![]()

LMDB offers:
- Transactions (full ACID semantics)
- Ordered keys (enabling very fast cursor-based iteration)
- Memory-mapped files (enabling optimal OS-level memory management)
- Zero copy design (no serialization or memory copy overhead)
- No blocking between readers and writers
- Configuration-free (no need to "tune" it to your storage)
- Instant crash recovery (no logs, journals or other complexity)
- Minimal file handle consumption (just one data file; not 100,000's like some stores)
- Same-thread operation (LMDB is invoked within your application thread; no compactor thread is needed)
- Freedom from application-side data caching (memory-mapped files are more efficient)
- Multi-threading support (each thread can have its own MVCC-isolated transaction)
- Multi-process support (on the same host with a local file system)
- Atomic hot backups
LmdbJava adds Java-specific features to LMDB:
- Extremely fast across a broad range of benchmarks, data sizes and access patterns
- Modern, idiomatic Java API (including iterators, key ranges, enums, exceptions etc)
- Nothing to install (the JAR embeds the latest LMDB libraries for Linux, OS X and Windows)
- Buffer agnostic (Java
ByteBuffer, AgronaDirectBuffer, NettyByteBuf, your own buffer) - 100% stock-standard, officially-released, widely-tested LMDB C code (no extra C/JNI code)
- Low latency design (allocation-free; buffer pools; optional checks can be easily disabled in production etc)
- Mature code (commenced in 2016) and used for heavy production workloads (eg > 500 TB of HFT data)
- Actively maintained and with a "Zero Bug Policy" before every release (see issues)
- Available from Maven Central and OSS Sonatype Snapshots
- Continuous integration testing on Linux, Windows and macOS with Java 8, 11, 17 and 21
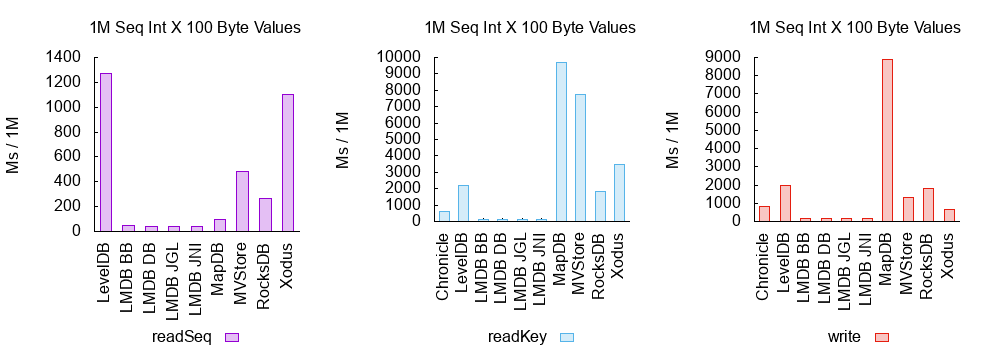
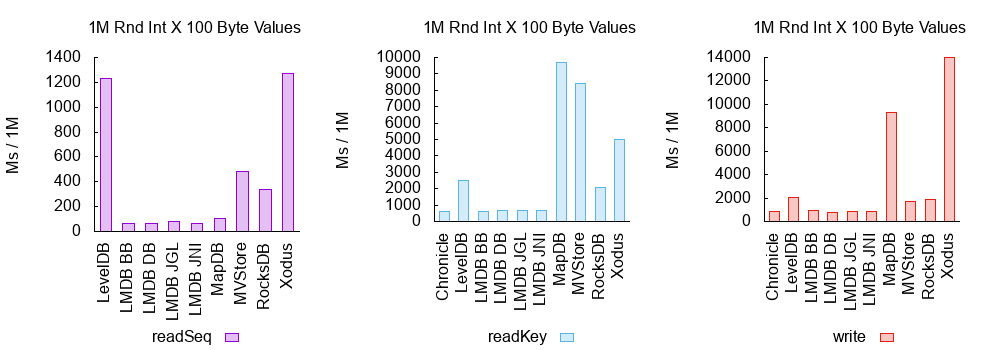
Full details are in the latest benchmark report.
We're happy to help you use LmdbJava. Simply open a GitHub issue if you have any questions.
This project uses Zig to cross-compile the LMDB native
library for all supported architectures. To locally build LmdbJava you must
firstly install a recent version of Zig and then execute the project's
cross-compile.sh
script. This only needs to be repeated when the cross-compile.sh script is
updated (eg following a new official release of the upstream LMDB library).
If you do not wish to install Zig and/or use an operating system which cannot
easily execute the cross-compile.sh script, you can download the compiled
LMDB native library for your platform from a location of your choice and set the
lmdbjava.native.lib system property to the resulting file system system
location. Possible sources of a compiled LMDB native library include operating
system package managers, running cross-compile.sh on a supported system, or
copying it from the org/lmdbjava directory of any recent, officially released
LmdbJava JAR.
Contributions are welcome! Please see the Contributing Guidelines.
This project is licensed under the Apache License, Version 2.0.
This project distribution JAR includes LMDB, which is licensed under The OpenLDAP Public License.












![lgtm-com[bot] avatar](https://avatars.githubusercontent.com/in/17324?v=4 "lgtm-com[bot]")

















































































































































