This project's goal is to build an Express API that can collect information from many websites and provide the user with the information in a structured fashion. The project intends to give developers access to news articles quickly and easily without requiring them to create their own web scrapers.
The project offers a solution to the time-consuming and challenging task of writing web scrapers from scratch. Developers are free to concentrate on creating their apps rather than worrying about how to collect data by offering a straightforward API that produces structured data.
The ability to search for specific news on websites, obtain news items and data feeds from multiple categories, and restrict the amount of results returned are some of the project's key features.
Developers that need to retrieve news articles from websites for their applications make up the project's target audience. Web designers/developers, data scientists, all fall under this category.
Overall, the project offers developers a quick and dependable way to get data without having to create their own web scrapers.
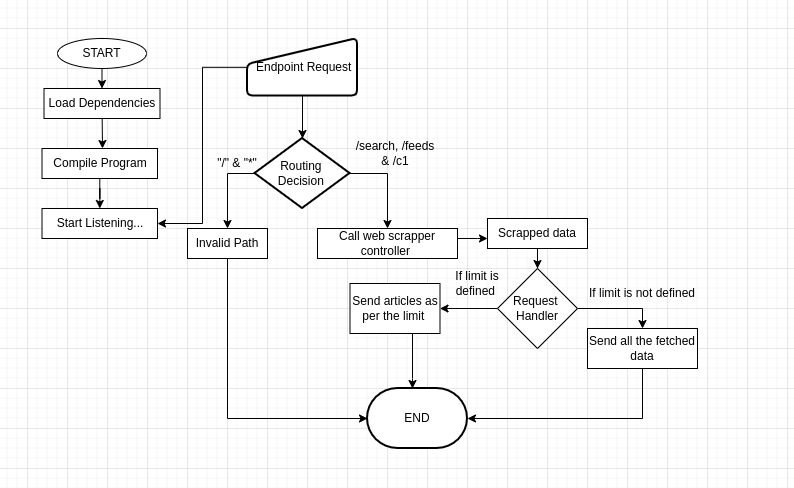
To use this API, you can send HTTP GET requests to the available endpoints. The base URL for the API is https://feedparsify.cyclic.app/
To send a request to any of the endpoints, you can use a tool like Postman or send a request via your preferred programming language.
The path argument can be used to specify the type of the RSS feed to be scraped and is supported by the endpoints /search/:[topic], /feeds/:[Article-type], and /c1/:[parameter].
Article-Type: - top_stories, latest_feeds, most_read, most_shared
Parameter -> Category:- education, tech, entertainment, cricket
Parameter -> Location:- india, us, uk, middle_east, delhi, mumbai, varanasi, bangalore
Moreover, an optional limit query parameter is accepted by the endpoints, which indicates the maximum number of Articles to retrieve.
The API returns a JSON response with an object containing a Data property, which holds an array of articles. Each article object has properties like title, image description, link, category, and pubDate.
{
"Data": [
{
"title": "Example Article",
"imageUrl":"https://dummyimage.com/600x400/000/fff",
"description": "This is an example article.",
"link": "https://www.example.com/article",
"category": "Example Category",
"pubDate": "2022-03-13T00:00:00.000Z"
}
]
}The API has three endpoints:
- /search/[topic]
This endpoint is used to search for data on the website. It takes a topic as parameter that specifies the topic to search and a query parameter limit that specifies the maximum number of articles to return.
GET /search/topic?limit=<integer>- /feeds/[Article-type] This endpoint is used to retrieve feeds from the websites. It takes a Article type and source as parameter that specifies the website to retrieve feeds from and a query parameter limit that specifies the maximum number of articles to return.
GET /feeds/article-type?limit=<integer>The API uses three controllers to retrieve data from websites:
-
scraper_controller/feeds.js This controller is used to retrieve feeds from a website. It takes a URL as input and returns an object containing an array of feed objects.
-
scraper_controller/search_feeds.js This controller is used to search for data on a website. It takes a URL as input and returns an object containing an array of search results.
The API uses a request handler function to handle the responses to the client. The reqHandler() function takes three arguments: result, amt, and res. result is the result returned from the controller function, amt is the maximum number of results to return, and res is the response object.
This API includes basic error handling to ensure that the server does not crash and returns appropriate responses to clients. The error handling includes:
- 404 Not Found: If a client tries to access an endpoint that does not exist, the server will respond with a 404 status code and an ASCII art.
- 500 Internal Server Error: If there is an error on the server, the server will respond with a 500 status code.
- Try-Catch: All functions in the API include a try-catch block to handle any errors that may occur and return a status code to the client.
These error handling methods are designed to ensure that the API remains stable and accessible to clients, even if unexpected errors occur.
This project is licensed under the MIT License - see the LICENSE file for details.
This Express API serves as a useful tool for web scraping data from website. It includes three endpoints for retrieving search results, feed information, and category information. The API is also set up to handle errors and gracefully respond with appropriate status codes.
This API can be easily customized to suit different web scraping needs. The modular design allows for easy addition of new scraping functionalities by creating new controller files and adding them to the main scrapper_controller module.
Feel free to use it and customize it to fit your needs.