


argilla-feedback.mp4
Argilla is an open-source data curation platform for LLMs. Using Argilla, everyone can build robust language models through faster data curation using both human and machine feedback. We provide support for each step in the MLOps cycle, from data labeling to model monitoring.
There are different options to get started:
-
Take a look at our quickstart page 🚀
-
Start contributing by looking at our contributor guidelines 🫱🏾🫲🏼
-
Skip some steps with our cheatsheet 🎼
pip install argilladocker run -d --name argilla -p 6900:6900 argilla/argilla-quickstart:latestHuggingFace Spaces now have persistent storage and this is supported from Argilla 1.11.0 onwards, but you will need to manually activate it via the HuggingFace Spaces settings. Otherwise, unless you're on a paid space upgrade, after 48 hours of inactivity the space will be shut off and you will lose all the data. To avoid losing data, we highly recommend using the persistent storage layer offered by HuggingFace.
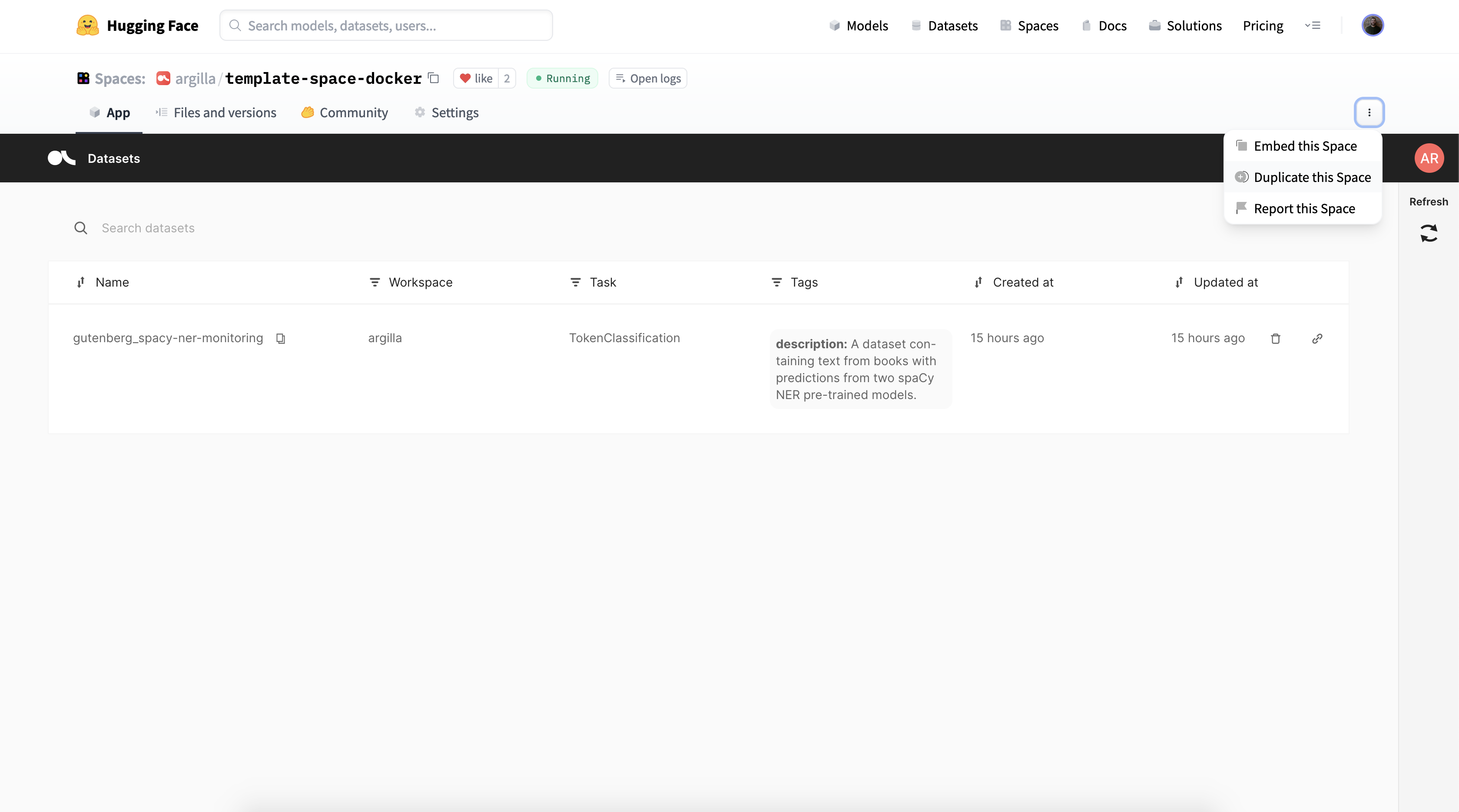
import argilla as rg
dataset = rg.FeedbackDataset(
guidelines="Please, read the question carefully and try to answer it as accurately as possible.",
fields=[
rg.TextField(name="question"),
rg.TextField(name="answer"),
],
questions=[
rg.RatingQuestion(
name="answer_quality",
description="How would you rate the quality of the answer?",
values=[1, 2, 3, 4, 5],
),
rg.TextQuestion(
name="answer_correction",
description="If you think the answer is not accurate, please, correct it.",
required=False,
),
]
)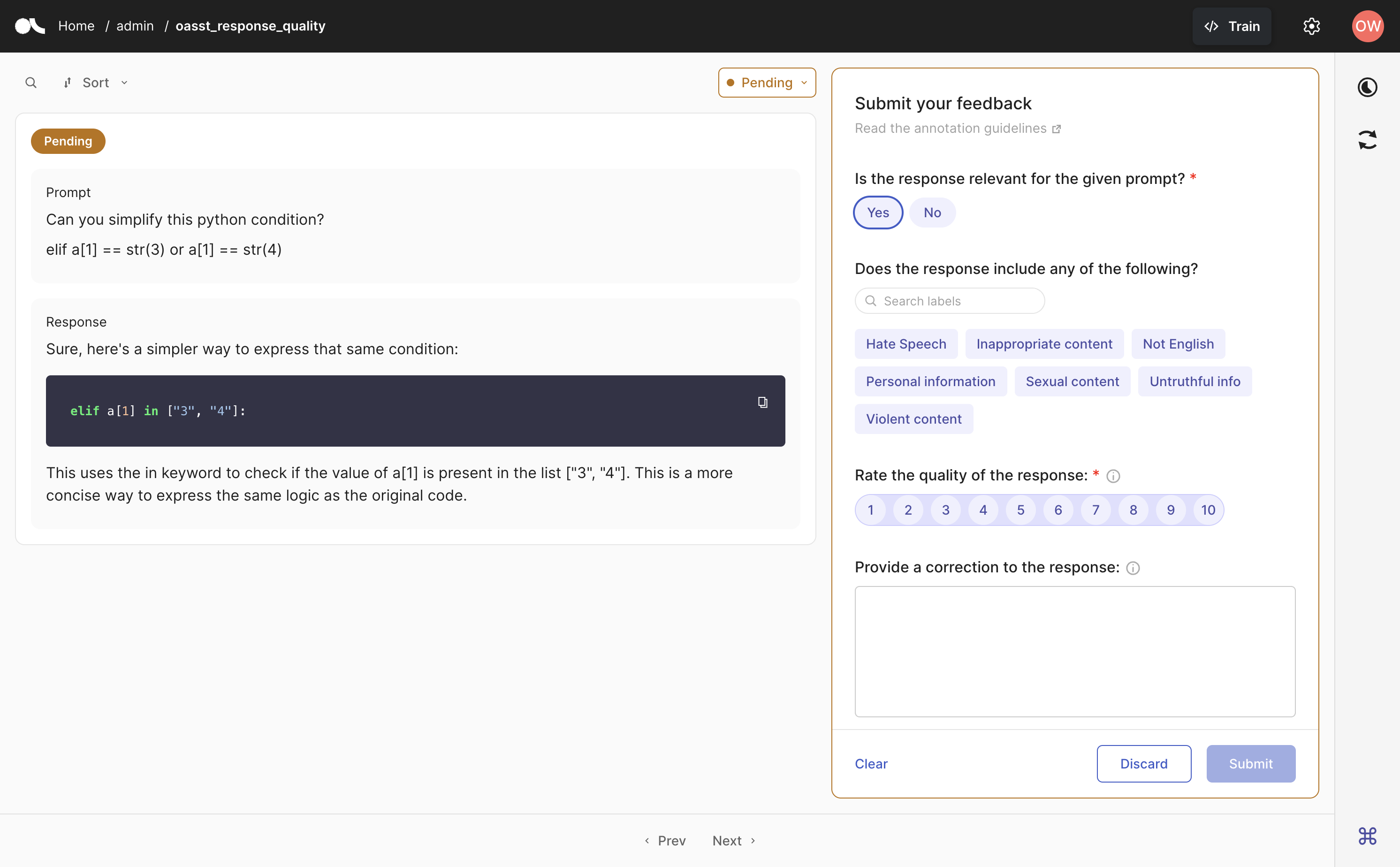
import argilla as rg
rec = rg.TextClassificationRecord(
text="Sun Is Closer... a parachute.",
prediction=[("Sci/Tech", 0.75), ("World", 0.25)],
annotation="Sci/Tech"
)
rg.log(records=record, name="news")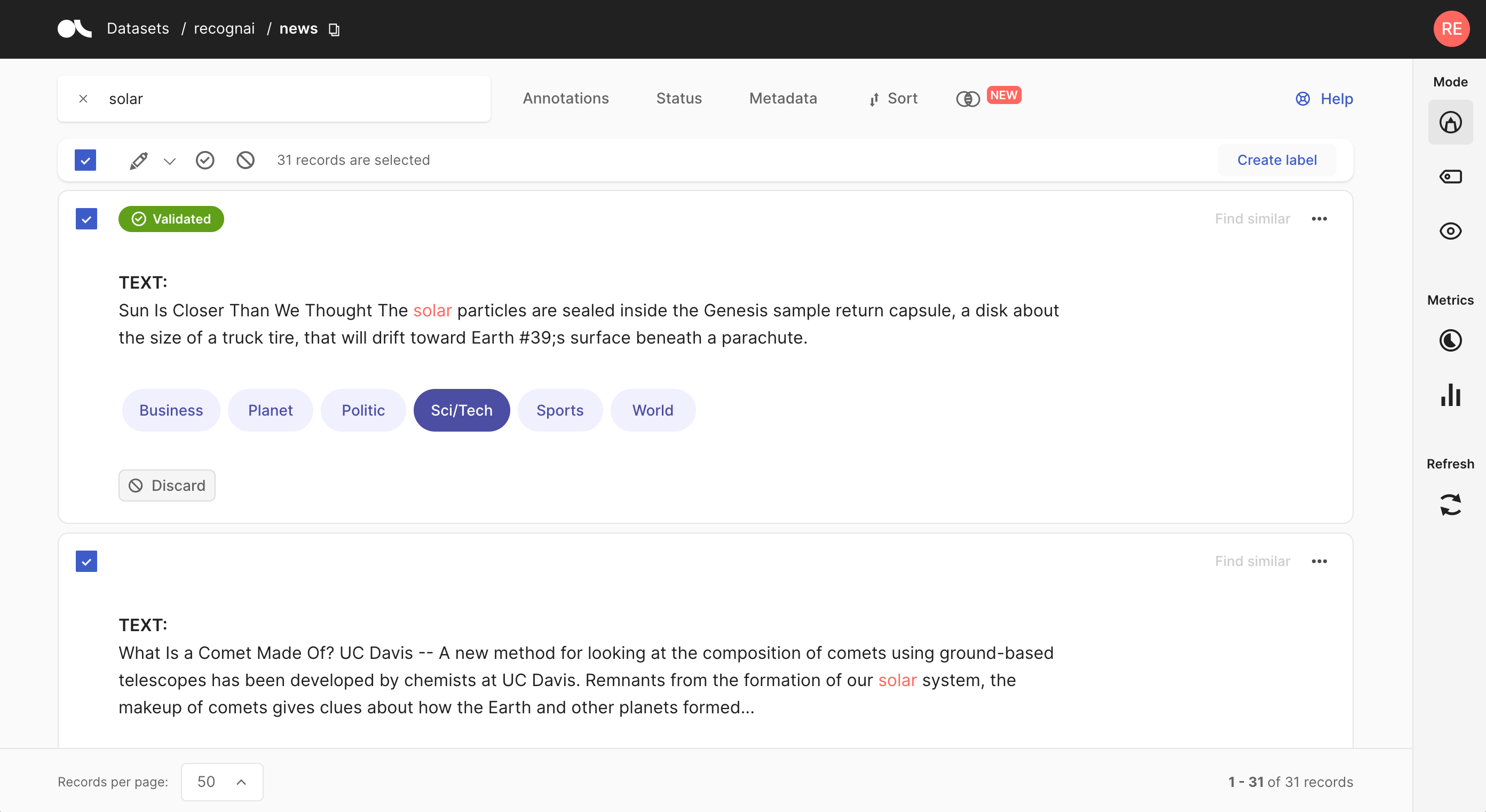
import argilla as rg
rg.load(name="news", query="text:spor*")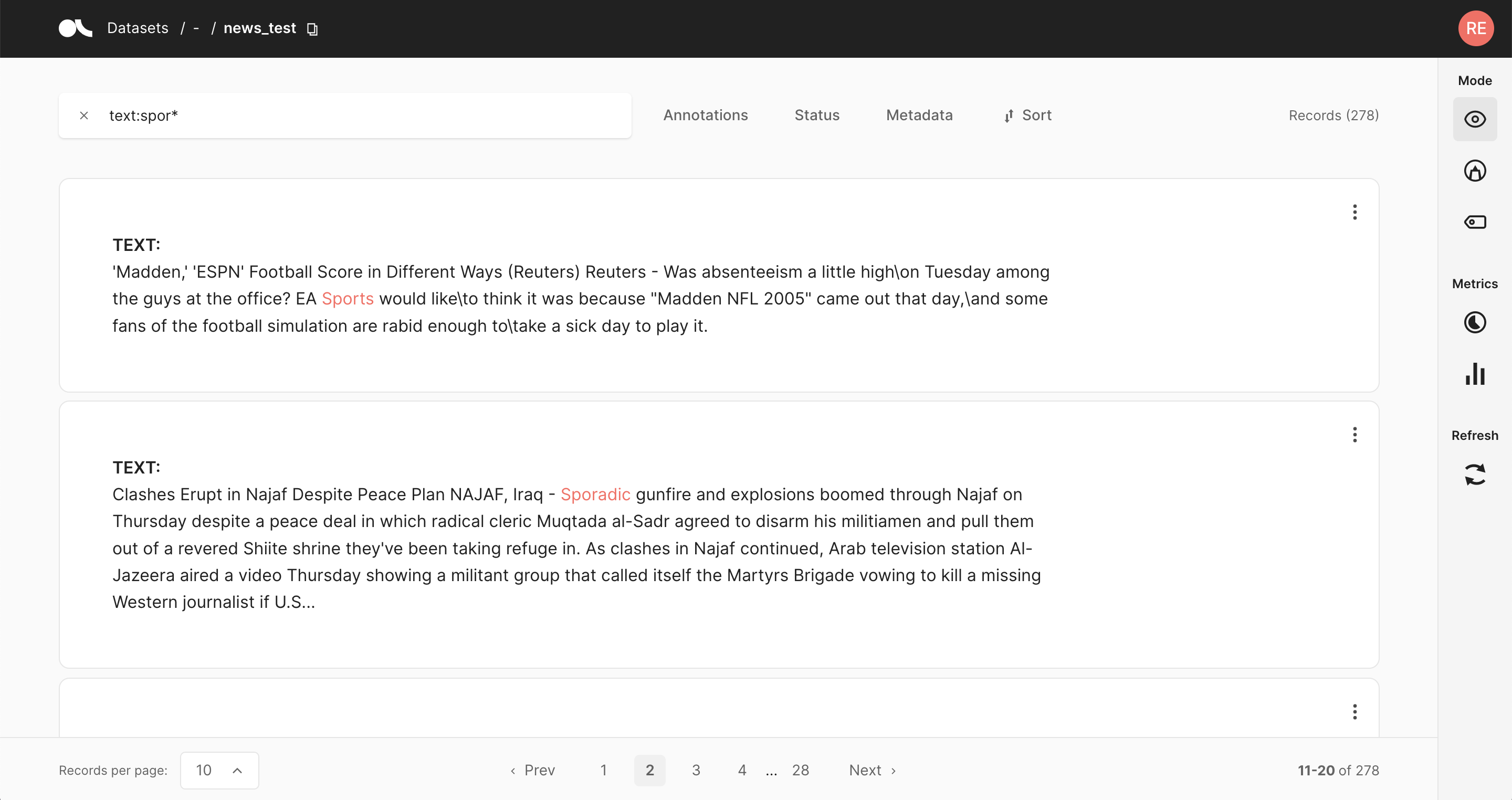
import argilla as rg
record = rg.TextClassificationRecord(
text="Hello world, I am a vector record!",
vectors= {"my_vector_name": [0, 42, 1984]}
)
rg.log(name="dataset", records=record)
rg.load(name="dataset", vector=("my_vector_name", [0, 43, 1985]))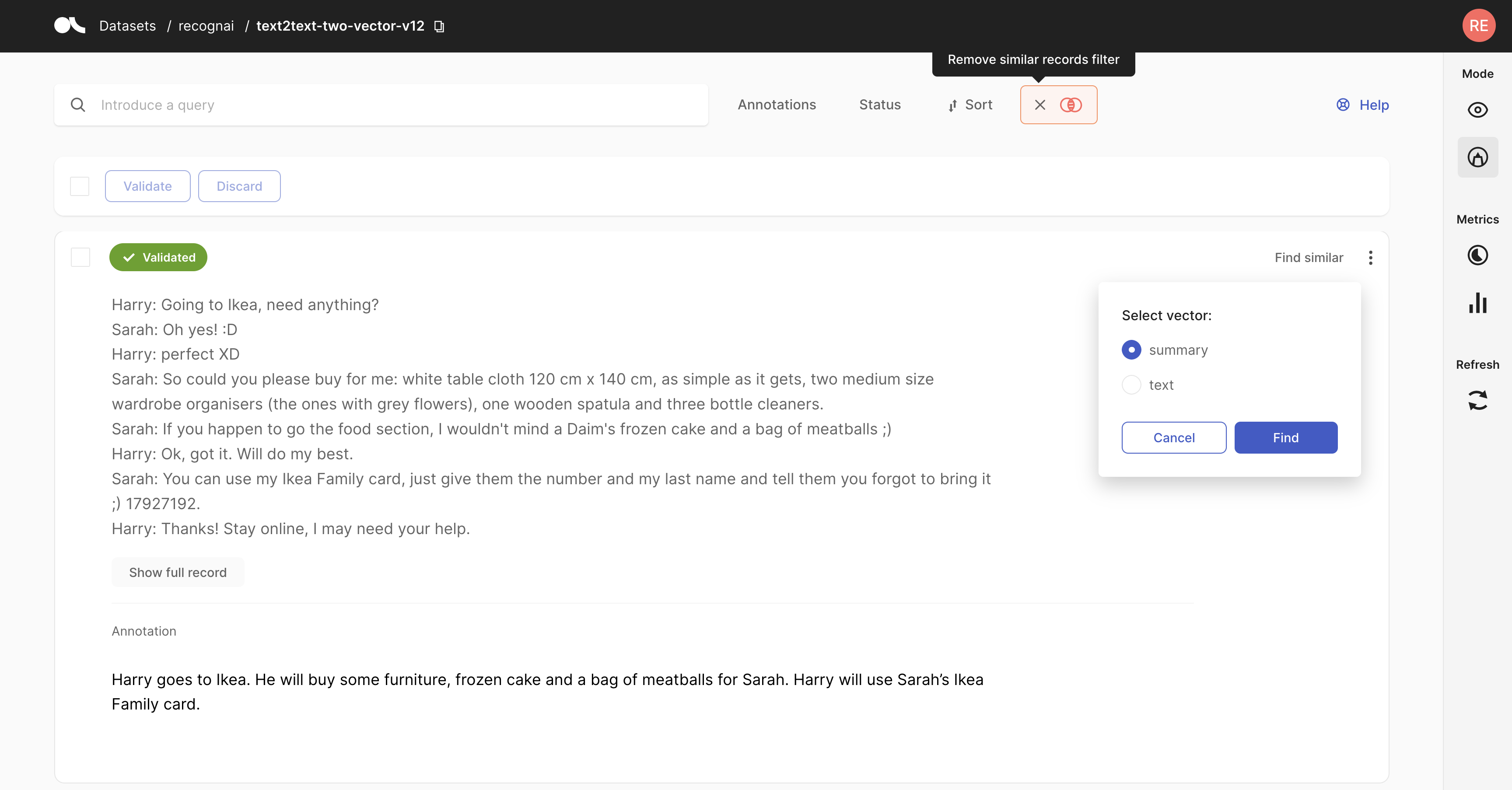
from argilla.labeling.text_classification import add_rules, Rule
rule = Rule(query="positive impact", label="optimism")
add_rules(dataset="go_emotion", rules=[rule])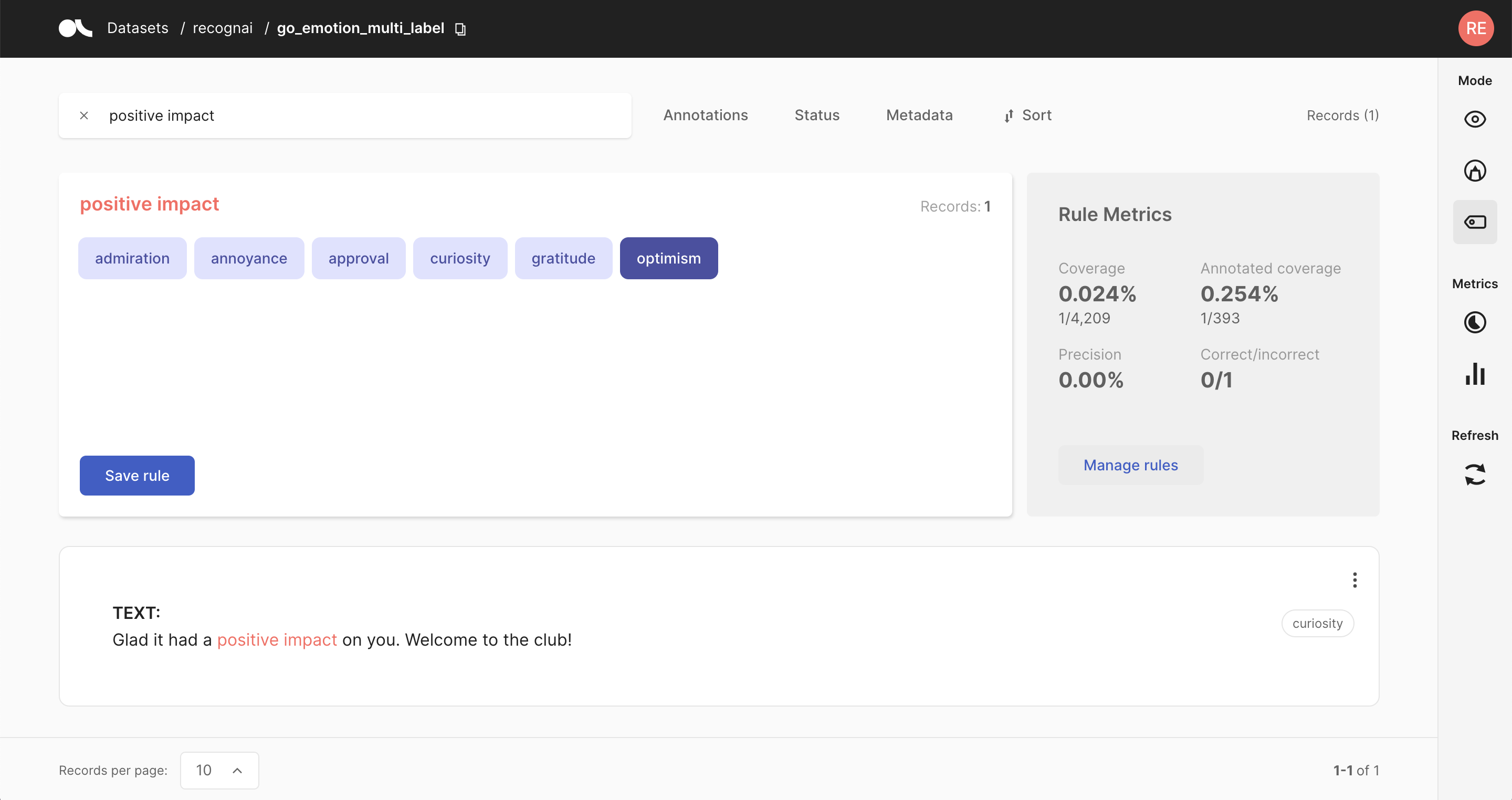
from argilla.training import ArgillaTrainer
trainer = ArgillaTrainer(name="news", workspace="recognai", framework="setfit")
trainer.train()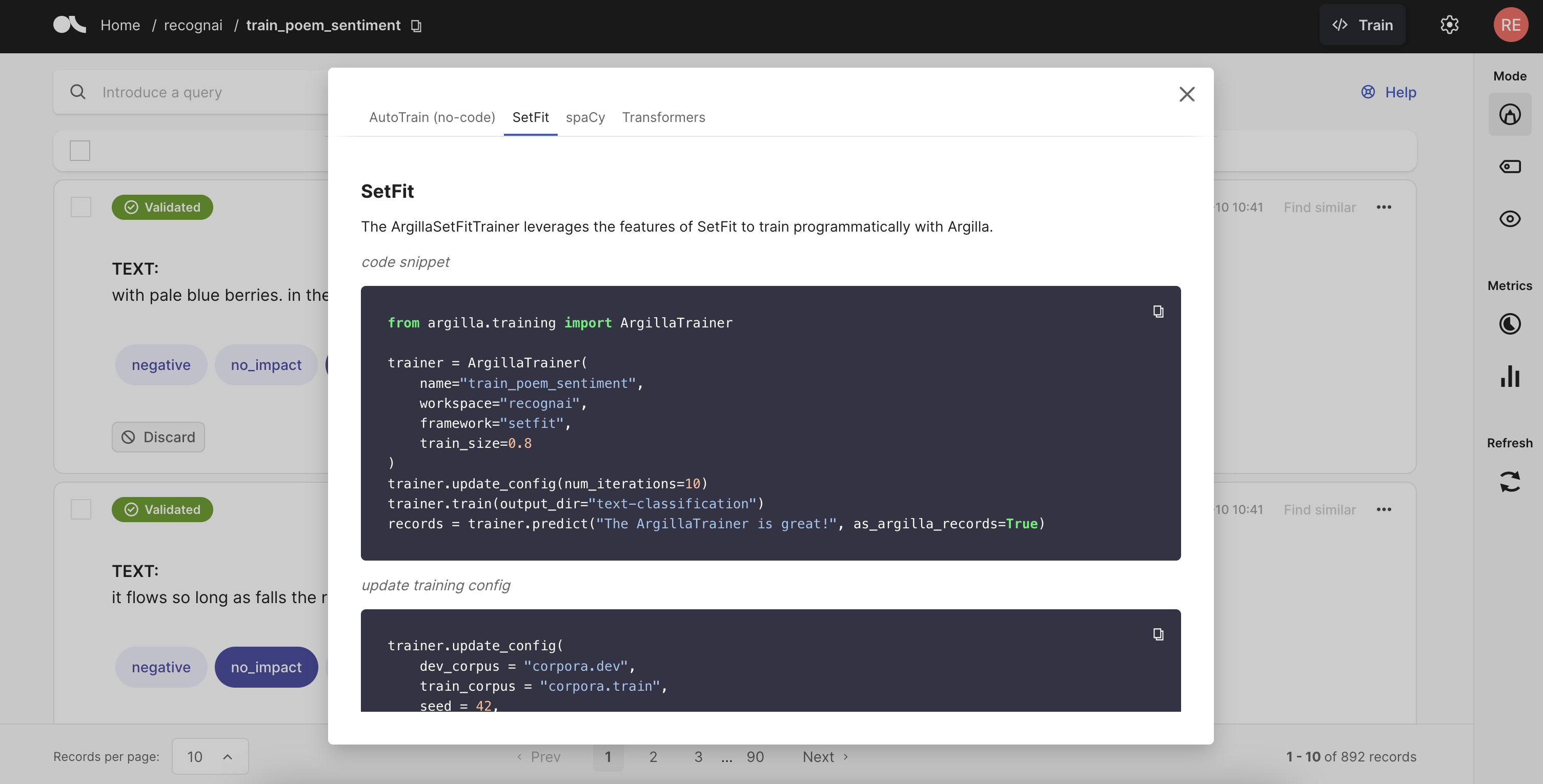
-
Open: Argilla is free, open-source, and 100% compatible with major NLP libraries (Hugging Face transformers, spaCy, Stanford Stanza, Flair, etc.). In fact, you can use and combine your preferred libraries without implementing any specific interface.
-
End-to-end: Most annotation tools treat data collection as a one-off activity at the beginning of each project. In real-world projects, data collection is a key activity of the iterative process of ML model development. Once a model goes into production, you want to monitor and analyze its predictions and collect more data to improve your model over time. Argilla is designed to close this gap, enabling you to iterate as much as you need.
-
User and Developer Experience: The key to sustainable NLP solutions are to make it easier for everyone to contribute to projects. Domain experts should feel comfortable interpreting and annotating data. Data scientists should feel free to experiment and iterate. Engineers should feel in control of data pipelines. Argilla optimizes the experience for these core users to make your teams more productive.
-
Beyond hand-labeling: Classical hand-labeling workflows are costly and inefficient, but having humans in the loop is essential. Easily combine hand-labeling with active learning, bulk-labeling, zero-shot models, and weak supervision in novel data annotation workflows**.
We love contributors and have launched a collaboration with JustDiggit to hand out our very own bunds and help the re-greening of sub-Saharan Africa. To help our community with the creation of contributions, we have created our developer and contributor docs. Additionally, you can always schedule a meeting with our Developer Advocacy team so they can get you up to speed.
We continuously work on updating our plans and our roadmap and we love to discuss those with our community. Feel encouraged to participate.