默认是不支持 hinting 的,如果要开启 hinting 支持,需要自己编译 libfreetype。不过参考文献中说了,如果系统中的 libfreetype 库是 libfreetype6 或以上版本,就说明已经开启 hinting 支持了。现在新一点的 Linux 发行版都满足要求。
没有对比就没有伤害,下面看看 CentOS 5 桌面系统对字体的支持是什么样的,下两图是原始大小:
怎一个模糊了得啊。网页中的字体非常的虚,一点都不饱满,而系统菜单中的字体显示得还比较清晰,因为系统菜单中的字体用的是点阵。基本上可以认为,小字显示为点阵会比较饱满锐利,而显示为轮廓字体则会发虚。下面是使用 Ctrl+鼠标滚轮 放大以后的效果:
将网页放大后,发虚的情况就会好很多,但是和 Windows 下的显示还是没法比。另外,在 CentOS 5 中它不能准确显示 sans-serif 和黑体,所有的字都显示为 serif 和 宋体,更离谱的是,它认为 serif 中夹杂的中文应该显示为楷体。总而言之,CentOS 5 中的字体配置是非常失败的。
当然,这是有历史原因的。CentOS 5 系统中对中文的支持主要依赖于 2001 年文鼎向开源界贡献的两套字体:文鼎PL中楷和文鼎PL细上海宋,如下图:
同时期 Windows 中用的宋体和黑体虽然好,但那是要钱的,在 Linux 中盗用是违法的。而同时期开源界又没有什么好的开源字体,所以只能那么将就了。这时我不得不提一下中科红旗的 Linux,大概也是在这个时期吧,因为字体的原因,我放弃过 Redhat,而选用了中科红旗 Linux。中科红旗 Linux 选用的是和 Windows 一样的中易的宋体,字体清晰锐利,而且中科红旗 Linux 也使用 rpm 管理软件包,所以用着还算顺手。不好的是,我那时对 Linux 字体配置理解不深,写了一些错误的随笔,不过后来都删了,而且这次删随笔致使我的博客排名严重下降,再也没升上来(当然,和我懒没有再继续发高质量博客也有很大关系)。
随着时间的流逝,2011 年,CentOS 6 发布了。在 CentOS 6 中,以上测试字体的内容显示为这样:
放大后,是这样:
从上两张图片可以看到,除了 Arial 显示为 sans-serif 之外,其它的字体都是显示为宋体,而且在小字时有了点阵。和 CentOS 5 相比算是有很大的进步了,因为小字采用点阵后,清晰锐利了不少,发虚的情况没了。不好的是,这个宋体并没有我们习惯的 SimSun 好看,而且逗号句号还不是在一行的偏下的部位,而是跑到了一行的正中。这个宋体是由哪个字体支持的呢?下图可以看到 CentOS 6 中安装的中文字体:
可以看到,CentOS 6 的主打字体是 AR PL UMing。从 AR PL 这几个字符可以看出,AR PL UMing 和文鼎贡献的那两套字体是一脉相承的。确实如此,只不过是经过合并、修改、增加了日语韩语及香港常用字型后,更名为 CJKUniFonts,据说含有点阵。从名字可以看出,有了这套字体,中日韩都可以搞定。而且,CentOS 6 中已经有了文泉驿字体,之所以没有显示黑体不是因为没有黑体,而是因为没有正确配置。
也就是说,至少在 CentOS 6 之前,Linux 桌面发行版都没有认识到黑体字的重要价值。
转眼到了 2014 年,CentOS 7 发布了,这个阶段对应的 Fedora 大约是 20 和 21 这两个版本。在 CentOS 7 中,字体测试显示效果是这样的:
放大后,是这样的:
从上面两张图片可以看出,除了明确指定为 Times New Roman 的字体之外,其它的字体都显示为黑体,而且小字有点阵。它的主打字体是什么呢?请看下图:
黑体选用的是文泉驿,依然安装有 AR PL UMing 作为宋体的支持,但是不作为主打。认识到点阵的重要性和认识到黑体的重要性,可以算是这个时期 Linux 桌面发行版的进步吧。但是,不能正确区分 serif 和 sans-serif,这也是一个巨大的不足吧。
这个时期的 Ubuntu 又是什么样子的呢?我们来看看 Ubuntu 15.04,这是 2015 年的发行版。下面直接连上三图:
我认为,这个时期的 Linux 桌面发行版应该是受到了 Android 手机和苹果 ipad mini 这样的小尺寸高分辨率屏幕的巨大影响,主要表现为认识到了黑体字的重要性,并逐渐放弃了点阵,因为屏幕的 ppi 比较高,点阵就不是必须的了。Ubuntu 15.04 是一种字体打天下,使用的是 Droid Sans Fallback,而这种字体正是 Google 公司为其 Android 系统设计的中日韩字体。这个时期的 Ubuntu,是有进军手机系统的野心的。但是作为 Linux 桌面发行版,不能准确区分 serif 和 sans-serif,也是有硬伤的。
到了 2018 年,Ubuntu 终于放弃了 Unity 桌面,而回归了 Gnome 3,这也标志着其在手机操作系统市场的失败。Ubuntu 18.04 桌面系统显示效果是这样的:
这个阶段,开源领域能够使用的字体也是越来越丰富了。Ubuntu 18.04 中使用的是思源黑体和思源宋体,同时,系统中也安装有 AR PL UMing 和 AR PL UKai。另外,如果有需要,我们随时也可以安装前面提到的文泉驿以及 Droid Sans Fallback。思源黑体和思源宋体的字形以及标点符号还是很漂亮的,可以作为主打字体。Ubuntu 18.04 中小字虽然没有使用点阵,但是其饱满程度和 CentOS 5 相比要强不少,没有明显发虚的感觉,说明不仅字体在进步,字体渲染技术也在进步。Ubuntu 18.04 可以正确区分 serif 和 sans-serif 字体,对它们分别选用宋体和黑体,这已经很令人满意了。
可以这么说,Ubuntu 18.04 可能是目前在字体方面最让人省心的 Linux 桌面发行版,在字体配置方面,我们只需要微调即可。例如,serif 字体显示的是 AR PL UMing,如果更改为思源宋体会更漂亮,Times New Roman 英文字体识别是正确的,但是里面夹杂的中文应该显示为宋体,而不应该是黑体,Georgia 字体应该是 serif 分类的,而不应该是 sans-serif 分类的,其中夹杂的中文也应该为宋体。另外,没有点阵也算是一个小小的缺陷。为什么说是小小的缺陷而不是说硬伤呢?那是因为我认为随着屏幕的发展和渲染技术的进步,点阵已经不是太重要了。
目前,在 Linux 系统上配置字体的工具是 Fontconfig。我们要感谢这个时代,曾经混乱不堪的字体配置方法终于被 Fontconfig 一统江湖,我们要配置系统中的字体,只需要学习 Fontconfig 就行了。我在文章的开始给出了参考资料,Fonts in X11R7.7 中说,X11 包含两套字体系统,一套是 The core X11 fonts system,另一套是 Xft fonts system。前者是伴随 X11R1 在 1987 年诞生的,最初只能使用单色的点阵字体,多年来虽小有改进,但是依然很难用。后者是专门为可缩放字体而设计的字体系统,还支持抗锯齿和次像素平滑。该参考文献中还特意指出,虽然 X.org 会继续维护 The core X11 fonts system,但是仍然建议 toolkits author 尽早切换到 Xft 字体系统。什么 toolkits 呢?在 Linux 下无非就是 Qt 和 GTK 而已。[Optimal Use of Fonts on Linux] 中说,从 QT3 和 GTK 2 开始,使用这两种库编写的程序就都是使用 Xft 字体系统了。Xft 只是一个接口,在目前的 Linux 中,普遍使用的 Fontconfig 进行字体的配置,使用 FreeType 进行字体渲染。前面我也给出了参考资料 FreeType 2 官网 和 Fontconfig 官网 ,有兴趣的朋友们可以自己去看。
在这里,我再次强调,玩 Linux 要与时俱进,网络上有很多信息是过时的,要注意鉴别。例如,如果在网络上搜索 Linux 字体安装、配置的文章,如果出来的结果还提及要使用mkfontdir和mkfontscale这样的命令,还使用像-misc-fixed-medium-r-normal--10-100-75-75-c-60-iso8859-1这么复杂的字体名称,甚至还提及要使用 xfs 字体服务器,那么这一定是很陈旧的内容了。有多陈旧呢?大概比 CentOS 5 还早 15 年吧。当然,如果你确实需要使用 The core X11 font system,可以阅读我给出的参考文献 Fonts in X11R7.7 ,系统地学习它。在我的 Linux 桌面中,我只需要使用 Fontconfig 就够了。
学习 Fontconfig 的最佳方式是阅读man fonts.conf手册页,其次,就是阅读/etc/fonts/conf.d目录下的配置文件,从实例中学习。
Fontconfig 是一个字体配置工具,在系统中,其它软件是如何和 Fontconfig 交互的呢?可以这么理解,当一个程序需要字体时,它先告诉 Fontconfig 需要什么字体,然后,Fontconfig 根据系统中是否安装有这个字体,以及系统对字体的配置,向这个程序返回一个信息,这个信息中包含有你可以用哪个字体,这个字体的文件是什么,包含哪些属性。程序收到 Fontconfig 的回应后,再调用 FreeType 库来渲染这个字体。这么说有点抽象,下面来一个具体点的例子。就以 Firefox 显示我的这篇随笔为例吧,我的博客设置的字体是 verdana 和微软雅黑,所以 Firefox 就会和 Fontconfig 说:“我要 verdana 和 微软雅黑。” Fontconfig 检查系统中的字体以及配置文件后,发现系统中没有 verdana 和微软雅黑,但是可以使用 DejaVu Sans 和 Noto Sans CJK 代替,就会回答:“请使用 DejaVu Sans 和 Noto Sans CJK,它们的文件分别是什么什么,它们的其它属性分别是什么什么。” 然后 Firefox 就会以 DejaVu Sans 和思源黑体显示我这篇随笔。
把上面的过程进行总结,就是一个程序需要字体时,它先构建一个 pattern,这个 pattern 其实是一个字体列表,而且这个字体列表的每一项并不总是像前面例子中那样只有字体名称,有时还包含一些更详细的要求,例如字体大小、语言、发行者、字符集、是否微调、dpi、像素大小等信息。而对于每一个字体,可以这样表示:
<families>-<point sizes>:<name1>=<values1>:<name2>=<values2>...
而常见的字体属性有哪些呢?请看下表:
| 属性 | 类型 | 描述 |
|---|---|---|
| family | String | 字族名称{例如"Microsoft YaHei" "微软雅黑"} |
| style | String | 字体风格名称(会覆盖slant与weight){例如"Bold" "Oblique"} |
| slant | Int | 倾斜度{0}。分为:Italic(100,斜体), oblique(110,合成斜体), roman(0,正体) |
| weight | Int | 粗细程度{80},从0-210,由最细到最粗。例如:light(50,细), regular(80,一般), medium(100,中等), bold(200,粗) |
| size | Double | 磅大小(point size),单位是绝对大小的"磅"(=1/72英寸) |
| pixelsize | Double | 像素大小(pixel size),单位是显示屏上的"像素"。[pixelsize = (size_scale_dpi)/72] |
| spacing | Int | 字符间距。分为:proportional(0,变宽), dual(90,双宽), mono(100,等宽), charcell(110,字符单元) |
| foundry | String | 字体制造商名称的缩写 |
| antialias | Bool | 渲染字形(glyph)时是否开启抗锯齿功能[建议对矢量字体设为"true"] |
| hinting | Bool | 渲染字形(glyph)时是否开启微调功能(包括内嵌微调与自动微调)[建议对矢量字体设为"true"] |
| autohint | Bool | "true"表示只使用自动微调;"false"表示优先使用内嵌微调,但对于没有内嵌微调的字体仍会使用自动微调。[建议设为"false"] |
| hintstyle | Int | 微调的程度(同时作用于内嵌微调与自动微调)。分为:none(0,关闭), slight(1,轻度), medium(2,中度), full(3,完全) |
| file | String | 字体文件的名称 |
| scalable | Bool | 字形(glyph)是否可以缩放{True} |
| dpi | Double | 目标dpi(像素/英寸)值 |
| rgba | Int | LCD子像素的排列顺序。分为:unknown(0), rgb(1), bgr(2), vrgb(3), vbgr(4), none(5) |
| lcdfilter | Int | LCD filter 的风格。lcdnone(0),lcddefault(1),lcdlight(2),lcdlegacy(3) |
| lang | String | 字体所支持的RFC-3066语言的列表{例如"zh-cn"} |
我只选择了一些最常用的属性,完整的属性列表请查看 Fontconfig 的文档。Fontconfig 对程序传过来的 pattern 进行扫描和替换,然后把能够满足程序要求的字体列表传回给程序。Fontconfig 还提供很多辅助工具,如fc-list、fc-pattern、fc-match、fc-cache等命令。下面,使用fc-match命令对常用的 serif-12 、 georgia-12 、 sans-serif-12 、 verdana-12 字体进行查询,看看 Fontconfig 返回什么字体,以及这些字体的属性是什么样的。如下图:
结果显示,我们向 Fontconfig 要 serif,Fontconfig 会回应 AR PL UMing,我们向 Fontconfig 要 sans-serif,Fontconfig 会回应 Noto Sans CJK SC。在字体的属性中,antialias、autohint、hinting、hintstyle 等属性都是没有问题的,唯独 dpi 不对,只有 75,所以画一个 12pt 的字只有 12.5 个像素。这不科学,后面我要把 dpi 改成 96。
Fontconfig 对字体列表的替换规则是在 Fontconfig 的配置文件中定义的。Fontconfig 会根据配置文件中的定义,对字体列表进行两次扫描,第一次是针对 pattern 进行替换和修改,第二次是对已经选中的字体的属性进行扫描和修改。Fontconfig 的配置文件是 XML 文件,其语法是自描述的,都是意义非常明确的单词,一看就懂。下面我们根据例子来学习Fontconfig 配置的语法。
首先,Fontconfig 配置文件的最外层 XML 元素一定是:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
...
</fontconfig>
再看系统中的/etc/fonts/fonts.conf文件,其内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<dir>/usr/share/fonts</dir>
<dir>/usr/local/share/fonts</dir>
<dir prefix="xdg">fonts</dir>
<dir>~/.fonts</dir>
<match target="pattern">
<test qual="any" name="family">
<string>mono</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>monospace</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>sans serif</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>sans-serif</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>sans</string>
</test>
<edit name="family" mode="assign" binding="same">
<string>sans-serif</string>
</edit>
</match>
<selectfont>
<rejectfont>
<glob>*.dpkg-tmp</glob>
</rejectfont>
</selectfont>
<selectfont>
<rejectfont>
<glob>*.dpkg-new</glob>
</rejectfont>
</selectfont>
<include ignore_missing="yes">conf.d</include>
<cachedir>/var/cache/fontconfig</cachedir>
<cachedir prefix="xdg">fontconfig</cachedir>
<cachedir>~/.fontconfig</cachedir>
<config>
<rescan>
<int>30</int>
</rescan>
</config>
</fontconfig>
其中,<dir></dir>元素中的内容,就是指定字体的存放目录,从文件中可以看出,如果是我们自己下载的字体,可以直接放到~/.fonts目录中,它是可以识别的;<include></include>元素指定从conf.d目录加载别的配置文件;<cachedir></cachedir>元素指定缓存目录;<selectfont><rejectfont></rejectfont></selectfont>指定哪些字体需要排除,相当于设置黑名单,而<selectfont><acceptfont></acceptfont></selectfont>则明确指定哪些字体必须接受,相当于设置白名单;至于<config><rescan></rescan></config>,就是设置每隔多长时间重新扫描一次配置文件。由此可见,其语法真的是自解释的,一看就懂。关于其中的<match></match>元素,后面再具体讲解。
在/etc/fonts/conf.d/目录中,有一个50-user.conf配置文件,其内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<include ignore_missing="yes" prefix="xdg">fontconfig/conf.d</include>
<include ignore_missing="yes" prefix="xdg">fontconfig/fonts.conf</include>
<include ignore_missing="yes" deprecated="yes">~/.fonts.conf.d</include>
<include ignore_missing="yes" deprecated="yes">~/.fonts.conf</include>
</fontconfig>
在这个文件中,它还是使用了<include></include>元素,只不过它这次指定的加载配置文件的地方是~/.fonts.conf.d和~/.fonts.conf,也就是说,我们可以把自己的配置文件放到自己的主目录下,Fontconfig 能够识别。
在 Fontconfig 的配置文件中,重点是<match></match>元素,它是对 pattern 进行修改的主要场所。它的基本格式是这样的:
<match target="目标">
<test qual="any|all" name="属性" target="目标" compare="比较">
</test>
<edit name="属性" mode="修改方式" binding="绑定">
</edit>
</match>
<match></match>必须首先包含一系列<test></test>组成的列表,可以为空,然后再包含一系列<edit></edit>组成的列表,可以为空,但是两种列表不能同时为空,而且<test></test>列表必须位于<edit></edit>列表之前。如果"目标"满足<test></test>列表的所有测试条件(当 qual="all" 时)或者列表中的任一测试条件(当 qual="any" 时),那么将被按照<edit></edit>列表中的指令序列进行修改。"目标"的默认值是"pattern",表示此<match>单元针对的是用于匹配的 pattern (第一次扫描)。如果"目标"的值是"font",那么就表示此<match>单元针对的是已被选定的字体(第二次扫描)。如果"目标"的值是"scan",那么就表示此<match>单元针对的是扫描字体以创建内部配置数据的初始化阶段。 <test></test>用于和"目标"的"属性"进行"比较"。"比较"的默认值是"eq"[等于],其他还有:"not_eq"[不等于]、 "less"[小于]、"less_eq"[小于等于]、"more"[大于]、 "more_eq"[大于等于]、"contains"[包含(用于字符串比较)]、"not_contains"[不包含(用于字符串比较)]。<edit></edit>用于修改"目标"的"属性"值列表。"绑定"仅在 name="family" 的情况下才有意义,其默认值是"weak",表示弱绑定;若设为"strong",则表示强绑定;而设为"same",则表示不改变当前的绑定。至于如何修改,则与两个因素有关:(1)"修改方式",(2)此<edit>的"属性"是否与同<match>内某个<test>的"属性"相同。具体如下表所示:
| "修改方式" | 有相同"属性" | 无相同"属性" |
|---|---|---|
| "assign"(默认值) | 替换第一个匹配的值 | 替换全部值 |
| "assign_replace" | 替换全部值 | 替换全部值 |
| "prepend" | 在第一个匹配的值之前插入 | 在值列表的首部插入 |
| "prepend_first" | 在值列表的首部插入 | 在值列表的首部插入 |
| "append" | 在第一个匹配的值之后添加 | 在值列表的尾部添加 |
| "append_last" | 在值列表的尾部添加 | 在值列表的尾部添加 |
| "delete" | 删除第一个匹配的值 | 删除全部值 |
| "delete_all" | 删除全部值 | 删除全部值 |
除了<match></match>元素之外,还有一个<alias></alias>元素,其基本格式是这样的:
<alias binding="绑定">
<family>"需要替换的字体"</family>
<prefer>
<family>"替换后的字体"</family>
<family>"替换后的字体"</family>
</prefer>
</alias>
<alias></alias>元素相当于为修改字族名称提供了一种专门的速记法。在<alias></alias>元素中,<prefer>, <accept>, <default>就等于前面"修改方式"中的"prepend"、"append"、"append_last"。
可以使用fc-pattern命令查看 Fontconfig 对应用程序传递进来的 pattern 进行替换后的结果,也可以使用fc-match命令查看 Fontconfig 最终返回给应用程序的字体列表。如下两图:
一般情况下,排列在 pattern 最前面的字体会被选用,如果最前面的字体中没有满足条件的字符,则使用 pattern 中的下一个字体。我们使用这种思路对字体进行制定。例如,如果把 pattern 修改为 " WenQuanYi Bitmap Song" "Noto Serif CJK SC",那么应用程序会优先使用文泉驿点阵宋体,但是当字体的大小超出了文泉驿点阵宋体能够提供的范围时,就会使用后面的思源宋体。再例如,如果把 pattern 修改为 "verdana" "Noto Sans CJK SC",那么应用程序就会优先使用 verdana 显示英文字体,但是当要显示的字符超出了英文字符的范围时,就会使用后面的思源黑体。
但是,binding 的设置会改变上面字体选择的过程。binding="strong"、binding="weak" 和 binding="same" 分别有不同的效果。如果该属性设置不合理,则可能会出现这样的问题:明明使用 fc-pattern 查看的时候是 WenQuanYi Bitmap Song 排在 Noto Serif CJK SC 前面,是 Verdana 排在 Noto Sans CJK SC 前面,但是使用 fc-match 匹配的时候,偏偏首选的是 Noto Serif CJK SC 和 Noto Sans CJK SC。为什么会这样呢?这是因为 Fontconfig 选择字体的时候不仅仅只看字族名称的排列顺序,还要综合考虑一种字体能覆盖的字符集和字体大小范围,所以,在前面的例子中,虽然 WenQuanYi Bitmap Song 排在 Noto Serif CJK SC 前面,但是它覆盖的字体大小范围只有 12px 到 16px,Verdana 虽然排在 Noto Sans CJK SC 前面,但是其覆盖的字符集不包含中日韩文,所以 Fontconfig 就会首选排在后面的字体。为了解决这个问题,就必须把 binding 属性设置为 strong,这样,不管什么情况都首选排在前面的字体,只有遇到该字体不能胜任的字符时才选择后面的字体。在我的配置文件中,我都是一路 strong 到底。
现在的 Linux 桌面发行版在使用 Fontconfig 配置字体的时候,都有固定的流程。我们进入/etc/fonts/conf.d目录看一下,发现里面有 90 多个配置文件,如下图:
每一个文件名前面都有一个数字,数字可以决定配置文件的加载顺序,而 Fontconfig 在对 pattern 进行替换时,就是按照<match></match>元素出现的先后顺序进行的。在该目录下,还有一个README文件,看一下其中的内容,如下图:
其中明确说明了系统字体配置的整个流程。00 到 09 开头的配置文件,用于设置字体文件的存放目录,在 Ubuntu 18.04 中,没有 00 到 09 开头的配置文件。10 到 19 开头的文件用于设置系统中字体的全局配置选项,例如 antialias、hintstyle 等属性,对系统中所有的字体有效。20 到 29 是针对特定字体设置属性,只对配置文件中指定的字体有效。30 到 39 是字体族的替换,用于把某一个字体替换成另外一个字体。40 到 49 是对字体进行分类,这样,当系统中找不到某一个字体时,可以用同一类别的字体进行代替。50 到 59 载入用户自定义的配置文件。60 到 69 是把字体分类进行填实。40 到 49 和 60 到 69 是互相配合的。例如,当应用程序要求的字体是微软雅黑,就会向 Fontconfig 提交一个 pattern "微软雅黑",而 Fontconfig 发现系统中没有微软雅黑字体,他就会对这个字进行分类,微软雅黑肯定是属于 sans-serif 分类的,所以 40 到 49 开头的配置文件就会把 pattern 修改为"微软雅黑" "sans-serif"。然后,到了 60 到 69 开头的配置文件,它发现 pattern 中有"sans-serif",但这只是个分类名,不是一个具体的字体名,它需要对这个分类进行填实,怎么填呢?可以把"Noto Sans CJK SC"放到"sans-serif"的前面。这时,pattern 被修改为"微软雅黑" "Noto Sans CJK SC" "sans-serif"。这就是系统中字体先分类再填实分类的过程,当然 Ubuntu 18.04 中需要分类的字体和用来填实分类的字体更多,这个替换后的 pattern 会更复杂,这是因为 Ubuntu 18.04 是一个面向全球的发行版,它必须考虑到所有可能的语言。而我们自己的系统只需要满足自己的需求就可以了,其实系统中的很多配置文件是可以裁减掉的。如果要看完全不用系统自带的配置文件,全部自己定义字体的过程,可以看我 2014 年写的Linux 桌面系统字体配置要略,里面是用 Fedora 20 做的示范。后来我就变懒了,再改系统的字体我只做加法,只在~/.fonts.conf.d目录中放少数几个配置文件了事。70 到 79 开头的配置文件对可用的字体做进一步的调整,明确指定选择哪些字体或排除哪些字体。80 到 89 定义 scan 阶段对字体属性的修改。90 到 99 定义字体合成。其实在 Ubuntu 18.04 中,70 到 99 开头的配置文件并没有严格遵守这些约定。
系统中的配置文件很多,下面挑少数几个学习以下。先看10-antialias.conf,内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<match target="pattern">
<edit name="antialias" mode="append"><bool>true</bool></edit>
</match>
</fontconfig>
这个文件最简单,只有一个<match></match>元素,而且里面的<test></test>元素为空,就是说,这个配置文件将所有字体的 antialias 属性设置为 true。而 20 开头的配置文件都是针对单个字体的属性进行设置的,例如20-unhint-small-dejavu-serif.conf,其内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE fontconfig SYSTEM "../fonts.dtd">
<fontconfig>
<match target="font">
<test name="family">
<string>DejaVu Serif</string>
</test>
<test compare="less" name="pixelsize">
<double>7.5</double>
</test>
<edit name="hinting">
<bool>false</bool>
</edit>
</match>
</fontconfig>
该配置设置当字体为 DejaVu Serif,pixelsize 小于 7.5 的时候,将 hinting 属性设置为 false。30 到 39 开头的配置文件用于字体替换,其中最复杂的是30-metric-alias.conf,就是对常用的一些英文字体进行交叉替换,这样,当某种字体缺乏的时候,可以马上用另外一个字体替代。这个配置文件太长了,我就不贴了。贴个短一点的,35-arphic-uming-alias.conf,内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<alias binding="same">
<family>AR PL ShanHeiSun Uni</family>
<prefer><family>AR PL UMing HK</family></prefer>
</alias>
<alias binding="same">
<family>AR PL ShanHeiSun Uni MBE</family>
<prefer><family>AR PL UMing TW MBE</family></prefer>
</alias>
</fontconfig>
也就是设置为当 pattern 中有 AR PL ShanHeiSun Uni 时,将 AR PL Uming HK 放到它的前面。这里使用了<alias>简写语法。
40 到 49 开头的配置文件对字体进行分类,这里也大量使用<alias>简写语法。例如45-latin.conf对所有的英文字体进行分类,因为要分类的字体特别多,多以该文件特别长。分类的方法,就是把 serif、sans-serif、monospace 这样的分类名添加到 pattern 的最后。内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<alias>
<family>Bitstream Vera Serif</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Cambria</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Constantia</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>DejaVu Serif</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Elephant</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Garamond</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Georgia</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Liberation Serif</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Luxi Serif</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>MS Serif</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Nimbus Roman No9 L</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Nimbus Roman</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Palatino Linotype</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Thorndale AMT</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Thorndale</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Times New Roman</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Times</family>
<default><family>serif</family></default>
</alias>
<alias>
<family>Albany AMT</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Albany</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Arial Unicode MS</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Arial</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Bitstream Vera Sans</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Britannic</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Calibri</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Candara</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Century Gothic</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Corbel</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>DejaVu Sans</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Helvetica</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Haettenschweiler</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Liberation Sans</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>MS Sans Serif</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Nimbus Sans L</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Nimbus Sans</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Luxi Sans</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Tahoma</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Trebuchet MS</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Twentieth Century</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Verdana</family>
<default><family>sans-serif</family></default>
</alias>
<alias>
<family>Andale Mono</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Bitstream Vera Sans Mono</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Consolas</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Courier New</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Courier</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Cumberland AMT</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Cumberland</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>DejaVu Sans Mono</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Fixedsys</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Inconsolata</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Liberation Mono</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Luxi Mono</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Nimbus Mono L</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Nimbus Mono</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Nimbus Mono PS</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Terminal</family>
<default><family>monospace</family></default>
</alias>
<alias>
<family>Bauhaus Std</family>
<default><family>fantasy</family></default>
</alias>
<alias>
<family>Cooper Std</family>
<default><family>fantasy</family></default>
</alias>
<alias>
<family>Copperplate Gothic Std</family>
<default><family>fantasy</family></default>
</alias>
<alias>
<family>Impact</family>
<default><family>fantasy</family></default>
</alias>
<alias>
<family>Comic Sans MS</family>
<default><family>cursive</family></default>
</alias>
<alias>
<family>ITC Zapf Chancery Std</family>
<default><family>cursive</family></default>
</alias>
<alias>
<family>Zapfino</family>
<default><family>cursive</family></default>
</alias>
</fontconfig>
肯定是不可能列出世界上所有的字体的,所以总会有不认识的字体。49-sansserif.conf配置文件就设置将所有不认识的字体,都分类为 sans-serif。内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<match target="pattern">
<test qual="all" name="family" compare="not_eq">
<string>sans-serif</string>
</test>
<test qual="all" name="family" compare="not_eq">
<string>serif</string>
</test>
<test qual="all" name="family" compare="not_eq">
<string>monospace</string>
</test>
<edit name="family" mode="append_last">
<string>sans-serif</string>
</edit>
</match>
</fontconfig>
解释一下就是说,一个 pattern 中既没有 sans-serif,又没有 serif,也没有 monospace,就说明这个 pattern 还没有被分类,没有被分类的原因肯定是出现了前面配置文件中没有见过的字体名称。那么,将 sans-serif 添加到这个 pattern 的最后。相当于把不认识的字体都分类为 sans-seirf。
而对分类进行填实,可以看一下60-latin.conf,内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<alias>
<family>serif</family>
<prefer>
<family>DejaVu Serif</family>
<family>Bitstream Vera Serif</family>
<family>Times New Roman</family>
<family>Thorndale AMT</family>
<family>Luxi Serif</family>
<family>Nimbus Roman No9 L</family>
<family>Nimbus Roman</family>
<family>Times</family>
</prefer>
</alias>
<alias>
<family>sans-serif</family>
<prefer>
<family>DejaVu Sans</family>
<family>Bitstream Vera Sans</family>
<family>Verdana</family>
<family>Arial</family>
<family>Albany AMT</family>
<family>Luxi Sans</family>
<family>Nimbus Sans L</family>
<family>Nimbus Sans</family>
<family>Helvetica</family>
<family>Lucida Sans Unicode</family>
<family>BPG Glaho International</family>
<family>Tahoma</family>
</prefer>
</alias>
<alias>
<family>monospace</family>
<prefer>
<family>DejaVu Sans Mono</family>
<family>Bitstream Vera Sans Mono</family>
<family>Inconsolata</family>
<family>Andale Mono</family>
<family>Courier New</family>
<family>Cumberland AMT</family>
<family>Luxi Mono</family>
<family>Nimbus Mono L</family>
<family>Nimbus Mono</family>
<family>Nimbus Mono PS</family>
<family>Courier</family>
</prefer>
</alias>
<alias>
<family>fantasy</family>
<prefer>
<family>Impact</family>
<family>Copperplate Gothic Std</family>
<family>Cooper Std</family>
<family>Bauhaus Std</family>
</prefer>
</alias>
<alias>
<family>cursive</family>
<prefer>
<family>ITC Zapf Chancery Std</family>
<family>Zapfino</family>
<family>Comic Sans MS</family>
</prefer>
</alias>
</fontconfig>
这里也大量使用<alias>简写语法。很显然,这只是对英文字体进行填实,不能满足我中文用户的需要。对中文字体进行填实,请看69-language-selector-zh-cn.conf的内容:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<match target="pattern">
<test name="lang">
<string>zh-cn</string>
</test>
<test qual="any" name="family">
<string>serif</string>
</test>
<edit name="family" mode="prepend" binding="strong">
<string>Noto Serif CJK SC</string>
<string>HYSong</string>
<string>AR PL UMing CN</string>
<string>AR PL UMing HK</string>
<string>AR PL New Sung</string>
<string>WenQuanYi Bitmap Song</string>
<string>AR PL UKai CN</string>
<string>AR PL ZenKai Uni</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>sans-serif</string>
</test>
<test name="lang">
<string>zh-cn</string>
</test>
<edit name="family" mode="prepend" binding="strong">
<string>Noto Sans CJK SC</string>
<string>WenQuanYi Zen Hei</string>
<string>HYSong</string>
<string>AR PL UMing CN</string>
<string>AR PL UMing HK</string>
<string>AR PL New Sung</string>
<string>AR PL UKai CN</string>
<string>AR PL ZenKai Uni</string>
</edit>
</match>
<match target="pattern">
<test qual="any" name="family">
<string>monospace</string>
</test>
<test name="lang">
<string>zh-cn</string>
</test>
<edit name="family" mode="prepend" binding="strong">
<string>DejaVu Sans Mono</string>
<string>Noto Sans Mono CJK SC</string>
<string>WenQuanYi Zen Hei Mono</string>
<string>HYSong</string>
<string>AR PL UMing CN</string>
<string>AR PL UMing HK</string>
<string>AR PL New Sung</string>
<string>AR PL UKai CN</string>
<string>AR PL ZenKai Uni</string>
</edit>
</match>
</fontconfig>
我们常见的中文字体基本上都在这里了。
最后再学习两个配置文件,一个是70-no-bitmaps.conf,内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<selectfont>
<rejectfont>
<pattern>
<patelt name="scalable"><bool>false</bool></patelt>
</pattern>
</rejectfont>
</selectfont>
</fontconfig>
这里出现了一个新元素<patelt name=...>,这个元素配置单个属性,但是其子元素可以是一个列表。上面这个配置文件就是说,凡是 scalable 属性为 false 的字体,都被 reject 掉,也就是不使用任何不可缩放的字体。而我们的 WenQuanYi Bitmap Song 恰恰就是这样一个不可缩放的点阵字体,怎么办?85-xfonts-wqy-1.conf这个配置文件就使用<acceptfont>元素为这个字体开了绿灯,内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<selectfont>
<acceptfont>
<pattern>
<patelt name="family"><string>WenQuanYi Bitmap Song</string></patelt>
</pattern>
</acceptfont>
</selectfont>
</fontconfig>
好了,对 Fontconfig 的学习就到这里吧。下面开始实战。
前面提到的所有 Linux 发行版都安装有 Times New Roman 字体,但是没有 Georgia、Verdana、Arial。后面这几个字体是微软公司设计的 webcore 字体,可以免费使用。而中文的 SimSun 和微软雅黑是不能免费使用的,我们只能用思源宋体和思源黑体。思源宋体没有点阵,不过没关系,我们可以使用文泉驿点阵宋体替代。使用如下命令安装文泉驿字体和 webcore 字体:
sudo aptitude install fonts-wqy-microhei fonts-wqy-zenhei xfonts-wqy
sudo aptitude install ttf-mscorefonts-installer
如下两图:
安装完毕之后,我们系统中就多了以下几种字体,如下图:
然后进行配置。思路是这样的:
1、先修改全局配置,将 dpi 改为 96。而 hinting 和抗锯齿是在 gnome-tweak-tool中设置的,还比较令人满意,就不改了。
2、 宋体和 serif 字体都使用思源宋体 Noto Serif CJK SC,但是宋体在小字时需要点阵,serif 在小字时不需要点阵。为什么呢?因为当页面设计者把字体设置为宋体时,他肯定是针对中文设计的,但是如果他设置为 serif,则一定是针对英语设计的,而英文字体往往没有点阵,搭配点阵的宋体并不好看。Times New Roman 和 Georgia 在英文的时候当然显示为 Times New Roman 和 Georgia,但是这两个字体没有中文,所以要把 Noto Serif CJK SC 添加到这两个字体的后面,当这两个字体中夹杂中文时,就显示为思源宋体。同理,如果页面设计者将字体设置为 Times New Roman 或者 Georgia,他肯定是针对英文设计的,所以其中夹杂的中文也不需要点阵。
3、黑体、微软雅黑、Verdana、Arial 和 sans-serif,完全不需要做任何修改,保持 Ubuntu 18.04 默认的配置就行了,不需要做任何修改,也不要试图给 sans-serif 的中文添加点阵,理由还是和上一条中说的一样,中文使用点阵是很漂亮的,但是和没有点阵的英文搭配时,就不是那么和谐了。
所以,我们只需要两个配置文件就行了。根据上一节的学习我们知道了,只需要把配置文件放到~/.fonts.conf.d/目录下就行了,为了配合系统字体配置文件的命名规律,我把它命名为10-dpi.conf和68-serif.conf,在第一个文件中,把 dpi 改成 96,在第二个文件中,针对 serif、Times New Roman、Georgia、宋体和 SimSun 进行配置,如下。
使用 gnome-tweak-tool 设置 hinting 和抗锯齿,如下图:
更改 dpi 的配置文件~/.fonts.conf.d/10-dpi.conf的内容如下:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<match target="pattern">
<edit name="dpi" mode="assign"><double>96</double></edit>
</match>
</fontconfig>
更改好 dpi 之后,使用fc-match查看字体,可以看到 12pt 的字的 pixelsize 是 16,能用更多的像素去渲染一个字,效果当然要好一些。如下图:
配置宋体及 serif 的文件~/fonts.conf.d/68-serif.conf的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE fontconfig SYSTEM "../fonts.dtd">
<fontconfig>
<match target="pattern">
<test name="family">
<string>serif</string>
</test>
<edit name="family" mode="assign" binding="strong">
<string>Noto Serif CJK SC</string>
</edit>
</match>
<match target="pattern">
<test name="family">
<string>宋体</string>
</test>
<edit name="family" mode="assign" binding="strong">
<string>WenQuanYi Bitmap Song</string>
<string>Noto Serif CJK SC</string>
</edit>
</match>
<match target="pattern">
<test name="family">
<string>SimSun</string>
</test>
<edit name="family" mode="assign" binding="strong">
<string>WenQuanYi Bitmap Song</string>
<string>Noto Serif CJK SC</string>
</edit>
</match>
<match target="pattern">
<test name="family">
<string>Times New Roman</string>
</test>
<edit name="family" mode="append" binding="strong">
<string>Noto Serif CJK SC</string>
</edit>
</match>
<match target="pattern">
<test name="family">
<string>Georgia</string>
</test>
<edit name="family" mode="append" binding="strong">
<string>Noto Serif CJK SC</string>
</edit>
</match>
</fontconfig>
配置完成后的效果:
这是我认为的最完美的效果。宋体、Serif 都显示为思源宋体,Georgia 和 Times New Roman 只有中文显示为思源宋体,而且,只有明确将字体指定为宋体或 SimSun 的字,才有点阵,而指定为 Serif、Georgia 和 Times New Roman 的字,没有点阵。黑体、微软雅黑、sans-serif 都显示为思源黑体,Verdana 和 Arial 的中文部分显示为思源黑体,都没有点阵。
为什么说如果页面设计者指定字体为宋体时最好用点阵呢?以新浪网首页为例就可以说明问题。如果我们的系统中宋体没有点阵,页面效果是这样的:
仔细看这个页面的效果,上半部分是分类导航,页面设计者指定的字体是微软雅黑,所以没有点阵显示得也很饱满,但是下半部分是新闻标题,页面设计者指定的字体是宋体,显示就很虚。如果我们的系统中宋体有点阵,看起来就会漂亮不少,效果是这样的:
为什么说黑体、微软雅黑以及英文字体不需要点阵呢?以我自己的博客为例就可以说明问题。我的博客字体用的是 verdana 搭配微软雅黑。如果设置了黑体显示点阵(这里使用文泉驿点阵正黑),效果是这样的:
当使用点阵时,中文字还是显示得很漂亮。但是,一和英文字体搭配,就不是那么协调了。如果都不用点阵,效果如下图:
中文和英文都很饱满,而且饱满程度基本一致,看起来非常协调。这就是我在 Ubuntu 18.04 中的最终配置,看博客和写博客都很舒服哦。
这篇随笔篇幅很长。先是用了很大的篇幅来展示各 Linux 桌面发行版的字体配置情况,充分展示了 Linux 桌面字体的历史变迁,还是很值得一看的。其次又用了很大的篇幅来介绍 Fontconfig 的配置语法,以及 Linux 桌面发行版中字体配置的思路和流程。最后,才在 Ubuntu 18.04 中进行字体配置实战,实战只占了很少的篇幅。但是,我认为前面的铺垫都是非常有意义的,我们只要充分掌握了 Fontconfig 的配置语法、Linux 桌面字体配置的思路和流程,那么,在字体配置方面,真的就可以为所欲为了。
该随笔由京山游侠在2018年09月19日发布于博客园,引用请注明出处,转载或出版请联系博主。QQ邮箱:[email protected]
作者:段兆轩、麦麦
B站视频字幕制作:宋青
B站视频链接:
https://www.bilibili.com/video/av59260623?from=search&seid=3463150575074799555
自07年全球经济危机后,到前几年的时间里,超过30%的世界经济增长都来自一个源头:**;当时站出来稳定局面的核心力量,是**。是**将资本主义从1930年代式的大危机边缘救了出来。
数据显示,在仅仅两年间,**的水泥消耗量甚至比美国过去一百年的总消耗量还要多45%。
从人性的角度来说,资本家并非都是坏人……资本家们并没有能力运行资本主义系统,是资本主义系统在“运行”他们。
但是自70年代以来,大量的剩余价值开始无处可去;于是……他们停止了生产商品,停止了创造价值;取而代之的是对价值攫取本身进行投资。
通过创造钱来吸收钱:你稍微思考一下就会发现这是个非常疯狂的系统,但是事实上各国就是这么做的。
导语
主持人劳拉·弗兰德斯开场白
大家好,欢迎大家来到2018年兰南基金会的最后一次访谈,这也将是美国中期选举之前的最后一场。今天,我们将讨论的主题是金钱。如果你现在口袋里还有钱,那很显然你们还没有读自己新收到的电子邮件——我们,选民,不名一文且充满恐慌(指2018年10月美股大幅下跌事件)*(笑声)
*注:2018年10月10日当天,道指收跌800点,收报25598.74点,创8月16日以来的收盘新低。标普500指数收跌3.29%,创2月以来最大单日跌幅,报2785.68点。纳斯达克指数重挫4.08%,报7422.05点,创7月3日以来的收盘新低。标普11大板块全线下跌,其中标普信息技术板块创近7年来的最差表现,众多明星科技股纷纷暴跌。(来源:新浪财经https://finance.sina.com.cn/stock/usstock/c/2018-10-12/doc-ifxeuwws3330064.shtml)
我从今晚的访谈嘉宾那里学到的一个重要知识点就是,金钱与我们的总统(特朗普)非常相像:霸占了很多电视时间,但是却没什么内在价值(Intrinsic Value,金融术语,特指公司、股票、货币、或货品等的由基本面决定的价值,非市场价格)。(笑声+掌声)
好了,回归正题。除今晚的嘉宾以外,我想不到还能有谁可以比他教育了更多大众,教给他们有关金钱,价值,关系,权力的概念。在他至今“短暂”的83年生命旅程中,大卫·哈维帮助了很多人搞明白了一些很复杂的问题,但是他的职业生涯并非一路如此明晰。五十年前(1968年),他还是一名不起眼的地理学家,在巴尔的摩穿着他地理学家风格的马甲研究地图。彼时,他的研究与他对马克思的深思的联系并不清晰。
1968年的时代背景是这样的:全世界的社会**主义者开始意识到自己被卷进了资本主义秩序的极端压迫中;即使在深陷**意识形态的美国,也有部分公民享有优质公立教育,医疗保障系统,公共图书馆,公共媒体等等。日月如梭,五十年过去了,这一切中的大部分都不复存在了。资本主义大行其道,大卫·哈维也成了一名摇滚巨星*。然而,当初到底是谁主张要对金融业放松监管的?(笑声)
*注:摇滚巨星,指大卫·哈维喜好走穴演讲。
我主持了一档电视广播节目,叫做劳拉·弗兰德斯秀,一个让说做不到的人靠边站,请努力做的人走进来的节目。每周我都会介绍一些在艺术、政治,或者经济领域,致力于消弭少数人与多数人差距的影响力人物或者项目。我无法数清,大卫哈维的名字在我的节目中被提及过多少次。无论是在贝尔法斯特、玻利维亚、巴西,还是最近我前往的布达佩斯,大卫哈维都是一名巨星。他不仅是一名**家、理论家,更是一个把握了马克思主义真谛的人:他认为我们的任务不应当仅仅是研究分析这个世界,而更应该努力去改变它。
几年前在布达佩斯,我当时正在寻找能有效抵抗法西斯主义崛起的方法。在此期间,我发现一个致力于此的传奇组织,是由一个无家可归者组成的,在我看来最有组织性的街头草根组织。他们有强大的组织性与明确的目标,并坚决拒绝一切媒体的采访。面对这种情况,我知道我需要做的就是拿出手机给他们看看我对大卫·哈维的采访,之后,感谢大卫·哈维,组织的大门一下就对我敞开了。
我刚才问大卫,他今天晚上想在如此短的时间内讲些什么,他说:今晚的主题是_资本主义和我为什么反对它_。今天晚上的谈话会是一场盛宴,混合了各种启示与可能性的大卫·哈维式经典观点会让各位大快朵颐。让我们有请大卫·哈维。
讲座正文
引言:为什么要反对资本主义?
今晚,我想讲讲我为什么会成为一个反资本主义者,并希望能说服你们也能成为反资本主义者。我经常被问到这样一个问题:“你为什么不说自己是社会主义者、或者马克思主义者,或者其他类似的左翼人士?”在我看来,从某种程度上讲如果你接受了这些身份,你就会对与之相关的特定的事例与观点过分专注而忽略了其他;所谓“只见树木,不见森林”。
我想用一个有趣的类比作为今晚话题的引子:资本主义有点像蚊子,因此反资本主义的立场很像反蚊子:无论在哪见到它,都会想方设法给它一巴掌(笑声)。有时候你会自言自语:如果世界上没有蚊子——没有资本家,世界会变得更好吗?资本家和蚊子对你做的事情如出一辙:它们叮咬你,吸你的血,让你的生活无比痛苦,有时还会致你于死地。
资本主义社会的生活有一个特性:如果你想要做出些改变,你总会发现自己要和资本的傀儡对抗。因此我希望我能处在这样一个状态:我能够尽我所能去对抗资本对大众的控制。
我之所以会成为一个反资本主义者,并不是因为像那些人所描述的那样:我的DNA出了问题或者我天生是个疯子;也不是因为我有特殊的家庭或教育背景。基于对现代世界的分析和世界各地正在发生、未来可能发生的冲突的认识,我认为反对资本主义是唯一的理性观点。资本主义的运行规律基于资本积累与持续增长;而解决冲突的唯一方法就是跳出引发冲突的“规律”。
谈资本主义的运行规律
几年前,我写了一本关于资本主义系统内部矛盾的书。在书中,我总结出了威胁整个资本主义系统的三个主要矛盾:第一个是对持续增长的追求,第二个是在面临环境问题时保持资本主义增长,第三个是普遍异化。在这次谈话中,我主要讲解前两点矛盾。
我有一点前言想补充:从人性的角度来说,资本家并非都是坏人——有些资本家确实是坏人,但也有些是好人;有些“好”资本家相信自己的举动可以帮助他人,造福人类。类似比尔·盖茨那样的资本家会高屋建瓴地四处宣传他们善良的想法与做法。这样的资本家们本质上并不坏,但是他们被困在了资本主义系统里,成为其傀儡。
剩余价值的诅咒
在过去的三四十年间,我持续研究了资本主义系统,得出了关于运行规律的一些不同见解,即资本家并没有自由选择的权力。换言之,资本家们并没有能力运行资本主义系统,是资本主义系统在“运行”他们。因而资本家们的行为必然与马克思所阐述的资本主义系统的运行规律相符。这个运行规律很难被全面理解,但是我想在这里简单介绍一下它。
资本主义系统的运行规律建立在这样一个逻辑上:假设你有一笔钱,你用这些钱购买了劳动力和生产资料;你将它们投入到产品生产中;经加工后生产出的新的产品,新的产品被高于初始货币量(你早上有的那笔钱的数额)的价格销售给他人,超额的部分即为马克思观点中的“剩余价值”;剩余价值被以不同方式分配给不同的人群:一部分流向地主*,一部分流向中间商,一部分支付利息……最后剩下来的部分属于你自己,这便是利润。到最后,资本家总要考虑该如何处理属于自己的利润。
*注:基于《资本论》第一卷和第三卷的剩余价值理论和地租理论(在资本主义社会中,这个剩余价值或剩余产品——如果我们把分配上的偶然变动撇开不说,只考察分配的调节规律,分配的正常界限——是作为一份份的股息,按照社会资本中每个资本应得的份额的比例,在资本家之间进行分配的。在这个形态上,剩余价值表现为资本应得的平均利润。这个平均利润又分为企业主收入和利息,并在这两个范畴下分归各种不同的资本家所有。但资本对于剩余价值或剩余产品的这种占有和分配,受到了土地所有权方面的限制。正如职能资本家从工人身上吸取剩余劳动,从而在利润的形式上吸取剩余价值和剩余产品一样,土地所有者也要在地租的形式上,按照以前已经说明的规律,再从资本家那里吸取这个剩余价值或剩余产品的一部分)
如果他们是我们这样的普通人,他们会花掉这些钱来享受生活。不幸的是正如马克思所说的,剩余价值成为了资本家们的浮士德式困境——他们确实也想和普通人一样通过金钱来提升生活品质,但是他们做不到。资本家们处在市场竞争当中,所以不得不将额外资金进行再投资。这就是马克思经常谈到的——竞争的强制性。它强迫你按照其内在规律运行,而与你的主观意图无关。因此,资本家只好被迫拿出部分的所得的剩余价值重新投入到生产中,来赚更多的钱。由此可以得出结论:这个系统的核心是无尽的资本积累;如果没有无尽的积累,资本主义系统就无法维持甚至从根本上无法存在。
*注:浮士德式困境,又作浮士德难题,指欲望与现实约束的冲突。
资本主义系统在18世纪晚期初露锋芒,在19世纪中期确立了它的地位。马克思对这一系统进行了详尽的分析;我认为他的分析十分有趣,并且仍然适用于当代世界。有趣的是,事实上,他的分析在今天比以往更加适用。适用的原因也十分简单:在马克思的时代,资本只**了世界的一些角落——英国、西欧、美国东岸;在此外的地方并没有**性的优势。当然,商业资本在世界范围内普遍存在,但是商业资本并不遵循我刚才阐述的规律;我阐述的规律属于工业资本(包含再生产过程)。
巴黎证券交易所,建于1724年(来源:https://zh.wikipedia.org/wiki/巴黎證券交易所,图片版权遵循CC-BY SA 协议)
工业资本主义系统是一个不断扩张的系统:根据一些经济历史学家的分析,工业资本增长率自1780年左右至今一直保持在每年2.25%。现在,工业增长率保持在3%及以上时人们才会感到满意。但是,请注意,这个3%是复合增长率。复合增长率意味着每年的增长是建立在前一年的增长之上的。我经常用一个故事对我的学生解释这个性质:
在古印度,有个智者发明了国际象棋,国王问他想要什么奖励。智者说:“我想要一些米粒:在棋盘的第一个格子里放一粒米,在之后的每个格子里放数量加倍的米粒。”国王答应了他。于是,在第一个格子里有一粒米,第二格里是两粒,然后是四粒,八粒,十六粒……放到一半数量格子的时候,国王已经用完了世界上差不多所有的米粒。于是国王突然明白,复合增长率是个严肃的问题。
在马克思的时代,复合增长率还不是个问题,因为整个世界是开放的;马克思时代的经济还处在棋盘的第一排方格上。时光流逝,出现了一个巨大的问题:现在的世界经济处于棋盘的哪个位置上?我们在棋盘的第几排的方格里?我们会在什么时候耗尽一切?
2007年金融危机前,世界生产总值(GWP)是大约55万亿美元;即使经历了金融危机,现在的世界生产总值仍达到了80万亿美元之多。这意味着在未来的20年内,世界生产总值可能将达到160万亿美元;在这之后的10到15年内,人们将会看到一个世界生产总值达到320万亿的世界。那么问题来了:这些钱那时究竟会值多少?我们又该用这些钱做点什么?320万亿美元能够投资些什么?这些问题背后是因为有一些这样的事实:资本家越来越难为其生产出的剩余价值找到有利可图的出路,世界正在面临资本长期过剩的问题。在20世纪60年代,资本有很多出路,经济也在合理范围内增长;但是自70年代以来,大量的剩余价值开始无处可去;于是资本家们开始用购买东西取代制造东西,开始对资产价值进行投机投资。他们停止了生产商品,停止了创造价值;取而代之的是对价值攫取本身进行投资。
这种剩余价值分配的方式创造了一个很容易受危机影响的经济体系。上世纪70年代之前,并没有那么频繁的金融危机。1930年代,一场严峻的金融危机席卷全球,但是第二次世界大战后我们便立刻走出了困境,并且资本主义在此之后运行良好。但战后,我们成功走出了困境,资本主义系统运转良好。而从1970年代开始,小型金融危机在世界范围内接连不断——这段时间的美国股灾就是其中之一。即便现在,当我们面对股市震荡的时候也只是会说:ok,又来了。这种小型危机已经稀松平常:总是会有股市波动,总是会有经济崩溃……问题是,危机具体会在何时出现?无人知晓。这成了人们最害怕的事。
事实上,今天的局面是对“特朗普经济”的一个绝妙讽刺:看看1月1日以来的道琼斯指数*就能够了解“特朗普经济“的本质了。你们应该还记得总统一直说:“一切都好,一切都好,一切都好……”然后今天一夜回到解放前,道琼斯指数甚至跌到比今年年初更低的点。这就是特朗普经济的本质:经济周期。顺便说一句,总统先生不再吹嘘他的“特朗普经济”了。他说这次暴跌与他无关;股市上涨时,他吹嘘:“是我们让我们的经济闪闪发光……美国是世界上最好的经济体……之类的”,实际上无论涨跌这都和特朗普无关,只与资本主义系统的规律和运作逻辑有关。
*注:道琼斯指数,全称道琼斯工业平均指数,是由华尔街日报和道琼斯公司创建者查尔斯·道创造的几种股票市场指数之一,是历史最悠久及最有公信力的美国市场指数之一。
回到永续增长的问题:资本的持续扩张是如何实现的?遵循什么规律?有何结论?关于这点,我想举一个有趣的例子:1945年后,美国面临一个十分严重的问题——产能过剩。在二战期间,美国产生了巨大的过剩产能;而产能过剩有可能将美国领向下一场1930年代式的大危机,这是美国绝对不能接受的。放任危机发生就等于对从二战(1939-1945)中归来的人们说:“你们为自由而战,凯旋归来,作为回报你们将得到另一次大萧条(1930年代的大危机)。”一大批人为更好的明天而战,但如果他们没有得到更好的明天,那他们有诸多可行的做法;但是基于美国与苏联在二战中的反法西斯同盟的关系,在美国建立一个社会主义政权恐怕是美国人民最有可能选择的出路。
二战中美国的强大工业能力(来源:https://en.wikipedia.org/wiki/Consolidated\_B-24\_Liberator)
二战后,美国开始出现各种政治与经济问题。政治问题被以一种经典方式解决了:镇压左派,发动**运动,实行麦卡锡主义等等,而过剩产能带来的经济问题仍需解决。美国作为当时世界第一大经济体,是资本主义体系的“发动机”。产能过剩问题迫在眉睫且需要保证经济增长和维持全球资本主义的情况下,美国执行了两个举措:
第一件事是发动军备竞赛——这导致了军工复合体*的诞生。冷战中的军备竞赛能够吸纳大量的过剩产能,而军事开支有一个特性:无穷无尽。军队总需要更先进的武器系统;总有一些事情对国家安全至关重要;苏联人已经追上我们了……很多专家都探讨过军备竞赛的逻辑,我在此不加赘述。
*注:军工复合体,全称军事工业复合体,又名军事工业国会复合体(MICC),是指一国之军队与军事工业以相关的政治经济利益二紧密结合而成的共生关系。于此关系中,军队过分仰赖私有产业提供武器及军需,私有的国防工业企图以政治游说国会议员(如为地方创造就业机会)等政经手段来确保政府提供相关预算,导致军费高企,甚至鼓动政府高层发动战争或代为外销武器等。这个名词最常被用于美国,而且是由第34任美国总统德怀特·戴维·艾森豪威尔在其1961年的总统告别演说中首创的。(来源:https://zh.wikipedia.org/wiki/军事工业复合体)
第二件事是推动郊区化。“郊区化”创造了一个全新的城市生活结构;在这个结构中,郊区成为了一个新型生活空间,成为参战归来的人们理想中家庭生活的载体。同时,郊区化也是满足意识形态方面需求的方式——“郊区式生活”成为了完美吸纳人口潜在不满的黑洞,从而创造了支持资本主义系统延续下去的公众。
郊区化:灵丹妙药还是饮鸩止渴?
事实上,郊区化既是经济工程,又是社会工程,是一种维护社会稳定的有效方式。旧金山联邦储备银行的某位专家说:“美国通常通过建造房屋和填满这些房屋来摆脱危机。”这就是郊区化的精髓。
郊区化的发展有两块基石:房屋私有制,有稳定收入的人口。**有一句古话:“有恒产者有恒心”,高房屋所有率是稳定社会的砝码。因此,推行郊区化以促进房屋所有率提高,本质上是一种“维稳”。彼时,工人阶级中相当一部分人靠贷款拥有了私人房屋;人们由此认识到背着房贷的房奴不会罢工——他们不会形成一个革命阶级,不会反抗体制。他们有属于自己的郊区空间,有自己的生活方式;他们需要消费品——汽车,和汽车需要的能源、轮胎等;他们需要资本主义系统提供的稳定收入来偿还房贷,维持自己不错的生活… 于是,这实际上造就了一个特殊的工人阶级——消费主义中产阶级的诞生;这个阶级以白人工人阶级为主,持保守**,是保守政治的中流砥柱。他们的存在需要坚实的经济基础,而坚实的经济基础必然支持了工会的发展——于是全美汽车工人联合会(UAW)*和其他的政治团体崛起了。工会与资本相互制约的结构维持了世界的动态平衡。
*注:全美汽车工人联合会(UAW)是全美最大的工会之一,成立于20世纪30年代,以提高汽车工人工资与退休金闻名;曾多次发动大规模罢工。

莱维镇,典型的美国郊区化居住区(来源:https://en.wikipedia.org/wiki/Levittown)
挥霍能源与土地的郊区化方案解决了当时的无尽资本积累问题。但是这个方案是有代价的:能源过度消耗,土地资源过度开发等等…现如今,我们仍然不知道应如何回答三个问题:郊区化是否是环境问题的罪魁祸首?我们该如何看待汽车?在没有重大技术进步且不改变汽车使用现状的情况下,如何解决环境问题?
但是,在1945年,除了创造郊区化和郊区生活方式之外,美国又有什么其他选择能够吸纳这无尽积累的资本呢?这实质上解释了资本积累的本质,以及关于我为什么是一个反资本主义者而不局限于社会主义者的问题。为了实现自身的永续发展,资本需要改变人们看待世界的方式;需要操纵人类的“想要“,”需要“,和”渴望“;需要伪造,或者一定程度上强行将郊区塑造成人们的梦中天堂。这就是罗伯特·摩斯*所做的,也是州际公路系统所做的。
*注:罗伯特·摩斯, 20世纪纽约和其市郊的建筑大师,1927年至1929年时曾任纽约州的州务卿。在设计时十分看重交通规划,他的规划将纽约与周边地区通过公路亲密连接起来,并主持修建了大量公共建筑与基础设施。(来源:https://zh.wikipedia.org/wiki/羅伯·摩斯)
资本改造了美国的物质环境以适应其规律;巨量的资本积累通过郊区化造成了自然环境变化、人居环境变化、人与自然关系和对自然看法的变化、人际关系的变化,以及文化形式的变化。资本积累所代表的资本规律是令你不满的一切的幕后黑手。
资本主义的太阳底下无新事
我经常提到的一个例子是1852年到1871年间发生在法兰西第二帝国**下的巴黎的改造;这与美国的郊区化有很多相似之处。1848年爆发了一场巨大的危机,路易·波拿巴借此上台掌权并于1852年加冕为王。他很清楚,如果放任身边大量失业劳动力和无处可去的资本,他很快就会重蹈上一任**者的覆辙。于是,他请来了奥斯曼来改造巴黎,——现在能看到的巴黎都是在1850、 1860年间改造的成果。这次改造在经济层面上提供了充足的就业机会,提高了金融市场流动性,重建了资本主义系统。与物质环境改造相伴的是其带来的社会文化环境变革;路易·波拿巴创造了新的社会生活方式、新的需求和欲望;他创造了一个诱人的巴黎。
1855年,巴黎,里沃利路 是奥斯曼改造的第一条主干道(来源:https://en.wikipedia.org/wiki/Haussmann%27s\_renovation\_of_Paris)
当然,并不是所有人都支持这次改造。有人反对改造,有人拒绝参与其中。美国的郊区化进程中也发生了类似的事:很多人没有被纳入到浩大的郊区化工程中,尤其是非裔美国人、社会边缘化人群、和移民等等——这便是为什么有人反对郊区化。首先站出来反对郊区化的是女权主义者——他们清晰地意识到了郊区化生活实际上是一种建立在性别角色分工的基础上,剥夺女性享受其他社会角色的权利,阻碍妇女解放的生活方式。
二战中像男人一样工作的美国女性不再甘做附庸(来源:https://en.wikipedia.org/wiki/We\_Can\_Do_It! )
由于郊区化无法将所有人都包含在内,也不是所有人都想被纳入其中,于是特定形式的对立与对抗产生了。这种对立导致了20世界60年代的各种城市危机和城市内部的各种暴动:底特律暴动,洛杉矶暴动……在马丁·路德·金被暗杀后,美国的每个城市几乎都发生了暴动。从那时起人们开始发现不平等问题在城市中广泛存在着。
以当今的视角回顾历史,我们可以更好地理解,郊区化过程并没有随着城市化而停止,因为资本积累仍在继续。在2007年之前,美国大力建造与交易房地产,并想尽办法填满这些房地产(笑声)事实上,美国彼时已经从建造城市化转向了投资城市化。
2007-2008年金融危机起源于美国各州普遍存在的住房制度问题。房地产投机过热造成了次级信用贷款问题。在大多数州,问题是可控的;但是在佛罗里达州、佐治亚州和西南各州,次级信用贷款*问题失控了,成为了次贷危机。人们终于意识到资本主义发展的实质是压榨给无能力偿债的人口。美国房地产的次贷危机给整个金融系统带来了流动性危机,金融系统的危机进而影响到那些投资于银行资产证券化产品或信贷衍生品的投资者们,并且波及世界其他国家,例如投资了大量担保债务凭证的挪威政府。政府们试图通过出手接管违约债券(因此将金融机构的债券转变为国家主权债券)而挽救岌岌可危的金融体系,然而没想到却引发了欧债危机(欧洲部分国家因大量负债并无力偿还或必须延迟偿还的主权债务危机), 例如希腊破产。危机以各种形式升级蔓延。
*注:次级信用贷款,又称次级贷款,次级按揭,是为信用评级较差,无法从正常途径获得贷款的人群所提供的贷款。(来源:https://zh.wikipedia.org/wiki/次级贷款)
那么,这场危机是如何平复下来的?我不知道你们是如何渡过危机的,但是当经济的大规模衰退与崩溃到来时,系统必须找到某种方法来稳定其自身。然而,系统稳定其自身的主要方式却是通过创造更多的钱和更高的流动性来吸收过剩资本,以求破坏已有的固化状态。
通过创造钱来吸收钱:你稍微思考一下就会发现这是个非常疯狂的系统,但是事实上各国就是这么做的。在危机发生后,20国集团立刻召开了峰会;不是G7或者G8,而是G20峰会。布什把20个国家召集在一起,号召各国共同努力让世界回到正轨。这也是很多年来的第一次——也是到目前为止最后一次——各国一致同意必须有所行动。
美国实施了问题资产救助计划(Troubled Asset Relief Program,简称TARP):从拯救所有的金融机构开始。但是在我看来这是个烂主意;因为一旦国家把自己放在拯救金融机构而不是拯救大众的立场上,就会立刻失去大众的支持,被大众憎恨。特别是,如果这个问题资产救助计划就是当时所谓的新自由主义解决方案,那么新自由主义解决方案的公共正当性就会被质疑。那时我写了一篇论证TARP为什么注定会失败的文章,里面指出了一个很简单却是要害所在的问题:救助计划的规模不够大。当我们回顾这段历史时,便会发现在那个时候,美国所做的任何事任何挽救措施都不够,都不足拯救这次空前的危机。
那么,这次危机是怎么样被稳定下来的呢?就让我来这么说吧,自07年全球经济危机后,到前几年的时间里,超过30%的世界经济增长都来自一个源头:**;当时站出来稳定局面的核心力量,是**。是**将资本主义从1930年代式的大危机边缘救了出来。忘了美联储和各个机构吧;这些小打小闹的努力或许有各种作用,但是其实微不足道——只有**成功拯救了资本主义。而且很有趣的一点是,现在的美国人普遍对**都很不满意,他们想遏制**。但是,你们都应当感谢**,因为是他们事实上稳定了全球资本主义。
那么**又是如何做到的?这有点像1945年之后的美国:不断地修建高速公路、拓展郊区之类的。但是有别于美国,**是从一穷二白的基础上开始建设这一切。在经济危机之前,**经济就已经以10%到12%的年增长率高速增长了。在危机中,**的出口额一落千丈。2007年时,**约12%的GDP来自出口相关行业;而两年之内却降到了GDP的4%。经济危机对**是一个巨大的打击,造成了大量的失业。在面临大量无处消耗的资本与劳动力时,**政府转而开始加速推进国内的基础设施建设。政府发现,其实**有很多可以立刻破土动工的工程,有很多可以建造的地方,这些建设机会是奥巴马梦寐以求的。2008年以前,**还没有高速铁路网;现在,**拥有近两万英里的高铁网——在十年内从无到有。这种宏大的建设工程人为加快了城市化——在有人口居住之前很多城市就已经建成了。
在这一进程中,我发现一个非常有趣非常令人惊讶的现象:在2009年到2011年间,**的水泥消耗量巨幅增加。数据显示,在仅仅两年间,**的水泥消耗量甚至比美国过去一百年的总消耗量还要多45%(惊讶声)。各位你们住在美国,你们肯定知道美国到底用了多大量的水泥(笑声)。而且**的脚步是至今没有停止的。在金融危机时期,**的水泥消费量增长没有像人们预期的那样停滞,反而在07和08年间增加了一倍之多,这出乎所有人的意料。**在城市化进程与高铁网等基础设施建设上需要大量的资源,因此,那些向**提供资源的国家,如提供铜矿的智利,提供铁矿的巴西等拉丁美洲国家便很快地走出了金融危机。
**高速铁路网中长期规划(2016)来源:https://zh.wikipedia.org/wiki/File:中长期高速铁路网规划图_(2016).jpg
人们开始意识到,**消耗了世界上一半的水泥,一半的钢铁,一半的铜——这是一个巨大的经济扩张计划。这和美国于1945年开始的郊区化计划十分类似,只是**将这一进程压缩到了两年。**政府通过高速城市化这一手段加大了救市计划的覆盖范围,因此在仅仅两年内便成功摆脱了金融危机;并且**将持续通过基础设施建设来促进经济发展。郊区化也改变了**人的消费模式,类似美国的过度消费主义中产阶级已经形成。典型例子是**全国性的汽车普及——**当下的交通拥堵问题已经闻名世界。
2013年9月17日,北京国贸桥大堵车(来源:http://news.163.com/photoview/00AN0001/38187.html#p=9936O0K800AN0001)
**将资本主义世界从分崩离析的边缘挽救回来,并维持其稳定。而资本主义世界可能并不会感谢**的所作所为,因为资本家们都知道**这么做并不是为了拯救资本主义世界;**政府这样做和法兰西第二帝国的路易·波拿巴、1945年的美国政府这样做的理由是并没有什么不同——为了自救:如果党不能处理好过剩劳动力与过剩资本的问题,他们就会失去执政的合法性,失去权力;动乱会席卷全国——这是他们无法接受的。
为此,他们将总建设需求分配到了各个地方政府,跟它们说:“动工!不管什么项目,想建就建!”并且,**的任免制度十分有趣;其由拥有九千万党员的**共产党运行;市长不是选出来,而是由上级政府任命。在市长的三到四年任期内,每个人面前都有一张“考绩表”,上面罗列了很多关键业绩指标。首先是你将当地的GDP提升了多少,然后是在任期内间完成了哪些项目…表的末尾是你是否成功维持了当地社会稳定……所以每一任市长上任都会苦苦思考:我有雄心壮志,我想大展宏图,那我作为市长到底应该做点什么?答案是:疯狂建设!
所以当你去**,你就会发现他们的城市化项目,无论是已经完成的还是正在进行中的,规模和速度都非常夸张。我曾在南京教书;第一次我去的时候,当地官员对我说:“我们对南京现在的市中心很不满意,所以我们决定再建一个新中心。”我说:“听起来不错。”下一年我回到南京时,建设用地已经清空准备建设了;今年我再去南京时,新中心已经建成了。这就是“**速度”。
环境与增长:房地产大旗还能打多久?
但是“**速度”在全球资源消耗方面意味着什么?全球贱金属消费量,尤其是铜消费量自2007、2008年至今已经翻了一倍,其他矿物消费量也已翻倍;**的经济也翻了一倍。但是现在**经济开始遇到问题,面临增长的瓶颈。这和1867、1868年的巴黎危机,1975年的美国纽约城市危机是一样的:所有这些通过城市化吸收过剩生产力与过剩资本的做法都会有一个阈值,而**正在逼近这个阈值。所以现在的问题便是:该如何提高这个阈值?
目前,全球的资本积累已经不再是最大问题了:货币化保证了全球资本积累的延续。回想关于永续积累,复合增长率的概念,你会好奇:什么样的资本才能无止境增长?
马克思在《资本论》中指出:唯一能够无限增长的资本是货币,是钱。于是,各国通过所谓的量化宽松政策来应对危机——在货币供给量的数字后面疯狂加零(笑声)。我们还需要更多流动性来解决危机,那我们就注入更多流动性。然而讽刺的是,如果阅读一下国际货币基金组织(IMF)在2007到2008年间的报告,你就会发现当时世界经济的症结在于流动性过剩。所以面对流动性过剩这个问题,同时也是问题的本质,各国解决问题的手段是:创造更高的流动性。
这就是掌控世界的癫狂系统,而这一系统逼迫我们的城市化进程也变得错乱,而且这种错乱无处不在。美国当下的建筑热潮实质是为了投资,而非为大众提供居所而存在。以纽约的建筑潮为例,满大街都是铅笔一样的摩天大厦——谁会想住在里面呢?答案是:谁在乎啊!(笑声)
美国正面临经济适用房短缺的社会问题,但是需要经济适用房的人并不能居住在那些热潮催生的大厦里。纽约市有一半人口年收入低于4万美元,他们住在哪里?在那些摩天大厦里吗?有时人们会想到发动占屋运动以对抗房地产开发;但是占屋运动*不可能成为长久的解决办法。
*占屋运动,指占用闲置或废弃的空间或建筑物 (通常为住宅), 而没有一般法律认定的拥有权或租用权。(来源:https://zh.wikipedia.org/wiki/占屋)
这些摩天大楼都是在布隆伯格*任纽约市长期间建设的。虽然布隆伯格是一位伟大的环保主义者,但是他任下这些大楼的建设却只关乎资本主义发展,与他的可持续发展理念毫无关联甚至相悖。这就是无休止的资本积累和复合增长率的又一个实例。
布隆伯格宣称他非常注重解决环境问题,但是他没想过这些环境问题正是他主导的开发造成的。全世界有很多公司在努力用技术手段改善环境;但是扬汤止沸,不如去薪。环境问题的根源在于无尽的资本积累。布隆伯格是面临环境问题时保持资本主义增长这一矛盾最典型的表现。与之相对,科赫兄弟*完全不在乎这一矛盾,他们直接反对任何形式的环境政治。
*注:迈克尔·布隆伯格,美国商人,第三代沙俄犹太移民,彭博有限合伙企业创始人,2001年至2013年间担任纽约市市长,C40城市气候领导组织主席。(来源:https://zh.wikipedia.org/wiki/迈克尔·布隆伯格)
*科赫兄弟,指查尔斯·科赫与大卫·科赫,兄弟二人均为美国富豪,掌控科氏工业集团,支持茶党运动,持自由主义观点。二人认为政府应当减少对经济的控制,例如征收环保税等。(来源:https://baike.baidu.com/item/大卫·科赫)
纽约**公园塔概念图,该建筑计划于2020年竣工(来源:https://www.archdaily.cn/cn/904249/shi-jie-di-gao-de-zhong-yang-gong-yuan-da-sha-jiang-zai-niu-yue-jian-cheng?ad_medium=gallery)
资本积累永不止息,所以我们必须意识到,即使结局本身无法被接受,但环境不得不被破坏,社会贫富不均不得不被扩大,普罗大众不得不不断降低自己对文化,对环境等其他方面的需求,直到我们最终深深地,向永续积累的资本屈服,过上一种无法忍受的生活。**现在就正在面对这样一个困境:**各城市的空气污染问题已经严重到成为居民死亡的主要原因之一。
资本主义系统在当下已经发生了转变:有史以来第一次,它成为了人类的预期寿命减少的罪魁祸首。戴维·卡梅伦是英国第一位任期结束时的国民预期寿命低于其任期开始时的首相。在美国的很多地区,预期寿命也在下降。**的国民预期寿命仍在高速增长,但是已经开始遇到障碍。你会发现预期寿命的提高与资本的无限增长存在着冲突。
**模式已经不能再继续支撑全球资本主义了,那么资本又该如何实现其无限增长?大资本已经认识到了这一点,它们也开始彷徨。用疯狂的货币化解决货币危机这一做法已经濒临崩溃,人们能清晰地看到现在的资本主义系统已经接近极限。人们必须开始思考另一种生存方式。
我认为,其他的生存方式已经开始出现了。现在,很多人发现现代城市的人居条件无法忍受。在过去的15到20年间,世界各地在不同时间、不同地方、因为不同原因都发生过几次重大的社会运动。这些运动互不相同,但并非孤立事件;它们有其内在联系:这些运动不再因就业而起,而是因日常生活环境过差而起。
因此,人们需要创造一种新的生产方式,新的生活方式,新的城市化模式。现在的疯狂的城市化模式为富人建造了一栋又一栋的房子——布隆伯格曾幻想全世界每一个顶级富人都在纽约有一套顶层公寓。(笑声)另外,如果这些富人每年可能最多只来纽约一次(如果他们真的会来的话);但是他们还希望纽约的一切都按照他们的设想去运行。这是我们目前的城市,这就是我们目前的生活状态。
冰冻三尺非一日之寒,其根本原因是世界被困在了资本主义系统里,被困在了无尽的资本积累,复合增长率和无限增加的货币化中。我认为,现在是所有人不得不开始积极思考世界的其他运转方式的时候了。
视频原址:https://youtu.be/zNCkDgP4wLA
**特别推荐:**雷锋第2篇 哈佛大学闵冠对话大卫·哈维《哈佛酒吧的共产主义浪潮》
END
全球知识雷锋”(微信号:gkleifeng2000) 为**建筑界唯一纯原创公众号。由清华大学建筑学院周榕老师发起,全球五大洲57所名校200余知识雷锋整理提炼,每周为你快递当代建筑最in新知,10分钟洞悉世界建筑最前沿讲座精华。
欢迎雷锋转发,谢绝私自转载
文章标签:permission 文件 Gnupg FIX GNU
gpg: WARNING: unsafe permissions on configuration file `/home/david/.gnupg/gpg.conf'
gpg: WARNING: unsafe enclosing directory permissions on configuration file `/home/david/.gnupg/gpg.conf'
gpg: external program calls are disabled due to unsafe options file permissions
gpg: keyserver communications error: general error
gpg: keyserver receive failed: general error
这意味着什么,以及如何修复?
gpg: 警告:配置文件的权限不安全 /home/david/.gnupg/gpg.conf' gpg: WARNING: unsafe enclosing directory permissions on configuration file /home/david/. gnupg/gpg。conf'由于不安全的选项文件权限,外部程序调用被禁用
这意味着 ~/.gnupg/gpg.conf 对正在运行的用户具有意外的权限,比如对"其他"。另一个用户或者可以执行位的写访问。 由于安全原因,这里文件应该总是只有用户可以读写,并且没有其他 one
$ ls -l ~/.gnupg/gpg.conf
-rw------- 1 braiam braiam 7890 Jul 8 18:51. gnupg/gpg.conf
你的用户可能有不同的用户或者权限。 使用 ls -l ~/.gnupg/gpg.conf 查看它们。 要解决这个问题,很简单:
chown $(whoami):$(whoami) ~/.gnupg/gpg.conf ## if this fails read at the bottom
chmod 600 ~/.gnupg/gpg.conf
如果某些命令失败,或者在遵循这些指令之后提到的错误消息时,应该删除 ~/.gnupg 目录。
rm -r ~/.gnupg/gpg.conf ## If this fails, use sudo
然后可以尝试运行与运行脚本的用户相同的gpg 命令,这样用户就可以使用适当的权限创建 ~/.gnupg 目录。
你可能从其他机器迁移了 .gnupg 文件夹,或者使用文件权限篡改了另一。
GnuPG强制文件夹的private 所有权,并为安全原因提供一些文件。
这两行修改了权限。 第一个确保 ~/.gnupg 文件夹( 还有里面的一切) 实际上是你的。 为了超过所有权,它需要 root 特权,因此 sudo。 第二行确保没有人可以读取它的内容( 删除组和其他用户的读。写和执行权限)。 你的用户名自动插入,这样你就可以直接将线路复制到你的终端:
sudo chown -R ${USER}:${USER} ~/.gnupg
chmod -R go-rwx ~/.gnupg
我遇到了同样的问题。 结果是我使用 sudo 运行 gpg 命令。 当我没有 sudo 再试一次,它工作正常并且没有显示错误。 所以,你也可能是这样的。
文章标签:文件 FIX GNU permission Gnupg
Plan-9是一个很棒的、很先进的,而且完全是全新实现的Unix系统,它的目的就是要最终解决Unix最初的诺言:一切皆为文件。你听说过这套系统吗?没有?那好,下面就是为什么。
我十分确信你不知道Plan-9是什么东西,并且很有可能你还是第一次听说这个名字。
Plan9bunnysmblack
Plan-9是一款神奇的新版Unix,几乎是由70年代当初开发Unix系统的同一个团队开发的。它的确是一款非常酷的操作系统。它跟Unix非常相似,但它不是Unix,它纠正了Unix系统里很多不一致的、古怪的、至今仍然存在的特性。
Unix在当初立项时有个这样的许诺:系统里任何的东西都是‘文件’——根据某些文件的定义。例如,sockets,也许称作网络连接更合适,它们就不是文件,进程也不是文件。
在Plan-9中,所有的这些问题都解决了!先进的9P虚拟文件系统协议最终让所有东西都成为了文件。目录变成了“命名空间”,资源被映射成了文件。多么神奇!现在,你可以通过对/proc目录(现在应该成其为一个命名空间)里的一个文件使用“cat”命令来查看进程的情况。同样,打开一个网络连接的方式变成了打开/net/tcp目录里的一个文件,这就是它。”iotcl”系统调用在这个系统里完全被根除了,因为基于操作系统上的现代文件形式中的这种怪胎已经不再需要了。
你从来没有听说过它的原因是,它并不是一款成功的操作系统。这怎么可能呢?是这样的,是因为Plan-9实际上没有解决任何问题。在Unix世界里,从来没有人抱怨说Unix没有兑现当初关于文件抽象的诺言。
在随后的日子里,Plan-9里的/proc文件系统概念被人移植到到了Solaris等很多其他商业版Unix系统里(Linux也采用了它)。 Plan-9里另外一个非常著名的首创——UTF-8——被迅速的被众多其它操作系统采用,不仅仅是Unix家族。在所有的操作系统里,即使存在一些由于各种原因没有采用UTF-8的,它们也开发出来将UTF-8和本地编码转换的程序库。
Plan-9的对于网络通信的特殊的处理方式需要在这里特别的说明一下。虽然用基于命名空间/文件系统的方式来代替专用API来处理网络操作,听起来很吸引人,但是整个Unix世界,不仅所有人都已经接受了使用伯克利Socket API做为标准方式来进行网络编程,甚至Windows平台也实现了几乎相同的API里简化各种网络应用向Windows上移植——虽然存在一些小问题。
更重要的是,Plan-9发明的这种与众不同的网络编程编程方式在诞生之日就注定了毫无用处。因为在当时,大部分做网络编程的人都已经转向了更高的网络抽象层。RPC和Corba已经诞生,所有的需要跟远程服务器通信的应用全都转向了它们。程序员为了跟远程服务通信时需要打开sockets的机会越来越少,所有的他们都已经习惯了使用Berkeley API。(旁注:曾经有一个POSIX模拟层,叫做APE“ANSI/POSIX Environment”,试图将Plan-9上的某些功能映射到POSIX对应的功能上。这个模拟层一直都没实现,因为一些应用——例如X11——的迁移过于复杂,不可能完成。“维持它正确运行的工作量太过巨大”——维基百科。)
Plan-9的一个最主要的问题出在AT&T和Unix幕后的这群人身上,尽管他们都是才华横溢的科学家和程序员,但他们不懂得如何去开发商业软件,而AT&T也从来没打算进入软件业。这些,我承认听起来有些大不敬,但事实就是这样。他们使用软件,他们喜欢开发内部软件来运行他们的高端网络设备,但是他们却从来不去开发要卖给别人的软件,而且跟Sun,IBM,微软等商业公司不一样,这从来不是他们的资金的主要来源。这就意味着他们不需要有外部世界需要什么样的软件的意识。举个例子,Sun公司就需要这样的意识,所以他们开发出了RPC。他们认识到人们在进行网络编程时很痛苦,他们看到了创建一个网络抽象层的商业机会:“嗨,大伙们,SunOS有一个很酷的东西,让我们能够不直接跟sockets打交道就可以开发出网络应用!你绝对应该使用SunOS”。
还有,在Plan-9中,很多“好的老的东西”被删除了,大量的跟其它Unix不兼容的东西被加入了系统。这几乎打消了众多公司试图将他们的应用迁移到Plan-9的念头。如果你不知道这样一个新系统是否能够获得成功,那为什么要耗费了大量的工作把自己的应用迁移到这个新平台上呢?这就是典型的鸡生蛋蛋生鸡问题:一个操作系统的价值就在于上面有大量应用可运行,无它。如果一个系统很新,你要做的是必须发展一个能够支持各种应用的生态系统,通过它们让这个系统变得有价值。只有两条路能做到这样。第一个就是让这个系统跟目前现存的系统保持最大的兼容,也就是Unix, POSIX 和 Motif 这些系统。第二个就是创建自己的生态系统,以此来提升新系统的价值,微软Windows和Office办公系统软件就是典型例子。
当然,我们至少可以获得下面这些:
这些看起来都是一些非常高层的东西,并不是特别跟程序员的日常开发相关。看起来是这样,但事实远非如此。现如今,你可以很容易的开创自己的事业,开始向用户提供某种的服务。然而,你的服务是一个有价值的产品?还是变成了另外一个Plan-9传奇?这并不是很容易判断的事。例如,你的打算开发一个报表系统,来展现监控数据或其它任何可视的状态,如果你没有提供用它将这些报表导入到Excel的功能,那你在写第一行代码前就输了。如果你打算开发一个新的Web社交应用,而你没有提供使用Fackbook、Twitter或LinkedIn登录的方式,那你在搭建WEB服务器前就输了。如果你web服务中信息的导出方式没有采用RSS或ATOM,而是采用了一种全新的格式,猜会怎么样?你在吸引到第一个用户前就输了。但是,比着一切更重要的是:你的产品真正的解决了一个现实存在的问题吗?
[英文原文:The Plan-9 Effect or why you should not fix it if it ain't broken ]
原译文标题:Plan-9效应:为什么东西不坏就不要去修它
via : http://www.aqee.net/the-plan-9-effect-or-why-you-should-not-fix-it-if-it-aint-broken/
订阅“Linux **”官方小程序来查看
上周,《中文技术文档写作规范》加入了文件的命名规则。
"文件名建议只使用小写字母,不使用大写字母。"
"为了醒目,某些说明文件的文件名,可以使用大写字母,比如
README、LICENSE。"
网友看见了,就提问为什么文件名要小写?
说实话,虽然这是 Linux 传统,我却从没认真想过原因。赶紧查资料,结果发现四个很有说服力的理由,支持这样做。
下面就是这四个理由。另外,文后我还会发布一条前端培训的消息。
Linux 系统是大小写敏感的,而 Windows 系统和 Mac 系统正好相反,大小写不敏感。一般来说,这不是大问题。
但是,如果两个文件名只有大小写不同,其他都相同,跨平台就会出问题。
foobarFoobarFOOBARfOObAr
上面四个文件名,Windows 系统会把它们都当作foobar。如果它们同时存在,你可能没办法打开后面三个文件。
另一方面,在 Mac 系统上开发时,有时会疏忽,写错大小写。
// 正确文件名是 MyModule.js const module = require('./myModule');
上面的代码在 Mac 上面可以运行,因为 Mac 认为MyModule.js和myModule.js是同一个文件。但是,一旦代码到服务器运行就会报错,因为 Linux 系统找不到myModule.js。
如果所有的文件名都采用小写,就不会出现上面的问题,可以保证项目有良好的可移植性。
小写文件名通常比大写文件名更易读,比如accessibility.txt就比ACCESSIBILITY.TXT易读。
有人习惯使用驼峰命名法,单词的第一个字母大写,其他字母小写。这种方法的问题是,如果遇到全部是大写的缩略词,就会不适用。
比如,一个姓李的纽约特警,无论写成NYPoliceSWATLee还是NyPoliceSwatlee,都怪怪的,还是写成ny-police-swat-lee比较容易接受。
某些系统会生成一些预置的用户目录,采用首字母大写的目录名。比如,Ubuntu 在用户主目录会默认生成Downloads、 Pictures、Documents等目录。
Mac 系统更过分,一部分系统目录也是大写的,比如/Library/Audio/Apple Loops/。
另外,某些常见的配置文件或说明文件,也采用大写的文件名,比如Makefile、INSTALL、CHANGELOG、.Xclients和.Xauthority等等。
所以,用户的文件都采用小写文件名,就很方便与上面这些目录或文件相区分。
如果你打破砂锅问到底,为什么操作系统会采用这样的大写文件名?原因也很简单,因为早期 Unix 系统上,ls命令先列出大写字母,再列出小写字母,大写的路径会排在前面。因此,如果目录名或文件名是大写的,就比较容易被用户首先看到。
文件名全部小写,还有利于命令行操作。比如,某些命令可以不使用-i参数了。
# 大小写敏感的搜索 $ find . -name abc $ locate "*.htmL" # 大小写不敏感的搜索 $ find . -iname abc $ locate -i "*.HtmL"
另外,大写字母需要按下 Shift 键,多多少少有些麻烦。如果文件名小写,就不用碰这个键了,不仅省事,还可以提高打字速度。
程序员长时间使用键盘,每分钟少按几次 Shift,一天下来就可以省掉很多手指动作。长年累月,也是对自己身体的一种保护。
综上所述,文件名全部使用小写字母和连词线(all-lowercase-with-dashes),是一种值得推广的正确做法。
(正文完)
下面是推广时间。
如果大家还有印象,以前我介绍过一家前端开发的在线教育平台"海棠学院"。
他们的特色就是保证课程质量,不吹牛,非常低调地将所有精力,都投入课程准备和学员的悉心指导,让学员循序渐进、多敲多练,掌握前端编程,做出好的项目。如果你想投入前端行业,或者了解互联网技术,他们是一个不错的选择。
根据我的提议,创始人张小河收集了前几期学员的反馈。
"身为一个应届生,接触前端完全是因为不喜欢自己的专业,又到了就业的时节,想想自己还是对互联网比较感兴趣,从网上了解了一下互联网各个方面的工作,发现自己对前端比较感兴趣,由此而入了坑......(全文)"
现在,2017年春季班开始招生了。和上次冬季班一样,依然是0成本入学,只需要缴纳 99 元,即可感受一周的课程,享受完全正式的待遇(录播 + 直播 + 教学监管 + 技术辅导)。一周后,如果觉得不满意,99 元可以退款。
不管你最后是否报名,只要参加培训,都可以免费获得一份前端学习资料。
春季班定在3月初开课,名额已经不多了。想从事前端开发,却不知道从何学起的朋友,不要错过这个机会,点击这里,了解详情吧。
(完)
A CMake-based buildsystem is organized as a set of high-level logical targets. Each target corresponds to an executable or library, or is a custom target containing custom commands. Dependencies between the targets are expressed in the buildsystem to determine the build order and the rules for regeneration in response to change.
Executables and libraries are defined using the add_executable() and add_library() commands. The resulting binary files have appropriate PREFIX, SUFFIX and extensions for the platform targeted. Dependencies between binary targets are expressed using the target_link_libraries() command:
add_library(archive archive.cpp zip.cpp lzma.cpp)
add_executable(zipapp zipapp.cpp)
target_link_libraries(zipapp archive)
archive is defined as a STATIC library – an archive containing objects compiled from archive.cpp, zip.cpp, and lzma.cpp. zipapp is defined as an executable formed by compiling and linking zipapp.cpp. When linking the zipapp executable, the archive static library is linked in.
The add_executable() command defines an executable target:
add_executable(mytool mytool.cpp)
Commands such as add_custom_command(), which generates rules to be run at build time can transparently use an EXECUTABLE target as a COMMAND executable. The buildsystem rules will ensure that the executable is built before attempting to run the command.
By default, the add_library() command defines a STATIC library, unless a type is specified. A type may be specified when using the command:
add_library(archive SHARED archive.cpp zip.cpp lzma.cpp)
add_library(archive STATIC archive.cpp zip.cpp lzma.cpp)
The BUILD_SHARED_LIBS variable may be enabled to change the behavior of add_library() to build shared libraries by default.
In the context of the buildsystem definition as a whole, it is largely irrelevant whether particular libraries are SHARED or STATIC – the commands, dependency specifications and other APIs work similarly regardless of the library type. The MODULE library type is dissimilar in that it is generally not linked to – it is not used in the right-hand-side of the target_link_libraries() command. It is a type which is loaded as a plugin using runtime techniques. If the library does not export any unmanaged symbols (e.g. Windows resource DLL, C++/CLI DLL), it is required that the library not be a SHARED library because CMake expects SHARED libraries to export at least one symbol.
add_library(archive MODULE 7z.cpp)
A SHARED library may be marked with the FRAMEWORK target property to create an macOS or iOS Framework Bundle. The MACOSX_FRAMEWORK_IDENTIFIER sets CFBundleIdentifier key and it uniquely identifies the bundle.
add_library(MyFramework SHARED MyFramework.cpp)
set_target_properties(MyFramework PROPERTIES
FRAMEWORK TRUE
FRAMEWORK_VERSION A
MACOSX_FRAMEWORK_IDENTIFIER org.cmake.MyFramework
)
The OBJECT library type defines a non-archival collection of object files resulting from compiling the given source files. The object files collection may be used as source inputs to other targets:
add_library(archive OBJECT archive.cpp zip.cpp lzma.cpp)
add_library(archiveExtras STATIC $<TARGET_OBJECTS:archive> extras.cpp)
add_executable(test_exe $<TARGET_OBJECTS:archive> test.cpp)
The link (or archiving) step of those other targets will use the object files collection in addition to those from their own sources.
Alternatively, object libraries may be linked into other targets:
add_library(archive OBJECT archive.cpp zip.cpp lzma.cpp)
add_library(archiveExtras STATIC extras.cpp)
target_link_libraries(archiveExtras PUBLIC archive)
add_executable(test_exe test.cpp)
target_link_libraries(test_exe archive)
The link (or archiving) step of those other targets will use the object files from OBJECT libraries that are directly linked. Additionally, usage requirements of the OBJECT libraries will be honored when compiling sources in those other targets. Furthermore, those usage requirements will propagate transitively to dependents of those other targets.
Object libraries may not be used as the TARGET in a use of the add_custom_command(TARGET) command signature. However, the list of objects can be used by add_custom_command(OUTPUT) or file(GENERATE) by using $<TARGET_OBJECTS:objlib>.
The target_include_directories(), target_compile_definitions() and target_compile_options() commands specify the build specifications and the usage requirements of binary targets. The commands populate the INCLUDE_DIRECTORIES, COMPILE_DEFINITIONS and COMPILE_OPTIONS target properties respectively, and/or the INTERFACE_INCLUDE_DIRECTORIES, INTERFACE_COMPILE_DEFINITIONS and INTERFACE_COMPILE_OPTIONS target properties.
Each of the commands has a PRIVATE, PUBLIC and INTERFACE mode. The PRIVATE mode populates only the non-INTERFACE_ variant of the target property and the INTERFACE mode populates only the INTERFACE_ variants. The PUBLIC mode populates both variants of the respective target property. Each command may be invoked with multiple uses of each keyword:
target_compile_definitions(archive
PRIVATE BUILDING_WITH_LZMA
INTERFACE USING_ARCHIVE_LIB
)
Note that usage requirements are not designed as a way to make downstreams use particular COMPILE_OPTIONS or COMPILE_DEFINITIONS etc for convenience only. The contents of the properties must be requirements, not merely recommendations or convenience.
See the Creating Relocatable Packages section of the cmake-packages(7) manual for discussion of additional care that must be taken when specifying usage requirements while creating packages for redistribution.
The contents of the INCLUDE_DIRECTORIES, COMPILE_DEFINITIONS and COMPILE_OPTIONS target properties are used appropriately when compiling the source files of a binary target.
Entries in the INCLUDE_DIRECTORIES are added to the compile line with -I or -isystem prefixes and in the order of appearance in the property value.
Entries in the COMPILE_DEFINITIONS are prefixed with -D or /D and added to the compile line in an unspecified order. The DEFINE_SYMBOL target property is also added as a compile definition as a special convenience case for SHARED and MODULE library targets.
Entries in the COMPILE_OPTIONS are escaped for the shell and added in the order of appearance in the property value. Several compile options have special separate handling, such as POSITION_INDEPENDENT_CODE.
The contents of the INTERFACE_INCLUDE_DIRECTORIES, INTERFACE_COMPILE_DEFINITIONS and INTERFACE_COMPILE_OPTIONS target properties are Usage Requirements – they specify content which consumers must use to correctly compile and link with the target they appear on. For any binary target, the contents of each INTERFACE_ property on each target specified in a target_link_libraries() command is consumed:
set(srcs archive.cpp zip.cpp)
if (LZMA_FOUND)
list(APPEND srcs lzma.cpp)
endif()
add_library(archive SHARED ${srcs})
if (LZMA_FOUND)
# The archive library sources are compiled with -DBUILDING_WITH_LZMA
target_compile_definitions(archive PRIVATE BUILDING_WITH_LZMA)
endif()
target_compile_definitions(archive INTERFACE USING_ARCHIVE_LIB)
add_executable(consumer)
# Link consumer to archive and consume its usage requirements. The consumer
# executable sources are compiled with -DUSING_ARCHIVE_LIB.
target_link_libraries(consumer archive)
Because it is common to require that the source directory and corresponding build directory are added to the INCLUDE_DIRECTORIES, the CMAKE_INCLUDE_CURRENT_DIR variable can be enabled to conveniently add the corresponding directories to the INCLUDE_DIRECTORIES of all targets. The variable CMAKE_INCLUDE_CURRENT_DIR_IN_INTERFACE can be enabled to add the corresponding directories to the INTERFACE_INCLUDE_DIRECTORIES of all targets. This makes use of targets in multiple different directories convenient through use of the target_link_libraries() command.
The usage requirements of a target can transitively propagate to dependents. The target_link_libraries() command has PRIVATE, INTERFACE and PUBLIC keywords to control the propagation.
add_library(archive archive.cpp)
target_compile_definitions(archive INTERFACE USING_ARCHIVE_LIB)
add_library(serialization serialization.cpp)
target_compile_definitions(serialization INTERFACE USING_SERIALIZATION_LIB)
add_library(archiveExtras extras.cpp)
target_link_libraries(archiveExtras PUBLIC archive)
target_link_libraries(archiveExtras PRIVATE serialization)
# archiveExtras is compiled with -DUSING_ARCHIVE_LIB
# and -DUSING_SERIALIZATION_LIB
add_executable(consumer consumer.cpp)
# consumer is compiled with -DUSING_ARCHIVE_LIB
target_link_libraries(consumer archiveExtras)
Because archive is a PUBLIC dependency of archiveExtras, the usage requirements of it are propagated to consumer too. Because serialization is a PRIVATE dependency of archiveExtras, the usage requirements of it are not propagated to consumer.
Generally, a dependency should be specified in a use of target_link_libraries() with the PRIVATE keyword if it is used by only the implementation of a library, and not in the header files. If a dependency is additionally used in the header files of a library (e.g. for class inheritance), then it should be specified as a PUBLIC dependency. A dependency which is not used by the implementation of a library, but only by its headers should be specified as an INTERFACE dependency. The target_link_libraries() command may be invoked with multiple uses of each keyword:
target_link_libraries(archiveExtras
PUBLIC archive
PRIVATE serialization
)
Usage requirements are propagated by reading the INTERFACE_ variants of target properties from dependencies and appending the values to the non-INTERFACE_ variants of the operand. For example, the INTERFACE_INCLUDE_DIRECTORIES of dependencies is read and appended to the INCLUDE_DIRECTORIES of the operand. In cases where order is relevant and maintained, and the order resulting from the target_link_libraries() calls does not allow correct compilation, use of an appropriate command to set the property directly may update the order.
For example, if the linked libraries for a target must be specified in the order lib1 lib2 lib3 , but the include directories must be specified in the order lib3 lib1 lib2:
target_link_libraries(myExe lib1 lib2 lib3)
target_include_directories(myExe
PRIVATE $<TARGET_PROPERTY:lib3,INTERFACE_INCLUDE_DIRECTORIES>)
Note that care must be taken when specifying usage requirements for targets which will be exported for installation using the install(EXPORT) command. See Creating Packages for more.
Some target properties are required to be compatible between a target and the interface of each dependency. For example, the POSITION_INDEPENDENT_CODE target property may specify a boolean value of whether a target should be compiled as position-independent-code, which has platform-specific consequences. A target may also specify the usage requirement INTERFACE_POSITION_INDEPENDENT_CODE to communicate that consumers must be compiled as position-independent-code.
add_executable(exe1 exe1.cpp)
set_property(TARGET exe1 PROPERTY POSITION_INDEPENDENT_CODE ON)
add_library(lib1 SHARED lib1.cpp)
set_property(TARGET lib1 PROPERTY INTERFACE_POSITION_INDEPENDENT_CODE ON)
add_executable(exe2 exe2.cpp)
target_link_libraries(exe2 lib1)
Here, both exe1 and exe2 will be compiled as position-independent-code. lib1 will also be compiled as position-independent-code because that is the default setting for SHARED libraries. If dependencies have conflicting, non-compatible requirements cmake(1) issues a diagnostic:
add_library(lib1 SHARED lib1.cpp)
set_property(TARGET lib1 PROPERTY INTERFACE_POSITION_INDEPENDENT_CODE ON)
add_library(lib2 SHARED lib2.cpp)
set_property(TARGET lib2 PROPERTY INTERFACE_POSITION_INDEPENDENT_CODE OFF)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 lib1)
set_property(TARGET exe1 PROPERTY POSITION_INDEPENDENT_CODE OFF)
add_executable(exe2 exe2.cpp)
target_link_libraries(exe2 lib1 lib2)
The lib1 requirement INTERFACE_POSITION_INDEPENDENT_CODE is not “compatible” with the POSITION_INDEPENDENT_CODE property of the exe1 target. The library requires that consumers are built as position-independent-code, while the executable specifies to not built as position-independent-code, so a diagnostic is issued.
The lib1 and lib2 requirements are not “compatible”. One of them requires that consumers are built as position-independent-code, while the other requires that consumers are not built as position-independent-code. Because exe2 links to both and they are in conflict, a diagnostic is issued.
To be “compatible”, the POSITION_INDEPENDENT_CODE property, if set must be either the same, in a boolean sense, as the INTERFACE_POSITION_INDEPENDENT_CODE property of all transitively specified dependencies on which that property is set.
This property of “compatible interface requirement” may be extended to other properties by specifying the property in the content of the COMPATIBLE_INTERFACE_BOOL target property. Each specified property must be compatible between the consuming target and the corresponding property with an INTERFACE_ prefix from each dependency:
add_library(lib1Version2 SHARED lib1_v2.cpp)
set_property(TARGET lib1Version2 PROPERTY INTERFACE_CUSTOM_PROP ON)
set_property(TARGET lib1Version2 APPEND PROPERTY
COMPATIBLE_INTERFACE_BOOL CUSTOM_PROP
)
add_library(lib1Version3 SHARED lib1_v3.cpp)
set_property(TARGET lib1Version3 PROPERTY INTERFACE_CUSTOM_PROP OFF)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 lib1Version2) # CUSTOM_PROP will be ON
add_executable(exe2 exe2.cpp)
target_link_libraries(exe2 lib1Version2 lib1Version3) # Diagnostic
Non-boolean properties may also participate in “compatible interface” computations. Properties specified in the COMPATIBLE_INTERFACE_STRING property must be either unspecified or compare to the same string among all transitively specified dependencies. This can be useful to ensure that multiple incompatible versions of a library are not linked together through transitive requirements of a target:
add_library(lib1Version2 SHARED lib1_v2.cpp)
set_property(TARGET lib1Version2 PROPERTY INTERFACE_LIB_VERSION 2)
set_property(TARGET lib1Version2 APPEND PROPERTY
COMPATIBLE_INTERFACE_STRING LIB_VERSION
)
add_library(lib1Version3 SHARED lib1_v3.cpp)
set_property(TARGET lib1Version3 PROPERTY INTERFACE_LIB_VERSION 3)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 lib1Version2) # LIB_VERSION will be "2"
add_executable(exe2 exe2.cpp)
target_link_libraries(exe2 lib1Version2 lib1Version3) # Diagnostic
The COMPATIBLE_INTERFACE_NUMBER_MAX target property specifies that content will be evaluated numerically and the maximum number among all specified will be calculated:
add_library(lib1Version2 SHARED lib1_v2.cpp)
set_property(TARGET lib1Version2 PROPERTY INTERFACE_CONTAINER_SIZE_REQUIRED 200)
set_property(TARGET lib1Version2 APPEND PROPERTY
COMPATIBLE_INTERFACE_NUMBER_MAX CONTAINER_SIZE_REQUIRED
)
add_library(lib1Version3 SHARED lib1_v3.cpp)
set_property(TARGET lib1Version3 PROPERTY INTERFACE_CONTAINER_SIZE_REQUIRED 1000)
add_executable(exe1 exe1.cpp)
# CONTAINER_SIZE_REQUIRED will be "200"
target_link_libraries(exe1 lib1Version2)
add_executable(exe2 exe2.cpp)
# CONTAINER_SIZE_REQUIRED will be "1000"
target_link_libraries(exe2 lib1Version2 lib1Version3)
Similarly, the COMPATIBLE_INTERFACE_NUMBER_MIN may be used to calculate the numeric minimum value for a property from dependencies.
Each calculated “compatible” property value may be read in the consumer at generate-time using generator expressions.
Note that for each dependee, the set of properties specified in each compatible interface property must not intersect with the set specified in any of the other properties.
Because build specifications can be determined by dependencies, the lack of locality of code which creates a target and code which is responsible for setting build specifications may make the code more difficult to reason about. cmake(1) provides a debugging facility to print the origin of the contents of properties which may be determined by dependencies. The properties which can be debugged are listed in the CMAKE_DEBUG_TARGET_PROPERTIES variable documentation:
set(CMAKE_DEBUG_TARGET_PROPERTIES
INCLUDE_DIRECTORIES
COMPILE_DEFINITIONS
POSITION_INDEPENDENT_CODE
CONTAINER_SIZE_REQUIRED
LIB_VERSION
)
add_executable(exe1 exe1.cpp)
In the case of properties listed in COMPATIBLE_INTERFACE_BOOL or COMPATIBLE_INTERFACE_STRING, the debug output shows which target was responsible for setting the property, and which other dependencies also defined the property. In the case of COMPATIBLE_INTERFACE_NUMBER_MAX and COMPATIBLE_INTERFACE_NUMBER_MIN, the debug output shows the value of the property from each dependency, and whether the value determines the new extreme.
Build specifications may use generator expressions containing content which may be conditional or known only at generate-time. For example, the calculated “compatible” value of a property may be read with the TARGET_PROPERTY expression:
add_library(lib1Version2 SHARED lib1_v2.cpp)
set_property(TARGET lib1Version2 PROPERTY
INTERFACE_CONTAINER_SIZE_REQUIRED 200)
set_property(TARGET lib1Version2 APPEND PROPERTY
COMPATIBLE_INTERFACE_NUMBER_MAX CONTAINER_SIZE_REQUIRED
)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 lib1Version2)
target_compile_definitions(exe1 PRIVATE
CONTAINER_SIZE=$<TARGET_PROPERTY:CONTAINER_SIZE_REQUIRED>
)
In this case, the exe1 source files will be compiled with -DCONTAINER_SIZE=200.
Configuration determined build specifications may be conveniently set using the CONFIG generator expression.
target_compile_definitions(exe1 PRIVATE
$<$CONFIG:Debug:DEBUG_BUILD>
)
The CONFIG parameter is compared case-insensitively with the configuration being built. In the presence of IMPORTED targets, the content of MAP_IMPORTED_CONFIG_DEBUG is also accounted for by this expression.
Some buildsystems generated by cmake(1) have a predetermined build-configuration set in the CMAKE_BUILD_TYPE variable. The buildsystem for the IDEs such as Visual Studio and Xcode are generated independent of the build-configuration, and the actual build configuration is not known until build-time. Therefore, code such as
string(TOLOWER ${CMAKE_BUILD_TYPE} _type)
if (_type STREQUAL debug)
target_compile_definitions(exe1 PRIVATE DEBUG_BUILD)
endif()
may appear to work for Makefile Generators and Ninja generators, but is not portable to IDE generators. Additionally, the IMPORTED configuration-mappings are not accounted for with code like this, so it should be avoided.
The unary TARGET_PROPERTY generator expression and the TARGET_POLICY generator expression are evaluated with the consuming target context. This means that a usage requirement specification may be evaluated differently based on the consumer:
add_library(lib1 lib1.cpp)
target_compile_definitions(lib1 INTERFACE
)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 lib1)
cmake_policy(SET CMP0041 NEW)
add_library(shared_lib shared_lib.cpp)
target_link_libraries(shared_lib lib1)
The exe1 executable will be compiled with -DLIB1_WITH_EXE, while the shared_lib shared library will be compiled with -DLIB1_WITH_SHARED_LIB and -DCONSUMER_CMP0041_NEW, because policy CMP0041 is NEW at the point where the shared_lib target is created.
The BUILD_INTERFACE expression wraps requirements which are only used when consumed from a target in the same buildsystem, or when consumed from a target exported to the build directory using the export() command. The INSTALL_INTERFACE expression wraps requirements which are only used when consumed from a target which has been installed and exported with the install(EXPORT) command:
add_library(ClimbingStats climbingstats.cpp)
target_compile_definitions(ClimbingStats INTERFACE
$<BUILD_INTERFACE:ClimbingStats_FROM_BUILD_LOCATION>
$<INSTALL_INTERFACE:ClimbingStats_FROM_INSTALLED_LOCATION>
)
install(TARGETS ClimbingStats EXPORT libExport ${InstallArgs})
install(EXPORT libExport NAMESPACE Upstream::
DESTINATION lib/cmake/ClimbingStats)
export(EXPORT libExport NAMESPACE Upstream::)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 ClimbingStats)
In this case, the exe1 executable will be compiled with -DClimbingStats_FROM_BUILD_LOCATION. The exporting commands generate IMPORTED targets with either the INSTALL_INTERFACE or the BUILD_INTERFACE omitted, and the *_INTERFACE marker stripped away. A separate project consuming the ClimbingStats package would contain:
find_package(ClimbingStats REQUIRED)
add_executable(Downstream main.cpp)
target_link_libraries(Downstream Upstream::ClimbingStats)
Depending on whether the ClimbingStats package was used from the build location or the install location, the Downstream target would be compiled with either -DClimbingStats_FROM_BUILD_LOCATION or -DClimbingStats_FROM_INSTALL_LOCATION. For more about packages and exporting see the cmake-packages(7) manual.
Include directories require some special consideration when specified as usage requirements and when used with generator expressions. The target_include_directories() command accepts both relative and absolute include directories:
add_library(lib1 lib1.cpp)
target_include_directories(lib1 PRIVATE
/absolute/path
relative/path
)
Relative paths are interpreted relative to the source directory where the command appears. Relative paths are not allowed in the INTERFACE_INCLUDE_DIRECTORIES of IMPORTED targets.
In cases where a non-trivial generator expression is used, the INSTALL_PREFIX expression may be used within the argument of an INSTALL_INTERFACE expression. It is a replacement marker which expands to the installation prefix when imported by a consuming project.
Include directories usage requirements commonly differ between the build-tree and the install-tree. The BUILD_INTERFACE and INSTALL_INTERFACE generator expressions can be used to describe separate usage requirements based on the usage location. Relative paths are allowed within the INSTALL_INTERFACE expression and are interpreted relative to the installation prefix. For example:
add_library(ClimbingStats climbingstats.cpp)
target_include_directories(ClimbingStats INTERFACE
$<INSTALL_INTERFACE:/absolute/path>
$<INSTALL_INTERFACE:relative/path>
)
Two convenience APIs are provided relating to include directories usage requirements. The CMAKE_INCLUDE_CURRENT_DIR_IN_INTERFACE variable may be enabled, with an equivalent effect to:
set_property(TARGET tgt APPEND PROPERTY INTERFACE_INCLUDE_DIRECTORIES
)
for each target affected. The convenience for installed targets is an INCLUDES DESTINATION component with the install(TARGETS) command:
install(TARGETS foo bar bat EXPORT tgts ${dest_args}
INCLUDES DESTINATION include
)
install(EXPORT tgts ${other_args})
install(FILES ${headers} DESTINATION include)
This is equivalent to appending ${CMAKE_INSTALL_PREFIX}/include to the INTERFACE_INCLUDE_DIRECTORIES of each of the installed IMPORTED targets when generated by install(EXPORT).
When the INTERFACE_INCLUDE_DIRECTORIES of an imported target is consumed, the entries in the property are treated as SYSTEM include directories, as if they were listed in the INTERFACE_SYSTEM_INCLUDE_DIRECTORIES of the dependency. This can result in omission of compiler warnings for headers found in those directories. This behavior for Imported Targets may be controlled by setting the NO_SYSTEM_FROM_IMPORTED target property on the consumers of imported targets.
If a binary target is linked transitively to a macOS FRAMEWORK, the Headers directory of the framework is also treated as a usage requirement. This has the same effect as passing the framework directory as an include directory.
Like build specifications, link libraries may be specified with generator expression conditions. However, as consumption of usage requirements is based on collection from linked dependencies, there is an additional limitation that the link dependencies must form a “directed acyclic graph”. That is, if linking to a target is dependent on the value of a target property, that target property may not be dependent on the linked dependencies:
add_library(lib1 lib1.cpp)
add_library(lib2 lib2.cpp)
target_link_libraries(lib1 PUBLIC
)
add_library(lib3 lib3.cpp)
set_property(TARGET lib3 PROPERTY INTERFACE_POSITION_INDEPENDENT_CODE ON)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 lib1 lib3)
As the value of the POSITION_INDEPENDENT_CODE property of the exe1 target is dependent on the linked libraries (lib3), and the edge of linking exe1 is determined by the same POSITION_INDEPENDENT_CODE property, the dependency graph above contains a cycle. cmake(1) issues a diagnostic in this case.
The buildsystem targets created by the add_library() and add_executable() commands create rules to create binary outputs. The exact output location of the binaries can only be determined at generate-time because it can depend on the build-configuration and the link-language of linked dependencies etc. TARGET_FILE, TARGET_LINKER_FILE and related expressions can be used to access the name and location of generated binaries. These expressions do not work for OBJECT libraries however, as there is no single file generated by such libraries which is relevant to the expressions.
There are three kinds of output artifacts that may be build by targets as detailed in the following sections. Their classification differs between DLL platforms and non-DLL platforms. All Windows-based systems including Cygwin are DLL platforms.
A library output artifact of a buildsystem target may be:
.dll or .so) of a module library target created by the add_library() command with the MODULE option..so or .dylib) of a shared library target created by the add_library() command with the SHARED option.The LIBRARY_OUTPUT_DIRECTORY and LIBRARY_OUTPUT_NAME target properties may be used to control library output artifact locations and names in the build tree.
An archive output artifact of a buildsystem target may be:
.lib or .a) of a static library target created by the add_library() command with the STATIC option..lib) of a shared library target created by the add_library() command with the SHARED option. This file is only guaranteed to exist if the library exports at least one unmanaged symbol..lib) of an executable target created by the add_executable() command when its ENABLE_EXPORTS target property is set..imp) of an executable target created by the add_executable() command when its ENABLE_EXPORTS target property is set.The ARCHIVE_OUTPUT_DIRECTORY and ARCHIVE_OUTPUT_NAME target properties may be used to control archive output artifact locations and names in the build tree.
Some target types do not represent outputs of the buildsystem, but only inputs such as external dependencies, aliases or other non-build artifacts. Pseudo targets are not represented in the generated buildsystem.
An ALIAS target is a name which may be used interchangeably with a binary target name in read-only contexts. A primary use-case for ALIAS targets is for example or unit test executables accompanying a library, which may be part of the same buildsystem or built separately based on user configuration.
add_library(lib1 lib1.cpp)
install(TARGETS lib1 EXPORT lib1Export ${dest_args})
install(EXPORT lib1Export NAMESPACE Upstream:: ${other_args})
add_library(Upstream::lib1 ALIAS lib1)
In another directory, we can link unconditionally to the Upstream::lib1 target, which may be an IMPORTED target from a package, or an ALIAS target if built as part of the same buildsystem.
if (NOT TARGET Upstream::lib1)
find_package(lib1 REQUIRED)
endif()
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 Upstream::lib1)
ALIAS targets are not mutable, installable or exportable. They are entirely local to the buildsystem description. A name can be tested for whether it is an ALIAS name by reading the ALIASED_TARGET property from it:
get_target_property(_aliased Upstream::lib1 ALIASED_TARGET)
if(_aliased)
message(STATUS "The name Upstream::lib1 is an ALIAS for ${_aliased}.")
endif()
An INTERFACE target has no LOCATION and is mutable, but is otherwise similar to an IMPORTED target.
It may specify usage requirements such as INTERFACE_INCLUDE_DIRECTORIES, INTERFACE_COMPILE_DEFINITIONS, INTERFACE_COMPILE_OPTIONS, INTERFACE_LINK_LIBRARIES, INTERFACE_SOURCES, and INTERFACE_POSITION_INDEPENDENT_CODE. Only the INTERFACE modes of the target_include_directories(), target_compile_definitions(), target_compile_options(), target_sources(), and target_link_libraries() commands may be used with INTERFACE libraries.
A primary use-case for INTERFACE libraries is header-only libraries.
add_library(Eigen INTERFACE)
target_include_directories(Eigen INTERFACE
$<INSTALL_INTERFACE:include/Eigen>
)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 Eigen)
Here, the usage requirements from the Eigen target are consumed and used when compiling, but it has no effect on linking.
Another use-case is to employ an entirely target-focussed design for usage requirements:
add_library(pic_on INTERFACE)
set_property(TARGET pic_on PROPERTY INTERFACE_POSITION_INDEPENDENT_CODE ON)
add_library(pic_off INTERFACE)
set_property(TARGET pic_off PROPERTY INTERFACE_POSITION_INDEPENDENT_CODE OFF)
add_library(enable_rtti INTERFACE)
target_compile_options(enable_rtti INTERFACE
)
add_executable(exe1 exe1.cpp)
target_link_libraries(exe1 pic_on enable_rtti)
This way, the build specification of exe1 is expressed entirely as linked targets, and the complexity of compiler-specific flags is encapsulated in an INTERFACE library target.
The properties permitted to be set on or read from an INTERFACE library are:
INTERFACE_*COMPATIBLE_INTERFACE_*EXPORT_NAMEEXPORT_PROPERTIESIMPORTEDMANUALLY_ADDED_DEPENDENCIESNAMEIMPORTED_LIBNAME_*MAP_IMPORTED_CONFIG_*INTERFACE libraries may be installed and exported. Any content they refer to must be installed separately:
add_library(Eigen INTERFACE)
target_include_directories(Eigen INTERFACE
$<INSTALL_INTERFACE:include/Eigen>
)
install(TARGETS Eigen EXPORT eigenExport)
install(EXPORT eigenExport NAMESPACE Upstream::
DESTINATION lib/cmake/Eigen
)
install(FILES
${CMAKE_CURRENT_SOURCE_DIR}/src/eigen.h
${CMAKE_CURRENT_SOURCE_DIR}/src/vector.h
${CMAKE_CURRENT_SOURCE_DIR}/src/matrix.h
DESTINATION include/Eigen
)
By - 七月, 7th 2019
Oxfs 的安装非常简单。
Oxfs 的用法也很简单。
| |
$ mkdir remote
$ sudo oxfs -s [email protected] -m remote -r /home/oxfs -p /tmp/oxfs
|



更多详情,可以访问 Oxfs 主页:oxfs.io
转载请在明显位置注明出处,否则必究相关责任。
字节跳动 (ByteDance)
毕马威 (KPMG)
诺华 (Novartis)
谷歌 (Google)
碧迪医疗器械 (BD)
中石油 (PetroChina Company)
阿里巴巴 (Alibaba)
高盛 (Goldman Sachs)
**航空 (Air China)
WeWork
维沃移动通信有限公司 (vivo)
法国兴业银行 (Société Générale)
渣打银行 (Standard Chartered Bank)
强生 (Johnson & Johnson)
江森自控 (Johnson Controls)
吉利德科学 (Gilead Sciences)
丰田汽车 (Toyota Motor)
安永 EY (Ernst & Young)
網易 (Netease)
巴斯夫 (BASF)
麦格纳 (Magna)
诺维信(**)投资有限公司 (Novozymes)
海尔 (Haier)
思科 (Cisco Systems)
中兴通讯 (ZTE)
碧桂园 (Country Garden)
华硕 (ASUS)
德勤 (Deloitte)
艾欧史密斯(**) A.O.Smith (China)
百时美施贵宝 (Bristol-Myers Squibb)
星巴克 (Starbucks)
宝马集团 (宝马,Mini,劳斯莱斯汽车) BMW Group (BMW, Mini, Rolls-Royce Motorcars)
摩根大通 (J.P. Morgan)
**五矿集团 (Minmetals)
耐克 (Nike)
奇虎 360 (Qihoo 360)
万科 (Vanke Co)
微软 (Microsoft)
雅诗兰黛集团 (Estée Lauder Companies)
隆基股份 (LONGi)
阿迪达斯集团**(包括锐步) (adidas (incl. Reebok))
广东核电集团 (China Guangdong Nuclear Power Group)
阿斯利康 (AstraZeneca)
阳光电源 (Sungrow)
科思创 (Covestro)
阿斯麦 (ASML)
麦当劳 (McDonald's)
普华永道 PwC (PricewaterhouseCoopers)
美国银行 (美林证券) Bank of America (Merrill Lynch)
汇丰银行 (HSBC)
建设银行 (China Construction Bank)
飞利浦 (Philips)
安利 (AMWAY)
杜邦 (DuPont)
欧莱雅集团 (L'Oréal Group)
上汽通用汽车 (SAIC General Motors)
拜耳 (Bayer)
惠普企业 (Hewlett Packard Enterprise)
麦肯锡 (McKinsey & Company)
空气产品公司 (Air Products)
**电信 (China Telecom)
施耐德电气 (Schneider Electric)
**国际金融有限公司 (China International Capital Corporation Limited)
摩根士丹利 (Morgan Stanley)
香格里拉 (Shangri-La)
博世 (Bosch)
**一汽 (China FAW Group)
费森尤斯医疗** (Fresenius Medical Care China)
辉瑞制药 (Pfizer)
瑞士信贷 (Credit Suisse)
大众汽车集团** (Volkswagen Group China)
埃克森美孚 (ExxonMobil)
惠普公司 (HP Inc.)
宝洁 Procter & Gamble (P&G)
嘉吉 (Cargill)
恒天然 (Fonterra)
**联通 (China Unicom)
天合光能 (Trina Solar)
默克集团 (Merck Group)
斯伦贝谢 (Schlumberger)
联想 (Lenovo)
亚马逊** (Amazon China)
洲际酒店集团 (洲际,皇冠假日,英迪格,假日,智选假日) (IHG)
**农业银行 (Agricultural bank of china)
**移动 (China Mobile)
百事公司 (PepsiCo)
沃尔玛 (Wal-Mart)
中粮集团 (China Oil & Foodstuffs Corporation)
卡夫亨氏** (KraftHeinz)
小米 (Xiaomi)
**海洋石油总公司 (China National Offshore Oil Corporation)
西门子 (Siemens)
花旗银行 (Citi)
辉瑞普强 (Pfizer Upjohn)
费森尤斯卡比 (Fresenius Kabi)
美敦力 (Medtronic)
可口可乐 (Coca-Cola Company)
**银行 (Bank of China)
雀巢 (Nestlé)
百度 (Baidu)
爱立信 (Ericsson)
酩悦·轩尼诗-路易·威登集团 (LVMH Moët Hennessy Louis Vuitton)
雅培 (Abbott)
空中客车 (Airbus)
中信集团 (CITIC)
工商银行 (ICBC)
赛诺菲 (Sanofi)
米其林 (Michelin)
苹果 (Apple)
上海迪士尼度假区 (Shanghai Disney Resort)
ABB
利乐** (Tetra Pak)
液化空气集团 (Air Liquide)
德意志银行 (Deutsche Bank)
招商银行 (China Merchants Bank)
萌蒂制药 (Mundipharma)
iHandy
京东方科技集团 (BOE)
3M
**中化集团 (Sinochem)
汉高(包括施华蔻、百得、百特) Henkel (Schwarzkopf, Pattex, Pritt)
BP** (BP)
玛氏 (包括箭牌) Mars (incl. Wrigley)
诺和诺德 (Novo Nordisk)
滴滴 (DiDi)
腾讯 (TENCENT)
三星 (Samsung)
中石化 (Sinopec)
宜家** (IKEA China)
福特汽车 (Ford Motor Company)
戴姆勒/梅赛德斯-奔驰 (Daimler/Mercedes-Benz)
通用电气 (GE - General Electric)
道达尔 (Total)
英特尔 (Intel)
亿滋** (Mondelēz China)
沃尔沃汽车 (Volvo Cars)
壳牌 (Shell)
罗氏 (Roche)
陶氏化学 (DOW Chemical)
百胜** (包括肯德基,必胜客) YumChina (KFC, Pizza Hut)
华夏幸福 (CFLD)
贝恩咨询 (Bain & Company)
索尼** (Sony China)
甲骨文 (Oracle)
国家电网 (State Grid Corporation of China)
药明康德 (WuXi AppTec)
诺基亚 (Nokia)
默沙东** (MSD)
百威** (AB InBev China)
蔡司** (ZEISS)
龙湖集团 (Longfor Group)
华特迪士尼 (The Walt Disney Company)
IBM
万达集团 (Wanda Group)
艾昆纬 (IQVIA)
希尔顿酒店集团 (Hilton Worldwide)
伽蓝集团 (JALA Group)
百济神州 (BeiGene)
波士顿咨询公司 Boston Consulting Group (BCG)
勃林格殷格翰** (Boehringer Ingelheim Pharmaceuticals)
沃尔沃集团 (Volvo Group)
华为 (Huawei)
葛兰素史克 GSK (GlaxoSmithKline)
阿克苏诺贝尔 (AkzoNobel)
礼来** (Eli Lilly and Company)
世茂集团 (Shimao Group)
赛默飞世尔科技 (Thermo Fisher)
2017.11.11 17:08:58字数 1,872阅读 584
我们经常会有这样的经历,向上司汇报工作,说得口干舌燥,却得不到认同;向客户滔滔不绝介绍产品却不被看好。
那么,我们到底要怎样说话,才能让对方get到你想表达的意思;当你要说服对方投资你的项目、购买你的产品时,你要去怎样表达才能发挥最佳的效果?关键要做到这几点:
一、结论先行,表达更有效率
商务过程的时间就是金钱,没有人有耐心听你啰嗦。所以要先说结论再说原因。
在结论先行的模式下,相应的思维模式应该是:先总后分、先重要后次要、先果后因、先框架后细节。这样,哪怕你与你的上司或者客户只有在电梯内一起的短短30秒钟,对方也能够接收到你最重要的信息,这就是30秒电梯法则。
类似的表达方式可以留意一下新闻事件的报道。随手拿起身边的报纸,或看看电视新闻,你会发现,新闻信息的报道几乎总是采取先总后分、先重要后次要、先果后因、先框架后细节这样的顺序去铺开。这样的好处是,在版面、时间有限的情况下,可以让采稿人截取前面最重要的部分,而又不会是一段不完整的信息。当你和对方只有在电梯内短短的30秒钟,你会选择说些什么?绝对不会说:“今天天气呵呵呵”。
二、一句话概括主题,观点更明确
你有没有留意,许多工作汇报的第一句话或每一个小标题,都不是一句表达主题的完整句子。比如,你向上司汇报工作,通常这样:第一 ,本月主营业务指标完成情况;第二、本月安全生产情况。第三、....
如果换一种表达方式——第一,本月主营业务指标完成环比上升15%;第二,本月安全生产实现零隐患。这样的表达,感觉就明显不同了,你的观点就出来了,听汇报的人会更容易记住你说了什么内容。
学会用一句话概括主题的更高一层,是学会包装主题。
举个例子,当年苹果公司对第一代i Pod产品描述时本打算是这样表述:“今天,我们发布一款全新的、超便携的数字音乐播放器,仅重0.19千克,硬盘存储量为5GB,还拥有苹果产品传奇般的易用性。”
而乔布斯在台上进行产品发布演讲时是这样说的:i Pod,能把1000首歌装进你的口袋(1000 songs in your pocket)。
作为消费者听来,没有再比后者这样的表达更美妙的了。
三、对信息进行结构化归类,形成逻辑性表达模式
有时候,当要表达的内容信息量比较大的时候,不要想到哪里说哪里,这样会显得像一团乱麻,让人觉得你不知所云。
你可尝试着对已有的信息进归类。归类时要注意类目之间不要有交叉。
比如,领导让你发表一下对一个促销方案的意见时,你可从三点阐述你的一见:
第一、价格方面还可以优惠,理由....;
第二、促销方式可线上线下同时进行,理由......
第三、促销产品的范围可扩大到其他产品,理由......
这样,你的意见就可以清晰明了地让听者接受到。
四、运用5W2H原则达成你的说服力
5W2H原则是什么?是一种工作思维或者说是一种做事情的方法,具体如下:
what:是什么?做什么?目的是什么?
why:为了什么?为什么这样做?理由是什么?原因是什么?
who:谁来做?谁来负责?由谁承担?谁来完成?
when:什么时候开始?什么时候完成?最佳时机是什么时候?
where:什么地方?在哪里做?从哪里入手?
how:如何做?以何种方式来做?
how much:做多少?完成量是多少?预算成本是多少?合格率是多少?
现在回想一下,你以往做过的工作方案中,一份完整的工作方案,上述信息是必不可少的。比如:工作目标(what)、项目组成员(who)、开展时间(when)、实施范围/地点(where)、程序步骤(how)、经费预算/工具材料(how much)。
可见,记住5W2H原则,是避免关键信息缺漏有效方法。今后每次你与上司沟通,请求他批准你申请费用或某个活动方案时,记住运用5W2H原则,确保你的信息充分地让上司接收到。避免因为你的表达不够完整,而上司以研究研究为由搁置你的计划,表面上工作的进展受影响,是乎是上级不批的原因,而实际上却是你表达信息不完整,造成重复沟通,浪费了时间。
五、提供给对方最关心的信息
我们和人沟通时,一个很普遍的毛病就是只说自己想说的事情,不去留意对方关心的问题。
比如,你在向上司汇报一项工作完成过程时,你不断向上司描述你们项目组成员如何加班如何劳累,而上司最关心的是这项工作最终达成的效果是什么。这样,就会造成,你只顾着说你的,而对方却早已不耐烦。因为你没有把对方最关心的事情放在前面来说,甚至你根本就没有意识到对方关心的是什么,你只顾着说你想说的事。这种情况,有些直性子的领导会直接简单粗暴地打断你,让你说重要的事情;有些领导虽然耐着性子听你讲完,但内心并不认可你的工作。
了解了上述高效沟通的方法,你就明白了,为什么有一些领导在台上开大会发言会成为成功的“催眠者”,台下的听众不是打嗑睡就是刷手机,因为他们说话几乎都没有按照上述几个原则去表达。
"你的打赏可以让我在熬夜写作之余煮两鸡蛋补补脑子!别忘点亮左侧的❤️灯 要不就毅然关注我吧。 "
还没有人赞赏,支持一下
谷穗风致Echo公众号gusui2017;Artand签约艺术家;作品主页:https://m.artand....
总资产1,164 (约109.90元)共写了24.3W字获得5,520个赞共16,853个粉丝
为什么世界总不听话 人们总是希望这个世界按照自己的意愿运转,希望身边的任何人都听从自己的安排。事实上你会发现,让别...
静888阅读 7,289评论 1赞 42
上一周股指呈现一种缩量牛皮式的振荡,这是对年线及缺口位置的压力顾忌,同时随着大妖股特力A遭受巨额罚款之后,第一批妖...
文/刘皇叔 之前有位简友在给我的简信中提到了一个问题:在实现自己既定目标的过程中,发现环境已经发生变化,导致自己的...
产品成分:纯度98%的活性胶原 产品使用:修护,保湿,去痘印,促进胶原蛋白增长及细胞生长 使用方法:直接涂抹在皮肤...
菩提禅心阅读 2,713评论 3赞 1
早晨七点起来给儿子做饭 然后 困 没和大家共修 十点半左右练了一遍 蚊子太厉害
编者按:本文来自微信公众号“砺石商业评论”(ID:libusiness),作者 金梅,编辑 世红36氪经授权发布。
砺石导言
联合利华作为日化巨头,已经广为人知。也许鲜有人知道联合利华是世界上最大的食品饮料公司之一,世界第一位的冷冻食品、调味品、冰激凌和茶饮料制造商。持续20年战略调整,减肥与增肥并举,联合利华要在新时代写怎样的品牌故事?
联合利华的股东也许很庆幸,没有卖掉联合利华。
至笔者截稿,联合利华的股价已经达到了59.7美元,超出了目标被收购价将近20%。
2017年2月,卡夫亨氏向比自己体量更大的联合利华,发出了1430亿美元的并购要约。市值约为1060亿美元的卡夫亨氏,敢于大开口的底气在于,其50.9%的股份由巴菲特的伯克希尔哈撒韦和巴西著名私募基金3G资本拥有。巴菲特的实力无需多说。3G资本曾经主导了多次震惊世界的巨大并购,如百威英博1040亿美元收购SABMiller。
收购要约的消息发布后,联合利华的股价涨至48.53美元,创历史新高,不过仍低于卡夫亨氏报出的每股50美元的价格。消息飞了三天就烟消云散了。联合利华认为收购价格低估了企业价值,称不会考虑这桩对公司财务和战略没有帮助的交易。
为了抚慰投资人,联合利华CEO表示,会将营业利润率从当下的17.5%,到2020年前提升到20%。于是联合利华开始频繁动作,调整产品组合,优化业务结构,以兑现承诺。2019年基本过去,眼看是递交成绩单的时候了,联合利华有没有实现目标?
11月12日,汉堡王在25个欧洲国家的2500多家门店推出了名为“叛逆皇堡”的“人造肉”汉堡。作为迄今为止汉堡王在欧洲规模最大的一次产品推广,本次活动引来了巨大的媒体关注。也许少有人注意到,为汉堡王提供植物肉饼供应的,是联合利华旗下的人造肉品牌素食屠夫(Vegetarian Butcher)。
这也是食品公司卡夫亨氏在自身业务增长乏力的情况下,向联合利华发起收购要约的根源所在。
联合利华旗下的和路雪冰激凌1993年进入**,仅仅过了半年,销售量就超过350万升。“冰柜策略”让和路雪短时间占据了**的大街小巷,打破了多个世界记录。另外,大家耳熟能详的梦龙、可爱多、立顿茶叶,也是联合利华的子品牌。
联合利华面向专业餐厅的家乐调味品,在**厨师中颇具影响力。从2012年开始,国内大众餐饮爆发。联合利华、雀巢为首的调味品供应商们都在闷声发大财。餐饮市场大约40%用于采购,采购中大约30%-40%用于调味品采购。到2018年底,全国调味品及发酵行业销售收入为3427.2亿元,同比增长10.6%。
联合利华的“饮食策划”业务1994年进入大中华区域时,就已经是世界最大的餐饮解决方案提供者之一,有坚实的产品线。其家乐品牌为主打的食品业务,包括鸡精鸡粉、浓汤宝、快熟汤、鲜露、炸粉、番茄沙司等。必胜客、肯德基、俏江南等连锁餐厅都是其合作伙伴。起源于香港的家乐,属于中餐血统,在大中华区的适应性非常强。
中餐味道复杂,酱汁的制作繁琐且味道难以把握。联合利华深谙厨师的痛点,通过海珍酱、黑胡椒汁、浓缩鸡汁、耗油、蒸鱼豉油、鸡粉等三十余种酱汁,对复杂的中餐口味进行了标准化。有了家乐产品,厨师无需炒酱,就可以做出色香味俱全的菜品,口感饱满,成品率极高。通过百余名厨务顾问专门研发产品,联合利华让厨师们买到的不但是调味品,还有新菜肴的方案,让其在中餐市场声名鹊起。
虽然联合利华并不认为雀巢是它的竞争对手,但它们在餐饮市场却日趋短兵相接。虽然产品线有众多重合,但与联合利华的思路不同,雀巢是按照使用场景,如西式快餐、街饮甜品、办公食堂、学校教育、酒店住宿等等,来提供一体化的解决方案。从调味料到乳品、饮料、咖啡,和餐企打包签合约,从而构筑竞争壁垒。而且,与联合利华遍地开花不同,雀巢主攻一二线城市的大客户。雀巢更多的与百胜、麦当劳等连锁企业合作,甚至和大的餐饮品牌一起做产品研发。如对海底捞火锅的汤底在色泽、耐煮性、口味等方面进行改良。
虽然在专业中餐调味领域,联合利华的家乐系列完胜雀巢的美极系列,不过在西餐和一体化解决方案上,联合利华被压制得很厉害。想要在食品领域出人头地,挑战很多。首先,发达国家的食品和饮料市场,竞争非常激烈。其次,食品、日化两条腿走的联合利华,日化领域已经深入人心,想要完成食品领域的市场教育并不简单。更何况,从最近公司大的战略布局上来说,食品业务越来越不吃香了。
马化腾说过一句话——“你没做错什么,你只是老了”,众多大品牌就因为这个简单的道理开始陷入中年危机。联合利华也不例外。旁氏在2014年销售渠道由专柜销售“降级”为货架。曾经红极一时的夏士莲,2017年市场份额跌至0.5%。在整个日化行业下行的情况下,联合利华想要一个完美的财务数字,谈何容易。
20世纪中叶的半个世纪以来,欧美国家年轻人的数量增长以及高生育率,撑起了一系列的商业奇迹。可口可乐、宝洁、联合利华、汉高,以及汽车工业的发达都与此紧密相关。但随后,市场环境的变化使企业开始进入停滞期。在飞速发展中急速壮大的宝洁、雀巢、卡夫亨氏这类公司,越来越像自行车赛道上的超重骑手。相比身边那些规模更小、更敏捷的竞争对手,它们看起来那么笨重、迟钝。围绕核心业务进行瘦身,成了很多企业的必然之举。
联合利华旗下品牌一度达2000多个。1996年,公司利润增长非常缓慢,几乎被臃肿的业务拖累死。1999年,联合利华开始聚焦核心业务,专攻家庭及个人护理用品、食品及饮料和冰激凌等三大优势系列。2000年,把“伊丽莎白·雅顿”这个香水业务卖给了FFI香水公司;2003年,又把几个家用护理产品卖给雷曼兄弟和Witko集团。逐步将一千多个品牌出售、清算或重组,留下400个核心品牌。组织上,公司数量也开始大幅精简,人员也开始加速优化,战略“瘦身”基本完成。
在做资产剥离的同时,联合利华完成了史上砸钱最多的一次收购,迎来了食品业务的高光时刻。2000年,其以240亿美元(约合217亿欧元)收购了贝斯特食品公司(Bestfoods),让联合利华成为食品领域雀巢之后的全球第二名。虽然协同效应和规模优势为联合利华带来了不错的市场前景,但亚军的喜悦没有在联合利华的脸上停留多久。巨大体量的收购与人们多变的需求,让联合利华此后花了十多年把一堆不受欢迎的品牌再剥离出去。
2012年,联合利华在另一核心业务——美妆个护领域,首次超越宝洁,成为紧跟欧莱雅集团的全球第二大化妆品公司。很快宝洁的品牌聚焦也开始了。2014年,宝洁一下就卖出去了43个品牌,其中包括沙宣、蜜丝佛陀等品牌。到了2017年8月,宝洁旗下的品牌已经从200多个减少到了65个。在宝洁sk2、玉兰油核心品牌的对比下,凡士林、旁氏之外,联合利华再无王牌可出。
重回日化领域的昔日高光时刻,是联合利华新的目标。首先,它看准了化妆品行业的高额利润率。目前,联合利华依旧是以食品和洗涤用品作为主营业务,但是其主营业务像洗衣粉之类的毛利率只有30%,而个人护理类产品的毛利率是主营业务的两倍,高达60%,甚至是80%。因此,剥离利润率较低的业务,距离公司的20%利润率允诺就更进了一步。其次,通过收购可以为联合利华节约产品研发和推广成本,迅速与欧莱雅、宝洁等公司进行竞争。2014年,联合利华开始继续边“瘦身”边“增肥”。
2015年以来,联合利华剥离增长缓慢的部分食品业务,出售了80亿欧元的资产,如曾经让联合利华起家的涂抹酱和人造黄油。将收购重点放在护肤品和化妆品领域。近4年,联合利华价值共计110亿欧元的30笔交易中,美容个护的交易额占据了近3/4。包括备受关注的韩国护肤品牌AHC,以及美国专业彩妆品牌Hourglass。2017年,联合利华收购美国彩妆品牌hourglass,是其百年征程中首次布局彩妆业务。
2001年至2017年间,联合利华的产品组合经历了重大调整。食品业务在营业额中的占比已从40%下降至23%,而美容和个护业务则从24%一路升至38%了。2017年4月,联合利华宣布将食品和茶点饮品(这个业务部门包括了和路雪冰淇淋、立顿茶两大业务)合并为一个部门。
2018年11月,原任联合利华美容与个人护理业务总裁的Alan Jope成为这家老牌日化巨头的新任CEO。他在上任后首次接受采访时就指出,联合利华的业务重点将转向利润更高的美容个护市场。
日化领域的宏伟蓝图和食品端的持续瘦身,甚至让人对其业务剥离一度产生了误解。11月23日,英国电讯报爆出联合利华正在考虑出售其传统茶业务PG Tips和立顿(Lipton)品牌给百事公司。谣言很快就澄清了,但从外界看,食品业务在公司的战略地位岌岌可危。
联合利华的食品端,貌似无可挽回走向萎缩。去年收购的荷兰食品巨头Vegetarian Butcher推出人造肉汉堡的消息,垂头丧气的食品业务终于“扬眉吐气”了一把。奶油和香皂公司合并而来的联合利华,拥有荷兰和英国双总部,荷兰食品业务的地位一时很难被抹杀。新兴市场的良好表现,使食品成为联合利华获得高市场占有的杀手锏,联合利华从葛兰素史克手中收购印度好立克品牌的逻辑正在于此。
2018年年度报告显示,包括和路雪、家乐、立顿和联合利华饮食策划在内的联合利华食品饮料业务,去年在**市场录得了双位数增长。联合利华食品和饮料业务在2018年实现了202亿欧元的销售收入,并且贡献了58%的营业利润。扣除剥离的黄油业务也给联合利华带来一次性43亿欧元的收益,占据联合利华整体收入的30%,相较于2017年有所提升。
看似不得势的食品板块,其实未来想象空间也不小。在完成市场教化之后,产品的高端化自然会给食品业务带来好看的利润率。此次的素汉堡即是一例。雀巢胶囊咖啡品牌高于其金牌雀巢十倍的定价,也为联合利华指明了未来。因此,两条腿走路的联合利华,迎来的不是美妆日化的高光时刻,而是“王牌”的高光时刻。
减肥与增肥活动,联合利华已经持续了20年。虽然在不同的阶段,业务重点略有不同。但聚焦核心业务,优化产品组合,为企业带来更高利润是一切活动的旨归。即将交卷的联合利华,“成绩”如何?
联合利华2019年第三季度销售额133亿欧元,同比增长5.8%,包括了汇率变动带来的2.3%的增长以及收购带来了0.8%的增长,终结了连续六个季度以来的负增长。但这距离一份完美的成绩单还有一定距离。
被寄予厚望的美容与个护业务增长平稳,未能撑起公司的预期。第三季度营业额56亿欧元,同比增长2.8%,其中销量增长2.1%,价格增长0.7%。营业利润率从2016年的19.8%,增长为2018年的20%。与宝洁超过20%的利润率相比,联合利华还是有增长空间的。但在大行业增长趋缓的背景下,增长并不容易。何况联合利华还有另外两块利润率并不乐观的业务。
第三季度联合利华食品和茶点营业额50亿欧元,同比增长1.7%。2017年食品业务的营业额为125亿欧元,占集团总营业额的23%和营业利润的26%。2018年度销售额达到202亿欧元,如果消除业务出售导致的43亿一次性利润和销售减少以及汇率波动的影响,实际利润率约为17.5%。
家庭护理产品第三季度营业额27亿欧元(约29.8亿美元),同比增长5.4%。该业务2018年度销售额达到101亿欧元,同比增长4.2%,但营业利润率仅为11.5%。
从近期的财报来看,联合利华虽然在东南亚和印度这样的新兴市场表现稳定,但欧洲、北美和**市场增长放缓,拉丁美洲市场运营艰难。在消费环境逐渐变化和市场升级的过程中,联合利华虽然在不断地做品牌调整,频繁的品牌变动为企业带来了业务重心的持续聚焦。但剧烈的变动,同样让企业在品牌升级和品牌协同上的功课呈现严重不足。而且,面对激烈的市场变化,做好品牌和服务升级,才能挽住既有市场,获得丰厚的利润。
20%的利润率在2020年前实现,对联合利华来说几乎不可能。即便实现了,数字也只是一时的战绩,品牌的协同和升级才是联合利华更大的持久战。
每天有190个国家,25亿人使用联合利华的产品。全球50个顶级日化品牌中,联合利华拥有30个。但成为品牌之父的却是宝洁,并非联合利华。不是跑到宝洁和欧莱雅的赛道上,就可以成为对方。
与联合利华纷乱的品牌相比,宝洁的品牌诉求线清晰,每种产品专供一个细分领域。而联合利华的品牌之间很难形成组合优势,夏士莲、力士、多芬自己的产品都在打架。联合利华也意识到了这一问题,开始着手产品线的优化组合,清扬的推出就是为了弥补去屑市场战线的不足。
与欧莱雅上到几千下到几元的坚固金字塔品牌组合不同,联合利华虽然把品牌精简出来了,但显然应对不同市场的品牌搭建还不够。过去一年中,联合利华在**市场新引进了近10个品牌,包括Grom、花漾星球、花木星球、The Laundress等,在**市场开启小批量、多品种以及定制化的时代。不过这些品牌目前来看尚未在市场上激起什么浪花。
在数字化营销与颜值经济的带动下,宝洁短短几年间的翻身,联合利华也在努力。渠道上,电子商务渠道已经是联合利华最重要的增长渠道,公司电子商务业务增长了30%。
但想要复制宝洁的成功也并非易事。宝洁的主要业务是日化与化妆品,联合利华的主要业务是日化与食品。虽然一系列的收购为联合利华业务快速转道提供了契机,但品牌的收购只是第一步,品牌金字塔的搭建和完善,才是终极考验。日化和食品双线资源争夺可能带来的企业内耗暂且不说,在**的大日化和食品增速放缓的情况下,联合利华押注**市场的增长故事并不好写。
Linux 命令大全
Linux 教程
Linux 教程 Linux 简介 Linux 安装 Linux 云服务器 Linux 系统启动过程 Linux 系统目录结构 Linux 忘记密码解决方法 Linux 远程登录 Linux 文件基本属性 Linux 文件与目录管理 Linux 用户和用户组管理 Linux 磁盘管理 Linux vi/vim linux yum 命令
Shell 教程 Shell 变量 Shell 传递参数 Shell 数组 Shell 运算符 Shell echo命令 Shell printf命令 Shell test 命令 Shell 流程控制 Shell 函数 Shell 输入/输出重定向 Shell 文件包含
Linux 命令大全 Nginx 安装配置 MySQL 安装配置
| Linux 命令大全 |
|---|
| 1、文件管理 |
| cat |
| chown |
| diffstat |
| gitview |
| less |
| mc |
| more |
| mtools |
| paste |
| slocate |
| touch |
| whereis |
| scp |
| 2、文档编辑 |
| col |
| ed |
| fmt |
| jed |
| mtype |
| sort |
| uniq |
| 3、文件传输 |
| lprm |
| bye |
| uucp |
| ftpshut |
| 4、磁盘管理 |
| cd |
| edquota |
| mdu |
| mrd |
| mount |
| stat |
| quotacheck |
| quotaon |
| 5、磁盘维护 |
| badblocks |
| ext2ed |
| fdformat |
| mkdosfs |
| mkinitrd |
| swapon |
| mkfs.minix |
| mkfs |
| 6、网络通讯 |
| apachectl |
| mingetty |
| uustat |
| httpd |
| dnsconf |
| pppstats |
| traceroute |
| netconf |
| pppsetup |
| smbd |
| 7、系统管理 |
| adduser |
| exit |
| suspend |
| kill |
| logname |
| procinfo |
| rlogin |
| shutdown |
| swatch |
| chsh |
| vlock |
| newgrp |
| w |
| 8、系统设置 |
| reset |
| aumix |
| crontab |
| enable |
| grpconv |
| lilo |
| set |
| passwd |
| rmmod |
| setup |
| timeconfig |
| apmd |
| unalias |
| 9、备份压缩 |
| ar |
| gunzip |
| dump |
| lha |
| unzip |
| 10、设备管理 |
| setleds |
| MAKEDEV |
formula 是一个 Ruby 写的 package 。It can be created with brew create <URL> where <URL> is a zip or tarball, installed with brew install <formula>, and debugged with brew install --debug --verbose <formula>. Formulae use the Formula API which provides various Homebrew-specific helpers.
| Term | Description | Example |
|---|---|---|
| Formula | The package definition | /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/Formula/foo.rb |
| Keg | The installation prefix of a Formula | /usr/local/Cellar/foo/0.1 |
| opt prefix | A symlink to the active version of a Keg | /usr/local/opt/foo |
| Cellar | All Kegs are installed here | /usr/local/Cellar |
| Tap | A Git repository of Formulae and/or commands | /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core |
| Bottle | Pre-built Keg used instead of building from source | qt-4.8.4.mavericks.bottle.tar.gz |
| Cask | An extension of Homebrew to install macOS native apps | /Applications/MacDown.app/Contents/SharedSupport/bin/macdown |
| Brew Bundle | An extension of Homebrew to describe dependencies | brew 'myservice', restart_service: true |
Homebrew uses Git for downloading updates and contributing to the project.
Homebrew installs to the Cellar and then symlinks some of the installation into /usr/local so that other programs can see what’s going on. We suggest you brew ls a few of the kegs in your Cellar to see how it is all arranged.
Packages are installed according to their formulae, which live in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/Formula. Check out a simple one, e.g. brew edit etl (or etl) or a more advanced one, e.g. brew edit git (or git).
Make sure you run brew update before you start. This turns your Homebrew installation into a Git repository.
Before submitting a new formula make sure your package:
brew search <formula>)brew audit --new-formula <formula> testsBefore submitting a new formula make sure you read over our contribution guidelines.
Run brew create with a URL to the source tarball:
brew create https://example.com/foo-0.1.tar.gz
This creates /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/Formula/foo.rb and opens it in your EDITOR. It’ll look something like:
class Foo < Formula
desc ""
homepage ""
url "https://example.com/foo-0.1.tar.gz"
sha256 "85cc828a96735bdafcf29eb6291ca91bac846579bcef7308536e0c875d6c81d7"
# depends_on "cmake" => :build
def install
# ENV.deparallelize
system "./configure", "--disable-debug",
"--disable-dependency-tracking",
"--disable-silent-rules",
"--prefix=#{prefix}"
# system "cmake", ".", *std_cmake_args
system "make", "install"
end
test do
system "false"
end
end
If brew said Warning: Version cannot be determined from URL when doing the create step, you’ll need to explicitly add the correct version to the formula and then save the formula.
Homebrew will try to guess the formula’s name from its URL. If it fails to do so you can override this with brew create <URL> --set-name <name>.
We don’t accept formulae without a homepage!
An SSL/TLS (https) homepage is preferred, if one is available.
Try to summarize from the homepage what the formula does in the description. Note that the description is automatically prepended with the formula name.
brew install --interactive foo
You’re now at a new prompt with the tarball extracted to a temporary sandbox.
Check the package’s README. Does the package install with ./configure, cmake, or something else? Delete the commented out cmake lines if the package uses ./configure.
The README probably tells you about dependencies and Homebrew or macOS probably already has them. You can check for Homebrew dependencies with brew search. Some common dependencies that macOS comes with:
libexpatlibGLlibiconvlibpcaplibxml2pythonrubyThere are plenty of others; check /usr/lib for them.
We generally try not to duplicate system libraries and complicated tools in core Homebrew but we do duplicate some commonly used tools.
Special exceptions are OpenSSL and LibreSSL. Things that use either should be built using Homebrew’s shipped equivalent and our Brew Test Bot’s post-install audit will warn if it detects you haven’t done this.
Homebrew’s OpenSSL is keg_only to avoid conflicting with the system so sometimes formulae need to have environment variables set or special configuration flags passed to locate our OpenSSL. You can see this mechanism in the clamav formula. Usually this is unnecessary because Homebrew sets up our build environment to favour finding keg_only formulae first.
Important: $(brew --prefix)/bin is NOT on the PATH during formula installation. If you have dependencies at build time, you must specify them and brew will add them to the PATH or create a Requirement.
class Foo < Formula
depends_on "pkg-config"
depends_on "jpeg"
depends_on "readline" => :recommended
depends_on "gtk+" => :optional
depends_on "httpd" => [:build, :test]
depends_on :x11 => :optional
depends_on :xcode => "9.3"
end
A String (e.g. "jpeg") specifies a formula dependency.
A Symbol (e.g. :x11) specifies a Requirement which can be fulfilled by one or more formulae, casks or other system-wide installed software (e.g. X11).
A Hash (e.g. =>) adds information to a dependency. Given a String or Symbol, the value can be one or more of the following values:
:build means that dependency is a build-time only dependency so it can be skipped when installing from a bottle or when listing missing dependencies using brew missing.
:test means that dependency is only required when running brew test.
:optional generates an implicit with-foo option for the formula. This means that, given depends_on "foo" => :optional, the user must pass --with-foo in order to use the dependency.
:recommended generates an implicit without-foo option, meaning that the dependency is enabled by default and the user must pass --without-foo to disable this dependency. The default description can be overridden using the normal option syntax (in this case, the option declaration must precede the dependency):
option "with-foo", "Compile with foo bindings" # This overrides the generated description if you want to
depends_on "foo" => :optional # Generated description would otherwise be "Build with foo support"
Some Requirements can also take a string specifying their minimum version that the formula depends on.
Note: options are not allowed in Homebrew/homebrew-core as they are not tested by CI.
Sometimes there’s hard conflict between formulae, and it can’t be avoided or circumvented with keg_only.
A good example formula for minor conflict is mbedtls, which ships and compiles a “Hello World” executable. This is obviously non-essential to mbedtls’s functionality, and conflict with the popular GNU hello formula would be overkill, so we just remove it during the installation process.
pdftohtml provides an example of a serious conflict, where both formula ship an identically-named binary that is essential to functionality, so a conflicts_with is preferable.
As a general rule, conflicts_with should be a last-resort option. It’s a fairly blunt instrument.
The syntax for a conflict that can’t be worked around is:
conflicts_with "blueduck", :because => "yellowduck also ships a duck binary"
In Homebrew we sometimes accept formulae updates that don’t include a version bump. These include resource updates, new patches or fixing a security issue with a formula.
Occasionally, these updates require a forced-recompile of the formula itself or its dependents to either ensure formulae continue to function as expected or to close a security issue. This forced-recompile is known as a revision and is inserted underneath the homepage/url/sha256 block.
When a dependent of a formula fails against a new version of that dependency it must receive a revision. An example of such failure can be seen here and the fix here.
revisions are also used for formulae that move from the system OpenSSL to the Homebrew-shipped OpenSSL without any other changes to that formula. This ensures users aren’t left exposed to the potential security issues of the outdated OpenSSL. An example of this can be seen in this commit.
Sometimes formulae have version schemes that change such that a direct comparison between two versions no longer produces the correct result. For example, a project might be version 13 and then decide to become 1.0.0. As 13 is translated to 13.0.0 by our versioning system by default this requires intervention.
When a version scheme of a formula fails to recognise a new version as newer it must receive a version_scheme. An example of this can be seen here.
When you already have a lot of formulae installed, it’s easy to miss a common dependency. You can double-check which libraries a binary links to with the otool command (perhaps you need to use xcrun otool):
$ otool -L /usr/local/bin/ldapvi
/usr/local/bin/ldapvi:
/usr/local/opt/openssl/lib/libssl.1.0.0.dylib (compatibility version 1.0.0, current version 1.0.0)
/usr/local/opt/openssl/lib/libcrypto.1.0.0.dylib (compatibility version 1.0.0, current version 1.0.0)
/usr/local/lib/libglib-2.0.0.dylib (compatibility version 4201.0.0, current version 4201.0.0)
/usr/local/opt/gettext/lib/libintl.8.dylib (compatibility version 10.0.0, current version 10.2.0)
/usr/local/opt/readline/lib/libreadline.6.dylib (compatibility version 6.0.0, current version 6.3.0)
/usr/local/lib/libpopt.0.dylib (compatibility version 1.0.0, current version 1.0.0)
/usr/lib/libncurses.5.4.dylib (compatibility version 5.4.0, current version 5.4.0)
/System/Library/Frameworks/LDAP.framework/Versions/A/LDAP (compatibility version 1.0.0, current version 2.4.0)
/usr/lib/libresolv.9.dylib (compatibility version 1.0.0, current version 1.0.0)
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1213.0.0)
Homebrew doesn’t package already-packaged language-specific libraries. These should be installed directly from gem/cpan/pip etc.
If you’re installing an application then use resources for all language-specific dependencies:
class Foo < Formula
resource "pycrypto" do
url "https://files.pythonhosted.org/packages/60/db/645aa9af249f059cc3a368b118de33889219e0362141e75d4eaf6f80f163/pycrypto-2.6.1.tar.gz"
sha256 "f2ce1e989b272cfcb677616763e0a2e7ec659effa67a88aa92b3a65528f60a3c"
end
def install
resource("pycrypto").stage { system "python", *Language::Python.setup_install_args(libexec/"vendor") }
end
end
jrnl is an example of a formula that does this well. The end result means the user doesn’t have to use pip or Python and can just run jrnl.
homebrew-pypi-poet can help you generate resource stanzas for the dependencies of your Python application.
brew install --verbose --debug foo
--debug will ask you to open an interactive shell if the build fails so you can try to figure out what went wrong.
Check the top of the e.g. ./configure output. Some configure scripts do not recognise e.g. --disable-debug. If you see a warning about it, remove the option from the formula.
Add a valid test to the test do block of the formula. This will be run by brew test foo and the Brew Test Bot.
The test do block automatically creates and changes to a temporary directory which is deleted after run. You can access this Pathname with the testpath function. The environment variable HOME is set to testpath within the test do block.
We want tests that don’t require any user input and test the basic functionality of the application. For example foo build-foo input.foo is a good test and (despite their widespread use) foo --version and foo --help are bad tests. However, a bad test is better than no test at all.
See cmake for an example of a formula with a good test. The formula writes a basic CMakeLists.txt file into the test directory then calls CMake to generate Makefiles. This test checks that CMake doesn’t e.g. segfault during basic operation.
You can check that the output is as expected with assert_equal or assert_match on the output of shell_output such as in this example from the envv formula:
assert_equal "mylist=A:C; export mylist", shell_output("#{bin}/envv del mylist B").strip
You can also check that an output file was created:
assert_predicate testpath/"output.txt", :exist?
Some advice for specific cases:
tinyxml2, which writes a small C++ source file into the test directory, compiles and links it against the tinyxml2 library and finally checks that the resulting program runs successfully.Homebrew expects to find manual pages in #{prefix}/share/man/..., and not in #{prefix}/man/....
Some software installs to man instead of share/man, so check the output and add a "--mandir=#{man}" to the ./configure line if needed.
In case there are specific issues with the Homebrew packaging (compared to how the software is installed from other sources) a caveats block can be added to the formula to warn users. This can indicate non-standard install paths, an example from the ruby formula:
==> Caveats
By default, binaries installed by gem will be placed into:
/usr/local/lib/ruby/gems/bin
You may want to add this to your PATH.
Name the formula like the project markets the product. So it’s pkg-config, not pkgconfig; sdl_mixer, not sdl-mixer or sdlmixer.
The only exception is stuff like “Apache Ant”. Apache sticks “Apache” in front of everything, but we use the formula name ant. We only include the prefix in cases like gnuplot (because it’s part of the name) and gnu-go (because everyone calls it “GNU Go”—nobody just calls it “Go”). The word “Go” is too common and there are too many implementations of it.
If you’re not sure about the name, check its homepage, Wikipedia page and what Debian calls it.
When Homebrew already has a formula called foo we typically do not accept requests to replace that formula with something else also named foo. This is to avoid both confusing and surprising users’ expectations.
When two formulae share an upstream name, e.g. AESCrypt and AES Crypt the newer formula must typically adapt its name to avoid conflict with the current formula.
If you’re still not sure, just commit. We’ll apply some arbitrary rule and make a decision 😉.
When importing classes, Homebrew will require the formula and then create an instance of the class. It does this by assuming the formula name can be directly converted to the class name using a regexp. The rules are simple:
foo-bar.rb => FooBarfoobar.rb => FoobarThus, if you change the name of the class, you must also rename the file. Filenames should be all lowercase, and class names should be the strict CamelCase equivalent, e.g. formulae gnu-go and sdl_mixer become classes GnuGo and SdlMixer, even if part of their name is an acronym.
Add aliases by creating symlinks in an Aliases directory in the tap root.
You can run brew audit --strict --online to test formulae for adherence to Homebrew house style. The audit command includes warnings for trailing whitespace, preferred URLs for certain source hosts, and a lot of other style issues. Fixing these warnings before committing will make the process a lot quicker for everyone.
New formulae being submitted to Homebrew should run brew audit --new-formula foo. This command is performed by the Brew Test Bot on new submissions as part of the automated build and test process, and highlights more potential issues than the standard audit.
Use brew info and check if the version guessed by Homebrew from the URL is correct. Add an explicit version if not.
Everything is built on Git, so contribution is easy:
brew update # required in more ways than you think (initializes the brew git repository if you don't already have it)
cd $(brew --repo homebrew/core)
# Create a new git branch for your formula so your pull request is easy to
# modify if any changes come up during review.
git checkout -b <some-descriptive-name> origin/master
git add Formula/foo.rb
git commit
The established standard for Git commit messages is:
At Homebrew, we like to put the name of the formula up front like so: foobar 7.3 (new formula). This may seem crazy short, but you’ll find that forcing yourself to summarise the commit encourages you to be atomic and concise. If you can’t summarise it in 50-80 characters, you’re probably trying to commit two commits as one. For a more thorough explanation, please read Tim Pope’s excellent blog post, A Note About Git Commit Messages.
The preferred commit message format for simple version updates is foobar 7.3 and for fixes is foobar: fix flibble matrix..
Ensure you reference any relevant GitHub issue, e.g. Closes #12345 in the commit message. Homebrew’s history is the first thing future contributors will look to when trying to understand the current state of formulae they’re interested in.
Now you just need to push your commit to GitHub.
If you haven’t forked Homebrew yet, go to the homebrew-core repository and hit the Fork button.
If you have already forked Homebrew on GitHub, then you can manually push (just make sure you have been pulling from the Homebrew/homebrew-core master):
git push https://github.com/myname/homebrew-core/ <what-you-called-your-branch>
Now, open a pull request for your changes.
Three commands are provided for displaying informational messages to the user:
ohai for general infoopoo for warning messagesodie for error messages and immediately exitingIn particular, when a test needs to be performed before installation use odie to bail out gracefully. For example:
if build.with?("qt") && build.with("qt5")
odie "Options --with-qt and --with-qt5 are mutually exclusive."
end
system "make", "install"
bin.install "foo"You’ll see stuff like this in some formulae. This moves the file foo into the formula’s bin directory (/usr/local/Cellar/pkg/0.1/bin) and makes it executable (chmod 0555 foo).
inreplaceinreplace is a convenience function that can edit files in-place. For example:
inreplace "path", before, after
before and after can be strings or regular expressions. You should use the block form if you need to make multiple replacements in a file:
inreplace "path" do |s|
s.gsub! /foo/, "bar"
s.gsub! "123", "456"
end
Make sure you modify s! This block ignores the returned value.
inreplace should be used instead of patches when patching something that will never be accepted upstream, e.g. making the software’s build system respect Homebrew’s installation hierarchy. If it’s something that affects both Homebrew and MacPorts (i.e. macOS specific) it should be turned into an upstream submitted patch instead.
If you need modify variables in a Makefile, rather than using inreplace, pass them as arguments to make:
system "make", "target", "VAR2=value1", "VAR2=value2", "VAR3=values can have spaces"
system "make", "CC=#{ENV.cc}", "PREFIX=#{prefix}"
Note that values can contain unescaped spaces if you use the multiple-argument form of system.
While patches should generally be avoided, sometimes they are temporarily necessary.
When patching (i.e. fixing header file inclusion, fixing compiler warnings, etc.) the first thing to do is check whether or not the upstream project is aware of the issue. If not, file a bug report and/or submit your patch for inclusion. We may sometimes still accept your patch before it was submitted upstream but by getting the ball rolling on fixing the upstream issue you reduce the length of time we have to carry the patch around.
Always justify a patch with a code comment! Otherwise, nobody will know when it is safe to remove the patch, or safe to leave it in when updating the formula. The comment should include a link to the relevant upstream issue(s).
External patches can be declared using resource-style blocks:
patch do
url "https://example.com/example_patch.diff"
sha256 "85cc828a96735bdafcf29eb6291ca91bac846579bcef7308536e0c875d6c81d7"
end
A strip level of -p1 is assumed. It can be overridden using a symbol argument:
patch :p0 do
url "https://example.com/example_patch.diff"
sha256 "85cc828a96735bdafcf29eb6291ca91bac846579bcef7308536e0c875d6c81d7"
end
patches can be declared in stable, devel, and head blocks. Always use a block instead of a conditional, i.e. stable do ... end instead of if build.stable? then ... end.
stable do
# some other things...
patch do
url "https://example.com/example_patch.diff"
sha256 "85cc828a96735bdafcf29eb6291ca91bac846579bcef7308536e0c875d6c81d7"
end
end
Embedded (END) patches can be declared like so:
patch :DATA
patch :p0, :DATA
with the patch data included at the end of the file:
__END__
diff --git a/foo/showfigfonts b/foo/showfigfonts
index 643c60b..543379c 100644
--- a/foo/showfigfonts
+++ b/foo/showfigfonts
@@ -14,6 +14,7 @@
…
Patches can also be embedded by passing a string. This makes it possible to provide multiple embedded patches while making only some of them conditional.
In embedded patches, the string “HOMEBREW_PREFIX” is replaced with the value of the constant HOMEBREW_PREFIX before the patch is applied.
brew install --interactive --git foo
# (make some edits)
git diff | pbcopy
brew edit foo
Now just paste into the formula after __END__. Instead of git diff | pbcopy, for some editors git diff >> path/to/your/formula/foo.rb might help you ensure that the patch is not touched, e.g. white space removal, indentation changes, etc.
If anything isn’t clear, you can usually figure it out by grepping the $(brew --repo homebrew/core) directory. Please submit a pull request to amend this document if you think it will help!
devel, head)Formulae can specify alternate downloads for the upstream project’s head (master/trunk) or devel release (unstable but not master/trunk).
headhead URLs (activated by passing --HEAD) build the development cutting edge. Specifying it is easy:
class Foo < Formula
head "https://github.com/mxcl/lastfm-cocoa.git"
end
Homebrew understands git, svn, and hg URLs, and has a way to specify cvs repositories as a URL as well. You can test whether the head is being built with build.head?.
To use a specific commit, tag, or branch from a repository, specify head with the :tag and :revision, :revision, or :branch option, like so:
class Foo < Formula
head "https://github.com/some/package.git", :revision => "090930930295adslfknsdfsdaffnasd13"
# or :branch => "develop" (the default is "master")
# or :tag => "1_0_release",
# :revision => "090930930295adslfknsdfsdaffnasd13"
end
develThe devel spec (activated by passing --devel) is used for a project’s unstable releases. devel specs are not allowed in Homebrew/homebrew-core.
A devel spec is specified in a block:
devel do
url "https://foo.com/foo-0.1.tar.gz"
sha256 "85cc828a96735bdafcf29eb6291ca91bac846579bcef7308536e0c875d6c81d7"
end
You can test if the devel spec is in use with build.devel?.
Sometimes a package fails to build when using a certain compiler. Since recent Xcode versions no longer include a GCC compiler we cannot simply force the use of GCC. Instead, the correct way to declare this is the fails_with DSL method. A properly constructed fails_with block documents the latest compiler build version known to cause compilation to fail, and the cause of the failure. For example:
fails_with :clang do
build 211
cause "Miscompilation resulting in segfault on queries"
end
build takes a Fixnum (an integer; you can find this number in your brew --config output). cause takes a String, and the use of heredocs is encouraged to improve readability and allow for more comprehensive documentation.
fails_with declarations can be used with any of :gcc, :llvm, and :clang. Homebrew will use this information to select a working compiler (if one is available).
To use one of Homebrew’s built-in download strategies, specify the :using => flag on a url or head. For example:
class Python3 < Formula
homepage "https://www.python.org/"
url "https://www.python.org/ftp/python/3.4.3/Python-3.4.3.tar.xz"
sha256 "b5b3963533768d5fc325a4d7a6bd6f666726002d696f1d399ec06b043ea996b8"
head "https://hg.python.org/cpython", :using => :hg
Homebrew offers anonymous download strategies.
:using value |
download strategy |
|---|---|
:bzr |
BazaarDownloadStrategy |
:curl |
CurlDownloadStrategy |
:cvs |
CVSDownloadStrategy |
:fossil |
FossilDownloadStrategy |
:git |
GitDownloadStrategy |
:hg |
MercurialDownloadStrategy |
:nounzip |
NoUnzipCurlDownloadStrategy |
:post |
CurlPostDownloadStrategy |
:svn |
SubversionDownloadStrategy |
If you need more control over the way files are downloaded and staged, you can create a custom download strategy and specify it using the url method’s :using option:
class MyDownloadStrategy < SomeHomebrewDownloadStrategy
def fetch
# downloads output to `temporary_path`
end
end
class Foo < Formula
url "something", :using => MyDownloadStrategy
end
When your code in the install function is run, the current working directory is set to the extracted tarball.
So it is easy to just move some files:
prefix.install "file1", "file2"
Or everything:
prefix.install Dir["output/*"]
Generally we’d rather you were specific about what files or directories need to be installed rather than installing everything.
| Name | Default | Example |
|---|---|---|
HOMEBREW_PREFIX |
/usr/local |
|
prefix |
#{HOMEBREW_PREFIX}/Cellar/#{name}/#{version} |
/usr/local/Cellar/foo/0.1 |
opt_prefix |
#{HOMEBREW_PREFIX}/opt/#{name} |
/usr/local/opt/foo |
bin |
#{prefix}/bin |
/usr/local/Cellar/foo/0.1/bin |
doc |
#{prefix}/share/doc/foo |
/usr/local/Cellar/foo/0.1/share/doc/foo |
include |
#{prefix}/include |
/usr/local/Cellar/foo/0.1/include |
info |
#{prefix}/share/info |
/usr/local/Cellar/foo/0.1/share/info |
lib |
#{prefix}/lib |
/usr/local/Cellar/foo/0.1/lib |
libexec |
#{prefix}/libexec |
/usr/local/Cellar/foo/0.1/libexec |
man |
#{prefix}/share/man |
/usr/local/Cellar/foo/0.1/share/man |
man[1-8] |
#{prefix}/share/man/man[1-8] |
/usr/local/Cellar/foo/0.1/share/man/man[1-8] |
sbin |
#{prefix}/sbin |
/usr/local/Cellar/foo/0.1/sbin |
share |
#{prefix}/share |
/usr/local/Cellar/foo/0.1/share |
pkgshare |
#{prefix}/share/foo |
/usr/local/Cellar/foo/0.1/share/foo |
etc |
#{HOMEBREW_PREFIX}/etc |
/usr/local/etc |
var |
#{HOMEBREW_PREFIX}/var |
/usr/local/var |
buildpath |
A temporary directory somewhere on your system | /private/tmp/[formula-name]-0q2b/[formula-name] |
These can be used, for instance, in code such as
bin.install Dir["output/*"]
to move binaries into their correct location into the Cellar, and
to create the directory structure for the manual page location.
To install man pages into specific locations, use man1.install "foo.1", "bar.1", man2.install "foo.2", etc.
Note that in the context of Homebrew, libexec is reserved for private use by the formula and therefore is not symlinked into HOMEBREW_PREFIX.
Note: options are not allowed in Homebrew/homebrew-core as they are not tested by CI.
If you want to add an option:
class Yourformula < Formula
...
option "with-ham", "Description of the option"
option "without-spam", "Another description"
depends_on "foo" => :optional # will automatically add a with-foo option
...
And then to define the effects the options have:
if build.with? "ham"
# note, no "with" in the option name (it is added by the build.with? method)
end
if build.without? "ham"
# works as you'd expect. True if `--without-ham` was given.
end
option names should be prefixed with the words with or without. For example, an option to run a test suite should be named --with-test or --with-check rather than --test, and an option to enable a shared library --with-shared rather than --shared or --enable-shared.
options that aren’t build.with? or build.without? should be deprecated with deprecated_option. See wget for an example.
You can use the file utilities provided by Ruby’s FileUtils. These are included in the Formula class, so you do not need the FileUtils. prefix to use them.
When creating symlinks, take special care to ensure they are relative symlinks. This makes it easier to create a relocatable bottle. For example, to create a symlink in bin to an executable in libexec, use
bin.install_symlink libexec/"name"
instead of:
The symlinks created by install_symlink are guaranteed to be relative. ln_s will only produce a relative symlink when given a relative path.
For example, Ruby 1.9’s gems should be installed to var/lib/ruby/ so that gems don’t need to be reinstalled when upgrading Ruby. You can usually do this with symlink trickery, or (ideally) a configure option.
Another example would be configuration files that should not be overwritten on package upgrades. If after installation you find that to-be-persisted configuration files are not copied but instead symlinked into /usr/local/etc/ from the Cellar, this can often be rectified by passing an appropriate argument to the package’s configure script. That argument will vary depending on a given package’s configure script and/or Makefile, but one example might be: --sysconfdir=#{etc}
Homebrew provides two formula DSL methods for launchd plist files:
plist_name will return e.g. homebrew.mxcl.<formula>plist_path will return e.g. /usr/local/Cellar/foo/0.1/homebrew.mxcl.foo.plistHomebrew has multiple levels of environment variable filtering which affects variables available to formulae.
Firstly, the overall environment in which Homebrew runs is filtered to avoid environment contamination breaking from-source builds (Homebrew/brew#932). In particular, this process filters all but the given whitelisted variables, but allows environment variables prefixed with HOMEBREW_. The specific implementation can be seen in bin/brew.
The second level of filtering removes sensitive environment variables (such as credentials like keys, passwords or tokens) to avoid malicious subprocesses obtaining them (Homebrew/brew#2524). This has the effect of preventing any such variables from reaching a formula’s Ruby code as they are filtered before it is called. The specific implementation can be seen in the ENV.clear_sensitive_environment! method.
In summary, environment variables used by a formula need to conform to these filtering rules in order to be available.
Eventually a new version of the software will be released. In this case you should update the url and sha256. If a revision line exists outside any bottle do block and the new release is stable rather than devel, it should be removed.
Leave the bottle do ... end block as-is; our CI system will update it when we pull your change.
Check if the formula you are updating is a dependency for any other formulae by running brew uses <formula>. If it is a dependency, run brew reinstall for all the dependencies after it is installed and verify they work correctly.
Homebrew wants to maintain a consistent Ruby style across all formulae mostly based on Ruby Style Guide. Other formulae may not have been updated to match this guide yet but all new ones should. Also:
def install goes before def post_install).__END__ line.Homebrew tries to automatically determine the version from the url to avoid duplication. If the tarball has an unusual name you may need to manually assign the version.
Not all projects have makefiles that will run in parallel so try to deparallelize by adding these lines to the install method:
ENV.deparallelize
system "make" # separate make and make install steps
system "make", "install"
If that fixes it, please open an issue so that we can fix it for everyone.
Check out what MacPorts and Fink do:
brew search --macports foo
brew search --fink foo
superenv is our “super environment” that isolates builds by removing /usr/local/bin and all user PATHs that are not essential for the build. It does this because user PATHs are often full of stuff that breaks builds. superenv also removes bad flags from the commands passed to clang/gcc and injects others (for example all keg_only dependencies are added to the -I and -L flags).
Some software requires a Fortran compiler. This can be declared by adding depends_on "gcc" to a formula.
Formula requiring MPI should use OpenMPI by adding depends_on "open-mpi" to the formula, rather than MPICH. These packages have conflicts and provide the same standardized interfaces. Choosing a default implementation and requiring it to be adopted allows software to link against multiple libraries that rely on MPI without creating un-anticipated incompatibilities due to differing MPI runtimes.
By default packages that require BLAS/LAPACK linear algebra interfaces should link to OpenBLAS using depends_on "openblas" and passing -DBLA_VENDOR=OpenBLAS to CMake (applies to CMake based formula only) rather than Apple’s Accelerate framework, or the default reference lapack implementation. Apple’s implementation of BLAS/LAPACK is outdated and may introduce hard-to-debug problems. The reference lapack formula is fine, although it is not actively maintained or tuned. For this reason, formulae needing BLAS/LAPACK should link with OpenBLAS.
master)Have you created a real mess in Git which stops you from creating a commit you want to submit to us? You might want to consider starting again from scratch. Your changes can be reset to the Homebrew master branch by running:
git checkout -f master
git reset --hard origin/master
前两章谈到空间剥削和消费主义,指出晚期资本主义在具体的、生活的细节上对生活进行渗透——但只讲述了经济方面,现在讨论“规则”方面——这个话题刚好必须放在空间剥削和消费主义后。
由前文可知,消费行为都是被引导的,市场是可以培养的。米歇尔.德.塞托在《日常生活实践》指出,虽然规则制定者在群体意义上有引导能力,但个体总有漏网之鱼——此即个人反抗的意义——等某一情势引爆时,个人如何反抗资本主义并保全自己。
讲居住的时候,我指出可以在街区寻找建立公社的机会;讲消费主义的时候,我指出一定要储蓄和理财--这就是情境主义。庸俗的情境主义者往往把情境主义理解为踢翻垃圾桶的对社会不满的小流氓(诚然早期的情境主义者确实号召大家随便丢弃垃圾),并且因为他们纷杂的行为艺术而搞不清楚他们到底在做些什么。虽然最早诞生于艺术领域,虽然表现形式上可能不同,但无论在何处,情境主义者就是试图做漏网之鱼的人,那么:
情境主义诞生于20世纪50年代末的欧洲。抛开最初的几个颇具传奇色彩的创始人,它实际上不是一小撮精英知识分子无病呻吟,而是有着深刻的社会背景的。
情境主义“巨头”们
马歇尔计划下的欧洲,随着 56 年对斯大林的反思开始,苏联神话破灭。美国的商品的文化席卷了整个欧洲,与此同时城市加速现代化,显然这就是当下**的现状,而情境主义者反对的正是 社会环境剧烈改变下 各方面的异化。
一个很浅显的例子是:
现在的皮带并不有比二十年前同样质量的皮带更昂贵。但前文所述的 消费升级 使“手工制造”、“镶满钻石”、“量身定做”的奢侈品皮带出现了。如果奢侈品皮带形成风潮,那么哪怕同样的皮带现在仍然可以买到,人们还是会感觉皮带变贵了——因为代表相同社会地位的皮带在二十年前没有这么昂贵(就是说虽然消费升级把皮带价格拉高了,但是皮带本身的价值依然没有变化?)——商品变成了人类的**者。
异化几乎体现在所有方面。比如,大多数人都认为“努力就能成功”,于是就像“社会前1%有钱就要有精神生活”的信念催生了仁波切市场一样,渴望成功的信念形成了市场,催生了一大批成功学,其中就有职业规划。职业规划到底是什么?你怎么可以想像未来的职业?职业在当下是剧烈变化的,每天都会出现新职业,死去老职业,没有什么是铁饭碗。当下的规划只会给人虚假的安全感——安心被剥削。
它不被拒绝本身就是一种默许,甚至可以看到一个奇怪的结论:自己是最好的投资。如果我们发现这个言论兴起自毕业生就业压力增大和培训学校兴起的双重背景下就可以理解国家希望你多读几年书,晚一些进入市场,而培训机构则希望赚你的钱。所以我们发现,个人不是主体,组织不是主体,甚至国家也不是,而是所有一切在市场的逻辑下形成了统一的结构——形成了结构性暴力。
当有三条路摆在面前时,很难想象每条路都是错误的
严谨的经济学研究指出本科学历会大幅度提高人的收入,但是这个趋势在硕士及以上递减,而过多的证书更对生活毫无帮助。这在**尤其严重,当你牺牲了积累财富和工作经验的时间,只是变成了结构性暴力下的棋子之一。(不敢苟同,目前还是需要的,硬性需要)
托马斯皮克提在《21世纪的资本》中明确指出了收入的提高永远慢低资本利得率??,如果刨除兴趣使然,只算成功学中的经济标准,真正的职业规划只能是尽一切可能获取资本,而不是跟风做任何市场要求的事情。
因为市场的唯一目的是要你的钱。
企业文化也是这样的逻辑,我曾经讲过一个段子:一次早会的是脑残创业公司,一次早会加一次早操的是我爱我家和链家,一次早会加一次早操加一次晚操的快报警,这是传销组织。创业公司和你谈情怀而不谈钱你可以轻易发现这是在耍流氓,但是大公司的企业文化实际上并没有什么本质区别,它在不提供任何实际支持的情况下增加虚假的认同感,增加凝聚力,降低成本。
敏锐的头脑。像聪明的中产阶级意识到消费文化已经把他们拉入深渊一样,意识到职业规划和企业文化都是虚妄的幻象,但不止是如此,你应该自己在生活中多发现类似的事情,其实这不难,他们一切都按市场的逻辑骗你,那么你就一切都按照市场的逻辑逆向演算即可。
保持学习。但未必需要占用工作时间和你的金钱,除非你的职业需要那一张证。近年流行一个词叫赛博社会主义,北欧反版权的海盗党们最提倡这个,意思是在这个知识爆炸的世界,你可以得到你想到的任何知识,只要你想,保持你的学习和思考,这足以让你跟上这个世界。
当然,鸡尾酒也不大好,把它换成鲜花以后回家吧
好好整理你的钱包。消费主义并非伤害不到你,只是你没钱去消费罢了。如果你陷入了赚的多花的也多的循环,那么建议你把补偿受到的结构性暴力伤害的方法从 消费 变成 其他东西,不要听信“开源就好”,正如看到这四个字的时候有种被洗地被合理化成功的松口气感,你并不像你想的那样认可这条逻辑。什么意思??
如果让我指出最重要的部分,我也许会说车子和孩子,现在一线城市养车的成本已经达到2000-3000,更不要说开出4S店第一秒就开始掉价了,而孩子更贵。排除少部分真心爱车爱娃的人,市场上一切呼唤买车生孩的声音都是因为前者能拉动消费,而后者可以为国家增加劳动力和扩大内需。
定存定投的习惯,但是注意首先考虑风险,“你看上他的利息,他看上你的本金”。
只有保持清醒头脑和不断的学习并开始积蓄,并且利率高过CPI,才能谈得上反抗的第一步。
马尔库塞认为,当资本的规则将人们所洗脑,人类就会变成“单面人”,只能接受,不能思考。而漏网之鱼的任务就是,首先保全自己,并且通过自己的行为(艺术,尤其是行为艺术)影响身边的人,以求把人们变回可以独立思考的双向度的人。
但仅仅变回独立思考的人只是第一步,对消费主义和资本规则的反抗都必须落实在具体的个人经济措施上,这就是资本主义个人反抗(四)的内容——卧室里的反抗。
大家都知道我拖更严重,不过现在面临我第一本书的整理出版,外加本文是我在706青年中心和staylight、郭妹合作的日本文化分享会的日本战后流行文化背景介绍(比方说你电影放映活动赏析点评时总要介绍一些大背景),尤其是在staylight大量硬核的资料和分析支持下,总算三事合一被逼动笔,希望等本系列过久的大家不要打我。
当然,还有一个大家都明白的原因,为了避免敏感,讲日本更合适——虽然不尽然相同,但毕竟我们未来面临的困境很可能是相似的。
-----------------------------------------------------------------------------------------------
以美国为镜,可以知兴。以日本为镜,可以明衰。
我最喜欢的日本漫画家望月峰太郎在他的代表作《末日》之中,把日本的结局描述为“终末飘流”,对于他来说,这是通过一场无法抗拒的灾难达成的。都说日本有灾难文化,体现了日本困守孤岛的恐惧心理,但和《日本沉没》的“末日之中的拯救”不同的是,《末日》讲了一个没有拯救,一切都是徒劳与必然的故事。
他甚至隐约的在期待末日。
《日本沉没》大受欢迎的电影版制作于70年代,而《末日》则获得了1997年的讲谈社第21界讲谈社一般部门漫画赏,二者的差别,就从时代讲起。
一、双团时代
讨论战后的日本,有两点是一定绕不开的,一个是“团块世代”,一个是“团地社区”。
团块世代专指战后出生的一代人。他们属于第一批战后婴儿潮,也是日本经济腾飞的主要贡献者。
团地社区则指日本住宅公团主要于1955年到1965年之间为了应对汹涌的出生人口和城市化而在城郊和大城市临近县市规划的一大批住宅单位。
团块世代住团地社区是这个世代日本的一个典型特征。因为团地社区一般位于郊区,所以一开始很强调“自给自足”——虽然团地楼本身比传统家宅更照顾个人与家庭的隐私,关上房门就是一个独立世界。但是它首次把人口从横向集中到了纵向,大量的人集中在了同一个社区里,在原子化社会发展成型之前,邻里互助,社区活动都非常踊跃。
与此同时团地虽然离城区较远,但因为是西式生活的代表,并应用了战后最新的设计理念(比如去中心化的户型分隔替代传统家宅的一间主屋白天是客厅晚上是卧室,并且提升了女性的地位,因为传统家宅中,厨房是房屋中最糟糕的角落)所以并不便宜,能住进来的往往是新兴的中产阶层年轻人。这些人往往共享相似的价值观,而这也进一步推动了互助与交流。
而迎接他们的是长达数十年的日本战后经济飞速增长。
当时的西方文化先锋人群,嬉皮在大学,雅痞在团地。富裕的年轻人住在一起,玩在一起,针对他们的文化作品自然也就应运而生。如果说大学中出了村上春树和坂本龙一们难以忘怀并反复在文艺作品中反刍的左翼运动,团地也产出了属于城市中产的流行文化。
这其中第一个节点是1971年南沙织的出道,现在来看她的歌并不算出彩,但要知道,在她之前日本的歌曲榜单里大多数是演歌等传统歌曲霸榜。
年轻人们会认为南沙织是在歌唱她的17岁,也是自己的17岁。
二、日本第一
不过1973年发生了另一件大事,中东石油危机导致日本经济遭受重创,超高速增长逐渐转为中高速增长。与此同时重工业、轻环保的经济结构也逐渐转型为知识密集型的重环保、促发展,金融业也发展了起来。
这时候城市化进程进一步加深,人们已经没有了迁移的记忆——大多数人从出生起就没有离开过城市。
于是1972年前后诞生的city pop(说个你们更熟悉的名称,蒸汽波,可以算作是city pop的延续之一)风格也流行了起来,其中关键节点是寺尾聪在1981年的《红宝石指环》,这张单曲爆卖160万盘,创下多项纪录。
【寺尾聰】 红宝石指环(ルビーの指環)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com
在这首单曲中,人的全部世界都收于大城市中的男女情爱,而它的大卖,说明日本流行文化的主要人群已经变成了城市中产阶层。
因为经济持续发展和人口增长带来的蛋糕本身扩大的大量红利,日本人逐渐推广了利于社会稳定的“年功序列制”,终身雇佣之下,人人都得以安放自己的人生,并在当时逐渐接受了“一亿总中流”的概念,也就是说大多数国民在采访中都认为自己是中流(中产阶层)。
在1980年到1985年,随着傅高义那本《日本第一》的出版,整个日本都接受了日本欣欣向荣的设定。
紧随其后的就是在豆瓣和知乎都曾经被广泛讨论过的泡沫经济时代。
泡沫经济时代并不是一个萧条的时代,反而因为广场协议导致的日元升值陷入了一种畸形繁荣。
三菱购买了洛克菲勒大厦,哥伦比亚电影公司也被索尼收购,就连普通人也在日本国内的地价上涨和股票上涨中收益颇丰——按照当时的说法,卖掉东京可以买下整个美国,虽然日本的外汇储备并不能支持这样的购买行为。
这个时代的日本流行文化呈现出一种极度自信样貌。
【Princess Princess】Diamonds (1989) 现场版合辑_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com
Princess Princess的Diamonds拿下89年的销量年冠,这首歌的歌词非常“泡沫经济”。
这个时代的日本流行文化不光有对社会的自信,还有对自己的自信——创作者们并不在意观众喜欢什么,他们直接塑造观众的审美,这和我们当下的迎合观众审美的截然不同的。这一点能成立的大前提是:观众确实也更喜欢自信和阳光的创作者。
但很快,不堪重负的日本主动刺破了泡沫,但泡沫经济不是一下子就破灭的,其标志性的事件是97年的山一证券和北海道拓殖银行倒闭,这说明系统性的金融风险已经发生,日本正式迎来失落的30年。
不光危机在更早一点似乎已经有了预兆,95年的阪神大地震摧毁了日本人对物质文明的信心,一切人类的造物在天灾之前都如同笑话。而同年的东京沙林毒气事件则暴露了日本人精神文明的空洞,麻原彰晃曾经说:他们不能拯救你的,我可以。
它的大背景除了是随着经济发展的新新宗教(对应早年新宗教运动)热,这里就不赘述了。
所以文化上的标志性事件稍早:95年,《新世纪福音战士》横空出世,这是第一部御宅族拍给御宅族的“献礼作品”,从文化批评的角度来说,它标志着日本人的关注点因为经济的失败进从物质生活转向了类似于明末家国破灭时士大夫的束手谈心性,大量引进了哲学与宗教的讨论。从精神分析的角度来讲,它虽然依旧和《太空堡垒》与《高达》一样惯性延续了庞大世界观的宏大叙事结构,但最终落于个人成长也标志着日本人的生活重点从向外转而向内。
因此日本人的救赎也产生了悄无声息的变化。
三、救赎
因为日本是一个男权社会,男性的经济地位远高于女性,所以男性心境的变化可以大幅度改变整个社会的文化供给形态。因为上述原因,当时的日本兴起了萌文化和援助交际。
萌文化和援助交际的共同点在于“治愈”。比日本贫穷的国家有很多,但少有经历过日本如此之大的落差的。所以幼态化的审美并不意味着日本人格外变态,反而意味着他们格外需要“治愈”。
另一个有趣的事实是,援助交际在80年代诞生的时候只是性交易的幌子,但它越来越成为真正的援助交际——大叔真的仅仅是想要陪伴和聊天而已。前几年有一个作品叫《不要和日本人谈性》,讲的就是这个问题,日本人宁可去购买躺在女孩子大腿上睡觉或者被掏耳朵的服务,也不想再去歌舞伎町了,这其实也属于援助交际的细分领域。
也因此,在90年代末21世纪初,出现了被称为世纪末景象的系列文化作品。
比方说大友克洋的《蒸汽男孩》,反思工业革命带来的进步与理性,进而对现代性本身表达了疑惑。而今敏的《东京教父》则直接把目光聚焦于底层(这个意向会在更后面的文化现象中反复出现,但内核已大有不同),押井守的《攻壳机动队》系列则把原作冷战焦虑的大背景变成了对未来反乌托邦世界的想象。
与此同时,进入了21世纪的日本,各种社会问题也逐渐暴露了出来。
我们在文章最前面提到的团块世代逐渐老去,他们的房子逐渐变成贫民窟,而他们的孩子一进入就业市场就陷入了求职难的问题中,其中相当一部分人被打击成了所谓尼特族(不升学、不就业、不进修),年功序列制的破产和原子化的社会也逐渐渗入日本的方方面面。
前者伴随着劳务派遣制度一起出现,终身雇佣的正职员岗位不再是理所应当的。你很可能比以前的人更辛苦,比以前的人收入更少,这导致你必须用更多的时间去工作。而原子化社会也让互助和文化交流更为凋零。两者合一,温情脉脉的昨日景象如同旧乡愁一样难以重现。
四、“政治决断”
这时候整个日本社会出现了两种截然不同的解决方案:
第一种是这样的:NHK在新世纪推出了一系列的《团块世代老后破产》、《穷忙族》、《女性贫困》等等的纪录片试图让社会重视问题,与此同时政府也在积极挣扎,其中最著名的就是团地改造计划。
除了翻新老楼外,日本政府还把团地建设时期因为人口和利润压力过于密集的住宅改变成花园式、宽松式的住宅模式,增加公共社交空间。
提倡并设计出适合老年人与青年人杂居以及适合两代人同居的住宅形式,重新激发社区活力,这一点和青老互助型养老公寓,青年人以帮扶老人换取低房租的思路是相同的。
但既然日本的问题是结构性的,那么日本的努力也就只能是挣扎。
所以第二种“解决方案”应运而生。
2006年,日本诞生了一部后来被豆瓣网友大数据投票为豆瓣TOP250中第78名成绩的现象级电影《被嫌弃的松子的一生》。
剧中主人公松子在人生彻底的失败后选择了什么呢?肥宅垃圾屋,还有偶像明星。
为什么是偶像明星?
我们前面讲到两点,一个是日本人的追求向内转变,另一个是日本的文化逐渐导向了治愈系。有多属于男性的援助交际,也有多属于女性的猫狗咖啡馆和摔盘子club,而偶像则是覆盖全民的集大成者。
日本人不需要别人再告诉他们应该要什么,他们痛苦不堪的寻找自己想要什么。
因为治愈,所以AKB48要有48个人,每个人有不同的人设,每个受众都能在里面找到自己的“本命”。
因为治愈,所以制作人要求成员不能是班里最漂亮的女孩儿,而要第二漂亮的那个——最漂亮的人会让我们感觉难以接近,第二漂亮的则更为亲民。
因此松子的选择实际上是一种介乎于有与无之间的政治决断,政治决断这个词是保守主义法哲学家施米特喜欢用的一个词,他很可能认为新教-盎格鲁撒克逊作为立国基本盘的美国选出特朗普去排外是一种好政治决断,而反民族主义(自由主义)作为二战后政治正确的欧洲是没有政治决断的,经济上的决断和民族同理。
但他很大概率无法设想,日本人的政治决断介乎于有和无之间。
怎么理解这个说法?
AKB48有这样一首意向性非常有趣的歌:【AKB48】PV ~ 恋爱幸运曲奇(中字)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在这首歌曲中,任何解决意见都被搁置了。
注意!这不是奶头乐文化,奶头乐文化是大哥潜移默化的引导你,而AKB48的这首歌开宗明义就告诉你,问题是不能被解决的,来跳舞吧。
不决断其实也是一种政治决断,它徘徊于小确幸和祈祷奇迹之间,同时因为不决断,去政治化偶像文化同时是最政治化的事情。
那么它有多适合于松子这样做错了一生所有选择的人自然是不言而喻的。
结尾、怎么办?
现在我们最后再转回文章的开头,望月峰太郎为什么把《末日》最后一幕叫末日漂流呢?人就是在一条奔向末日的河流之中随波逐流的,你只能试着调整自己的姿势,稍微舒适一些。
这是你唯一能做的事情。
并且隐藏起不敢和任何人表达的末日期待,那期待是一个再差也不会比末日本身更差的“新世界”。
当然,现实生活中的我们似乎不需要那么悲观,人类历史的末日复末日早就在一个个无穷循环的马尔萨斯陷阱和经济周期之中“安然”度过,但在最艰难的时期,你似乎确实可以试着用最取巧的方式度过。
一方面确实如同日本人一样,如同我在1-8章所建议的那样拼命挣扎。一方面也拥抱消遣的、娱乐的、让人可以短期逃避的娱乐工业,但是一定要记住——不能付费。
这就是我在文章中藏的彩蛋,你知道AKB48的制作人是谁吗?秋元康,我在前半部分提到的日本左翼运动青年之一,而在今天,他连这件事情本身都可以消费。
AKB48 - 不需要翅膀 (華納 official HD 高畫質官方中字版) 3 個月期間放送限定_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com
PS:对本文其他两位作者以及对我们的分享会感兴趣的小朋友可以加我微信加我们的群哈哈哈哈!
2011年8月的一个中午,美国马萨诸塞州海岸的海面上浮出一条熟悉的背鳍。这条带有白色小斑点的背鳍,属于一头雌性座头鲸。科学家们从上世纪七十年代就开始研究这头座头鲸,并根据她背鳍上的显眼斑点,给它取名为绍特(Salt)。
绍特是一只有着独特标记的座头鲸,自20世纪70年代以来,科学家们一直在研究它。
海鸥号(Shearwater)科考船上,座头鲸研究者乔克·罗宾斯(Jooke Robbins)正用十字弩瞄准绍特,准备射击。十字弩上装着取样箭,箭上装着特制的箭头和黄色浮标。发射!取样箭击中了目标,按照设计,取样箭收回时会带走几立方毫米的肉——相对于鲸的体型,这点伤害就像人被蚊子叮了一下。
罗宾斯和她的团队把收集的样本保存到液氮中,然后送去分析。八年转瞬即逝。在5月份的《分子生物学与进化》杂志上,亚利桑那州立大学癌症演化中心(ACE)的一个研究团队发表论文称,绍特以及其他鲸目动物,包括鲸、海豚和鼠海豚等,进化出了对抗癌症的高明手段,例如一系列的肿瘤抑制基因。
这个新发现,还有此前在大象身上进行的类似研究,都表明一件事:**治疗人类癌症的新方法,可能就隐藏在大型哺乳动物的演化史里,躺在它们遗传密码的某个地方。**可是即使知道了这点,科学家们也正在渐渐地失去研究这些巨型动物的机会。由于受到人类的持续威胁,这些动物的数量以及栖息地的生物多样性,都在急剧下降。
毫无疑问,像绍特这样的鲸本身就具有极高的价值。无论从伦理上还是生态上,保护大型哺乳动物都有很多正当理由。但“它们的基因可能有助于癌症研究”这个想法的确新颖。
“我从没想过,有一天癌症能成为鲸类研究的课题之一,更不要说对任何人类癌症的影响了,”她说,“虽然它非常有价值,让人出乎意料,但我从没计划过研究这个项目。”
从理论上讲,座头鲸绍特这样长寿的大型生物应该有很高的癌症发病率。
癌症始于细胞分裂,先是一个细胞分裂时出错,潜在的致命突变扩散到邻近的细胞,假如这个错误没有被发现被抑制,就会扩散到整个身体,引发癌症。
**鲸和大象同人类一样长寿,而且它们的细胞数量是人类细胞数量的数百倍。可是,它们细胞发生变异、导致癌变、以及癌变致死的频率却都很低。**ACE团队正在研究这种被称为“佩托悖论”(Peto 's Paradox)的奇怪自然现象。“佩托悖论”以英国流行病学家理查德·佩托(Richard Peto)的名字命名。在20世纪70年代末,佩托提出,自然界一定存在某种对抑癌机制的自然选择,因为尽管人类比老鼠的寿命更长,体型也大得多,但两者的患癌几率却很相似。
在2011年,ACE的研究人员和全球其他11个研究所的科学家们首次开始在座头鲸的基因组中研究“佩托悖论”。他们采用的方法就是比较绍特的基因与其他鲸类基因组。根据今年公布的研究结果,鲸基因组中决定细胞分裂方式和时间的部分进化得很快,而且时间点与鲸获得庞大身躯的时间点一致。
北亚利桑那大学的生物学家马克·托里斯(Marc Tollis)于2015年加入并领导ACE,他希望能够将鲸的基因组中的一个抗癌基因转移到其他的小型哺乳动物体内,帮助它们对抗细胞癌变——首先可以在小鼠身上测试,最终应用于人类。
还有些科学家也在研究“佩托悖论”,用的是另一种大型动物——大象。2012年,犹他大学的儿科肿瘤学家乔舒亚·希夫曼(Joshua Schiffman)得知大象的基因组中有额外的抗癌基因拷贝之后,开始致力于研究大象的癌症防御能力。他的病人正是缺乏这种抗癌基因,才导致的李-佛美尼综合征(Li-Fraumeni syndrome)——一种使人易患癌症的罕见遗传病。
希夫曼团队的合作对象包括ACE的卡罗·马利(Carlo Maley)、当地动物园、玲玲马戏团、巴纳姆贝利马戏团以及大象保护中心,在马戏团停止大象表演之前以及兽医定期检查期间收集大象的血液样本。在2015年发表于《美国医学协会杂志》(JAMA)的论文中,他们报告称,大象体内这种额外基因拷贝,能够引发一种程序性细胞死亡,以及一种名为凋亡的癌症防御机制。
当一个细胞分裂并经历某种DNA损伤时——例如,化学物质造成的损伤——细胞要么试图修复自身,要么自我毁灭,防止突变扩散到其他细胞。相比人类细胞,鲸和大象的细胞都更经常地发生凋亡。
希夫曼说:“人是很聪明,但大自然更聪明。经过数亿年的进化,大自然已经找到解决癌症的方法。”
在大象的遗传密码深处,可能藏着治愈人类癌症的线索
希夫曼补充说,很明显大象和鲸鱼经过无数代的进化,已经获得了对癌症的免疫力。他的团队还在寻找大象基因中的其他癌症防御机制,并试图将这些能力转移到人类身上。
“(这些动物)不止是找到了癌症的治疗方法,”他补充说,“更令人兴奋的是它们通过自然进化,找到了从一开始就不得癌症的预防方法。”
现存的90多种鲸类中,有22种已经被基因组测序,测序数据已经添加到美国国家生物技术信息中心数据库(NCBI)中,未来也将有更多基因数据持续不断地添加到其中。但是,当托里斯在2015年开始研究绍特的基因组时,只有5种鲸类的基因组数据。托里斯说,随着新技术出现,测序变得更便宜也更容易,相关的研究领域也得到迅速发展。
科学家还对现存的三种大象的基因组进行了测序。但这只是一个开始,科学家们可能还没有足够的数据来全面了解这些动物是如何抵御癌症的。而由于人类活动导致的生态系统破坏、气候变化等诸多问题正不断蚕食着这些种群,研究人员收集样本的机会越来越少。这些生物越来越难找到,保护它们的法规越来越严格,研究也会被一再拖延。
鉴于这些物种的减少速度,托里斯希望这项研究能让人们认识到癌症研究和环境保护的重要性。
“总而言之,由于我们现在正生活在一场生物大灭绝事件中,”他说,“我们需要每一个保护物种的理由。”
根据国际自然保护联盟(IUCN)的数据,这些大型哺乳动物的保护状况喜忧参半。一些鲸类的种群已经从几个世纪的滥捕中恢复不少,比如座头鲸。而另一些鲸类仍然濒临灭绝,比如北大西洋露脊鲸和塞鲸。
大象的状况也不佳,非洲象被列为易危物种,亚洲象则是濒危物种。
最近,博茨瓦纳解除了为期五年的猎象禁令,日本在7月恢复了商业捕鲸。而保护专家们更关心的是一些不在明处而在暗处的潜在危害因素,比如丧失栖息地。
肯尼亚有个大象研究和保护组织,“拯救大象”(Save the Elephants)。其战略顾问克里斯·索利斯(Chris Thouless)说,大象之所以遭受痛苦,是因为它们以前的栖息地,如今变成了工业区或农田,这也导致了“人-象冲突”。
在斯里兰卡的大象。随着越来越多土地被人类开发,留给大象的栖息地越来越少
世界自然保护联盟的鲸类专家哈尔·怀特海德(Hal Whitehead)说,**在海洋中,鲸鱼正日益受到海洋塑料微粒和船舶噪音的威胁。**因为视觉和嗅觉在水下效率很低,鲸类利用声音来寻找食物、形成社会联系,噪音会令这些动物紧张。
怀特海德补充说:“那些与人类接触最密切的物种,受影响也最严重。”
即使这些物种的数量恢复了,从大量物种中收集基因数据也面临着其他挑战。不列颠哥伦比亚省伯纳比西蒙弗雷泽大学的分子生物学家大卫·贝利(David Baillie)说,仅从一只动物身上提取的样本不能代表整个物种。
从许多样本中获得的某个物种的代表性基因组虽然很有价值,但个体基因组中可能出现的某些奇怪状况也有价值。基因多样性和庞大的种群数量为突变留下了很大的回旋余地,这些突变可能对生物本身和人类都有益处——如果未来人类能正确理解它们的话。
“我们拥有的基因组越多,就越能深入理解冗余的多样性,那是种群结构的基础,”贝利在一封电子邮件中写道。他补充说,“例如,在试图了解对疾病的抗性时,罕见的突变可能非常重要。”
托里斯说,有证据表明,同一物种的不同区域群体之间存在很强的遗传变异,我们需要付出更多的努力来对动物近亲的基因进行分类。
希夫曼也表达了类似的观点,他说,偷猎、栖息地丧失和近亲繁殖已经造成了一个瓶颈,压缩了许多物种的遗传多样性,对那些体型最大的生物尤其如此。
联合国生物多样性公约执行秘书克里斯提娜·帕斯卡·帕默(Cristiana Pașca Palmer)表示,我们还不知道,栖息地和物种损失对医学研究造成了多广泛的影响。
她在一封电子邮件中写道:“大象和鲸鱼等大型物种的消失只是全球生态系统物种多样性急剧减少的一个缩影。当我们采取行动,去保护生物多样性时,我们其实只是在保护人类自己。”
鲸身上潜藏的线索,远比鲸肉有价值得多 | undark
我们不知道人类活动将如何改变这些动物几代之后的基因组,以及如何改变它们拥有的潜力无穷的数据。例如,英国南安普敦大学的研究表明,如果人类继续破坏未开发的栖息地,哺乳动物的体型中位数将缩小四分之一。动物的遗传基因需要适应人类对地球越来越强的控制。一个物种曾用来战胜许多疾病的基因,还有其他有价值的基因突变,可能会不经意间在下一代中迅速消失。
“如果我们失去了在野外研究这些动物的机会,如果我们不保护它们,”希夫曼说,“我们可能会失去许多疾病的治疗方法。”
作者:Doug Johnson
翻译:莫轩
编辑:游识猷
编译来源:Undark
译文版权属于果壳,未经授权不得转载.
如有需要请联系[email protected]
前文讲到 女性在生物角度是天然被压迫的,所以反抗 必须做必要的修正。
madobet 注:这是不恰当的,后面作者也有论述。
今天就这个问题展开讲,必须照顾阅读顺序和逻辑一致性,一个引出一个,一个接着一个…本文有一半左右的内容和我的老文《女权主义三小节》一致,但是也有一半内容是为了突出和符合个人反抗的主题而新作,对女权主义格外有兴趣的朋友可以移步我的老文,对照着看,我已经把它挪到豆瓣了。
一般即便对女权持赞许的男性,往往也认为女权运动是“女性的事业”,自己最多出于同情和道义去支持,这是错误的。
以社会主义标榜自己的法国的社会党内阁要求男女部长数量一致,并认为不达到这样的目标无论在姿态还是实质目的上都是不可被接受的。当然,我们可以说这是发达资本主义国家的人血馒头,吃起来都噎人,那我们可以看看发展**家的激进左翼是怎么做的。
巴西无地农民运动是巴西最大的底层左翼组织,以争取土改,平均地权为目标。他们指出:在性别方面的工作是非常重要的,在运动里我们有专门的性别委员会,而且在各个层次各个运动空间要保证50%的妇女来参加,有些时候可能不能保证,但是这是我们的目标。另外性别委员会关注性别问题,还包括少数性倾向的问题。因为巴西还是一个男权制度的国家,性别工作和占领工作是一样重要的。我们运动中有一个口号是:没有女权主义,就没有社会主义。
那么为什么社会主义必须伴随女性解放?
因为私有制。私有制和分工让男性获得了巨大的话语权和地位,私有制的灭亡必然导致性别不平等的灭亡。
男权社会是伴随阶级与私有制诞生、依靠法律或文化形成的等级社会,在这个前提下,男性面临的仅仅是 公侯伯子男,天地君亲师 的阶级压迫,而女性——排除少数适应社会的”成功者“——不光要接受社会地位的阶级不平等,同时还要接受家庭地位的阶级不平等。这两种不平等实际上都是阶级分化与私有制经济在不同领域的不同表现,而非两种不同矛盾。私有制必然伴随阶级社会,进而导致?伴随?性别压迫。男女矛盾不是阶级矛盾,而是阶级矛盾的副产品、伴生物。流行的说法是,“一个阶级消灭了另一个阶级,人类不会灭亡;而一个性别消灭了另外一个性别是不可想象的”。(因为本质上这不是矛盾)人类学、社会学和考古学研究告诉我们,不存在脱离了私有制与阶级的性别沙文主义社会。而共产主义社会因为生产资料的再分配和生产力的解放,必将不存在性别压迫。
既然是个人反抗,作为男性已经没有这个问题了,能不能不管?
不能。男性同样是男权社会的受害者,与女性仅仅是表现形式和程度上的区别。男人们支持女性解放就是支持自我解放,支持人类解放。这个解放并不是一个性别以自身的经验和动机为基础而争取权利,而是把性别解放寓于社会本质的斗争之中,从根源上排除任何形式的性别沙文主义的可能。
以当下 **式婚姻 为例。为什么要求男生有车有房?婚姻作为一个契约关系,是两个不带任何的自然人的结合。而不是一方依附一方或者一方供养一方,所以法律上有婚姻法,而没有嫁娶法。不过虽然法律解释看似公正,但是事实总是受社会“现实”钳制。结婚要求男方有车有房毫无疑问是对男方,男方家庭的一种巨大的压力和剥削。而事实上女方也未必真的占了便宜——作为回报车房等经济待遇的行为,女方潜在的要负担起照顾公婆,免费保姆的”责任“,同时在家庭话语权上也有所降低。于是这样的婚姻构成事实上的买卖行为:男方拿金钱向女方家庭、女方自己购买永久的佣人和性伴侣;成为了婚姻法外的”道德法律“。这种行为不仅在封建王朝的时代里司空见惯,而且在现代社会依然以更隐蔽的形式存在。“买卖婚姻”双方都是输家,因为双方都觉得自己吃了亏,都是受害者。(注:一定?)只有摆脱了男权社会的影响婚姻才能真正平等。
综上所述,男权社会是私有制阶级社会的表现形式之一,是作为压迫人性,异化作为整体的人类的”背景性的声音“。男女都是受害者,解放女人就是解放男人。女权不是男人的敌人而是盟友。
在《资本主义个人反抗指南(四):卧室里的反抗》中讲到,如果双方关系不对等,多边关系或开放关系都会变成21世纪的三妻四妾。虽然往往依附是精神上的,对方没有要求你做什么,但是亲密关系中,你处于低位,自然处处受限。如果在一场亲密关系中你一无所有,那么一切表面上的公平都是瞎扯。
在《资本主义个人反抗指南(五)》一章提到,人类不光是自然的,也是超越自然的,比如虽然先天女性因为生育和月经等角度在演化上“吃亏”了,但因为理性可以超越简单的防御程序成为一个有自我学习和思考能力的主体?什么拗口的表达,所以我们才能后天弥补它,显然这也应当是女权理论真正的预设前提。
madobet 注:这也太软绵绵了,应该这样:
一方面,一切压迫的根源只能来自社会,生物间只存在合作、互助或者杀戮,生物角度的压迫是不存在的。你可以说女性在体力上不如男性,但这种劣势不仅是不主要的而且是可逆转的。体力或者说体格的差距在一些情况下成为劣势,在另一些情况下成为优势,自然界是平衡的,体力的强大必然伴随其他能力或特性的损失,顶级捕食者可以存在,但绝对优势和完美的物种不可能存在?老虎比羚羊有力气,但是羚羊比老虎更敏捷,羚羊可以避开老虎的扑杀而以更快的速度、更精确的打击反击捕食者。女性也是如此。更何况人类的定义就是制造和使用工具,所以男性和女性的战斗只会以平等的使用工具的形式展开,而不是肉搏。肉搏称不上以人类的方式进行战斗。
另一方面,压迫只在社会阶层形成后产生。对于石器时代的人类来说,女性不存在压迫,甚至有时地位高于男性,难道石器时代的女人比男人强壮?不。很大一部分原因是家庭和部落的食物主要来源于女人们的采集活动,而辅以男人们的捕猎活动。
不妨假设有更强的体魄的男人们产生了超越时代的男权**——且不论动机——准备造反要把女人们囚禁成生育和采集机器。作为那个时代的女性会坐以待毙吗?显然不会。女人们会进行同等的回击。因为**上,她们和男人平等;物理上,同是血肉之躯,男人再怎么强壮也挡不住锋利的长矛。)
所以从另一个角度讲,我又必须把我在最前面的**式婚姻的男性受害者做一个限定:男女地位极度不平等时必须例外。
试想如果一个女性在工作中比男性难以晋升,又因为生育消耗了大量的心血和本来可以拿来工作和学习的时间——导致更难以晋升,那么在这种情况下强行要求家庭AA,显然是不合理的,男性多付出一些显然是公正的,也是更符合我们人类应有的认知能力的。强行否定这一点,显然是屁股而非理性认识的问题。
这就是新自由主义的平等观,他们认为穷人和富人更多是努力和天资差异,那么给他们机会平等就好了:每个人都可以凭能力竞选董事长,你没有能力,你走开。
瑞典强行要求董事会中女性必须达到40%,因为如果你拿能力做辩解而不给女性培养能力的机会,那么女性将永远没有能力。这实际上和白人对黑奴的所做所为完全一致。
公社甚至亲密关系,如果外部环境打压而又没有内部资源倾斜,显然是难以为继的。虽然现实情况显然没有能力要求外部环境对部长和董事会成员进行扶持性限定,但是在我们的关系内部,做到这一点显然容易的多。
当然,说到这里,一个自然而然的疑问就出现了“如果我很可能既不要孩子,又认清楚了婚姻存在的问题,是否就可以成为一个不婚主义者呢?”这似乎是一个不证自明的事情,但是如果你不是多边关系的爱好者,那么无论身处任何环境之中,婚姻都是必要的。
前面说到,婚姻的问题是经济不平等导致”道德法律“登场的问题。回到在第三章提到的寻求正确伙伴的问题:你们必须一起反对新自由主义平等观甚至各种奇葩的不平等有理观,并且给出符合自身的解决方案。
所以如果亲密关系是必需的,那么个人反抗也就不仅是一个人的战争,需要联结两人的反抗才能获得胜利。
今天本打算把著名语言学家、戴耐德创始人之一的Lance的语言学习理论整理一下,遂重读其2008年发表的一篇论文。这篇论文我已经读了三遍了,大概的**是明白的,但是真要用自己的话语复述出来,发现无从下手。这只能说明催这个理论的掌握还不到位,仍然需要继续研习。这印证了昨天所言,写作能帮助厘清思路。
记忆分两种,一种是explicit memory,一种是implicit memory,前者需要有意识的去记忆,对应的是知识;后者需要特定时间段不断的重复和练习,带来的是技能。语言学习不仅仅是知识,更多的是一种技能(skill)。我们多年来学习语言的误区就是把语言当作知识来学习,因而很多人会从单词、语法和音标学起,这些都是可以通过记忆来掌握的,而且很快就能掌握和学会,并能通过考试获得高分,然后并未能掌握语言这本技能。
知识和技能的学习或掌握对应的大脑的区域是不一样的,因而我们在语言学习的过程中就要充分利用已知的大脑的认知规律,掌握科学的学习方法提升语言学习的效率。
语言的是一门技能,是通过不断的重复和练习习得的,进而在大脑中形成一种模式,然后自发自动的进行启动,表现为我们在说话的过程中其实并没有经过多少思考。如果经过层层的思考,那只能说明你掌握的仍然是一种知识而非技能。技能的习得是需要一个过程的,但一旦习得就将是长久的。举个例子:一旦你学会了骑自行车,即使多年不骑,你仍然驾驭自如。
仔细想想我们自己的英语。面对一个老外,我们的语言交流过程是什么样的呢?英文-翻译-中文-英文。这是一种知识层面的交流,而非语言技能的灵活运用。
论文题目“Recursive Hierarchical Recognition: A Brainbased Theory of Language Learning”,通过分解题目我们能把握其理论的核心。首先该文阐述的是一种理论,什么理论呢,有关语言学习的理论,这种理论有什么特点呢,它是brainbased,也就是说它和大脑是紧密相关的。简而言之,这是一个基于大脑的语言学习理论。那这种理论的核心要素有哪些呢?毫无疑问是三个关键词,recursive/hierachical/recognition。我们逐一分解。recursive这是一个非常抽象的形容词,我们追奔溯源至其词根。recursive是recur的形容词形态,而recur对象的涵义比较容易理解:重复发生。当然这是一种简单粗暴的解释,更为专业的解释见wikipediahttps://en.wikipedia.org/wiki/Recursion。Hierarchical这个单词比较容易理解,等级的、层级的,大意是说语言学习是有层级的、循序渐进的,不可超越你当前的认知水平。举一个通俗的例子。“然并卵”是一个非常抽象的用语,一个中文基础不好的老外是很难理解的,但我们年轻的**人却很容易理解,这是建立在我们对“然而”“并没有”“卵用”三个单独的词语非常熟悉的基础之上的。“然而”“并没有”“卵用”是一个层级的用语,而“然并卵”是另外一个层级上的用语。语言学习也是一样,遵循的是从简单到复杂、从具体到抽象的过程。
recognition翻译成中文的意思就是识别。google的词条解释有三个。the action or process of recognizing or being recognized, in particular;identification of a thing or person from previous encounters or knowledge;acknowledgment of something's existence, validity, or legality。识别是个动词?那识别的对象是什么呢?pattern,以前已经存在脑海里的pattern。继续上面的例子,当有人说“然并卵”这个俗语的时候,在“卵”子还没有出现之前,大脑就已经识别出“然并卵”这种pattern,并迅速对应相应的含义,根本就没有思考(翻译)的过程。所以,语言技能的本质上是一种模式识别。那我们学习语言的过程就是存储各种pattern的过程,而二中pattern也是有等级的。而我们建立各种pattern需要不断的recursion。借助于现代计算机技术和神经科学,我们可以设计一种activity,加速这种模式的确立,这就是这篇文章的精华所在。
观察者网、春秋综合研究院和华尔街资本
观察者网
观察者网(www.guancha.cn),根据百度百科的介绍,“创立于2010年,依傍春秋综合研究院与各行各界领军人士进行线上及线下的沟通互动。”但是该网网站上的自我介绍是这样的:“2012年4月16日,观察者网www.guancha.cn正式上线,新闻理想正式启航”。
虽然时间上相差两年,但是春秋综合研究院的重要性是得到承认的。“观察者网(www.guancha.cn)携手上海春秋发展战略研究院,旨在为全球华人读者提供集新鲜、热点、深度、趣味于一体的时政资讯。”
观察者网曾经是《社会观察》的网络平台,《社会观察》刊登一些比较严谨、中庸的文章,相对轻松或者较为敏感的文章,放在观察者网上。对《社会观察》,百度上的介绍是这样的:“《社会观察》杂志是由春秋综合研究院、上海社科院等机构联合主办的政经时评类杂志,与网络平台观察者网一起着力打造具有‘**关怀 全球视野’的新媒体。社会观察可以理解为人们有计划、有目的地运用一定的手段和方法,对有关社会事实进行资料收集整理和分析研究,进而做出描述、解释和提出对策的社会实践活动和认识活动。它是一个由系统的理论和方法组成的完整的知识体系,其主要内容包括基本理论、基本方法、基本类型、基本程序和基本原则等。”
《社会观察》本是上海社会科学院主管、主办的刊物,后来由上海社会科学杂志社和上海观察者文化传媒有限公司共同出版,春秋综合研究院提供“学术支持”。百度百科上所谓观察者网创立于2010年,可能实际上是指2010年春秋综合研究院接办《社会观察》。该杂志2011上半年更改为“《社会观察》编辑部出版”,“上海观察者文化传媒有限公司”运营。保留了春秋综合研究院提供“学术支持”的内容。再后来,改为“上海社会科学杂志社”出版,“《社会观察》编辑部出版”编辑,并沿袭到2014年。
当时《社会观察》编辑部的地址为:上海市番禺路300弄3号B座。而这正是观察者网的编辑部地址。《社会观察》与观察者网的编辑部是一个。这足以说明当时《社会观察》与观察者网一个机构两块牌子的真实情况。当然观察者网与《社会观察》的风格有很大不同,这是传统纸媒和新媒体的区别。
从2014年6月起,《社会观察》与观察者网脱离关系。观察者网方面曾有其解释,但是真实原因显然只能是上海社会科学院与其终止了合作关系。至于上海社科院这么做的原因是什么,外人自然无法揣测。
运营方上海观察者文化传媒有限公司成立于2010年5月7日,经营范围是:文化艺术交流策划,设计、制作、代理、发布各类广告,礼仪服务,投资管理(除股权投资和股权投资管理),公关活动策划,图文设计、制作,企业形象策划,会务服务,展览展示服务,企业管理咨询,计算机信息技术领域内的技术开发、技术咨询、技术转让、技术服务。 【企业经营涉及行政许可的,凭许可证件经营】。
其中并不包括杂志的经营。上海观察者文化传媒有限公司的法人代表是金仲伟。此人曾任《东方早报》副总编辑,现在的伪春秋综合研究院研究员。2010年一篇文章中,曾经提到过他是春秋综合研究院的执行董事。还有另一家公司上海观察者信息技术有限公司以金仲伟为法人代表,注册于2012年11月6日,注册地址为上海市长宁区番禺路300弄7号2幢403室,与观察者网编辑部近在咫尺。观察者网的域名就归这个公司所有。
所以观察者网与《社会观察》的共同的实际主办方为:春秋综合研究院。上海社科院只不过是挂了个牌子。现在上海社科院不给他们挂这块牌子了,或者说他们不需要上海社科院这块牌子了。正是以主办《社会观察》为契机,观察者网出现了。现在观察者网已经壮大了。
春秋综合研究院
观察者网和《社会观察》经常提到春秋综合研究院。但是实际上并没有这么一个合法的研究院。它至少是到目前都并没有完成注册,但是却已经在多年前就已经以春秋综合研究院的名义活动了。这本身恐怕就是一种非法的行为。
伪春秋综合研究院的理事长是张维为,副理事长分别为金仲伟、沙烨、冯绍雷,曹锦清,可能还有其他一些人。在观察者网上的诸多文章中等处零散提及到的春秋综合研究院的研究员,还有:李世默,韩竹(韩杼)、陈平、宋鲁郑、金仲伟,张文木,张军,沈逸,吴新文,罗岗,肖功秦等人。
张维为是***的秘书,除了伪春秋综合研究院,还是复旦大学**发展模式研究中心主任。冯绍雷是华东师范大学国际关系与地区发展研究院院长,俄罗斯研究中心主任;华东理工大学社会与公共管理学院教授、博导、社会发展研究所所长、**城乡发展研究中心名誉主任。金仲伟来自《东方早报》,曾经是21世纪环球报道上海站负责人,与传统媒体和南方系有密切关系。沙烨是成为资本的董事总经理。值得注意的是,观察者网的一篇报道中称沙烨为“成为基金高级合伙人”,而甚至连李世默都不一定是成为资本的合伙人。当初四月网饶谨事发,也曾有人提到过一个姓沙的出资人。由于沙烨的技术背景,他还很可能是观察者网的技术方面的负责人。
陈平是复旦大学新政治经济学中心高级研究员,是一个号称“研究经济的物理学家”。不必过多提醒,这种捞偏门的大多都是信口雌黄的骗子。李世默是复旦大学国际关系及公共事务学院博士。张军、沈逸、吴新文也都是复旦的人。罗岗是华东师范大学的。肖功秦是上海师范大学的,宋鲁郑说肖功秦拒绝为他的书作序,因为他的书中有批评**的内容。张文木是北航的教授。宋鲁郑是旅法时评家(据说在观察者网和四月网上很活跃的边芹是他的妻子),在2013年接受BBC采访时,他说有三个作家对他有影响,分别是张维为、肖功秦和郑永年。前两个都已与其会师春秋综合研究院。宋鲁郑的经历看似平淡无奇,即无学术成就,也无商业成就(虽然被称为商人),但是却联系广泛,按照百度百科的说法,“现任旅法山东同乡会副会长、巴黎文化沙龙秘书长、旅法**同学会副会长、山东省海外交流协会常务理事、法国《欧洲时报》时事撰稿人。四次应邀访问**,并参加2008、09年大选观察团。两次访问凤凰网北京总部,包括接受视频采访一次。在法国两次应邀参与凤凰电视政论节目。”所以很多人都认为他有一个很深的背景。
韩竹、韩杼和寒竹都是一个人,是旅美时评家或者学者。煞费苦心用这么多笔名把自己包装起来,肯定也不是个省油的灯。
因此,所谓春秋综合研究院实际上就是一个以复旦同学、同事为核心的圈子,整合了高校中的若干人脉和资源,在法国和美国有特派员,利用了复旦的诸多资源,与某些上层势力有某种说不清楚的关系,与《东方早报》、《文汇报》、《瞭望东方周刊》等媒体有一定合作关系,扎根于上海的一个宣扬国家主义的政治团体。
伪春秋综合研究院绝不只观察者网和四月网这么两条线。观察者网和四月网只不过是伪春秋综合研究院的大众媒体,面向大众的造势的。伪春秋综合研究院与高校和媒体甚至某些有官方色彩的机构(比如曾经合办《社会观察》的上海社科院)的合作很频繁。早在2010年,伪春秋综合研究院就与文汇报理论部组织过月度研讨会。伪春秋综合研究院与复旦、清华、上海世纪出版集团等等都有过合作。不论他们在大众中如何造势,他们的眼睛始终在学术圈和高层。
李世默
在所有伪春秋综合研究院的研究员中,李世默是比较活跃的一个人。他于2013年6月份在TED环球大会上的演讲广为传播,并成为2013 TED年度最佳演讲。这个演讲就是于当年6月19日在观察者网独家首发的。
稍微了解一点内情的人都知道,李世默是四月网和观察者网的出资人,网上这方面的资料也有很多。观察者网和四月网的人也从不讳言。这也就等于是说,他也就是伪春秋综合研究院的出资人。四月网的情况大家都比较了解,从开始创建到后来的丑闻,这里就不多说了。
在百度百科中,对李世默的介绍是这样的:加州大学伯克利分校学士,斯坦福大学工商管理学硕士,复旦大学国际关系及公共事务学院博士,是一名风险投资家和政治学学者,春秋综合研究院研究员、中欧国际工商学院校董及中欧出版集团副董事长,中欧创业营讲师、成为资本创始人及执行董事,美国阿斯本研究所研究员,美国卡内基和平基金会顾问,伯克利加州大学艺术博物馆董事,是纽约时报、南华早报、环球时报,外交事务杂志,基督教科学箴言报以及郝芬顿邮报撰稿人。
可见李世默主要有这样几个身份:伯克利、斯坦福和复旦大学的三重校友;风险投资家(成为资本);伪春秋综合研究院研究员;中欧集团有头衔;美国若干机构的头衔;若干报纸的赚稿人。
借助这些头衔,李世默成了一个前台人物,中美通吃,左右封源,在美国和**宣扬民族主义和国家主义,捞取政治资本,为成为资本在**的投资创造良好条件,也就是为美国资本在**赚钱创造良好条件。
在这些身份中,最关键的就是成为资本的创始人和执行董事。李世默对观察者网(因此也就是伪春秋综合研究院)和四月网的投资,就来源于此。复旦的身份,只要看看张维为和春秋综合研究院与复旦的关系就一目了然了。由于成为资本对中欧国际工商学院也有投资,我们可以认为他在中欧集团的头衔是花钱买来的。在中欧国际工商学院网上的一篇文章中,直言不讳李世默和成为资本“在中欧的成功过程中发挥着重要作用。”在该文中,还指出“李世默本人还参与了我院的非洲课程,担任顾问委员会成员。这个等式中还有商业化的一面:成为基金是**最大的私营钻井服务商安东石油(Anton Oil)的最大股东,安东在非洲有业务。”
中欧商学院以高额学费,大量在国有企业高管和民营企业主中招收学员,为国有企业腐败和官私商人相互勾结、私下交易、利益输送、扰乱市场是做了不少贡献的。
关于李世默本人的出身,有这样一个传奇故事:李世默出生于1968年(百度百科上也说他出生于**时期的**上海);他的父亲是上海大学电机工程系的教授,**中被关押。而他的母亲则在被软禁前逃离**,在加州大学伯克利分校学习建筑学。李世默本人由其祖母抚养大,1986年其母将其带往加州。
成为资本是观察者网和春秋综合研究院运作的资本力量。从成为资本的执行董事沙烨担任伪春秋综合研究院的副理事长即可看出。
成为资本
百度百科上的李世默词条中有这样的介绍:“90年代中旬,李世默在斯坦福大学完成MBA学业后回到上海,并于1999年成立成为资本。”
这与事实不符。成为资本是在美国成立的,创始人是冯波和李世默。当时李世默主要待在国内,所以主要是冯波张罗的结果。是冯波启发李世默投资于网络公司。1999年,冯波和李世默共同创建“成为资本”,这个名字也是冯波起的。可笑的是,后来大讲共产党优越之处的李世默,在筹资时回答过美国佬这样的问题:如果**再出现一个***怎么办?很想知道他是怎么回答的。
1999年成为资本在美国成立,募集资本6000万美元。出资人中包括许多美国金融资本家、风投资本家,其中也包括Donald Rumsfeld。此人是前尼克森时代的美国驻北大西洋公约组织大使,福特总统的幕僚长和国防部长,里根时代的中东地区外交使节。后来他再度出任国防部长,因为他通过成为资本在**的投资引起国会里的一场风波。
成为资本是一个彻头彻尾的外资风投,是一个合伙人基金。李世默只是发起人之一,甚至很可能不是合伙人。至今在成为资本的官方网站上,也没有李世默是合伙人的字样。不过在一些投资咨询类网站上,倒时常描述李世默是合伙人。在成为资本的许多投资项目中,都有外国人的身影。比如,百度百科上提到的成为资本的唯一一项业务,就是“策划了土豆与优酷网的联姻,促成了两大视频网站最终实现合并。”现在优酷土豆网,有一个叫作George Leonard Baker的人,担任Independent Director(独立董事), Member of Audit Committee and Member of Compensation Committee(审计委员会和薪酬委员会成员)。而George Leonard Baker正是成为资本的重要投资人。
对这个George Leonard Baker,我们后边还会谈到。
成为资本的**关系网
成为资本在**有一张非常复杂的关系网络。伪春秋综合研究院的网络我在前边已经介绍过了,由成为资本支撑,在学术圈子和媒体圈子里广播人脉。成为资本自身的关系网则更加复杂许多。
冯波之父冯之浚是第九届民盟**副主席。冯波的妻子姓卓,是某人的外孙女。他的哥哥是著名投资家冯涛,目前是上海永宣创业投资管理有限公司管理合伙人。永宣创业的网站很有特色,有兴趣的人不妨去看看。永宣创业“的投资人众多,国内有上海联和投资有限公司和国家计委、国家经贸委、**科学院科技促进经济基金委员会;海外投资者有新加坡政府投资公司、嘉里集团、K.Wah集团、SUNeVision、JAFCO、摩托罗拉、阿尔卡特以及一些知名公司。上海永宣是国内首家同时管理境内及离岸基金的风险投资管理公司,目前管理的基金规模大约为5.2亿美金。”
冯波离开成为资本后,经他父亲的老朋友介绍,和某一个姓江的合作成立了上海创联和联创策源。冯波与冯涛兄弟俩都与新浪有渊源,曾任新浪CEO的茅道临是成为资本的高级顾问,茅道临的老婆姓胡。
前文提到过,成为资本是“安东石油的最大股东”。安东石油发家于90年代末的**,在迪拜设有国际总部,在伊拉克有多项投资,在香港上市,是恒生综合指数成份股。安东石油的老板罗林,毕业于西南石油大学。这样的履历,强烈暗示该公司及个人与某位周姓人士有某种关系。
所有这些错综复杂的关系中,李世默的出身最为清白,因此一些事情由他出面最为安全,这是可想而知的。风投资本家就政治问题大发议论,这种反常的现象能够出现,当然不会是没有原因的。
李世默去年6月那篇著名的演说,把**成功全部归功于神奇的组织部。从政治正确的角度讲,这种说法是不妥当的。因为,按照我党一贯原则,当说到成绩时,只能归功于两者:要么是党**、要么是党主席或总书记的正确领导。把功劳归于组织部这一具体部门是非常规的做法,这不禁让人想到这是有某种原因的。这里边的深意,恐怕只能从**组织部长及其派系的角度去理解了。神奇的是,由于成为资本与本任和上任**组织部长及其派系都能扯上关系,所以无从猜测起李世默到底是在挺哪一位。要是再算上和观察者网关系暧昧的一些泛左派,算上对茅于轼的专访,再算上伪春秋综合研究院的各色人等,观察者网简直是浓缩了这三十年来**的一切主要派系了。
成为资本的海外关系网
1999年成为资本成立时,美方投资人很多。不久后又有**人邵仰东加入。现在的成为资本中,还有代表**风投的康霈,代表麦肯锡的平苹。
成为资本的主要投资还是来自于美国。成为资本的一个“合作合伙人”是裴一凡,看似一个非常**的名字,实际是美国人,真正的名字是Griffith Baker,2002年毕业于耶鲁大学。Griffith Baker的父亲就是我前边提到的George Leonard Baker。成为资本还公开提及一个美方合作伙伴,SUTTER HILL VENTURES。SHV的网站上也公开显示它投资成为资本。George Leonard Baker也是促成SHV对成为资本投资的关键人物。
G.L.Baker与李世默是老相识,在成为资本草创阶段就帮助过李世默和冯波,而且是第一批投资人之一。
G.L.Baker是美国著名的风险投资家。他与美国诸多风投都有错综复杂的关系,有很多投资。G.L.Baker 与耶鲁大学有密切关系,他1964年毕业于耶鲁大学,曾是耶鲁大学顾问委员会成员,耶鲁大学财务委员会主席和投资委员会成员。正是通过G.L.Baker 的运作,李世默和冯波获得了一笔耶鲁1000万美元的投资,而耶鲁的投资在很大程度上促使其他投资人决定投资。
G.L.Baker 非常活跃,除了投资之外,还是新加坡政府投资公司国际顾问委员会的成员。据说他与新加坡方面关系密切,有部分原因在于耶鲁意图与新加坡合作办学。除了耶鲁,他与斯坦福也有关系。G.L.Baker 还是Environmental Defense Fund, Incorporated的受托人,Environmental Defense Fund, Incorporated注册为外资非赢利企业,但是它有一项收入是政府拨款,2013财年政府及其他拨款为3934539美元。
春秋综合研究院与华尔街
有了上边的介绍,观察者网、春秋综合研究院鼓吹国家主义的缘由也就一目了然了。对于成为资本国内网络中的那些人来说,“国”与“家”还真差不多是一回事。我们同样能理解,为什么斯诺登事件后,伪春秋综合研究院大批极端自由主义,反对网络过分自由。
李世默是个合适的前台人物,没太多的故事可挖,因此长期以来被推在前边。李世默的主战场在国外,不念其烦地讴歌**特色,组织部的英明、一党制的优越、**制度的无效率和不为**人民接受,**腐败现象的根源是官员收入太低,解决腐败问题靠得是儒家道德,等等等等。这些长久以来国人耳熟能详的陈词滥调源源不断地出现在境外媒体上,再出口转内销出现在观察者网和四月网上。
李世默能够在国外媒体上这么风光,当然不是因为他见识超人。李世默所有文章加起来的分量也超不过半两猪油,连驳斥的必要都没有。李世默作为一个风投资本家大反常态,到处曝光,显然是有人在后边运作的结果。不论是TED,还是《纽约时报》,还是别的什么媒体。他的风投资本家的身份,他的美国留学背景,他的体制外身份,使其特别适合在国外从容胡说八道。而转回国内之后,则有了一层“受到外国人重视”的光环。
这种对外宣传,也是一种国家战略,文化输出、软实力输出的一种方式。近些年来,代表**在国际上,特别是在发达资本主义国家出现的,往往是一些民间人士。比如要在尼加拉瓜挖运河的王靖,在北欧投资买地的黄怒波,在美国办企业的三一,等等。除了经济领域,在文化和意识形态领域也是如此。像李世默、宋鲁郑这种在国外培养起来的为**说好话的人,当然是宝贝了。反过来李世默们也在**宣传来自国外的类似垃圾货色,比如李世默命令观察者网翻译刊登的西奥多·罗斯福1899年《奋斗不息》的演讲。
也因为成为资本与中外金融资本的联系,伪春秋综合研究院的各位研究员们,虽然大吹**模式,但是对华尔街资本却是推崇备至。比如韩杼的《“占领华尔街”救得了美国吗?》就写道:” 美国的经济身体中已然流动着金融的血液。抽离了金融,意味着美国经济的迟早死亡。”
成为资本的美国金主、风投家G.L.Baker 虽然在投资上很是活跃,但绝不像李世默这等出头露面。但这并不意味着G.L.Baker 不从事政治活动。和所有金融资本家一样,G.L.Baker 是共和党的坚定拥趸。在2012年,G.L.Baker 对共和党的竞选捐款6万美元。在政治家中,G.L.Baker 捐献最多的是共和党总统候选人罗姆尼,59200美元。在他的政治家捐款列表上,唯一一个**党人是Max Baucus,此人是**党中的温和派,与美国商界和华尔街有关系,巧的是,他还是现任美国驻华大使,网友称其中文名为“没咳死?包咳死”。
美国共和党主张新自由主义政策,主张经济自由化,政治精英化,反对国家干预,一向代表美国大资本家的利益。同时,共和党也是美国的亲华派。虽然**的经济体制从哪个方面来看,都不太符合共和党的理念;但是那套精英政治观念,与共和党心里所望八九不离十。而且随着**金融自由化的发展,美国大资本家、金融资产阶级在**收益颇丰罢了。只要有钱赚,管它三七二十一。
类似G.L.Baker 这样在华搞风投的金融资本家还有很多。这些金融资本家与**国内的金融资本家紧密合作,而**国内的金融资本家,又多半身份复杂,血统高贵。鼓吹国家主义、民族主义、开明专制那一套,对所有这些**外国的金融骗子们都是皆大欢喜的事情。老外出钱办网站,抛出投名状,土鳖接招,锸血为盟。很好的故事。
至于说,G.L.Baker 的背后是不是还有更多的故事,有更多的、更加隐蔽、无从查起的背景,有美国政治任务,借观察者网和伪春秋综合研究院在**形成一个中外资产阶级和政治力量的同盟,那就是谁也说不准的事了。
从80年代以来,国内一直有势力主张以美国为鉴,全面向美国学习。当然不排除,如今在美国有另一股势力,在美国的国内斗争中,假借推崇**模式、反思美国衰落,以求在美国实现保守主义的反动。
观察者网有很多撰稿人,这些人当然不会全是同谋,我给你写稿子你给我钱而已,表达的观点也各样。观察者网有许多工作者,有这样那样的政治理想和抱负,未必与观察者网或春秋综合研究院一致,但确实是在为其“事业”添砖加瓦。许多左翼小团体与观察者网关系密切,目前对此我不置一词。风传有大人物对观察者网感兴趣,亦有重量级单位谋求与之合作。我不禁要问:难道他们真的不知道观察者网背后的美国资本力量?还是本身就是冲着这个力量来的呢?几个小小的风投家能有那么大的吸引力吗?
前文我们讲过关于债务的小问题,如果你没有债务,或者对债务问题已经胸有成竹,正常情况下你就会想到发展。而相信对大多数个人来说,发展的极限就是所谓财务自由,为了这个目标你开始不断努力,而你奋斗逼的身份也就从这一刻开始确立。
一、罪恶财务自由
那么我们先确定概念:财务自由的意思就是资产性收入覆盖生活成本,由此衍生出菜市场自由,车厘子自由等等概念,我们先不去想对于什么人群需要怎样的财务状况才能达到怎样的财务自由,我们从资产性收入讲起。
首先你的资产性收入就是别人的劳动收入,也就是说一个人财务自由,就有(更多人)不能财务自由。其次在你追求财务自由的路途中,很可能你会因为错误的投资或创业变得更不自由。
到达突破点之前,你会听到天空传来一声巨响:对不起,你已经死了!
这个东西就是我们前文有所涉及的资本主义结构性暴力。
这个社会,高收入岗位是有数的,食利者也是有数的,不然资本主义体系没法运转,没法保持内生的活性,这个大前提之下,总会有绝大多数人是失败者,所以我说开源是让你更心安理得花钱的鸡汤,你真正能控制的是节流。
我也说最愚蠢的就是“投资”教育,因为当扩招远远高于社会需求(对比分配工作时代一个萝卜一个坑)的时候,要么岗位工资下降,增设岗位,要么大多数人没法获得自己高学历本该对应的岗位,这在文科生里格外突出了。
还有出国留学,作为梦想是可以理解和支持的,但是你卖掉房子的钱,大概率不是你镀金以后提高的收入能赚回来的,还耽误了几年时间,是纯粹的赔本买卖。
类似的还有找工作首先考虑的应该是工作距离和工作时间而不是收入和“发展”,道理很简单,多赚的钱全部因为更贵的房租,更多的夜宵犒劳,更多的医疗支出抵消了,你除了过劳肥一无所得,还变成怨气满满,痛苦不堪的人,变成一万多只够温饱言论的支持者。
为什么不要考虑发展,因为除了少数类似销售这样依靠人脉的岗位,你发展再好,华为35也是要裁员你的,你觉得你的经验很重要,但是你的身体确实扛不住了,而且最重要的是,你的工资已经太高了,一有风吹草动,裁员的往往是收入更高的,而被裁员的你真是到了拿钱换命的年纪,而这时候你往往还有自身膨胀时期的后遗症-各种债务,房贷还好,超前消费的呢?这时问题就和消费主义(参考本书第二章)结合在一起爆发了,足以瞬间,彻底击垮一个人。
这些东西就是我反对“奋斗逼”和的一个基本预设,反对奋斗逼在个人生活中可能比反对消费主义还要重要,但为什么是消费主义而不是奋斗逼变成了众矢之的,显而易见的就是,反对消费主义只需要更改当下,而质问自己奋斗逼的内心往往摧毁的是自己二十多年来受到的教育和信仰。
二、武则天还是宫女?
当然有人会说,奋斗还有一线希望,不奋斗一点希望也没有了。
非常巧,武则天也思考过这个问题。
对于武则天来说,当皇帝的难度都比在大唐掀起女权运动要低,结构性暴力是她不能抵抗的——就变成结构的一环,正所谓不服来养蛊…不过糟糕的是,看过一个很有趣的统计,几乎每个司机都认为自己的车技在平均水平之上,那么车技烂的人是谁?这种老司机的幻觉支撑奋斗逼变成了武则天的养料,这也就是我开篇说的,追求财务自由可能让你变得更不自由。
所以现在你再想想,你觉得你更可能是蛊王武则天,还是一个宫女?
老娘这个位置是这么好当的吗?你连四个技能都没有,我一刀就能砍死你
到这时奋斗逼的完整定义就出来了:第一类是在一个只有比较小的可能性的情况下却认为是确定性的人(人人都能致富)。第二类是知道可能性比较小但是选择不反对架构换一个可能性大的架构,而去赌运气,踩踏他人的人(自认武则天式人物)。前者蠢后者坏,但都能理解,都值得同情,两者共同点是都想翻身不想直接反对游戏规则,区别在于一个成功了一个没成功。我支持的做法是,要么舍得一身剐,你直接站在结构性暴力对立面,要么做一点微小的资本主义个人反抗,而后者我认为更有指导意义。
那么具体怎么办?
三、找到你的大理
人们很难想象,采集狩猎时代人类的生活水平是高于农业时代的大部分时期的,身高和寿命都是如此,所以后来有所谓桃花源,老外还弄了一本书叫《逃避**的艺术》,说一堆人跑到山上去搞无政府公社balbalaba。这个书最有趣的部分不是zz破害,而是说明桃花源里的居民发现不逃避税收已经快活不下去了,战乱结束他们也没有试图搬出桃花源。
但是税收本身是没错的,是所谓必要之恶,唯一遗憾的是,“正常”的税收经常也能逼死人。
这里就涉及一个所谓内卷化的概念,比方说30亩地如果养一户人,耕牛和风车灌溉等机械就会被利用,人的生活水平也会提高,但是30亩地养三十户人的时候,机械化的趋势就让位于精耕细作,提高单产,人的痛苦感提高但实际生活水平下降。
明清的精耕细作趋势正是来源于此,宋朝畜力和水力风力的趋势都被打断了。
我们以此类推,关键的问题不是在于要不要工作,而是要做什么工作,如果你进入一个激烈竞争的体系里,难免要求爷爷告奶奶,为了争夺资源办公室斗争,考这考那,痛苦感高,获得感低。
90年代老外来**看啥都发财,但是**人看啥都不能发财,为啥呢,因为老外的国内发展完毕了,他一眼能看到**缺什么,但是**人就不行。
同理,你现在看东南亚,八成也能知道干啥能发财,比如他们承接低端产业经济开始发展,城市化加速,但是房价又很低,早些年去金边曼谷买房的现在都发了,当然我不是劝你现在去东南亚炒房,你现在去是给**人接盘去了,但是这种意识我觉得是最重要的。
比如说社会上作为体面标准的教师和医生,可以想象的生活就是累得要死钱也不多,还得装孙子,家长/患者和领导谁不能轻松拿捏你?
能想工作才奇了怪了吧。
那我自己是自由职业者,做做理财和写写东西,我要是还留在北京,我的获得感也不强,但是如果我在大理,俨然他妈是富人,房租也就几百块,而我还拿和北京一样的钱。
当然,我的经验也不可复制,每个人都有自己生财的门道,但无论我说的东南亚炒房还是我自己的大理生活,其核心都是避开激烈竞争的地方,避开内卷的情况,选择一条新路,这才是最重要的。
所以给有困惑的人的答案是,如果你觉得特别特别痛苦,肯定是哪出问题了,这时候不要把答案简约为要迎难而上还是当个废物,你实际上还有第三条路,就是看看是不是换个获得感更高的方向努力是不是更有前途,这时候你就能发现又不是很难,你也不是个废物。
也别说什么转行难,前些年文科生去北大青鸟临时学写代码,赶上互联网红利缺人,还不是一个月几万块到手,你专业对口当新媒体运营给你5000算恩赐了吧?
但还是那句话,我说的,都是已经发生过的,你现在去当码农就是赶上互联网红利衰退到处裁员了,也许你真正需要努力的部分是开阔眼界,发现机会,这话挺鸡汤的,但是真的好使,跳出自己的一亩三分地,多琢磨一下,反正你现在是个无声反抗的人,时间最多。
我们举个例子,日本年轻人是怎么反抗996的?3个小时做完工作,其他时间摸鱼,就和电影里的最后一秒救援一样,他总是在加班结束的最后一刻结束工作。
结尾、睡个好觉
为什么我们总是强调巴特勒著名的卧室里的反抗这个概念?因为你能在不直接和结构性暴力对抗的前提下做无穷无尽的事情,包括不限于我前文提到过的购买二手产品,薅外卖羊毛,不要孩子,减少消费,做一个第三章提到的情境主义者,也可以直接寻找你的高地和桃花源,你不需要承担推翻资本主义的历史重任也不用捏着鼻子做武则天,还可以按照本书第一章和第四章的内容搞个节点玩玩。
所以为什么我极度厌恶“小确幸”?小确幸就是存在主义的鬼岛翻版:不要考虑持久的痛苦,只在意生活中偶发的乐趣。这和存在主义说不要在意西西弗斯式的生活,要在意路边的小鸟是同义重复的。
道理本身没毛病,但是存在主义实际上是纳粹创伤文学,对应的是奥斯维辛后诗何以存在的问题。与此同时60,70s的贫富差距是不那么猖獗的,凯恩斯主义也没有退潮。
存在主义思潮在伤痛消失,新自由主义80年代全面反攻倒算的时期自然而然就退潮了,而在21世纪被提出小确幸,实际上就是一种最糟糕的奋斗逼哲学:你加班到12点出来,霓虹闪烁,好美呢——但老子本来应该在睡觉啊!
2019年3月于大理
AI造假影片為害日益氾濫,微軟和臉書共同發起名為Deepfake Detection Challenge大賽,以總獎金上千萬美元鼓勵辨識Deepfake影片的技術開發。
Deepfake影片是以人工智慧(AI)技術將名人臉部和色情片主角或其他人的嘴形或身體移花接木,製作造假影片,達成惡作劇或毁謗目的。
大會表示,愈來愈多極端人士製作Deepfake影片來製造假新聞、煽動群眾或激化衝突。另一方面,這類技術快速演進,使偵測愈形困難。現在沒有一家公司能單憑一己之力解決這些問題,Deepfake Detection Challenge即希望邀集各方好手打造能供大家辨識造假影片的技術,主辦者包括臉書、微軟、康乃爾、牛津、馬里蘭、加州大學柏克萊分校、紐約市立大學阿巴尼分校、麻省理工學院、及社區大學(College Park)市。
這項大賽預計從2019年10月舉行到2020年3月。臉書會和外部廠商合作以AI技術將一些真實影片加工製作出一批Deepfake影片,供參賽AI模型偵測。參賽者上傳的模型最後由大會的測試團隊評選出最優秀的模型。臉書強調這些真實影片都是經過授權取得,且未動用到臉書用戶的影片。
單單臉書即捐贈1000多萬元贊助這項大賽。臉書本身也會加入競賽,但不會參與角逐獎金。
臉書會在今年稍晚公佈比賽規則、競賽獎金及開放影片資料的授權。
臉書不但是許多假影片上傳的平台,自己也深受其害。今年IG上流傳一則造假臉書執行長祖克柏(Mark Zuckerberg)的影片,片中假的祖克柏聲稱自己擁有數百萬人的被竊資料、祕密,也掌握了這些人的未來。
報名獲取於11月20日在台北舉行的Microsoft IoT in Action活動門票,從其他公司的物聯網(IoT)體驗中獲得寶貴的深入解析。
Sponsored Content
得益于IT外包服务的发达,现在的运维已经不包括搬机器上架、接网线、安装操作系统等基础工作,运维人员一般会从一台已安装好指定版本的操作系统、分配好IP地址和账号的服务器入手,工作范围大致包括:服务器管理(操作系统层面,比如重启、下线)、软件包管理、代码上下线、日志管理和分析、监控(区分系统、业务)和告警、流量管理(分发、转移、降级、限流等),以及一些日常的优化、故障排查等。
随着业务的发展、服务器规模的扩大,才及云化(公有云和混合云)、虚拟化的逐步落实,运维工作就扩展到了容量管理、弹性(自动化)扩缩容、安全管理,以及(引入各种容器、开源框架带来的复杂度提高而导致的)故障分析和定位等范围。
听上去每一类工作都不简单。不过,好在这些领域都有成熟的解决方案、开源软件和系统,运维工作的重点就是如何应用好这些工具来解决问题。
传统的运维工作经过不断发展(服务器规模的不断扩大),大致经历了人工、工具和自动化、平台化和智能运维(AIOps)几个阶段。这里的AIOps不是指Artificial Intelligence for IT Operations,而是指Algorithmic IT Operations(基于Gartner的定义标准)。
基于算法的IT运维,能利用数据和算法提高运维的自动化程度和效率,比如将其用于告警收敛和合并、Root分析、关联分析、容量评估、自动扩缩容等运维工作中。
在Monitoring(监控)、Service Desk(服务台)、Automation(自动化)之上,利用大数据和机器学习持续优化,用机器智能扩展人类的能力极限,这就是智能运维的实质含义。
智能运维具体的落地方式,各团队也都在摸索中,较早见效的是在异常检测、故障分析和定位(有赖于业务系统标准化的推进)等方面的应用。智能运维平台逻辑架构如图所示。
智能运维平台逻辑架构图
智能运维决不是一个跳跃发展的过程,而是一个长期演进的系统,其根基还是运维自动化、监控、数据收集、分析和处理等具体的工程。人们很容易忽略智能运维在工程上的投入,认为只要有算法就可以了,其实工程能力和算法能力在这里同样重要。
智能运维需要解决的问题有:海量数据存储、分析、处理,多维度,多数据源,信息过载,复杂业务模型下的故障定位。这些难题是否会随着智能运维的深入应用而得到一定程度的解决呢?我们会在下一篇文章中逐步展开这些问题,并提供一些解决方案。
本文选自《智能运维:从0搭建大规模分布式AIOps系统》,作者彭冬、朱伟、刘俊等,电子工业出版社2018年7月出版。
------------
更多科技资讯请见微信公众号:博文视点Broadview(微信号:bvbooks)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.


































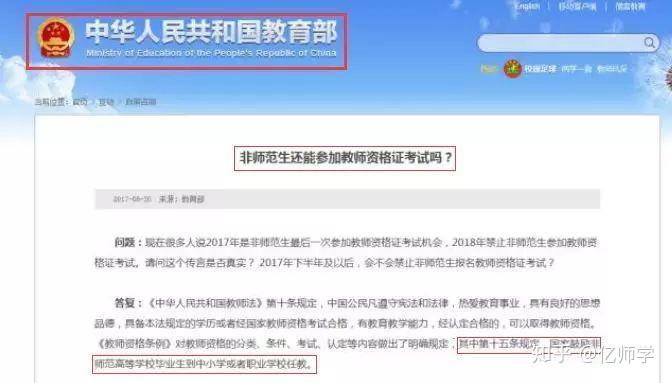
































































































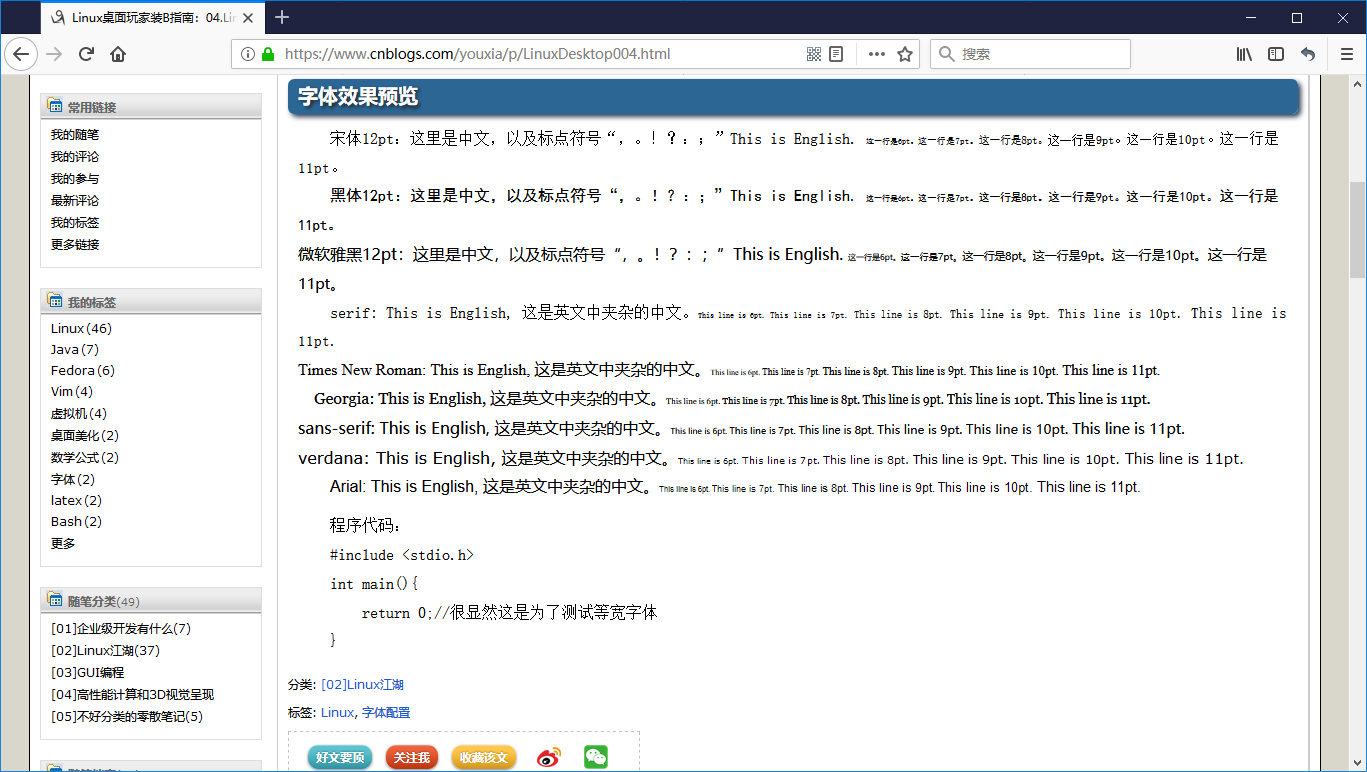
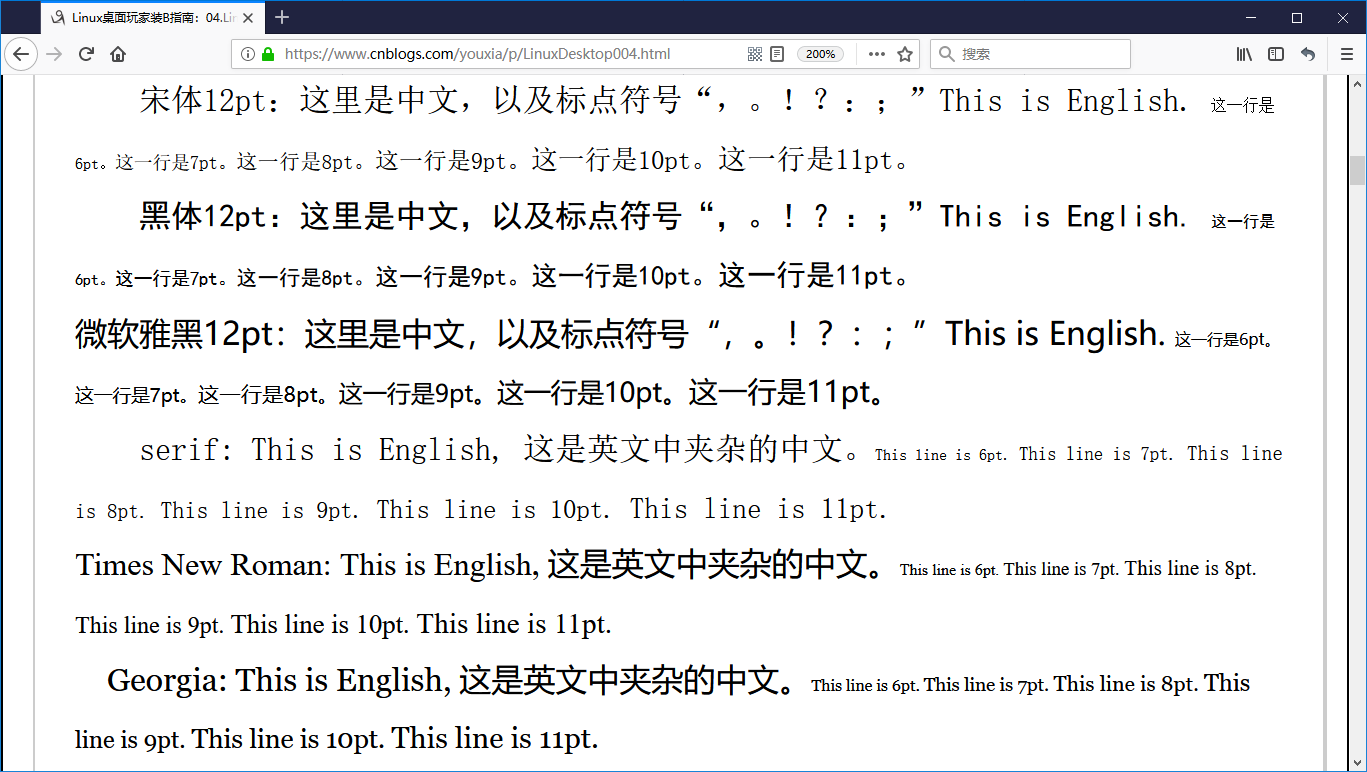


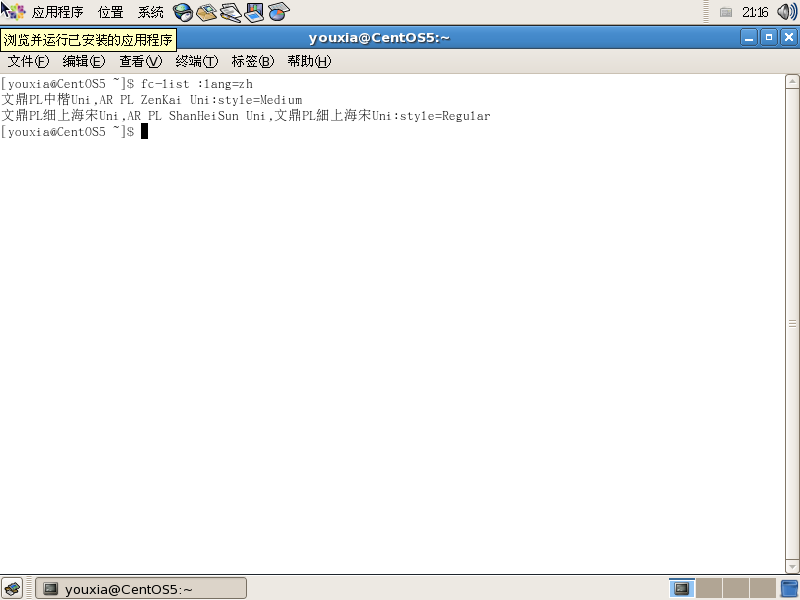

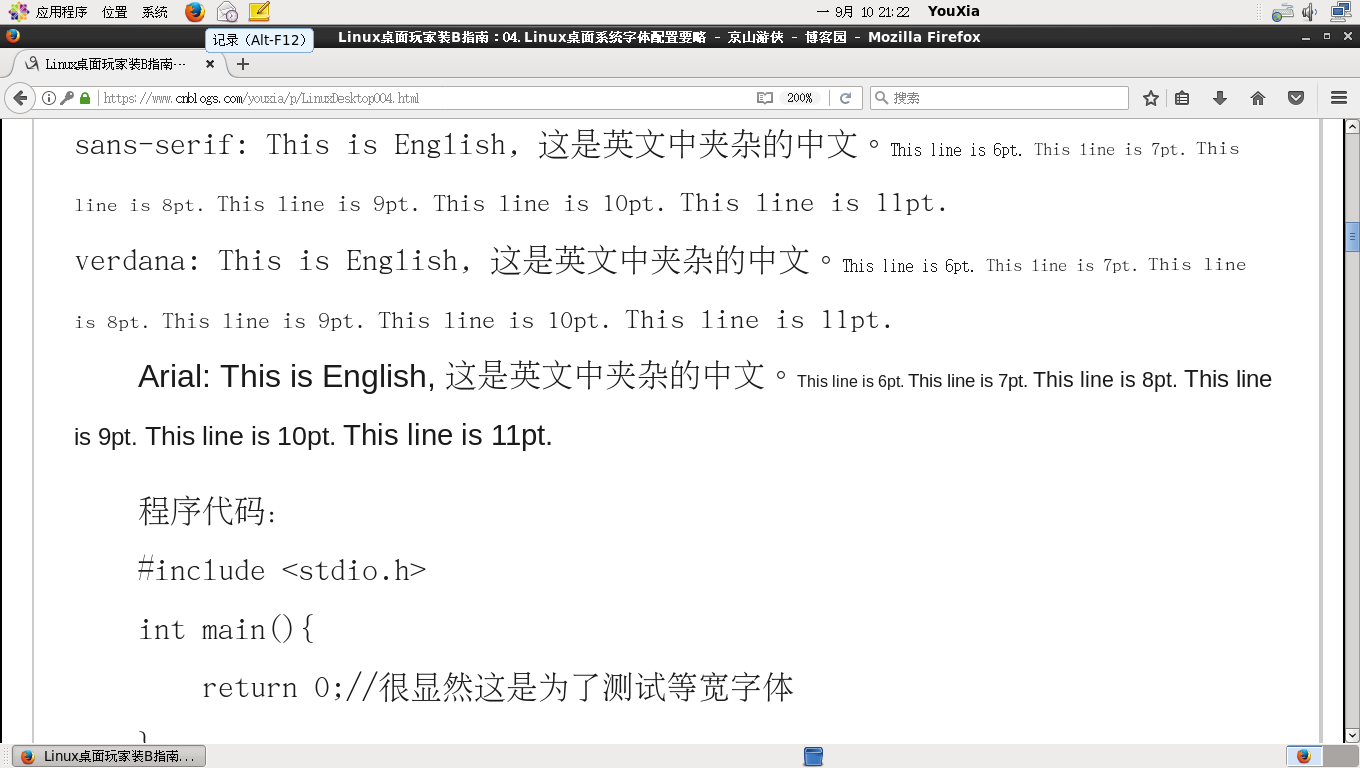

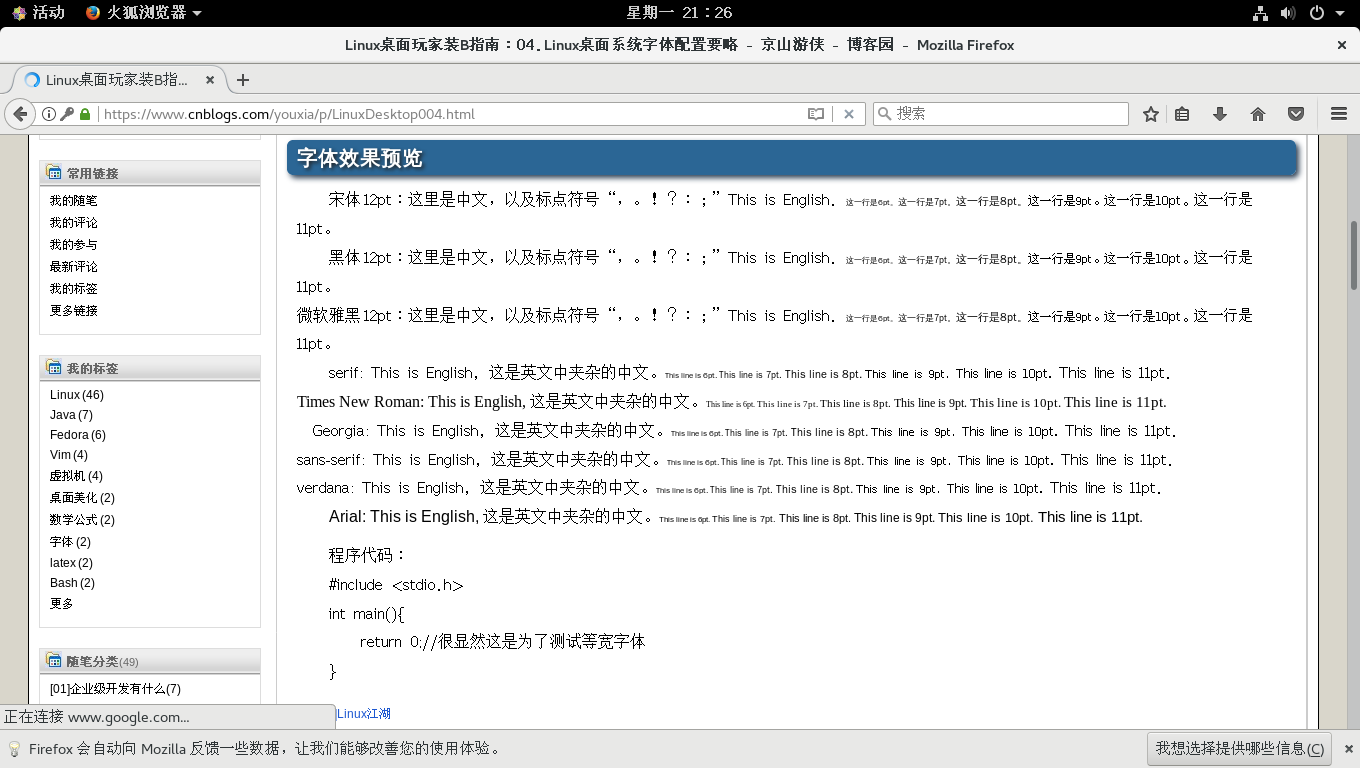


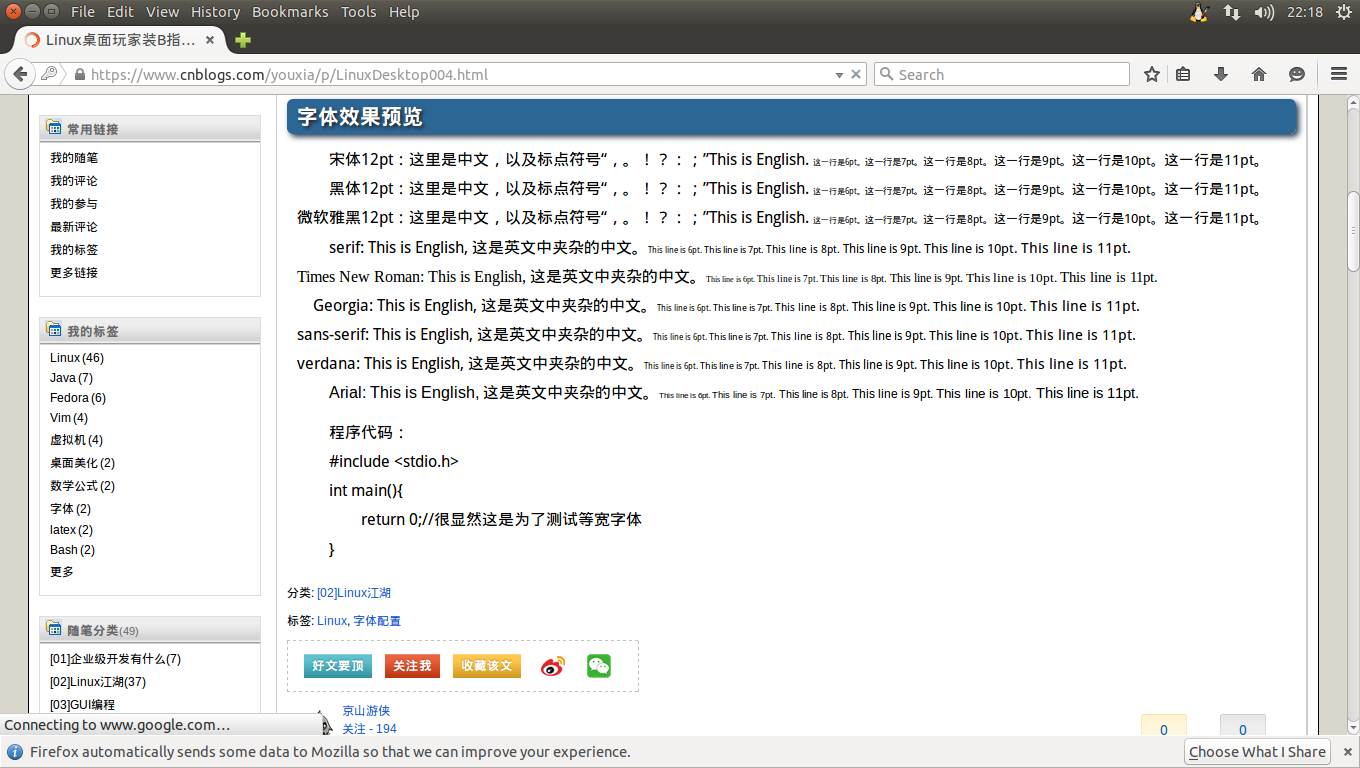






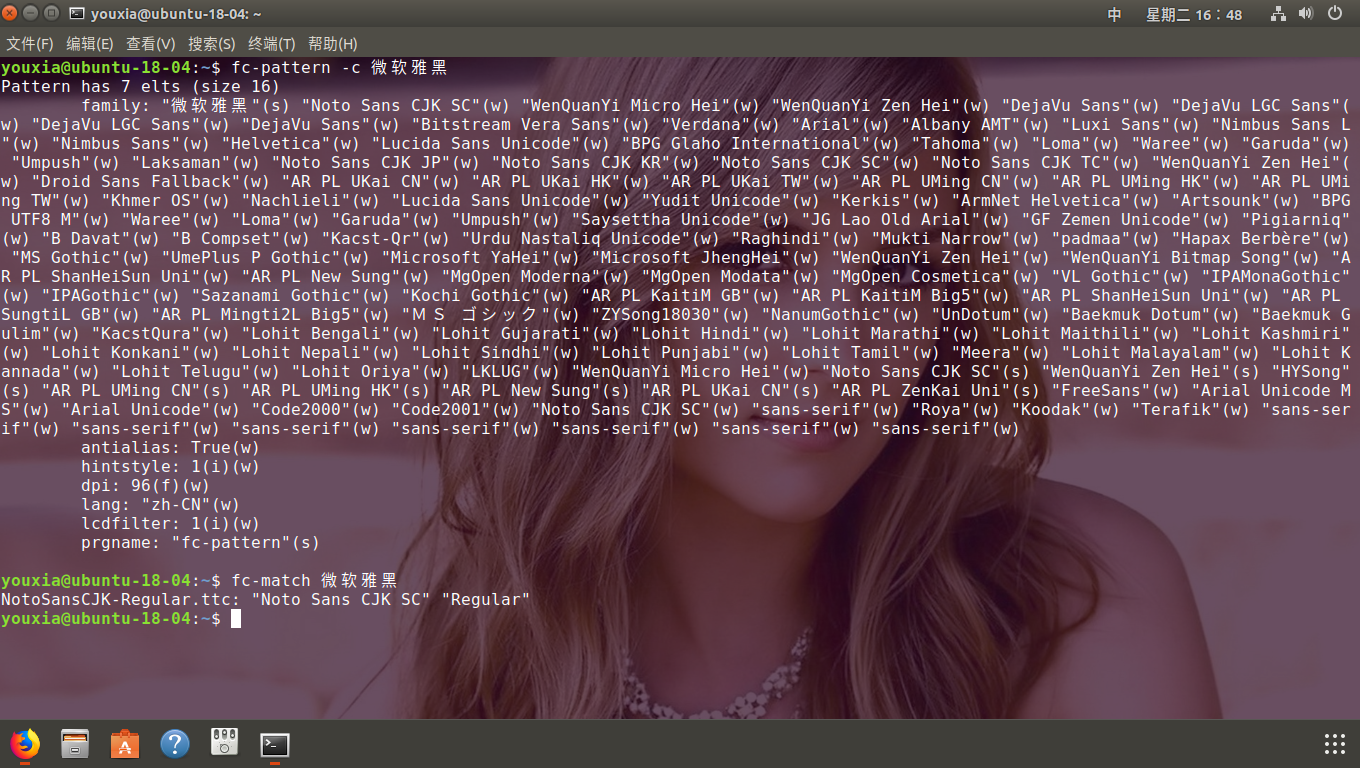









































































.jpg){kind=link}