lllyasviel / controlnet-v1-1-nightly Goto Github PK
View Code? Open in Web Editor NEWNightly release of ControlNet 1.1
Nightly release of ControlNet 1.1
































































































































































thanks ❤ for the v1.1 it is amazing 🥳
I have 2 GPUs when I want to use cuda:1, I try to modify gradio_*.py , but throw error like this:
Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0 Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0
I suspect there is a bug in the Zoe annotator where width and height are being swapped?
Would be great to have a discord server so we can change ideas about Controlnet
like pose and canny control
Just curious -- now that there is an anime lineart cnet, was there plans to eventually make/release one of the scribble lineart models or color scribble model previously referenced in Style2Paints?
https://github.com/lllyasviel/style2paints/tree/master/V5_preview#style2paints-v5-alice
https://github.com/lllyasviel/style2paints/tree/master/V5_preview#supporting-color-scribbles
Or, would your suggestion be: to replicate the lineart scribble, use the existing scribble model or the anime lineart model at a low strength, and then for color scribbles, use the anime lineart model in combination with img2img (perhaps that's essentially what it was already doing)?
Hello, we have been trying (at neural.love) to train the colorization model based on the ControlNet architecture.
The model was trained on different LR's on the manually collected b&w-colorful image pares dataset.
Any recommendations regarding the training process are highly appreciated.
Current model problems:
It is still heavily work-in-progress, but it could already (sometimes) colorize quite well, which is why we decided to share it. I have created a pull request here, and here are some results of the first version:








Hi, would it be possible to upload diff'd versions of control_v11p_sd15 models to HF? As a side concern, should we use a shared naming convention for difference models? I am unaware of how difference models are detected at the moment, so I don't know if it could help with user experience as well.
I run CN on 3060 12gb and my Vram is filled to the maximum and the process does not go at all

Hi!
I saw that there is a control specifically to inpaint. Given that multi controlnet exists, how does inpaint work with multi-controlnet. Is there a possibility of using huggingface controlnet pipeline with inpaint, and pass mask ? Does this replace the need to use inpainting with controlnet?
Is there a reference (paper, dataset, or anything) describing which color represents which concept? It is very useful to build masks manually for ControlNet.
Thank you for your nice work and new contribution!
I don't know if you plan to release a new version of your paper but meanwhile I would have some question about the training procedure and details for the inpaint model.
My main question is about the "random optical flow occlusion masks". Could we have more details about it? It is a mask where the optical flow is higher than a threshold between 2 video frames?
Also, all the training details possible would be appreciate mostly number of training steps, batch size and datasets used?
I'm getting the weirdest bug with ControlNet 1.1 (used to work on an earlier release, broken for a week or so). This is through the sdapi/v1/txt2img endpoint.
I'm trying to use 2 controlnet steps (webui is configured for 2). Seed is fixed at 12345.
I'm using the following configuration (excerpt from the logs):
Loading preprocessor: scribble_xdog
Pixel Perfect Mode Enabled.
resize_mode = ResizeMode.INNER_FIT
raw_H = 512
raw_W = 512
target_H = 512
target_W = 512
estimation = 512.0
preprocessor resolution = 512
Loading model from cache: t2iadapter_style_sd14v1 [202e85cc]
Loading preprocessor: clip_vision
Pixel Perfect Mode Enabled.
resize_mode = ResizeMode.INNER_FIT
raw_H = 512
raw_W = 512
target_H = 512
target_W = 512
estimation = 512.0
preprocessor resolution = 512
Data shape for DDIM sampling is (1, 4, 64, 64), eta 0.0
Things work okay-ish when I set the batch_size to 1. Here's an example:

If I keep the exact same parameters but change the batch_size to 4, images come out more and more distorted on each iteration. Here's the outputs in that case:

It's as if the batch_size is somehow re-feeding the outputs on the batch?
I have tried two clean installs and still cannot get ControlNet to show in the 1111 UI.. any ideas?
Trying out the new ControlNet 1.1 softedge, and I get this error on all the softedge preprocessors. Can't import safe_step?
Loading model from cache: control_v11p_sd15_softedge [a8575a2a]0:00, 1.30it/s]
Loading preprocessor: pidinet_safe
Error running process: F:\repos\auto111\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py
Traceback (most recent call last):
File "F:\repos\auto111\stable-diffusion-webui\modules\scripts.py", line 417, in process
script.process(p, *script_args)
File "F:\repos\auto111\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 870, in process
detected_map, is_image = preprocessor(input_image, res=unit.processor_res, thr_a=unit.threshold_a, thr_b=unit.threshold_b)
File "F:\repos\auto111\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\processor.py", line 281, in pidinet_safe
from annotator.pidinet import apply_pidinet
File "F:\repos\auto111\stable-diffusion-webui\extensions\sd-webui-controlnet\annotator\pidinet\__init__.py", line 6, in <module>
from annotator.util import safe_step
ImportError: cannot import name 'safe_step' from 'annotator.util' (F:\repos\auto111\stable-diffusion-webui\extensions\sd-webui-controlnet\annotator\util.py)
if yes how do I install?
as title.
(control-v11) M:\ControlNet-v1-1-nightly>python gradio_lineart_anime.py
logging improved.
Enabled sliced_attention.
logging improved.
Enabled clip hacks.
No module 'xformers'. Proceeding without it.
ControlLDM: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Loaded model config from [./models/control_v11p_sd15s2_lineart_anime.yaml]
Loaded state_dict from [./models/anything-v3-full.safetensors]
Loaded state_dict from [./models/control_v11p_sd15s2_lineart_anime.pth]
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Traceback (most recent call last):
File "F:\2\envs\control-v11\lib\site-packages\gradio\routes.py", line 337, in run_predict
output = await app.get_blocks().process_api(
File "F:\2\envs\control-v11\lib\site-packages\gradio\blocks.py", line 1015, in process_api
result = await self.call_function(
File "F:\2\envs\control-v11\lib\site-packages\gradio\blocks.py", line 833, in call_function
prediction = await anyio.to_thread.run_sync(
File "F:\2\envs\control-v11\lib\site-packages\anyio\to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "F:\2\envs\control-v11\lib\site-packages\anyio\_backends\_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "F:\2\envs\control-v11\lib\site-packages\anyio\_backends\_asyncio.py", line 867, in run
result = context.run(func, *args)
File "gradio_lineart_anime.py", line 46, in process
detected_map = preprocessor(resize_image(input_image, detect_resolution))
File "M:\ControlNet-v1-1-nightly\annotator\lineart_anime\__init__.py", line 141, in __call__
line = self.model(image_feed)[0, 0] * 127.5 + 127.5
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "M:\ControlNet-v1-1-nightly\annotator\lineart_anime\__init__.py", line 40, in forward
return self.model(input)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "M:\ControlNet-v1-1-nightly\annotator\lineart_anime\__init__.py", line 107, in forward
return self.model(x)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\container.py", line 139, in forward
input = module(input)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\conv.py", line 457, in forward
return self._conv_forward(input, self.weight, self.bias)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\conv.py", line 453, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZEDHi @lllyasviel,
I noticed that there are mainly two differences between v1.1 and v1.0:
What modifications did you make to get better results in v1.1? Did you re-train the model with better data or there are other important changes?
Hey!
Do you think it's possible to adapt ControlNet onto a LoRA network?
I think it could be really powerful for real-world tasks where a very specific output is desired. So potentially anyone could take a LoRA model from https://civitai.com and append a ControlNet to it.
Let me know if you have any pointers and I'll take it from there.
Thanks!
Hi, Thanks for your good works!
And about future most desired Condition Control, I have one suggestion and wish you could have a deployment about it in the future.
Now midjourney is a very famous tool and most people use it in design area. What attracts me the most is the way it uses reference images. It seems to use both the style and structure of the reference images, but the structure is not exactly the same as the reference images.
This method of using reference diagrams is very useful for design, so I hope to have a similar conditional control to achieve the same effect.

(control-v11) M:\ControlNet-v1-1-nightly>python gradio_lineart_anime.py
logging improved.
Enabled sliced_attention.
logging improved.
Enabled clip hacks.
No module 'xformers'. Proceeding without it.
ControlLDM: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Loaded model config from [./models/control_v11p_sd15s2_lineart_anime.yaml]
Loaded state_dict from [./models/anything-v3-full.safetensors]
Loaded state_dict from [./models/control_v11p_sd15s2_lineart_anime.pth]
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Global seed set to 12345
Traceback (most recent call last):
File "F:\2\envs\control-v11\lib\site-packages\gradio\routes.py", line 337, in run_predict
output = await app.get_blocks().process_api(
File "F:\2\envs\control-v11\lib\site-packages\gradio\blocks.py", line 1015, in process_api
result = await self.call_function(
File "F:\2\envs\control-v11\lib\site-packages\gradio\blocks.py", line 833, in call_function
prediction = await anyio.to_thread.run_sync(
File "F:\2\envs\control-v11\lib\site-packages\anyio\to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "F:\2\envs\control-v11\lib\site-packages\anyio\_backends\_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "F:\2\envs\control-v11\lib\site-packages\anyio\_backends\_asyncio.py", line 867, in run
result = context.run(func, *args)
File "gradio_lineart_anime.py", line 65, in process
cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]}
File "M:\ControlNet-v1-1-nightly\ldm\models\diffusion\ddpm.py", line 667, in get_learned_conditioning
c = self.cond_stage_model.encode(c)
File "M:\ControlNet-v1-1-nightly\ldm\modules\encoders\modules.py", line 131, in encode
return self(text)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "M:\ControlNet-v1-1-nightly\cldm\hack.py", line 65, in _hacked_clip_forward
y = transformer_encode(feed)
File "M:\ControlNet-v1-1-nightly\cldm\hack.py", line 42, in transformer_encode
rt = self.transformer(input_ids=t, output_hidden_states=True)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\transformers\models\clip\modeling_clip.py", line 722, in forward
return self.text_model(
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\transformers\models\clip\modeling_clip.py", line 643, in forward
encoder_outputs = self.encoder(
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\transformers\models\clip\modeling_clip.py", line 574, in forward
layer_outputs = encoder_layer(
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\transformers\models\clip\modeling_clip.py", line 317, in forward
hidden_states, attn_weights = self.self_attn(
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\transformers\models\clip\modeling_clip.py", line 209, in forward
query_states = self.q_proj(hidden_states) * self.scale
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "F:\2\envs\control-v11\lib\site-packages\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`Original Title: Is it possible to enhance the straight-line conditioning?
Hello, thank you for the great work. CN + SD really changed the design field a lot.
I'm from both architecture and computer science background, and am currently investigating how far we can go in this direction for conceptual design phase.
There's one issue that we've tried to improve for a while, but cannot get through:
SD w/o CN

SD with CN

If you look at the image above, the mullions and window frames are not straight, the lines are wobbly.
We used a screenshot of a 3D model for the conditioning, but regardless of the preprocessor used, the generated images always have more or less issues like this.
What we thought about the cause might be:
We also tried to use volume screenshot without the mullions, but the results are similar:
SD with CN

At this point, we'd like to seek advice from the developers how this issue can be improved:
awacke1/Image-to-Line-Drawings looks like a fork with minimal changes. The origin of the lineart annotator appears to be https://huggingface.co/spaces/carolineec/informativedrawings
Evidence:
Interestingly, there's a third model linked from the github page, which might be a good alternative to the current "softedge + blur + threshold" approach for estimating sketches
Hey! Thanks for all the amazing work on this project @lllyasviel.
We at Virtual Staging AI are experimenting with modifying ControlNet for virtual staging (adding furniture to empty rooms). Here's an example input/output pair using a 3D reconstruction model.

With ControlNet we've achieved fairly good results by superimposing M-LSD lines on top of the original room image
Obviously you can get powerful results by combining multiple conditions as described in the ControlNet article on Hugging Face but does it also make sense to jointly train ControlNets with different conditions?
For example, train with two conditions as input:
If so, is there code to train multiple ControlNets jointly? Or one ControlNet on multiple conditions?
Pardon me if I missed something, but the example for the filename format has sd21 and sd21 768 as hints that they exist, but they're not in the models folder. Is it just the config that sets the difference up? I would think the model has to be actually trained for 2.1.
The link in question: https://github.com/lllyasviel/ControlNet-v1-1-nightly
I tried typing git restore --source=HEAD :/ into a command line but nothing happened. Also deleted folders and tried again, no luck.
GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git clone -v -- https://github.com/lllyasviel/ControlNet-v1-1-nightly E:\AI\stable-diffusion-webui\stable-diffusion-webui\tmp\ControlNet-v1-1-nightly stderr: 'Cloning into 'E:\AI\stable-diffusion-webui\stable-diffusion-webui\tmp\ControlNet-v1-1-nightly'... POST git-upload-pack (185 bytes) POST git-upload-pack (227 bytes) Updating files: 72% (727/1009) Updating files: 73% (737/1009) Updating files: 74% (747/1009) error: unable to create file annotator/zoe/zoedepth/models/base_models/midas_repo/mobile/android/lib_support/src/main/java/org/tensorflow/lite/examples/classification/tflite/ClassifierQuantizedEfficientNet.java: Filename too long Updating files: 75% (757/1009) error: unable to create file annotator/zoe/zoedepth/models/base_models/midas_repo/mobile/android/lib_task_api/src/main/java/org/tensorflow/lite/examples/classification/tflite/ClassifierQuantizedEfficientNet.java: Filename too long Updating files: 76% (767/1009) Updating files: 77% (777/1009) Updating files: 78% (788/1009) Updating files: 79% (798/1009) Updating files: 80% (808/1009) Updating files: 81% (818/1009) Updating files: 82% (828/1009) Updating files: 83% (838/1009) Updating files: 84% (848/1009) Updating files: 85% (858/1009) Updating files: 86% (868/1009) Updating files: 87% (878/1009) Updating files: 88% (888/1009) Updating files: 89% (899/1009) Updating files: 90% (909/1009) Updating files: 91% (919/1009) Updating files: 92% (929/1009) Updating files: 93% (939/1009) Updating files: 94% (949/1009) Updating files: 95% (959/1009) Updating files: 96% (969/1009) Updating files: 97% (979/1009) Updating files: 98% (989/1009) Updating files: 99% (999/1009) Updating files: 100% (1009/1009) Updating files: 100% (1009/1009), done. fatal: unable to checkout working tree warning: Clone succeeded, but checkout failed. You can inspect what was checked out with 'git status' and retry with 'git restore --source=HEAD :/' '
Hi, thanks again for this amazing repo!
Os the process to train this repo, the same as the old one?
https://github.com/TencentARC/T2I-Adapter/blob/main/docs/coadapter.md
Can this system developed by Tencent improve control net in any way?
Thank you for creating such a wonderful work.
I would like to make a request to choose a different model for "line_art_anime model" instead of anything_v3_full.safetensors.
Of course, I understand that I can fork the gradio_lineart_anime.py file and modify the following line of code:
27 model.load_state_dict(load_state_dict('./models/anything-v3-full.safetensors', location='cuda'), strict=False)
to that for waifu or other anime model.
However, Anything-v3 model includes the NovelAI Leak, which may make it unusable in the future.
Therefore, if it is possible to select a model for line art anime from ./stable-diffusion-webui/models/Stable-diffusion or so on, and check it in the Automatic1111 WebUI Settings, it would be very helpful.
I'm sorry for my skilllessness and poor English.
Every pass with the inpainting model causes the image to become more desaturated and gain an increasingly green tint. It's a shame because it works really well otherwise. I hope some kind of update can fix this.
Problem:
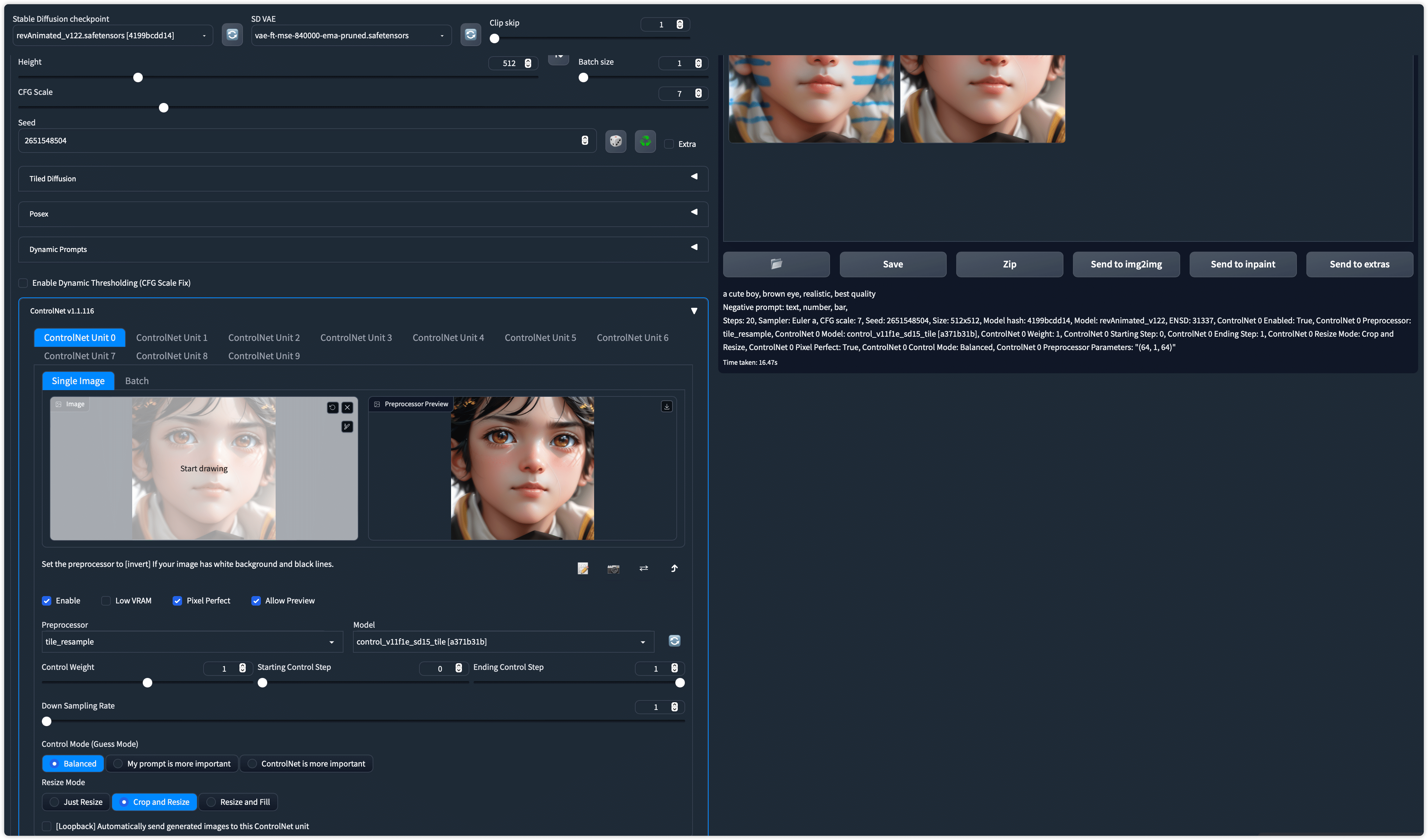
Blue color blocks always coming with the generated image when using control_v11f1e_sd15_tile (with or without preprocessor).
I'm not sure if it's caused by hardware because I'm using M1 Max 64G and running stable diffusion in CPU mode, I've seen others on Windows who don't have this issue.
Sample images generated with control_v11f1e_sd15_tile:
https://ax.minicg.com/images/cnet/1-0.png (original)
https://ax.minicg.com/images/cnet/1-1.png
https://ax.minicg.com/images/cnet/1-2.png
https://ax.minicg.com/images/cnet/1-3.png
https://ax.minicg.com/images/cnet/1-4.png
https://ax.minicg.com/images/cnet/2-0.png (original)
https://ax.minicg.com/images/cnet/2-1.png
https://ax.minicg.com/images/cnet/2-2.png
https://ax.minicg.com/images/cnet/2-3.png
https://ax.minicg.com/images/cnet/2-4.png
https://ax.minicg.com/images/cnet/2-5.png
https://ax.minicg.com/images/cnet/3-0.png (original)
https://ax.minicg.com/images/cnet/3-1.png
https://ax.minicg.com/images/cnet/3-2.png
https://ax.minicg.com/images/cnet/3-3.png
https://ax.minicg.com/images/cnet/3-4.png
https://ax.minicg.com/images/cnet/settings.png (Down Sampling Rate from 1~8 tested)
Parameters attached with PNG file, can be read using PNG INFO in sd-webui.
Hello, I wanted to express my gratitude for the incredible work you and your team have done on ControlNet1.1. It's truly fantastic and awe-inspiring.
I was wondering if there's any further information available on the training and implementation details of this update (especially the amazing 'tile' mode). Would there be a blog, discussion, or paper where I could learn more about it? I believe this would greatly benefit the research community and advance the progress in this field.
Thank you once again for your hard work and dedication to advancing the state-of-the-art.
Great works.
By the way I am planning to make a tutorial for v 1.1 too
will it come to automatic1111 very fast or should I make a new tutorial right now?
Hi everyone, thank you @lllyasviel for this wonderful tool you made !
I've been trying to finetune one of the latest V1.1 model : openpose.
I managed to modify the tutorial_train.py and tutorial_dataset.py from the original repo to make the training start but it doesn't seem to be following the openpose at all in the current early stages of training (< 10k steps).
I've tried to hack the tool_add_control and tool_transfer_control scripts to create a model with the latest of V1.1 ControlNet Openpose weights that I could feed to tutorial_train but it seems it's restarting from scratch anyway.
Can you provide some guidelines or feedback on how to finetune an existing model please ?
Thanks
Hi! I know using shuffle with deforum is probably a bad idea anyway but I sorta want to play and see if I can wrangle it into doing anything interesting. I get this error when I try and use it anyway (with no preprocessor. That works fine in regular img2img)
Error running process: D:\Users\Ben\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py
Traceback (most recent call last):
File "D:\Users\Ben\stable-diffusion-webui\modules\scripts.py", line 409, in process
script.process(p, *script_args)
File "D:\Users\Ben\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 719, in process
model_net = self.load_control_model(p, unet, unit.model, unit.low_vram)
File "D:\Users\Ben\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 502, in load_control_model
model_net = self.build_control_model(p, unet, model, lowvram)
File "D:\Users\Ben\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 544, in build_control_model
assert os.path.exists(override_config), f'Error: The model config {override_config} is missing. ControlNet 1.1 must have configs.'
AssertionError: Error: The model config D:\Users\Ben\stable-diffusion-webui\models\ControlNet\controlnet11Models_shuffle.yaml is missing. ControlNet 1.1 must have configs.
Dear Lvmin,
Thank you for sharing these good models.
I try the ControlNet 1.1 Instruct Pix2Pix, but the results are not very good. I use the default parameters.



Any thing I can do to make the results look better?
Thank you for your help.
Best Wishes,
Zongze
我的需求是这样的,我在文生图里面,已经生成好了角色的全裸姿态的图了。然后用CN的lineArtAnime控制好了主体画面的构图和要素了。接着下一步流程就是生成衣服了,我试着把CN里面的身体部分的控制线给擦除了,但是CN始终能把我擦除的部分给猜出来,只能画出很贴身体的服装出来,无法生成蓬松的衣服的样子。
所以我希望CN能出个蒙版功能,让SD在我指定的蒙版范围不受到到CN的控制,可以自由地画各种各样的衣服,来实现迭代的样子。
PS:如果是用inpaint的话,会多一次性能消耗,而且流程上会复杂很多的样子。
谢谢,伊莉雅大人。
Dear Lvmin,
Thank you for sharing these great models.
Could you tell me what is the PIDI estimator in the scribble model? Could you provide me the reference?
Thank you for your help.
Best Wishes,
Zongze
Hi,
I want to put some of the 1.1 models converted into Diffusers format on Hugging Face. Is the license for ControlNet 1.1 models the same as for 1.0 (The CreativeML OpenRAIL M license)?
Hi,
The gradio script for inpainting controlnet set -1 for the masked areas.
How can we do this via diffusers library that takes a PIL image? I tried creating the PIL image of float32 type, but it does not work for RGB or RGBA images.
i updated my controlnet yesterday and its very good to use, thank you!
but everytime i select openpose(face/faceonly/full) in preprocessor it wont work, show "AttributeError: 'NoneType' object has no attribute 'model'"
is that a bug or i operate incorrectlly?(other preprocessor works well, and three pth files were saved in "extensions\sd-webui-controlnet\annotator\downloads\openpose")
how to use TILE? it is super interesting but i dont get it, tryed everything
The main instruction page has this recommendation:
Note that if you use 8GB GPU, you need to set "save_memory = True" in "config.py".
Like at least one other person on Reddit, I have (as the owner of a 2070S with 8GB memory) no idea how to follow this instruction. There are multiple config.py files in the ControlNet folder alone, and dozens in AUTO1111. Are we supposed to create this file and put the flag in there? If so, saved where?
Is it possible that this instruction could be made much clearer on the main page?
when running large images, i noticed the softedge hed model very slightly warps large images, this causes problems when you're using it with any systems that combine 4 images into 1 image to be processed, then recombine as it makes the result jump around.
I have attached demonstration images, you can tell by overlaying them, this does not happen with openpose only i have observed and happens with pixel perfect both on and off.


Could you share some details of training the shuffle controlnet, e.g. about the training datasets and strategies?
When I change the resolution to 320 or more,it's much better.Does anyone have the same problem?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}