
| Nome | Matrícula |
|---|---|
| Adrianne Alves da Silva | 16/0047595 |
| Lucas Arthur Lermen | 16/0012961 |
Este repositório apresenta um algoritmo de ordenação, o Quick Sort, escrito em linguagem c, para fins didáticos. Consiste em uma atividade apresentada como avaliação parcial da disciplina de Estrutura de dados 2 do curso de Engenharia de software da Universidade de Brasília (UnB), Campus de Engenharias - Faculdade do Gama (FGA).
Algoritmos de ordenação, como o próprio nome explicita, refere-se à estruturas lógicas que independente da linguagem são capazes de ordenar um dado, seja em ordem crescente ou decrescente. Em geral, cada tipo de algoritmo possui uma abordagem diferenciada, por esse motivo, segue abaixo uma explicação suscinta a respeito do Quick Sort.
Existem variadas maneiras de realizar a ordenação de um dado, as mais simples delas,q foram construídas por meio da observação do processo natural de ordenação, concentram-se em encontrar o maior ou menor número do vetor e levá-lo até a sua posição. Dentre estes estes algorítmos, encontram-se o selection sort, o insertion sort, o bubble sort e o shell sort, com complexidade O(n²) e entre os algorítmos de O(log(n)) estão o Bucket Sort e o Quick Sort.
O bucket Sort é o pior entre os algoritmos com essa complexidade, mas ele funciona a partir do conceito de "dividir para conquistar", em que ele particiona o vetor em baldes infinitos, sendo bastante eficiente com valores limitados. Cada balde pode ser ordenado por outro tipo de algorítmo, o que pode aumentar a complexidade ou ele pode ser utilizado como uma espécie de "estilo de vida" de ordenação, dividindo em baldes até restar apenas um elemento. Por sua vez o Quick Sort é uma excelente solução caso se deseje realizar pesquisas por chave.
O funcionamento do Quick Sort assim como o algorítmo anterior funciona com o esquema "Dividir para conquistar", em uma operação de partição. Nesse sentido, escolhe-se um pivô, que determina a relação de velocidade nos diferentes casos de complexidade, assim é uma ação importante para a implementação. A partir de então, basta mover os maiores valores para direita e os menores para a esquerda.
Segue abaixo alguns exemplos das duas tecnologias apresentadas:
Bucket Sort
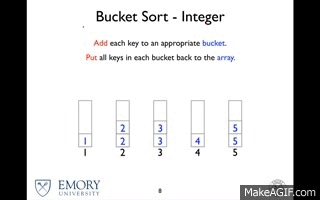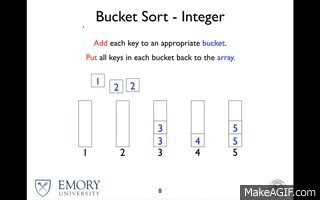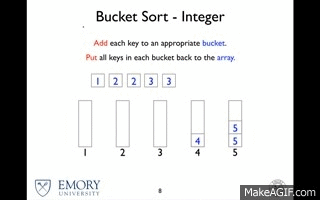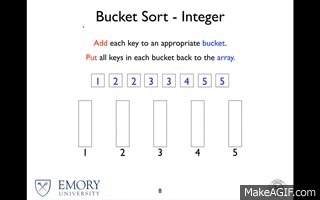
Quick Sort

Dentre estes a dupla implementará o Quick Sort
Com fins didáticos, o algoritmo implementado aqui corresponde à uma ordenação através do quick sort com vetor preenchido por valores aleatórios, em que o tamanho do mesmo será mudado a fim de medir a velocidade do algoritmo. Dessa forma, será gerado gráfico de modo a demonstrar visualmente a complexidade O(log n) do algoritmo.
Levando em consideração que o sistema usado seja linux, basta entrar na pasta pelo terminal e digitar gcc -o exec sortingAlgorithm.c para utilizar o ordenador. O gerador de gráfico foi desenvolvido em python, assim, basta digitar no terminal python3 gerandoGraficos.py.
Para coletar o tempo de execução do algoritmo a ser analisado utilizou-se a coleta do clock inicial e final e a fórmula expressa no pedaço de código a seguir, para capturar em até milisegundos :
''' clock_t tempo; tempo = clock();
int i, j, aux; for (i = 1; i < TAMREGISTROS; i++) { for (j = 0; j < TAMREGISTROS - 1; j++) { if (registros[j] > registros[j + 1]) { aux = registros[j]; registros[j] = registros[j + 1]; registros[j + 1] = aux; } } }
printf("Tempo:%f",(clock() - tempo) / (double)CLOCKS_PER_SEC);
'''
Assim, os valores foram destinados a um vetor, o Quick Sort, principal tema dessa entrega . Nesse sentido, obteve-se o gráfico esperado através dos dados que foram coletados, conforme apresentado abaixo.

