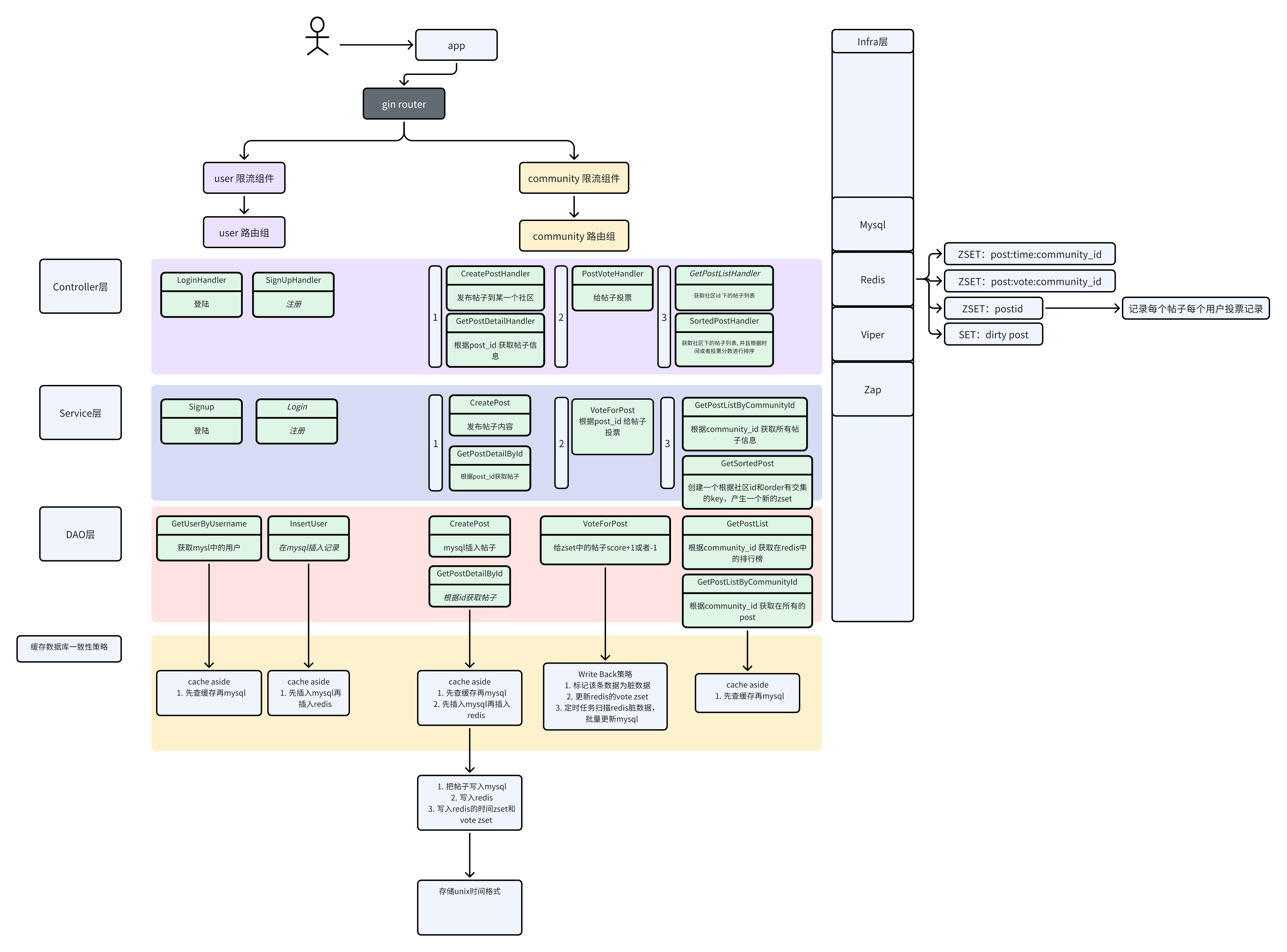
用户可以注册登陆,在不同的主题(“王者荣耀”,“幻兽帕鲁”。。。)上发布帖子;用户还可以给自己喜欢的帖子点赞,给不喜欢的帖子点踩。 用户需要获取到某个主题下的所有帖子,这里有两个选择,这个主题下的所有帖子可以按照创建时间排序,也可以按照投票数量排序。
- 使用MVC架构快速开发
- 拆分成两个路由组
- User:负责注册登陆
- Community 1. API1:用户在community下有发帖的权限 2. API2: 用户可以给帖子投票,根据帖子ID 3. API3: 可以根据社区ID获取到所有排序数据,根据帖子ID和发帖时间
本文档描述了一个用于实现限流的组件。该组件基于 Golang 中的并发原理和数据结构来限制每秒内的请求并发数。使用了 sync.Map 和 chan 数据结构来存储和控制请求的并发量。
本次设计主要借鉴了Uber的漏桶算法。
channel chan struct{}:用于限制请求并发数的通道。每个路由组拥有一个独立的限流通道。once sync.Once:用于控制排水任务只执行一次的同步机制。
sync.Map类型,用于存储每个路由组对应的限流器。路由组名称作为键,rateLimiter结构体指针作为值。
- 参数:
ctx控制排水任务结束的上下文,chanName指定队列名称,capacity指定队列长度(每秒内最多可以承受的最大并发数)。 - 逻辑:
- 创建一个限流队列并开启对应的出水口。
- 使用
LoadOrStore从ratelimitMap中加载或存储通道。 - 若键存在,则返回已存在的值;若键不存在,则存储一个新的值(创建一个带有指定容量的通道)。
- 确保排水任务只执行一次,并根据容量开启排水任务。
- 使用
- 放入请求:
- 根据名称获取对应通道,将请求放入通道。
- 如果能在限定时间内写入,则继续执行请求;否则返回限流信息。
- 创建一个限流队列并开启对应的出水口。
- 参数:
ctx控制排水任务结束的上下文,name队列名称,c限流通道,perRequest每个请求的间隔时间。 - 逻辑:
- 开启一个 goroutine 执行漏水任务,定时排出队列中的水。
- 当接收到上下文的结束信号时,安全退出漏水任务。
- 定时排水任务:
- 每隔一定时间执行排水操作。
- 从通道中取出一个元素,表示请求处理完毕。
- 打印排水成功的信息和当前队列容量。
下面是一个使用该限流组件的示例代码:
package main
import (
"context"
"fmt"
"time"
"github.com/gin-gonic/gin"
)
func main() {
r := gin.Default()
// 创建一个上下文,用于控制漏水口的结束
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 绑定名为route1的限流器,每秒最多10个请求
r.GET("/limited", RateLimit(ctx, "route1", 10), func(c *gin.Context) {
c.JSON(200, gin.H{"message": "Request Allowed"})
})
r.Run(":8080")
}该示例展示了如何在路由上使用 RateLimit 函数来限制请求的并发数。
深度分页问题是在数据库进行分页操作时,随着偏移量(offset)增大,查询效率急剧下降的情况。在典型的分页查询中,假设我们想要获取页面上的第 N 页数据,通常会用 LIMIT 和 OFFSET(或类似的语法)来指定起始位置和要获取的行数。然而,当数据量庞大时,比如数百万或数千万条数据,并且偏移量非常大时,数据库需要扫描并跳过大量的行才能到达目标页,导致查询效率急剧下降。
使用 offset 和 limit 存在效率下降的原因主要有两点:
-
大量跳过数据行:
OFFSET操作实际上是告诉数据库要跳过多少行数据,然后再开始返回结果。随着偏移量的增大,数据库需要逐行扫描并跳过这些行,这导致了大量的资源浪费。例如,LIMIT 100000, 10意味着要跳过前 100,000 行才开始返回接下来的 10 行数据。
-
数据页扫描的增加:
- MySQL在执行 offset 操作时,需要扫描并跳过指定的行数。这会导致数据库引擎扫描更多的数据页,尤其是当偏移量较大时,会增加磁盘 I/O 操作的次数,降低查询效率。
举例来说,如果要获取第 101 页的数据(假设每页有 10 条数据),使用 OFFSET 1000,数据库需要先扫描并跳过前面 1000 条数据才开始返回目标数据。这种方式随着页数增多,查询效率呈指数级下降。
尽管数据库可能知道要跳过前面的数据行,但由于索引和数据存储方式的特性,它仍然需要逐行扫描并丢弃指定数量的行,而不能直接跳到指定位置开始读取数据。这就导致了即使知道偏移量,数据库也无法直接从指定位置开始读取数据的情况。
-
索引的顺序和存储方式:
- 数据库中的索引是按照 B+ 树等数据结构组织的,这些索引是有序的,允许数据库快速定位和检索数据。然而,当需要跳过大量行时,数据库引擎并不会直接跳到所需行,而是需要沿着索引顺序逐行扫描并丢弃跳过的行,因为数据库引擎是按照索引的物理存储顺序来访问数据的。
-
数据页和磁盘 I/O:
- 数据库的数据通常存储在数据页中,数据库引擎在执行查询时会读取数据页。跳过大量行意味着需要扫描更多的数据页,这可能导致更多的磁盘 I/O 操作。即使数据库知道跳过了前面的数据,但它仍需按照物理存储的顺序逐行读取数据页,因为数据在磁盘上是按页存储的。
-
子查询优化方案:
- 使用子查询进行优化,避免大量的跳跃扫描,提高查询效率。
-
内连接(INNER JOIN)延迟关联:
- 将查询操作改为内连接,避免深度分页问题的出现。
在我的代码中,使用子查询来减少:
SELECT
post_id,
title,
content,
author_id,
community_id,
create_at,
update_at
FROM (
SELECT
post_id,
title,
content,
author_id,
community_id,
create_at,
update_at,
ROW_NUMBER() OVER (ORDER BY create_at DESC) AS row_num
FROM post
WHERE community_id = ?
) AS sub
WHERE row_num > ?
LIMIT ?-
子查询解决方案的核心思路:
- 在子查询中,使用
ROW_NUMBER()函数按照特定的排序方式(这里是按照create_at字段降序)对数据进行编号。
- 在子查询中,使用
-
ROW_NUMBER()的作用:ROW_NUMBER()函数为每一行数据分配一个唯一的连续序号。
-
子查询的嵌套方式:
- 外层的
SELECT语句从子查询中选择具有特定row_num值的行,并且通过LIMIT控制返回的行数。
- 外层的
-
为什么有效?
- 这种方法避免了大量偏移量的跳跃扫描,它通过子查询在数据集中添加了连续的序号,允许数据库直接跳到目标行,避免了耗时的偏移量扫描,从而提高了查询效率。
子查询在优化深度分页查询时主要减少了回表的次数,从而使查询速度变快。
当执行类似 limit 100000,10 这样的语句时,数据库会首先根据条件获取满足条件的前100010行数据,然后扔掉前面的100000行,最终只返回后面的10行数据。这个过程实际上意味着数据库需要访问并处理100010行数据,但实际只返回了后面的10行给用户。这样的操作会增加数据库的负担,特别是当偏移量特别大时,会对性能产生明显的影响。
而通过使用子查询优化的方法,将回表的次数减少到最小限度。子查询根据特定的条件(例如根据 update_time),首先找到相应的主键或行ID,然后将这个结果用于外部查询,这样就直接命中了主键索引,减少了回表次数。因此,优化后的查询可以更快地定位到所需的数据,而不需要扫描和丢弃大量不必要的行,从而提高了查询效率。
##TODO 插图1,2
