laizimo / zimo-article Goto Github PK
View Code? Open in Web Editor NEW:books:博客——源于实践,乐于分享,欢迎Star~
:books:博客——源于实践,乐于分享,欢迎Star~





































































































































































































react很容易上手,这是真的!!!毕竟对于ES6的知识点熟知度高的话,开发普通的小应用,react不再话下。可是,你是否考虑过,应用中组件间props传递的问题。比方说,我们需要向一个子子子子组件中传递一个props,一层一层的传递是不是过于丑陋了一些呢!那么,你或许会说用redux吧,做一个全局的store管理,这样就不会有这么多的麻烦了。可是,redux本身就不容易上手,何况你的程序可能并没有需要用到它那么复杂。那么,解决办法只有一个——context。这个东西,说实话,并不好用,或许对于不熟悉的你或许会踩坑,那么今天,我们就来好好聊聊它吧。
context是一个尝试性的API,官方也并不建议去使用它。因为它会使得整个程序并不稳定。
首先,我们来尝试一下context的使用。
我们先来模拟一个列表应用,整个列表应用包含、、、
在不使用context的情况下:
class Button extends React.Component { //一个Button组件,返回一个根据颜色定义的按钮
render(){
return (
<button style={{'color' : this.props.color}}> //在button中使用props中的color
{this.props.children}
</button>
);
}
}
class Message extends React.Component { //在列表的子项目组件,其中包括Button组件
render(){
return (
<div>
{this.props.text}<Button color={this.props.color}>Delete</Button> //向Button传递color
</div>
);
}
}
class MessageList extends React.Component { //列表组件
render(){
const children = this.props.message.map((item, index) =>
<Message text={item} color={this.props.color} key={item}/> //向Message传递color
);
return (
<div>{children}</div>
);
}
}
class App extends React.Component { //app组件
constructor(props){
super(props);
this.state={
message: [
'hello1', 'hello2'
],
color: 'red'
};
}
render(){
return (
<div>
<MessageList message={this.state.message} color={this.state.color}/> //传递state中的color
</div>
);
}
}
ReactDOM.render(<App/>, document.getElementById('root'));从这个例子中,我们要聊的是color这个属性。你会发现color一直从App->MessageList->Message->Button,其中一共穿过了2个组件,当然了,这是我们有意为之。但是,我们传递的方式实在是丑陋。
那么,如果我们对之前的进行改写,使用context来直接跨组件传递,或许会好一点。将之前的代码进行修改
// Button部分修改
class Button extends React.Component {
render () {
return (
<button style={{color: this.context.color}}> //此处直接使用context
{this.props.children}
</button>
);
}
}
Button.contextTypes = { //增加Button组件中的contextTypes校验
color: PropTypes.String
};
//App组件部分修改
class App extends React.Component {
constructor(props){
super(props);
this.state = {
messages: [
'message1', 'message2'
],
color: 'red'
};
}
getChildContext(){ //增加一个返回context对象的函数getChildContext
return {color: 'red'};
}
render () {
return (
<div>
<MessageList messages={this.state.messages}/>
</div>
);
}
}
App.childContextTypes = { //这里增加childContextTypes校验
color: PropTypes.String
};其实就是在App中增加了getChildContext()函数,以及childContextTypes和contextTypes两个context的类型校验——这里需要使用到prop-types。我们可以发现,经过这样子的处理,整个传递流程变成了App->Button,中间少了两层组件。整体看上去的风格简洁,有效。
context使用问题
看过上面的测试用例,我们会发现context其实使用起来挺方便的,那么,为何它只作为尝试性API,官方都不推荐使用呢?
因此,我对上述例子进行了一些改动,从这里我们可以看到context的最大的问题。
首先,我们在App组件中增加一个可以改变color值的按钮
class App extends React.Component { //修改后的App
constructor(props){
super(props);
this.state = {
messages: [
'message1', 'message2'
],
color: 'red'
};
this.changeColor = this.changeColor.bind(this);
}
getChildContext(){
return {color: this.state.color};
}
changeColor(){ //增加一个函数可以改变state中的color值
this.setState({
color: 'green'
});
}
render () {
return (
<div>
<MessageList messages={this.state.messages}/>
<button onClick={this.changeColor}>changeColor</button>
</div>
);
}
}这样我们就可以完成将red转变成green的效果,但是,我们需要去Message组件中添加一个生命周期shouldComponentUpdate,让它的返回值为false,即判断它不更新。
class Message extends React.Component {
shouldComponentUpdate(){
return false;
}
render () {
return (
<div>
{this.props.text}<Button>Delete</Button>
</div>
);
}
}这时,你再次点击按钮,你会发现无法改变button的颜色。
原因呢?主要是Message组件处阻断了组件的更新,导致的问题就是虽然context值被修改了,但是更深层次的组件却为更新,这或许是context最大的问题吧。而且context是一个全局的对象,或许存在会污染全局空间,这也是官方不建议使用它的原因。
对于这种深层次的组件状态传递问题,现在的解决办法其实极为有限。
个人觉得,一般组件超过3层以上的传递,就建议使用redux或者redux模拟。因为一般需要传递3层以上组件的,复杂度已经有点大了
现在的移动端的使用率,已经远远大于PC端了。前端在移动端开发领域也起到了越来越大的用处。但是,移动端复杂的开发环境,往往是一大问题。谷歌开源Android以来,各大手机厂家不断对其内核进行修改,形成自己的版本(包括浏览器方面)。在移动端开发时,我们往往会遇到几个主要的开发环境:Android webview、UI webview(IOS)、微信的X5浏览器内核、UC浏览器等。可能,我们开发时时常会使用chrome来进行调试,但是真实用户使用时,往往只会使用UC或者QQ浏览器。
正是这样子的环境,导致我们的开发成本逐渐地增加,开发问题层出不穷。本篇我将对移动端开发时所遇到的问题进行一个总结,便于之后碰到相同的问题能够轻松地解决。
meta元素基础问题
- 禁止页面缩放
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no"/>
- 禁止电话号码识别
<meta name="format-detection" content="telephone=no" />
- 禁止Android邮箱识别
<meta name="format-detection" content="email=no" />
移动端font-family问题
两个手机系统Android和iOS系统,对于中文来说,都不支持微软雅黑,但是系统自带的字体与微软雅黑的字体差异不大,都是无衬线字体,因此中文可以默认使用系统自带字体。
而英文字体的话,可以使用Helevatic字体,系统都是支持的,设置如下:font-family: Helevatic;
px或者rem的选择问题
对于那些页面比较简单的设计图来说,使用px就可以了,再加上简单的弹性布局,并不需要使用rem;而对于那些页面复杂,内容繁多的设计图来说,例如,手淘主页,这种是需要使用rem来适配大小机型的。
click 300ms延时问题
开发过移动端的人,总会了解过这300ms的来历(简述为:当手机访问PC网页时,可以双击进行缩放,因此会在第一次点击之后,延迟300ms,看是否会进行第二次点击。)。那么,对于正常的网页来说,这300ms的慢启动,会影响用户体验的。我们可以使用fastclick或者zepto.js的touch模块中的tap事件(touchstart+touchmove+touchend)来替代click事件。或者可以直接使用touchstart来替代click事件。
整个事件执行顺序:touchstart->touchmove->touchend->click
retina高清屏
现在的手机高清屏越来越多了,何为retina屏幕?即那些一个点,显示多个像素的屏幕。最早是由苹果公司开发的。在这种高清屏下, 往往原先显示的正常的图片会被放大,而导致模糊的情况。这种情况下,我们就得让设计师准备多张图,如[email protected],[email protected]。这样之后,我们可以写一个媒体查询,对图片进行选择。
1px边框问题
现在,我们被称为前端工程师。然而,早年给我们的称呼却是页面仔。或许是职责越来越大,整体的前端井喷式的发展,使我们只关注了js,而疏远了css和html。
其实,我们可能经常在聊组件化,咋地咋地。但是,回过头来思考一下,如果你看到一张设计稿的时候,连布局都不清不楚,谈何组件化呢。所以,我们需要在分清楚组件之前,先来分清楚布局。废话说了这么多,只是想告诉你,布局这个东西真的很重要。本篇内容概括了布局的基础+基本的PC端布局+移动端适配等内容。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
或许对于你来说,喜欢js的背后,是看不懂css的深层。入门级的css非常简单,但是,精通它却没有想象的容易。我们本篇聊的是布局。前端开发,从拿到设计稿的那一刻,布局的思考就已经开始了。
举个例子,建筑师在设计房屋的时候,需要丈量开发地块的长度,以及每幢房屋相对于其他房屋的位置。
在css布局中,似乎也是这样开始的。我们也会去区分每个元素的尺寸和定位,力争完美的实现整个设计稿。所以,我们的布局应该从定位和尺寸开始聊起
定位的概念就是它允许你定义一个元素相对于其他正常元素的位置,它应该出现在哪里,这里的其他元素可以是父元素,另一个元素甚至是浏览器窗口本身。还有就是浮动了,其实浮动并不完全算是定位,它的特性非常的神奇,以至于它在布局中被人广泛的应用。我们会在后文中专门提及它的。
谈及定位,我们就得从position属性说起。你能准确的说出position的属性值吗?相信你可以完美地说出这么六个属性值:static、relative、absolute、fixed、sticky和inherit。
简单地,介绍一下position的属性值的含义后,在来看一下偏移量top、right、bottom、left四个属性。
不清楚,当初在初学css的时候,会不会与margin这个属性混淆?其实,它们之间是很容易去辨识地。因为这四个属性值,其实是,定位时的偏移量。偏移量不会对static的元素起到作用。而margin,相对应的是盒子模型的外边距,它会对每个元素框起到作用,使得元素框与其他元素之间产生空白。
下面:我们来看一下一些常用定位的偏移
relative:它的偏移是相对于原先在文档流中的位置,如图:
这里设置了top:100px,left:100px。
absolute:它的偏移量是相对于最近一级position不是static的祖先元素的
fixed:它的偏移量是相对于视口的。
其实,这里说描述的内容,应该都是需要理解的。这些相对于布局来说是基础的,同时也是非常重要的。需要注意的是,这里的偏移量其实已经涉及到了接下来要说的尺寸。在做自适应布局设计时,往往希望这些偏移量的单位能够使用百分比,或者相对的单位例如rem等。
那之前上面谈到过尺寸的单位——百分比。那么,下面部分我们就围绕着尺寸单位展开。
尺寸,我们就应该从单位聊起,对于px这个单位,做网页的应该在熟悉不过了,因此不多做介绍。
那么,我们可以来介绍一下下面几个单位:
单位只是一个来定义元素大小的相应参考。另一个概念,或许可以用房子来打一个比方,在早年每幢房子都会在房子的外围建一层栅栏,使得整一块地区可以看成房子+内部地块+栅栏+外围地块的模型。而在css中,每个元素也会有盒子模型的概念。
盒子模型:每个元素,都会形成一个矩形块,主要包括四部分:margin(外边距)+border(边框)+padding(内边距)+content(内容)
css中存在两种不同的盒子模型,可以通过box-sizing设置不同的模型。两种盒子模型,主要是width的宽度不同。如图:
这是标准盒子模型,可以看到width的长度等于content的宽度;而当将box-sizing的属性值设置成border-box时,盒子模型的width=border+padding+content的总和。
可以看出,对于不同的模型的宽度是不同的。宽度默认的属性值是auto,这个属性值会使得内部元素的长度自动填充满父元素的width。如图:
但是,height的属性值也是默认的auto,为什么没有像width一样呢?
其实,auto这个属性值表示的是浏览器自动计算。这种自动计算,需要一个基准,一般浏览器都是允许高度滚动的,所以,会导致一个问题——浏览器找不到垂直方向上的基准。
同样地道理也会被应用在margin属性上。相信如果考察居中时,水平居中你可能闭着眼睛都能写出来,但是垂直居中却绕着脑袋想。这是因为如果是块级元素水平居中只要将水平方向上的margin设置成auto就可以了。但是,垂直方向上却没有这么简单,因为你设置成auto时,margin为0。这个问题,还是需要仔细思考一下的。
到此为止,布局最基本的部分我们已经将去大半,还有就是一块浮动。
浮动,这是一个非常有意思的东西,在布局中被广泛的应用。最初,设计浮动时,其实并不是为了布局的,而是为了实现文字环绕的特效,如图:
但是,浮动并不是仅仅这样而已。何为浮动?浮动应该说是‘自成一派’,类似于ps中的图层一样,浮动的元素会在浮动层上面进行排布,而在原先文档流中的元素位置,会被以某种方式进行删除,但是还是会影响布局。你可能会觉得有疑问,什么叫影响布局?我们可以来举个例子:
首先,我们准备两个颜色块,如图:
之后我们将left的块设置成左浮动,如图:
可以,发现虽然left块因为左浮动,而使得原先元素在文档流中占有的位置被删除,但是,当right块补上原先的位置时,right块中的字体却被挤出来了。这就是所谓的影响布局。
浮动为什么会被使用在布局中呢?因为设置浮动后的元素会形成BFC(使得内部的元素不会被外部所干扰),并且元素的宽度也不再自适应父元素宽度,而是适应自身内容。这样就可以,轻松地实现多栏布局的效果。
浮动的内容还需要介绍一块——清除浮动。可以看到,浮动元素,其实对于布局来说,是特别危险的。因为你可能这一块做过浮动,但未做清除,那么造成高度塌陷的问题。就是上面图示的那种情况。
清除浮动,最常用的方法有两种:
这里只是稍微的提上一嘴。下面我们正式来介绍一下网页的布局,本篇最核心的东西。
最初的时候,网页简单到可能只有文字和链接。这时候,大家最常用的就是table。因为table可以展示出多个块的排布。
这种布局现在应该不常用了,因为在形色单一时,使用起来方便。但是,现在的网页变得越来越复杂,适配的问题也是越来越多,这种布局已经不再时候了。
主要是div块的出现,可以使得网页进行灵活的排布,使得网页变得繁荣。这时,开发者也开始思索如何去更加清晰地分辨网页的层次。接下来,我们可以看看有哪些比较出名的布局方式。
是否记得,那些一边主体内容,一边目录的网页,如图:
类似于上图的布局,可以定义为两栏布局。
**两栏布局:**一栏定宽,一栏自适应。这样子做的好处是定宽的那一栏可以做广告,自适应的可以作为内容主体。
实现的方式:
<body>
<div class="left">定宽</div>
<div class="right">自适应</div>
</body>.left{
width: 200px;
height: 600px;
background: red;
float: left;
display: table;
text-align: center;
line-height: 600px;
color: #fff;
}
.right{
margin-left: 210px;
height: 600px;
background: yellow;
text-align: center;
line-height: 600px;
}如图所示:
其他的方法:还可以使用position的absolute,可以使用同样的效果
三栏布局,也是经常会被使用到的一种布局。
它的特点:两边定宽,然后中间的width是auto的,可以自适应内容,再加上margin边距,来进行设定。
三栏布局可以有4种实现方式,每种实现方式都有各自的优缺点。
1.使用左右两栏使用float属性,中间栏使用margin属性进行撑开,注意的是html的结果
<div class="left">左栏</div>
<div class="right">右栏</div>
<div class="middle">中间栏</div>.left{
width: 200px;height: 300px; background: red; float: left;
}
.right{
width: 150px; height: 300px; background: green; float: right;
}
.middle{
height: 300px; background: yellow; margin-left: 220px; margin-right: 160px;
}缺点是:1. 当宽度小于左右两边宽度之和时,右侧栏会被挤下去;2. html的结构不正确
2. 使用position定位实现,即左右两栏使用position进行定位,中间栏使用margin进行定位
<div class="left">左栏</div>
<div class="middle">中间栏</div>
<div class="right">右栏</div>.left{
background: red;
width: 200px;
height: 300px;
position: absolute;
top: 0;
left: 0;
}
.middle{
height: 300px;
margin: 0 220px;
background: yellow;
}
.right{
height: 300px;
width: 200px;
position: absolute;
top: 0;
right: 0;
background: green;
}好处是:html结构正常。
缺点时:当父元素有内外边距时,会导致中间栏的位置出现偏差
3. 使用float和BFC配合圣杯布局
将middle的宽度设置为100%,然后将其float设置为left,其中的main块设置margin属性,然后左边栏设置float为left,之后设置margin为-100%,右栏也设置为float:left,之后margin-left为自身大小。
<div class="wrapper">
<div class="middle">
<div class="main">中间</div>
</div>
<div class="left">
左栏
</div>
<div class="right">
右栏
</div>
</div>.wrapper{
overflow: hidden; //清除浮动
}
.middle{
width: 100%;
float: left;
}
.middle .main{
margin: 0 220px;
background: yellow;
}
.left{
width: 200px;
height: 300px;
float: left;
background: red;
margin-left: -100%;
}
.right{
width: 200px;
height: 300px;
float: left;
background: green;
margin-left: -200px;
}缺点是:1. 结构不正确 2. 多了一层标签
4. flex布局
<div class="wrapper">
<div class="left">左栏</div>
<div class="middle">中间</div>
<div class="right">右栏</div>
</div>.wrapper{
display: flex;
}
.left{
width: 200px;
height: 300px;
background: red;
}
.middle{
width: 100%;
background: yellow;
marign: 0 20px;
}
.right{
width: 200px;
height: 3000px;
background: green;
}除了兼容性,一般没有太大的缺陷
三栏布局使用较为广泛,不过也是比较基础的布局方式。对于PC端的网页来说,使用较多,但是移动端,本身宽度的限制,很难做到三栏的方式。因此,移动端盛行的现在,我们应该掌握一些自适应布局技巧和flex等方式。
或许,手机占用了人们大部分的时间,对于前端工程师来说,不仅需要会h5和大前端的技术,还需要去适配不同的手机屏幕。PC端称王的时代已经过去,现在要求的网页都是需要能够去适配PC和移动端的。
之前,所聊的两栏和三栏布局,一般只能在PC中去使用,在移动端,由于屏幕尺寸有限,很难去做到类似的操作,所以,我们需要来了解新的东西。
1. 媒体查询
如果你需要一张网页能够在PC和移动端都能按照不同的设计稿显示出来,那么你需要做的就是去设置媒体查询。
媒体查询的css标识符是@media,它的媒体类型可以分为:
代码示例:
@media screen {
p.test {font-family:verdana,sans-serif;font-size:14px;}
}
@media print {
p.test {font-family:times,serif;font-size:10px;}
}
@media screen,print {
p.test {font-weight:bold;}
}
/*移动端样式*/
@media only screen and (min-device-width : 320px) and (max-device-width : 480px) {
/* Styles */
}媒体查询的主要原理:它像是给整个css样式设置了断点,通过给定的条件去判断,在不同的条件下,显示不同的样式。例如:手机端的尺寸在750px,而PC端则是大于750px的,我们可以将样式写成:
@media screen and (min-width: 750px){
.media{
height: 100px;
background: red;
}
}
@media (max-width: 750px){
.media{
height: 200px;
background: green;
}
}效果图:
flex弹性盒子
其实移动端会经常使用到flex布局,因为在简单的页面适配方面,flex可以起到很好的拉伸的效果。我们先看几张图体会一下:
可以从图中看出,这个网页不管屏幕分辨率怎么发生变化,它的高度和位置都不变,而且里面的元素排布也没有发生变化,总是图标信息在左边和薪资状况在右边。
这就是很明显的,flex布局。flex可以在移动端适配比较简单的,元素比较单一的页面。
具体的flex布局内容,在这里不详细说明。flex传送门
rem适配
rem可以说是移动端适配的一个神器。类似于手淘等界面,都是使用的rem进行的适配。这种界面有个特点就是页面元素的复杂度比较高,而使用flex进行布局会导致页面被拉伸,但是上下的高度却没有变化等问题。示例图:
具体的讲解可以看这篇比较好的文章。rem传送门
分析到这里,布局的很多东西都已经非常的清晰了。相信这是一篇值得去收藏的一篇文章。内容可能有点多,所以这里做一个总结:
相信你看完这些,在以后,一定可以拿到设计稿的时候,内心大致有个算盘,应该如何区分,如何布局。
最后,如果你对我写的有疑问,可以与我讨论。如果我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
至上一篇基础常识讲完之后,这次我们将开启新的篇章。本篇我们会来讲述你在操作时需要去增加的监听事件,焦点控制,按钮的状态同步等问题。同时,还需要完成的是当标题栏聚焦时,你需要去控制按钮的禁止点击,例如插入图片按钮等。所以综合而言,本篇还是相对比较重要的。接下来,我们会就上述提到的点进行一一讲述。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客。
首先,我们第一步来讲一下焦点控制的问题。那么,你会认为焦点控制只是简单的使用focus函数聚焦这么简单吗?当然不是。一旦,你这样操作了,你会发现一个问题,你的焦点永远在起始处,往往会造成不良的用户体验。这里我们需要明白的第一点——焦点控制。
我们知道焦点其实就是一个range。每个range都会又一个collapsed去判断,前后是否重叠。一旦,前后重叠了,这个range就会称为焦点。所以,我们如果想去控制焦点,就必须学会控制range块。
回到上一篇的range介绍,我们知道range具备4个常用属性:startContainer、startOffset、endContainer、endOffset等4个属性。我们只要学会如何去控制这4个属性,我们就能将range块变出任意的样子。
那么,我们可以先从「聚焦功能」说起:
这里,我们所谓的聚焦是可以区分为两种,一种是保证聚焦到尾部,另一种就是聚焦到用户输入的位置。
之前,我们已经说过,focus函数使得整个编辑块聚焦,但是它是使得焦点聚焦在起始处,而我们现在需要将整个焦点聚焦到末尾,我们源码中的逻辑可以这样:
我们可以来看一下源码:
focus: function(){ //聚焦
const _self = this;
const range = document.createRange();
range.selectNodeContents(_self.cache.editor);
range.collapse(false);
const select = window.getSelection();
select.removeAllRanges();
select.addRange(range);
_self.cache.editor.focus();
}这里,我们创建了一个range,然后将这个range的节点内容设置为编辑块,之后使用collapse来使得它的先后合并。同时,我们需要去获得选区,将选区中的range都清除掉,再将新创建的range对象添加到选区对象中。最后,使编辑块聚焦。
这时,你去测试一下,你就会发现焦点会自动聚焦到尾部去
之前,我们也讲述过还有一种焦点控制的方式——聚焦到原先用户输入的位置
那么,我们需要如何去完成这一个功能呢?我们首先需要去保存用户输入的焦点。
我们可以先来看一下源码:
saveRange: function(){
const _self = this;
const selection = window.getSelection();
if(selection.rangeCount > 0){
const range = selection.getRangeAt(0);
const { startContainer, startOffset, endContainer, endOffset} = range;
_self.currentRange = {
startContainer: startContainer,
startOffset: startOffset,
endContainer: endContainer,
endOffset: endOffset
};
}
}这里的saveRange方法就是我们在源码中用来保存Range的方法。其实,它的原理非常的简单:
既然你看到了保存焦点时的原理,那么,相信还原焦点的原理你应该也已经清楚一点了吧。
接下来,我们就来看一下还原焦点的过程:
源码:
reduceRange: function(){
const _self = this;
const { startContainer, startOffset, endContainer, endOffset} = _self.currentRange;
const range = document.createRange();
const selection = window.getSelection();
selection.removeAllRanges();
range.setStart(startContainer, startOffset);
range.setEnd(endContainer, endOffset);
selection.addRange(range);
}至此,我们已经将富文本中需要去控制焦点的部分内容分析完了。之后,我们先来看一下按钮的状态同步。
何为状态同步?你或许还没有一个比较清晰的概念。那么,我们给定一个场景,来帮助大家理解一下:
最初,你会按下加粗按钮之后,输入部分的内容会加粗;但是,当你这时发现之前有个地方的内容,需要修改,这时你会点击那个部分进行修改。这时问题来了:在没点击之前,你的加粗按钮是高亮显示的,而点击之后,你首先要确定那个位置是否具备加粗,然后去控制按钮的高亮问题。这就是我们之后需要处理的问题——状态同步。
我们可以先简单的阐述一下状态同步的原理:
我们只需要去获得当前焦点处所含有的标签就可以了。因为我们所插入的bold、italic等都是通过execCommand的命令插入的。同样,document也提供了API让我们来获取当前焦点处的标签。我们可以看一下源码中的这个方法:
getEditItem: function(evt = {}){
const _self = this;
const { STATE_SCHEME, CHANGE_SCHEME } = _self.schemeCache;
if(evt.target && evt.target.tagName === 'A'){
_self.cache.currentLink = evt.target;
const name = evt.target.innerText;
const href = evt.target.getAttribute('href');
window.location.href = CHANGE_SCHEME + encodeURI(name + '@_@' + href);
}else{
if(e.which == 8){
AndroidInterface.staticWords(_self.staticWords());
}
const items = [];
_self.commandSet.forEach((item) => {
if(document.queryCommandState(item)){
items.push(item);
}
});
if(document.queryCommandValue('formatBlock')){
items.push(document.queryCommandValue('formatBlock'));
}
window.location.href = STATE_SCHEME + encodeURI(items.join(','));
}
}这里的源码内容有点复杂,因为我们还有其他的一些情况需要考虑,所以这里我们可以来提取一部分进行分析:
const items = [];
_self.commandSet.forEach((item) => {
if(document.queryCommandState(item)){
items.push(item);
}
});
if(document.queryCommandValue('formatBlock')){
items.push(document.queryCommandValue('formatBlock'));
}
window.location.href = STATE_SCHEME + encodeURI(items.join(','));这个部分就是实际去获取标签的部分,我们可以先来了解两个API:
queryCommandState: 这个函数返回的boolean类型的值,然后它会去测试当前这个state中是否具备这个标签。
我们可以做个测试:
document.execCommand('bold', false, null);
const state = document.queryCommandState('bold');
console.log(state); //true这样我们就可以明白上面第一部分操作的原理:
queryCommandValue:这个函数也是返回boolean类型的值。我们可以直接来做个测试:
document.execCommand('formatBlock', false, '<h1>');
const value = document.queryCommandValue('formatBlock');
console.log(value); //h1这里的不同点就是,无参数命令和有参数命令的区别了。类似于h1标签这种,需要我们自定义标签参数的值,往往就需要使用这部分的测试方式,所以,我们也会将获取到的value放入items集合中
最后,一步就是一个通信的问题了。我们之前一篇中,聊到如果js与webView之间进行交互时,可以通过url劫持的方式来完成。我们将这个URL头进行定义,相对应这种特殊的URL头,webView会做相应的处理。
因为URL中添加参数时,都需要将值进行URL编码。所以,我们需要做一个编码的过程。
那么,至此我们提取出来的代码部分讲完了。我们回过头来再去分析一下原来的代码。
有些特殊情况或许你的考虑到:
首先,来看一下修改链接的,我们并不需要去进行状态的同步。所以,我们需要确定点击时,判断这个节点元素是否是A标签,我们可以看一下源码:
if(evt.target && evt.target.tagName === 'A'){
_self.cache.currentLink = evt.target;
const name = evt.target.innerText;
const href = evt.target.getAttribute('href');
window.location.href = CHANGE_SCHEME + encodeURI(name + '@_@' + href);
}因为,我们需要修改链接,所以需要将当前这个链接的节点保留下来,方便之后的修改;同时,我们也需要向webview传递链接的name和url的信息。使用的方式——URL劫持。
之后,我们需要去考虑的是一些键位,比方说回车操作,删除操作。它们本身也不会去通知webview对其进行监听。键位的话,我们可以考虑按键时的键位code来进行特殊键位的判断,如下:
_self.cache.editor.addEventListener('keyup', (evt) => {
if(evt.which == 37 || evt.which == 39 || evt.which == 13 || evt.which == 8){
_self.getEditItem(evt);
}
}, false);这里我们对删除键、回车键、左尖括号『<』,右尖括号『>』,做了监听,然后当用户按下这几个键时,都会调用getEditItem的方法。
状态同步的问题我们就聊那么多。之后我们来看一下我们设置的监听事件。
直接先放上源码来让大家看一下:
bind: function(){
const _self = this;
document.addEventListener('selectionchange', _self.saveRange, false);
_self.cache.title.addEventListener('focus', function(){
AndroidInterface.setViewEnabled(true);
}, false);
_self.cache.title.addEventListener('blur', () => {
AndroidInterface.setViewEnabled(false);
}, false);
_self.cache.editor.addEventListener('blur', () => {
_self.saveRange();
}, false);
_self.cache.editor.addEventListener('click', (evt) => {
_self.saveRange();
_self.getEditItem(evt);
}, false);
_self.cache.editor.addEventListener('keyup', (evt) => {
if(evt.which == 37 || evt.which == 39 || evt.which == 13 || evt.which == 8){
_self.getEditItem(evt);
}
}, false);
_self.cache.editor.addEventListener('input', () => {
AndroidInterface.staticWords(_self.staticWords());
}, false);
}直接按照顺序阐述下去吧!!
selectionchange事件,则是检测选区的变化,因为选区发送变化的时候。往往指定是焦点的变化。
每次焦点发生变化时,都需要去保存当前的range,以便于还原焦点。
focus和blur事件,其实就是需要去控制底栏按钮的可用性。因为我们的界面上面有标题栏,标题栏是不允许插入图片、插入链接、字体操作的。所以这里通过对象映射的方式,提醒webView去禁止底栏显示。
同样的,对于编辑块来说,需要监听blur事件,然后保存原来的焦点。
接下来,就是我们之前所说的点击事件的监听了。首先,点击编辑块时,需要你去保存焦点,同时同步这个位置的状态,调用getEditItem方法。
最后,需要去监听一个输入事件,因为我们需要去同步字体的数量,每当用户输入时,我们就要调用staticWords方法来同步字体的数目。
最后,我们本篇文章的内容都已经分析完了。当然,你也可以细细理解我们在这里说做的所有操作,可以说这篇内容解决了我们在开发富文本编辑器时,大部分的问题。同时,也内涵了我们的思考。希望你能喜欢我们这个项目,同时帮助你的进步。
最后,如果你对我写的有疑问,可以与我讨论。如果我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客。同时也希望你关注我们的项目,github项目地址,谢谢支持
在前端开发中,缓存有利于加快网页的加载速度,同时缓存能够被反复利用,所以可以减少流量和带宽的开销。
缓存的分类有很多种,CDN缓存、数据库缓存、代理服务器缓存和浏览器缓存。本篇将来讲解一下Web开发中的浏览器缓存。这个在实际开发环境中往往也会被问到,或者使用到。如何去准确认清楚缓存的概念,是前端必须要去学习的。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
浏览器的缓存问题,主要指的是http的缓存——即协议层。而h5新增的storage和数据库缓存,那是应用层缓存,并不被计入本篇的分析内容里面。下面我们正式开始来进行缓存的分析。
协议层的缓存,其实,可以被分成强制缓存和对比缓存。
首先,我们先来看一张强制缓存时的时序图,来了解一下强制缓存在不同情况下的请求模式:
从图中,我们不难看出,只有当缓存失效时,才会去服务器获取最新资源的方式,就是强制缓存。而在协议层的字段中,可以造成强制缓存的字段有两个Expires和Cache-Control。
最早使用的是Expires字段,该字段表示缓存到期时间,即有效时间+当时服务器的时间,然后将这个时间设置在header中返回给服务器。因此,该时间是一个绝对时间,举例说明:
Expires: Thu, 10 Nov 2017 08:45:11 GMT图片示例:
在响应消息头中,设置这个字段之后,就可以告诉浏览器,在未过期之前不需要再次请求。
但是,这个字段设置时有缺点:
由于是绝对时间,用户可能会将客户端本地的时间进行修改,而导致浏览器判断缓存失效,重新请求该资源,同时,还导致客户端与服务端的时间不一致,致使缓存失效。
已知Expires的缺点之后,在HTTP/1.1中,增加了一个字段Cache-Control,该字段表示资源缓存的最大有效时间,在该时间内,客户端不需要向服务器发送请求
这两者的区别就是前者是绝对时间,而后者是相对时间。我们不妨举个例子来说明一下:
Cache-Control: max-age=2592000图片示例:
下面列举一下Cache-Control的字段可以带的值:
max-age:即最大有效时间,在上面的例子中我们可以看到
no-cache:表示没有缓存,即告诉浏览器该资源并没有设置缓存
s-maxage:同max-age,但是仅用于共享缓存,如CDN缓存
public:多用户共享缓存,默认设置
private:不能够多用户共享,HTTP认证之后,字段会自动转换成private。
总结一下,自从http1.1开始,Expires逐渐被Cache-Control取代。Cache-Control是一个相对时间,即使客户端时间发生改变,相对时间也不会随之改变,这样可以保持服务器和客户端的时间一致性。而且Cache-Control的可配置性比较强大。
扯完强制缓存,我们来看看对比缓存。在解释这个之前,是否可以先猜想一下,强制缓存是,缓存在未过有效期时,不需要请求资源。那么,对比缓存的原理又该如何呢?
废话不多说,我们也先从对比缓存的时序图讲起,如图:
对比缓存的过程是,先从缓存中获取对应的数据标识,然后向服务器发送请求,确认数据是否更新,如果更新,则返回新数据和新缓存;反之,则返回304状态码,告知客户端缓存未更新,可继续使用。
这正好弥补了一些强制缓存的缺陷。对比缓存主要应用于一些时常需要动态更新的资源文件。
对比缓存在协议里的字段是Last-Modified和If-Modified-Since。
Last-Modified:服务器告知客户端,资源最后一次被修改的时间,例如
Last-Modified: Thu, 10 Nov 2015 08:45:11 GMTIf-Modified-Since:再次请求时,请求头中带有该字段,服务器会将If-Modified-Since的值与Last-Modified字段进行对比,如果相等,则表示未修改,响应304;反之,则表示修改了,响应200状态码,返回数据。
这个字段可以和Cache-Control配合使用。
但是他还是有一定缺陷的:
如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
由于Last-modified还是存在缺陷的,尽管大多数情况下,会使用它,但当遇到我们上面所说的场景时,我们可能就需要了解一下,我们另一个小伙伴了——Etag。
Etag存储的是文件的特殊标识(一般都是hash生成的),服务器存储着文件的Etag字段,可以在与每次客户端传送If-no-match的字段进行比较,如果相等,则表示未修改,响应304;反之,则表示已修改,响应200状态码,返回数据。
最后,通过一张原理图,我们来加深一下记忆:
至此为止,两种缓存类型的缓存方式已经阐述完成了,不知你是否已经心中已经有个大致的印象,当别人问起时,你可以对答如流。希望我们一同进步吧,fighting。
最后,我们来聊聊浏览器行为会引起缓存的变化吧。
下面说一下浏览器的行为会产生怎样的请求:
在PC端或许这样子的缓存机制就已经足够了,因为PC端不需要为网络的问题担心。
但是,移动端却不行,任何一个网络请求的增加,对于移动端的加载消耗时间都是比较大的(谁叫移动端的网太差呢,3G、2G)。那么,上述的缓存有什么问题呢?其实,强制缓存是没有太大问题的,因为只要缓存不到期,是不会想服务器发送请求的;但是如果是对比缓存的情况下,304的问题就比较巨大,因为它会造成无用的请求。每次在使用缓存前,都会向服务器发送请求确认,导致网络的延时。
一次完美的缓存必须保证两点:
所以,一般我们会运用的方式是:
在资源文件后面加上表示,如config.f1ec3.js、config.v1.js之类的,然后给资源设置较长的缓存时间,如一年
Cache-Control: max-age=31536000这样子,就不会造成304的回包现象。
然后一旦资源发生更新时,我们可以改变资源后面的标识符,实现静态资源非覆盖式更新。
本篇大致分析了浏览器缓存部分的分类情况,以及细化分析。主要可分为:
强制缓存
Expires字段
Cache-Control字段
对比缓存
Last-Modefied字段
Etag标识
浏览器行为引起的缓存变化
移动端的缓存策略
其实,在讲述移动端的缓存策略时,并没有分析的特别详细,只是大致的讲解了一下目前大家都在使用的缓存策略。可能之后,还会写一篇移动端缓存的细分文章。
最后,如果你对我写的有疑问,可以与我讨论。如果我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
本篇内容主要是详解图片上传、重传、进度条、遮罩、错误显示、以及图片删除等功能的分析。
本篇记录了我在搭建整个后端开发环境的整体过程。后端开发环境,从框架选型,到单测环境、规范校验、打包等。其实,GitHub上面具备着纵多的脚手架可以快速搭建出一个后端开发的环境。但是,那样操作其实并没有实际的效果,只能满足快速开发而已。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
首先,我们需要确定开发环境主体的框架,我的选择时koa2,虽然需要去满足nodeJS大于7.6.0以上,但是其利用了ES7中的async/await,实在是令人满意。最大的优势就是服务器上的nodeJS版本是我们所控制的。如果你不清楚如何控制nodeJS版本的话,可以安装nvm来进行node版本的切换。
开始创建一个空项目文件夹,命名为koa-scaffold:
mkdir koa-scaffold
然后进入新创建的文件目录中:
cd koa-scaffold
然后,我们可以初始化package.json文件
npm init -y
同时,我们还需要去创建一些空文件目录,统一整体的开发目录:
mkdir -p server/{routes,db,controllers,models,services} test
最后,安装koa2:
npm install --save koa
这里所使用的数据库是MongoDB,不过听说它的模糊查询并(qi)不(shi)优(la)秀(ji)。但是,考虑到操作方便,而且作为前端的开发者,接触到MongoDB这种NoSQL型数据库是迟早的事情。所以,我们会选择mongoose这个数据库连接库,如果你使用的是其他的数据库的话,那么我推荐knex.js。(有兴趣了解可以自行Google)
安装mongoose:
npm install --save mongoose
然后,我们进行一下测试,在test目录下建立一个dbtest.js文件:
const mongoose = require('mongoose');
mongoose.connect('mongodb://localhose/test');
const db = mongoose.connection;
db.on('error', (err) => {
console.log('connection error: ' + err);
});
db.on('open', () => {
console.log('connection success!');
});通过这段代码,然后运行一下dbtest.js。之后,我们会发现我们的本地MongoDB中多了test数据库名。
这里的测试选择了mocha和chai,不需要追求原因。因为就目前前端的测试框架良莠不齐,种类繁多,但是可以说前端工程师,却很少做单测之类的事情。所以,测试框架可以根据自己的喜好来决定。
这里选用了一下一套测试框架:
Mocha: 它是一个Javascript测试框架。你可以使用它来自动化测试你的代码
Chai:这是Javascript的一个断言库。
ChaiHTTP:这是Chai的一个插件
安装过程:
npm install mocha chai chai-http --save-dev
然后,在package.json中配置script字段:
"script": {
"test": "mocha"
}
这里需要大家熟悉mocha+chai的用法,具体可上官网查看
本篇文章大致分析了一下,我们需要在搭建一个后端集成环境时的选择方向。
参考文章An Introduction to Building TDD RESTful APIs with Koa 2, Mocha and Chai
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
最近由于适应新环境,更博也少了。不过想在本周总结一下cookie的东西。虽然开头起了一个非常垮的标题,但是相信内容一定不会垮,满满的干货。
国庆假期已过一半,来篇干货压压惊。
ES6,并不是一个新鲜的东西,ES7、ES8已经赶脚了。但是,东西不在于新,而在于总结。每个学前端的人,身边也必定有本阮老师的《ES6标准入门》或者翻译的《深入理解ECMAScript6》。本篇主要是对ES6的一些常用知识点进行一个总结。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
我们会更具之前的罗列的内容进行一个深入的分析。
在ES6没有被普及时,我们会用的变量定义的方法是var。其实,var对于一个刚刚接触js的人说,或许并不觉得怪异。但是,对于一个开发者而言,或许会在内心抨击它。因为它就是javascript的败笔之一,在其他语言看来的一个怪胎。那我们就来看看怪在何处呢?
可以重复定义。不知道你的代码里面会不会出现这样子的代码,举例:
var a = 10;
var a = 11;或许,你会看到这样子的写法觉得没啥,那么你很厉(wei)害(xian)。其实,这样子的坏处不言而喻。在大型的工程化开发中,你定义一个a,我定义一个a,还有千千万万个你和我,这时,技术总监就该着急了。所以,这是var的第一点令人讨厌的地方,但是如果你会说不是有严格模式嘛。的确,严格模式做了一定的规范,但是我们不加以讨论。毕竟,这时ES6的地盘(^-^)。
可随意修改。何为可随意修改?并不是指变量,而是指常量。举例:
var PI = 3.1415926
PI = 4.1415926从例子中,我们可以看到,PI是一个我们经常会使用的常量,是公认的不可变动的。但在javascript中并不是如此。那天,如果你的PI被你们公司新晋的实习生改了,可能你找错误都得找半天,但这可不是实习生的锅,也许,他并不知道这里是个常量。不过,这种情况也是玩笑话(^_^)。
没有块级作用域。如果你连块级作用域都不知道的话,赶紧收藏一下^_^,回头再来看哈~,举例:
if(true){
var i = 10;
}
console.log(i); //10相信,这变量不存在块级作用域给我们带来过不少麻烦吧。不知道啥时候,又得在循环中套一层闭包呢。而且,在非js开发者来说,可能觉得是个特(xiao)点(hua)。
所以,let和const就来拯救var了,如何一个拯救法呢?
在同一个块级作用域中,不允许重复定义。那之前的例子来使用一下的话,你会发现浏览器报错了,如图:
const定义的变量不允许二次修改。还原一下之前的例子,如图:
是不是再也不用担心之前的实习生啦,呦!!!
let和const定义的变量会形成块级作用域。直接上图,看看:
它们定义的变量不存在变量提升,以及存在暂时性死区
这个问题,我想举个例子可以更加方便的说明。首先,我们来看一题简单的笔试题:
var a = 10;
function hello(){
console.log(a);
var a = 11;
console.log(a);
}
hello();我想这个答案不言而喻,是undefined和11。原因:就是第一个console时,下面定义的变量a被提升了,所以a变成了undefined,第二个的话,就比较好理解。这个例子,我想会给初学者带来不小的麻烦,和当初的我一样哈。
使用let和const就会不一样,它们并不存在变量提升,如图:
何为箭头函数,我们先上例子:
export const addToCart = productId => (dispatch, getState) => {
if (getState().products.byId[productId].inventory > 0) {
dispatch(addToCartUnsafe(productId))
}
}这是,我从redux例子中摘取的一个片段,第一感觉就是『代码风格简洁』,整体代码规范很好,毕竟是示例代码么。但是会让人难以理解。因此,为了避免以后看不懂的尴尬,还是来好好聊聊这个神奇的东西吧。
其实,这个东西类似于python的lambda。但是,它的确特别适合js这门语言,就一个字「酷」。它的几个规则:
如果你一开始不会写,那就必须得多练习,这样才能在以后的工作中真正谋求便利。
当然咯,它有好处,但是在使用的时候,也得注意它的禁区。注意事项:
箭头函数不能作为构造函数。如图:
箭头函数没有它自己的this值,箭头函数内的this值继承自外围作用域。如图:
箭头函数没有arguments。这个我们直接测试一下就可以了,如图:
啥?没有arguments,那我如果正好要用到呢?这可咋办呢?下面再来说个有意思的改动——剩余参数。
什么叫剩余参数?别着急,看个例子就懂了。
const restParam = function(a, ...args){
console.log(args);
};
restParam(1, 2, 3, 4); //[2, 3, 4]这里你会发现这个args变量似乎包含了之后输入的所有参数,除了a以外。所以,这就是所谓的剩余参数。其中,运用到了一个…这个符号。其实这个符号的用处非常的多,ES6中可以将它称为扩展符。那么,我们来看看在箭头函数中的运用。
当然,在使用剩余参数时,需要注意一个问题,就是剩余参数设置的位置。我们先来看张图:
所以,在使用剩余参数时,需要注意的是,将这部分放在所有参数的最后位置。其实,ES6还带来了另一个参数的变动——默认参数。或许,我们可以先看一下默认参数这个问题,我们之前是怎么处理的。场景:一般在设置延迟的时候,都会有一个时间的默认值,防止用户在没有设置的情况下使用,看看下面的例子:
function defaultParam(time){
let wait = time || 1000;
setTimeout(() => {
//...
}, wait);
}这种写法应该非常的常见,使用的也比较广泛。但是,使用ES6的语法的话,就会变成这样子,例子:
function defaultParam(time = 1000){
setTimeout(() => {
//...
}, time);
}看上去这样子的写法,会使得函数更加的简洁明了。
说到解构赋值呢?大家千万别误解为这是数组的特性。不是的,对象也能够满足。只是觉得放在这边来写会比较好而已
解构赋值这个新特性,说实话是真的好用。我们可以先来看一个复杂一点的例子:
let [a, b , {name, age}, ...args ] = [1, 2, {name: 'zimo', age: 24}, 3, 4];
console.log(a, b, name, age, args); //1, 2, 'zimo', 24, [3, 4]你会发现例子中,有一个特点——对仗工整。
这是解构赋值时,必须要去满足的条件——想要解构的部分,内容保持一致。这样才能保证完美解构。对于解构而言,左右两边的内容长度不一致,不会出问题。比如,当你右边内容多一点的时候,其实没啥事,你只需要保证你左边的结构有一部分是你想要的,举例:
let [a, b, c] = [1, 2, 3, 4, 5];
console.log(a, b, c); //1, 2, 3这种叫做部分解构,左边也是一样的,对于多处来的部分,会变成undefined。举例:
let [a,b,c] = [1, 2];
console.log(a, b, c); //1 2 undefined解构赋值在使用过程中,也是有需要注意的部分:
必须保证有赋值的过程。看个例子:
你可以看到图中的例子,单独先声明了a和b,但是没有赋值的过程,会报错。
左边内容部分的结构必须与右边保持一致。如图:
这里两边的结构没有一致,如果是foo,bar的话,是可以正常解构的。但是这个例子的意图可能是想去解构foo中的值,但是写法上有一定的问题。
其实,解构也有没多种玩法:
默认值的使用。由于之前说过的部分解构的情况出现,所以我们在解构时,可以使用默认值的形式。
let [a, b = 10] = [1];
console.log(a, b); //1, 10在这个例子中b原先是undefined,但是设置了默认值的情况下,undefined的变量会被赋上默认值
函数变量中使用解构。对于一个函数而言,它的参数也可能会是数组或对象,这是我们就可以使用解构赋值的方式
function destructuring({name, age}){
console.log(name, age);
}
destructuring({name: 'zimo', age: 21}); // zimo 21解构赋值现在被使用的频率也是非常之大,好好掌握一下也是有必要的。
之后的话,我们可以聊一下二进制数组的概念。
何为二进制数组?其实,我们可以先来了解一下javascript的数组。熟悉js的人都知道,其实js的数组的性能并不高,它的本质是一个对象。之所以现在你看到数组在使用时速度还可以,是因为js的引擎在处理时,做了不同的优化。拿v8引擎举例的话,对于内部元素类型相同的数组在编译运行的时候,会使用c编译器。如果对于内部元素类型不同的时候,它会先将数组分离开来,然后再进行编译。具体可以查看深入 JavaScript 数组:进化与性能
所以,我们可以直接了解一下二进制数组的使用。二进制数组可以由Int8Array、Int16Array、Int32Array等形式组成,在整数方面,可用性较强。
const buffer = new Buffer(100000000);
const arr = new Int8Array(buffer);
console.time('test time');
for(let i = 0; i < arr.length; i++){
arr[i] = i;
}
console.timeEnd('test time');其实,现在二进制数组使用的频率并不多,ES6也仅仅是提出,后续还会对数组这一块进行一个更加详细的完善。
在ES6中,对字符串也做了一定的改进。先来聊聊我们的新朋友——模版字符串。其实,在语言中,字符串有多种表示方式:单引号、双引号和倒引号。在javascript中,双引号和单引号都是一样的,这点与一些静态语言不一样。但是,往往有时候,对于字符串的拼接会使得开发者厌烦。如何解决呢?
ES6带来了解决方案——模版字符串。何为模版字符串呢?由倒引号包裹``,然后使用${}来包裹变量。我们可以来实践一下
const name="zimo";
const str = `My name is ${name}`;
console.log(str); //My name is zimo这样,我们就可以非常方便的在其中添加变量了。或许,你会觉得这样的拼接,使用普通的方式也可以非常好的完成。但是,在开发过程中,我们或许会碰到更佳复杂的情况,比如说,我们现在要去创建一个DOM元素,以及它的内部元素。这种情况,通常还会带有表达式。
const width = 100;
const height = 200;
const src = "http://www.example.com/example.png";
const html = `<div class="block" width="${0.5 * width}px" height="${height}"><img src="${src}" /></div>`;往往这样子的元素在手动拼接的过程中,总是会出错,因此,使用模版字符串是一种既「高效」又「简洁」的方式。
有了模版字符串,你可以解决非常棘手的问题。那么,标题中带有的startsWith和endsWith又是起到什么作用呢?可能你会使用正则表达式,那么你就有可能不会使用到这两个API。
按照惯例,还是需要来介绍一下这两个API的。
startsWith:返回值为boolean型,然后去匹配字符串开头的部分,举个例子:
const str = "start in the head";
console.log(str.startsWith('start')); //true
console.log(str.startsWith('head')); //false其实,这也是可以使用正则表达式来达到这一目的。还原上例:
const str = "start in the head";
console.log(/^start/.test(str)); //true
console.log(/^head/.test(str)); //false其实,两者方式的区别基本上没有,但是正则表达式的功能更佳的完善。这个API仅仅在一些场景下起到一定的便捷。比方说,我们需要去匹配一个URL的协议头是什么时,我们往往需要用到这种方式。例子:
const url = "http://www.example.com";
if(url.startsWith('http')){
console.log('this is http');
}else if(url.startsWith('https')){
console.log('this is https');
}else if(url.startsWith('ws')){
console.log('this is websocket');
} //this is http同理,endWith也是一样的效果。
endsWith:返回值是boolean类型,然后去匹配字符串的结尾。举个例子:
const str = "something in the end";
console.log(str.endsWith('end')); //true
console.log(str.endsWith('something')); //false同样的,它也可以使用正则表达式来实现:
const str = "something in the end";
console.log(/end$/.test(str)); //true
console.log(/something$/.test(str)); //false这种情况的使用场景是,往往我们需要为上传的文件准备图标,那么我们就可以根据后缀来确定图标。
const filename = "upload.jpg";
if(filename.endsWith('.jpg')){
console.log('this is jpg file');
}else if(filename.endsWith('.png')){
console.log('this is png file');
}else if(filename.endsWith('.webp')){
console.log('this is webp file');
} //this is jpg file同时,字符串还增加了许许多多的东西,有兴趣的,可以自己去翻书本详细的了解
Iterator的概念是迭代器。在ES6中,终于正式的添加了这个属性。迭代器,主要是一个集合类元素的遍历机制。何为集合类元素?最常见的就是数组,还有对象。迭代器可以帮助开发者完成遍历集合的过程。最开始javascript并没有设置接口,来自定义迭代器,但是从ES6开始,我们可以自定义迭代器了。在自定义迭代器之前,我们要清楚迭代器的作用有哪些:
迭代器,往往就是一个指针对象,不断调用,然后不断地指向下一个对象的过程,直到结束。ES6中,我们可以创建一个指针对象,然后调用next的函数,使得指针对象向下移动。同时,next函数会返回value和done,确定是否到达末尾。
同时,ES6还提供了Iterator接口——Symbol.iterator。首先,我们来看一下具备原生接口的集合类——数组,类数组对象、Set和Map。这样我们就可以直接调用它的接口来进行循环:
let arr = ['my', 'name', 'is', 'iterator'];
let iter = arr[Symbol.iterator]();
console.log(iter.next()); //{ value: 'my', done: false}
console.log(iter.next()); //{ value: 'name', done: false}
console.log(iter.next()); //{ value: 'is', done: false}同时,定义iterator接口的数据结构可以轻松的使用for...of进行值的遍历
let arr = ['I', 'has', 'iterator'];
for(let item of arr){
console.log(item);
} //'I', 'has', 'iterator'但是,如果没有定义iterator接口的数据结构就没有办法使用这种方式进行遍历,如图:
这时,我们又该如何呢?其实,针对一些可迭代的数据结构,我们是可以自定义迭代器的,例如:
let iteratorObj = {
0: 'a',
1: 'b',
2: 'c',
length: 3,
[Symbol.iterator]: Array.prototype[Symbol.iterator]
}
for(let item of iteratorObj){
console.log(item);
} // 'a', 'b', 'c'迭代器是一个非常实用的东西,不妨你也可以试试,同时去改善你的代码。
其实,这两个是比较难以理解的东西。如果只是粗浅的了解一下,还是有许多的新东西的。在ES6中,引入了generator和promise两个概念。可能在这之前,你已经使用过了,通过其他的类库实现的。那么,其实ES6中的新概念也是差不多的,只是标准化了而已。
generator,叫做生成器。可以说与iterator有点相似,同样是通过next函数,来一步步往下执行的。同时,它的定义时,所使用的是function*的标识符。还具备yield这个操作符,可以实现逐步逐步向下执行。我们来看个例子:
function* generator(){
yield 1;
yield 2;
yield 3;
};
let generate = generator();
console.log(generate.next()); //{value: 1, done: false}
console.log(generate.next()); //{value: 2, done: false}
console.log(generate.next()); //{value: 3, done: true}
console.log(generate.next()); //{value: undefined, done: true}这样子看起来,似乎就是迭代器的步骤。其实,iterator的接口,可以定义成这样子的形式。但是,generator的作用不仅仅如此。它就像一个状态机,可以在上一个状态到下一个状态之间进行切换。而一旦遇到yield部分,则可以表示当前是可以步骤的暂停。需要等到调用next方法才能进行下一步骤。同时,我们还可以使用上一步的结果值,进行下一步的运算。示例:
function* generator(){
yield 1;
let value = yield 2;
yield 3 + value;
};
let generate = generator();
let value1 = generate.next();
let value2 = generate.next();
let value3 = generate.next(value2.value);
console.log(value1); //{value: 1, done: false}
console.log(value2); //{value: 2, done: false}
console.log(value3); //{value: 5, done: true}这样的话,就可以将value作为你第三步的参数值,进行使用。
之前说过,generator的next是需要自己调用的。但是,我们如何使它自己自动调用呢。我们可以使用for...of来自动调用next,就像迭代器一样。示例:
function* generator(){
yield 1;
yield 2;
yield 3;
};
for(let value of generator()){
console.log(value);
} //1, 2, 3其实,之前所讲的只是generator的基本使用。generator主要被使用在异步编程领域。因为我们之前所讲的特性,非常适合在异步编程中使用。当然了,我们也需要去提一下promise这个异步编程的功臣。
Promise,翻译过来叫做承诺。我们可以理解为一种约定。大家都知道异步编程的时候,我们一般会使用到回调函数这个东西。但是,回调函数会导致的问题,也非常的明显。示例:
callback1(function(data){
//...
callback2(function(data1){
const prevData = data;
//...
callback3(function(){
//...
callback4(function(){
//...
});
});
});
});回调函数,写多了之后我们会发现,这个倒金字塔会越来越深,而我们会越来越难以管理。
这时,或许promise会起到一定的作用。试想一下,为什么这几个回调函数都能在另一个回调函数之外进行?主要原因:
基于这两点,我们就会发现,一旦你需要这样去编写代码,就必须保证你的上一个回调函数在下一个回调函数之前进行。我们还可以发现,它们之间缺乏一种约定,就是一旦上一个发生了,无论是正确还是错误,都会通知对应的回调函数的约定。
Promise,或许就是起到了这样的一种作用。它具备三种状态:pending、resolved、rejected。它们之间分别对应:正在进行、已解决、已拒绝等三种结果。一个回调函数会开始从pending状态,它会向resolved和rejected的两者之一进行转换。而且这种转换是不可变的,即一旦你从pending状态转变到resolved状态,就不可以再变到rejected状态去了。
然后,promise会有一个then函数,可以向下传递之前回调函数返回的结果值。我们可以写个promise示例:
new Promise((resolved, rejected) => {
resolved(1);
}).then(data => {
console.log(data);
}, err => {
console.log(err);
}).catch(err => {
console.log(err);
}); // 1其实,只需要记住这样子的一种形式,就可以写好promise。Promise是一个比较容易书写的东西。因为它的形式比较单一,而且现在有许多封装的比较好的异步请求库,都带有Promise的属性,例如axios。
Promise,还带有其他的一些API,上面我们也使用到了一个。
Promise可以和之前所讲的Generator一起使用,我们可以看一下使用场景:
通过Generator函数来管理流程,遇到异步操作,就使用Promise进行处理。
function usePromise(){
return new Promise(resolve => {
resolve('my name is promise');
});
}
function* generator(){
try{
let item = yield usePromise();
console.log(item);
}catch(err){
console.log(err);
}
}
let generate = generator();
generate.next().value.then(data => {
console.log(data);
}, err => {
console.log(err);
}).catch(err => {
console.log(err);
}); //my name is promise或许,你还可以写出更加复杂的程序。
最后要聊的一个主题就是class。相信抱怨javascript没有类的特性数不胜数。同时,还需要去了解js的类继承式概念。那么,ES6也带来了我们最欢迎的class module部分。我们就不介绍之前我们是如果去构建对象的了(好像是构造函数)。
那么,我们可以来看一下,ES6给我带来的新变化:
class Animal{
constructor(name){
this.name = name;
}
sayName(){
return this.name;
}
}
const animal = new Animal('dog');
console.log(animal.sayName()); // 'dog'似乎这样子的形式比之前的构造函数的方式强对了。我们可以理解一下这个结构:
因此,上面那个其实可以写成原先的:
function Animal(name){
this.name = name;
}
Animal.prototype.sayName = function(){
return this.name;
}其实,就是class在ES6中得到了封装,可以使得现在的方式更加的优美。
之后,我们简单了解一下继承这个概念吧。
任何的东西,都是需要继承的。因为我们不可能都是从头去写这个类。往往是在原有类的基础之上,对它进行完善。在ES6之前,我们可能对构造函数完成的是组合式继承。示例:
function Animal(name){
this.name = name;
}
Animal.prototype.sayName = function(){
return this.name;
}
function Dog(name, barking){
Animal.call(this, name);
this.barking = barking;
}
Dog.prototype = new Animal();
Dog.prototype.constructor = Dog;
Dog.prototype.makeBarking = function(){
return this.barking;
}
const dog = new Dog('zimo', '汪汪汪');
console.log(dog.makeBarking()); //汪汪汪
console.log(dog.sayName()); //zimo这样子的组合式继承书写起来,比较麻烦,需要重新去对每个元素设置,然后还要重新定义新类的原型。那么,我们可以来看一下ES6对于继承的封装:
class Animal{
constructor(name){
this.name = name;
}
sayName(){
return this.name;
}
}
class Dog extends Animal{
constructor(name, barking){
super(name);
this.barking = barking;
}
makeBarking(){
return this.barking;
}
}这样子,就可以轻松的完成之前的组合式继承步骤了。如果你对extends的封装感兴趣的话,不妨看一下这篇文章javascript之模拟类继承
在这里ES6的内容只是总结了部分,大致可以分为这么几个部分:
希望,你可以从这些内容中对ES6多一些了解,同时,如果你还想深入ES6进行了解的话,最直接的方式就是看书。希望你的代码写的越来越优雅。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
最近,公司在做系统,选型时选择了vue作为前端开发的部分。做了一个demo,随便总结一下vue的一些使用内容。其实,从react映射到vue,一点也不容易。总是会有多多少少的**转变不过来。不过大体上手还是挺快的。这样一来,算是集齐神龙了。三个框架都用了一遍。用来用去还是觉得react顺手一点。
今天刷了一下网易往年的编程笔试题,之后我将做个总结。其实,对于一个前端开发的人来说,算法是一个可有可无的东西。因为你或许一辈子都不需要接触这个东西,至于界面打交道。但是,你的职业水平也会止步于此。我是一个热衷于算法的少年,由于需要模拟控制台的输入与输出,而js的实现又非常的拙劣,所以,我会选择python。一门与js一样神奇的语言。
题目:小易有一个圆心在坐标原点的圆,小易知道圆的半径的平方。小易认为在圆上的点而且横纵坐标都是整数的点是优雅的,小易现在想寻找一个算法计算出优雅的点的个数,请你来帮帮他。
例如:半径的平方如果为25
优雅的点就有:(+/-3, +/-4), (+/-4, +/-3), (0, +/-5) (+/-5, 0),一共12个点。
输入描述:
输入为一个整数,即为圆半径的平方,范围在32位int范围内。
输出描述:
输出为一个整数,即为优雅的点的个数
输入例子1:
25
输出例子1:
12
理解:其实这道题我是这么考虑的类似与坐标轴上的四个象限,只需要去考虑其中的一个象限,但是象限的端点处只能取其中之一,如图:

然后就可以写py代码了:只要在这条曲线上的点,然后在总和中乘以4倍,即是返回值
from math import sqrt
def main():
inputN = int(raw_input())
sum = 0
i = 1
while i * i <= inputN:
tem = sqrt(inputN - i * i)
if int(tem) == tem:
sum += 1
i += 1
print sum * 4
if __name__ == '__main__':
main()题目:小易来到了一条石板路前,每块石板上从1挨着编号为:1、2、3.......
这条石板路要根据特殊的规则才能前进:对于小易当前所在的编号为K的 石板,小易单次只能往前跳K的一个约数(不含1和K)步,即跳到K+X(X为K的一个非1和本身的约数)的位置。 小易当前处在编号为N的石板,他想跳到编号恰好为M的石板去,小易想知道最少需要跳跃几次可以到达。
例如:
N = 4,M = 24:
4->6->8->12->18->24
于是小易最少需要跳跃5次,就可以从4号石板跳到24号石板
输入描述:
输入为一行,有两个整数N,M,以空格隔开。
(4 ≤ N ≤ 100000)
(N ≤ M ≤ 100000)
输出描述:
输出小易最少需要跳跃的步数,如果不能到达输出-1
输入例子1:
4 24
输出例子1:
5
理解:这一题其实是一题动态规划类的算法题,其实只要保证走x时,i+x是最小的,那么最后N,M之间的步数也会是最小的。下面我们来看一副图片理解一下:

看着图解之后,我们再来写一些这个动态规划的代码理解一下,py代码:
def factor(number):
res = []
i = 2
while i * i <= number:
if number % i == 0:
res.append(i)
if number / i != i:
res.append(number / i)
i += 1
return res
def main():
arr = raw_input().split(' ')
N = int(arr[0])
M = int(arr[1])
dp = []
for i in range(0, M+1):
dp.append(9999999) #fill array
dp[N] = 0
for i in range(N, M):
if dp[i] == 9999999:
dp[i] = 0 #9999999 mean can not to reach, set 0 mean to reduce space
continue
temp = factor(i)
for item in temp:
sum = item + i
if sum <= M:
dp[sum] = min(dp[sum], dp[i]+1) # get min dept
if dp[M] == 0:
print -1
else:
print dp[M]
if __name__ == '__main__':
main()算法题还是比较好玩的,即使是前端开发的人也应该时常练习,时常刷一下leetcode和oj平台
在网页中,我们常常会遇到布局这么一个概念。而对于一种相同的布局,可以使用不同的css来完成,这也是css有趣的地方。今天我们要讨论地布局就是最常见的三栏布局(也是面试中面试官喜欢问的话题)。
其实,三栏布局可以有4种实现方式,每种实现方式都有各自的优缺点。
1.使用左右两栏使用float属性,中间栏使用margin属性进行撑开,注意的是html的结果
<div class="left">左栏</div>
<div class="right">右栏</div>
<div class="middle">中间栏</div>.left{
width: 200px;height: 300px; background: yellow; float: left;
}
.right{
width: 150px; height: 300px; background: green; float: right;
}
.middle{
height: 300px; background: red; margin-left: 220px; margin-right: 160px;
}缺点是:1. 当宽度小于左右两边宽度之和时,右侧栏会被挤下去;2. html的结构不正确
2. 使用position定位实现,即左右两栏使用position进行定位,中间栏使用margin进行定位
<div class="left">左栏</div>
<div class="middle">中间栏</div>
<div class="right">右栏</div>.left{
background: yellow;
width: 200px;
height: 300px;
position: absolute;
top: 0;
left: 0;
}
.middle{
height: 300px;
margin: 0 220px;
background: red;
}
.right{
height: 300px;
width: 200px;
position: absolute;
top: 0;
right: 0;
background: green;
}
好处是:html结构正常。
缺点时:当父元素有内外边距时,会导致中间栏的位置出现偏差
3. 使用float和BFC配合圣杯布局
将middle的宽度设置为100%,然后将其float设置为left,其中的main块设置margin属性,然后左边栏设置float为left,之后设置margin为-100%,右栏也设置为float:left,之后margin-left为自身大小。
<div class="wrapper">
<div class="middle">
<div class="main">中间</div>
</div>
<div class="left">
左栏
</div>
<div class="right">
右栏
</div>
</div>.wrapper{
overflow: hidden; //清除浮动
}
.middle{
width: 100%;
float: left;
}
.middle .main{
margin: 0 220px;
background: red;
}
.left{
width: 200px;
height: 300px;
float: left;
background: green;
margin-left: -100%;
}
.right{
width: 200px;
height: 300px;
float: left;
background: yellow;
margin-left: -200px;
}缺点是:1. 结构不正确 2. 多了一层标签
4. flex布局
<div class="wrapper">
<div class="left">左栏</div>
<div class="middle">中间</div>
<div class="right">右栏</div>
</div>.wrapper{
display: flex;
}
.left{
width: 200px;
height: 300px;
background: green;
}
.middle{
width: 100%;
background: red;
marign: 0 20px;
}
.right{
width: 200px;
height: 3000px;
background: yellow;
}除了兼容性,一般没有太大的缺陷
一般现在使用较多的都是flex布局,这种布局是真的好用,哈哈
这篇文章是翻译了yslow 35rules的一部分,因为本人重来没有做过这方面的优化,因此,来自原文的翻译可以更加清晰的来解释这个问题。
CSS expressions
CSS expressions are a powerful (and dangerous) way to set CSS properties dynamically. They were supported in Internet Explorer starting with version 5, but were deprecated starting with IE8. As an example, the background color could be set to alternate every hour using CSS expressions:
使用css表达式去设置css动态属性是一种有力的(却又危险的)行为。它们在IE5浏览器开始被支持,但在IE8开始被启用。举个例子:背景颜色的值可以通过css表达式来计算每小时的值,将其赋值给背景颜色:
background-color: expression( (new Date()).getHours()%2 ? "#B8D4FF" : "#F08A00" );As shown here, the expression method accepts a JavaScript expression. The CSS property is set to the result of evaluating the JavaScript expression. The expression method is ignored by other browsers, so it is useful for setting properties in Internet Explorer needed to create a consistent experience across browsers.
这里展示的例子中,表达式可以接受一个javascript表达式。css属性通过计算javascript表达式来进行设置。表达式被其他浏览器忽略,因此在IE浏览器中设置属性以在浏览器之间创建一致的体验是非常有用的。
The problem with expressions is that they are evaluated more frequently than most people expect. Not only are they evaluated when the page is rendered and resized, but also when the page is scrolled and even when the user moves the mouse over the page. Adding a counter to the CSS expression allows us to keep track of when and how often a CSS expression is evaluated. Moving the mouse around the page can easily generate more than 10,000 evaluations.
表达式的问题是它们被计算的过于频繁超过了大多数人的期望。不仅当页面被重绘和重排时它们被重新计算,而且当页面滚动,甚至当用户移动鼠标经过页面时,它们也会被重新计算。使用css表达式增加一个计算器,将会导致无论何时何种方式css表达式都会被重新计算。移动鼠标划过页面的行为可以轻松地使得表达式被重新计算超过10000次。
One way to reduce the number of times your CSS expression is evaluated is to use one-time expressions, where the first time the expression is evaluated it sets the style property to an explicit value, which replaces the CSS expression. If the style property must be set dynamically throughout the life of the page, using event handlers instead of CSS expressions is an alternative approach. If you must use CSS expressions, remember that they may be evaluated thousands of times and could affect the performance of your page.
减少你的css表达式重复计算次数的方式是去使用一次表达式,那么在第一次的时候,表达式将会被计算,作为一个普通的css表达式的替换的值,来设置css样式属性。如果这个样式属性一定要在整个页面周期中被动态调整的话,可以使用事件处理来代替css表达式的使用。如果你一定要使用css表达式的话,请记住它们有可能被重新计算成千上万次,并且可能影响你的页面性能。
css表达式这个东西,其实说到底js可以来实现的,还是js实现起来轻松方便
前端框架的变迁,体系架构的完善,使得我们只知道框架,却不明白它背后的道理。我们应该抱着一颗好奇心,在探索框架模式的变迁过程中,体会前人的一些理解和思考
本篇将讲述的是前端框架变化过程中的一些思考,前端框架模式的变化:从无到有,从MVC(Flux或者Redux)->MVP->MVVM。这段变化的过程,会让人不断琢磨,每次的变化,都是一次大的进步。现在在前端的框架都是MVVM的模式,还有像Flux和Redux之类的MVC变种——独特的单向数据流框架。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
其实,这些框架模式我们平时都会有所接触。它遵循着将整体应用的功能块进行分离的原则,对开发者开发软件进行一定的规范,以保持系统的稳定以及可维护性。
讲述前端框架变迁的过程中,我们可以通过梳理最近几十年的前端发展时间线,来深入分析前端的从无到有,从有到优的过程。
最初的时代,应该是web1.0时代吧。当时,开发者们并没有前端的概念。开发一个应用,或许只要5个人的小团队,就能够很快的配置出可运行的环境。而开发的语言使用的也是最初的JSP、ASP和PHP。拿JSP举例的话,当时系统的整体架构图可能是这样子的:
记得在学校的时候,最早搭建系统就是使用的这种架构。
这种架构的好处是简单快捷。使用Eclipse+tomcat就可以之间把程序跑起来,以及jsp的强大功能,足够满足小应用的开发。
但是,同样缺点也非常明显:
业务体系增大,调试困难:随着业务体系的增大,后台service也会逐步膨胀,大致需要建设一个开发服务器进行存放,这会导致一个问题就是前端无法在本地进行调试,每次进行修改之后,都必须上传到开发服务器进行测试(况且开发服务器可能本身就不稳定)。
JSP代码难以维护:或许人少的时候,学JSP挺简单的。但是,一旦团队人数增多,JSP内参杂的业务逻辑也会逐渐增加,这会导致的是JSP本身难以维护。
为了让开发更加的便捷,代码变得更加的可维护,同时使得前后端的职责加以分离。这时,我们或许会考虑改变一下开发模式,将后端MVC化,而前端的展示则以模板的形式进行嵌套。典型的框架就是Spring、Structs。整体的框架,如图所示:
使用这样子的架构,复杂度被降低了,职责也会比较清晰。这个时代被称为后端的MVC时代。这个时候,前后端开始形成了一定的分离。前端只需要在本地编写好相应的页面,然后交给后端开发的人,让他们可以根据模板进行一个嵌套。这是前端只完成了后端开发中的view层内容。淘宝的早期使用的就是这种模式。现在仍有小部分创业型的公司会使用这种方式进行开发,主要是节约用人成本。
但是,同样的这种模式存在着一些:
前端页面开发效率不高:其实,早期的时候根本也没啥前端开发工程师,有的只是页面仔。更多公司可能也有后端的人使用js在写页面的。因此,问题就暴露了出来,前端所做出来的页面需要放到后端环境去运行,使得前端开发的效率并不是特别之高,因为对于后端环境的依赖程度比较大。
前后端职责不清:由于前端并未做太多的工作,以至于后端的开发体量比较庞大。就拿路由管理来举例子,本来路由管理可以由前端开发的人员来进行开发和管理。但是,使用这种架构时,后端需要去维护一个庞大的路由表,增加了后端的开发量。
有个东西带来了前端的第一个春天——AJAX。自从Gmail的出现,ajax技术开始风靡全球。许多公司和开发者都不断地利用它做实验。有了ajax之后,前后端的职责就更加的清晰了。因为前端可以通过Ajax与后端进行数据交互,因此,整体的架构图也变化成了下面这幅图:
通过ajax与后台服务器进行数据的交换,前端开发的人员,只需要开发自己页面这部分的内容,数据可由后台进行提供。而且ajax可以使得页面实现部分刷新,极大的减少了之前需要反复开发的页面。这时,才开始有前端工程师开始慢慢从事前端。同时前端的类库也慢慢的开始发展,最著名的就是jQuery了。
但其实,这样子的架构中还是存在一定的问题——前端缺乏一种可行的开发模式。整体的内容都杂糅在一起,一旦应用增大,就会导致难以维护了。举个例子,当图书少的时候,我们就算随意放置,整理起来都比较方便;但是,一旦具有像图书馆一样多的图书时,必须有一种统一的管理方式。同样的,前后端分离之后,前端的开发业务逐渐增多,责任也愈加的巨大,开发者急需一种比较好的框架来规范整个应用。因此,前端的MVC也随之而来。
前端的MVC应该与后端类似,具备着View、Controller和Model。
Model:负责保存应用数据,与后端数据进行同步
Controller:负责业务逻辑,根据用户行为对Model数据进行修改
View:负责视图展示,将model中的数据可视化出来。
理论上,他们三者形成了一个如图所示的模型:
这样的模型,在理论上是可行的。但往往在实际开发中,并不会这样去操作。因为开发的过程需要灵活,而这种模式并不满足灵活的条件。例如,一个小小的事件操作,都必须经过这样的一个流程,那么开发就不再便捷了。
在实际场景中,我们往往会看到另一种模式,如图:
这种模式在开发中更加的灵活,backbone.js框架就是这种的模式。
但是,这种灵活,也会导致一些严重的问题:
这幅图中,特别是model和view这一块的数据交互,感觉看起来像是连连看,非常的混乱,而且维护起来非常麻烦。这就是灵活开发带来的后遗症。拿backbone举个例子,backbone将Model的set和on方法暴露出来,方便外部对其进行直接操作。
既然有缺陷,就会有变革。前端的变化中,好像少了MVP的这种模式,或许是因为Angular早早地将MVVM的框架模式带入了前端,这也许就是Google工程师的智慧吧。那我们还是需要来了解一下MVP这种模式,虽然前端开发并不常用,但是在安卓等native开发时,开发者都会考虑到它的。
MVP与MVC很接近,P指的是Presenter,presenter可以理解为一个中间人,它负责着View和Model之间的数据流动,防止View和Model之间直接交流。我们可以看一下图示:
我们可以通过看到,presenter负责和Model进行双向交互,还和View进行双向交互。这种交互方式,相对于MVC来说少了一些灵活,VIew变成了被动视图,并且本身变得很小。虽然它分离了View和Model。但是应用逐渐变大之后,缺陷也会随之暴露。
缺陷:
由于大部分逻辑都需要presenter去进行管理,从而导致presenter的体积增大,难以维护。如果需要去解决这个问题,或许可以从MVVM的**中找到答案。
首先,何为MVVM呢?MVVM可以分解成(Model-View-VIewModel)。ViewModel可以理解为在presenter基础上的进阶版。废话不多说,先上图例:
在这里View是ViewModel的外在显示,和ViewModel的数据是同步的。一旦View中的数据发生变化,会自动同步到ViewModel,然后ViewModel可以将变化的数据传给Model;反过来也是一样的,Model中的数据一旦发生改变,就会将值传给ViewModel,而ViewModel也会同步更新到view中。现在的框架实现这样的形式,各有各的不同。主要的三个框架angular2、vue、react都是实现了这样子的模式。
这种的好处就是View和Model之间被分离开来。view不知道model的存在,viewmodel和model也觉察不到view。事实上,model也完全忽略viewmodel和view的存在。这是一个非常松散耦合的设计。
但它也不是所用地方都适用的,例如,后端开发是适用的。因为网络资源成本过高,开发成本过高导致的。
讨论完上面的三种框架,我们再来看一下Flux。之前,我们在讨论MVC的时候,提及过MVC最主要的缺点就是数据流混乱,难以管理。但是,Facebook却在这个基础上对MVC做出了改变,那就是——单向数据流。只要将数据流进行规范,那么原来的模式还是大有可为的。
我们可以来看一下,Flux框架的图示:
从图中,我们可以看到形成了一条Action到Dispatcher,再到Store,之后是View的,一条单向数据流。在这里Dispatcher会严格限行我们操作数据的行为,而Store也不会暴露setter接口,让其随意被修改。最终,这样的一套框架在大多数场景下,比MVC更加完美。(细节部分我们不做探究,有兴趣可以研究一下Redux源码,也就近千行代码)。
我们依据前端发展为时间线,整理了前端整体框架的从无到有,从有到优的过程。
希望这些能够帮你理解现在的前端,理解框架之间的卓越点。同时也希望大家一起进步,一起成长。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
在面试过程中,不免会被问到网页优化的问题。对于一个网页的好坏,取决于访问速度的快慢。往往1秒钟的差距,会流失大量的潜在客户。所以,优化网页是前端开发人员的必备技能。优化的问题也一致探讨,最著名的则是Yahoo的35军规,它总结了网页在大部分情况下如何去进行优化措施。但往往规则靠死记硬背是不现实的,只有动手实践才能真真的掌握。
往往在真实的生产环境中,前端花费大部分的时间去加载资源,下载资源。所以,加快网页加载速度最为有效的方法是减少http请求。
以前,我们经常可以在网站后台看到如下的场景:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link rel="stylesheet" href="example1.css">
<link rel="stylesheet" href="example2.css">
<link rel="stylesheet" href="example3.css">
<link rel="stylesheet" href="example4.css">
<link rel="stylesheet" href="example5.css">
<title>example</title>
</head>
<body>
// ...dom内容
<script src="example1.js"></script>
<script src="example2.js"></script>
<script src="example3.js"></script>
<script src="example4.js"></script>
<script src="example5.js"></script>
</body>
</html>在这样的情况下,往往页面的加载速度会降低,一般页面大概适合2-3个script文件进行加载,所以,我们第一步要做的就是,将这么多的资源文件适当的合并起来,css文件也是如此。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link rel="stylesheet" href="bundle.css">
<title>example</title>
</head>
<body>
//...
<script src="bundle1.js"></script>
<script src="bundle2.js"></script>
</body>
</html>在现在的工业化开发中,都往往会用到打包工具,像webpack、gulp等,对文件进行打包,分块,部分加载等。因此,这一类的问题造成的影响正在逐步的降低。
往往在大型项目的开发中,对于图片资源的处理是一件很费力的事情,我们单从减少http请求的角度来,看待图片请求的问题,最简单的方法往往是使用雪碧图的方式。如图:
在写css样式时,会使用background-image和background-position去加载各种背景图片资源。但是,如果将这些资源进行合并是能减少整体网页的请求次数,加载网页性能的。
首先,有人会疑问何为base64的图片资源。通常,图片在网络传输中,都是以base64加密的方式进行传输的。因此,我们为了减少不必要的网络请求,我们可以将一下图片进行base64加密,然后直接放到img标签的src中,或者图片背景资源的url中。
<img src="data:image/gif;base64,R0lGODlhHAAmAKIHAKqqqsvLy0hISObm5vf394uLiwAAAP///yH5B…EoqQqJKAIBaQOVKHAXr3t7txgBjboSvB8EpLoFZywOAo3LFE5lYs/QW9LT1TRk1V7S2xYJADs=" 注:这种情况的使用,往往是在图片比较小的情况下,如果图片较大的话,往往会增加整体资源的体积,而使得下载资源时间增长。
<img src="image.png" alt="Website map" usemap="#mapname" />
<map name="mapname">
<area shape="rect" coords="9,372,66,397" href="http://en.wikipedia.org/" alt="Wikipedia" title="Wikipedia" >
</map>这种图片处理的方式,也与雪碧图的原理差不多,可以减少对图片资源的请求
在优化网站性能的方式有很多种,这只是第一篇——减少http请求的方式。
富文本编辑器,是写文章的利器。对于一个网站来说,好的富文本编辑器更是锦上添花
本篇为移动端富文本实践篇的前言篇,文章主要介绍了现状,项目起因,以及接下来篇章的主要内容概要。如果你对这个话题,或者这个项目感兴趣,不妨先访问一下github项目。如果你看了之后,表示喜欢,那么,请动动你的小手点一下Star,表示对我们的支持。同时,如果你对项目的使用有任何疑问,或者建议,可以在issues里面给我们提出你宝贵的意见。我们也将不断丰富与完善整个项目,打造出一个优质的富文本项目。github项目地址
每个项目都有初衷,也同样会有目标。本来实践篇的文章都是上来就是干,直接丢代码。但是,本篇只分析一下,在项目初期的考量。只有清楚现有的项目中的不足,才能够优化它们的不足,打造出一款优质的项目。那么,我们首先要来清楚一下富文本编辑器的现状。
现状概述:
现在市面上,好的富文本编辑器都得数不胜数。强大如ueditor,功能齐全,被广泛运用;小如Pell,整体大小才不到1kb,风格单一,简约。但是这些富文本编辑器大多数是针对PC端的,移动端的却有点少,而且不精。项目不多的原因,就是移动端其实在这方面需求并不多,而且这一方面的产品少。唯一只有简书和知乎等产品上的富文本编辑器,小而精,风格统一,简约。尤其是,像简书的移动端富文本编辑器,体验良好,在图片等处理上面,下了很大的功夫。可是,由于是其公司产品,并未有开源的。现在移动端的流量逐渐增加,文章的产出不断增加,移动端的富文本编辑器需求也会不断增加。或许,某个晚上,你就会躺在床上,使用手机码字,写心得和感悟呢。
项目初衷:
在今年的五月份,我们一起接手了一个外包项目。其中,就需要使用到移动端的富文本编辑器,主要是让用户来描述自己的需求。可是,在github上面,真正移动端的富文本编辑器并没有太多,而且大多都没有图片处理的部分。自从那一次项目之后,我们粗涉富文本编辑器,里面的坑是一个接着一个。后来,我与我安卓的朋友萌生了一个自己开发一个类似于简书等优质的移动端富文本应用的想法。这个项目的目的是打造一个功能基本齐全的,可配置不同主题风格的富文本编辑器。
目前,整个项目已被放到github网站上面,版本属于v1.0版,后续还会进行不断的优化。github项目地址
内容概要:
或许,真正做富文本开发的人员并不多,网上也并未找到比较详尽的开发方案等,大多数时候都是自己摸着石头过河。同时,也总结了一下自己在开发过程中的一些经验,下面的文章是接下来篇幅内容的一个概要:
移动端富文本实践篇(一):富文本开发之前的一些基础知识普及,以及实践中的大致应用。
移动端富文本实践篇(二): 本篇的内容,主要是讲述一些dom元素的事件的监听情况,以及一些安全措施
移动端富文本实践篇(三):本篇内容主要是讲一下文章中文字部分的处理,如'bold'、'italic'、'blockqueto'、'h1'等,以及分割行的插入和链接的插入和修改等模块的代码分析。
本节并没有太多的干货,更多的是我们做项目的初衷。现在github社区上面,开源项目千千万万,我们更应该明确项目的目标与初衷,才能在一众项目中脱颖而出。相信,并且希望我们能够一同学习,一同进步。
最后,如果你对我写的有疑问,可以与我讨论。如果我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客。同时也希望你关注我们的项目,github项目地址,谢谢支持
上篇写到:
在网页性能优化的过程中,我们可以通过在服务器配置cdn或者缓存来达到优化性能的作用。
cdn有些专门的网站提供这类的服务,而缓存在整个过程中起到很大的作用,相信我们之后还能了解这个东西的用处。
这篇文章主要了解一下压缩文件,以及一些写法上的规范来优化网页的性能。
gzip压缩
gzip压缩是http协议上的gzip压缩编码技术。首先,我们应该要清楚的是压缩可以达到怎样的目的。比如说纯文本内容进行压缩之后,大小可以缩小大概40%左右。大小减小了最直接的就是传输的速度将会加快,以及流量将会减少。尤其是对于大流量类网站来说,压缩文件内容大小,减少流量是很有必要的(毕竟省钱嘛!),另一方面,压缩过的内容将减少存储空间。
那一般gzip压缩需要如何实现呢?一般会在www服务器上配置服务,然后将压缩过的文件传输到客户端,由客户端进行内容的显示。比方说nginx服务器就可以进行gzip配置,默认会压缩text/html的文件进行压缩,当然了,对于图片资源也是可以进行压缩的,这需要进行一下配置。
//first to open gzip service
gzip on
gzip_http_version 1.0;
gzip_disable "MSIE [1-6].";
gzip_types text/plain application/x-javascript text/css text/javascript application/x-httpd-php image/jpeg image/gif image/png;需要注意的是:
在HTTP1.1中使用gzip的方式:
.
请求头:
Accept-Encoding: gzip, deflate响应头:
Content-Encoding: gzipcss、script标签位置规范的问题
如何正确的使用css标签和script标签?css标签应该放在head标签内,而script标签应该放在body标签的末尾。
<html>
<head>
<title>citerion</title>
<link href="./test.css" ref="stylesheet"/>
</head>
<body>
<!--dom内容-->
<script src="./test.js"></script>
</body>
</html>在搞清楚为什么这两个标签要这么去放置之前,我们先来了解一下网页文件的渲染过程:
这里有还有两个点需要搞清楚的是:
该篇总结了优化网页的两种方法:1. gzip压缩 2. css文件放在头部、js文件放在尾部
在上一篇文章中,我们以及聊过了减少http请求的四个方法:
今天,我们来了解一下服务器相关方面,我们可以做的优化
首先,我们必须知道一个神器——CDN。它在现在的网站中发挥着无尽的作用。CDN(Content Delivery Network),即基于内容的分布式分发网络,它帮助现在大多数网站进行静态资源的部署。正如,军规中提到的网络请求中,有80%-90%的响应时间是在资源下载中度过的,而CDN的机制可以帮助我们更快的获取到这些静态的资源。
首先,我们需要清楚为什么需要CDN这个东西,仅仅只是帮助网站提高加载速度么!其实,不仅仅如此,试想一下一些大型的网站(全国、甚至是全世界),访问的基数非常之大,静态资源的访问频繁,会使得主站服务器吃不消,即使给单个端口增至最大的带宽,也无法满足需求。因此,CDN在这里扮演者重要的角色。
CDN的网络结构大概是中心节点加上边缘节点组成的。这就相当于每个人访问网站时,如果网站部署了CDN,那么就会向最近的CDN服务器请求静态资源,而不是想传统的网站一样,只会去访问主站服务器。使用CDN时,还可以对内容进行缓存,以加快网站的访问速度。
例子:
当我们看到网页的资源是如下表示的,就表示它使用了CDN来进行静态资源的分发
<link crossorigin="anonymous" href="https://assets-cdn.github.com/assets/frameworks-77c3b874f32e71b14cded5a120f42f5c7288fa52e0a37f2d5919fbd8bcfca63c.css" integrity="sha256-d8O4dPMucbFM3tWhIPQvXHKI+lLgo38tWRn72Lz8pjw=" media="all" rel="stylesheet">大致了解了CDN,我们再来哔哔缓存。一直以来,我都一度认为缓存是一个好东西,毕竟,很多时候只要做了这个处理,都可以得到良好的收益。
例如,你总是会频繁的访问一个网站,你可能会不断重复的去请求和下载同一个资源N次。这是相当不可取的。一旦,服务器做了缓存,那么,网站就会告诉你,这个东西你还能继续使用。在响应头中设置expires或者cache-control的属性,来设置相应资源文件的响应时间。这样,在你第一次访问完一个网站之后,当你再一次访问时,往往会收到304的响应状态码,因为资源的缓存还未到期。如果你有个资源万年不变,你就可以将expires的有效时间设置为10000年(当然是不可以的,expires是有最大值的哈)。
Expires: Thu, 15 Apr 2020 20:00:00 GMT
一旦你设置了这个值,浏览器将认为资源不会更新。但是,突然你又想更新一下资源你又要怎么办呢。那就在资源后面加上hash值或者版本号,example-2c3fde.js类似。
在服务器上做优化,会使得整体网站的访问速度提升很多
今年是2017年,也是我大学以来最为繁忙的一年,可能是因为大三了吧。由于实习,每天留给我整理博客的时间减少了。我不想自己每天在无知(不知道一天干了点什么的状态)度过,并且将博客移步到了github上面。因为心中有个梦想,希望自己能够在今年完成一项star的收集任务。对于我而言,工业级的架构谈不上,系统化的层级实现不了,nb的类库写不出来,也只能在这里为每位看官留下一笔好的财富(喜欢的话,给我加star哦)。
今天先来讲一讲我眼中认为的前端疲劳,其实,每天的我都是这样的感觉(累)——并不是心累,而是眼睛累。我真的感觉每天都能在medium上面看到和学到很多的东西,但是,看完之后,就忘记了。
这几年的前端处于井喷的状态,三足鼎立(angular5-beta、react、vue)、打包工具(webpack3和rollup)、(typescript、JavaScript、es6、es7和最近的es8)、性能优化、自动化测试、h5技术、RN、PWA、(css、less、sass、stylus)。看着这么多的东西,第一感觉就是厉害(6666!),但是还是得学,面试得问,项目得用。
其实,每个人都会说,前端你必须得掌握html、css、JavaScript(这三个是基础)。但是,谁都知道,谁都明白,让人的感觉就是白讲。其实,我想表达的是一个方向。接触前端到现在,其实,很多时候前端不一定会都使用框架。回想一下,自己当初学习前端那份初衷在哪里——为了去实现设计师交付给你的那份设计稿,同时也为了交付给用户一个体验良好的产品。其实,前端还有很多其他的东西可以玩,像canvas、svg、webGL、three.js。就像是阿里这样的大公司,还是需要那些做活动界面的前端,或许他们并不会框架,但是他们对于css的掌握,页面的性能,动画的了解一定是一级棒的。每个人找准自己的方向,才是对前端的真正发展。
曾经有个面试官是这么问我的:
你是喜欢css还是js?
我回答了js。(结果他在之后的面试中问了大部分的问题,而css的部分只是简略了解了一下而已)
我似乎有些佩服这位面试官,因为他懂得区分侧重点。似乎道理也是这么一个道理,平时都在用js、用框架的人,对于css的了解会很深吗?了解css的继承和模块吗?
往往应对疲劳的方法就是,找准自己的侧重点,然后开始进行深入的学习,才能成为真正的工程师。
继续上一篇的话题,我们来看看算法复杂度在O(n*log2n)的算法。
这篇开头我们就来分析一下最受欢迎的快速排序
快速排序,从它的名字就应该知道它很快,时间复杂度很低,性能很好。它将排序算法的时间复杂度降低到O(nlogn)
思路:
首先,我们需要找到一个基数,然后将比基数小的值放在基数的左边,将比基数大的值放在基数的右边,之后进行递归那两组已经归类好的数组。
图例:
原图片太大,放一张小图,并且附上原图片地址,有兴趣的可以看一下:
代码实现:
const arr = [30, 32, 6, 24, 37, 32, 45, 21, 38, 23, 47];
function quickSort(arr){
if(arr.length <= 1){
return arr;
}
let temp = arr[0];
const left = [];
const right = [];
for(var i = 1; i < arr.length; i++){
if(arr[i] > temp){
right.push(arr[i]);
}else{
left.push(arr[i]);
}
}
return quickSort(left).concat([temp], quickSort(right));
}
console.log(quickSort(arr));性能:
归并排序,即将数组分成不同部分,然后注意排序之后,进行合并
思路:
首先,将相邻的两个数进行排序,形成n/2对,然后在每两对进行合并,不断重复,直至排序完。
图例:
代码实现:
//迭代版本
const arr = [3,44,38,5,47,15,36,26,27,2,46,4,19,50,48]
function mergeSort(arr){
const len = arr.length;
for(let seg = 1; seg < len; seg += seg){
let arrB = [];
for(let start = 0; start < len; start += 2*seg){
let row = start, mid = Math.min(start+seg, len), heig = Math.min(start + 2*seg, len);
let start1 = start, end1 = mid;
let start2 = mid, end2 = heig;
while(start1 < end1 && start2 < end2){
arr[start1] < arr[start2] ? arrB.push(arr[start1++]) : arrB.push(arr[start2++]);
}
while(start1 < end1){
arrB.push(arr[start1++]);
}
while(start2 < end2){
arrB.push(arr[start2++]);
}
}
arr = arrB;
}
return arr;
}
console.log(mergeSort(arr));//递归版
const arr = [3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
function mergeSort(arr, seg = 1){
const len = arr.length;
if(seg > len){
return arr;
}
const arrB = [];
for(var start = 0; start < len; start += 2*seg){
let low = start, mid = Math.min(start+seg, len), heig = Math.min(start+2*seg, len);
let start1 = low, end1 = mid;
let start2 = mid, end2 = heig;
while(start1 < end1 && start2 < end2){
arr[start1] < arr[start2] ? arrB.push(arr[start1++]) : arrB.push(arr[start2++]);
}
while(start1 < end1){
arrB.push(arr[start1++]);
}
while(start2 < end2){
arrB.push(arr[start2++]);
}
}
return mergeSort(arrB, seg * 2);
}
console.log(mergeSort(arr));性能:
基数排序,就是将数的每一位进行一次排序,最终返回一个正常顺序的数组。
思路:
首先,比较个位的数字大小,将数组的顺序变成按个位依次递增的,之后再比较十位,再比较百位的,直至最后一位。
图例:
代码实现:
const arr = [3221, 1, 10, 9680, 577, 9420, 7, 5622, 4793, 2030, 3138, 82, 2599, 743, 4127, 10000];
function radixSort(arr){
let maxNum = Math.max(...arr);
let dis = 0;
const len = arr.length;
const count = new Array(10);
const tmp = new Array(len);
while(maxNum >=1){
maxNum /= 10;
dis++;
}
for(let i = 1, radix = 1; i <= dis; i++){
for(let j = 0; j < 10; j++){
count[j] = 0;
}
for(let j = 0; j < len; j++){
let k = parseInt(arr[j] / radix) % 10;
count[k]++;
}
for(let j = 1; j < 10; j++){
count[j] += count[j - 1];
}
for(let j = len - 1; j >= 0 ; j--){
let k = parseInt(arr[j] / radix) % 10;
tmp[count[k] - 1] = arr[j];
count[k]--;
}
for(let j = 0; j < len; j++){
arr[j] = tmp[j];
}
radix *= 10;
}
return arr;
}
console.log(radixSort(arr));性能:
我们一共实现了6种排序算法,对于前端开发来说,熟悉前面4种是必须的。特别是快排,基本面试必考题。本篇的内容总结分为六部分:
排序算法,是算法的基础部分,需要明白它的原理,总结下来排序可以分为比较排序和统计排序两种方式,本篇前5种均为比较排序,基数排序属于统计排序的一种。希望看完的你,能够去动手敲敲代码,理解一下
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
本篇讲述的是react的生命周期的管理的知识点整理。大体的内容都来自于《深入react技术栈》的生命周期部分。不得不说,这是我看过讲解react源码的最好的一本教科书。生命周期的机制在现在大部分框架中都存在,并且这种机制有着它独有的好处。
首先,我们来了解一下生命周期是什么,表现出怎样的特质。从react的角度,react的生命周期钩子主要有:componentWillMount、render、componentDidMount、componentWillReceiveProps、shouldComponentUpdate、componentWillUpdate、componentDidUpdate、componentWillUnmount这样8个。每个生命周期对应着各自的状态,整个生命周期的运作更像是状态机的运作——在不同的阶段,运行不同的方法。
而react就是通过这样子的方式实现了“生命周期——状态——组件”的过程(通过setState方法实现)。
整个react的组件的生命周期可以分成几种情况去执行:
如图所示:
那么,react的生命周期又是通过什么来管理的呢?其实,react的生命周期主要分为三个阶段MOUNTING、RECEIVE_PROPS和UNMOUNTING。在源码中,这三个阶段分别对应着三个函数,分别为mountComponent、updateComponent和unmountComponent。
详细了解这三个阶段之前,可以先来看一下上述执行情况中第一次渲染的时候,这时候组件刚好被生成,react是通过createClass方法来创建自定义组件的。而getDefaultProps方法只执行一次,它是由构造函数来管理的,用来设置初始化defaultProps的。
然后我们再来深入了解这三个阶段分别管理的函数:
阶段一:MOUNTING
mountComponent 负责管理生命周期中的getInitialState、componentWillMount、render和componentDidMount。
通过mountComponent挂载组件,初始化序号、标记等参数,判断是否为无状态组件,并进行对应的组件初始化工作,比如初始化props、context等参数。利用getInitialState获取初始化state、初始化更新队列和更新状态。
注:在componentWillMount中调用setState方法,是不会触发re-render的,而会进行state合并。由于inst.state = this._processPendingState(inst.props, inst.context)是在componentWillMount之后执行的,因此componentWillMount中的this.state并不是最新的,最新的可在render中获取。
mountComponent还有一个特点:通过递归渲染内容,即由父组件开始componentWillMount开始,接着子组件的componentWillMount,之后是子组件的componentDidMount,最后才会到父组件的componentDidMount调用。
执行顺序图:
阶段二:RECEIVE_PROPS
updateComponent负责管理生命周期中的componentWillReciveProps、shouldComponentUpdate、componentWillUpdate、render和componentDidUpdate。
通过updateComponent来更新组件,如果前后元素不一致,说明需要更新。
此时,如果组件中存在componentWillReciveProps的话,则执行,但是在这个生命周期中调用setState函数并不会触发re-render,只会进行state的合并。同样的,state的最新状态并不能在componentWillReceiveProps、shouldComponentUpdate和componentWillUpdate中通过this.state得到。因为只有当触发了inst.state = nextState这个语句时,才会更新最新的状态,因此,也只能在render和componentDidUpdate这两个环节取得。
注:setState函数并不能在shouldComponentUpdate和componentWillUpdate中进行使用。因为会产生死循环,使得内存爆炸。大致的原理在接下来的setState机制中会详细解释。
和mountComponent的流程差不多,updateComponent也是递归渲染的。
执行流程如图:
阶段三: UNMOUNTING
这个阶段主要管理的生命周期是componentWillUnmount。
执行componentWillUnmount时,会重置相关参数、更新队列以及更新状态。并且这里使用setState方法是不会造成组件的re-render的。
setState的更新机制
在react中,或许被使用最频繁的就是setState这个API了。或许,你有没有思考过,为什么需要这样一个API呢?既然state是一个对象,为何不直接修改对象中的值呢!这样做不是更加方便吗?在react中,基本是禁止这样子做的。1. 直接修改state不会引起组件的更新 2. 或许这样子做了,会导致后面的组件状态被覆盖。
那么说回setState的更新问题?react有一个公式UI = f(state),这个公式表示只需要改变状态,就可以改变UI界面。试想一下,如果频繁地使用setState,react会频繁的去进行重渲染吗?很显然,这是不被允许发生的。这样的结果会导致react的性能急剧下降。首先来看一个例子:
componentDidMount(){
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
}这个例子最后的输出结果都是0, 0, 0。或许,与你试想的1,2,3的结果有很大的不同。这是因为setState的更新机制导致的。在同一个生命周期中,setState会将每一次的操作都放到一个状态队列中,最后对这个状态队列进行一个合并操作。这也就是setState的批量更新——即setState的更新是异步的。
那么,问题来了,有的时候,你必须得这么去做,业务的要求,又该如何呢?那就通过函数的形式,就像Redux一样,具备reducer这种类型的函数,setState本身也推荐使用函数的方式。
this.setState((prevState, props) => {
count: prevState.count + 1
});这是比较流行的写法,可以充分的解决异步更新带来的状态不统一的问题。其实这是一种函数式的编程方式,setState接受一个函数,而函数会返回一个新的对象。这样的话,当你需要连续更新时,就可以写一个合并函数,在里面进行操作。
再来看一下另一个例子:
class Counter extends React.Component {
constructor(props){
super(props);
this.state = {
count: 0
};
}
componentDidMount(){
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
setTimeout(() => {
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
}, 0)
}
render(){
return (
<div>{this.state.count}</div>
);
}
}这里的输出结果是0、0、2、3。
前面两个0的输出,看懂上面的机制之后,就可以很明白了。那么,后面两个输出又发生了什么呢?为什么会是2,3,而不是2,2呢。
首先,来看一下setState调用栈的逻辑判断:
这里有个判断的过程,会去判断是否处于批量更新的模式,如果是,则进行批量更新,只render一遍;如果不是,这每次都render。这个判断的源码中涉及到了事务的概念。
setState调用死循环
在上面生命周期阶段调用时,谈及到shouldComponentUpdate和componentWillUpdate方法时,说过在其中调用setState的方法会造成死循环。原因是因为调用setState,会执行enqueueSetState方法,并对partialState以及_pendingstateQueue更新队列进行合并操作,最终通过enqueueUpdate执行state更新。
而performUpdateIfNecessary方法会获取_pendingElement、_pendingStateQueue、_pendingForceUpdate,并调用receiveComponent和updateComponent方法进行组件更新。
在shouldComponentUpdate或componentWillUpdate方法中调用时,this._pendingStateQueue != null,则performUpdateIfNecessary方法就会调用updateComponent方法进行组件更新。这样就形成了死循环。
这里总结了大部分的react的生命周期的内容,大部分的内容也是来自于《深入浅出react技术栈》。只是书上还有一部分源码没有贴出来。这篇文章也算是对自己看完这部分内容的总结吧
在前端工程师面试中js部分一般会分成四个部分进行询问:
本人打算从这么四个方面对于收集到的面试题进行总结,也是对于接下来的面试的一种补充。基本上,现在的大厂,都是三轮面试(一轮基础面,二轮项目+技术面,三轮hr面)。其实,很多时候,书看的太多,反而记忆是混淆的,因此,由面试题开始进行总结是非常有用的途径。内容分为四篇,也将包括上述的4点。
1. 闭包是什么?闭包的用处。
闭包是内部函数对外部函数作用域的引用。而在函数外部引用函数内部变量,可以通过闭包实现。闭包的用处往往是在模块封装的时候。可以将模块内部公有部分暴露出来。(闭包是基础性的问题,这里只是简要的阐述了一下它的概念) 闭包详解(阮一峰)
2. 原型以及原型链
js与常用的编程语言不一样,他是靠原型继承的,并不是类。使用造零件的方式进行类比,通过类继承的方式就是通过一个模型盒铸件,而原型的方式,则是从另一个零件克隆一份,在这基础上进行修改。而那份被克隆的零件就是原型 原型及原型链详解。原型链就是它们之间产生的联系,往往可以通过画图来阐述:
3. 垃圾回收机制和内存泄漏
js引擎有自己的一套垃圾回收的机制,主要的回收机制有两种标记清除和循环引用。标记清除,即是在局部变量在使用过程中打上标记,一旦离开了执行环境,标记将会被清除,这是垃圾回收器将会知道,该变量已经不使用,可回收。而循环引用是在较早版本的IE浏览器中被使用,即初始化的变量引用数为0,一旦被赋值给另一个变量,引用就加1;而另一个变量一旦被赋予其他值,则该值的引用数减一。垃圾回收器会去判断该变量的引用数是否为0,为0,则会被回收掉。这个机制会存在循环引用的问题,即两个变量相互引用。垃圾回收
内存泄漏的问题。可以罗列为:
- 无意识的变量使用
function func(){ i = 2; }这种方式在严格模式下是不生效的。
2. 闭包导致的问题其实,闭包导致的内存泄漏主要是在IE引用dom元素的时候。IE中的部分dom元素并非原生的,而是COM。这时使用,往往会导致循环引用,而导致内存泄漏。还有就是无意识的使用闭包导致的问题。1. 在函数内部添加时间时,会造成dom元素的引用,而导致内存泄漏;2. 在删除dom时,在之前不小心添加了事件等情况内存泄漏
4. 柯里化
js的柯里化就是将函数的部分参数分成多次进行调用。例子:
function func(a, b, c){ // } function fun(a){ return function(b){ return function(c){ } } } //箭头函数表达方式 const func = (a) => (b) => (c) => { ... };柯里化是函数式编程必备的一种简化函数参数的方式。柯里化
5. 异步
面试之中主要会问你何为异步?其实,js是一门单线程的语言,正常的方式是整个程序按照顺序一步一步的执行下去,这就是所谓的同步模式,但是往往js中会有许多的任务耗时比较长(比如说ajax请求)等,如果按照同步的方式,往往会导致浏览器的无响应。这时,就需要通过异步的形式。异步模式:js的任务往往具备一个或多个回调函数,在执行的过程中,后一个任务无需前一个任务执行返回结果,而是继续执行,之后前一个任务可以调用回调函数,将结果返回回来。异步
6. setTimeout和setInterval的区别,以及setTimeout的原理,setInterval会造成什么问题
首先,我们来应该了解一下setTimeout的原理。浏览器是一个事件为主体的事物。总是有一个队列在不停的循环。当使用setTimeout时,浏览器会创建一个定时器,然后将函数中的回调函数放入handle队列里面。然后浏览器会不停的循环整个handle,一旦handle中的内容满足条件,就会调用其中的回调函数。setTimeout的满足条件就是它后面的设置的时间差。
setTimeout和setInterval之间的区别主要是setTimeout是一个延迟函数,只执行一次,而setInterval会间隔一定的时间反复的执行。setTimeout和setInterval的区别
setInterval的原理,其实与之前的setTimeout的原理有点类似。只是在每个Event Loop之后,都会去检测是否满足条件,如果满足条件的话,就执行回调函数,如果不满足,放入下一轮的event loop中。主要的问题就是,如果一个setInterval中的回调函数不能够被执行,会引起系统阻塞的问题,之后的所有的定时器都会积累起来,之后就会直接执行,没有时间间隔。setInterval机制;
function interval(func, wait){ var interv = function(){ func.call(null); setTimeout(interv, wait); }; setTimeout(interv, wait); } interval(() => { console.log(1); }, 1000); //1 1 1
7. postmessage和iframe怎么结合使用
postmessage是html5新出的一个API,可以解决多窗口、页面与新标签、窗口和iframe之间的消息通信的跨域问题。使用方法就是postmessage(data, origin),其中data指的就是需要传递的数据,origin指的是具体的数据源地址(包括协议+域名+端口)。然后window对message事件进行监听。postMessage解决跨域
8. js模板引擎
js模版引擎,其实就是预处理器,将一些字符串去匹配数据,然后将数据插入到固定的html模版之中。js的模版引擎主要是使用正则表达式去过滤一些字符串,然后将里面的每个语句片段都放到固定的数组之中,然后在对数组进行解析,之后拼成一个固定的js代码,将内容返回出来。著名的模版引擎ejs。js模版引擎原理解析
9. WebSocket?长轮询和短轮询
webSocket是一种网络通信协议,基于TCP/IP的另一种通信协议(还有一种是http协议)。它与http的主要区别就是,http是单向通信的,客户端可以向服务器发送请求,但是,服务端如果有消息,无法向客户端推送。在没有websock之前,都是通过http定期发送请求的方式——轮询。轮询的效率是相对较低的。websock协议
之后的长轮询和短轮询呢?这个问题还得更实际的场景相结合起来。首先,我们在写电商网站的时候,商品的库存是实时变化的,这时,你要和服务器同步这个变化,才能够使得信息正确。那么,最简单的方式就是我们写一个ajax请求,不断的去给服务器请求,同步这个数据。而服务器每次接收到请求就返回一次信息。这就是所谓的短轮询,这种方式其实非常的消耗服务器的资源,试想服务器每次接收到请求就要去查询数据库,获取信息,而往往库存是没有这么快改变的。那么,或许长轮询可以更加方便地解决这个问题。我们可以写一个ajax请求,同时给这个请求设置超时机制,一旦超时之后,再次重新发送。而服务器每次接收到这个请求,只需要将之挂起,等检测到库存变化时,在响应这个请求,这样就有效的降低了轮询的次数。同样的问题,服务器的资源还是会有所损耗,毕竟一个请求相当于一个线程。对于大型的电商网站来说,这不是一种好的解决方式。长轮询、短轮询、长链接、短链接
10. cookie、LocalStorage 和 SessionStorage 的概念以及它们之间的区别
首先,cookie是我们比较熟悉的,是浏览器与服务器之间数据传递的方式,之前通常也会用来做一些数据的缓存,例如:用户的用户名等。但是cookie在做数据缓存的时候往往有缺点:
- cookie数据最多只能缓存4kb,大于4kb的cookie会被浏览器默认弃用
- cookie在做数据缓存时,往往会将数据发送给服务器,但是,有的时候这些数据并不需要发送给服务器
- cookie在每个域中的数量是有限的,往往超过一定数量,那么之前的cookie将被抛弃
html5新特性中就带来了相应的客户端storage,就是localStorage和sessionStorage。localStorage是本地存储,数据不会发送给服务器,同时它的缓存大小大约在5M左右,数据是永久存储的,除非手动删除。sessionStorage则是会话存储,大部分的特性和localStorage一样,但是,sessionStorage中的内容会在浏览器或者页面关闭之后被清除掉。cookie、LocalStorage和SessionStorage
11. 浏览器事件代理的原理
其实,事件代理和事件委托是同一个概念。举个例子说明或许会更加形象。场景是:DOM结构为一个列表,而你需要在点击每个li标签时,在控制台输出它的内容。这时,你或许会在每个li上面添加点击事件,然后输出每个li的内容。但是,往往这样子做,会使得整个应用的性能降低,而且使得添加过程繁琐,不灵活。我们可以使用事件代理的方式,在整个列表的ul上面去添加点击事件,然后在内部使用target(真实点击元素)来使其输出它的内容。这样,我们就可以只写一个事件,而完成多个li之间的内容输出。事件代理的原理是使用了事件冒泡的特性。但是,有时候有些事件没有冒泡机制,如focus,blurs等,就不能使用事件代理,还有些类似于mouseover等事件,会导致实时的触发,也不宜使用事件代理事件代理
12. 前端安全 XSS,CSRF ?避免方法?
XSS,被称为跨站脚本攻击,主要分为三种反射型、存储型和DOM型。反射型主要是一些恶意链接的发送,存储型主要出现在评论等,可以插入到服务器数据库中,这种攻击比较持久;DOM型非常的少见。XSS主要是盗取用户的cookie等数据。CSRF,被称为跨站伪造请求攻击,主要与xss相结合XSS和CSRF
13. 前端性能优化的方法
14. 同源和跨域
15. 面向对象和继承
16. object.create的实现原理
17. object的深拷贝和浅拷贝
18. 面向切面编程和函数式编程
**19. **
前段时间,在投票系统中实现了h5的瀑布流加载,demo地址。整体的demo实现效果上可分成三个部分:瀑布流+下拉刷新+上拉加载。下面就具体来分析一下如何实现的。
首先,瀑布流的实现方式只要有三种:
在获取内容时,计算出内容的高度,然后使用定位的方式来形成瀑布流(这种方式目前比较常用,但是需要实时计算,性能不是特别高)。
获得页面的宽度,然后根据页面的宽度计算列数,在进行固定列表的插入(我是用的就是这一种)
使用css3的列布局,由于兼容性问题需要使用前缀(-moz,-webkit)
由于本人使用的是第二种方式,因此,我就详细分析一下第二种方式。
由于设计图是640px的,且整体分成两列,所以,对于列数这个概念,我们可以设定为2,当然了,如果你是PC端的,并不确定列数,你也可以通过window.innerWidth来获取整体的宽度,然后相对于每列的宽度做一个除法。
分析一下整体的html内容部分,主要分为外层的ul,对应的li,以及li里面的内容。
<ul class="container">
<li class="list">
<div class="list-item item1">
</div>
<div class="list-item">
</div>
</li>
<li class="list">
<div class="list-item">
</div>
<div class="list-item">
</div>
</li>
</ul>然后设置css的样式时,将ul的布局设置为flex布局。
.container{
display: flex;
list-style: none;
padding: 0;
}
.list{
flex: 1;
margin: 10px;
}
.list-item{
width: 100%;
height: 200px;
margin-top: 20px;
background: red;
}
.item1{
height: 100px;
}这样大致的效果图如下:
之后,我们来写div块的模板函数,方便之后获取数据的插入tepl()
templ: function(data){
const block = doc.createElement('div');
block.className = 'list-item';
const value = `
<img src="${data.image}" alt="person-image">
<div class="name">${data.name}</div>
<div class="info">
<span class="id">编号: ${data.id}</span>
<span class="vote"><span class="count">${data.vote}</span>票</span>
</div>
<div class="desc">
${data.desc}
</div>
<div class="btn-group">
<button class="btn detail" data-value="${data.id}">候选详情</button>
<button class="btn vote" data-value="${data.id}">为TA投票</button>
</div>`;
block.innerHTML = value;
return block;
}该函数中,就是创建了一个div块,然后给div块赋上classname,之后就是一些固定数据的插入(如果会使用js模板引擎的话,也可以使用,推荐ejs吧)。
之后写一个函数将获取到的数据插入到列表中(由于,我这里还考虑了列表不确定的情况,所以li也是需要临时生成的,同时还需要一个list_number去记录列表数)。先来看一下这部分的函数:
setHtml: function(data){
const _self = this;
const fragments = _self.setFragements(data);
$('.list-wrapper').each((index, item) => {
$(item).append(fragments[index]);
});
},
initHtml: function(data){ //initial html template
const _self = this;
const fragment = doc.createDocumentFragment();
const fragments = _self.setFragements(data);
fragments.forEach((item, index) => {
const listItem = doc.createElement('li');
listItem.className = 'list-wrapper';
listItem.appendChild(item);
fragment.appendChild(listItem);
});
$('.wrapper').html(fragment);
},
setFragements: function(data){ //generate some fragment
const _self = this;
const count = _self.config['list_number'];
const fragments = _self.getFragments(count);
data.forEach((item, index) => {
const i = index % count;
const block = _self.templ(item);
fragments[i].appendChild(block);
});
return fragments;
},
getFragments: function(num){
const arr = [];
for(let i = 0; i < num; i++){
arr.push(doc.createDocumentFragment());
}
return arr;
}这里的函数主要分为几个功能:插入到html中(非第一次)、初始化html部分、创建fragment。
主要的思路就是第一次加载的时候创建对应的li数量,然后通过fragment片段的形式插入ul中,之后的加载只要获取li的内容,在它的后面进行添加就可以了。
这部分主要是瀑布流以及模板的加载,之后的一篇将会讲下拉刷新和上拉加载的主要思路与实现。整体demo的源码地址在我的github上(demo地址)
模块对于node来说是不可或缺的一部分,是服务端编程的基础。趁着整理模块之际,先将node部分的模块的封装等做一个总结。希望能够切实的帮助到你。本篇将对CommenJS规范,node的文件模块和核心模块等做一个综合的整理。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
我觉得模块的出现是js进步最大的地方。因为有了模块,才使得很多优秀的东西可以真正被共享出来,而不用去担心变量污染、命名空间的问题。
node作为一门服务端的javascript,它借鉴了CommonJS的规范,形成了一套易用的模块规范。
首先,看看下面这个最常见的例子:
//circle.js
const { PI } = Math;
exports.area = x => PI*x**2;
exports.circle = x => 2*PI*x;//main.js
const circle = require('./circle');
console.log(circle.area(4)); //50.26548245743669其实,我们可以清晰地看到两个文件中,模块规范部分可以分成三部分:
这三块内容可以使用一张图片概括:
如图:
从这幅图中,我们可以看到,模块之间可以通过exports将接口暴露出来,然后通过require来对另一个模块内的内容进行引入。
这样我们就大概懂得了模块的定义。它主要分为三部分:模块的引用、模块定义和模块标识。
然而,整个模块部分我们最需要去了解的是require机制。node对于require实现,有很多的东西可以去欣赏。
首先,需要明白的是整个模块引入的步骤。从上面的例子中,可以看出这三部分:
有的时候,情况是特殊的。模块本身就分成核心模块和文件模块。而核心模块在node源代码编译的时候。就被编译成二进制文件。并且部分核心模块会在node进程启动时,直接加载到内存中,因此这一部分的核心模块引入是不需要经过文件定位和编译执行的步骤的。
还有特殊就是在缓存部分。每个模块首次加载之后,node会缓存其编译执行后的对象,方便二次加载。所以,二次加载时,是以缓存优先的,从缓存中加载的模块也是不需要文件定位和编译的。
单从路径分析说起,可以分成三种不同的方式:
查找方式: 1. 从当前目录下面的node_modules中查找是否具备相应的模块 2. 若具备,则直接加载使用,否则,会去查找父目录下的node_modules目录,直至查找到根目录下的node_modules中。这种方式是最慢的。
再来分析文件定位:
第一个例子中的标识符是'./circle'。可以发现,这个文件标识符是没有后缀名的。那么,node是如何来进行定位的呢?其实,node有一个默认的定位顺序:js、node、json。这里会最先识别js,之后一次对json和node的文件进行识别。因此,这里有个小技巧:在识别.node和.json的文件的时候,带上文件后缀名会快一点, 为什么呢?是因为,node是使用fs同步阻塞的方式,逐一去尝试,该文件是否存在,存在着直接加载;不存在的话,尝试下一个后缀名。
还有对于那些自定义的模块,如npm包。node的定位方式也是不同的。通常来说,npm包中都会具备package.json文件,这个文件中有个main属性,这指向的就是整个包的入口文件;如果没有这些条件,node会去默认加载index.js、index.json和index.node
最后就是模块编译部分的分析了:
首先,编译执行也可以通过上面的三类后缀文件名来进行分析:
javascript文件编译
在使用fs读取文件之后,读取出来的内容node会如何去处理呢?会造成变量污染吗?很显然是不会的。node是根据CommonJS的规范,对读取进入的内容,在头部和尾部进行包装,包装成function(exports, require, module, __dirname,__filename){ ...读取内容 }。这样子,就起到了一个作用域隔绝的作用,不会对现有模块中的内容污染。而__dirname、__filename是node中存在的。
然后将这个函数代码使用vm原生的模块runInThisContext()方法执行(类似eval => 将字符串转化成可执行的js的代码)。然后返回一个具体的对象,供现有模块中的内容进行使用。
C/C++模块的编译
这个编译主要是依靠node的process.dlopen()方法进行执行,同时node使用libuv对windows和*nix平台做了兼容性的处理。这种模块的性能相对于普通文件模块来说较高,但是编写成本也会相应地提高。
json文件编译
json文件编译会比较简单,就是通过fs读取文件,然后通过JSON.parse方法进行编译,最终将内容给予现有模块中命名的那个变量。
至此我们对node的模块整体的机制,大致已经整理清楚了,从模块的导出,到引入,以及标识符的分析。均可从CommonJS中找到影子,但是node对其进行的加工又相对比较完美。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
之前,几篇文章我们了解到了一定的基础知识,如果你还未曾看过,可以点击这个链接观看。
本篇内容主要是讲一下文章中文字部分的处理,如'bold'、'italic'、'blockqueto'、'h1'等,以及分割行的插入和链接的插入和修改等模块的代码分析。那么接下来,我们就源码开始,对于我们上述所概述的知识点进行分析。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
从这里开始我们就会根据源码来对每个模块的实现,进行深入的分析和探讨。
首先,我们可以来看一下加粗,斜体和删除线的实现。我们先来看一下,源码:
commandSet: ['bold', 'italic', 'strikethrough', 'redo', 'undo'],
exec: function(command){
const _self = this;
if(_self.commandSet.indexOf(command) !== -1){
document.execCommand(command, false, null);
}else{
let value = '<'+command+'>';
document.execCommand('formatBlock', false, value);
}
},首先,我们来了解一下document.execCommand()函数,它具备3个参数:
讲一下,这里的设计。由于我们需要去区分有参数的命令和无参数的命令,所以我们首先将无参数命令,做成一个集合。每当调用这个函数时,首先回去查找是否这个命令是无参数命令。我们来看两个例子:
//bold
document.execCommand('bold', false, null);
//h1
document.execCommand('formatBlock', false, '<h1>');那么,你可以讲个上面的优化,然后在调用函数的过程中,使用如下的方式:
//bold
RE.exec('bold');
//h1
RE.exec('h1');这样整体等代码风格会非常的节俭,之后需要添加无参数命令时,只需要在命令集中增加原生命令就可以实现增加。
此处,在编写函数时使用了一点小技巧,有兴趣的朋友可以学习一下
这个函数可以满足我们接下来的字体处理部分,包括引用块。下面我将列举每个功能的调用方式,当然了,android调用也是一样的。
//bold 加粗
RE.exec('bold');
//italic 斜体
RE.exec('italic');
//strikethrough 删除线
RE.exec('strikethrough');
//h1 h1标签
RE.exec('h1');
//h2 h2标签
RE.exec('h2');
//h3 h3标签
RE.exec('h3');
//h4 h4标签
RE.exec('h4');
//blockquote 引用块
RE.exec('blockquote');有兴趣的同学也可以将JS部分内容进行扣取,然后自己去进行实现。同时,IOS中的运用也是一致的。
接下来,我们来聊一下分割行的插入问题。
首先,我们来知道一下如何插入分割行。通过execCommand函数中的insertHtml命令执行,例子:
//hr
document.execCommand('insertHtml', false, '<hr>');这样子,是可以形成一个分割行,但是,你会发现一个问题——焦点不会置换行。
「焦点无法换行」,其感觉就是缺乏一个回车操作。但是,我们不可能要求用户在插入的过程中,都去执行一个回车操作,所以我们需要来讲解一个小知识:
回车操作:在大多数人的认识中,回车就是插入的一个
标签,但是,如果你仔细去观察dom中时,会发现回车操作其实是在后面插入了这样子的格式块。这里是一个小技巧,在后面插入图片的时候,也会被使用到。
所以,我们需要将代码修改一下:
//hr
document.execCommand('insertHtml', false, '<hr><div><br></div>');这样,我们就实现了一个正常的分割行的插入,同时也保证了焦点的换行。下面我们需要对上述的操作进行封装,因为这个命令会被频繁的调用,而变化的只是后面value部分。
所以,我们的源码中会进行这样子的封装:
insertHtml: function(html){
const _self = this;
document.execCommand('insertHtml', false, html);
},
insertLine: function(){
const _self = this;
const html = '<hr><div><br></div>';
_self.insertHtml(html);
},其中,这里的insertHtml函数,我们在之后的链接和图片插入过程都会被使用到。所以,我只能提前在这里先分析掉了。
讲完分割行的操作,我们紧接着来分析一下链接的操作。
链接的操作,或许会比较繁琐一点,因为,我们必须保证这个链接的插入和修改。
插入过程会比较简单,我们可以先来看一下源码:
//link
insertLink: function(name, url){
const _self = this;
const html = `<a href="${url}" class="editor-link">${name}</a>`;
_self.insertHtml(html);
}你会发现,这里需要一个name参数和一个url参数。所以,需要android在调用时,先获取到用户输入的链接名和链接地址。这个具体的样式,在github项目中有展示,所以,你也可以模仿我们样式,在点击插入链接按钮的时候,跳出一个输入表单,然后让用户进行输入,最终获得到相应的数据之后,调用这个值。
这个部分比较简单,主要的逻辑部分还在android部分,有兴趣的同学,可以自行去研究android的源码。
之后,我们需要来阐述一下修改链接部分。
按照惯例,我们也先来看一下修改链接部分的源码:
//change link
changeLink: function(name, url){
const _self = this;
const current = _self.cache.currentLink;
const len = name.length;
current.innerText = name;
current.setAttribute('href', url);
const selection = window.getSelection();
const range = selection.getRangeAt(0).cloneRange();
const { startContainer, endContainer } = _self.currentRange;
selection.removeAllRanges();
range.setStart(startContainer, len);
range.setEnd(endContainer, len);
selection.addRange(range);
}首先,要明白的是,我们在修改链接部分的逻辑并不是简单的索取name和url这么简单。
从头开始说起的话,我们要继续插入链接之后的话题说起。当我们插入链接之后,我们如果需要修改一个链接的逻辑部分可以看成一下几个步骤:
所以,看过这个部分的内容之后,我们就可以来理解一下源码中我们所作的处理了。
这里,我们就将修改链接部分的逻辑表述完了,不知道你现在是否清楚我们为什么需要这样去操作了呢。欢迎讨论。
这篇文章中,我们对于字体部分的内容,分割行,最后是链接等三部分的操作做了一个详尽的分析。也将我在开发过程中的思考,写在了里面,可以说是一篇十足的实践类的干货文章。同时,也希望你在看完这篇文章之后,会对富文本操作方面有更加深入的了解,下面一篇文章,讲述的主题是图片操作这块的内容,尽情期待!!!
最后,如果你对我写的有疑问,可以与我讨论。如果我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客。同时也希望你关注我们的项目,github项目地址,谢谢支持
这段时间,算是空出手来写几篇文章了。由于很久都没有时间整理现在所用的东西了,所以,接下来会慢慢整理出一些文档来记录前段时间的工作和生活。
这篇文章的主题是vue-cli的理解。或许,很多人在开发vue的时候,我们会发现一个问题——只会去用,而不明白它的里面的东西。现在的框架可以说是足够的优秀,让开发者不用为搭建开发环境而烦恼。但是有时候,我们还是得回到原始生活体验一下,才能够让自己更上层楼,希望大家共勉。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
首先,我们来说一下安装的东西吧!处于有头有尾的目的,还是几句话草草了事。步骤如下:
安装vue-cli
npm install vue-cli -g
以webpack模版安装目录
vue init webapck webpack-template
这样之后,我们就可以使用IDE打开目录了。
此处注明我的vue-cli的版本2.9.2,以免之后改版之后,误导读者。
之后,附上自己的目录截图,并没有做改动,如图:
首先,第一个问题,从何看起呢?当然,是从webpack.base.conf.js开始看起了。这个是dev和prod环境都会去加载的东西。然后,我们可以先从webpack.base.conf.js中会被用到的几个文件看起。其实,base中被用到了如下的文件,我们可以从代码中看出:
'use strict'
const path = require('path')
const utils = require('./utils')
const config = require('../config')
const vueLoaderConfig = require('./vue-loader.conf')分别是:
path路径
这个模块可以看nodejs官网的介绍,其实,就是一个文件路径的获取和设置等模块,学习node的时候,我们往往会看到这个模块被大量运用。
path模块提供了用于处理文件和目录路径的使用工具
我们可以到其中去看一下代码,其实光从名字上我们可以推断出,它可能是为整个脚手架提供方法的。我们可以先来看一下头部引用的资源文件:
const path = require('path')
const config = require('../config')
const ExtractTextPlugin = require('extract-text-webpack-plugin')
const packageConfig = require('../package.json')同样的,它也引用了path模块和config目录中的index.js文件,之后的话是一个npm包——extract-text-webpack-plugin。这个包的话,是用来分离css和js的内容的。后续我们可以详细了解一下。同时,它还引用的package.json文件,这是一个json文件,加载过来之后,会变成一个对象。
所以,我们需要从它的头部依赖开始说起:
path模块我们之前提到过,这里就不细说。我们可以来分析一下config目录下的index.js文件。
index.js
这个文件中,其实有十分充足的代码注释,我们也可以来深入探究一下。
从代码中,我们可以看到通过module.exports导出了一个对象,其中包含两个设置dev和build。
在dev中,设置了一些配置,代码如下:
modules.exports = {
dev: {
// Paths
assetsSubDirectory: 'static',
assetsPublicPath: '/',
proxyTable: {},
// Various Dev Server settings
host: 'localhost', // can be overwritten by process.env.HOST
port: 8080, // can be overwritten by process.env.PORT, if port is in use, a free one will be determined
autoOpenBrowser: false,
errorOverlay: true,
notifyOnErrors: true,
poll: false, // https://webpack.js.org/configuration/dev-server/#devserver-watchoptions-
// Use Eslint Loader?
// If true, your code will be linted during bundling and
// linting errors and warnings will be shown in the console.
useEslint: true,
// If true, eslint errors and warnings will also be shown in the error overlay
// in the browser.
showEslintErrorsInOverlay: false,
/**
* Source Maps
*/
// https://webpack.js.org/configuration/devtool/#development
devtool: 'eval-source-map',
// If you have problems debugging vue-files in devtools,
// set this to false - it *may* help
// https://vue-loader.vuejs.org/en/options.html#cachebusting
cacheBusting: true,
// CSS Sourcemaps off by default because relative paths are "buggy"
// with this option, according to the CSS-Loader README
// (https://github.com/webpack/css-loader#sourcemaps)
// In our experience, they generally work as expected,
// just be aware of this issue when enabling this option.
cssSourceMap: false,
}
}通过它的注释,我们可以理解它在dev中配置了静态路径、本地服务器配置项、Eslint、Source Maps等参数。如果我们需要在开发中,改动静态资源文件、服务器端口等设置,可以在这个文件中进行修改。
下面还有一个build的对象,它是在vue本地服务器启动时,打包的一些配置, 代码如下:
build: {
// Template for index.html
index: path.resolve(__dirname, '../dist/index.html'),
// Paths
assetsRoot: path.resolve(__dirname, '../dist'),
assetsSubDirectory: 'static',
assetsPublicPath: '/',
/**
* Source Maps
*/
productionSourceMap: true,
// https://webpack.js.org/configuration/devtool/#production
devtool: '#source-map',
// Gzip off by default as many popular static hosts such as
// Surge or Netlify already gzip all static assets for you.
// Before setting to `true`, make sure to:
// npm install --save-dev compression-webpack-plugin
productionGzip: false,
productionGzipExtensions: ['js', 'css'],
// Run the build command with an extra argument to
// View the bundle analyzer report after build finishes:
// `npm run build --report`
// Set to `true` or `false` to always turn it on or off
bundleAnalyzerReport: process.env.npm_config_report
}其中包括模版文件的修改,打包完目录之后的一些路径设置,gzip压缩等。明白了这些字段的意思之后,就可以在之后的开发中,主动根据项目需求,改动目录内容。
聊完config下的index.js文件,回到utils.js文件中,我们可以来看几个其中的方法,来分析它们分别起到了什么作用。
assetsPath方法
接受一个_path参数
返回static目录位置拼接的路径。
它根据nodejs的proccess.env.NODE_ENV变量,来判断当前运行的环境。返回不同环境下面的不同static目录位置拼接给定的_path参数。
cssLoaders方法
接受一个options参数,参数还有的属性:sourceMap、usePostCSS。
同时,这里用到了我们之前提到的extract-text-webpack-plugin插件,来分离出js中的css代码,然后分别进行打包。同时,它返回一个对象,其中包含了css预编译器(less、sass、stylus)loader生成方法等。如果你的文档明确只需要一门css语言,那么可以稍微清楚一些语言,同时可以减少npm包的大小(毕竟这是一个令人烦躁的东西)。
styleLoaders方法
接受的options对象和上面的方法一致。该方法只是根据cssLoaders中的方法配置,生成不同loaders。然后将其返回。
createNotifierCallback方法
此处调用了一个模块,可以在GitHub上找到,它是一个原生的操作系统上发送通知的nodeJS模块。用于返回脚手架错误的函数
一共这么四个函数方法,在utils中被定义到。
回看到webpack.base.conf.js文件中,我们可以直接跳过config目录下的index.js文件,之前已经分析过了。直接来看一下vue-loader.conf.js下的内容。
这个文件中的代码非常的少,我们可以直接贴上代码,然后来分析,其中的作用。代码如下:
'use strict'
const utils = require('./utils')
const config = require('../config')
const isProduction = process.env.NODE_ENV === 'production'
const sourceMapEnabled = isProduction
? config.build.productionSourceMap
: config.dev.cssSourceMap
module.exports = {
loaders: utils.cssLoaders({
sourceMap: sourceMapEnabled,
extract: isProduction
}),
cssSourceMap: sourceMapEnabled,
cacheBusting: config.dev.cacheBusting,
transformToRequire: {
video: ['src', 'poster'],
source: 'src',
img: 'src',
image: 'xlink:href'
}
}其中,主要就是根据NODE_ENV这个变量,然后分析是否是生产环境,然后将根据不同的环境来加载,不同的环境,来判断是否开启了sourceMap的功能。方便之后在cssLoaders中加上sourceMap功能。然后判断是否设置了cacheBusting属性,它指的是缓存破坏,特别是进行sourceMap debug时,设置成false是非常有帮助的。最后就是一个转化请求的内容,video、source、img、image等的属性进行配置。
具体的还是需要去了解vue-loader这个webpack的loader加载器。
分析了这么多,最终回到webpack.base.conf.js文件中
其实的两个方法,其中一个是来合并path路径的,另一个是加载Eslint的rules的。
我们直接看后面那个函数,createLintingRule方法:
其中,加载了一个formatter,这个可以在终端中显示eslint的规则错误,方便开发者直接找到相应的位置,然后修改代码。
之后的一个对象,就是webpack的基础配置信息。我们可以逐一字段进行分析:
看完这些,你或许对webapck.base.conf.js中的内容有了一些初步的了解。其实,看懂它还需要你了解webpack这个非常有用的打包工具。
之后,我们在来回看webpack.dev.conf.js这个文件
这个文件中,引用了webapck-merge这npm包,它可以将两个配置对象,进行合并。代码如下:
const merge = require('webpack-merge');
const devWebpackConfig = merge(baseWebpackConfig, {
...
}这样就合并了base中的webpack配置项。之后,我们可以来看一下dev环境中的新增了那些配置项,它们分别起到了什么作用?
首先,在module的rules中增加了cssSourceMap的功能
然后就是devtools,通过注释的英文翻译,可以知道cheap-module-eval-source-map使得开发更快。
之后,就是devSever的一些配置项了。其中包块客户端报错级别、端口、host等等
还有新增的plugins,我们可以来看一下实际新增的plugins(具体可以看webpack文档):
之后,还有一个函数,确保启动程序时,如果端口被占用时,会通过portfinder来发布新的端口,然后输出运行的host字符串。
这是打包到生产环境中,会被用到的文件。我们可以看到,它相对于之前的webapck.dev.conf.js文件少了一些插件,多了更多的插件。我们也可以和之前一样,通过它新增的一些东西,来知道它到底干了什么!(此处的新增是相对于webpack.dev.conf.js没有的内容)
新增了output的配置,我们可以看到它在output中新增了一些属性,将js打包成不同的块chunk,然后使用hash尾缀进行命名
添加了一些插件:
如果没有进行gzip压缩,调用CompressionWebpackPlugin插件进行压缩
这样,我们的webpack配置文件内容基本上就全部看完了。或许,会有点蒙,还是看官方文档来的实在。
最后,还需要分析一个build.js文件。
这个文件是在打包的时候,会被用到的。
首先,文件的开头请求了check-version.js中的函数,然后确定了一下node和npm的版本。相对于较低版本的node和npm,在打包过程中,会产生警告。之后,设置环境参数,设置成生产环境,之后就是一系列打包的流程。
本篇文章,主要总结了一下vue-cli生成的文件中,其中的一些配置参数和文件大致的作用。有不到位的地方,希望大家可以指正。同时希望我们共同进步,共勉。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦github博客
往往在移动端开发过程中,弹性布局是非常实用的一种手段。往往你并不需要去反复的使用媒体查询的。整整的响应式布局是使界面能够自动的根据屏幕进行变化,做到完美的弹性布局,在必要的时候,去使用媒体查询,对页面进行调整。本篇所讲述的正是,在移动端响应式布局当中被经过使用的一个东西flexbox(弹性盒子)
flex布局,被称为弹性布局。看懂flex可以从两个地方出发:容器和子项目。
何为容器,就是设定display为flex的地方。如图所示:
而容器内部的直接子项就是flex item,简称为项目。如图所示:
在清楚了flex的结构划分之后,我们还要牢记的是flex的轴线(axis)。正如坐标系,具备着x轴与y轴,flex在整个布局当中,也可分为水平方向和垂直方向,简称为主轴和交叉轴,如图所示:
整个图片上还有main start,就是项目到容器的开始位置,而main end,就是项目到容器结束的位置。同理,cross start和cross end就是交叉轴上面的开始和结束的位置。当然了,还有main size和cross size就是项目的水平距离和垂直距离。
分析完,这一部分,下面的东西是需要记忆和实践的。因为,往往在面试中提问flex也是针对于容器和项目的一些内部属性值展开的。
首先,我们来了解一下container的一些基本属性值
- display 表示容器展示的布局类型,可设定为flex和inline-flex。两者的设定也就是inline和block的区别。当然了,在webkit内核的浏览器(safari)中使用时,需要在其前面加上前缀(-webkit-flex)
.container{
display: -webkit-flex;
display: flex; /* or inline-flex*/
}
- flex-direction 表示容器内部子项目的展示方向。它主要有四个方向,如图:
而这四个方向也有四个值row,row-reverse,column,column-reverse。css的表示如下
.container{
flex-direction: row /* 默认 行正序*/ || row-reverse /*行倒序*/ || column /* 列正序*/ || column-reverse /*列倒序*/
}
- flex-wrap 表示当容器内部内容超出容器时,容器是否分行展示。
如图所示:
这个属性的值,有三种:nowrap(浏览器默认,不分行) 、wrap(超出的部分分行处理)、wrap-reverse(分行逆序).
.container{
flex-wrap: nowrap || wrap || wrap-reverse;
}
- flex-flow: 这个属性就是可以将上面两个属性合起来写的属性,
示例:
.container{
flex-flow: row wrap;
}
- justify-content: 表示容器内部的子项目的水平对齐方式。而水平的对齐方式主要有六种: flex-start、flex-end、center、space-between、space-around、space-evenly。
如图所示:
flex-start:对应的对齐方式是水平向左对齐。(浏览器默认)
flex-end:对应的对齐方式是水平向右对齐。
center:对应的对齐方式是居中对齐。
space-between: 对应的是,每个元素之间中间流出间隙是一样的,两边无间隙。
space-around:对应的是,每个元素周围的间隙是一样的,而不是元素之间的,因此,可以从途中看出两边的间隙会比中间小一半。
space-evenly:对应的是,每个元素之间的间隙大小一致。
使用示例:
justify-content: flex-start || flex-end || center || space-between || space-around || space-evenly
- align-items: 表示容器内部的子项目的垂直方向上的对齐方式。在垂直方向上的对齐方式有5种:flex-start、flex-end、center、stretch(浏览器默认)、baseline。
如图所示:
flex-start: 对应的对齐方式是垂直向上对齐。
flex-end: 对应的对齐方式是垂直向下对齐。
center:对应的对齐方式是垂直居中对齐。
stretch:对应的对齐方式是将整个子项目的长度拉伸到最大块的高度(浏览器默认)
baseline: 对应的对齐方式是子项目内部的文字基线对齐。
使用示例:
.container{
align-items: flex-start || flex-end || center || stretch || baseline;
}
- align-content: 表示在对行的情况下,每行所对应的垂直方向上的对齐方式。主要有六种对齐方式:flex-start、flex-end、center、stretch、space-between、space-around。
如图所示:
flex-start:对应的是每一行在垂直方向上向上对齐的方式
flex-end:对应的是每一行在垂直方向上向下对齐的方式
center:对应的是每一行在垂直方向上居中对齐的方式
stretch:对应的是每一行延展到铺满整个垂直方向。
space-between:对应的就是每行之间留有空隙,而两边没有空隙
space-around:对应的就是每行周围的空隙均相等
container的属性就是上述的7种,只要熟练的掌握这些属性,就能对整体容器进行一个基础的布局了。当然了,要改变内部子项目时,还得需要搞清楚子项目上面的几个属性。
下面,我们就来分析分析内部的子项目属性,可分为以下几个部分:
在css中的使用为:
order: <integer> //如1在css中的使用:
flex-grow: <integer> /默认为0/3, flex-shrink:表示子项目的伸缩
在css中的使用:
flex-shrink: number /*default to 1*/在css中的使用:
flex-basis:<length> | auto /*default auto*/在css中的使用:
flex: <flex-grow> <flex-shrink> <flex-basis>如图所示:
它的值也和align-items一样,flex-start、flex-end、center、stretch、baseline还有auto。默认为auto,即为容器的排列方式。
align-self: auto | flex-start | flex-end | center | stretch | baselineflex的一些基础内容基本上都已经总结完成了,但是对于flex布局的认识其实还应该更深入一点,这些都得从平时的练习当中来锻炼自己。
数据结构,是学习编程的基础。如果说人是由脑子和身体组成的话,无疑地,数据结构就可以类比为程序的身体,而算法是脑子。
本篇将对本人学过的数据结构做一个细节化的总结。对于一个学前端的人来说,其实javascript在实现部分数据结构时,已经非常完善了。至少只说数组、栈、队列的话,js只需要一个数组就能全部实现了。因此,js的数组性能比其他语言差,它是一个对象。所以,本篇主要探讨链表、树、图这么三大块的数据结构内容。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
微信小程序从今年开始,正式可以给个人开发。最开始,趁着寒假的时间,尝试开发了一个投票系统。当时的微信小程序还有些许的不完整。因此,搁置了非常长的时间,但是,从现在开始,似乎它的生命力越来越强劲,同时,在工作中也开始需要去开发小程序。因此,开始写小程序的学习笔记。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
vue,在2017已经不是什么新鲜词了!作为一个前端学习者,今天写下学习总结。
本篇主要是一些vue的学习总结。开始写的原因——也是工作中,对于它的使用,逐渐增多了。并且也觉得是时候做一个总结。其实,我也算是三大框架的使用者啦!!!从最早期的angular,中期的react,直至vue。那么,就此开始做一个总结。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
其实,我并不知道从何开始去总结vue,因为vue的官方文档,可谓“中文开发者”的福音,实在是太全了!再次致敬悠大大。那么,我们废话不多说,还是从基本的东西说起——对象。
相信看了文档的小伙伴,都会意识到Vue具备一个Vue的构造函数。如果使用ES5的语法来书写vue时,我们往往可以看到以下的实例:
var app = new Vue({
//....
});在其中配置各种的参数,例如:
当然咯,还会有其他的属性,例如components等等。具体的可以看官方文档。
此处,我们引出了对象,那么我们就从vue的响应式原理讲起吧。Vue的**可以说是从angular1.x开始衍生出来的,元素的基因,让他具备了一些轻便的指令。当然,从react中,它借鉴了VDOM等**。那么,你是否考虑过它的响应式原理。
它同React一样,属于数据驱动型框架,它们均有一个范式:F(data) = view。同时,react可以通过setState这个关键方法达到这样子的效果,那么,Vue呢?Vue是如何实现的呢?
答案——「数据劫持」。其实,从ES5开始,对象就可以通过一个API来定义属性,如下:
var obj = {};
Object.defineProperty(obj, 'name', {
value: 'zimo'
});
console.log(obj.name);这里可以看到,我们通过这样子的方式也可以定义对象的属性。所以Vue在获得data中的内容之后,会将其中的数据,通过这样子的形式定义到Vue对象上面。然后,我们通过set和get方法的监听,来劫持数据,我们可以通过一个例子来说明:
var obj = {};
Object.defineProperty(obj, 'name', {
get: function(){
console.log('get');
return val;
},
set: function(value){
console.log('set');
val = value;
}
});
obj.name = 'zimo'; //'set'
console.log(obj.name); //'get', 'zimo'看过例子之后,我们会发现这defineProperty的API中使用set和get方法时,可以对对象数据进行劫持。这种效果,就可以达到setState的效果。
注:vue中,必须保证数据驱动的数据保证在对象创建时设置,即在data中设置。这样才可以达到数据劫持的效果。
官网原话:值得注意的是只有当实例被创建时 data 中存在的属性是响应式的
但是,你会觉得这种方式是完美的吗?当然不是,我们可以来看一个例子(该例子通过上面改编的):
var obj = {};
Object.defineProperty(obj, 'name', {
get: function(){
console.log('get');
return val;
},
set: function(value){
console.log('set');
console.log(value);
val = value;
}
});
obj.name = ['zimo'];
obj.name[0] = 1;
console.log(obj.name);
// "set"
// ["zimo"]
// "get"
// "get"
// [1]这个例子中发生了什么你一定好奇?或者说,你已经看出来了!那么我们直接说吧!
这里的obj.name[0]=1表达式并没有触发setter的函数。不信的话,你可以亲自动手尝试一下。相信只有亲自动手才会使得记忆深刻一些。
数组通过索引的方式去改变数据,适合并不会触发setter进行数据劫持。这个问题在早期的vue中的确存在。当然了,这么严重的问题,自然是会被解决的。相信熟悉ES6的人都知道,ES6中具备一个非常好的特性可以解决这个问题——proxy。每次就是数据代理,这种方式,可以在上述方法的基础上,进一步解决我们之前提到的缺点。
那么,关于proxy的问题,我在此处并不会做深入分析。
上面我们大致搞清楚了vue的数据响应原理,那么data中的数据一旦发生变化,除了数据劫持发生之外,总该谈谈生命周期的话题了。
生命周期,就是一个组件,或是一个对象的存在时期。从最初的创建、安装、更新、卸载。我们可以通过官网的图来实际说明:
这幅图中,清晰地讲明了,vue组件地从构造函数建立到销毁地全过程。
既然我们知道了vue是由对象组成的,那么,我们往往会有些方法,并不仅仅是在一个Vue对象中使用的,举个例子:
我需要在vue中使用图表highchart,那么我可以做如下的操作:
import Highchart from 'highchart';
Vue.prototype.$highchart = Highchart;
const app = new Vue({
methods: {
init: function () {
this.$highchart() //...
}
}
})当然了,我们只是举了一个通俗的例子,通过这样子的方式,你就可以在Vue对象中新增许多原型方法,但是,需要记得的是——在方法定义时,请带上'$'符号,方便进行区分。
vue2.0是一个大版本的更迭,同时它的改变,使得越来越多的人喜欢使用它。它在这个版本中,引入了VDOM的概念。相信接触过React的小伙伴们,对VDOM这个概念应该一点也不陌生吧。
不得不说地是这样的改变,使得vue的性能得到了极大的提升。尤其是像diff算法的优化,react中体现地淋漓尽致。获取可以看我的另一篇文章——react diff算法。
关于vue的东西,其实还有很多。作为可以与react、angular并驾齐驱的三架马车。它的优越之处在于总结了angular1.0的失败之处,综合了react的优雅之点。同时,它也深深地嵌入了尤大大的个人智慧。同时,为前端程序员提供了良好的学习环境。本篇浅入浅出vue.js到此结束。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
ES6时代的来临,使得类继承变得如此的圆滑。但是,你有思考过ES6的类继承模式吗?如何去实现它呢?
类继承对于JavaScript来说,实现方式与Java等类语言大不相同。熟悉JavaScript的开发者都清楚,JavaScript是基于原型模式的。那么,在es6没有出来之前,js是如何继承的呢?这是一个非常有意思的话题。希望带着疑问看文章,或许对你的提升会更加巨大。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
其实,js模拟一个类的方式非常的简单——构造函数。或许,这是所有人都在普遍使用的方式。我们先来看一个例子:
function Person(name){
this.name = name;
}
Person.prototype.sayName = function(){
console.log(this.name);
}
const person = new Person('zimo');
person.sayName(); //zimo这里通过构造函数模拟出来的类,其实和其他语言的类行为上是基本一致的,唯一的区别就是它不具备私有方法。而且,他们同样是通过new操作符来进行实例化的,但是js的new操作与其它语言的new操作又会有所不同。比方说:
const person = Person('zimo');
console.log(person) //undefined构造函数前面没有加new的情况下,会导致这个对象没有返回值来进行赋值。但是,在类语言中,在类名前不使用new是会报错的。
下面,我们应该进一步来看一下js的new操作符的原理,以及实现。
new方法原理:
js代码实现部分:
const person = new Person(args);
//相当于
const person = Person.new(args);
Function.prototype.new = function(){
let obj = new Object();
obj.__proto__ = this.prototype;
const ret = this.apply(obj, arguments);
return (typeof ret == 'object' && ret) || obj;
}到此为止,js如何去模拟类,我们已经讲述完了。接下来,我们应该看一下如何去实现类似与其他语言的类继承模式。
尽管ES6已经对extends关键词进行了实现,但是原理性的知识,我们应该需要明白。
先来看一个场景,无论是狗或者是猫,它们都有一个共同的类animal,如图:
在真实开发中,我们必须去实现类与类之间的继承关系,不然的话,我们就必须重复地去命名构造函数(这样的方式是丑陋的)。
所以,像上述的场景,开发过程中多的数不胜数,但是本质都是不变的。接下来,那我们以一个例子来做说明,并且明白大致是如何去实现的。
例子:我们需要去构造一个交通工具类,该类具备属性:轮子、速度和颜色(默认为黑),它还具备方法run(time)返回距离。之后,我们还需要去通过该类继承一个‘汽车’类和一个‘单车’类。
如图:
实现:
function Vehicle(wheel, speed){ //首先构造一个交通工具类
this.wheel = wheel;
this.speed = speed;
this.color = 'black';
}
Vehicle.prototype.run = function(time){ //在它的原型上定义方法
return this.speed * time;
}
function Car(wheel, speed, brand){ //通过在汽车类中去调用父类
Vehicle.call(this, wheel, speed);
this.brand = brand;
}
Car.prototype = new Vehicle(); //将汽车类的原型指向交通工具的实例
function Bicycle(wheel, speed, owner){ //同样,构造一个自行车类,在其中调用父类
Vehicle.call(this, wheel, speed);
this.owner = owner;
}
Bicycle.prototype = new Vehicle(); //将其原型指向交通工具实例
const car = new Car(4, 10, 'baoma');
const bicycle = new Bicycle(2, 5, 'zimo');
console.log(car.run(10)); //100
console.log(bicycle.run(10)); //50这样子,就实现了类的继承。
大致的思路是:在继承类中调用父类,以及将继承类的原型赋值为父类的实例。
但是,每次实现如果都是这样子的话,又会显得非常的累赘,我们并没有将可以重复使用的部分。因此,我们需要将不变的部分进行封装,封装成一个方法,然后将可变的部分当中参数传递进来。
接下来,我们来分析一下类继承的封装方法extend。
首先,我们来看一下,我们需要实现怎样的继承:
function Animal(name){ //构造一个动物类
this.name = name;
}
Animal.prototype.sayName = function(){
console.log('My name is ' + this.name);
}
/**
extends方法其中包含子类的constructor、自身的属性、和来自父元素继承的属性
*/
var Dog = Animal.extends({ //使用extends方法来实现类的封装
constructor: function(name, lan){
this._super(name);
this.lan = lan
},
sayname: function(){
this._super.sayName();
},
sayLan: function(){
console.log(this.lan);
}
});
var animal = new Animal('animal');
var dog = new Dog('dog', '汪汪汪');
animal.sayName(); //My name is animal
dog.sayName(); // My name is dog
dog.sayLan(); // '汪汪汪'其中的extend方法是我们需要去实现的,在实现之前,我们可以来对比一下ES6的语法
class Animal {
constructor(name){
this.name = name;
}
sayName(){
console.log('My name is ' + this.name);
}
}
/**
对比上面的extend封装和es6的语法,我们会发现,其实差异并没有太大
*/
class Dog extends Animal{
constructor(name, lan){
super(name);
this.lan = lan;
}
sayName(){
super.sayName();
}
sayLan(){
console.log(this.lan);
}
}其实,很多地方是相似的,比方说super和this._super。这个对象其实是看起来是父构造函数,因为他可以直接调用this._super(name),但它同时还具备父构造函数原型上的函数,因此我们可以把它称为父包装器。但是,必须保证的是_super中的函数对象上下文必须都是指向子构造函数的。
使用一张简陋的图来表示整个关系的话,如图:

下面我们来实现一下这个extend方法。
Function.prototype.extend = function(props){
var Super = this;
var Temp = function(){};
Temp.prototype = Super.prototype;
var superProto = new Temp(); //去创建一个指向Super.prototype的实例
var _super = function(){ //创建一个父类包装器
return Super.apply(this, arguments);
}
var Child = function(){
if(props.constructor){
props.constructor.apply(this, arguments);
}
for(var i in Super.prototype){
_super[i] = Super.prototype[i].bind(this); //确保Super的原型方法拷贝过来时,this指向Child构造函数
}
}
Child.prototype = superProto; //将子类的原型指向父类的纯实例
Child.prototype._super = _super; //构建一个引用指向父类的包装器
for(var i in props){
if( i !== 'constructor'){
Child.prototype[i] = props[i]; //将props中方法放到Child的原型上面
}
}
return Child;
}继承的一些内容就分析到这里。其实,自从ES6标准出来之后,类的继承已经非常普遍了,因为真心好用。但是,也是越来越有人不懂得如何去理解这个继承的原理了。其实ES6中的继承的实现,也是挺简单的。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
接触过react的人应该对redux并不陌生。但是,redux并不是react的伴生产物,即使你使用其他类库,也可以使用redux框架来管理状态,但是,有react如此好的选择,没人会考虑其他的技术选型。但是,多多少少还是会有人误解redux。
redux框架在使用过程中有三个原则:
唯一的状态树(数据源)
The first principle of Redux is whether your app is a really simple one like this counter example, or a complex application with a lot of UI, and change of state, you are going to represent the whole state of your application as a single JavaScript object.
这是react作者的原话。译文则是:
Redux的第一原则是无论你的应用是一个像计数器一样简单的应用,或者是有大量UI的复杂组件,但去改变状态时,你都应该将整个应用的状态表示成一个单一的JavaScript对象。
这也是它与flux不同的地方,flux使得整个程序拥有多个store对象,而在多个store对象之间依赖时,需要使用waitFor去进行控制,redux轻松的解决了这一缺点。
状态树是只读的
作为一个状态管理的框架,将状态放在状态树中进行严格控制,这样可以形成一个单向数据流,使得整个项目便于维护。
那对于一个数据驱动的框架,如果不能改变state,那如何去进行变化呢。在redux中有着action这么一个概念。store对象通过dispatch来进行行为的分发,以此来修改每一次chang。
使用一个纯函数
纯函数这个概念,或许你没听说过,或许你已经深入理解。不过没关系,我们先来了解一下他的反义词impure function。不纯函数,听起来怪别扭的,叫他普通函数吧。何为普通函数,来看一下,下面的例子:
function square(x){
updateDatabase(x);
x = x*x
return x;
}这里的函数做了两件事情,一件更新数据库,以及返回参数的平方。为何说它不是纯函数呢,主要是因为函数在执行过程中执行了类似于更新数据库,或者调用其他函数的过程。真正的纯函数需要满足几个条件:
function square(x){
return x*x;
}而在redux中,需要你去创建一个纯函数,称之为reducer。传入的参数为上一个状态和行为,返回值为下一个新状态。
在使用redux的过程中,应该使用记住这三个原则,才能使得开发出来的程序,风格更加的严谨。
2017年的秋招,截至今天已经有了三场面试,接下来的篇幅,主要会对面试题做一下总结,为自己接下来的面试打一下基础,积累一些运气。
这是本次秋招的第一次内推面试,面试官挺温和的。面试总时长在45分钟左右,前面大约5分钟做了一些自我介绍,下面进入正题。
1. js的事件,事件流,以及事件委托的理解
原生的js可以通过addEventListener的函数来为元素增加监听事件,在IE上会使用attachEvent来增加元素的监听事件,当然,还有最原始的写法通过onClick类似的方式来为元素增加监听事件。
js中的事件流可以分为两种事件冒泡和事件捕获。两种最主要的区别是,事件冒泡是从最具体的元素开始向外层传递事件,而事件捕获是从外层开始,像里层元素传递事件。现在主要使用的是事件冒泡的事件流机制。
事件委托,就是一个元素将监听事件的请求委托给其他的元素,使用的是事件冒泡的机制。最常见的就是子元素将监听事件挂在到父元素上,然后当点击子元素的时候,由于事件冒泡,最终会在父元素上触发监听函数,然后执行子元素的回调函数。这样做的好处,就是可以避免在每个子元素上都去挂载监听事件。坏处是有些事件没有冒泡机制,如focus、blur,就无法使用事件委托的方式,还有像一些事件mousemove、mouseout只能通过位置去计算定位,性能消耗太大,不适宜使用事件委托。
2. jquery的链式写法的原理
其实对于链式的这种写法,最终返回的都是自身的对象,即return this;举另一个例子Rxjs,它的使用也是链式的写法,而它的实现方式,也是每次操作一种函数操作完之后,就返回一个Observable对象。或许,这个例子举的不是特别形象,因为一个是函数式的编程,而另一个并不是。但是,其实某些原理性的东西还是相似的。
3. 对于跨域的理解(面试必问)
主要是将如何造成的,以及如何解决。其实跨域这个问题,我们平时做项目的时候也会遇到,造成的原因就是浏览器的同源策略。同源策略规定不同域下面的脚本资源,在未经授权的前提下,不能对其他域的资源进行修改。所谓的同源,指的是协议、域名、端口相同的。
使用最频繁的两种方式是jsonp和CORS。首先,来理解一下第一种jsonp。jsonp的原理就是通过script标签的src接受后端发送的资源,然后通过对约定好的回调函数的调用将资源导入进来。这个方法的优点就是使用起来方便快捷,而且简单,但是缺点也比较明显,只能对GET请求起作用。之后是CORS的原理。CORS,即在http响应头中添加一个属性Access-Control-Allow-Origin,并且在它的后面加上运行访问的ip以及端口,或者使用*表示都允许。
4. web存储
最初,web存储的方式就是cookie。通常,开发者会在其中存储一些用户的信息数据,存储的大小是在4kb以下,4kb以上的cookie会被浏览器自动丢弃。cookie在使用过程中,往往有很多的缺点:1. 存储大小有限 2. 客户端不同域下cookie的数量也是有限的 3. 每次存储的数据都会向服务端发送,而往往存储的数据并不需要如此 4. cookie本身的不安全性,很容易导致信息的泄漏和盗取。
html5提出了新的数据存储的方式localstorage和sessionstorage。localstorage和sessionstorage本身都是客户端的存储。可存储大小在50M左右。localstorage的存储是持久型的,除非手动对数据进行清除,否则,数据将会被一直保留。sessionstorage的存储会在浏览器关闭的时候,被清除掉。
5. 继承
6. 闭包
闭包是js内部函数对外部函数作用域的引用。而在外部作用域使用函数作用域的变量是闭包的一种实现。闭包的用法,往往在模块的使用中较为突出。通常,封装好的模块,都会将一部分内部变量通过闭包的形式,导出到外部,给外部的函数使用。
7. ES6的特性
在ES6方面,主要问了一下generator的使用。generator,即生成器,通常会用来写迭代器,以及异步转化成同步写法时的使用。迭代器的原理,往往也就是给Symbol.iterator的属性值,赋值一个generator的生成器,然后使用next()进行一步一步的迭代。而异步方面,generator往往可以配合回调函数,将值赋给当前步骤的变量,方便在下一步骤中调用。通常也会和promise进行结合,来完成一系列的异步操作。
apply、call和bind的区别
问了一下,这么三个函数的作用是什么?这么三个函数的作用就是调整上下文,即this的指向。在js中,this的指向是琢磨不定的,往往有四条规律可以总结它,
- 在全局空间中调用函数,this往往会指向window,而在严格模式下,会指向undefined。
- 在对象的方法中调用this,往往会指向该对象,但是这种方式很容易造成this的隐性丢失
- 显示调用,即使用apply、call、bind等对this进行显式指向,this会指向指定的元素。
- new构造函数时的this,会指向新生成的实例。
在讲讲它们之间的区别:
apply和call的区别是,apply只接受两个参数,一个是this的指向参数,另一个则是数组类型的参数;而call后面可以接受多个参数。
bind和前两者的区别就是bind绑定完之后,函数并不直接运行,并且bind的绑定是硬绑定,无法被修改;而前两者绑定完之后,直接调用函数。
css盒子模型
这个感觉是前端面试基础面必问的题目。盒子模型,即在DOM元素中,元素呈现矩形的盒子。盒子模型主要可分为四部分:content、padding、border和margin。盒子模型也主要分为两类,一类是W3C标准的盒子模型,另一类是早期的IE浏览器下的盒子模型。主要的区别是:W3C标准的盒子模型的width长度是等于内容的长度,并不包含padding和border部分。而IE下的盒子模型包含了content+padding+border的部分。
渐进增强和优雅降级
首先,何为渐进增强,何为优雅降级。这两种方式是实现浏览器界面时的一种选择,对于不同的浏览器版本而言,如果同样的代码,呈现的效果是不同的,因此需要这两种方式进行填补。渐进增强,指的是现在低版本浏览器上面实现基础的功能,然后在给高版本浏览器添加更好的功能。而优雅降级则是将实现思路相反了一下,先在高版本浏览器上面实现响应的功能,然后通过一些补充的方式,在低版本浏览器中将界面尽量的实现完全。
清除浮动的方式
其实,清除浮动的方式有三种。首先,谈的是最实用的一种方式,就是after的伪类,在父元素块上添加after伪类,然后将after伪类中的content设置为空,之后是display设置为block,clear设置为both。
.clearfix:after{
content: '';
display: block;
clear: both;
}
.clearfix{
zoom:1;
}这是第一种方式,也是最简单的方法。第二种,就是在父元素后面添加一个clearfix的块,进行浮动的清除.
<div class="parent">
<div class="child"></div>
</div>
<div class="clearfix"></div>
<div class="parent1"></div>.parent{
width: 100%;
position: relative;
border: 1px solid black;
}
.clearfix{
clear: both;
display: block;
}
.parent .child{
float: left;
width: 100px;
height: 100px;
background: red;
}
.parent1{
width: 200px;
height: 200px;
background: yellow;
}这种方式并不好,而且会导致标签混乱,让人无法理解。还有一种方法就是,在父元素中将overflow设置为hidden,这种情况往往会将一些溢出的部分隐藏,而达不到预期的效果。
阿里的一面覆盖面比较广,当然也问了一些http协议和缓存的问题,我会将我在面试中有疑问的地方,单独拿出来详细的分析,顺便帮助自己巩固。有http缓存优化,flex布局及其兼容性,js引擎和js模块等。
临近2017的尾声,总是希望来盘点一下这一年中前端的发展。到目前为止,前端的井喷期也快临近尾声了。并不像几年前一样,总是会有层出不穷的新东西迸发出来。同时,前端技术也慢慢的趋于稳固,自成一套体系。
我们何处说起?自然是离不开那三驾马车。
自从2015年,react的问世,开始了三驾马车时代的先河。同时,jQuery也逐渐让出了其霸主的地位。后续的,angular开始了大型的改版,似乎想要追逐react的步伐。两种完全不同思路的体现,在前端开发的技术栈中发光发亮。同时,Vue就像一匹黑马一样,一路披荆斩棘,快速地进步着。
因此,从2017年开始,3架马车可以说是并驾齐驱。似乎需要看些对比数据,来表示它们目前的现状。(来自国外的数据)
可以看到react的深紫色是最多的,表示用户对于react还是十分满意的。虽然,早前的React收到了协议的影响,但是,这似乎并不影响它在开发者心目当中的地位。另外,react如此受欢迎的另一个重要原因就应该是React Native了吧。今年以来,React Native一直以两周一次的小版本更迭周期,迅速发展着。或许,2018年将会迎来最重大的正式版本1.0。(这个还是值得期待的。)
对于大多数开发者而言,学习了React的时候,对于它们学习React Native是有直接性质的帮助的,所以一般的国外开发者不会拒绝学习React这个框架的。
介绍完,React的情况,我们或许可以回望一下Angular的情况吧。
Angular可以说是一个最早问世的MVVM的框架。2009年,angular像一枚重磅炸弹一样,震撼了前端的开发者们。当时,W3C似乎还未推出正式的Web Component标准。React和Vue也还在襁褓之中安眠。可想而知,之后的几年Angular一直影响着后续前端的发展。但是,Angular有着许许多多的问题,也使得它在后续的框架之争中,处于下风。2016年9月正式推出的angular2,将angular引领向了另一种形式——以HTML为中心的框架。一套完整的体现,其中加入了TypeScript+RxJS等组合,可想而知,一套内容的学习成本相当之高,与React以JS为中心的**完全不同。不过似乎这一次Google将框架的定位目标换成了企业,国内外在使用这套框架的往往是银行、证券类企业。不过,它的发展还是被看好的,毕竟它的背后可都是一群Google的顶尖开发工程师呢!!
最后,我们来了解一下三驾马车中的黑马——Vue。
从第一张图中,虽然React一直处于领导地位,但是,Vue2的使用,也将于其他两个框架持平快了。毕竟,在国内的前端环境中,Vue可以说是非常受欢迎的。(据说印度开发前端,会用Angular,**人开发前端,会用Vue)不得不说的是,Vue与Weex的结合,虽然体验不及RN,但是有着阿里的技术支持,也将有希望突破吧。
如果在国外,你今年听到的热词一定会有PWA这个东西。前不久,Safari已经开始支持PWA了,那么也就意味着PWA的时代不会太远了。当然,国内实践PWA的公司也不占少数,例如饿了么、阿里等。从去年开始,对其有所耳闻,到今年Google开发者大会上的现场演示,相信更多的开发者对于这门技术的狂热。对于国内开发者而言,唯一不好的优势应该就是文档了。因为目前来说,大部分的文档都是以英文的形式存在于GitHub或者国外书籍中的。翻译过来的书,也不会这么快的速度问世,所以目前研究PWA的中文资料少之又少。
不过相信,它的发展在之后的一两年的是强而有力的。
今年,在国内会被称为“小程序年”。从1月份开始,微信正式将公测了小程序。继而在7月份开始,支付宝也推出了相应的小程序。在国内,这样子的重大消息是不容忽视的。两大巨头之争,推动的是无与伦比的流量红利。基于小程序的开发,也将成为国内的前端的一大重点。将原用的整体化的内容,逐步分割成一个个小的模块,将至放入到微信这个大环境中去分享,最后起到一个引流的效果。回到技术的成面,小程序或许会有着与PWA一样的**,将之前在移动端难以为继的Web端,放入到自家应用中,来确保它的长久与稳定。更多的是说,这两者起到了异曲同工的效果。同样的,这项技术,将在2018年持续发展下去,同时,也会有更多的前端投入到这项开发中去。
这项技术,也是从上半年开始有所耳闻的。主要是作为react库的衍生物的形式出现的。它将css部分的代码以js的形式展现在代码中,那么之后只需要开发js就可以完成整个应用的开发了。同时,它还有一个好处,它的样式是基于组件的,所以可以做到复用,同时,往往js的变量在css中去使用时,是一个令人头疼的问题。而styled-components很好的解决了这个问题,因为它本身就是在组件中开发样式,js的变量依然可以被使用在css的部分代码中。这项技术也是可期的,因为越来越多的人在自己的react项目中开始了这项技术的尝试。
这是啥?没错,又有一个模块打包工具来了。或许,大家熟知的更多的是webpack这个模块打包工具。今年的4月份,React做了一个大动作——在React的主分支上合并了一个PR,将当时的构建工具换成了Rollup。可想而知,这个东西将会是多么的重要。好奇的是,它与其他的不同之处吧!它是一款基于ES2015模块进行打包的打包器。在过去的打包工具(包括webpack在内)中,都是基于CommonJS的规范去进行模块的打包的,所以,过去很多库的前面总是会有一大堆webpack等自家的逻辑填充在开头。Rollup不同,他是后天生的,出生的基准点就表明它的高度将不限于此。但是,相对于巨头webpack来说,它或许在今年并未体现出它的优势,但是相信它会厚积薄发的。
建议:在开发应用时,使用webpack,在开发库时,可以考虑Rollup。
这个东西,或许在国内鲜有闻之。但是,它仍是一项不错的技术,同时在调查中,也体现出不俗的潜力,如图:
它是有Facebook开发的一款API查询语言,或将替代Rest在后端的地位。虽然,目前来说,其性能并不是特别的优秀,也会bug不断。但是,2018年或将是GraphQL的一年。那么,和前端又有什么关系呢?别忘了,我们手里还有一个利器NodeJS呢!能够用好它,对于你开发nodeJS,或许使用便利。
这一项由微软老大开发的语言,处处在弥补着JavaScript的缺陷。一出生,就打着“取代JavaScript”的旗号,发展的速度也是惊人的。当然了,W3C也在努力的推进着JavaScript的进步,之后的几年,应该会是着两门语言并驾齐驱的发展吧。因为开发人口众多,不可能走到谁取代谁的地步。
最后,贴出一张Stackoverflow上面的一项数据统计表吧!
图片来源:I just asked 23,000 developers what they think of JavaScript. Here’s what I learned.
我们盘点了一年以来前端的发展,有着不错新技术不断被推出着,相信前端会发展的越来越好。因为在JSConf大会上,有人发言说,之后将会发展成“前端+云端”的组合。那么,也并不存在全栈类开发的说法了。前端开发的小伙伴加油吧!!我们共勉
如果你对我的文章感兴趣的话,欢迎关注我的微信公众号。
排序算法可能是你学编程第一个学习的算法,还记得冒泡吗?
当然,排序和查找两类算法是面试的热门选项。如果你是一个会写快排的程序猿,面试官在比较你和一个连快排都不会写的人的时候,会优先选择你的。那么,前端需要会排序吗?答案是毋庸置疑的,必须会。现在的前端对计算机基础要求越来越高了,如果连排序这些算法都不会,那么发展前景就有限了。本篇将会总结一下,在前端的一些排序算法。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
首先,我们可以先来看一下js自身的排序算法sort()
相信每个使用js的都用过这个函数,但是,这个函数本身有些优点和缺点。我们可以通过一个例子来看一下它的功能:
const arr = [1, 20, 10, 30, 22, 11, 55, 24, 31, 88, 12, 100, 50];
console.log(arr.sort()); //[ 1, 10, 100, 11, 12, 20, 22, 24, 30, 31, 50, 55, 88 ]
console.log(arr.sort((item1, item2) => item1 - item2)); //[ 1, 10, 11, 12, 20, 22, 24, 30, 31, 50, 55, 88, 100 ]相信你也已经看出来它在处理上的一些差异了吧。首先,js中的sort会将排序的元素类型转化成字符串进行排序。不过它是一个高阶函数,可以接受一个函数作为参数。而我们可以通过传入内部的函数,来调整数组的升序或者降序。
sort函数的性能:相信对于排序算法性能来说,时间复杂度是至关重要的一个参考因素。那么,sort函数的算法性能如何呢?通过v8引擎的源码可以看出,Array.sort是通过javascript来实现的,而使用的算法是快速排序,但是从源码的角度来看,在实现上明显比我们所使用的快速排序复杂多了,主要是做了性能上的优化。所以,我们可以放心的使用sort()进行排序。
冒泡排序,它的名字由来于一副图——鱼吐泡泡,泡泡越往上越大。
回忆起这个算法,还是最初大一的c++课上面。还是自己上台,在黑板上实现的呢!
思路:第一次循环,开始比较当前元素与下一个元素的大小,如果比下一个元素小或者相等,则不需要交换两个元素的值;若比下一个元素大的话,则交换两个元素的值。然后,遍历整个数组,第一次遍历完之后,相同操作遍历第二遍。
图例:
代码实现:
const arr = [1, 20, 10, 30, 22, 11, 55, 24, 31, 88, 12, 100, 50];
function bubbleSort(arr){
for(let i = 0; i < arr.length - 1; i++){
for(let j = 0; j < arr.length - i - 1; j++){
if(arr[j] > arr[j + 1]){
swap(arr, j, j+1);
}
}
}
return arr;
}
function swap(arr, i, j){
let temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
console.log(arr);性能:
改进:
我们可以对冒泡排序进行改进,使得它的时间复杂度在大多数顺序的情况下,减小到O(n);
const arr = [1, 20, 10, 30, 22, 11, 55, 24, 31, 88, 12, 100, 50];
function swap(arr, i, j){
const temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
for(let i = 0; i < arr.length - 1; i++){
let flag = false;
for(let j = 0; j < arr.length - 1 - i; j++){
if(arr[j] > arr[j+1]){
swap(arr, j, j+1);
flag = true;
}
}
if(!flag){
break;
}
}
console.log(arr); //[ 1, 10, 11, 12, 20, 22, 24, 30, 31, 50, 55, 88, 100 ]const arr = [1, 20, 10, 30, 22, 11, 55, 24, 31, 88, 12, 100, 50 ,112];
function swap(arr, i, j){
let temp = arr[i];
arr[i] = arr[j];
arr[j] = temp
}
function improveBubble(arr, len){
for(let i = len - 1; i >= 0; i--){
let pos = 0;
for(let j = 0; j < i; j++){
if(arr[j] > arr[j+1]){
swap(arr, j, j+1);
pos = j + 1;
}
}
len = pos + 1;
}
return arr;
}
console.log(improveBubble(arr, arr.length)); //[ 1, 10, 11, 12, 20, 22, 24, 30, 31, 50, 55, 88, 100, 112 ]选择排序,即每次都选择最小的,然后换位置
思路:
第一遍,从数组中选出最小的,与第一个元素进行交换;第二遍,从第二个元素开始,找出最小的,与第二个元素进行交换;依次循环,完成排序
图例:
代码实现:
const arr = [1, 20, 10, 30, 22, 11, 55, 24, 31, 88, 12, 100, 50];
function swap(arr, i, j){
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function selectionSort(arr){
for(let i = 0; i < arr.length - 1; i++){
let index = i;
for(let j = i+1; j < arr.length; j++){
if(arr[index] > arr[j]){
index = j;
}
}
swap(arr, i, index);
}
return arr;
}
console.log(selectionSort(arr)); //[ 1, 10, 11, 12, 20, 22, 24, 30, 31, 50, 55, 88, 100 ]性能:
时间复杂度:平均时间复杂度是O(n^2),这是一个不稳定的算法,因为每次交换之后,它都改变了后续数组的顺序。
空间复杂度:辅助空间是常数,空间复杂度为O(1);
插入排序,即将元素插入到已排序好的数组中
思路:
首先,循环原数组,然后,将当前位置的元素,插入到之前已排序好的数组中,依次操作。
图例:
代码实现:
const arr = [1, 20, 10, 30, 22, 11, 55, 24, 0, 31, 88, 12, 100, 50 ,112];
function insertSort(arr){
for(let i = 0; i < arr.length; i++){
let temp = arr[i];
for(let j = 0; j < i; j++){
if(temp < arr[j] && j === 0){
arr.splice(i, 1);
arr.unshift(temp);
break;
}else if(temp > arr[j] && temp < arr[j+1] && j < i - 1){
arr.splice(i, 1);
arr.splice(j+1, 0, temp);
break;
}
}
}
return arr;
}
console.log(insertSort(arr)); //[ 0, 1, 10, 11, 12, 20, 22, 24, 30, 31, 50, 55, 88, 100, 112 ]性能:
其实,三个算法都是难兄难弟,因为算法的时间复杂度都是在O(n^2)。在最坏情况下,它们都需要对整个数组进行重新调整。只是选择排序比较不稳定。
快速排序,从它的名字就应该知道它很快,时间复杂度很低,性能很好。它将排序算法的时间复杂度降低到O(nlogn)
思路:
首先,我们需要找到一个基数,然后将比基数小的值放在基数的左边,将比基数大的值放在基数的右边,之后进行递归那两组已经归类好的数组。
图例:
原图片太大,放一张小图,并且附上原图片地址,有兴趣的可以看一下:
代码实现:
const arr = [30, 32, 6, 24, 37, 32, 45, 21, 38, 23, 47];
function quickSort(arr){
if(arr.length <= 1){
return arr;
}
let temp = arr[0];
const left = [];
const right = [];
for(var i = 1; i < arr.length; i++){
if(arr[i] > temp){
right.push(arr[i]);
}else{
left.push(arr[i]);
}
}
return quickSort(left).concat([temp], quickSort(right));
}
console.log(quickSort(arr));性能:
归并排序,即将数组分成不同部分,然后注意排序之后,进行合并
思路:
首先,将相邻的两个数进行排序,形成n/2对,然后在每两对进行合并,不断重复,直至排序完。
图例:
代码实现:
//迭代版本
const arr = [3,44,38,5,47,15,36,26,27,2,46,4,19,50,48]
function mergeSort(arr){
const len = arr.length;
for(let seg = 1; seg < len; seg += seg){
let arrB = [];
for(let start = 0; start < len; start += 2*seg){
let row = start, mid = Math.min(start+seg, len), heig = Math.min(start + 2*seg, len);
let start1 = start, end1 = mid;
let start2 = mid, end2 = heig;
while(start1 < end1 && start2 < end2){
arr[start1] < arr[start2] ? arrB.push(arr[start1++]) : arrB.push(arr[start2++]);
}
while(start1 < end1){
arrB.push(arr[start1++]);
}
while(start2 < end2){
arrB.push(arr[start2++]);
}
}
arr = arrB;
}
return arr;
}
console.log(mergeSort(arr));//递归版
const arr = [3,44,38,5,47,15,36,26,27,2,46,4,19,50,48];
function mergeSort(arr, seg = 1){
const len = arr.length;
if(seg > len){
return arr;
}
const arrB = [];
for(var start = 0; start < len; start += 2*seg){
let low = start, mid = Math.min(start+seg, len), heig = Math.min(start+2*seg, len);
let start1 = low, end1 = mid;
let start2 = mid, end2 = heig;
while(start1 < end1 && start2 < end2){
arr[start1] < arr[start2] ? arrB.push(arr[start1++]) : arrB.push(arr[start2++]);
}
while(start1 < end1){
arrB.push(arr[start1++]);
}
while(start2 < end2){
arrB.push(arr[start2++]);
}
}
return mergeSort(arrB, seg * 2);
}
console.log(mergeSort(arr));性能:
基数排序,就是将数的每一位进行一次排序,最终返回一个正常顺序的数组。
思路:
首先,比较个位的数字大小,将数组的顺序变成按个位依次递增的,之后再比较十位,再比较百位的,直至最后一位。
图例:
代码实现:
const arr = [3221, 1, 10, 9680, 577, 9420, 7, 5622, 4793, 2030, 3138, 82, 2599, 743, 4127, 10000];
function radixSort(arr){
let maxNum = Math.max(...arr);
let dis = 0;
const len = arr.length;
const count = new Array(10);
const tmp = new Array(len);
while(maxNum >=1){
maxNum /= 10;
dis++;
}
for(let i = 1, radix = 1; i <= dis; i++){
for(let j = 0; j < 10; j++){
count[j] = 0;
}
for(let j = 0; j < len; j++){
let k = parseInt(arr[j] / radix) % 10;
count[k]++;
}
for(let j = 1; j < 10; j++){
count[j] += count[j - 1];
}
for(let j = len - 1; j >= 0 ; j--){
let k = parseInt(arr[j] / radix) % 10;
tmp[count[k] - 1] = arr[j];
count[k]--;
}
for(let j = 0; j < len; j++){
arr[j] = tmp[j];
}
radix *= 10;
}
return arr;
}
console.log(radixSort(arr));性能:
我们一共实现了6种排序算法,对于前端开发来说,熟悉前面4种是必须的。特别是快排,基本面试必考题。本篇的内容总结分为六部分:
排序算法,是算法的基础部分,需要明白它的原理,总结下来排序可以分为比较排序和统计排序两种方式,本篇前5种均为比较排序,基数排序属于统计排序的一种。希望看完的你,能够去动手敲敲代码,理解一下
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
增删改查(CRUD)是每个数据结构内容都不可或缺的部分
本篇主要来分析一下查找算法。往往在真是的算法题中查找是非常难的一个问题,因为简单的有顺序查找,难的有深度和广度。更重要的是,本身它是需要结合数据结构的,所以它的考察是面试中比较重要的一项,也是面试官比较喜欢的。本篇将罗列一些算法结合数据结构进行分析。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
一般我们大多在使用的查找方式是顺序查找。
对于一个数组而言,我们会使用遍历数组的方式:
def find(arr, item):
for index in range(0, len(arr)):
if arr[index] == item:
return index;这种方式,在最坏的情况下(想要找的数在最后一个),时间复杂度是在O(n),比较不稳定。
而对于一个顺序列表(排序好的)来说,我们可以使用折半查找的方式:
def binary_Search(arr, item):
found = False
first = 0
last = len(arr) - 1
loc = 0
while first <= last and found == False:
loc = (first + last) / 2
if item < arr[loc]:
last = loc - 1
elif item > arr[loc]:
first = loc + 1
else:
found = True
break
if(found): print 'this item\'s index is ' + str(loc)
else: print 'not found'相信2017年下半年最火热的词一定是——bitcoin。神秘的比特币,火爆了2017年整个下半年,全球的人都为之疯狂。而同时,区块链这个技术进入了人们的视野。写这些文章的初始原因是我想要去完成一个关于区块链的毕业设计。同时,在开发的过程中使用的就是nodeJS。所以,本篇是一个系列的开篇。让我们来聊聊关于区块链的东西。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
区块链,作为数字货币的底层技术,其实并不是难以理解的。通俗地讲,我们可以称之为“分布式的数据库”。那么,这个分布式的数据库是如何运作的呢?我们可以来了解一下P2P网络。
P2P(Point to Point):点对点网络。这个东西其实早就存在了,早期的Bit下载,就是基于这个P2P网络的。它就像是一个点与另一个点之间,相互联系的线一样,形成的交织地网络。优点是便于去中心化,它并没有**服务器,或者说“弱中心化”。
目前,很多支付第三方公司,例如支付宝。在交易的过程中,都具备一个中心系统,去完成这一切的交易。这样的好处是,服务交易速度快,同时,第三方的公司还可以收取一定的交易费。但是,同样,这种方式也具备一定的坏处:
所以,我们很容易体会到现在的金融系统也是不容易的^_^。
那么对于使用区块链技术的数字货币来说,是否会体现出如我们上面说的一样,对于系统的稳定性和安全性要求呢?
回顾之前我们聊过的P2P网络,我们可以知道相对于区块链的系统,它并没有**服务器,所以它的交易是在整个网络中进行的。那么,什么去保证它的稳定性和安全性呢,其实就是——加密和共识机制。
我们来做个比喻:
人与人之间做交易时,我们如何保证它的安全性呢?首先,我们会在交易之前,在自己的脑中去判断交易人的可靠性,通过他之前一系列的行为,往往可以判断成功。所以,在建立信任的基础上,我们才会与之进行交易;然后,我们往往不会在私下里进行巨额的交易,我们会在一个大家都具备公证人时,进行交易;这样保证,你们交易完之后不会耍赖(因为生活中不存在如此强大的人,可以去买通在场的所有人)。
当然了,例子中我们使用了现实生活中的例子,那么,我们在网络上进行交易往往会需要用到加密技术。区块链的加密,从理论上讲,加密货币的交易地址、每一笔交易等都是加密解密中的一部分,破解一个毫无意义,全部破解相当不易,加之P2P网络节点众多,破解一个节点也没有任何价值,所以加密货币的安全级别应该是目前最高的。这样,我们就并不需要去担心交易记录被篡改,因为黑客需要破解的成本非常的高。
那么,至于稳定性呢?或许,没有什么东西可以比P2P网络更加稳定了吧。因为它相当于一个去中心化的系统,不用担心会有服务器宕机影响系统的可能性。
但是,在这里我们需要去了解一下共识机制,这个相当于是一种奖励机制。
我们在做一个比喻:
在早期,实施人民公社化制度的时候,人们劳动的激情就没有了;因为所有产出的产品,人人均分,这种使人们的劳动激情丧失了。后来,改成了按劳分配的机制,之后人们的劳动激情又恢复过来了,因为,勤奋的人可以得到更多的东西。
在区块链中,同样如此。每个参与的节点需要有一种机制,来使得每个节点提供他们的CPU资源以及之后的等等。这样才能使得整个系统正常的运行。但是,这种机制在开发中,都与选择的算法有很大的关系,我们可以在之后在慢慢了解。
我们再来将另一个层面的东西——为何选择nodeJS。
我觉得现在的nodeJS开发的系统,或许稳定性上面还存在的一定问题。不过,对于区块链形成的交易系统来说,其交易速度并不是很理想(1S中只能够交易几笔数目)。所以,可以说它的并发性并不是特别高。所以,nodeJS还是可以支撑起整个系统的。
还有一个重要的原因,就是我是一个前端开发者。所熟悉的语言除了JavaScript,也就只能是Java了。但是,我的Java水平并不足以支持我去开发一个复杂的系统。所以,我会选择nodeJS来进行这样子的实践操作。
这一篇文章我们或许对区块链技术有了一些初步的了解。同样地,我们应该更加深入地去研究区块链技术,相信它会在将来大有可为的。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
对于前端的性能话题,从来都没有断绝过。因为这个东西没有最好,只有更好。而且往往也是业务的繁杂程度去决定优化程度的。作为一个前端开发者,性能是我们关注的指标。它直接影响着我们的用户,同时也影响着产品本身。前端发展以来,优化方式,琳琅满目,有雅虎军规等。这些内容复杂繁多,往往容易被人遗忘。因此,本篇对于这些常用的优化方式进行总结,或许,并不全面,见谅。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
前端优化层出不穷,移动端大行其道的现在,我们可以说优化好移动端,PC端也将会更好。所以,我们可以综合以下图片进行一些分析,如图:
图中已经对前端性能做了一些概括。但其实,我觉得我们可以将这个概括更加精准,扼要,丰富。所以,接下来我会从三个方面就前端性能进行总结:网络方面、DOM操作及渲染方面、数据方面。
web应用,总是会有一部分的时间浪费在网络连接和资源下载方面。往往建立一次网络连接是需要时间成本的。而且浏览器同一时间所发送的网络请求数是有限的。所以,这个层面的优化可以从「减少请求数目」开始:
减少http请求:在YUI35规则中也有提到,主要是优化js、css和图片资源三个方面,因为html是没有办法避免的。因此,我们可以做一下的几项操作:
上述四个方法,前面两者我们可以使用webpack之类的打包工具进行打包;雪碧图的话,也有专门的制作工具;图片的编码是使用base64的,所以,对于一些简单的图片,例如空白图等,可以使用base64直接写入html中。
回到之前网络层面的问题,除了减少请求数量来加快网络加载速度,往往整个资源的体积也是,平时我们会关注的方面。
减小资源体积:可以通过以下几个方面进行实施:
gzip压缩主要是针对html文件来说的,它可以将html中重复的部分进行一个打包,多次复用的过程。js的混淆可以有简单的压缩(将空白字符删除)、丑化(丑化的方法,就是将一些变量缩小)、或者可以使用php对js进行混淆加密。css压缩,就是进行简单的压缩。图片的压缩,主要也是减小体积,在不影响观感的前提下,尽量压缩图片,使用png等图片格式,减少矢量图、高清图等的使用。这样子的做法不仅可以加快网页显示,也能减少流量的损耗。
除了以上两部分的操作之外,在网络层面我们还需要做好缓存工作。真正的性能优化来说,缓存是效率最高的一种,往往缩短的加载时间也是最大的。
缓存:可以通过以下几个方面来描述:
由于浏览器会在DNS解析步骤中消耗一定的时间,所以,对于一些高访问量网站来说,做好DNS的缓存工作,就会一定程度上提升网站效率。CDN缓存,CDN作为静态资源文件的分发网络,本身就已经提升了,网站静态资源的获取速度,加快网站的加载速度,同时也给静态资源做好缓存工作,有效的利用已缓存的静态资源,加快获取速度。http缓存,也是给资源设定缓存时间,防止在有效的缓存时间内对资源进行重复的下载,从而提升整体网页的加载速度。
其实,网络层面的优化还有很多,特别是针对于移动端页面来说。众所周知,移动端对于网络的敏感度更加的高,除了目前的4G和WIFI之外,其他的移动端网络相当于弱网环境,在这种环境下,资源的缓存利用是相当重要的。而且,减少http的请求次数,也是至关重要的,移动端弱网环境下,对于http请求的时间也会增加。所以,我们可以看一下我们在移动端网络方面可以做的优化:
移动端优化:使用以下几种方式来加快移动端网络方面的优化:
「使用长cache」,可以使得移动端的部分资源设定长期缓存,这样可以保证资源不用向服务器发送请求,来比较资源是否更新,从而避免304的情况。304重定向,在PC端或许并不会影响网页的加载速度,但是,在移动端网络不稳定的前提下,多一次请求,就多了一部分加载时间。「首屏优化」,对于移动端来说是至关重要的。2s时间是用户的最佳体验,一旦超出这个时间,将会导致用户的流失。所以,针对移动端的网络情况,不可能在这么短时间内加载完成所有的网页资源,所以我们必须保证首屏中的内容被优先显示出来,而且基于TCP的慢启动和拥塞控制,第一个14kb的数据是非常重要的,所以需要保证首部加载数据能够小于14kb。「不滥用web字体」,web字体的好处就是,可以代替某些图片资源,但是,在移动端过多的web字体的使用,会导致页面资源加载的繁重,所以,慎用web字体
首先,简单的聊一下优化渲染的重要性。在网页初步加载时,获取到HTML文件之后,最初的工作是构建DOM和构建CSSOM两个树,之后将他们合并形成渲染树,最后对其进行打印。我们可以通过图片来看一下,简单的过程:
这里整个过程拉出来写,具体可以再写一篇文章,恕我偷下懒,推荐一篇比较好的文章给大家吧。浏览器渲染过程与性能优化
继续我们的话题,我们可以如何去缩短这个过程呢?可以从以下几个操作进行优化。
优化网页渲染:
css文件放在「头部加载」,可以保证解析DOM的同时,解析css文件。因为,CSS(外链或内联)会阻塞整个DOM的渲染,然而DOM解析会正常进行,所以将css文件放在头部进行解析,可以加快网页的构建速度。假设将其放在尾部,那时DOM树几乎构建,这时就得等到CSSOM树构建完成,才能够继续下面的步骤。「js放在尾部」:js文件不同,将js文件放在尾部或者异步加载的原因是JS(外链或内联)会阻塞后续DOM的解析,后续DOM的渲染也将被阻塞,而且一旦js中遇到DOM元素的操作,很可能会影响。这方面可以推荐一篇文章——异步脚本载入提高页面性能。「避免使用内联样式」,可以有效的减少html的体积,一般考虑内联样式的时候,往往是样式本身体积比较小,往往加载网络资源的时间会大于它的时候。
除了页面渲染层面的优化,当然最重要的就是DOM操作方面的优化,这部分的优化应该是最多的,而且也是平时开发可以注意的地方。如果开发前期明白这些原理,同时付诸实践的话,就可以在后期的性能完善上面少下很多功夫。那么,接下来我们可以来看一下具体的操作:
DOM操作优化:
前面三个操作,其实都是希望『减少回流和重绘』。其实,进行一次DOM操作的代价是非常之大的,以前可以通过网页操作是否卡顿来进行判断,但是,现代浏览器的进步已经大大减少了这方面的影响。但是,我们还是需要清楚,如何去减少回流和重绘的问题。因为这里不想细说这方面的知识,想要了解的话,可以看这篇文章——回流与重绘:CSS性能让JavaScript变慢?。这可是张鑫旭大大的一篇文章呦(^.^)。「尽量使用css动画」,是因为本身css动画比较简单,而且相较于js的复杂动画,浏览器本身对其进行了优化,使用上面不会出现卡顿等问题。「使用requestAnimationFrame代替setInterval操作」,相信大家都有所耳闻,setInterval定时器会有一定的延时,对于变动性高的动画来说,会出现卡顿现象。而requestAnimationFrame正好解决的整个问题。「适当使用canvas」,不得不说canvas是前端的一个进步,出现了它之后,前端界面的复杂性也随之提升了。一些难以完成的动画,都可以使用canvas进行辅助完成。但是,canvas使用频繁的话,会加重浏览器渲染的压力,同时导致性能的下降。所以,适当时候使用canvas是一个不错的建议。「尽量减少css表达式的使用」,这个在YUI规则中也被提到过,往往css的表达式在设计之初都是美好的,但在使用过程中,由于其频繁触发的特性,会拖累网页的性能,出现卡顿。因此在使用过程中尽量减少css表达式的使用,可以改换成js进行操作。「使用事件代理」:往往对于具备冒泡性质的事件来说,使用事件代理不失为一种好的方法。举个例子:一段列表都需要设定点击事件,这时如果你给列表中的每一项设定监听,往往会导致整体的性能下降,但是如果你给整个列表设置一个事件,然后通过点击定位目标来触发相应的操作,往往性能就会得到改善。
DOM操作的优化,还有很多,当然也包括移动端的。这个会在之后移动端优化部分被提及,此处先卖个关子。上面我们概述了开始渲染的时候和DOM操作的时候的一些注意事项。接下来要讲的是一些小细节的注意,这些细节可能对于页面影响不大,但是一旦堆积多了,性能也会有所影响。
操作细节注意:
上述的一些操作细节,是平时在开发中被要求的,更可以理解为开发规范。(基本操作,坐下^_^)
列举完基本操作之后,我们再来聊一下移动端在DOM操作方面的一些优化。
移动端优化:
首先,长列表滚动问题,是移动端需要面对的,IOS尽量使用局部滚动,android尽量使用全局滚动。同时,需要给body添加上-webkit-overflow-scrolling: touch来优化移动段的滚动。如果有兴趣的同学,可以去了解一下ios和android滚动操作上的区别以及优化。「防抖和节流」,设计到滚动等会被频繁触发的DOM事件,需要做好防抖和节流的工作。它们都是为了限制函数的执行频次,以优化函数触发频率过高导致的响应速度跟不上触发频率,出现延迟,假死或卡顿的现象。
介绍:函数防抖,当调用动作过n毫秒后,才会执行该动作,若在这n毫秒内又调用此动作则将重新计算执行时间;函数节流,预先设定一个执行周期,当调用动作的时刻大于等于执行周期则执行该动作,然后进入下一个新周期。
「touchstart、touchend代替click」,也是移动端比较常用的操作。click在移动端会有300ms延时,这应该是一个常识呗。(不知道的小伙伴该收藏一下呦)。这种方法会影响用户的体验。所以做优化时,最简单的方法就是使用touchstart或者touchend代替click。因为它们事件执行顺序是touchstart->touchmove->touchend->click。或者,使用fastclick或者zepto的tap事件代替click事件。「HTML的viewport设置」,可以防止页面的缩放,来优化性能。「开启GPU渲染加速」,小伙伴们一定听过CPU吧,但是这里的GPU不能和CPU混为一谈呦。GPU的全名是Graphics Processing Unit,是一种硬件加速方式。一般的css渲染,浏览器的渲染引擎都不会使用到它。但是,在3D渲染时,计算量较大,繁重,浏览器会开启显卡的硬件加速来帮助完成这些操作。所以,我们这里可以使用css中的translateZ设定,来欺骗浏览器,让其帮忙开启GPU加速,加快渲染进程。
DOM部分的优化,更多的是习惯。需要自己强制要求自己在开发过程中去注意这些规范。所以,这部分的内容可以多关注一下,才能够慢慢了解。同时,本人对于上述几点的描述是概括性的。并没有对其进行详细的展开。因此,也要求你去细细的查阅Google呦。
数据,也可以说是前端优化方面比较重要的一块内容。页面与用户的交互响应,往往伴随着数据交互,处理,以及ajax的异步请求等内容。所以,我们也可以来聊聊这一块的知识。首先是对于图片数据的处理:
图片加载处理:
「图片预加载」,预加载的寓意就是提前加载内容。而图片的预加载往往会被用在图片资源比较大,即时加载时会导致很长的等待过程时,才会被使用的。常见场景:图片漫画展示时。往往会预加载一张到两张的图片。「图片懒加载」,懒加载或许你是第一次听说,但是,这种方式在开发中会被经常使用。首先,我们需要明白一个道理:往往只有看到的资源是必须的,其他资源是可以随着用户的滚动,随即显示的。所以,特别是对于图片资源特别多的网站来说,做好图片的懒加载是可以大大提升网页的载入速度的。
常见的图片懒加载的方式就是:在最初给图片的src设置一个比较简单的图片,然后将图片的真实地址设置给自定义的属性,做一个占位,然后给图片设置监听事件,一旦图片到达视口范围,从图片的自定义属性中获取出真是地址,然后赋值给src,让其进行加载。
「首屏进度条的显示」:往往对于首屏优化后的数据量并不满意的话,同时也不能进一步缩短首屏包的长度了,就可以使用进度条的方式,来提醒用户进行等待。
讲完了图片这一块数据资源的处理,往往我们需要去优化一下异步请求这一部分的内容。因为,异步的数据获取也是前端不可分割的。这一部分我们也可以做一定的处理:
异步请求的优化:
「JSON交互」,JSON的数据格式轻巧,结构简单,往往可以大大优化前后端的数据通信。「常用数据的缓存」,可以将一些用户的基本信息等常用的信息做一个缓存,这样可以保证ajax请求的减少。同时,HTML5新增的storage的内容,也不用怕cookie暴露,引起的信息泄漏问题。「数据埋点和统计」,对于资深的程序员来说,比较了解。而且目前的大部分公司也会做这方面的处理。有心的小伙伴可以自行查阅。
最后,还有就是大量数据的运算。对于javascript语言来说,本身的单线程就限制了它并不能计算大量的数据,往往会造成页面的卡顿。而可能业务中有些复杂的UI需要去运行大量的运算,所以,webWorker的使用是至关重要的。或许,前端标准普及的落后,会导致大家对于这些新生事物的短暂缺失吧。
本篇文章就前端性能这个话题做了一个总结。或许,并不全面,但是都是一些平时开发中会被经常用到的知识。希望有心者能够去亲身的尝试一下这些方面的优化。本篇的概述了一下几个知识点:
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
本篇文章之前,有一篇前言篇,如果你还未读过,建议你花一分钟的时间,先读一下前言篇。前言篇,篇幅较少,并不会花费你太多的时间,但是概括了接下来几篇文章的主要内容。
本篇文章主要是讲一些移动端富文本开发之前,所需要了解的基础内容。基础内容可以分成三部分。我们首先考虑的是webView与js之间的交互,之后就是原生富文本功能,最后就是Selection和Range的概念。所以,本篇会根据这三部分来详细阐述基础内容。欢迎关注我的github博客。同时也希望你关注和支持我们的项目,github项目地址,谢谢支持。
我这里并不具体聊webView的具体使用,而是讲一下我们在项目中会使用的js与webView之间的一些信息交互。在这个项目中,我们主要使用了两种方式进行通信:
所谓的url拦截,在我的理解中,就是网页可以通过跳转url的方式,将内部信息填入url中,然后webView在其跳转前,将它的url获取到,然后阻断这个过程。然后在对url进行解密,之后拆分里面的信息。都知道url其实是base64编码的,在传输信息的过程,js需要去调用encodeComponentURI函数加密整个信息的。
这里的表达方式有一点俗气,哈哈,也没啥办法,因为通俗易懂吧
对象映射的方式就是,在Android建立一个对象,并添加上webView中提供的注解,然后在内部添加方法,这些添加的方法是可以被js使用的。但是,似乎这种对象映射的方式,并不是特别的安全,容易遭到注入攻击。
这种方式,并没有在我们的项目中使用到。只是,当时使用的是比较老的版本的webview,那里还是具备之前的两种方法的。看过很多的博文,似乎这种方法或许是目前最常用的一种方式,而另外两种已经在新版本的webView中被淘汰了。所以,我们或许会在下个版本去考虑更新这种机制。
交互通信这一方面就聊这么多吧,毕竟我是一个研究js的小渣渣,具体的webView的操作,网上的大佬们已经书写万字了,也并不需要我去多做讲解。之后,会有具体的参考博文赋上。
说到富文本应用的开发,你或许会直接考虑到contenteditable这个属性。因为它可以使得一个块可编辑。但是富文本应用并不仅仅如此。接下来,我们来看看一些我在项目中会经常使用到的API接口:
最重要的接口一定是execCommand函数,这个函数是富文本的灵魂。因为之后所需要去完成的功能——加粗、斜体、删除线、引用、标题h1、h2、h3、h4等,当然也包括图片、链接、分割符,都是需要通过这个函数去进行的。
这个函数接收三个参数:
command => 就是命令,因为原生的函数已经定义了一部分的命令在函数的内部,例如加粗:
document.execCommand('bold', false, null);showDefaultUI => 是否展示用户界面,一般都会使用false,项目中并未对这个属性进行设置(忽略)
value => 一些特殊的命令需要插入值时,需要用到这个参数。之后在讲解项目细节时会详细说明。
第二个会使用到的API是——queryCommandState();
它接受一个参数command,然后返回boolean。主要是去判断当前的焦点是否具备command。打个比方,你在使用富文本的时候,你需要去点击内容中的一个部分进行编辑,但是,当你点击时,你需要去做一下底栏按钮间的状态同步。可能这一部分是bold,但是你加粗按钮却没有被激活的话,就非常尴尬了。
第三个会使用的API是——queryCommandValue():
这里也是接受一些特定的命令的插入内容是否存在。我们可以来详细的举个例子:
**场景:**我们需要去插入一个h1标签元素,之后我们又需要去获取到当前位置是否具备h1标签
//插入h1
document.execCommand('formatBlock', false, 'h1');
//获取状态时
var isExist = document.queryCommandValue('formatBlock');这样我们就可以去,获取当前是否具备h1标签
最后,我们来看一下,我们之后会涉及到的知识点Selection和Range。
Selection,可以解释为选区。讲的通俗点,整个选区就是文本可以编辑的区块。一般整个窗口只有一个选区。
如何取得选区?可以通过window.getSelection()来获得选区。
讲到选区的话,就必须牵扯到一个概念——Range。Range:字面意思是范围。这个东西大家都见识过。当你在屏幕上,选择复制块的时候,那块全部被蓝色包裹的区域。(底色也可能不是蓝色的,颜色可以修改)。这种块往往可以具备多个,通过ctrl键来增加多个范围块。在富文本的开发中,对于这个运用的也非常之多。
同时,其实焦点也是Range。只是这个Range的start和end重合在了一起。在聚焦的过程中,也会对这一概念进行运用。详情可见
富文本开发的基础内容,就简单的介绍这么一点。后续会随着js的源码一步步的展开分析。
本篇的内容可概括为:
这些内容,都是我在富文本开发中会使用到的知识点。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
现在的前端,javascript的发展有目共睹,框架林立。同时,html也是齐头并进,推出了HTML5标准,并且得到了普及。这样的发展却唯独少了一个角色?
CSS,就是这个看似不起眼的家伙,却在开发中发挥着和js一样重要的作用。css,是一种样式脚本,好像和编程语言有着一定的距离,我们可以将之理解为一种描述方法。这似乎导致css被轻视了。不过,css近几年来正在经历着一次巨变——CSS Module。我记得js的井喷期应该可以说是node带来的,它带来了Module的概念,使得JS可以被工程化开发项目。那么,今天的css,也将越来越美好。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
既然作为一篇推广PostCSS的文章,我们就应该先来了解一下这是什么,和我们之前讲的CSS Module有啥关系?此处让我为你们娓娓道来。
目前,在工程化开发中,使用最多的应该就是Less、Sass和Stylus。首先,还是介绍一下它们吧。它们有个统一的名字——css预处理器。何为CSS预处理器?应该就是一种可以将你根据它的规则写出来的格式转成css的东西(还是讲的通俗一点)。它们的出现可以说是恰逢其时,解决了css的一些缺憾:
面对以上问题,css预处理器给出了非常可行的解决方案:
变量:就像其他编程语言一样,免于多处修改。
作用域:有了变量,就必须得有作用域进行管理。就想js一样,它会从局部作用域开始往上查找变量。
嵌套:对于css来说,有嵌套的写法无疑是完美的,更像是父子层级之间明确关系
有了这些方案,会使得我们可以在保证DPY、可维护性、灵活性的前提下,编写css样式。
回到话题中,之所以会出现向预处理器这样子的解决方案,归根结底还是css标准发展的滞后性导致的。同时,我们也应该考虑一下,真的只要预处理器就够了吗?往往在项目过大时,由于缺乏模块的概念,全局变量的问题会持续困扰着你。每次定义选择器时,总是要顾及到其他文件中是否也使用了同样的命名。毕竟项目是团队的,而不是个人的。哪是否有方式可以解决这些问题呢?
对于css命名冲突的问题,由来已久,可以说我们前端开发人员,天天在苦思冥想,如何去优雅的解决这些问题。css并未像js一样出现了AMD、CMD和ES6 Module的模块化方案。
那么,回到问题,如何去解决呢?我们的前人也有提出过不同的方案:
方案可以说是层出不穷,不乏有团队内部的解决方案。但是大多数都是一个共同点——为选择器增加前缀。
这可是一个体力活,你可能需要手动的去编写长长的选择器,或许你可以使用预编译的css语言。但是,它们似乎并为解决本质的问题——为何会造成这种缺憾。我们不妨来看看,使用BEM规范写出来的例子:
<!-- 正确的。元素都位于 'search-form' 模块内 -->
<!-- 'search-form' 模块 -->
<form class="search-form">
<!-- 在 'search-form' 模块内的 'input' 元素 -->
<input class="search-form__input" />
<!-- 在 'search-form' 模块内的 'button' 元素 -->
<button class="search-form__button"></button>
</form>
<!-- 不正确的。元素位于 'search-form' 模块的上下文之外 -->
<!-- 'search-form' 模块 -->
<form class=""search-block>
</form>
<!-- 在 'search-form' 模块内的 'input' 元素 -->
<input class="search-form__input"/>
<!-- 在 'search-form' 模块内的 'button' 元素 -->
<button class="search-form__button"></button>每次这样子写,估计是个程序员,都得加班吧,哈哈!
现在的网页开发,讲究的是组件化的**,因此,急需要可行的css Module方式来完成网页组件的开发。自从2015年开始,国外就流行了CSS-in-JS(典型的代表,react的styled-components),还有一种就是CSS Module。
本篇谈及后者,需要对前者进行了解的话,自行Google即可
对于css,大家都知道,它是一门描述类语言,并不存在动态性。那么,要如何去形成module呢。我们可以先来看一个react使用postcss的例子:
//example.css
.article {
font-size: 14px;
}
.title {
font-size: 20px;
}之后,将这些命名打乱:
.zxcvb{
font-size: 14px;
}
.zxcva{
font-size: 20px;
}将之命名对应的内容,放入到JSON文件中去:
{
"article": "zxcvb",
"title": "zxcva"
}之后,在js文件中运用:
import style from 'style.json';
class Example extends Component{
render() {
return (
<div classname={style.article}>
<div classname={style.title}></div>
</div>
)
}
}这样子,就描绘出了一副css module的原型。当然,我们不可能每次都需要手动去写这些东西。我们需要自动化的插件帮助我们完成这一个过程。之后,我们应该先来了解一下postCSS。
PostCSS是什么?或许,你会认为它是预处理器、或者后处理器等等。其实,它什么都不是。它可以理解为一种插件系统。使用它GitHub主页上的介绍:
PostCSS is a tool for transforming CSS with JS plugins. These plugins can support variables and mixins, transpile future CSS syntax, inline images, and more.
你可以在使用预处理器的情况下使用它,也可以在原生的css中使用它。它都是支持的,并且它具备着一个庞大的生态系统,例如你可能常用的Autoprefixer,就是PostCSS的一个非常受欢迎的插件,被Google, Shopify, Twitter, Bootstrap和CodePen等公司广泛使用。
当然,我们也可以在CodePen中使用它:
这里推荐大家看一下PostCSS的深入系列
接下来,我们来看一下PostCSS的配置:
这里我们使用webpack+postcss+postcss-loader+cssnext+postcss-import的组合。
首先,我们可以通过yarn来安装这些包:
yarn add --dev webpack extract-text-webpack-plugin css-loader file-loader postcss postcss-loader postcss-cssnext postcss-import
然后,我们配置一下webpack.config.js:
const webpack = require('webpack');
const path = require('path');
const ExtractTextPlugin = require('extract-text-webpack-plugin');
module.exports = {
context: path.resolve(__dirname, 'src'),
entry: {
app: './app.js';
},
module: {
loaders: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
use: [
{
loader: 'css-loader',
options: { importLoaders: 1 },
},
'postcss-loader',
],
}),
},
],
},
output: {
path: path.resolve(__dirname, 'dist/assets'),
},
plugins: [
new ExtractTextPlugin('[name].bundle.css'),
],
};然后在根目录下配置postcss.config.js
module.exports = {
plugins: {
'postcss-import': {},
'postcss-cssnext': {
browsers: ['last 2 versions', '> 5%'],
},
},
};之后,就可以在开发中使用cssnext的特性了
/* Shared */
@import "shared/colors.css";
@import "shared/typography.css";
/* Components */
@import "components/Article.css";/* shared/colors.css */
:root {
--color-black: rgb(0,0,0);
--color-blue: #32c7ff;
}
/* shared/typography.css */
:root {
--font-text: "FF DIN", sans-serif;
--font-weight: 300;
--line-height: 1.5;
}
/* components/Article.css */
.article {
font-size: 14px;
& a {
color: var(--color-blue);
}
& p {
color: var(--color-black);
font-family: var(--font-text);
font-weight: var(--font-weight);
line-height: var(--line-height);
}
@media (width > 600px) {
max-width: 30em;
}
}最后使用webpack进行编译就可以了。
PostCSS,国内还没有太流行起来,不过相信不久的将来也会逐渐的热门,并且国内的资源较少,不过最近新出了一本大漠老师们一起翻译的书——《深入PostCSS Web设计》。有兴趣的人也可以去看一下,学习一些前言的东西。本篇也只是大概的写了一下PostCSS的东西,鉴于国内资源较少,所以参考了一下国外的博文教材,下面会有链接。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
作为一个程序员,要出去装逼,手中必备的技能就是正则表达式。程序员的正则表达式,医生的处方和道士的鬼画符,都是利器。
在js中,很多的场景需要去使用到它(毕竟,js刚刚诞生的时候,是用来做表单等验证的)。其实,正则表达式是一门语言,有自己独特的语法,还拥有自己的解释器。但是,作为使用来说,我们只需要掌握它的语法,多多运用,才能熟练。其实,我想过很多种详解表达式的方式,但是,似乎每种方式都有缺陷,因为正则表达式的语法需要记忆的部分比较多。最后,我觉得可以通过比较和分类的方式去记忆。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
在正则表达式中,有两种方式可以去创建正则表达式:
const reg = /abc/;const reg = new RegExp('abc');对于这两种方式,如果正则表达式是静态的,那么,使用第一种字面量的方式,性能会比较好。但是,如果正则表达式是动态的,是根据变量来定义的,那么,只能使用第二种构造函数的方式。
^ 和 $的对比
^:匹配字符串的行首。示例说明:
const reg = /^A/;
console.log(reg.test('Ant')); //true
console.log(reg.test(' Ant')); //false$:匹配字符串的行尾。示例说明:
const reg = /t$/;
console.log(reg.test('eat')); //true
console.log(reg.test('enter')); //false重复限定符(*、+、?、{n}、{n,}、{n, m})
*:匹配前一个字符0次或多次,(x >= 0)
const reg = /a*/;
console.log(reg.test('ba')); //true
console.log(reg.test('b')); //true
console.log(reg.test('baaa')); //true+:匹配前一个字符1次或多次,(x >= 1)
const reg = /a+/;
console.log(reg.test('ba')); //true
console.log(reg.test('baaa')); //true
console.log(reg.test('b')); //false?:匹配前一个字符的0次或1次,(x = 0 || x = 1)
const reg = /ba?/;
console.log(reg.exec('ba')); //['ba']
console.log(reg.exec('baaa')); //['ba']
console.log(reg.exec('b')); //['b']注:这里只是指明了?字符的限定符方面的用法,它还可以控制贪婪模式和非贪婪模式(下文可见)
{n}: 匹配前一个字符n次,(x = n)
const reg = /ba{3}/;
console.log(reg.test('ba')); //false
console.log(reg.test('baaa')); //true
console.log(reg.test('b')); //false{n,}:匹配前一个字符n次或大于n次,(x >=n)
const reg = /ba{3,}/;
console.log(reg.test('ba')); //false
console.log(reg.test('baaa')); //true
console.log(reg.test('baaaa')); //true
console.log(reg.test('b')); //false{n, m}:匹配前一个字符n次到m次之间,(n <= x <= m)
const reg = /ba{2,3}/;
console.log(reg.test('ba')); //false
console.log(reg.test('baaa')); //true
console.log(reg.test('baa')); //true
console.log(reg.test('b')); //false元字符(.、\d、\w、\s、\b)
.:匹配除换行符以外的所有字符
const reg = /b.?/;
console.log(reg.exec('ba')); //['ba']
console.log(reg.exec('bxaa')); //['bx']
console.log(reg.exec('bza')); //['bz']
console.log(reg.exec('b')); //['b']\d:匹配数字字符,与[0-9]一致(单词记忆法 => 数字【digital】)
const reg = /b\d/;
console.log(reg.exec('b1')); //['b1']
console.log(reg.exec('b2aa')); //['b2']
console.log(reg.exec('bza')); //null
console.log(reg.exec('b')); //null\w:匹配字母、数字和下划线(单词记忆法 => 单词【word】)
const reg = /b\w/;
console.log(reg.exec('b1')); //['b1']
console.log(reg.exec('b2aa')); //['b2']
console.log(reg.exec('bza')); //['bz']
console.log(reg.exec('b')); //null\b:匹配一个边界,一个独立单词的开头或结尾(单词记忆法 => 边界【border】)
const str = 'moon is white';
console.log(str.match(/\bm/)); //['m']
console.log(str.match(/oon\b/)); //['oon']\s:匹配空白符(空格、换行符、制表符)(单词记忆法 => 符号【space】)
const str = 'moon is white';
console.log(str.match(/is\swhite/)); //['is white']
console.log(str.match(/moon\sis/)); // ['moon is']反元字符([^x]、\D、\W、\B、\S)
[^x]:匹配除x之外的任意字符
const reg = /b[^a]/;
console.log(reg.exec('ba')); //null
console.log(reg.exec('bz')); //['bz']
console.log(reg.exec('by')); //['by']\D:匹配除数字之外的任意字符,与\d相反
const reg = /b\D/;
console.log(reg.exec('b1')); //null
console.log(reg.exec('b2')); //null
console.log(reg.exec('by')); //['by']\W:匹配除数字、字母和下划线以外的任意字符,与\w相反
const reg = /b\W/;
console.log(reg.exec('b1')); //null
console.log(reg.exec('ba')); //null
console.log(reg.exec('b_')); //null
console.log(reg.exec('b*')); //['b*']\B:匹配非单词边界的字符,与\b相反
const str = 'moon is white';
console.log(str.match(/\Boon/)); //['oon']
console.log(str.match(/whit\B/)); //['whit']\S:匹配非空白字符,与\s相反
const str = 'moon is white';
console.log(str.match(/mo\Sn/)); //['moon']
console.log(str.match(/whit\S/)); //['white']字符组([...])
[...]:匹配方括号中的字符集合,例如[0-9] => 匹配数字字符
const reg = /b[a-z]/;
console.log(reg.test('ba')); //true
console.log(reg.test('bA')); //false分组((...))
(X):将括号中的字符看成一个组进行匹配,例如(ab)+ => 可以匹配'ababab'
const reg = /(abab)+/;
console.log(reg.exec('ababab')); //['abab', 'abab']
console.log(reg.exec('abababab')); //['abababab','abab'](?:X):匹配X,但是不记录匹配项。而上面的(X)是记录匹配项的。
(?=X):正向肯定查找,即匹配后面紧跟X的字符串。
const reg = /\d+(?=\.)/;
console.log(reg.exec('3.141')) //['3'](?!X):正向否定查找,即匹配后面不跟X的字符串,与(?:X)相反。
const reg = /\d+(?!\.)/;
console.log(reg.exec('3.141')) //['141']多选符 (|)
|:匹配两者中的一个,例如a|b => 匹配a或b
const reg = /a|b/;
console.log(reg.exec('a')); //['a']
console.log(reg.exec('b')); //['b']
console.log(reg.exec('c')); //['c']转移字符(\)
\:表示转义字符,将特殊的字符转义成普通字符进行匹配
匹配方式,即正则表达式在匹配过程中,当具备多个结果时,按照一定的模式进行匹配。
匹配方式可分为两种,贪婪模式和非贪婪模式。
贪婪模式:即以限定符最大重复标准进行匹配。例如:使用/ba*/匹配'baaaaa'时,结果可返回'baaaaa'
非贪婪模式:即以限定符最小重复标准进行匹配。例如:使用/ba*?/匹配'baaaaa'时,结果可返回'b'
const str = 'baaaaa';
console.log(str.match(/ba*/)); //['baaaaa']
console.log(str.match(/ba*?/)); //['b']其中?符号起到了贪婪与非贪婪模式之间的转变,在重复限定符后加上?,按非贪婪模式进行匹配;默认为贪婪模式。
标识方式,就是正则表达式后面跟的匹配方式,flag
g:全局匹配,记忆方式【global】
i:忽略大小写,记忆方式【ignore】
m:多行搜索,记忆方式【multline】
使用正则表达式的方式一共有6种,可以分成:reg有两种,string有四种。
首先,我们来看一下reg对象带的两种方法:exec和test
测试用例:
const reg = /abc/;
console.log(reg.test('abca')); //true
console.log(reg.test('abac')); //falseconst reg = /\d+/;
console.log(reg.exec('1234dhi343sf2')); //['1234']之后是string的四种方法:match、search、replace、split
const str = 'this is reg expression test'
console.log(str.match(/\bi.\s\w+/)); //['is reg']const str = 'this is reg expression test'
console.log(str.search(/\bi.\s\w+/)); //5replace:查找字符串中匹配的字符串,对其进行替换(这是一个个人觉得比较厉害的技能)
var str = 'this is reg expression test'
console.log(str.replace(/\b(i.)\s(\w+)/, '$1 hello $2')); //'this is hello reg expression test'var str = 'this is reg expression test'
str.replace(/\b(i.)\s(\w+)/, (...args) => {
console.log(args);
}); //["is reg", "is", "reg", 5, "this is reg expression test"]注:这个函数会有一些参数,第一个是匹配的字符串,第二个是第一项匹配的,第三个是第二项匹配的,第四个是匹配的下标,第五个是原字符串
var str = 'this is reg expression test'
console.log(str.split(/\s/)) //["this", "is", "reg", "expression", "test"]js部分的正则表达式很多东西都以及讲完了,剩下的就是练习了。这种记忆性的东西,需要不断的使用,才会孰能生巧。下面部分提供一下练习的语句,答案在js正则表达式练习整理
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦。大家一起总结一起进步。欢迎关注我的github博客
涉及到多个异步事件执行的时候,大家会不会产生思考!执行顺序,还和原来一样么?还是有什么固定的规则,让我们去判断!今天我们就来了解一下Event Loop的概念。
在聊起这个概念之前,我们先来听一段JavaScript语言的自述。
众所周知,JavaScript是一门单线程的语言。为什么浏览器会去选择它呢!原因就是——简单。在浏览器端,复杂的UI环境会限制多线程语言的开发。例如:
一个线程在操作一个DOM元素的时候,另一个线程需要去删除这个DOM元素。这种情况下,我们就需要进行状态的同步。可怕的是,浏览器往往不止去操作一个DOM元素!所以,为了避免开发中处理这种复杂的情况,单线程语言不失为一种好的解决方案。
但是,单线程也会有它的缺陷——同步阻塞。如图所示:
CPU在进行一个I/O操作的时候,需要去请求数据,期间需要等待数据返回之后,才能够继续执行下面的任务。这个等待期,就阻塞了其他任务的执行。因此,JavaScript在执行过程中,将任务分成了同步任务和异步任务,来解决类似的情况。
每个线程都有一个执行栈,会根据先进后出的顺序来执行线程中的任务,所有的同步任务,都会被放到这个执行栈中,我们可以来看一段代码:
function fun1(){
return 'hello hip-hop';
}
function fun2(){
return fun1();
}
function fun3(){
console.log(fun2());
}
fun3(); //'hello hip-hop'它的执行顺序如下:
或者我们可以通过浏览器后台的报错来看整个执行顺序,如下:
function fun1(){
throw new Error('hello hip-hop');
}
function fun2(){
return fun1();
}
function fun3(){
console.log(fun2());
}
fun3();浏览器后台的报错提示,如图:
在此基础上,我们如果加入异步任务,会发生什么样的情况呢,如下:
console.log('first');
setTimeout(() => {
console.log('second');
}, 500);
console.log('three');我们依然通过画图的形式,来直观地感受一下执行栈的顺序,如图:
从图中,我们可以清晰地看到setTimeout执行完成之后,就出栈了!那么,后来的console.log('second')是如何入栈的呢?
其实,在主线程之外,还存在一个任务队列。异步任务,都会被放到任务队列中。只有当指定事件触发之后,异步任务才会被放到主线程中执行。
任务队列中,是一个事件队列。拿setTimeout举例来说:
上述流程,规范为一张图如下:
这里有个循环,是一个死循环,无论哪种情况都是闭环,这个就是事件循环。事件循环不断地在检测队列是否存在已触发的任务,如果有的话,就放到主线程中执行(注:这个过程往往在主线程执行完之后进行)。
这幅图里面,我们看到了有浏览器的点击事件、ajax请求、Promise等这里。但是不同之处在于,它们的任务性质存在不同。
自从,ES6出现之后,Promise逐渐被开发者热议。这里我们来讨论一下它这方面的特殊性。
首先,我们来看一段代码:
setTimeout(() => {
console.log(1);
}, 0);
Promise.resolve().then(() => {
console.log(2);
}).then(() => {
console.log(3);
});
console.log(4); // 4 2 3 1你会不会有所疑问,为啥不是4 1 2 3的顺序呢?
其实,这个执行顺序和任务队列有关系!任务队列中存在两种队列类型:宏任务和微任务。宏任务可以有多个队列,微任务只能有一个!同时,宏任务是一个一个出队的,而微任务是一队一队出队的。
在执行事件循环的过程中:
了解清楚这个后,我们再回头看,心中亦如明镜。setTimeout是宏任务,Promise是微任务。具体分类如下:
本文我们回顾了:
希望对于你来说有所收获,感谢阅读。
欢迎您扫一扫上面的微信公众号,订阅我的博客!
本篇为图片上传模块的实践篇。
上篇我在文章中分析了如何去实现瀑布流的布局,以及怎么使用模版去实现数据的插入到html之中。这一篇,主要讲一下三部分的实现,1.数据mock、2.下拉加载、3.上拉刷新。本次demo的地址在此,喜欢的可以给一个Star
首先,我们来分析一下数据的mock部分。由于想要实现与具备后台一样的效果,我们必须使用node去实现一个mock的后台,将数据放在json中,然后使用fs模块读取里面的内容,然后根据url进行数据的检索。
一般来说,下拉加载的数据都是具备分页特性的。主要可分为data(数据段)、page(当前页码)、next(告知前端接下来是否还有数据内容)。
之后,我们通过express框架对整个后端的数据进行一下模拟。我的demo目录下,有已经构造好的json文件,一共是两份,一份是更新前的数据,一份是更新后的数据。具体实现的代码:
const Express = require('express');
const app = new Express();
const path = require('path');
const fs = require('fs');
//data part
app.get('/:id', function(req, res){
const page = req.params.id;
res.setHeader("Access-Control-Allow-Origin", "*");
// console.log(page);
fs.readFile(path.resolve(__dirname, 'mock.json'), function(err, data){
if(err){
throw err;
}
const static = JSON.parse(data).data;
const arr = Array.from(static);
const len = arr.length;
const next = page - 0 + 1 <= len ? true : false;
for(let value of arr){
if(value.page == page){
res.json({data: value.data, next: next});
}
}
});
});
app.get('/update/:id', function(req, res){
const page = req.params.id;
res.setHeader('Access-Control-Allow-Origin', '*');
fs.readFile(path.resolve(__dirname, 'update.json'), function(err, data){
if(err){
throw err;
}
const static = JSON.parse(data).data;
const arr = Array.from(static);
const next = page - 0 + 1 <= arr.length ? true : false;
let result = [];
for(let value of arr){
if(value.page <= page){
result = result.concat(value.data);
}
}
res.json({data: result, next: next});
});
});
app.listen(3000);这部分主要是读取json文件中的数据,然后将它一个固定的json格式返回给前端。源码地址。
之后,我么开始来实现h5的下拉加载部分。
如果是我自己写的话,我会将下拉加载分成三个步骤进行实现:
但是,这样子的实现方式往往不是最佳的方式。最佳的方式,是类似与iscroll和better-scroll插件的方式。原理:在最外层设置一个wrapper(包),将包的大小绝对定位和内容隐藏,然后给内部的内容添加transform的动画属性,使得它可以进行上下的滚动。这样的好处是,可以实现回弹的效果。
原理图:
better-scroll在iscroll上面做了一些修缮,尤其是在触摸滚动方面吧。所以可以使用better-scroll来实现下拉加载和上拉刷新。
第一步:固定外层包的大小,使用绝对定位的方式。然后在内容的上下都添加loading图。示例:
<div id="wrapper">
<div>
<div class="pull-refresh" id="pull-refresh">
<div class="arrow" id="arrow">
<img src="https://raw.githubusercontent.com/AlloyTeam/AlloyTouch/master/refresh/pull_refresh/asset/arrow.png" alt="arrow"><br>
</div>
</div>
<div id="toploading">
<img src="./images/200.gif" alt="loading">
</div>
<ul class="wrapper">
</ul>
<div class="bottom" id="bottom">
<span class="line"></span>
<span class="tip">我是底线</span>
<span class="line"></span>
</div>
<div class="loading" id="loading">
<img src="./images/200.gif" alt="loading">
</div>
</div>
</div>之后就是一些样式的设置。
第二步:初始化scroll的对象,可以通过BScroll去进行构造。然后在每次载入内容的时候都需要去刷新一下scroll,保证它对内部内容的识别是正确的。否则,你可能只能滚动一部分。(由于是ajax载入数据的,所以在刷新的时候需要一定的延时,才能保证内容的正确)
//init scroll part
_initScroll: function(){
const _self = this;
const wrapper = document.getElementById('wrapper')
const options = {
probeType: 1,
click: true,
scrollbar: false,
bounduceTime: 2000
};
_self.scroll = new BScroll(wrapper, options);
},
//ajax part
fetch: function(url){
return new Promise((resolve, reject) => {
$.ajax({
url: url,
type: 'GET',
dataType: 'json',
data: {},
success: function(data){
resolve(data);
},
error: function(){
reject('request timeout');
}
});
});
},
load: function(fn){
const _self = this;
const url = _self.config.base_url + _self.data.page;
_self.operations.bShow();
_self.scroll.refresh();
return _self.fetch(url).then(data => {
setTimeout(() => {
_self.operations.bHide();
_self.data.next = data.next;
if(!data.next){
_self.bottomLine();
}
_self.data.page++;
fn.call(_self, data.data);
_self.data.status = 'ready';
}, 500);
setTimeout(() => {
_self.scroll.refresh();
}, 600);
}, err => {
console.log(err);
}).catch(e => console.log(e));
},
update: function(fn){
const _self = this;
const url = _self.config.base_url + 'update/' + (_self.data.page - 1);
_self.operations.tShow();
_self.operations.aHide();
return _self.fetch(url).then(data => {
setTimeout(() => {
_self.operations.tHide();
_self.operations.aShow();
_self.data.next = data.next;
fn.call(_self, data.data);
}, 500);
setTimeout(() => {
_self.scroll.refresh();
_self.data.status = 'ready';
}, 600);
}, er => {
console.log(err);
}).catch(e => console.log(e));
},这部分主要分为三个函数fetch、load、update。它们的作用分别是fetch主要是一个发起ajax请求的函数,以promise的形式,将内容返回回来,便于后面的数据操作。load主要作用就是获取下拉加载的数据,将它加载到html中去,update是上拉刷新后的数据,将它重新替换html中列表部分的内容。这里有一个status去控制加载的状态,防止重复发送ajax请求。
第三步:就是给scroll去添加事件。主要是两个事件touchEnd和scroll事件。这里的scroll事件是当滚动列表时发生整体的滚动时才会触发的。因为我们的html结构中,wrapper内的内容除了ul列表之外头部和尾部都还具备loading的标签。
bind: function(){
const _self = this;
_self.scroll.on('touchEnd', function(position){
if(position.y < _self.scroll.maxScrollY - 20){
_self.more();
}else if(position.y > 80){
_self.update(_self.initHtml);
}
});
_self.scroll.on('scroll', function(position){
if(position.y > 80){
_self.operations.up();
}else{
_self.operations.down();
}
});
},然后通过后端传过来的next可以帮助我们去判断是否还有后续内容,position.y对应的就是transform动画滚动时的值。然后,去判断是否到达底部是,我们还需要的是scroll中maxScrollY这个值。其中的20只是一个阈值。
这样其实一个下拉刷新和上拉加载的过程就算是完成了。后续还可以改进的地方有是图片的懒加载和js模版引擎的使用。
不知你是否会感到好奇,MongoDB是一个神奇的数据库。前端们手中的利器,配合起nodeJS一点都不含糊
本篇我将总结一些我在平时使用MongoDB时,通常会遇到的问题和实践结论。或许,你也对MongoDB感兴趣,那么我们也将一起探讨这个有趣的数据库。当然了,这个过程往往会涉及到nodeJS,或者其他的后端语言,但是我这里使用的是nodeJS。当然,包含介绍mongoose这个ODM库。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
一入前端,深似海;海上扬帆,不自知
知识是用来收集和分享的,本篇只是我收集前端知识的开始,目的是收集最近几年优秀的文章。
本篇将总结阿里二面所涉及到的知识点,以及便利蜂的视频面试
本次总结的是阿里的第二次面试(总体感觉来说答的不是特别好,感觉会挂,表示已挂,不过没关系,面试就是最好的知识总结)
下面我们来聊一聊阿里的面试问题
1. 三大框架(angular2、react、vue)各自的优缺点
这个问题回答起来比较的蛋疼。因为本人并未使用所有的框架,只会angular2和react,vue只是初步的了解。所以,只答了一些angular2和react之间的优缺点。
首先我们来聊一下angular2和react之间的差别(个人观点,后面放一篇专门的文章)
angular2的分析:
好处:angular2本身是一个框架,它具备组件化的思维,可构造出高复用的组件。它具备指令的特性可以与组件进行结合,衍生出复杂的UI。以及它的依赖注入的**的运用、脏检测实现的双向绑定机制、管道的使用,模块的封装,路由的模块懒加载,zone的异步控制,自身html模版的错误检测等,都是它本身的一些特点。
劣势:由于它本身是一个框架,所以自身具备的约束条件无法满足开发的高度可定制化;而且本身的内容比较庞大,往往会造成一些框架本身内容的堆积(aot可以解决这个问题);本身的上手难度较大,自身模版的语法较多。
react的分析:
好处:react本身是一个类库,它具备小而美,灵活的特点。visual DOM的机制,可以避免我们频繁的操作DOM;diff方法的低复杂度高性能,使得更新DOM时的高效;setState机制,可以保持整个系统的数据化驱动;还有对于事件,react自身实现了事件合成系统,可以方便我们轻易的操控事件;还有就是它本身的js语言的使用,非常容易上手。
劣势:react在大型系统中使用时,往往会导致状态的混乱,需要加入redux等单向数据流框架对其进行约束。它的setState机制,对于新手来说不容易掌握,如果不能深入理解它的原理的话,可能会制造出意想不到的小问题。
对于一个影子杀手而言,总能杀人于无形。前端也有影子杀手,它总是防不胜防地危害着你的网站
本篇打算介绍一些前端的影子杀手们——XSS和CSRF。或许,你对它恨之入骨;又或者,你运用的得心应手。恨之入骨,可能是因为你的网站被它搞得苦不堪言;得心应手,可能是因为你从事这项工作,每天都在和此类问题打交道。那我们今天就来了解它,防御它。如果你喜欢我的文章,欢迎评论,欢迎Star~。欢迎关注我的github博客
注:在开始正文之前,先声明一下,所有的实验环境均为本地搭建——DVWA。
影子杀手们,由来已久,几乎伴随着整个互联网的发展。历史的潮流,总是值得去考究,去深思的。可能在十年之前,这些问题层出不穷;随着开发者安全意识的提高,总是多多少少可以避免的。那么,我们就先来看看,今天的第一位主角——XSS。
记得在学校的时候,玩过CTF,应对类似于XSS等网络漏洞,总是会有固定的套路。今天我们也来了解了解这些套路。
XSS的全名叫做Cross-site Scripting。不知你可否会有个疑问,老外都喜欢将英文缩写,但是为什么这个缩写却是XSS呢?因为只能怪它来的晚咯,被css抢先一步^_^。不过没关系,并不阻碍我们记忆它。
XSS是一种代码注入类攻击,它允许攻击者在其他人的电脑上面执行恶意的脚本代码。往往XSS并不需要攻击者去直接攻击受害者的浏览器。攻击者可以利用网站的漏洞,将这一段恶意代码提交。然后,通过网站去传递给受害者,同时窃取受害者的信息等。
我们可以先看一个简单的例子:
或许,你会好奇,我应该怎么去运用网站的漏洞,那我们先来看一张图:
这是一个评论框,然后我们可以在其中输入:
然后,你提交这条信息,如果该网站没有做防护(例如:过滤),那么,你所在的页面会跳出如下画面:
看了这个信息,或许你已经意识到了它的危害。因为如果可以这样子随意的运行js脚本,对于你客户端的信息(例如:cookie)将统统被窃取。
回到我们的话题,在看到xss的基本效果之后,你会认为JavaScript是危险的吗?
其实不然,真正的JavaScript是运行在比较严格的环境下面,并不会对操作系统或者其他应用造成伤害。不信的话,你可以打开控制台,在里面随意尝试,你会发现你并没有造成任何危害。那么,我们所谓的XSS的严重性,是吹的吗?
那就更加不是了。首先,我们要申明的是——何为恶意代码?恶意代码的叫法,并不是因为它本身是有危害的,而是它的意图是对使用者有害的。我们可以来看看,何为对使用者有害?例子:
这些行为,如果是不善的人所为,那么,将对使用者造成不可估量的损失。
XSS整个流程中,会出现不同的角色。演员表可分为:网站、受害者、攻击者。
网站,通常是指那些会被受害者访问的HTML页面。
受害者,指的是那些访问网站的普通用户
攻击者,则是那些躲在阴暗角落,敲击着键盘的恶意用户。通常,攻击者还会具备一台自己的服务器,用来接收发送过来的用户信息。
整个流程图,如下:
整个流程中,演员都是必须的环节,不然整个攻击都无法完成。可从图中看出4个步骤:
希望你对这幅流程图多看几眼,因为它也将会是我们后续防御XSS的先决条件。之后,我们来看看XSS的分类情况
XSS的目标是在受害者的浏览器中执行恶意代码。而实现这一目标,往往只有不同的途径,主要可以分为三种:反射型XSS、存储型XSS、基于DOM的XSS。
由于存储型的XSS的流程图,我们已经在上面看到过了。之后,我们需要来看一看反射型的XSS流程图,如图:
可以看到流程中,并未向网站的数据库中插入恶意代码,而是由以下4步骤组成:
这种形式往往是需要用户进行点击的。
还有一种基于DOM的XSS,平时运用较少,而且攻击条件较为苛刻。在此不做讨论。
我们看完分类之后,对于攻击的大体流程已经掌握。
接下来的操作平台,我比较推荐——DVWA。因为目前网上XSS漏洞比较少,主要也是因为开发者的重视,而且网上操作会导致一定的危害,所以在本地搭建开发环境是最好的选择。
实际操作:
最初,我们需要安装DVWA,这个教程网上有很多,所以,可以自行百度。
第一步,我们需要将DVWA的安全级别调低,因为不同的安全级别采取的防御措施不同。
第二步,我们开始在XSS reflected中进行xss试验。
第三步,在输入框中输入"<script>alert(document.cookie)</script>",如图:
第四步:提交之后,我们即可看到弹窗(这里提醒一下尽量不要使用chrome,那个浏览器会屏蔽这些,最好使用老版本的IE),如图:
如果你具备后台服务器的话,那么就可以将这个cookie通过请求的形式发送到服务器后台上面,此处就不做演示了。
既然有人企图使用这些玩意来危害使用者,那么,我们这些开发者在开发应用的过程中,自然会有应对之策。不知你还记得上面的攻击流程图没有?如果忘记了,不妨回去看一眼。因为,最好的防御措施就是截断攻击环节中的任意一个环节。
首先,作为一个开发者,必须达成的一点共识是所有的用户输入都是不安全的。尤其是类似于XSS这类的注入型漏洞。我们可以通过两个方式对其进行防御——编码和验证。
编码:对于用户的输入而言,所输入的内容只会作为数据,而不是代码。
验证:通过正则表达式等方式,去检查用户的输入中是否带有敏感字符等。
所以,我们的解决方案可以围绕上述两点进行展开:
输入检测
对用户输入的数据进行检测。对于这些代码注入类的漏洞原则上是不相信用户输入的数据的。所以,我们要对用户输入的数据进行一定程度上的过滤,将输入数据中的特殊字符与关键词都过滤掉,并且对输入的长度进行一定的限制。只要开发的人员严格检查每个输入点,对每个输入点的数据进行检测和xss过滤,是可以阻止xss攻击的。
输出编码
通过前面xss的原理分析,我们知道造成xss的还有一个原因是应用程序直接将用户输入的数据嵌入HTML页面中了。如果我们对用户输入的数据进行编码,之后在嵌入页面中,那么html页面会将输入的数据当作是普通的数据进行处理。
Cookie安全
利用xss攻击,我们可以轻易的获取到用户的cookie信息。那么我们需要对用户的cookie进行一定的处理。首先,我们尽可能减少cookie中敏感信息的存储,并且尽量对cookie使用hash算法多次散列存放。合理的使用cookie的httponly的属性值。这样可以防止恶意的js代码对cookie的调用。
禁用脚本
可以在浏览器中进行js的安全设置。类似与chrome等浏览器都会拦截一些危险的xss操作,例如:想要读取cookie时,浏览器会阻止这个操作,征求用户指示,同时提醒用户此类操作的危害性。
对于XSS而言,我们可以了解的内容就到此为止。如果你想要深究,可以看一些网络安全的书籍,或者查阅其他的文章,均可得到详细的解答。下面我们需要介绍我们的第二位主角——CSRF
还记得第一位主角的名字叫什么吗?是叫——跨站脚本攻击。那么第二位主角也有一个类似的名字——跨站请求伪造(Cross-site request forgery)。
CSRF 顾名思义,是伪造请求,冒充用户在站内的正常操作。我们知道,绝大多数网站是通过 cookie 等方式辨识用户身份(包括使用服务器端 Session 的网站,因为 Session ID 也是大多保存在 cookie 里面的),再予以授权的。所以要伪造用户的正常操作,最好的方法是通过 XSS 或链接欺骗等途径,让用户在本机(即拥有身份 cookie 的浏览器端)发起用户所不知道的请求。
CSRF这种攻击方式在2000年已经被国外的安全人员提出,但在国内,直到06年才开始被关注,08年,国内外的多个大型社区和交互网站分别爆出CSRF漏洞,如:NYTimes.com(纽约时报)、Metafilter(一个大型的BLOG网站),YouTube和百度HI......
或许,我们现在对它了解的少了,但是网络中的确还留有它的足迹。我们具体的操作就不实际操作了。我们可以来看一下CSRF的原理,如图(该图来自一篇知名的博客,在此注明):
可以从图中看到以下步骤:
CSRF也可会分成两种形式的攻击:站内攻击和站外攻击
CSRF站内类型的漏洞在一定程度上是由于程序员滥用$_REQUEST类变量造成的,一些敏感的操作本来是要求用户从表单提交发起POST请求传参给程序,但是由于使用了$_REQUEST等变量,程序也接收GET请求传参,这样就给攻击者使用CSRF攻击创造了条件,一般攻击者只要把预测好的请求参数放在站内一个贴子或者留言的图片链接里,受害者浏览了这样的页面就会被强迫发起请求。
CSRF站外类型的漏洞其实就是传统意义上的外部提交数据问题,一般程序员会考虑给一些留言评论等的表单加上水印以防止SPAM问题,但是为了用户的体验性,一些操作可能没有做任何限制,所以攻击者可以先预测好请求的参数,在站外的Web页面里编写javascript脚本伪造文件请求或和自动提交的表单来实现GET、POST请求,用户在会话状态下点击链接访问站外的Web页面,客户端就被强迫发起请求。
CSRF,对于目前而言攻击较少,也是因为对于这方面的防御手段越来越成熟所导致的。下面,我们来看一下如何去防护CSRF的攻击。
预防CSRF攻击可以从两方面入手:
何为正确使用GET和POST呢?拿RESTful API举例来说,GET是获取资源,而POST是提交修改资源。那么我们在定义一个url时,遵循这个规则,就可以保证GET的非用户请求,无法对服务器资源进行修改,这样就可以防止GET的CSRF攻击。
那么,你可能会疑惑,要是POST的请求攻击怎么办呢?这就需要从第二方面下手。
增加伪随机码的方式,一般可以分为三种:
为每个用户生成一个cookie token,这样可以保证在每次表单验证时附带上同一个伪随机码。这种方式是最简单的,但是同时也需要保证cookie的安全。往往cookie中的信息是非常容易被盗取的,所以这种方案在保证没有XSS的前提下是比较安全的。
每次请求生成验证码。这种方法是安全的,但是相对于用户体验来说,并不友好
不同表单包含一个不同的token。有兴趣可以去了解一下,这种是比较安全的POST请求方式。
由于,现在对于CSRF的攻击预防比较彻底,一般在没有XSS的前提下,已经很难进行此类攻击了。所以真实的实际操作环境并没有多少。以往主要的攻击手段还是,通过XSS对于cookie进行盗取,然后通过CSRF用户数据进行修改。我们可以一个例子来说明最经典的银行的例子:
如果银行A允许以GET请求的形式来转账,我们这里大多指的不是实际生活中的,因为实际生活中银行不可能只用get请求转账这么简单操作:http://www.mybank.com/Transfer.php?toBankId=11&money=1000
这是危险网站B的代码段中有这么一句:
<img src=” http://www.mybank.com/Transfer.php?toBankId=11&money=1000”>那么当你再回A银行时,就会发现你的账户上已经少了1000元。
当然,这是假的。
前端安全,一直以来都是被关注的重点对象。我们在了解他们的同时,应该注重他们的防护,这就是对用户的包含。可以是XSS的漏洞,时有发生,BAT等大厂的产品也不例外。今天总结了XSS和CSRF的攻击与防护,是警醒自己,在以后的开发中多加注意,同时,也希望和你们一起分享。
如果你对我写的有疑问,可以评论,如我写的有错误,欢迎指正。你喜欢我的博客,请给我关注Star~呦github博客
之前,有讲述过react的生命周期和setState机制。其实,react还有一个重要的东西,堪称是react的灵魂——diff算法。如果没有它,实现visual DOM的更新,不会那么容易,react的性能也不会那么好。接下来,我们可以来见识一下react的diff算法的特色。
通常来说,计算一棵树形结构转换成另一棵树形结构的算法复杂度在O(n^3),n表示树中的节点个数。这个结果是经过数学计算论证的。我们可以举个例子来量化这个概念:在整个页面中有1000个node节点,如果一处地方发生改变,整个浏览器需要经过十亿次的计算。这个结果对于客户端来讲,是无法接受的。那么,对于这样一个高复杂度算法来讲,在VDOM模型中使用,明显是不现实的。因此,react团队对于它的优化绝对是点睛之笔。
如何去减少复杂度呢?方法就是通过增加一定的条件,来减少没有必要的比较。react团队在这个方面,做出了三个策略,最终使得diff算法的复杂度降低到了O(n)。
三大策略:
基于这三大策略,我们可以将整颗树的比较分成三部分来进行。在分析前,我们先来看一张经典图:
这是一张react diff的核心图,或许你现在还看不明白,但是看了之后的分析之后,回过头来,你必将有所领悟。
tree diff
react只会对同层级的组件进行比较,如果新树中节点不存在,react会直接删除该节点,不进行后续的比较;同样的,如果新增了子节点,那么react会在该位置新插入一个节点。
那么,如果是上述的少数情况——跨层级移动怎么解决。
举例为证:
react会执行以下操作:创建A——>创建B、C——>删除A
注:这里可以去进行优化的方式是,可以不进行跨层级的移动,而对元素进行可见或隐藏的操作,这样会优化性能。
component diff
react会根据策略二制定的规则来进行比较:
如果是同类型组件,则进行更深层次的比较;如果不是同类型,直接替换掉原先的组件。
那么,如果出现两个组件,类型不同而结构相同的情况下,会对diff算法的性能产生影响,尽量避免此类型的操作。
注:这里可以使用shouldComponentUpdate来进行判断,是否需要更新。如果不需要更新,就可以阻断接下来的子树的比较过程,从而达到优化react性能的效果;同时,使用无状态组件也可以起到这样子的效果
element diff
对于第三种策略,在同一组子节点设置唯一的key来进行识别,也是一种优化非常好的方法。
首先,我们从一张图开始,分析一组子节点之间如何比较不同的。
如图所示,在没有key的情况下,通常会如何进行处理?
这样的流程,或许你也发现了,他们所消耗的成本太大,只有移除和插入的操作,远远没有使用到旧的组件。因为,没有唯一key的存在,react无法去判断是否在之前的树中存在着已有的组件,从而无法将旧组件进行复用。
回到如果回到具备key值的情况下,又是另一番场景了。
这里react会到旧树中去查找是否已经具有相同的组件,然后进行移动操作。移动操作会发生在旧树节点的位置下标小于新树节点位置下标时。我们先来看看整个的比较过程。
C和D的操作是一样的。那么,我们来看看,如果有新节点变化的图,又是如何进行比较的。
这样,整个diff比较就完成了,回顾之前不存在key的情况时的操作,这是的性能会相对良好。
当然了,这种比较法则大多数情况下是良好的,但是,如果是最后一个节点移动到第一个节点的极端情况下,会发现之前的节点都得发生移动,会造成一定的性能下降。
diff算法是react的佳作,经过优化的diff,甚至于可以让你在开发时,不用去考虑react性能。当然了,作为一个程序员来说,追求完美是必不可少的。即便于diff算法是优秀的,我们也应该懂得它的原理,然后在一定的基础上对它进行优化,例如,文章最后提到的这种情况。
海明距离(Hamming distance)
**题目:**The Hamming distance between two integers is the number of positions at which the corresponding bits are different.Given two integers x and y, calculate the Hamming distance.
**翻译:**两个整数之间的海明距离是在相应的位不同的位置数目。给两个整数x和y,计算海明距离
思路解析:可以通过将两个整数异或,然后计算二进制中的1的数目,即是海明距离。
位操作符详解:
&:按位与 |:按位或 ^:按位异或 >>:右移,相当于除2 >>:左移,相当于除3
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

















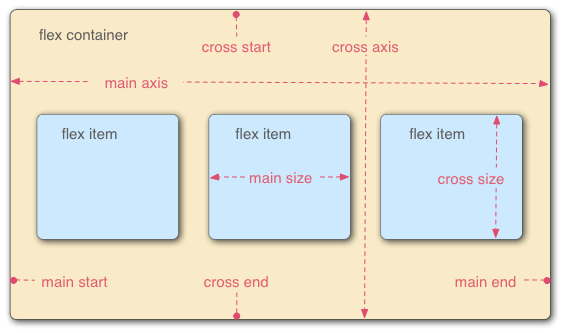














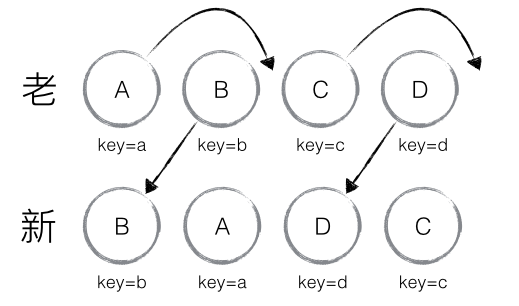
{kind=link}