This is an attempt at implementing Sequence to Sequence Learning with Neural Networks (seq2seq) and reproducing the results in A Neural Conversational Model (aka the Google chatbot).
The Google chatbot paper became famous after cleverly answering a few philosophical questions, such as:
Human: What is the purpose of living?
Machine: To live forever.
The model is based on two LSTM layers. One for encoding the input sentence into a "thought vector", and another for decoding that vector into a response. This model is called Sequence-to-sequence or seq2seq.
Source: http://googleresearch.blogspot.ca/2015/11/computer-respond-to-this-email.html
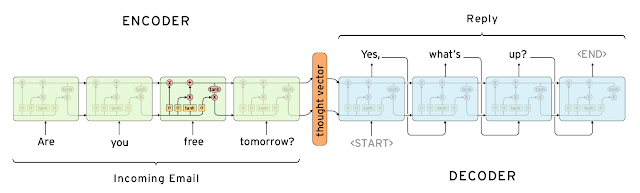
In this experiment, we train the seq2seq model with movie dialogs from the Cornell Movie-Dialogs Corpus. The lines are shortened to the first sentence.
Here's a sample conversation after training for 20 epoch with 50000 examples, using the following command:
th train.lua --cuda --dataset 50000 --hiddenSize 1000(Took 3 days to train on my GeForce GTX 780M.)
For OpenCL, use --opencl instead of --cuda. To train on CPU, don't provide any of those two.
WARNING: I can no longer reproduce those results. The cause seems to be a change in one of dependencies. But I'm currently working on a new implementation based on harvardnlp/seq2seq-attn.
me: Hello?
bot: Hi.me: How are you?
bot: I'm fine.me: What's your name?
bot: It's hard to describe.me: How so?
bot: I'm not sure.me: What color is the sky?
bot: It's blue.me: What is your job?
bot: It's not that i'm a fucking werewolf!me: What is the purpose of life?
bot: A gift.me: Are you intelligent?
bot: Yes, well...me: Are you a machine?
bot: That's a lie.me: Are you human?
bot: No, i'm not.me: What are you?
bot: I'm not sure.me: Do you plan on taking over the world?
bot: No, i don't.
Phew! That was close. Good thing I didn't train it on the full dataset. Please experiment responsibly.
(Disclaimer: nonsensical responses have been removed.)
-
Install the following additional Lua libs:
luarocks install nn luarocks install rnn luarocks install penlight
To train with CUDA install the latest CUDA drivers, toolkit and run:
luarocks install cutorch luarocks install cunn
To train with opencl install the lastest Opencl torch lib:
luarocks install cltorch luarocks install clnn
-
Download the Cornell Movie-Dialogs Corpus and extract all the files into data/cornell_movie_dialogs.
th train.lua [-h / options]The model will be saved to data/model.t7 after each epoch if it has improved (error decreased).
--opencluse opencl for computation (requires torch-cl)--cudause cuda for computation--gpu [index]use the nth GPU for computation (eg. on a 2015 MacBook--gpu 0results in the Intel GPU being used while--gpu 1uses the far more powerful AMD GPU)-- dataset [size]control the size of the dataset--maxEpoch [amount]specify the number of epochs to run
To load the model and have a conversation:
th eval.luaMIT License
Copyright (c) 2016 Marc-Andre Cournoyer
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.


















































































































































































