liqihan / blog Goto Github PK
View Code? Open in Web Editor NEW博客、文章、代码......随便写点东西,记一下
License: MIT License
博客、文章、代码......随便写点东西,记一下
License: MIT License
取这样的标题可能会被打,可是我确实顺带解决了淘宝flexible.js的问题。
先声明两个变量供下文使用:
//html style font-size
docElementFontSize= document.documentElement.style.fontSize;
//html 最终的 font-size
finalDocElementFontSize= window.getComputedStyle(window.document.documentElement).getPropertyValue("font-size")
rem是根据html的最终font-size进行响应: 1rem === finalDocElementFontSize(重点!) 。对于大部分机型,docElementFontSize和finalDocElementFontSize是相等的,但是有些网页在某些情况下打开的话,会得到docElementFontSize和finalDocElementFontSize不相等的情况,比如我公司的小米Max和荣耀8机型,在市场上算是比较新的机型,测试数据都是在QQ上演示,公司的土豪APP也会有这种情况。如下图:
小米Max
这是在小米Max的QQ开的测试页面 ,大佬可以扒网页看js,屏幕宽度是393px,html的style.fontSize是39.3px(页面宽度分成10等分),然而html最终fontSize是45.195px!!!下面设置一个灰色的box,高度是1rem,得到的样式高度是45.1875px!!!看到这很毁三观有木有。我在百度和谷歌没有查到关于这个的任何问题和资料。众所周知淘宝玩rem玩的飞起,用QQ打开m.taobao.com如下图:
小米Max 淘宝
淘宝在body写了overflow:hidden;width:100%;所以页面宽度超出部分隐藏了,再结合我测试的第一张图,页面宽度是393px,1rem=45.1875px,那10rem就超出了页面宽度。事实确实如此,如果设置页面宽度10rem,页面会出现横向滚动条。
解决方法也很简单,因为这类异常手机html的style.fontSize、html最终的fontSize和页面元素1rem的值都不相等,但是1rem和html的最终fontSize很接近。代码如下
/*
* 适用于获取屏幕宽度等分设置html的font-size情况,比如 flexible.js库
*/
//计算最终html font-size
functionmodifileRootRem(){
varroot= window.document.documentElement;
varfontSize= parseFloat(root.style.fontSize);
varfinalFontSize= parseFloat(window.getComputedStyle(root).getPropertyValue("font-size"));
if(finalFontSize=== fontSize)return;
root.style.fontSize= fontSize+(fontSize-finalFontSize)+ "px";
}
if(typeofwindow.=== 'function'){
varoldFun= window.;
window.= function(){
oldFun();
modifileRootRem();
}
}else{
window.= modifileRootRem;
}
通过docElementFontSize+(docElementFontSize – finalDocElementFontSize) 得到html.fontSize的值。适用这类特异机型的html.fontSize!
这个问题我特意问了下大漠老师,大佬只是说进行“特定”处理,看淘宝首页的情况也没做好很好的兼容,不出意外,我这是针对这类机型rem布局兼容的首创代码!
如有疑问欢迎评论讨论
觉得本文对你有帮助?请分享给更多人
关于Hybrid模式开发app的好处,网络上已有很多文章阐述了,这里不展开。
本文将从以下几个方面阐述Hybrid app架构设计的一些经验和思考。
原文及讨论请到 github issue
作为一种跨语言开发模式,通讯层是Hybrid架构首先应该考虑和设计的,往后所有的逻辑都是基于通讯层展开。
Native(以Android为例)和H5通讯,基本原理:
Android调用H5:通过webview类的loadUrl方法可以直接执行js代码,类似浏览器地址栏输入一段js一样的效果
webview.loadUrl(<span class="hljs-string">"javascript: alert('hello world')"</span>);`</pre>
H5调用Android:webview可以拦截H5发起的任意url请求,webview通过约定的规则对拦截到的url进行处理(消费),即可实现H5调用Android
`var ifm = document.createElement('iframe'); ifm.src = 'jsbridge://namespace.method?[...args]';`
JSBridge即我们通常说的桥协议,基本的通讯原理很简单,接下来就是桥协议具体实现。
P.S:注册私有协议的做法很常见,我们经常遇到的在网页里拉起一个系统app就是采用私有协议实现的。app在安装完成之后会注册私有协议到OS,浏览器发现自身不能识别的协议(http、https、file等)时,会将链接抛给OS,OS会寻找可识别此协议的app并用该app处理链接。比如在网页里以itunes://开头的链接是Apple Store的私有协议,点击后可以启动Apple Store并且跳转到相应的界面。国内软件开发商也经常这么做,比如支付宝的私有协议alipay://,腾讯的tencent://等等。
由于JavaScript语言自身的特殊性(单进程),为了不阻塞主进程并且保证H5调用的有序性,与Native通讯时对于需要获取结果的接口(GET类),采用类似于JSONP的设计理念:
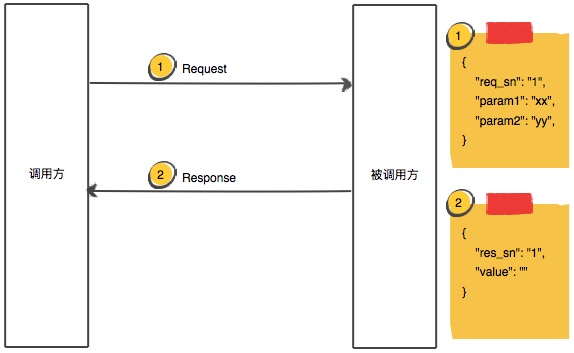
类比HTTP的request和response对象,调用方会将调用的api、参数、以及请求签名(由调用方生成)带上传给被调用方,被调用方处理完之后会吧结果以及请求签名回传调用方,调用方再根据请求签名找到本次请求对应的回调函数并执行,至此完成了一次通讯闭环。
H5调用Native(以Android为例)示意图:
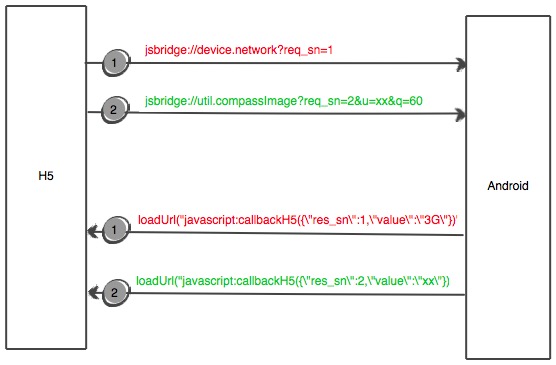
Native(以Android为例)调用H5示意图:
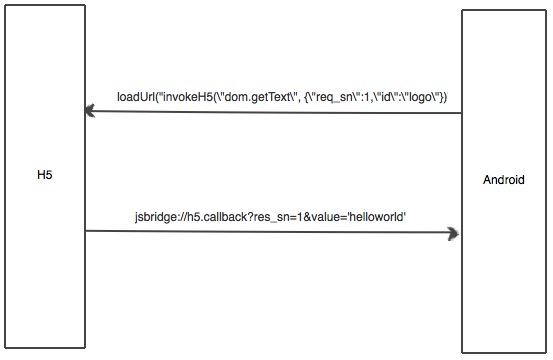
jsbridge作为一种通用私有协议,一般会在团队级或者公司级产品进行共享,所以需要和业务层进行解耦,将jsbridge的内部细节进行封装,对外暴露平台级的API。
以下是笔者剥离公司业务代码后抽象出的一份HybridApi js部分的实现,项目地址:
另外,对于Native提供的各种接口,也可以简单封装下,使之更贴近前端工程师的使用习惯:
`// /lib/jsbridge/core.js
function assignAPI(name, callback) {
var names = name.split(/./);
var ns = names.shift();<span class="hljs-keyword">var</span> fnName = names.pop(); <span class="hljs-keyword">var</span> root = createNamespace(JSBridge[ns], names); <span class="hljs-keyword">if</span>(fnName) root[fnName] = callback || <span class="hljs-function"><span class="hljs-keyword">function</span>(<span class="hljs-params"></span>) </span>{};}`
增加api:
`// /lib/jsbridge/api.js var assign = require('./core.js').assignAPI; ... assign('util.compassImage', function(path, callback, quality, width, height) { JSBridge.invokeApp('os.getInfo', { path: path, quality: quality || 80, width: width || 'auto', height: height || 'auto', callback: callback }); });`H5上层应用调用:
`// h5/music/index.js JSBridge.util.compassImage('http://cdn.foo.com/images/bar.png', function(r) { console.log(r.value); // => base64 data });`界面与交互(Native与H5职责划分)
本质上,Native和H5都能完成界面开发。几乎所有hybrid的开发模式都会碰到同样的一个问题:哪些由Native负责哪些由H5负责?
这个回到原始的问题上来:我们为什么要采用hybrid模式开发?简而言之就是同时利用H5的跨平台、快速迭代能力以及Native的流畅性、系统API调用能力。
根据这个原则,为了充分利用二者的优势,应该尽可能地将app内容使用H5来呈现,而对于js语言本身的缺陷,应该使用Native语言来弥补,如转场动画、多线程作业(密集型任务)、IO性能等。即总的原则是H5提供内容,Native提供容器,在有可能的条件下对Android原生webview进行优化和改造(参考阿里Hybrid容器的JSM),提升H5的渲染效率。
但是,在实际的项目中,将整个app所有界面都使用H5来开发也有不妥之处,根据经验,以下情形还是使用Native界面为好:
关键界面、交互性强的的界面使用Native
因H5比较容易被恶意攻击,对于安全性要求比较高的界面,如注册界面、登陆、支付等界面,会采用Native来取代H5开发,保证数据的安全性,这些页面通常UI变更的频率也不高。
对于这些界面,降级的方案也有,就是HTTPS。但是想说的是在国内的若网络环境下,HTTPS的体验实在是不咋地(主要是慢),而且只能走现网不能走离线通道。
另外,H5本身的动画开发成本比较高,在低端机器上可能有些绕不过的性能坎,原生js对于手势的支持也比较弱,因此对于这些类型的界面,可以选择使用Native来实现,这也是Native本身的优势不是。比如要实现下面这个音乐播放界面,用H5开发门槛不小吧,留意下中间的波浪线背景,手指左右滑动可以切换动画。
导航组件采用Native
导航组件,就是页面的头组件,左上角一般都是一个back键,中间一般都是界面的标题,右边的话有时是一个隐藏的悬浮菜单触发按钮有时则什么也没有。
移动端有一个特性就是界面下拉有个回弹效果,头不动body部分跟着滑动,这种效果H5比较难实现。
再者,也是最重要的一点,如果整个界面都是H5的,在H5加载过程中界面将是白屏,在弱网络下用户可能会很疑惑。
所以基于这两点,打开的界面都是Native的导航组件+webview来组成,这样即使H5加载失败或者太慢用户可以选择直接关闭。
在API层面,会相应的有一个接口来实现这一逻辑(例如叫
JSBridge.layout.setHeader),下面代码演示定制一个只有back键和标题的导航组件:`// /h5/pages/index.js JSBridge.layout.setHeader({ background: { color: '#00FF00', opacity: 0.8 }, buttons: [ // 默认只有back键,并且back键的默认点击处理函数就是back() { icon: '../images/back.png', width: 16, height: 16, onClick: function() { // todo... JSBridge.back(); } }, { text: '音乐首页', color: '#00FF00', fontSize: 14, left: 10 } ] });`上面的接口,可以满足绝大多数的需求,但是还有一些特殊的界面,通过H5代码控制生成导航组件这种方式达不到需求:
如上图所示,界面含有tab,且可以左右滑动切换,tab标题的下划线会跟着手势左右滑动。大多见于app的首页(mainActivity)或者分频道首页,这种界面一般采用定制webview的做法:定制的导航组件和内容框架(为了支持左右滑动手势),H5打开此类界面一般也是开特殊的API:
`// /h5/pages/index.js // 开打音乐频道下“我的音乐”tab JSBridge.view.openMusic({'tab': 'personal'});`这种打开特殊的界面的API之所以特殊,是因为它内部要么是纯Native实现,要么是和某个约定的html文件绑定,调用时打开指定的html。假设这个例子中,tab内容是H5的,如果H5是SPA架构的那么
openMusic({'tab': 'personal'})则对应/music.html#personal这个url,反之多页面的则可能对应/mucic-personal.html。至于一般的打开新界面,则有两种可能:
app内H5界面
`指的是由app开发者开发的H5页面,也即是app的功能界面,一般互相跳转需要转场动画,打开方式是采用Native提供的接口打开,例如: ``JSBridge.view.openUrl({ url: '/music-list.html', title: '音乐列表' });``再配合下面即将提到的离线访问方式,基本可以做到模拟Native界面的效果。 `第三方H5页面
`指的是app内嵌的第三方页面,一般由`a`标签直接打开,没有转场动画,但是要求打开webview默认的历史列表,以免打开多个链接后点回退直接回到Native主界面。 `系统级UI组件采用Native
基于以下原因,一些通用的UI组件,如alert、toast等将采用Native来实现:
H5本身有这些组件,但是通常比较简陋,不能和APP UI风格统一,需要再定制,比如alert组件背景增加遮罩层
H5来实现这些组件有时会存在坐标、尺寸计算误差,比如笔者之前遇到的是页面load异常需要调用对话框组件提示,但是这时候页面高度为0,所以会出现弹窗“消失”的现象
这些组件通常功能单一但是通用,适合做成公用组件整合到HybridApi里边
下面代码演示H5调用Native提供的UI组件:
`JSBridge.ui.toast('Hello world!');`默认界面采用Native
由于H5是在H5容器里进行加载和渲染,所以Native很容易对H5页面的行为进行监控,包括进度条、loading动画、404监控、5xx监控、网络诊断等,并且在H5加载异常时提供默认界面供用户操作,防止APP“假死”。
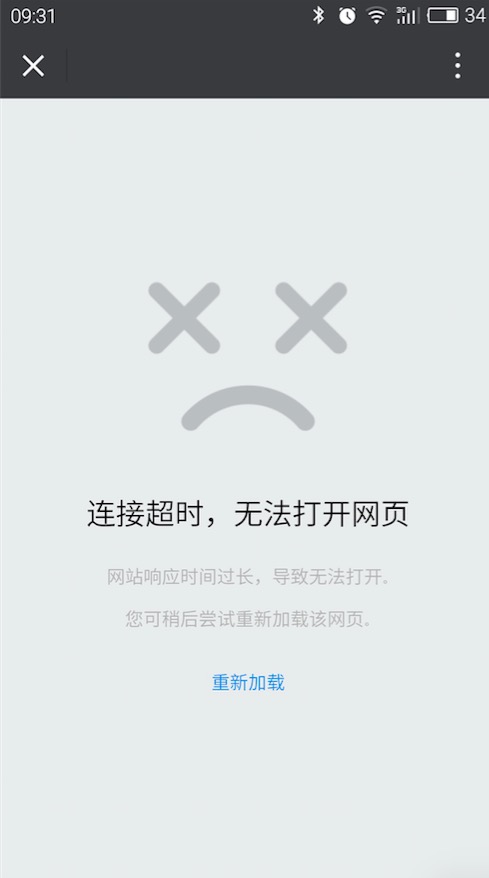
下面是微信的5xx界面示意:
设计H5容器
Native除了负责部分界面开发和公共UI组件设计之外,作为H5的runtime,H5容器是hybrid架构的核心部分,为了让H5运行更快速稳定和健壮,还应当提供并但不局限于下面几方面。
H5离线访问
之所以选择hybrid方式来开发,其中一个原因就是要解决webapp访问慢的问题。即使我们的H5性能优化做的再好服务器在牛逼,碰到蜗牛一样的运营商网络你也没辙,有时候还会碰到流氓运营商再给webapp插点广告。。。哎说多了都是泪。
离线访问,顾名思义就是将H5预先放到用户手机,这样访问时就不会再走网络从而做到看起来和Native APP一样的快了。
但是离线机制绝不是把H5打包解压到手机sd卡这么简单粗暴,应该解决以下几个问题:
H5应该有线上版本
`作为访问离线资源的降级方案,当本地资源不存在的时候应该走现网去拉取对应资源,保证H5可用。另外就是,对于H5,我们不会把所有页面都使用离线访问,例如活动页面,这类快速上线又快速下线的页面,设计离线访问方式开发周期比较高,也有可能是页面完全是动态的,不同的用户在不同的时间看到的页面不一样,没法落地成静态页面,还有一类就是一些说明类的静态页面,更新频率很小的,也没必要做成离线占用手机存储空间。 `开发调试&抓包
`我们知道,基于file协议开发是完全基于开发机的,代码必须存放于物理机器,这意味着修改代码需要push到sd卡再看效果,虽然可以通过假链接访问开发机本地server发布时移除的方式,但是个人觉得还是太麻烦易出错。 `为了实现同一资源的线上和离线访问,Native需要对H5的静态资源请求进行拦截判断,将静态资源“映射”到sd卡资源,即实现一个处理H5资源的本地路由,实现这一逻辑的模块暂且称之为
Local Url Router,具体实现细节在文章后面。H5离线动态更新机制
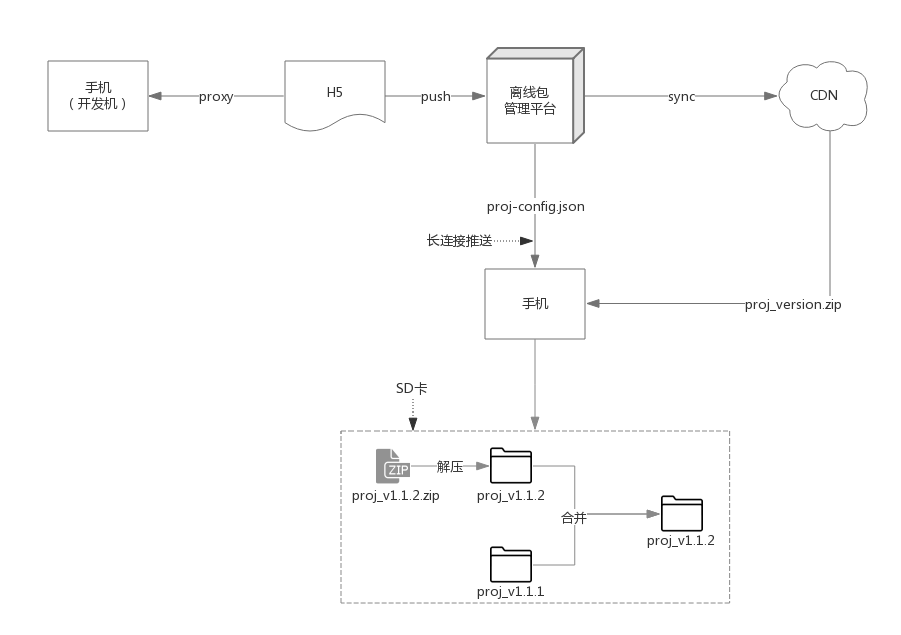
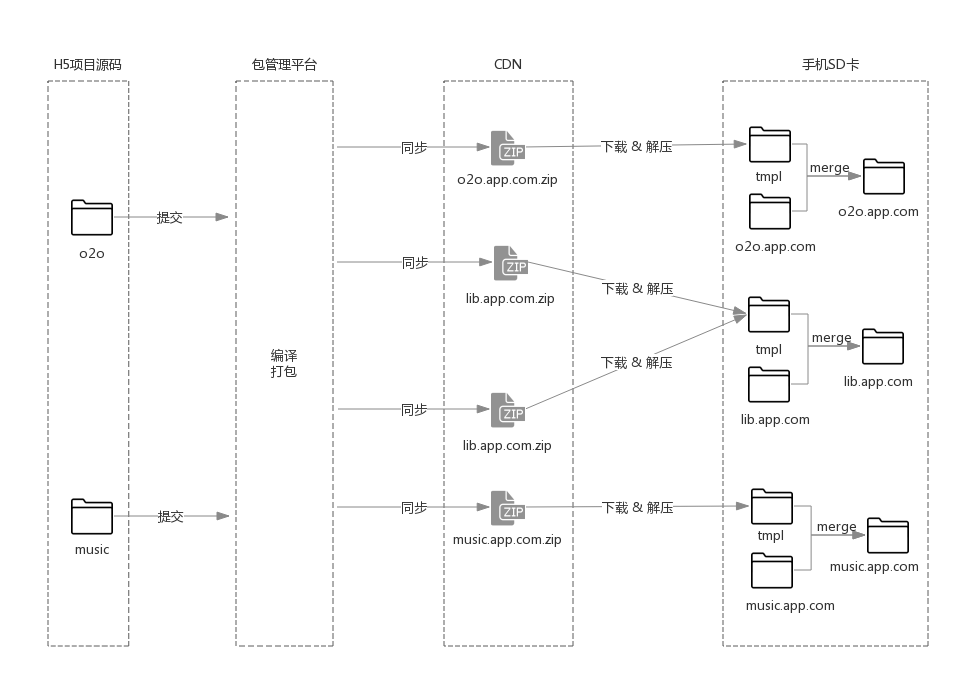
将H5资源放置到本地离线访问,最大的挑战就是本地资源的动态更新如何设计,这部分可以说是最复杂的了,因为这同时涉及到H5、Native和服务器三方,覆盖式离线更新示意图如下:
解释下上图,开发阶段H5代码可以通过手机设置HTTP代理方式直接访问开发机。完成开发之后,将H5代码推送到管理平台进行构建、打包,然后管理平台再通过事先设计好的长连接通道将H5新版本信息推送给客户端,客户端收到更新指令后开始下载新包、对包进行完整性校验、merge回本地对应的包,更新结束。
其中,管理平台推送给客户端的信息主要包括项目名(包名)、版本号、更新策略(增量or全量)、包CDN地址、MD5等。
通常来说,H5资源分为两种,经常更新的业务代码和不经常更新的框架、库代码和公用组件代码,为了实现离线资源的共享,在H5打包时可以采用分包的策略,将公用部分单独打包,在本地也是单独存放,分包及合并示意图:
Local Url Router
离线资源更新的问题解决了,剩下的就是如何使用离线资源了。
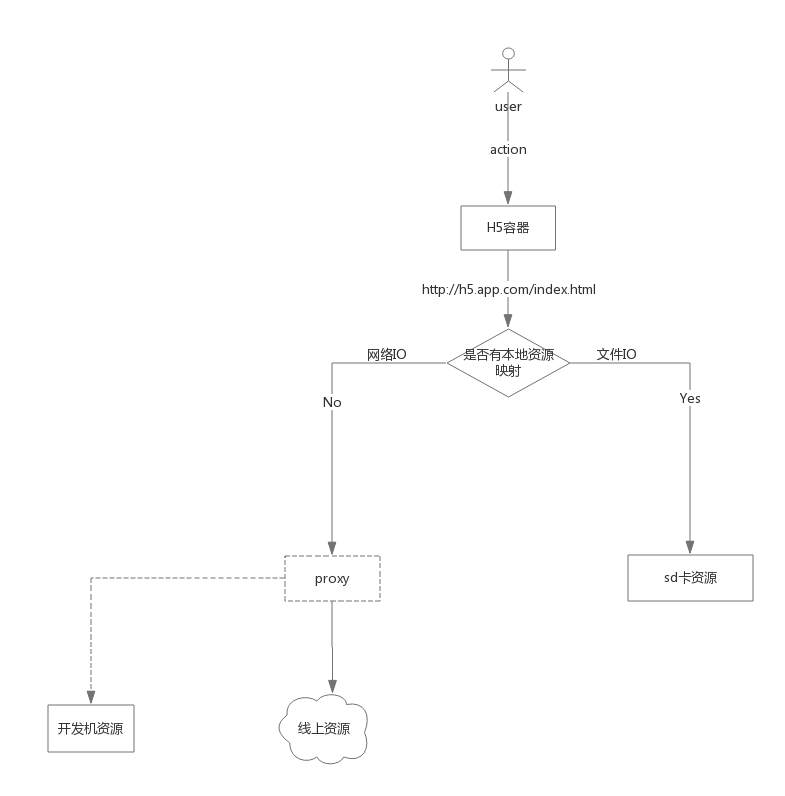
上面已经提到,对于H5的请求,线上和离线采用相同的url访问,这就需要H5容器对H5的资源请求进行拦截“映射”到本地,即
Local Url Router。Local Url Router主要负责H5静态资源请求的分发(线上资源到sd卡资源的映射),但是不管是白名单还是过滤静态文件类型,Native拦截规则和映射规则将变得比较复杂。这里,阿里去啊app的思路就比较赞,我们借鉴一下,将映射规则交给H5去生成:H5开发完成之后会扫描H5项目然后生成一份线上资源和离线资源路径的映射表(souce-router.json),H5容器只需负责解析这个映射表即可。
H5资源包解压之后在本地的目录结构类似:
`$ cd h5 && tree . ├── js/ ├── css/ ├── img/ ├── pages │ ├── index.html │ └── list.html └── souce-router.json`souce-router.json的数据结构类似:
`{ "protocol": "http", "host": "o2o.xx.com", "localRoot": "[/storage/0/data/h5/o2o/]", "localFolder": "o2o.xx.com", "rules": { "/index.html": "pages/index.html", "/js/": "js/" } }H5容器拦截到静态资源请求时,如果本地有对应的文件则直接读取本地文件返回,否则发起HTTP请求获取线上资源,如果设计完整一点还可以考虑同时开启新线程去下载这个资源到本地,下次就走离线了。
下图演示资源在app内部的访问流程图:
其中proxy指的是开发时手机设置代理http代理到开发机。
数据通道
- 上报
由于界面由H5和Native共同完成,界面上的用户交互埋点数据最好由H5容器统一采集、上报,还有,由页面跳转产生的浏览轨迹(转化漏斗),也由H5容器记录和上报
- ajax代理
因ajax受同源策略限制,可以在hybridApi层对ajax进行统一封装,同时兼容H5容器和浏览器runtime,采用更高效的通讯通道加速H5的数据传输
Native对H5的扩展
主要指扩展H5的硬件接口调用能力,比如屏幕旋转、摄像头、麦克风、位置服务等等,将Native的能力通过接口的形式提供给H5。
综述
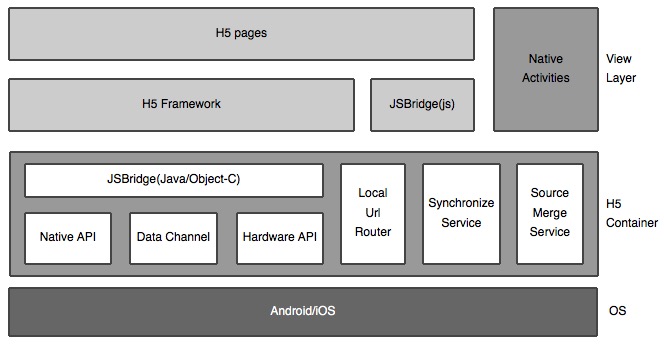
最后来张图总结下,hybrid客户端整体架构图:
其中的
Synchronize Service模块表示和服务器的长连接通信模块,用于接受服务器端各种推送,包括离线包等。Source Merge Service模块表示对解压后的H5资源进行更新,包括增加文件、以旧换新以及删除过期文件等。可以看到,hybrid模式的app架构,最核心和最难的部分都是H5容器的设计。
单页应用中在微信页面中设置标题
单页应用在微信中设置标题
正常来说,一个h5页面分享到微信中,或者用微信扫一扫打开的页面,微信会默认赌气head标签中的title,来设置成当前页面的标题。
但是当我们使用vue或者react来构建单页面应用的时候,比如文章详情页面中,底部有相关阅读的跳转,点击之后并不会设置当前页面的标题。所以会导致体验不是特别好。后来试了一下,用iframe完美的解决了这个问题,
详情代码请看
补充:
为什么可以通过iframe来设置微信中页面的标题呢?
以为iframe中加载的是文档,加载完成会触发ios监听中的onpageshow方法,所以同理可以在其他app内,但前提是ios提供了监听方法前端代码异常监控
前端代码异常监控实战
前言
之前在对公司的前端代码脚本错误进行排查,试图降低 JS Error 的错误量,结合自己之前的经验对这方面内容进行了实践并总结,下面就此谈谈我对前端代码异常监控的一些见解。
本文大致围绕下面几点展开讨论:
- JS 处理异常的方式
- 上报方式
- 异常监控上报常见问题
JS 异常处理
对于 Javascript 而言,我们面对的仅仅只是异常,异常的出现不会直接导致 JS 引擎崩溃,最多只会使当前执行的任务终止。
- 当前代码块将作为一个任务压入任务队列中,JS 线程会不断地从任务队列中提取任务执行。
- 当任务执行过程中出现异常,且异常没有捕获处理,则会一直沿着调用栈一层层向外抛出,最终终止当前任务的执行。
- JS 线程会继续从任务队列中提取下一个任务继续执行。
<script> error console.log('永远不会执行'); </script> <script> console.log('我继续执行') </script>
在对脚本错误进行上报之前,我们需要对异常进行处理,程序需要先感知到脚本错误的发生,然后再谈异常上报。
脚本错误一般分为两种:语法错误,运行时错误。
下面就谈谈几种异常监控的处理方式:
try-catch 异常处理
try-catch 在我们的代码中经常见到,通过给代码块进行 try-catch 进行包装后,当代码块发生出错时 catch 将能捕捉到错误的信息,页面也将可以继续执行。
但是 try-catch 处理异常的能力有限,只能捕获捉到运行时非异步错误,对于语法错误和异步错误就显得无能为力,捕捉不到。
示例:运行时错误
try { error // 未定义变量 } catch(e) { console.log('我知道错误了'); console.log(e); }
然而对于语法错误和异步错误就捕捉不到了。
示例:语法错误
try { var error = 'error'; // 大写分号 } catch(e) { console.log('我感知不到错误'); console.log(e); }
一般语法错误在编辑器就会体现出来,常表现的错误信息为: Uncaught SyntaxError: Invalid or unexpected token xxx 这样。但是这种错误会直接抛出异常,常使程序崩溃,一般在编码时候容易观察得到。
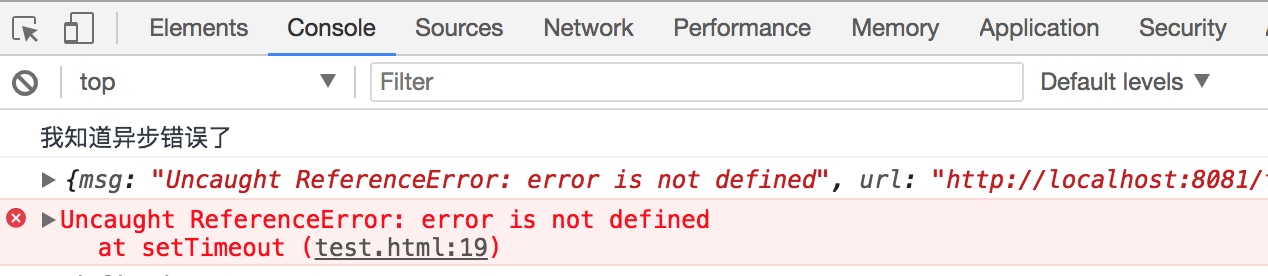
示例:异步错误
try { setTimeout(() => { error // 异步错误 }) } catch(e) { console.log('我感知不到错误'); console.log(e); }
除非你在 setTimeout 函数中再套上一层 try-catch,否则就无法感知到其错误,但这样代码写起来比较啰嗦。
window.onerror 异常处理
window.onerror 捕获异常能力比 try-catch 稍微强点,无论是异步还是非异步错误,onerror 都能捕获到运行时错误。
示例:运行时同步错误
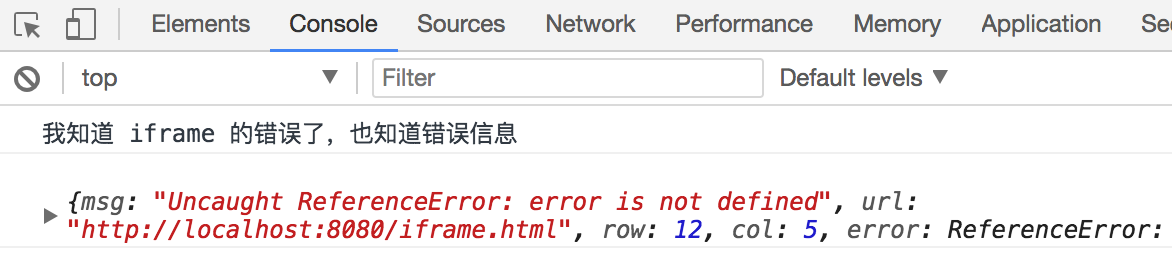
/** * @param {String} msg 错误信息 * @param {String} url 出错文件 * @param {Number} row 行号 * @param {Number} col 列号 * @param {Object} error 错误详细信息 */ window.onerror = function (msg, url, row, col, error) { console.log('我知道错误了'); console.log({ msg, url, row, col, error }) return true; }; error;
示例:异步错误
window.onerror = function (msg, url, row, col, error) { console.log('我知道异步错误了'); console.log({ msg, url, row, col, error }) return true; }; setTimeout(() => { error; });
然而 window.onerror 对于语法错误还是无能为力,所以我们在写代码的时候要尽可能避免语法错误的,不过一般这样的错误会使得整个页面崩溃,还是比较容易能够察觉到的。
在实际的使用过程中,onerror 主要是来捕获预料之外的错误,而 try-catch 则是用来在可预见情况下监控特定的错误,两者结合使用更加高效。
需要注意的是,window.onerror 函数只有在返回 true 的时候,异常才不会向上抛出,否则即使是知道异常的发生控制台还是会显示 Uncaught Error: xxxxx。
关于 window.onerror 还有两点需要值得注意
- 对于 onerror 这种全局捕获,最好写在所有 JS 脚本的前面,因为你无法保证你写的代码是否出错,如果写在后面,一旦发生错误的话是不会被 onerror 捕获到的。
- 另外 onerror 是无法捕获到网络异常的错误。
当我们遇到
<img src="./404.png">报 404 网络请求异常的时候,onerror 是无法帮助我们捕获到异常的。<script> window.onerror = function (msg, url, row, col, error) { console.log('我知道异步错误了'); console.log({ msg, url, row, col, error }) return true; }; </script> <img src="./404.png">
由于网络请求异常不会事件冒泡,因此必须在捕获阶段将其捕捉到才行,但是这种方式虽然可以捕捉到网络请求的异常,但是无法判断 HTTP 的状态是 404 还是其他比如 500 等等,所以还需要配合服务端日志才进行排查分析才可以。
<script> window.addEventListener('error', (msg, url, row, col, error) => { console.log('我知道 404 错误了'); console.log( msg, url, row, col, error ); return true; }, true); </script> <img src="./404.png" alt="">
这点知识还是需要知道,要不然用户访问网站,图片 CDN 无法服务,图片加载不出来而开发人员没有察觉就尴尬了。
Promise 错误
通过 Promise 可以帮助我们解决异步回调地狱的问题,但是一旦 Promise 实例抛出异常而你没有用 catch 去捕获的话,onerror 或 try-catch 也无能为力,无法捕捉到错误。
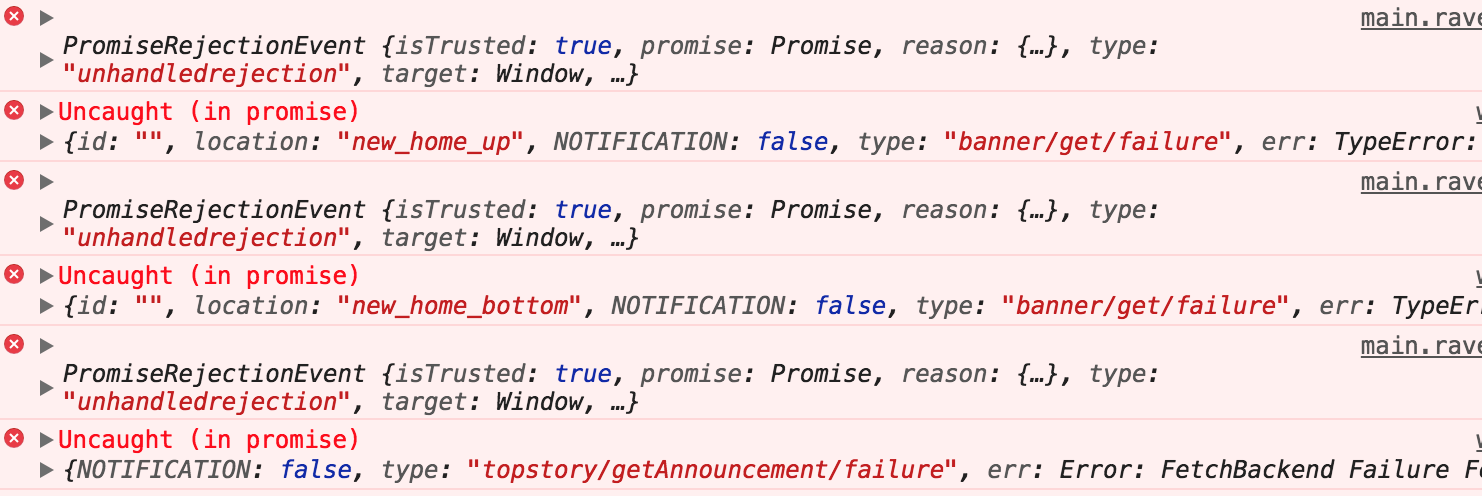
window.addEventListener('error', (msg, url, row, col, error) => { console.log('我感知不到 promise 错误'); console.log( msg, url, row, col, error ); }, true); Promise.reject('promise error'); new Promise((resolve, reject) => { reject('promise error'); }); new Promise((resolve) => { resolve(); }).then(() => { throw 'promise error' });
虽然在写 Promise 实例的时候养成最后写上 catch 函数是个好习惯,但是代码写多了就容易糊涂,忘记写 catch。
所以如果你的应用用到很多的 Promise 实例的话,特别是你在一些基于 promise 的异步库比如 axios 等一定要小心,因为你不知道什么时候这些异步请求会抛出异常而你并没有处理它,所以你最好添加一个 Promise 全局异常捕获事件 unhandledrejection。
window.addEventListener("unhandledrejection", function(e){ e.preventDefault() console.log('我知道 promise 的错误了'); console.log(e.reason); return true; }); Promise.reject('promise error'); new Promise((resolve, reject) => { reject('promise error'); }); new Promise((resolve) => { resolve(); }).then(() => { throw 'promise error' });
当然,如果你的应用没有做 Promise 全局异常处理的话,那很可能就像某乎首页这样:
异常上报方式
监控拿到报错信息之后,接下来就需要将捕捉到的错误信息发送到信息收集平台上,常用的发送形式主要有两种:
- 通过 Ajax 发送数据
- 动态创建 img 标签的形式
实例 - 动态创建 img 标签进行上报
function report(error) { var reportUrl = 'http://xxxx/report'; new Image().src = reportUrl + 'error=' + error; }监控上报常见问题
下述例子我全部放在我的 github 上,读者可以自行查阅,后面不再赘述。
git clone https://github.com/happylindz/blog.git cd blog/code/jserror/ npm installScript error 脚本错误是什么
因为我们在线上的版本,经常做静态资源 CDN 化,这就会导致我们常访问的页面跟脚本文件来自不同的域名,这时候如果没有进行额外的配置,就会容易产生 Script error。
可通过
npm run nocors查看效果。Script error 是浏览器在同源策略限制下产生的,浏览器处于对安全性上的考虑,当页面引用非同域名外部脚本文件时中抛出异常的话,此时本页面是没有权利知道这个报错信息的,取而代之的是输出 Script error 这样的信息。
这样做的目的是避免数据泄露到不安全的域中,举个简单的例子,
<script src="xxxx.com/login.html"></script>上面我们并没有引入一个 js 文件,而是一个 html,这个 html 是银行的登录页面,如果你已经登录了,那 login 页面就会自动跳转到
Welcome xxx...,如果未登录则跳转到Please Login...,那么报错也会是Welcome xxx... is not defined,Please Login... is not defined,通过这些信息可以判断一个用户是否登录他的帐号,给入侵者提供了十分便利的判断渠道,这是相当不安全的。介绍完背景后,那么我们应该去解决这个问题?
首先可以想到的方案肯定是同源化策略,将 JS 文件内联到 html 或者放到同域下,虽然能简单有效地解决 script error 问题,但是这样无法利用好文件缓存和 CDN 的优势,不推荐使用。正确的方法应该是从根本上解决 script error 的错误。
跨源资源共享机制( CORS )
首先为页面上的 script 标签添加 crossOrigin 属性
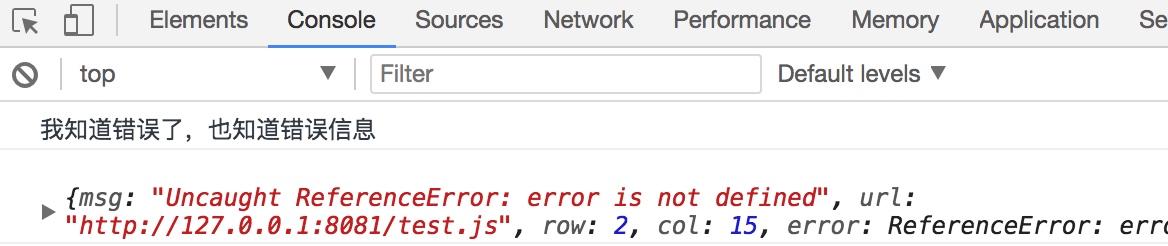
// http://localhost:8080/index.html <script> window.onerror = function (msg, url, row, col, error) { console.log('我知道错误了,也知道错误信息'); console.log({ msg, url, row, col, error }) return true; }; </script> <script src="http://localhost:8081/test.js" crossorigin></script>// http://localhost:8081/test.js
setTimeout(() => {
console.log(error);
});当你修改完前端代码后,你还需要额外给后端在响应头里加上
Access-Control-Allow-Origin: localhost:8080,这里我以 Koa 为例。const Koa = require('koa'); const path = require('path'); const cors = require('koa-cors'); const app = new Koa();app.use(cors());
app.use(require('koa-static')(path.resolve(__dirname, './public')));app.listen(8081, () => {
console.log('koa app listening at 8081')
});
读者可通过
npm run cors详细的跨域知识我就不展开了,有兴趣可以看看我之前写的文章:跨域,你需要知道的全在这里你以为这样就完了吗?并没有,下面就说一些 Script error 你不常遇见的点:
我们都知道 JSONP 是用来跨域获取数据的,并且兼容性良好,在一些应用中仍然会使用到,所以你的项目中可能会用这样的代码:
// http://localhost:8080/index.html window.onerror = function (msg, url, row, col, error) { console.log('我知道错误了,但不知道错误信息'); console.log({ msg, url, row, col, error }) return true; }; function jsonpCallback(data) { console.log(data); } const url = 'http://localhost:8081/data?callback=jsonpCallback'; const script = document.createElement('script'); script.src = url; document.body.appendChild(script);因为返回的信息会当做脚本文件来执行,一旦返回的脚本内容出错了,也是无法捕捉到错误的信息。
解决办法也不难,跟之前一样,在添加动态添加脚本的时候加上 crossOrigin,并且在后端配上相应的 CORS 字段即可.
const script = document.createElement('script'); script.crossOrigin = 'anonymous'; script.src = url; document.body.appendChild(script);读者可以通过
npm run jsonp查看效果
知道原理之后你可能会觉得没什么,不就是给每个动态生成的脚本添加 crossOrigin 字段嘛,但是在实际工程中,你可能是面向很多库来编程,比如使用 jQuery,Seajs 或者 webpack 来异步加载脚本,许多库封装了异步加载脚本的能力,以 jQeury 为例你可能是这样来触发异步脚本。
$.ajax({ url: 'http://localhost:8081/data', dataType: 'jsonp', success: (data) => { console.log(data); } })假如这些库中没有提供 crossOrigin 的能力的话(jQuery jsonp 可能有,假装你不知道),那你只能去修改人家写的源代码了,所以我这里提供一个思路,就是去劫持 document.createElement,从根源上去为每个动态生成的脚本添加 crossOrigin 字段。
document.createElement = (function() { const fn = document.createElement.bind(document); return function(type) { const result = fn(type); if(type === 'script') { result.crossOrigin = 'anonymous'; } return result; } })(); window.onerror = function (msg, url, row, col, error) { console.log('我知道错误了,也知道错误信息'); console.log({ msg, url, row, col, error }) return true; }; $.ajax({ url: 'http://localhost:8081/data', dataType: 'jsonp', success: (data) => { console.log(data); } })效果也是一样的,读者可以通过
npm run jsonpjq来查看效果:
这样重写 createElement 理论上没什么问题,但是入侵了原本的代码,不保证一定不会出错,在工程上还是需要多尝试下看看再使用,可能存在兼容性上问题,如果你觉得会出现什么问题的话也欢迎留言讨论下。
关于 Script error 的问题就写到这里,如果你理解了上面的内容,基本上绝大部分的 Script error 都能迎刃而解。
window.onerror 能否捕获 iframe 的错误
当你的页面有使用 iframe 的时候,你需要对你引入的 iframe 做异常监控的处理,否则一旦你引入的 iframe 页面出现了问题,你的主站显示不出来,而你却浑然不知。
首先需要强调,父窗口直接使用 window.onerror 是无法直接捕获,如果你想要捕获 iframe 的异常的话,有分好几种情况。
如果你的 iframe 页面和你的主站是同域名的话,直接给 iframe 添加 onerror 事件即可。
<iframe src="./iframe.html" frameborder="0"></iframe> <script> window.frames[0].onerror = function (msg, url, row, col, error) { console.log('我知道 iframe 的错误了,也知道错误信息'); console.log({ msg, url, row, col, error }) return true; }; </script>读者可以通过
npm run iframe查看效果:
如果你嵌入的 iframe 页面和你的主站不是同个域名的,但是 iframe 内容不属于第三方,是你可以控制的,那么可以通过与 iframe 通信的方式将异常信息抛给主站接收。与 iframe 通信的方式有很多,常用的如:postMessage,hash 或者 name 字段跨域等等,这里就不展开了,感兴趣的话可以看:跨域,你需要知道的全在这里
如果是非同域且网站不受自己控制的话,除了通过控制台看到详细的错误信息外,没办法捕获,这是出于安全性的考虑,你引入了一个百度首页,人家页面报出的错误凭啥让你去监控呢,这会引出很多安全性的问题。
压缩代码如何定位到脚本异常位置
线上的代码几乎都经过了压缩处理,几十个文件打包成了一个并丑化代码,当我们收到
a is not defined的时候,我们根本不知道这个变量 a 究竟是什么含义,此时报错的错误日志显然是无效的。第一想到的办法是利用 sourcemap 定位到错误代码的具体位置,详细内容可以参考:Sourcemap 定位脚本错误
另外也可以通过在打包的时候,在每个合并的文件之间添加几行空格,并相应加上一些注释,这样在定位问题的时候很容易可以知道是哪个文件报的错误,然后再通过一些关键词的搜索,可以快速地定位到问题的所在位置。
收集异常信息量太多,怎么办
如果你的网站访问量很大,假如网页的 PV 有 1kw,那么一个必然的错误发送的信息就有 1kw 条,我们可以给网站设置一个采集率:
Reporter.send = function(data) { // 只采集 30% if(Math.random() < 0.3) { send(data) // 上报错误信息 } }这个采集率可以通过具体实际的情况来设定,方法多样化,可以使用一个随机数,也可以具体根据用户的某些特征来进行判定。
上面差不多是我对前端代码监控的一些理解,说起来容易,但是一旦在工程化运用,难免需要考虑到兼容性等种种问题,读者可以通过自己的具体情况进行调整,前端代码异常监控对于我们的网站的稳定性起着至关重要的作用。如若文中所有不对的地方,还望指正。
参考文章
区块链入门教程(转自阮一峰)
区块链(blockchain)是眼下的大热门,新闻媒体大量报道,宣称它将创造未来。
可是,简单易懂的入门文章却很少。区块链到底是什么,有何特别之处,很少有解释。
下面,我就来尝试,写一篇最好懂的区块链教程。毕竟它也不是很难的东西,核心概念非常简单,几句话就能说清楚。我希望读完本文,你不仅可以理解区块链,还会明白什么是挖矿、为什么挖矿越来越难等问题。
需要说明的是,我并非这方面的专家。虽然很早就关注,但是仔细地了解区块链,还是从今年初开始。文中的错误和不准确的地方,欢迎大家指正。
一、区块链的本质
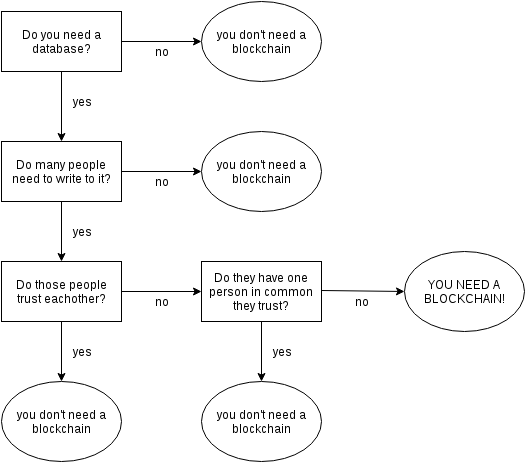
区块链是什么?一句话,它是一种特殊的分布式数据库。
首先,区块链的主要作用是储存信息。任何需要保存的信息,都可以写入区块链,也可以从里面读取,所以它是数据库。
其次,任何人都可以架设服务器,加入区块链网络,成为一个节点。区块链的世界里面,没有中心节点,每个节点都是平等的,都保存着整个数据库。你可以向任何一个节点,写入/读取数据,因为所有节点最后都会同步,保证区块链一致。
二、区块链的最大特点
分布式数据库并非新发明,市场上早有此类产品。但是,区块链有一个革命性特点。
**区块链没有管理员,它是彻底无中心的。**其他的数据库都有管理员,但是区块链没有。如果有人想对区块链添加审核,也实现不了,因为它的设计目标就是防止出现居于中心地位的管理当局。
正是因为无法管理,区块链才能做到无法被控制。否则一旦大公司大集团控制了管理权,他们就会控制整个平台,其他使用者就都必须听命于他们了。
但是,没有了管理员,人人都可以往里面写入数据,怎么才能保证数据是可信的呢?被坏人改了怎么办?请接着往下读,这就是区块链奇妙的地方。
三、区块
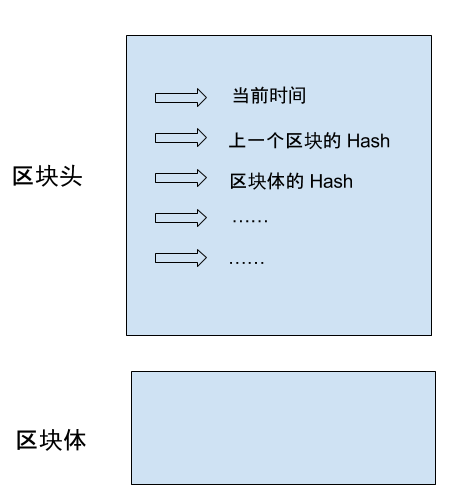
区块链由一个个区块(block)组成。区块很像数据库的记录,每次写入数据,就是创建一个区块。
每个区块包含两个部分。
- 区块头(Head):记录当前区块的元信息
- 区块体(Body):实际数据
区块头包含了当前区块的多项元信息。
- 生成时间
- 实际数据(即区块体)的 Hash
- 上一个区块的 Hash
- ...
这里,你需要理解什么叫 Hash,这是理解区块链必需的。
所谓 Hash 就是计算机可以对任意内容,计算出一个长度相同的特征值。区块链的 Hash 长度是256位,这就是说,不管原始内容是什么,最后都会计算出一个256位的二进制数字。而且可以保证,只要原始内容不同,对应的 Hash 一定是不同的。
举例来说,字符串
123的 Hash 是a8fdc205a9f19cc1c7507a60c4f01b13d11d7fd0(十六进制),转成二进制就是256位,而且只有123能得到这个 Hash。因此,就有两个重要的推论。
- 推论1:每个区块的 Hash 都是不一样的,可以通过 Hash 标识区块。
- 推论2:如果区块的内容变了,它的 Hash 一定会改变。
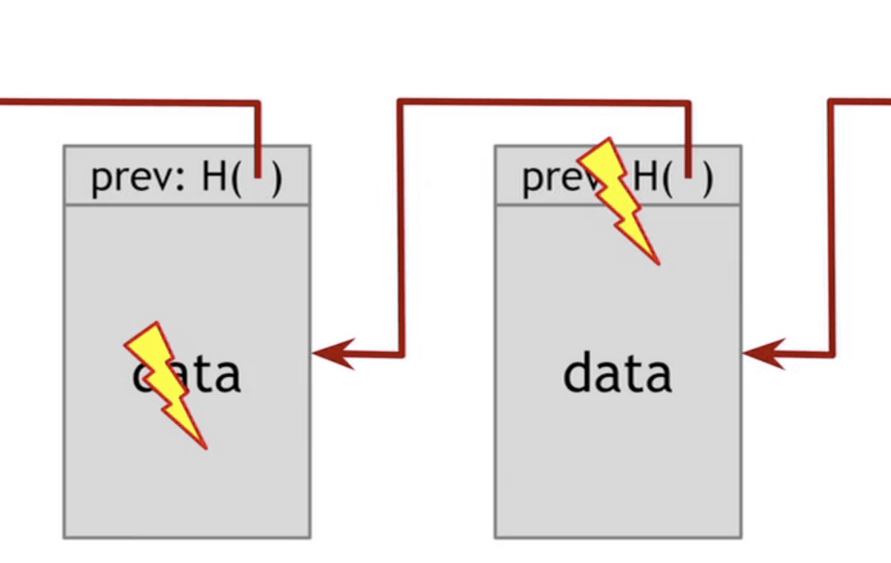
四、 Hash 的不可修改性
区块与 Hash 是一一对应的,每个区块的 Hash 都是针对"区块头"(Head)计算的。
Hash = SHA256(区块头)
上面就是区块 Hash 的计算公式,Hash 由区块头唯一决定,
SHA256是区块链的 Hash 算法。前面说过,区块头包含很多内容,其中有当前区块体的 Hash(注意是"区块体"的 Hash,而不是整个区块),还有上一个区块的 Hash。这意味着,如果当前区块的内容变了,或者上一个区块的 Hash 变了,一定会引起当前区块的 Hash 改变。
这一点对区块链有重大意义。如果有人修改了一个区块,该区块的 Hash 就变了。为了让后面的区块还能连到它,该人必须同时修改后面所有的区块,否则被改掉的区块就脱离区块链了。由于后面要提到的原因,Hash 的计算很耗时,同时修改多个区块几乎不可能发生,除非有人掌握了全网51%以上的计算能力。
正是通过这种联动机制,区块链保证了自身的可靠性,数据一旦写入,就无法被篡改。这就像历史一样,发生了就是发生了,从此再无法改变。
每个区块都连着上一个区块,这也是"区块链"这个名字的由来。
五、采矿
由于必须保证节点之间的同步,所以新区块的添加速度不能太快。试想一下,你刚刚同步了一个区块,准备基于它生成下一个区块,但这时别的节点又有新区块生成,你不得不放弃做了一半的计算,再次去同步。因为每个区块的后面,只能跟着一个区块,你永远只能在最新区块的后面,生成下一个区块。所以,你别无选择,一听到信号,就必须立刻同步。
所以,区块链的发明者中本聪(这是假名,真实身份至今未知)故意让添加新区块,变得很困难。他的设计是,平均每10分钟,全网才能生成一个新区块,一小时也就六个。
这种产出速度不是通过命令达成的,而是故意设置了海量的计算。也就是说,只有通过极其大量的计算,才能得到当前区块的有效 Hash,从而把新区块添加到区块链。由于计算量太大,所以快不起来。
这个过程就叫做采矿(mining),因为计算有效 Hash 的难度,好比在全世界的沙子里面,找到一粒符合条件的沙子。计算 Hash 的机器就叫做矿机,操作矿机的人就叫做矿工。
六、难度系数
读到这里,你可能会有一个疑问,人们都说采矿很难,可是采矿不就是用计算机算出一个 Hash 吗,这正是计算机的强项啊,怎么会变得很难,迟迟算不出来呢?
原来不是任意一个 Hash 都可以,只有满足条件的 Hash 才会被区块链接受。这个条件特别苛刻,使得绝大部分 Hash 都不满足要求,必须重算。
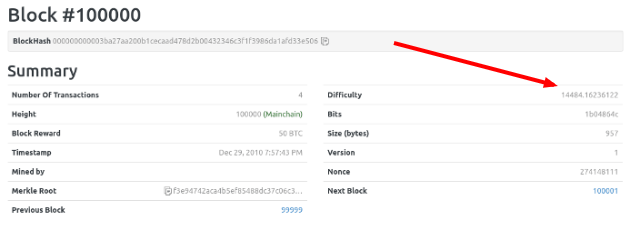
原来,区块头包含一个难度系数(difficulty),这个值决定了计算 Hash 的难度。举例来说,第100000个区块的难度系数是 14484.16236122。
区块链协议规定,使用一个常量除以难度系数,可以得到目标值(target)。显然,难度系数越大,目标值就越小。
Hash 的有效性跟目标值密切相关,只有小于目标值的 Hash 才是有效的,否则 Hash 无效,必须重算。由于目标值非常小,Hash 小于该值的机会极其渺茫,可能计算10亿次,才算中一次。这就是采矿如此之慢的根本原因。
区块头里面还有一个 Nonce 值,记录了 Hash 重算的次数。第 100000 个区块的 Nonce 值是
274148111,即计算了 2.74 亿次,才得到了一个有效的 Hash,该区块才能加入区块链。七、难度系数的动态调节
就算采矿很难,但也没法保证,正好十分钟产出一个区块,有时一分钟就算出来了,有时几个小时可能也没结果。总体来看,随着硬件设备的提升,以及矿机的数量增长,计算速度一定会越来越快。
为了将产出速率恒定在十分钟,中本聪还设计了难度系数的动态调节机制。他规定,难度系数每两周(2016个区块)调整一次。如果这两周里面,区块的平均生成速度是9分钟,就意味着比法定速度快了10%,因此难度系数就要调高10%;如果平均生成速度是11分钟,就意味着比法定速度慢了10%,因此难度系数就要调低10%。
难度系数越调越高(目标值越来越小),导致了采矿越来越难。
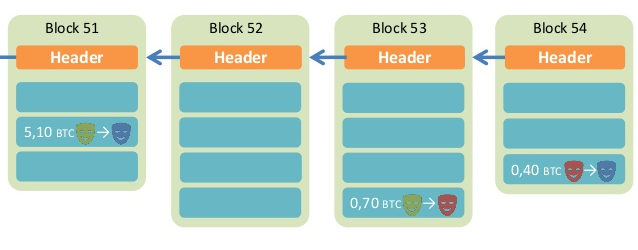
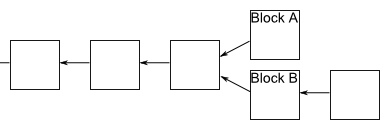
八、区块链的分叉
即使区块链是可靠的,现在还有一个问题没有解决:如果两个人同时向区块链写入数据,也就是说,同时有两个区块加入,因为它们都连着前一个区块,就形成了分叉。这时应该采纳哪一个区块呢?
现在的规则是,新节点总是采用最长的那条区块链。如果区块链有分叉,将看哪个分支在分叉点后面,先达到6个新区块(称为"六次确认")。按照10分钟一个区块计算,一小时就可以确认。
由于新区块的生成速度由计算能力决定,所以这条规则就是说,拥有大多数计算能力的那条分支,就是正宗的比特链。
九、总结
区块链作为无人管理的分布式数据库,从2009年开始已经运行了8年,没有出现大的问题。这证明它是可行的。
但是,为了保证数据的可靠性,区块链也有自己的代价。一是效率,数据写入区块链,最少要等待十分钟,所有节点都同步数据,则需要更多的时间;二是能耗,区块的生成需要矿工进行无数无意义的计算,这是非常耗费能源的。
因此,区块链的适用场景,其实非常有限。
- 不存在所有成员都信任的管理当局
- 写入的数据不要求实时使用
- 挖矿的收益能够弥补本身的成本
如果无法满足上述的条件,那么传统的数据库是更好的解决方案。
目前,区块链最大的应用场景(可能也是唯一的应用场景),就是以比特币为代表的加密货币。下一篇文章,我将会介绍比特币的入门知识。
十、参考链接
- How does blockchain really work?, by Sean Han
- Bitcoin mining the hard way: the algorithms, protocols, and bytes, by Ken Shirriff
(完)
关于Promise的一些理解
本文仅是阐述个人的一些理解,如有不对的地方,请指正
关于Promise
现在主流的Promise有很多,个人用过的有Q,bluebird等,有兴趣的可以了解,性能和写法也相差很多。
Promise规范有很多,现在最流行的是Promise/A+规范,ES6也是采用这个规范,具体可以参考:
虽然规范很多,刨去一些细节,最核心的部分总结下来有以下几点:
- Promise内部有三种状态:pending、fulfilled、rejected。状态的变化只能从pending => fulfilled或者从pending => rejected。
- Promise的接收函数中只能执行一次resolve或者reject,如果没有调用,应该默认返回resolve。
- then方法默认返回一个promise的实例,比较流行的方式是返回一个新的promise以避免老的promsie中的状态被修改
- 值穿透
怎么实现一个简单的Promise
想看源码的可以直接戳这里,里面加了些个人理解的注释。
Promise是一个类对象,在ES6中我们可以称为类,需要用new来实例化,简化下来(去除Promise.all和Promise.race等),一个最最简单的Promise需要有以下几个api:
function Promise(resolver) {} Promise.prototype.then = function() {} Promise.prototype.catch = function() {} Promise.resolve = function() {} Promise.reject = function() {}下面就具体一步步实现每个函数内部的一些功能
// Promsie的三种状态 var PENDING = 0; var FULFILLED = 1; var REJECTED = 2; var Promise = function(resolver) { if (!isFunction(resolver)) { throw new Error("resolver must be a function"); } this.state = PENDING; this.value = undefined; this.queue = []; safelyResolveThen(this, resolver); };上面是一个Promise的构造函数,state用来存储promise实例中的状态,初始默认为PENDING,value用来存储resolver的返回值,当 state 是 FULFILLED 时存储返回值,当 state 是 REJECTED 时存储错误。queue是个数组用来存放回调事件。看下safelyResolveThen函数
function safelyResolveThen(self, then) { var called = false; try { then( function(value) { if (called) { return; } called = true; doResolve(self, value); }, function(error) { if (called) { return; } called = true; doReject(self, error); } ); } catch (err) { if (called) { return; } called = true; doReject(self, err); } }顾名思义,此函数存在的意义就是安全的执行then函数,then中的两个参数就是resolve之后执行的函数和reject掉之后执行的函数,主要有下面3个作用👇:
- resolve或者reject只能被执行一次,用called来控制,多次调用没有意义
- try…catch捕获异常
- 正常情况下执行doResolve,错误情况下执行doReject
接下来看下doResolve和doReject函数
// 具体成功的执行函数,返回一个promise function doResolve(self, value) { try { var then = getThen(value); // 如果返回的还是一个promise的话,则把这个promise.then执行完 if (then) { safelyResolveThen(self, then); } else { // 正常设置FULFILLED状态,然后进入.then方法中,这里把成功和失败的方法统一包装成了一个对象 self.state = FULFILLED; self.value = value; self.queue.forEach(function(queueItem) { queueItem.callFulfilled(value); }); } return self; } catch (err) { return doReject(self, err); } } function doReject(self, error) { // 有错误或者Reject掉的情况 self.state = REJECTED; self.value = error; self.queue.forEach(function(queueItem) { queueItem.callRejected(error); }); return self; }doResolve和doReejct主要是来改变promise实例中的state和value,即promise实例中内部的状态从PENDING =>FULFILLED或者PENDING =>REJECTED并且执行回调队列中queue对应的回调函数,并且返回自身。
getThen是一个辅助函数,如果返回值是一个promise对象的话,拿到then函数并且改写this的指向:
// 辅助函数,获取then函数的 function getThen(obj) { var then = obj && obj.then; if (obj && (isObject(obj) || isFunction(obj)) && isFunction(then)) { return function applyThen() { then.apply(obj, arguments); }; } }规范中规定:如果 then 是函数,将 x(这里是 obj) 作为函数的 this 调用。
doResolve和doReject中最后会执行queue中的回调函数
queueItem.callRejected(error)orqueueItem.callFulfilled(value),queueitem也是一个对象,是下面构造函数QueueItem实例出的结果// then中onFulfilled,onRejected包装成了一个类对象 function QueueItem(promise, onFulfilled, onRejected) { this.promise = promise; // 为了兼容值穿透的情况,返回value this.callFulfilled = function(value) { doResolve(this.promise, value); }; this.callRejected = function(error) { doReject(this.promise, error); }; if (isFunction(onFulfilled)) { this.callFulfilled = function(value) { unwrap(this.promise, onFulfilled, value); }; } if (isFunction(onRejected)) { this.callRejected = function(error) { unwrap(this.promise, onRejected, error); }; } }有三个参数,promise是一个Promise的实例,因为最上面说到要返回一个新的promise,而后两个参数onFulfilled, onRejected则是then(resolve,reject)中的参数,把上面三个参数统一包装成了一个对象,进入queue队列中。如果对应的函数不存在,则初始化了一个默认的值,以此来兼容值穿透的情况。
值穿透
promise.then('hehe').then(console.log)then中包裹的不是函数,这样就造成了值穿透的情况,这种情况就需要特殊处理一下
unwap函数代码如下:
function unwrap(promise, func, value) { // 执行异步操作 setTimeout(function() { var returnValue; try { // promise的then中的回调结合返回值 returnValue = func(value); } catch (error) { return doReject(promise, error); } if (returnValue === promise) { doReject( promise, new TypeError("Cannot resolve promise with itself") ); } else { doResolve(promise, returnValue); } }); }第一个参数是子 promise,第二个参数是父 promise 的 then 的回调(onFulfilled/onRejected),第三个参数是父 promise 的值(正常值/错误),使用setTimeout来执行异步操作,使用try...catch来捕获异常。
Promise.prototype.then 和 Promise.prototype.catch
// then方法内默认返回一个新的promise Promise.prototype.then = function(onFulfilled, onRejected) { // 如果是值穿透的情况 if ( (!isFunction(onFulfilled) && this.state === FULFILLED) || (!isFunction(onRejected) && this.state === REJECTED) ) { return this; } // 创建一个新的promise, // 或者使用,var promise = new Promise(INTERNAL); var promise = new this.constructor(INTERNAL); if (this.state !== PENDING) { // 如Promse.resolve('234234').then(() => {}),或者reject的情况 // 会创造一个新的Promise并且this.value指向234234 var resolver = this.state === FULFILLED ? onFulfilled : onRejected; // 直接执行回调了 unwrap(promise, resolver, this.value); } else { // 正常进来都是PENDING状态,所以放到队列中,resolve或者reject掉之后返回 this.queue.push(new QueueItem(promise, onFulfilled, onRejected)); } return promise; }; Promise.prototype.catch = function(onRejected) { return this.then(null, onRejected); };Promise.resolve 和 Promise.reject
Promise.resolve = function resolve(value) { // 当 Promise.resolve 参数是一个 promise 时,直接返回该值。 if (value instanceof this) { return value; } return doResolve(new this(INTERNAL), value); } Promise.reject = function reject(reason) { var promise = new this(INTERNAL); return doReject(promise, reason); }这样基本上算是实现了一个简单的Promise,只有核心的部分,后续应该还会再加吧!
参考
深入 Promise(一)——Promise 实现详解: https://zhuanlan.zhihu.com/p/25178630
【翻译】Promises/A+规范http://www.ituring.com.cn/article/66566
node无处不在的 path 模块
path到底是什么鬼? 为啥老看见它
虽然我不写node.js,但是总能在各种配置文件(gulpfile.js/webpack.config.js)中看到这段代码,还有好多配置工具的例子中也总是用到它,所以让我们来一起解读一下这段代码中蕴含的所有知识点吧
var path = require('path');首先所有用到这段代码的文件都是node.js的一个模块文件
Node应用由模块组成,采用CommonJS模块规范,path就是其中的一个应用模块,path模块提供了一些用于处理文件路径的小工具
内置的require命令用于加载模块文件
require命令的基本功能是,读入并执行一个JavaScript文件,然后返回该模块的exports对象
require命令用于加载文件,后缀名默认为.jsvar path = require('path');//等同于
var path = require('path.js');根据参数的不同格式,require命令去不同路径寻找模块文件
怎么样没想到吧,一行代码里面竟然蕴含着这么多信息和知识,所以path是node中node_modules目录的已安装模块,在我们的文件中可以按照上述方式加载使用path对外暴露的接口path中一些常用的方法总结
1.path.basename(path[, ext])获取路径中文件名,后缀是可选的,如果加请使用'.xxx'方式来匹配,则返回值中不包括后缀名;
path.basename('/foo/bar/baz/asdf/quux.html') // Returns: 'quux.html' path.basename('/foo/bar/baz/asdf/quux.html', '.html') // Returns: 'quux'2.path.delimiter
返回操作系统中目录分隔符,如window是';', Unix,linux,mac os中是':',下面举一个POSIX(除了Windows统称)的例子console.log(process.env.PATH) // Prints: '/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin' process.env.PATH.split(path.delimiter) // Returns: ['/usr/bin', '/bin', '/usr/sbin', '/sbin', '/usr/local/bin']3.path.dirname(path)
获取路径中目录名var myPath = path.dirname(__dirname + '/test/util/you.mp3'); console.log(myPath); //Users/cayley/Documents/webpack-demo/test/util__dirname是node.js中的一个全局变量,用来获取当前模块文件所在目录的完整绝对路径
4.path.extname(path)
获取路径中的扩展名,如果没有'.',则返回空path.extname('index.html') // Returns: '.html' path.extname('index.coffee.md') // Returns: '.md' path.extname('index.') // Returns: '.' path.extname('index') // Returns: '' path.extname('.index') // Returns: ''5.path.join([...paths])
路径结合、合并,路径最后不会带目录分隔符path.join('/foo', 'bar', 'baz/asdf', 'quux', '..') // Returns: '/foo/bar/baz/asdf' path.join('foo', {}, 'bar') // throws TypeError: Arguments to path.join must be strings6.path.normalize(path)
路径解析,得到规范化的路径格式,对window系统,目录分隔为'', 对于UNIX系统,分隔符为'/',针对'..'返回上一级;/与\都被统一转换//For example on POSIX: path.normalize('/foo/bar//baz/asdf/quux/..') // Returns: '/foo/bar/baz/asdf' //On Windows: path.normalize('C:\\temp\\\\foo\\bar\\..\\'); // Returns: 'C:\\temp\\foo\\'7.path.relative(from, to)
获取两路径之间的相对关系from 当前路径,并且方法返回值是基于from指定到to的相对路径
to 到哪路径path.relative('/data/orandea/test/aaa', '/data/orandea/impl/bbb') // Returns: '../../impl/bbb'8.path.resolve([...paths])
以应用程序为起点,根据参数字符串解析出一个绝对路径var myPath = path.resolve('path1' + '/dist/bundle.js'); console.log(myPath); //Users/cayley/Documents/webpack-demo/path1/dist/bundle.js9.path.sep
返回操作系统中文件分隔符; window是'\', Unix是'/'第一次写博客,很多地方不熟悉,见谅
22
啊是打发发
操作记录,参考浏览器前进,后退
###模拟用户的行为操作,不改变浏览器历史的情况下,实现了用户行为的记录,项目中可以结合vuex,也可以单独使用单独使用
/* * @Author: grove.liqihan * @Date: 2017-10-10 10:08:14 * @Desc: 记录下操作历史 */ import _ from 'lodash'; // var state = { // data: { // a: 1 // } // } // let historyRemember = new HistoryRemember(state, () => { // }) // historyRemember.push({ // selector: 'data.a', // value: 3 // }) // console.log(state); // { data: { a: 3 } } // historyRemember.back(); // console.log(state); // { data: { a: 1 } } // historyRemember.forward(); // console.log(state); // { data: { a: 3 } } class HistoryRemember { constructor(state, onchange) { this.state = state; this.history = [null]; this.index = 0; this.onchange = onchange || function () {} } get length () { return this.history.length; } push(changes) { if (!Array.isArray(changes)) { changes = [changes]; } changes.forEach((change) => { change.oldValue = _.get(this.state, change.selector) || null; _.set(this.state, change.selector, _.cloneDeep(change.value)); }); this.index += 1; this.history.length = this.index; this.history.push(_.cloneDeep(changes)); this.onchange(); return true; } // 返回 back () { if (this.index === 0) { return false; } let changes = this.history[this.index]; changes.forEach(change => { _.set(this.state, change.selector, _.cloneDeep(change.oldValue)) }) this.index -=1; this.onchange(); return true; } forward () { if (this.index === this.history.length - 1) { return false; } var changes = this.history[this.index + 1]; changes.forEach(change => { if (change.value == null) { _.unset(this.state, change.selector) } else { _.set(this.state, change.selector, _.cloneDeep(change.value)) } }) this.index += 1; this.onchange(); return true; } clear () { this.history.length = 1 this.index = 0 this.onchange() return true } } export default HistoryRemember转转hybrid app web静态资源离线系统实践[转载]
一.前言
> 目前的转转app是一个典型的hybrid app,采用的是业内主流的做法: 客户端内有大量业务页面使用webview内加载h5页面承载。其优点是显而易见的,即:web页面上线频度满足快速迭代的业务需求,不受客户端审核和发版的时间限制,也可以将各个业务线的开发工作分摊到各个业务的fe团队上,使得个业务线可以并行开发。
而缺点,则不言而喻的在于客户端内webview加载h5页面,准确来说是web应用的性能和体验,是肯定不及客户端的。本篇文章中,笔者将会梳理立足于本团队内,根据团队的特点和制约,开发并实践web应用的静态资源离线系统的过程与实践。
痛点1:
现今本团队内的端内web应用,均是由webpack构建打包而成的单页或多页web应用,前端工程构建完成的结果是这样的画风
可以看出其静态资源中,不乏体积几百k~几m不等,而这些静态资源均是首次打开页面时需要下载的,并且在web应用有更新时,这些静态资源文件均会发生变化,也需要重新下载。
导致:首次打开·线上h5资源更新·网络条件差的时候,或者本地页面缓存失效的时候。 出现:
这使得移动端网页体验像一块巨石—它包含了大量 CPU 计算的 JavaScript 包,拖延了页面的加载和可交互的速度。 而对于任何一家互联网公司,性能往往与利益直接相关。 面对海量的交易用户,提升web应用加载的体验成为了fe和app 工程师极力重视解决的一个问题。
痛点2
其一: 笔者之前也调研过 service worker等利用web api 来实现pwa的离线缓存方案,但目前转转的app使用的还是系统原生的webview。暂时不兼容pwa特性.(点击查看本团队过往对于pwa项目的尝试总结)
其二: 目前各个业务团队使用的技术栈的范围比较广,涵盖vue及react等生态方案。同时各个业务线均在保持快节奏的业务开发,需要设计一套能良好工作,更重要的是可以让各业务线前端工程可以低成本无痛接入,对业务代码不会产生侵入,不会引发风险与问题的接入方案。
我们的方案:
在调研了腾讯 手机QQ 阿里 美团 新浪 等公司的实现方案后,我们设计了自己的web应用静态资源离线系统方案:
图片是粗糙的,印象是模糊的。下面我们从 前端构建和发布测 和 app测 两个方向分别来分别阐述:
1.前端构建和发布测:
我们采用腾讯alloy团队出品的webpack离线包插件:ak-webpack-plugin,其可以根据配置,将webpack的构建出的静态资源,压缩成映射了静态资源在cdn路径url的zip压缩包。 同时在配置的过程中,也可以选择 排除掉 部份文件(比如图片,并不是所有构建出的图片都是用得到的)。其生成的压缩结构如下:
在此过程中,我们不需要关注资源之间加载的依赖关系,更不需要关注具体的业务逻辑。 只需要关注webpack构建后生成的资源文件夹的结构。
把生成和上传离线资源包的过程封装成了一个npm script后,就可以方便地在各个需要接入离线系统的项目中移植,相比起pwa等方法,算是一个改造成本很低的方案。解决了接入的痛点。
> ##### 生成的离线资源如何让客户端如何上传呢?交由各个fe工程师手动上传吗? 这样显然不符合效率最大化的原则。幸好我们有持续集成和发布工具jenkins。在本团队的发布与上线流程中,jenkins代替fe工程师构建与部署前端项目。使前端项目也像传统的app与后端项目一样做到了开发与构建部署分离,提高了团队的效率。 而我们生成和部署离线包的操作,也交由jenkins替我们完成。
2.转转app测
在客户端内,预制了一份最新的各业务线的离线包与版本号的配置表。app安装后首次启动时,会将压缩包解压到手机rom中。 各业务线配置中包含app访问线上的静态资源时需拦截的url规则map:
,当app访问到与规则map相匹配的地址时,就转为使用本地的资源,达到离线访问的目的。
> ##### 离线化后的资源如何更新呢?客户端启动后,向离线系统查询最新的各个业务的离线包版本号,依次跟本地配置中的对应业务线比较。 如果需要更新,则再次向离线系统查询此业务线的离线包信息,离线系统会提供此业务线的离线包的信息(包括基础包,更新包的信息)。
> ##### 是否需要更新?判断某一业务线是否需要更新离线包的的具体原则如下:
- 线上的各业务线的离线包的版本号与本地配置中 同一业务线的配置不同 (不论最新的离线包版本比本地的更高还是更低。)
- 线上的各业务线的配置中中包含有本地配置有没有的业务线。
三.资源包加载的优化
1. 增量的资源更新(bsdiff/bspatch)
客户端在内置(或者在wifi环境下载)了各业务全量包的基础上,为了减少每次下载更新的资源包的体积,我们采用了增量更新策略,具体为:每次发布版本的时候,如果此业务线之前已有离线包,则通过 离线系统生成差分包放在cdn。
增量更新的策略使用的是基于node的 bsdiff/bspatch 二进制差量算法工具npm包-- bsdp。(坑点:因为安装此node module 含有编译c语言的过程,所以对于liunx的gcc版本有一定要求,要求必须为4.7以上版本,低于此版本则无法安装) 客户端下载差分包后使用bspatch合成更新包。
经过比较 影响bsdiff生成的差分包的体积的因素主要有以下几类:
- zip包的压缩等级。
- zip包中文件内容的修改:比如js进行了uglify压缩,变量名的变化可能引起大幅的变更等。
项目A:
<table> <thead> <tr> <th>11月30日版本</th> <th>12月8日版本</th> <th>bsdiff增量包</th> </tr> </thead> <tbody> <tr> <td>740.2k</td> <td>740.2k</td> <td>36.85k</td> </tr> </tbody> </table>项目b:
<table> <thead> <tr> <th>11月23日版本</th> <th>12月19日版本</th> <th>bsdiff增量包</th> </tr> </thead> <tbody> <tr> <td>415.8k</td> <td>418.4k</td> <td>172.3k</td> </tr> </tbody> </table>可以看出:虽然增量包的体积与全量包的体积的比值虽然各不相同,但无疑是大大减小了客户端升级离线资源需要下载的流量。
2. 单独控制各个业务线web应用是否使用离线机制:
为了更好的监控离线包服务端和客户端的运行情况,并且降低使用离线资源带来的不可预料的风险,将隐患做到可控。 我们在每一个业务上都加入了使用离线资源的开关和灰度放量的控制。
3. 数据一致性校验 与 数据安全性
为了防止客户端下载离线资源时数据在传输过程中出现窜扰,导致下载的离线包无法解压,我们在服务端通过接口中将资源包的md5值告知客户端,客户端下载后通过计算得到的资源包的md5值,与之比较,可以保证数据的一致性。
同时为了保证传输过程中,资源文件不被篡改,我们将上述的md5值通过rsa加密算法进行加密。在服务端和客户端分别使用一对非对称的密钥进行加解密。
4.批量下载
在启动app时,app会集中批量的下载各个业务线的离线包资源,我们在存放离线包资源的cdn中使用了http/2协议,这样客户端与cdn只需要建立一次连接,就可以并行下载所有的资源。 在需要下载离线包个数较多的情况下,可以比传统的http1 有更快的传输速度。 同时,客户端只需要运行一次下载器。减少多次运行下载时对手机cpu的消耗。
四.回退机制:
在实际情况中,为了避免用户下载离线资源或者解压资源失败等问题,导致无法加载相应的离线资源,我们设计了回退机制,在
> * 本地内置的 base包(zip文件)解压失败的时候
离线系统接口超时
下载离线资源失败
增量的离线资源合并失败等情况下
我们转而请求线上文件。
五.离线资源管理平台
对于接入了离线系统的各个业务线的前端工程生成的不同时间版本的离线包 ,我们需要有一个直观明晰的方案来对其进行管理。 我们开发了离线资源管理平台,对接离线后台系统:
其主要的功能包含有:
- 查看与管理各个业务线信息及其离线功能的灰度放量的比例。 对于新接入离线系统的前端工程,灰度放量可以使得部分用户先使用其离线的特性,并防止不可预料的问题发生在全体用户上。
通过业务线,版本号,发布时间等条件,查询各个版本的离线资源包的列表及其详细信息。 如 离线包的类型,体积,上线时间等属性。
并在此基础上允许将某版本的离线包下线,以实现离线资源版本的回滚功能。
- 针对全局的离线功能,提供了离线功能的开关。
六.技术栈与选型介绍
本篇文章通篇介绍的大体都是思路,实现原理和架构,作为一个技术项目当然也要把使用的技术栈简单的介绍一下:
离线系统的服务端使用的为nodejs实现,因为是一个fe工程师推动的性能基础项目。自然选择自己熟悉的语言开发。开发的主动权也可以掌握在自己手上。node版本为较新的LTS版本8.x。
node 框架的选型: 市面上主流框架有两种,express koa ,还有一些是经过一些封装和定制的框架,例如eggjs等。 对于框架的选型,我们看趋势。在7.6版本之后,node 就支持了async/await 语法糖,不需要再用yield 和*函数了,koa天生选用await/async的结构,解决了回调地狱,确实是下一代的开发框架,现在也有大量的中间件帮你解决诸多的问题。 而基于koa2的企业级框架eggjs在一开始的时候考虑过, 但是eggjs的功能很强大,有很多功能,多到有些根本用不着,从而导致了他不会轻量级,扩展上的灵活性有待考究,并且eggjs对于我来说是个黑盒,如果有什么问题,我解决起来将会花费很长的时间。
使用了log4js进行node日志的采集和记录,log4js作为目前在node上最强大的日志记录框架,现在每天其npm包下载量均为6位数。我们将node服务分为resLogger和errorLogger两个不用等级的分类分别记录,并使用-yyyy-MM-dd-hh.log的pattern分割日志,在出问题的时候方便快速定位到日志文件。
使用了log4js进行node日志的采集和记录,log4js作为目前在node上最强大的日志记录框架,现在每天其npm包下载量均为6位数。我们将node服务分为resLogger和errorLogger两个不用等级的分类分别记录,并使用-yyyy-MM-dd-hh.log的pattern分割日志,在出问题的时候方便快速定位到日志文件。
使用轻量级的nosql数据库mongodb记录各离线资源包的数据信息,使用对象模型工具mongoose进行nosql的操作。
md5的加密,使用node-rsa库进行非对称密钥的生成,操作和加解密处理。
前端离线系统的后台页面,采用主流的vue及组件技术栈,并使用talkingdata出品的iview组件库进行搭建,灰常好用,也向大家推荐。
压力测试:因为是直接面向转转客户端全量的基础服务,并且预期要接入所有业务的m页,我们做了几次不同层面的压测,保证其起性能可以达到要求。 我是用的为liunx下的基于命令行的压力测试工具siege, 在并发数200,测试50次的情况下,其结果为:
可以看出其表现相对稳定,但上线后就要依赖下述的性能监控系统了。
可以看出其表现相对稳定,但上线后就要依赖下述的性能监控系统了。
对于这样的一套基础服务,对其运行情况的相关监控也是非常重要的,不管是及运行的是否稳定,承载的压力,占用服务器硬件的资源情况,我们都需要有详细的指标来进行观察,才能采取措施来对服务保驾护航,并采取措施改进。
六.运行情况
目前离线系统支撑着转转几乎所有的m页,每天其api的访问量为几百万次。接口响应时间平均只有20ms,也说明node的稳定轻量,以及koa框架的迅速。
以下为占用机器的cpu和内存情况,如果后续出现内存泄漏,性能瓶颈,我们会加入缓存层解决。
七.收益:
截止目前转转h5静态资源离线系统已经无痛地 接入了多个端内web应用,在页面静态资源加载耗时和由此延伸的可操作时间等性能指标上,均取得了很好的收益。
我们通过录屏的对比直观感受一下使用了离线系统后,在加载速度上带来的提升. 下图为4G网络情况下,某web应用首次打开的速度对比。左侧为使用离线系统,右侧为未使用:
通过本团队开发的性能统计平台与埋点sdk,我们可以看到几个关键指标的提升:
页面的静态资源加载(js,css)耗时的对比数据
平均时间提升约为75%左右
页面的可操作时间耗时的对比数据
平均时间提升约为15%左右
(采样页面为客服中心项目)
面对海量的用户,节约的流量和网络请求时间消耗都是我们为用户带来的价值。
八.展望:
对于技术完美的追求是一个永无止境的过程,而面对复杂网络情况下离线资源下载的一整套过程。我们仍有诸多细节仍需完善和优化,比如:
下载引擎的优化 。目前还待实现的功能有离线包下载的断点续传和分块下载的功能,以及下载失败后重试的逻辑。
离线资源下载的统计 虽然我们拥有完善的数据打点采集系统,但是对于各个业务线的离线资源的下载量,现在的统计还有待完善,有个下载量的统计,就可以为后续功能的完善提供建议(此统计可以在node api层或者cdn的nginx层实施)
2017年是PWA技术大放光彩的一年, 由它带来的Service Worker的离线缓存和服务端推送能力可以将web应用的体验提升一大截。虽然在安卓原生的webview中并不具备一个很好的兼容性。但我们仍在探索通过接入功能更为强大的第三方浏览器内核来让hybrid app可以支持.
除此之外,离线存储技术也在业界不断的探索有呈现百花齐放的局面,出了pwa和本文基于文件的离线策略,也有其他团队开创了自己的离线存储方法。
结束语
时至今日,Hybrid模式已经过了它最火的时候,市面上也出现如weex,react-native等直接写原生组件的框架, 但是,现在使用最多,应用最广的仍然要属这种传统的Hybrid模式,它已经进入了稳定期。但设法提升内嵌h5的性能和体验,依然是一个永不止步的话题。
控制微信中点击返回按钮事件
在微信中控制点击返回的事件
一般我们把h5页面分享到微信朋友圈之后,点击进入,然后点击返回,其实就是直接退出了,但是看了一下网易新闻和进入头条之后,分享页点击进去之后直接进入了列表页,这样做的好处是显而易见的,能够增加用户的转化率,所以自己就研究了下怎么实现。
详情请看
https://github.com/Liqihan/blog/blob/master/js/backToEveryWhereInWx.js所以,当用户在朋友圈点击返回的时候,我们就可以控制让用户看到什么了
前端持久化 -- evercookie
原文链接:http://www.cnblogs.com/DevinnZ/p/6752574.html
evercookie 是由 Samy Kamkar(美国白帽黑客、安全研究员)开发的一组 jsApi,它的目的在于持久化 cookie,即使用户清除标准 cookie、Flash cookie 等之后依然能够获取设置过的数据,并且重新恢复清除掉的 cookie(比较狭隘,本质上是恢复所有维度,一个重新写的动作) —— 由Chccc分享引言:
前端持久化就是要将数据永久的保存在前端,让数据难以删除或者删除后能够重新恢复。存储的数据可以理解为是一种 “僵尸数据”,下面介绍一种前端持久化方法 -- evercookie。
一.evercookie简介:
evercookie是由Samy Kamkar(美国白帽黑客、安全研究员)开发的一组jsApi,它的目的在于持久化cookie,即使用户清除标准cookie、Flash cookie等之后依然能够获取设置过的数据,并且重新恢复清除掉的cookie(比较狭隘,本质上是恢复所有维度,一个重新写的动作)。
二.evercookie原理:
evercookie的原理很简单,就是将数据写入浏览器各个维度,获取的时候再从各个维度中读出来,无论用户怎样清洗,只要其中一个维度有数据就可以得到数据。比较强大的地方在于:1.存储的维度非常多,用户很难清理;2.取数据的时候会将已经清除的数据重新恢复,名副其实的僵尸cookie。
下面介绍下存储的维度以及读取数据的方式和思路:
evercookie 存储数据的维度:
1.标准HTTP Cookie:
evercookie会将数据存在 document.cookie 中,获取的时候直接获取就可以了,没什么可说的,这部分数据是比较容易被清除的,比如浏览器清除cookie、js脚本设置等,分享关于cookie的两个点:
http请求自带本域以及根域下所有cookie,CSRF的根源就在这里;
js设置cookie默认在当前域以及当前路径下, cookie一般都会跨路径使用,一定注意设置path字段;
2.Flash Cookie:evercookie提供了一个flash文件,使用的时候会将数据存储在flash的本地对象中,只有删除对应的flash存储文件才可以清除,把flash文件反编译了一下,得到了AS源码:
shared = sharedobject.getlocal("evercookie"); if (everdata) { var newdata = everdata.split("="); var str = shared.data.cookie; var results = str.split("&"); var i = 0; while (i < results.length) { var elem = results[i].split("="); if (elem[0] != newdata[0]) { everdata = everdata + ("&" + results[i]); } i++; } shared.data.cookie = everdata.replace("\\", "\\\\"); shared.flush(); } flash.external.ExternalInterface.call("_evercookie_flash_var", shared.data.cookie);存数据的时候调用swfObject中的接口存入即可,可以看下js源码:
this.evercookie_lso = function (name, value) { var div = document.getElementById("swfcontainer"), flashvars = {}, params = {}, attributes = {}; if (div===null || div === undefined || !div.length) { div = document.createElement("div"); div.setAttribute("id", "swfcontainer"); document.body.appendChild(div); } if (value !== undefined) { flashvars.everdata = name + "=" + value; } params.swliveconnect = "true"; attributes.id = "myswf"; attributes.name = "myswf"; //写入flash swfobject.embedSWF(_ec_baseurl + _ec_asseturi + _ec_swf_file_name, "swfcontainer", "1", "1", "9.0.0", false, flashvars, params, attributes); };而flash加载后会使用 flash.external.ExternalInterface.call("_evercookie_flash_var", shared.data.cookie) 调用window下的javascript方法 _evercookie_flash_var 将数据传给js,对js来说就是读取flash数据。
var _global_lso; function _evercookie_flash_var(cookie) { _global_lso = cookie; // remove the flash object now var swf = document.getElementById("myswf"); if (swf && swf.parentNode) { swf.parentNode.removeChild(swf); } } window._evercookie_flash_var = _evercookie_flash_var;3.localStorage:localStorage是HTML5的一个新特性,可以将数据永久存储在本地,获取时没有窗口的限制,同域下即可获取,可以调用localStorage的接口来清除,浏览器直接清除缓存数据也能清掉;
4.sessionStorage:同localStorage类似,生存周期是当前对话,浏览器关闭重新打开后消失;
5.globalStorage:同localStorage类似,同样是永久存储在本地,目前只有 Firefox48 以上才支持;
6.openDatabase:HTML5的WebSQL数据库,可以理解为本地存储 Local Storage 和 Session Storage 的一个加强,用来操纵大量结构化数据,由于各个浏览器实现原因,WebSQL规范已经被废弃掉了;
7.IndexedDB:浏览器内置的一种数据库,永久保存数据,IndexDB与WebSQL比较,IndexedDB更像是一个NoSQL数据库,而WebSQL更像是关系型数据库,使用SQL查询数据。
8.图片缓存数据存储:
evercookie利用了图片的缓存进行了存储,简单介绍下:
写数据的时候根据key构造一个http请求,将值通过document.cookie传给后台;
后台根据cookie中传入的值按照每三位生成一个像素点的方式生成一张200个像素点的png图片(最大为600个字符),并且设置缓存到前端;
读数据的时候同样根据key构造相同的http请求,获取缓存的图片并用canvas解析出对应的像素点,恢复出数据。
这里面可以看出两点,一个 evercookiejs 设置的图片存储支持的最大数据为600个字符,二是此种方式必须使用canvas进行解析,有兼容性要求。这种方式显然可以通过浏览器清除缓存直接清掉了。9.ETag存储:
ETag存储也要依靠后台,利用的原理主要是当浏览器第一次访问一个请求的时候如果服务器响应设置ETag标签,浏览器第二次访问会自动带上一个IF-NONE-MATCH上来(跟ETag设置的值相同),所以只要把数据值存在ETag上,取数据的时候直接去后台查链接上的 IF-NONE-MATCH 字段就可以了, 跟上面png图片缓存类似。
10.web Cache:看evercookie的思路是对 http cookie 的一种加强,相当于通过后台对cookie设置个过期时间,evercookie提供的脚本感觉有问题。
11.silvelright客户端存储:
silvelright也是一种本地存储方式,可以将数据直接存在本地,类似于flash可以跨浏览器获取,需要安装silverlight插件。evercookie提供了相应的编译文件可以通过sliverlight进行存取数据,对sliverlighr不大了解,有兴趣的同学可以研究一下。
12.java应用程序本地存储:通过使用JNLP调用Java Applet的能力将数据存在了本地文件中,代码量比较大不细分析了,反编译了jar包以及class文件,放在文件中有兴趣的可以看下。
13.IE的userData存储:
userData是IE独有的一种存储方式,可以通过XML、HTML标签将数据存储在本地,一般支持IE5以上,官方文档看存储数据大小一般在单个域名640k左右,使用方法很简单
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <style> .userData{ behavior: url(#default#userdata) } </style> </head> <body> <div id="userData" class="userData"></div> </body> <script> var persistDom = document.getElementById("userData"); function set(name, value){ persistDom.setAttribute(name, value); persistDom.save(name); } function get(name){ persistDom.load(name); return persistDom.getAttribute(name) } set("devinn", 1990); window.console && console.log(get("devinn"));//1990 </script> </html>14.window.name:
window.name是window的一个很特殊的属性,可以设置,有两个特点:
window.name设置后刷新页面不会消失;
iframe从一个src跳转到另一个src 获取contentWindow.name 不会发生变化;
evercookie主要是利用了上面的一点,只要页面不刷新,页面随便清理都不会发生变化(奇特的是放在iframe里面清缓存就可以清掉 TT)。window.name经常用于跨域通信,顺便说下window.name跨域通信原理:
iframe src 从 A.html跳转到 B.html 的时候 window.name 是不变的, 所以如果一个域的页面想跨域获取数据可以设置一个iframe 先将src指向想要获取数据的域页面(此页面将想要传递的数据放在window.name中, ps:此时由于跨域无法获取iframe的contentWindow),之后src指向自己域名下的一个页面(已变成同域)通过iframe的contentWindow即可获取;
跨域获取注意两个关键点:
必须放在iframe中;
必须使用name属性(console了一下contentWindow,测试了几个其他属性都不行);
15.标签历史访问状态存储:浏览器中的 标签有个特性, 同一个浏览器被访问过后状态会变成 "visited" 状态,一般只有清理浏览器浏览记录才会消失,evercookie利用了这点进行存储。
简单说下思路:
构造标签并预设visited样式(a:visited)作为访问校验值;
构造http请求,请求的地址为设置的键以及值的各个字符(多个http,个数是值的长度);
写数据通过构造iframe对上面的http请求进行一次访问;
读数据用键和一个字符构造一个链接赋予标签的href,获取标签的样式与预设visited样式进行
直接将http请求赋给标签的href,获取如果样式为预设visited的样式说明这个http请求访问过,解出字符;
说明:2中设置的值是个encode后的值,最后一步解出的字符拼装后需要decode后才能获取到原来的值,evercookie里面的实现很有意思,有兴趣的可以看下。16.HSTS存储:
HSTS一般用来防止中间人攻击, 简单来说,如果一个域名的http响应设置过 Strict-Transport-Security,那么此域名再次发送http请求时浏览器会直接转成https请求(可以设置prelist,第一次请求也可以直接在浏览器端转成https),利用这点可以做数据存储:
申请多个域名(例如32个),构造好服务,设置(端口注意设置成443或者80)、清除、查询;
将设置的值转为二进制整数,比如 1101, 1的bit发送到对应的第一个域名设置 Strict-Transport-Security,0的清除掉 Strict-Transport-Security: max-age=0;
获取时向上面32个域名发送请求进行查询,服务器返回是否是http,对应的bit位设置为0,对应的二进制转成数值就是获取的结果;
直接看实现:<?php //header('Access-Control-Allow-Origin: *'); $is_ssl = !empty($_SERVER['HTTPS']) && $_SERVER['HTTPS'] !== 'off' || $_SERVER['SERVER_PORT'] == 443; if(isset($_GET['SET'])){ if($is_ssl){ header('Strict-Transport-Security: max-age=31536000'); header('Content-type: image/png'); echo base64_decode('iVBORw0KGgoAAAANSUhEUgAAAAgAAAAJCAIAAACAMfp5AAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsMAAA7DAcdvqGQAAAAYSURBVBhXY/z//z8DNsAEpTHAkJJgYAAAo0sDD8axyJQAAAAASUVORK5CYII='); }else{ $redirect = "https://".$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI']; header("Location: $redirect"); } die(); } if(isset($_GET['DEL'])){ if($is_ssl){ header('Strict-Transport-Security: max-age=0'); }else{ $redirect = "https://".$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI']; header("Location: $redirect"); } die(); } if($is_ssl){ header('Content-type: image/png'); // some white pixel echo base64_decode('iVBORw0KGgoAAAANSUhEUgAAAAgAAAAJCAIAAACAMfp5AAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsMAAA7DAcdvqGQAAAAYSURBVBhXY/z//z8DNsAEpTHAkJJgYAAAo0sDD8axyJQAAAAASUVORK5CYII='); die(); }else{ header('X-PHP-Response-Code: 404', true, 404); } ?>HSTS存储方式缺点比较大,要申请多个域名,发送多个请求,evercookie默认关闭HSTS存储,chrome和firefox兼容新比较好、IE不支持HSTS设置, 浏览器也可以手动设置关闭HSTS。
evercookie读数据:
evercookie读数据只说一点就可以了,它的**并不是从任意维度获取到数据就直接返回结果,而是要将所有设置的维度全部取出进行最优解查找,可以防止部分数据被篡改导致的数据异常;也带来一个问题,因为很多都是异步获取,比如数据库、e-tag等,那么获取数据就不是立即获取,会有一部分等待时长。
三.应用:
使用evercookie进行持久化,可以让我们的数据常驻浏览器。利用它不仅可以收集各种浏览器数据,更重要的是,即使用户对浏览器cookie进行了大清洗,这些数据仍然可以起死回生。比如,利用它可以给浏览器建立一个长期有效的身份标识符,利用标识符上报数据对用户的历史信息进行分析进而判断一个操作是善意还是恶意, 对前端风控体系有很大作用。
四.总结:
evercookie简单来讲就是存数据取数据,并没有多少东西,比较闪光的地方在于里面的存取数据的维度和方法,各种奇淫巧技。同时要注意到里面的一些方法,比如HSTS会带来很大开销,获取数据是一个异步过程也会有时间开销,应用的时候尽量根据业务额场景来调整使用。
scrollInToView方法
移动端input获取焦点的时候,弹出的软键盘可能会挡住input输入框,相当影响体验,查了一下用scrollInToView能解决这个问题,让输入框不被挡住,使用方法如下
element.scrollIntoView(alignToTop); // Boolean parameterscrollIntoView()可以在所有的HTML元素上调用,通过滚动浏览器窗口或某个容器元素,调用元素就可以出现在视窗中。如果给该方法传入true作为参数,或者不传入任何参数,那么窗口滚动之后会让调动元素顶部和视窗顶部尽可能齐平。如果传入false作为参数,调用元素会尽可能全部出现在视口中(可能的话,调用元素的底部会与视口的顶部齐平。)不过顶部不一定齐平
Demo
<html> <head> <title>HTML5_ScrollInToView方法</title> <meta charset="utf-8"> <script type="text/javascript"> window.onload = function(){ document.querySelector("#roll1").onclick = function(){ document.querySelector("#roll_top").scrollIntoView(false); } document.querySelector("#roll2").onclick = function(){ document.querySelector("#roll_top").scrollIntoView(true); } } </script> <style type="text/css"> #myDiv{ height:900px; background-color:gray; } #roll_top{ height:900px; background-color:green; color:#FFF; font-size:50px; position:relative; } #bottom{ position:absolute; display:block; left:0;bottom:0; } </style> </head> <body> <button id="roll1">scrollIntoView(false)</button> <button id="roll2">scrollIntoView(true)</button> <div id="myDiv"></div> <div id="roll_top"> scrollIntoView(ture)元素上边框与视窗顶部齐平 <span id="bottom">scrollIntoView(false)元素下边框与视窗底部齐平</span> </div> </body> </html>支持该方法的浏览器有 IE、Firefox、Safari和Opera。
HTTP:2 头部压缩技术介绍
##原文转载自https://imququ.com/post/header-compression-in-http2.html
我们知道,HTTP/2 协议由两个 RFC 组成:一个是 RFC 7540,描述了 HTTP/2 协议本身;一个是 RFC 7541,描述了 HTTP/2 协议中使用的头部压缩技术。本文将通过实际案例带领大家详细地认识 HTTP/2 头部压缩这门技术。
为什么要压缩
在 HTTP/1 中,HTTP 请求和响应都是由「状态行、请求 / 响应头部、消息主体」三部分组成。一般而言,消息主体都会经过 gzip 压缩,或者本身传输的就是压缩过后的二进制文件(例如图片、音频),但状态行和头部却没有经过任何压缩,直接以纯文本传输。
随着 Web 功能越来越复杂,每个页面产生的请求数也越来越多,根据 HTTP Archive 的统计,当前平均每个页面都会产生上百个请求。越来越多的请求导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费。
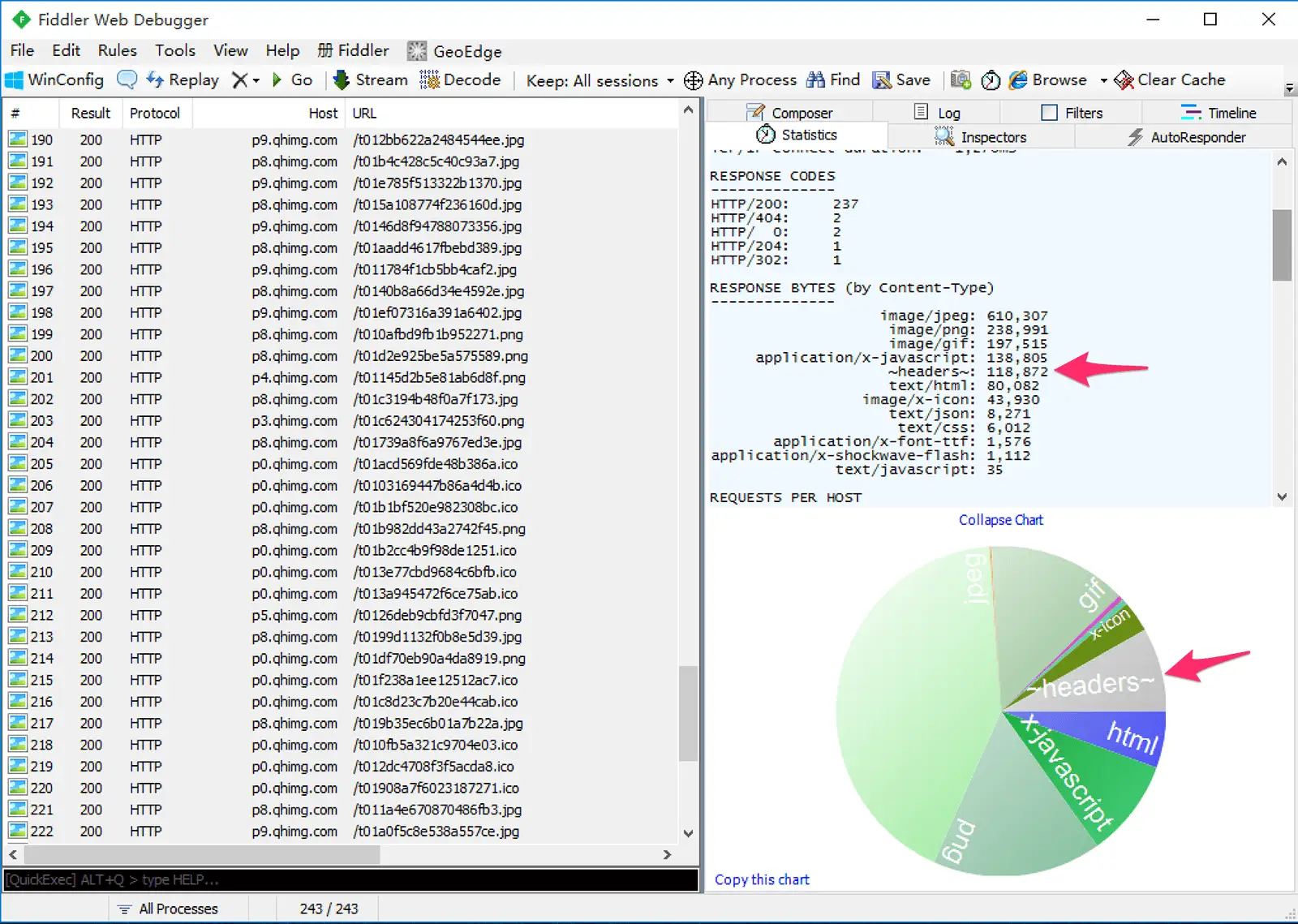
以下是我随手打开的一个页面的抓包结果。可以看到,传输头部的网络开销超过 100kb,比 HTML 还多:
下面是其中一个请求的明细。可以看到,为了获得 58 字节的数据,在头部传输上花费了好几倍的流量:
HTTP/1 时代,为了减少头部消耗的流量,有很多优化方案可以尝试,例如合并请求、启用 Cookie-Free 域名等等,但是这些方案或多或少会引入一些新的问题,这里不展开讨论。
压缩后的效果
接下来我将使用访问本博客的抓包记录来说明 HTTP/2 头部压缩带来的变化。如何使用 Wireshark 对 HTTPS 网站进行抓包并解密,请看我的这篇文章。
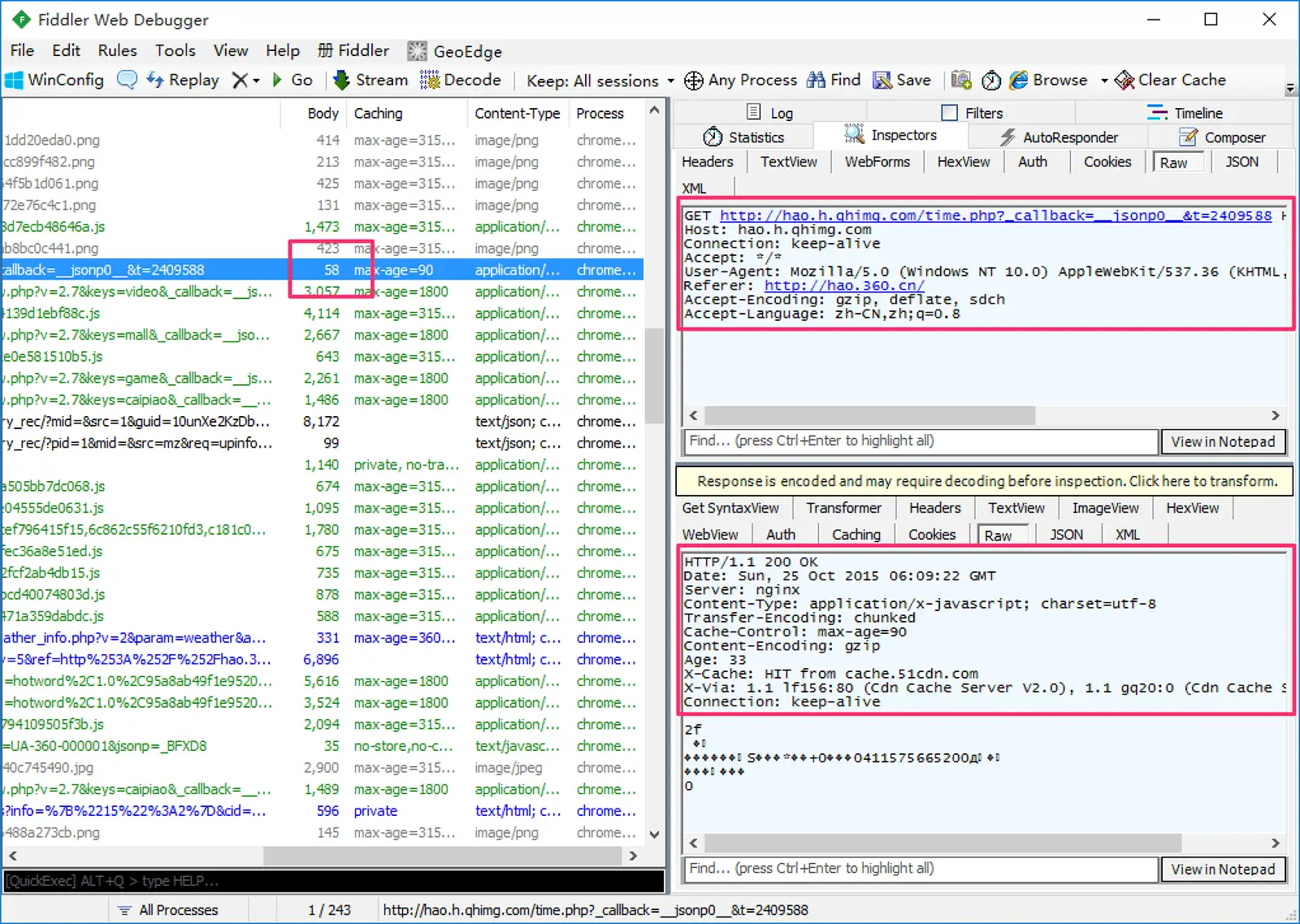
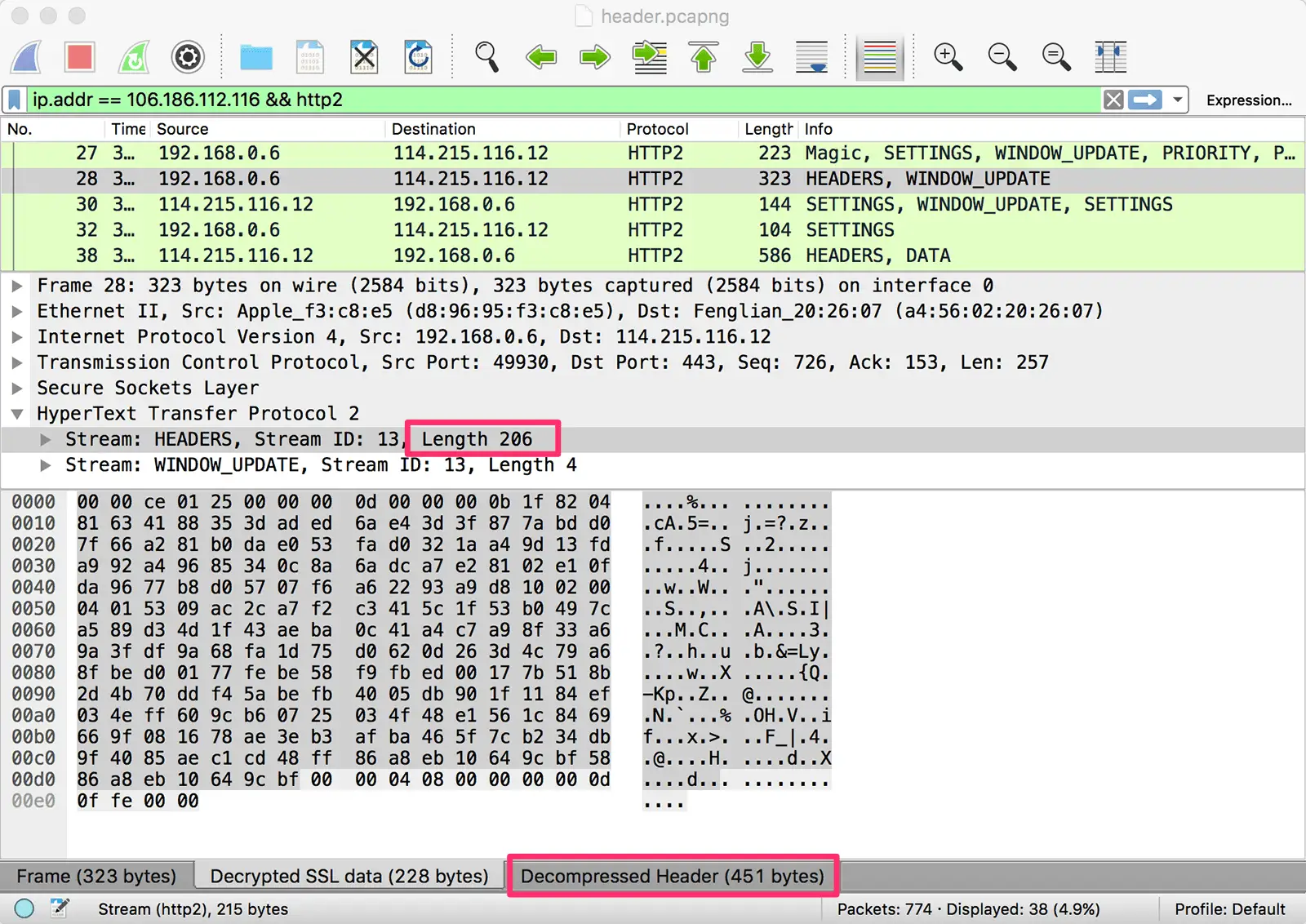
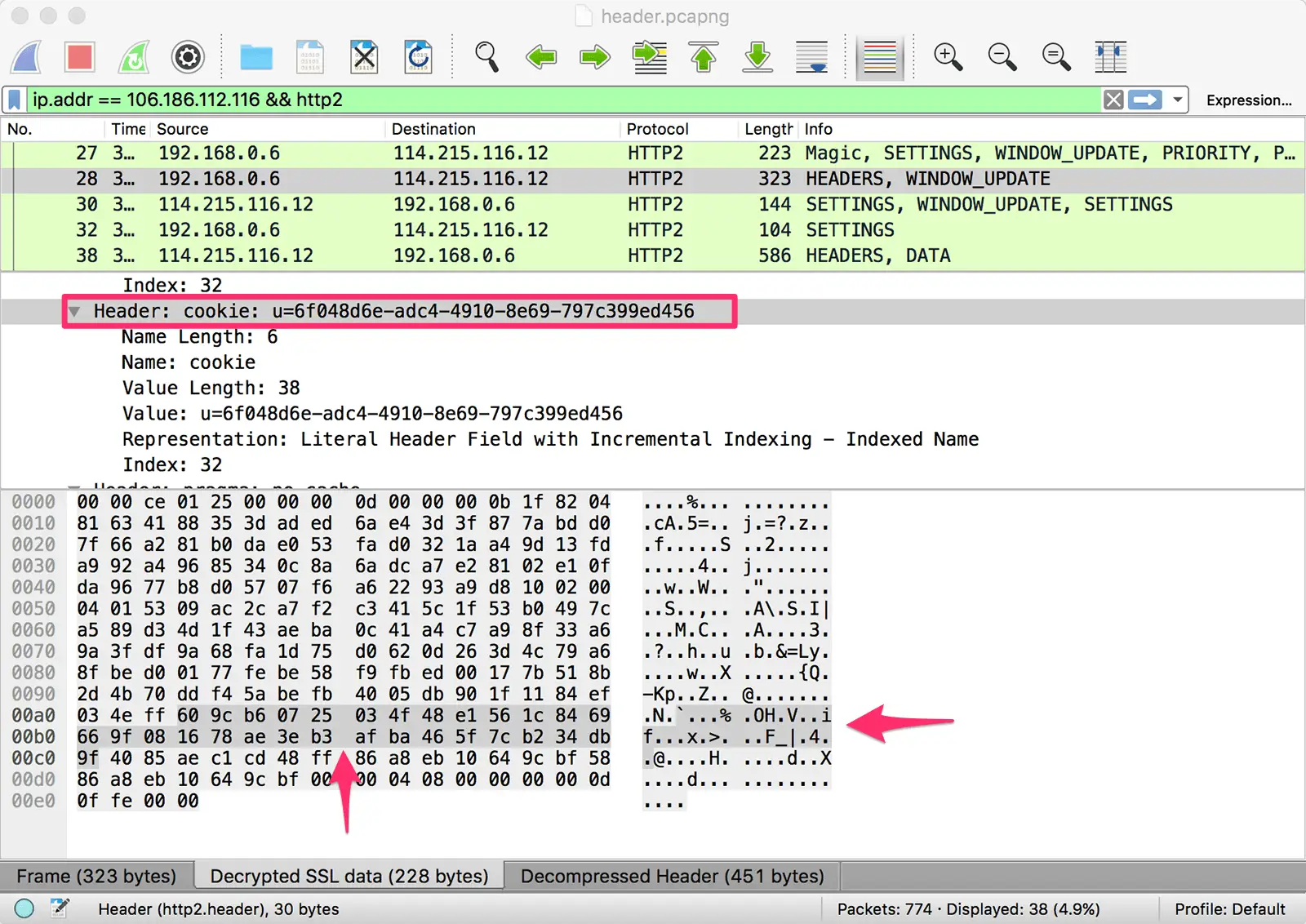
首先直接上图。下图选中的 Stream 是首次访问本站,浏览器发出的请求头:
从图片中可以看到这个 HEADERS 流的长度是 206 个字节,而解码后的头部长度有 451 个字节。由此可见,压缩后的头部大小减少了一半多。
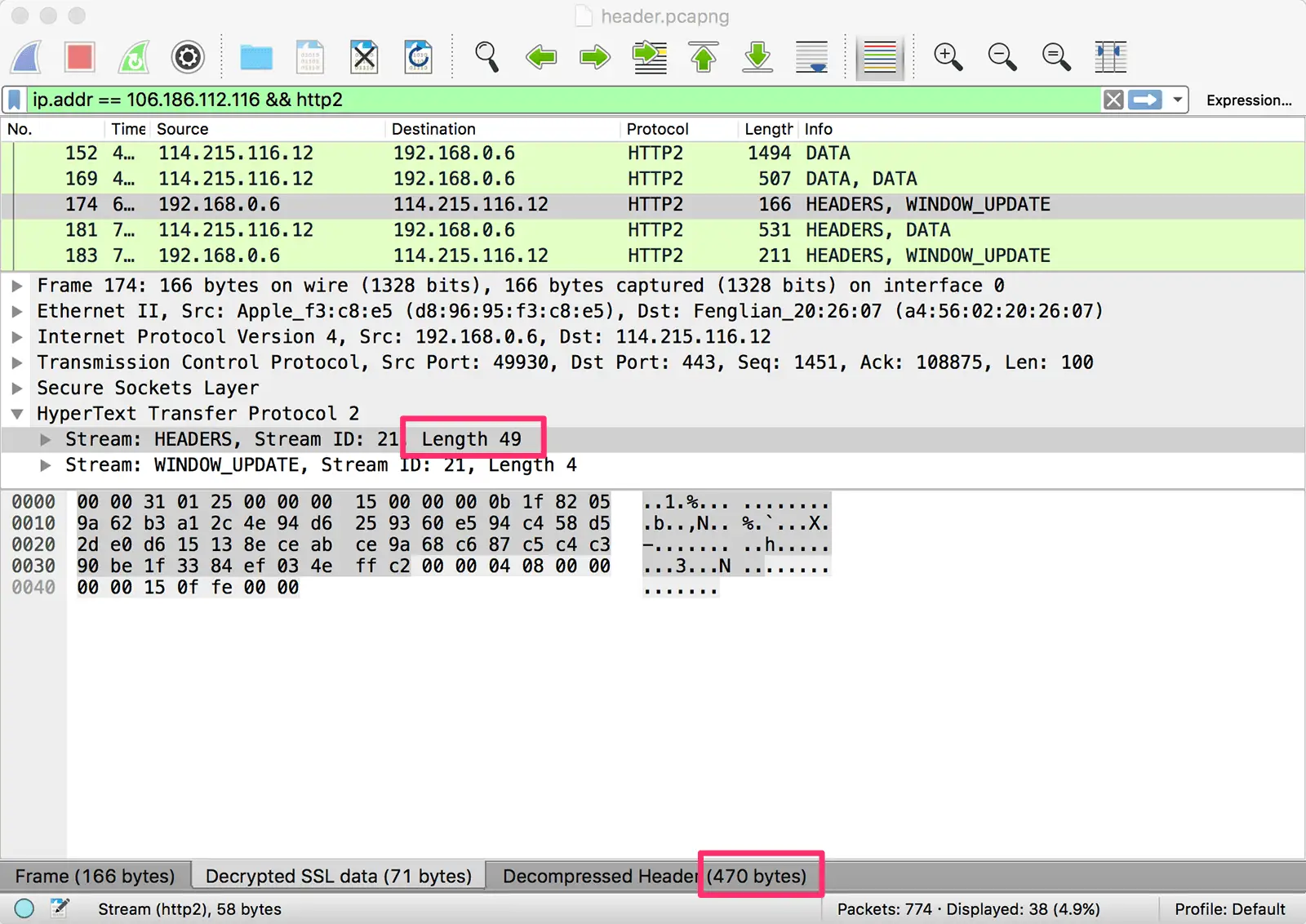
然而这就是全部吗?再上一张图。下图选中的 Stream 是点击本站链接后,浏览器发出的请求头:
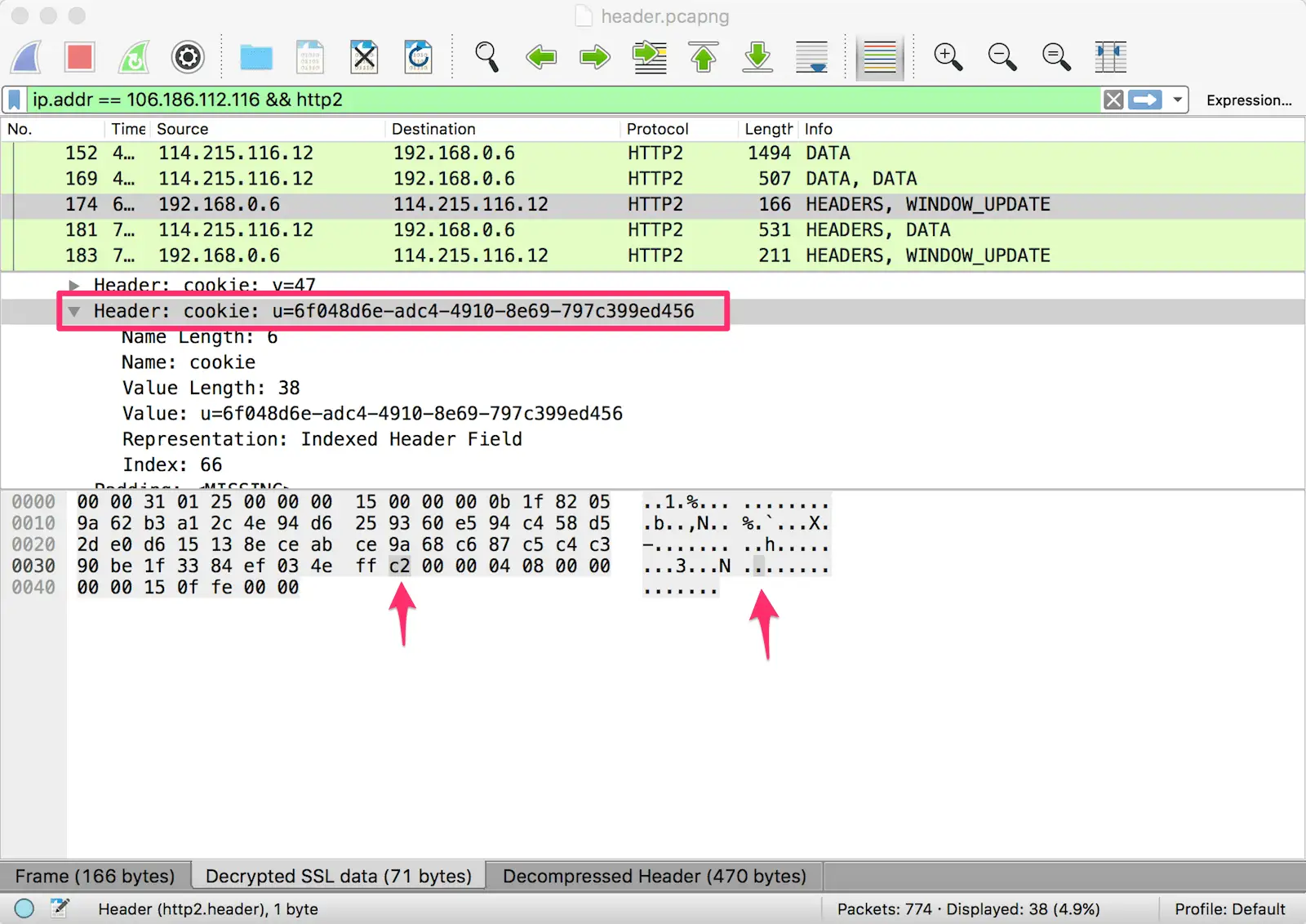
可以看到这一次,HEADERS 流的长度只有 49 个字节,但是解码后的头部长度却有 470 个字节。这一次,压缩后的头部大小几乎只有原始大小的 1/10。
为什么前后两次差距这么大呢?我们把两次的头部信息展开,查看同一个字段两次传输所占用的字节数:
对比后可以发现,第二次的请求头部之所以非常小,是因为大部分键值对只占用了一个字节。尤其是 UserAgent、Cookie 这样的头部,首次请求中需要占用很多字节,后续请求中都只需要一个字节。
技术原理
下面这张截图,取自 Google 的性能专家 Ilya Grigorik 在 Velocity 2015 • SC 会议中分享的「HTTP/2 is here, let's optimize!」,非常直观地描述了 HTTP/2 中头部压缩的原理:
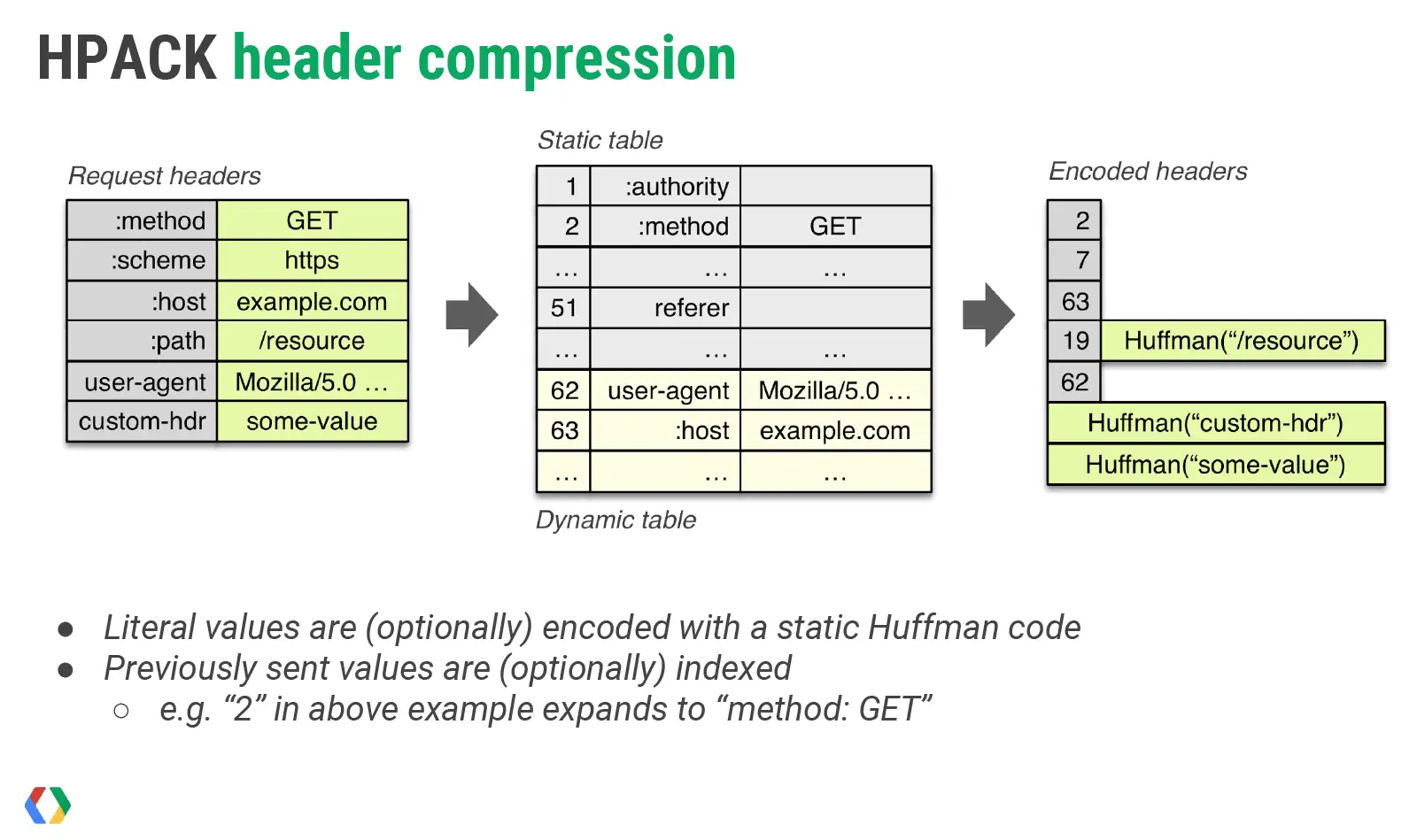
我再用通俗的语言解释下,头部压缩需要在支持 HTTP/2 的浏览器和服务端之间:
- 维护一份相同的静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合;
- 维护一份相同的动态字典(Dynamic Table),可以动态地添加内容;
- 支持基于静态哈夫曼码表的哈夫曼编码(Huffman Coding);
静态字典的作用有两个:1)对于完全匹配的头部键值对,例如
:method: GET,可以直接使用一个字符表示;2)对于头部名称可以匹配的键值对,例如cookie: xxxxxxx,可以将名称使用一个字符表示。HTTP/2 中的静态字典如下(以下只截取了部分,完整表格在这里):
Index Header Name Header Value 1 :authority 2 :method GET 3 :method POST 4 :path / 5 :path /index.html 6 :scheme http 7 :scheme https 8 :status 200 ... ... ... 32 cookie ... ... ... 60 via 61 www-authenticate 同时,浏览器可以告知服务端,将
cookie: xxxxxxx添加到动态字典中,这样后续整个键值对就可以使用一个字符表示了。类似的,服务端也可以更新对方的动态字典。需要注意的是,动态字典上下文有关,需要为每个 HTTP/2 连接维护不同的字典。使用字典可以极大地提升压缩效果,其中静态字典在首次请求中就可以使用。对于静态、动态字典中不存在的内容,还可以使用哈夫曼编码来减小体积。HTTP/2 使用了一份静态哈夫曼码表(详见),也需要内置在客户端和服务端之中。
这里顺便说一下,HTTP/1 的状态行信息(Method、Path、Status 等),在 HTTP/2 中被拆成键值对放入头部(冒号开头的那些),同样可以享受到字典和哈夫曼压缩。另外,HTTP/2 中所有头部名称必须小写。
实现细节
了解了 HTTP/2 头部压缩的基本原理,最后我们来看一下具体的实现细节。HTTP/2 的头部键值对有以下这些情况:
1)整个头部键值对都在字典中
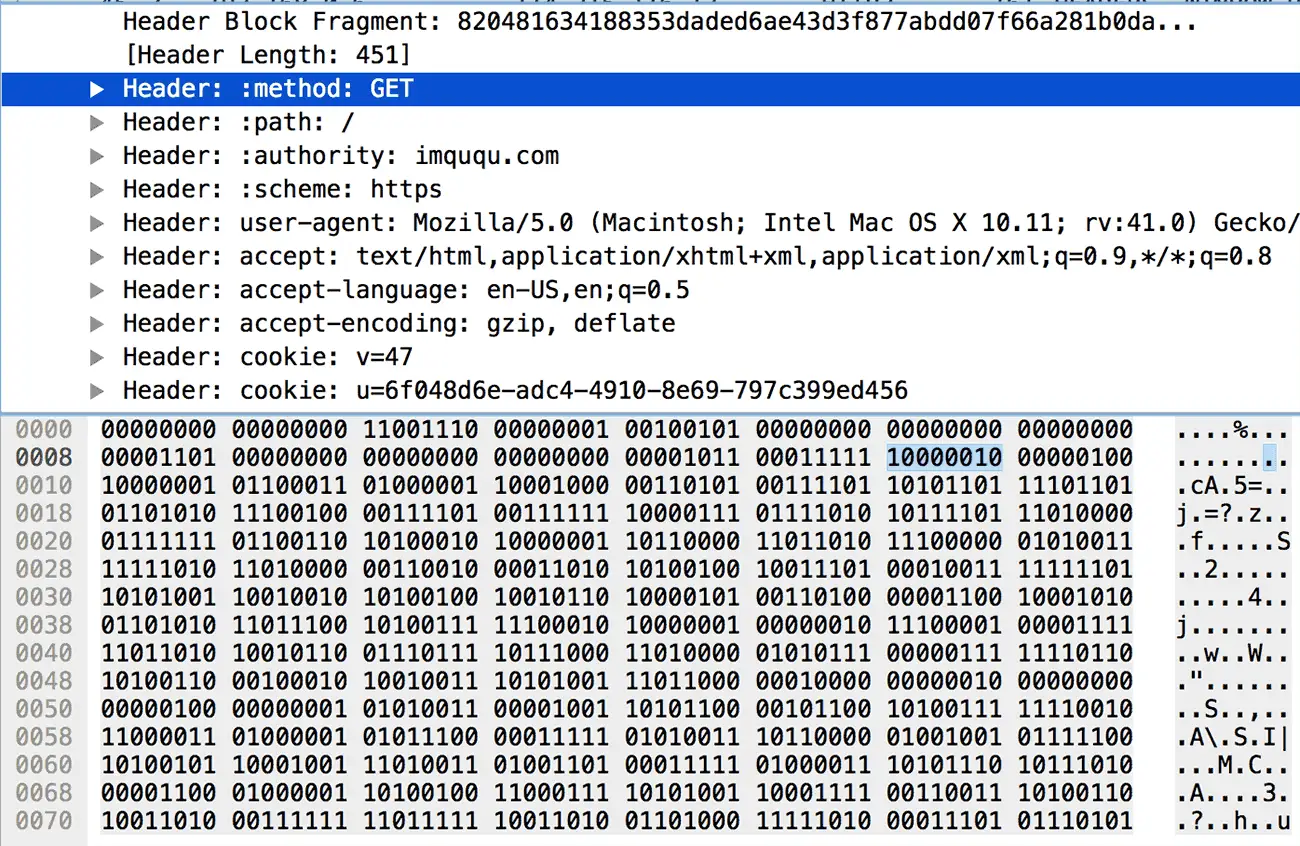
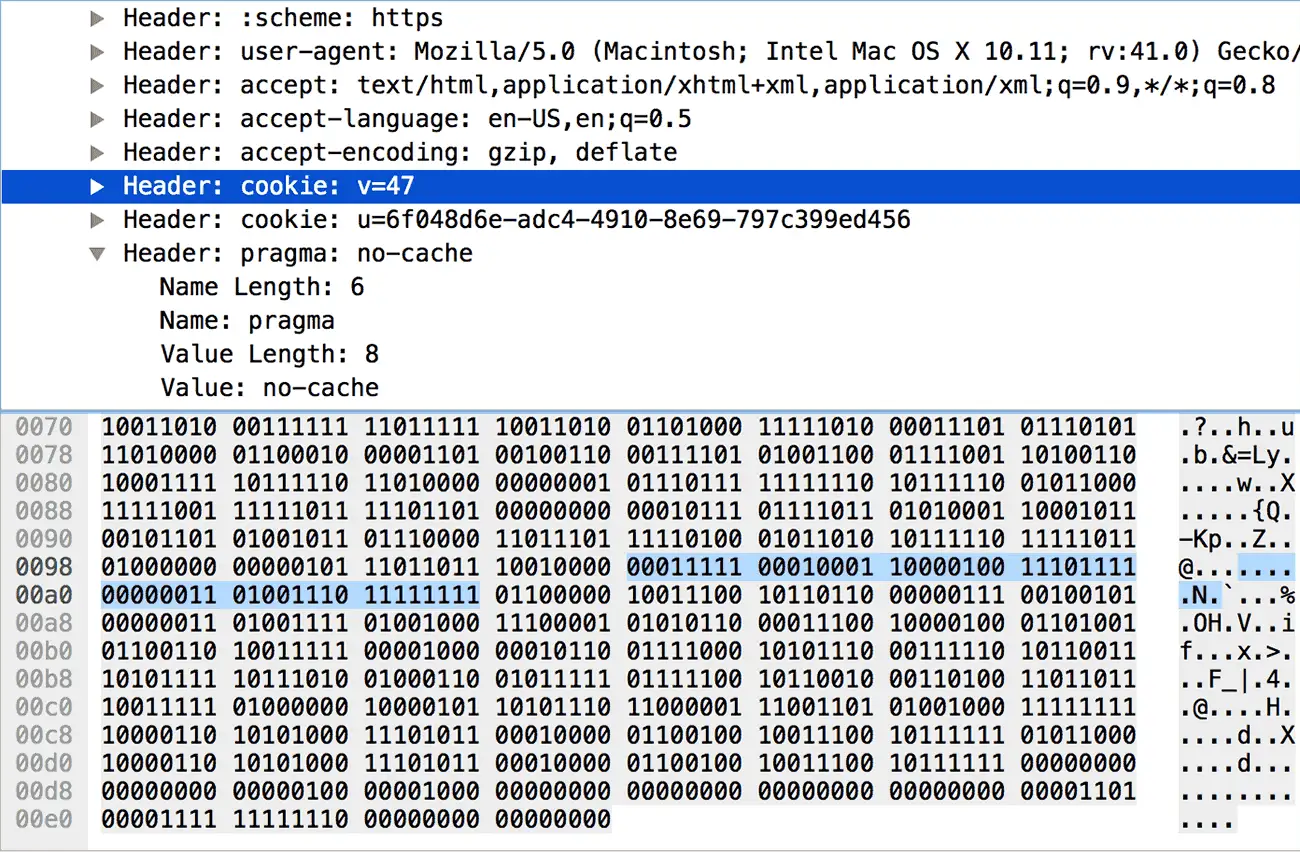
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 1 | Index (7+) | +---+---------------------------+这是最简单的情况,使用一个字节就可以表示这个头部了,最左一位固定为 1,之后七位存放键值对在静态或动态字典中的索引。例如下图中,头部索引值为 2(0000010),在静态字典中查询可得
:method: GET。
2)头部名称在字典中,更新动态字典
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | Index (6+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+对于这种情况,首先需要使用一个字节表示头部名称:左两位固定为 01,之后六位存放头部名称在静态或动态字典中的索引。接下来的一个字节第一位 H 表示头部值是否使用了哈夫曼编码,剩余七位表示头部值的长度 L,后续 L 个字节就是头部值的具体内容了。例如下图中索引值为 32(100000),在静态字典中查询可得
cookie;头部值使用了哈夫曼编码(1),长度是 28(0011100);接下来的 28 个字节是cookie的值,将其进行哈夫曼解码就能得到具体内容。
客户端或服务端看到这种格式的头部键值对,会将其添加到自己的动态字典中。后续传输这样的内容,就符合第 1 种情况了。
3)头部名称不在字典中,更新动态字典
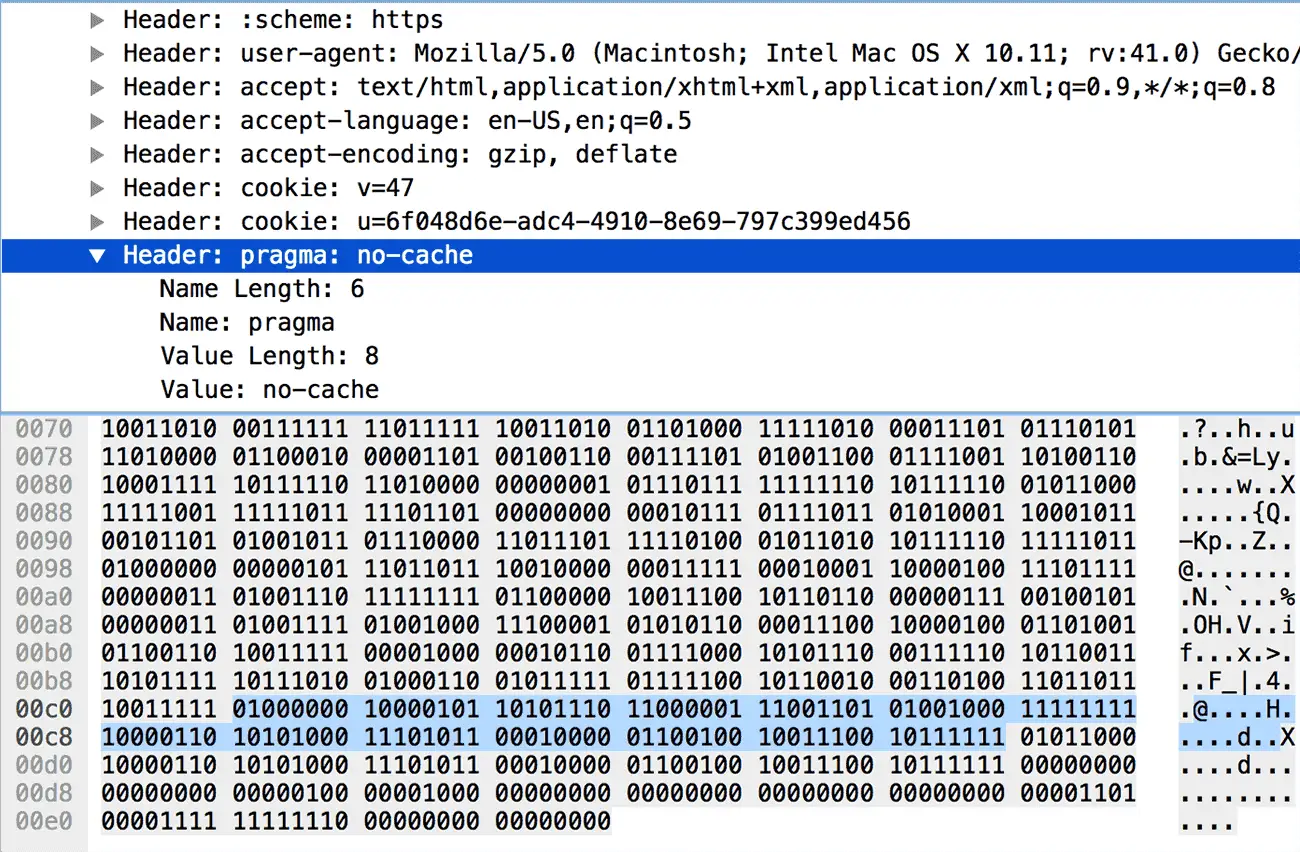
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+这种情况与第 2 种情况类似,只是由于头部名称不在字典中,所以第一个字节固定为 01000000;接着申明名称是否使用哈夫曼编码及长度,并放上名称的具体内容;再申明值是否使用哈夫曼编码及长度,最后放上值的具体内容。例如下图中名称的长度是 5(0000101),值的长度是 6(0000110)。对其具体内容进行哈夫曼解码后,可得
pragma: no-cache。
客户端或服务端看到这种格式的头部键值对,会将其添加到自己的动态字典中。后续传输这样的内容,就符合第 1 种情况了。
4)头部名称在字典中,不允许更新动态字典
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | Index (4+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+这种情况与第 2 种情况非常类似,唯一不同之处是:第一个字节左四位固定为 0001,只剩下四位来存放索引了,如下图:
这里需要介绍另外一个知识点:对整数的解码。上图中第一个字节为 00011111,并不代表头部名称的索引为 15(1111)。第一个字节去掉固定的 0001,只剩四位可用,将位数用 N 表示,它只能用来表示小于「2 ^ N - 1 = 15」的整数 I。对于 I,需要按照以下规则求值(RFC 7541 中的伪代码,via):
PYTHONif I < 2 ^ N - 1, return I # I 小于 2 ^ N - 1 时,直接返回 else M = 0 repeat B = next octet # 让 B 等于下一个八位 I = I + (B & 127) * 2 ^ M # I = I + (B 低七位 * 2 ^ M) M = M + 7 while B & 128 == 128 # B 最高位 = 1 时继续,否则返回 I return I对于上图中的数据,按照这个规则算出索引值为 32(00011111 00010001,15 + 17),代表
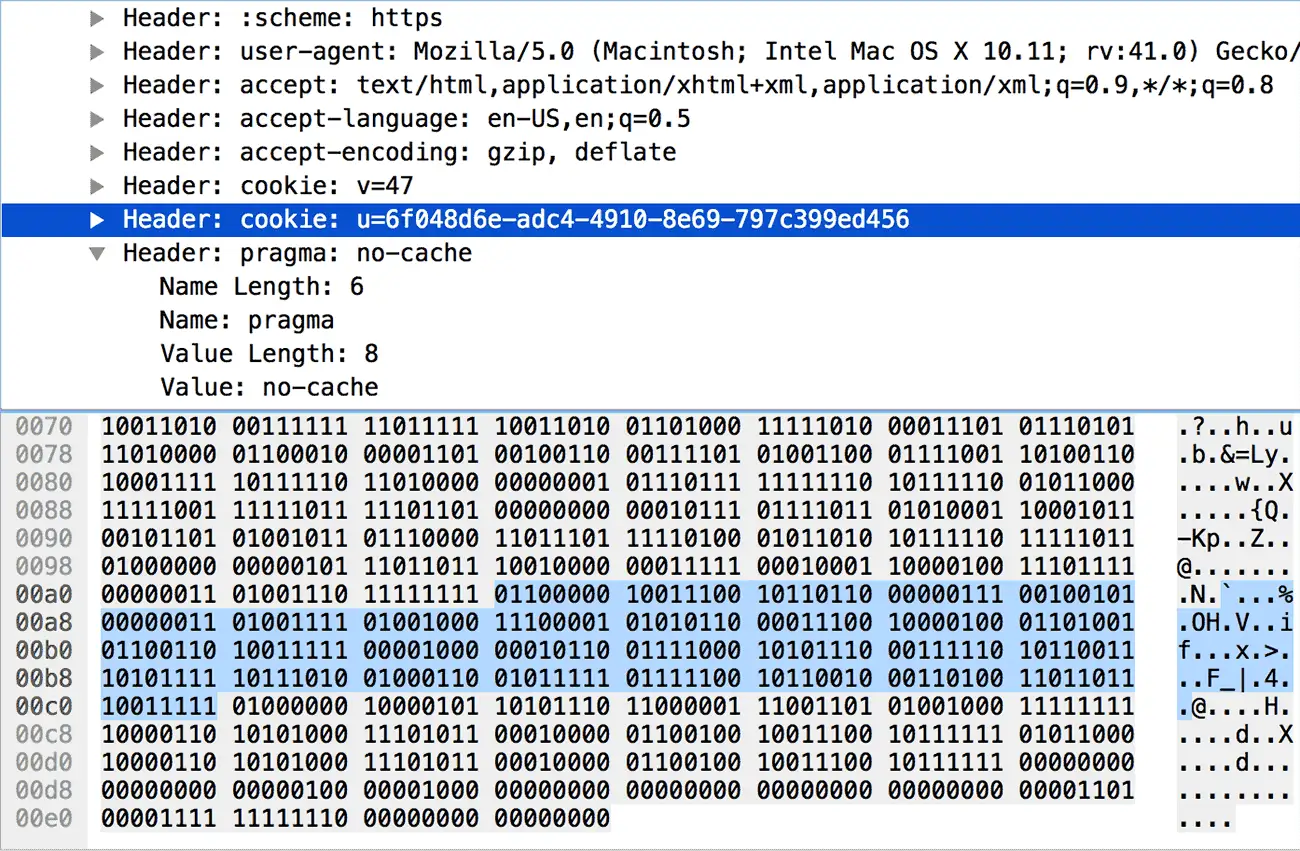
cookie。需要注意的是,协议中所有写成(N+)的数字,例如 Index (4+)、Name Length (7+),都需要按照这个规则来编码和解码。这种格式的头部键值对,不允许被添加到动态字典中(但可以使用哈夫曼编码)。对于一些非常敏感的头部,比如用来认证的 Cookie,这么做可以提高安全性。
5)头部名称不在字典中,不允许更新动态字典
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+这种情况与第 3 种情况非常类似,唯一不同之处是:第一个字节固定为 00010000。这种情况比较少见,没有截图,各位可以脑补。同样,这种格式的头部键值对,也不允许被添加到动态字典中,只能使用哈夫曼编码来减少体积。
实际上,协议中还规定了与 4、5 非常类似的另外两种格式:将 4、5 格式中的第一个字节第四位由 1 改为 0 即可。它表示「本次不更新动态词典」,而 4、5 表示「绝对不允许更新动态词典」。区别不是很大,这里略过。
明白了头部压缩的技术细节,理论上可以很轻松写出 HTTP/2 头部解码工具了。我比较懒,直接找来 node-http2 中的 compressor.js 验证一下:
JSvar Decompressor = require('./compressor').Decompressor; var testLog = require('bunyan').createLogger({name: 'test'}); var decompressor = new Decompressor(testLog, 'REQUEST'); var buffer = new Buffer('820481634188353daded6ae43d3f877abdd07f66a281b0dae053fad0321aa49d13fda992a49685340c8a6adca7e28102e10fda9677b8d05707f6a62293a9d810020004015309ac2ca7f2c3415c1f53b0497ca589d34d1f43aeba0c41a4c7a98f33a69a3fdf9a68fa1d75d0620d263d4c79a68fbed00177febe58f9fbed00177b518b2d4b70ddf45abefb4005db901f1184ef034eff609cb60725034f48e1561c8469669f081678ae3eb3afba465f7cb234db9f4085aec1cd48ff86a8eb10649cbf', 'hex'); console.log(decompressor.decompress(buffer)); decompressor._table.forEach(function(row, index) { console.log(index + 1, row[0], row[1]); });头部原始数据来自于本文第三张截图,运行结果如下(静态字典只截取了一部分):
BASH{ ':method': 'GET', ':path': '/', ':authority': 'imququ.com', ':scheme': 'https', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:41.0) Gecko/20100101 Firefox/41.0', accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'accept-language': 'en-US,en;q=0.5', 'accept-encoding': 'gzip, deflate', cookie: 'v=47; u=6f048d6e-adc4-4910-8e69-797c399ed456', pragma: 'no-cache' } 1 ':authority' '' 2 ':method' 'GET' 3 ':method' 'POST' 4 ':path' '/' 5 ':path' '/index.html' 6 ':scheme' 'http' 7 ':scheme' 'https' 8 ':status' '200' ... ... 32 'cookie' '' ... ... 60 'via' '' 61 'www-authenticate' '' 62 'pragma' 'no-cache' 63 'cookie' 'u=6f048d6e-adc4-4910-8e69-797c399ed456' 64 'accept-language' 'en-US,en;q=0.5' 65 'accept' 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8' 66 'user-agent' 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:41.0) Gecko/20100101 Firefox/41.0' 67 ':authority' 'imququ.com'可以看到,这段从 Wireshark 拷出来的头部数据可以正常解码,动态字典也得到了更新(62 - 67)。
总结
在进行 HTTP/2 网站性能优化时很重要一点是「使用尽可能少的连接数」,本文提到的头部压缩是其中一个很重要的原因:同一个连接上产生的请求和响应越多,动态字典积累得越全,头部压缩效果也就越好。所以,针对 HTTP/2 网站,最佳实践是不要合并资源,不要散列域名。
默认情况下,浏览器会针对这些情况使用同一个连接:
- 同一域名下的资源;
- 不同域名下的资源,但是满足两个条件:1)解析到同一个 IP;2)使用同一个证书;
上面第一点容易理解,第二点则很容易被忽略。实际上 Google 已经这么做了,Google 一系列网站都共用了同一个证书,可以这样验证:
BASH$ openssl s_client -connect google.com:443 |openssl x509 -noout -text | grep DNS depth=2 C = US, O = GeoTrust Inc., CN = GeoTrust Global CA verify error:num=20:unable to get local issuer certificate verify return:0 DNS:*.google.com, DNS:*.android.com, DNS:*.appengine.google.com, DNS:*.cloud.google.com, DNS:*.google-analytics.com, DNS:*.google.ca, DNS:*.google.cl, DNS:*.google.co.in, DNS:*.google.co.jp, DNS:*.google.co.uk, DNS:*.google.com.ar, DNS:*.google.com.au, DNS:*.google.com.br, DNS:*.google.com.co, DNS:*.google.com.mx, DNS:*.google.com.tr, DNS:*.google.com.vn, DNS:*.google.de, DNS:*.google.es, DNS:*.google.fr, DNS:*.google.hu, DNS:*.google.it, DNS:*.google.nl, DNS:*.google.pl, DNS:*.google.pt, DNS:*.googleadapis.com, DNS:*.googleapis.cn, DNS:*.googlecommerce.com, DNS:*.googlevideo.com, DNS:*.gstatic.cn, DNS:*.gstatic.com, DNS:*.gvt1.com, DNS:*.gvt2.com, DNS:*.metric.gstatic.com, DNS:*.urchin.com, DNS:*.url.google.com, DNS:*.youtube-nocookie.com, DNS:*.youtube.com, DNS:*.youtubeeducation.com, DNS:*.ytimg.com, DNS:android.com, DNS:g.co, DNS:goo.gl, DNS:google-analytics.com, DNS:google.com, DNS:googlecommerce.com, DNS:urchin.com, DNS:youtu.be, DNS:youtube.com, DNS:youtubeeducation.com使用多域名加上相同的 IP 和证书部署 Web 服务有特殊的意义:让支持 HTTP/2 的终端只建立一个连接,用上 HTTP/2 协议带来的各种好处;而只支持 HTTP/1.1 的终端则会建立多个连接,达到同时更多并发请求的目的。这在 HTTP/2 完全普及前也是一个不错的选择。
本文就写到这里,希望能给对 HTTP/2 感兴趣的同学带来帮助,也欢迎大家继续关注本博客的「HTTP/2 专题」。
本文链接:https://imququ.com/post/header-compression-in-http2.html,参与评论 »
Git 如何提交只改了文件名大小写的变更?
之前遇到了这个问题,查看了好久才解决,发现是git这边没有提交变更
git config core.ignorecase falseor
git mv -f OldFileNameCase newfilenamecasenode文件更新自动重载
文件更新自动重载
const fs = require('fs'), path = require('path'), projectRootPath = path.resolve(__dirname, './src'); const watch = project => { require('./src'); // 启动 APP,自动检索到 src/index.js try { // 监听文件夹 fs.watch(project, { recursive: true }, cacheClean) } catch(e) { console.error('watch file error'); } } // 清除缓存 const cacheClean = () => { Object.keys(require.cache).forEach(function (id) { if (/[\/\\](src)[\/\\]/.test(id)) { delete require.cache[id] } }) } // 启动开发模式 watch(projectRootPath);or
const pm2 = require('pm2'); pm2.connect(function(err) { if (err) { console.error(err); process.exit(2); } pm2.start({ "watch": ["./app"], // 开启 watch 模式,并监听 app 文件夹下的改动 "ignore_watch": ["node_modules", "assets"], // 忽略监听的文件 "watch_options": { "followSymlinks": false // 不允许符号链接 }, name: 'httpServer', script: './server/index.js', // APP 入口 exec_mode: 'fockMode', // 开发模式下建议使用 fockModel instances: 1, // 仅启用 1 个 CPU max_memory_restart: '100M' // 当占用 100M 内存时重启 APP }, function(err, apps) { pm2.disconnect(); // Disconnects from PM2 if (err) throw err }); });Recommend Projects
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
TensorFlow
An Open Source Machine Learning Framework for Everyone
Django
The Web framework for perfectionists with deadlines.
Laravel
A PHP framework for web artisans
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
web
Some thing interesting about web. New door for the world.
server
A server is a program made to process requests and deliver data to clients.
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Visualization
Some thing interesting about visualization, use data art
Game
Some thing interesting about game, make everyone happy.
Recommend Org
We are working to build community through open source technology. NB: members must have two-factor auth.
Microsoft
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba
Alibaba Open Source for everyone
D3
Data-Driven Documents codes.
Tencent
China tencent open source team.